Embed Size (px)
Citation preview

Formation du Club des Affiliés du LAAS-CNRS, Toulouse, 22 mars 2016
Frédéric Parienté, Tesla Accelerated Computing, NVIDIA
GPU EN CALCUL SCIENTIFIQUE

2
ENTERPRISE AUTOGAMING DATA CENTERPRO VISUALIZATION
THE WORLD LEADER IN VISUAL COMPUTING

3
FIVE THINGS TO REMEMBER
Time of accelerators has come
NVIDIA is focused on co-design from top-to-bottom
Accelerators are surging in supercomputing
Machine learning is the next killer application for HPC
Tesla platform leads in every way
4
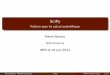
“It’s time to start planning for the end of Moore’s Law, and it’s worth pondering how it will end, not just when.”
Robert Colwell Director, Microsystems Technology Office, DARPA
5
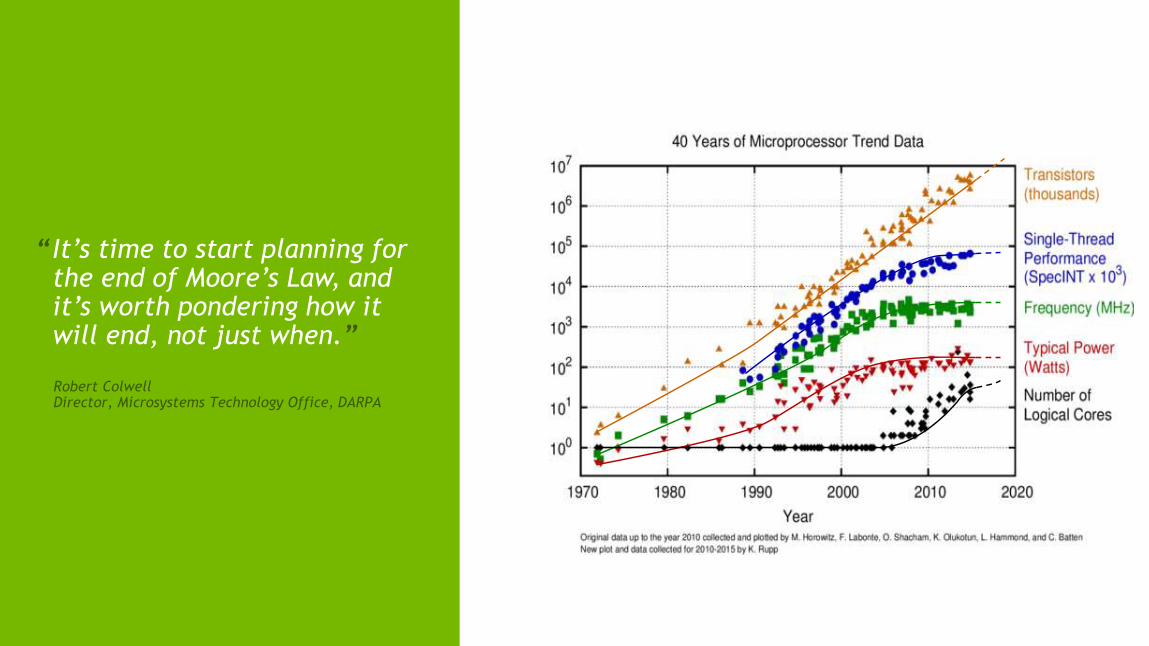
TESLA ACCELERATED COMPUTING PLATFORMFocused on Co-Design from Top to Bottom
ProductiveProgrammingModel & Tools
Expert Co-Design
Accessibility
APPLICATION
MIDDLEWARE
SYS SW
LARGE SYSTEMS
PROCESSOR
Fast GPUEngineered for High Throughput
0,0
0,5
1,0
1,5
2,0
2,5
3,0
2008 2009 2010 2011 2012 2013 2014
NVIDIA GPU x86 CPUTFLOPS
M2090
M1060
K20
K80
K40
Fast GPU+
Strong CPU
6
0
25
50
75
100
125
2013 2014 2015
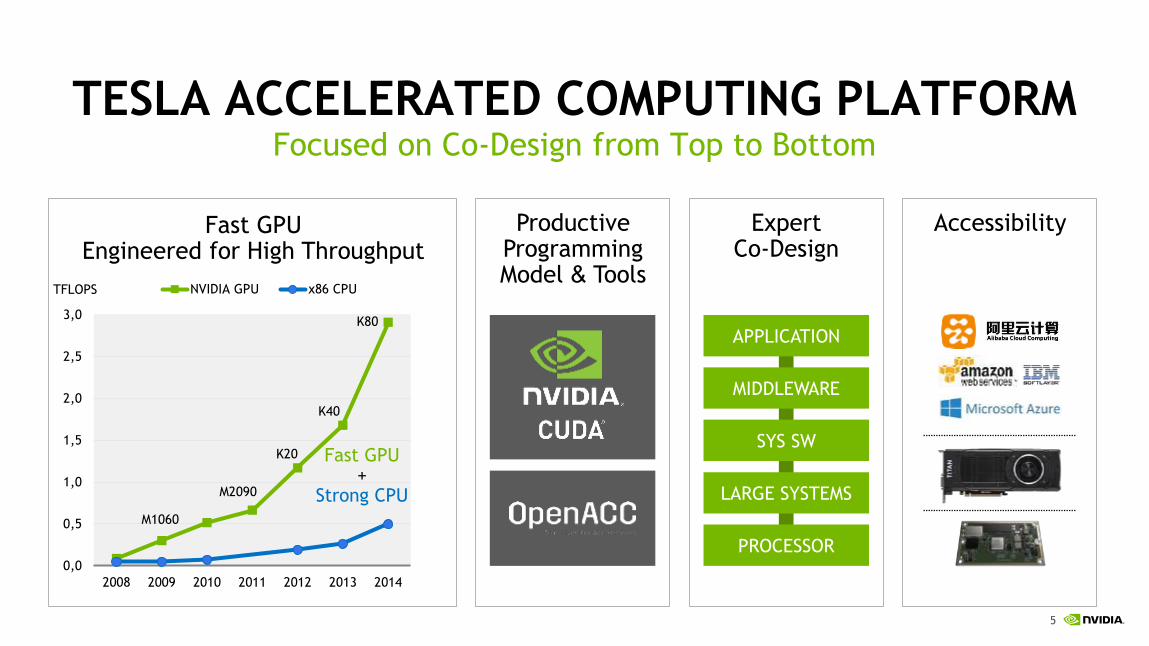
ACCELERATORS SURGE IN WORLD’S TOP SUPERCOMPUTERS
100+ accelerated systems now on Top500 list
1/3 of total FLOPS powered by accelerators
NVIDIA Tesla GPUs sweep 23 of 24 new accelerated supercomputers
Tesla supercomputers growing at 50% CAGR over past five years
Top500: # of Accelerated Supercomputers

7
70% OF TOP HPC APPS ACCELERATEDTOP 25 APPS IN SURVEYINTERSECT360 SURVEY OF TOP APPS
GROMACSSIMULIA AbaqusNAMDAMBERANSYS MechanicalMSC NASTRANSPECFEM3D
ANSYS FluentWRFVASPOpenFOAMCHARMMQuantum Espresso
LAMMPSNWChemLS-DYNASchrodinger
GaussianGAMESS
ANSYS CFXStar-CDCCSMCOMSOLStar-CCM+BLAST
= All popular functions accelerated
Top 10 HPC Apps90%
Accelerated
Top 50 HPC Apps70%
Accelerated
Intersect360, Nov 2015“HPC Application Support for GPU Computing”
= Some popular functions accelerated= In development= Not supported

8
370 GPU-Accelerated Applications
www.nvidia.com/appscatalog
9
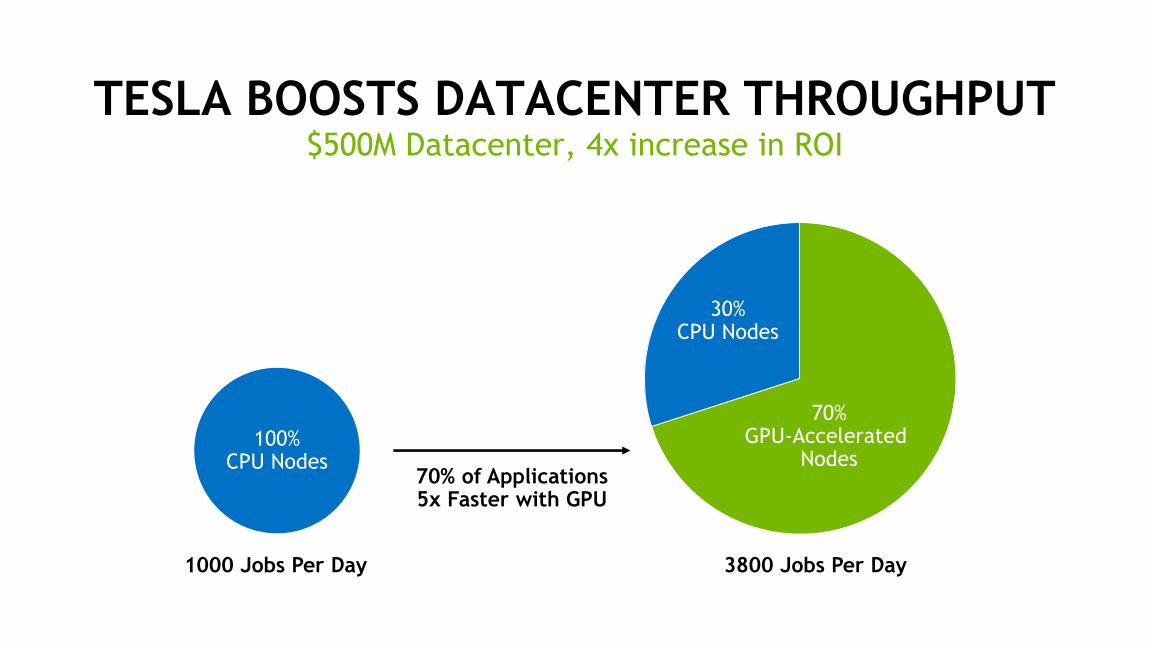
TESLA BOOSTS DATACENTER THROUGHPUT$500M Datacenter, 4x increase in ROI
1000 Jobs Per Day
70%GPU-Accelerated
Nodes
30%CPU Nodes
3800 Jobs Per Day
100%CPU Nodes
70% of Applications5x Faster with GPU

10
U.S. Dept. of EnergyPre-Exascale Supercomputers
for Science
NEXT-GEN SUPERCOMPUTERS ARE GPU-ACCELERATED
NOAANew Supercomputer for Next-Gen
Weather Forecasting
IBM WatsonBreakthrough Natural Language
Processing for Cognitive Computing
SUMMIT
SIERRA

11
MACHINE LEARNINGHPC 1ST CONSUMER KILLER-APP
MICROSOFT OPEN-SOURCE
DMTK
GOOGLE OPEN-SOURCETENSORFLOW
YOUTUBE CLICK-TO-BUY ADS GOOGLE PHOTO
MICROSOFT CORTANAFACEBOOK MESSENGER FACIAL RECOGNITION
12
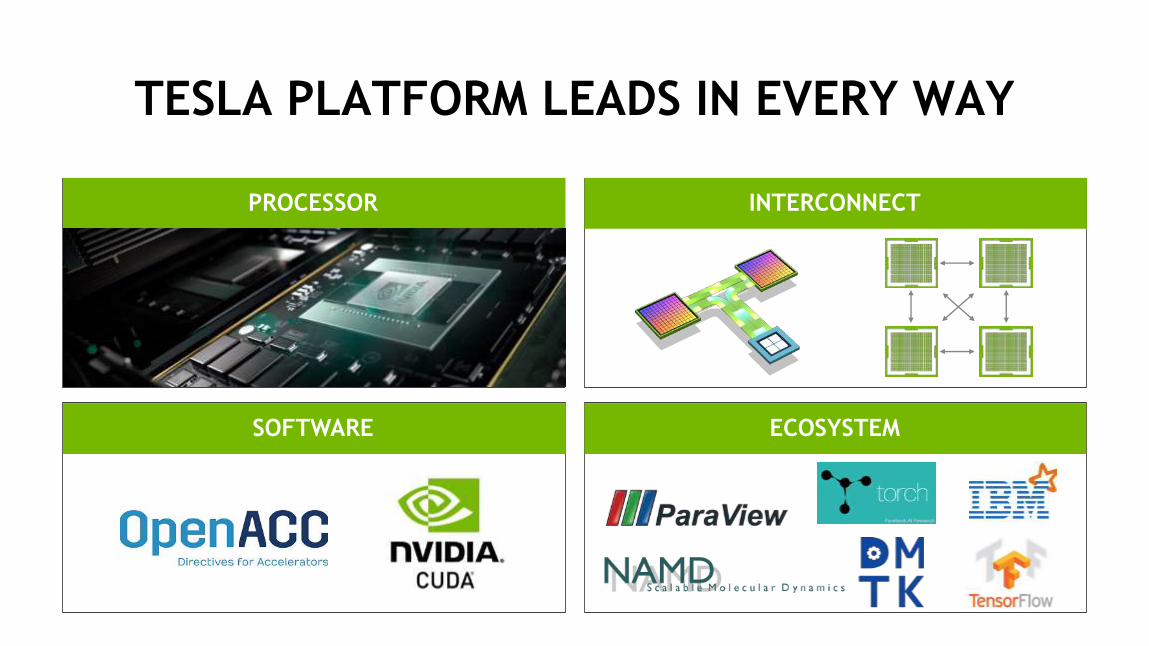
TESLA PLATFORM LEADS IN EVERY WAY
PROCESSOR INTERCONNECT
ECOSYSTEMSOFTWARE

13
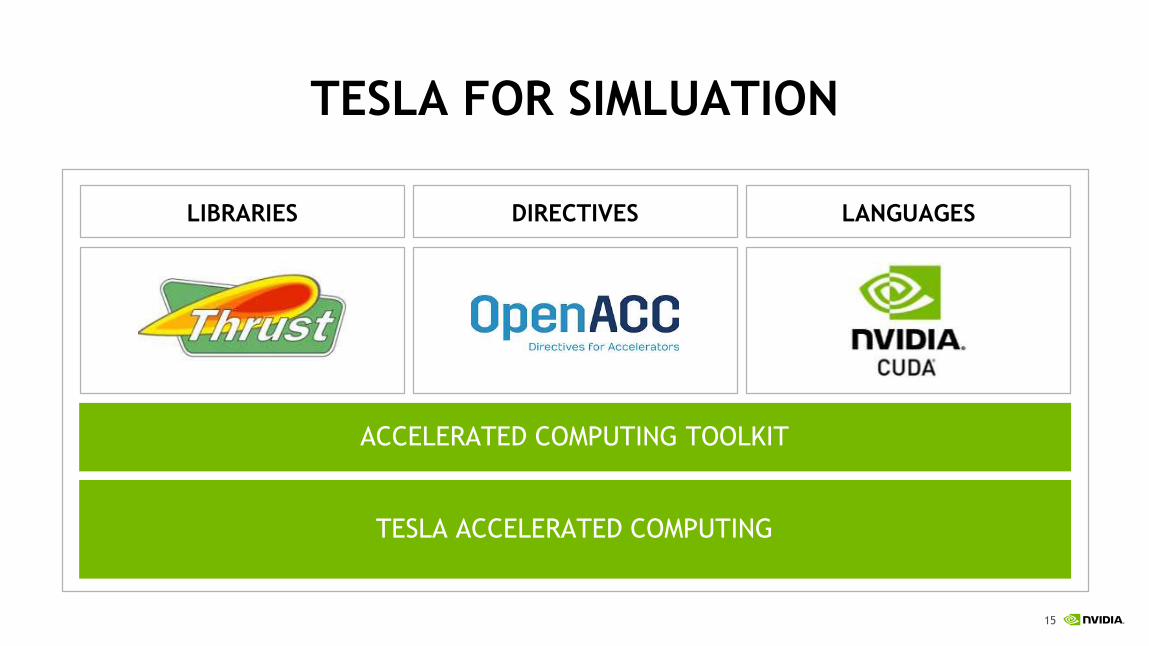
TESLA PLATFORM FOR HPC

14
“Approximately a third of HPC systems operating today are equipped with accelerators and nearly half of all newly deployed systems have them.”
Source: ACCELERATED COMPUTING: A TIPPING POINT FOR HPC Intersect360 Nov 2015
15
TESLA FOR SIMLUATION
LIBRARIES
TESLA ACCELERATED COMPUTING
LANGUAGESDIRECTIVES
ACCELERATED COMPUTING TOOLKIT

16
Tesla Accelerates Discoveries
Using a supercomputer powered by the Tesla Platform with over 3,000 Tesla accelerators, University of Illinois scientists performed the first all-atom simulation of the HIV virus and discovered the chemical structure of its capsid —“the perfect target for fighting the infection.”
Without GPU, the supercomputer would need to be 5x larger for similar performance.

17
TESLA K80World’s Fastest Accelerator for HPC & Data Analytics
0 5 10 15 20 25 30
Tesla K80 Server
Dual CPU Server
# of Days
AMBER Benchmark: PME-JAC-NVE Simulation for 1 microsecondCPU: E5-2698v3 @ 2.3GHz. 64GB System Memory, CentOS 6.2
CUDA Cores 4992
Peak DP 1.9 TFLOPS
Peak DP w/ Boost 2.9 TFLOPS
GDDR5 Memory 24 GB
Bandwidth 480 GB/s
Power 300 W
GPU Boost Dynamic
Simulation Time from 1 Month to 1 Week
5x FasterAMBER Performance
18
0x
5x
10x
15x
K80 CPU
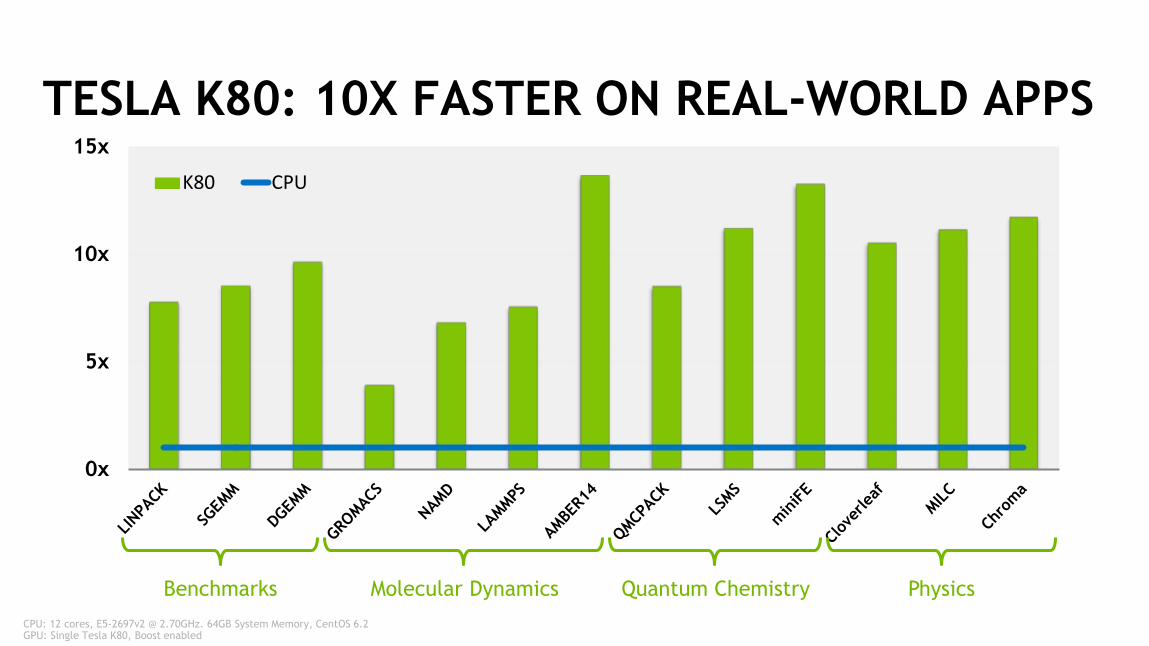
TESLA K80: 10X FASTER ON REAL-WORLD APPS
CPU: 12 cores, E5-2697v2 @ 2.70GHz. 64GB System Memory, CentOS 6.2GPU: Single Tesla K80, Boost enabled
Quantum ChemistryMolecular Dynamics PhysicsBenchmarks
19
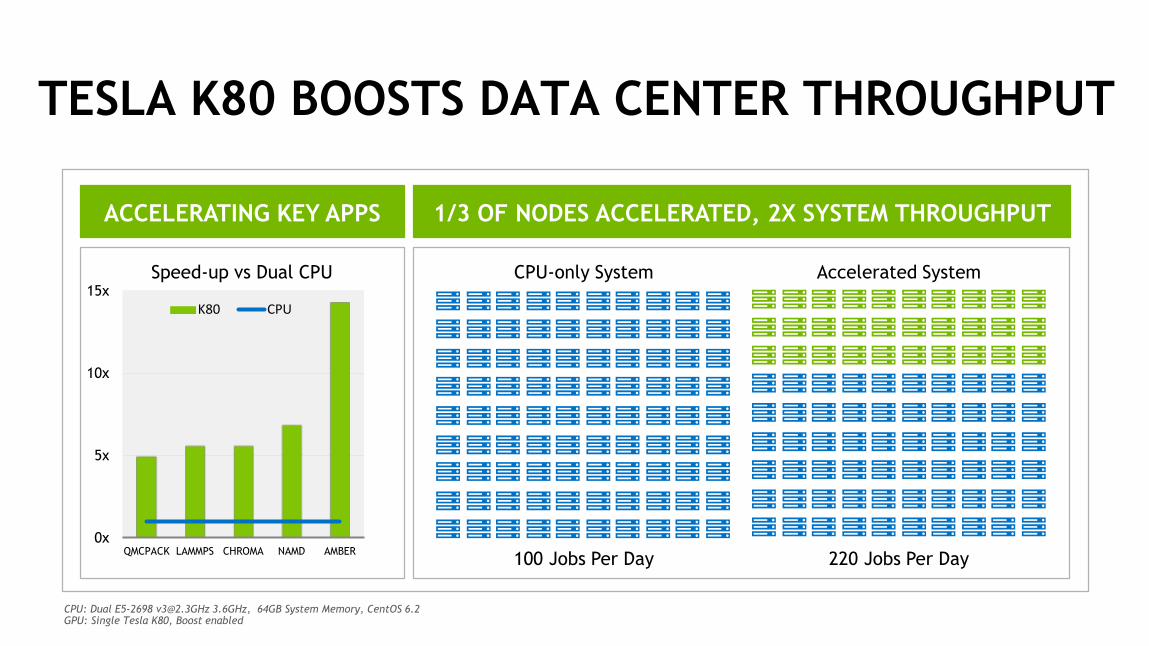
TESLA K80 BOOSTS DATA CENTER THROUGHPUT
ACCELERATING KEY APPS 1/3 OF NODES ACCELERATED, 2X SYSTEM THROUGHPUT
100 Jobs Per Day 220 Jobs Per Day
CPU-only System Accelerated System
0x
5x
10x
15x
QMCPACK LAMMPS CHROMA NAMD AMBER
K80 CPU
CPU: Dual E5-2698 [email protected] 3.6GHz, 64GB System Memory, CentOS 6.2GPU: Single Tesla K80, Boost enabled
Speed-up vs Dual CPU

20
TESLA FOR VISUALIZATION
IRAY
TESLA ACCELERATED COMPUTING
INDEXOPTIX
VISUALIZATION TOOLS FOR HPC
21
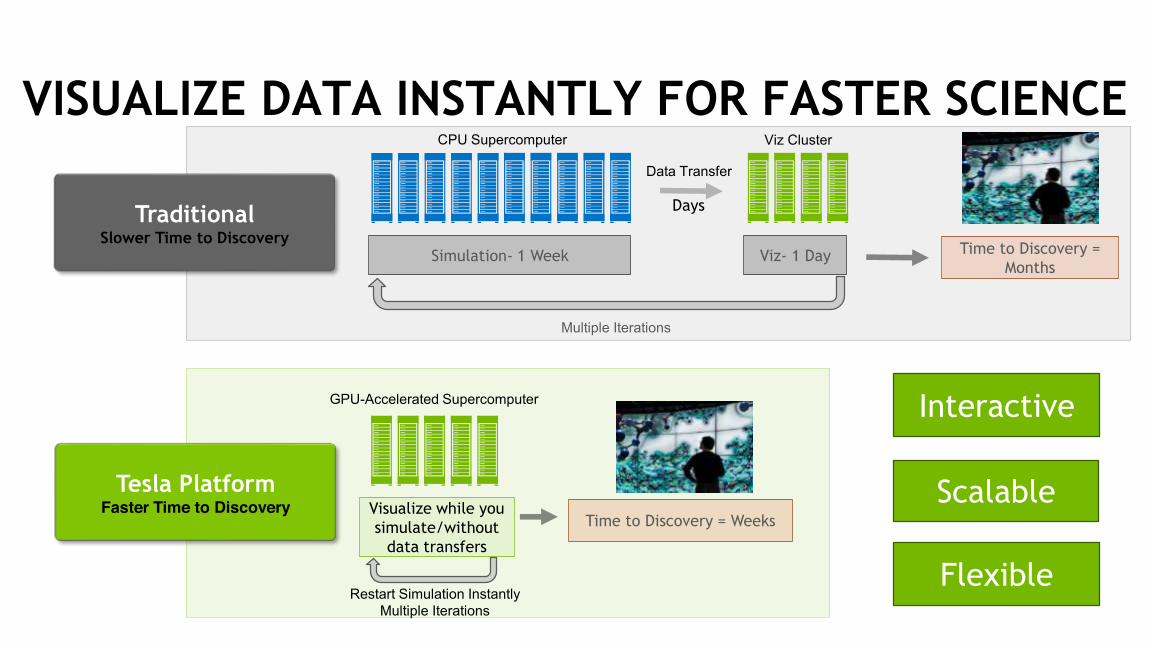
VISUALIZE DATA INSTANTLY FOR FASTER SCIENCE
TraditionalSlower Time to Discovery
CPU Supercomputer Viz Cluster
Simulation- 1 Week Viz- 1 Day
Multiple Iterations
Time to Discovery = Months
Tesla PlatformFaster Time to Discovery
GPU-Accelerated Supercomputer
Visualize while you simulate/without
data transfers
Restart Simulation InstantlyMultiple Iterations
Time to Discovery = Weeks
Flexible
Scalable
Interactive
Days
Data Transfer

22
VISUALIZATION-ENABLED SUPERCOMPUTERSSimulation + Visualization
CSCS Piz Daint NCSA Blue Waters
Galaxy Formation
ORNL Titan
Molecular Dynamics Cosmology

23
GROWING ADOPTION IN CLIMATE & WEATHER
MeteoSwiss Deploys World’s First Accelerated Weather Supercomputer
2x higher resolution for daily forecasts
14x more simulation with ensemble approach for medium-range forecasts
NOAA Chooses Tesla To Improve Weather Forecast Research
Develop global model with 3km resolution, five-fold increase from today’s resolution
Improved resolution requires 100x computational complexity

24
U.S. TO BUILD TWO FLAGSHIP SUPERCOMPUTERSPowered by the Tesla Platform
100-300 PFLOPS Peak
10x in Scientific App Performance
IBM POWER9 CPU + NVIDIA Volta GPU
NVLink High Speed Interconnect
40 TFLOPS per Node, >3,400 Nodes
2017
Major Step Forward on the Path to Exascale

25
IBM POWER CPUMost Powerful Serial Processor
NVIDIA NVLinkFastest CPU-GPU Interconnect
NVIDIA Volta GPUMost Powerful Parallel Processor
ACCELERATED COMPUTING DELIVERS 5X HIGHER ENERGY EFFICIENCY
80-200 GB/s

26
CORAL: BUILT FOR GRAND SCIENTIFIC CHALLENGES
Fusion EnergyRole of material disorder, statistics, and fluctuations in nanoscale materials and systems
CombustionCombustion simulations to enable the next gen diesel/bio-fuels to burn more efficiently
Climate Change Study climate change adaptation and mitigation scenarios; realistically represent detailed features
Nuclear EnergyUnprecedented high-fidelity radiation transport calculations for nuclear energy applications
BiofuelsSearch for renewable and more efficient energy sources
AstrophysicsRadiation transport – critical to astrophysics, laser fusion, atmospheric dynamics, and medical imaging

27
TESLA PLATFORM FOR MACHINE LEARNING

28
THE BIG BANG IN MACHINE LEARNING
“ Google’s AI engine also reflects how the world of computer hardware is changing. (It) depends on machines equipped with GPUs… And it depends on these chips more than the larger tech universe realizes.”
DNN GPUBIG DATA

29
Tesla Revolutionizes Machine Learning
GOOGLE BRAIN APPLICATION – DEEP LEARNING
BEFORE TESLA AFTER TESLA
Cost $5,000K $200K
Servers 1,000 Servers 16 Tesla Servers
Energy 600 KW 4 KW
Performance 1x 6x

30
THE AI RACE IS ON
31
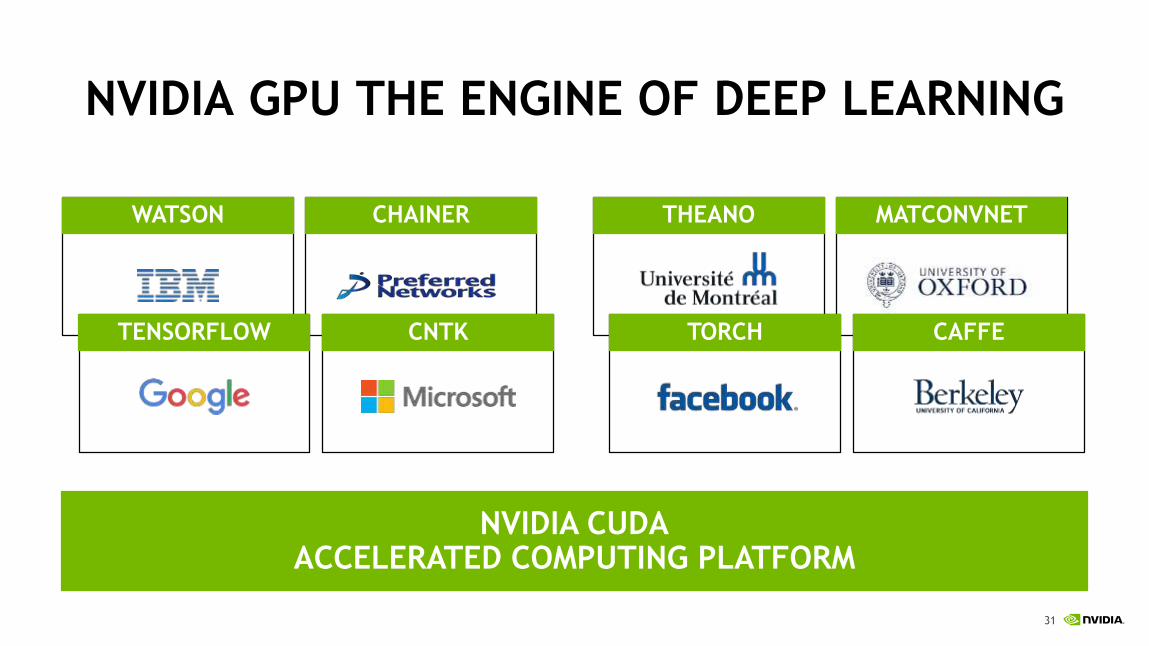
NVIDIA GPU THE ENGINE OF DEEP LEARNING
NVIDIA CUDAACCELERATED COMPUTING PLATFORM
WATSON CHAINER THEANO MATCONVNET
TENSORFLOW CNTK TORCH CAFFE
32
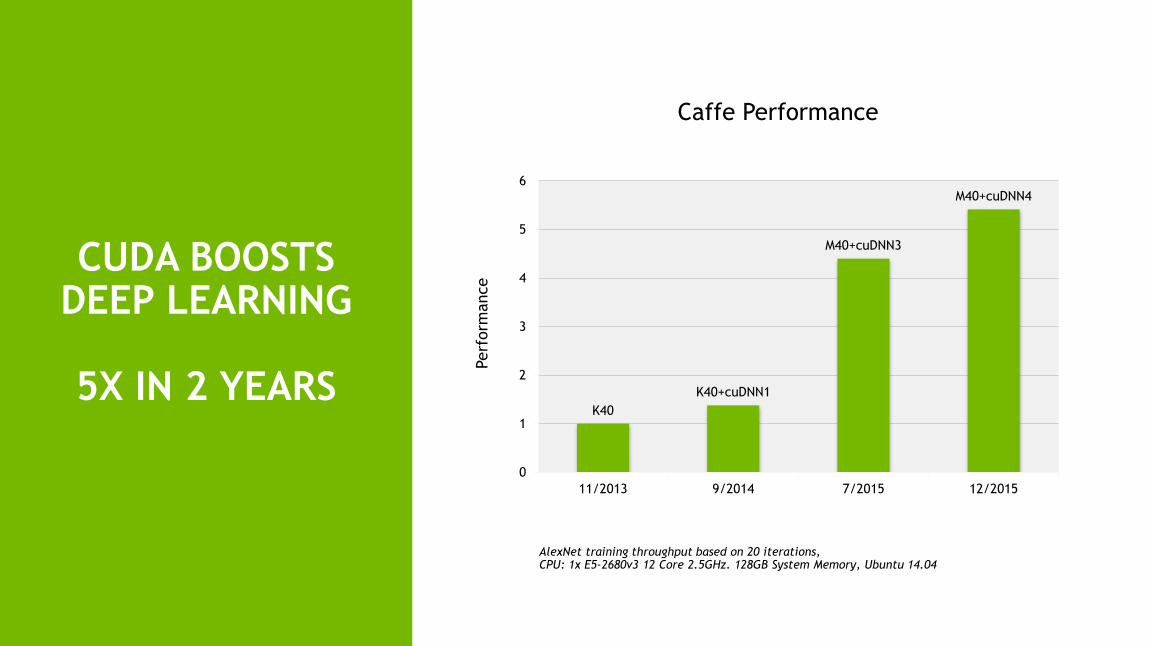
CUDA BOOSTS DEEP LEARNING
5X IN 2 YEARS
Perf
orm
ance
AlexNet training throughput based on 20 iterations, CPU: 1x E5-2680v3 12 Core 2.5GHz. 128GB System Memory, Ubuntu 14.04
Caffe Performance
K40K40+cuDNN1
M40+cuDNN3
M40+cuDNN4
0
1
2
3
4
5
6
11/2013 9/2014 7/2015 12/2015
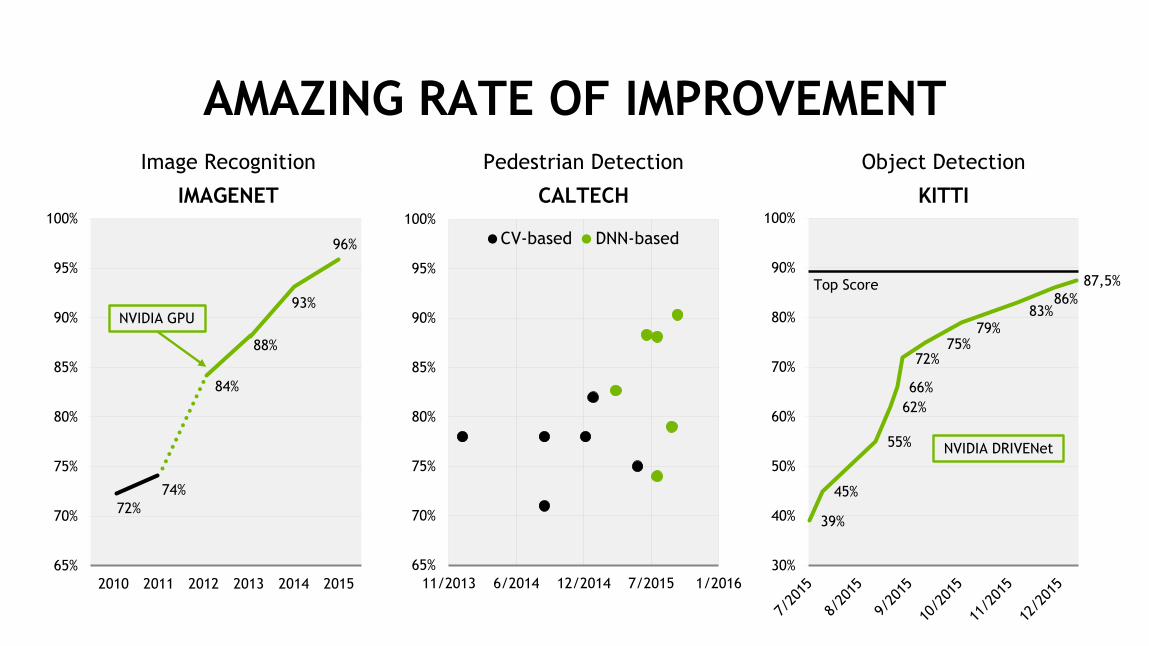
33
39%
45%
55%
62%66%
72%75%
79%83%
86%87,5%
30%
40%
50%
60%
70%
80%
90%
100%
72%74%
84%
88%
93%
96%
65%
70%
75%
80%
85%
90%
95%
100%
2010 2011 2012 2013 2014 2015
ImageNet Accuracy
NVIDIA GPU
AMAZING RATE OF IMPROVEMENTPedestrian Detection
CALTECH
65%
70%
75%
80%
85%
90%
95%
100%
11/2013 6/2014 12/2014 7/2015 1/2016
Accu
racy
CV-based DNN-based
Object Detection
KITTI
Image Recognition
IMAGENET
Top Score
NVIDIA DRIVENet

34
CUDA FOR DEEP LEARNING DEVELOPMENT
TITAN X GPU CLOUDDEVBOX
DEEP LEARNING SDK
cuSPARSE cuBLASDIGITS NCCLcuDNN

35
FACEBOOK’S DEEP LEARNING MACHINEPurpose-Built for Deep Learning Training
2x Faster Training for Faster Deployment
2x Larger Networks for Higher Accuracy
Powered by Eight Tesla M40 GPUs
Open Rack Compliant
Serkan PiantinoEngineering Director of Facebook AI Research
“Most of the major advances in machine learning and AI in the past few years have been contingent on tapping into powerful
GPUs and huge data sets to build and train advanced models”

36
DESIGNED FOR AI COMPUTING AT LARGE SCALE
Built on the NVIDIA Tesla Platform
• 8 Tesla M40s deliver aggregate 96 GB GDDR5 memory and 56 teraflops of SP performance
• Leverages world’s leading deep learning platform to tap into frameworks such as Torch and libraries such as cuDNN
Operational Efficiency and Serviceability
• Free-air Cooled Design Optimizes Thermal and Power Efficiency
• Components swappable without tools
• Configurable PCI-e for versatility

37
TESLA M40World’s Fastest Accelerator for Deep Learning Training
0 1 2 3 4 5
GPU Server with4x TESLA M40
Dual CPU Server
13x Faster TrainingCaffe
Number of Days
CUDA Cores 3072
Peak SP 7 TFLOPS
GDDR5 Memory 12 GB
Bandwidth 288 GB/s
Power 250W
Reduce Training Time from 5 Days to less than 10 Hours
Note: Caffe benchmark with AlexNet, training 1.3M images with 90 epochsCPU server uses 2x Xeon E5-2699v3 CPU, 128GB System Memory, Ubuntu 14.04

38
TESLA M4Highest Throughput
Hyperscale Workload Acceleration
CUDA Cores 1024
Peak SP 2.2 TFLOPS
GDDR5 Memory 4 GB
Bandwidth 88 GB/s
Form Factor PCIe Low Profile
Power 50 – 75 W
Video Processing
4x
Image Processing
5x
Video Transcode
2x
Machine Learning Inference
2x
H.264 & H.265, SD & HD
Stabilization and Enhancements
Resize, Filter, Search, Auto-Enhance
Preliminary specifications. Subject to change.

39
TESLA PLATFORM FOR DEVELOPERS
40
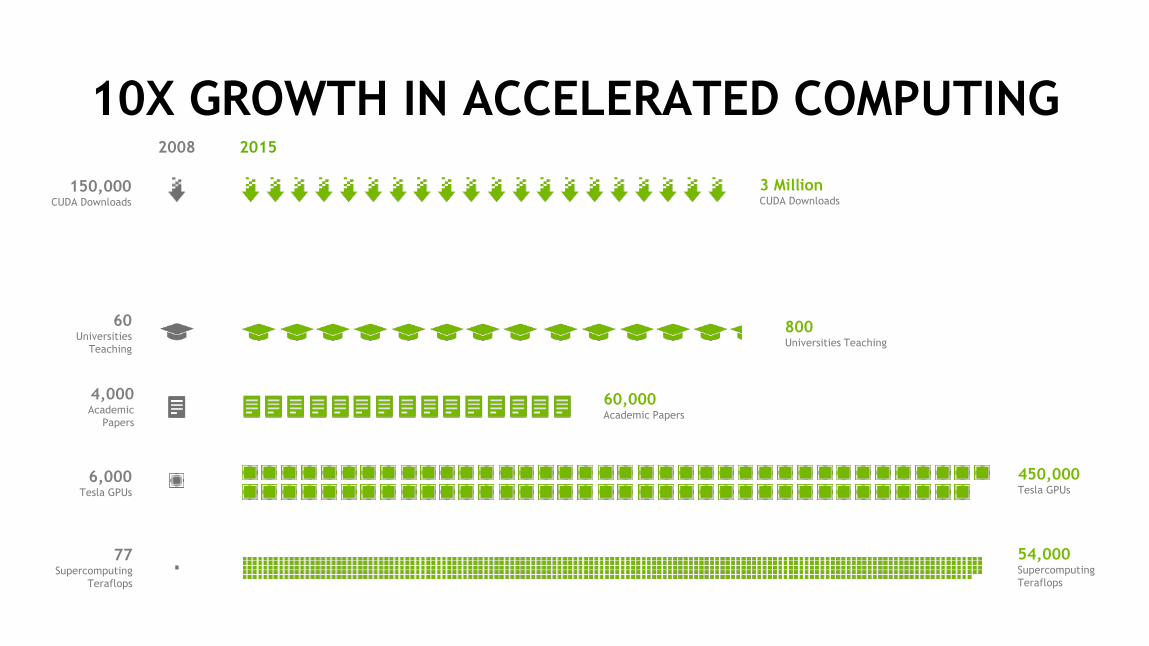
10X GROWTH IN ACCELERATED COMPUTING20152008
3 MillionCUDA Downloads
150,000CUDA Downloads
60,000 Academic Papers
4,000Academic
Papers
800Universities Teaching
60Universities
Teaching
54,000SupercomputingTeraflops
77Supercomputing
Teraflops
450,000Tesla GPUs
6,000Tesla GPUs
370CUDA Apps
27CUDA Apps
41
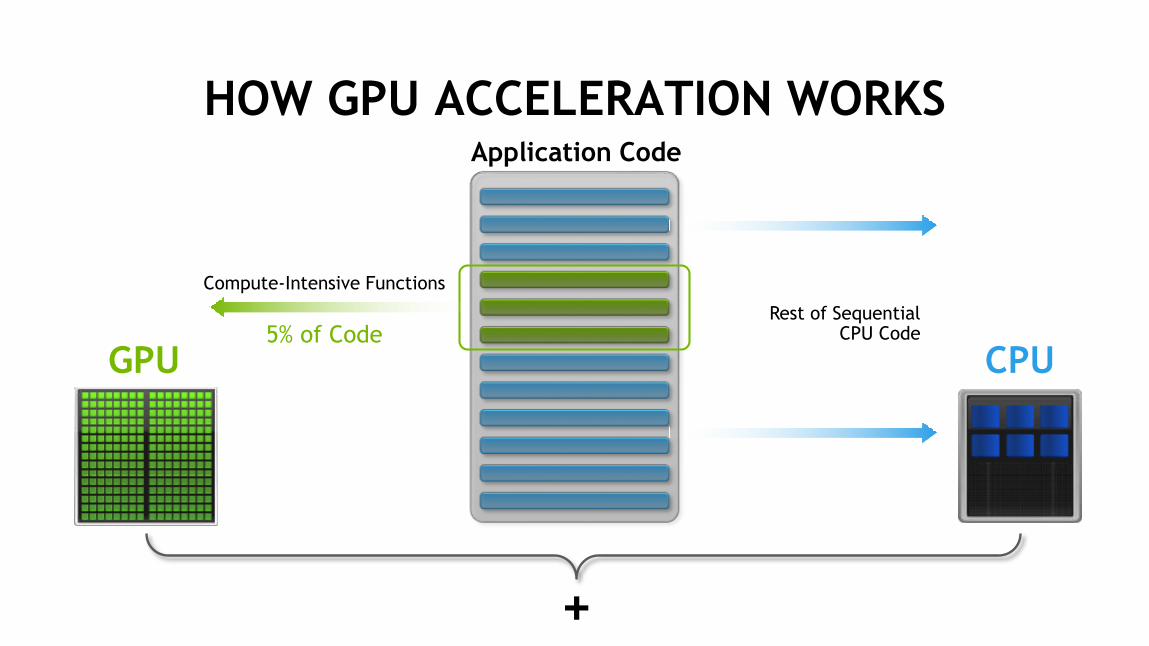
HOW GPU ACCELERATION WORKSApplication Code
+
GPU CPU5% of Code
Compute-Intensive Functions
Rest of SequentialCPU Code
42
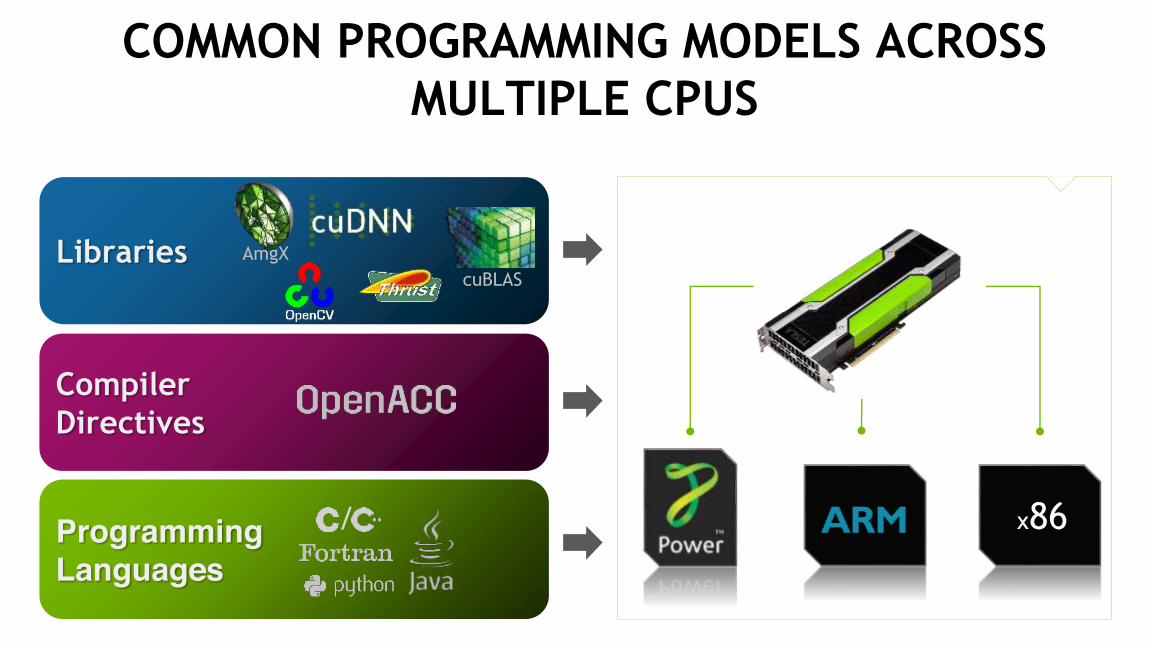
COMMON PROGRAMMING MODELS ACROSS MULTIPLE CPUS
x86
Libraries
Programming Languages
CompilerDirectives
AmgXcuBLAS
/

43
GPU ACCELERATED LIBRARIES“Drop-in” Acceleration for Your Applications
Domain-specificDeep Learning, GIS, EDA,Bioinformatics, Fluids
Visual ProcessingImage & Video
Linear AlgebraDense, Sparse, Matrix
Math AlgorithmsAMG, Templates, Solvers
NVIDIA cuRAND
NVIDIANPPNVIDIA CODEC SDK
NVBIO Triton Ocean SDK
NVIDIAcuBLAS, cuSPARSE
AmgX cuSOLVER
developer.nvidia.com/gpu-accelerated-libraries
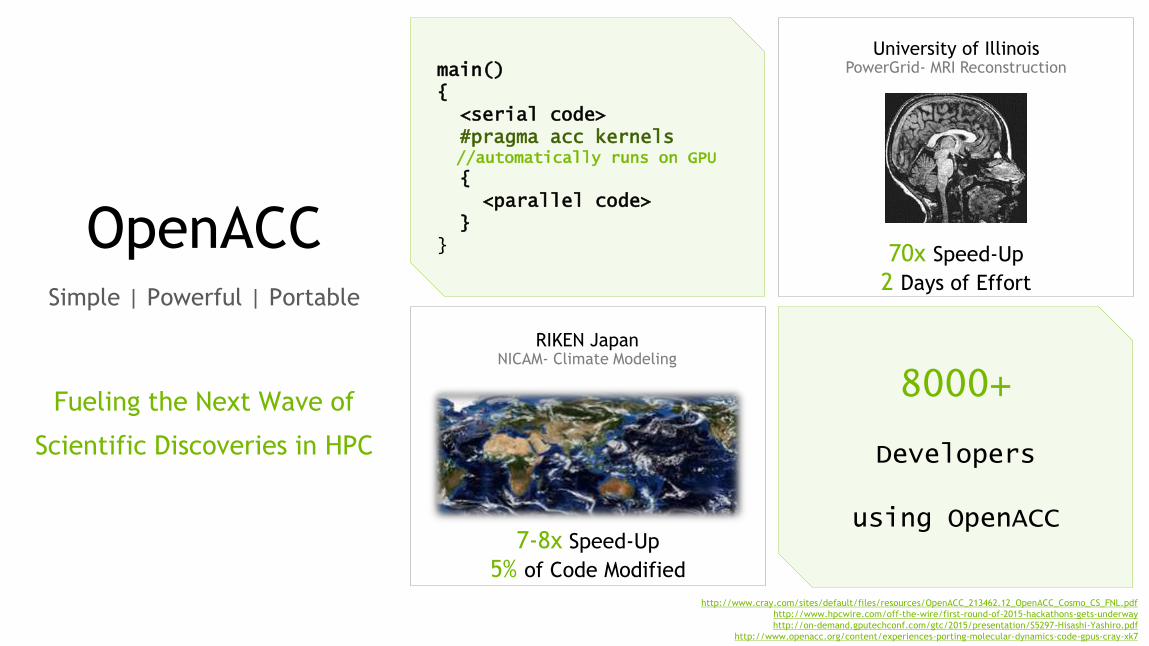
44
OpenACCSimple | Powerful | Portable
Fueling the Next Wave of
Scientific Discoveries in HPC
University of IllinoisPowerGrid- MRI Reconstruction
70x Speed-Up2 Days of Effort
http://www.cray.com/sites/default/files/resources/OpenACC_213462.12_OpenACC_Cosmo_CS_FNL.pdfhttp://www.hpcwire.com/off-the-wire/first-round-of-2015-hackathons-gets-underwayhttp://on-demand.gputechconf.com/gtc/2015/presentation/S5297-Hisashi-Yashiro.pdf
http://www.openacc.org/content/experiences-porting-molecular-dynamics-code-gpus-cray-xk7
RIKEN JapanNICAM- Climate Modeling
7-8x Speed-Up5% of Code Modified
main() {
<serial code>#pragma acc kernels//automatically runs on GPU
{ <parallel code>
}}
8000+
Developers
using OpenACC
45
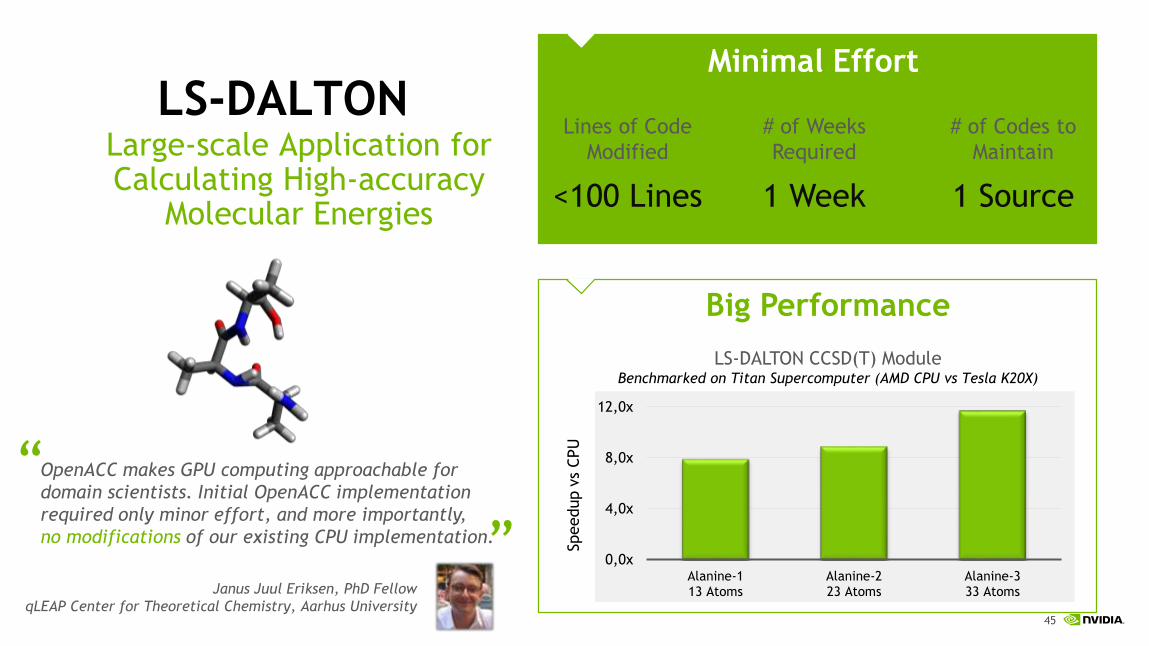
Janus Juul Eriksen, PhD FellowqLEAP Center for Theoretical Chemistry, Aarhus University
“OpenACC makes GPU computing approachable for domain scientists. Initial OpenACC implementation required only minor effort, and more importantly,no modifications of our existing CPU implementation.
“
Lines of Code Modified
# of Weeks Required
# of Codes to Maintain
<100 Lines 1 Week 1 Source
Big Performance
0,0x
4,0x
8,0x
12,0x
Alanine-113 Atoms
Alanine-223 Atoms
Alanine-333 Atoms
Spee
dup
vs C
PU
Minimal Effort
LS-DALTON CCSD(T) ModuleBenchmarked on Titan Supercomputer (AMD CPU vs Tesla K20X)
LS-DALTONLarge-scale Application for Calculating High-accuracy
Molecular Energies
46
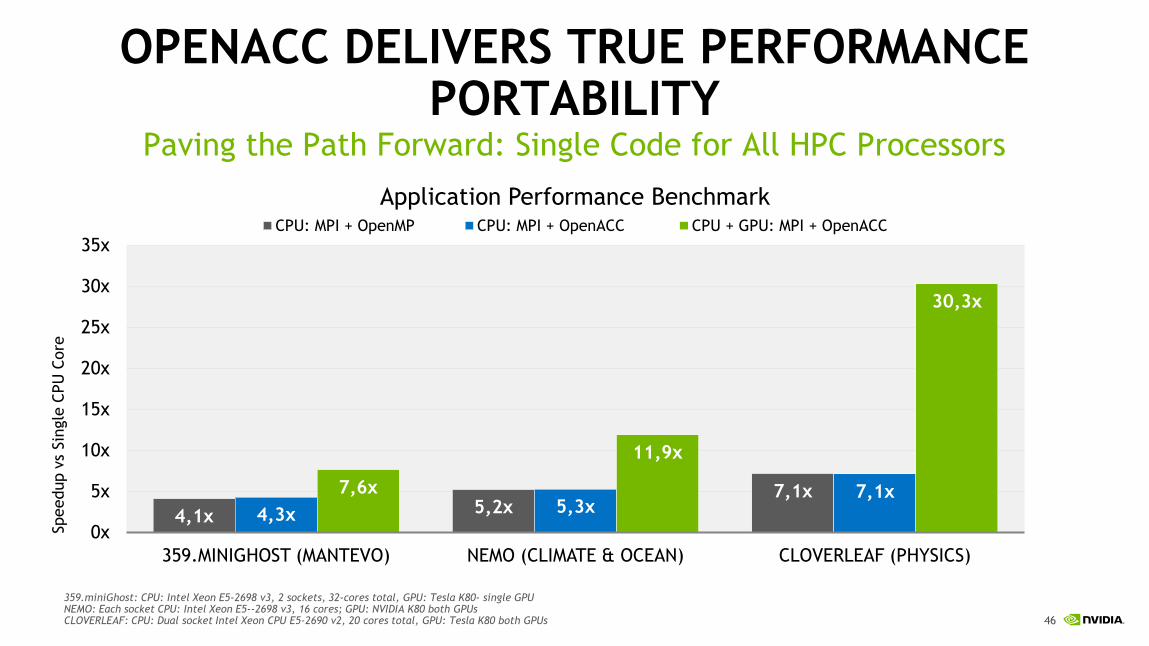
OPENACC DELIVERS TRUE PERFORMANCE PORTABILITY
Paving the Path Forward: Single Code for All HPC Processors
4,1x 5,2x7,1x
4,3x 5,3x7,1x7,6x
11,9x
30,3x
0x
5x
10x
15x
20x
25x
30x
35x
359.MINIGHOST (MANTEVO) NEMO (CLIMATE & OCEAN) CLOVERLEAF (PHYSICS)
CPU: MPI + OpenMP CPU: MPI + OpenACC CPU + GPU: MPI + OpenACC
Spee
dup
vs S
ingl
e CP
U C
ore
Application Performance Benchmark
359.miniGhost: CPU: Intel Xeon E5-2698 v3, 2 sockets, 32-cores total, GPU: Tesla K80- single GPU NEMO: Each socket CPU: Intel Xeon E5-‐2698 v3, 16 cores; GPU: NVIDIA K80 both GPUsCLOVERLEAF: CPU: Dual socket Intel Xeon CPU E5-2690 v2, 20 cores total, GPU: Tesla K80 both GPUs

47
CUDASuper Simplified Memory Management Code
void sortfile(FILE *fp, int N) {char *data;data = (char *)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, compare);
use_data(data);
free(data);}
void sortfile(FILE *fp, int N) {char *data;cudaMallocManaged(&data, N);
fread(data, 1, N, fp);
qsort<<<...>>>(data,N,1,compare);cudaDeviceSynchronize();
use_data(data);
cudaFree(data);}
CPU Code CUDA 6 Code with Unified Memory
48
GPU DEVELOPER ECO-SYSTEM
Consultants & Training
ANEO GPU Tech
OEM Solution Providers
Debuggers& Profilers
CUDA-GDBNV Visual Profiler
NVIDIA NsightVisual Studio
AllineaTotalView
MATLABMathematica
LabView
Numerical Packages
GPUDirect RDMADatacenter
GPU Manager
Cluster Tools
FFTBLAS
SPARSELAPACK
NPPVideo
Imaging
LibrariesCC++
FortranJava
PythonOpenACCOpenMP
Languages & Directives

49
DEVELOP ON GEFORCE, DEPLOY ON TESLA
Designed for Developers & Gamers
Available Everywhere
developer.nvidia.com/cuda-gpusdeveloper.nvidia.com/devbox
Designed for the Data CenterECC
24x7 RuntimeGPU Monitoring
Cluster ManagementGPUDirect-RDMAHyper-Q for MPI3 Year Warranty
Integrated OEM Systems, Professional Support


51
DEEP LEARNING & ARTIFICIAL INTELLIGENCE
Sep 28-29, 2016 | Amsterdamwww.gputechconf.eu #GTC16
SELF-DRIVING CARS VIRTUAL REALITY & AUGMENTED REALITY
SUPERCOMPUTING & HPC
GTC Europe is a two-day conference designed to expose the innovative ways developers, businesses and academics are using parallel computing to transform our world.
EUROPE’S BRIGHTEST MINDS & BEST IDEAS
2 Days | 800 Attendees | 50+ Exhibitors | 50+ Speakers | 15+ Tracks | 15+ Workshops | 1-to-1 Meetings







![HAYDAR Bassel - [Groupe Calcul]calcul.math.cnrs.fr/IMG/pdf/merged_document_7.pdf · HAYDAR Bassel 5 rue Mozart, ... la magnéto-hydrodynamique, ... Analyse numérique et calcul scientifique,](https://img.pdfslide.net/doc/110x75/5a7901d97f8b9adb5a8c8400/haydar-bassel-groupe-calcul-bassel-5-rue-mozart-la-magnto-hydrodynamique.jpg)