Embed Size (px)
Citation preview

UNIVERSIDADE ESTADUAL DE CAMPINAS
Instituto de Matematica, Estatıstica eComputacao Cientıfica
JULIANNA PINELE SANTOS PORTO
Geometria do Modelo Estatıstico dasDistribuicoes Normais Multivariadas
Campinas2017

Julianna Pinele Santos Porto
Geometria do Modelo Estatıstico das DistribuicoesNormais Multivariadas
Tese apresentada ao Instituto deMatematica, Estatıstica e ComputacaoCientıfica da Universidade Estadual deCampinas como parte dos requisitos exigidospara a obtencao do tıtulo de Doutora emMatematica Aplicada.
Orientador: Joao Eloir StrapassonCoorientadora: Sueli Irene Rodrigues Costa
Este exemplar corresponde a versao daTese defendida pela aluna Julianna PineleSantos Porto e orientada pelo Prof. Dr.Joao Eloir Strapasson.
Campinas2017

Agência(s) de fomento e nº(s) de processo(s): CNPq, 140364/2015-3; CAPES
Ficha catalográficaUniversidade Estadual de Campinas
Biblioteca do Instituto de Matemática, Estatística e Computação CientíficaAna Regina Machado - CRB 8/5467
Porto, Julianna Pinele Santos, 1990- P838g PorGeometria do modelo estatístico das distribuições normais multivariadas /
Julianna Pinele Santos Porto. – Campinas, SP : [s.n.], 2017.
PorOrientador: João Eloir Strapasson. PorCoorientador: Sueli Irene Rodrigues Costa. PorTese (doutorado) – Universidade Estadual de Campinas, Instituto de
Matemática, Estatística e Computação Científica.
Por1. Geometria da informação. 2. Matriz de informação de Fisher. 3. Distância
de Rao. 4. Distribuição guaussiana. 5. Algoritmo k-means. I. Strapasson, JoãoEloir,1979-. II. Costa, Sueli Irene Rodrigues,1949-. III. Universidade Estadualde Campinas. Instituto de Matemática, Estatística e Computação Científica. IV.Título.
Informações para Biblioteca Digital
Título em outro idioma: Geometry of the statistical model of the multivariate normaldistributionsPalavras-chave em inglês:Information geometryFisher information matrixRao distanceGaussian distributionk-means algorithmÁrea de concentração: Matemática AplicadaTitulação: Doutora em Matemática AplicadaBanca examinadora:João Eloir Strapasson [Orientador]Pedro Jose CatuognoLeonardo Tomazeli DuarteRui Facundo VigelisMarcelo Muniz Silva AlvesData de defesa: 03-08-2017Programa de Pós-Graduação: Matemática Aplicada
Powered by TCPDF (www.tcpdf.org)

Tese de Doutorado defendida em 03 de agosto de 2017 e aprovada
pela banca examinadora composta pelos Profs. Drs.
Prof(a). Dr(a). JOÃO ELOIR STRAPASSON
Prof(a). Dr(a). PEDRO JOSE CATUOGNO
Prof(a). Dr(a). LEONARDO TOMAZELI DUARTE
Prof(a). Dr(a). RUI FACUNDO VIGELIS
Prof(a). Dr(a). MARCELO MUNIZ SILVA ALVES
As respectivas assinaturas dos membros encontram-se na Ata de defesa

A minha famılia.

Agradecimentos
Agradeco a minha mae por todo apoio que sempre me deu nessa longa caminhadaate aqui, por ser a minha inspiracao sendo a mulher lutadora que e, fornecendo a melhoreducacao possıvel aos seus filhos e os apoiando em suas decisoes. Agradeco ao meu irmaoSandro, por ter me apresentado a matematica e por sempre estar ao meu lado.
Agradeco a toda a minha famılia, por estarem sempre presentes, me dando forcapara continuar, por torcerem por mim e por me receberem de bracos abertos, compartil-hando comigo todas as glorias e dificuldades.
Agradeco ao meu orientador Joao Strapasson o qual sem ele nao poderia ter feitoesse trabalho. Agradeco pelo apoio, forca, paciencia e dedicacao durante esses seis anosde trabalho (mestrado e doutorado).
A minha coorientadora Sueli Costa, por todos os trabalhos que realizamos juntas,e pela forca e incentivo que me deu nos momentos difıceis.
Agradeco ao Professor Aurelio de Oliveira por toda a atencao, paciencia e por seruma pessoa com quem eu sempre pude contar durante esses meus seis anos na Unicamp.
Agradeco ao Joao, por ser meu companheiro de todas as horas nesses quatro anosde doutorado, por ter compartilhando comigo os momentos de exito e de dificuldades, portoda a paciencia, persistencia, cuidado e por todo carinho.
Agradeco aos amigos que conquistei aqui em Campinas, muitos deles hoje saominha famılia tambem. Com tanto tempo fora de casa, acabamos construindo outrasfamılias, compostas por pessoas que conquistam nosso coracao e que a gente sabe quepode contar sempre. Agradeco pelo apoio nos momento de cansaco, pelas comemoracoesnos momentos de alegria e aos nossos “reggaes” no Estacao Barao que nos permitiramaproveitar um pouco todos esses momentos.
Ao pessoal do Laboratorio MDC, pela companhia e pelos diversos momentos quecompartilhamos, e importante fazer parte de um grupo.
Ao apoio financeiro da CAPES (Coordenacao de Aperfeicoamento de Pessoal de

Nıvel Superior) e do CNPQ (Conselho Nacional de Desenvolvimento Cientıfico e Tec-nologico), sem o mesmo este trabalho nao seria possıvel.

“A geometria e uma ciencia de todasas especies possıveis de espacos.”
Immanuel Kant

Resumo
Na area de Geometria da Informacao, ferramentas de geometria diferencial saoutilizadas no estudo de modelos estatısticos. Num trabalho pioneiro em 1945, C. Rao in-troduziu uma metrica Riemanniana, dada pela matriz de informacao de Fisher, no espacocomposto por distribuicoes de probabilidade parametrizadas. Atraves dessa metrica, adistancia entre as distribuicoes (chamada de distancia de Fisher-Rao), geodesicas, curva-turas e outras propriedades do espaco sao analisadas.
Abordamos neste trabalho a distancia de Fisher-Rao na variedade composta pordistribuicoes normais multivariadas. Descrevemos a distancia de Fisher-Rao e as cur-vas geodesicas em algumas subvariedades e apresentamos alguns limitantes para estadistancia no caso geral. Alem disso, utilizamos a distancia de Fisher-Rao como medidade dissimilaridade em dois algoritmos de agrupamento de dados (algoritmos k-medias eagrupamento hierarquico). Por fim, apresentamos algumas aplicacoes desses algoritmosde agrupamentos na area de segmentacao de imagens.
Palavras-chave: Geometria da Informacao, metrica de Fisher, distancia de Fisher-Rao, dis-
tribuicao normal multivariada, algoritmo k-medias, algoritmo de agrupamento hierarquico, di-
vergencia de Kullback-Leibler.

Abstract
In the Information Geometry area, geometry differential tools are used to studystatistical models. In a pioneer work in 1945, C. Rao introduced a Riemannian metricgiven by the Fisher information matrix, on the space composed by parametrized proba-bility distributions. Through this metric, a distance between the distributions (called theFisher-Rao distance), geodesics, curvatures and other space properties are analyzed.
In this work, we approach the Fisher-Rao distance in the multivariate normaldistributions manifold. We describe the Fisher-Rao distance and the geodesic curves insome submanifolds and we present some bounds for the Fisher-Rao distance in generalcase. Furthermore, we use the Fisher-Rao distance as a dissimilarity measure in twoclustering algorithms (the k-means and the hierarchical clustering algorithms). Someapplications of these clustering algorithms in the image segmentation are presented.
Palavras-chave: Information Geometry, Fisher metric, Fisher-Rao distance, multivariate nor-mal distribution, k-means algorithm, hierarchical clustering algorithm, Kullback-Leibler diver-gence.

Sumario
Introducao 13
1 Preliminares em Geometria da Informacao 16
1.1 Modelo estatıstico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.2 Metrica de Fisher . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.3 Distancia de Fisher-Rao . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
1.4 Curvaturas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
1.5 Divergencia de Kullback-Leibler . . . . . . . . . . . . . . . . . . . . . . . . 33
1.5.1 Relacao com a Distancia de Fisher-Rao . . . . . . . . . . . . . . . . 34
1.5.2 Relacao com a Divergencia de Bregman . . . . . . . . . . . . . . . . 35
2 Distribuicao Normal Multivariada 36
2.1 Distancia de Fisher-Rao . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.1.1 A subvariedade MΣ0 onde Σ0 e constante . . . . . . . . . . . . . . 43
2.1.2 A subvariedade Mµµµ0 onde µµµ0 e constante . . . . . . . . . . . . . . . 44
2.1.3 A subvariedade MD onde Σ e diagonal . . . . . . . . . . . . . . . . 46
2.1.4 A subvariedade MDµµµ em que Σ e diagonal e µµµ e um autovetor de Σ 47
2.1.5 Produto de Subvariedades totalmente geodesica . . . . . . . . . . . 51
2.2 Algoritmos Numericos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
2.2.1 Algoritmo Geodesic shooting . . . . . . . . . . . . . . . . . . . . . . 53
2.2.2 Sistema de Equacoes . . . . . . . . . . . . . . . . . . . . . . . . . . 54
2.3 Limitantes para a distancia de Fisher-Rao . . . . . . . . . . . . . . . . . . 69
2.3.1 Limitante Inferior . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
2.3.2 Limitantes Superiores . . . . . . . . . . . . . . . . . . . . . . . . . . 69
2.3.3 Comparacao dos Limitantes . . . . . . . . . . . . . . . . . . . . . . 75
2.4 Curvaturas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80

3 Simplificacao de Misturas Gaussianas e Aplicacoes 83
3.1 Algoritmos de Agrupamento . . . . . . . . . . . . . . . . . . . . . . . . . . 84
3.1.1 Algoritmo Maximizacao de Expectativa . . . . . . . . . . . . . . . 84
3.1.2 Algoritmo k-medias . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.1.3 Agrupamento Hierarquico . . . . . . . . . . . . . . . . . . . . . . . 86
3.2 Centroides no Modelos das Distribuicoes Normais Multivariadas . . . . . . 87
3.2.1 Centroides de Bregman . . . . . . . . . . . . . . . . . . . . . . . . . 87
3.2.2 Centroide de Galperin . . . . . . . . . . . . . . . . . . . . . . . . . 88
3.3 Algoritmos de Simplificacao de Misturas Gaussianas . . . . . . . . . . . . . 91
3.3.1 Algoritmo k-medias Fisher-Rao Diagonal . . . . . . . . . . . . . . . 91
3.3.2 Agrupamentos Hierarquico . . . . . . . . . . . . . . . . . . . . . . . 92
3.4 Aplicacao em Segmentacao de Imagens . . . . . . . . . . . . . . . . . . . . 93
4 Conclusoes e perspectivas 102
Bibliografia 103
A Prova do Teorema 2.1 109
B Calculo dos sımbolos de Christoffel do Teorema 2.9 111

13
Introducao
Metricas e distancias entre distribuicoes de probabilidade tem um importante papel
em diversas areas e aplicacoes. Consideremos as distribuicoes normais univariadas com
media µ e desvio padrao σ,
p(x;µ, σ) =1√2πσ
exp
(−1
2
(x− µσ
)2).
A Figura 1 ilustra uma comparacao entre as distribuicoes normais: a esquerda estao repre-
sentadas distribuicoes normais com parametros A, B, C eD e a direita os parametros estao
representados no plano media×desvio padrao. Fixando o valor da media e aumentando
o valor do desvio padrao e intuitivo notar que, num mesmo intervalo, a dissimilaridade
entre as distribuicoes com parametros C e D e menor que a dissimilaridade entre as dis-
tribuicoes parametrizadas por A e B. Logo, observando as posicoes dos parametros A, B,
C e D no plano media×desvio padrao, concluımos que a distancia Euclidiana nao e uma
boa medida para calcular a distancia entre esses parametros [18].
Figura 1: Distribuicoes normais univariadas e seus parametros no plano µ × σ (figuraretirada de [18]).

14 Introducao
Em busca de uma medida adequada para determinar a distancia entre duas popu-
lacoes, C. R. Rao [49] em 1945 introduziu metodos de geometria diferencial para modelar
um espaco composto por distribuicoes de probabilidade (modelos estatısticos) utilizando
a matriz de informacao dada por R. Fisher [26] em 1921. Esse importante trabalho foi
o precursor da area conhecida hoje como Geometria da Informacao. Embora autores
como Mahalanobis [40] e Bhattacharyya [7] ja tivessem feito relacoes entre geometria e
estatıstica, foi Rao quem estudou conceitos de geometria diferencial e fez conexoes com a
matriz de informacao de Fisher, ver referencia [46]. Ele introduziu os conceitos de metrica
de Fisher (uma metrica Riemanniana) e de distancia geodesica entre duas distribuicoes
de probabilidade, chamada nesse trabalho de distancia de Fisher-Rao.
Em [49], Rao calculou a distancia de Fisher-Rao entre duas distribuicoes normais
univariadas. Esse trabalho motivou diversos autores a utilizarem ferramentas geometricas
no estudo de modelos estatıstico, assim como estimulou o estudo de outras medidas de
dissimilaridade entre distribuicoes de probabilidade e o interesse em determinar formulas
fechadas para a expressao da distancias entre as mesmas. Efron [24] em 1975, introduziu
a nocao de curvatura nos modelos compostos por distribuicoes com apenas um parametro.
Este trabalho foi seguido por contribuicoes significantes de Dawid [22] e Reeds [50]. Amari
[2,3] foi quem unificou a teoria introduzindo outros conceitos de conexoes em modelos de
distribuicoes de probabilidade. Num trabalho independentemente, Chentsov [17] calculou
a distancia de Fisher-Rao entre algumas distribuicoes de probabilidade e mostrou que
a metrica de Fisher e a unica metrica Riemanniana invariante no espaco composto por
distribuicoes de probabilidade.
No calculo da distancia de Fisher-Rao entre distribuicoes em geral destacam-se os
trabalhos de Atkinson e Mitchell [5], no qual os autores calcularam a distancia de Fisher-
Rao entre distribuicoes com apenas um parametro, e de Burbea [10], onde o autor fez um
estudo do modelo das distribuicoes multinomiais. Alem disso, eles tambem apresentaram
alguns resultados sobre a distancia de Fisher-Rao no espaco composto por distribuicoes
normais multivariadas em casos particulares. Sato et. al. [51] em 1979 descreveram algu-
mas propriedades geometricas do espaco composto por distribuicoes normais bivariadas,
um trabalho que foi generalizado por Skovgaard [54] em 1984. Ademais, Eriksen [25] e
Calvo e Oller [13] calcularam expressoes para a curva geodesica no espaco das distribuicoes
normais multivariadas. Hoje em dia, ainda nao e conhecida uma formula fechada para a
distancia de Fisher-Rao no modelo das distribuicoes normais multivariadas no caso geral.
Distribuicoes de probabilidade sao elementos fundamentais em areas como es-
tatıstica, processamento estocasticos, aprendizado de maquina e teoria da informacao.
Rao [49] e Skovgaard [54] utilizaram a distancia de Fisher-Rao em problemas de inferencia
estatıstica. A distancia de Fisher-Rao tambem foi utilizada no estudo de tensores de di-
fusao de imagens de ressonancia magnetica em [31,37,43]. Aplicacoes da metrica de Fisher
no espaco das distribuicoes normais univariadas nas areas de morfologia e deformacao de

Introducao 15
imagens sao apresentadas, respectivamente, em [41] e [4]. Alem disso, em [52] a distancia
de Fisher-Rao foi utilizada para simplificar misturas Gaussianas atraves do algoritmo de
agrupamento k-medias. Uma aplicacao da distancia de Fisher-Rao entre distribuicoes
normais multivariadas na area de sistemas de radares e apresentada em [47].
Neste trabalho, fazemos um estudo da distancia de Fisher-Rao no modelo es-
tatıstico composto por distribuicoes normais multivariadas. Resumimos alguns resultados
ja conhecidos na literatura exibindo a distancia de Fisher-Rao em alguns subvariedades
deste modelo estatıstico. Encontramos duas subvariedades totalmente geodesicas e exibi-
mos uma formula fechada para a distancia de Fisher-Rao nessas subvariedades. Apresen-
tamos tambem o calculo da distancia entre certos pares de pontos atraves da resolucao de
sistemas. Utilizando uma isometria neste espaco, derivamos alguns limitantes superiores
para a distancia de Fisher-Rao no caso geral. Atraves de algumas simulacoes, mostramos
que, em alguns casos, os limitantes apresentam boas aproximacoes para distancia. Alem
disso, aplicamos a distancia de Fisher-Rao ao problema de simplificacao de misturas gaus-
sianas atraves de algoritmos de agrupamento. Experimentos na area de segmentacao de
imagens sao apresentados.
A organizacao do trabalho e descrita abaixo.
No Capıtulo 1, apresentamos alguns conceitos de Geometria da Informacao e in-
troduzimos a metrica de Fisher e a distancia de Fisher-Rao. Relembramos a definicao de
curvatura numa variedade Riemanniana e mostramos algumas relacoes entre a distancia
de Fisher e a divergencia de Kullback-Leibler, uma outra medida de dissimilaridade entre
distribuicoes.
Apresentamos, no Capıtulo 2, uma analise da distancia de Fisher-Rao no espaco
composto por distribuicoes normais multivariadas. Descrevemos uma isometria neste
espaco e mostramos formulas fechadas para a distancia de Fisher-Rao em alguns casos par-
ticulares. Derivamos duas subvariedades totalmente geodesicas e calculamos a distancia
de Fisher-Rao para certos pares de pontos. Apresentamos tambem alguns limitantes para
a distancia de Fisher-Rao e fazemos algumas comparacoes entre os mesmos.
O problema de simplificacao de misturas Gaussianas e apresentado no Capıtulo 3.
Descrevemos os algoritmos de agrupamento de dados k-medias e hierarquico e apresen-
tamos algumas definicoes de centroide no modelo das distribuicoes normais multivari-
adas. Fazemos algumas adaptacoes dos algoritmos de agrupamentos apresentados para
serem utilizados no problema de simplificacao de misturas Gaussianas com matrizes de
covariancia diagonais atraves do uso da distancia de Fisher-Rao. Alem disso, mostramos
tambem uma aplicacao na area de segmentacao de imagens.
No ultimo capıtulo apresentamos algumas consideracoes finais e perspectivas de
futuros trabalhos.

16
Capıtulo 1
Preliminares em Geometria da
Informacao
Neste capıtulo, apresentamos alguns conceitos e resultados preliminares em Geome-
tria da Informacao. O objetivo e introduzir as principais ferramentas que serao utilizadas
ao longo do texto. As principais referencias sobre Geometria da Informacao nas quais
foram baseadas este capıtulo foram [2], [3] e [11]. Assumimos tambem conhecimento
previo dos resultados basicos em geometria Riemanniana que podem ser encontrados
em [15] e [32].
1.1 Modelo estatıstico
Seja Ω o conjunto de todos os resultados possıveis de um experimento aleatorio,
chamado de espaco amostral. Uma σ-algebra F sobre o conjunto Ω e uma colecao de sub-
conjuntos de Ω a qual e fechada sobre unioes, intersecoes enumeraveis e complementacoes
de subconjuntos de F . Os elementos de F sao chamados de eventos e dizemos que o par
(Ω,F) e um espaco mensuravel.
Definicao 1.1. Uma funcao P : F → R e chamada uma medida probabilidade sobre Fquando
(i) 0 ≤ P (E) ≤ 1, para todo E ∈ F ;
(ii) P (∅) = 0;
(iii) Se E1, E2, . . . sao conjuntos disjuntos dois a dois no espaco mensuravel (Ω,F) entao
P
(⋃i≥1
Ei
)=∑i≥1
P (Ei).

1.1. Modelo estatıstico 17
Um espaco de probabilidade e um espaco mensuravel (Ω,F , P ) com medida de
probabilidade P .
Uma variavel aleatoria real X : Ω → R sobre um espaco de probabilidade e uma
funcao real, definida no espaco amostral Ω, tal que ω ∈ Ω; X(ω) ≤ x ∈ F para
todo x ∈ R. Uma variavel aleatoria de dimensao n, X = (X1, . . . , Xn), e um vetor
cujas componentes Xi : Ω → R, i = 1, . . . , n, sao variaveis aleatorias reais. Seja X um
subconjunto de Rn. Dizemos que X : Ω → X e uma variavel aleatoria discreta quando
X e um conjunto enumeravel de pontos. A funcao de massa de probabilidade de X (uma
distribuicao de probabilidade discreta) e uma funcao p : X → R dada por
p(x) = P (X = x) = P
(⋂x∈X
ω ∈ Ω; Xi(ω) = xi)
a qual satisfaz ∑x∈X
p(x) = 1.
Quando X = Rn ou X e uma uniao de bolas em Rn dizemos queX : Ω→ X e uma variavel
aleatoria contınua. A funcao de densidade de probabilidade de X (uma distribuicao de
probabilidade contınua) e uma funcao p : X → R satisfazendo
p(x) ≥ 0, ∀ x ∈ X e
∫Xp(x)dx = 1,
em que∫X e a integral com respeito a medida de Lebesgue sobre X . Dado um conjunto
aberto D ⊂ X , a relacao entre a medida de probabilidade P e a funcao de densidade p(x)
e dada por
P (X ∈ D) =
∫Dp(x)dx.
Um modelo estatıstico S e uma famılia de distribuicoes de probabilidade sobre
X . Neste trabalho estamos interessados em uma famılia de funcoes de distribuicoes de
probabilidade que depende de varios parametros e pode ser vista como uma variedade.
Definicao 1.2. Seja
S = pθ(x) = p(x;θ); θ = (θ1, θ2, . . . , θn) ∈ Θ,
uma famılia de distribuicoes de probabilidade sobre X . Suponha que cada elemento pθ de
S seja parametrizado por n variaveis reais θ = (θ1, θ2, . . . , θn) ∈ Θ, em que Θ, chamado
de espaco dos parametros, e um subconjunto aberto do Rn (ou de um espaco isomorfo ao
Rn). O conjunto S e um subconjunto do espaco das funcoes
P(X ) =
f : X → R; f(x) ≥ 0 ∀ x ∈ X e
∫Xf(x)dx = 1
.

18 Preliminares em Geometria da Informacao
Suponhamos que
(i) a aplicacao ϕ : Θ → S definida por ϕ(θ) = pθ e injetiva e suficientemente suave
(isto e, diferenciavel quantas vezes forem necessarias);
(ii) o conjunto ∂pθ∂θ1
, . . . ,∂pθ∂θn
e linearmente independente sobre X .
Dizemos que S e um modelo parametrico de dimensao n.
As condicoes (i) e (ii) da definicao acima sao chamadas condicoes de regularidade
do modelo estatıstico S.
Uma aplicacao bastante utilizada em teoria estatıstica e a funcao de verossimil-
hanca L : S → F(X ,R), em que F(X ,R) = f ; f : X → R e diferenciavel, definida
por
L(pθ(x)) = log p(x;θ).
As derivadas parciais da aplicacao L,
∂L(pθ(x))
∂θj=∂ log p(x;θ)
∂θj,
para todo 1 ≤ j ≤ n, sao chamadas funcoes score e descrevem como a informacao contida
em pθ varia na direcao de θj.
Proposicao 1.3. [11] A segunda condicao de regularidade de um modelo estatıstico
S = pθ; θ ∈ Θ vale se, e somente se, pra todo θ ∈ Θ o conjunto∂L(pθ(x))
∂θ1
, . . . ,∂L(pθ(x))
∂θn
e linearmente independente.
Demonstracao. Basta observar que
∂L(pθ(x))
∂θj=∂ log p(x;θ)
∂θj=
1
p(x;θ)
∂p(x;θ)
∂θj.
Para dar continuidade a teoria, vamos assumir que as ordens de integracao e de
diferenciacao podem ser livremente trocadas, assim poderemos fazer contas do tipo∫X
∂p(x;θ)
∂θidx =
∂
∂θi
∫Xp(x;θ)dx =
∂
∂θi(1) = 0.

1.1. Modelo estatıstico 19
O modelo estatıstico S = pθ; θ ∈ Θ e a imagem de uma aplicacao injetiva ϕ,
dada por ϕ(θ) = pθ, a qual pode ser vista como um sistema de coordenadas (Θ, ϕ) para S.
Ou seja, a propria parametrizacao do modelo estatıstico S e um sistema de coordenadas
global (o que ocorre com a maioria de modelos parametricos). A parametrizacao de
um modelo estatıstico nao e unica. Seja ψ um difeomorfismo de classe C∞ de Θ em
ψ(Θ) ⊂ Rn, a aplicacao ϕ ψ−1 : ψ(Θ) → S, e um outro sistema de coordenadas
para S, ver Figura 1.1. Entao, tomando ξ = ψ(θ) como parametro em vez de θ, obtemos
S = pψ−1(ξ); ξ ∈ ψ(Θ). Se tomarmos parametrizacoes que sao difeomorfismos C∞ entao
podemos considerar S uma variedade diferenciavel C∞, a qual chamamos de variedade
estatıstica.
S
pθ
Θ
ψ(Θ)
θ
ϕ
ψ
ϕ ψ−1
ψ(θ)
Figura 1.1: Sistemas de coordenadas.
Dada uma parametrizacao do modelo estatıstico S, ϕ(θ) = pθ, o conjunto(∂
∂θ1
)θ
, . . . ,
(∂
∂θn
)θ
e uma base do espaco tangente de S em pθ.
Observamos que, para facilitar a notacao, muitas vezes ao longo do texto vamos
identificar o modelo estatıstico S com o seu espaco de parametros Θ, isto e, S ≡ Θ. Dessa
forma, vamos nos referir a distribuicao pθ como θ e usar frases como “o ponto θ” e “o
espaco tangente TθS”.
Exemplo 1.4 (Distribuicao de Poisson). Uma variavel aleatoria discreta X, em que
X = 0, 1, 2, . . ., segue uma distribuicao de Poisson com parametro λ > 0 quando a sua
funcao de massa de probabilidade e dada por
p(x;λ) = P (X = x) =λx
x!e−λ .
O modelo estatıstico unidimensional composto por essas distribuicoes e dado por

20 Preliminares em Geometria da Informacao
S = pλ = p(x, λ); λ ∈ Θ em que Θ = R+∗ . Notemos que a aplicacao λ 7→ pλ e injetiva
e, alem disso, o conjunto ∂pλ(x)
∂λ
=
e−λ(x− λ)λx−1
x!
tem apenas uma funcao nao identicamente nula e portanto as condicoes de regularidade
da Definicao 1.2 sao satisfeitas.
Exemplo 1.5 (Distribuicao Normal Univariada). Uma variavel aleatoria real contınua X,
X = R, segue uma distribuicao normal univariada (tambem conhecida como distribuicao
Gaussiana univariada) com media µ ∈ R e desvio padrao σ ∈ (0,∞) quando a sua funcao
de densidade de probabilidade e definida por
p(x;µ, σ) =1√2πσ
exp
(−1
2
(x− µσ
)2).
Chamaremos de MH = pθ = p(x;µ, σ); θ = (µ, σ) ∈ Θ, em que Θ = (µ, σ); µ ∈R e θ ∈ (0,+∞), o modelo estatıstico de dimensao 2 composto por essas distribuicoes.
Como observado acima, muitas vezes vamos identificar o modelo estatıstico com o seu
espaco de parametros e portanto podemos escreverMH = θ;θ = (µ, σ) ∈ R× (0,+∞).Para verificar as condicoes de regularidade da Definicao 1.2, primeiro consideremos
a funcao de verossimilhanca
L(pθ(x)) = −(x− µ)2
2σ2− log σ − log
√2π.
As derivadas parciais de L sao dadas por
∂L(pθ(x))
∂µ=x− µσ2
,
∂L(pθ(x))
∂σ=
(x− µ)2
σ3− 1
σ,
logo, pela Proposicao 1.3, para mostrar que a condicao (ii) vale, basta mostrar que o
conjuntox−µσ2 ,
(x−µ)2
σ3 − 1σ
e linearmente independente. De fato, fazendo a mudanca
de variavel y = x − µ, segue que o conjunto de polinomios
yσ2 ,
y2
σ3 − 1σ
e linearmente
independente. Agora, dados (µ1, σ1) e (µ2, σ2) em Θ, segue que
p(x;µ1, σ1) =p(x;µ2, σ2)⇒log p(x;µ1, σ1) = log p(x;µ2, σ2)⇒
−(x− µ1)2
2σ21
− log σ1 =− (x− µ2)2
2σ22
− log σ2

1.1. Modelo estatıstico 21
e, atraves de algumas manipulacoes algebricas, e facil ver que µ1 = µ2 e σ1 = σ2. Portanto
vale a condicao (i).
No exemplo abaixo destacamos um modelo estatıstico que e bastante utilizado em
Geometria da Informacao.
Exemplo 1.6 (Famılia de Distribuicoes Exponencial). Seja S = pθ;θ ∈ Θ um modelo
estatıstico de dimensao n. Suponhamos que cada elemento de S admite a decomposicao
p(x;θ) = exp
(n∑i=1
θiti(x)− F (θ) + C(x)
),
em que F (θ) e uma funcao diferenciavel sobre Θ (chamada de funcao de log-normalizer),
C(x), t1(x), . . . , tn(x) sao funcoes reais e diferenciaveis sobre X ⊂ Rk e, o conjunto
1, t1(x), . . . , tn(x) e linearmente independente. Entao, dizemos que S e uma famılia
de distribuicoes exponencial e que os parametros θi’s, 1 ≤ i ≤ n, sao seus parametros nat-
urais ou parametros canonicos. Vamos verificar as condicoes de regularidade do modelo
estatıstico S. Para mostrar a injetividade de ϕ : Θ → S, suponhamos que ϕ(θ) = ϕ(ξ),
entaop(x;θ) =p(x; ξ)⇒
log p(x;θ) = log p(x; ξ)⇒n∑i=1
θiti(x)− F (θ) =n∑i=1
ξiti(x)− F (ξ).
Como 1, t1(x), . . . , tn(x) e um conjunto linearmente independente segue que θi = ξi
para todo 1 ≤ i ≤ n. Consideremos agora a funcao de verossimillhanca L e as suas
derivadas parciais dadas por
L(pθ(x)) =n∑i=1
θiti(x)− F (θ) + C(x)
∂L(pθ(x))
∂θi=ti(x)− ∂F (θ)
∂θi, , 1 ≤ i ≤ n.
Novamente, pela independencia linear do conjunto 1, t1(x), . . . , tn(x), temos que∂L(pθ(x))
∂θ1
, . . . ,∂L(pθ(x))
∂θn
e tambem um conjunto linearmente independente e, pela Proposicao 1.3, vale a condicao
(ii).
Notemos que a condicao∫X p(x;θ)dx = 1 implica
F (θ) = log
∫X
exp
(n∑i=1
θiti(x) + C(x)
)dx

22 Preliminares em Geometria da Informacao
e portanto e facil ver que F e uma funcao estritamente convexa. Na teoria de analise
convexa, uma dualidade fundamental e dada pela transformacao de Legendre-Fenchel:
toda funcao convexa F admite uma funcao dual conjugada convexa F ∗ dada por
F ∗(η) = supη〈η,θ〉 − F (θ).
O supremo e atingido no unico ponto em que o gradiente de F ∗ se anula, isto e, quando
η = ∇F (θ). O parametro η e chamado de parametros de expectativa e θ e η sao chamados
de parametros duais, ver referencia [44].
A famılia de distribuicoes exponenciais representam uma ampla classe de dis-
tribuicoes discretas e contınuas que sao determinadas pela sua funcao de log-normalizer,
tais como Bernoulli, multinomial, gamma, Poisson, normal, entre outras . Em [44] os
autores disponibilizaram uma tabela com a funcao de log-normalizer e as mudancas de
parametros das distribuicoes de probabilidade mais utilizadas. Por exemplo, a distribuicao
normal univariada apresentadas no Exemplo 1.5 pode ser escrita como
p(x;µ, σ) =1
σ√
2πexp
(− µ2
2σ2
)exp
(− x2
2σ2+µx
σ2
).
Seus parametros naturais sao dados por
ϑ = (ϑ1, ϑ2) =
(µ
σ2,− 1
2σ2
)∈ R× (−∞, 0)
e a sua funcao de log-normalizer e
F (ϑ) = − ϑ21
4ϑ2
+1
2log
(− π
ϑ2
).
Dessa forma, seus parametros de expectativa sao
η = ∇F (θ) =
(− ϑ1
2ϑ2
,− 1
2ϑ2
+− ϑ21
4ϑ22
)= (µ, µ2 + σ2) ∈ R× (0,∞).
1.2 Metrica de Fisher
Seja S um modelo estatıstico, em 1945 Rao [49] introduziu uma estrutura Rieman-
niana em S atraves da matriz de informacao de Fisher.
Essencialmente, a matriz de informacao de Fisher e uma medida da quantidade de
informacao que um conjunto de dados observados “carrega” sobre um parametro descon-
hecido θ em qualquer direcao dada, [19].
Definicao 1.7. Seja S = pθ; θ ∈ Θ um modelo estatıstico de dimensao n. Dado um
ponto θ ∈ Θ, a matriz de informacao de Fisher de S em θ e a matriz G(θ) = [gij(θ)] de

1.2. Metrica de Fisher 23
ordem n, tal que
gij(θ) =Eθ
(∂
∂θi
(log p(x;θ)
) ∂
∂θj
(log p(x;θ)
))=
∫X
∂
∂θi
(log p(x;θ)
) ∂
∂θj
(log p(x;θ)
)p(x;θ)dx,
(1.1)
em que Eθ(f) =∫X f(x)p(x;θ)dx e a esperanca com respeito a distribuicao pθ. Quando
n = 1 chamamos o escalar G(θ) de informacao de Fisher.
Observacao 1.8. Embora algumas vezes a integral dada na equacao (1.1) seja divergente,
neste trabalho vamos assumir que gij(θ) e finita para todo θ e todo i, j, e que gij : Θ→ Re C∞.
Teorema 1.9. [11] A matriz de informacao de Fisher sobre qualquer modelo estatıstico
e simetrica, definida positiva e nao-degenerada.
Demonstracao. A simetria da matriz G(θ) segue diretamente da definicao.
Observemos que cada entrada gij(θ) pode ser escrita como
gij(θ) = 4
∫X
(∂
∂θi
√p(x;θ)
)(∂
∂θj
√p(x;θ)
)dx.
De fato,
gij(θ) =
∫X
∂
∂θi
(log p(x;θ)
) ∂
∂θj
(log p(x;θ)
)p(x;θ)dx
=
∫X
1
p(x;θ)
∂p(x;θ)
∂θi
1
p(x;θ)
∂p(x;θ)
∂θjp(x;θ)dx
=4
∫X
1
2√p(x;θ)
∂p(x;θ)
∂θi
1
2√p(x;θ)
∂p(x;θ)
∂θjdx
=4
∫X
(∂
∂θi
√p(x;θ)
)(∂
∂θj
√p(x;θ)
)dx.
Assim, para todo θ e para todo v = (v1, . . . , vn)t ∈ TθS, v 6= 0, segue que
vtGv =∑i,j
gijvivj
=4∑i,j
∫X
(vi∂
∂θi
√p(x;θ)
)(vj
∂
∂θj
√p(x;θ)
)dx
=4
∫X
(∑i
vi∂
∂θi
√p(x;θ)
)(∑j
vj∂
∂θj
√p(x;θ)
)dx
=4
∫X
(∑i
vi∂
∂θi
√p(x;θ)
)2
dx ≥ 0,

24 Preliminares em Geometria da Informacao
logo G(θ) e uma matriz definida nao-negativa. Alem disso,
vtGv = 0⇔∫X
(∑i
vi∂
∂θi
√p(x;θ)
)2
dx = 0⇔(∑i
vi∂
∂θi
√p(x;θ)
)2
= 0⇔∑i
vi∂
∂θi
√p(x;θ) = 0⇔
∑i
vi∂p(x;θ)
∂θi= 0⇔ vi = 0, ∀ i = 1, . . . , n, e ∀ x ∈ X ,
uma vez que, pelas condicoes de regularidade do modelo estatıstico S, o conjunto∂pθ∂θ1
, . . . ,∂pθ∂θn
e linearmente independente. Logo G(θ) e nao degenerada e consequentemente G(θ) e
definida positiva.
A proposicao acima nos diz que a matriz de informacao de Fisher e uma metrica
Riemanniana, tambem conhecida como metrica de Fisher. Portanto, segue que o modelo
estatıstico S, munido da metrica Fisher, e uma variedade Riemanniana.
Exemplo 1.10. Seja o modelo estatıstico MH = θ;θ = (µ, σ) ∈ R × (0,+∞) das
distribuicoes normais univariadas dado no Exemplo 1.5. A matriz de informacao de
Fisher de MH em θ e dada por
G(θ) =
(1σ2 0
0 2σ2
), (1.2)
ver referencia [18]. Logo, MH e uma variedade Riemanniana.
Os proximos dois teoremas descrevem duas importantes propriedades da metrica
de Fisher.
Teorema 1.11. [11] A metrica de Fisher e invariante em relacao a reparametrizacao do
espaco amostral.
Demonstracao. Seja S = pθ(x) = p(x,θ); θ ∈ Θ um modelo estatıstico sobre X ⊆ Rn
e seja f : X → Y uma transformacao invertıvel que induz um modelo estatıstico Sf =
qθ(y) = q(y,θ); y = f(x) e θ ∈ Θ sobre Y ⊆ Rn. A relacao entre as funcoes de
densidade e a aplicacao f e dada por
pθ(x) = qθ(y) Det(Jf (x)), (1.3)

1.2. Metrica de Fisher 25
em que Jf (x) e a matriz Jacobiana da transformacao f . Dessa forma
log pθ(x) = log qθ(y) + log Det(Jf (x)),
diferenciado em relacao a θi, temos que
∂
∂θi
(log pθ(x)
)=
∂
∂θi
(log qθ(y)
), (1.4)
i = 1, . . . , n, pois f nao depende de θ.
Assim, segue de (1.3) e (1.4) que
gij(θ) =
∫X
∂
∂θi
(log pθ(x)
) ∂
∂θj
(log pθ(x)
)pθ(x)dx
=
∫X
∂
∂θi
(log qθ(y)
) ∂
∂θj
(log qθ(y)
)qθ(y) Det(Jf (x))dx
=
∫Y
∂
∂θi
(log qθ(y)
) ∂
∂θj
(log qθ(y)
)qθ(y)dy
e portanto segue a prova do Teorema.
Teorema 1.12. [11] A metrica de Fisher e invariante em relacao a reparametrizacao do
espaco dos parametros. Isto e, sejam θ = (θ1, . . . , θn) e ξ = (ξ1, . . . , ξn) dois sistemas de
coordenadas do modelo estatıstico S tais que θ = θ(ξ), ou seja, θi = θi(ξ1, . . . , ξn), e sejam
G(θ) e G(ξ) as metricas de Fisher em relacao as coordenadas θ e ξ, respectivemente,
entao vale
gij(ξ) = gkr(θ)∣∣∣θ=θ(ξ)
∂θk∂ξi
∂θr∂ξj
.
Demonstracao. Consideremos a distribuicao pξ(x) = pθ(ξ)(x), temos que
∂pξ(x)
∂ξi=∂θk∂ξi
∂pθ(x)
∂θke
∂pξ(x)
∂ξj=∂θr∂ξj
∂pθ(x)
∂θr.
Logo,
gij(ξ) =
∫X
∂
∂ξi
(log pξ(x)
) ∂
∂ξj
(log pξ(x)
)pξ(x)dx
=
∫X
1
pξ(x)
∂pξ(x)
∂ξi
∂pξ(x)
∂ξjdx
=
(∫X
1
pθ(ξ)(x)
∂pθ(x)
∂θk
∂pθ(x)
∂θrdx
)∂θk∂ξi
∂θr∂ξj
=gkr(θ)∣∣∣θ=θ(ξ)
∂θk∂ξi
∂θr∂ξj
.
Uma metrica Riemanniana sobre um modelo estatıstico S = pθ(x); θ ∈ Θsatisfazendo os teoremas acima e unica (a menos de um fator constante) e, portanto,

26 Preliminares em Geometria da Informacao
igual a metrica de Fisher. Esse importante resultado foi provado em 1972 por Chentsov
em [17, Cap. 11].
Abaixo listamos dois dos principais resultados da teoria de informacao que estao
relacionados com a matriz de informacao de Fisher.
Entropia de Shannon
Em [8], Burbea e Rao mostram que a matriz de informacao de Fisher G(θ) pode
ser vista como a matriz Hessiana da entropia de Shannon,
H(p) = −∫p(x;θ) log p(x;θ)dx.
Isto e,
gij(θ) =∂2H(p)
∂θi∂θj.
Limitante de Cramer-Rao
Suponha que um conjunto de dados x foi gerado aleatoriamente, sujeito a uma
distribuicao de probabilidade a qual e desconhecida mas assumida pertencer a um modelo
estatıstico S = pθ; θ ∈ Θ. Consideremos o problema de estimar o parametro descon-
hecido θ por uma funcao θ(x) dos dados x. A aplicacao θ = (θ1, . . . , θn) : X → Rn
introduzida para esse proposito e chamada de estimador. Dizemos que θ e um estimador
nao enviesado quando
Eθ(θ(X)) = θ para todo θ ∈ Θ.
O erro medio de um estimador nao enviesado θ pode ser expresso como a matriz de
covariancia
covθ(θ) = Eθ
((θ(X)− θ)(θ(X)− θ)t
).
Uma questao a ser analisada e: o quao bom um estimador pode ser? De maneira
independente, C. Rao em [49] e H. Cramer em [20] resolveram esse problema, mais ou
menos na mesma epoca, e determinaram o que e conhecido hoje como o limitante de
Cramer-Rao. Este limitante afirma que a variancia de qualquer estimador nao enviesado
e, pelo menos, maior que o inverso da informacao de Fisher. Um estimador que atinge
esse limitante inferior e chamado de estimador eficiente.
Teorema 1.13 (Limitante de Cramer-Rao). A matriz de variancia covθ(θ) de um esti-
mador nao enviesado θ satisfaz covθ(θ) ≥ G(θ)−1, isto e, a matriz covθ(θ) − G(θ)−1 e
semidefinida positiva.

1.3. Distancia de Fisher-Rao 27
1.3 Distancia de Fisher-Rao
Seja M uma variedade Riemanniana munida de uma metrica G = [gij(p)], p ∈M .
Consideremos (U,ϕ), U ⊂ Rn aberto, um sistema de coordenadas para M em torno do
ponto p tal que ϕ(x1, . . . , xn) = p, o elemento infinitesimal da metrica G e dado por
ds2 =n∑
i,j=1
gij(p)dxidxj.
Seja γ uma curva diferenciavel por partes em M , definida no intervalo [t1, t2],
conectando dois pontos p e q em M , isto e, γ(t1) = p e γ(t2) = q. O comprimento de arco
da curva γ e dado por
`(γ) =
∫ t2
t1
√〈γ′(t), γ′(t)〉G dt,
em que 〈u,v〉G = ut[gij(p)]v e o produto interno definido por G e u,v ∈ TpM sao vetores
coluna.
A distancia geodesica entre dois pontos p e q em M e dada pelo menor comprimento
de arco de uma curva γ conectando p e q. Essa curva e chamada de curva geodesica.
Uma curva geodesica γ em um sistema de coordenadas (U,ϕ), γ(t) = (x1(t), . . . , xn(t)),
e dada pela solucao das equacoes de Euler-Lagrange,
d2xkdt2
+∑i,j
Γkijdxidt
dxjdt
= 0, k = 1, · · · , n, (1.5)
na qual Γkij sao os sımbolos de Christoffel dados por
Γmij =1
2
∑k
(∂
∂xigjk +
∂
∂xjgki −
∂
∂xkgij
)gkm, (1.6)
em que [gij] e a matriz inversa de G.
Observemos que, por definicao, o vetor tangente γ′(t) tem comprimento constante
[15], isto e,
‖γ′(t)‖2 =n∑
i,j=1
gij(γ(t))dθidt
dθjdt
= cte. (1.7)
Definicao 1.14. Seja o modelo estatıstico S = pθ; θ ∈ Θ. A distancia de Fisher-Rao
entre duas distribuicoes pθ1 e pθ2 em S, dF , e dada pelo menor comprimento de arco de
uma curva em Θ conectando θ1 e θ2.
A curva geodesica γ contida S, definida em [t1, t2], ligando pθ1 e pθ2 e determinada

28 Preliminares em Geometria da Informacao
pelas equacoes (1.5) e pelas condicoes de contornoγ(t1) = pθ1
γ(t2) = pθ2. (1.8)
A distancia de Fisher-Rao foi introduzida por C. Rao em [49] como uma medida
adequada para o calculo da distancia entre duas populacoes. Na pratica e muito difıcil
o calculo da distancia de Fisher-Rao na maioria dos modelos estatısticos, uma vez que
envolve a solucao de equacoes diferenciais de segunda ordem. Em alguns casos podemos
simplificar o calculo dessa distancia relacionando a metrica do espaco com a metrica
de espacos ja conhecidos (por exemplo, os espacos Euclidiano, hiperbolico, e esferico).
Atkinson e Mitchell [5] e Burbea [10] descreveram a distancia de Fisher-Rao entre algumas
distribuicoes de probabilidade: distribuicao de Poisson, Multinomial, Gamma, normal,
entre outras. No Exemplo 1.18, descreveremos a distancia de Fisher-Rao no espaco das
distribuicoes normais univariadas. A metrica de Fisher nesse espaco esta relacionada com
a metrica do espaco hiperbolico e, portanto, existe uma formula explıcita para a distancia
de Fisher-Rao. No caso do espaco formado por distribuicoes normais multivariadas, ainda
nao se tem uma formula fechada para a distancia de Fisher-Rao no caso geral, como
veremos no Capıtulo 2.
Observacao 1.15. Neste texto, vamos nos referir a distancia de Fisher-Rao entre as
distribuicoes pθ1 e pθ2 como a distancia entre os pontos θ1 e θ2.
Notemos que, como a metrica de Fisher e invariante em relacao a mudanca de
parametrizacao, a distancia de Fisher-Rao tambem o e.
Nas definicoes abaixo, introduzimos o conceito de subvariedade totalmente geodesica.
Definicao 1.16. Seja M uma variedade de dimensao n. Quando N e um subconjunto de
M e a inclusao i : N →M e um mergulho (isto e, i e diferenciavel e di(p) : TpN → Ti(p)M
e injetiva para todo p ∈ N) dizemos que N e uma subvariedade de M .
Definicao 1.17. Uma subvariedade N de uma variedade Riemanniana M e dita total-
mente geodesica quando toda geodesica de N e geodesica de M .
Exemplo 1.18 (Distancia entre duas distribuicoes normais univariadas). Voltemos ao
modelo estatıstico MH = θ;θ = (µ, σ) ∈ R × (0,+∞) composto por distribuicoes
normais univariadas, apresentado no Exemplo 1.5. Neste espaco, uma forma fechada
para a distancia de Fisher-Rao e conhecida via uma associacao com o modelo do plano
hiperbolico, ver referencias [5], [10] e [18].
Pela matriz de informacao de Fisher em MH dada na equacao (1.2), segue que a
expressao da metrica em MH e dada por
ds2 =dµ2 + 2dσ2
σ2.

1.3. Distancia de Fisher-Rao 29
Como a matriz da metrica no modelo do plano superior de Poincare, H2 = (x, y) ∈R2; y > 0, e dada por
GP (x, y) =
(1y2
0
0 1y2
), (1.9)
segue que a metrica em MH esta relacionada com a metrica de H2 atraves da aplicacao
f :MH → H2
(µ, σ) 7→(µ√2, σ
).
(1.10)
Logo, a distancia de Fisher-Rao entre os pontos (µ1, σ1) e (µ2, σ2) pertencentes a MH,
pode ser expressa em termos da distancia hiperbolica de Poincare , dH2 , como
dF ((µ1, σ1), (µ2, σ2)) =√
2dH2
((µ1√
2, σ1
),
(µ2√
2, σ2
)).
Uma expressao analıtica para dF por ser dada por, ver referencia [1],
dF ((µ1, σ1), (µ2, σ2)) =√
2 arccosh
1 +
∣∣∣( µ1√2, σ1
)−(µ2√
2, σ2
)∣∣∣22σ1σ2
(1.11)
em que |.| e a norma Euclidiana em R2.
As curvas geodesicas de MH sao as imagens inversas, por meio da transformacao
f , das curvas geodesicas de H2. Essas geodesicas sao as semirretas verticais positivas e
as semi-elipses, centradas em σ = 0, com excentricidade 1√2. Resolvendo o sistema de
γ1
γ2
Figura 1.2: Geodesicas de MH.
equacoes dado em (1.5), obtemos uma parametrizacao, com velocidade constante, de uma

30 Preliminares em Geometria da Informacao
curva geodesica γ : [0, 1]→MH, tal que γ(0) = (µ1, σ1) e γ(1) = (µ2, σ2),dada por
γ(t) =
(µ1, σ1 exp
(log
(σ2
σ1
)t
)),
se µ1 = µ2 (semirreta). Se µ1 6= µ2 (semi-elipse),
γ(t) =
(c2
4
√c3 tanh
(√c3(c2 + t)
)2sgn(µ2 − µ1)
+ c1, c4
√c2
4c3
cosh(√
c3(c2 + t))
+ 1
),
na qual
c1 =µ2
1 − µ22 + 2σ2
1 − 2σ22
2(µ1 − µ2),
c2 =−tanh−1
(µ1−c4√
c24−2c4µ1+µ21+2σ21
)tanh−1
(µ1−c4√
c24−2c4µ1+µ21+2σ21
)− tanh−1
(µ2−c4√
c24−2c4µ1+µ21+2σ21
) ,c3 =4
(tanh−1
(µ1 − c4√
c24 − 2c4µ1 + µ2
1 + 2σ21
)− tanh−1
(µ2 − c4√
c24 − 2c4µ1 + µ2
1 + 2σ21
))2
,
c4 =(c2
4 − 2c4µ1 + µ21 + 2σ2
1)1/4
c3
.
A Figura 1.3 ilustra a curva geodesica que liga os pontos P = (−0.5, 1) e Q =
(1, 1.5) no plano MH e a Figura 1.4 ilustra o grafico de algumas distribuicoes que estao
relacionadas com pontos dessa curva.
P
RQ
Figura 1.3: Curva geodesica ligando P e Q.
P
RQ
Figura 1.4: Grafico das distribuicoes normais.
SejaMHµ0 a subvariedade deMH formada pelas distribuicoes normais univariadas
com media constante, MHµ0 = θ ∈ MH;µ = µ0 ∈ R constante. A distancia de Fisher-

1.4. Curvaturas 31
Rao entre dois pontos (µ0, σ1) e (µ0, σ2) em MHµ0 e dada por
dµ0((µ0, σ1), (µ0, σ2)) =√
2 log
(σ2
σ1
).
As curvas geodesicas em MHµ0 sao as semirretas verticais positivas e portanto, MHµ0 e
uma subvariedade totalmente geodesica, ver Figuras 1.5 e 1.6. Ou seja, a distancia em
Fisher-Rao restrita a subvariedadeMHµ0 e igual a distancia na variedadeMH, dµ0 = dF .
A
B
C
Figura 1.5: Reta ligando A e B.
A
B
C
Figura 1.6: Grafico das distribuicoes normais.
Consideremos agora a subvariedade MHσ0 formada pelas distribuicoes normais
univariadas com o mesmo desvio padrao,MHσ0 = θ ∈MH;σ = σ0 ∈ (0,∞) constante.A distancia de Fisher-Rao entre duas distribuicoes (µ1, σ0) e (µ2, σ0) em MHσ0 e
dσ0((µ1, σ0), (µ2, σ0)) =|µ1 − µ2|
σ0
.
A subvariedadeMHσ0 nao e totalmente geodesica, ver Figura 1.7 . De fato, dados
dois pontos (µ1, σ0) e (µ2, σ0), temos que
dF ((µ1, σ0), (µ2, σ0)) =√
2 log
((µ1 − µ2)2 + 4σ2
0 + |µ1 − µ2|√
(µ1 − µ2)2 + 8σ20
4σ20
)
<|µ1 − µ2|
σ0
.
1.4 Curvaturas
Nesta secao, vamos relembrar as definicoes de curvatura seccional e curvatura
escalar.

32 Preliminares em Geometria da Informacao
M N
Figura 1.7: Distancia nao geodesica.
Dada uma metrica Riemanniana G = [gij] em uma variedade M , consideremos
(U,ϕ), U ⊂ Rn aberto, um sistema de coordenadas para M em torno do ponto p tal que
ϕ(x1, . . . , xn) = p.
Definicao 1.19. Seja E ∈ TpM um subespaco de dimensao 2 do espaco tangente TpM e
sejam x, y ∈ E dois vetores linearmente independentes. Entao a curvatura seccional de
E em p e dada por
K(E;x, y) =
∑i,j,k,lRijklxiyjxkyl∑
i,j,k,l(gikgjl − gilgjk)xiyjxkyl,
em que
Rijkl =∑l
Rlijkgls
e o tensor curvatura Riemanniana, no qual os termos Rlijk podem ser expressos em termos
dos sımbolos de Christoffel
Rlijk =
∑s
ΓsikΓljs −
∑s
ΓsjkΓlis +
∂
∂xjΓlik −
∂
∂xiΓljk.
A curvatura seccional e uma generalizacao natural da curvatura Gaussiana das
superfıcies, quando M = Rn, K(E;x, y) = 0 para todo E [15]. Variedades Riemannianas
de curvatura seccional constante sao as mais simples e suas propriedades ja foram bastante
estudadas, por exemplo, o espaco Euclidiano (K ≡ 0), a esfera unitaria (K ≡ 1) e o espaco
hiperbolico (K ≡ −1). No Exemplo abaixo mostramos que a variedadeMH tem curvatura
constante igual a −1/2.
Exemplo 1.20. Voltemos a variedadeMH e consideremos a matriz da metrica de Fisher
em MH, G, dada em (1.2). Como a variedade e de dimensao 2, temos apenas uma
curvatura seccional. Um calculo direto dos sımbolos de Cristoffel (1.6) associados a essa
metrica mostra que os unicos sımbolos nao nulos sao
Γ112 = Γ1
21 = − 1
σ, Γ2
11 =1
2σe Γ2
22 = − 1
σ.

1.5. Divergencia de Kullback-Leibler 33
Logo, os unicos tensores de curvatura Riemanniana nao nulos sao
R1212 = R2121 = − 1
σ4e R1221 = R2112 =
1
σ4.
Para x = (1, 0) e y = (0, 1), segue que
K(E, ;x, y) =R1212
g11g22
=−1/σ4
2/σ4= −1
2.
Uma outra nocao de curvatura bastante utilizada e a de curvatura media, tambem
conhecida como curvatura escalar.
Definicao 1.21. A curvatura escalar de uma variedade Riemanniana M e dada por
R =∑i,j
gijRij,
em que Rij sao os tensores de Ricci dados por
Rik =∑i,j
Rijksgsj.
1.5 Divergencia de Kullback-Leibler
A divergencia de Kullback-Leibler ou entropia relativa e uma das medidas de dis-
similaridade entre distribuicoes mais utilizadas. Dadas duas distribuicoes de probabilidade
p e q pertencentes a um mesmo modelo estatıstico a divergencia de Kullback-Leibler, DKL,
e dada por
DKL(p‖q) =
∑xi∈X
p(xi) logp(xi)
q(xi), se X e discreto∫
Xp(x) log
p(x)
q(x)dx, se X e contınuo
(1.12)
Dada uma distribuicao p determinada a partir de um conjunto de observacoes, pode-
mos dizer que DKL mede a informacao perdida quando q e usada para aproximar p. A
divergencia de Kullback-Leibler nao e uma distancia pois nao satisfaz a condicao de sime-
tria. Por isso, muitas vezes, uma versao simetrizada da divergencia e considerada. A
divergencia de Kullback-Leibler simetrizada e definida por
DKL(θ1,θ2) =1
2(DKL(θ1‖θ2) +DKL(θ2‖θ1)) .
Exemplo 1.22 (Divergencia de Kullback-Leibler entre duas distribuicoes normais univari-
adas). Dadas duas distribuicoes normais univariadas p1 = p(x;µ1, σ1) e p2 = p(x;µ2, σ2),

34 Preliminares em Geometria da Informacao
a divergencia de Kullback-Leibler entre elas e dada por, ver referencia [11],
DKL(p1‖p2) =1
2
(2 log
(σ2
σ1
)+σ2
1
σ22
+(µ1 − µ2)2
σ22
− 1
).
1.5.1 Relacao com a Distancia de Fisher-Rao
A metrica de Fisher pode ser vista como uma aproximacao de segunda ordem
da divergencia de Kullback-Leibler. As demostracoes dos resultados apresentados nessa
subsecao podem ser encontradas em [11].
Proposicao 1.23. [11] Dado um modelo estatıstico S = pθ; θ ∈ Θ, seja ∆θi = θi−θ0i.
Entao
DKL(pθ‖pθ0) =1
2
∑i,j
gij(θ0)∆θi∆θj + o(|∆θ|2),
em que [gij(θ0)] e a matriz de informacao de Fisher dada em (1.1) e o(|∆θ|2) representa
a quantidade que tende a zero mais rapido que |∆θ|2 quando ∆θ tende a zero.
Proposicao 1.24. [11] Sejam pθ1 e pθ2 duas distribuicoes pertencentes ao modelo es-
tatıstico S. Entao
DKL(θ1‖θ2) =1
2d2F (θ1,θ2) + o(d2
F (θ1,θ2)).
Corolario 1.25. [11] Sejam pθ1 e pθ2 duas distribuicoes pertencentes ao modelo estatıstico
S e seja a divergencia de Kullback-Leibler simetrizada
DKL(θ1,θ2) =1
2(DKL(θ1‖θ2) +DKL(θ2‖θ1)).
Entao
DKL(θ1,θ2) = d2F (θ1,θ2) + o(d2
F (θ1,θ2)).
Considerando o modeloMH, e possıvel escrever a divergencia de Kullback-Leibler
em funcao da distancia de Fisher-Rao, ver referencia [18]. Dados dois pontos (µ, σ1) e
(µ, σ2), vimos no Exemplo 1.18 que a distancia de Fisher-Rao entre eles e dada por
d = dµ0((µ, σ1), (µ, σ2)) =√
2 log
(σ2
σ1
).
Sendo assim, segue que
DKL((µ, σ1)‖(µ, σ2)) =1
2
(exp(−
√2d) + 2
d√2− 1
)e
DKL((µ, σ1), (µ, σ2)) =exp(√
2d) + exp(−√
2d)
2− 1.

1.5. Divergencia de Kullback-Leibler 35
1.5.2 Relacao com a Divergencia de Bregman
Seja F : Θ→ R+ uma funcao diferenciavel estritamente convexa, sobre um domınio
convexo Θ ⊂ Rn. A divergencia de Bregman, DF , e definida por, ver referencia [45],
DF (θ1‖θ2) = F (θ1)− F (θ2)− 〈θ1 − θ2,∇F (θ2)〉, (1.13)
em que 〈·, ·〉 e o produto interno usual do Rn e ∇F (θ2) e o vetor gradiente de F no ponto
θ2.
A divergencia de Bregman define uma famılia de medidas de dissimilaridades. Por
exemplo, quando
F (θ) =n∑i=1
θ2i
a divergencia de Bregman e o quadrado da distancia Euclidiana.
Consideremos agora S uma famılia de distribuicoes exponencial, dada no Exemplo
1.6. Sejam p(x;θp) e p(x;θq) duas distribuicoes em S e seja F a funcao de log nomalizer
que determina a famılia S. A divergencia de Kullback-Leibler entre p(x;θp) e p(x;θq) e
equivalente a divergencia de Bregman com os parametros naturais trocados, isto e,
DKL(p(x;θp)‖p(x;θq)) = DF (θq‖θp). (1.14)

36
Capıtulo 2
Distribuicao Normal Multivariada
Neste capıtulo vamos fazer um estudo da distancia de Fisher-Rao no modelo es-
tatıstico composto por distribuicoes normais multivariadas. Neste modelo uma formula
fechada para a distancia de Fisher-Rao no caso geral ainda nao e conhecida.
Uma variavel aleatoria X, X ⊂ Rn, segue uma distribuicao normal multivariada
quando a sua funcao de densidade de probabilidade e definida por
p(x;µ,Σ) =(2π)−(n2 )√
Det(Σ)exp
(−(x− µ)tΣ−1(x− µ)
2
),
em que xt = (x1, . . . , xn) ∈ Rn e um vetor aleatorio, µt = (µ1, . . . , µn) ∈ Rn e o vetor de
medias e Σ = [σij] ∈ Pn(R) e a matriz de covariancia (Pn(R) e o conjunto das matrizes
simetricas definidas positivas de ordem n). Seja M = θ;θ = (µ,Σ) ∈ Rn × Pn(R) o
modelo estatıstico formado por essas distribuicoes. Atraves da identificacao
(µ,Σ) 7→ (µ1, . . . , µn, σ11, . . . , σ1n, . . . , σkk, . . . , σkn, . . . , σnn)
temos que M e isomorfo a um subconjunto aberto de Rp, p = n+ n(n+1)2
, [54].
Ao longo do capıtulo, descrevemos a distancia de Fisher-Rao em algumas subvar-
iedades de M e apresentamos alguns algoritmos numericos que permitem o calculo da
distancia de Fisher-Rao . Alem disso, derivamos alguns limitantes para essa distancia.
2.1 Distancia de Fisher-Rao
Seja a variedade estatıstica M = θ;θ = (µ,Σ) ∈ Rn × Pn(R). Dado θ ∈ M a
matriz de informacao de Fisher de M em θ, G(θ) = [gij(θ)], pode ser escrita na forma

2.1. Distancia de Fisher-Rao 37
matricial como
gij(θ) =∂µt
∂θiΣ−1 ∂µ
∂θj+
1
2tr
(Σ−1 ∂Σ
∂θiΣ−1 ∂Σ
∂θi
), (2.1)
ver referencia [48].
Dado θ ∈ M, o espaco tangente de M em θ e o conjunto TθM = (x, A);x ∈Rn e A ∈ Sn(R), em que Sn(R) e o espaco das matrizes simetricas de ordem n com
entradas reais, [54]. Sejam V = (x, A) e W = (y, B) vetores pertencentes a TθM, o
produto interno no ponto θ = (µ,Σ) associado a matriz de informacao de Fisher G(θ),
dada em (2.1), e
〈V,W 〉θ = xtΣ−1y +1
2tr(Σ−1AΣ−1B). (2.2)
Logo, o elemento infinitesimal da metrica de Fisher pode ser expresso por
ds2 = dµtΣ−1dµ+1
2tr[(Σ−1dΣ)2], (2.3)
na qual dµt = (dµ1, . . . , dµn) ∈ Rn e dΣ ∈ Sn(R) e a matriz cujas entradas sao as
derivadas da entradas correspondentes da matriz Σ, [54].
Uma importante propriedade da metrica de Fisher deM e que ela e invariante em
relacao a transformacoes afins. O resultado abaixo foi dado em [10] sem demonstracao,
apresentamos uma prova do mesmo no Apendice A.
Teorema 2.1. Para todo (c, Q) ∈ Rn×GLn(R), em que Gln(R) e o espacos das matrizes
invertıveis de ordem n, a aplicacao
ψ(c,Q) : M → M(µ,Σ) 7→ (Qµ+ c, QΣQt),
(2.4)
estabelece uma isometria em M. Isto e, ψ(c,Q) e um difeomorfismo e, para todo θ ∈M e
U, V,∈ TθM, vale
〈U, V 〉θ = 〈dψ(c,Q)(θ) · U, dψ(c,Q)(θ) · V 〉ψ(c,Q)(θ). (2.5)
Corolario 2.2. A distancia de Fisher-Rao entre θ1 = (µ1,Σ1) e θ2 = (µ2,Σ2) em Msatisfaz
dF (θ1,θ2) = dF (ψ(c,Q)(θ1), ψ(c,Q)(θ2)) = dF ((Qµ1 +c, QΣ1Qt), (Qµ2 +c, QΣ2Q
t)), (2.6)
para todo (c, Q) ∈ Rn ×GLn(R).
Demonstracao. A prova desse corolario segue diretamente da definicao da distancia de
Fisher-Rao e da definicao de isometria.
No corolario a seguir, apresentamos algumas isometrias que decorrem do Teorema

38 Distribuicao Normal Multivariada
2.1 e que serao utilizadas ao longo desse capıtulo. Antes de enunciarmos este resultado
recordamos que a raiz quadrada de uma matriz A, denotada por A1/2 ou√A, e uma matriz
X tal que XX = A. Quando A e uma matriz diagonal, A1/2 e uma matriz diagonal tal
que cada elemento e a raiz quadrada do elemento correspondente da diagonal de A. Se
A e uma matriz simetrica definida positiva entao, dada a sua decomposicao ortogonal
A = OΛOt, em que O e uma matriz ortogonal cujas colunas sao os autovetores de A e
Λ e uma matriz diagonal formada pelos autovalores de A, a raiz quadrada de A pode ser
dada por A1/2 = OΛ1/2Ot.
Corolario 2.3. Sejam θ1 = (µ1,Σ1) e θ2 = (µ2,Σ2) e θ0 := (0, In), em que 0 e o vetor
nulo de dimensao n e In e a matriz identidade de ordem n, pontos em M. Entao:
(i) Dada Σ1 = OΛ1Ot a decomposicao ortogonal da matriz Σ1, seja Σ
−1/21 = OΛ
−1/21 Ot,
segue que ψ1 = ψ(−Σ−1/21 µ1,Σ
−1/21
) e uma isometria e
dF (θ1,θ2) = dF (θ0, ψ1(θ2)),
em que ψ1(θ2) = (Σ−1/21 (µ2 − µ1),Σ
−1/21 Σ2Σ
−1/21 ), ver referencia [10].
(ii) Dada Σ1 = GGt a fatoracao de Cholesky da matriz Σ1 segue que ψ2 = ψ(−G−1µ1,G−1)
e uma isometria e
dF (θ1,θ2) = dF (θ0, ψ2(θ2)),
em que ψ2(θ2) = (G−1(µ2 − µ1), G−1Σ2G−t)
(iii) Considerando θ = (µ,Σ) = ψ1(θ2) ou θ = (µ,Σ) = ψ2(θ2) e Σ = OΛOt a de-
composicao ortogonal de Σ, segue que ψ3 = ψ(0,Ot) ψi, i = 1, 2, e uma isometria
e
dF (θ1,θ2) = dF (θ0, ψ3(θ)),
onde ψ3(θ) = (Otµ,Λ).
(iv) Considerando θ = (µ,Σ) = ψ1(θ2) ou θ = (µ,Σ) = ψ2(θ2) e P uma matriz de
projecao ortogonal tal que Pµ = ‖µ‖ej, em que ej e um dos vetores canonicos do
Rn, segue que ψ4 = ψ(0,P ) ψi, i = 1, 2, e uma isometria e
dF (θ1,θ2) = dF (θ0, ψ4(θ)),
onde ψ4(θ) = (‖µ‖ej, PΣP t).
Demonstracao. Para mostrar o item (i), observemos que Σ−(1/2)1 e invertıvel e pelo Teo-
rema 2.1, a aplicacao ψ1 = ψ(−Σ(−1/2)1 µ1,Σ
−(1/2)1
) e uma isometria. Portanto segue do
Corolario 2.2 que
d(θ1,θ2) = dF (ψ1(θ1), ψ1(θ2)) = dF ((0, In), (Σ−(1/2)1 (µ2 − µ1),Σ
−(1/2)1 Σ2Σ
−(1/2)1 ).

2.1. Distancia de Fisher-Rao 39
No item (ii), como G e invertıvel, de forma analoga a demonstracao do item (i), a
aplicacao ψ2 = ψ(−G−1µ1,G−1) e uma isometria e
dF (θ1,θ2) = dF (ψ2(θ1), ψ2(θ2)) = dF ((0, In), (G−1(µ2 − µ1), G−1Σ2G−t).
Seja a isometria θ = ψi(θ2) = (µ,Σ), i = 1, 2, e seja Σ = OΛOt. Como O e uma
matriz ortogonal, pelo Teorema 2.1, ψ(0,Ot) e uma isometria e logo, segue do Corolario 2.2
que a isometria ψ3 = ψ(0,Ot) ψi, i = 1, 2, e tal que
dF (θ1,θ2) =dF (ψ3(θ1), ψ3(θ2))
=dF (ψ(0,Ot)(ψi(θ0)), ψ(0,Ot)(ψi(θ2)))
=dF (ψ(0,Ot)(θ0), ψ(0,Ot)(θ))
=dF ((Ot0, OtO), (Otµ, OtOΛOtO))
=dF ((0, In), (Otµ,Λ)),
logo mostramos o item (iii).
Finalmente, par mostrar o item (iv), observemos que, de forma analoga a demon-
stracao do item (iii), ψ4 = ψ(0,P ) ψi, i = 1, 2, e uma isometria e
dF (θ1,θ2) =dF (ψ4(θ1), ψ4(θ2))
=dF (ψ(0,P )(ψi(θ0)), ψ(0,P )(ψi(θ2)))
=dF (ψ(0,P )(θ0), ψ(0,P )(θ))
=dF ((P0, PP t), (Pµ, PΣP t))
=dF ((0, In), (‖µ‖ej, PΣP t)).
Observemos que a isometria ψ2 e mais barata de ser calculada computacionalmente,
uma vez que o calculo do fator Cholesky de uma matriz e mais barato que o calculo da
sua decomposicao ortogonal. Esse fato torna-se mais evidente em dimensoes maiores.
Na Secao 2.3.2 vamos utilizar os resultados acima para derivar alguns limitantes para a
distancia de Fisher-Rao.
Exemplo 2.4. Consideremos duas distribuicoes normais bivariadas pθ1 e pθ2 parametrizadas,
respectivamente, por
θ1 =
((−1
−1
),
(1.25 0.43
0.43 0.75
))e θ2 =
((2
1
),
(1.375 −0.65
−0.65 2.125
)).
A Figura 2.1(a) ilustra os graficos e as curvas de nıvel de pθ1 e pθ2 . Sejam ψ1 e ψ2, as

40 Distribuicao Normal Multivariada
isometrias dadas no Corolario 2.3, a Figura 2.1(b) ilustra os graficos e as curvas de nıvel
das distribuicoes com parametros θ0,
ψ1(θ2) =
((−1
−1
),
(1.75 −1.88
−1.88 3.92
))e ψ2(θ2) =
((2
1
),
(1.1 −1.3
−1.3 4.57
)).
Fazendo θ = ψ1(θ2), temos que
-4 -2 0 2 4
-2
0
2
4
Parâmetros
θ1
θ2
(a) Graficos e curvas de nıvel das distribuicoes normais bivariadas com parametros θ1 e θ2.
-4 -2 0 2 4
-2
0
2
4
Parâmetros
θ0
ψ1(θ2)
ψ2(θ2)
(b) Graficos e curvas de nıvel das distribuicoes normais bivariadas com parametros θ0,ψ1(θ2) e ψ2(θ2), dF (θ0, ψ1(θ2)) = dF (θ0, ψ2(θ2)).
Figura 2.1
ψ3(θ2) =
((0.33
−2.94
),
(5 0
0 0.67
))e ψ4(θ2) =
((2.96
0
),
(1.25 0.43
0.43 0.75
)).
As curvas de nıvel das distribuicoes com parametros θ0 e ψ3(θ2) e com parametros θ0 e
ψ4(θ2), estao ilustradas nas Figuras 2.2(a) e 2.2(b), respectivamente. Notemos que, pelo
Corolario 2.3, dF (θ1,θ2) = dF (θ0, ψi(θ2)), para todo i = 1, . . . , 4.
Seja γ uma curva diferenciavel em M, definida no intervalo [t1, t2], dada por

2.1. Distancia de Fisher-Rao 41
Parâmetros
θ0 ψ3(θ2)
-4 -2 0 2 4 6
-4
-2
0
2
(a) Curvas de nıvel das distribuicoes normaisbivariadas com parametros θ0 e ψ3(θ2).
Parâmetros
θ0 ψ4(θ2)
-4 -2 0 2 4 6
-4
-2
0
2
(b) Curvas de nıvel das distribuicoes normaisbivariadas com parametros θ0 e ψ4(θ2).
Figura 2.2
γ(t) = (µ(t),Σ(t)). A curva γ e uma curva geodesica de M se suas funcoes coorde-
nadas satisfazem as seguintes equacoes [54]d2µ
dt2−(dΣ
dt
)Σ−1
(dµ
dt
)= 0
d2Σ
dt2+
(dµ
dt
)(dµ
dt
)t−(dΣ
dt
)Σ−1
(dΣ
dt
)= 0
. (2.7)
Essas equacoes podem ser parcialmente integraveis como [25]dµ
dt= Σx
dΣ
dt= Σ(B − xtµ),
(2.8)
em que (x, B) ∈ TθM sao as constantes de integracao.
Consideremos a mudanca natural de parametros dada pela aplicacao ϕ, definida
em M, dada por
ϕ(µ(t),Σ(t)) = (δ(t),∆(t)) = (Σ(t)−1µ(t),Σ(t)−1).
O sistema de equacoes diferenciais (2.8) torna-sed∆
dt= −B∆ + xδt
dδ
dt= −Bδ + (1 + δ∆−1δ)x
. (2.9)

42 Distribuicao Normal Multivariada
Suponhamos que as equacoes acima estao sujeitas as seguintes condicoes iniciais(δ(0),∆(0)) = (δ0,∆0)(dδ
dt(0),
d∆
dt(0)
)= (x0,−B0),
(2.10)
ou seja, a velocidade inicial da curva geodesica no ponto (δ0,∆0) ∈ M e (x0,−B0).
Observemos que as condicoes (2.10) podem ser tomadas como(δ(0),∆(0)) = (0, In)(dδ
dt(0),
d∆
dt(0)
)= (x,−B).
(2.11)
De fato, seja ∆0 = GGt a decomposicao de Cholesky da matriz ∆0 e seja
(x, B) = (G−1x0, G−1B0G
−t).
Seja (δ(t), ∆(t)) a curva geodesica satisfazendo (2.11) e consideremos a isometria ψ =
ψ(δ0,G), entao (δ(t),∆(t)) = ψ(δ(t), ∆(t)) = (Gδ(t) + δ0, G∆(t)Gt) e a curva geodesica
que satisfaz as condicoes iniciais (2.10).
Eriksen [25] em 1986 e Calvo e Oller [13] em 1990 resolveram, independentemente,
o problema de valor inicial dado pelas equacoes (2.9) e (2.11). Eriksen descreveu a curva
geodesica em termos de uma aplicacao exponencial, porem ele nao derivou uma formula
explıcita para tal geodesica. Por outro lado, Calvo e Oller resolveram um sistema de
equacoes diferencial muito mais geral e, dessa forma, encontraram uma formula explıcita
para a curva geodesica. Em [34] os autores conseguiram calcular a curva geodesica atraves
do resultado obtido por Eriksen e mostraram que a curva era a mesma dada em [13]. Essa
formula explıcita e dada por
δ(t) =−B(cosh(tG)− In)(G−)2x+ senh(tG)G−x
∆(t) =In +1
2(cosh(tG)− In) +
1
2B(cosh(tG)− In)(G−)2B
− 1
2senh(tG)G−B − 1
2B senh(tG)G−
, (2.12)
em que G2 = B2 + 2xxt e G− e a matriz inversa generalizada da matriz quadrada G, isto
e, GG−G = G.
Como uma curva geodesica tem velocidade constante em todo ponto, dado (x, B) ∈TθM, a distancia de Fisher-Rao entre (0, In) e (δ(1),∆(1)) e dada por∫ 1
0
√‖(δ′(t),∆′(t))‖ dt =
√1
2tr(B2) + ‖x‖2.

2.1. Distancia de Fisher-Rao 43
Mesmo com a solucao dada em (2.12), dados dois pontos θ1 = (µ1,Σ1) e θ2 =
(µ2,Σ2) em M, em geral, ainda nao se tem uma formula fechada para a distancia de
Fisher-Rao entre θ1 e θ2 e nem uma formula explıcita para a curva geodesica ligando
esses dois pontos. Para isso, e necessario resolver o problema de valor de contorno dado
pelas equacoes (2.7) e por (µ(0),Σ(0)) = (µ1,Σ1)
(µ(1),Σ(1)) = (µ2,Σ2). (2.13)
Uma questao a ser abordada e se essa geodesica existe.
Definicao 2.5. Uma variedade Riemanniana M e completa quando para todo p ∈ M ,
a aplicacao exponencial, expp (a curva geodesica partindo de p no instante t = 0), esta
definida para todo v ∈ TpM . Isto e, se as geodesicas γ(t) que partem de p estao definidas
para todos os valores do parametro t ∈ R.
Vimos que todo θ ∈M pode ser levado isometricamente para o ponto θ0 logo, pela
solucao dada nas equacoes (2.12), a curva γ(t) esta definida para todo t ∈ R e portanto
segue queM e completa. Dessa forma, pelo Teorema de Hopf e Rinow [15, Cap. 7], para
todo ponto θ1 e θ2 pertencente a M, existe uma curva geodesica γ que liga esses pontos
e `(γ) = dF (θ1,θ2).
A seguir, descreveremos a distancia de Fisher-Rao e as curvas geodesicas em algu-
mas subvariedades de M.
2.1.1 A subvariedade MΣ0onde Σ0 e constante
Seja MΣ0 = θ ∈ M, Σ = Σ0 ∈ Pn(R) constante a subvariedade de dimensao n
composta pelas distribuicoes normais multivariadas com a mesma matriz de covariancia.
A metrica de Fisher de MΣ0 e
ds2 = dµtΣ−10 dµ,
a qual, a menos da matriz constante Σ0 e essencialmente a metrica Euclidiana [5]. A
distancia de Fisher-Rao entre θ1 = (µ1,Σ0) e θ2 = (µ2,Σ0) e igual a
dΣ0(θ1,θ2) =√
(µ1 − µ2)tΣ−10 (µ1 − µ2). (2.14)
A distancia acima e igual a distancia dada por Mahalanobis [40] (chamada de distancia
de Mahalanobis), um dos pioneiros no estudo de medidas de similaridade entre dados que
tinham algum tipo de correlacao.
Uma curva geodesica tal que γ(0) = θ1 e γ(1) = θ2 em MΣ0 e dada por
γ(t) = ((1− t)µ1 − tµ2,Σ0).

44 Distribuicao Normal Multivariada
Observemos que, assim como no caso univariado, a subvariedade MΣ0 nao e totalmente
geodesica [54].
Exemplo 2.6. Sejam duas distribuicoes bivariadas com parametros θ1 = ((−1, 0)t,Σ0) e
θ2 = ((6, 3)t,Σ0), em que
Σ0 =
(1.1 0.9
0.9 1.1
).
A Figura 2.3 ilustra a curva geodesica em MΣ0 conectando essas distribuicoes: as cur-
vas em vermelho sao as curvas de nıveis das distribuicoes pθ1 e pθ2 , as curvas em azul
representam algumas curvas de nıvel das distribuicoes por onde a curva geodesica passa
e, o segmento em cinza, representa a curva geodesica no plano µ1 × µ2. A distancia de
Fisher-Rao em MΣ0 entre os pontos θ1 e θ2 e dΣ0(θ1,θ2) = 8.06226.
-4 -2 0 2 4 6 8 10
-2
0
2
4
Figura 2.3: Curva geodesica emMΣ0(segmento cinza) ligando duas distribuicoes normaisbivariadas com parametros θ1 = ((−1, 0)t,Σ0) e θ2 = ((6, 3)t,Σ0).
2.1.2 A subvariedade Mµµµ0onde µµµ0 e constante
Seja Mµ0 = θ ∈M; µ = µ0 ∈ Rn constante ⊂ M a subvariedade de dimensaon(n+1)
2composta por distribuicoes com o mesmo vetor de medias µ0. A metrica de Fisher
nessa subvariedade e dada por
ds2 =1
2tr[(Σ−1dΣ)2].
Essa metrica foi estudada por varios autores como, por exemplo, Siegel [53] atraves
de matrizes Hermitianas e por Atkinson-Mitchell [5] e Burbea [10] atraves das subvar-
iedades de M.
A distancia entre θ1 = (µ0,Σ1) e θ2 = (µ0,Σ2) e
d2µ0
(θ1,θ2) =1
2
n∑i=1
[log(λi)]2, (2.15)

2.1. Distancia de Fisher-Rao 45
em que 0 < λ1 ≤ λ2 ≤ · · · ≤ λn sao os autovalores de Σ−11 Σ2.
Uma curva geodesica γ(t) = (µ(t),Σ(t)) emMµ0 ligando dois pontos θ1 = (µ0,Σ1)
e θ2 = (µ0,Σ2) com γ(0) = θ1 e γ(1) = θ2 e dada por [43]
γ(t) = (µ0,Σ1/21 exp(t log(Σ
−1/21 Σ2Σ
−1/21 ))Σ
1/21 ).
Novamente, assim como no caso univariado, a subvariedade Mµ0 e uma subvar-
iedade totalmente geodesica [54]. Ou seja, toda curva geodesica de Mµ0 e tambem uma
geodesica de M. Assim, dµ0(θ1,θ2) = dF (θ1,θ2) para todo θ1, θ2 ∈Mµ0 .
Exemplo 2.7. Sejam duas distribuicoes bivariadas com parametros θ1 = ((0, 0)t,Σ1) e
θ2 = ((0, 0)t,Σ2), em que
Σ1 =
(1 0
0 8
)e Σ2 =
(8 0
0 1
).
Na Figura 2.4, as curvas em vermelho ilustram as curvas de nıveis das distribuicoes pθ1 e
pθ2 e as curvas em azul representam algumas curvas de nıvel das distribuicoes por onde a
curva geodesica passa. Alem disso dF (θ1,θ2) = 2.07944.
-4 -2 0 2 4
-4
-2
0
2
4
Figura 2.4: Curva geodesica em Mµ0 ligando duas distribuicoes normais bivariadas comparametros θ1 = ((0, 0)t,Σ1) e θ2 = ((0, 0)t,Σ2).

46 Distribuicao Normal Multivariada
2.1.3 A subvariedade MD onde Σ e diagonal
Seja MD = θ ∈ M; Σ ∈ Pn(R) e uma matriz diagonal, uma subvariedade de
M formada pelas distribuicoes cuja matriz de covariancia e uma matriz diagonal
Σ = diag(σ21, σ
22, . . . , σ
2n) =
σ2
1 0 · · · 0
0 σ22 · · · 0
......
. . ....
0 0 · · · σ2n
,
σi > 0, ∀i. Considerando como parametro θ = (µ1, σ1, µ2, σ2, . . . , µn, σn), a matriz de
informacao de Fisher e dada por [18]
1σ21
0 · · · 0 0
0 2σ21· · · 0 0
......
. . ....
...
0 0 · · · 1σ2n
0
0 0 · · · 0 2σ2n
.
A subvariedade MD e um espaco de dimensao 2n e pode ser identificado como
o espaco M2nH = (MH)n. Como a metrica em MH esta relacionada com a metrica do
modelo do plano superior de Poincare H2 (como descrito no Exemplo 1.18), a metrica em
M2nH esta relacionada com a metrica produto no espaco produto (H2)n = H2 × · · · ×H2︸ ︷︷ ︸
n vezes
.
A distancia de Fisher-Rao entre θ1 = (µ11, σ11, . . . , µ1n, σ1n) e θ2 = (µ21, σ21, . . . , µ2n, σ2n)
e [10, 18]
dD(θ1,θ2) =
√√√√ n∑i=1
dF ((µ1i, σ1i), (µ2i, σ2i))2, (2.16)
em que dF e a distancia dada em (1.11).
Nesse espaco, uma curva γ(t) = (γ1(t), . . . , γn(t)) ligando θ1 e θ2 e uma geodesica
se, e somente se, γi(t) e uma curva geodesica em,MH, conectando (µ1i, σ1i) e (µ2i, σ2i)
para i = 1, . . . , n.
MD ⊂M nao e uma subvariedade totalmente geodesica [54].
Neste trabalho, encontramos uma outra subvariedade totalmente geodesica deM,
na qual e possıvel exibir uma formula fechada para a distancia de Fisher-Rao.

2.1. Distancia de Fisher-Rao 47
2.1.4 A subvariedade MDµµµ em que Σ e diagonal e µµµ e um au-
tovetor de Σ
Seja a subvariedade de MD de dimensao n + 1, MDµ = θ ∈ M; µ = µei, µ ∈R, ei ∈ Rn e um vetor canonico e Σ e uma matriz diagonal, composta por distribuicoes
cujo vetor media µ = µei, em que ei e um vetor canonico de Rn, a e matriz de covariancia
e diagonal, Σ = diag(σ21, σ
22, . . . , σ
2n), σi > 0, para todo i = 1 . . . , n. Sem perda de
generalidade, vamos supor que ei = e1. De fato, basta considerar a isometria ψ(0,P ) em
que P e uma matriz de permutacao.
Considerando o parametro θ = (µ, σ1, σ2, . . . , σn), a matriz de informacao de Fisher
em MDµ e
1σ21
0 0 · · · 0
0 2σ21
0 · · · 0
0 0 2σ22· · · 0
......
.... . .
...
0 0 0 · · · 2σ2n
. (2.17)
Como MDµ e uma subvariedade de MD, a distancia de Fisher-Rao entre θ1 =
(µ1, σ11, σ12, . . . , σ1n) e θ2 = (µ2, σ21, σ21, . . . , σ2n) e
dDµ(θ1,θ2) =
√√√√d2F ((µ1, σ11), (µ2, σ21)) +
n∑i=2
d2F ((0, σ1i), (0, σ2i))
em que dF e a distancia dada em (1.11).
Uma curva geodesica emMDµ ligando θ1 a θ2 e dada por γ(t) = (γ1(t), γ2(t), . . . , γn(t))
na qual γ1(t) e uma curva geodesica emMH conectando (µ1, σ11) a (µ2, σ21) e as semirretas
verticais αi(t) =(
0, σ1i exp(
log(σ2iσ1i
)t))
para i = 2, . . . , n.
Exemplo 2.8. Sejam duas distribuicoes bivariadas com parametros
θ1 =
((0
0
),
(0.1 0
0 1
))e θ2 =
((3
0
),
(1 0
0 0.1
)),
temos que dDµ(θ1,θ2) = 4.37431 . A Figura 2.5 ilustra, no plano µ1×µ2, a curva geodesica
em MDµ conectando θ1 a θ2 e algumas curvas de nıvel das distribuicoes por onde essa
geodesica passa.
Teorema 2.9. A subvariedade MDµ e uma subvariedade totalmente geodesica de M.
Demonstracao. Para provar este teorema, iremos mostrar que as equacoes geodesicas de
M quando restritas a MDµ sao iguais as equacoes geodesicas de MDµ.

48 Distribuicao Normal Multivariada
-1 0 1 2 3 4
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
Figura 2.5: Curva geodesica emMΣ0(segmento cinza) ligando duas distribuicoes normaisbivariadas com parametros θ1 = ((−1, 0)t,Σ0) e θ2 = ((6, 3)t,Σ0).
Considerando Σ = diag(σ21, σ
22, · · · , σ2
n), σi > 0, para todo i = 1, 2, . . . , n e µ =
(µ, 0, · · · , 0)t nas equacoes dadas em (2.7) temos que as equacoes geodesicas deM restritas
a subvariedade MDµ sao
d2µ
dt2− 2σ1
dσ1
dt
1
σ21
dµ
dt= 0
2σ1d2σ1
dt2+
(dµ
dt
)2
− 2
(dσ1
dt
)2
= 0
2σ2d2σ2
dt2− 2
(dσ2
dt
)2
= 0
......
...
2σnd2σndt2− 2
(dσndt
)2
= 0.
(2.18)
Para calcular as equacoes geodesicas de MDµ, consideremos a metrica dada pela
matriz de informacao de Fisher dada em (2.17) e, um calculo dos sımbolos de Christoffel
definidos em (1.6), ver Apendice B, mostra que os unicos sımbolos de Christoffel nao nulos
sao
Γ112 = Γ1
21 = − 1
σ1
, Γ211 =
1
2σ1
e Γmmm = − 1
σm−1
, ∀m ≥ 2.
Substituindo esses valores nas equacoes dadas em (1.5), segue que as equacoes geodesicas
de MDµ sao as mesmas dadas na equacao (2.18).
Assim, comoMDµ e uma subvariedade totalmente geodesica, utilizando a distancia
emMDµ e a isometria dada no Teorema 2.1, agora sabemos calcular a distancia de Fisher-
Rao entre diversos pares de pontos. O corolario abaixo mostra o calculo da distancia de
Fisher-Rao entre pontos cuja matriz de covariancia e multipla da matriz identidade.
Corolario 2.10. Sejam θ1 = (µ1, σ21In) e θ2 = (µ2, σ
22In) dois pontos emM. A distancia

2.1. Distancia de Fisher-Rao 49
de Fisher-Rao entre θ1 e θ2 e dada por
dF (θ1,θ2) = dDµ((0, σ21In), (|µ2 − µ1|e1, σ
22In)).
Demonstracao. Consideremos a isometria ψ = ψ(−Pµ1,P ), em que P e uma matriz ortog-
onal tal que P (µ2 − µ1) = |µ2 − µ1|e1 e e1 e o primeiro vetor canonico do Rn. Dessa
forma, pelo Corolario 2.2, segue que
dF (θ1,θ2) = dF (ψ(−Pµ1,P )(θ1), ψ(−Pµ1,P )(θ2))
= dF ((Pµ1 − Pµ1, Pσ21InP
t), (Pµ2 − Pµ1, Pσ22InP
t))
= dF ((0, σ21InPP
t), (P (µ2 − µ1), σ22InPP
t))
= dF ((0, σ21In), (|µ2 − µ1|e1, σ
22In)).
Como (0, σ21In) e (|µ2 − µ1|e1, σ
22In) sao pontos na subvariedade totalmente geodesica
MDµ,
dF (θ1,θ2) = dDµ((0, σ21In), (|µ2 − µ1|e1, σ
22In)).
Exemplo 2.11. Sejam θ1 = ((0, 0)t, I2) e θ2 = ((4√
3, 4)t, 0.25I2) pontos emM. Tomemos
a isometria ψ = ψ(−Pµ1,P ) dada na demonstracao do Corolario acima, onde
P =
( √3
2−1
2
−12
√3
2
).
Segue que dF (θ1,θ2) = dF (ψ(θ1), ψ(θ2)) = 6.01582, em que ψ(θ1) = ((0, 0)t, I2) e ψ(θ2) =
((8, 0)t, 0.25I2). Observemos que se γ(t) = (µ(t),Σ(t)) e a curva geodesica ligando ψ(θ1)
a ψ(θ2) entao ψ−1(γ(t)) = ψ(P tµ1,P t)(γ(t)) e a curva geodesica ligando θ1 a θ2, ver Figuras
2.6(a) e 2.6(b)
Sabemos tambem calcular a distancia de Fisher-Rao entre dois pontos cuja matriz
de covariancia e a mesma.
Corolario 2.12. Sejam θ1 = (µ1,Σ) e θ2 = (µ2,Σ) dois pontos em M. Seja P uma
matriz ortogonal tal que P (µ2−µ1) = |µ2−µ1|e1 e consideremos a decomposicao UDU t
da matriz PΣP t, isto e
PΣP t = UDU t, (2.19)
em que U e uma matriz triangular superior, com diagonal composta por 1′s, e D e uma
matriz diagonal - esta decomposicao e possıvel pois a matriz Σ e simetrica e definida
positiva. Entao,
dF (θ1,θ2) = dDµ((0, D), (|µ2 − µ1|e1, D)).

50 Distribuicao Normal Multivariada
-2 0 2 4 6 8 10
-2
0
2
4
6
(a) Curva geodesica, no plano µ1×µ2, (segmentocinza) ligando duas distribuicoes com parametrosθ1 = ((0, 0)t, I2) e θ2 = ((8, 0)t, 0.25I2).
-2 0 2 4 6 8 10
-2
0
2
4
6
(b) Curva geodesica, no planoµ1 × µ2, (segmentocinza) ligando duas distribuicoes com parametrosθ1 = ((0, 0)t, I2) e θ2 = ((4
√3, 4)t, 0.25I2).
Figura 2.6
Demonstracao. Consideremos a isometria ψ = ψ(−Pµ1,P ), pelo Corolario 2.2, temos que
dF (θ1,θ2) = dF (ψ(−Pµ1,P )(θ1), ψ(−Pµ1,P )(θ2))
= dF ((Pµ1 − Pµ1, PΣP t), (Pµ2 − Pµ1, PΣP t))
= dF ((0, PΣP t), (|µ2 − µ1|e1, PΣP t)).
Seja decomposicao UDU t da matriz PΣP t (2.19), e tomemos a ψ = ψ(0,U−1), segue
tambem do Corolario 2.2 que
dF (θ1,θ2) = dF ((0, PΣP t), (|µ2 − µ1|e1, PΣP t))
= dF (ψ(0, PΣP t), ψ(|µ2 − µ1|e1, PΣP t))
= dF ((U−10, U−1PΣP tU−t), (|µ2 − µ1|U−1e1, U−1PΣP tU−t))
= dF ((0, U−1UDU tU−t), (|µ2 − µ1|e1, U−1UDU tU−t))
= dF ((0, D), (|µ2 − µ1|e1, D)).
Como (0, D) e (|µ2 − µ1|e1, D) sao pontos em MDµ,
dF (θ1,θ2) = dDµ((0, D), (|µ2 − µ1|e1, D)).
Exemplo 2.13. Sejam duas distribuicoes normais bivariadas com parametros θ1 = ((−1, 0)t,Σ)
e θ2 = ((6, 3)t,Σ), em que
Σ =
(1.1 0.9
0.9 1.1
),
a Figura 2.7(a) ilustra a curva geodesica conectando essas distribuicoes. A Figura 2.7(b)

2.1. Distancia de Fisher-Rao 51
ilustra a curva geodesica conectando os pontos (ψ(0,U−1) ψ(−Pµ1,P ))(θ1) = ((0, 0)t, D)
e (ψ(0,U−1) ψ(−Pµ1,P ))(θ2) = ((7.61588, 0)t, D) em que D = diag(0.8923, 0.4483). A
distancia de Fisher-Rao entre θ1 e θ2 e dF (θ1,θ2) = 5.00648. Observemos que esta
distancia nao e igual a distancia de Mahalanobis dada na equacao (2.14), a qual e maior
que a distancia de Fisher-Rao pois MΣ0 nao e uma subvariedade totalmente geodesica.
De fato, dΣ0(θ1,θ2) = 8.06226 ≥ dF (θ1,θ2).
-4 -2 0 2 4 6 8 10
-2
0
2
4
(a) Curva geodesica (segmento cinza) ligandoduas distribuicoes normais bivariadas comparametros θ1 = ((−1, 0)t,Σ) e θ2 = ((6, 3)t,Σ).
-4 -2 0 2 4 6 8 10
-2
0
2
4
(b) Curva geodesica (segmento cinza) lig-ando duas distribuicoes normais bivari-adas com parametros θ1 = ((0, 0)t, D) eθ2 = ((7.61588, 0)t, D).
Figura 2.7
2.1.5 Produto de Subvariedades totalmente geodesica
Seja a subvariedadeMDµ×Mµ0 de dimensao p+ q+1, em que p+1 e a dimensao
deMDµ e q e a dimensao deMµ0 . Essa subvariedade e composta por pontos θ = (µ,Σ)
tais que, a menos de uma permutacao nas linhas do vetor de medias e nas linhas e colunas
da matriz de covariancia, o vetor de medias tem apenas a primeira entrada nao nula e a
matriz de covariancia e uma matriz diagonal por blocos em que o primeiro bloco e uma
matriz diagonal. Isto e, um ponto θ ∈MDµ ×Mµ0 pode ser escrito como
θ = (µ,Σ) =
((µ
0
),
(D 0t
0 Σ
)),
onde µ = (µ, 0, . . . , 0)t e um vetor de dimensao p, D = diag(d211, . . . , d
2pp) e Σ e uma matriz
simetrica definida positiva de dimensao q.
A metrica de Fisher nessa subvariedade e dada por

52 Distribuicao Normal Multivariada
ds2 =dµtΣ−1dµ+1
2tr[(Σ−1dΣ)2]
=(dµ 0
)(D 0t
0 Σ
)−1(dµ
0
)+
1
2tr
(D 0t
0 Σ
)−1(dD 0t
0 dΣ
)2=(dµ 0
)(D−1 0t
0 Σ−1
)(dµ
0
)+
1
2tr
((D−1 0t
0 Σ−1
)(dD 0t
0 dΣ
))2
=dµtD−1dµ+1
2tr
(D−1dD 0t
0 Σ−1dΣ
)2
=dµ2
1
d211
+1
2tr
[((D−1dD)2 0t
0 (Σ−1dΣ)2
)]
=dµ2
1
d211
+1
2tr[(D−1dD)2
]+
1
2tr[(Σ−1dΣ)2
]=ds2
1 + ds22,
em que ds21 =
dµ21d211
+ 12
tr [(D−1dD)2] e a metrica de Fisher emMDµ e ds22 = 1
2tr[(Σ−1dΣ)2
]e a metrica em Mµ0 .
Portanto, dados
θ1 =
((µ1
0
),
(D1 0t
0 Σ1
))e θ2 =
((µ2
0
),
(D2 0t
0 Σ2
))
pontos em MDµ ×Mµ0 , a distancia de Fisher-Rao entre eles e dada por
dF (θ1,θ2) =
√d2Dµ ((µ1, D1), (µ2, D2)) + d2
µ0
((0, Σ1), (0, Σ2)
)Observemos que, como MDµ ×Mµ0 e uma variedade produto de duas subvar-
iedades totalmente geodesicas deM, segue queMDµ×Mµ0 tambem e uma subvariedade
totalmente geodesica.
2.2 Algoritmos Numericos
Nesta secao apresentamos alguns algoritmos que calculam a distancia de Fisher-
Rao numericamente.

2.2. Algoritmos Numericos 53
2.2.1 Algoritmo Geodesic shooting
Em [31], Han e Park propuseram um algoritmo numerico, chamado de geodesic
shotting, para o calculo da curva geodesica conectando duas distribuicoes normais mul-
tivariadas. Esse algoritmo foi inspirado no metodo shooting, um metodo numerico para
resolver problemas de valor de contorno de uma equacao diferencial de segunda ordem.
Seja a equacao diferencialy′′(t) = f(t, y, y′)
y(a) = α
y(b) = β
a ≤ t ≤ b.
Para resolver a equacao acima, o metodo shooting cria uma sequencia de problemas de
valor inicial y′′ = f(t, y, y′)
y(a) = α
y′(a) = vk
, (2.20)
onde vk sao os “chutes” para o vetor velocidade inicial no instante t = a, escolhidos tais
que
limk→∞
y(b, vk) = β,
em que y(b, vk) e o valor da solucao do problema (2.20) no instante t = b. O algoritmo
procede da seguinte maneira: dado uma velocidade y(a) = v0, encontra-se uma solucao
para (2.20) e atualiza-se o valor de vk ate y(b, vk) ser suficiente proximo de β. A atualizacao
de vk e dada pela solucao da equacao
y(b, vk)− β = 0,
que pode ser calculada atraves de metodos numericos.
No algoritmo geodesic shooting os autores levaram em conta o espaco ambiente
dado pela variedade M. Eles criaram um processo de atualizacao do vetor velocidade
inicial que garantisse que a solucao do sistema de equacoes dado em (2.7) nao escapasse
de M. Para isso, eles utilizaram o transporte paralelo de um campo de vetores em M.
O algoritmo geodesic shooting esta descrito no Algoritmo 1 de [31].
Como os proprios autores ressaltaram, o algoritmo falha no calculo da distancia
de Fisher-Rao entre pontos cuja distancia e maior que 7. Para resolver esse problema os
autores sugerem uma extensao do algoritmo. Dados os pontos θ1 e θ2 em M, escolhe-se
pontos θ1, . . . , θN entre θ1 e θ2 tais que θ1 = θ1, θN = θ2 e dF (θi, θi+1) ≤ 1 para
i = 1, . . . , N − 1. Depois, atualiza-se θi = expθi−1(0.5 logθi−1
(θi+1)) para i par, e em
seguida faz-se a mesma atualizacao para i ımpar, em que B = expA(V ) e o ponto final da

54 Distribuicao Normal Multivariada
curva geodesica partindo do ponto A com velocidade inicial V e V = logA(B) e o vetor
tangente inicial da curva geodesica ligando A ate B. Esse procedimento e repetido ate a
somaN−1∑i=1
dF (θi, θi+1)
convergir. O valor para o qual essa soma converge e a distancia de Fisher-Rao entre θ1
e θ2. Han e Park em [31] nao descrevem como os pontos θ1, . . . , θN sao escolhidos.
Apresentamos, na Secao 2.3.2, uma maneira de escolher esses pontos.
O algoritmo geodesic shooting e muito caro computacionalmente uma vez que,
para cada iteracao, e necessario o calculo da solucao de tres problemas de valor inicial.
Na proxima Secao apresentamos uma tabela com algumas simulacoes que mostram que
em alguns casos o calculo da distancia por esse algoritmo pode ser muito demorado.
A seguir descrevemos uma maneira de calcular a distancia de Fisher-Rao entre
alguns pares de pontos apenas resolvendo um sistema de equacoes. Vamos derivar um
sistema de equacoes, o qual pode ser resolvido atraves de metodos iterativos ja conhecidos,
pelo qual e possıvel determinar a distancia de Fisher-Rao entre esses pares de uma maneira
muito mais rapida quando comparado com o metodo geodesic shooting.
2.2.2 Sistema de Equacoes
Atraves de observacoes do comportamento das curvas geodesicas em M, feitas
utilizando o algoritmo geodesic shooting, transformamos o problema de valor de contorno,
para certos pares de pontos, em um problema de resolucao de um sistema equacoes.
Sistema 5× 5
Consideremos o caso bivariado e tomemos um par de pontos do tipo
θ1 =
((µ1
µ0
),
(σ11 σ12
σ12 σ22
))e θ2 =
((µ2
µ0
)(σ11 −σ12
−σ12 σ22
)). (2.21)
Sem perda de generalidade, vamos supor µ2 > µ1. Fazendo a decomposicao ortogonal
da matriz de covariancia desses pontos, observamos que elas tem os mesmos autovalores,
logo θ1 e θ2 podem ser escritos como
θ1 =
((µ1
µ0
), Rα
(λ1 0
0 λ2
)Rtα
)e θ2 =
((µ2
µ0
), Rt
α
(λ1 0
0 λ2
)Rα
),
em que
Rα =
(cos(α) sen(α)
− sen(α) cos(α)
)

2.2. Algoritmos Numericos 55
e a matriz de rotacao de angulo α, ver Figura 2.8.
Parâmetros
θ1 θ2
-2 -1 0 1 2-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
Figura 2.8: Curvas de nıveis das distribuicoes com parametros θ1 e θ2.
Aplicando o algoritmo geodesic shooting para os pontos θ1 e θ2, notamos que a
aproximacao para a curva geodesica conectando esses dois pontos, γ(t) = (µ(t), Σ(t)),
com γ(0) = θ1 e γ(1) = θ2, no instante t = 0.5, e
γ(0.5) ≈ θ1/2 = (µ1/2,Σ1/2) =
((µ1+µ2
2
η
),
(d2
11 0
0 d222
)),
em que η, d11, d22 sao valores reais, Figura 2.9 . Alem disso
γ′(0.5) ≈ θ′1/2 = (µ′1/2,Σ′1/2) =
((µ′(0.5)
0
),
(0 σ′12(0, 5)
σ′12(0, 5) 0
)).
Observemos que estamos mais interessados na “estrutura” dos pontos do que nos seus
valores propriamente ditos. Ou seja, o importante aqui e que no instante t = 0.5, o ponto
θ1/2 possui uma matriz de covariancia diagonal e o vetor tangente θ′1/2 e dado por um
vetor de medias cuja segunda entrada e nula e por uma matriz simetrica com diagonal
nula.
Seja γ(t) = (µ(t),Σ(t)), −1 ≤ t ≤ 1, a curva geodesica em M ligando θ1 e
θ2 e suponhamos que γ(0) = θ1/2 e γ′(0) = θ′1/2. Considerando a isometria ψ =
ψ(−Σ−1/21/2
µ1/2,Σ−1/21/2
), temos que γ(t) = ψ(γ(t)) e dada por
γ(t) = (µ(t), Σ(t)) =(
Σ−1/21/2 (µ(t)− µ1/2),Σ
−1/21/2 Σ(t) Σ
−1/21/2
)

56 Distribuicao Normal Multivariada
Parâmetros
θ1 θ2 θ1/2
-2 -1 0 1 2-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
Figura 2.9: Aproximacao da curva geodesica (pelo algoritmo geodesic shooting) ligandoas distribuicoes θ1 e θ2. A curva de nıvel tracejada representa a aproximacao da curva denıvel da distribuicao θ1/2.
e
γ′(t) =
(dµ(t)
dt,Σ(t)
dt
)=
(Σ−1/21/2
(dµ(t)
dt
),Σ−1/21/2
(Σ(t)
dt
)Σ−1/21/2
).
Logo,
γ(0) =(
Σ−1/21/2 (µ1/2 − µ1/2),Σ
−1/21/2 Σ1/2 Σ
−1/21/2
)=(0, I2) =: θ0,
eγ′(0) =
(Σ−1/21/2 µ′1/2,Σ
−1/21/2 Σ′1/2 Σ
−1/21/2
)=
((µ′(0)d11
0
),
(0
σ′12(0)
d11d22σ′12(0)
d11d220
)).
A Figura 2.10 ilustra as curvas de nıvel das distribuicoes θ0 = γ(0) = ψ(θ1/2), θ1 =
γ(−1) = ψ(θ1) e θ2 = γ(1) = ψ(θ2).
Fazendo agora a mudanca natural de parametros
(δ(t),∆(t)) = ϕ(µ(t), Σ(t)) = (Σ(t)−1µ(t), Σ(t)−1),
temos que d∆
dt(t) =−∆(t)
(dΣ
dt(t)
)∆(t)
dδ
dt(t) =
(d∆
dt(t)
)µ(t) + ∆(t)
(dµ
dt(t)
) .
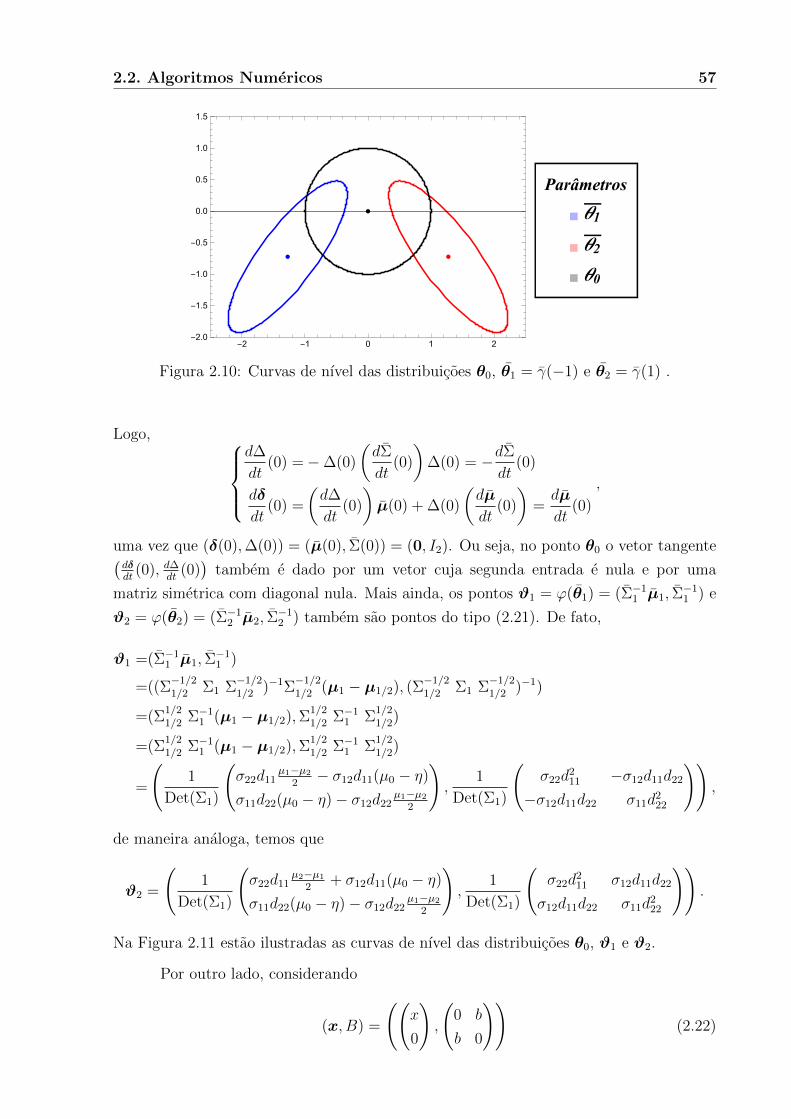
2.2. Algoritmos Numericos 57
-2 -1 0 1 2-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
Parâmetros
θ1
θ2
θ0
Figura 2.10: Curvas de nıvel das distribuicoes θ0, θ1 = γ(−1) e θ2 = γ(1) .
Logo, d∆
dt(0) =−∆(0)
(dΣ
dt(0)
)∆(0) = −dΣ
dt(0)
dδ
dt(0) =
(d∆
dt(0)
)µ(0) + ∆(0)
(dµ
dt(0)
)=dµ
dt(0)
,
uma vez que (δ(0),∆(0)) = (µ(0), Σ(0)) = (0, I2). Ou seja, no ponto θ0 o vetor tangente(dδdt
(0), d∆dt
(0))
tambem e dado por um vetor cuja segunda entrada e nula e por uma
matriz simetrica com diagonal nula. Mais ainda, os pontos ϑ1 = ϕ(θ1) = (Σ−11 µ1, Σ
−11 ) e
ϑ2 = ϕ(θ2) = (Σ−12 µ2, Σ
−12 ) tambem sao pontos do tipo (2.21). De fato,
ϑ1 =(Σ−11 µ1, Σ
−11 )
=((Σ−1/21/2 Σ1 Σ
−1/21/2 )−1Σ
−1/21/2 (µ1 − µ1/2), (Σ
−1/21/2 Σ1 Σ
−1/21/2 )−1)
=(Σ1/21/2 Σ−1
1 (µ1 − µ1/2),Σ1/21/2 Σ−1
1 Σ1/21/2)
=(Σ1/21/2 Σ−1
1 (µ1 − µ1/2),Σ1/21/2 Σ−1
1 Σ1/21/2)
=
(1
Det(Σ1)
(σ22d11
µ1−µ22− σ12d11(µ0 − η)
σ11d22(µ0 − η)− σ12d22µ1−µ2
2
),
1
Det(Σ1)
(σ22d
211 −σ12d11d22
−σ12d11d22 σ11d222
)),
de maneira analoga, temos que
ϑ2 =
(1
Det(Σ1)
(σ22d11
µ2−µ12
+ σ12d11(µ0 − η)
σ11d22(µ0 − η)− σ12d22µ1−µ2
2
),
1
Det(Σ1)
(σ22d
211 σ12d11d22
σ12d11d22 σ11d222
)).
Na Figura 2.11 estao ilustradas as curvas de nıvel das distribuicoes θ0, ϑ1 e ϑ2.
Por outro lado, considerando
(x, B) =
((x
0
),
(0 b
b 0
))(2.22)

58 Distribuicao Normal Multivariada
Parâmetros
ϑ1 ϑ2 θ0
-4 -2 0 2 4-2
-1
0
1
2
3
Figura 2.11: Curvas de nıvel das distribuicoes ϑ1 = ϕ(θ1) e ϑ2 = ϕ(θ2).
no problema de valor inicial dado pelas equacoes (2.9) e (2.11), segue que a matriz G,
tal que G2 = B2 + xxt, e uma matriz diagonal. Portanto, a solucao da curva geodesica
(δ(t),∆(t)) partindo do ponto (δ(0),∆(0)) = θ0 com vetor tangente (x, B), dada na
equacao (2.12), pode ser simplificada emδ(t) =
(x senh(t
√b2+2x2)√
b2+2x2
− bx(cosh(t√b2+2x2)−1)
b2+2x2
)
∆(t) =
12(cosh(bt) + cosh(t
√b2 + 2x2)) −1
2
(senh(bt) + b senh(t
√b2+2x2)√
b2+2x2
)−1
2
(senh(bt) + b senh(t
√b2+2x2)√
b2+2x2
)12
(cosh(bt) + 2x2+b2 cosh(t
√b2+2x2)
b2+2x2
) .
(2.23)
Observemos que δ(t) satisfaz a equacao de uma hiperbole com eixos paralelos aos eixos
coordenados, de fato,
(− bx(cosh(t√b2+2x2)−1)
b2+2x2− bx
b2+2x2)2(
bxb2+2x2
)2 −
(x senh(t
√b2+2x2)√
b2+2x2
)2
(x√
b2+2x2
)2 = 1.
Alem disso, temos tambem que, como a funcao senh(t) e uma funcao ımpar e cosh(t) e
uma funcao par, dado t0 ∈ R, os pontos
(δ(−t0),∆(−t0)) e (δ(t0),∆(t0))
sao pontos do tipo (2.21).
Consideremos t0 = 1. Seja a mudanca de parametros
ϕ−1(δ(t),∆(t)) = (∆−1(t)δ(t),∆−1(t))

2.2. Algoritmos Numericos 59
e uma isometria ψ(c,D), em que D e uma matriz diagonal, segue que o par de pontos
θ1 = ψ(c,D)(ϕ−1(δ(−1),∆(−1))) e θ2 = ψ(c,D)(ϕ
−1(δ(1),∆(1))) tambem satisfaz (2.21).
Mais ainda, atraves de calculos similares aos feitos acima e possıvel mostrar que a curva
geodesica γ(t) = ψ(c,D)(ϕ−1(δ(t),∆(t))) e tal que no ponto γ(0) a matriz de covariancia e
diagonal e o vetor tangente γ′(0) e dado por um vetor cuja segunda entrada e nula e por
uma matriz simetrica com diagonal nula. Em particular, isso vale para para a isometria
ψ−1 = ψ(µ1/2,Σ
1/21/2
).Portanto, dada uma curva geodesica γ(t) ligando dois pontos do tipo (2.21), θ1 e
θ2, acabamos de mostrar que supor que γ(0) = θ1/2 e γ′(0) = θ′1/2 e equivalente a supor
que o vetor tangente a curva (δ(t),∆(t)) no ponto θ0 e igual a (δ(0)dt, ∆(0)
dt) = (x, B) em que
(x, B) e dado em 2.22. As operacoes feitas ate agora podem ser resumidas no seguinte
diagrama
(µ,Σ) ooψ
ψ−1// (µ, Σ) oo
ϕ
ϕ−1// (δ,∆)
em que ψ = ψ(−Σ−1/21/2
µ1/2,Σ−1/21/2
) e ϕ e a mudanca natural de parametros.
Pelo exposto acima, para determinar a curva geodesica ligando θ1 e θ2 precisamos
que θ1 = θ1 e θ2 = θ2. Isto e, para calcular dF (θ1,θ2) precisamos encontrar as variaveis
η, d11 e d22 da isometria ψ e o valor de (x, B) tais queϕ(ψ(θ1)) =(δ(−1),∆(−1))
ϕ(ψ(θ2)) =(δ(1),∆(1)).
As duas equacoes acima sao equivalentes, assim precisamos considerar apenas uma delas,
digamos a segunda. Dado θ2 = (µ2,Σ2), temos que resolver a equacao
(δ(1),∆(1)) =ϕ(ψ(µ2,Σ2))
=ϕ(
Σ(−1/2)1/2 (µ2 − µ1/2),Σ
(−1/2)1/2 Σ2Σ
(−1/2)1/2
)=(
Σ(1/2)1/2 Σ−1
2 Σ(1/2)1/2 Σ
(−1/2)1/2 (µ2 − µ1/2),Σ
(1/2)1/2 Σ−1
2 Σ(1/2)1/2
)=(
Σ(1/2)1/2 (δ−1
2 −∆2µ1/2),Σ(1/2)1/2 ∆2Σ
(1/2)1/2
),
em que (δ2,∆2) = ϕ(µ2,Σ2). Isto e equivalente a resolver o seguinte sistema
(1d11
0
0 1d22
)∆(1)
(1d11
0
0 1d22
)= ∆2(
1d11
0
0 1d22
)δ(1) + ∆2
(µ1+µ2
2
η
)= δ2
. (2.24)
Como ∆(1) e ∆2 sao matrizes simetricas, segue que o sistema acima e um sistema
nao linear com cinco equacoes e cinco variaveis (d11, d22, η, x e b) o qual pode ser resolvido

60 Distribuicao Normal Multivariada
atraves de metodos iterativos, como o metodo de Newton-Raphson, por exemplo. Ao
resolver o sistema acima encontramos o valor de (x, B) que fornece a equacao da curva
geodesica ligando θ1 a θ2 dada por
γ(t) = ψ−1(ϕ−1(δ(t),∆(t)), −1 ≤ t ≤ 1,
onde a curva (δ(t),∆(t)) e dada em (2.23) e, alem disso, encontramos o valor do ponto
θ1/2. As Figuras 2.12(a) e 2.12(b) ilustram a curva geodesica (segmento cinza) conectando
as distribuicoes ϑ1 = (δ(−1),∆(−1)) e ϑ2 = (δ(1),∆(1)) e a curva geodesica conectando
as distribuicoes θ1 e θ2, respectivamente. Como a distancia de Fisher-Rao e invariante
em relacao a uma mudanca de parametros e ψ e uma isometria, temos que
dF (θ0,θ2) = dF ((0, In), (δ(1),∆(1))) =
√1
2tr(B2) + xtx =
√b2 + x2,
logo, a distancia de Fisher-Rao entre θ1 e θ2 e
dF (θ1,θ2) = 2√b2 + x2.
Parâmetros
ϑ1 ϑ2 θ0
-4 -2 0 2 4
-2
0
2
4
(a) Curvas geodesica conectando as dis-tribuicoes ϑ1 e ϑ2 passando porθ0.
Parâmetros
θ1 θ2 θ1/2
-2 -1 0 1 2-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
(b) Curvas geodesica conectando as dis-tribuicoes θ1 e θ2 passando porθ1/2.
Figura 2.12
Notemos que, tambem sabemos calcular a distancia de Fisher-Rao entre pontos do
tipo
θ1 =
((µ0
µ1
),
(σ11 σ12
σ12 σ22
))e θ2 =
((µ0
µ2
)(σ11 −σ12
−σ12 σ22
)),

2.2. Algoritmos Numericos 61
basta considerar a isometria ψ(0,P ), em que P e uma matriz que permuta as linhas do
vetor de medias.
Podemos generalizar o procedimento acima para certos tipos de pontos no caso
n-variado.
Definicao 2.14. Uma matriz de rotacao de Givens e uma matriz da forma
G(i, j, α) =
1 · · · 0 · · · 0 · · · 0...
. . ....
......
0 · · · c · · · s · · · 0...
.... . .
......
0 · · · −s · · · c · · · 0...
......
. . ....
0 · · · 0 · · · 0 · · · 1
, (2.25)
em que os valores c = cos(α) e s = sen(α) aparecem nas intersecoes das i-esimas e j-esimas
linhas e colunas. Isto e, os unicos elementos nao nulos da matriz G(i, j, α) sao dados por
gkk =1, para k 6= i, j
gii =gjj = c
gij =s
gji =− s para i > j
. (2.26)
O produto G(i, j, α)v representa a rotacao no sentido anti-horario do vetor v no
plano (i, j) de α radianos.
Consideremos agora pontos do tipo
θ1 =(µ1ek, G(i, j, α)ΛG(i, j, α)t)
θ2 =(µ2ek, G(i, j, α)tΛG(i, j, α)),(2.27)
em que k = i ou k = j, com i, j ∈ 1, . . . , n, e Λ = diag(λ1, . . . , λn). Sem perda de
generalidade vamos assumir k = i e µ2 > µ1.
De maneira analoga a anterior, e possıvel mostrar que supor que a curva geodesica
γ(t) = (µ(t),Σ(t)) em M, satisfazendo γ(−1) = θ1 e γ(1) = θ2, e tal que, no instante
t = 0,
γ(0) = θ1/2 = (µ1/2,Σ1/2) =
(µ1 + µ2
2ei + ηej,D
), (2.28)
em que D = diag(λ1, . . . , λi−1, dii, λi+1, . . . , λj−1, djj, λj+1, . . . , λn), e
γ′(0) =
(dµ
dt(0),
dΣ
dt(0)
),

62 Distribuicao Normal Multivariada
na qual dµdt
(0) = µ′(0)ei e dΣdt
(0) e uma matriz simetrica tal que as unicas entradas nao
nulas sao as entradas (i, j) e (j, i), e equivalente a supor que, no ponto (0, In), a curva
geodesica (δ(t),∆(t)) tem vetor tangente
(x, B) =
0...
x...
0...
0
,
0 · · · 0 · · · 0 · · · 0...
. . ....
......
0 · · · 0 · · · b · · · 0...
.... . .
......
0 · · · b · · · 0 · · · 0...
......
. . ....
0 · · · 0 · · · 0 · · · 0
,
em que x = xei e as unicas entradas nao nulas da matriz B sao b = bij = bji.
Substituindo os valores de x e B em (2.12) segue que
(δ(t),∆(t)) =
0...
δi(t)...
δj(t)...
0
,
0 · · · 0 · · · 0 · · · 0...
. . ....
......
0 · · · ∆ii(t) · · · ∆ij(t) · · · 0...
.... . .
......
0 · · · ∆ji(t) · · · ∆jj(t) · · · 0...
......
. . ....
0 · · · 0 · · · 0 · · · 0
,
onde o vetor δij(t) = (δi(t), δj(t))t e a submatriz ∆ij(t), composta pela intersecao das
i-esimas e j-esimas linhas e colunas da matriz ∆(t), sao dadas em (2.23). Assim, para
calcular a distancia de Fisher-Rao entre θ1 e θ2 basta resolver o sistema
(dii 0
0 djj
)∆ij(1)
(dii 0
0 djj
)= ∆ij
2(dii 0
0 djj
)δij(1) + ∆ij
2
(µ1+µ2
2
η
)= δij2
(2.29)
onde (δ2,∆2) = ϕ(θ2), e segue que
dF (θ1,θ2) = 2√b2 + x2.

2.2. Algoritmos Numericos 63
Sistema 9× 9
Consideremos agora pontos que, a menos de uma permutacao nas linhas do vetor
de medias e nas linhas e colunas da matriz de covariancia, sao do tipo
θ1 =
µ1
µ01
µ02
,
σ11 σ12 σ13
σ12 σ22 σ23
σ13 σ23 σ33
e θ2 =
µ2
µ01
µ02
,
σ11 −σ12 −σ13
−σ12 σ22 σ23
−σ13 σ23 σ33
.
(2.30)
De maneira analoga ao caso bivariado, vamos descrever uma maneira de calcular a
distancia de Fisher-Rao entre esses pontos atraves da solucao de um sistema de equacoes.
Aplicando o algoritmo geodesic shooting para os pontos θ1 e θ2, notamos que a
aproximacao para a curva geodesica conectando esses dois pontos, γ(t) = (µ(t), Σ(t)),
com γ(0) = θ1 e γ(1) = θ2, e tal que, no instante t = 0.5,
γ(0.5) ≈ θ1/2 = (µ1/2,Σ1/2) =
µ1+µ22
η1
η2
,
d11 0 0
0 d22 d23
0 d23 d33
,
em que ηi, com i = 1, 2, e dij, com i, j = 1, 2, 3, sao valores reais, e
γ′(0.5) ≈ θ′1/2 = (µ′1/2,Σ′1/2) =
µ
′(0.5)
0
0
,
0 σ′12(0, 5) σ′13(0, 5)
σ′12(0, 5) 0 0
σ′13(0, 5) 0 0
,
ou seja, no ponto θ1/2 o vetor velocidade e dado por um vetor cuja unica entrada nao nula
e a primeira e por uma matriz simetrica que tem apenas as entradas (1, i+ 1) = (i+ 1, 1),
i = 1, 2, diferentes de zero. Novamente, vale ressaltar que estamos mais interessados na
estrutura desses pontos no que nos seus valores propriamente ditos.
Seja γ(t) = (µ(t),Σ(t)), −1 ≤ t ≤ 1, a curva geodescia em M ligando θ1 e θ2 e
suponha que γ(0) = θ1/2 e γ′(0) = θ′1/2. Seja Σ1/2 = LLt a decomposicao de Cholesky da
matriz Σ1/2,
L =
√d11 0 0
0√d22 0
0 d23√d22
√d33 − d223
d22
,
e consideremos a isometria ψ = ψ(−L−1µ1/2,L−1), segue que γ(t) = ψ(γ(t)) e tal que γ(0) =
θ0 e

64 Distribuicao Normal Multivariada
γ′(0) =(L−1 µ′1/2, L
−1Σ′1/2L−1)
=
µ′(0.5)√d11
0
0
,
0σ′12(0.5)√d11d22
σ′13(0.5)−σ′12(0.5)d23d22√
d11
(d33−
d223d22
)σ′12(0.5)√d11d22
0 0
σ′13(0.5)−σ′12(0.5)d23d22√
d11
(d33−
d223d22
) 0 0
.
Fazendo agora a mudanca natural de parametros, (δ(t),∆(t)) = ϕ(µ(t),Σ(t)), de
maneira analoga ao caso bivariado, temos qued∆
dt(0) =− dΣ
dt(0)
dδ
dt(0) =
dµ
dt(0).
Ou seja, no ponto (0, I3) o vetor tangente tambem e dado por um vetor cuja unica entrada
nao nula e a primeira e por uma matriz simetrica que tem apenas as entradas (1, i+ 1) =
(i + 1, 1), i = 1, 2, diferentes de zero. Alem disso, os pontos ϑ1 = ϕ(θ1) = (Σ−11 µ1, Σ
−11 )
e ϑ2 = ϕ(θ2) = (Σ−12 µ2, Σ
−12 ) sao pontos do tipo (2.30).
Por outro lado, considerando
(x, B) =
x0
0
,
0 b1 b2
b1 0 0
b2 0 0
no problema de valor inicial dado pelas equacoes (2.9) e (2.11), segue que a solucao dada
na equacao (2.12) pode ser simplificada em
δ(t) =
x senh
(t√b21+b22+2x2
)√b21+b22+2x2
− b1x(cosh(t√b21+b22+2x2
)−1)
b21+b22+2x2
− b2x(cosh(t√b21+b22+2x2
)−1)
b21+b22+2x2
∆(t) =

2.2. Algoritmos Numericos 65
∆11(t) =1
2
(cosh
(t√b2
1 + b22
)+ cosh
(t√b2
1 + b22 + 2x2
))
∆1j(t) =∆j1(t) = −1
2bj−1
senh(t√b2
1 + b22
)√b2
1 + b22
+senh
(t√b2
1 + b22 + 2x2
)√b2
1 + b22 + 2x2
, j = 2, 3
∆ii(t) =1
2b2i−1
cosh(t√b2
1 + b22
)− 1
b21 + b2
2
+cosh
(t√b2
1 + b22 + 2x2
)− 1
b21 + b2
2 + 2x2
+ 1, i = 2, 3
∆23(t) =1
2b1b2
cosh(t√b2
1 + b22
)− 1
b21 + b2
2
+cosh
(t√b2
1 + b22 + 2x2
)− 1
b21 + b2
2 + 2x2
∆32(t) =∆23(t)
Notemos que δ(t) satisfaz a equacao de uma hiperbole no plano gerado pelos vetores
(1, 0, 0)t e (0, b1, b2)t,
δ(t) =x senh
(t√b2
1 + b22 + 2x2
)√b2
1 + b22 + 2x2
1
0
0
− x(cosh(t√b2
1 + b22 + 2x2
)− 1)
b21 + b2
2 + 2x2
0
b1
b2
.
Alem disso, temos que, pela paridade das funcoes senh(t) e cosh(t) , dado t0 ∈ R,
os pontos (δ(−t0),∆(−t0)) e (δ(t0),∆(t0)) tambem sao pontos do tipo (2.30).
De maneira analoga ao caso bivariado, aplicando a mudanca de parametros
ϕ−1(δ(t),∆(t)) = (∆−1(t)δ(t),∆−1(t)) e a isometria ψ(c,L)), em que L e uma matriz
triangular inferior, segue que o par de pontos θ1 = ψ(c,L))(ϕ−1(δ(−1),∆(−1))) e θ2 =
ψ(c,L))(ϕ−1(δ(1),∆(1))) satisfaz (2.30) e a curva geodesica γ(t) = ψ−1(ϕ−1(δ(t),∆(t))) e
tal que no ponto γ(0) a matriz de covariancia e diagonal por blocos e o vetor tangente
γ′(0) tambem e dado por um vetor cuja unica entrada nao nula e a primeira e por uma
matriz simetrica que tem apenas as entradas (1, i+ 1) = (i+ 1, 1), i = 1, 2, diferentes de
zero.
Assim, para calcular a distancia de Fisher-Rao entre θ1 e θ2, precisamos resolver
o sistema
√d11 0 0
0√d22 0
0 d23√d22
√d33 − d223
d22
∆(1)
√d11 0 0
0√d22 0
0 d23√d22
√d33 − d223
d22
= ∆2
√d11 0 0
0√d22 0
0 d23√d22
√d33 − d223
d22
δ(1) + ∆2
µ1+µ2
2
η1
η2
= δ2
, (2.31)
com (δ2,∆2) = ϕ(θ2), o qual e um sistema nao linear com nove equacoes e nove variaveis e

66 Distribuicao Normal Multivariada
que tambem pode ser resolvidos atraves de metodos iterativos. A distancia de Fisher-Rao
entre θ1 e θ2 e dada por
dF (θ1,θ2) = 2dF ((0, In), (δ(1),∆(1))) = 2√b2
1 + b22 + x2.
Sistema p× p
Vamos agora, generalizar o procedimento feita no caso acima.
Consideremos agora pontos que, a menos de uma permutacao nas linhas do vetor
de medias e nas linhas e colunas da matriz de covariancia, sao do tipo
θ1 = (µ1e1,Σ1) e θ2 = (µ2e1,Σ2), (2.32)
em que Σ1 = (σij) e Σ2 = (σij) e dado por
Σ2 =
σ1j =− σ1j, j = 2, . . . , n
σj1 =σ1j, j = 2, . . . , n
σij =σij, c.c.
De maneira analoga ao caso anterior, supor que a curva geodesica γ(t) = (µ(t),Σ(t))
em M, satisfazendo γ(−1) = θ1 e γ(1) = θ2, e tal que, no instante t = 0, γ(0) =
(µ1/2,Σ1/2), onde
µ1/2 =
(µ1 + µ2
2, η1, . . . , ηn−1
)tΣ1/2 =
(d11 0t
0 D
)em que D e uma matriz simetrica de ordem n− 1 e, γ′(0) = (µ′1/2,Σ
′1/2), e
γ′(0) = (µ′1/2,Σ′1/2)) =
µ′(0)
0...
0
,
0 σ′12(0) · · · σ′1n(0)
σ′12(0) 0 · · · 0...
.... . .
...
σ′1n(0) 0 · · · 0
,
e equivalente a supor que, no ponto (0, In), a curva geodesica (δ(t),∆(t)) tem vetor
tangente
(x, B) =
x
0...
0
,
0 b1 · · · bn−1
b1 0 · · · 0...
.... . .
...
bn−1 0 · · · 0
.

2.2. Algoritmos Numericos 67
Substituindo os valores de x e B em (2.12) segue que
δ(t) =
x senh(t√∑n−1
l=1 b2l+2x2)
√∑n−1l=1 b2l+2x2
− b1x(cosh(t√∑n−1
l=1 b2l+2x2)−1)∑n−1
l=1 b2l+2x2
...
− bn−1x(cosh(t√∑n−1
l=1 b2l+2x2)−1)∑n−1
l=1 b2l+2x2
e as entradas da matriz ∆(t) sao
∆11(t) =1
2
cosh
t√√√√n−1∑
l=1
b2l
+ cosh
t√√√√n−1∑
l=1
b2l + 2x2
;
Se j = 2, . . . , n,
∆1j(t) =∆j1(t) = −1
2bj−1
senh
(t√∑n−1
l=1 b2l
)√∑n−1
l=1 b2l
+
senh
(t√∑n−1
l=1 b2l + 2x2
)√∑n−1
l=1 b2l + 2x2
;
Se i = 2, . . . , n,
∆ii(t) =1
2b2i−1
cosh
(t√∑n−1
l=1 b2l
)− 1∑n−1
l=1 b2l
+
cosh
(t√∑n−1
l=1 b2l + 2x2
)− 1∑n−1
l=1 b2l + 2x2
+ 1;
Se i 6= j, i, j >2
∆ij(t) =1
2bi−1bj−1
cosh
(t√∑n−1
l=1 b2l
)− 1∑n−1
l=1 b2l
+
cosh
(t√∑n−1
l=1 b2l + 2x2
)− 1∑n−1
l=1 b2l + 2x22
.
De maneira analoga ao caso trivariado e possıvel notar que δ(t) e uma hiperbole no plano
gerado pelos vetores (1, 0, . . . , 0) e (0, b1, . . . , bn−1).
Para calcular a distancia de Fisher-Rao entre θ1 e θ2, precisamos resolver o sistemaL−1∆(1)L−1 = ∆2
L−1δ(1) + ∆2µ1/2 = δ2
, (2.33)
em que L e o fator de Cholesky da matriz Σ1/2. Observemos que o sistema tem a mesma
dimensao da variedadeM, isto e, o sistema tem dimensao p = n+ n(n+1)2
. A distancia de
Fisher-Rao entre θ1 e θ2 e dada por

68 Distribuicao Normal Multivariada
dF (θ1,θ2) = 2
√√√√n−1∑l=1
b2l + x2. (2.34)
A Tabela 2.1 fornece algumas comparacoes do tempo do calculo da distancia de
Fisher Rao entre alguns pares de pontos utilizando o metodo geodesic shooting e resolvendo
sistemas. Para as comparacoes utilizamos os pontos
θ1 =
((−µ0
),
(0.55 −0.45
−0.45 0.55
))e θ2 =
((µ
0
)(0.55 0.45
0.45 0.55
)).
e variamos o valor de µ. A precisao considerada foi de cinco casas decimais.
µ dF (θ1,θ2) Tempo Sistemas (s) Tempo G.Shooting (s)
1 2.77395 0.046875 4.703132 3.67027 0.046875 5.609383 4.52933 0.0625 7.109384 5.26093 0.078125 9.171885 5.87480 0.046875 12.53136 6.39439 0.0625 18.42197 6.84043 0.078125 492.5638 7.22903 0.0625 574.4229 7.57221 0.046875 917.85910 7.87896 0.046875 1007.13
Tabela 2.1: Comparacao entre o tempo do calculo da distancia de Fisher-Rao atraves daresolucao de sistemas e pelo algoritmo geodesic shooting para diferentes valores de µ.
Observamos que o tempo do calculo da distancia de Fisher-Rao pelo algoritmo
geodesic shooting e muito maior que o tempo do calculo da distancia resolvendo o sistema.
Alem disso, notamos que a medida que a distancia entre as medias das distribuicoes
aumenta o algoritmo geodesic shooting fica cada vez mais lento. A partir de µ = 7, o
algoritmo geodesic shooting a princıpio nao convergiu e foi necessario utilizar a adaptacao
proposta na secao 2.2.1 onde pontos adicionais sao utilizados para o calculo da distancia.
Isso justifica o aumento do tempo de calculo da distancia de Fisher-Rao. Dessa forma,
concluımos que apesar do algoritmo geodesic shooting apresentar boas aproximacoes para
a distancia de Fisher-Rao ele e muito caro computacionalmente. Logo o seu uso em
algoritmos de agrupamentos de dados e pouco viavel uma vez que a cada iteracao desses
algoritmos o calculo da distancia e feito muitas vezes, como veremos no Capıtulo 3.
Na proxima secao apresentamos alguns limitantes para a distancia de Fisher-Rao.

2.3. Limitantes para a distancia de Fisher-Rao 69
2.3 Limitantes para a distancia de Fisher-Rao
Como ja foi dito anteriormente, uma formula fechada para distancia de Fisher-Rao
entre distribuicoes normais multivariadas no caso geral ainda nao e conhecida. Nessa secao
mostraremos alguns limitantes para esta distancia. Primeiro, mostramos um limitante
inferior dado por Calvo and Oller [12]. Depois, derivamos alguns limitantes superiores,
utilizando a isometria dada na Secao 2.1. Com esse limitantes podemos determinar um
intervalo no qual se encontra a distancia de Fisher-Rao entre duas distribuicoes normais
multivariadas.
2.3.1 Limitante Inferior
Em 1990, Calvo and Oller [12] calcularam um limitante inferior para a distancia
de Fisher-Rao atraves de um mergulho isometrico do espaco M no espaco das matrizes
simetricas positivas definidas.
Proposicao 2.15. [12] Sejam θ1 = (µ1,Σ1) e θ2 = (µ2,Σ2) pontos em M e defina
Si =
(Σi + µtiµi µti
µi 1
),
i = 1, 2. Um limitante inferior para a distancia de Fisher-Rao entre θ1 and θ2 e dado por
LI(θ1,θ2) =
√√√√1
2
n+1∑i=1
[log(λi)]2, (2.35)
onde λk, 1 ≤ k ≤ n+ 1, sao os autovalores de S−11 S2.
Observemos que o limitante LI tambem pode ser interpretado como uma distancia.
2.3.2 Limitantes Superiores
Nos casos abaixo descrevemos alguns limitantes superiores para a distancia de
Fisher-Rao.
Limitante Superior LS1
Em [55] propomos um limitante superior para a distancia de Fisher-Rao baseado
no fato de que a subvariedade MD nao e totalmente geodesica.
Dados dois pontos θ1 e θ2 em M, a isometria ψ3 dada no Corolario 2.3, nos diz
que calcular a distancia de Fisher-Rao entre θ1 e θ2 e o mesmo que calcular a distancia
entre θ0 e ψ3(θ2) = θ = (µ,Λ) em que Λ e uma matriz diagonal. Dessa forma, os pontos
θ0 e θ pertencem a subvariedade MD. Como MD nao e uma subvariedade totalmente

70 Distribuicao Normal Multivariada
geodesica, a distancia de Fisher-Rao entre θ0 e θ, nessa subvariedade, nos fornece uma
formula fechada para um limitante superior para dF (θ1,θ2).
Proposicao 2.16. [55] A distancia de Fisher-Rao entre duas distribuicoes normais mul-
tivariadas θ1 = (µ1,Σ1) e θ2 = (µ2,Σ2) e limitada por,
LS1(θ1,θ2) =n∑i=1
√√√√√2 log2
√|1− Λii|2 + |µi|2 +
√|Λii + 1|2 + |µi|2√
|Λii + 1|2 + |µi|2 −√|1− Λii|2 + |µi|2
, (2.36)
onde Λii sao os elementos da diagonal de Λ e µi sao as coordenadas de µ. A matriz Λ e
diagonal composta pelos autovalores de Σ = Σ−1/21 Σ2Σ
−1/21 , O e a matriz ortogonal cujas
colunas sao os respectivos autovetores de Σ = OΛOt e µ = OtΣ−1/21 (µ2 − µ1).
Demonstracao. Basta calcular a distancia dD entre os pontos θ0 e θ, dada na equacao
(2.16).
Utilizando o limitante superior LS1 estabelecemos uma maneira de determinar a
escolha dos pontos intermediarios dados na extensao do algoritmo geodesic shooting na
Secao 2.2.1. Dados os pontos θ1 e θ2 em M, para escolher os pontos intermediarios
θ1, . . . , θN procedemos da seguinte maneira. Ja vimos que utilizando a isometria ψ1
dada no Corolario 2.3 conseguimos transformar os pontos θ1 e θ2 em θ0 e θ pertencentes
a MD. Assim, calculamos a curva geodesica γD em MD tal que γD(0) = θ0 e γD(1) = θ
e dD(θ0,θ). Os pontos θi’s sao escolhidos sobre a curva γd da seguinte maneira, seja N o
menor numero natural maior que dD(θ0,θ),
θi = γD
(i
N
).
Como,
dD(θi, θi+1) =1
NdD(θ0,θ) ≤ 1, (2.37)
segue que dF (θi, θi+1) ≤ dD(θi, θi+1) ≤ 1.
Limitante Superior LSα
Calvo e Oller [13] estabeleceram um limitante superior para a distancia de Fisher-
Rao em M.
Seja a subvariedade Mα ⊂M dada por
Mα = pθ;θ = (µ,Σ) ∈ Θ; Σ = αΣ0,Σ0 ∈ Pn(R), α ∈ R∗+.
A distancia de Fisher-Rao entre duas distribuicoes θ1 = (µ1,Σ0) e θ2 = (µ2, αΣ0) em

2.3. Limitantes para a distancia de Fisher-Rao 71
Mα e
d2α(θ1,θ2) = 2 arccosh
(√α
2+
1
2√α
+1
4√αδtδ
)+n− 1
2log2 α,
onde δ = Σ− 1
20 (µ2 − µ1) [13].
Consideremos os pontos θ1 = (µ1,Σ1), θ2 = (µ2,Σ2) e θα = (µ2, αΣ1) em M,
pela desigualdade triangular segue que
dF (θ1,θ2) ≤ dF (θ1,θα) + dF (θα,θ2).
Como θ1 e θα pertencem a subvariedade Mα segue que dF (θ1,θα) ≤ dα(θ1,θα). Alem
disso, como θα e θ2 pertencem a subvariedade totalmente geodesica Mµ0 , dF (θα,θ2) =
dµ0(θα,θ2). Portanto
dF (θ1,θ2) ≤ dα(θ1,θα) + dµ(θα,θ2)
e segue que
LSα = dα(θ1,θα) + dµ0(θα,θ2) (2.38)
e um limitante superior para a distancia de Fisher-Rao entre θ1 and θ2.
Limitante Superior LS2
Considerando a distancia na subvariedade totalmente geodesicaMDµ e a desigual-
dade triangular, assim como no limitante dado por Calvo e Oller [13], encontramos um
outro limitante superior para a distancia de Fisher-Rao, ver referencia [56].
Dados dois pontos θ1 e θ2 em M, pela isometria ψ4 dada no Corolario 2.3, pode-
mos considerar os pontos θ0 e θ = (µ,Σ), em que µ = |µ|e1. Seja θ = (µ, Σ), pela
desigualdade triangular segue que
dF (θ0,θ) ≤ dF (θ0, θ) + dF (θ,θ).
Para calcular o limitante vamos escolher θ de forma conveniente. Escolhendo
µ = µ temos que dF (θ,θ) = dµ0(θ,θ). Alem disso, fazendo Σ = D = diag(d21, d
22, . . . , d
2n),
uma matriz diagonal, segue que dF (θ0, θ) = dDµ(θ0, θ). Portanto
LS2 = dDµ(θ0, θ) + dµ0(θ,θ). (2.39)
e um limitante superior para a distancia de Fisher-Rao entre θ1 e θ2, ver Figura 2.13.
Podemos otimizar o limitante LS2 minimizando a soma atraves de processos numericos,
isto e, calculando
min(d1,d2,...,dn)>0
dDµ(θ0, θ) + dµ0(θ,θ). (2.40)
e fazendo D = diag(d21, d
22, . . . , d
2n).

72 Distribuicao Normal Multivariada
Parâmetros
θ0 θ
-2 0 2 4 6-2
-1
0
1
2
Parâmetros
θ0 θ θ
-2 0 2 4 6-2
-1
0
1
2
Figura 2.13: Limitante LS2, dF (θ0,θ) ≤ dDµ(θ0, θ) + dµ0(θ,θ).
A Proposicao abaixo mostra que o limitante LS2 generaliza o limitante LSα.
Proposicao 2.17. O limitante LSα e um caso particular do limitante LS2 quando D =
diag(α, · · · , α).
Demonstracao. Consideremos a distancia entre θ0 = (0, In) e θ = (µ,Σ). Pela equacao
(2.39),
LS2 = dDµ(θ0, θ) + dµ0(θ,θ),
em que θ = (|µ|e1, D). Fazendo D = αIn, temos que
d2Dµ(θ0, θ) = d2
Dµ((0, In), (|µ|e1, αIn))
= d2F
((0, 1), (|µ|,√α)
)+
n∑i=2
d2F ((0, 1), (0,
√α)).
Observemos que
d2F
((0, 1), (|µ|,√α)
)=2 arccosh2
1 +
∣∣∣(0, 1)−(|µ|√
2,√α)∣∣∣2
2√α
=2 arccosh2
(1 +
( |µ|22
+ (1−√α)2
)1
2√α
)=2 arccosh2
( |µ|24√α
+1
2√α
+
√α
2
).
(2.41)
Alem disso,
n∑i=2
d2F ((0, 1), (0,
√α)) =2(n− 1) arccosh2
(1 +|1−√α|2
2√α
)=2(n− 1) arccosh2
(1
2√α
+
√α
2
)=2(n− 1) arccosh2
(1 + α
2√α
),

2.3. Limitantes para a distancia de Fisher-Rao 73
como arccosh(x) = log(x+√x2 − 1), segue que
n∑i=2
d2F ((0, 1), (0,
√α)) =2(n− 1) log2
1 + α
2√α
+
√(1 + α
2√α
)2
− 1
=2(n− 1) log2
(1 + α
2√α
+
√(1− α)2
4α
)=n− 1
2log2 α.
(2.42)
Logo, segue de (2.41) e (2.42) que
dDµ(θ0, θ) = dDµ((0, In), (|µ|e1, αIn))
= dα((0, In), (|µ|e1, αIn)),
Portanto,
LS2 = dα(θ0, θ) + dµ0(θ,θ) = LSα.
Atraves da proposicao acima, concluımos que o limitante LS2 e sempre melhor
que o limitante superior LSα, pois obtemos maior grau de liberdade nos processos de
minimizacao de LS2.
Limitante Superior LS3
Considerando os pontos θ e θ como acima, propomos tambem um limitante analıtico,
LS3, minimizado a distancia dDµ(θ0, θ).
Lema 2.18. Considere os pontos θ0 e θ como exposto acima. A distancia entre θ0 e θ,
dDµ(θ0, θ), atinge o seu valor mınimo quando
D = diag
( |µ|2 + 2
2, 1, . . . , 1
). (2.43)
Demonstracao. Sejam θ0 = (0, In) e θ = (|µ|e1, D). Pelas equacoes (2.15) e (1.11), segue
que
d2Dµ(θ0, θ) = d2
F ((0, 1), (|µ|, d1)) +n∑i=2
d2F ((0, 1), (0, di))
= 2 arccosh2
1 +
∣∣∣(0, 1)−(|µ|√
2, d1
)∣∣∣22d1
+ 2n∑i=2
arccosh2
(1 +|(0, 1)− (0, di)|2
2di
).

74 Distribuicao Normal Multivariada
Para encontrar o ponto θ no qual a distancia dDµ(θ0, θ) atinge seu valor mınimo, va-
mos minimizar a funcao de n variaveis f(d1, . . . , dn) = d2Dµ(θ0, θ). Como cada variavel di,
i = 1, . . . , n, esta em uma unica parcela da soma acima, basta minimizar cada parcela sep-
aradamente. Alem disso, como a funcao arccosh e uma funcao crescente, para minimizar
f basta minimizar cada uma das funcoes
g1(t) =1 +
∣∣∣(0, 1)−(|µ|√
2, t)∣∣∣2
2t,
gi(t) =1 +|(0, 1)− (0, t)|2
2t, i = 2, . . . , n,
com t > 0. Observemos que
g1(t) = 1 +
∣∣∣(0, 1)−(|µ|√
2, t)∣∣∣2
2t=t
2+|µ|2 + 2
4t,
logo
g′1(t) = 0⇔ 1
2− |µ|
2 + 2
4t2= 0⇔ 2t2 − (|µ|2 + 2) = 0⇔ t =
√|µ|2 + 2
2.
Portanto, como t ∈ (0,∞), t =√|µ|2+2
2e um ponto de mınimo absoluto para g1. Da
mesma forma, para todo i = 2, . . . , n, temos que
gi(t) = 1 +|(0, 1)− (0, t)|2
2t=t
2+
1
2t,
e calculos analogos ao anterior mostram que t = 1 e ponto de mınimo para gi, i = 2, . . . , n.
Assim, a funcao f atinge o seu valor mınimo em(√|µ|2 + 2
2, 1, . . . , 1
).
O limitante analıtico LS3 e dada por
LS3 = dDµ(θ0, θ) + dµ(θ,θ),
onde θ = (|µ|e1, D) e
D = diag
( |µ|2 + 2
2, 1, . . . , 1
). (2.44)

2.3. Limitantes para a distancia de Fisher-Rao 75
Limitante Superior LS4
Dados dois pontos θ1 e θ2 emM, novamente, pela isometria ψ4 dada no Corolario
2.3, podemos considerar os pontos θ0 = (0, In) e θ = (µ,Σ), em que µ = |µ|e1. Seja
θ = (0, Σ) em que
Σ =
σ1j =− σ1j, j = 2, . . . , n
σj1 =σ1j, j = 2, . . . , n
σij =σij, c.c.
temos que θ e θ sao pontos do tipo (2.32), ver Figura 2.14. Pela desigualdade triangular,
Parâmetros
θ0 θ
-2 0 2 4 6-2
-1
0
1
2
Parâmetros
θ0 θ θ
-2 0 2 4 6-2
-1
0
1
2
Figura 2.14: Limitante LS4, dF (θ0,θ) ≤ dµ0(θ0, θ) + dF (θ,θ).
segue que
dF (θ0,θ) ≤ dF (θ0, θ) + dF (θ,θ).
Como dF (θ0, θ) = dµ0(θ0, θ) e dF (θ,θ) e dada em (2.34), temos que
LS4 = dµ0(θ0, θ) + dF (θ,θ),
e um outro limitante superior para a distancia de Fisher-Rao entre θ1 e θ2.
2.3.3 Comparacao dos Limitantes
Nesta secao vamos comparar os limitantes apresentados acima atraves de algumas
simulacoes.
Seja M o espaco das distribuicoes normais bivariadas, n = 2. Para as simulacoes
vamos considerar pontos do tipo θ0 e θ = (µ, Σ), onde
θ = (µ, Σ) =
((µ
0
),
(cos(α) sen(α)
− sen(α) cos(α)
)(λ1 0
0 λ2
)(cos(α) − sen(α)
sen(α) cos(α)
)),
ver Figura 2.15.

76 Distribuicao Normal Multivariada
α
λ2
λ1
µ
Figura 2.15: Tipos de pontos utilizados nas simulacoes .
Vamos fixar o ponto θ0 e analisar os limitantes para a distancia entre θ0 e θ,
sempre variando algum dos parametros µ, λ1, λ2 ou α.
Simulacao 1: λ1 = 2, λ2 = 0.5, α = 0 e µ livre. Inicialmente analisamos o
limitante inferior LI (2.35). Comparamos o limitante com a distancia de Fisher-Rao,
dF , na subvariedade MDµ para observar o comportamento do limitante em relacao a
distancia de fato. Como nessa subvariedade a matriz de covariancia e diagonal, tomamos
α = 0. Na primeira simulacao fixamos os autovalores (λ1 = 2 e λ2 = 0.5) e fizemos a
media µ variar entre 0 e 10. A Figura 2.16 ilustra os grafico dos valores de dF e LI em
funcao da media µ. Observamos que quanto mais distante e a media entre as distribuicoes
maior e a distancia de Fisher-Rao entre elas e o limitante inferior tambem apresenta o
mesmo comportamento. Porem, quanto maior e distancia entre os vetores de media mais
o limitante LI se afasta da distancia real.
Simulacao 2: λ1 = 2, λ2 = 0.5, µ = 1 e α livre. Nesta simulacao analisamos todos
os limitantes apresentados na secao anterior juntamente com a distancia de Fisher-Rao
calculada atraves do algoritmo geodesic shooting (plotamos apenas a distancia entre vinte
pontos utilizando o algoritmo geodesic shooting pois o calculo da distancia para mais
pontos e muito caro computacionalmente). Fixamos µ = 1, λ1 = 2, λ2 = 0.5 e variamos α
entre 0 e π/2. ver Figura 2.17. Observamos que os valores dos limitantes LI e LS1 estao
bem proximos. Mais ainda, observando a figura vemos que o limitante superior LS1, nos
pontos que em a distancia de Fisher-Rao foi calculada pelo geodesic shooting, e uma boa
aproximacao para a distancia de Fisher-Rao. Notamos tambem que apesar do valor do
limitante LS3 estar bem acima do valor de LS1 ele apresenta um comportamento bem
similar aos do limitantes LI e LS1.

2.3. Limitantes para a distancia de Fisher-Rao 77
Simulacao 3: λ1 = 2, λ2 = 0.5, µ = 10 e α livre. Nesta simulacao utilizamos
parametros similares aos utilizados na simulacao anterior, mudando apenas o valor da
media, µ = 10. Isto e, fizemos com que o vetor de media se afastasse da origem. Na
Figura 2.18 vemos que, neste caso, o valor do limitante LI esta bem abaixo do valor da
distancia de Fisher-Rao. Ou seja, como visto na Simulacao 1, para distribuicoes cuja
diferenca entre as medias e grande o valor de LI nao e proximo do valor da distancia de
Fisher-Rao. Alem disso, os limitantes superiores que melhor se aproximam da distancia
sao os limitantes LS2 e LS3, vale lembrar que LS3 e um limitante com uma formula
fechada. Observamos tambem que quando o valor de α vai se aproximando de π/4 maior
fica o valor do limitante LS1.
Simulacao 4: λ1 = 0.5, λ2 = 2, µ = 10 e α livre. Nesta simulacao trocamos
os valores dos parametros λ1 e λ2, utilizados na simulacao anterior. O que se observa
e um comportamento muito similar da Simulacao 3, ver Figura 2.19, porem no sentido
contrario. Isto e, se fizessemos α variar de π/2 ate 0, os graficos das duas simulacoes
seriam os mesmos.
Simulacao 5: λ1 = 2, λ2 = 0.5, α = π/4 e µ livre. Fixamos os valores λ1 = 2,
λ2 = 0.5, α = π/4 e fizemos a media variar µ de 1 a 10. Neste caso, ver Figura 2.20,
observamos que os valores dos limitantes superiores LS2 e LS3 estao proximos, apresen-
tam um comportamento semelhante e, quanto maior o valor de µ, mais eles se aproximam
do valor da distancia calculada pelo algoritmo geodesic shooting. Vemos tambem que a
medida que o valor de µ vai aumentando, tanto o limitante inferior LI quanto o limitante
superior LS1 se afastam do valor da distancia. Alem disso, vemos que, mesmo apre-
sentando valores maiores que os outros limitantes superiores, o limitante LS4 apresenta
um comportamento similar a curva obtida ligando os pontos dados atraves do algoritmo
numerico.
Simulacao 6: λ1 = 10, λ2 = 0.5, α = 5π/12 e µ livre. Nesta simulacao, usamos
praticamente os mesmos parametros da simulacao anterior, mudando apenas o valor do
primeiro autovalor, λ1 = 10. Na Figura 2.21, observamos que o limitante LS1 apresenta
valores menores que os limitantes LS2, LS3 e LS4 e que ate µ = 4 , LS1 e uma boa
aproximacao para a distancia de Fisher-Rao.

78 Distribuicao Normal Multivariada
2 4 6 8 10Parâmetro μ
1
2
3
4
5
Limitantes
LI dF
Figura 2.16: Grafico µ × Limitantes comparando o limitante LI com a distancia dF nasubvariedade MDµ (Simulacao 1:λ1 = 2, λ2 = 0.5, α = 0).
0.5 1.0 1.5Parâmetro α
1.0
1.2
1.4
1.6
1.8
2.0
2.2
2.4
Limitantes
LI LS1
LS2 LS3
LS4 GS
Figura 2.17: Grafico α×Limitantes comparando os limitantes LI, LS1, LS2, LS3, LS4 coma distancia de Fisher-Rao calculada atraves do geodesic shooting (Simulacao 2: λ1 = 2,λ2 = 0.5, µ = 1).

2.3. Limitantes para a distancia de Fisher-Rao 79
0.5 1.0 1.5Parâmetro α
4.5
5.0
5.5
6.0
6.5
7.0
Limitantes
LI LS1
LS2 LS3
LS4 GS
Figura 2.18: Grafico α×Limitantes comparando os limitantes LI, LS1, LS2, LS3, LS4 coma distancia de Fisher-Rao calculada atraves do geodesic shooting (Simulacao 3: λ1 = 2,λ2 = 0.5, µ = 10).
0.5 1.0 1.5Parâmetro α
4.5
5.0
5.5
6.0
6.5
7.0
Limitantes
LI LS1
LS2 LS3
LS4 GS
Figura 2.19: Grafico α×Limitantes comparando os limitantes LI, LS1, LS2, LS3, LS4 coma distancia de Fisher-Rao calculada atraves do geodesic shooting (Simulacao 4: λ1 = 0.5,λ2 = 2, µ = 10).

80 Distribuicao Normal Multivariada
2 4 6 8 10Parameter μ
1
2
3
4
5
6
7Limitantes
LI LS1
LS2 LS3
LS4 GS
Figura 2.20: Grafico µ×Limitantes comparando os limitantes LI, LS1, LS2, LS3, LS4 coma distancia de Fisher-Rao calculada atraves do geodesic shooting (Simulacao 5: λ1 = 2,λ2 = 0.5, α = π/4).
Com essas simulacoes, observamos que os limitantes superiores dados na Secao
2.3.2 aproximam muito bem a distancia de Fisher em alguns casos. Por exemplo quando
os valores da media µ dos autovalores λ1 e λ2 sao “relativamente proximos”o limitante
LS1 e muito proximo dos valores da distancia de Fisher-Rao calculados pelo algoritmo
geodesic shooting, com a vantagem que para esse limitante existe uma formula fechada.
Pilte e Barbaresco [47] utilizaram esse limitante em aplicacoes em monitoramento de radar.
Alem disso, nos casos nos quais o limitante LS1 esta distante dos valores da distancia de
Fisher-Rao (quando os valores da media dos autovalores estao “relativamente distantes”),
os limitantes LS2 e LS3 sao uma boa aproximacao para a distancia, lembrando ainda que
existe uma expressao para LS3. Em geral, o limitante LS4 nao apresentou bons resultados.
2.4 Curvaturas
Seja o modelo estatıstico M. O teorema abaixo, cuja prova foi dada por Skov-
gaard [54], determina uma formula explıcita para as curvatura seccionais dos subespacos
bidimensionais de TθM. Antes de apresentarmos o teorema observemos que spanx,y e
o conjunto gerados pelos vetores x e y e que o conjunto
∂∂µi
ni=1
,
∂∂σij
nj≤i=1
e uma
base para TθM.

2.4. Curvaturas 81
2 4 6 8 10Parameter μ
1
2
3
4
5
6
7
Limitantes
LI LS1
LS2 LS3
LS4 GS
Figura 2.21: Grafico µ×Limitantes comparando os limitantes LI, LS1, LS2, LS3, LS4 coma distancia de Fisher-Rao calculada atraves do geodesic shooting (Simulacao 6: λ1 = 10,λ2 = 0.5, α = π/4).
Teorema 2.19. Seja M a variedade estatıstica das distrbuicoes normais univariadas.
Para todo θ ∈M, a curvatura seccional de um subespaco gerado por dois vetores da base
de TθM e dada por
(i) Para todo i, j, i 6= j,
K
(span
∂
∂µi,∂
∂µj
;∂
∂µi,∂
∂µj
)=
1
4.
(ii) Para todo i, j, k = 1, . . . ,m, j ≤ k,
K
(span
∂
∂µi,∂
∂σjk
;∂
∂µi,∂
∂σjk
)= −2aijkρijρkjρki + ρ2
ij + ρ2ik
4(1 + ρ2jk)
,
em que aijk = −1 quando i, j, e k sao todos diferentes e aijk = 1 caso contrario e
ρij = σij/σiiσjj e o chamado coeficiente de correlacao.

82 Distribuicao Normal Multivariada
(iii) Para todo i, j, i 6= j,
K
(span
∂
∂σii,∂
∂σjj
;∂
∂σii,∂
∂σjj
)=− ρ2
ij
1 + ρ2ij
K
(span
∂
∂σii,∂
∂σij
;∂
∂σii,∂
∂σij
)=− 1
2.
Ou seja, pelo teorema acima vemos que as curvaturas seccionais de M nao tem o
mesmo sinal e muito menos sao constantes.
Sato et. al. [51] mostrou atraves de calculos diretos, utilizando softwares, que o
curvatura escalar R da variedade composta por distribuicoes normais bivariadas e R =
−9/2. Tambem com o auxılio de softwares, calculamos o valor da curvatura escalar da
variedade M para n = 3 e n = 4, ver Tabela 2.2.
n Curvatura escalar R
1 -1
2 -4.5
3 -12
4 -25
Tabela 2.2: Curvatura escalar
A partir dos calculos feitos na construcao da Tabela 2.2, conjecturamos um valor
para a curvatura escalar R de M em funcao de n.
Conjectura 2.20. Seja M o modelo estatıstico das distribuicoes normais n-variadas.
Entao a curvatura escalar de M e dada por
R = −1
4n(n+ 1)2.

83
Capıtulo 3
Simplificacao de Misturas
Gaussianas e Aplicacoes
Uma mistura gaussiana parametrizada f de m componentes e uma soma ponderada
de m distribuicoes normais, isto e,
f(x) =m∑i=1
wip(x;µi,Σi), (3.1)
onde x ∈ Rn, p(x;µi,Σi), i = 1, . . . ,m sao as distribuicoes normais e wi, i = 1, . . . ,m,
sao os pesos da mistura, que satisfazem a restricao∑m
i=1wi = 1.
Modelos de mistura gaussiana (denotado aqui por MMG) sao frequentemente uti-
lizados para modelar pontos de um conjunto de dados. Eles sao muitos utilizados em
algoritmos de agrupamentos, processamento de imagem, processamento de sinais e prob-
lemas de estimacao de densidade, ver referencias [21, 30, 58]. Em muitas aplicacoes que
envolvem modelos de mistura, a custo computacional e muito alto devido o grande numero
de componentes da mistura. Esse custo pode ser fortemente diminuıdo se reduzirmos o
numero de componente da mistura: dada uma mistura f de m componentes queremos
encontrar uma mistura g de l componentes, 1 ≤ l < m tal que g seja a melhor aprox-
imacao para f com respeito a alguma medida de similaridade [28]. A necessidade de
simplificar misturas gaussianas pode ser vista em modelos dinamicos de trocas lineares
(em ingles, switching dynamic linear models) na area de inferencia estatıstica [9] e para
uma decodificacao eficiente de codigos reticulados corretores de erro [36].
Neste capıtulo, descrevemos os algoritmos de agrupamento Maximizacao da Ex-
pectativa, k-medias e algoritmo de agrupamento hierarquico. Utilizamos os dois ultimos
algoritmos para simplificar misturas gaussianas cujas matrizes de covariancia sao diag-
onais fazendo o uso da distancia de Fisher-Rao na subvariedade MD. Apresentamos
tambem algumas aplicacoes desses algoritmos na area de segmentacao de imagens.

84 Simplificacao de Misturas Gaussianas e Aplicacoes
3.1 Algoritmos de Agrupamento
Analise de agrupamento, tambem conhecida como clustering, e um conjunto de
tecnicas computacionais que consiste em separar objetos em grupos (clusters) baseado
nas suas caracterısticas. O objetivo e colocar em um mesmo grupo objetos que sejam
similares de acordo com algum criterio pre-determinado. Esse criterio normalmente e
uma funcao de dissimilaridade. A seguir apresentamos alguns algoritmos de agrupamento
de dados.
3.1.1 Algoritmo Maximizacao de Expectativa
Dado um conjunto de dados muitas vezes queremos aproxima-lo por uma certa
distribuicao de probabilidade. Uma maneira de fazer isso e dada pelo metodo da maxima
verossimilhanca. Esse metodo consiste em estimar parametros de um modelo utilizando
estimativas que maximizam a funcao de verossimilhanca. Em geral, encontrar parametros
que maximizam a funcao de verossimilhanca pode ser extremamente complicado de se
resolver explicitamente. O algoritmo Maximizacao da Expectativa (Expectation Maxi-
mization), tambem conhecido como algoritmo EM, e um metodo iterativo que encontra
o estimador de maxima verossimilhanca (localmente).
O algoritmo EM foi proposto por Dempster [23] em 1977 e desde entao tem sido
utilizado por varios estatısticos. Ele estima parametros que maximizam a funcao de
verossimilhanca de dados incompletos e e bastante usado para estimar parametros de um
modelo de mistura. O algoritmo EM alterna entre duas etapas essenciais: a de expectativa
(passo-E) e a de maximizacao (passo-M). No passo-E o algoritmo calcula o valor esperado
do logaritmo da verossimihanca e no passo-M encontra o seu maximo. Abaixo daremos
uma breve discussao do algoritmo no caso de estimacao de parametros de uma mistura
Gaussiana [16].
Consideremos um conjunto de n amostras independentes e identicamente dis-
tribuıdas (i.i.d.) y1,y2, . . . ,yn ∈ Rd de um MMG com m componentes, queremos estimar
os seus parametros (ωj,θj)mj=1, em que θj = (µj,Σj) para todo j = 1 . . .m. Para uma
mistura Gaussiana a funcao de verossimilhanca e dada por
L(θ) =n∏i=1
m∑j=1
wj p(yi;θj).
Dado um conjunto de parametros iniciais ω(0)j ,θ
(0)j )mj=1, no passo-E calculamos γ
(k)ij , a
probabilidade da i-esima amostra pertencer a j-esima componente da mistura na k-esima
iteracao dada por
γ(k)ij =
ω(k)j p(yi;θj(k))∑ml=1 ω
(k)l p(yi;θ
(k)l )
,

3.1. Algoritmos de Agrupamento 85
a qual satisfaz∑m
j=1 γij = 1. Dessa forma, o valor da esperanca do logaritmo da funcao
da verossimilhanca e dado por
Q((w,θ)|(w(k),θ(k))) =m∑j=1
γ(k)ij log(wj p(yi;θj)).
No passo-M obtemos o vetor de parametros (w,θ) que maximiza a esperanca do
logaritmo da funcao de verossimilhanca e o atualizamos,
(w(k+1),θ(k+1)) = argmax(w,θ)
Q((w,θ)|(w(k),θ(k))).
Repetimos o algoritmo ate quando o valor absoluto |Q((w,θ)|(w(k+1),θ(k+1))) −Q((w,θ)|(w(k),θ(k)))| atingir uma dada precisao.
O algoritmo EM tem a propriedade de que a cada iteracao o valor da funcao de
verossimilhanca aumenta. Alem disso, se existe pelo menos um maximo local da funcao
de verossimilhanca o algoritmo converge para esse maximo. Esse algoritmo tambem e
conhecido como soft clustering, isto e, cada elemento do conjunto de dados tem uma
probabilidade de pertencer a cada grupo.
Neste trabalho utilizamos uma adaptacao do algoritmo EM proposto por Banerjee
[6] para uma mistura distribuicoes exponenciais, o Bregman soft clustering. Banerjee
mostrou que no caso de modelos de misturas de famılias exponenciais
p(x;θ) = exp(−DF (t(x),η)) exp(C(x)),
em que η e o parametro de expectativa e DF e a divergencia de Bregman associada a
funcao F , ver Secao 1.5.2. Com essa adaptacao o passo-M, que em geral e computacional-
mente caro, torna-se muito mais facil de calcular. Observemos que essa facilidade ocorre
apenas quando os parametros de expectativa da distribuicao em questao sao conhecidos.
No caso das distribuicoes exponenciais os parametros naturais e de expectativas estao
deduzidos em [44].
3.1.2 Algoritmo k-medias
Um dos algoritmos mais utilizado na area de agrupamento de dados e o algoritmo
k-medias (k-means) [35] . Ele foi proposto num trabalho pioneiro de S. Lloyd [38]. Esse
algoritmo busca minimizar a distancia dos elementos de um conjunto de dados com k
centros de forma iterativa. Dado um conjunto de dados C = p1, . . . , pn o algoritmo
comeca com a escolha de k centros para o clustering e depois associa cada ponto do
conjunto de dados seu centro mais proximo, segundo a uma dada distancia, formando
clusters Ci . Entao, atualiza-se os centros (centroide) de cada grupo ate nenhum elemento

86 Simplificacao de Misturas Gaussianas e Aplicacoes
mudar de grupo em duas iteracoes sucessivas. Lloyd escolheu para o centroide de cada
cluster o ponto que minimiza a soma do quadrado da distancia Euclidiana entre ele mesmo
e cada ponto do conjunto,
c = argminc
∑pj∈Ci
|c− pj|2.
Esse ponto e justamente o centro de massa do cluster Ci e e dado por
c =p1 + · · ·+ pn
|Ci|,
em que |Ci| denota a cardinalidade de Ci.Um outro ponto de centro, chamado ponto de Fermat, e o ponto que minimiza a
distancia Euclidiana em vez do seu quadrado. Para esse ponto nao se tem uma formula
fechada.
A depender do problema a ser analisado, muitas vezes e necessario o uso de uma
outra distancia ou medida de dissimilaridade para fazer os agrupamentos. Em [29], por
exemplo, os autores propuseram o uso da distancia de Mahalanobis [40] para o clustering
levando em conta a correlacao entre os pontos do conjunto de dados.
Dada uma mistura Gaussiana (3.1), vamos utilizar o algoritmo k-medias para sim-
plifica-la. Garcia e Nielsen [28] propuseram uma simplificacao para uma mistura Gaus-
siana atraves do Bregman hard clustering, uma adaptacao do algoritmo k-medias para
misturas de famılias exponencial utilizando a divergencia de Bregman. Para esse algo-
ritmo, eles utilizaram os centroides de Bregman [45] definidos na Secao 3.2.1.
3.1.3 Agrupamento Hierarquico
O algoritmo de agrupamento hierarquico e um dos algoritmos de agrupamento
mais simples. Ele consiste na construcao de conjuntos de objetos de forma hierarquica. O
algoritmo e dividido nos metodos: aglomerativos e divisivos. Os metodos aglomerativos
iniciam-se com conjuntos compostos por apenas um elemento e, de forma iterativa, os
conjuntos sao mesclados ate formar grupos maiores. Ja os metodos divisivos iniciam-se
com um unico grupo que contem todos os elementos e, recursivamente, os conjuntos sao
repartidos ate formar grupos com um unico elemento. Neste trabalho vamos utilizar o
metodo aglomerativo o qual e o mais utilizado em aplicacoes praticas.
Seja C um conjunto de n objetos, consideremos n subconjuntos C1, . . . , Cl que for-
mam uma particao de C. Isto e, C = ∪iCi e Ci ∩ Cj = ∅ para todo i 6= j. O primeiro
passo do algoritmo e determinar os dois subconjuntos mais proximos segundo uma dada
distancia D(·, ·) dentre as n(n − 1) combinacoes possıveis. O segundo passo e mesclar
os dois subconjuntos mais proximos em um unico subconjunto. O algoritmo hierarquico
inicia-se com uma particao tal que cada conjunto contem apenas um unico elemento de
C e alterna entre primeiro e o segundo passo ate a obtencao de um unico conjunto igual

3.2. Centroides no Modelos das Distribuicoes Normais Multivariadas 87
a C. A distancia D(·, ·) entre os subconjuntos e chamada de criterio de linkage. Os tres
criterios de linkage mais utilizados sao os criterios da distancia: mınima, maxima e media
dados, respectivamente, por
Dmin(A,B) = mind(a, b); a ∈ A,∈ B,Dmax(A,B) = maxd(a, b); a ∈ A,∈ B,
Dav(A,B) =1
|A||B|d(a, b); a ∈ A,∈ B,(3.2)
em que d e uma distancia entre os objetos dos conjuntos.
Diferentes algoritmos de agrupamento hierarquico podem ser obtidos a depender
da distancia d escolhida. Alem disso, e preciso tambem determinar um ponto que rep-
resente cada conjunto (centroide). Na Secao 3.3.2 definimos dois algoritmos hierarquicos
para simplificar misturas Gaussianas com matrizes de covariancia diagonais utilizando a
distancia de Fisher-Rao.
Na proxima secao vamos mostrar dois modos de definir centroide no modelo Mdas distribuicoes normais multivariadas.
3.2 Centroides no Modelos das Distribuicoes Nor-
mais Multivariadas
O calculo do centroide na variedadeM e um problema ainda em aberto, ate mesmo
porque nao se tem uma formula fechada para a distancia no caso geral. Abaixo vamos
apresentar alguns centroides definidos na variedadeM: os primeiros utilizam a divergencia
de Bregman e o ultimo utiliza a distancia de Fisher-Rao na subvariedade MD.
3.2.1 Centroides de Bregman
Dado um conjunto C com os m parametros de uma mistura Gaussiana de dis-
tribuicoes exponencial (parametrizada com seus parametros naturais),
C = α1,ϑ1, α2,ϑ2, . . . , αn,ϑn,
o centroide de Bregman e um ponto que minimiza a media da divergencia e Bragman.
Como a divergencia de Bregman nao e simetrica, consideramos tres tipos de centroides: o
centroide de Bregman a direita ϑD, o centroide de Bregman a esquerda ϑE e o centroide
de Bregman simetrizado ϑS, que satisfazem, respectivamente, as seguintes equacoes [45]
ϑD = argminϑ
1∑i αi
∑i
αiDF (ϑi‖ϑ), (3.3)

88 Simplificacao de Misturas Gaussianas e Aplicacoes
ϑE = argminϑ
1∑i αi
∑i
αiDF (ϑ‖ϑi), (3.4)
ϑS = argminϑ
1∑i αi
∑i
αiSDF (ϑ‖ϑi),
onde SDF e a divergencia de Bregman simetrizada dada por
SDF (ϑ,ϑi) =DF (ϑi‖ϑ) +DF (ϑ‖ϑi)
2.
Observemos que devido a relacao entre a divergencia de Bregman e a divergencia de
Kullback-Leibler (1.14), podemos considerar DF (ϑi‖ϑ) = DKL(p(x;θ)‖p(x;θi))..
A minimizacao das equacoes (3.3) e (3.4) fornece uma formula fechada para os
centroides direito e esquerdo, respectivamente, dados por
ϑD =
∑i αiϑi∑i αi
(3.5)
ϑE = ∇F ∗(∑
i αi∇F (ϑi)∑i αi
), (3.6)
em que ∇F ∗ e o gradiente do dual de Legendre da funcao de log-normalizer F [45]. Nao
existe uma formula fechada para o centroide simetrico mas ele pode ser estimado atraves
do algoritmo geodesic walk dado em [45].
Observemos que, como a divergencia de Kullback-Leibler e uma aproximacao de
segunda ordem da distancia do quadrado da distancia de Fisher-Rao, ver a Proposicao 1.24
e o Corolario 1.25,os centroides de Bregman podem ser utilizados como uma aproximacao
para um centroide que minimize o quadrado da distancia de Fisher-Rao.
Algoritmos de agrupamento de distribuicoes normais multivariadas usando a dis-
tancia de Fisher-Rao sao poucos utilizados dado que nao se tem uma formula fechada para
a distancia. Entretanto, Schwander e Nielsen [52] propuseram o algoritmo k-medias para
simplificar misturas gaussianas univariadas usando a distancia de Fisher-Rao dada em
(1.11). Eles obtiveram bons resultados em comparacao com o algoritmo k-media baseado
na divergencia de Kullback-Leibler. Para fazer as iteracoes do k-medias eles definiram
centroides no espaco parametrico das distribuicoes normais univariadasMH usando o cen-
troide dado por Galperin [27] para espacos de curvatura constante (Euclidiano, hiperbolico
ou esferico).
3.2.2 Centroide de Galperin
Seja H2 o plano superior de Poincare. Galperin [27] definiu um centroide no espaco
hiperbolico utilizando o modelo de Minkowski, o qual e dado pela folha superior do hiper-
boloide z2 = 1+x2+y2. Para levar um conjunto de pontos de H2 no modelo de Minkowiski

3.2. Centroides no Modelos das Distribuicoes Normais Multivariadas 89
e calcular o centroide, Schwander e Nielsen [52] utilizaram diversos modelos do espaco
hiperbolico (disco de Poincare, disco de Klein, modelo de Minkowski ) e suas relacoes.
Seja (a, b) um ponto de H2, fazendo z = a + bi, sua representacao no disco de
Poincare e
z′ =z − 1
z + 1.
Reciprocamente, dado z′ no disco de Poincare, sua representacao no plano hiperbolico e
(Re(z), Im(z)), onde
z =(z′ + 1)i
1− z′ .
Agora, dado um ponto z′ no disco de Poincare e um ponto p no disco de Klein, a relacao
entre eles e dada por
z′ =1−
√1− 〈p,p〉〈p,p〉 p e p =
2
1 + 〈z′, z′〉z′.
Por fim, dado p = (xp, yp) no disco de Klein, seu mergulho no modelo de Minkowski e
dada por p′ com coordenadas:
xp′ =xp
1− x2p − y2
p
, yp′ =yp
1− x2p − y2
p
e zp′ =zp
1− x2p − y2
p
.
E, dado p′ = (xp′ , yp′ , zp′) no modelo de Minkowski,
p =
(xp′
zp′,yp′
zp′
)e a sua representacao no disco de Klein.
Sejam p′i’s pontos no modelo de Minkowski com pesos associados wi’s, i = 1, . . . , n.
O centro de massa do conjunto C = (w1,p′1), . . . , (wn,p
′n) e dado por
c′′ =n∑i=1
wip′i.
Para que esse ponto pertenca ao modelo de Minkowski, Galperin normaliza o ponto por
meio da intersecao do vetor Oc′′ e do hiperboloide z2 = 1 + x2 + y2, ver Figura 3.1. Logo,
o centroide no modelo de Minkowski e dado por
c′ =c′′
−x2c′′ − y2
c′′ + z2c′′,
em que c′′ = (xc′′ , yc′′ , zc′′).
Portanto, munidos das relacoes acima e do centroide definido por Galperin no
modelo de Minkowski, temos uma formula fechada de um centroide para um conjunto de

90 Simplificacao de Misturas Gaussianas e Aplicacoes
Figura 3.1: Determinacao do centroide c entre os pontos (w1,p1) e (w2,p2) (Figura reti-rada de [52]).
pontos em H2.
Para calcular o centroide de Galperin c de um conjunto de pontos C = (wj,θj),θj = (µj, σj), no modelo composto por distribuicoes normais univariadas, MH, basta
utilizar a relacao entre MH e H2F dada em (1.10).
Como temos uma formula fechada para a distancia na subvariedade MD, em [57]
propomos um centroide nesse espaco. Foi visto na secao 2.1.3 que a distancia nessa
subvariedade e dada pela metrica produto no espaco MH. Dado um conjunto de pontos
C = (wi,θi)mi=1, θi = (µ1i, σ1i, . . . , µni, σni) ⊂ MD, i = 1, . . . ,m, definimos o centroide
de C como
c = (c1, . . . , cn/2), (3.7)
onde cj, j = 1, . . . , n/2, e o centroide do conjunto Cj = (wji,θji)mi=1, θji = (µji, σji) ∈MH.
A Figura 3.2 ilustra uma comparacao entre os centroides apresentados nesta secao.
Consideramos quatro distribuicoes normais univariadas com desvio padrao σ =√
6 e
medias dadas, respectivamente, por µ1 = 10, µ2 = 10, µ3 = 30, µ4 = 40. Calculamos os
centroides de Bregman ϑD = (µ = 25, σ =√
6), ϑE = (µ = 25, σ =√
131) e ϑS = (µ =
25, σ =√
28) e o centroide dado por Galperin cG = (µ = 25, σ = 8.27647). Alem disso,
calculamos tambem, atraves de algoritmos numericos, o centroide cN = (µ = 25, σ =
7.845) dado por
cN = argminc
4∑i=1
dF (c, (µi, σ))2,
ou seja, o centroide que minimiza o quadrado da distancia de Fisher-Rao. Como o desvio
padrao foi o mesmo para todas as distribuicoes, todos os centroides obtiveram o mesmo

3.3. Algoritmos de Simplificacao de Misturas Gaussianas 91
valor para a media µ = 25. O desvio padrao do centroide de Bregman a direita coincide
com o desvio padrao das distribuicoes pois ele, neste caso, ele e o centro de massa Euclid-
iano. Como esperado, o desvio padrao do centroide de Bregman simetrizado esta entre
os desvios dos centroides a esquerda e direita. Observamos tambem que o centroide de
Galperin e o que mais se aproxima do centroide cN .
-10 10 20 30 40 50 60x
0.05
0.10
0.15
p(x;μ,σ)
Bregman à direita
Bregman à esquerda
Bregman simetrizado
Galperin
Numérico
Figura 3.2: Comparacao dos centroides.
Notamos que a escolha dos centroides e da distancia utilizada vai depender de cada
aplicacao.
3.3 Algoritmos de Simplificacao de Misturas Gaus-
sianas
Nesta secao apresentamos adaptacoes dos algoritmo k-medias e do agrupamento
hierarquico para simplificar misturas Gaussianas.
3.3.1 Algoritmo k-medias Fisher-Rao Diagonal
Garcia e Nielsen propuseram em [28] uma simplificacao para misturas gaussianas
atraves do Bregman hard clustering, uma adaptacao do algoritmo k-medias para simpli-
ficar misturas de famılias exponencial utilizando a divergencia de Bregman. Para esse
algoritmo, eles utilizaram os centroides de Bregman definidos na secao anterior.
Utilizando raciocınio similar ao utilizado no Bregman hard clustering, nesta secao
descrevemos uma outra adaptacao do algoritmo k-medias para simplificar misturas gaus-

92 Simplificacao de Misturas Gaussianas e Aplicacoes
sianas multivariadas cujas matrizes de covariancia sao todas diagonais, o qual foi proposto
em [57]. Chamaremos esse algoritmo aqui de algoritmo k-medias Fisher-Rao diagonal.
Para esse algoritmo, usamos a distancia na subvariedadeMD e o centroide dado em (3.7).
Um modelo de mistura Gaussiana diagonal (denotado por MMDG), e uma soma
ponderada de m distribuicoes normais)
fD(x) =m∑i=1
wip(x;µi,Σi),
em que Σi, i = 1, · · · ,m, e uma matriz de covariancia diagonal. MMDG sao muitos
utilizados para modelar um conjunto de dados uma vez que, como a matriz de covariancia
e diagonal, a mistura apresenta uma menor quantidade de parametros.
Para simplificar a mistura fD, consideremos o conjunto C = (w1,θ1), . . . , (wm,θm),θj = (µj,Σj) ∈ MD para todo j = 1, . . . ,m, composto pelos parametros da mistura fD.
O algoritmo k-medias Fisher-Rao diagonal consiste em obter um conjunto de l elementos
C = (w1, θ1), . . . , (wl, θl), os quais serao os parametros da mistura gaussiana simplifi-
cada. Abaixo seguem os passos do algoritmo.
Inicializacao: Dado o conjunto C = (w1,θ1), . . . , (wm,θm), escolhemos aleato-
riamente l pontos de C, cj = (wj, θj), com j ∈ 1, . . . , L, para os centroides iniciais.
Agrupamento: Dados os l centroides cj = (wj, θj), com j ∈ 1, · · · , L, dizemos
que o ponto (wi,θi) pertence ao cluster Cj quando dD(θi, θj) ≤ dD(θi, θs), com s ∈1, · · · , l.
Atualizacao: Atualizamos o centroide cj de cada cluster Cj usando o centroide
definido em (3.7) e fazendo wj =∑
iwi, com (wi,θi) ∈ Cj.O algoritmo termina quando o centro de cada grupo nao muda em duas iteracoes
sucessivas.
Na secao 3.4 apresentamos uma aplicacao desse algoritmo na area de segmentacao
de imagens e fazemos uma comparacao do mesmo com o algoritmo Breman hard clustering.
3.3.2 Agrupamentos Hierarquico
Garcia e Nielsen [28] propuseram um algoritmo hierarquico para simplificar mis-
turas gaussianas utilizando a divergencia de Bregman, o Bregman hierarchical clustering.
Nessa secao apresentamos algumas adaptacoes do algoritmo hierarquico para simplificar
MMDG utilizando a distancia de Fisher Rao.
Seja C = (w1,θ1), · · · , (wm,θm), um conjunto composto pelos parametros de
uma mistura gaussiana diagonal fD. O algoritmo e analogo ao apresentado na Secao
3.1.3, a diferenca e dada pela distancia entre os elementos do conjunto escolhida. Para

3.4. Aplicacao em Segmentacao de Imagens 93
este algoritmo escolhemos o criterio de linkage dado pela distancia maxima
D(A,B) = maxdD(a, b); a ∈ A, b ∈ B,
em que dD e a distancia de Fisher-Rao na subvariedade MD. A mistura gaussiana sim-
plificada
g =l∑
j=1
βjgj
de l componentes e construıda a partir dos l subconjuntos C1, ..., Cl restantes depois de
m− l iteracoes do algoritmo. Os parametros de gj sao dados pelo centroide do conjunto
Cj, escolhemos esse centroide de duas maneiras diferentes, definindo assim dois algoritmos
de agrupamento hierarquico:
(i) Agrupamento Hierarquico Fisher-Rao diagonal : o centroide de Cj e dado pelo cen-
troide na subvariedade MD definido em (3.7) [57];
(i) Agrupamento Hierarquico Bregman-Fisher-Rao: o centroide de Cj e dado pelo cen-
troide de Bregman a esquerda.
Alem disso, os pesos βj sao dados por βj =∑
iwi, onde (wi,θi) ∈ Cj.Como pontuado em [28], o algoritmo de agrupamento hierarquico permite intro-
duzir um metodo para encontrar um numero otimo de componentes da mistura sim-
plificada g. A mistura g deve ser a mais compacta possıvel e atingir uma qualidade
pre-estabelecia DKL(fD||g) ≤ τ .
Na secao a seguir apresentamos uma aplicacao desses algoritmos na area de seg-
mentacao de imagens.
3.4 Aplicacao em Segmentacao de Imagens
Nesta secao vamos fazer uma aplicacao dos algoritmos apresentados nas Secoes
3.3.1 e 3.3.2 em segmentacao de imagens, assim como foi feito para os algoritmos Bregman
hard e hierarchical clustering em [28].
A segmentacao de uma imagem e uma tecnica da area de processamento de sinais
que permite a particao da imagem em diferentes regioes homogeneas. Segmentacoes de
imagens sao muito utilizadas em areas como recuperacao de imagens, reconhecimento de
falas, sistemas de controles de trafico, entre outras.
Dada uma imagem de entrada I, utilizamos o Bregman soft clustering [28] para
gerar os parametros de um MMGD fD de 32 componentes que modela os pixels da im-
agem. Notemos que para utilizar o Bregman soft clustering, calculamos a funcao de
log-normalizer, os parametros naturais e os parametros de expectativa das distribuicoes
normais multivariadas com matriz de covariancia diagonal, ver Tabela 3.1.

94 Simplificacao de Misturas Gaussianas e Aplicacoes
Distribuicao p(x,µ,Σ) = 2πn/2√∏ni=1 σ
21
exp(−1
2
∑ni=1
(xi−µi)2σ2i
), x ∈ Rn
P. fontes θ = (µ1, . . . , µn, σ1, . . . , σn), σi > 0, ∀ i1, . . . , nP. naturais ϑ = (ϑ1, . . . , ϑ2n)
P. de expectativa η = (η1, · · · , η2n)
θ → ϑ ϑ =(µ1σ21, . . . , µn
σ2n, 1
2σ21, . . . , 1
2σ2n
)ϑ→ θ θ =
(ϑ1
2ϑn+1, . . . , ϑn
2ϑ2n, 1√
2ϑn, . . . , 1√
2ϑ2n
)θ → η η = (µ1, . . . , µn,−µ2
1 − σ21, . . . ,−µ2
n − σ2n)
η → θ θ =(η1, . . . , ηn,
√−(η2
1 + ηn+1), . . . ,√−(η2
n + η2n))
Log-normalizer F F (ϑ) = 14
∑ni=1
ϑ2iϑn+i− 1
2log∏n
i=1 θi + n2
log π
Gradiente de F ∇F (ϑ) =(
ϑ12ϑn+1
, . . . , ϑn2ϑ2n
,− 12ϑn+1
− ϑ214ϑ2n+1
, . . . ,− 12ϑ2n− ϑ21
4ϑ22n
)Dual de F F ∗(η) = −1
2log(−(η2
1 + ηn+1))− 12
log(−(η2n + η2n))− n
2log(2πe)
Gradiente de F ∗ ∇F ∗(η) =(− η1η21+ηn+1
, . . . ,− η1η2n+η2n
,− 12(η21+ηn+1)
, . . . ,− 1η2n+η2n
)Tabela 3.1: Parametros da distribuicao normal multivariada com matriz de covarianciadiagonal.
Consideramos aqui, um pixel ρ = (ρR, ρG, ρB) como um ponto do R3, onde ρR, ρG,
ρB sao as informacoes RGB de cada pixel. Para a segmentacao dizemos que cada pixel ρ
da imagem pertence a classe Cj quando
p(ρ;µj,Σj) > p(ρ;µi,Σi), ∀i ∈ 1, · · · ,m \ j.
Assim, a segmentacao da imagem e dada pela troca do valor da cor do pixel ρ pela media
µj da Gaussiana p(ρ;µj,Σj).
As imagens utilizadas nos experimentos foram Baboon, Lena e Palhaca, ver Figura
3.3 (cada imagem de entrada continha 2562 pixels). Utilizamos o Bregman soft clustering
para modelar os dados da imagem gerando assim uma mistura fD de 32 componentes.
Essa primeira mistura ja fornece uma segmentacao da imagem. Utilizamos o algoritmo k-
medias Fisher-Rao diagonal para simplificar a mistura fD na mistura g de l componentes
com l = 2, 4, 8, 16. Cada mistura fornece uma segmentacao da imagem. A Figura 3.3
mostra a segmentacao das imagens de Baboon, Lena e Palhaca . O numero de cores de
cada imagem e igual ao numero de componentes da mistura simplificada g. Comparamos
o algoritmo k-medias Fisher-Rao diagonal com os algoritmos Left-Bregman hard clustering
e Right-Bregman hard clustering, dados em [28], em que sao usadas, respectivamente, as
divergencia de Bregman a esquerda e a direita.

3.4. Aplicacao em Segmentacao de Imagens 95
l=2
l=4
l=8
l=16
l=32
Original
Figura 3.3: Ilustracao da segmentacao das imagens Baboon, Lena e Palhaca pelo algoritmok-medias Fisher-Rao diagonal.

96 Simplificacao de Misturas Gaussianas e Aplicacoes
A qualidade da segmentacao e dada em funcao de l atraves da divergencia de
Kullback-Leibler, DKL(f ||g), estimada atraves do metodo de Monte-Carlo [33] uma vez
que nao existe uma formula fechada para medir a divergencia de Kullback-Leibler en-
tre misturas Gaussianas (cinco mil pontos foram gerados aleatoriamente para estimar
DKL(f ||g). As Figuras 3.4, 3.5 e 3.6 mostram qualidade da simplificacao das misturas.
Observamos que a qualidade da simplificacao aumenta (DKL(f ||g) diminui) com l e o
comportamento e similar em todos os algoritmos de agrupamentos analisados. Observa-
mos que o Left-Bregman hard clustering apresenta uma melhor simplificacao da mistura
para todas as figuras analisadas, entretanto o algoritmo k-medias Fisher-Rao diagonal
apresenta valores bem proximos.
o
o
o
o
o
o
o
o
o
o
2 4 6 8 10 12 14 160
1
2
3
4
5
6
l
DKL(fD||g)
o Left-Bregman hard clustering
o Right-Bregman hard clustering
o k-médias Fisher-Rao diagonal
Baboon
Figura 3.4: Grafico ilustrando a qualidade das simplificacoes da mistura fD que modelaos dados da imagem Baboon.
Comparamos tambem a qualidade da segmentacao de todos os metodos usando o
classico ındice conhecido como PSNR (Peak Signal-to-Noise) medido entre a figura inicial
e as outras figuras segmentadas. O ındice PSNR, medido em dB, e dado por
PSNR = 10 log10
((T − 1)2
MSE
),
em que T e a quantidade de pixels e MSE e o erro quadratico medio (mean square error)
definido por
1
T 3
T∑i=1
T∑j=1
T∑k=1
|X(i, j, k)− Y (i, j, k)|2,

3.4. Aplicacao em Segmentacao de Imagens 97
o
o
o
o
o
o
o
o
o
o
o
2 4 6 8 10 12 14 160
1
2
3
4
5
6
l
DKL(fD||g)
o Left-Bregman hard clustering
o Right-Bregman hard clustering
o k-médias Fisher-Rao diagonal
Lena
Figura 3.5: Grafico ilustrando a qualidade das simplificacoes da mistura fD que modelaos dados da imagem Lena.
oo
o
o
o
o
o
o
o
o
2 4 6 8 10 12 14 160
1
2
3
4
5
6
l
DKL(fD||g)
o Left-Bregman hard clustering
o Right-Bregman hard clustering
o k-médias Fisher-Rao diagonal
Palhaça
Figura 3.6: Grafico ilustrando a qualidade das simplificacoes da mistura fD que modelaos dados da imagem Palhaca.

98 Simplificacao de Misturas Gaussianas e Aplicacoes
onde X(i, j, k) e Y (i, j, k) sao as entradas dos vetores com as informacoes RGB da imagem
X e da imagem Y , respectivamente. As Figuras 3.7, 3.8 e 3.9 exibem o grafico do ındice
PSNR em funcao de l. Observamos que a qualidade da segmentacao (no geral) aumenta
com l e que o algoritmo k-medias Fisher Rao diagonal apresentou os melhores resultados.
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
2 4 6 8 10 12 14 16
20
25
30
35
l
PSNR
o Left-Bregman hard clustering
o Right-Bregman hard clustering
o k-médias Fisher-Rao diagonal
Baboon
Figura 3.7: Grafico ilustrando a qualidade da segmentacao da imagem Baboon (ındicePSNR).
Utilizamos tambem os algoritmos de agrupamento Hierarquico Fisher-Rao diagonal
e Hierarquico Bregman Fisher-Rao para simplificar a mistura fD de 32 componentes
estimada pelas imagens Baboon, Lena e Palhaca.
As Figuras 3.10, 3.11 e 3.12 mostram a evolucao da qualidade da simplificacao da
mistura como funcao do numero de componentes l da mistura simplificada dos algoritmos
Hierarquico Fisher-Rao diagonal e Hierarquico Bregman Fisher-Rao e Bregman hierar-
chical clustering (utilizando a divergencia de Bregman a esquerda a qual apresentou os
melhores resultados em [28]). Vemos que o algoritmo que apresentou melhores resultados
foi o agrupamento Hierarquico Bregman Fisher-Rao. As qualidades da simplificacao dos
algoritmos apresentados k-medias Fisher-Rao diagonal e os Hierarquicos apresentados na
Secao 3.3.2 foram bastante similares. Considerando τ = 0.2 como uma qualidade pre-
estabelecida, vemos que o algoritmo de agrupamento Hierarquico Bregman Fisher-Rao
fornece uma mistura de 18, 21 e 21 componentes como uma simplificacao otima para as
segmentacoes das imagens Baboon, Lena e Palhaca, respectivamente.

3.4. Aplicacao em Segmentacao de Imagens 99
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
2 4 6 8 10 12 14 16
20
25
30
35
40
45
l
PSNR
o Left-Bregman hard clustering
o Right-Bregman hard clustering
o k-médias Fisher-Rao diagonal
Lena
Figura 3.8: Grafico ilustrando a qualidade da segmentacao da imagem Lena (ındicePSNR).
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
2 4 6 8 10 12 14 16
20
25
30
35
40
45
l
PSNR
o Left-Bregman hard clustering
o Right-Bregman hard clustering
o k-médias Fisher-Rao diagonal
Palhaça
Figura 3.9: Grafico ilustrando a qualidade da segmentacao da imagem Palhaca (ındicePSNR).

100 Simplificacao de Misturas Gaussianas e Aplicacoes
o
o
o
o
o
o
oo
o
oo
o o oo
o
o
oo
o
oo
oo
oo
o o oo
o
o
o
o
o
oo
oo
o
oo o
o o
o
o Hierárquico Fisher-Rao diagonal
o Hierárquico Bregman Fisher-Rao
o Bregman Hierarchical Clustering
5 10 15 20 25 300.0
0.5
1.0
1.5
l
DKL(fD||g)
Baboon
Figura 3.10: Grafico ilustrando a qualidade das simplificacoes da mistura fD que modelaos dados da imagem Baboon pelos algoritmos hierarquicos.
o
o
o
o
o
o
o
oo
oo
oo
oo o
o
o
o
oo
o
oo
oo
oo
oo
o
o
oo
o
oo
o
o
oo
oo
o
o
o Hierárquico Fisher-Rao diagonal
o Hierárquico Bregman Fisher-Rao
o Bregman Hierarchical Clustering
5 10 15 20 25 300.0
0.5
1.0
1.5
l
DKL(fD||g)
Lena
Figura 3.11: Grafico ilustrando a qualidade das simplificacoes da mistura fD que modelaos dados da imagem Lena pelos algoritmos hierarquicos.
o
o
o
o
o
o
oo
oo
o oo
ooo
o
o
o
o
o
oo
oo
o o
o o o
o
o
o
o
oo
oo
oo
o
oo o
o
o Hierárquico Fisher-Rao diagonal
o Hierárquico Bregman Fisher-Rao
o Bregman Hierarchical Clustering
5 10 15 20 25 300.0
0.5
1.0
1.5
l
DKL(fD||g)
Palhaça
Figura 3.12: Grafico ilustrando a qualidade das simplificacoes da mistura fD que modelaos dados da imagem Palhaca pelos algoritmos hierarquicos.

3.4. Aplicacao em Segmentacao de Imagens 101
As aplicacoes apresentadas nessa secao mostram que a simplificacao de uma mis-
tura Gaussiana pelo metodo k-medias Fisher-Rao diagonal apresentam uma qualidade de
simplificacao pior que a do Left-Bregman Hierarchical Clustering em relacao a divergencia
de Kullback-Leibler. Porem, em relacao a qualidade de segmentacao de imagem me-
dida pelo ındice PSNR, o algoritmo apresenta bons resultados. Quanto aos algoritmos
hierarquicos, vimos que o algoritmo Hierarquico Bregaman Fisher-Rao foi o que apresen-
tou o melhor desempenho.

102
Capıtulo 4
Conclusoes e perspectivas
A seguir fazemos um breve resumo dos resultados apresentados e listamos algumas
perspectivas futuras.
Neste trabalho fizemos um estudo da distancia de Fisher-Rao no modelo estatıstico
composto por distribuicoes normais multivariadas. Descrevemos a metrica de Fisher em
M e apresentamos uma demonstracao de um resultado ja conhecido sobre uma isometria
nesse espaco. Alem disso, relembramos os casos particulares nos quais uma expressao
para a distancia de Fisher-Rao ja era conhecida. Apresentamos uma formula fechada
para a distancia de Fisher-Rao numa subvariedade deM a qual mostramos ser totalmente
geodesica, permitindo assim o calculo da distancia de Fisher-Rao entre alguns pares de
pontos cuja distancia ainda nao era conhecida. Alem disso, tambem apresentamos uma
outra subvariedade totalmente geodesica dada pela variedade produto das subvariedades
totalmente geodesicas MDµ e Mµ0 , ampliando o conhecimento da distancia de Fisher-
Rao entre mais algumas distribuicoes normais multivariadas. Transformamos o problema
de valor de contorno que fornece a curva geodesica ligando dois pontos em M, para
certos pares de pontos, em um problema de resolucao de um sistema equacoes. Com isso,
agora podemos calcular a distancia de Fisher Rao entre esses pontos de uma maneira
mais eficiente que a dada pelo algoritmo geodesic shooting. Determinamos tambem uma
maneira de escolher os pontos que sao utilizados para garantir uma boa performance do
algoritmo geodesic shooting para distancias de Fisher-Rao maiores que sete.
Limitantes superiores para a distancia de Fisher-Rao no caso geral foram apresen-
tados. Vale ressaltar que a maioria desses limitantes apresentam uma formula fechada e
mostramos, atraves de simulacoes, que em alguns casos eles apresentam uma boa aprox-
imacao para a distancia de Fisher-Rao. Uma perspectiva obvia e a de tentar encontrar
uma expressao para a distancia de Fisher-Rao no caso geral. Ou, caso nao seja possıvel,
melhorar os algoritmos numericos que calculam a distancia de Fisher-Rao, assim como
fizemos para certos pares de pontos atraves da resolucao de sistemas. Uma outra per-

103
spectiva e tentar utilizar os resultados obtidos ate aqui para distribuicoes normais mul-
tivariadas para estudar distribuicoes elıpticas, uma classe de distribuicoes que generaliza
as distribuicoes normais, ver referencias [14,42]. Alem disso, temos tambem a perspectiva
de provar a Conjectura 2.20.
No Capıtulo 3, descrevemos os algoritmos de agrupamento de dados k-medias e
hierarquico e apresentamos algumas definicoes de centroide no modelo das distribuicoes
normais multivariadas. Apresentamos adaptacoes desses algoritmos (os algoritmo k-
medias Fisher-Rao diagonal, agrupamentos hierarquico Fisher-Rao diagonal e Bregman-
Fisher-Rao) os quais foram utilizados no problema de simplificacao de misturas Gaus-
sianas com matrizes de covariancia diagonais atraves do uso da distancia de Fisher-Rao.
Mostramos tambem uma aplicacao desses algoritmos na area de segmentacao de imagens,
os quais em alguns casos apresentaram bons resultados. Como perspectivas de trabalhos
na area de agrupamento de dados, temos a de estudar outros algoritmos de agrupamento
como o k-medoides, por exemplo. Alem disso, temos tambem a perspectiva de analisar
outras aplicacoes onde a distancia de Fisher-Rao e seus limitantes podem ser utilizados.
As simulacoes apresentadas neste trabalho foram feitas utilizando o Wolfram Re-
search, Inc., Mathematica, Version 11.2, Champaign, IL (2017).

104
Bibliografia
[1] Agustini, E., Constelacoes de Sinais em Espacos Hiperbolicos, Tese de Doutorado,
Universidade Estadual de Campinas, 2002.
[2] Amari, S. e Nagaoka, H., Differential Geometrical Methods in Statistics, Lecture
Notes in Statistics, 28, Springer-Verlag, Heidelberg, 1986.
[3] Amari, S. e Nagaoka, H. Methods of Information Geometry, Translations of Mathe-
matical Monographs, Vol.191, Am. Math. Soc., 2000.
[4] Angulo, J., e Velasco-Forero, S., Morphological processing of univariate Gaussian
distribution-valued images based on Poincare upper-half plane representation, Geo-
metric Theory of Information. Springer International Publishing, 331-366, 2014.
[5] Atkinson, C. e Mitchell, A. F. S., Rao’s Distance Measure, Samkhya- The Indian
Journal of Statistics, 43:345-365, 1981.
[6] Banerjee, A., Merugu, S., Dhillon, I. S., e Ghosh, J., Clustering with Bregman diver-
gences, The Journal of Machine Learning Research 6: 1705-1749, 2005.
[7] Bhattacharyya, A., On a measure of divergence between two statistical populations
defined by their probability distributions Bull. Calcutta Math. Soc. 35, 99?110, 1943.
[8] Burbea, J., e Rao, C. R.. Entropy differential metric, distance and divergence mea-
sures in probability spaces: A unified approach, Journal of Multivariate Analysis 12.4:
575-596, 1982.
[9] Bar-Shalom Y., e Li, X., Estimation and Tracking: Principles, Techniques and Soft-
ware, Artech House, 1993.
[10] Burbea, J., Informative geometry of probability spaces, Expositiones Mathematica 4,
347-378, 1986.

BIBLIOGRAFIA 105
[11] Calin, O. e Udriste, C., Geometric modeling in probability and statistics, Cham:
Springer, 2014.
[12] Calvo, M. e Oller, J. M., A distance between multivariate normal distributions based
in an embedding into the Siegel group, Journal of Multivariate Analysis 35.2, 223-242,
1990.
[13] Calvo, M., e Oller, J. M., An explicit solution of information geodesic equations for
the multivariate normal model, Statistics and Decisions 9, 119-138, 1991.
[14] Calvo, M., e Oller, J. M., A distance between elliptical distributions based in an
embedding into the Siegel group, Journal of Computational and Applied Mathematics
145.2: 319-334, 2002.
[15] Carmo, M. P. Geometria Riemanniana, IMPA, Rio de Janeiro, 2008.
[16] Chen, Y., e Gupta, M. R., Em demystified: An expectation-maximization tutorial,
Electrical Engineering. 2010.
[17] Chentsov, N. N., Statistical decision rules and optimal inference, Vol. 53, AMS Book-
store, 1982.
[18] Costa, S. I., Santos, S. A., e Strapasson, J. E., Fisher information distance: a geo-
metrical reading, Discrete Applied Mathematics, 2014.
[19] Cover, T. M. e Joy, A. T., Elements of information theory, John Wiley e Sons, 2012.
[20] Cramer, H., Mathematical Methods of Statistics, NJ, USA: Princeton University
Press, 1946.
[21] Davis, J. V., e Dhillon, I. S., Differential entropic clustering of multivariate gaussians,
Advances in Neural Information Processing Systems, 2007.
[22] Dawid, A. P., Discussions to Efron’s paper, Ann. Statist., v. 3, p. 1231-1234, 1975.
[23] Dempster, A. P., Laird, N. M., e Rubin, D. B., Maximum likelihood from incom-
plete data via the EM algorithm, Journal of the royal statistical society. Series B
(methodological): 1-38, 1997.
[24] Efron, B., Defining the curvature of a statistical problem (with applications to second
order efficiency), The Annals of Statistics, p. 1189-1242, 1975.
[25] Eriksen, P. S., Geodesics Connected with the Fischer Metric on the Multivariate
Normal Manifold, Institute of Electronic Systems, Aalborg University Centre, 1986.

106 BIBLIOGRAFIA
[26] Fisher, R. A., On the mathematical foundations of theoretical statistics, Philosoph-
ical Transactions of the Royal Society of London, Series A, Containing Papers of a
Mathematical or Physical Character, 222, 309-368, 1921.
[27] Galperin, G. A., A concept of the mass center of a system of material points in the
constant curvature spaces, Communications in Mathematical Physics 154.1: 63-84,
1993.
[28] Garcia, V., e Nielsen, F., Simplification and hierarchical representations of mixtures
of exponential families, Signal Processing 90.12: 3197-3212, 2010.
[29] Gnanadesikan, R., Harvey, J. W., e Kettenring, J. R., Mahalanobis metrics for cluster
analysis, Sankhya: The Indian Journal of Statistics, Series A: 494-505, 1993.
[30] Goldberger, J., Greenspan, H. K., e Dreyfuss, J., Simplifying mixture models us-
ing the unscented transform, IEEE Transactions on Pattern Analysis and Machine
Intelligence 30.8: 1496-1502, 2008.
[31] Han, M., e Park, F. C., DTI Segmentation and Fiber Tracking Using Metrics on
Multivariate Normal Distributions, Journal of mathematical imaging and vision, 49.2:
317-334, 2014.
[32] Helgason, S., Differential geometry and symmetric spaces, Vol. 12. Academic press,
1962.
[33] Hershey, J. R., e Olsen, P. A., Approximating the Kullback Leibler divergence between
Gaussian mixture models, Acoustics, Speech and Signal Processing, 2007. ICASSP
2007. IEEE International Conference on. Vol. 4. IEEE, 2007.
[34] Imai, T., Takaesu, A. e Wakayama, M., Remarks on geodesics for multivariate
normal models, Journal of Math-for-Industry 3.6 (2011): 125-130.
[35] Jain, A. K., Data clustering: 50 years beyond K-means, Pattern recognition letters
31.8: 651-666, 2010.
[36] Kurkoski, B., e Dauwels, J., Message-passing decoding of lattices using Gaussian
mixtures, IEEE International Symposium on. IEEE, 2008.
[37] Lenglet, C., Rousson, M., Deriche, R., e Faugeras, O., Statistics on the manifold of
multivariate normal distributions: Theory and application to diffusion tensor MRI
processing, Journal of Mathematical Imaging and Vision 25.3: 423-444, 2006.
[38] Lloyd, S., Least squares quantization in PCM, IEEE transactions on information
theory 28.2: 129-137, 1982.

BIBLIOGRAFIA 107
[39] Magnus, J. R., e Neudecker, H., Matrix Differential Calculus with Applications in
Statistics and Econometrics, John Wiley e Sons Ltd, Chichester, 2007.
[40] Mahalanobis, P. C., On the generalized distance in statistics, Proceedings of the
National Institute of Sciences (Calcutta) 2, 49-55, 1936.
[41] Maybank, S. J., Ieng S., e Benosman, R., A Fisher-Rao metric for paracatadioptric
images of lines International journal of computer vision 99.2: 147-165, 2012.
[42] Micchelli, C. A., e Noakes, L., Rao distances, Journal of Multivariate Analysis 92.1:
97-115, 2005.
[43] Moakher, M., A differential geometric approach to the geometric mean of symmetric
positive-definite matrices, SIAM Journal on Matrix Analysis and Applications 26(3),
735-747, 2005.
[44] Nielsen, F., e Garcia, V., Statistical exponential families: A digest with flash cards,
arXiv preprint arXiv:0911.4863, 2009.
[45] Nielsen, F., e Nock, R., Sided and symmetrized Bregman centroids, Information The-
ory, IEEE Transactions on 55.6: 2882-2904, 2009.
[46] Nielsen, F., Cramer-Rao lower bound and information geometry, arXiv preprint
arXiv:1301.3578, 2013.
[47] Pilte, M., e Barbaresco, F., Tracking quality monitoring based on information geom-
etry and geodesic shooting, Radar Symposium (IRS), 2016 17th International. IEEE,
2016.
[48] Porat, B., e Benjamin F., Computation of the exact information matrix of Gaus-
sian time series with stationary random components, IEEE transactions on acoustics,
speech, and signal processing 34.1: 118-130, 1986.
[49] Rao, C. R., Information and the accuracy attainable in the estimation of statistical
parameters, Bulletin of the Calcutta Math. Soc. 37:81-91, 1945.
[50] Reeds, J., Discussion of paper by B. Efron, Ann. Statist, v. 3, p. 1234-1238, 1975.
[51] Sato, Y., Sugawa, K. e Kawaguchi, M., The geometrical structure of the parameter
space of the two-dimensional normal distribution, Reports on Mathematical Physics
16.1: 111-119, 1979.
[52] Schwander, O., e Nielsen, F., Model centroids for the simplification of kernel density
estimators, Acoustics, Speech and Signal Processing (ICASSP), IEEE International
Conference on. IEEE, 2012.

108 BIBLIOGRAFIA
[53] Siegel, C. L., Symplectic geometry, American Journal of Mathematics 65.1: 1-86,
1943.
[54] Skovgaard, L. T., A Riemannian geometry of the multivariate normal model, Scand,
J. Statist., 11:211-223, 1984.
[55] Strapasson, J. E., Porto, J. , e Costa, S. I., On bounds for the Fisher-Rao distance
between multivariate normal distributions, Bayesian Inference and Maximum Entropy
Methods in Science and Engineering (MAXENT 2014), Vol. 1641, AIP Publishing,
2015.
[56] Strapasson, J. E., Pinele, J., e Costa, S. I., A totally geodesic submanifold of the mul-
tivariate normal distributions and bounds for the Fisher-Rao distance, Information
Theory Workshop (ITW), IEEE, 2016.
[57] Strapasson, J. E., Pinele, J. e Costa, S. I., Clustering using the Fisher-Rao distance,
Sensor Array and Multichannel Signal Processing Workshop (SAM), 2016 IEEE.
IEEE, 2016.
[58] Zhang, K., e Kwok, J. T., Simplifying mixture models through function approxima-
tion, IEEE transactions on neural networks 21.4 : 644-658, 2010.

109
Apendice A
Prova do Teorema 2.1
Antes de apresentar uma demonstracao para o Teorema 2.1, enunciaremos algumas
definicoes e resultados sobre matrizes que podem ser encontrados em [39].
Definicao A.1. Sejam as matrizes A ∈ Mp×q(R) e B ∈ Mr×s(R) (Mm×n(R) e o espaco
das matrizes com entradas reais de ordem m× n). O produto de Kronecker entre A e B
e uma matriz de ordem pr × qs dada por,
A⊗B =
a11B · · · a1qB
.... . .
...
ap1B · · · apqB
.
Lema A.2. Sejam A e B matrizes de ordem p e r, respectivamente. Entao,
Det(A⊗B) = Det(A)p Det(B)r.
Definicao A.3. Seja a matriz A ∈ Mm×m(R), o operador vec de A, vec(A), e definido
por
vec(A) =
a1
a2
...
an
,
em que aj e a j-esima coluna da matriz A.
O produto de Kronecker e o operador vec satisfazem a seguinte propriedade, dadas
as matrizes A, B e C,
vecACB = (Bt ⊗ A) vec(C). (A.1)
Lema A.4. Sejam as matrizes A, B e X pertencentes a Mn(R) e o vetor x ∈ Rn. Entao,

110 Prova do Teorema 2.1
(i) ∂∂xAx = A;
(ii) ∂∂XAXB = vec(Bt ⊗ A).
Vamos agora, fazer a demonstracao do Teorema.
Demonstracao do Teorema 2.1. Primeiramente, vamos mostrar que a aplicacao ψ(c,Q) e
um difeomorfismo. Para mostrar que ψ(c,Q) e injetiva, sejam (µ1,Σ1) e (µ2,Σ2) perten-
centes a M, logo
ψ(c,Q)(µ1,Σ1) = ψ(c,Q)(µ2,Σ2)⇒ (Qµ1 + c,QΣ1Qt) = (Qµ2 + c,QΣ2Q
t),
como Q e invertıvel segue que µ1 = µ2 e Σ1 = Σ2. Alem disso, dado (Qµ+c, QΣQt) ∈M,
a isometria ψ(−Q−1c,Q−1) e tal que
ψ(Q−1c,Q−1)(Qµ+ c, QΣQt) = (Q−1(Qµ+ c)−Q−1c, Q−1QΣQtQ−t) = (µ,Σ),
logo ψ(c,Q) e sobrejetiva e portanto bijetiva. Agora, dado θ = (µ,Σ) ∈ M, pelo Lema
A.4, temos que
dψ(c,Q)(θ) =
(Q 0
0 Q⊗Q
).
Logo, segue do Lema A.2 que Det(dψ(c,Q)(θ)) = det(Q)2n . Como Q e invertıvel temos
que det(dψ(c,Q)(θ)) e invertıvel e portanto, pelo Teorema da Funcao Inversa, ψ(c,Q) e um
difeomorfismo. Alem disso, escrevendo U = (x, A) ∈ TθM como U = (x, vec(A)), segue
da equacao (A.1) que
dψ(c,Q)(θ).U = (Qx, (Q⊗Q vec(A)) = (Qx, vec(QAQt)).
Ou seja,
dψ(c,Q)(θ).U = (Qx, QAQt).
Para mostrar que vale a equacao (2.5), sejam U = (x, A) e U = (y, B) em ∈ TθM,
logo
〈dψ(c,Q)(θ) · U, dψ(c,Q)(θ) · V 〉ψ(c,Q)(θ) =xtQt(Q−tΣ−1Q−1)Qy
+1
2tr[(Q−tΣ−1Q−1)QAQt(Q−tΣ−1Q−1)QBQt]
=xtΣ−1y +1
2tr(Q−tΣ−1AΣ−1BQt)
=xtΣ−1y +1
2tr(Σ−1AΣ−1B)
=〈U, V 〉θ.
Portanto segue a demonstracao.

111
Apendice B
Calculo dos sımbolos de Christoffel
do Teorema 2.9
Vamos calcular o sımbolos de Cristoffel associados a metrica de Fisher na subvar-
iedade MDµ. Como visto em (1.6), os sımbolos de Christoffel Γkij sao dados por
Γmij =1
2
∑k
(∂
∂θigjk +
∂
∂θjgki −
∂
∂θkgij
)gkm, (B.1)
em que [gij] e a matriz inversa de G = [gij].
Considerando θ = (θ1, θ2, . . . , θm) = (µ1, σ1, σ2, . . . , σn), em que m = n + 1, como
parametros da subvariedade MDµ, vemos pela matriz da metrica dada em (2.17) que
gij =
1
σ21
, para i = j = 1
2
σ2i−1
, para i = j = 2, . . . ,m
0, para i 6= j
. (B.2)
Dessa forma, segue que
∂
∂θlgij =
∂
∂µ1
gij = 0, para l = 1, ∀ i, j∂
∂σ1
gij = − 2
σ31
, para l = 2 e i = j = 1
∂
∂σl−1
gij = − 4
σ3i−1
, para l = i e i = j = 2, . . . ,m
0, c.c.
. (B.3)
Alem disso, como gkm = 0 para todo k 6= m, a equacao (B.1) pode ser simplificada

112 Calculo dos sımbolos de Christoffel do Teorema 2.9
em
Γmij =1
2
(∂
∂θigjm +
∂
∂θjgmi −
∂
∂θmgij
)gmm.
Vamos supor i ≥ j, pois como a matriz de informacao de Fisher e simetrica, temos
que Γmij = Γmji .
A demonstracao sera dividida em alguns casos.
Caso 1: m = 1.
Nesta caso,
Γ1ij =
1
2
(∂
∂θigj1 +
∂
∂θjg1i −
∂
∂θ1
gij
)g11
=1
2
(∂
∂θigjm +
∂
∂θjg1i
)g11,
em que a ultima igualdade segue do fato que∂
∂θ1
gij = 0, ∀ i, j.Para i = 1,
Γ11j =
1
2
(∂
∂θ1
gj1 +∂
∂θjg11
)g11
Γ11j =
1
2
(∂
∂θjg11
)g11
,
assim, segue da equacao (B.3) que Γ11j = 0 para j 6= 2 e que
Γ112 = Γ1
21 =1
2
(∂
∂θ1
g21 +∂
∂θ2
g11
)g11
=1
2
(− 2
σ31
)σ2
1
= − 1
σ1
,
Para 1 < i ≤ j, temos que
Γ1ij =
1
2
(∂
∂θigj1 +
∂
∂θjg1i
)g11 = 0,
pois pela equacao (B.2), gj1 = g1i = 0 para todo i, j > 1.
Caso 2: m = 2.
Seja agora m = 2, logo
Γ2ij =
1
2
(∂
∂θigj2 +
∂
∂θjg2i −
∂
∂θ2
gij
)g22.

113
Para i = j = 1,
Γ211 =
1
2
(∂
∂θ1
g12 +∂
∂θ1
g21 −∂
∂θ2
g11
)g22
=1
2
(− ∂
∂θ2
g11
)g22
=1
2
(2
σ31
)σ2
1
2
=1
2σ1
.
Para i = j = 2,
Γ222 =
1
2
(∂
∂θ2
g22 +∂
∂θ2
g22 −∂
∂θ2
g22
)g22
=1
2
(∂
∂θ2
g22
)g22
=1
2
(− 4
σ31
)σ2
1
2
= − 1
σ1
.
Para i = j > 2,
Γ2ii =
1
2
(∂
∂θigi2 +
∂
∂θig2i −
∂
∂θ2
gii
)g22
=1
2
(2∂
∂θig2i −
∂
∂θ2
gii
)g22
= 0
,
na qual a ultima desigualdade segue das equacoes (B.2) e (B.3).
Quando i < j, temos que
Γ2ij =
1
2
(∂
∂θigj2 +
∂
∂θjg2i −
∂
∂θ2
gij
)g22
=1
2
(∂
∂θigj2 +
∂
∂θjg2i
)g22
,
pois gij = 0.
Para i = 1,
Γ21j =
1
2
(∂
∂θ1
gj2 +∂
∂θjg21
)g22 = 0,
pois∂
∂θ1
gj2 = 0, ∀ j, e g21 = 0.

114 Calculo dos sımbolos de Christoffel do Teorema 2.9
Para 2 ≤ i < j,
Γ2ij =
1
2
(∂
∂θigj2 +
∂
∂θjg2i
)g22 = 0,
pois gj2 = 0, ∀ j > 2 e∂
∂θjg2i = 0 para 2 6= j > i.
Caso 3: m > 2.
Finalmente, para m > 2, temos
Γmij =1
2
(∂
∂θigjm +
∂
∂θjgmi −
∂
∂θmgij
)gmm. (B.4)
Para i = j = m,
Γmmm =1
2
(∂
∂θmgmm +
∂
∂θmgmm −
∂
∂θmgmm
)gmm
=1
2
(∂
∂θmgmm
)gmm
=1
2
(− 4
σ3m−1
)σ2m−1
2
= − 1
σm−1
= − 1
σn
Para i = j 6= m,
Γ2ii =
1
2
(∂
∂θigim +
∂
∂θigmi −
∂
∂θmgii
)gmm
=1
2
(2∂
∂θigmi −
∂
∂θmgii
)gmm
= 0
.
Quando i < j, temos que
Γmij =1
2
(∂
∂θigjm +
∂
∂θjgmi −
∂
∂θmgij
)gmm
=1
2
(∂
∂θigjm +
∂
∂θjgmi
)gmm
,
pois gij = 0.
Para m = i < j,
Γmmj =1
2
(∂
∂θmgjm +
∂
∂θjgmm
)gmm = 0,

115
pois gjm = 0 e∂
∂θjgmm = 0, ∀ j > 2.
Para m 6= i < j,
Γmij =1
2
(∂
∂θigjm +
∂
∂θjgmi
)gmm = 0, ,
pois gmi = 0, ∀ j > 2 e∂
∂θigjm = 0 para i 6= m > 2.
Analisando todos os casos concluımos que os unicos sımbolos de Christoffel nao
nulos sao
Γ112 = Γ1
21 = − 1
σ1
, Γ211 =
1
2σ1
e Γmmm = − 1
σm−1
, ∀m ≥ 2.





























