Embed Size (px)
Citation preview

High Performance Content Centric Networking on Virtual Infrastructure
by
Tang Tang
A thesis submitted in conformity with the requirementsfor the degree of Master of Applied Science
Graduate Department of Electrical and Computer EngineeringUniversity of Toronto
© Copyright 2013 by Tang Tang

Abstract
High Performance Content Centric Networking on Virtual Infrastructure
Tang Tang
Master of Applied Science
Graduate Department of Electrical and Computer Engineering
University of Toronto
2013
Content Centric Networking (CCN) is a novel networking architecture in which communication
is resolved based on names, or descriptions of the data transferred instead of addresses of the end-
hosts. While CCN demonstrates many promising potentials, its current implementation suffers from
severe performance limitations. In this thesis we study the performance and analyze the bottleneck
of the existing CCN prototype. Based on the analysis, a variety of design alternatives are proposed
for realizing high performance content centric networking over virtual infrastructure. Preliminary
implementations for two of the approaches are developed and evaluated on Smart Applications on
Virtual Infrastructure (SAVI) testbed. The evaluation results demonstrate that our design is capable
of providing scalable content centric routing solution beyond 1Gbps throughput under realistic traffic
load.
ii

Contents
1 Introduction 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Problem Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Organisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Background 5
2.1 Information Centric Networking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Advantages of ICN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.2 Open Issues and Challenges in ICN . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.3 Major ICN Projects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.4 Main Components of an ICN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Content Centric Networking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Advantages of the CCN Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.2 CCN Architecture Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3 Smart Application on Virtual Infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 Related Work 19
3.1 ICN Testbeds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2 Performance of CCN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 CCN Router Designs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4 Bottleneck Analysis and Service Decomposition of CCN 23
4.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2 CCNx Performance Benchmark and Bottleneck Analysis . . . . . . . . . . . . . . . . . . . 24
4.2.1 Experiment Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
iii

4.2.2 Performance Benchmarking Results . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.2.3 Data Chunk Digest: Calculation and Impact on Performance . . . . . . . . . . . . . 30
4.2.4 Bottleneck Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.3 CCNx Node Service Decomposition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3.1 Augmented Functional Flow for Interest and Content Chunks . . . . . . . . . . . . 32
4.3.2 Extracted Service Model of a CCN Router . . . . . . . . . . . . . . . . . . . . . . . . 35
4.4 Concluding Remark . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5 SAVI CCN Design Alternatives 40
5.1 Design Requirements and Criteria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.2 SAVI Testbed User Topology and Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.3 Alternative 1: Header Decoder Optimization . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.3.1 SAVI Resource Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.3.2 Advantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.3.3 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.4 Alternative 2: Parallel Table Access within Single Node . . . . . . . . . . . . . . . . . . . . 44
5.4.1 SAVI Resource Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.4.2 Advantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.4.3 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.5 Alternative 3: Distributed Chunk Processing with Synchronized Table Services . . . . . . 47
5.5.1 Out-of-sync Tables and “Good enough” Table Look-ups . . . . . . . . . . . . . . . 50
5.5.2 SAVI Resource Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.5.3 Advantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.5.4 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.6 Alternative 4: Distributed Chunk Processing with Central Table Service . . . . . . . . . . 51
5.6.1 Chunk Processing Pipelining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.6.2 Optionally Centralized Name Codec Services . . . . . . . . . . . . . . . . . . . . . 53
5.6.3 SAVI Resource Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.6.4 Advantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.6.5 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.7 Alternative 5: Distributed Chunk Processing with Partitioned Tables . . . . . . . . . . . . 55
5.7.1 Redefine a CCN Node Using Partitioned Table Approach . . . . . . . . . . . . . . . 56
5.7.2 Table (Name Space) Partitioning and Dynamic Re-partitioning . . . . . . . . . . . 58
iv

5.7.3 Duplication of Popular Name Entries . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.7.4 Handling Different CCN Message Types . . . . . . . . . . . . . . . . . . . . . . . . 59
5.7.5 Internal Topology and Routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.7.6 Reliability, Robustness, and Ability to Scale . . . . . . . . . . . . . . . . . . . . . . . 61
5.7.7 SAVI Resource Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.7.8 Advantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.7.9 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.8 Concluding Remark . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6 SAVI CCN Implementation and Evaluation 65
6.1 Optimized Header Decoder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.1.1 Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
6.1.2 Experiment Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
6.1.3 Remarks and Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
6.2 Distributed Chunk Processing with Partitioned Tables . . . . . . . . . . . . . . . . . . . . 78
6.2.1 Using CCNx as Processing Units . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
6.2.2 Two Approaches Towards Realizing Pre-routing . . . . . . . . . . . . . . . . . . . . 79
6.2.3 Estimated Upper and Lower Bounds of Performance Scaling . . . . . . . . . . . . . 83
6.2.4 Preliminary Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
6.3 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
7 Conclusions 94
7.1 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
7.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
Bibliography 96
v

List of Tables
4.1 CPU usage and throughput of vanilla CCNx . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.2 Statistics on header processing time for Content Store size = 50000 . . . . . . . . . . . . . . 27
4.3 Statistics on header processing time for Content Store size = 0 . . . . . . . . . . . . . . . . 28
4.4 Top 5 time-consuming functions in CCNx under various settings . . . . . . . . . . . . . . 31
5.1 Summary of the proposed design alternatives . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6.1 Observed ccn_skeleton_decoder−>state values as input to ccn_skeleton_decode . . . . . . 70
6.2 OpenFlow entries to implement the unified virtual interface . . . . . . . . . . . . . . . . . 81
vi

List of Figures
2.1 CCN chunk structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 CCN node model [1] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 CCN node forwarding logic flow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.1 Experiment topology for performance benchmarking . . . . . . . . . . . . . . . . . . . . . 25
4.2 Histograms showing header processing time for each individual Interest and Data chunk
for Unique Name (top) and Shared Name (bottom) settings, with Content Store size set
to 50000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.3 Histograms showing header processing time for each individual Interest and Data chunk
for Unique Name (top) and Shared Name (bottom) settings, with Content Store size set to 0 29
4.4 Augmented functional flow of CCN forwarding logic . . . . . . . . . . . . . . . . . . . . . 33
4.5 CCN node model highlighting the 6 core services . . . . . . . . . . . . . . . . . . . . . . . 36
5.1 SAVI testbed user topology [2] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.2 Functional flow for parallel table access within single node . . . . . . . . . . . . . . . . . . 46
5.3 Service model for distributed chunk processing with synchronized table services . . . . . 49
5.4 Service model for distributed chunk processing with central table service . . . . . . . . . . 52
5.5 Service model for distributed chunk processing with partitioned tables . . . . . . . . . . . 56
5.6 Recursively redefining CCN nodes as networks of collaborating member nodes . . . . . . 57
6.1 Functional flow for testing and verification routine . . . . . . . . . . . . . . . . . . . . . . . 72
6.2 Physical topology of experiments evaluating optimized ccn_skeleton_decode . . . . . . . . 73
6.3 Logical topology of experiments evaluating optimized ccn_skeleton_decode using unique
content names . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.4 Unique content names: CPU usage and data rate vs. number of client-server pairs . . . . 75
vii

6.5 Logical topology of experiments evaluating optimized ccn_skeleton_decode using shared
content names . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
6.6 Shared content names: CPU usage and data rate vs. number of clients . . . . . . . . . . . 76
6.7 Logic flow of a processing unit with per-node re-routing function . . . . . . . . . . . . . . 80
6.8 Data rate analysis for one processing unit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.9 Topology emulating the implementation of partitioned tables with centralized pre-routing
unit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.10 Topology emulating the implementation of partitioned tables with per-node pre-routing
module . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.11 Preliminary evaluation for partitioned tables: unique content name case, system through-
put vs. number of routing nodes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.12 Preliminary evaluation for partitioned tables: same content name case, system through-
put vs. number of routing nodes. Higher throughput was achieved by avoiding instan-
tiating all routing nodes on the same computing agent. . . . . . . . . . . . . . . . . . . . . 92
viii

List of Acronyms and Definitions
API Application Programming Interface
ASCII American Standard Code for Information Interchange
BEE Berkeley Emulation Engine
BM Baremetal
CATT Cache Aware Target idenTification
CCN Content Centric Network(ing)
CDN Content Delivery Network
COMET COntent Mediator architecture for content-aware nETworks
CONET COntent NETworking project
CPU Central Processing Unit
CS Content Store
CUDA Compute Unified Device Architecture
DHT Distributed Hash Tables
DONA Data-Oriented Network Architecture
DoS Denial of Service
DPI Deep Packet Inspection
FIB Forwarding Information Base
GB Gigabyte
ix

Gbps Gigabit per second
GENI Global Environment for Network Innovations
GPGPU General Purpose Graphic Processing Units
HPC High Performance Computing
IaaS Infrastructure-as-a-Service
ICN Information Centric Networking
IP Internet Protocol
LFU Least Frequently Used
LRU Least Recently Used
MB Megabyte
Mbps Megabit per second
MPI Message Passing Interface
MTU Maximum Transmission Unit
NDN Named Data Network(ing)
NetInf Network of Information
OSPF Open Shortest Path First
OSPFN OSPF for NDN
OVS Open vSwitch
P2P Peer-to-Peer
PBR Potential Based Routing
PIT Pending Interest Table
PSIRP Publish-Subscribe Internet Routing Paradigm
pub/sub publish-subscribe
PURSUIT Publish-Subscribe Internet Technology
x

QoS Quality of Service
ROFL Routing on Flat Labels
Rx/Tx Receive/Transmit
SAIL Scalable and Adaptive Internet Solutions
SAVI Smart Application on Virtual Infrastructure
SDI Software Defined Infrastructure
SDN Software Defined Network(ing)
SIMD Single Instruction Multiple Data
Std.Dev. Standard Deviation
TCP Transmission Control Protocol
TRIAD Translating Relaying Internet Architecture integrating Active Directories
UDP User Datagram Protocol
VANET Vehicular Ad-hoc Networks
VM Virtual Machine
VoCCN Voice-over-CCN
VoIP Voice-over-IP
XML Extensible Markup Language
xi

Chapter 1
Introduction
Over the past few decades, the Internet has become an essential infrastructure of the modern society.
Although its simple design has been stunningly successful, the Internet has been pushed by its users
to face many new challenges [3]. For example, a recent study has estimated that up to 98% of Internet
traffic today consists of data related to content distribution [4], despite the fact that the original design
of the Internet was based on a point-to-point communication model.
Such mismatches between the functional objectives and the canonical architecture of the Internet
has stimulated much research and engineering efforts. One of the many approaches of realizing
large-scale content distribution over the existing Internet is through the Peer-to-Peer (P2P) overlay
networks [5–7]. In a P2P network, the content consumers (peers) allow access to each others’ resources
such as computational power, storage, and network bandwidth without requiring centralized control
by the content providers. Such collaboration among peers allows content to be distributed not only
from providers to consumers, but also between consumers. The P2P architecture dissolves the barrier
between servers and clients in the traditional server-client networking model, and possesses many
advantages such as high scalability and availability [5]. Recent research has also demonstrated that
through collaboration of peers, the virtual community can utilize diverse resources provided by each
peer to accomplish greater tasks beyond the potential of each individual participant [8].
Another approach is the Content Delivery Network (CDN) [9–12]. CDNs are designed to provide
reliable and high-performance content delivery services to content consumers. There are two general
approaches to achieve such goal: overlay approach and network approach. In overlay CDNs, contents are
duplicated and distributed across the Internet at multiple distinct surrogate servers. Users requesting
the data are directed to the closest surrogate server and contents are served by traversing only a
1

Chapter 1. Introduction 2
local portion of the Internet. Such design decouples the content delivery from the core network
infrastructure, allowing direct deployment over existing Internet infrastructure. The overlay model
has achieved commercial success by companies such as Akamai [13], Amazon CloudFront [14], and
CDNetworks [15]. In network-oriented CDNs, on the other hand, devices such as routers and switches
are augmented to make application-specific forwarding decisions. An example of early network-based
content delivery solution is Internet Protocol (IP) Multicast [11].
In a recent trend multiple methods are combined to explore novel alternatives: [16] and [17] inves-
tigated the usage of P2P methodology in CDNs for improved scalability and reliability; [18] looked
at bringing Distributed Hash Tables (DHT) and other P2P techniques to publish-subscribe (pub/sub)
networks for high-performance content distribution; [19] focused on content caching and accessing in
pub/sub system as an alternative way of implementing high-performance CDNs.
All approaches described above focus on realizing high-performance content distribution over
existing Internet architecture. While several have been quite successful in both academia and industry,
none of them resolves the fundamental conflicts between efficient content dissemination and the point-
to-point communication model of Internet today. Motivated by the limitations of existing Internet
architecture, researchers around the world have been re-evaluating and re-designing Internet from
lower levels. Many have come to the agreement that the center of future Internet needs to be shifted
from hosts to content, which forms the foundation of Information Centric Networking.
Information Centric Networking (ICN) describes the paradigm shift of content dissemination strat-
egy from host addressing to content naming. In an ICN, data are described by names, and communication
is resolved based on the names of content instead of the location of hosts. Such approach brings many
benefits as outlined in Section 2.1.
1.1 Motivation
ICN is proposed as an approach towards efficient content dissemination over the Internet. Because the
ultimate goal of ICN is to deliver data to the interested entities on the network quickly and reliably,
the performance, specifically throughput is one of the most important metrics among many critical
specifications of an ICN system.
Currently there is a clear gap between the two streams of research concerning ICN and its perfor-
mance (Chapter 3): on the one hand, researchers focusing on improving the performance of existing
ICN projects propose novel mechanisms for specific components of an ICN system, and show their
results through numerical analysis or simulations. On the other hand, researchers implementing the

Chapter 1. Introduction 3
ICN prototypes build testbeds with functional verification and refinement as their primary objectives.
This thesis is motivated by such gap between the proposed novel mechanisms in improving ICN
performance and the practical implementation and evaluation of these mechanisms in realistic settings.
Specifically we plan to design, implement, and evaluate practical ways of improving the performance
of an ICN system, and demonstrate the throughput gain through experiments using realistic traffic.
1.2 Problem Statement
The goal of this thesis is to design, implement, and evaluate a high performance network application
based on an existing ICN prototype. Specifically we aim to improve the throughput of Content Centric
Networking (CCN) [1] using the CCNx open source project [20] on the Smart Application on Virtual
Infrastructure (SAVI) testbed.
We propose the following objectives for this thesis:
1. Firstly, we will study and analyze the existing CCN scheme and CCNx code, understand the
underlying architecture, and find the bottleneck(s) of the current implementation;
2. Next, we will propose and compare design alternatives towards improving the performance of the
existing implementation, with mapping between CCN functional modules and SAVI resources;
3. Finally, based on the results of above studies, we will implement a preliminary prototype of
improved CCN application and evaluate its performance on SAVI testbed.
Some of the expected challenges of this thesis project include:
• Finding effective ways of benchmarking the existing CCNx project and locating the system bot-
tleneck under realistic operating conditions;
• Designing a practical high performance CCNx-based system, preferably compatible with the
existing CCNx architecture, which fully utilizes resources of a virtual infrastructure;
• Implementing a functional prototype within the project time limit;
• Testing and evaluating the prototype on SAVI at scale.
1.3 Contributions
This thesis presents a practical ICN design approach towards realizing high performance Content Cen-
tric Networking on virtual infrastructure. A preliminary implementation based on CCNx is deployed,

Chapter 1. Introduction 4
tested, and evaluated on SAVI testbed. Several contributions are made during the course of this thesis.
They include:
• A study on the performance of existing CCNx prototype is presented, based on which bottleneck
of the current system is identified;
• The logic flow of a CCN node is augmented with highlights of the bottleneck functions. A high
level service model is extracted from the logic flow, which identifies the critical services of a CCN
node;
• Five design alternatives are proposed for realizing high performance content centric networking
on virtual infrastructure. SAVI resource mapping as well as pros and cons for each design approach
are discussed;
• Preliminary implementation of two of the design approaches are deployed and tested on SAVI
testbed. Evaluation using realistic traffic load shows that our design is scalable and it is capable
of sustaining throughput beyond 1Gbps.
1.4 Organisation
The rest of this thesis report is organized as follows: in Chapter 2 we provide the background information
on ICN, CCN, and SAVI testbed in general. In Chapter 3 we review some of the existing literature on the
topics of ICN testbeds around the globe, performance of CCN, as well as CCN router designs. Then in
Chapter 4, we explain our methodology of benchmarking CCNx on SAVI. Based on the benchmarking
results, we locate the bottleneck function and present a service decomposition of the CCN node.
Chapter 5 takes the analysis further by proposing design alternatives for a high performance content
centric networking solution. For each proposal, mapping from services to SAVI resources is also
discussed. In Chapter 6, we examine two distinct methods of improving CCN throughput, and present
preliminary implementations using CCNx. Evaluation results on SAVI testbed are then presented and
discussed for both approaches. In the last chapter, we conclude this thesis with a summary and plans
for future works.

Chapter 2
Background
2.1 Information Centric Networking
Information Centric Networking (ICN), also known as Named Data Networking (NDN) or Content
Centric Networking (CCN), describes collectively the approaches towards future Internet architecture
in which the communication model is built around names (description of content) of the information
instead of hosts or locations of the information. ICN designs treat identity, security, and access of
information as the primitive of their communication models, and as a result, decouples the retrieval of
information from its location.
2.1.1 Advantages of ICN
ICN has many advantages over the current Internet due to the shift of emphasis from hosts to names of
information. Some of the most noted ones include:
Efficient Content Distribution
A primary feature of ICN is caching of contents at arbitrary network locations. This is enabled by
characterizing contents by ‘names’ which describe contents themselves instead of URLs which de-
scribe the locations. In comparison to the existing packet caching feature offered by some network
devices, the caching in ICN is built into the communication model, and offers greater flexibility in
management of cached contents. Caching of content allows efficient content dissemination over
an ICN enabled network by serving clients with the nearest local copy. Research has shown that
the ICN scheme can substantially improve bandwidth utility and network delay [21–23].
Security
5

Chapter 2. Background 6
The paradigm shift from host locations to content has also promoted new security strategies
in the communication scheme. Because the content can be obtained from any network entity,
security was designed to focus on the content itself instead of where (host identity) and how
(communication channel) it was obtained. Security and related features such as digitally signing
every data packet are not only recommended but usually required by ICN. As a result, though still
an active field of research, ICN is believed to be more secure and robust against various threats
seen in today’s Internet, including identity fraud and denial of services (DoS) attacks [24].
Resilience and Mobility
Because ICN data packets can be temporarily stored at any network location, ICN can be used to
provide resiliency in networks in which connections or physical channels are not always available.
In ICN, if a request for content is not satisfied due to temporary network outage, the issuer (content
consumer) can resend the request once the connection is back. Depending on the timeout settings
and caching policy, the requested content could be retrieved by a much closer network entity than
the original content source. This allows a much faster and more efficient ‘reconnect’ after an outage
occurs. The same feature can be used to support networks requiring mobility of nodes: when the
access point changes for a network node, it is able to quickly continue its communication because
previously requested information can be easily retrieved. One example of ICN’s application
in networks with high resilience and mobility requirements is the Vehicular Ad-hoc Networks
(VANET) [25, 26].
Support for Applications and Services
As a direct consequence of all the above characteristics, ICN is believed to support certain ap-
plications and services better than today’s Internet. Efficient content distribution ensures ICN
performs well for content distribution and information multicast, which is what ICN was initially
conceived for; the unique security related features allow ICN to be used for services requiring high
data integrity; its resilience and support for mobility enables ICN as a viable option for Vehicular
Ad-hoc Networks (VANET) [25, 26] and many more.
2.1.2 Open Issues and Challenges in ICN
Though much potential is seen in ICN, it is also agreed that the current ICN scheme has many open
issues. Some of the challenges brought by the content-centric approach towards Internetworking
include:

Chapter 2. Background 7
Support for Point-to-point Applications
Although the majority of traffic on Internet today are for content distribution, there are many
applications which are inherently point-to-point. For example in financial transactions, unicast
messaging, and Voice over IP (VoIP) services, the packet exchanges are strictly of interest to only
the participating hosts, and often should not be cached due to security reasons. Researchers have
been looking into these communication models. Prototypes like Voice-over-CCN (VoCCN) [27]
were built to demonstrate ICN’s capability in supporting traditional point-to-point applications,
though much work still remains with respect to efficiency and security [24].
Performance
Because ICN traffic is characterized by ‘names’ which are usually more flexible than fixed length
addresses of hosts, more complex mechanisms are involved in name resolution, data routing, and
content caching. Such complexity has profound implication on the overall performance of the
system because any performance bottleneck in the pipeline can slow down the entire system. In
addition, performance of ICN can go much beyond the basic throughput to include a variety of
metrics such as power consumption, bandwidth efficiency, latency, etc.
Quality of Service
Quality of Service (QoS) is another metric closely related to performance. QoS describes how ICN
can meet the different requirements from various applications and services it needs to support
beyond best-effort. QoS is also related to other topics such as resource management, reliability,
and priority determination. While the significance of QoS in ICN has been recognized, there has
not been much published work describing implementation-level details about QoS in ICNs.
2.1.3 Major ICN Projects
Because of all the advantages outlined above, ICN is seen as a promising approach towards designing
future Internet by researchers around the globe. Pioneered by Translating Relaying Internet Architecture
integrating Active Directories (TRIAD) [28] and Routing on Flat Labels (ROFL) [29], many projects
have flourished based on the fundamental concepts of ICN. Some of the most influential ones include:
• Data-Oriented Network Architecture (DONA) [30];
• Content Centric Networking (CCN) [1, 20] in the Named Data Network (NDN) project [31];
• Publish-Subscribe Internet Routing Paradigm (PSIRP) [32] and its continuation: the Publish-
Subscribe Internet Technology (PURSUIT) [33];

Chapter 2. Background 8
• Network of Information (NetInf) [34–36] from the Architecture and Design for the Future Internet
(4WARD) [37], which is also part of the Scalable and Adaptive Internet Solutions (SAIL) project
[38];
• COntent Mediator architecture for content-aware nETworks (COMET) [39, 40] funded by the EU
Framework 7 Programme (FP7);
• The CONVERGENCE project [41] including the COntent NETworking (CONET) project [42], also
funded by FP7.
Descriptions and in-depth comparisons of these projects can be found in survey papers [24, 43, 44].
2.1.4 Main Components of an ICN
Despite the large number of incarnations of the ICN concept, the main architectural components of any
ICN project remain within the following 4 categories:
Naming
Naming describes the format of content names and how they are associated with the content pieces
they describe. Some key metrics of a naming scheme include: structural hierarchy, readability
by human, available character sets, flexibility, and extensibility. Based on the naming conven-
tion, different algorithms or methodologies are implemented to generate, associate, distribute,
certify, and search for the names. Naming forms the foundation of an ICN implementation and
profoundly influences the design and performance of other components in the system.
Name Resolution and Data Routing
Name resolution describes how names are ‘understood’ by network entities within an ICN. It
determines how any given piece of information is located, whether at the original content source
or any cached location. It must also be able to handle changes (deletion and addition) of the
content names in an ICN. While name resolution usually gives direction on where to find the
requested content, data routing describes how the data is delivered. One of the main issues is how
to scale any routing methodology to the size of today’s Internet. Many proposals use techniques
from IP routing into ICNs for certainty in functionality, while others adopt new schemes to avoid
existing problems in IP routing [44].
In-network Caching
In-network caching builds on top of the naming and routing scheme, and is what enables efficient

Chapter 2. Background 9
content distribution in an ICN. It involves caching and duplication mechanisms, caching policies,
cache space management, as well as deployment and dynamic update of caching information for
joint optimization.
Security
Today’s Internet was designed based on a trusted environment, and utilizes add-on services
like firewalls to achieve security goals. In contrast, security is raised as a primary and required
function in ICNs, and covers topic such as data integrity, entity (content and host) authentication
and verification, cryptographic key management, access control, etc.
Because ICN is an on-going project in which little clear consensus has been reached for any of the
components, the four topics listed above are also active fields for research efforts. Pros and cons of
various ways of implementing the components in some of the projects have been discussed in [24].
2.2 Content Centric Networking
Content-Centric Networking (CCN) [1,20] from the Named Data Network (NDN) project [31] is one of
the many Information Centric Networking prototypes drawing much research attention recently.
2.2.1 Advantages of the CCN Approach
In this thesis project we choose to follow CCN’s architecture for designing and implementing our
system, because it provides the following additional benefits in comparison to other ICN approaches:
CCNx open source project
The most important reason why we choose CCN as the basis of our design is the CCNx open
source project [20]. CCNx is a fully functional Linux-based application conforming to the CCN
protocol. Its source code is available to the public through CCNx website [20] and is based on
popular languages: the low-level control and management routines are written in C for high
performance, and the high-level APIs are provided in Java for extensibility.
CCNx is helpful to us in 2 ways: firstly it implements all essential components of a practical ICN
system in a very accessible way. Any new components or modifications we make can utilize
the existing functions, reducing the development time of our project. Secondly CCNx provides
a window through which we can gain confident insights into the behavior and performance of
a practical ICN system, a fundamental requirement to our project which other ICN approaches
cannot provide.

Chapter 2. Background 10
CCNx-based application prototypes
In addition to the implementation of the CCN protocol itself, CCNx and its APIs also lead to a
range of applications developed by other researchers. Some example applications include point to
point message passing (ccnchat), file sharing (the repository ccnr), video streaming (VLC plugin),
voice (VoCCN [27]), and automated traffic generation (ccntraffic and ccndelphi [45]). These
available applications enables us to quickly test our own implementation, and to evaluate it under
various realistic use case scenarios.
Optional human-readable content names
Besides the CCNx code, CCN also possesses some helpful features defined in its protocol, one of
which being the naming scheme. CCN uses hierarchical strings of arbitrary length as the content
names, which is explicitly visible in the packet headers. While it may have its own pros and
cons, the optionally human-readable content names can be helpful to both implementation and
debugging of our project. By capturing the packets, we are able to directly see and analyze the
packet transactions.
Support from existing devices
Another characteristic of the CCN protocol is its transport layer implementation: CCN uses IP as
its transport layer support, and is proposed as an IP overlay. The choice of IP overlay instead of a
more “clean slate” approach enables direct deployment over existing Internet devices, and allows
coexistence of CCN and other IP traffic [1]. We see this design decision a positive feature because
it allows fast prototyping on existing networking devices. At the same time the open nature of
CCNx does not lock our project on IP-based devices as long as the interface is compatible. In
addition, the SAVI testbed is based heavily on OpenFlow [46, 47] for its networking capability,
which supports IP extensively. As a result the IP transport of CCNx minimizes any possible
compatibility issues between our project and the SAVI hardware.
2.2.2 CCN Architecture Overview
This section provides a brief overview of the CCN Architecture. We focus on the components most
relevant to our project, and therefore will not cover all the details about CCN protocol. A complete cov-
erage of the CCN architecture is provided in [1], and details of the CCNx protocol and implementation
can be found on the CCNx website at [20].

Chapter 2. Background 11
�
Content Name
Interest Structure
Selector
Nonce
Content Name
Data Structure
Signature
Signed Info
Data
Figure 2.1: CCN chunk structure
CCN Chunk Types
The CCN protocol categorizes any traffic in a CCN network into one of the two types: Interest and
Data (Fig. 2.1). The basic units of information exchange in CCN are referred to as chunks. Similar to an
IP network, chunks transferred in a CCN network have two parts: header and payload. Unlike in IP
packets, the headers of CCN chunks have variable length and therefore are logically defined.
Interests are sent out by content consumers as requests for content. An Interest contains only a
header without any payload and consists of three components: a Content Name used to described what
content the consumer is interested in, a Selector describing additional filtering if multiple Data match the
current Interest, and a Nonce to distinguish Interests with the same Content Name for avoiding Interest
looping. The lengths of Content Name and Selector can be variable based on amount of information
they contain, while Nonce is usually a randomly generated binary value of fixed length.
Data are sent out by content providers in response to any received Interests. A CCN Data consists
of both header and payload, and is typically much larger in size than Interests due to the addition of
payload. The Data header comprises three components: a Content Name describing the content of
the payload, a Signature containing information such as digest algorithm and witness, and a Signed
Info field containing publisher ID, key locator, stale time, etc. The Signature and Signed Info field
work together to provide security-related features such as authentication and authorization in a CCN
network.
According to the CCN protocol, a Data chunk is said to ‘satisfy’ an Interest if 1) the Content Name
in the Interest is a prefix of the Content Name in the Data, and 2) the Data passes any additional
filtering defined by the Selector in Interest. It is worth to mention that this definition and the structures
described in Fig. 2.1 are all based on the canonical CCN protocol defined in [1]. CCNx adds much
more implementation-level details and one additional packet type (control messages) which we will not
explain here due to space limitation. More information is available on the documentation page of CCNx

Chapter 2. Background 12
website [20] as well as documentations in the code base.
Information Exchange on CCN
Information exchange on a CCN network is initiated by any content consumer sending out Interests to
its immediate neighbor nodes as a request for Data. Any node that receives an Interest but does not
hold a copy of the requested Data will keep a copy of the Interest and forward the Interest to whom
it believes may know where to find the Data. Once the Interest reaches a node with the request Data,
whether it is a routing node or the content provider, the Interest is consumed, and the requested Data
is sent back to the content consumer through the same route as the Interest but in reverse order. This is
possible because each node traversed by the Interest holds a copy of the Interest (called pending Interest)
with the interface from which it arrives. All pending Interest are consumed as well when the Data
traverses the network back to the content consumer. More details on how each CCN node handles
Interest and Data chunks are discussed in Section 2.2.2.
Packet Aggregation in CCNx
In this thesis we deliberately use the word chunk to refer to the basic unit of CCN transaction because
one CCN chunk usually does not map to one IP packet directly. This is because the large size of a CCN
chunk header relative to the 1500 byte maximum transmission unit (MTU) of a non-jumbo Ethernet
frame. As a typical CCN header can have anywhere between 50 to 1000 octets, little space would be left
for content payload if every IP packet were to contain the full header. To avoid excessive overhead, a
CCN node ‘aggregates’ chunks sent to the same destination by interface, and encapsulates CCN chunks
into IP packets with necessary segmentation. Such transport level segmentation (CCN chunk to IP
packets) happens in addition to the application level segmentation (content to CCN chunks).
In the CCNx implementation, aggregation of CCN chunks to IP packets is handled automatically by
socket GNU C libraries and the Linux network stack: applications construct CCN chunks (which can
be either Interest or Data) and push them through sockets, which perform necessary segmentation and
encapsulation transparent to the application.
Naming
As mentioned in the previous section, CCN incorporates a hierarchical naming scheme with optionally
human-readable components. Typically a CCN name defines a tree structure much like the URLs used
in today’s Internet. The root of the tree structure is a globally routable name, which is a content name

Chapter 2. Background 13
understood by all relevant CCN nodes. The leaves are referred to as organizational names, which are only
resolved by CCN nodes within the organization. The name trees with different roots collaboratively
describe the name space containing all the possible content names.
In addition to the American Standard Code for Information Interchange (ASCII) string describing
the content, a CCN name is suffixed by components for versioning and segmentation of the data.
This typically binary (non-ASCII) part of the name is usually automatically generated and handled by
applications, and it contains crucial information for versioning and transport sequencing in CCN. More
information on the topic can be found in [1].
XML Formatting and Binary Encoding in CCNx
In CCNx, the content name is only one part of a chunk. Unlike in IP networks where each packet is
divided into fixed length headers and variable length payload, chunks in CCNx networks do not have
any fixed length fields. Instead, data chunks in CCNx implementation are formatted using Extensible
Markup Language (XML) schema with explicit field boundaries.
The XML-formatted chunks in CCNx support extension of application-specific components in ad-
dition to the canonical components defined in the CCN protocol such as content name and chunk type.
Users or developers of CCNx can define their own chunk components and remain backward compatible
to the vanilla CCNx node implementation because any unrecognized header components are ignored
by default. However such improved extensibility flexibility come at the cost of low performance in
CCNx header resolution. We will discuss this further in Chapter 4.
The XML-formatted chunks are not transmitted directly on CCNx networks in human readable
form. Instead, the wire format of CCNx chunks is a binary encoding of the XML structure. The utility
used for binary encoding and decoding in CCNx is called ccnb. ccnb defines a fixed order of components
within a CCNx chunk, so that the binary encoding of the same chunk has the same bit sequence for
transmission regardless of what order is used in its human-readable representation. More information
about the ccnb specifications can be found on [20].
CCN Node Model: the 3 Components
A CCN node can be abstracted as a core forwarding engine with multiple faces. A face is a generalized
notion of interface: it can represent not only the hardware network interface through which communi-
cation with other CCN network entities is realized, but also the logical interface used for exchanging
information with attached applications. CCN chunks arrive at the faces, longest prefix matching is

Chapter 2. Background 14
Figure 2.2: CCN node model [1]
performed on its content name, and based on the matching results actions are taken on the chunks.
The core forwarding engine of a CCN node contains three main components: Content Store (CS) ,
Pending Interest Table (PIT) , and Forwarding Information Base (FIB) (Fig. 2.2).
The Content Store is the key component for realizing in-network caching. Similar to the memory
buffer in IP routers, a Content Store temporarily stores any Data chunks passing through the CCN node.
The difference is that CS in a CCN node uses additional filtering and caching policies to define which
CCN chunks to cache and how replacement is done.
The Pending Interest Table stores any unsatisfied Interest chunks forwarded towards the content
sources. It keeps a copy of any incoming pending Interests with the face from which they come from,
which is ‘consumed’ when matched Data chunks are sent back to the content consumers. PITs are
necessary because routing in CCN is done only on Interests: Data simply trace back the Interests
requesting them.
The Forwarding Information Base acts much like FIBs in IP routers and is used to route Interest
chunks towards potential content sources. The difference between a CCN FIB and a FIB in IP routers is
that the CCN FIB allows multiple outgoing faces, which implies that routing in CCN is not restricted to
a spanning tree: multiple potential sources of content can be queried in parallel.
To illustrate how the three components of a CCN node function, let us consider a CCN chunk arriving
at one of the faces of a CCN node. First of all, the node identifies the type of the incoming chunk as
either Interest or Data. In the case of an incoming Interest, it is first checked against the Content Store.

Chapter 2. Background 15
If any matching entry is found, meaning a cached Data satisfies the incoming Interest, the matched
Data is sent directly to the face Interest comes from, and no further action is needed. If the CS look-up
misses, the Interest is then looked up in the Pending Interest Table. Any matched entry means there are
already pending Interests recorded at this node possibly from other faces, and the incoming face of the
current Interest is added to the list of faces interested in such Data without the current Interest being
forwarded. If the PIT look-up misses too, the incoming Interest is first recorded in the PIT, then looked
up for the final time in the Forwarding Information Base. If a matching entry is found, the Interest is
forwarded according to the matched entry; otherwise, it implies that the incoming Interest cannot be
resolved by the current node, and the CCN protocol requires the incoming Interest to be dropped to
avoid flooding of Interest on network.
In the case of an incoming Data chunk, its name is first looked up in Pending Interest Table. If no
matching pending interest is found, the incoming Data is said to be unsolicited and should then be
discarded as it may be the result of a system malfunction or even malicious attack. If any number of
entries in the PIT can be satisfied by the incoming Data, the Data is forwarded to all the requesting faces
of every matched pending Interest, and all matched pending Interest are erased from PIT because they
have been satisfied. Before it is finally forwarded, the Data chunk is added to Content Store for future
Interests.
The logic flow described above on how a CCN node resolves incoming chunks is also illustrated in
Fig. 2.3.
Transport: Reliability and Flow Control
CCN is designed as an IP overlay, implying that it relies on an IP stack for underlying network
substrate. Comparing to other more “clean-slate” ICN approaches, CCN presents a much simpler
solution for features of networking and lower layers by assuming IP connectivity, and it enables CCN
to be incrementally deployed on existing Internet infrastructure. However the use of IP protocol stack
also imposes certain limitations on current CCN design. The fundamentally point-to-point nature of
IP goes against the content-based network model. We believe much work remains in bringing CCN
forward without assuming IP dependency, but this will be the topic of a future project.
According to the CCN protocol, CCN does not require a reliable network substrate. This implies
that Interests and/or Data can be corrupted during transport. In addition, communications over CCN
are consumer-driven, and the content providers are stateless. As a result, any unsatisfied Interest needs
to be resent by consumers upon certain conditions such as a time-out. This effectively constructs a

Chapter 2. Background 16
Incoming CCN chunk
Interest or Data?
Pending Interest Table (PIT)
Look-up
Content Store (CS)Look-up
Interest Data
Match?Send Data back, consume Interest
Yes
Pending Interest Table (PIT)
Look-up
No
Match?Add incoming face,
drop InterestYes
No
Forwarding Information Base
(FIB) Look-up
Match?
Yes
Forward Interest
NoDrop Interest
Match? No Discard Data
Yes
Content Store (CS) Insertion
Forward Data
Figure 2.3: CCN node forwarding logic flow

Chapter 2. Background 17
host-to-host reliability model in which hop-by-hop reliable transmission is not guaranteed by CCN
nodes.
Similarly, flow control is also handled by content consumers by how they send out Interests. CCN
protocol requires that Interest and Data chunks are one-to-one, i.e. exactly one Data chunk is delivered
in response to one Interest by any CCN node. This maintains a flow balance within the network at each
hop, and allows CCN Interest chunks to be used as tools of achieving flow control by applications much
like the ACK packets in Transmission Control Protocol (TCP).
2.3 Smart Application on Virtual Infrastructure
The NSERC Strategic Network for Smart Applications on Virtual Infrastructure (SAVI) [48] is an initiative
building a large scale testbed for research in future Internet applications. SAVI envisions an application
platform in the form of an extended cloud infrastructure with extremely large scale computing, storage,
and network resources. Some of the characteristics of SAVI testbed include: agile resource management,
scalability, reliability, accountability, security, interconnect and federation, and rapid deployment of
applications [49].
SAVI has five research themes: smart applications, extended cloud computing, smart converged
edge, integrated wireless optical access, and SAVI application platform testbed. A detailed description
of each theme is provided in [50]. In this thesis project, we focus on the last theme, i.e. the SAVI
application platform testbed, as explained in the upcoming subsection.
SAVI Testbed for Networking Experiments
The application platform testbed of SAVI is designed and implemented to help researchers to overcome
the difficulty in deploying and testing new networking applications at scale. The testbed takes the form
of federated smart-edge clusters from which researchers can reserve a variety of resources isolated from
other users or projects.
In terms of implementation, SAVI testbed demonstrates the following key technology highlights:
• Infrastructure-as-a-Service (IaaS) cloud capability, including computing, storage, networking,
dashboard, identity management, and image services, enabled by OpenStack [51];
• Software defined networking (SDN) capability enabled by OpenFlow [46, 47];
• Network virtualization through resource (bandwidth, link, port, etc.) slicing using FlowVisor [52];

Chapter 2. Background 18
• Software defined infrastructure (SDI) capability enabled by SAVI SDI Manager, which is currently
under development.
These technologies connect and enable a wide variety of hardware as available resources to SAVI
users. Some of the key hardware available to users include:
• High performance multi-CPU server blades called Computing Agents, which are available in the
form of virtual machines (VM);
• Dedicated machines called Baremetal (BM) with dedicated gigabit Ethernet connectivity. Baremetal
comes with a variety of flavors including high performance, low power, and legacy support;
• Highly parallel co-processors such as general purpose graphic processing units (GPGPU) attached
to high performance Baremetal;
• Programmable hardware available both as attached devices (NetFPGA [53, 54]) to high perfor-
mance Baremetals and as standalone network devices (BEE2 and miniBEE development plat-
forms [55]);
• OpenFlow enabled switches available as slices through FlowVisor.
These resources, together with the underlying technologies supporting them, make the SAVI testbed
a preferred platform over other cloud services or computing facilities for designing, implementing, and
evaluating our project due to the following reasons:
• Variety of available resources enables a larger design space and more design alternatives;
• Flexible edge-core architecture of SAVI allows prototyping and experimentation in different envi-
ronments;
• Federation of SAVI edges and highly scalable SAVI core enables testing and experiments at scale;
• Software defined infrastructure allows more transparency and control over resources from users’
perspective through knowledge of physical topology, ability to suggest physical host of virtual
instances, etc.
In addition, because the SAVI testbed is a relatively young project itself, we are able to enjoy the
additional benefits of 1) a more controlled environment due to the low number of active users and
running projects, and 2) more interactions with the testbed development group for requesting features
and enhancements at the cost of occasional system instability.

Chapter 3
Related Work
In this chapter we go over some of the existing works related to this thesis. Specifically we will cover
three areas: the ICN testbed initiatives around the globe, literature on improving the performance of
CCN or other ICN approaches, and high performance content-centric router designs.
3.1 ICN Testbeds
In Section 2.1.3, we gave a list of major ICN-themed initiatives. Though most of them are still research
projects under development, some of the projects have reached the stage of testing and evaluation on
testbeds. We surveyed a few of the ICN testbeds because we believe they are closely related to our goal
of designing, implementing, and evaluating an ICN prototype on SAVI testbed.
NDN testbed
As part of the Named Data Networking (NDN) project, the NDN testbed is an open initiative
running CCN on a large scale [56]. Essentially, the NDN testbed deploys the CCNx software
on a slice of the Global Environment for Network Innovations (GENI) testbed [57], and uses
OSPFN [58] as the routing solution. As of the time this thesis is written, NDN is actively running
and collaboratively maintained by many universities and research facilities in the U.S. A video
streaming application was demonstrated during CCNxCon2012 using the NDN testbed [59].
The main goal of NDN testbed is to study the different components of current CCN design,
and push the specifications forward towards standardization. Although performance is one
of the metrics under investigation, it is not the main concern for NDN project and its testbed
deployment.
19

Chapter 3. RelatedWork 20
CONET on OFELIA
Initially described in [60], CONET is a ICN framework within the CONVERGENCE project [41].
The implementation of CONET is described in [61] as coCONET, and is designed based on a
software defined network enabled by OpenFlow. The discussion is extended in [62] to describe a
plan of deploying CONET on OpenFlow-enabled testbeds, or specifically the OFELIA (OpenFlow
in Europe - Linking Infrastructure and Applications) project [63]. In a more detailed technical
report [64], CONET researchers propose to use dedicated Boundary Nodes to interface between
traditional IP networks and CONET ICN, both based on IP network stack enabled by OpenFlow.
In practice, the implementation of CONET is based on CCNx, with focus on CONET-specific
lookup-and-cache forwarding mechanisms and transport [42]. Little information is publicly
available on the OpenFlow-specific features of CONET implementation beyond [64].
PURSUIT testbed
PURSUIT [33] is an EU FP7 project proposed as a more “clean slate” approach towards ICN.
Unlike CCNx and its derivatives, it does not require IP stack, and is designed based on Ethernet.
The resulting prototype implementation is named Blackadder and is publicly available as an open
source project. Blackadder is developed based on the Click Router [65] platform, and its testbed
deployment relies on OpenVPN [66] to create a virtual Ethernet substrate over Internet with
IP-based equipment.
Similar to the NDN testbed, the PURSUIT testbed is used mainly for functional verification and
testing of the PURSUIT prototype. Performance is not one of the primary objectives.
NetInf testbed
The Network of Information (NetInf [36]) on EU FP7 project SAIL is an ICN initiative focusing on
caching content in the Internet and re-expressing them as information objects. In NetInf, centralized
servers are used to find and cache content from Internet in real-time, and clients queries data from
the servers using content descriptions (names). Its implementation, OpenNetInf [35] consists of
both server and client applications. The servers are publicly available as preconfigured virtual
machines, and clients as plugins for Mozilla Firefox® browser and Mozilla Thunderbird® email
client. Source code for both server and client applications are also available.
NetInf testbed is a complete set of virtual NetInf nodes run by the NetInf development group,
and is used for testing purposes only as substitute for local NetInf nodes. Performance is mostly
considered in NetInf protocol specifications and OpenNetInf design, without being emphasized

Chapter 3. RelatedWork 21
on testbed deployment.
3.2 Performance of CCN
Though performance is currently not one of the major concerns on existing ICN testbeds, much research
effort has been put on improving performance of ICN systems from a variety of angles.
As one of the fundamental component of any ICN, in-network caching is a topic drawing much
attention. [67] shows through mathematical analysis and simulations that simple caching policies such
as Least Frequently Used (LFU) can give significant performance improvement by reducing average
hop count when compared to ICNs without in-network caching. Building on the most basic caching
policies, a large variety of caching mechanisms are proposed and evaluated, and performance improve-
ments beyond simple LFU or LRU caching are demonstrated usually through numerical analysis or
simulations. Some examples of existing work on alternative caching policies include: [68], [69], [70]
and [71] on various forms of collaborative caching among ICN peers, [72] on diffusive caching, [73] on
probabilistic caching, and [74] on selective neighbor caching.
Another area of research related to improving ICN performance is on the layer of networking and
transport. [75] discusses congestion avoidance in data-centric opportunistic networks and recommends
high data refresh rate for optimal delivery efficiency. [75] discusses the economic incentives behind
routing policies in NDN and proposes the use of Cache Sharing between peers and Routing Rebates
between customers and provides. [76] introduces Potential Based Routing (PBR) for ICN and Cache
Aware Target idenTification (CATT) caching policy, and demonstrates their potential of achieving near
optimal routing performance using simulations. [77] proposes to simplify the existing CCN forwarding
structure and argues that their design can achieve 1Gbps forwarding performance with software and
10Gbps with hardware acceleration through numerical analysis. [78] proposes Popularity-Aware Load
Balancing for content networks and shows that differentiating popular and unpopular content favors
multi-path routing patterns in simulations. [79] investigates segmentation and chunk sizing in ICN and
recommends segmentation of data chunks into smaller units for reliability and congestion control.
In addition to the above, research has also focused on performance in ICN. For example, [80]
evaluates CCN performance with different storage management algorithms on a testbed; [81] looks at
alternative data structure implementation and algorithms for Content Store in CCNx to improve CS
hit probability; [82] analyzes the performance implication of content integrity check in a more generic
system with in-network caching; [83] proposes a wrapper to enable CCNx on Ethernet substrate without
IP and shows it lowers the latency; and [84] introduces parallelization to FIB lookup and shows that

Chapter 3. RelatedWork 22
system performance is improved using either bloom filter or hash table as the lookup algorithm.
3.3 CCN Router Designs
Another research topic highly related to this thesis is the design of high performance content centric
routers. In [85], researchers evaluated the bandwidth, latency, and cost of current state-of-the-art
hardware in the context of the three key components of a CCN router (CS, PIT, and FIB). Conclusion
drawn is that with today’s technology, hardware implementation of CCN can support traffic up to the
scale of a campus or service provider network but not the Internet. The same group of researchers
extend the discussion to [86], in which Caesar, a hardware implementation of CCNx-compatible router
is proposed. Two key design decisions are made in [86]: 1) one forwarding engine is attached to each
physical interface, and is responsible for a subset of the entire CS, PIT, and FIB; 2) hardware bloom filter
is used to filter incoming packets, and packets that cannot be handled by current interface are routed to
the correct interface through a switching fabric internal to all physical interfaces.
Besides Caesar, other work on CCN router designs include: [87] provides an alternative content
centric router design on programmable hardware with emphasis on the Content Store and supporting
operations (however like Caesar, the design is evaluated by simulation only); [88] discusses 3 different
memory structures for realizing a generalized name lookup table for CCN nodes; and [89] focuses
specifically how Pending Interest Table can be implemented in CCN routers.

Chapter 4
Bottleneck Analysis and Service
Decomposition of CCN
4.1 Motivation
The goal of this thesis project is to design and implement a high performance CCN routing solution on
SAVI tesbed. Though [1] gives a thorough explanation of the CCN protocol (see Section 2.2.2 for some
of the highlights), we have little knowledge about the practical implementation of CCN (i.e. the CCNx
project) beyond the limited documentation in [20], which are also quite out of date. Before setting out
for the actual design, however, it is crucial for us to understand the performance metrics and current
bottlenecks of the existing CCN implementation.
Specifically, we dedicate this chapter of the thesis to answering the following questions:
• What is the performance of the current CCN implementation, or specifically, how fast can CCNx
process CCN chunks (Interests and Data)?
• What is the bottleneck in the current CCNx project limiting its performance?
• If we were to build our system using CCNx, what specific functional module(s) should we work
on in order to avoid or relieve the bottlenecks?
23

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 24
4.2 CCNx Performance Benchmark and Bottleneck Analysis
To understand the real performance and bottlenecks of a practical CCN implementation, we believe it
is necessary to go beyond numerical analysis and simulations. As a result, we decide to deploy CCNx
software on SAVI and to systematically evaluate its performance under realistic traffic load.
4.2.1 Experiment Setup
We set up our performance evaluation experiments on SAVI using vanilla CCNx 0.7.1 on a combination
of virtual machines (VM) and baremetal (BM). We ran the ccnd routing daemon on a baremetal with
Intel® Core™i7 CPU at 3.6GHz and 16GB RAM. This baremetal acted as the single routing node
without consuming or generating CCN chunks, and all performance measurements were conducted
on it. Connected to the routing node were 4 virtual machines instantiated on SAVI computing agents.
Each VM had access to one virtual CPU at 2.2GHz with 2GB RAM. Among the 4 VMs, 2 of them ran
ccndwith ccntraffic, and the other 2 ran ccndwith ccndelphi.
ccntraffic and ccndelphi from [45] are a pair of traffic generating applications running on CCNx.
When deployed, ccntrafficgenerates CCN Interest chunks according to a predefined list, and ccndelphi←↩
generates CCN Data chunks with a specified root name. We utilize these two applications throughout
our thesis work for testing and evaluation purposes because they provide a simple way of generating
realistic CCN traffic with arbitrary predefined patterns. In addition, because ccntraffic generates In-
terests and ccndelphi generates Data, we commonly refer to CCN nodes running ccntraffic as content
consumers or clients and those running ccndelphi as content providers or servers.
We chose to use baremetal on SAVI testbed for our performance analysis because of 2 reasons: firstly,
it has the most powerful CPU (Intel® Core™i7 3.5GHz) for executing single-threaded application, which
should give a good estimation on the best possible performance metric of CCNx running on current
commercial state-of-the-art hardware; secondly, instances running on baremetals have exclusive access
to the hardware, which minimizes influences external to the running CCNx program.
For our benchmarking experiments, we logically connected the 2 server nodes and 2 client nodes
directly to the routing nodes using ccndc commands. The resulting topology and direction of packet
flow are shown in Fig. 4.1
For all experiments, CCNx was configured to run in TCP mode; servers were configured to generate
Data chunks with payload of 1024 bytes; software on all 5 nodes were compiled using GNU C compiler
version 4.6.3 and ran on 64-bit Ubuntu 12.04 LTS. We also turned compiler optimization off because we
used GDB to step through the code as a way to study the code. More discussion on this topic will be

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 25
������������������������������������������
Routing Node
Server_2
������������������������������������������
Client_2
������������������������������������������
Client_1Server_1
Interests
Data
Figure 4.1: Experiment topology for performance benchmarking
presented in the later sections of this chapter.
We constructed 2 scenarios for evaluating CCN and studying its bottlenecks: unique content name
case and shared content name case. Under unique content name settings, Server 1 and Client 1
exchanged information based on content name pattern ccnx:/gen/1/chunk index, while Server 2 and
Client 2 were configured to use content names ccnx:/gen/2/chunk index, where chunk index is simply
an integer starting as 0 and increases. In contrast, for shared content name case, both clients sent Interest
of format ccnx:/gen/chunk index to the routing node, and both servers could generate Data satisfying
the Interests. These cases cover the two extremes of possible traffic scenarios: unique content name,
on the one hand, represents the ‘worst’ use case for CCN in which no content transferred from any
server to a client can be re-used by another client, and Content Store in each node is not providing
any benefit because CS look-ups from Interests always miss. Shared content name, on the other hand,
represents the ‘best’ traffic scenario for CCN because Data used to serve the early Interests are cached
in the Content Stores on the routing node, and are used to satisfy all subsequent Interests from other
clients before the Data expire. This reduces the delay and bandwidth resulting from the communication
between the routing node and servers and thus improves the overall system performance.
4.2.2 Performance Benchmarking Results
Preliminary evaluation of CPU usage and throughput
As a first step, we benchmarked vanilla CCNx on SAVI testbed using the experiment settings described
above. We measured two metrics on the routing node: CPU usage of the ccnd process and total inbound
and outbound throughput. All the ccnd instances were configured with the same default settings (e.g.
Content Store size set to 50000). The experiments were first run for approximately 3 minutes after clients
started sending Interests for the system to reach steady state. Then during the next 100 seconds CPU

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 26
Experiment setting ccnd CPU usage Inbound data rate (MB/s) Outbound data rate (MB/s)Unique content names 71.02% 5.70 5.69Shared content names 69.41% 5.11 9.31
Table 4.1: CPU usage and throughput of vanilla CCNx
usage measurements were taken using the top utility at a rate of 1 instantaneous reading per second.
The readings were average after 100 such measurements were taken. The throughput measurement in
megabytes-per-second (MB/s) was taken using the ifconfig command by dividing the total amount of
inbound and outbound traffic by 100. Every experiment setting was run 3 times, and results were shown
in Table 4.1 by averaging the measurements for the 3 runs. All data rates shown are in megabytes-
per-second (MB/s). Number of IP packets transmitted through the physical interface is not shown in
the table because they do not directly translate to number of CCN chunks per second processed due
to packet aggregation in CCNx (Section 2.2.2). Instead, CCN chunks processed can be estimated1 by
assuming size of Interests and Data chunks being 500 bytes and 1500 bytes respectively.
It can be seen from Table 4.1 that though the CPU is not at full load, the data rate for both unique
content name and shared content name cases are far below the 1 gigabit-per-second (Gbps) link capacity
of the routing node: assuming 70% CPU usages corresponds to at most 50% of the full capacity of the
routing nodes, we expect a maximum throughput of 23MB/s or 184 megabit-per-second (Mbps) for
unique content name case, and a maximum throughput of 30MB/s or 240Mbps for shared content name
case. There is plenty of room for improvement if we were to set 1Gbps as our design goal. Similar
observation is also described in [77].
It is interesting to note that the effect of in-network caching can be clearly seen from Table 4.1: for
shared content name case, outbound data rate (data to clients) is 1.83 times the inbound data rate (data
from servers). As a comparison, the ratio of outbound to inbound data rate is 1.00 for unique content
name case.
Header processing time
While the above experiments evaluated the performance of CCNx prototype on a system level, they did
not provide much insight in performance of header processing on a chunk-level. In order to quantify
how much time it takes to process each CCN chunk and to understand how CCNx implements the
chunk forwarding mechanism, we identified the part of the code which performs Interest and Data
header processing, and re-ran the experiments to measure how much time it took each function call of
1CCNx provides API which measures the chunk-per-second rate on each face. However from our experiments we found thatsuch probing is expensive and invoking the API frequently degrades the performance of the system. As a result, we generallyavoided using the API when conducting performance-sensitive readings.

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 27
XXXXXXXXXXMetricsSettings Unique Names Shared Names
Interest Data Interest DataTotal Number of Chunks 210,129 209,928 347,682 213,926
Mean (µs) 71.65 93.11 72.55 95.44Median (µs) 70 91 72 94
Std. Dev. (µs) 22.12 35.62 24.44 35.50
Table 4.2: Statistics on header processing time for Content Store size = 50000
processing Interest or Data header to return.
The experiments were first run with Content Store size set to the default value of 50000. We take
measurements as soon as clients started sending Interests, and recorded processing time of both Interest
and Data chunks for approximately 200 seconds. Readings from the first 100 seconds were discarded
as system reached steady state (Content Stores fully populated) at the end of the first 100 seconds. The
measured processing times for the later 100 seconds are plotted in histogram as Fig. 4.2 for both unique
content name setting and shared content name setting. Some of the key values for the two runs are
summarized in Table 4.2.
A few observations can be drawn from Fig. 4.2 and Table 4.2: first of all, the total count of Interest
and Data chunks sampled is well below the typical value for a CCNx node operating under normal
conditions. This is because that probing the processing time for each and every CCN chunk placed a
significant I/O overhead which only exists within the settings of this experiment. Secondly, processing
each Data chunk takes approximately 20 microseconds more than processing one Interest, and such
difference is consistent across both unique and shared name cases. The extra 20 microseconds processing
time for Data chunks came from the calculation of Data Digest. Further discussion on this topic is
provided in Section 4.2.3. Thirdly, processing time for Interests or Data does not differ much for unique
and shared name settings, though Fig. 2.3 suggests a shorter flow for shared name case because CS-
matched Interests skip PIT and FIB look-ups. This implies that looking up PIT and FIB takes negligible
amount of processing time in the actual CCNx implementation under our experiment settings.
After revisiting the chunk logic flow defined in CCN protocol (Fig. 2.3), we realized that for our
experiments, the sizes of both PIT and FIB are small compared to CS: Content Store can cache up to 50000
CCN data chunks, while FIB contains only a few routes and PIT holds around a few hundred pending
interests. To verify that searching and modifying the Content Store are the most time-consuming part
of processing a header, we repeat the above experiments with Content Store size set to 02. Results of
this run are shown in Fig. 4.3 and Table 4.3.
2The current CCNx implementation does not support turning off the Content Store. By setting CCND CAP environmentalvariable to 0 for ccnd, every Data chunk cached will time out in a short period of time, effectively allowing minimal Data chunksharing between interfaces.

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 28
05
101520253035404550
10 20 30 40 50 60 70 80 90 100
110
120
130
140
150
160
170
180
190
200
200+
No
. of
CC
N C
hu
nks
(*
1000
)
Chunk Header Processing Time (us)
Unique Names, Content Store Size = 50000
Interest
Data
0
10
20
30
40
50
60
70
80
10 20 30 40 50 60 70 80 90 100
110
120
130
140
150
160
170
180
190
200
200+
No
. of
CC
N C
hu
nks
(*
1000
)
Chunk Header Processing Time (us)
Shared Names, Content Store Size = 50000
Interest
Data
Figure 4.2: Histograms showing header processing time for each individual Interest and Data chunkfor Unique Name (top) and Shared Name (bottom) settings, with Content Store size set to 50000
XXXXXXXXXXMetricsSettings Unique Names Shared Names
Interest Data Interest DataTotal Number of Chunks 213,750 213,525 328,919 304,324
Mean (µs) 31.84 52.35 31.11 54.58Median (µs) 30 51 32 53
Std. Dev. (µs) 11.77 17.43 15.01 16.23
Table 4.3: Statistics on header processing time for Content Store size = 0

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 29
0
20
40
60
80
100
120
10 20 30 40 50 60 70 80 90 100
110
120
130
140
150
160
170
180
190
200
200+
No
. of
CC
N C
hu
nks
(*
1000
)
Chunk Header Processing Time (us)
Unique Name, Content Store Size = 0
Interest
Data
0
20
40
60
80
100
120
140
10 20 30 40 50 60 70 80 90 100
110
120
130
140
150
160
170
180
190
200
200+
No
. of
CC
N C
hu
nks
(*
1000
)
Chunk Header Processing Time (us)
Shared Name, Content Store Size = 0
Interest
Data
Figure 4.3: Histograms showing header processing time for each individual Interest and Data chunkfor Unique Name (top) and Shared Name (bottom) settings, with Content Store size set to 0

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 30
Comparing the results from Table 4.2 and Table 4.3, it is clear that most of the time spent on
processing chunk headers are for operations on Content Store: for Interests, processing time dropped
from more than 70 microseconds to approximately 30 microseconds (40µs or 57% reduction), and for
Data, processing time decreased from approximately 92 microseconds to 52 microseconds (40µs or 44%
reduction). The reduced processing time (approximately 40µs for both Interests and Data) accounts for
the processing time spent in looking up Content Stores. More discussions on such observation will be
presented in the next section.
4.2.3 Data Chunk Digest: Calculation and Impact on Performance
One key observation we made from measuring the header processing time is that processing Data
chunk headers consistently takes approximately 20 microseconds more than Interest headers. This is
somewhat unexpected according to the CCN protocol’s specifications Fig. 2.3 because the logic flow for
processing Data chunks is shorter than that for Interest chunks. The outdated CCNx documentation
provided little explanation on this issue as well. After further analysis on the code using a combination
of debugging tools and finer grain benchmarking, we found that the extra 20 microsecond comes mainly
from the calculation of Data digest.
The Data digest is a hashed value of one Data chunk. In CCNx, nodes use SHA-256 algorithm
to compute the digest of a Data chunk upon its arrival. The digest is used to uniquely identify a
specific Data chunk for matching and filtering operations. The CCN protocol specifies the inclusion of
digest calculation algorithm and its version but not the digest itself for two reasons: 1) each CCN node
is allowed to calculate and use digest values according to its specific needs, and 2) the digest is seen
as a redundant information of the Data chunk itself and should not be transmitted for the purpose of
conserving bandwidth.
While both are valid considerations, calculating the digest for each Data chunk on-the-fly at every
CCNx node it visits is not optimal from the perspective of performance. According to our observation,
the processing time or CPU power spent on calculating Data chunk digest at each CCNx node is a
significant performance overhead which can easily be avoided by including the digest value in the
header as a fixed-length component instead of a description of digest algorithm. The bandwidth
overhead for this approach should not be significant either, as the digest value has a small size (32 byte
for SHA-256) comparing to the typical size of a Data chunk (> 1000 byte). Such approach, however,
requires modification to the CCN protocol as all nodes now must agree on a single digest algorithm
and version should they decide to calculate the digest from the Data payload. As a result, we put this

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 31
Settings Content Store size = 50000Unique Names Shared Names
Rank Function Name CPU Time Function Name CPU Time1 ccn_skeleton_decode 51.89% ccn_skeleton_decode 49.57%2 content_skiplist_findbefore 5.60% content_skiplist_findbefore 6.62%3 ccn_buf_advance 5.51% ccn_buf_advance 4.46%4 ccn_compare_names 4.46% ccn_parse_Signature 4.18%5 ccn_parse_Signature 3.96% ccn_compare_names 4.09%
Other functions 28.58% Other functions 31.08%Total 100% Total 100%
Settings Content Store size = 0Unique Names Shared Names
Rank Function Name CPU Time Function Name CPU Time1 ccn_skeleton_decode 45.28% ccn_skeleton_decode 42.47%2 hashtb_hash 6.52% hashtb_hash 7.23%3 ccn_buf_advance 4.78% ccn_parse_Signature 4.15%4 ccn_parse_Signature 3.55% content_skiplist_findbefore 3.90%5 ccn_compare_names 3.26% ccn_buf_advance 3.43%
Other functions 36.61% Other functions 38.82%Total 100% Total 100%
Table 4.4: Top 5 time-consuming functions in CCNx under various settings
modification as one of the future works as in this thesis project we aim to stay compatible with the
current CCN protocol.
4.2.4 Bottleneck Analysis
Through the previous benchmarking, we drew the conclusion that operations on Content Store is
currently the most time-consuming within a CCNx node. However, it is still unclear what specific
operation(s) or function(s) are the bottlenecks. In this section we try to address the bottleneck of
the CCNx implementation by using the gprof profiling tool to identify from the function level which
operation or component of the system is the limiting factor in CCNx’s header processing capability.
We ran the same set of experiments again with profiling compiler option on, and the results are
summarized in Table 4.4.
Surprisingly, the profiling results showed that around half of the CPU processing time was spent on
functions related to chunk header decoding (ccn_skeleton_decode and ccn_buf_advance). In particular,
the lowest-level function for header decoding ccn_skeleton_decode consumed up to 52% of the CPU
time.
As a review, CCN header decoding is the process of parsing a CCN chunk header from its binary
encoded bit stream to XML-formatted structure for CCNx forwarding engine. We then investigated why
such seemingly trivial routine (comparing to the actual table manipulation operations on CS, PIt, and

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 32
FIB) is taking much of the processing power of a CCNx forwarding engine, and found that it is related
to how the Content Store is implemented today. In CCNx, Data chunks are cached in Content Store in
encoded format for 2 reasons: 1) encoded chunk headers are much smaller in size and therefore are more
space efficient, and 2) encoded Data chunks can be sent out directly upon matching of any incoming
Interest without the need of re-encoding. In addition, Content Store uses a skip list of encoded headers
as index, and any search or modification operations on skip lists have complexity O(log n) where n is
the size of the Content Store, which invokes O(log n) header decoding operations on the cached Data
chunk headers. A similar observation is made by the authors of [77].
Additionally, initial parsing and validity check of the incoming chunk as well as header comparison
between incoming chunk and PIT entries also involve calling ccn_skeleton_decode. This explains why
ccn_skeleton_decode function consumes much CPU time even when Content Store size is set to 0. We
also noticed that for all of the experiment settings above, memory usage on the routing node never
exceeded 500MB, which is much less than the physical memory available (16GB). Furthermore, the
ccn_skeleton_decode function does not involve any I/O operations, implying that I/O is also not the
factor limiting the throughput of the CCNx routing node.
Based on the above observations we conclude that the throughput of the current CCN implementa-
tion is limited by the processing power of each CCN node. Specifically, the CCN protocol relies heavily
on the name decoding functions for packet header processing, which is the performance bottleneck for
the CCNx prototype.
4.3 CCNx Node Service Decomposition
4.3.1 Augmented Functional Flow for Interest and Content Chunks
From the studies conducted so far, we realize that the simple logic flow of a CCN forwarding engine as
described in Fig. 2.3 does not provide sufficient level of detail in describing the actual implementation of
CCNx. In particular, it failed to signify the bottleneck component within the system and key functions
to the system performance.
To address this issue, we augmented Fig. 2.3 to include our findings through the previous bottleneck
analysis. The effort also serves as the first step towards presenting our design for high performance
content centric networking. The result is shown in Fig. 4.43.
In addition to identifying the parts of the system influenced by the demanding name decoder
3Average run time for each part of the flow marked in Fig. 4.4 are only rough approximations due to the disturbance introducedto run time by probing the system.

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 33
Incoming Message
Initial Decode & Parse
Check Integrity and Validity
Interest
Calculate Digest
Pass
PIT Exact Match
Pass
FailDiscard Interest
Discard Interest
Found
Name Prefix Lookup
Not Found
Name Prefix Insertion
Not Found
CS Skiplist Lookup
Check Additional
Filters
Found
510
Found
FIB Longest Prefix Match
Not Found
Consumes Interest and
Prefixes
Match
Not Match
Forward Matched Content
45
Modify PIT (Add New Interface)
Forward Interest
10
520
CS LookupExactMatch
Discard Content
Update CS
No Match
PIT Lookup
45
Discard Content
NotMatch
Consume Matched PIT
Entries
Match
Note:• Red names represent functional blocks which invoke
ccn_skeleton_decode or related name coding/decoding functions;
• Vertical numbers represent approximated average run time for each part of the flow with roughly 50000 Content Store entries and small PIT and FIB (< 1000 entries).
1010
Forward Content
Check Integrity and Validity
Data
FailDiscard Content
Figure 4.4: Augmented functional flow of CCN forwarding logic

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 34
(marked by red names), we added a few blocks representing functions which we believe play a vital
role in a practical CCN system. These include:
• Initial Decode & Parse for both Interest and Data: upon arrival of any CCN chunk, the entire
header is decoded and parsed to identify the chunk type. A sanity check is also performed on the
header to ensure format and version compatibility.
• Check Integrity and Validity for both Interest and Data: before analyzing the chunk headers, the
integrity and validity of the entire chunk is checked using the negotiated security measurement.
This step is optional according to the CCN protocol specification.
• Name Prefix Lookup and Name Prefix Insertion for Interest: for processing Interest, a list of all
name prefixes understood by the current CCN node is managed by both PIT and FIB. In CCNx
it is implemented as a hash table and is called Name Prefix Hash Table. Any new name prefixes
introduced by incoming Interest chunks must be registered in the name prefix so that they can be
looked up or referenced in the future.
• Check Additional Filters for Interest: Interest chunks can specify additional filter in their header
if necessary. One use case example is if two or more data chunks use the same content name, a
content consumer can specify a filter to exclude uninterested data chunks using Data digests. Such
filtering happens after matching Data chunk(s) are found in CS but before Interest is consumed
and Data is forwarded.
• Calculate Digest for Data: as discussed in Section 4.2.3, the digest of a Data is calculated upon
its arrival at any CCN node. While we believe much can be debated regarding the efficiency of
such practice, Calculate Digest is included here to ensure compatibility with the CCN protocol
specifications.
A few interesting observations can be drawn from Fig. 4.4. Firstly, as discussed previously, CS lookup
consumes the most processing time for both Interests and Data among all functional blocks. Behind this
observation is the bottleneck functions responsible chunk header decoding. All blocks involving header
decoding are marked with red names in the figure. These blocks are potential parts for performance
improvement in the flow as by optimizing the name decoder, we can reduce the processing time for
these blocks. Secondly, CS lookup is the first lookup performed for any valid Data chunks and the
second for Interests in CCN regardless of the lookup results from PIT and FIB. This puts a fundamental
limit on the overall system performance as chunk header processing cannot be faster than the CS lookup

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 35
for both Interest and Data. Thirdly as discussed previously, the “Calculate Digest” block for Data chunk
processing is a significant overhead and can be easily removed if Data Digest is included in Data chunk
header. This is a potential topic for future research as in this thesis we restrict our design within the
existing CCN protocol specification.
Before concluding this section, it is worth noting that Fig. 4.4, though augmented and improved
from the simplistic logic view of CCN chunk processing, is by no means a complete coverage of
all implementation details. This is because we do not wish to limit our discussion to the CCNx
implementation by including details such as data structure and algorithm used by CCNx. If the reader
is interested, however, more information on how CCNx implements each functional block can be found
in [77].
4.3.2 Extracted Service Model of a CCN Router
Based on Fig. 4.4, we extracted the service model of a CCN router. A service is defined as a group of related
functions which act together as a core component of a CCN node. We identified 6 services critical to the
functionality for a CCN node, which are:
Pre-processing
When incoming IP packets or Ethernet frames arrive at the network interface of a CCN node, it
is first assembled to CCN chunk. Before further processing happens, the checksum and digital
signature of the CCN chunk are verified to ensure chunk integrity and validity. Only upon passing
these sanity test should a CCN chunk proceed to the next stage. In the case of multiple CCN chunk
arriving at rate faster than the node’s processing capability, the incoming chunks will be queued.
The Processing Scheduler then determines from the queue which chunk should be processed next,
enforcing any necessary QoS policies. Only the decoded chunk header will be included in the
look-up requests sent to the 3 tables (CS, PIT, and FIB) by the Processing Scheduler. Essentially,
any necessary function prior to looking up the chunk header in the CS, PIT, or FIB will be included
in the pre-processing service.
CS, PIT, and FIB Services
As the three main components defined in the CCN specification, each of the CS, PIT, and FIB will be
grouped with their corresponding look-up handlers and modification handlers as a core service.
The look-up handler is responsible for any read (look-up) request from Processing Scheduler in
Pre-processing, and will report the look-up results to the Decision Engine in Post-processing. In
contrast, the modification handler will listen to any table update request (e.g. replacing entries

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 36
Shared Name Prefix List
Network Interfaces
Pre-processing
Packet-to-Chunk Aggregation
Integrity and Validity Check
Processing Scheduler
Post-processing
Decision Engine
Forwarding Engine
Chunk-to-Packet Segmentation
PIT Service
PIT Look-up Handler
PIT Modification Handler
Pending Interest Table
CS Service
CS Look-up Handler
CS Modification Handler
Content Store
FIB Service
FIB Look-up Handler
FIB Modification Handler
Forwarding Information
Base
Name Codec
Name Encoder
Name Decoder
Dictionary
Figure 4.5: CCN node model highlighting the 6 core services

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 37
in CS, consume pending interests in PIT, add FIB entries, etc.), and is responsible for keeping the
tables up-to-date while maintaining integrity. It also needs to resolve any read-write or write-write
conflicts to the tables. As a side note, the PIT and FIB services have the option to share one name
prefix list to keep a consistent view on the available name prefixes, similar to what is currently
implemented in CCNx.
Post-processing
After table look-up results are given by each of the CS, PIT, and FIB services, a Decision Engine
will collect the results and give necessary action(s) according to the logic described in Fig. 2.3.
The Decision Engine can output two types of actions: 1) table modification requests which will
be handled by the Modification Handler of corresponding table, and 2) chunk forwarding in-
structions which will be handed to the Forwarding Engine. The Forwarding Engine will then
obtain the designated CCN chunk from either input queue or Content Store buffer (in the case of
a satisfied incoming Interest) and forward it to the correct interface with necessary segmentation
for transmission.
Name Codec
Because the current CCN implementation relies heavily on the name decoding function, it deserves
more considerations than other services when performance is a key design requirement. For this
reason we extract it with the name encoder as a dedicated service named Name Codec. The Name
Codec can potentially interact with any other service, particularly the Pre-processing, CS, and PIT
services, to support conversion between XML formatted header and its binary encoded version.
A Dictionary is also included in the Name Codec to represent the collection of rules defining the
binary encoding scheme.
The 6 core services of a CCN node and their interactions are illustrated in Fig. 4.5. Upon the arrival of
CCN packets, it is first handed to the pre-processing service by the network interface. In pre-processing
stage, packets are assembled into chunks, and its type (Interest, Data, or control message) is determined.
The name decoder is invoked for the first time for the incoming chunk for initial parsing and integrity
check. The integrity and validity of the CCN chunk is checked using the attached digital signature.
Once these checks pass, the header of the chunk is sent to the table services (CS, PIT, and FIB services) by
the Processing Scheduler, which is the module responsible for initiating table look-up activities based
on the chunk type.
For an Interest chunk, its header is first sent to the PIT Service for exact match look-up. If exact
match is found by the PIT Look-up Handler, the result is given to the Post-processing Service which

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 38
will discard the incoming Interest. If no exact match is found in PIT, the header is given to the Name
Prefix List shared by both PIT and FIB Services for necessary name prefix insertion. The Interest header
is then given to the CS Service where the CS Look-up Handler looks the name up and determines
whether there is a cached Data chunk matching current Interest. Upon finding a match, the matching
Data is given directly to the post-processing service for forwarding. If not match is found in CS, the
Interest header is given to the FIB Service. Based on the result returned by FIB Look-up Handler, the
Interest is either discarded (no FIB entry found) or sent to PIT Modification Handler for registering
the pending Interest. Interactions between CS Service and Name Codec Service can be frequent as
Content Store keeps only the encoded version of cached Data chunks, and therefore whenever the
header of a potentially matching Data chunk needs to be checked for additional filters, Name Decoder
is called to decode the cached Data header. PIT Service also needs to consult the Name Decoder for PIT
exact match, though possibly less frequent. After the table services finished processing the header, the
entire Interest is handed to the Decision Engine in Post-processing Service, where forwarding decision
(discard or which outbound face to forward to) is made and results given to the Forwarding Engine.
The Forwarding Engine then arranges the correct outbound face for forwarding the Interest to and
re-encapsulates the chunk into packets for transferring to the next hop.
Similarly for a Data chunk, the flow between services also follows that described in Fig. 4.4. A few
difference worth noting in comparison to the Interest chunk flow is that in the Pre-processing Service,
the digest needs to be calculated before sending it to the table services with the Data chunk header.
The digest calculation module is not shown in our service decomposition because we believe it is
non-essential and should be eliminated in future revision of CCN protocol for improved performance.
The CS Modification Handler is used by Data chunks exclusively and is responsible for implementing
the cache replacement policies. Also for Data chunks the header is only sent to CS and PIT Services
for look-up as well as modification because FIB is not used for forwarding Data. The functionality
of Post-processing Service remains roughly the same, which handles discarding or forwarding of the
entire Data chunk based on the CS and PIT look-up results.
4.4 Concluding Remark
In this chapter, we started with an experimental evaluation of the current CCN implementation, the
CCNx prototype. We evaluated its throughput performance under realistic traffic load, and found much
space for improvement before reaching the 1Gbps check mark. A set of bottleneck analysis followed
the performance benchmark, and demonstrated that the limiting factor for existing CCN nodes is the

Chapter 4. Bottleneck Analysis and Service Decomposition of CCN 39
computation power. Specifically, we discovered that the functional modules responsible for decoding
the CCN chunk names are consuming approximately half of the processing power. It is worth noting
that for the bottleneck analysis, we take a similar approach as described in [77]. While the authors of [77]
used gprof to profile CCNx 0.4.0 release, we used the same tool to profile CCNx 0.7.1 release. Though
both [77] and our work concluded that ccn_skeleton_decode and related header decoder functions are
the bottleneck of the CCNx implementation, we discovered that the ccn_skeleton_decode consumes
even higher percentage of CPU time in the latest CCNx release.
In the second half of this chapter, we used the information gathered to augment the node logic flow
defined in CCN protocol. The resulting flow captured some of most important details of the current
CCN node design, with estimation of processing time used on each function for average CCN chunks.
A extracted functional module was also presented to highlight the key services of a CCN node and their
interactions.
With the help of both the augmented node flow and the extracted service model, we are now ready to
discuss design alternatives for high performance CCN networking on SAVI testbed in the next chapter.

Chapter 5
SAVI CCN Design Alternatives
In the previous chapter, we presented our studies on the performance and bottlenecks of the current
CCN prototype, i.e. the CCNx project. Based on the observations and analysis presented, we start
this chapter with a summary of the design requirements and criteria for our CCN-over-SAVI project.
After a brief review of SAVI user topology and available resources, we propose 5 design alternatives
for implementing high performance CCN system on SAVI. For each design alternative, we focus our
presentation on the architectural design with mapping of SAVI resources to the key components. The
advantages and limitations of each alternative are also discussed at a high level.
5.1 Design Requirements and Criteria
After studying the performance of the current CCN prototype, we propose the following requirements
and criteria for our design of CCN on SAVI:
• Performance: our design needs to reach 1Gbps throughput when serving Data chunks to multiple
clients under maximal load. This goal implies an improvement with at least a factor of 4 over the
existing CCNx prototype;
• Scalability: the system should be able to adjust its resource usage based on load demand. Though
resources on SAVI testbed can scale as needed, building a system that takes full advantage of SAVI
resources can be challenging;
• Compatibility: the system should be compatible with the current CCN protocol and should
support existing CCN applications;
40

Chapter 5. SAVI CCN Design Alternatives 41
�
ORION
Edge U of T
Core U of T
Edge UWaterloo
Edge YorkU
Edge UVictoria
Edge McGill
Partner Networks
Partner Networks
Edge UCarleton
Figure 5.1: SAVI testbed user topology [2]
• Implementation and evaluation: a preliminary implementation of the system needs to be devel-
oped and evaluated on SAVI testbed within the time frame of this thesis project.
5.2 SAVI Testbed User Topology and Resources
In this section, we revisit the SAVI testbed with focus on its topology and available resources from a
testbed user’s perspective.
The SAVI testbed consists of multiple edge nodes and a core node. These are essentially clusters of
computing resources interconnected by dedicated Layer 2 network substrate. SAVI nodes are located
at geographically separate sites, with the exception of the Toronto edge node (TR-EDGE-1) and the core
node (CORE), which are both hosted on University of Toronto campus. The topology is illustrated in
Fig. 5.1.
The topology within each SAVI node typically varies from node to node. In general, each SAVI node
features one or more computing agents and optionally baremetal resources interconnected by one or more
OpenFlow-enabled Ethernet switches. Computing agents are usually server blades with large amount
of computing resources (virtual CPU and memory) used for hosting virtual machines (VM). Networking
between VMs on one agent and between VMs and external network is handled by the Open vSwitch
(OVS) software switch. Baremetal resources are special hardware devices without a virtualization layer,
and can be reserved by a project for exclusive access.
In this thesis we base our design considerations and resource mapping strategies primarily on
TR-EDGE-1 and CORE, because 1) TR-EDGE-1 features a wide range of specialized hardware as BMs
including parallel co-processors (i.e. General Purpose Graphic Processing Units, or GPGPUs), pro-

Chapter 5. SAVI CCN Design Alternatives 42
grammable devices (NetFPGA 1G and 10G, BEE2 and miniBEE), and processors with low power
consumption (Intel® Atom™CPU); 2)CORE provides the largest amount of virtualized resources for
scalable VM deployment.
The OpenFlow-enabled network substrate of SAVI testbed is realized collaboratively by hardware
switches and OVS, both of which support OpenFlow Switch Specification up to Version 1.0.0 [90]. This
implies that while simple manipulations on headers of up to Layer 4 are supported based on flows
defined by these headers, any operation requiring deep packet inspection (DPI) such as CCN header
analysis cannot be performed at line rate. It is also worth noting that as of the time this thesis is
prepared, most network links between devices within a SAVI node as well as between SAVI nodes have
the capacity of 1Gbps, though several 10Gbps bandwidth upgrade projects are ongoing for some of the
major links.
5.3 Alternative 1: Header Decoder Optimization
The first approach we propose is directly motivated by the bottleneck analysis on CCNx presented in
the previous chapter. We have shown in Section 4.2 that under typical operating conditions, around 50%
of the CPU processing time was spent in ccn_skeleton_decode and other decoding-related functions,
which is in fact the limiting factor in the performance of existing CCNx nodes. Similar results were
also presented in [77]. It therefore follows that if we manage to optimize the main function responsible
for header decoding, namely ccn_skeleton_decode, we can reduce the overall CPU usage of ccnd←↩
routing daemon, and in turn improve the throughput of the CCNx software routers. In other words,
the objective of this design alternative is to optimize the CCN header decoder so it runs faster while
keeping the behavior of the system unchanged.
It is worth noting that although [77] categorizes the effort of optimizing specific components in
CCNx as engineering work, and claims such effort being insignificant and uninteresting, we believe the
opposite is true for two reasons: firstly in order to construct a high-performance system, it is not only
preferred, but also sometimes necessary to tune each component to operate with optimal efficiency;
secondly, and more importantly, investigating and optimizing the existing solution help us understand
better the system bottleneck, i.e. the parts that we should pay special attention to when we investigate
other design alternatives.

Chapter 5. SAVI CCN Design Alternatives 43
5.3.1 SAVI Resource Mapping
Because header decoder optimization is completely based on existing CCN implementation and uses
CCNx prototype directly, the required resources for this approach will not go beyond what CCNx
currently supports. Any computing instance running Linux operation system can be used to instantiate
a complete CCN node with optimized header decoder. Moreover, the computing instance only needs
one single CPU, because the CCNx software implementation is single-threaded and will not benefit
from multicore CPUs. Its memory requirement, though based on the table sizes of CS, PIT, and FIB,
would be reasonably low as suggested by our previous experiment results.
Though such computing instance can be deployed as either virtual machine or baremetal, we
recommend using baremetals for optimal system performance for 2 reasons: 1) some baremetals are
equipped with CPUs running at higher frequency than servers, making them faster in executing single-
threaded applications, and 2) baremetals do not have the overhead of virtualization similar to the virtual
machines.
5.3.2 Advantages
The header decoder optimization design alternative has 3 clear advantages over other approaches we
propose. These advantages are:
CCN Compatibility
Since this design is completely based on the existing CCNx prototype, maintaining compatibility
with current CCN protocol is easy. In fact if we only modify the implementation of header
decoders without introducing functional modification, the instantiated CCN node should operate
just as before, with the only difference being faster header processing. In other words, for header
decoder optimization we do not introduce any system-level modification and rely completely on
the original CCNx architecture for implementing CCN nodes.
Potential for Integration with Other Approaches
Header decoding remains one of the core services of a CCN node as long as CCN chunk headers are
transmitted in binary encoded format, which is one of the main specifications of CCN protocol.
This implies that any design alternative we propose compatible to the current CCN protocol
will include a header decoder in some way. As a result, our work here on optimizing the header
decoder can potentially be integrated with other design alternatives to further improve the system
performance.

Chapter 5. SAVI CCN Design Alternatives 44
Easy Implementation
Another advantage of using CCNx as the basis of our design is the ease of implementation. In
fact if our sole target is to optimize the header decoder in CCNx, implementing the design will be
mostly software engineering work. Testing and verification are expected to be relatively simple
too as much of the existing testing framework for CCNx can be directly used.
5.3.3 Limitations
This proposed approach has a few obvious drawbacks as well. Many limitations of the original CCNx
implementations are directly inherited, which include: limited efficiency of software implementation,
overhead of Linux network stack, no utilization of parallel computing resources, limited flexibility and
extensibility as IP overlay, etc.
The performance gain from optimizing header decoder will also be quite limited: the bottleneck
analysis showed that up to half of the CPU processing time is spent on name decoding for CCNx.
Even by assuming the most optimistic case in which the bottleneck is completely eliminated and header
decoding costs negligible CPU time, the throughput could be doubled but still fall short from our 1Gbps
objective. To fully understand how much performance gain we can expect, however, requires actual
implementation and evaluation on SAVI testbed, whose effort we believe is still worthwhile.
5.4 Alternative 2: Parallel Table Access within Single Node
One of the major limitations of the previous design approach is the single threaded implementation of
CCNx: it limits the utilization of processing power to single CPU instances. Due to the fundamental
limit of the clock frequency, sequential logic such as the forwarding engine of CCNx can only execute
within the hardware limit and will not scale well. As a result, parallelization is essential for scaling our
design beyond the single CPU capability.
This design alternative describes one of the first parallelization options we investigated: parallel
table access within a single CCN node. Processing each CCN chunk involves looking up the chunk
header in one or more of the three core components of CCN forwarding engine, i.e. Content Store,
Pending Interest Table, and Forwarding Information Base. Though CCN protocol specifies an ordered
sequence of accessing these tables as shown in Fig. 2.3, the same resulting actions can be determined
by accessing the three tables simultaneously. Specifically, we propose to allow simultaneous lookup in
CS, PIT, and FIB for processing CCN chunk headers within a single CCN node.

Chapter 5. SAVI CCN Design Alternatives 45
We start from Fig. 4.4 by grouping the functional blocks into 4 stages as following:
• Stage 1: Pre-processing, which includes everything from initial decoding and parsing up to but
not including PIT look-up for Interest and CS look-up for Data;
• Stage 2: Table Look-up, which includes all functions reading from the 3 tables, i.e. CS, PIT, and
FIB;
• Stage 3: Table Update, which includes all functions writing to the 3 tables, and,
• Stage 4: Post-processing and Forwarding, which includes all functions called after table modifi-
cations are completed.
Within the Table Lookup stage and the Table Update stage, operations done on each of the three
tables can be performed in parallel, because reading from and writing to each table does not logically
depend on other tables. To realize such parallelization, we propose to add two collaborating modules
to the header processing work flow: a table look-up event dispatcher, and a decision engine (Fig. 5.2). The
event dispatcher will be responsible for launching the requests at the end of Pre-processing stage to
the 3 table services, and signaling the launch to the decision engine. The decision engine registers the
requests sent, and waits until look-up results (read results) are collected from all 3 table services at the
end of Table Look-up stage. Based on the look-up results, the decision engine launches table update
requests to appropriate table services and handles necessary Post-processing tasks.
Because chunk processing is no longer sequential, the logic implemented by the decision engine for
this design alternative needs to be slightly modified to handle multiple simultaneous inputs (look-up
results from the Table Look-up stage) and outputs (requests to proceed to Table Update stage). The new
logic together with the modified function flow for both Interest and Data chunks is described in Fig. 5.2.
5.4.1 SAVI Resource Mapping
We propose the parallel table access within single node design as a modification to the existing CCNx
scheme. As a result, the required SAVI resources are similar to that of the previous design alternative,
i.e. VM or BM running Linux operating system supporting CCNx.
One difference should be noted however: for this design alternative, we can take advantages of
multi-core CPUs up to 4 cores (one for each table service plus one for event dispatcher and decision
engine) as a result of the introduced parallelization.

Chapter 5. SAVI CCN Design Alternatives 46
Fail(2)
Initial Decode & Parse
Integrity and Validity Check
PIT Exact Match
Fail
Discard Interest
Name Prefix Lookup
Not Found
Name Prefix Insertion if (1)
AND (2)
Not Found(1)
CS Skiplist Lookup
Check Additional Filters
Found
5
10
FIB Longest Prefix Match
Not Found(a)
Consume Interest and its Name
Prefixes
Pass
Fail(b)
Forward Matched Content
45
PIT Modification (Add New
Interface) if ((a) OR (b)) AND (c)
Found(c)
Forward In terest
10
Incoming Interest
Interest
10
Pre-processing
Table Look-up
Table Update
Found
Post-processing &Forwarding Discard Interest
Not Found
PassTable Look-upEvent Dispatch
Decision Making
Initial Decode & Parse
Integrity and Validity Check
PIT Lookup(Including
Additional Filters)
Fail
Discard Data
CS Update (Insert New Data)
CS Lookup
5
10
Exact Match
Consume Pending Inte rests and
Name Prefixes if (I) AND (II)
Forward Data
45
Incoming Data
Data
10
Pre-processing
Table Look-up
Table Update
Not Found
Post-processing &Forwarding Discard Data
Pass
Table Look-upEvent Dispatch
Decision Making
Calculate Digest
20
No Exact Match (II)
No Exact Match��������
Note:• Ver tical numbers represent estimated average run
time for each part of the flow with roughly 50000 Content Store entries and small P IT and FIB (< 1000 entries) in microseconds (us).
Figure 5.2: Functional flow for parallel table access within single node

Chapter 5. SAVI CCN Design Alternatives 47
5.4.2 Advantages
As we plan to use CCNx again as the underlying framework, for parallel table access within single node
we still enjoy the advantages of full compatibility with CCN protocol and easy implementation similar
to that of the optimized header decoder approach.
In addition, we expect the performance to be higher than that of simply optimizing the header
decoder, as multiple parts of the originally sequential logic can now be executed in parallel. Theoretically
this leads to less real-world clock time in processing the same CCN chunk header, which in-turn results
in higher node throughput.
5.4.3 Limitations
Though we expect improvements in performance from parallelized table access, such improvements
can be quite limited. Based on our benchmarking results for the time each functional block takes to
execute (numbers shown in Fig. 4.4), we estimated the time for each part of the parallel table access
design, and similarly marked the time in microseconds in Fig. 5.2.
According to our estimation, in the best case where Interests cannot be found in CS or PIT and Data
can be found in PIT, the maximum processing time for each CCN header can be reduced from 70us to
60us for Interests and from 90us to 80us for Data. On the one hand, larger PITs and FIBs can leads to
more improvements as sequential logic will suffer more from longer PIT and FIB look-ups, on the other
hand, however,we expect the actual improvement under our use case to be less than this because our
estimation optimistically assumes zero overhead from parallelization.
As a result, one of the major limitations of parallel table access within single node is the limited
improvements. Scalability is another issue because this solution will not scale beyond one multi-
core computing instance. Many CCNx-bound limitations also remain such as overhead of software,
inflexibility of IP overlay, etc.
5.5 Alternative 3: Distributed Chunk Processing with Synchronized
Table Services
In the previous sections, we described two design alternatives based on existing CCNx software imple-
mentation. While they both demonstrate certain advantages and potential in improving the performance
of CCN prototype, they suffer from the limitations inherent to the CCNx implementation. Starting from

Chapter 5. SAVI CCN Design Alternatives 48
this design alternative, we “zoom out” from the functional view of a CCN node, and shift our focus
more onto the service level of a CCN routing system.
The limited performance improvement for the previous design alternative, i.e. parallel table access
within single node, is due to the architecture that only one processing engine is implemented for each
CCN node. In other words, CCN chunks arriving at different interfaces queue before they are picked up
one at a time by the Pre-processing stage. As a result, the overall system performance is limited by how
fast the single forwarding engine can process CCN headers. To deal with such limitation, we propose to
duplicate the functionality of one CCN processing engine and distribute them across multiple instances
called processing units. Each processing unit has one or more physical ports, and is responsible for
analyzing and forwarding all CCN chunks arriving at its port(s).
In this design, each processing unit has one copy of all 3 table services (CS, PIT, and FIB), and
performs look-ups and updates directly on its local copy. As a result, the tables on each processing units
must be kept synchronized of any change in order to route CCN chunks arriving at different interfaces
correctly. To perform such task, a synchronization module is implemented on top of the 3 table services.
Upon any change in the local tables, the synchronization module generates and sends synchronization
messages containing the full change to other peer processing units. The synchronization module is also
responsible for receiving and applying any synchronization messages sent by other processing units.
Fig. 5.3 illustrates our designed service model for distributed chunk processing with synchronized table
services.
As in any distributed system with synchronization requirement, it is possible to run into synchro-
nization conflicts for this design alternative. For example considering a 3-unit system as shown in
Fig. 5.3. Assuming the cache replacement policy implemented for all units is Least Recently Used
(LRU), it is possible for Unit 2 to send a message updating the timer on the entries of a cached data,
while Unit 3 sends a message deleting it for a new Data at the same time. Under such circumstances, all
3 units need to work together to resolve the conflicting updates and propagate the final decision. The
synchronization module must be able to resolve such conflicts in a timely manner, which may not be
trivial.
Furthermore, delays associated with sending and processing synchronization messages can also
cause other complications such as out-of-sync tables or incorrect chunk discard. While we do not aim
to provide a comprehensive solution to all issues mentioned above due to the limitation of this thesis,
we wish our discussion above provides a direction towards which future research can proceed.

Chapter 5. SAVI CCN Design Alternatives 49
Pre-processing
CS/PIT/FIB Services
Network Interface
2
Name Codec
Post-processing
Processing Unit 2
Table Synchronization
Messages
TableSynchronization
Messages
Table Synchronization Messages
Synchronization Module
Pre-processing
CS/PIT/FIB Services
Network Interface
1
Name Codec
Post-processing
Processing Unit 1
Synchronization Module
Pre-processing
CS/PIT/FIB Services
Network Interface
3
Name Codec
Post-processing
Processing Unit 3
Synchronization Module
Figure 5.3: Service model for distributed chunk processing with synchronized table services

Chapter 5. SAVI CCN Design Alternatives 50
5.5.1 Out-of-sync Tables and “Good enough” Table Look-ups
Another issue with the table synchronization approach proposed in this design is the overhead intro-
duced by synchronization operations. Our proposal relies on table synchronization because to process
each CCN chunk, an up-to-date view of all three tables is required. This poses a significant amount
of load on the synchronization module, as each CCN chunk processed can alter the content of at least
one of the tables. This reflects CCN’s approach towards a stateful node design as oppose to the stateless
design of IP routers.
One way to deal with such overhead is to send the synchronization in batches according to some
predetermined time interval. For example, instead of sending one synchronization message every time
some update occurs, the synchronization module can keep a buffer storing all updates happen in a
few milliseconds and send out one message containing all the updates buffered. This will significantly
reduce the total number of synchronization messages sent, saving network bandwidth as well as
processing power for each synchronization module.
However, synchronization batching inevitably causes tables to be out-of-sync during the time inter-
val between synchronization messages are received. As a result, one question rises naturally: are “good
enough” table look-ups, i.e. look-ups done on partially synchronized tables sufficient for the correct
functionality of a CCN node?
To answer this question, we investigate possible outcome from both false positive and false negative
look-up results. On the one hand, false negative or false positive alone mostly causes undesired packet
drop or excessive Interest forwarding, which can degrade the system performance depending on the
probability of false negative results. On the other hand, combination of false positive and false negative
results can lead to more subtle issues such as circulation of Interests and flooding of Data. In either case,
additional exception handling mechanisms must be added to the synchronization module and possibly
table services to ensure correct system behavior.
At the current stage of development, many of the open questions remain unanswered. It is also not
clear how much performance degradation is expected from “good enough” table look-up results. As a
result, while it remains a viable option, we recommend against the use of out-of-sync tables and “good
enough” table look-ups.
5.5.2 SAVI Resource Mapping
Since the proposed synchronization module as well as the messaging protocol can be prototyped in
software, virtual instances and baremetals with multi-core CPUs (one additional processor core for

Chapter 5. SAVI CCN Design Alternatives 51
synchronization module) are still feasible options.
In addition, each processing unit can be implemented using programmable hardware as long as the
device has sufficient amount of memory (approximately 1GB). On the topic of implementation using
programmable hardware, [86] presents a preliminary design of CCN router on NetFPGA platform.
Though their design is quite different, many of the ideas such as using bloom filter to implement
longest prefix matching can be a valuable reference.
5.5.3 Advantages
By duplicating and distributing header processing units onto multiple instances, we remove the lim-
itation of single processing engine. Therefore the main advantage of distributed processing with
synchronized tables is its better scalability compared to the previous two designs: theoretically we can
keep increasing the number of distributed processing units to scale up the routing capability of the
system, with the assumption of an efficient synchronization mechanism.
5.5.4 Limitations
We realize that a perfect synchronization mechanism is very difficult, if not impossible to implement.
As a result, the main limitation is of this design alternative is the possible new bottleneck introduced
by synchronization of tables.
In fact in the worst case, we expect the performance of this design to be worse than that of the
single-threaded solution if a naive synchronization mechanism such as “one message per update” is
used, because the overhead of sending messages and synchronizing the tables can be so high that each
processing unit wastes most of its time waiting for tables to be synchronized.
5.6 Alternative 4: Distributed Chunk Processing with Central Table
Service
To deal with the synchronization issue in the previous design alternative, we investigated a different
strategy of realizing a global view of the table services for all processing units. The resulting design is
described in this section as distributed chunk processing with central table service.
The key idea behind this design alternative is simple: instead of letting each processing unit keep
a local copy of all the tables and try to synchronize them, we can use a separate, centralized entity to

Chapter 5. SAVI CCN Design Alternatives 52
Pre-processing
Network Interface
1
Name Codec
Post-processing
Processing Unit 1
Shared Name Prefix List
CS Service
CS Modification Handler
Content Store
CS Look-up Handler
PIT Service
PIT Modification Handler
Pending Interest Table
PIT Look-up Handler
FIB Service
FIB Modification Handler
Forwarding Information
Base
FIB Look-up Handler
Table Service Unit
Decision Engine
Requests
Responses
Pre-processing
Network Interface
2
Name Codec
Post-processing
Processing Unit 2
Decision Engine
Requests
Responses
Pre-processing
Network Interface
3
Name Codec
Post-processing
Processing Unit 3
Decision Engine
Requests
Responses
Name Codec
Figure 5.4: Service model for distributed chunk processing with central table service
manage the tables. Each processing unit, whenever necessary, sends look-up or update requests to the
central table services and uses the returned results to make decisions on next-step actions.
The service model of the design is illustrated in Fig. 5.4. A few differences can be noticed comparing
to Fig. 5.3: first of all, the table services of each processing unit are extracted into a separate instance called
table service unit. As a result, each processing unit is simplified to contain 3 services: pre-processing,
name codec, and post-processing; secondly, multiple table look-up handlers are implemented for each
table at the table service unit to allow simultaneous look-up (read) from multiple processing units. In
contrast, however, only one modification handler is implemented for each table in order to resolve
conflicting modification requests collectively. This also helps avoid table write race condition as all

Chapter 5. SAVI CCN Design Alternatives 53
modification requests will be queued and handled sequentially.
The techniques discussed previously in Alternative 1 and 2 can also be applied here: optimized name
decoder can be used on all processing units and table service unit for faster chunk name processing,
and parallel table look-ups can be allowed by encapsulating multiple look-up requests in the request
messages.
5.6.1 Chunk Processing Pipelining
One challenge we must face when offloading table services to a separate instance is the latency of sending
requests and receiving responses. In a realistic Ethernet-based network, latency across one switching
device can be in the order of microseconds to tens of microseconds [91]. Including other overhead on
the end devices, the total time for requests and responses to reach their corresponding destination can
be comparable to the total time needed for processing chunks by a single threaded software application
(e.g. CCNx). In other words, if each processing unit waits until one chunk processing is finished before
starting the next, its performance can be worse than the single-threaded software solution.
We propose to deal with the network latency by pipelining the chunk processing. Consider a stream
of CCN chunks arriving at one processing unit. Chunk 1 reaches pre-processing and launches requests
to the table service unit for table look-ups. While waiting for the results to come back, chunk 1 is buffered
and the pre-processor starts to work on chunk 2. By the time look-up results come back from the table
service units, post-processor picks up the buffered chunk 1 and decides what actions to take next, while
pre-processor may already have sent out look-up requests for chunk 2 and started processing chunk
3. As a result, by allowing the pre-processing and post-processing modules of one processing unit to
work on different CCN chunk simultaneously, we can improve the average time it takes to process one
chunk, and in-turn improve the overall system performance.
5.6.2 Optionally Centralized Name Codec Services
Another design alternative we considered as a variation of the central table service approach is to
centralize the name codec service as well. This proposal is motivated by our observation that name
decoder is the most computationally demanding module in the current CCNx system. The idea is to
use specialized hardware such as programmable devices to implement header decoder and possibly
achieve faster header decoding on average. However this will add even more network latency to the
chunk processing pipeline, and the benefits may not justify the extra complexity. As a result, we reserve
the proposal of such centralized name codec approach as another design alternative, and recommend

Chapter 5. SAVI CCN Design Alternatives 54
duplicating name codec at all processing units as well as table service unit for now.
5.6.3 SAVI Resource Mapping
Similar to Alternative 3, processing units can be instantiated either using software on multi-core virtual
machines or baremetal resources, or using hardware on programmable devices such as NetFPGA. The
hardware approach is more attractive for this design approach because the requirement of large memory
has been removed.
The table service unit, on the other hand, prefers specialized hardware supporting massive paral-
lelization. This is because the large number of simultaneous requests it needs to handle potentially.
For this reason, we recommend using baremetal with co-processors for software approach, and large
programmable devices with sufficient memory for hardware approach
5.6.4 Advantages
Comparing centralization of table services to keeping multiple synchronized copies of the tables, the
system no longer needs to deal with the frequent synchronizations loading all the peer processing units.
As a result, we expect the central table service approach to be simpler to implement and gives better
overall performance than Alternative 3, while the system still enjoys the scalability brought by using
multiple processing units.
5.6.5 Limitations
While centralization of table services brings many potential benefits, it also creates new limitations for
the system. Since the performance of the entire system depends more than ever on the table services
now, the central table service unit must be carefully designed and implemented to avoid becoming the
new bottleneck. In addition just like many other systems with centralized components, the table service
unit can prevent system from scaling up beyond certain limit once its capacity is reached. It also creates
a potential single point of failure for the system as every processing unit now depends on the services
it provides.

Chapter 5. SAVI CCN Design Alternatives 55
5.7 Alternative 5: Distributed Chunk Processing with Partitioned
Tables
So far we have discussed two ways of distributing chunk processing to multiple instances for paral-
lelization in order to take full advantage of the scalable virtual infrastructure. While they both show
potential as well as challenging limitations, a critical bottleneck for both designs is the high latency on
communication channels (network connections between virtual instances). The designs are sensitive
to the network latency because processing one CCN chunk requires the collaboration of more than one
virtual instance.
Network latency is not an uncommon bottleneck in distributed computing [92,93], and it is usually
difficult to directly lower the latency given a specific network substrate (Ethernet in our case). For
performance considerations, it is therefore necessary to minimize communications between distributed
processing units when processing each CCN chunk.
To address the additional design goal, we propose to partition the 3 table services to multiple sub-
tables, and let each processing unit be responsible for only one set of the sub-tables. The resulting design,
namely distributed chunk processing with partitioned tables, consists of multiple interconnected CCN
processing units. Each unit has a complete set of services necessary for processing one CCN chunk,
though the table services on each unit holds only a subset of all possible name entries. This allows each
processing unit to “understand” a subset of all names, and therefore to be able to handle a certain subset
of all incoming CCN chunks. Assuming a good partitioning strategy, the incoming CCN chunks can be
equally distributed among the processing units, which allows scalable deployment of processing units
based on the load demand.
In order to make sure each incoming CCN chunk is delivered to the processing unit which has the
correct subtables to handle it, an additional pre-routing module must be added before each chunk enters
the processing pipeline. This pre-routing module is responsible for collecting incoming CCN chunks
from the network interfaces and delivery them to corresponding processing unit without analyzing the
full header.
The architecture of this design alternative is summarized in Fig. 5.5. It is worth noting that although
in Fig. 5.5 the pre-routing module is illustrated as a separate service from the processing units, we do not
restrict our design to instantiating the module on a separate device. In fact we believe the pre-routing
module can be implemented either as an additional service on every processing unit or as a specialized
hardware. More discussion on the implementation of this design alternative is provided in Section 6.2.

Chapter 5. SAVI CCN Design Alternatives 56
Pre-processing
CS/PIT/FIB Services
Network Interface
1
Name Codec
Post-processing
Processing Unit 1
Subtable 1
Pre-processing
CS/PIT/FIB Services
Network Interface
2
Name Codec
Post-processing
Processing Unit 2
Subtable 2
Pre-processing
CS/PIT/FIB Services
Network Interface
3
Name Codec
Post-processing
Processing Unit 3
Subtable 3
Pre-routing Module
Figure 5.5: Service model for distributed chunk processing with partitioned tables
5.7.1 Redefine a CCN Node Using Partitioned Table Approach
One of the highlights of the distributed chunk processing with partitioned tables design approach is
that the chunk processing engine of a processing unit is very similar to that of a CCN node with the
addition of the pre-routing module. This allows us to describe our design as a redefinition of traditional
CCN nodes. Specifically, our design approach recursively redefines a traditional CCN node as a network
of collaborating nodes. In one such network, each member node acts as a processing unit and is
responsible for a partition of the entire name space, where the name space is defined as the collection
of all possible content descriptors within the scope of one content centric network. This concept is
illustrated in Fig. 5.6.
Such simple yet powerful view of the partitioned table design alternative opens up a range of
new research questions which must be carefully examined before the design reaches production level
maturity. In the rest of this section, we discuss some of the most important design issues that need to
be addressed.
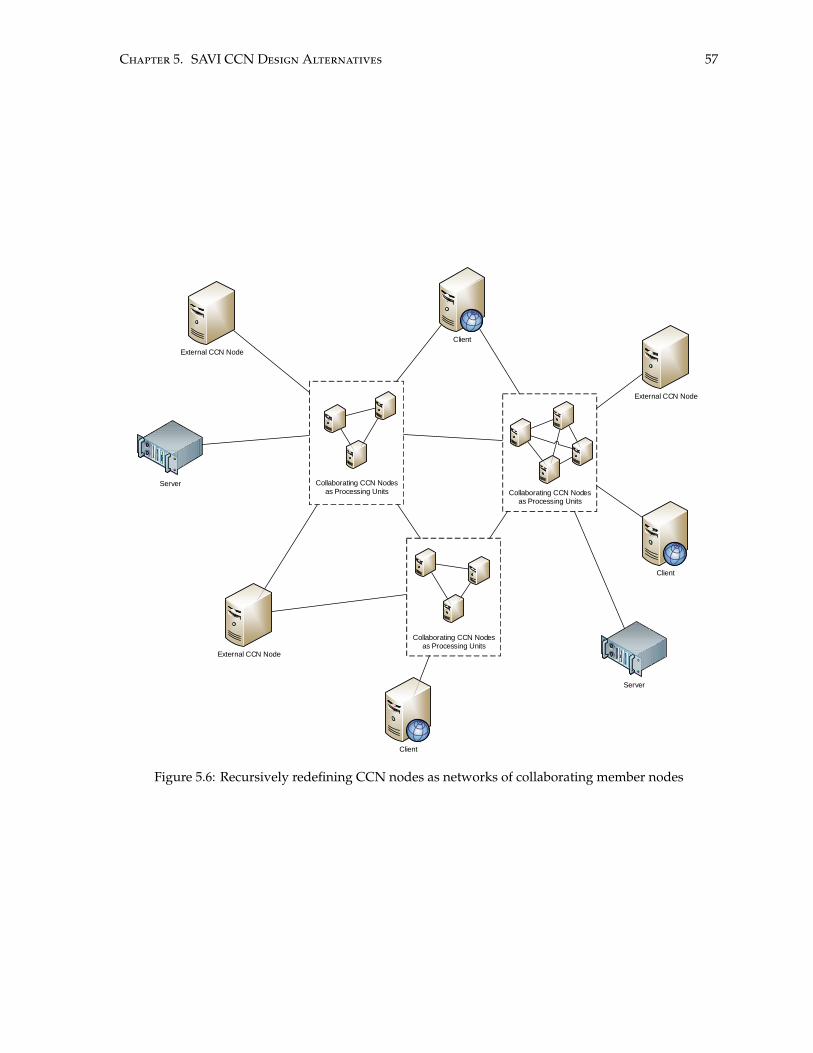
Chapter 5. SAVI CCN Design Alternatives 57
������������������������������������������
Client
������������������������������������������
Client
Server
������������������������������
External CCN Node������������������������������������������
External CCN Node
Server
������������������������������������������
External CCN Node
������������������������������������������
Client
������������
�������
��������������
Collaborating CCN Nodes as Processing Units
��������������
�������
��������������
��������������
Collaborating CCN Nodes as Processing Units
��������������
������������
��������������
Collaborating CCN Nodes as Processing Units
Figure 5.6: Recursively redefining CCN nodes as networks of collaborating member nodes

Chapter 5. SAVI CCN Design Alternatives 58
5.7.2 Table (Name Space) Partitioning and Dynamic Re-partitioning
As one of the most important components of the design, a table or name space partitioning method is
a challenging research topic which deserves much research by itself. A good partitioning method, as
mentioned previously, is vital to not only the functionality but also the overall performance of the entire
system. We believe a well designed partitioning method must be able to meet the following design
goals:
• It should enable fast lookup of destination node during pre-routing. For this reason we recommend
partitioning method based on the hierarchical structure of the content names: names with the same
high level (root) components should be more likely to be grouped into one partition than those
without common roots.
• It should provide adequate load balancing among member nodes. A bad partitioning can put all
popular contents on the same member node, resulting in a system performance possibly worse
than a single-node solution.
• It needs to be scalable: the partitioning algorithm should be able to generate ideally an arbitrary
number of partitions for systems of various sizes.
• It should support dynamic adjustment and load re-balancing as discussed below, and at the same
time minimize the frequency and complexity of such events.
An important characteristic of a scalable partitioning method is the ability to dynamically adjust the
partitions: a deployed system with multiple processing units should be able to change how the name
space is partitioned on-the-fly, thus to shift work load between processing units. This is because the
traffic pattern and popular contents are difficult to predict and rarely static in a real environment. As a
result, the system must have the ability to adapt to changes such as shift of consumers’ interest in topics
by adjusting the partitions or the entries in the subtable services.
Supporting dynamic re-partitioning raises an array of new questions, for example how to make
sure the table entries migrate safely when the partitions are being adjusted. It may be necessary to
divert from a fully decentralized architecture by having a centralized partition manager to coordinate
the changes in subtable services. Some related research topics include Distributed Hash Tables (DHT)
used in production peer-to-peer networks [94, 95], work load prediction and distribution [96, 97], load
balancing algorithms and implementations [78, 98, 99], etc.
Through this thesis project we would like to emphasize the significance of a scalable partitioning
method and to initiate the discussion on the related topics. An actual implementation however, would

Chapter 5. SAVI CCN Design Alternatives 59
be beyond our scope.
5.7.3 Duplication of Popular Name Entries
In our design, the partitions handled by each processing units do not need to be non-overlapping. In
other words, we do not require a content name to be handled exclusively by one and only one processing
unit. This brings many benefits as well as interesting research questions under realistic traffic loads.
Consider the case in which a number of content chunks under the same root name are very popular
in the traffic passing our system (e.g. a popular video divided into multiple data chunks). With a
hierarchy-based table partitioning algorithm these contents are very likely to be handled by the same
member nodes, which may result in a performance degradation.
One possible solution to the situation is to re-partition the tables by breaking the name space
governed by the popular root name into finer-grain subspaces. By distributing the pieces to more
member nodes, multiple member nodes can work on the incoming requests in parallel. This method
would not scale beyond one-chunk-per-node however, as the smallest subtables contain at least one
content name.
An alternative to re-partitioning, inspired by how large data centers handle unbalanced requests
[100], is to duplicate popular names (thus their corresponding subtables entries) at multiple processing
units. In the example of a popular video, we could allow multiple processing units to have complete
information of the same video in their CS, PIT, and FIB services. Any incoming external Interests for
the video can then be anycast to one of the processing units. A Data chunk, on the other hand, needs to
be forwarded by the re-routing module to the processing unit where its corresponding pending Interest
is located in order to consume the pending Interest. In addition a control message would have to be
multicast to all processing units in order to update all relevant table entries.
Duplication of popular content names effectively allows overlaps between content name subtables,
and raises many new research questions. Mechanisms including re-routing module implementation,
table partitioning and re-partitioning strategy, in-network topology and routing, etc. are all relevant
and have to be carefully studied to leverage its benefits.
5.7.4 Handling Different CCN Message Types
So far our discussions of CCN chunk handling within our design has focused mainly on Interest CCN
chunks. It is necessary to examine the implication of the re-routing module for Data chunks and control
messages as well.

Chapter 5. SAVI CCN Design Alternatives 60
Data CCN chunks must be re-routed to the same processing unit as the Interest chunks requesting
them, because the pending interests in the PIT need to be consumed. This places one additional
requirement on the re-routing module design: external Interests and Data passing the module have
to arrive at the same processing unit if they have matching content names. This is not as simple as
comparing the bit stream of two chunk headers however, as two distinct XML headers (even in encoded
binary format) can match in according to CCN protocol (e.g. Interests with name ccnx:/1/2 is a match
for Data with name ccnx:/1 due to the hierarchical definition of CCN names). In addition to supporting
this functionality, the re-routing module must do so fast enough, ideally at line rate (as fast as external
packets arrival rate).
Similarly, control messages (e.g. FIB update messages) must be delivered to the same processing
units as corresponding Data and Interest chunks too, because the states of the table services on every
processing unit must be updated correctly.
These features require further study and may not be easily available under the current CCN naming
and encoding schemes, because the current XML naming scheme and its binary encoding provide
much flexibility at the cost of header complexity. It may be necessary to reevaluate the trade-off
between flexibility and performance in CCN protocol, as suggested by other researches as well [77].
5.7.5 Internal Topology and Routing
In our previous discussion about the re-routing module we have assumed that every incoming CCN
chunk can be re-routed directly to the corresponding processing unit, which implies a mesh (if re-routing
module is on processing units) or star (if re-routing module is on a separate device) topology.
Though in practice this may not be possible due to physical limitation of underlying network
substrate, other logical topologies such as ring or tree are also possible as long as pre-routed CCN
chunks are able to reach their designated processing unit. Under such circumstances, however, how
routing is done between processing units for both pre-routed Interest/Data chunks and delivery of
control messages can be non-trivial. Fortunately, because our design can be implemented as a recursive
expansion of one CCN node into a network of CCN nodes, knowledge from existing research can be
referenced. One example of realizing routing within a CCN network is the OSPFN from [58]. As a
routing protocol specifically designed for CCN protocol, its prototype can be modified to recognize our
table partitioning strategy and be deployed inside our system.
On the other hand, the underlying physical topology may have a more profound impact on the
performance of the system: physical instances hosting the processing units may be connected through

Chapter 5. SAVI CCN Design Alternatives 61
a single Ethernet switch (star topology), or multiple levels of switches (tree topology). Depending on
the scale of the system, each physical link can be subject to variable, possibly very high data rate due to
internal pre-routing. As a result, the physical topology on which processing units are instantiated must
be carefully examined when designing and implementing a practical system.
5.7.6 Reliability, Robustness, and Ability to Scale
An interesting topic for this design approach is the reliability and robustness of the proposed system
towards possible component failures. They follow our proposal naturally, because redundancy is an
architectural characteristic of the design. Specifically, many previously discussed mechanisms such
as in-network routing, table re-partitioning, and content duplication can collaborate in improving the
accessibility of the system when components (nodes or/and links between nodes) fail.
For example in the case of a peer processing unit going offline unexpectedly, the re-routing module
would know it as all packets sent to that node will get dropped. Upon confirmation of node’s mal-
function, a table re-partitioning mechanism kicks in to adjust the subtables on remaining processing
units to handle what is left by the broken unit. Internal topology and routing are updated as well so
that external nodes connecting to the system would not know the malfunction except for a few possible
timeouts of the pending Interests previously stored on the broken unit. If the content consumers are
still interested in the content, they can re-send new Interested which will be handled correctly.
Another related design issue is how the proposed design can scale up/down based on load. As traffic
load rises, the system should be able to take advantage of the virtual infrastructure by requesting and
instantiating new processing units and re-distribute the load through table re-partitioning. Similarly as
demand drops, the system would reassign the load on fewer processing units and release or shut down
any unused resources to save energy.
Such ability to dynamically scale the system based on demand is a natural extension to the table
re-partitioning functionality. Yet it should be one of the most important features of our proposed design
and therefore deserves further studies.
5.7.7 SAVI Resource Mapping
Most discussion for previous design alternatives can still apply to mapping the traditional services of a
processing unit (services other than the pre-routing module) on SAVI resources: virtual machines and
baremetals can be used to instantiate processing units implemented in software, and programmable
devices such as BEE2 boards can be used for hardware implementation. NetFPGAs may require further

Chapter 5. SAVI CCN Design Alternatives 62
tuning due to its limited memory for on-unit content store.
Though it seems intuitive to geographically collocate the processing units to reduce communication
latency and cost, it is not a requirement due to improved tolerance towards network latency. For
example, processing units instantiated on two or more geographically separate campus networks can
join to form one such system as long as CCN chunks can be routed between participating processing
units.
The new re-routing module can be implemented in one of the two ways: 1) it can be realized as
an additional service on each processing units, in which case it maps to the same resources as the
processing units themselves, or 2) it can be implemented on a separate entity, for which we recommend
the use of programmable hardware due to its low overhead.
5.7.8 Advantages
By collecting all necessary services at each processing unit, processing incoming CCN chunk can be
done locally without consulting remote service units. The only transaction between processing units
happens once at the pre-routing stage, which minimizes the impact of latency on system design as well
as performance. In addition, because the fundamental services of a processing unit remains mostly
unchanged comparing to a single CCN node, we can make full use of existing CCN implementation to
prototype our design.
Moreover, as we have mentioned in the previous discussion of design issues, the proposed design
enjoys additional reliability, robustness against component failure, and scalability when compared to
the current CCN implementation.
5.7.9 Limitations
The design alternative of distributed chunk processing with partitioned tables is proposed as an answer
to the limitations of previously proposed design alternatives. Though it provides a promising solution
to many issues such as network latency and scalability, this design alternative has its own limitations.
One such limitation is its dependency on the partitioning algorithm. A non-optimal partitioning
algorithm can significantly reduce the system performance if, for example, incoming traffic load is
poorly distributed among the processing units. Another limitation of this design is the low efficiency of
bandwidth utilization on internal links due to the extra pre-routing. Depending on the implementation
of the pre-routing module, up to half of the internal bandwidth can be spent on pre-routing the incoming
CCN chunks.

Chapter 5. SAVI CCN Design Alternatives 63
5.8 Concluding Remark
In this chapter we examined five design alternatives for realizing high performance content centric
networking on virtual infrastructure. The discussions covered a broad range of approaches from
optimization of existing CCNx code to more “clean-slate” designs utilizing parallel computing resources,
each with their own strength and weakness. A summary of the discussion is provided in Table 5.1.
A particularly interesting approach among them is the distributed chunk processing with partitioned
tables, in which we recursively expand the definition of one CCN node to a network of collaborating
nodes. Some of the key design issues of this approach were discussed, though we were unable to
quantify its performance gain. In the next chapter, we extend our discussion to the preliminary
implementation and evaluation of both optimized header decoder and partitioned table approach
as an effort to understand how much performance gain can be expected from these two designs.

Chapter 5. SAVI CCN Design Alternatives 64
DesignName
SAVI ResourceMapping
Advantages Limitations AdditionalComments
HeaderDecoderOptimiza-tion
CCNx (software)on VM or BM withsingle-core CPUs
Full compatibilitywith CCN;Potential forintegration withother approaches;Easyimplementation
Software overhead;IP overlay; Notscalable beyondsingle thread
It helps in gainingbetterunderstanding ofthe name decoderbottleneck
ParallelTableAccesswithinSingleNode
Software on VM orBM withmulti-core CPUs
Full compatibilitywith CCN; Easyimplementation;Speed-up withparallel computingresources
Software overhead;IP overlay; limitedperformanceimprovement; notscalable beyondsingle node
Softwareparallelizationoverhead can betoo significant;This design maybring moreimprovement ifPIT and FIB arelarge.
DistributedChunkProcessingwith Syn-chronizedTableServices
VM or BM withmulti-core CPUs(software);Programmablehardware withlarge memories(hardware);
Scalable beyondsingle node;
Requires frequentsynchronization,which introducesnew overhead andbottleneck;Sensitive tonetwork delays
Batchingsynchronizationmessages andallowing “goodenough” tablelook-ups can bechallenging yetnecessary for thisapproach.
DistributedChunkProcessingwithCentralTableServices
VM or BM withmulti-core CPUs(softwareprocessing units);BM with parallelco-processors(software centralservices);Programmablehardware withlarge memories(hardware)
Scalable beyondsingle node;centralizedbottleneck modulefor accelerationusing specializedhardware
Requires frequentcommunicationbetween devices;Very sensitive tonetwork delays;
Pipelining thechunk processingfor each processingunit is necessary tomitigate thenetwork delays.
DistributedChunkProcessingwithPartitionedTables
VM or BM withnon-uniformspecifications(software);Programmablehardware withlarge memories(hardware)
Flexible, robust,and scalable; lesssensitive tonetwork delays
Dependency onspecific tablepartitioningalgorithm andimplementation;Possible lowefficiency ofbandwidthutilization
It is ourrecommendedapproach towardshigh performancecontent centricnetworking.
Table 5.1: Summary of the proposed design alternatives

Chapter 6
SAVI CCN Implementation and
Evaluation
In the previous chapter, we presented five high-level design alternatives for realizing high performance
content centric networking on virtualized infrastructure. For each design alternative, characteristics
of SAVI resources are considered for critical system components, and some key design issues are
discussed. In this chapter, we extend our discussion to the implementation and evaluation of two of
the designs proposed, namely the header decoder optimization and the distributed chunk processing
with partitioned tables. We chose these two approaches because we believe they represent two distinct
directions towards realizing high performance CCN on SAVI, both of which present unique insights
and promising potentials.
6.1 Optimized Header Decoder
The first design alternative presented in Chapter 5 is the optimization of header decoder in CCNx from
a software engineering perspective. Though we expected the throughput gain by taking this approach
exclusively being limited, we were unable to quantify the actual improvement.
In this section, we first explain our method of optimizing the header decoder in CCNx by proposing
and comparing two distinct implementation approaches. We then present the evaluation results based
on deployment on SAVI and testing using realistic traffic load.
65

Chapter 6. SAVI CCN Implementation and Evaluation 66
6.1.1 Methodology
The benchmarking of CCNx 0.7.1 in Section 4.2 demonstrates that a large amount of the CPU time
is spent in function ccn_skeleton_decode. In addition, the function ccn_skeleton_decode together with
some of its callers (i.e. ccn_buf_*) are called a large number of times over a short period of clock time of
ccnd execution. A quick scanning through the source code shows that ccn_skeleton_decode is in fact the
lowest level utility which does not further call any ccn_* functions.
Such observation leads to two possible approaches towards making header decoding faster in CCNx:
reducing the number of ccn_skeleton_decode calls, and making each call run for less time. The former
requires system level modification to the CCNx software due to the complexity it involves: the function
ccn_skeleton_decode is invoked at more than 30 different places across over 10 files in the entire code
base, and some of them are common library functions many subsystems depend on. Despite of the
limited set of unit tests bundled with the original source code, testing of the system after any system level
change will be complex and non-trivial. On the other hand, however, because the ccn_skeleton_decode
function is a bottom level function with well-defined function prototype, it is relatively easier to take
the later approach both in terms of implementation and testing. In other words, we aim to modify
ccn_skeleton_decode function so that it takes less wall clock time to give the same results than the
original implementation.
Code analysis
Before optimizing it, it is important to understand what role ccn_skeleton_decode function plays in
CCNx and how. Defined in /csrc/include/ccn/coding.h, the function has the prototye as shown in
Code 6.1.
1 ssize_t ccn_skeleton_decode ( struct ccn_skeleton_decoder *d ,2 const unsigned char *p ,3 size_t n ) ;
Code 6.1: Function prototype of ccn_skeleton_decode
1 struct ccn_skeleton_decoder { / * i n i t i a l i z e to a l l 0 * /2 ssize_t index ; / * *< Number of bytes processed * /3 int state ; / * *< Decoder s t a t e * /4 int nest ; / * *< Element nes t ing * /5 size_t numval ; / * *< Current numval , meaning depends on s t a t e * /6 size_t token_index ; / * *< S t a r t i n g index of most−r e c e n t token * /7 size_t element_index ; / * *< S t a r t i n g index of most−r e c e n t element * /8 } ;

Chapter 6. SAVI CCN Implementation and Evaluation 67
Code 6.2: Definition of struct ccn_skeleton_decoder
By stepping through the code using GNU debugger, we found that the function has the following
inputs and outputs:
Inputs
struct ccn_skeleton_decoder *d: pointer to the decoder struct (definition as shown in Code 6.2)
const unsigned char *p: C-style string representing the encoded chunk header
size_t n: integer representing the length of the encoded chunk header
Outputs
ssize_t: returned integer indicating number of processed bytes in the encoded chunk header as a
result of the current function call
struct ccn_skeleton_decoder *d: the decoder struct is modified to store the current decoded com-
ponents of the chunk header
When the function gets called, it first examines the value of state integer in ccn_skeleton_decoder
struct. Based on whether specific bits in state are set or not, the function branches into a variety of
cases, and the first few bytes from the encoded chunk header is looked up from a dictionary defined in
/csrc/include/ccn/coding.h. The number of processed bytes depends on both the value of state and the
encoded header itself. The results of dictionary look-up are stored back into ccn_skeleton_decoder struct
in the numval value. Other values in ccn_skeleton_decoder including index (representing location of the
byte being processed by decoder), state (updated if necessary for next call of ccn_skeleton_decode),
nest (level of nesting in the XML structure of chunk header), token_index and element_index (starting
index of most-recent token and element, respectively) are also modified/updated as necessary.
A number of interesting observations can be made from how ccn_skeleton_decode is called:
• For each chunk header, ccn_skeleton_decode is usually called multiple times. And the number of
times is proportional to the number of XML elements in the header. ccn_skeleton_decode is called
on the same header to process components of the header sequentially, starting from the highest
level in the corresponding XML scheme;
• Most ccn_skeleton_decode calls process only up to 2 bytes of the chunk header. In other words,
the returned ssize_t value is typically 0, 1, or 2; 1
1Exceptions to this observation usually occur when the function is called 1) to verify the integrity of the chunk header, inwhich case the entire header is examined and number of processed bytes is equal to input size_t n if no error is found; 2) toextract one component of the ASCII content name, in which case the number of processed bytes is equal to the number of ASCIIcharacters plus any trailing NULL characters in the current component.

Chapter 6. SAVI CCN Implementation and Evaluation 68
• The chunk header const unsigned char *p is not modified by calling ccn_skeleton_decode in any
way;
• Despite being a 32-bit2 int value, the input state in struct ccn_skeleton_decoder only takes a
handful (less than 10) of possible values for the majority of function calls.
The last observation is of special interest to our approach in optimizing the decoder, and will be
discussed further.
Speedup through parallelization
It is a common practice in software engineering to parallelize sequential logic in order to achieve better
scalability and to reduce wall clock execution time when working with large problems. In fact in
the design alternatives we discussed earlier (Chapter 5), parallelization was heavily emphasized for
scalability.
We’ve also studied the possibilities of using parallelization to speed up the name decoding functions
from a variety of directions. The first approach we investigated is to parallelize the process of each
individual chunk header: from our observation it appears that XML components of the header are pro-
cessed sequentially by calling ccn_skeleton_decode repeatedly. Such process can be easily parallelized
if processing of each component (input and output) is independent from other components. This is,
however, not the case, as the inherent structure of XML-based headers is not flat, and therefore each
component in the header is interpreted within the context instead of standalone. In other words, the
conversion from byte sequence (encoded header) to hierarchical XML structure (decoded header) needs
to be serial under the current header definition.
The second approach we evaluated is to parallelize decoding of multiple distinct chunk headers.
Because the header decoding does not involve modification of any of the three tables (CS, PIT, and FIB)
of a CCN router, it is possible in theory to decode multiple distinct chunk headers in parallel. Based
on resource types available on SAVI, we looked into three possible implementations of this approach,
largely inspired by software engineering techniques for High Performance Computing (HPC) :
OpenCL/CUDA on Co-processor/GPGPU
First candidate we consider is the NVIDIA GPGPU available on SAVI in the form of GPU Baremet-
als. Co-processors like GPGPU excel at dealing with large data sets such as matrix computation.
In addition, APIs such as OpenCL [101] and CUDA [102] are available in natively C-compatible
2Exact size of the int type is platform and compiler dependent. We refer to int as 32-bit in this project because it complieswith our platform (32/64 bit Ubuntu 12.04 with GNU C compiler).

Chapter 6. SAVI CCN Implementation and Evaluation 69
forms, which enables direct integration with existing CCNx code base.
However two issues stopped us from moving forward with this approach: firstly, programming
co-processors follows a fundamentally different programming model, in which any data (the
chunk headers) required by co-processor routines (or ‘kernels’ in CUDA terminology) needs to be
explicitly sent from host memory to device. The time overhead associated with one such transfer
is in the order of 10’s of microseconds (µs) minimum, and scales up with the size of data trans-
ferred [103,104]. In comparison, the total time spent (including two such transfers and other logics
such as table look-ups) in processing one chunk header is on the same order of magnitude, making
such overhead difficult to justify even when parallel processing of multiple headers is assumed.
Secondly and more importantly, processing chunk headers involves lots of logic branching in the
code as discussed earlier. Handling such task efficiently is challenging for GPGPUs which are
based on Single-Instruction-Multiple-Data (SIMD) architecture [105].
Multi-threading on Multi-core CPU
We also considered modifying the existing CCNx code so that the chunk header decoding is
handled in parallel threads to make better use of the multi-core resources (VMs and BMs) on
SAVI. Besides the complexity involved in making simultaneous header decodings possible, we
face similar issue as the GPGPU case in terms of overhead: launching threads has a small fixed
overhead, and more significantly, dynamic scheduling of jobs has overhead comparable to the
total processing time of one CCN chunk [106]. Job scheduling needs to be dynamic because the
workload for decoder is not static as it depends heavily on arrival rate of chunks and size of the
headers. As a result, we believe that the benefit of going multi-threaded for header decoding
could not justify the complex code change required.
MPI with Parallel Computing Nodes
Another parallelization technique commonly adopted in HPC field is to spread the workload
among multiple computing nodes running in parallel, and use Message Passing Interface (MPI)
to communicate between different running processes. However, depending on the hardware and
message size, communication overhead of such methodology can range from 10’s of microseconds
(µs) to milliseconds (ms) [107], which clearly is beyond the requirements of our application.
In conclusion, we believe that parallelizing only the chunk header decoder could not bring enough
benefits to overall system performance to justify the complex code change required. The reason is that
the overheads inherent to available parallelization techniques on current platforms are too significant
comparing to the time constraints on header processing.

Chapter 6. SAVI CCN Implementation and Evaluation 70
state value Number of occurrence Speculated meaning of state0 1,585 Initial header processing; check
integrity of the entire header164097 234,787 Start of tag (XML markup) token
257 1 Unknown32768 70,678 Start/end of XML level
360454 157,193 Start of ASCII name component(XML content)
425987 2,363 Unknown491520 3,921 End of header491521 107,110 End of XML element
6 56 Control message headerTotal 577,694
Table 6.1: Observed ccn_skeleton_decoder−>state values as input to ccn_skeleton_decode
Table lookup as the alternative approach
One of the more interesting observations we noticed during reverse engineering the header decoder
functions is the limited number of possible input values for ccn_skeleton_decoder−>state. Despite being
declared as a full integer type, only a handful of bits in state are used by ccn_skeleton_decode. Because
logic branching inside ccn_skeleton_decode depends heavily on the value of state, such observation, if
holds true universally, will effectively collapse the input space to one of much lower dimension.
To verify this more systematically, we set up a 5-node (2 clients, 2 servers, 1 router) experiment on
SAVI similar to that used for benchmarking the system (Section 4.2.1). We modified ccn_skeleton_decode←↩
function on the routing node to write all its input and corresponding output parameters to file. The
system ran under full load for approximately 10 seconds, and a total of 577,694 function calls were
recorded3. The captured input ccn_skeleton_decoder−>state values are counted and results are sum-
marized in Table 6.1. The table also includes the speculated meaning of some more frequently occurring
state values. The speculations were based on our reverse-engineering the CCNx code as little docu-
mentation was available at the time of this project.
Based on the observation, we believe it is reasonable to conclude that a small set of values
appear a lot more frequently than others as the input ccn_skeleton_decoder−>state value to the
ccn_skeleton_decode function.
We then looked into the number of bytes processed by each ccn_skeleton_decode function call for
state inputs 0, 164097, 32768, 360454, 425987, 491520, and 491521. We found that most of the function
calls examined no more than two bytes of the input chunk header (const unsigned char * p). Exceptions
include state input 0 and 360454, where the number of processed bytes depends on the length of the
3It is worth noting that the system in this test processed headers significantly slower due to the large amount of I/O performed.

Chapter 6. SAVI CCN Implementation and Evaluation 71
entire header and that of the ASCII name component respectively. This implies that the entire output
(including returned ssize_t and the struct ccn_skeleton_decoder pointer passed in) can be determined
completely from the input struct ccn_skeleton_decoder and the first two bytes of chunk header.
We then constructed a table that maps inputs directly to outputs for ccn_skeleton_decode, where
the entries include only those with input pattern appearing more than 100 times (< 0.02%) in our test
sample data. The resulting table has less than 30 entries. Due to the small size and the requirement of
minimizing the number of instructions executed from input to output, we decided to implement the table
as a 2-level tree. The look-up operation is therefore done in two steps: the input ccn_skeleton_decoder←↩
−>state is matched first, after which the first two bytes of the chunk header is looked up. If in either
step a mismatch is confirmed, the function falls back to the original branching logic to calculate the
output.
It is worth noting that the above implementation does not guarantee performance improvement
for all possible inputs due to two reasons: firstly only the common input cases which can be easily
processed (i.e. inputs where maximum of 2 bytes in the header are processed) are included in the table.
Such approach limits the number of entries in the table yet is able to cover a significant portion of the
input space. The average execution time of ccn_skeleton_decode is reduced because for inputs that are
found in the table, the number of instructions required to arrive at the output is significantly reduced,
at the cost of 1) slight increase of execution time for inputs not included in the table and 2) increased
memory usage. Secondly, the table is empirically constructed based on our experiment, in which all
traffic was generated as emulation to realistic production environment. As a result, we expect that
the effectiveness of our table (portion of inputs matched) will vary based on actual traffic pattern. For
example in the extreme case where the majority of traffic are control messages resulted from ccndc calls,
our implementation would in fact decrease the overall performance due to missed table look-ups.
Testing and verification routine
Using an empirically constructed table in our approach may lead to false positive and false negative
responses. While false negative eventually leads to execution of the original branching logic and possible
performance degradation to the system, false positive matches, in which incorrect outputs are given
by the look-up table, can be a more serious vulnerability because it leads to incorrect header decoding
results. In order to deal with this issue, we designed and implemented a testing and verification routine
for ccn_skeleton_decode. As shown in Fig. 6.1, the idea behind it is to compare the output values
obtained from table look-up and the original branching logic. If the results do not match, the routine

Chapter 6. SAVI CCN Implementation and Evaluation 72
ccn_skeleton _decodestart
I/O Table Look-up
Hit (positive response)?
Original Branching Logic (OBL)
Compare the results
Yes
Match?
Write error message with I/O dump to stderr
No
ccn_skeleton _decode return
Return results from OBL
Yes
No
Figure 6.1: Functional flow for testing and verification routine

Chapter 6. SAVI CCN Implementation and Evaluation 73
1GE
1GE * 2
1GE each
1GE
1GE
1GE OF Switch(tr-edge-1)
Agent-1 (with OVS)
Agent-2 (with OVS)
Non-OF Switch
Atom BM����������
Figure 6.2: Physical topology of experiments evaluating optimized ccn_skeleton_decode
will give informative error message to stderr. These messages are collected and used to improve the
look-up table for better accuracy.
The testing and verification routine provides a way to automate testing of our design under any use
case at the cost of function execution time. The routine is implemented inside a compiler macro block
so that it can be turned on in compile time only when needed. Specifically, for all the experiments we
will discuss in the next section, we first ran them with the testing and verification routine turned on to
ensure no false positive under required experiment settings. Only upon passing such tests should we
proceed with the experiment in which data are collected and testing routine is turned off.
6.1.2 Experiment Results
We deployed CCNx 0.7.1 with our change on SAVI testbed and compared its performance (throughput
and CPU usage) with the original CCNx 0.7.1 under various load conditions. The rest of this section
explains the experiment setup and summarizes the key observations we made.
For all experiments, one CCNx instance was configured as the routing node through which servers
and clients were connected and generated traffic was routed. All nodes ran ccnd over Ubuntu 12.04
with necessary packages installed to compile and execute CCNx 0.7.1. All C code was compiled using
GNU C compiler version 4.6.3 with optimization level set to −Ofast. Environmental variables such as
Content Store size were left as default (e.g. 50,000 for Content Store size). All traffic was sent over
TCP/IP stack. In addition to the CCNx daemon, client nodes ran ccntraffic [45] to generate Interest
packages according to the specified name patterns and were configured to each keep a maximum of
100 pending Interests. Server nodes ran ccndelphi [45, 77] to answer these Interests by generating Data
packets of fixed length (1024 bytes by default) with matching names.
We chose to deploy the routing node on a SAVI baremetal because it offers exclusive access to the

Chapter 6. SAVI CCN Implementation and Evaluation 74
Routing Node
Server_i
DATAccnx:/gen/i-1/chunk_index
Client_i
Client_1
DATAccnx:/gen/i-1/chunk_index
DATAccnx:/gen/0/chunk_indexServer_1
DATAccnx:/gen/0/chunk_index
Figure 6.3: Logical topology of experiments evaluating optimized ccn_skeleton_decode using uniquecontent names
hardware and therefore avoids possible interference from other projects running on SAVI. Additionally
because the experiments were conducted to evaluate the effectiveness of ccn_skeleton_decode optimiza-
tion relative to the original implementation (instead of the absolute performance of the CCNx system),
we decided to use the baremetal with Intel® Atom™D2700 (1M Cache, 2.13 GHz) processor. Similar
to [77] we use multiple traffic-generating clients and servers to saturate the routing node. Using a less
powerful CPU has the advantage of being easier to saturate the routing node’s processing power, and
therefore leads to easier experiment setups as it requires less servers and clients for traffic generation.
For server and client deployment we used a mixture of virtual machines and baremetals on SAVI to dis-
tribute the traffic load to multiple physical links in order to avoid possible bottlenecks and to minimize
interference with other running projects on SAVI testbed. The resulting physical topology is shown in
Fig. 6.2.
We evaluated our change under two use cases: unique content names and shared content names.
Unique content names, multiple server-client pairs
In the first experiment we set up server-client pairs to send CCN packets through the single routing
node. Each server-client pair used content names ccnx:/gen/pair index/chunk index, where pair index
ranges from 0 to (number of server-client pairs - 1) and is the same for all packets exchanged by one
pair of server and clients; chunk index starts at 0 and increases by 1 for each Interest packet generated.
The resulting logical topology is shown in Fig. 6.3.
We started with 1 server-client pair and increased the number to 6 when no significant throughput
gain was observed on the routing node. As the traffic load increased, the CPU usage of ccnd and total
inbound and outbound data rate (in MB/s) were measured and recorded on the routing node. For each
configuration (number of server-client pairs), the system was set up and run for 3 minutes to allow the

Chapter 6. SAVI CCN Implementation and Evaluation 75
85
87
89
91
93
95
97
99
101
103
105
3
4
4
5
5
6
1 2 3 4 5 6
CP
U U
sage
(%
)
Rx/
Tx
Rat
e (M
B/s
)
Number of Server/Client Pairs
Unique Content Name, Multiple S-C Pairs
Tx Rate (Before)
Rx Rate (Before)
Tx Rate (After)
Rx Rate (After)
CPU (Before)
CPU (After)
Figure 6.4: Unique content names: CPU usage and data rate vs. number of client-server pairs
routing node to fill up its Content Store and the data rate to stabilize. Measurement was then taken
over the next 5 minutes, during which CPU usage was sampled by top system utility tool per second
and averaged over the 300 samples, and the data rate (MB/s) was calculated by dividing the total data
transmitted over the time period by 300.
The experiment was conducted on SAVI Toronto Edge 1. Data was collected before and after enabling
our changes to the decoder. The results are shown in Fig. 6.4, where the dashed lines (Before) indicate
performance curves of the original CCNx 0.7.1 and the solid lines (After) are from CCNx 0.7.1 with
optimized decoder implementation.
A few things are interesting to note on Fig. 6.4: firstly the inbound data rate (Rx Rate) is very close to
outbound data rate (Tx Rate) both before and after our change. This is because for unique content name
between server-client pairs, no packets are shared or re-used for transmission, meaning that Content
Store searches always miss, and all data has to be fetched from servers. Secondly even after CPU usage
reaches 100%, increasing the number of servers and clients is still able to push the data rate higher. We
believe this is due to the way Linux applications handle network I/O: some CPU time is spent waiting
between I/O events, and this time reduces as I/O occurs more often. As a result, more CPU time is spent
on packet processing.
Fig. 6.4 shows that our new decoder implementation is able to 1) decrease CPU usage when system
is not fully loaded (when only 1 pair of server and client exist) and 2) improve system throughput by
up to 13% when the CPU usage is maxed out.

Chapter 6. SAVI CCN Implementation and Evaluation 76
Routing Node
Client_i
Client_1
DATAccnx:/gen/chunk_index
DATAccnx:/gen/chunk_index
Server_1
DATAccnx:/gen/chunk_index
Figure 6.5: Logical topology of experiments evaluating optimized ccn_skeleton_decode using sharedcontent names
88
90
92
94
96
98
100
102
0
5
10
15
20
25
30
35
2 4 6 8 10 12
CP
U U
sage
(%
)
Rx/
Tx
Rat
e (M
B/s
)
Number of Clients (Always 1 Server)
Shared Content Names, 1SnC
Tx Rate (Before)
Rx Rate (Before)
Tx Rate (After)
Rx Rate (After)
CPU (Before)
CPU (After)
Figure 6.6: Shared content names: CPU usage and data rate vs. number of clients
Shared content names, single server multiple clients
The second set of experiments involved the routing node, one single server, and multiple clients which
generated Interests following the same content name pattern: ccnx:/gen/chunk index, where chunk index
started at 0 and increased as Interests were generated. All Interests were sent to the single server through
the routing node, therefore the Data chunks from server were shared by all clients. The resulting logical
topology is shown in Fig. 6.5.
The experiment was conducted similar to that of the previous experiment, and the same set of
parameters, i.e. inbound data rate, outbound data rate, and CPU usage of the routing node were
measured before and after our change. The results are shown in Fig. 6.6.
From Fig. 6.6 it can be seen clearly that the outbound data rate (Tx Rate) is significantly more than
inbound data rate (Rx Rate) because ideally each content chunk only needs to be fetched from server

Chapter 6. SAVI CCN Implementation and Evaluation 77
once, and subsequent Interests will be replied by routing node directly using the cached copy in its
Content Store. In reality, however, because the server is heavily loaded, some incoming Interests were
dropped and as a result, the outbound data rate is less than inbound data rate multiplied by the number
of running clients.
Nevertheless, it is clear from Fig. 6.6 that our modification to the decoder reduced overall CPU usage
for content name processing, and as a result improved CCNx’s throughput under full load by more
than 12%.
6.1.3 Remarks and Limitations
In this section of the project, we applied common software engineering techniques in benchmarking
and improving the performance of CCNx software router. Our change was able to achieve on average
12%-13% throughput gain when the system is under high work load.
The results lead to a few interesting remarks: firstly, name decoder is in fact a key functional module
many previous researches have overlooked (see Chapter 3). While such performance bottleneck is
inherent to the architecture of CCNx itself, specifically its design of keeping binary encoded data
chunks in the Content Store, we have shown through our work that by optimizing the content decoder
implementation, a significant performance improvement can be achieved. As a result, when designing
high performance content centric networking systems, we should pay close attention to the content
name decoder, or the name encoding/decoding services in general. From our studies we believe that
it is possible to remove the bottleneck by reducing the frequency of invoking such services. However
such modification will require modifying the system-level CCN node architecture, and is beyond the
scope of this thesis project. The second remark we would like to make is that the current CCNx project
is by no means an optimized system in terms of performance: much engineering effort can be applied
to improve it. This is again something we should keep in mind when designing and implementing a
practical system.
There are a few limitations to our approach of optimizing the name decoder. One of the limitations
is that our implementation is based on a hard coded look-up table constructed empirically. Though
we added a testing and verification logic to make sure all test we ran are correct (i.e. system having
the same behavior as without our change) in addition to passing all unit tests coming with the 0.7.1
release of CCNx, there is no guarantee that it will behave the same for any arbitrary input. In fact if
the encoding/decoding dictionary (defined in coding.h) is altered, our implementation will very likely
give erroneous results because the mapping between inputs to outputs for name decoder is different.

Chapter 6. SAVI CCN Implementation and Evaluation 78
This issue can be solved by implementing the look-up table as a cache: the table entries are filled when
a new input is given to the name decoder for the first time and corresponding output is generated by
the original branching logic. Subsequent calls with the same or similar inputs can then be resolved by
looking up the cached outputs. The effectiveness of such approach must be reevaluated however, as
additional overheads of constructing and validating the cache entries are introduced. Due to the limited
time frame of this thesis the cache implementation will be left as one of the possible future works.
Another major limitation to our approach is that it does not scale well: there is only so much a
single-threaded program can do. Our experiment results above show that even in the case where
all clients request data with the same name, the routing node could only sustain less than 250Mbps
(31.25MB/s) outbound data rate. In the worst case where all clients request unique content, the data
rate both inbound and outbound drops to around 45Mbps (5.626MB/s). Admittedly we used a less
powerful CPU for the purpose of easy experimentation. However a simple test run on SAVI using a
state-of-the-art Intel® Core™i7 3770 CPU can only raise the number to less than 200Mbps for unique
content name case, which is far from the 1GE link capacity of the routing node. Combined with the
difficulty we encountered in parallelizing the current CCN architecture, this leads our discussion to the
next section: a Content Centric Routing Network with collaborating nodes.
6.2 Distributed Chunk Processing with Partitioned Tables
In the previous section, we described our method of optimizing the header decoder in CCNx. Through
experiments on SAVI testbed, we showed that the system throughput is capped at around 250Mbps even
with one of the most powerful CPUs commercially available today. Such performance is significantly
below our 1Gbps design goal, and suggests that although our work on optimizing the header decoder
in CCNx has brought substantial improvements, it alone is not scalable enough for achieving high
performance content centric networking.
Motivated by such limitation, we revisited the various design alternatives proposed in Chapter 5 and
decided to move forward with the partitioned table approach. In the rest of this chapter we explain our
approach towards implementing and testing the design on SAVI testbed, and present the preliminary
evaluation results which demonstrates the potential of such design alternative.

Chapter 6. SAVI CCN Implementation and Evaluation 79
6.2.1 Using CCNx as Processing Units
As one of the advantages of the partitioned table design alternative, the chunk processing units consist
of services much similar to those of a regular CCN node. This enables us to use the CCNx prototype as
the building block for implementing the processing units in our prototype.
Using CCNx as the processing units for our system significantly reduces the development time of
prototyping and evaluation, which helps us to meet the time constraint of this thesis project. However it
also put certain limitations on our implementation because bottlenecks of the existing CCNx prototype
are carried over. Specifically, using CCNx limits the throughput of each individual processing unit in
our system at the maximum throughput achievable by the current CCNx implementation. While it
negatively affects the overall system performance, we do not believe such limitations will invalidates
our discussion as the main benefit of the partitioned table approach is its scalability beyond the capacity
of a single processing unit.
6.2.2 Two Approaches Towards Realizing Pre-routing
We mentioned in Section 5.7 that there are two ways of implementing the pre-routing module in our
system. As a review, the pre-routing module is responsible for receiving incoming CCN chunks from
all external4 interfaces of the system. In this section we describe our proposals for both approaches and
briefly discuss the pros and cons of either approach.
Per-node re-routing function with unified virtual interface by OpenFlow
One of the approaches to implement the re-routing module is to implement an additional function on
each and every processing unit. For this approach, CCN chunks arriving at the external interfaces of
any processing unit can hit or miss the subtable services: an incoming CCN chunk ‘hits’ the processing
unit if its name prefixes exist in the unit’s CS, PIT, and FIB services and therefore can be processed
by the current processing unit, and the chunk ‘misses’ if otherwise and has to be re-routed to another
processing unit.
To determine whether an incoming CCN chunk hits or misses, one additional pre-routing function
must be added to each processing unit. For CCN protocol and CCNx prototype, it can be done through
a simple hashing function whose input is the encoded chunk header and output is the identifier of
the responsible processing unit. Using encoded chunk header as the input to the hash function works
4We define external interfaces to be the ones that send and receive CCN chunks to and from any entity that is not a peerprocessing unit within the system. Similarly the interfaces used by each processing units to communicate with other peer unitsare referred to as internal interfaces.

Chapter 6. SAVI CCN Implementation and Evaluation 80
Incoming CCN chunk
Chunk from external interface?
Hash content header to get worker node ID
Yes
Is the ID pointing to current node
Miss: forward chunk to correct member node
through internal interface
No
Hit: process chunk using regular header
processing functions
No
Yes
Figure 6.7: Logic flow of a processing unit with per-node re-routing function
because by CCN protocol, encoded chunk header in binary format is unique for each unique CCN chunk
even though the corresponding XML-formatted header can be different [108]. The resulting logic flow
of a processing unit is shown in Fig. 6.7 No other modification would be required on the regular header
processing services, as by pre-routing the packets, the name processing thread of each member node
will only see the CCN chunks with the relevant content names, and its own Content Store and Pending
Interest Table will be populated by only corresponding CCN Data and Interest chunks respectively.
As an example, consider a system consisting of 4 processing units, node1 to node4. A CCN chunk
(Interest or Data) arrives at one of the 4 nodes. The node first checks to see that the chunk is from an
external interface (i.e. not a chunk already re-routed by another member node), after which the hash
function is applied to the encoded content name. Assume an arbitrary hash function that generates
an integer value h from the header, the destination node ID i for re-routing can be calculated simply
by (i = (h%4) + 1) where % denotes the modulo operation. The chunk is then forwarded to the nodei

Chapter 6. SAVI CCN Implementation and Evaluation 81
Matching Condition ActionFlow 1 Source IP is the IP from the packet AND
destination IP is the virtual IP of thesystem
Change destination IP and MAC to theIP and MAC of a processing unit
Flow 2 Source IP is the IP of one of the internalprocessing unit AND destination IP isthe IP from the incoming packet
Change source IP and MAC to the IPand MAC of the incoming packet
Table 6.2: OpenFlow entries to implement the unified virtual interface
through internal interface if not already at nodei. At this stage the chunk has arrived at the processing
unit which is responsible for and capable of handling it, and the chunk processing functions of a regular
CCN node will be invoked. Any modification to the CS (Data caching) or PIT (Interest recording) also
happens only locally at that node, independent of the other peer processing units.
For the per-node implementation of re-routing module, network interfaces are distributed with
processing units, and will be recognized by external CCN nodes as separate network entities. Optionally,
a unified virtual interface can be implemented to allow all processing units being recognized as a single
CCN node by external CCN nodes. Because CCNx is designed and implemented as an IP overlay, the
virtual interface can be realized using OpenFlow given SAVI’s OpenFlow-enabled network substrate.
Specifically, when an IP-based CCNx packet first arrives at an OpenFlow-enabled routing system,
it is sent to the OpenFlow controller. The controller recognizes that its source IP is from outside of the
system, and its destination IP is that of the unified virtual interface. Two flows are then installed by the
controller into the OpenFlow-enabled switch which receives this packet, with the matching condition
and action shown in Table 6.2.
Flow 1 in Table 6.2 is for routing incoming packets to one of the processing units (referred to as the first
visited node, and Flow 2 is to handle any reply packets from any processing unit inside the system back
to the external CCN node. The first visited node can be selected by the controller with load-balancing
considerations.
At the current stage of OpenFlow development (OpenFlow Specification Version 1.1.0 [109]), the
pre-routing function (i.e. determining which processing unit is responsible for the incoming node)
cannot be merged with the assignment of first visited node by OpenFlow. This is because the pre-
routing function from the perspective of an IP network, which OpenFlow supports at line rate, involves
deep packet inspection, and cannot be performed at line rate by OpenFlow switches: the overhead
of sending a packet to controller for action can be justified on a per-flow basis but is too expensive if
required by every packet [46,109]. Though we do not rule out the possibility of CCN header support in
future OpenFlow specifications, in this thesis project we base our design on what is supported on SAVI

Chapter 6. SAVI CCN Implementation and Evaluation 82
testbed, i.e. OpenFlow Specification Version 1.0.0 [90].
Centralized re-routing using hardware Bloom filter
The other approach of implementing the re-routing function is to use a device or computing instance
separate from all the processing units. In this case a centralized re-routing unit will be responsible
for receiving all external CCN chunks and distributing them to the processing units holding relevant
name prefixes. For this approach we recommend the use of a hardware-based Bloom filter, possibly
implemented in programmable hardware on SAVI testbed. The Bloom filter will keep a list of processing
unit IDs with a bit array masking the name prefixes they are responsible for. When external CCN packets
arrive at the Bloom filter, they are first assembled into CCN chunks, and the content name within the
header is identified and used as input to the filter. Other parts of the header may need to be ignored
because Interest and Data with the same name prefix should be mapped to the same processing unit.
The output bit array of the filter is compared to the mask of each processing unit. Action is performed
on the incoming chunk based on the matching results as following:
• No match: chunk is discarded because no processing unit knows how to handle this CCN chunk;
• Exactly one match: chunk is forwarded directly to the input queue of the matched processing
unit;
• Multiple matches: packet is duplicated and forwarded (multicasted) to every processing unit
with a matching bit mask. Such case is possible because the Bloom filter is prone to false positive
results. In case of a false positive, the CCN chunk will be dropped when the processing unit
determines that it cannot process the chunk after consulting its table services.
Using a single Bloom filter as the pre-routing module for the entire system is feasible because
researches have shown that Bloom filters can operate at line rate when used for prefix matching [110,111].
For the centralized approach towards implementing the re-routing module, CCNx implementation
can be directly used as software-based processing units, because each processing node essentially sees
only the CCN chunks with relevant name prefixes. OpenFlow can still be applied to create a virtual
interface to the external nodes: destination port and address in the IP headers of incoming packets
can be modified to be those of the processing units, and the source port and address in the headers of
outgoing packets can be modified to be those of the central re-routing device.

Chapter 6. SAVI CCN Implementation and Evaluation 83
Our Recommendation
We recommend taking centralized re-routing approach implemented as hardware Bloom filter, because
it presents many advantages over a distributed re-routing approach based on hash tables. Some of the
advantages include:
• The task of pre-routing is offloaded to a dedicated hardware. As a result processing power on
each processing unit can be saved for the main tasks of name decoding, table look-ups, etc.;
• The OpenFlow control logic is simplified because the OpenFlow controller no longer needs to
perform load-balancing for incoming packets;
• It saves bandwidth on internal links: all incoming packets are directed to Bloom filter, effectively
eliminating the notion of first visited node;
6.2.3 Estimated Upper and Lower Bounds of Performance Scaling
In this section, we present a numerical analysis estimating the upper and lower bounds of performance
scaling by using distributed chunk processing with partitioned tables.
Consider a system consisting of n processing units. Assume each processing unit has header
processing power equivalent to ρ external chunks per second, i.e. if only one processing unit is used
(n = 1), it is able to handle incoming CCN chunks at ρ chunks/second. Assume the cost of re-routing
external chunks to be β of the cost of processing the full header, then the processing power on each
processing unit is able to re-route ρ/β chunks per second. We expect 0 ≤ βwith β = 0 denoting the most
optimistic case in which pre-route CCN chunks costs no extra processing power. In practice, we expect
β < 1 because β = 1 implies an inefficient pre-routing module implementation which costs as much
processing power to re-route a CCN chunk as to analyze its full header.
Now assume that one processing unit receives CCN chunks from external interfaces at rate rext, and
from internal interfaces at rate rint. Among all the external chunks, a fraction (0 ≤ α ≤ 1) of them can
be processed without re-routing the chunks to other processing units (Fig. 6.8). The fraction α is the
probability of hit for external CCN chunks arriving at any given node, and it represents the probability
for which each incoming CCN chunk from external interfaces can be handled directly by the receiving
processing unit without re-routing. As a result, (1− α)rext amount of the total traffic will be re-routed to
other processing units whose CS, PIT, FIB services holds necessary name prefixes to process them, while
the rest αrext + rint will be processed by the current processing unit and will leave the system through
external interfaces, assuming chunk re-routing can be done within one hop.

Chapter 6. SAVI CCN Implementation and Evaluation 84
α rext + rint
Processing Unitwith Total Capacity
ρ = [α rext + rint] + β[(1�α)rext]
rint (1�α )rext
From other Processing Units
From external interfaces To external interfaces
To other Processing Units
rext
Figure 6.8: Data rate analysis for one processing unit
For an ideal table partitioning method, the (1 − α)rext re-routed CCN chunks are evenly distributed
across the other (n−1) processing units, and every other processing units re-route equal portion of their
own external incoming chunks at rate (1 − α)rext/(n − 1). This implies that at steady state, the following
equation holds true:
rint =(1 − α)rext
n − 1· (n − 1) = (1 − α)rext (6.1)
At maximal load, each processing unit will make full use of its processing power ρ, which gives:
ρ = [αrext + rint] + β [(1 − α)rext] (6.2)
= [αrext + (1 − α)rext] + β [(1 − α)rext] (6.3)
=[1 + β(1 − α)
]· rext (6.4)
And if the processing units are identical, the total throughput of the system R is then given by:
R = n · rext (6.5)
=n · ρ
1 + β(1 − α)(6.6)
At α = 1 regardless of the value of β, Equation 6.6 yields its maximum value as:
R = n · ρ (6.7)
Equation 6.7 implies that the upper bound of performance scaling through our design is achieved

Chapter 6. SAVI CCN Implementation and Evaluation 85
when probability of hit for external incoming chunks is 100%, or no re-routing is needed for any
incoming CCN chunk. Under such circumstances the system’s total throughput scales linearly with the
number of processing unit.
On the other hand, when α < 1, as β approaches +∞, R approaches 0. This represents the case where
chunk re-routing is required, but cost of re-routing is so high that all the processing power is used on
re-routing, and no external chunks can be accepted at steady state. In practice however, we expect
α = 1/n, and β = 1 as the pessimistic case where each incoming CCN chunk has a probability of 1/n
hitting the correct processing unit upon their arrival (no shared name prefixes among processing units),
and re-routing takes as much computing resource as processing the full header. This gives the lower
bound of performance scaling as following:
R =n · ρ
1 + 1 · (1 − 1/n)(6.8)
=n2ρ
2n − 1(6.9)
As n increases, Equation 6.9 converges to R = nρ/2, implying that under such circumstances, the
total throughput of the system still scales linearly with the number of processing units, but with a
penalty constant of 1/2. Conceptually, this means that half of the processing power of each node is used
on internal re-routing of CCN chunks.
Considering the two approaches of implementing the pre-routing module, we believe Equation 6.7
gives an optimistic estimation of the system performance for the centralized pre-routing unit approach
where the pre-routing unit operates at line-rate and does not introduce additional overhead to the
throughput overhead. Equation 6.9, on the other hand, gives an pessimistic performance estimation
for the per-node pre-routing function approach where cost of pre-routing is the same as full header
processing and no name prefixes are shared by multiple processing units.
It is worth noting that for realistic traffic load, the name prefixes of all data transferred are not
uniformly distributed across the entire name space. This means that a large portion of the traffic are for
distributing content within a relatively small set of name prefixes. In our design and implementation,
such observation encourages the duplication of popular name prefixes at multiple processing nodes. By
duplicating a small set of name prefixes denoting the popular content, the probability of hit or α can be
increased substantially, which boosts the total throughput of system R in Equation 6.6. Specifically for
α = 0.8, R =[n/(1 + 0.2β
)]ρ > (n/1.2)ρ gives a minimum scaling factor of (n/1.2) for 80% probability

Chapter 6. SAVI CCN Implementation and Evaluation 86
of hit. And for α = 0.5, R =[n/(1 + 0.5β
)]ρ > (n/1.5)ρ gives a slightly less optimistic scaling factor of
(n/1.5) when half of the incoming chunks ‘hit’ the current processing unit.
6.2.4 Preliminary Evaluation
In this section, we present the evaluation method and results of our preliminary deployment of dis-
tributed chunk processing with partitioned table on SAVI testbed. Specifically we are interested in
knowing how our design scales under realistic traffic load and compare it with our numerical analysis.
Similar to the evaluation of optimized header decoder, we evaluated our design under both unique
content name setting and shared content name setting.
Assumptions
Due to the development time constraint of this thesis project, we do not present a full implementation
of the proposed pre-routing module. Specifically for our evaluation, we use the vanilla CCNx 0.7.1 as
the processing units, and make the following assumptions:
• For centralized pre-routing module approach, we assume a hardware Bloom filter is used which is
capable of operating at line-rate and does not introduce additional overhead to system throughput;
• For per-node pre-routing function approach, we use the header processing engine of CCNx directly
for pre-routing purposes, which implies that pre-routing CCN chunk costs the same amount of
processing power on processing units as full header processing (β = 1 in Equation 6.6);
• We use traffic generating application (i.e. ccntraffic) to generate Interests with certain pattern,
which emulates the table partitioning mechanism by manually distributing the Interests among
processing units.
Experiment Setup: Basic Setup
The basic experiment setup is very similar to that of the evaluation of optimized header decoder (Sec-
tion 6.1.2): CCNx 0.7.1 and traffic generation applications are compiled using GNU C Compiler version
4.6.3 and deployed on single-CPU virtual machines with 64-bit Ubuntu 12.04 LTS operating system.
Compiler optimization level is set to optimize for execution speed (−Ofast). All CCNx parameters are
set to default values, including 50000 maximum Content Store entries and use of TCP.
VMs running ccnd and ccntraffic are used as clients which generate Interests, those running ccnd
and ccndelphi are used as servers which generate Data upon receiving Interests, and a few more VMs

Chapter 6. SAVI CCN Implementation and Evaluation 87
running only ccnd are used as routers which routes Interest and Data between servers and clients.
All tests were conducted on SAVI’s CORE node using virtual machines due to the large amount of
computing resources required. Throughput measurements were taken on all clients and servers. The
aggregated inbound data rate of all clients are recorded as the Tx Rate of our routing system, and the
aggregated outbound data rate of all servers are recorded as its Rx Rate. Sampling method was similar
to that of the previous experiments: we waited approximately 3 minutes for the system to reach steady
state, and took measurements over the next 5 minutes. Every test case was repeated 3 times, and the
highest value was recorded.
Experiment Setup: Topology
We used two logical topologies to reflect the two designs of pre-routing module. In the first topology,
every client is allowed to send Interests to any routing node, and each Server is connected to only one
of the routing nodes. Any Interest received by routing nodes are directly routed to servers for matching
Data. Such topology is illustrated in Fig. 6.9.
Topology shown in Fig. 6.9 emulates the ideal implementation of partitioned tables approach with
centralized re-routing unit, as chunks from external CCN nodes (servers and clients) are sent to their
corresponding processing units (routing nodes) without additional re-routing.
The second topology we deploy, which is shown in Fig. 6.10, emulates the per-node pre-routing
module implementation. For this topology, each client is connecting to one routing node, and therefore
some of the Interests generated by each client need to be re-routed to other routing nodes (processing
units) before reaching the corresponding servers. Similarly Data chunks will trace back the Interests’
route, possibly visiting more than one routing node. The logical topology between the routing node is
mesh, meaning that the number of processing units traversed by each CCN chunk is either 1 (hit) or 2
(miss).
Experiment Setup: Content Name Pattern
Similar to the evaluation of optimized name decoder, we evaluate the throughput of the system under
two scenarios: unique content name from all clients and shared content names between clients.
In the unique content name case, 40 clients and 40 servers where deployed, with 1 to 6 routing
nodes. Clients and servers are indexed using integers between 0 and 19 inclusive, and routing nodes
are indexed using integers between 0 and (R − 1) where R is the total number of routing nodes. Each
client i sends Interests with names ccnx:/ j/k/chunk index, where j is an integer between 0 and 19 inclusive,

Chapter 6. SAVI CCN Implementation and Evaluation 88
Processing Unit
Client
Client
���������������������������������������������
Server
������������������������������
Server
Processing Unit
Processing Unit
Processing Unit
Interests Data
Figure 6.9: Topology emulating the implementation of partitioned tables with centralized pre-routingunit
Client
ClientInterests
Interests
����������������
Server
����������������
Server
Data Data
����������������
Server
������������������
Server
Data Data
Client
ClientInterests
Interests
Client
Client
Interests
Interests
����������������
Server
����������������
Server
Data Data
����������������
Server
������������������
Server
Client
Client
Interests
InterestsDataData
Figure 6.10: Topology emulating the implementation of partitioned tables with per-node pre-routingmodule

Chapter 6. SAVI CCN Implementation and Evaluation 89
3
8
13
18
23
28
33
1 2 3 4 5 6
Dat
a R
ate
(MB
/s)
Number of Processing Units
Unique Content Name (Partitioned Tables Preliminary)
Tx Rate (Central Pre-routing)
Rx Rate (Central Pre-routing)
Tx Rate (Per-node Pre-routing)
Rx Rate (Per-node Pre-routing)
Tx/Rx Rate (Central Pre-routing,Estimated)
Tx/Rx Rate (Per-node Pre-routing,Estimated)
Figure 6.11: Preliminary evaluation for partitioned tables: unique content name case, system throughputvs. number of routing nodes.
k is another integer between 5i and 5i+4 inclusive, and chunk index is an increasing integer starting from
0. Each server j serves data with prefix ccnx:/ j/, and the payload size of each data chunk is 1024 byte.
Each routing node r is responsible for forwarding and caching Interests and Data with name prefixes
ccnx:/m/ for any 0 ≤ m ≤ 19 satisfying m%R = r where % denotes the modulo operation. Such naming
pattern effectively allows clients to ask for content from every server with equal probability.
For the shared content name case, 72 clients and 6 servers were deployed, with 1 to 6 routing nodes.
All clients generate Interests with names ccnx:/ j/k/chunk index, where j is an integer between 0 and 19
inclusive, k is another integer between 0 and 4 inclusive, and chunk index is an increasing integer starting
from 0. Rules for routing and content generation are the same as those of the unique content name case.
By configuring all clients to generate the same Interests, the routing nodes as processing units make full
use of the Content Store, and reply Interests directly with cached Data whenever possible.
Results: Unique Content Names
We first ran the experiments using unique content name settings on both topologies. 40 servers and 40
clients were connected via 1 to 6 routing nodes, and all routing nodes were instantiated on the same
computing agent in order to minimize network latency and bandwidth usage between processing units.
The results of the experiments are summarized in Fig. 6.11.
In Fig. 6.11, aggregated throughput for the group of routing nodes, which represent the multi-
processing-unit system with partitioned tables (y-axis), is plotted against number of processing units
(x-axis). The rate curves marked as (Central Pre-routing) are measurements taken using topology shown

Chapter 6. SAVI CCN Implementation and Evaluation 90
in Fig. 6.9, which emulates a partitioned tables design with an ideal centralized pre-routing unit. In
contrast, the rate curves marked as (Per-node Pre-routing) are based on topology shown in Fig. 6.10,
and reflect the performance scaling when pre-routing shares the processing power with regular header
processing on each processing unit. In addition, using the single-node data rate as the base value,
numerical estimations given by Equation 6.7 and Equation 6.9 are also shown for both cases with mark
(Central Pre-routing, Estimated) and (Per-node Pre-routing, Estimated) respectively.
A few observations can be made from Fig. 6.11. Firstly, the Tx Rate and Rx Rate are very similar
(within 1% difference) for both cases. This is expected as every Interest sent by the clients is unique,
and has to be forwarded to the servers by the processing units. Every data, as a result, enters and exists
the routing system exactly once, leading to the observation that each Tx Rate being very close to the
corresponding Rx Rate.
Secondly, the throughput scales up with increasing number of processing units for both topologies.
This demonstrates the potential of our design: using one routing node, the data rate is 5.2MB/s (megabyte
per second) each way, resulting in a total throughput of 83.2Mbps. With 6 processing units, central pre-
routing approach estimates a data rate of 26.2MB/s each direction (419.2Mbps total), or an improvement
with a factor of approximately 5.03. Per-node pre-routing approach gives a lower per-direction data
rate of 14.7MB/s (235.2Mbps total) also with 6 processing units, which is roughly 2.83 times better than
the single node configuration. While Equation 6.7 and Equation 6.9 give a numerical estimation of
the upper and lower bounds of the performance of our partitioned table design approach, the (Central
Pre-routing) and (Per-node Pre-routing) curves on Fig. 6.11 estimate the performance region within
which a practical implementation of the system can operate if all Interests have unique names and Content
Store is not utilized.
Thirdly, the throughput scaling is lower than the numerical estimation, and suffers the effect of
diminishing return, i.e. every additional processing unit give less incremental throughput improvement.
We have two possible explanations for the reasons behind this observation: firstly it is possible that
as the number of processing units increases, the CPU load on all servers and clients increases as well
as they need to send out packets faster. Because all servers and clients are instantiated on the SAVI
CORE cluster of computing agents, many of them share the same physical CPUs. As the CPU usage
increases for every virtual machine instance, the physical computing resource becomes scarce, and the
virtualization overhead can get more significant and affect the performance of not only servers and
clients, but also routing nodes. A second possible reason is related to the IP overlay design of the CCNx
implementation. All CCN chunks are encapsulated in IP packets, and sent with TCP protocol. Due to
TCP’s congestion control mechanism, any congestion on internal links causes throughput degradation

Chapter 6. SAVI CCN Implementation and Evaluation 91
at involved network entities. Though the average data rate is less than half of the link capacity, spikes
in traffic are possible. Furthermore, congestion is more likely when data rate is higher, which explains
why the diminishing return effect is more significant for central pre-routing topology than for per-node
pre-routing topology.
Results: Shared Content Names
We conducted a similar set of experiments using shared content name settings. With shared names,
clients request the same pieces of content from all servers. By launching all client applications roughly
at the same time, multiple Interests with identical content names will be received by each processing
units, in which case only the first Interest will be forwarded to next hop. When matching Data arrives,
multiple pending Interests will be consumed at the processing units.
Under shared content name setting, both topologies (Fig. 6.9 and Fig. 6.10) give similar throughput
results, with per-node pre-routing topology having slightly lower throughput. This is because we use
the regular header processing services to perform the pre-routing tasks, which allows pending Interests
resolution and content caching to occur at the first-hop processing units. As a result, the Content Stores
at all processing units are populated by the same Data at steady state and most Interests are served at
the first processing units they visit without re-routing for both topologies.
72 clients, 6 servers, and 1 to 6 routing nodes were deployed using topology shown in Fig. 6.9 for
shared content name experiments. At first all routing nodes were instantiated on the same computing
node similar to that of the unique content name experiments. The resulting performance scaling curves
are marked as (Single Agent) on Fig. 6.12.
Our observation is rather interesting: besides the significantly higher Tx Rate comparing to the Rx
Rate due to the utilization of Content Store, the system throughput increased until the third processing
unit was added to the network. For 4 to 6 routing nodes, no apparent improvement in throughput
was observed. Further investigation into the performance cap quickly revealed that the aggregated Tx
Rate for all processing units reached approximately 102MB/s, or 816Mbps. Together with the Rx Rate,
the total throughput is close to the 1GE link capacity between the computing agent and the central
OpenFlow switch.
In order to verify that the physical link capacity was indeed the bottleneck, we conducted a new set
of experiments in which processing units were instantiated across 6 different computing agents, which
are shared by clients and servers virtual machines. Results of the new experiments were shown in
Fig. 6.12 as (Multiple Agents).

Chapter 6. SAVI CCN Implementation and Evaluation 92
0
20
40
60
80
100
120
140
160
180
200
1 2 3 4 5 6
Dat
a R
ate
(MB
/s)
Number of Processing Units
Shared Content Names (Partitioned Tables Preliminary)
Tx Rate (Single Agent)
Rx Rate (Single Agent)
Tx Rate (Multiple Agents)
Rx Rate (Multiple Agents)
Figure 6.12: Preliminary evaluation for partitioned tables: same content name case, system throughputvs. number of routing nodes. Higher throughput was achieved by avoiding instantiating all routingnodes on the same computing agent.
Splitting routing nodes among multiple computing agents greatly improved throughput for routing
network with more than 3 processing units. With 6 processing units, the aggregate traffic rate for the
routing system scales up to 9.0MB/s (72.0Mbps) inbound and 177.9MB/s (1.4Gbps) outbound. Though a
diminishing return effect is also observed, the throughput is significantly higher than that of the unique
content name case, demonstrating the advantage of content centric networking and its utilization of
in-network caching of popular content.
The difference between the (Single Agent) and (Multiple Agents) throughput curves in Fig. 6.12
demonstrates the importance of underlying physical topology: though resources on a virtual infras-
tructure are abstracted and can scale up or down based on demand, the physical hardware (in this case
the link capacity) has its limitations and may become bottlenecks of the entire system. Therefore we
recommend careful consideration over the mapping between virtual resources and physical devices
when implementing performance critical systems such as our design.
In conclusion, Fig. 6.12 shows that our design of distributed chunk processing with partitioned table
is scalable when requested contents are shared among clients. Though some of the assumptions made
it a rather optimistic estimation of a full implementation, our preliminary evaluation of the partitioned
table design shows its encouraging potential of scaling beyond our design goal of 1Gbps throughput.
Fig. 6.11 and Fig. 6.12 show two extreme use cases of content centric networking. By comparing
the two, the advantages of in-network caching of popular content can be clearly observed. While
throughput results shown in both figures are measured using artificially generated traffic patterns, they

Chapter 6. SAVI CCN Implementation and Evaluation 93
nevertheless give good estimation to the performance region we can expect from our design. As the real
traffic on Internet today is a mixture of unique content and shared content, we expect our design, once
fully implemented, to operate between the two throughput curves: (Per-node Pre-routing) in Fig. 6.11
and (Multiple Agents) in Fig. 6.12. And with the help of techniques such as duplicating popular contents
at multiple processing units, further improvements on throughput performance are possible.
6.3 Concluding Remarks
In this chapter, we presented two distinct approaches towards implementing and evaluating high-
performance content centric networking solutions. In the first part we presented our approach towards
optimizing the header decoder in CCNx without modifying its architecture. The modified CCNx
was deployed and tested on SAVI testbed, and we showed that under realistic traffic conditions our
implementation improved the throughput of a CCNx routing node by more than 12% under full load.
In the second part of this chapter, we pursued the distributed chunk processing with partitioned ta-
bles design alternative. Two approaches towards implementing the pre-routing module were discussed,
and a numerical estimation of performance scaling for both approaches were presented. Preliminary
evaluation on SAVI testbed showed promising results on the performance of our design and demon-
strated its potential of scaling beyond 1Gbps throughput when Content Store on each processing unit
is fully utilized.

Chapter 7
Conclusions
7.1 Summary
As one of the major research initiatives in future Internet architecture, Content Centric Networks (CCN)
show both potential and limitations. In this thesis, we focused our attention on one of the most
pressing issues of CCN: the throughput performance, and presented our solution to realizing high
performance content centric networking on virtual infrastructure enabled by Smart Application on
Virtual Infrastructure (SAVI) testbed.
We started the discussion by extensively studying the performance of existing CCN implementation,
i.e. the CCNx prototype. We found that the throughput of each node is currently throttled by its
processing power, and the specific bottleneck function is the header decoder. Based on the studies, we
identified the critical path in CCN header processing and decomposed each CCN node into 6 essential
services.
Using the knowledge gained, we proposed 5 design alternatives covering a broad range of ap-
proaches towards designing and implementing high performance content centric networking solutions.
For each design proposed, we initiated discussed some of the design considerations, its advantages and
limitations, and possible SAVI resource mapping strategies.
From the 5 alternatives, we chose 2 approaches, namely optimized header decoder and distributed
chunk processing with partitioned tables, and presented their preliminary implementation and deploy-
ment on SAVI testbed. Evaluation using real traffic load demonstrated that 1) our optimization of
header decoder brings over 12% throughput improvement to the single threaded CCNx prototype, and
2) the distributed chunk processing with partitioned tables design scales well with increasing number
94

Chapter 7. Conclusions 95
of processing units and can potentially delivery throughput beyond our 1Gbps design goal if Content
Stores are fully utilized.
7.2 Future Work
Though we are able to show promising potentials of our design through implementation and evaluation
on SAVI testbed, much work is left as possible future research topics. In terms of optimizing header
decoder, we plan to develop self-learning algorithms for constructing the look-up table so that hard-
coding can be avoided. We also plan to evaluate the possibility of keeping decoded headers within
Content Store to reduce the frequency of header decoder invocation. For distributed chunk processing
with partitioned tables, design issues listed in Section 5.7 must be addressed. Specifically, our focus
will be on 1) developing efficient name space partitioning and re-partitioning algorithms, 2) addressing
control message handling, 3) evaluating internal topologies other than mesh and developing necessary
discovery and routing methods, and 4) implementing hardware Bloom filter as the pre-routing module.
Upon completion of these tasks, the two approaches can be integrated: the optimized header decoder
can be used on each software processing units of a partitioned tables system. Together with the hardware
based pre-routing module, further improvements in the throughput performance can be expected.
Beyond the software approach implemented and evaluated in this thesis, we believe efficient hard-
ware implementation of processing units is another avenue for future research. By using specialized
hardware such as programmable devices, significant performance improvement is possible because
overheads related to software network stack and resource virtualization can be eliminated.
Throughout our studies of the existing CCN protocol, we found that a few design decisions from
the original CCN proposal should be challenged. Specifically, we believe for high performance content
centric networking, Data digests should be included in Data chunk headers to avoid computing it at
every CCN node. The flexibility-performance trade-off should also be reconsidered for the current
CCN header specification: instead of allowing all fields in the header to be XML extensible, some
critical fields such as chunk type should have fixed length and position to reduce the header processing
complexity. In addition, we plan to evaluate using Ethernet directly as the network substrates for CCN
deployment. This can help remove some of the limitations inherent to TCP/IP and further improve the
system performance.
In summary, we plan to push forward our design of distributed chunk processing with partitioned
tables by researching algorithms for critical services and implementing the system components using
specialized hardware on SAVI testbed. We envision the resulting system as a viable high performance

Chapter 7. Conclusions 96
CCN solution which generally follows the CCN protocol but may not be completely compatible with
the existing CCNx prototype.

Bibliography
[1] V. Jacobson, D. K. Smetters, J. D. Thornton, M. F. Plass, N. H. Briggs, and R. L. Braynard, “Net-
working named content,” in Proceedings of the 5th international conference on Emerging networking
experiments and technologies, ser. CoNEXT ’09. New York, NY, USA: ACM, 2009, pp. 1–12.
[2] J.M. Kang, H. Bannazadeh, H. Rahimi, T. Lin, M. Faraji, and A. Leon-Garcia, “Software-Defined
Infrastructure and the Future CO,” July 2013, SAVI Annual General Meeting 2013.
[3] T. Anderson, L. Peterson, S. Shenker, and J. Turner, “Overcoming the internet impasse through
virtualization,” Computer, vol. 38, no. 4, pp. 34–41, 2005.
[4] M. Kende. (2012, Sep.) Internet global growth: lessons for the future. [Online].
Available: http://www.analysysmason.com/Research/Content/Reports/Internet-global-growth-
lessons-for-the-future/Internet-global-growth-lessons-for-the-future/
[5] C. G. Plaxton, R. Rajaraman, and A. W. Richa, “Accessing nearby copies of replicated objects in a
distributed environment,” in Proceedings of the ninth annual ACM symposium on Parallel algorithms
and architectures, ser. SPAA ’97. New York, NY, USA: ACM, 1997, pp. 311–320.
[6] S. Ratnasamy, P. Francis, M. Handley, R. Karp, and S. Shenker, “A scalable content-addressable
network,” SIGCOMM Comput. Commun. Rev., vol. 31, no. 4, pp. 161–172, Aug. 2001.
[7] R. Gold and D. Tidhar, “Towards a content-based aggregation network,” in Peer-to-Peer Computing,
2001. Proceedings. First International Conference on, 2001, pp. 62–68.
[8] H. Bandara and A. Jayasumana, “Collaborative applications over peer-to-peer systemschallenges
and solutions,” Peer-to-Peer Networking and Applications, vol. 6, no. 3, pp. 257–276, 2013.
[9] F. Douglis and M. Kaashoek, “Scalable internet services,” Internet Computing, IEEE, vol. 5, no. 4,
pp. 36–37, 2001.
97

Bibliography 98
[10] B. Krishnamurthy, C. Wills, and Y. Zhang, “On the use and performance of content distribution
networks,” in Proceedings of the 1st ACM SIGCOMM Workshop on Internet Measurement, ser. IMW
’01. New York, NY, USA: ACM, 2001, pp. 169–182.
[11] I. Lazar and W. Terrill, “Exploring content delivery networking,” IT Professional, vol. 3, no. 4, pp.
47–49, 2001.
[12] A. Vakali and G. Pallis, “Content delivery networks: status and trends,” Internet Computing, IEEE,
vol. 7, no. 6, pp. 68–74, 2003.
[13] Akamai Technologies, Inc. (2013, May) Akamai Homepage. [Online]. Available: http:
//www.akamai.com/
[14] Amazon.com, Inc. (2013, May) Amazon CloudFront CDN. [Online]. Available: http:
//aws.amazon.com/cloudfront/
[15] CDNetworks. (2013, May) Global Content Delivery Network (CDN). [Online]. Available:
http://www.cdnetworks.com/
[16] Z. Lu, X. Gao, S. Huang, and Y. Huang, “Scalable and reliable live streaming service through co-
ordinating cdn and p2p,” in Parallel and Distributed Systems (ICPADS), 2011 IEEE 17th International
Conference on, 2011, pp. 581–588.
[17] M. El Dick, E. Pacitti, and B. Kemme, “A highly robust p2p-cdn under large-scale and dynamic
participation,” in Advances in P2P Systems, 2009. AP2PS ’09. First International Conference on, 2009,
pp. 180–185.
[18] D. Shi, J. Yin, Z. Wu, and J. Dong, “A peer-to-peer approach to large-scale content-based publish-
subscribe,” in Web Intelligence and Intelligent Agent Technology Workshops, 2006. WI-IAT 2006 Work-
shops. 2006 IEEE/WIC/ACM International Conference on, 2006, pp. 172–175.
[19] M. Chen, A. LaPaugh, and J. P. Singh, “Content distribution for publish/subscribe services,” in
Proceedings of the ACM/IFIP/USENIX 2003 International Conference on Middleware, ser. Middleware
’03. New York, NY, USA: Springer-Verlag New York, Inc., 2003, pp. 83–102.
[20] Palo Alto Research Center. (2013, Apr.) Project CCNx. [Online]. Available: http://www.ccnx.org/
[21] I. Psaras, R. G. Clegg, R. Landa, W. K. Chai, and G. Pavlou, “Modelling and evaluation of ccn-
caching trees,” in NETWORKING 2011. Springer, 2011, pp. 78–91.

Bibliography 99
[22] G. Tyson, S. Kaune, S. Miles, Y. El-khatib, A. Mauthe, and A. Taweel, “A trace-driven analysis
of caching in content-centric networks,” in Computer Communications and Networks (ICCCN), 2012
21st International Conference on, 2012, pp. 1–7.
[23] S. Arianfar, P. Nikander, and J. Ott, “Packet-level caching for information-centric networking,” in
ACM SIGCOMM, ReArch Workshop, 2010.
[24] G. Xylomenos, C. Ververidis, V. Siris, N. Fotiou, C. Tsilopoulos, X. Vasilakos, K. Katsaros, and
G. Polyzos, “A survey of information-centric networking research,” Communications Surveys Tu-
torials, IEEE, vol. PP, no. 99, pp. 1–26, 2013.
[25] P. TalebiFard and V. C. Leung, “A content centric approach to dissemination of information in
vehicular networks,” in Proceedings of the second ACM international symposium on Design and analysis
of intelligent vehicular networks and applications, ser. DIVANet ’12. New York, NY, USA: ACM,
2012, pp. 17–24.
[26] M. Amadeo, C. Campolo, and A. Molinaro, “Crown: Content-centric networking in vehicular ad
hoc networks,” Communications Letters, IEEE, vol. 16, no. 9, pp. 1380–1383, 2012.
[27] V. Jacobson, D. K. Smetters, N. H. Briggs, M. F. Plass, P. Stewart, J. D. Thornton, and R. L. Braynard,
“Voccn: voice-over content-centric networks,” in Proceedings of the 2009 workshop on Re-architecting
the internet, ser. ReArch ’09. New York, NY, USA: ACM, 2009, pp. 1–6.
[28] Stanford University Distributed Systems Group. (2013) TRIAD homepage. [Online]. Available:
http://gregorio.stanford.edu/triad/
[29] M. Caesar, T. Condie, J. Kannan, K. Lakshminarayanan, and I. Stoica, “ROFL: routing on flat
labels,” SIGCOMM Comput. Commun. Rev., vol. 36, no. 4, pp. 363–374, Aug. 2006.
[30] T. Koponen, M. Chawla, B.-G. Chun, A. Ermolinskiy, K. H. Kim, S. Shenker, and I. Stoica, “A
data-oriented (and beyond) network architecture,” SIGCOMM Comput. Commun. Rev., vol. 37,
no. 4, pp. 181–192, Aug. 2007.
[31] (2013, May) Named Data Networking. [Online]. Available: http://www.named-data.net/index.
html
[32] (2013) PSIRP: Publish-Subscribe Internet Routing Paradigm. [Online]. Available: http:
//www.psirp.org/index.html
[33] (2013) PURSUIT. [Online]. Available: http://www.fp7-pursuit.eu/PursuitWeb/

Bibliography 100
[34] D. Kutscher, S. Farrell, and E. Davies, “The NetInf Protocol, draft-kutscher-icnrg-netinf-proto-01,”
February 2013, Network Working Group Internet-Draft.
[35] C. Dannewitz, M. Herlich, and H. Karl, “Opennetinf - prototyping an information-centric network
architecture,” in Local Computer Networks Workshops (LCN Workshops), 2012 IEEE 37th Conference
on, 2012, pp. 1061–1069.
[36] (2013) NetInf: Network of Information. [Online]. Available: http://www.netinf.org/
[37] (2013) The FP7 4WARD Project. [Online]. Available: http://www.4ward-project.eu/
[38] (2013) SAIL: Scalable and Adaptive Internet Solutions. [Online]. Available: http://www.sail-
project.eu/
[39] G. Garcia, A. Beben, F. Ramon, A. Maeso, I. Psaras, G. Pavlou, N. Wang, J. Sliwinski, S. Spirou,
S. Soursos, and E. Hadjioannou, “Comet: Content mediator architecture for content-aware net-
works,” in Future Network Mobile Summit (FutureNetw), 2011, 2011, pp. 1–8.
[40] T. C. Consortium. (2013) ICT COMET Project Website. [Online]. Available: http://www.comet-
project.org/
[41] (2013) The Convergence Project. [Online]. Available: http://www.ict-convergence.eu/
[42] Networking Group, University of Rome “Tor Vergata”. (2013) CONET - COntent NETworking.
[Online]. Available: http://netgroup.uniroma2.it/CONET/
[43] B. Ahlgren, C. Dannewitz, C. Imbrenda, D. Kutscher, and B. Ohlman, “A survey of information-
centric networking,” Communications Magazine, IEEE, vol. 50, no. 7, pp. 26–36, 2012.
[44] M. Bari, S. Chowdhury, R. Ahmed, R. Boutaba, and B. Mathieu, “A survey of naming and routing
in information-centric networks,” Communications Magazine, IEEE, vol. 50, no. 12, pp. 44–53, 2012.
[45] Washington University in St. Louis Applied Research Lab. (2013) CCNx: traffic generation.
[Online]. Available: http://wiki.arl.wustl.edu/onl/index.php/CCNx: traffic generation
[46] N. McKeown, T. Anderson, H. Balakrishnan, G. Parulkar, L. Peterson, J. Rexford, S. Shenker, and
J. Turner, “Openflow: enabling innovation in campus networks,” SIGCOMM Comput. Commun.
Rev., vol. 38, no. 2, pp. 69–74, Mar. 2008.
[47] (2013) OpenFlow - Enabling Innovation in Your Network. [Online]. Available: http:
//www.openflow.org/

Bibliography 101
[48] (2013) Smart Application on Virtual Infrastructure. [Online]. Available: http://www.savinetwork.
ca/
[49] A. Leon-Garcia, “NSERC Strategic Network on Smart Application on Virtual Infrastructure,”
in CASCON2011, 2011. [Online]. Available: http://www.savinetwork.ca/wp-content/uploads/Al-
Leon-Garcia-SAVI-Introduction.pdf
[50] (2013) Research Plan — Smart Application on Virtual Infrastructure. [Online]. Available:
http://www.savinetwork.ca/research/research-plan/
[51] (2013) OpenStack Open Source Cloud Computing Software. [Online]. Available: http:
//www.openstack.org/
[52] R. Sherwood, G. Gibb, K.-K. Yap, G. Appenzeller, M. Casado, N. McKeown, and G. Parulkar,
“Flowvisor: A network virtualization layer,” OpenFlow Switch Consortium, Tech. Rep, 2009.
[53] J. Lockwood, N. McKeown, G. Watson, G. Gibb, P. Hartke, J. Naous, R. Raghuraman, and J. Luo,
“Netfpga–an open platform for gigabit-rate network switching and routing,” in Microelectronic
Systems Education, 2007. MSE ’07. IEEE International Conference on, 2007, pp. 160–161.
[54] (2013) NetFPGA - NetFPGA. [Online]. Available: http://netfpga.org/
[55] BEEcube Inc. (2013) BEEcube Inc. - High-performance Reconfigurable Processing Systems.
[Online]. Available: http://beecube.com/
[56] (2013) NDN Routing Home. [Online]. Available: http://netlab.cs.memphis.edu/script/htm/home.
html
[57] (2013) GENI. [Online]. Available: http://www.geni.net/
[58] L. Wang, A K M M. Hoque, C. Yi, A. Alyyan, and B. Zhang, “OSPFN: An OSPF Based Routing
Protocol for Named Data Networking,” July 2012, NDN Technical Report NDN-0003.
[59] P. Crowley, J. DeHart, J. Parwatikar, H. Yuan, and S. James, “Large Scale CCN
Deployment,” September 2012, CCNxCon2012 Technical Talks: Session 1. [Online]. Available:
http://www.ccnx.org/wp-content/uploads/2012/08/2Crowley.pdf
[60] A. Detti, N. Blefari Melazzi, S. Salsano, and M. Pomposini, “Conet: a content centric inter-
networking architecture,” in Proceedings of the ACM SIGCOMM workshop on Information-centric
networking, ser. ICN ’11. New York, NY, USA: ACM, 2011, pp. 50–55.

Bibliography 102
[61] L. Veltri, G. Morabito, S. Salsano, N. Blefari-Melazzi, and A. Detti, “Supporting information-centric
functionality in software defined networks,” in Communications (ICC), 2012 IEEE International
Conference on, 2012, pp. 6645–6650.
[62] N. Melazzi, A. Detti, G. Mazza, G. Morabito, S. Salsano, and L. Veltri, “An openflow-based testbed
for information centric networking,” in Future Network Mobile Summit (FutureNetw), 2012, 2012,
pp. 1–9.
[63] (2013) OFELIA - Home. [Online]. Available: http://www.fp7-ofelia.eu/
[64] S. Salsano, N.Blefari-Melazzi, A. Detti, G. Mazza, G. Morabito, A. Araldo, L. Linguaglossa, and
L. Veltri, “Supporting COntent NETworking in Software Defined Networks,” July 2012, Technical
Report - Version 0.3.
[65] (2013) click [Click]. [Online]. Available: http://read.cs.ucla.edu/click/click
[66] OpenVPN Technologies, Inc. (2013) OpenVPN - Open Source VPN. [Online]. Available:
http://openvpn.net/
[67] S. Wang, J. Bi, J. Wu, Z. Li, W. Zhang, and X. Yang, “Could in-network caching benefit information-
centric networking?” in Proceedings of the 7th Asian Internet Engineering Conference, ser. AINTEC
’11. New York, NY, USA: ACM, 2011, pp. 112–115.
[68] S. Guo, H. Xie, and G. Shi, “Collaborative forwarding and caching in content centric networks,”
in Proceedings of the 11th international IFIP TC 6 conference on Networking - Volume Part I, ser. IFIP’12.
Berlin, Heidelberg: Springer-Verlag, 2012, pp. 41–55.
[69] Z. Ming, M. Xu, and D. Wang, “Age-based cooperative caching in information-centric networks,”
in Computer Communications Workshops (INFOCOM WKSHPS), 2012 IEEE Conference on, 2012, pp.
268–273.
[70] J. Li, H. Wu, B. Liu, J. Lu, Y. Wang, X. Wang, Y. Zhang, and L. Dong, “Popularity-driven co-
ordinated caching in named data networking,” in Proceedings of the eighth ACM/IEEE symposium
on Architectures for networking and communications systems, ser. ANCS ’12. New York, NY, USA:
ACM, 2012, pp. 15–26.
[71] S. Saha, A. Lukyanenko, and A. Yla-Jaaski, “Cooperative caching through routing control in
information-centric networks,” in INFOCOM, 2013 Proceedings IEEE, 2013, pp. 100–104.

Bibliography 103
[72] R. Ishiyama, K. Tsukamoto, Y. Koizumi, H. Ohsaki, K. Hato, J. Murayama, and M. Imase, “On
the effectiveness of diffusive content caching in content-centric networking,” in Information and
Telecommunication Technologies (APSITT), 2012 9th Asia-Pacific Symposium on, 2012, pp. 1–5.
[73] I. Psaras, W. K. Chai, and G. Pavlou, “Probabilistic in-network caching for information-centric
networks,” in Proceedings of the second edition of the ICN workshop on Information-centric
networking, ser. ICN ’12. New York, NY, USA: ACM, 2012, pp. 55–60. [Online]. Available:
http://doi.acm.org.myaccess.library.utoronto.ca/10.1145/2342488.2342501
[74] X. Vasilakos, V. A. Siris, G. C. Polyzos, and M. Pomonis, “Proactive selective
neighbor caching for enhancing mobility support in information-centric networks,” in
Proceedings of the second edition of the ICN workshop on Information-centric networking,
ser. ICN ’12. New York, NY, USA: ACM, 2012, pp. 61–66. [Online]. Available:
http://doi.acm.org.myaccess.library.utoronto.ca/10.1145/2342488.2342502
[75] F. Bjurefors, P. Gunningberg, C. Rohner, and S. Tavakoli, “Congestion avoidance in a data-centric
opportunistic network,” in Proceedings of the ACM SIGCOMM workshop on Information-centric
networking, ser. ICN ’11. New York, NY, USA: ACM, 2011, pp. 32–37.
[76] S. Eum, K. Nakauchi, M. Murata, Y. Shoji, and N. Nishinaga, “CATT: potential based routing with
content caching for ICN,” in Proceedings of the second edition of the ICN workshop on Information-
centric networking, ser. ICN ’12. New York, NY, USA: ACM, 2012, pp. 49–54.
[77] H. Yuan, T. Song, and P. Crowley, “Scalable NDN Forwarding: Concepts, Issues and Principles,”
in Computer Communications and Networks (ICCCN), 2012 21st International Conference on, 2012, pp.
1–9.
[78] T. Janaszka, D. Bursztynowski, and M. Dzida, “On popularity-based load balancing in content
networks,” in Proceedings of the 24th International Teletraffic Congress, ser. ITC ’12. International
Teletraffic Congress, 2012, pp. 12:1–12:8.
[79] S. Salsano, A. Detti, M. Cancellieri, M. Pomposini, and N. Blefari-Melazzi, “Transport-layer
issues in information centric networks,” in Proceedings of the second edition of the ICN workshop on
Information-centric networking, ser. ICN ’12. New York, NY, USA: ACM, 2012, pp. 19–24.
[80] G. Carofiglio, V. Gehlen, and D. Perino, “Experimental evaluation of memory management in
content-centric networking,” in Communications (ICC), 2011 IEEE International Conference on, 2011,
pp. 1–6.

Bibliography 104
[81] H. Wang, Z. Chen, F. Xie, and F. Han, “A data structure for content cache management in content-
centric networking,” in Networking and Distributed Computing (ICNDC), 2012 Third International
Conference on, 2012, pp. 11–15.
[82] G. Bianchi, A. Detti, A. Caponi, and N. Blefari Melazzi, “Check before storing: what is the
performance price of content integrity verification in lru caching?” SIGCOMM Comput. Commun.
Rev., vol. 43, no. 3, pp. 59–67, Jul. 2013.
[83] J. Shi and B. Zhang, “NDNLP: A Link Protocol for NDN,” July 2012, NDN Technical Report
NDN-0006.
[84] S. Ding, Z. Chen, and Z. Liu, “Parallelizing fib lookup in content centric networking,” in Network-
ing and Distributed Computing (ICNDC), 2012 Third International Conference on, 2012, pp. 6–10.
[85] D. Perino and M. Varvello, “A reality check for content centric networking,” in Proceedings of the
ACM SIGCOMM workshop on Information-centric networking, ser. ICN ’11. New York, NY, USA:
ACM, 2011, pp. 44–49.
[86] M. Varvello, D. Perino, and J. Esteban, “Caesar: a content router for high speed forwarding,” in
Proceedings of the second edition of the ICN workshop on Information-centric networking, ser. ICN ’12.
New York, NY, USA: ACM, 2012, pp. 73–78.
[87] S. Arianfar, P. Nikander, and J. Ott, “On content-centric router design and implications,” in
Proceedings of the Re-Architecting the Internet Workshop, ser. ReARCH ’10. New York, NY, USA:
ACM, 2010, pp. 5:1–5:6.
[88] H. Hwang, S. Ata, and M. Murata, “Realization of name lookup table in routers towards content-
centric networks,” in Network and Service Management (CNSM), 2011 7th International Conference
on, 2011, pp. 1–5.
[89] W. You, B. Mathieu, P. Truong, J. Peltier, and G. Simon, “Realistic storage of pending requests in
content-centric network routers,” in Communications in China (ICCC), 2012 1st IEEE International
Conference on, 2012, pp. 120–125.
[90] Stanford OpenFlow Team. (2009) OpenFlow Switch Specification Version 1.0.0 Implemented
(Wire Protocol 0x01). [Online]. Available: http://www.openflow.org/documents/openflow-spec-
v1.0.0.pdf

Bibliography 105
[91] Cisco Systems, Inc., “Cisco Nexus 7000 F2-Series 48-Port 1 and 10 Gigabit Ethernet Module Data
Sheet,” July 2013. [Online]. Available: http://www.cisco.com/en/US/prod/collateral/switches/
ps9441/ps9402/data sheet c78-685394.html
[92] J. A. Chandy, “A generalized replica placement strategy to optimize latency in a wide area dis-
tributed storage system,” in Proceedings of the 2008 international workshop on Data-aware distributed
computing, ser. DADC ’08. New York, NY, USA: ACM, 2008, pp. 49–54.
[93] A. Klein, I. Fuyuki, and S. Honiden, “Sanga: A self-adaptive network-aware approach to service
composition,” Services Computing, IEEE Transactions on, vol. PP, no. 99, pp. 1–1, 2013.
[94] G. Giakkoupis and V. Hadzilacos, “A scheme for load balancing in heterogenous distributed
hash tables,” in Proceedings of the twenty-fourth annual ACM symposium on Principles of distributed
computing, ser. PODC ’05. New York, NY, USA: ACM, 2005, pp. 302–311.
[95] D. R. Karger and M. Ruhl, “Simple efficient load balancing algorithms for peer-to-peer systems,”
in Proceedings of the sixteenth annual ACM symposium on Parallelism in algorithms and architectures,
ser. SPAA ’04. New York, NY, USA: ACM, 2004, pp. 36–43.
[96] M. Holze and N. Ritter, “Towards workload shift detection and prediction for autonomic
databases,” in Proceedings of the ACM first Ph.D. workshop in CIKM, ser. PIKM ’07. New York, NY,
USA: ACM, 2007, pp. 109–116.
[97] H. Bannazadeh, “Application-oriented networking through virtualization and service composi-
tion,” Ph.D. dissertation, University of Toronto, 2010.
[98] D. Boukhelef and H. Kitagawa, “Dynamic load balancing in rcan content addressable network,”
in Proceedings of the 3rd International Conference on Ubiquitous Information Management and Commu-
nication, ser. ICUIMC ’09. New York, NY, USA: ACM, 2009, pp. 98–106.
[99] O. Sahin, D. Agrawal, and A. El Abbadi, “Techniques for efficient routing and load balancing in
content-addressable networks,” in Peer-to-Peer Computing, 2005. P2P 2005. Fifth IEEE International
Conference on, 2005, pp. 67–74.
[100] J. Dean and L. A. Barroso, “The tail at scale,” Commun. ACM, vol. 56, no. 2, pp. 74–80, Feb. 2013.
[101] Khronos Group. (2013) OpenCL - The open standard for parallel programming of heterogeneous
systems. [Online]. Available: http://www.khronos.org/opencl/

Bibliography 106
[102] NVIDIA Corporation. (2013) CUDA Parallel Computing Platform. [Online]. Available:
http://www.nvidia.ca/object/cuda home new.html
[103] M. Boyer. (2013) CUDA memory transfer overhead. [Online]. Available: http://www.cs.virginia.
edu/∼mwb7w/cuda support/memory transfer overhead.html
[104] High Performance Computing Consortia in Ontario. (2013, May) Summer school on high
performance and technical computing. [Online]. Available: http://ss2013-central.sharcnet.ca/
[105] W. W. L. Fung, I. Sham, G. Yuan, and T. M. Aamodt, “Dynamic warp formation: Efficient MIMD
control flow on SIMD graphics hardware,” ACM Trans. Archit. Code Optim., vol. 6, no. 2, pp.
7:1–7:37, Jul. 2009.
[106] N. R. Fredrickson, A. Afsahi, and Y. Qian, “Performance characteristics of openMP constructs, and
application benchmarks on a large symmetric multiprocessor,” in Proceedings of the 17th annual
international conference on Supercomputing, ser. ICS ’03. New York, NY, USA: ACM, 2003, pp.
140–149.
[107] P. M. Mattheakis and I. Papaefstathiou, “Significantly reducing MPI intercommunication latency
and power overhead in both embedded and HPC systems,” ACM Trans. Archit. Code Optim., vol. 9,
no. 4, pp. 51:1–51:25, Jan. 2013.
[108] CCNx Open Source Project. (2013) CCNx Binary Encoding (ccnb). [Online]. Available:
http://www.ccnx.org/releases/latest/doc/technical/BinaryEncoding.html
[109] Stanford OpenFlow Team. (2011) OpenFlow Switch Specification Version 1.1.0 Implemented
(Wire Protocol 0x02). [Online]. Available: http://www.openflow.org/documents/openflow-spec-
v1.1.0.pdf
[110] S. Dharmapurikar, P. Krishnamurthy, and D. E. Taylor, “Longest prefix matching using bloom
filters,” IEEE/ACM Trans. Netw., vol. 14, no. 2, pp. 397–409, Apr. 2006.
[111] H. Song, F. Hao, M. Kodialam, and T. V. Lakshman, “Ipv6 lookups using distributed and load
balanced bloom filters for 100gbps core router line cards,” in INFOCOM 2009, IEEE, 2009, pp.
2518–2526.





























