Embed Size (px)
DESCRIPTION
Teleinformatica
Citation preview

(Diciembre 2013) © DIT/UPM
Diseño de sistemas distribuidos: Google
1
Sistemas Operativos Distribuidos
Diseño de SistemasDistribuidos: Google
Alejandro Alonso
Dpto. Ing. de Sistemas Telemáticos

Tabla de
(Diciembre 2013) © DIT/UPM
Diseño de sistemas distribuidos: Google
2
1. Introducción al caso de estudio
2. Arquitectura global y principios de diseño
3. Paradigmas de comunicación
4. Servicios de almacenamiento de datos y coordinación
5. Servicios de computación distribuida
6. Resumen

1. Introducción al caso de
(Diciembre 2013) © DIT/UPM
Diseño de sistemas distribuidos: Google
3
Presentación de la infraestructura de Google Es uno de los sistemas distribuidos más complejos en uso
Su infraestructura ha satisfecho requisitos exigentes:escalabilidad, rendimiento, fiabilidad y carácter abierto
Objetivo: organizar la información global y hacerla útil y accesible universalmente
Funciones básicas de google: Motor de búsqueda: dada una consulta, retorna una lista ordenadas de referencias
Proveedor de servicios en la nube: Ofrece un conjunto de aplicaciones y servicios en la nube

Motor de
(Diciembre 2013) © DIT/UPM
Diseño de sistemas distribuidos: Google
4
Dada una consulta, devuelve una lista ordenada de los resultados más relevantes
Aspectos: rastreo, indexación, clasificación y arquitectura
Rastreo (crawling): localizar y obtener los contenidos de la web: Googlebot
Lee recursivamente un página web, obteniendo los enlaces y planificando nuevas operaciones de rastreo
La frecuencia de las visitas depende de cuanto cambia
Actualmente emplea un sistema basado en una infraestructura (Percolator) que admite actualización incremental de grandes conjuntos de datos

Motor de
(Diciembre 2013) © DIT/UPM
Diseño de sistemas distribuidos: Google
5
Indexación: produce un índice invertido ordenado de los contenidos Web
Relaciona palabras o recursos documentales con las posiciones donde se encuentran en las páginas
También mantiene un índice de enlaces: qué páginas apuntan a una página web
Clasificación: Importancia relativa de las páginas (PageRank)
Importancia: depende del número de enlaces que la apuntan
También considera:
• la importancia de los sitios que apuntan
• la posición del enlace, el tamaño de su letra o si está en mayúsculas
• proximidad de las palabras de la consulta

Motor de búsqueda: arquitectura
(Diciembre 2013) © DIT/UPM
Diseño de sistemas distribuidos: Google
6
Para comparar con la arquitectura actual

Servicios en la
(Diciembre 2013) © Diseño de sistemas distribuidos: 7
Computación en la nube Conjunto de aplicaciones y servicios de almacenamiento y cómputo, basados en Internet
Suficientes para la muchos usuarios, que les evita disponer de almacenamiento o aplicaciones locales
Aplicaciones Google como servicios Aplicaciones web: tratan de reemplazar al software tradicional
Programas ofimáticos, calendarios, herramientas decolaboración, etc.
Plataforma Google como un servicio: APIs de sistemas distribuidos, para desarrollo de aplicaciones
Google AppEngine: Ofrece su infraestructura de sistemasdistribuidos como un servicio en la nube.

Ejemplos de de
Application
Gmail
Google Docs
Google Sites
Google Talk
Google Calendar
Google Wave
GoogleNews
GoogleMaps
Google Earth
GoogleAppEngine
Description
Mail system with messages hosted by Google but desktop-like message management.
Web-based office suite supporting shared editing of documents held on Google servers.
Wiki-like web sites with shared editing facilities.
Supports instant text messaging and Voice over IP.
Web-based calendar witb all data hosted on Google servers.
Collaboration tool integrating email, instant messaging, wikis and social networks .
Fully automated news aggregator site.
Scalable web-based world map including high-resolution imagery and unlimited usergenerated overlays.
Scalable near-3D view of the globe with unlimited user-generated overlays.
Google distributed infrastructure made available to outside parties as a service (platform as a service).
(Diciembre 2013) © DITIUPM Diseño de sistemas distribuidos: Google
Ull8 UPM

(Diciembre 2013) © Diseño de sistemas distribuidos: 9
2. Arquitectura global y p r in c ipio s d e di se ño : M od e l o Fí s i co
Principio básico: usar un gran número de PCs comunes, para construir un entorno efectivo de cómputo y almacenamiento distribuido
PC con 2 TB de disco y 16 GB de DRAM
Versión adaptada del núcleo de Linux
La arquitectura es tolerante a fallos El software es el origen de fallos. 20 máquinas en medias se re-arrancan diariamente por fallos de software
El hardware produce 1/10 de los fallos. Alrededor del 3% fallan al año. Normalmente, discos y DRAM

Arquitectura
(Diciembre 2013) © Diseño de sistemas distribuidos: 1
Los PCs se organizan en racks de entre 40-80 Tiene un switch ethernet para conectividad interna y externa
Los racks se organizan en clusters Son la unidad de gestión
principal Contiene al menos 30
racks
Dos switches para conectividad con el exterior: redundancia
Los clusters están en centros de datos de Google
La capacidad total de almacenamiento: rack de 80 PCs, en un cluster de 30: 4,9 petabytes
Alrededor de 200 clusters

Arquitectura
(Diciembre 2013) © Diseño de sistemas distribuidos: 1
Cifras totales no divulgadas

Diseño de sistemas distribuidos: UP(Diciembre 2013) © 1
Arquitectura
Racks
l.AI
Cluster
l.AI Switches
Racks
Cluster
Racks
Switches
Cluster
Data centre architecture
To other data centres and the Internet

Diseño de sistemas distribuidos: UP(Diciembre 2013) © 1
Arquitectura
dit

Arquitectur físic
Diseño de sistemas distribuidos: UP(Diciembre 2013) © 1
dit

Arquitectur físic
Diseño de sistemas distribuidos: UP(Diciembre 2013) © 1
dit

Principios de diseño: Re qui s i t o s f und ame n ta l es
Escalabilidad Gestionar más información
Resolver más consultas
Obtener mejores resultados
Fiabilidad Requisitos exigentes de disponibilidad
Mecanismos de detección, redundancia y tolerancia a fallos
Rendimiento Proporcionar respuesta rápida, aumenta las consultas
Respuesta: depende de los tiempo entre extremos
Apertura (Openness): Facilitar el desarrollo de nuevas aplicaciones
(Diciembre 2013) © DIT/UPM Diseño de sistemas distribuidos: Google 14

Infraestructur de
diUPDiseño de sistemas distribuidos: (Diciembre DITIUP 1
Google applications and services
Google infrastructure (middleware)
Google platform

Infraestructur de
diUPDiseño de sistemas distribuidos: (Diciembre DITIUP 1
Distributed computation MapReduce Sawzall
Data and coordination GFS Chubby Bigtable
Communication paradigms Protocol buffers Publish-subscr ibe

Principios de
(Diciembre 2013) © Diseño de sistemas distribuidos: 1
Simplicidad: El software hace una cosa y la hace bien
APIs tan sencillas como sea posible
Rendimiento Cada milisegundo cuenta
Estimación del rendimiento de un diseño:• Tamaño de mensajes, acceso a disco, acceso a mutex, etc.
Pruebas Pruebas exhaustivas al software
Trazas y bitácoras

(Diciembre 2013) © Diseño de sistemas distribuidos: 1
3. Paradigmas de comunicación: In v o cac ió n rem o ta
Protocol buffers: Se usa para almacenamiento e invocación
Proporciona un mecanismo para especificar y serializar datos
Neutral respecto al lenguaje y a la plataforma
Simple y muy eficiente
Los mensajes se describen mediante un lenguaje
Conjuntos de campos enumerados con identificador único
Se indica el tipo de la información
Etiquetas para caracterizar los campos: Requerido, opcional o repetido

Invocació remot
message Book {required string title = 1; repeated string author =
2; enum Status {IN PRESS = O·- '
PUBLISHED = l ;OUT_OF_PRINT = 2;
}message BookStats {
required int32 sales = 1;optional int32 citations = 2;optional Status bookstatus = 3 [default = PUBLJSHED};
}optional BookStats statistics =
3;repeated string keyword = 4;
}
dit(Diciembre 2013) DITIUPM Diseño de sistemas distribuidos: Google 19 UPM

(Diciembre 2013) © Diseño de sistemas distribuidos: 2
Invocació remot
La especificación se compila Se genera código para manipular los mensajes:
Funciones: getters, setters, borrado y comprobar existencia de campos, toString
Para los campos repetidos: Son una especie de arrays
Funciones: longitud, obtener valor, cambiar valor, añadir, añadir conjunto de valores, borrar.
Formato más sencillo que XML Adaptado a las necesidades de Google
• No considera interoperabilidad
• No es autodefinido: los mensajes no incluyen metadatos
Más rápido y conciso

Invocació remot
(Diciembre 2013) © Diseño de sistemas distribuidos: 2
Permite expresar servicios remotos
service SearchService {rpc Search (RequestType) returns (ResponseType)
}
El compilador produce un interfaz abstractos y un suplente (stub) para hacer invocaciones remotas
Agnóstico respecto al protocolo de RPC subyacente Interfaz abstracto: RpcChannel y RpcController
Sólo un parámetro de entrada y uno de salida Facilita extensibilidad y evolución del software
Pone la complejidad en los datos, en lugar de en la interfaz

E
(Diciembre 2013) © Diseño de sistemas distribuidos: 2
Diseminación de eventos rápidamente y con garantía de fiabilidad un gran número de receptores
El sistema está basado en temas Más eficiente que si estuviera basado en contenidos, aunque tiene menos poder expresivo
Un evento: cabecera, conjunto de palabras clave e información
Suscripción: indica un tema y un filtro sobre las palabras clave
Canales Se proporcionan canales asociados a temas
Flujos de datos estáticos, con alta transferencia de eventos (1Mbps)
Si un canal genera poco flujo, se incluye en otro

E
(Diciembre 2013) © Diseño de sistemas distribuidos: 2
Se implementa como un conjunto de árboles La raíz es el tema
Las hojas son los suscriptores
Los filtros se aplican lo más cerca de la raíz posible
Fiabilidad: se mantienen árboles redundantes: Al menos dos por tema
Calidad de servicio: se fuerza un límite por usuario y por tema.

Support for a More efficient,
example, with XML
Lack ofstyle of RPC (taking a single message as a
extensible andsupports service evolution
expressiveness whencompared with otherRPC or RMI packagesparameter and
retuming a singlemessage asresult)
Protocol-agnosticdesign
Different RPC implementation
No common semantics for RPC exchanges
Resumen de de
Element Design choice Rationale Trade-offs
Protocol buffers The use of a Flexible in thatlanguage for the same specifying data language can be formats used for
serializing data for storage or communication
Simplicity of the Efficient Lack oflanguage implementation expressiveness when
compared, for
s can be used dit(Diciembre 2013) DITIUPM Diseño de sistemas distribuidos: Google 24 UPM

Resumen de de
Publish-subscribe Topic-basedapproach
Supports efficient implementation
Less expressive than content-based approaches (mitigated by the additional filtering capabilities)
Real-time and reliability guarantees
Supports maintenance of consistent views in a timely
Additional algorithrnic support required with associated overhead
manner
(Diciembre 2013) © DITIUPM Diseño de sistemas distribuidos: Google 25

Resumen de de ditUPM

(Diciembre 2013) © Diseño de sistemas distribuidos: 2
4. Servicios de almacenamiento de d at o s y c oo r din ac ió n
Sistema de ficheros distribuido (GFS) Acceso a datos no estructurados
Optimizados para el estilo de datos y accesos requeridos por Google
Chubby: Cerrojos distribuidos para coordinación distribuida
Almacenamiento de pequeñas cantidades de datos
Bigtable: Acceso a datos estructurados, en forma de tablas, que pueden ser indexadas de varias formas, como por fila o columna
Base de datos distribuida que no proporciona todos los operadores relacionales

Sistema de ficheros Google:
(Diciembre 2013) © Diseño de sistemas distribuidos: 2
Ejecuta sobre la plataforma de Google Debe supervisar su funcionamiento y detectar, tolerar y recuperarse de fallos
Optimizarse para el tipo de uso dentro de Google
El número de ficheros no es muy grande. Lo es su tamaño
El acceso es normalmente secuencial:• Lecturas secuenciales
• Escrituras secuenciales, que añaden información al final del fichero
Acceso concurrente de lectura y escritura
Requisitos de la infraestructura Google Es importante el ancho de banda, más que la velocidad de respuesta

Sistema de ficheros Google:
(Diciembre 2013) © Diseño de sistemas distribuidos: 2
Interfaz de un sistema de ficheros convencional
Espacio de nombres jerárquico. Ficheros identificados por el camino donde se encuentran.
Operaciones comunes: crear, borrar, abrir, cerrar, leer, escribir.
Operaciones especiales: Snapshot: Mecanismo eficiente para copiar un fichero o una estructura de directorios
Record Append : Múltiples clientes añaden información al final del fichero.

Arquitectura de
Almacenamiento en trozos (chunks) de 64MB GFS relaciona ficheros con trozos
Cada grupo (cluster) de GFS tiene un maestro y varios servidores de trozos
El maestro gestiona los metadatos de los ficheros: Espacio de nombres, control de acceso, los trozos que lo forman
(Diciembre 2013) © DIT/UPM Diseño de sistemas distribuidos: Google 29

(Diciembre 2013) © Diseño de sistemas distribuidos: 3
Arquitectura de
Los trozos están replicados (por defecto, tres veces) El maestro gestiona las réplicas
Los metadatos se almacenan en una bitácora para recuperación de fallos
No se guarda la localización de réplicas, se consultan los trozos
El maestro es único, pero la bitácora de operaciones se almacena en máquinas remotas
El maestro centralizado tiene una visión global del sistema de ficheros y optimiza su funcionamiento
El maestro informa del trozo (incluidas réplicas) donde están los datos requeridos y el cliente accede a ellos:

Arquitectura de
(Diciembre 2013) © Diseño de sistemas distribuidos: 3
El tamaño de los trozos Reduce la necesidad de contactar con el maestro
Reduce la cantidad de metadatos a gestionar
Problemas; está en desarrollo un maestro distribuido El maestro se convierte en un cuello de botella
El tamaño de los metadatos de un maestro aumenta, y no es posible mantenerlos en memoria
Cache en el cliente: limitada a los metadatos del trozo. Se reducen problemas de coherencia
Cache en el servidor, sólo la que realiza Linux
Bitácora: Se almacenan gran cantidad de información, que se supervisa para detectar fallos

Consistencia en
(Diciembre 2013) © Diseño de sistemas distribuidos: 3
Necesaria consistencia entre réplicas: Se relaja la coherencia y aumenta el rendimiento
Funcionamiento: Cuando recibe un petición de un cliente, el maestro le indica un primario y las réplicas restantes
El cliente manda datos a las réplicas, que los guardan en buffer
Cuando las réplicas reconocen la recepción de los datos,ordena al primario la escritura, impone el orden y lo aplicalocalmente
Luego, ordena a las réplicas el mismo orden y mandan reconocimiento
Si todos correctos, el primario informa del éxito de la operación.En caso contrario, se informa del fallo. Entonces se vuelve a realizar la operación. Si persiste el fallo, puede haber incoherencias

Chubb
(Diciembre 2013) © Diseño de sistemas distribuidos: 3
Proporciona cerrojos distribuidos para sincronizar actividades en un entorno de gran escala y asíncrono
Proporciona un sistema de ficheros, con almacenamiento fiable de ficheros pequeños
Seleccionar un primario entre un conjunto de réplicas
Se usa como un servicio de nombres en Google
El consenso distribuido es su funcionalidad más importante
Hincapié en fiabilidad y disponibilidad, frente a rendimiento

(Diciembre 2013) © Diseño de sistemas distribuidos: 3
Chubb
Cada entidad/objeto con datos es un fichero Espacio de nombres: /ls/chubby_cell/directorio/../fichero
Una entidad combina un fichero y un cerrojo Se detectó la utilidad de añadir información al cerrojo
Las operaciones sobre ficheros Se transfiere el fichero completo
Se realizan de forma atómica
Los cerrojos son informativos El sistema no bloquea el acceso a los datos asociados
Los programadores deben usarlos de forma adecuada

Interfaz de Role Operation
General Open
Clase
Delete
Effect
Opens a given named file or directory and returns a handle
Closes the file associated with the handlc
Deletes the file or directory
File GetContentsAndStat
GetStat
ReadDir
SetContents
SetACL
Returns (atomically) the whole file contents and metadata associated with the file
Returns just the metadata
Returns the contents of a directory -that is, the names and metadata of any children
Writes the whole contents of a file (atomically)
Writes new access control list informationLock Acquire
TryAquire
Acquires a lock on a file
Tries to acquire a lock on a file
Releas e Relc a ses a lock
dit(Diciembre 2013) © DITIUPM Diseño de sistemas distribuidos: Google 35 UPM

Funciones de
(Diciembre 2013) © Diseño de sistemas distribuidos: 3
Elección de un primario: elección sobre consenso Los candidatos tratan de adquirir un cerrojo asociado a la elección
El que tiene éxito es el primero. Escribe en el fichero su identidad
Selección de un primario, basada en servicio de consenso
Proporciona un servicio sencillo de eventos Pueden ser cambios en un fichero, manejador inválido, etc.
Se ejecuta una función asíncronamente (callback)
Otras características No permite mover un fichero, ni enlaces simbólicos
Mantiene pocos metadatos

Arquitectura de
(Diciembre 2013) © Diseño de sistemas distribuidos: 3
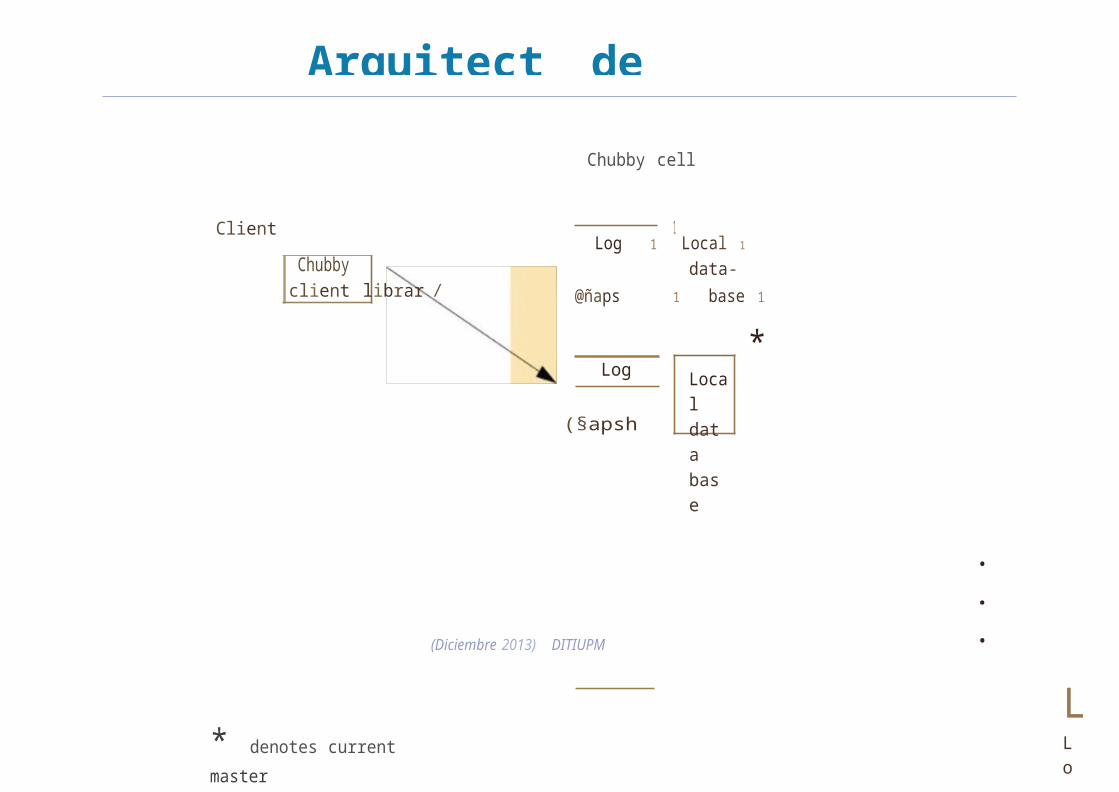
Los componentes fundamentales: Cliente, que emplea una biblioteca para llamadas
Una célula Chubby
Se comunican mediante RPC
La célula Chubby Compuesta por cinco réplicas
• Al menos tres deben estar operativas
Las réplicas se sitúan en diferentes racks
La célula suele estar en el mismo cluster
Las réplicas mantienen copias de una BD sencilla• Contienen entidades chubby: cerrojos/ficheros
• Sólo el maestro inicia operaciones de lectura/escritura de la BD
• Se emplea un protocolo de consenso

Arquitectur de
Chubby cell
Client
Chubbyclient librar /
1Log 1 Local 1
data-@ñaps 1 base 1
*Log
(§apsh
Local data base
* denotes current master
(Diciembre 2013) DITIUPM
•
•
•
LLog ] 1 Local 1
data-l Snapshotq 1 base 1
Diseño de sistemas distribuidos: Google
dit38 UPM

(Diciembre 2013) © Diseño de sistemas distribuidos: 3
Arquitectur de
Los clientes buscan al maestro y le envían peticiones Si el maestro cae, las réplicas eligen otro
Se establece una sesión entre el cliente y el maestro Se mantiene mientras ambos están operativos (KeepAlive)
La biblioteca copia localmente los ficheros usados
Consistencia: para hacer una mutación de un fichero: Se bloquea la operación, hasta invalidar todas las caches
Las caches nunca se modifican directamente

Consistencia entre las
(Diciembre 2013) © Diseño de sistemas distribuidos: 4
Basada en Paxos: familia de protocolos para consenso distribuido para sistemas asíncronos
No es posible garantizar consistencia
Puede que no termine
Características del entorno Las réplicas operan a diferente velocidad y pueden fallar
Tienen acceso a almacenamiento estable y persistente, que sobrevive a los fallos
Los mensajes, se pueden perder, reordenar o duplicar. Se envían sin corrupción y se puede retrasar un tiempo arbitrario
Acuerdo: réplicas guardan el mismo valor en bitácoras La mayoría de las réplicas funcionan el tiempo suficiente y con

Consistencia entre las
(Diciembre 2013) © Diseño de sistemas distribuidos: 4
suficiente estabilidad de la red

Consistencia entre las
(Diciembre 2013) © Diseño de sistemas distribuidos: 4
Propiedades de vivacidad: Si hay una mayoría estable de servidores, si uno del conjunto inicia una actualización, algunos miembros del mismo ejecutarán la operación en algún momento
Si un servidor s ejecuta una operación y existe un conjunto de servidores con s y r, si no hay fallos, entonces r ejecutará la actualización
Características del algoritmo: El algoritmo debe elegir un coordinador, que puede fallar
Los mensajes llevan el número de secuencia del coordinador t
En la elección, se envía un número único mayor que el observado: s | s mod n = ir y s es el menor valor > t
• n: número de réplicas
• ir: identificador de la réplica, 0 <= ir <= n-1

(Diciembre 2013) © Diseño de sistemas distribuidos: 4
Consistencia entre las
Características del algoritmo: Las réplicas responden:
• Prometen seguir a la réplica, pues no han observado un número mayor
• Ack negativo, no votan por este coordinador e indican el mayor número observado
Coordinador: la réplica con más promesas recibidas (quorum)
El coordinador elige un valor y manda el valor al quorum
Las réplicas aceptan el valor y mandan un ack
Si la mayoría de las réplicas aceptan, se envía confirma el valor
Si no el coordinador abandona la propuesta y se inicia elección
Es necesario acuerdo en una secuencia de valores Multi-Paxos: se elige un coordinador para un conjunto de valores

Consistencia entre las
Step 1: electing a coordinator
Propase (seq_number)
CoordinatorPromise
Replicas
(Diciembre 2013) © DITIUPM Diseño de sistema<; distribuidos: Googledit
43 UPM

diDiseño de sistemas distribuidos: UP(Diciembre 2013) © 4
Consistencia entre las
Step 2: seeking consensus
Accept (value)
CoordinatorAcknowledgement
Replicas

Consistencia entre las
diDiseño de sistemas distribuidos: UP(Diciembre 2013) © 4
Step 3: achieving consensus
CommitReplicas

B
(Diciembre 2013) © Diseño de sistemas distribuidos: 4
Sistema de almacenamiento distribuido para grandes volúmenes de datos estructurados
Gestiona el almacenamiento tolerante a fallos, creación, borrado y gestión de grandes tablas
Google Analytics almacena información de enlaces visitados asociados con usuarios que visitan un sitio en una tabla (200TB) y resume la información analizada en otra (20TB)
Las bases de datos relacionales no sirven No proporcionan buen rendimiento y escalabilidad
Bigtable Sigue el modelo de tablas
Con una interfaz muy sencilla, adaptada a las necesidades de Google

Interfaz de
(Diciembre 2013) © Diseño de sistemas distribuidos: 4
Acceso indexado por fila, columna y marca de tiempo: Filas:
• Identificadas por una clave, que es una tira de caracteres de hasta 64KB
• Ej. dirección de una web
• Ordenadas lexicográficamente por la clave
• Filas relacionadas se almacenan juntas
• Los accesos a las filas son atómicos
Columnas:• Nombre de columna: Nombre de familia:calificador
• Enfoque: pocas familias y muchas columnas
• Ej. información de la dirección de web: enlaces, lenguajes, etc
Marca de tiempo• Una celda tiene varias versiones, indexadas con este parámetro
• Puede ser tiempo real o tiempo lógico

lnteñaz de
Column families and qualifiers
CF1· CF2·q1 CF3·q1
Rows
'ªJ=
t=170 timestampst=3
Rs
(Diciembre 2013) © DITIUPM Diseño de sistema<; distribuidos: Google 48

lnteñaz de ditUPM

Interfaz de
(Diciembre 2013) © Diseño de sistemas distribuidos: 4
Proporciona funciones, como Creación y borrado de tablas
Creación y borrado de familias de columnas
Acceso a datos de una fila
Escritura y borrado de datos de las celdas
Mutaciones atómicas en filas, como acceso, escritura y borrado de datos
Iteración sobre familias de columnas, incluyendo el uso de expresiones regulares
Asociar metadatos con tablas y familias de columnas, como listas de acceso

Arquitectura de
(Diciembre 2013) © Diseño de sistemas distribuidos: 5
Se divide en tabletas, que son un conjunto de filas Relaciona las tabletas con ficheros en GFS
Garantiza equilibrado de la carga entre los servidores
Cluster: una instancia de Bigtable Almacena y gestiona un conjunto de tabletas
Arquitectura similar a GFS: biblioteca, maestro y servidores de tabletas

Almacenamiento de datos en
(Diciembre 2013) © Diseño de sistemas distribuidos: 5
El almacenamiento de tablas en GFS: La tabla se dividen en tabletas, por filas, con un tamaño medio 100-200 MB
Una tableta se representa mediante• conjunto de ficheros que almacenan datos en formato SSTable
• otras estructuras de almacenamiento para las bitácoras
Relación entre tabletas y SSTables mediante índice jerárquico
SSTable: mapa ordenado e inmutable de pares (clave, valor)
operaciones para acceso y gestión eficiente
incluye un índice, que se carga en memoria inicialmente
los cambios se escriben en una bitácora en GFS
las lecturas se hacen combinando los datos en SSTable y en la

Almacenamient de datos en
Held in
maín
memory
Memtable
HeldínGFS
iWríte
Persistent log
SSTable files
dit

Almacenamient de datos en (Diciembre 2013) © DITIUPM Diseño de sistemas distribuidos: Google
52 UPM

(Diciembre 2013) © Diseño de sistemas distribuidos: 5
Almacenamient de datos en
La relación entre tabletas y ficheros en memoria se gestiona en una estructura en árbol, donde se almacenan metadatos y la situación de los datos de las tabletas

Supervisión del
(Diciembre 2013) © Diseño de sistemas distribuidos: 5
Uso interesante de Chubby: Mantiene un directorio en Chubby con ficheros representado los servidores de tabletas
Los servidores obtienen un cerrojo sobre el fichero
Su existencia indica la correcta operación del servidor
Operación del servidor de tableta• Los servidores supervisan su cerrojo. Si se pierde, se paran
• Intentan adquirir el cerrojo. Si el fichero se borra, terminan
• Si el servidor debe terminar, libera el cerrojo
Operación del maestro• El maestro consulta el valor del cerrojo periódicamente
• Si está liberado, entonces intenta adquirirlo
• Si tiene éxito, el problema está en el servidor
• Borra el fichero y asigna la tableta a otro servidor

Equilibrado de
(Diciembre 2013) © Diseño de sistemas distribuidos: 5
El maestro tiene una visión global del sistema Servidores existentes, asignación de tabletas del cluster
Asigna tabletas a servidores, según su carga
El maestro tiene otro cerrojo Si se pierde, el maestro se para
El sistema sigue operando, aunque sin funciones de control
Al crear un nuevo maestro:• Se asegura de que es el único
• Recupera información de estado de los servidores

Element
GFS
Design choice
The use of a large
Rationale
Suited to the size of files in GFS;
Trade-offs
Would be vcry ineffieientchunk size (64 megabytes)
efficient for large scqucntialreads and appends; minimizes the
for random access to smallparts ofliles
amount ofmetadata
The use ofa The master maintains a global Single point of failureccntralized master view that infonns managcmcnt
decisions; simpler to implement(mitigatcd by maintainingreplicas of operations logs)
Separation of control High-pcrformanee file access Complicates thc clientand data flows with minimal master library as it must deal with
involvement both the master andchunkservers
Relaxed consistency High performance, exploiting Data may be inconsistent,modcl semantics ofthe GFS operations in panicular duplicated
Chubby Combined lock andfile abstraction
Multipurpose, for cxamplc supporting elcctions
Nccd to understand and diITcrentiate between dHTcrent faccts
Whole-file reading Very efficient for small files lnappropriate for largeand writing files
Clicnt caching with Detcrministic semantics Ovcrhead ofmaintainingstrict consistcncy strict consistcncy
Bigtable The use of a table Supports structured data Less expressive than aabstraction efficienlly relational database
The use ofa As above, master has a global Single point of failure;ccntralized master view; simpler to implement possiblc botlleneck
Scparation of control High-pcrformance data accessand data ílows with minimal master
involvement
Emphasis on Ability to support very largc Ovcrhcad associatcd withmonitoring and load numbers of parallcl clicnts maintaining global st.atesbalancing
Resumen de de
(Diciem1
dit56 UPM

5. Servicios de computación distribuida: Ma p Re du ce
Modelo sencillo de programación para el desarrollo de aplicaciones paralelas y distribuidas
Fragmentación de datos de entrada y análisis y procesamiento de estos fragmentos en paralelo
Oculta los detalles de este enfoque al programador
Interfaz de MapReduce: Basado en el siguiente patrón de funcionamiento:
• Partir los datos de entrada en un conjunto de trozos (chunks)
• Procesamiento paralelo de los trozos y generación de un resultado intermedio
• Combinación de los resultados intermedios
Expresión en forma de dos funciones:• Map: Parte de un conjunto de pares (clave, valor) y genera un
conjunto intermedio de pares del mismo tipo
(Diciembre 2013) © DIT/UPM Diseño de sistemas distribuidos: Google 57

Ejemplos del uso de MapReduce
Function lnitial step Mapphase lntermediate step Reduce phase
Word count For each occurrence of For each word
inword in data partition, the interrnediaryemit <word, 1> set, count the
number of ls
Grep Output a line if it Null matches a given pattem
Sort Partition data For each entry in the Merge/sort all NullN.B. This intofixed-size input data, output the key-value keysrelies heavily chunks for key-value pairs to be according to their on the processzng sorted intermediary key intermedia/estep
lnverted Parse the associated For each word ,index documents and output produce a list of
a <word , document (sorted)ID> pair wherever that document IDsword exists

dit(Diciembre 2013) © DITIUPM Diseño de sistemas distribuidos: Google 58 UPM

Arquitectura de
(Diciembre 2013) © Diseño de sistemas distribuidos: 5
Biblioteca que permite al programador centrarse en las funciones Map y Reduce
Se crean un conjunto de trabajadores Un maestro para supervisar

Tolerancia de
(Diciembre 2013) © Diseño de sistemas distribuidos: 6
Garantiza el determinismo de las operaciones El maestro comprueba si los trabajadores funcionan. Si fallo:
• Map: Se reprograma la operación. Los resultados no estarán disponibles, pues se escriben en almacenamiento local
• Reduce: Se comprueba si se completó. Entonces, se usan los datos que estarán en GFS. En caso contrario, se vuelve a realizar
Las salidas de los trabajadores se escriben atómicamente
Gestión de trabajadores lentos Ocurre con cierta frecuencia (a veces problemas hardware)
Cuanto se está completando una operación, lanza trabajadores nuevos como respaldo a los lentos

S
(Diciembre 2013) © Diseño de sistemas distribuidos: 6
Lenguaje de programación interpretado para realizar análisis de datos paralelos sobre grandes conjuntos de datos en entornos altamente distribuidos
Tamaño de programas, menor que con
MapReduce Esquema de cómputo dado y supone:• La ejecución de filtros y agregadores es conmutativa respecto a los
registros. Se pueden ejecutar en cualquier orden
• Las operaciones de agregación son asociativas
(Diciembre 2013) © Diseño de sistemas distribuidos: 6
S
Se proporcionan un conjunto de agregadores por defecto:
sumar, crear una colección, valor más común, etc
Ejemplo
count: table sum of int; total: table sum of float;
x: float = input; emit count <- 1; emit total <- x;

Element
MapReduce
Design choice
The use of a
Rationale
Hides details of parallelization and
Trade-offs
Design choices withincommon distribution from the programmer; the framework may notframework improvemcnts to the infrastructure be appropriate for ali
immediately exploited by all styles of distributedMapReduce applications computation
Programming of Very simple programming model Agaio, may not besystem via two allowing rapid dcvelopment of appropriate for alloperations, mapand reduce
complex distributed compulations problem domains
Inherent support Programmer does not need to worry Overhead associatedfor fault-tolerant about dealing with faults with fault-recoverydistributed (particularly important for long- st:rategiescomputations running tasks running overa physical
infrastructure where failures areexpected)
Sawzall Provision of a Again, support for rapid Assumes that programsspecial ized development of often complex can be written in thcprogrammmg distributed computations with style supported (inlanguage for complexity hidden from the terms of filters anddistributed prograrnmer (even more so than with aggregators)computation MapReduce)
Resumen de de
dit(Diciembre 2013) © DITIUPM Diseño de sistemas distribuidos: Google 63 UPM

6.
(Diciembre 2013) © Diseño de sistemas distribuidos: 6
Google proporciona un motor de búsqueda, aplicaciones y una plataforma de cómputo en la nube
Infraestructura Google Conjunto de componentes y modelo físico para el desarrollo de aplicaciones en sistemas masivamente distribuidos
Priman soluciones adaptadas a las necesidades de Google.
Requisitos: escalabilidad, rendimiento, fiabilidad, apertura
Entorno en continua evolución

B
(Diciembre 2013) © Diseño de sistemas distribuidos: 6
Coulouris, Dollimore, Kindberg and Blair, Distributed Systems: Concepts and Design, Edición 5, Addison- Wesley 2012, capítulo 21
Este capítulo incluye referencias artículos originales de los desarrolladores de Google





























