Embed Size (px)
Citation preview

2015.12.07
Do You Need a Graph Database?Web Sem
Graph Database “Shootout”
Josh Perryman, Sebastian GoodPalladium Consulting
Graph Day TexasJanuary 2016

Sebastian GoodPractice Lead: Architecture & Development
@PalladiumCS @SebastianGood
Ask me about: distributed systems, graphs, high-performance computing, cloud deployments, web applications, oil & gas, functional programming, C++, .NET, JavaScript, and Julia
Josh PerrymanTechnical Lead, Data Junkie
@JoshPerryman
Ask me about: data, database engines, relational database performance, graph databases, systems design, technical talent assessment, picking the right tool for the job, focusing on solving the right problems
Hello!

What We Do: Design & Build Complex Products

Partners
Clients. Partners.
OPENDOOR TRADING

Today’s Talk
A Customer’s Problem
The Legacy Architecture
Evaluation Criteria / Methodology
The Four Alternatives & Architectures
Closing Thoughts

Bringing home the appliance industry.
A Customer’s Problem

Legacy Java Application is Slow
Over 15 years of continuous development
Larger installations needed larger and larger database server hardware backends to meet performance requirements.
Running ahead of Moore’s Law: salvation by hardware upgrade was getting more difficult to achieve
We evaluated both front-end and back-end performance
Our Back-end Task: Could they improve system performance, particularly at the persistence & query layers, in light of increasing data size?
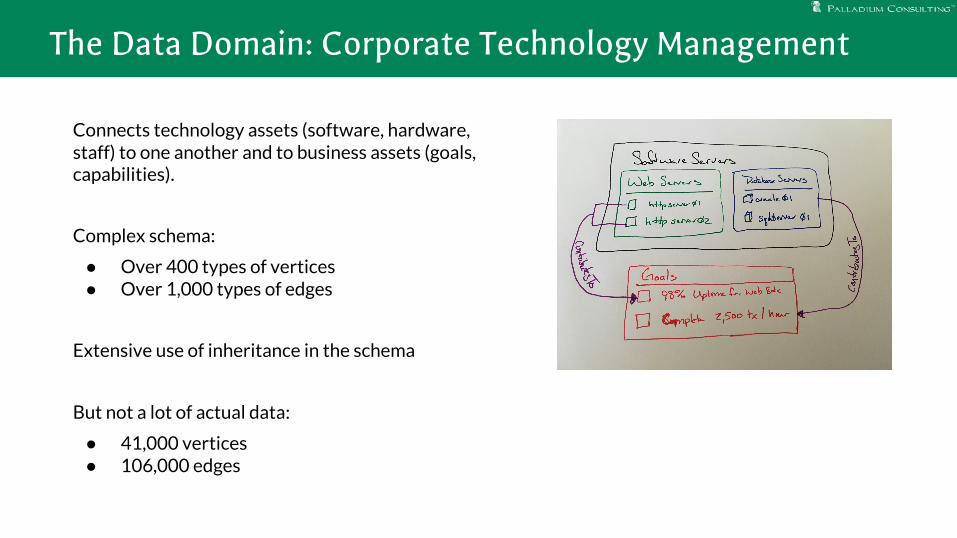
The Data Domain: Corporate Technology Management
Connects technology assets (software, hardware, staff) to one another and to business assets (goals, capabilities).
Complex schema:
● Over 400 types of vertices● Over 1,000 types of edges
Extensive use of inheritance in the schema
But not a lot of actual data:
● 41,000 vertices ● 106,000 edges

Complex Schema: Multiple Vertex Types, Type Inheritance
Basic Vertex
Software
Software Server
Database Server postgresql73
cassandra01
cassandra02
cassandra03
Web Server http-server-01
http-server-02
http-server-03 IIS2

A Complex Schema: Even More Edge Types
Server
hp-linux-01OS
Ubuntu 14.10
WebServer
http-server-03
runs
Capability
Share Web Content
enablesWebSite
www.ace.com
deploys
hosts

A Vast Schema that is both Deep ...
Vertex types in the schema:● Total count: 414● Depth: 9 levels● Width: 167 at the 4th level

... and Wide
Edge types in the schema:● Total count: 1,072● Depth: 5 levels● Width: 773 at the 4th level

Bringing home the appliance industry.
The Legacy Architecture

Entity-Attribute-Value Schema in an RDMBS
One set of tables for schema:● vertex_types● edge_types● attribute_definitions
Another set of tables for data: ● vertex● edge● attribute

Table Samples - Schema Tables
type_name parent
GenericVertex (null)
Capability GenericNode
Hardware GenericNode
Computer Hardware
Server Computer
Desktop Computer
type_name parent
genericEdge (null)
deploys genericEdge
consistsOf genericEdge
provides genericEdge
uses genericEdge
has genericEdge
edge_type (1,072 rows)vertex_type (414 rows)

Table Samples - Data Tables
id name type_name
123 Mapmarker Application
234 Reuters Plus Application
345 Speaker Mgmt Capability
456 Managed Care Capability
567 Chrome v.2.0.172 SwVersion
678 .NET Framework 2.0 SwVersion
begin end type_name
123 135 deploys
234 246 consistsOf
345 357 provides
456 468 provides
567 579 uses
678 680 has
edge (105,948 rows)vertex (40,854 rows)

Entity-Attribute-Value: The Good & Bad
Good: ● Flexible schema, easily customized● No DDL operations
Bad: ● Even trivial queries require multiple joins● Neuters the query optimizer● Queries verbose, difficult to write

WITH RECURSIVE
cte_application (type_id) AS (
SELECT type_id FROM node_type WHERE code_name = 'Application'
UNION ALL
SELECT nt.type_id FROM node_type AS nt JOIN cte_application AS cte ON nt.parent_id = cte.type_id)
Entity-Attribute-Value: Sample Query, part 1

Entity-Attribute-Value: Sample Query, part 2
SELECT app.name, app.node_uuid AS uuid , coalesce(sw.value::FLOAT, 0) AS software_cost , coalesce(hw.value::FLOAT, 0) AS hardware_cost , coalesce(la.value::FLOAT, 0) AS labor_cost , coalesce(de.value::FLOAT, 0) AS depreciation_cost , coalesce(ot.value::FLOAT, 0) AS other_cost , coalesce(sw.value::FLOAT, 0) + coalesce(hw.value::FLOAT, 0) + la.value::FLOAT + coalesce(de.value::FLOAT, 0) + ot.value::FLOAT AS total_costFROM node AS app LEFT OUTER JOIN attribute AS sw ON sw.context_object_uuid = app.uuid AND sw.attribute_definition_id = 758 LEFT OUTER JOIN attribute AS hw ON hw.context_object_uuid = app.uuid AND hw.attribute_definition_id = 759 LEFT OUTER JOIN attribute AS la ON la.context_object_uuid = app.uuid AND la.attribute_definition_id = 760 LEFT OUTER JOIN attribute AS de ON de.context_object_uuid = app.uuid AND de.attribute_definition_id = 761 LEFT OUTER JOIN attribute AS ot ON ot.context_object_uuid = app.uuid AND ot.attribute_definition_id = 762 JOIN cte_application AS cte_app ON cte_app.type_id = app.type_id;

Bringing home the appliance industry.
Evaluation Criteria
What We Evaluated
1. Installation / Configuration2. Schema Capabilities3. Data Modeling4. Data Import Capabilities5. Query Writing6. General Tooling / Ecosystem7. Read Performance

Things We Didn’t Look At
1. Whole-graph analytics (e.g. OLAP-type queries)2. Special capabilities: full-text indexing, geolocation3. Really large data sets4. Clustering, high availability, scale up or out options5. Licensing, commercial considerations

The Queries, Data Sets
● Client provided EAV queries and data sets
● Covered their worse-performing scenarios
The Testing
● Local on developer laptop
● No other activity modeled
The Testing
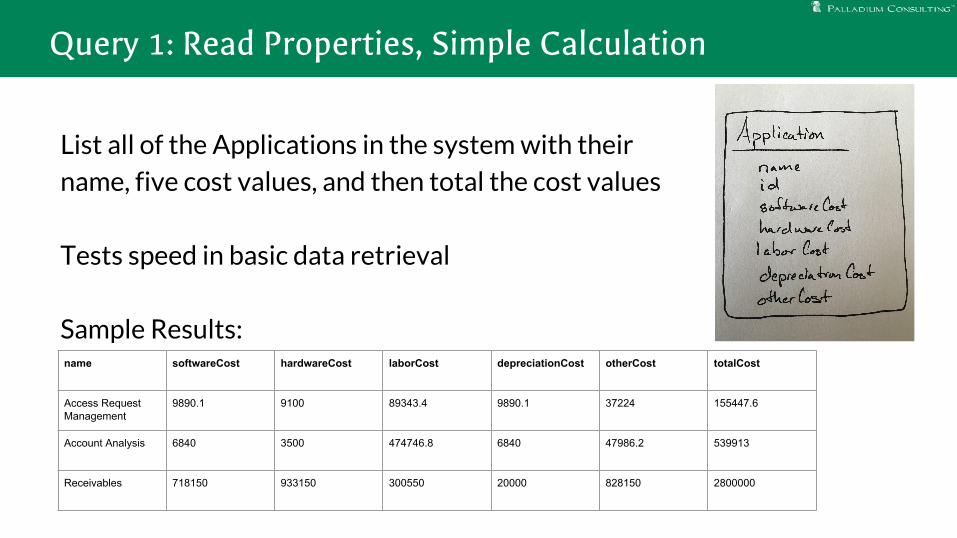
List all of the Applications in the system with their
name, five cost values, and then total the cost values
Tests speed in basic data retrieval
Sample Results:
Query 1: Read Properties, Simple Calculation
name softwareCost hardwareCost laborCost depreciationCost otherCost totalCost
Access Request Management
9890.1 9100 89343.4 9890.1 37224 155447.6
Account Analysis 6840 3500 474746.8 6840 47986.2 539913
Receivables 718150 933150 300550 20000 828150 2800000

Quotient of the number of Applications connected
through provided Business Functions, divided by the
number of provided Business Functions
Sample Results:
Query 2: Redundancy Calculation
name Count of provided Applications Count of provided Business Functions Redundancy
App1 3 = 3 1 3 / 1 = 3.0
App2 3 + 3 = 5 2 5 / 2 = 2.5
App3 3 + 2 + 1 = 6 3 6 / 3 = 2.0
App4 1 = 1 1 1 / 1 = 1.0
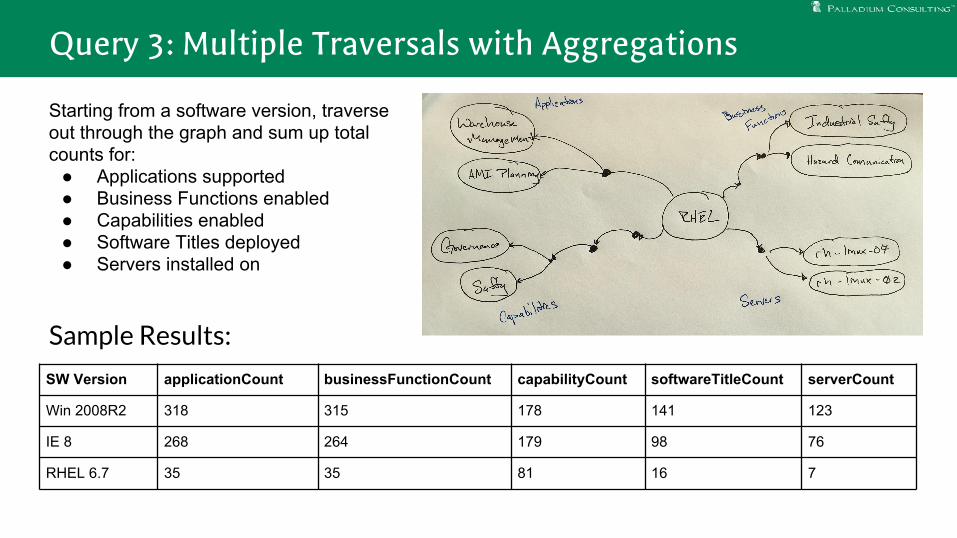
Sample Results:
Query 3: Multiple Traversals with Aggregations
SW Version applicationCount businessFunctionCount capabilityCount softwareTitleCount serverCount
Win 2008R2 318 315 178 141 123
IE 8 268 264 179 98 76
RHEL 6.7 35 35 81 16 7
Starting from a software version, traverse out through the graph and sum up total counts for:
● Applications supported● Business Functions enabled● Capabilities enabled● Software Titles deployed● Servers installed on
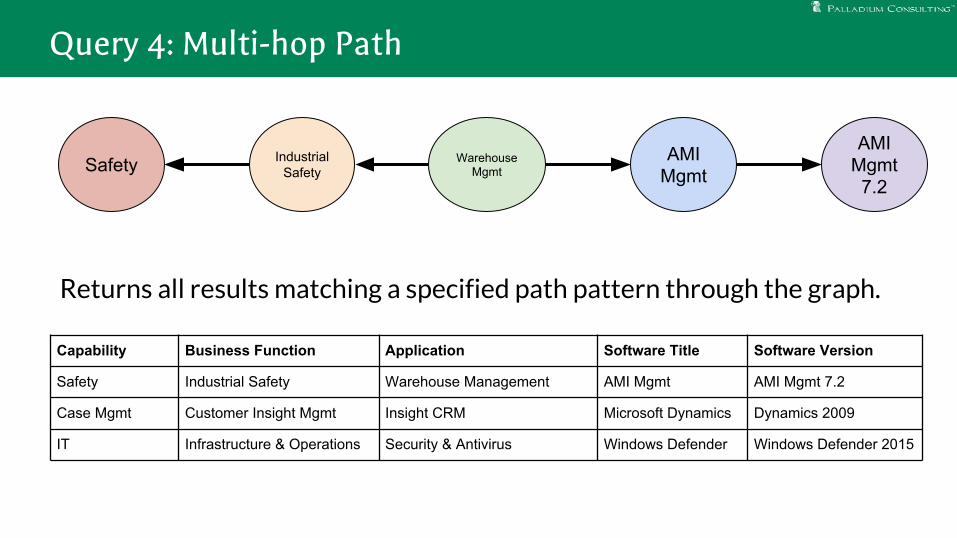
Returns all results matching a specified path pattern through the graph.
Query 4: Multi-hop Path
Safety Warehouse Mgmt
AMI Mgmt
AMI Mgmt
7.2
Capability Business Function Application Software Title Software Version
Safety Industrial Safety Warehouse Management AMI Mgmt AMI Mgmt 7.2
Case Mgmt Customer Insight Mgmt Insight CRM Microsoft Dynamics Dynamics 2009
IT Infrastructure & Operations Security & Antivirus Windows Defender Windows Defender 2015
Industrial Safety

Bringing home the appliance industry.
The Four Alternatives

The Four Alternatives
● Neo4j (version 2.3.1)● Titan (version 1.0.0, based on TinkerPop 3.0.1)● OrientDB (version 2.1.9)● “Wide Tables” - a Reporting Schema RDBMS
(PostgreSQL 9.4.5)

Bringing home the appliance industry.
Neo4j

Neo4j
Great for tool for graph database discovery & evaluation

Neo4j - Schema Capabilities
A property graph database: ● Nodes & relationships (e.g. vertices & edges)● Multiple labels capability for nodes● Relationships can be distinguished by type ● Relationships can have properties. ● Simple data types for properties● Can enforce property existence & uniqueness

Neo4j - Schema Definition
CREATE CONSTRAINT ON (nt:NodeType) ASSERT nt.codeName IS UNIQUE;
CREATE CONSTRAINT ON (n:Node) ASSERT n.uuid IS UNIQUE;
CREATE INDEX ON :Node(name);

Neo4j - Data Modeling: Inheritance
Inheritance Modeling Options: ● Multiple labels ● A “node type” collection property ● Create a “Schema Graph”

Neo4j - Data Modeling
Inheritance with Multiple labels
CREATE (n:Node:BasicNode:Software:SoftwareServer:WebServer { uuid: ‘4088E284-7590-4A20-9653-F487E1EADDCD’, name: ‘http-server-01’ } )

Neo4j - Data Modeling
Inheritance with collection property
CREATE (n:Node { uuid: ‘4088E284-7590-4A20-9653-F487E1EADDCD’, name: ‘http-server-01’ typeCodeName: [“BasicNode”, ”Software”, “SoftwareServer”, “WebServer” ] } )

Inheritance with Schema Graph
CREATE (n:Node { uuid: ‘4088E284-7590-4A20-9653-F487E1EADDCD’, name: ‘http-server-01’ typeCodeName: ‘WebServer’ } )MATCH (nt:NodeType { codeName: n.typeCodeName })MERGE (n)-[:IS_NODE_TYPE]->(nt);
Neo4j - Data Modeling

Neo4j - Data Import
Three tools: ● Cypher’s CSV LOAD command● A command line batch tool● A batch insertion Java tool

USING PERIODIC COMMIT 10000LOAD CSV WITH HEADERS FROM 'file:///Neo4j_Nodes.csv' AS lineCREATE (n:Node { id: toInt(line.id), uuid: line.uuid, name: line.name, typeCodeName:line.typeCodeName } )WITH nMATCH (nt:NodeType { codeName: n.typeCodeName })MERGE (n)-[:IS_NODE_TYPE]->(nt);
Neo4j - Data Import, CSV LOAD & import tool Example

Neo4j - CLI Tool to create edges
Used CLI Tool to load edges from CSV: bin/neo4j-import --into graphday2016.db\ / --relationships neo4jDataEdges.csv
neo4jDataEdges.csv: ":START_ID",":END_ID",":TYPE"7BCB14DDF1FE49,0ABE8664D09A44,"provides"

Neo4j - Query Writing
match(app:Application) return app.name, app.uuid , app.softwareCost , app.hardwareCost , app.laborCost , app.depreciationCost , app.otherCost , ( app.softwareCost + app.hardwareCost + app.laborCost + app.depreciationCost + app.otherCost) AS totalCost

Neo4j - Query Writing
MATCH (cap:Capability) <-[r1:PROVIDES]-
(bf:BusinessFunction) <-[r2:PROVIDES]-
(app:Application) -[r3:CONSISTS_OF]->
(sw:SoftwareTitle) -[r4:DEPLOYS]-> (v:SoftwareVersion)RETURN cap.name, bf.name, app.name, sw.name, v.name
Neo4j - Tooling
Neo4j browser graphgist.org

Bringing home the appliance industry.
Titan

Titan
Steep learning curve, but a powerful language makes a lot of things easy & uniform once learned

Titan - Schema Capabilities
A property graph database: ● Vertices & edges● One label on a vertex● Edges can have labels & properties also● Multiple data types for properties
Schema capabilities: ● Five cardinality settings for edges: (many2many, many2one,...)● Three cardinality settings for properties (single, list, set)● Property uniqueness enforceable

mgmt = graph.openManagement()
SoftwareServer = mgmt.makeVertexLabel('SoftwareServer').make()WebServer = mgmt.makeVertexLabel('WebServer').make()
isNodeType = mgmt.makeEdgeLabel('isVertexType'). multiplicity(Multiplicity.MANY2ONE).make()
// codeNames array of strings initialized with all Vertex type code namescodeNames.each { mgmt.makeVertexLabel(it).make() }
Titan - Data Import: Schema Construction

Titan - Data Import: Schema Construction
name = mgmt.makePropertyKey('name'). dataType(String.class). cardinality(Cardinality.SINGLE).make()uuid = mgmt.makePropertyKey('uuid'). dataType(String.class).make()vertexTypeSet = mgmt.makePropertyKey(‘vertexTypeSet’). dataType(String.class). cardinality(Cardinality.SET).make()
mgmt.buildIndex('idxByName', Vertex.class). addKey(name).buildCompositeIndex()mgmt.buildIndex('idxByUUID', Vertex.class). addKey(uuid). unique().buildCompositeIndex()mgmt.commit()

Titan - Data Modeling:Inheritance
Edges back to a schema object graph
v.addEdge(‘isVertexType’, vertexType)
Or use a set property
v.property(‘codeName’, [‘SoftwareServer’, ‘WebServer’])

csv = new File(pathAndFilename).getText(); []vertices = new CsvParser().parse(csv, readFirstLine: false, columnNames: ["uuid","name",”description”,"typeCodeName"]); []
for (v in vertices) {vertexType = g.V().has('codeName', v.typeCodeName).next()vertex = graph.addVertex(label, vertexType.values('codeName').next())
vertex.property('uuid', v.uuid)vertex.property('name', v.name)if (!v.description.equalsIgnoreCase('NULL') || !v.description) {
vertex.property('description', v.description)}vertex.addEdge('isVertexType', vertexType)
}graph.tx().commit()
Titan - Data Import

g.V().has(label, 'Application'). valueMap('name', 'uuid', 'softwareCost', 'hardwareCost', 'laborCost', 'depreciationCost', 'otherCost')
Titan - Query Writing

g.V().has('codeName','Capability'). in('isVertexType').as('cap'). in('provides').as('bf'). in('provides').as('app'). out('consistsOf').as('sw'). out('deploys').as('v'). select('cap','bf','app','sw','v').by('name')
Titan - Query Writing
Titan - Tooling

Bringing home the appliance industry.
OrientDB

OrientDB
Sure demos well, but don’t get too sophisticated with your graph queries

OrientDB - Schema Capabilities
A document database with graph capabilities: ● Vertices & edges● Vertices: generic (use built-in V class) or own class such
as SoftwareServer● Edges: either generic ( use built-in E class) or lightweight● Inheritance built into the engine ● Lots & lots of property types● Only solution with security features: Users & Roles

CREATE CLASS WebServer EXTENDS SoftwareServer;
INSERT INTO WebServer (uuid, name) VALUES ('155D8C8D326F4AB3842917DD83C5342A', 'http-server-01'); SELECT FROM SoftwareServer;
OrientDB - Data Modeling:Inheritance
name uuid
http-server-01 '155D8C8D326F4AB3842917DD83C5342A'

OrientDB - Data Import
A very slick command line tool$ cd $ORIENTDB_HOME/bin$ ./oetl.sh config-import.json
config-import.json{ "source": { "file": { "path": "/temp/datasets/data.csv" } }, "extractor": { "csv": {} }, "transformers": [ { "vertex": { "class": "MyClass" } } ], "loader": { "orientdb": { "dbURL": "plocal:/temp/databases/mydb", "dbType": "graph", "classes": [ {"name": "MyClass", "extends": "V"}], "indexes": [ {"class":"MyClass", "fields":["id:integer"], "type":"UNIQUE" }] } }}
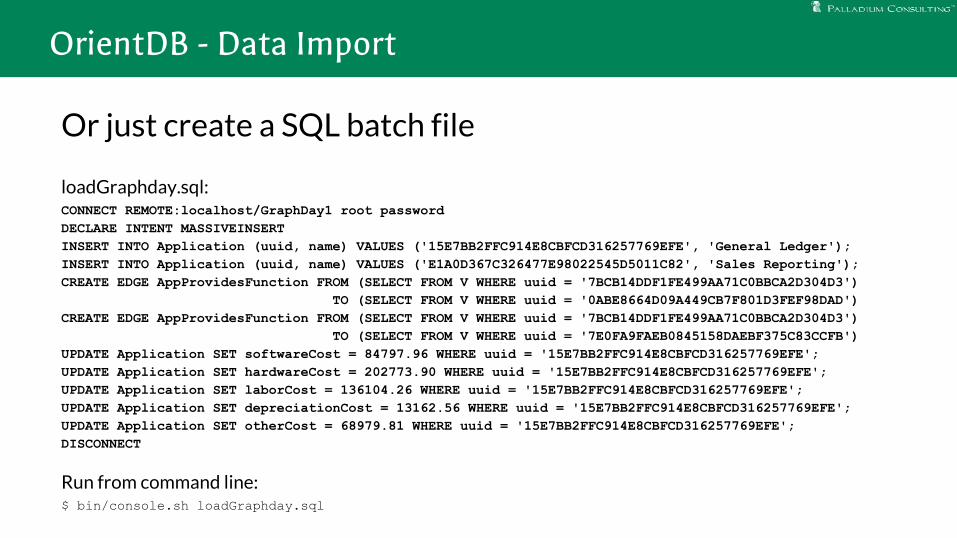
OrientDB - Data Import
Or just create a SQL batch file
loadGraphday.sql:CONNECT REMOTE:localhost/GraphDay1 root passwordDECLARE INTENT MASSIVEINSERTINSERT INTO Application (uuid, name) VALUES ('15E7BB2FFC914E8CBFCD316257769EFE', 'General Ledger');INSERT INTO Application (uuid, name) VALUES ('E1A0D367C326477E98022545D5011C82', 'Sales Reporting');CREATE EDGE AppProvidesFunction FROM (SELECT FROM V WHERE uuid = '7BCB14DDF1FE499AA71C0BBCA2D304D3') TO (SELECT FROM V WHERE uuid = '0ABE8664D09A449CB7F801D3FEF98DAD')CREATE EDGE AppProvidesFunction FROM (SELECT FROM V WHERE uuid = '7BCB14DDF1FE499AA71C0BBCA2D304D3') TO (SELECT FROM V WHERE uuid = '7E0FA9FAEB0845158DAEBF375C83CCFB')UPDATE Application SET softwareCost = 84797.96 WHERE uuid = '15E7BB2FFC914E8CBFCD316257769EFE';UPDATE Application SET hardwareCost = 202773.90 WHERE uuid = '15E7BB2FFC914E8CBFCD316257769EFE';UPDATE Application SET laborCost = 136104.26 WHERE uuid = '15E7BB2FFC914E8CBFCD316257769EFE';UPDATE Application SET depreciationCost = 13162.56 WHERE uuid = '15E7BB2FFC914E8CBFCD316257769EFE';UPDATE Application SET otherCost = 68979.81 WHERE uuid = '15E7BB2FFC914E8CBFCD316257769EFE';DISCONNECT
Run from command line:$ bin/console.sh loadGraphday.sql

select name, uuid , softwareCost , hardwareCost , laborCost , depreciationCost , otherCostfrom Application
OrientDB - Query Writing

select name, in(‘Provides’).name, in(‘Provides’).in('Provides').name, in(‘Provides’).in('Provides').out('ConsistsOf').name,
in(‘Provides’).in('Provides').out('ConsistsOf'). out('Deploys').namefrom Capability
OrientDB - Query Writing

OrientDB - Tooling

Bringing home the appliance industry.
Wide Tablesw/ PostgreSQL

Wide Tables - PostgreSQL
Decades of development makes for some fast software … when the query optimizer is used

Wide Tables - Schema Capabilities
Its a Relational Database Management System
… with Inheritance

CREATE TABLE BasicNode (id bigint PRIMARY KEY,uuid uuid, name varchar(255),description text, type_id integer NOT NULL,code_name varchar(30)
);
CREATE INDEX idx_BasicNode_id ON BasicNode (id);CREATE INDEX idx_BasicNode_uuid ON BasicNode (uuid);
Wide Tables - Data Modeling: Inheritance

CREATE TABLE Software () INHERITS (BasicNode);
CREATE TABLE Application (softwareCost numeric(28,6) null,hardwareCost numeric(28,6) null,laborCost numeric(28,6) null,depreciationCost numeric(28,6) null,otherCost numeric(28,6) null
) INHERITS (Software);
Wide Tables - Data Modeling: Inheritance

COPY Application (id,uuid,name,description,node_type_id)FROM '/Data/Application.csv'WITH CSV HEADER;
Wide Tables - Data Import

INSERT INTO Application (id,uuid,name,description, type_id,code_name)
SELECT node.node_id, node.node_uuid, node.name, node.description, node.type_id, node_type.code_nameFROM node
JOIN node_type ON node_type.node_type_id = node.node_type_idWHERE node_type.code_name = ‘Application’
Wide Tables - Data Import

SELECT name, uuid , softwareCost , hardwareCost , laborCost , depreciationCost , otherCost , ( softwareCost + hardwareCost + laborCost + depreciationCost + otherCost ) totalOpExFROM Application;
Wide Tables - Query Writing

Wide Tables - Query Writing
SELECT cap.name AS cap_name, bf.name AS bf_name, app.name AS app_name, sw.name AS sw_name, v.name AS version_nameFROM Capability cap JOIN Provides e1 ON e1.end_node_uuid = cap.uuid JOIN Provides e2 ON e2.end_node_uuid = e1.begin_node_uuid JOIN ConsistsOf e3 ON e3.begin_node_uuid = e2.begin_node_uuid JOIN Deploys e4 ON e4.begin_node_uuid = e3.end_node_uuid JOIN BusinessFunction bf ON bf.uuid = e1.begin_node_uuid JOIN Application app ON app.uuid = e2.begin_node_uuid JOIN SoftwareTitle sw ON sw.uuid = e3.end_node_uuid JOIN SoftwareVersion v ON v.uuid = e4.end_node_uuid

Wide Tables - Tools
It is a relational world. Our customer needed a good data warehouse for 3rd party integrations as well. The graph ecosystem is advancing dramatically, but is still smaller than the RDBMS ecosystem.

Bringing home the appliance industry.
Performance Summary

Performance Summary
● Titan handily outperformed other Graph DBs
● “Tall Tables” were a mess, especially as more properties were needed
● “Wide Tables” handily outperformed other options
Application Properties
Four Hop Path

Why?
● These queries were not very “graphy”○ Known # of hops○ Small # of joins (4)
○ Predictable Query Plan● Even for straightforward queries, postgresql has one
decade more engineering work built-in● Follow on work not completed at time of this
presentation finds different results for “graphier” queries

But Performance isn’t everything
Subjective Conclusion from Client
Developer productivity and intuition in the graph query languages is significantly higher than SQL for most queries
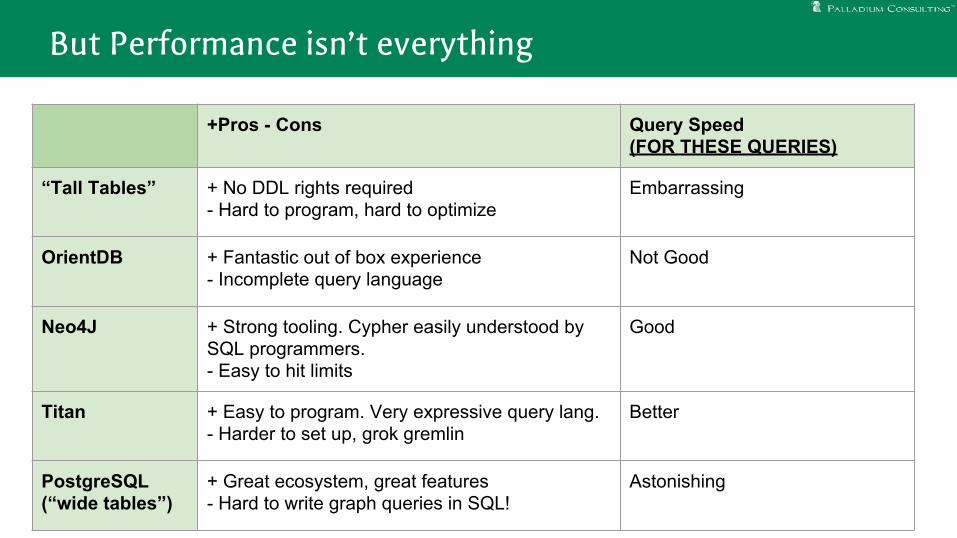
But Performance isn’t everything
+Pros - Cons Query Speed (FOR THESE QUERIES)
“Tall Tables” + No DDL rights required- Hard to program, hard to optimize
Embarrassing
OrientDB + Fantastic out of box experience- Incomplete query language
Not Good
Neo4J + Strong tooling. Cypher easily understood by SQL programmers.- Easy to hit limits
Good
Titan + Easy to program. Very expressive query lang.- Harder to set up, grok gremlin
Better
PostgreSQL (“wide tables”)
+ Great ecosystem, great features- Hard to write graph queries in SQL!
Astonishing

Bringing home the appliance industry.
Deeper Dive on Implementation:Why are some faster than others?

Bringing home the appliance industry.
“Tall Tables”
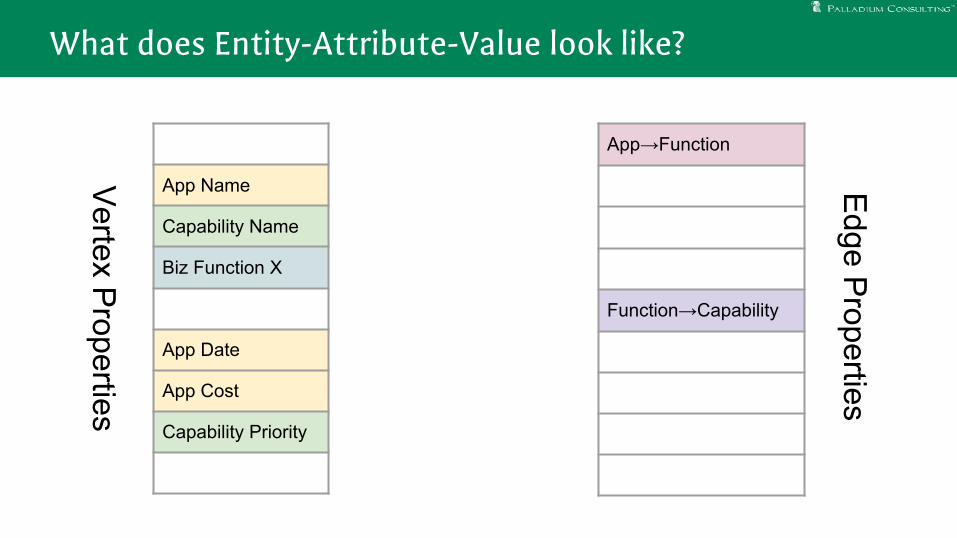
What does Entity-Attribute-Value look like?
App Name
Capability Name
Biz Function X
App Date
App Cost
Capability Priority
App→Function
Function→Capability
Vertex P
roperties
Edge P
roperties

What does EVA look like?
App Name
Capability Name
Biz Function X
App Date
App Cost
Capability Priority
App→Function
Function→Capability
Vertex P
roperties
Edge P
roperties
1
23
4
56
7
8

You can always add indexes, right?
App Name
Capability Name
Biz Function X
App Date
App Cost
Capability Priority
App→Function
Function→Capability
Vertex P
roperties
Edge P
roperties

Yeah, so you can add indexes
App Name
Capability Name
Biz Function X
App Date
App Cost
Capability Priority
App→Function
Function→Capability
12
7
3
4
5
6
8
9
10
11
12
13
14
15

Conclusions
● In a lot of ways like a triple store (Keep adding indexes until the indexes look like the representation you should have used in the first place…)
● Lots of hops
● You can get away with it when your database is small ● Degrades suddenly as I/O shifts from memory to disk

Bringing home the appliance industry.
OrientDB
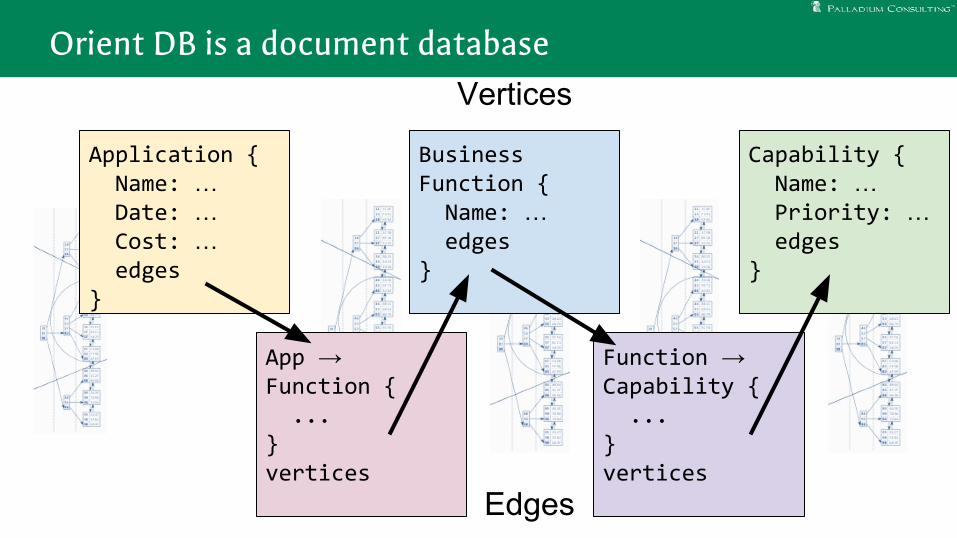
Orient DB is a document database
Application { Name: … Date: … Cost: … edges}
Capability { Name: … Priority: … edges}
Business Function { Name: … edges}
App → Function { ...}vertices
Function → Capability { ...}vertices
Vertices
Edges

Performance Conclusions
● All-or-nothing document I/O● Each vertex type is held in a different “cluster”
● Edges are documents → twice the I/O
● Less mature engineering● Reminder: not talking about scale today

Bringing home the appliance industry.
Neo4J


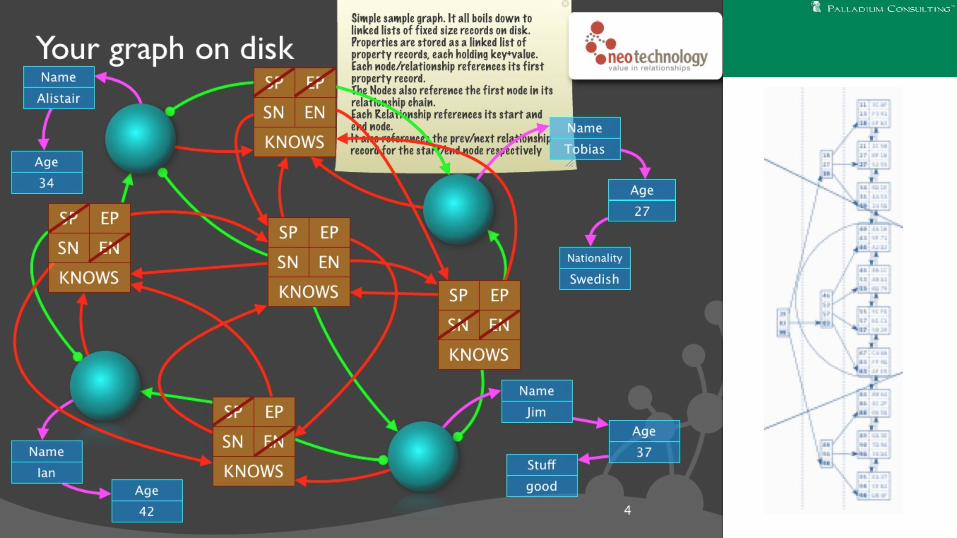
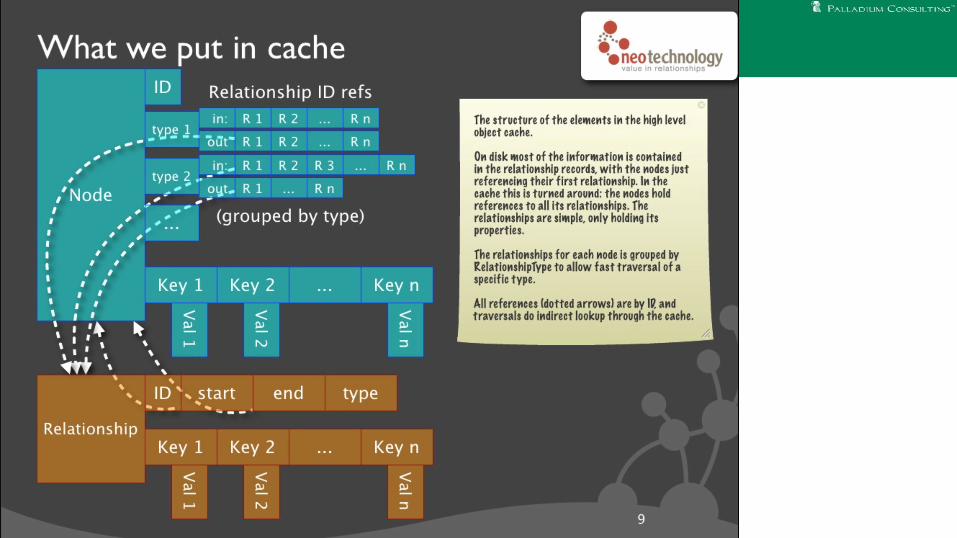

Performance Conclusions
● More complex on-disk structure (lists)● Reprojected in-memory● Tons of work done on JVM-related issues
● Pretty good performance
● Reminder: not talking about scale today

Bringing home the appliance industry.
Titan

Each Vertex is a BigTable Row
Pros: Has the virtue of simplicity, and takes advantage of massive engineering work put into a backend like CassandraCons: Can involve additional latency

TITAN
And Big Tables are Distributed

Compare a Table Representation
ID Name
1 Spider Man Lunchbox
2 Iron Man Toothbrush
3 Superman Pillowcase
4 Ziploc Sandwich Bags
5 Water Balloons
ID Name
1 Marvel
2 DC Comics
PRODUCT_ID FRANCHINSE_ID
1 1
2 1
3 2
PRODUCT FRANCHISEPRODUCT_IN_FRANCHISEID_1 ID_2
1 2
FRANCHISE_SIMILAR
ID Name
1 A
2 B
3 C
CUSTOMERCUSTOMER_ID PRODUCT_ID
1 1
2 5
3 4
CUSTOMER_BOUGHT
PRODUCT_ID AGES_ID
1 1
2 1
RECOMMENDED
ID MIN MAX
1 3 8
AGES

… So Joins Require Lots of Seeks or Loops
ID Name
1 Spider Man Lunchbox
2 Iron Man Toothbrush
3 Superman Pillowcase
4 Ziploc Sandwich Bags
5 Water Balloons
ID Name
1 Marvel
2 DC Comics
PRODUCT_ID FRANCHINSE_ID
1 1
2 1
3 2
PRODUCT FRANCHISEPRODUCT_IN_FRANCHISEID_1 ID_2
1 2
FRANCHISE_SIMILAR
ID Name
1 A
2 B
3 C
CUSTOMERCUSTOMER_ID PRODUCT_ID
1 1
2 5
3 4
CUSTOMER_BOUGHT
PRODUCT_ID AGES_ID
1 1
2 1
RECOMMENDED
ID MIN MAX
1 3 8
AGES
1 2 3 4567

With Local Edge Storage
1 Product Spider Man Lunchbox
Part Of 2 Recommended 3 Bought by 4 Bought By 5
2 Franchise Marvel 1 is Part Of 7 is Part of Similar To 6
3 Ages 3-8 1 is Recommended
6 is Recommended
4 Customer A Bought 1 Friends With 8
5 Customer C Bought 1 Bought 9
6 Franchise DC 2 is Similar 10 is Part Of
7 Product Iron Man Toothbrush
Part Of 1 Recommended 3
10 Product Superman Pillowcase
Part Of 2
Vertex Edges
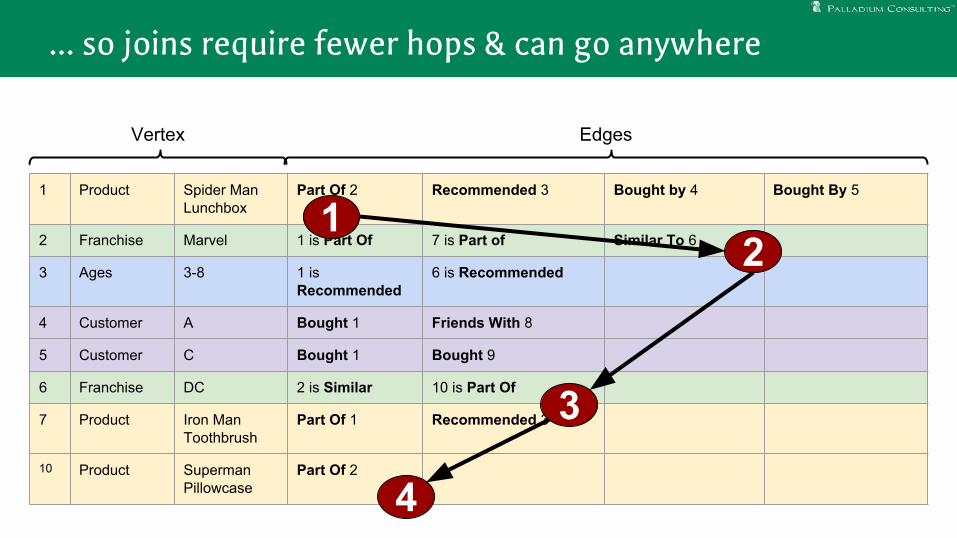
… so joins require fewer hops & can go anywhere
1 Product Spider Man Lunchbox
Part Of 2 Recommended 3 Bought by 4 Bought By 5
2 Franchise Marvel 1 is Part Of 7 is Part of Similar To 6
3 Ages 3-8 1 is Recommended
6 is Recommended
4 Customer A Bought 1 Friends With 8
5 Customer C Bought 1 Bought 9
6 Franchise DC 2 is Similar 10 is Part Of
7 Product Iron Man Toothbrush
Part Of 1 Recommended 3
10 Product Superman Pillowcase
Part Of 2
Vertex Edges
12
3
4
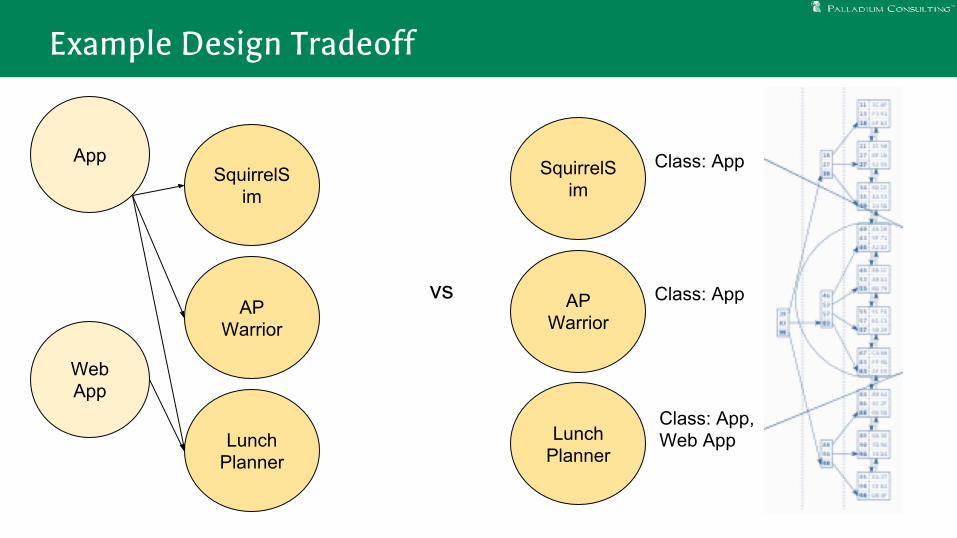
Example Design Tradeoff
AppSquirrelS
im
AP Warrior
Lunch Planner
vs
Web App
SquirrelSim
AP Warrior
Lunch Planner
Class: App
Class: App
Class: App, Web App

Conclusions
● Simpler “index-free adjacency” (and actual constant time)● Takes advantage of massive engineering in backends, e.g. Cassandra
● Also allows selective I/O● Extra features for high degree vertices or very very large graphs
● Fast

Bringing home the appliance industry.
Relational Reporting Database
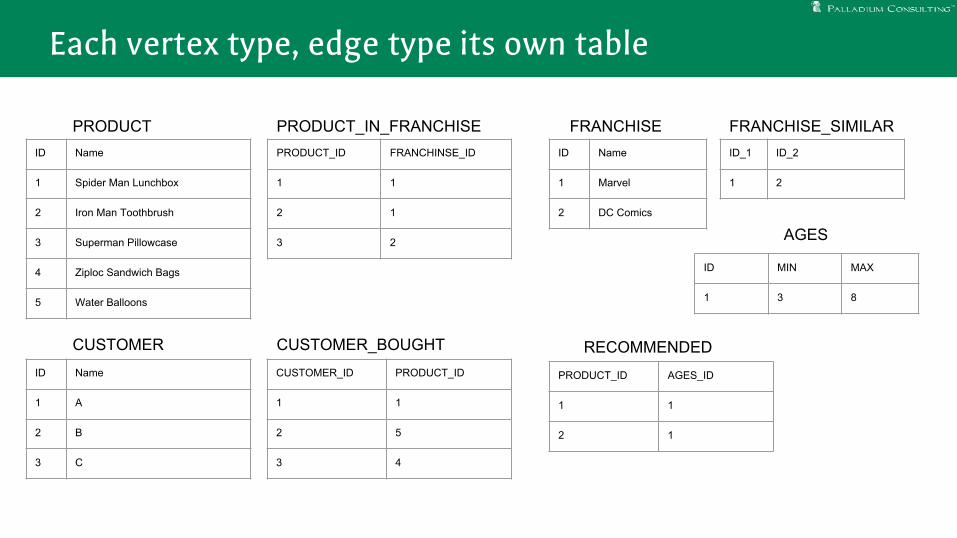
Each vertex type, edge type its own table
ID Name
1 Spider Man Lunchbox
2 Iron Man Toothbrush
3 Superman Pillowcase
4 Ziploc Sandwich Bags
5 Water Balloons
ID Name
1 Marvel
2 DC Comics
PRODUCT_ID FRANCHINSE_ID
1 1
2 1
3 2
PRODUCT FRANCHISEPRODUCT_IN_FRANCHISEID_1 ID_2
1 2
FRANCHISE_SIMILAR
ID Name
1 A
2 B
3 C
CUSTOMERCUSTOMER_ID PRODUCT_ID
1 1
2 5
3 4
CUSTOMER_BOUGHT
PRODUCT_ID AGES_ID
1 1
2 1
RECOMMENDED
ID MIN MAX
1 3 8
AGES

● PostgreSQL has amazing engineering: you won’t beat it if your query plan looks like a relational query plan
● The inheritance implementation is 1st class
● It’s all fun and games until you can’t use hash joins● Variable length paths are hard to write and worse to execute
● Great ecosystem support
Conclusions

Bringing home the appliance industry.
So What?
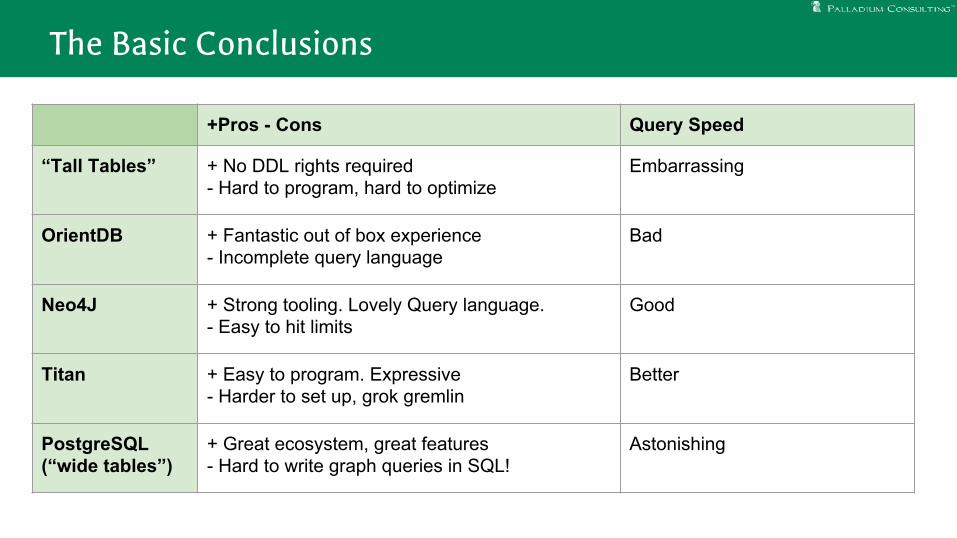
The Basic Conclusions
+Pros - Cons Query Speed
“Tall Tables” + No DDL rights required- Hard to program, hard to optimize
Embarrassing
OrientDB + Fantastic out of box experience- Incomplete query language
Bad
Neo4J + Strong tooling. Lovely Query language.- Easy to hit limits
Good
Titan + Easy to program. Expressive- Harder to set up, grok gremlin
Better
PostgreSQL (“wide tables”)
+ Great ecosystem, great features- Hard to write graph queries in SQL!
Astonishing
Browser Server Databases
A Hybrid Recommendation

● Graph DBs keep getting faster● Tinkerpop 3.0 is a big change
● Dependency, variable length queries play to a graph DBs strength● Fixed path joins play to RDBMS strength● Know which your data supports: our client’s graph was anemic● A graph data warehouse may be easier to understand: data scientists
● Push work into your indices
● Benchmark your real use cases, understand the underlying engines’ strengths
● Consider ecosystem support, future data loads
Our thoughts