Embed Size (px)
Citation preview

Green Governors: A
Framework for Continuously
Adaptive DVFSVasileios Spiliopoulos, Stefanos KaxirasVasileios Spiliopoulos, Stefanos KaxirasUppsala University, SwedenUppsala University, Sweden

2
Introduction
Optimize power efficiency• Reduce power without harming performance• Goal: minimize power efficiency metrics
— Energy delay product (EDP), energy delay square product (ED2P) etc.Exploit memory slack
• Applications with many LLC misses memory becomes bottleneck• Performance insensitive to processor frequency
— Scaling frequency down high energy benefit at low performance cost
Develop analytical models to predict impact of frequency scaling
• No empirical parameters• No training period• Suitable for run-time use

3
Modeling DVFS Theoretical (work in simulator)
• Extend previous Interval-based models (Karkhanis and Smith, ISCA 2004, Eyerman et. al , ACM TOCS, 2010) Two models for runtime DVFS management
• Miss-based & Stall-based models differ in accuracy and ease of implementation
• Estimate energy benefits – performance loss• G. Keramidas, V. Spiliopoulos, and S. Kaxiras. Interval-Based Models for Run-
Time DVFS Orchestration in SuperScalar Processors. Proc. of Int. Conference on Computing Frontiers, 2010
Implementation in real hardware• Apply model for power-performance adaptation in real processors
— Case study: Intel Core i7— Approximate models based on available performance monitoring hardware
• Estimate power characteristics of real hardware• V. Spiliopoulos, S. Kaxiras, G. Keramidas "Green governors: A framework for
Continuously Adaptive DVFS" International Green Computing Conference (IGCC'11).
44
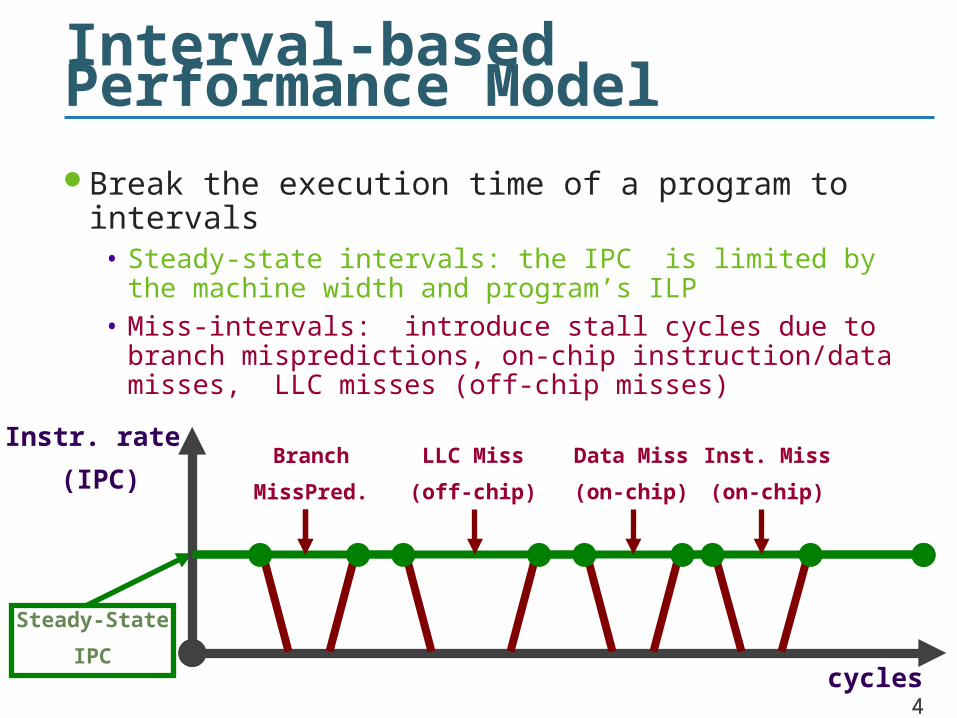
Interval-based Performance Model
Break the execution time of a program to intervals• Steady-state intervals: the IPC is limited by the machine
width and program’s ILP• Miss-intervals: introduce stall cycles due to branch
mispredictions, on-chip instruction/data misses, LLC misses (off-chip misses)
Instr. rate
(IPC)
cycles
Steady-State
IPC
Branch
MissPred.
Inst. Miss
(on-chip)
Data Miss
(on-chip)
LLC Miss
(off-chip)

55
Interval-based DVFS Model (step 1) Miss Intervals and Frequency scaling (time measured in cycles)
• Branch-MissPredictions Miss Intervals — same penalty (in cycles) in all frequencies
• On-chip data/instruction Miss-Intervals — same penalty (in cycles) in all frequencies
• LLC (off-chip) Miss intervals — for DVFS only account for this interval
Instr. rate
(IPC)
cycles
Steady-State
IPC
Branch
MissPred.
Instr Miss
(on-chip)
Data Miss
(on-chip)
LLC Miss
(off-chip)

66
Interval-based DVFS Model (step 2)
LLC Miss Interval and Frequency scaling• Model core frequency scaling as change in memory
latency in cycles• Example: memory access time = 100ns f = 1GHz T = 1ns mem_lat = 100 cycles f = 500MHz T = 2ns mem_lat = 50 cycles

77
RoB fill
Interval-based DVFS Model (step 2)
LLC Miss Interval and Frequency scaling• Model core frequency scaling as change in memory
latency in cycles
Instr. rate
(IPC)
cycles
Steady-State
IPC
LLC Miss
(off-chip)LLC Miss
IQ Drain
Full-stall
Ramp-up
Mem. latency

88
Frequency scaling == Change in memory latency
Frequency: memory latency, full stall area
— Other areas (ROB–fill, IQ-drain and ramp-up) remain intact
RoB fill
Instr. rate
(IPC)
cycles
Steady-State
IPC
LLC Miss
IQ Drain
Full-stall
Ramp-up
Mem. latency
Ramp-up
Mem. latency

99
DVFS target: Eliminate the slack
Memory latency up to ROB fill time• No more available slack due to off chip misses• Further reduction performance penalty
RoB fill
Instr. rate
(IPC)
cycles
Steady-State
IPC
LLC Miss
IQ Drain
Full-stall
Ramp-upRamp-upRamp-up
Mem. latency
RoB fill
Instr. rate
(IPC)
cycles
Steady-State
IPC
LLC Miss
Mem. latency

1010
Elastic and Non-Elastic Areas
Target: Eliminate “slack” by reducing Memory Latency but:
• ROB fill area: DOES NOT shrink inelastic area• Full-stall, IQ drain and Ramp-up: DO shrink elastic areas
RoB fill
Instr. rate
(IPC)
cycles
Steady-State
IPC
LLC Miss
IQ Drain
Full-stall
Ramp-up
Mem. latency

1111
Two Simple Interval-Based ModelsStall-based Model
• Fed by in-core information• Assumes all stalls scale with frequency
— Disregards ROB fill area• Can be used in real hardware
Miss-based Model• Fed by information from the memory system • Accounts for both elastic-inelastic areas• Required information not available in current hardware

12
Stall-based Model
Assume (all) stalls scale with f• Not true due to RoB Fill• Exec cycles at f/k: cinit – stalls + (stalls/k)
1212
RoB fill
Instr. rate
(IPC)
cycles
Steady-State
IPC
LLC Miss
Mem. latency
stalls

13
Miss-based Model
Assumes whole miss interval scales with f• Exec cycles at f/k:
cinit – misses*mem_lat + (misses*mem_lat/k)
1313
RoB fill
Instr. rate
(IPC)
cycles
Steady-State
IPC
LLC Miss
Mem. latency

14
Miss-based Model, more …
But important implication for overlapping misses!Stalls of misses under a miss do not scale because
of the inelastic Rob fill
14
d
Instr. rate
(IPC)
cycles
Steady-State
IPC
Miss1Miss2
Miss based model predicts execution cycles based on the number of clusters of misses
Mem. latencyd
Mem. latency
dMem. latency
Mem. latency

15
Real Hardware ApproximationsCannot apply miss-based model
• No cluster of misses counter availableCannot apply stall-based model as it is
• No stalls due to LLC misses counter availableApproximate stall-based model
• Approximate LLC stalls with the minimum between all pipeline stalls and worst case stalls due to LLC misses (LLC misses * mem_lat)
Good accuracy• Predict execution time going from fmin to fmax and vice versa
• Less than 5% avg error

Measuring power
16

Power prediction
Previous researchers correlated total power (P = a C f V2 + Pstatic) with performance counter events
We correlate effective capacitance (P = a C f V2 + Pstatic) with performance counter events
• Run a set of benchmarks• Compute effective C of benchmark i as• Estimate Ci as • Minimize
17
2,i i esti specs
C C
1
,1
jk k
i est jk i
param eventC param
cycles
2i static
i
P PC
f V

Power prediction
Only need to train the model for a single frequency:• Prediction in other frequencies:
Events monitored• Uops executed• L2 misses• L2 accesses• Resource stalls• FP operations• Branch mispredictions
18
2,i i est staticP f C V P

19
Implementing Linux Frequency GovernorsLinux kernel module that selects frequencyWindow-based approach
• Run application for a time window • Estimate performance (using stall-based model) and power in any
frequency• Scale frequency based on policy of interest
Implement different policies• Optimize EDP/ED2P with/without performance constraints
Single & multi-process managementExperimental framework
• Intel Core i7• SPEC2006 benchmark suite
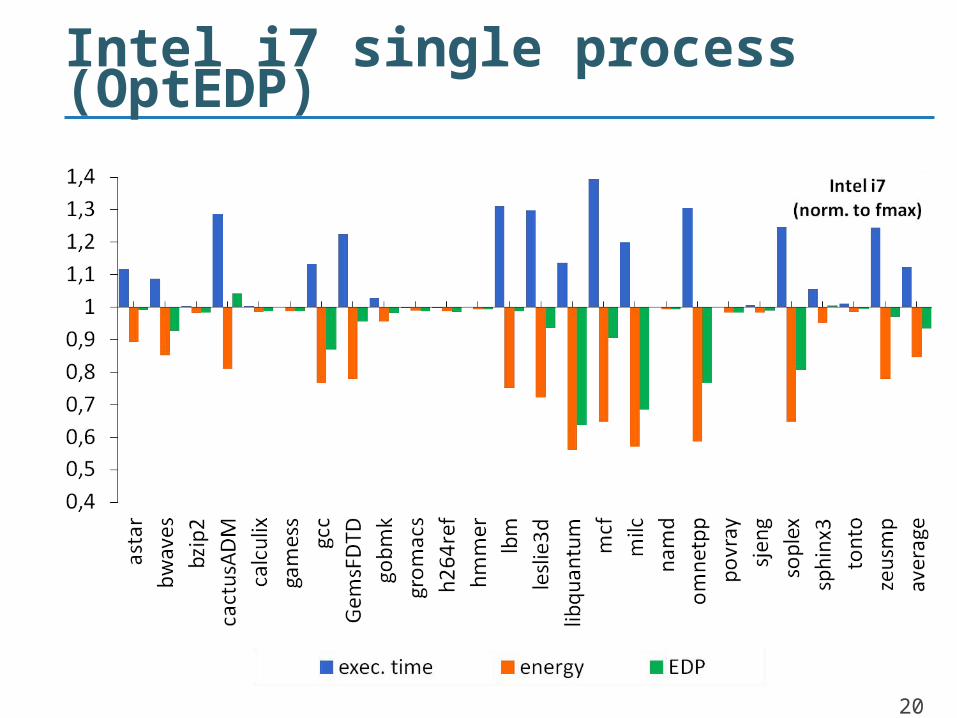
Intel i7 single process (OptEDP)
20

Intel i7 single process (OptEDPlimit)
21

Intel i7 multi-process (OptEDP)
22

23
Conclusions
DVFS modeling in simulatorsImplement the model in real processors
• Apply, explain and validate our model for SPEC2006Contribution: optimize power efficiency using
linux frequency governorsOther uses of the models
• PowerSleuth: combine models with phase detection to characterize the power behavior of applications
Future work• Multi-threading applications

2424
Thank You!
Any questions?





























