Embed Size (px)
Citation preview

GUSTAVO ALONSO SYSTEMS GROUP
DEPT. OF COMPUTER SCIENCE ETH ZURICH
Crazy little thing called hardware
HTDC 2014

Systems Group = www.systems.ethz.ch Enterprise Computing Center = www.ecc.ethz.ch

Hardware rules
Multicore, Many core Transactional Memory SIMD, AVX, vectorization SSDs, persistent memory Infiniband, RDMA GPUs, FPGAs (hardware acceleration) Intelligent storage engines, main memory Database appliances
Reacting to changes we do not control

Do we care?
Software
producer of performance
instead of
consumer of performance
Mark D. Hill (U. of Wisconsin)

What does it mean?
Many good ideas from decades ago are no longer good ideas (as conceived):
• General purpose solutions
• Threading, thread based parallelism
• Locking, shared state
• Centralized synchronization
• Concurrency control
• STM (sorry …)

The take away message
Ignoring hardware trends is irresponsible
• Software evolves more slowly than hardware
Focus on the end (solve a problem), not on the means (the technique used)
How to succeed in research:
• Make hardware your friend
• Influence hardware evolution

Outline
1. Hardware as a problem for system design
a) A jungle of improvements
b) An example (database joins)
2. The case for custom systems
a) Economies of scale
b) An example (Crescando)
3. Ideas and directions

1. Hardware as a problem for system design
a) A jungle of improvements
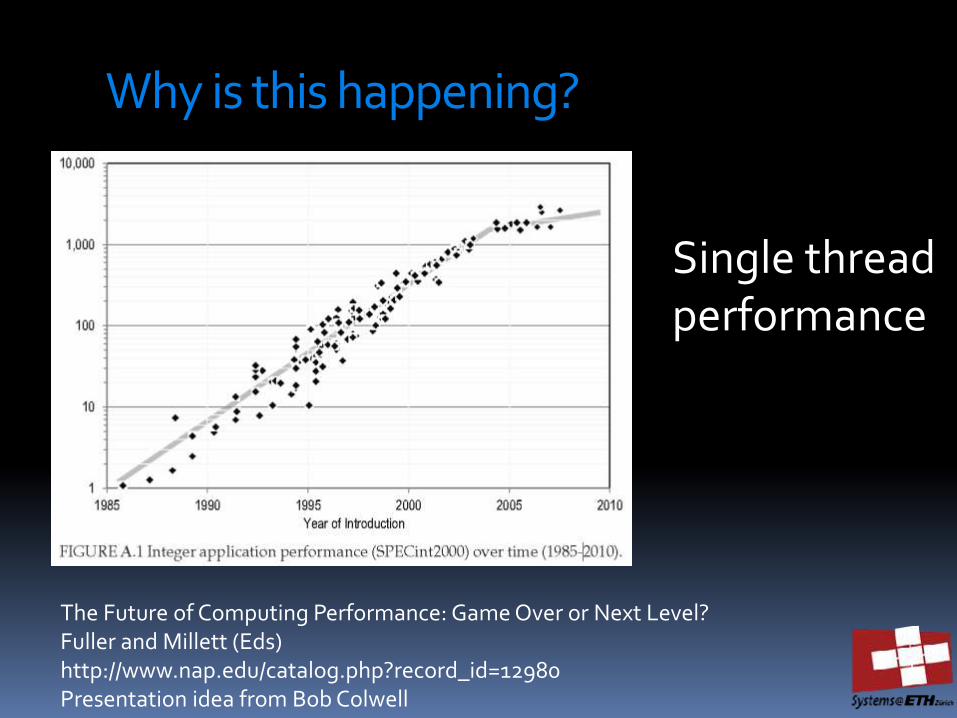
Why is this happening?
Single thread performance
The Future of Computing Performance: Game Over or Next Level? Fuller and Millett (Eds) http://www.nap.edu/catalog.php?record_id=12980 Presentation idea from Bob Colwell
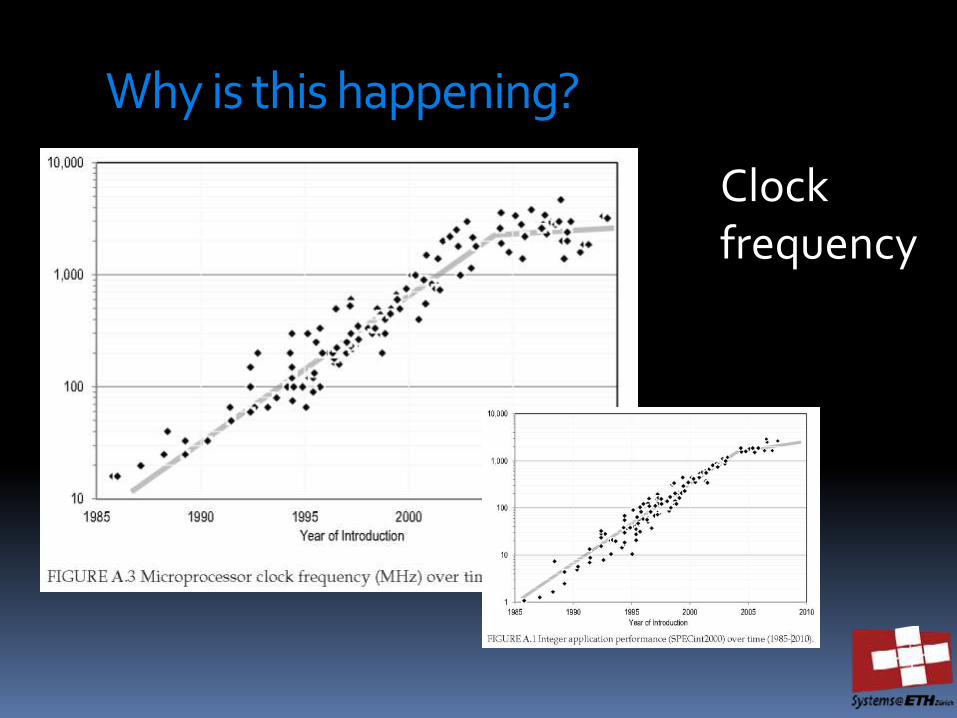
Why is this happening?
Clock frequency
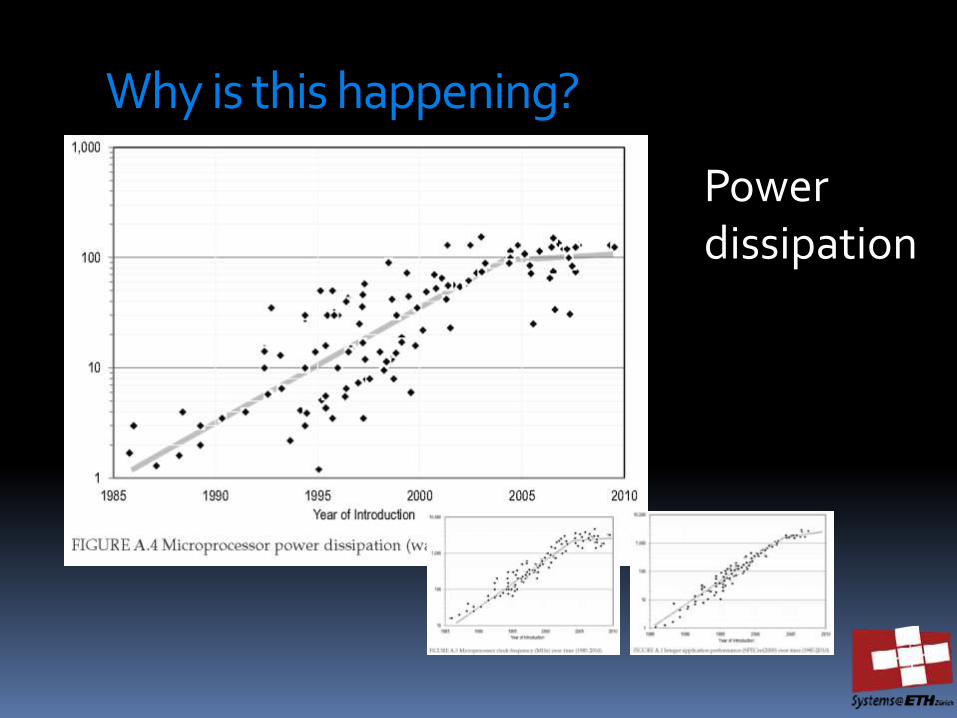
Why is this happening?
Power dissipation
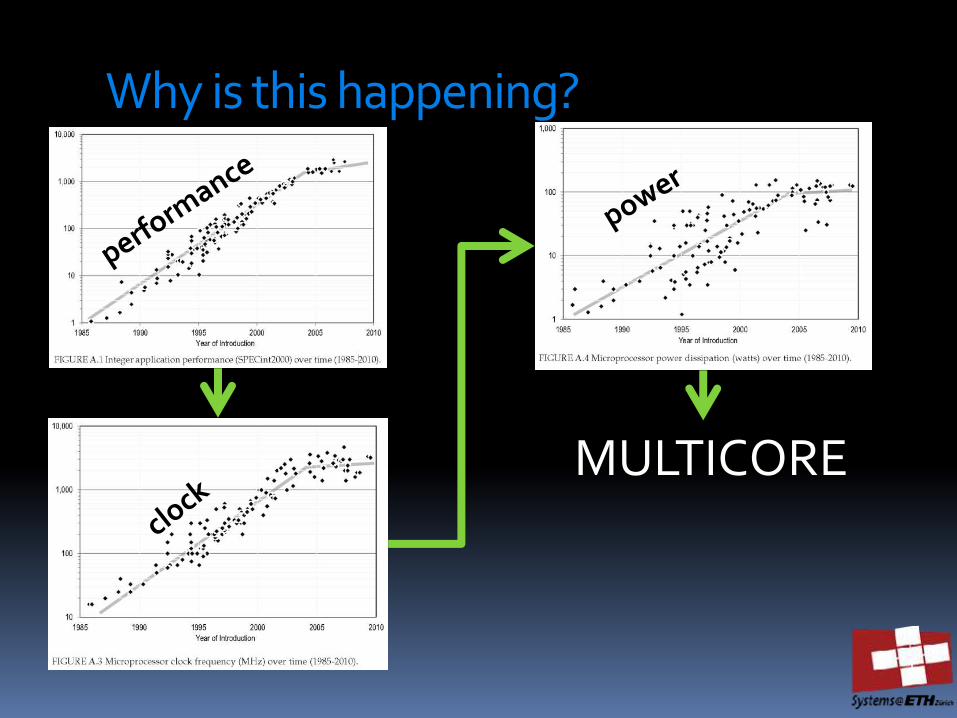
Why is this happening?
MULTICORE

Multicore is great: avoid distribution
• Analysis of MapReduce workloads: – Microsoft: median job size < 14 GB
– Yahoo: median job size < 12.5 GB
– Facebook: 90% of jobs less than 100 GB
• Fit in main memory
• One server more efficient than a cluster
• Adding memory to a big server better than using a cluster
Nobody ever got fired for using Hadoop on a Cluster A. Rowstron, D. Narayanan, A. Donnely, G. O’Shea, A. Douglas
HotCDP 2012, Bern, Switzerland
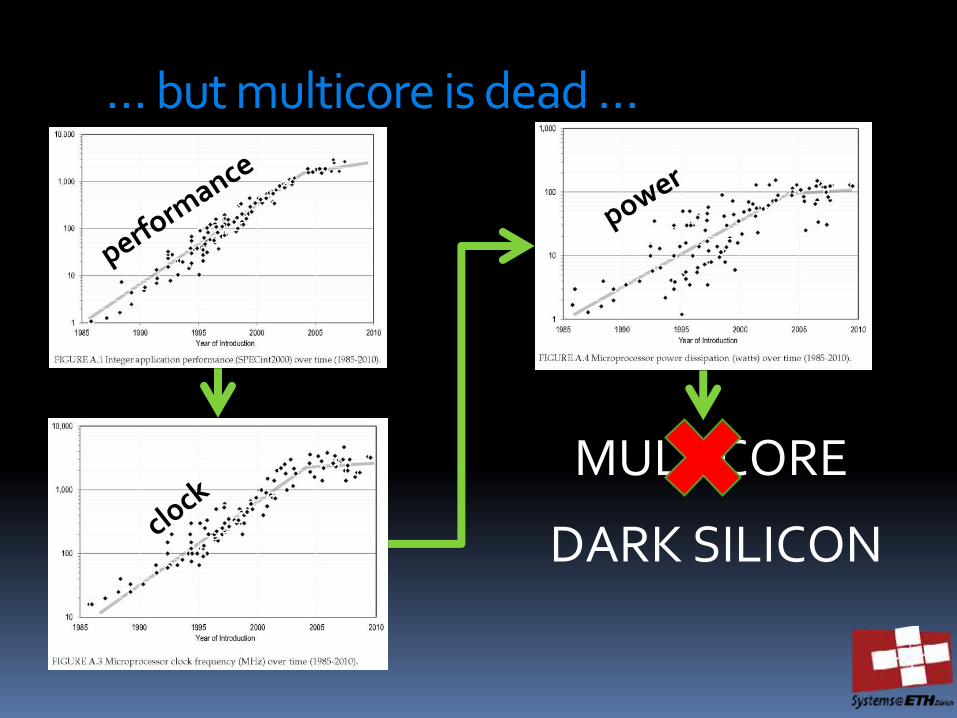
… but multicore is dead …
MULTICORE
DARK SILICON

Dark Silicon = heterogeneity
Symmetric
Asymmetric
Dynamic (power)
Specialized/dynamic
Probabilistic

Heterogeneity is a mess
Experiment setup • 8GB datastore size • SLA latency requirement 8s • 4 different machines
Example: deployment on multicores
Min Cores Partition Size [GB] RT [s]
Intel Nehalem 2 4 6.54
AMD Barcelona 5 1.6 3.55
AMD Shanghai 3 2.6 4.33
AMD MagnyCours 2 2 7.37
Jana Giceva, Tudor-Ioan Salomie, Adrian Schüpbach,
Gustavo Alonso, Timothy Roscoe: COD: Database /
Operating System Co-Design. CIDR 2013
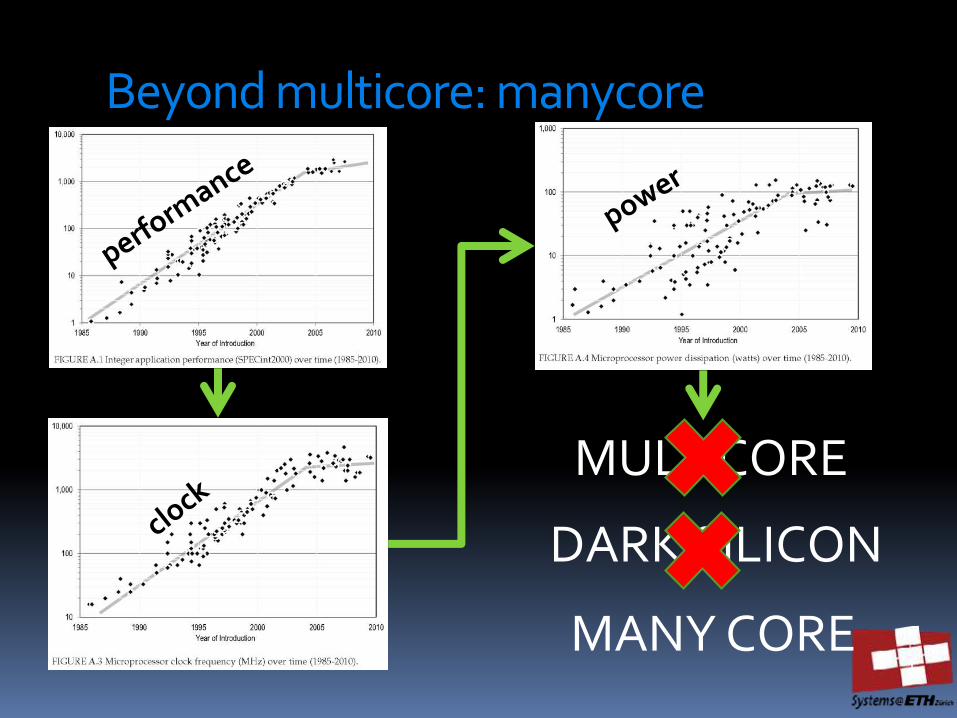
Beyond multicore: manycore
MULTICORE
DARK SILICON
MANY CORE

Manycore (example)
“normal” CPU
PC
Ie

Extreme manycore: Intelligent storage
Louis Woods, Zsolt István, Gustavo Alonso: Hybrid
FPGA-accelerated SQL query processing. FPL
2013
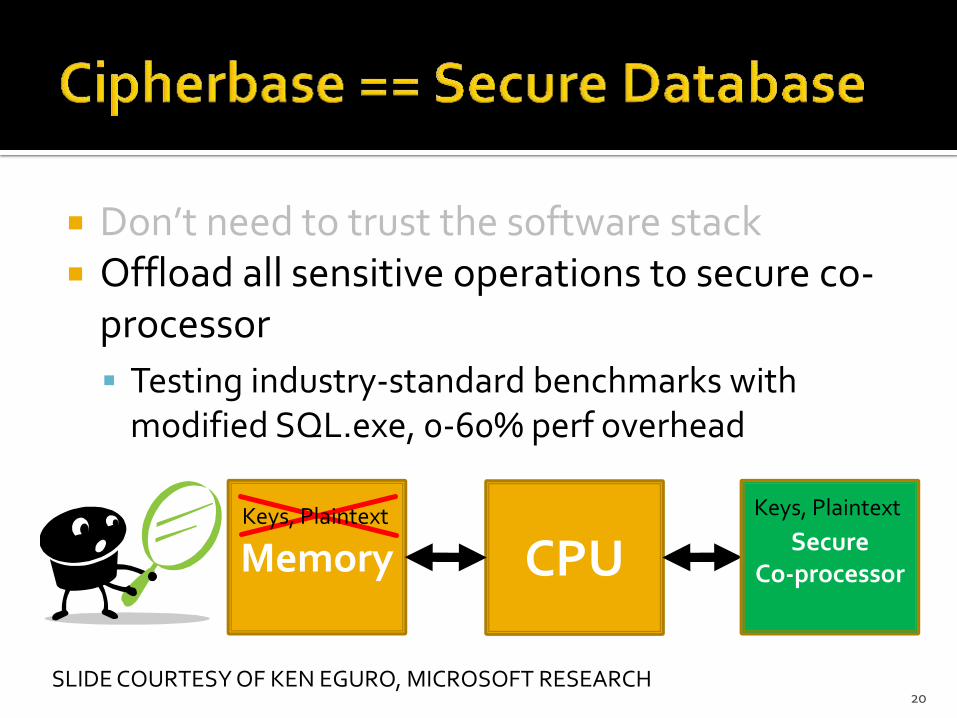
Don’t need to trust the software stack Offload all sensitive operations to secure co-
processor
Testing industry-standard benchmarks with modified SQL.exe, 0-60% perf overhead
20
CPU Memory Secure
Co-processor
Keys, Plaintext Keys, Plaintext
SLIDE COURTESY OF KEN EGURO, MICROSOFT RESEARCH

The take away message
Ignoring hardware trends at your own peril
• You will be solving the wrong problem
• Your solution will irrelevant very quickly
• Your solution will be making the wrong assumptions
• Hardware might solve the problem that you are trying to solve (may have solved it already)

1. Hardware as a problem for system design
b) An example (database joins)

The joy of joins
"Main-Memory Hash Joins on Multi-Core CPUs: Tuning to the Underlying Hardware" by Cagri
Balkesen, Jens Teubner, Gustavo Alonso, and Tamer Ozsu, ICDE 2013
Cagri Balkesen, Gustavo Alonso, Jens Teubner, M. Tamer Özsu: Multi-Core, Main-Memory Joins: Sort
vs. Hash Revisited. PVLDB 7(1): 85-96 (2013)

Performance in the multicore era 24
Joins are a complex and demanding operation
Lots of work on implementing all kinds of joins
In 2009
– Kim, Sedlar et al. paper (PVLDB 2009)
Radix join on multicore
Sort Merge join on multicore
Claim fastest implementation to date
Key message: when SIMD wide enough, sort merge will be faster than radix join
Hardware conscious

Performance in the multicore era 25
In 2011
– Blanas, Li et al. (SIGMOD 2011)
No partitioning join
(vs. radix join version of Kim paper)
Claim: Hardware is good enough, no need for careful tailoring to the underlying hardware
Hardware oblivious

Performance in the multicore era 26
In 2012
– Albutiu, Kemper et al. (PVLDB 2012)
Sort merge joins
(vs join version of Blanas)
Claim: Sort merge already better and without using SIMD
Hardware confusion

The basic hash join
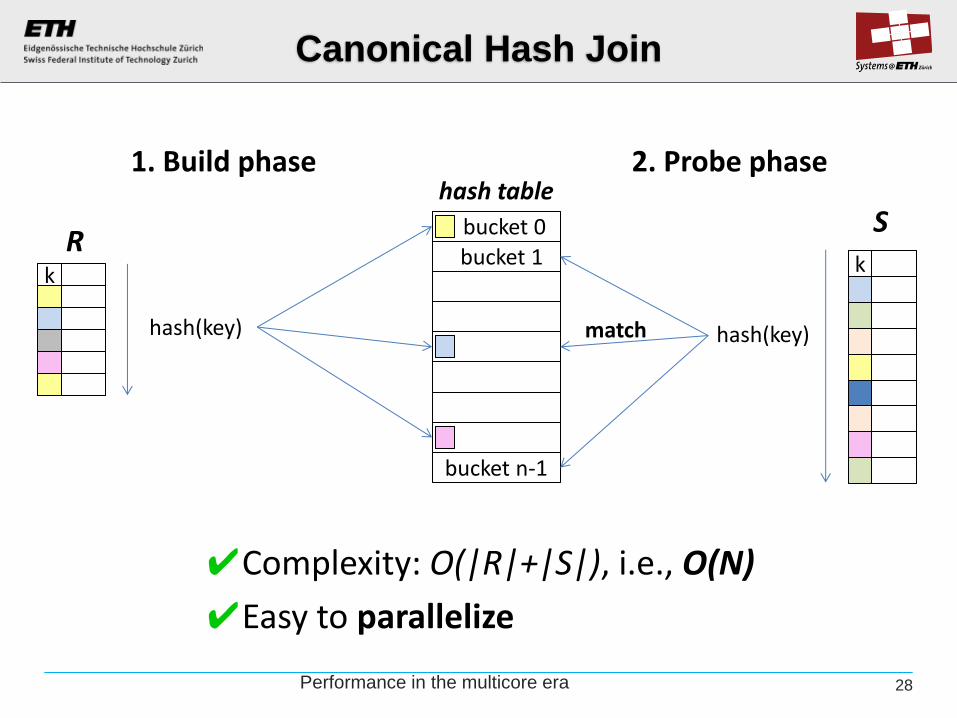
✔Complexity: O(|R|+|S|), i.e., O(N)
✔Easy to parallelize
Canonical Hash Join
k
hash(key)
1. Build phase
bucket 1
bucket n-1
bucket 0
hash table 2. Probe phase
k R
S
hash(key) match
Performance in the multicore era 28

Need for Speed
Hardware-Conscious Hash Joins
No more cache misses during the join
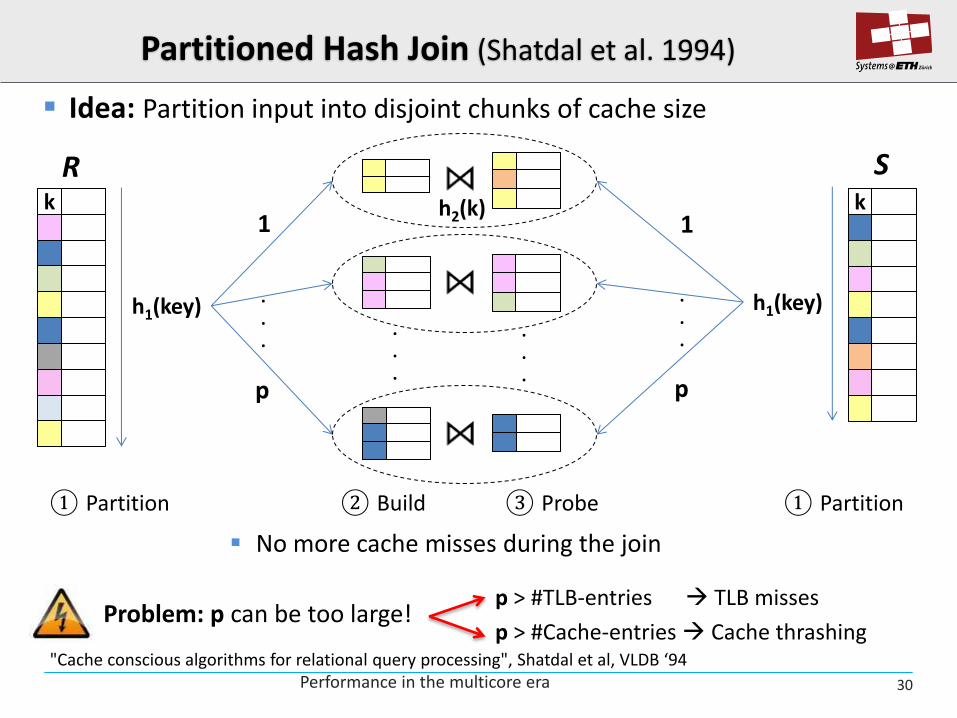
Partitioned Hash Join (Shatdal et al. 1994)
k
R S
h1(key) h1(key) . . .
1
p
1
p
"Cache conscious algorithms for relational query processing", Shatdal et al, VLDB ‘94
k
.
.
.
.
.
.
.
.
.
Idea: Partition input into disjoint chunks of cache size
① Partition ① Partition ② Build ③ Probe
h2(k)
p > #TLB-entries TLB misses
p > #Cache-entries Cache thrashing Problem: p can be too large!
30 Performance in the multicore era
31
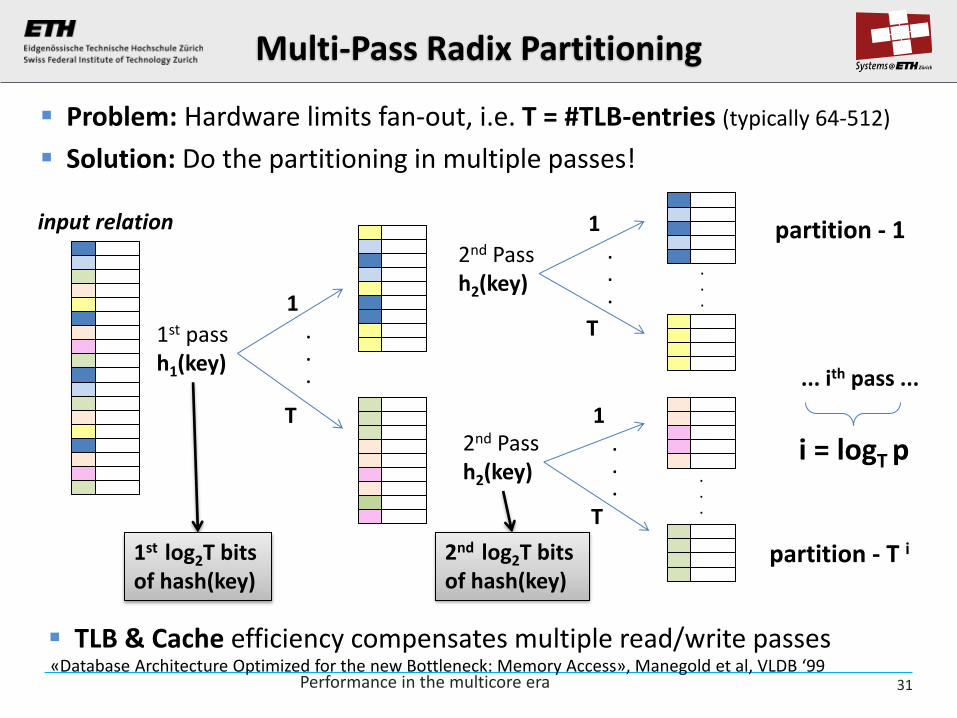
Problem: Hardware limits fan-out, i.e. T = #TLB-entries (typically 64-512)
Solution: Do the partitioning in multiple passes!
Multi-Pass Radix Partitioning
1st pass h1(key)
1
T
.
.
.
2nd Pass h2(key)
1
T
.
.
.
2nd Pass h2(key)
1
T
.
.
.
.
.
.
.
.
.
... ith pass ...
1st log2T bits of hash(key)
2nd log2T bits of hash(key)
partition - 1
partition - T i
TLB & Cache efficiency compensates multiple read/write passes
input relation
i = logT p
«Database Architecture Optimized for the new Bottleneck: Memory Access», Manegold et al, VLDB ‘99 Performance in the multicore era
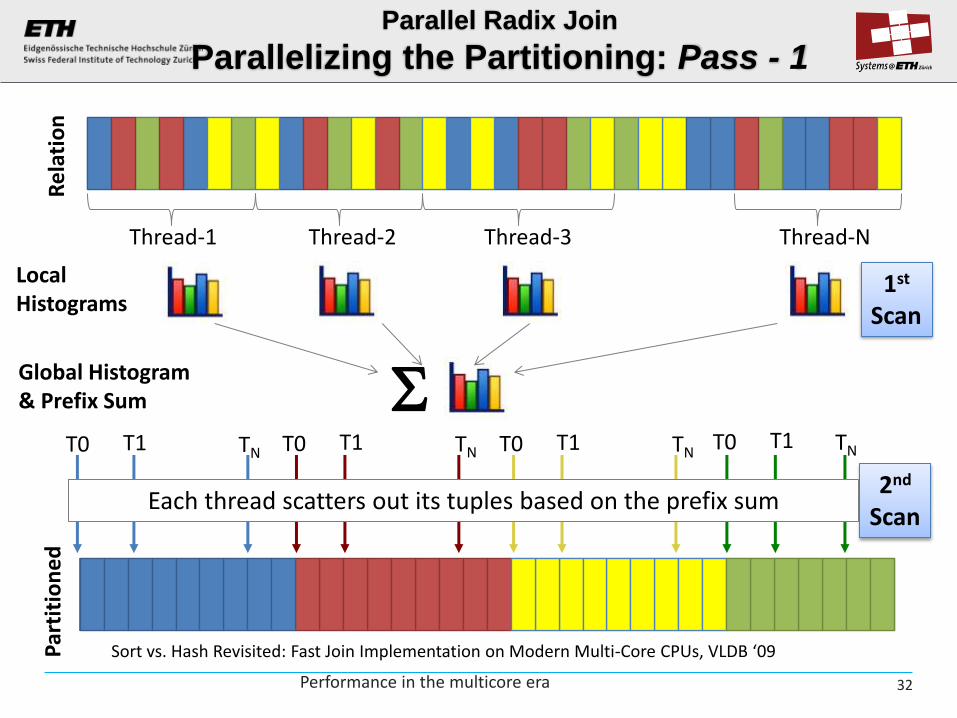
Thread-1 Thread-2 Thread-3 Thread-N
Re
lati
on
Local Histograms
Global Histogram & Prefix Sum
Par
titi
on
ed
1st Scan
2nd Scan
Each thread scatters out its tuples based on the prefix sum
Parallel Radix Join
Parallelizing the Partitioning: Pass - 1
Sort vs. Hash Revisited: Fast Join Implementation on Modern Multi-Core CPUs, VLDB ‘09
32
T0 T1 TN T0 T1 TN T0 T1 TN T0 T1 TN
Performance in the multicore era
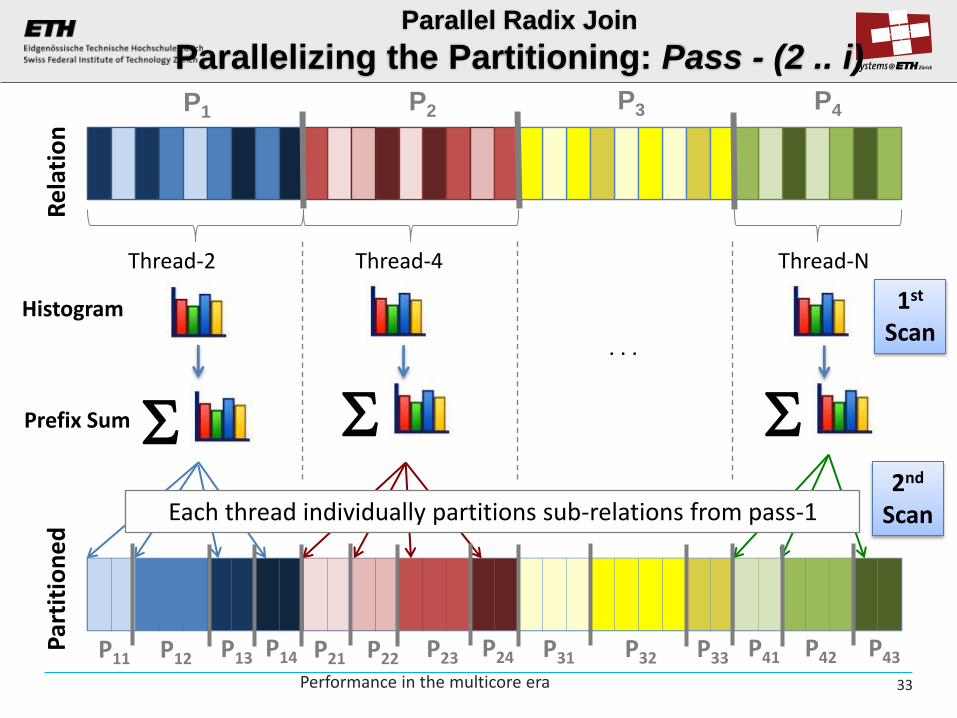
Parallel Radix Join
Parallelizing the Partitioning: Pass - (2 .. i)
Thread-2 Thread-4 Thread-N
Re
lati
on
Histogram
Prefix Sum
Par
titi
on
ed
1st Scan
2nd Scan Each thread individually partitions sub-relations from pass-1
. . .
33
P1 P2 P3 P4
P11 P12 P13 P14 P21 P22 P23 P24 P31 P32 P33 P41 P42 P43 Performance in the multicore era

Trust the force
Hardware-Oblivious Hash Joins
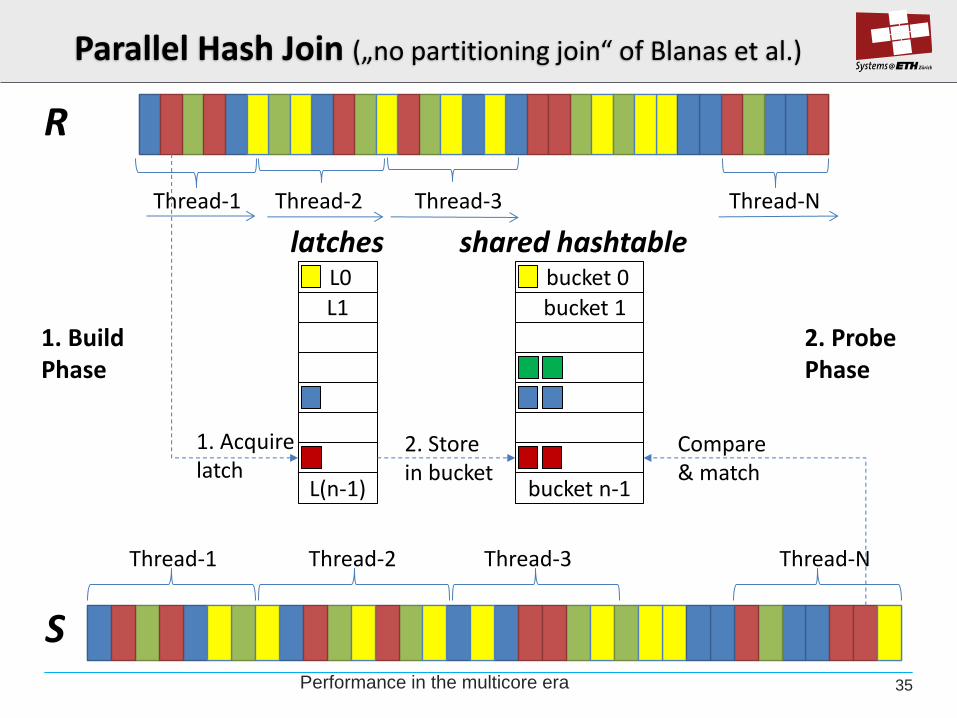
Parallel Hash Join („no partitioning join“ of Blanas et al.)
Thread-1 Thread-2 Thread-3 Thread-N
R
shared hashtable
bucket 1
bucket n-1
bucket 0
latches
L1
L(n-1)
L0
1. Acquire latch
2. Store in bucket
1. Build Phase
S
2. Probe Phase
Thread-1 Thread-2 Thread-3 Thread-N
Compare & match
Performance in the multicore era 35

And the winner is …
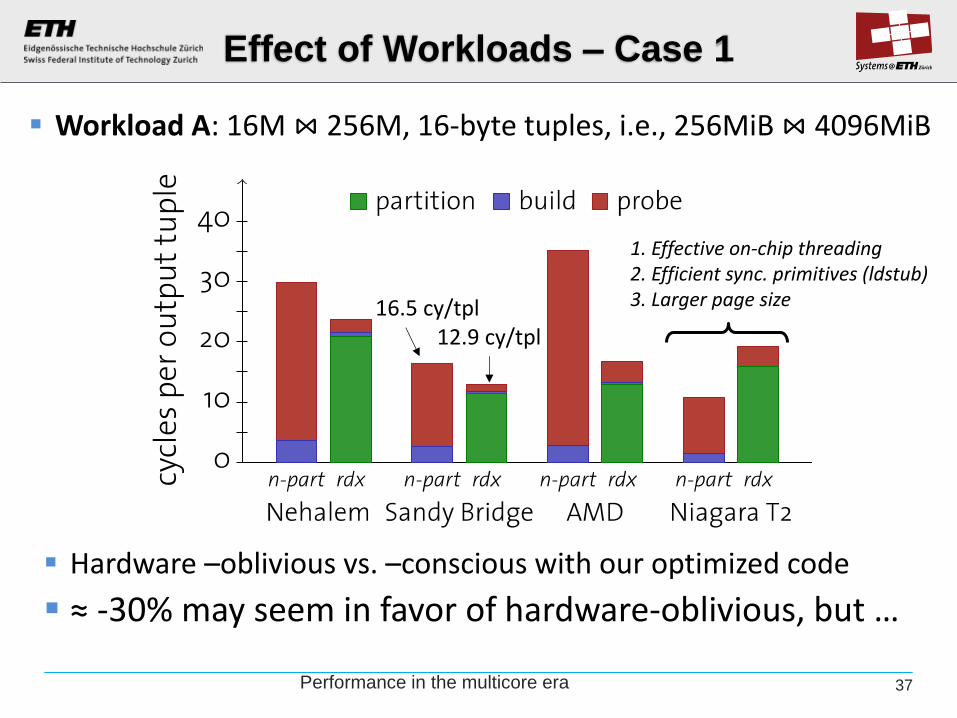
Effect of Workloads – Case 1
Hardware –oblivious vs. –conscious with our optimized code
≈ -30% may seem in favor of hardware-oblivious, but …
Workload A: 16M ⋈ 256M, 16-byte tuples, i.e., 256MiB ⋈ 4096MiB
16.5 cy/tpl 12.9 cy/tpl
1. Effective on-chip threading 2. Efficient sync. primitives (ldstub) 3. Larger page size
Performance in the multicore era 37
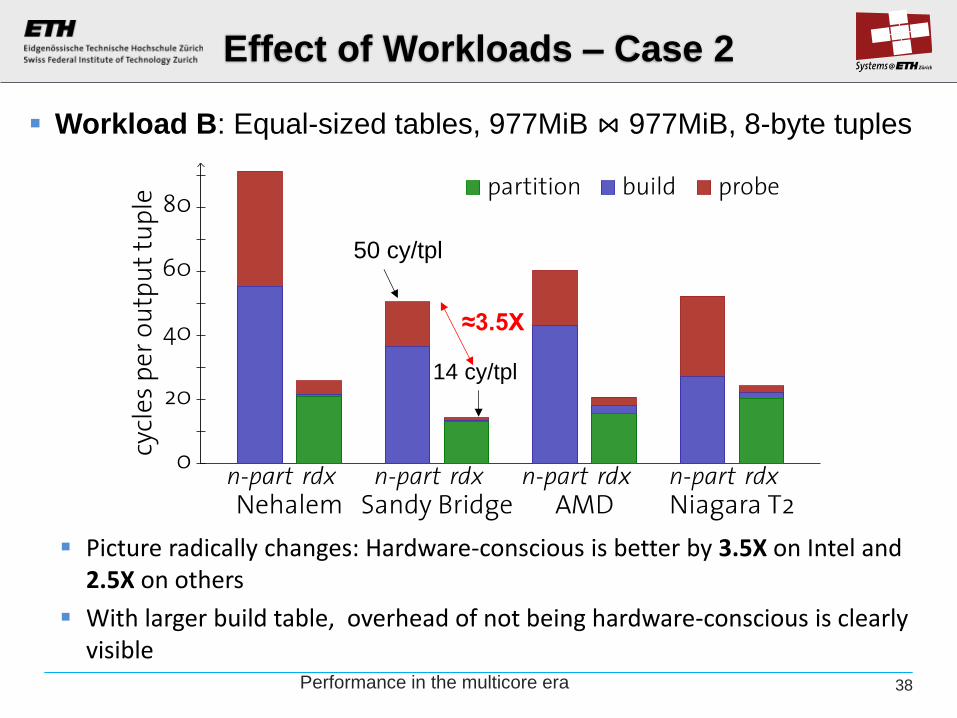
Effect of Workloads – Case 2
Picture radically changes: Hardware-conscious is better by 3.5X on Intel and 2.5X on others
With larger build table, overhead of not being hardware-conscious is clearly visible
Workload B: Equal-sized tables, 977MiB ⋈ 977MiB, 8-byte tuples
50 cy/tpl
14 cy/tpl
≈3.5X
Performance in the multicore era 38
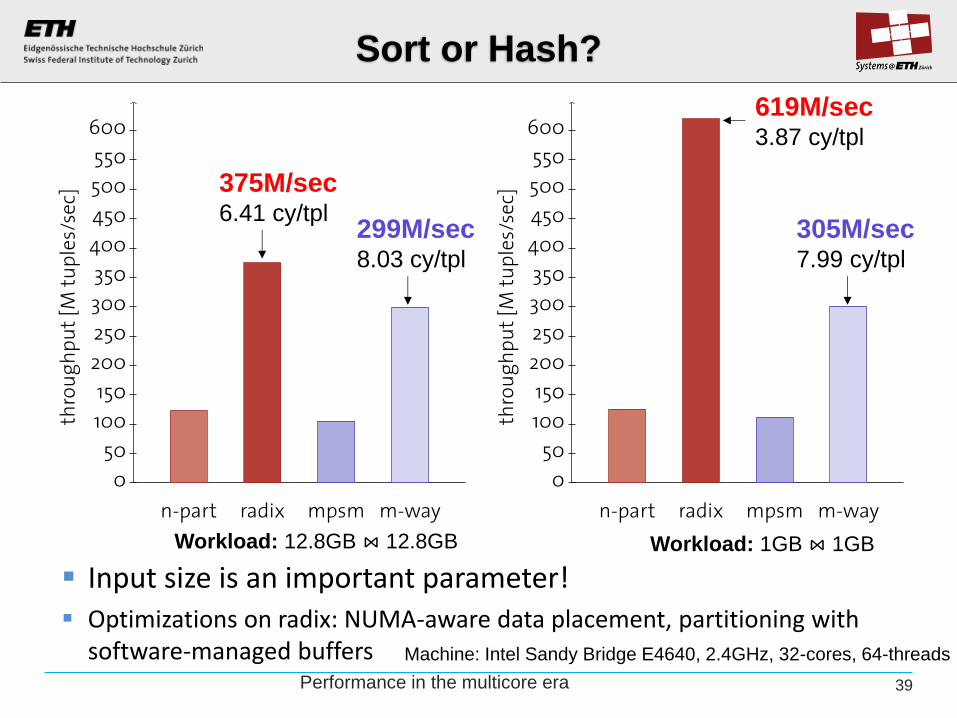
Input size is an important parameter! Optimizations on radix: NUMA-aware data placement, partitioning with
software-managed buffers
Sort or Hash?
375M/sec 6.41 cy/tpl
299M/sec 8.03 cy/tpl
619M/sec 3.87 cy/tpl
305M/sec 7.99 cy/tpl
Workload: 12.8GB ⋈ 12.8GB Workload: 1GB ⋈ 1GB
Machine: Intel Sandy Bridge E4640, 2.4GHz, 32-cores, 64-threads
39 Performance in the multicore era

Game on for academia
• The next several hundred papers …
1. Pick an algorithm
2. Pick an architecture
3. Optimize
4. Publish
5. Go to 1
• Algorithm can be used in parallel for increased throughput

2. The case for custom systems
a) Economies of scale

Game changers
Hardware evolution:
One size does not fit all
Cloud computing
IT industry as service industry
Big X (X=data volume, loads, system costs, requirements, scale)
Demand for customized solutions

• Intelligent storage manager • Massive caching • RAC based architecture • Fast network interconnect
ORACLE EXADATA
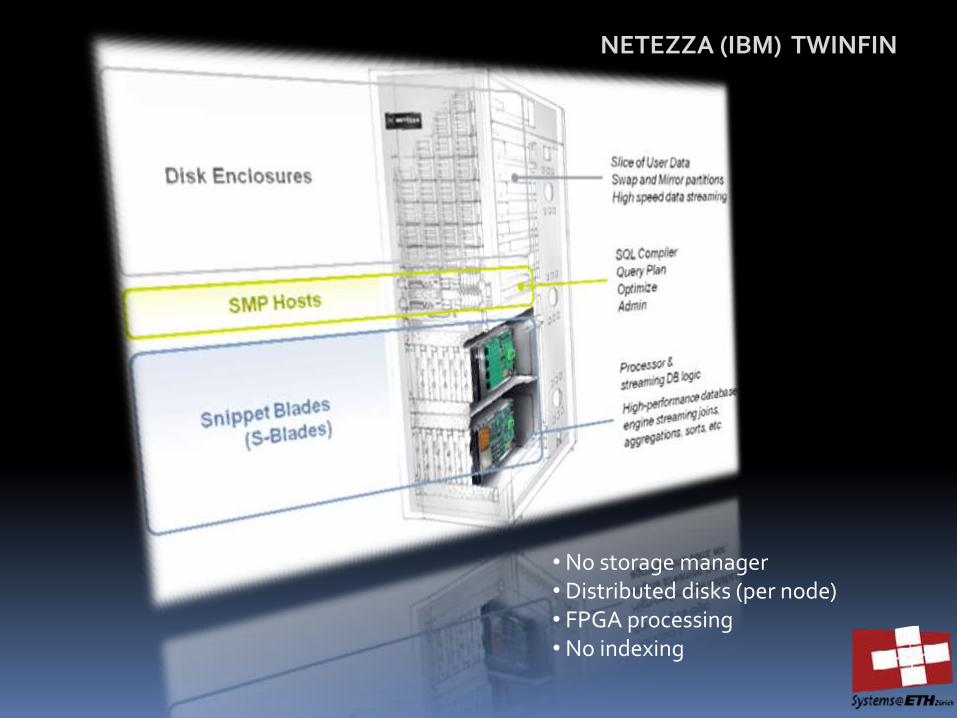
NETEZZA (IBM) TWINFIN
• No storage manager • Distributed disks (per node) • FPGA processing • No indexing

Has been tried before …
The idea that database workloads are relevant enough to justify customization is not new
Decades ago it was difficult to fight the progress of general purpose systems.
Not any more …
Gamma Database Machine (Dewitt)

2. The case for custom systems
b) An example (Crescando)

Amadeus Workload
Passenger-Booking Database
• ~ 600 GB of raw data (two years of bookings)
• single table, denormalized
• ~ 50 attributes: flight-no, name, date, ..., many flags
Query Workload
• up to 4000 queries / second
• latency guarantees: 2 seconds
• today: only pre-canned queries allowed
Update Workload • avg. 600 updates per second
(1 update per GB per sec) • peak of 12000 updates per
second • data freshness guarantee: 2
seconds
Problems with State-of-the Art • Simple queries work only
because of mat. views multi-month project to
implement new query / process
• Complex queries do not work at all

Crescando: the Amadeus use case
Remove load interaction
Remove unpredictability
Simplify design for scalability and modeling
Treat a multicore machine as a collection of individual nodes (not as a parallel machine)
Run only on main memory
One thread per core
Highly tune the code at each core

Scan on a core
READ CURSOR
WRITE CURSOR DATA IN
CIRCULAR BUFFER
(WIDE TABLE)
BUILD QUERY INDEX FOR NEXT SCAN QUERIES
UPDATES
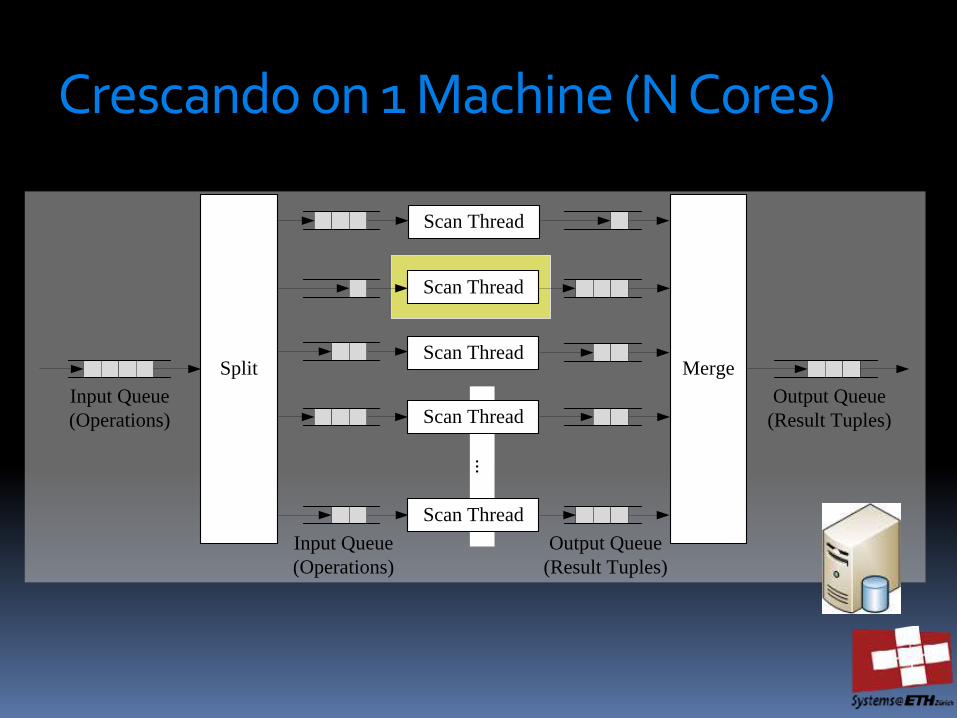
Crescando on 1 Machine (N Cores)
...
Split
Scan Thread
Scan Thread
Scan Thread
Scan Thread
Scan Thread
Merge
Input Queue
(Operations)
Input Queue
(Operations)
Output Queue
(Result Tuples)
Output Queue
(Result Tuples)
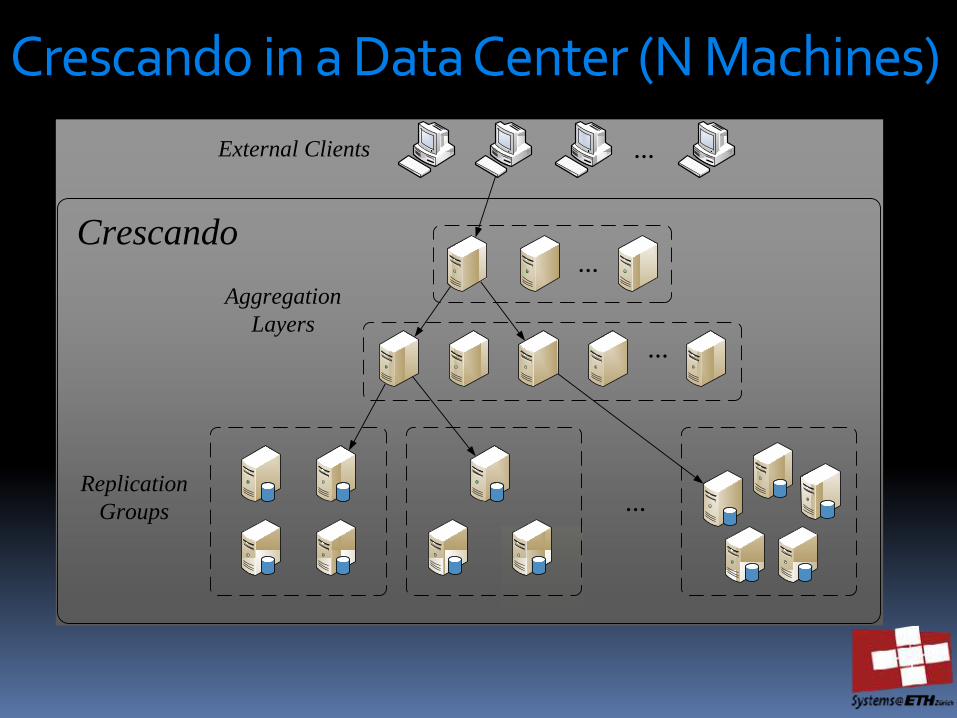
Crescando in a Data Center (N Machines)
...
Aggregation
Layers
Replication
Groups
...
...
External Clients
Crescando
...

Why is this interesting?
Fully predictable performance
• Response time determined by design regardless of load
Only two parameters:
• Size of the scan
• Number of queries per scan
Scalable to arbitrary numbers of nodes
Philipp Unterbrunner, Georgios Giannikis, Gustavo Alonso, Dietmar Fauser, Donald Kossmann: Predictable Performance for Unpredictable Workloads. PVLDB 2(1): 706-717 (2009)

Even more interesting
On such a system (or a key value store, No-SQL database, etc.):
• Why using a general purpose CPU?
• Many other options available
Smaller CPUs
FPGAs
ASIC
…
Zsolt István, Gustavo Alonso, Michaela Blott, Kees A. Vissers: A flexible hash table design for 10GBPS key-value stores on FPGAS. FPL 2013

3. Ideas and directions
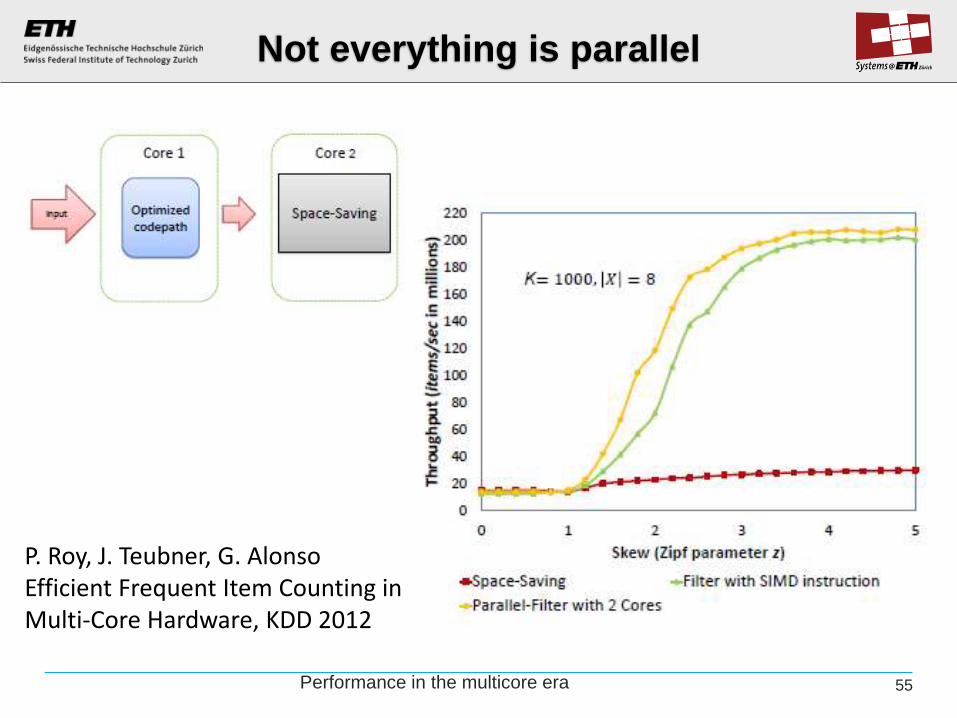
Performance in the multicore era 55
Not everything is parallel
P. Roy, J. Teubner, G. Alonso Efficient Frequent Item Counting in Multi-Core Hardware, KDD 2012

Not everything is a CPU
Louis Woods, Zsolt István, Gustavo Alonso: Hybrid
FPGA-accelerated SQL query processing. FPL
2013
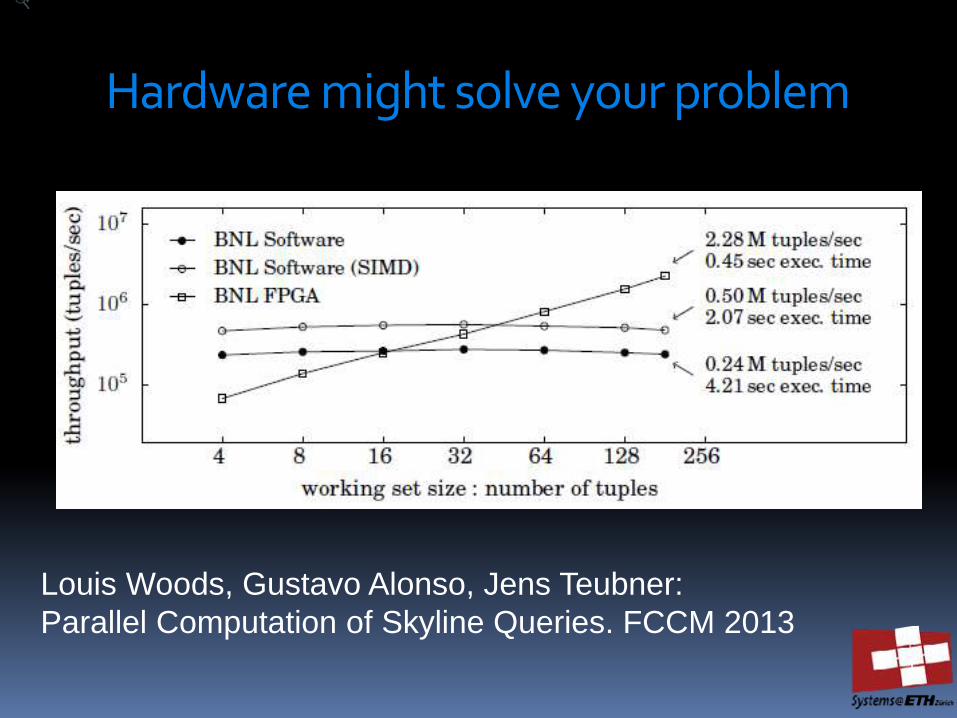
Hardware might solve your problem
Louis Woods, Gustavo Alonso, Jens Teubner:
Parallel Computation of Skyline Queries. FCCM 2013

Pipeline parallelism
SharedDB does not run queries individually (each one in one thread). Instead, it runs operators that process queries in batches thousands of queries at a time
Georgios Giannikis, Gustavo Alonso, Donald Kossmann: SharedDB: Killing One Thousand Queries With One Stone. PVLDB 5(6): 526-537 (2012)
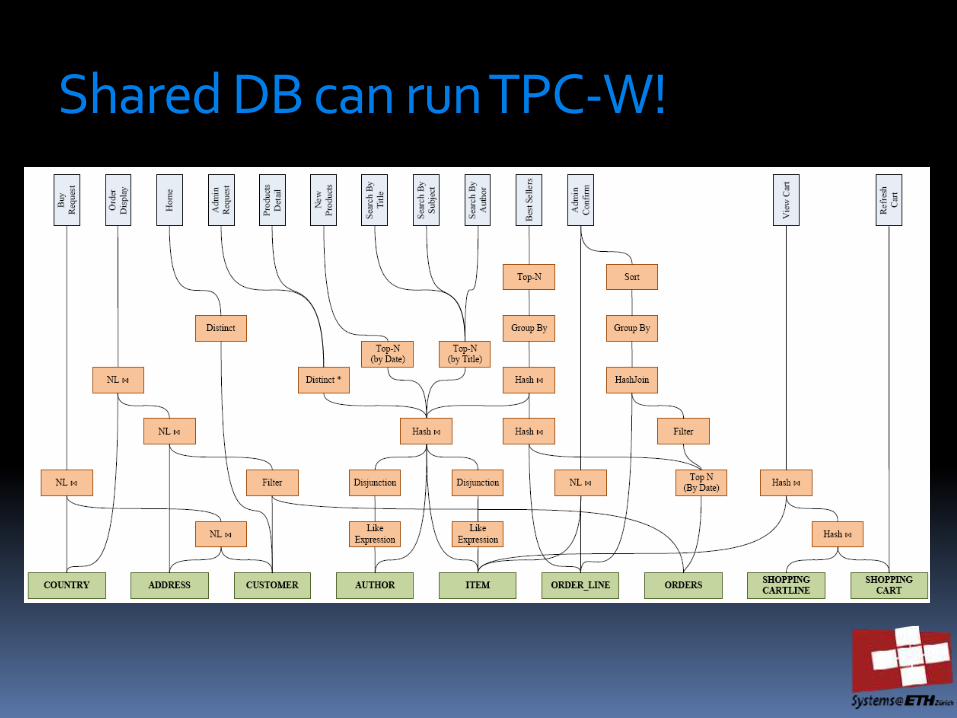
Shared DB can run TPC-W!

For the non-db people
TPC-W has updates!!!
Full consistency without conventional transaction manager
Transactions are no longer what you read in textbooks …
• Sequential execution
• Memory CoW (Hyder, TU Munich)
• Snapshot isolation
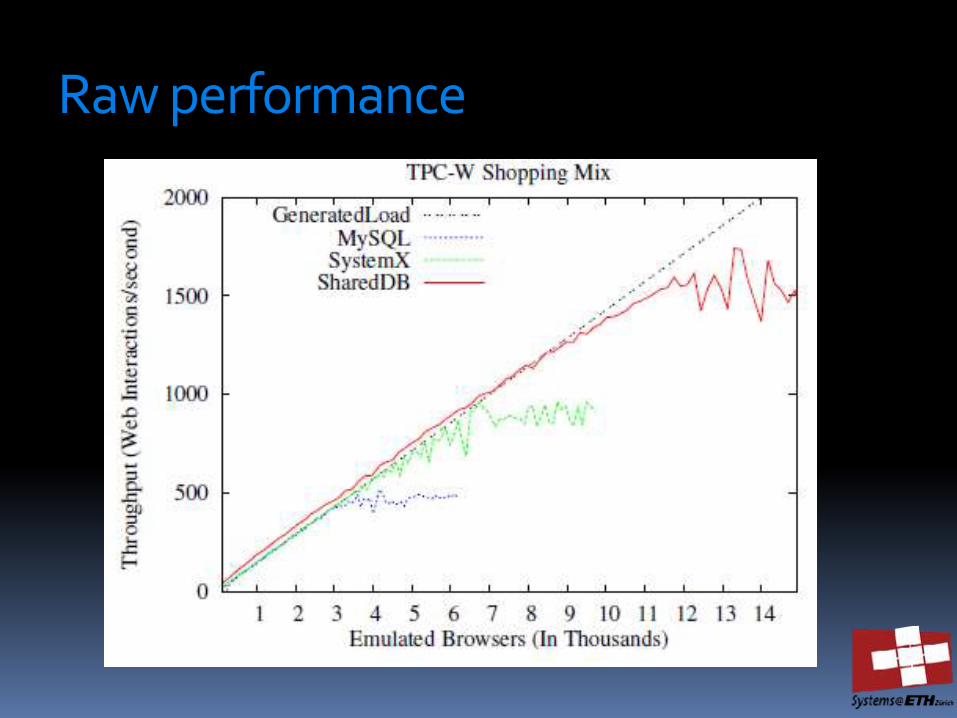
Raw performance
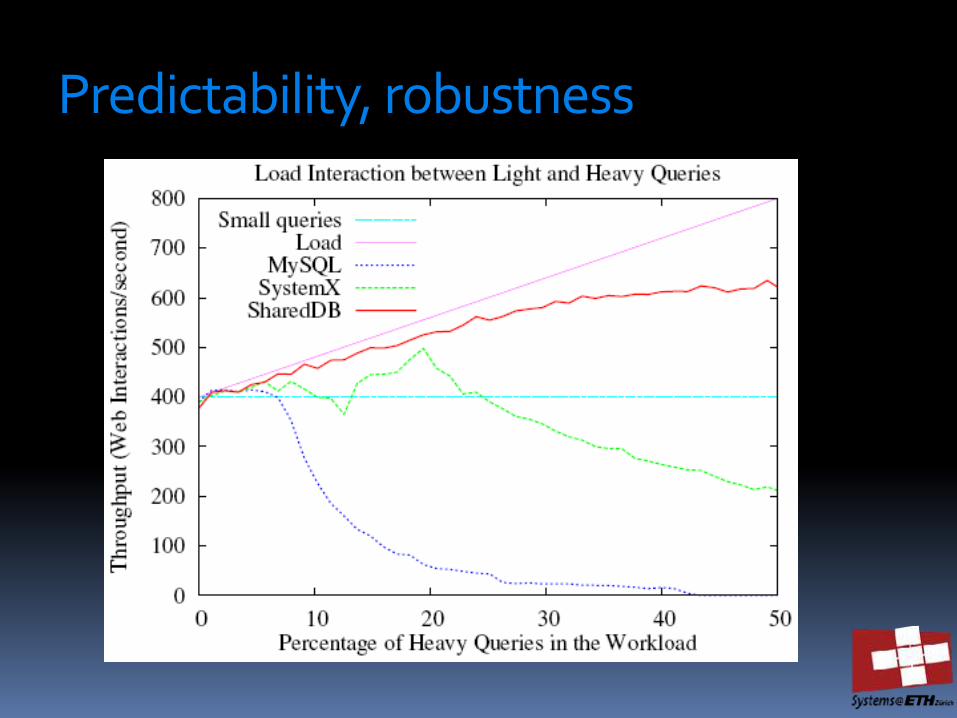
Predictability, robustness
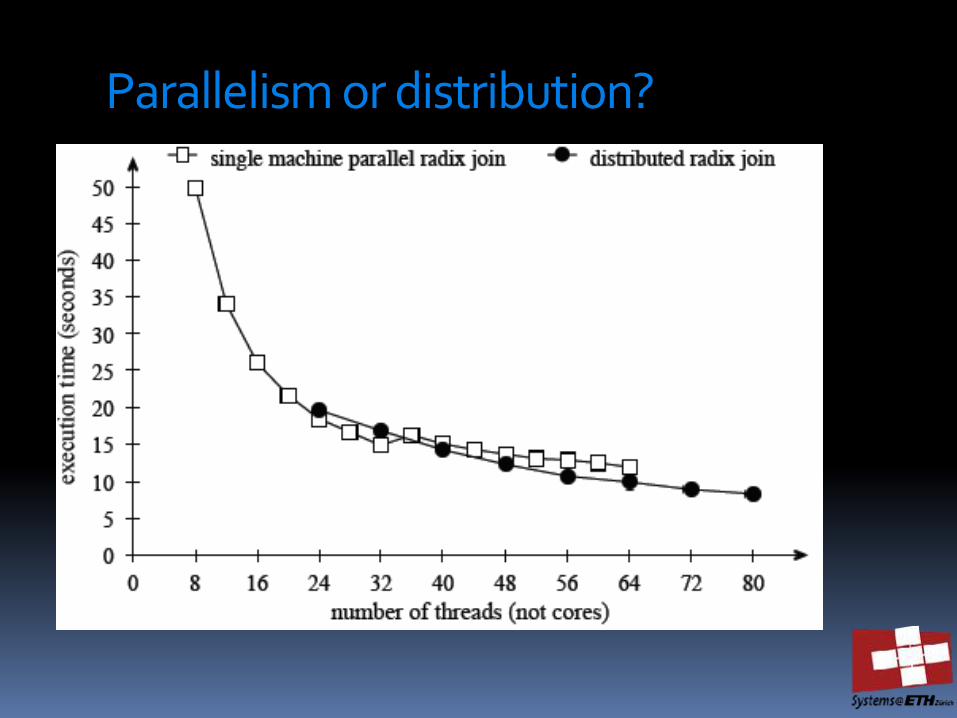
Parallelism or distribution?
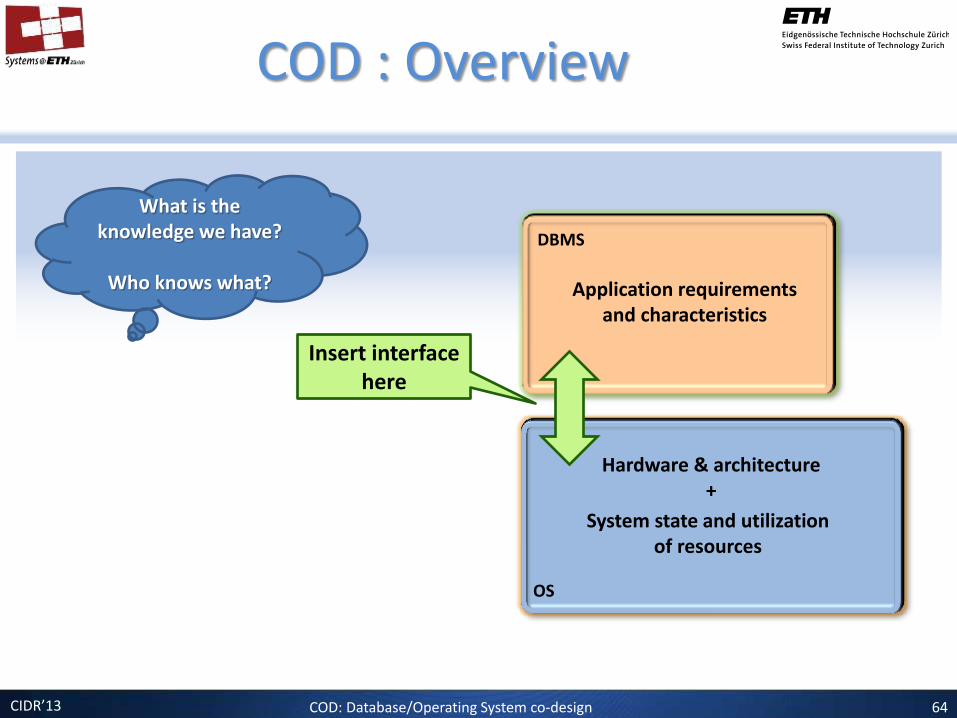
CIDR’13
COD : Overview
64
OS
DBMS
Application requirements and characteristics
System state and utilization of resources
Hardware & architecture +
What is the knowledge we have?
Who knows what?
Insert interface here
COD: Database/Operating System co-design
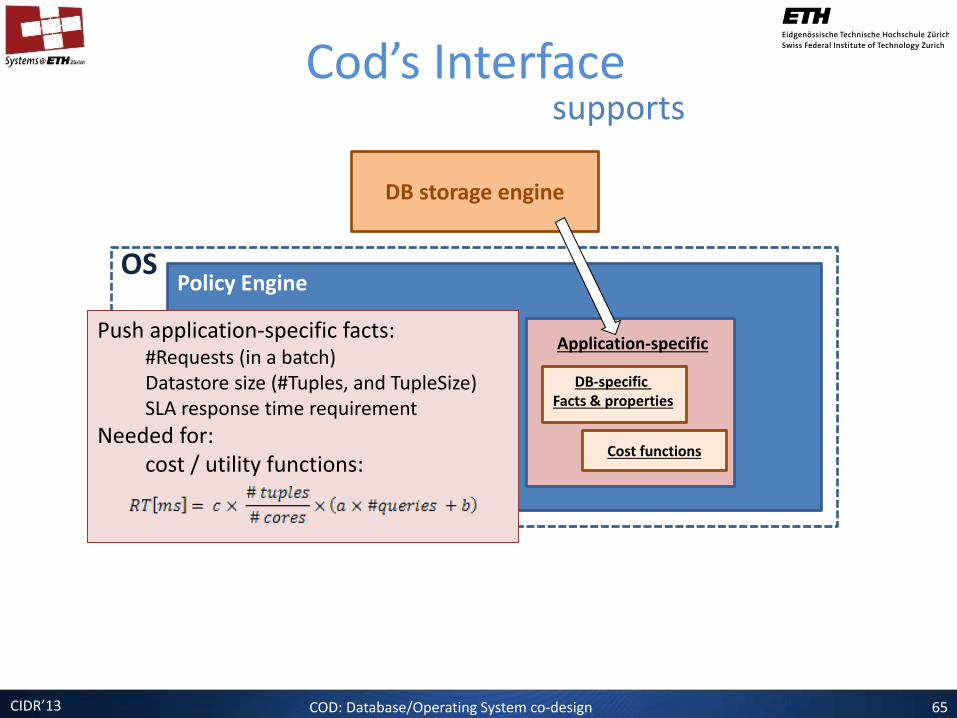
CIDR’13 COD: Database/Operating System co-design 65
Policy Engine
System-level
OS
System-level facts
DB storage engine
DB system-level properties
Application-specific
DB-specific Facts & properties
Cod’s Interface supports
Push application-specific facts: #Requests (in a batch) Datastore size (#Tuples, and TupleSize) SLA response time requirement
Needed for: cost / utility functions:
Cost functions

CIDR’13
COD’s key features
Declarative interface
Resource allocation for imperative requests
Resource allocation based on cost functions
Proactive interface
Inform of system state
Request releasing of resources
Recommend reallocation of resources
COD: Database/Operating System co-design 66
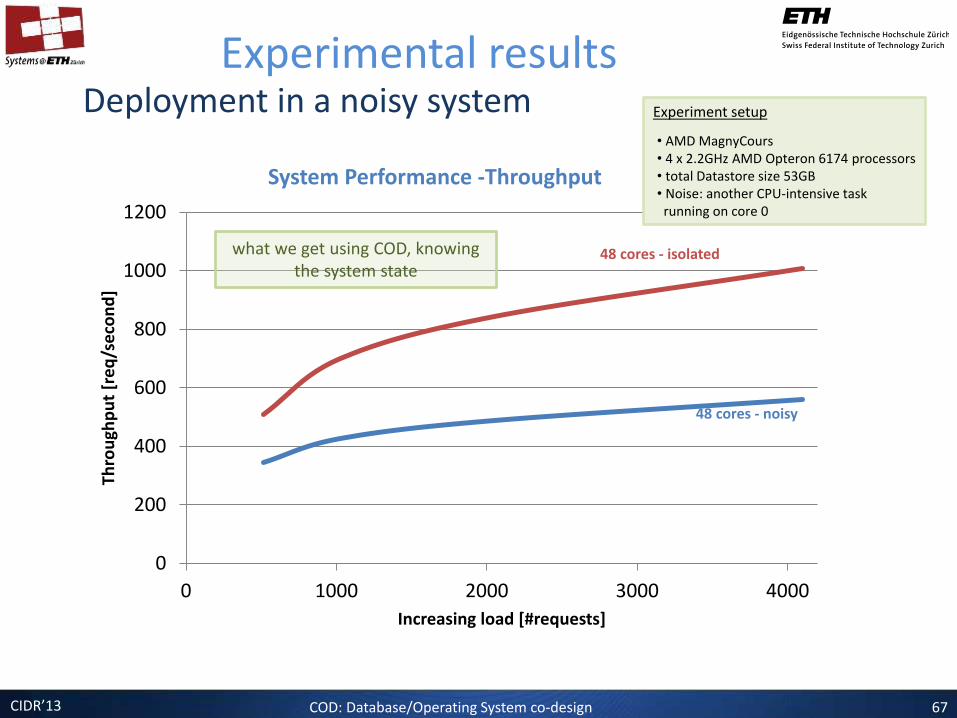
CIDR’13
0
200
400
600
800
1000
1200
0 1000 2000 3000 4000
Thro
ugh
pu
t [r
eq
/se
con
d]
Increasing load [#requests]
System Performance -Throughput
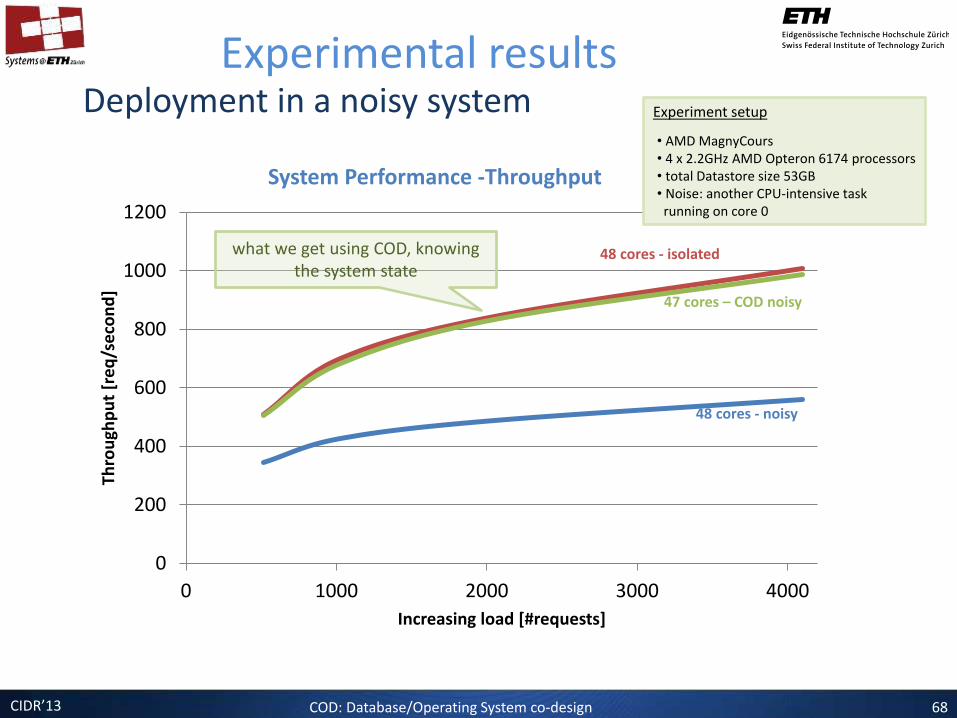
COD: Database/Operating System co-design 67
48 cores - isolated
48 cores - noisy
what we get using COD, knowing the system state
Deployment in a noisy system Experimental results
Experiment setup
• AMD MagnyCours • 4 x 2.2GHz AMD Opteron 6174 processors • total Datastore size 53GB • Noise: another CPU-intensive task running on core 0
CIDR’13
0
200
400
600
800
1000
1200
0 1000 2000 3000 4000
Thro
ugh
pu
t [r
eq
/se
con
d]
Increasing load [#requests]
System Performance -Throughput
COD: Database/Operating System co-design 68
48 cores - isolated
47 cores – COD noisy
48 cores - noisy
what we get using COD, knowing the system state
Deployment in a noisy system Experimental results
Experiment setup
• AMD MagnyCours • 4 x 2.2GHz AMD Opteron 6174 processors • total Datastore size 53GB • Noise: another CPU-intensive task running on core 0
CIDR’13 COD: Database/Operating System co-design 69
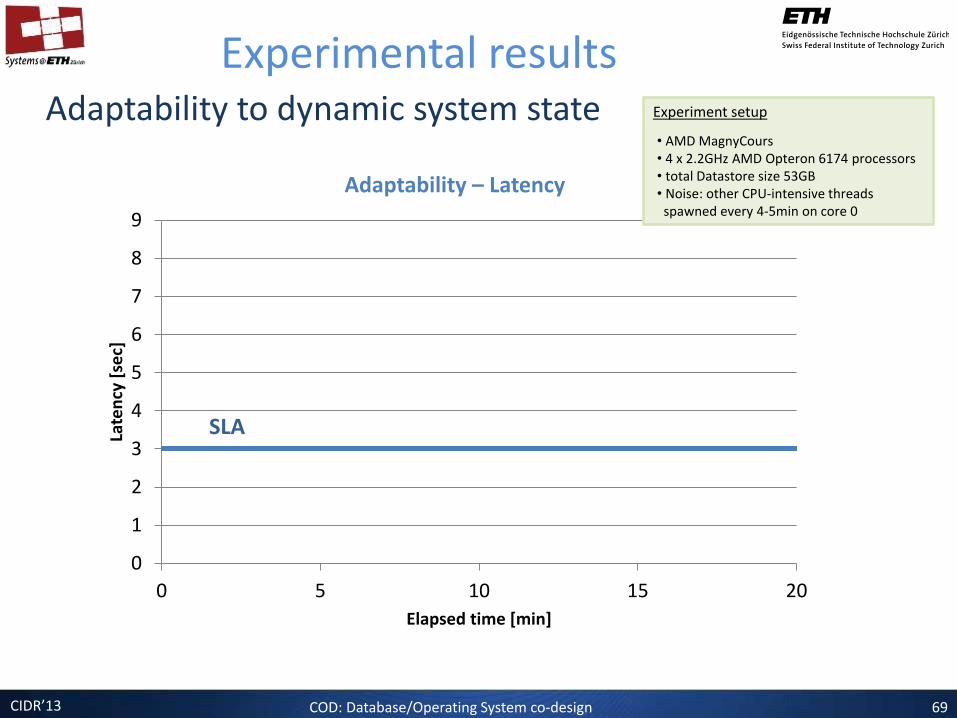
Adaptability to dynamic system state
Experimental results
0
1
2
3
4
5
6
7
8
9
0 5 10 15 20
Late
ncy
[se
c]
Elapsed time [min]
Adaptability – Latency
SLA
Experiment setup
• AMD MagnyCours • 4 x 2.2GHz AMD Opteron 6174 processors • total Datastore size 53GB • Noise: other CPU-intensive threads spawned every 4-5min on core 0
CIDR’13 COD: Database/Operating System co-design 70
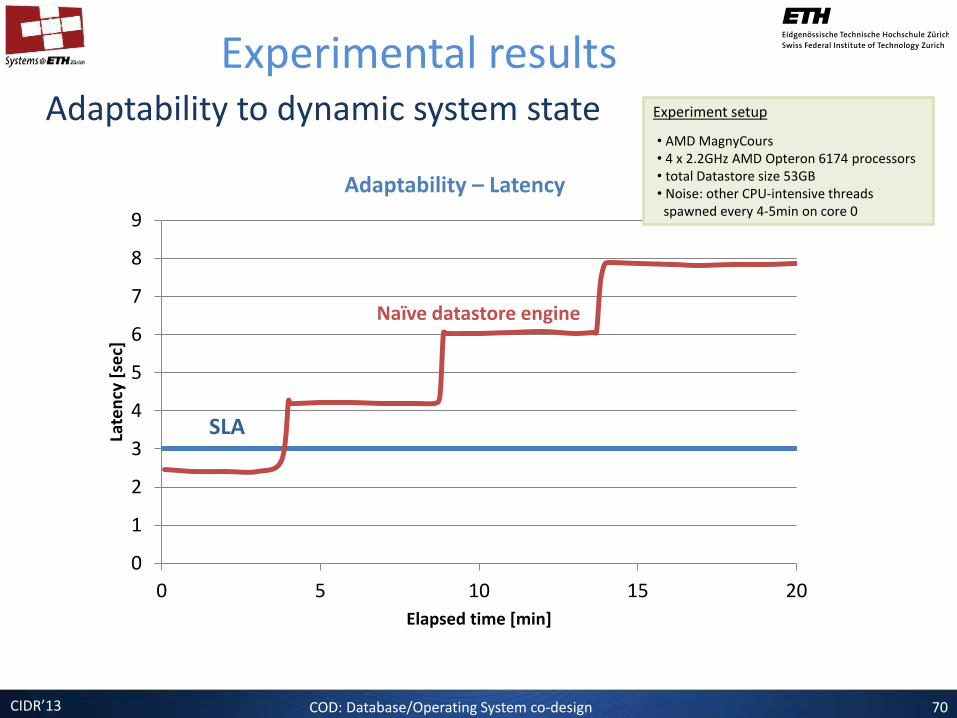
Adaptability to dynamic system state
Experimental results
0
1
2
3
4
5
6
7
8
9
0 5 10 15 20
Late
ncy
[se
c]
Elapsed time [min]
Adaptability – Latency
Naïve datastore engine
SLA
Experiment setup
• AMD MagnyCours • 4 x 2.2GHz AMD Opteron 6174 processors • total Datastore size 53GB • Noise: other CPU-intensive threads spawned every 4-5min on core 0
CIDR’13 COD: Database/Operating System co-design 71
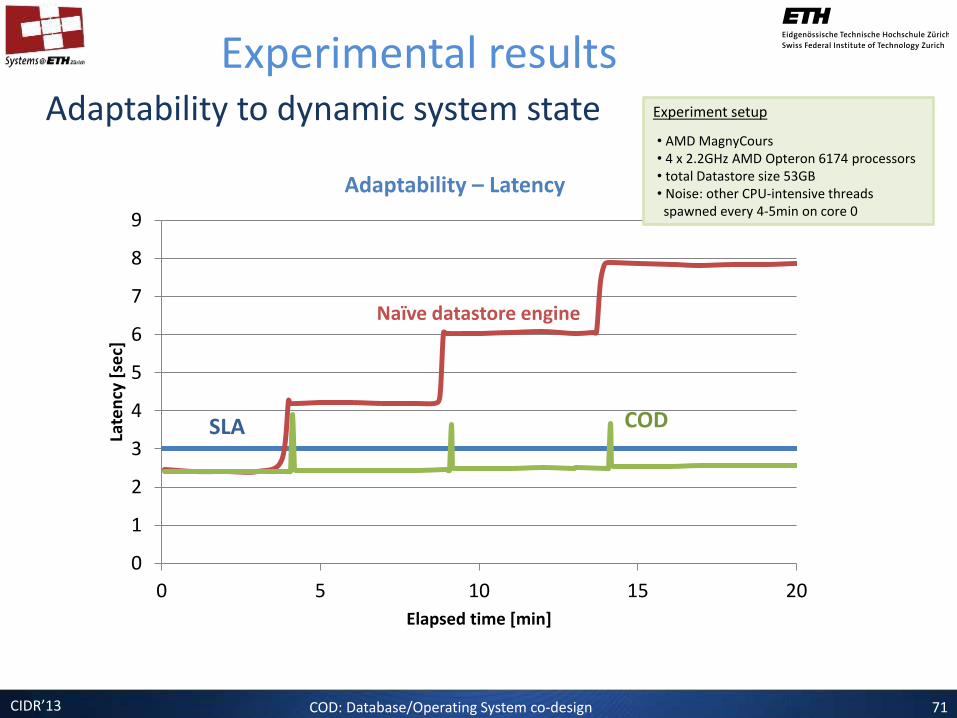
Adaptability to dynamic system state
Experimental results
0
1
2
3
4
5
6
7
8
9
0 5 10 15 20
Late
ncy
[se
c]
Elapsed time [min]
Adaptability – Latency
Naïve datastore engine
SLA COD
Experiment setup
• AMD MagnyCours • 4 x 2.2GHz AMD Opteron 6174 processors • total Datastore size 53GB • Noise: other CPU-intensive threads spawned every 4-5min on core 0

Conclusions

The opportunity is now
Consensus on major crisis in hardware (from the sw perspective)
Hardware not really improving, responsibility passed on to software
Business models and IT systems moving towards specialization





























