Embed Size (px)
Citation preview

Rokicki Simon - Irisa / Université de Rennes 1Steven Derrien - Irisa / Université de Rennes 1
Erven Rohou - Inria Rennes
RISC-V Hardware-Accelerated Dynamic Binary Translation
6th RISC-V Workshop

Embedded Systems
Tight constraints in• Power consumption• Production cost• Performance
2Hardware Accelerated Dynamic Binary Translation

Systems on a Chip
• Complex heterogeneous designs• Heterogeneity brings new power/performance trade-off
3Hardware Accelerated Dynamic Binary Translation
Out-of-order SuperscalarIn-order core
Performance
Pow
er
Overhead from in-orderto Out-of-Order

Systems on a Chip
4HW/SW Dynamic Compilation for Adaptive Embedded Systems
Out-of-order SuperscalarIn-order coreVLIW
Performance
Pow
er
• Complex heterogeneous designs• Heterogeneity brings new power/performance trade-off• Are there better trade-off?

Out-of-Order processor
• Dynamic Scheduling
• Performance portability
• Poor energy efficiency
VLIW processor
• Static scheduling
• No portability
• High energy efficiency
Architectural choice
VLI
W
ins2
ins3
Ins4
ins1
ins2
ins3
Ins4
ins1
ins2
ins3
Ins4
ins1
……
……
ins3 ins2 ins1ins4… ROBD
eco
de
& R
enam
ing
5Hardware Accelerated Dynamic Binary Translation

Dynamically translate native binaries into VLIW binaries:• Performance close to Out-of-Order processor
• Energy consumption close to VLIW processor
The best of both world ?
VLI
WBinaries(RISC-V)
VLIWBinaries
Dynamic BinaryTranslation
6Hardware Accelerated Dynamic Binary Translation

• Transmeta Code Morphing Software & Crusoe architectures• x86 on VLIW architecture• User experience polluted by cold-code execution penalty
• Nvidia Denver architecture• ARM on VLIW architecture
Existing approaches
7
• Translation overhead is critical
• Too few information on closed platforms
Hardware Accelerated Dynamic Binary Translation

• Hardware accelerated DBT framework Make the DBT cheaper (time & energy)
First approach that try to accelerate binary translation
• Open source framework Allows research
Our contribution
HardwareAccelerators
VLI
WBinaries(RISC-V)
VLIWBinaries
Dynamic BinaryTranslation
Hardware Accelerated Dynamic Binary Translation 7

• Hybrid-DBT Platform• How does it work? • What does it cost?• Focus on optimization levels
• Experimental Study• Impact on translation overhead• Impact on area utilization• Performance results
• Conclusion & Future work
Outline
9Hardware Accelerated Dynamic Binary Translation

Outline
10
• Hybrid-DBT Platform• How does it work? • What does it cost?• Focus on optimization levels
• Experimental Study• Impact on translation overhead• Impact on area utilization• Performance results
• Conclusion & Future work
Hardware Accelerated Dynamic Binary Translation

How does it work?
VLI
WRISC-Vbinaries
11
• RISC-V binaries cannot be executed on VLIW
Hardware Accelerated Dynamic Binary Translation

How does it work?
• Direct, naive translation from native to VLIW binaries• Does not take advantage of Instruction Level Parallelism
VLI
WRISC-Vbinaries
Direct Translation
VLIWbinaries
Optimizationlevel 0 No ILP
Hardware Accelerated Dynamic Binary Translation 12

13
How does it work?
• Build an Intermediate Representation (CFG + dependencies)• Reschedule Instructions on VLIW execution units
VLI
WRISC-Vbinaries
Direct Translation
VLIWbinaries
IR Builder IR SchedulerIR
Optimizationlevel 0
Optimizationlevel 1
No ILP
ILP
Hardware Accelerated Dynamic Binary Translation

14
How does it work?
• Code profiling to detect hotspot• Optimization level 1 only on hotspots
VLI
WRISC-Vbinaries
Direct Translation
VLIWbinaries
Insert Profiling
IR Builder IR SchedulerIR
Optimizationlevel 0
Optimizationlevel 1
No ILP
ILP
Hardware Accelerated Dynamic Binary Translation

VLI
WRISC-Vbinaries
Direct Translation
VLIWbinaries
Insert Profiling
IR Builder IR SchedulerIR
Optimizationlevel 0
Optimizationlevel 1
15
150 cycle/instr
400 cycle/instr 500 cycle/instr
What does it cost?
No ILP
ILP
• Cycle/instr : number of cycles to translate one RISC-V instruction• Need to accelerate time consuming parts of the translation
Hardware Accelerated Dynamic Binary Translation

Hybrid-DBT framework
VLI
WRISC-Vbinaries
First-PassTranslation
VLIWbinaries
Insert Profiling
IR Builder IR SchedulerIR
Optimizationlevel 0
Optimizationlevel 1
16
Software pass
Hardware accelerators
No ILP
ILP
• Hardware acceleration of critical steps of DBT• Can be seen as a hardware accelerated compiler back-end
Hardware Accelerated Dynamic Binary Translation

Optimization level 0
RISC-Vbinaries
rs1 funct rd opcodeimm12 rs1 rd opcodeimm13
VLIWbinaries
• Implemented as a Finite State Machine• Translate each native instruction separately• Produces 1 VLIW instruction per cycle• 1 RISC-V instruction => up to 2 VLIW instructions
• Simple because ISA are similar
17
First-PassTranslation
Hardware Accelerated Dynamic Binary Translation

Optimization level 1
18Hardware Accelerated Dynamic Binary Translation
VLIWbinaries
IR Builder IR SchedulerIRVLIW
binaries
• Build an higher level intermediate representation• Perform Instruction Scheduling
• Critical to start exploiting VLIW capabilities

Choosing an Intermediate Representation
19
g1 1 g3 0
stld+
-
st
r 3
012
3
4
0
mv5
g2
op registers[4]
nbSuccnbDSuccnbDep96 64 32 0
0 - st
1 - ld
2 - addi
3 - sub
4 - st
@g3 = 0
r1 = @g2
g1 = g1 1
r3 = r1 g1
@g2 = r3
0
1
0
2
2
0
2
1
1
0
1
2
1
2
1
1
3
3
4
5
4
-
5
- - - - - -
-
- -
-- -
-
-
- -
-
-
-
-
-
- -
-
-
-
succNames[8]
-
-
-
-
-
5- mov r3 = 0 2 0 0 - - - -- - --
-
IR advantages:• Direct access to dependencies and successors• Regular structure (no pointers / variable size)
Hardware Accelerated Dynamic Binary Translation

Details on hardware accelerators
• Developing such accelerators using VHDL is out of reach• Accelerators are developed using High-Level Synthesis
• Loops unrolling/pipelining• Memory partitioning• Memory accesses factorization• Explicit forwarding
VLIWbinaries
IR Builder IR SchedulerIRVLIW
binaries
One-pass dependencies analysis List-scheduling algorithm
Hardware Accelerated Dynamic Binary Translation 20
See DATE’17 paper for more details !

Outline
21
• Hybrid-DBT Platform• How does it work? • What does it cost?• Focus on optimization levels
• Experimental Study• Impact on translation overhead• Impact on area utilization• Performance results
• Conclusion & Future work
Hardware Accelerated Dynamic Binary Translation

Impact on translation overhead
22
VLI
WRISC-Vbinaries
First-PassTranslation
VLIWbinaries
IR BuilderIR
SchedulerIR
Optimizationlevel 0
Optimizationlevel 1
150 cycle/instr
400 cycle/instr 500 cycle/instr
• VLIW baseline is executed with ST200simVLIW
• Fully functionnal Hybrid-DBT platform on FPGA • JIT processor: Nios II
• Altera DE2-115
Hardware Accelerated Dynamic Binary Translation
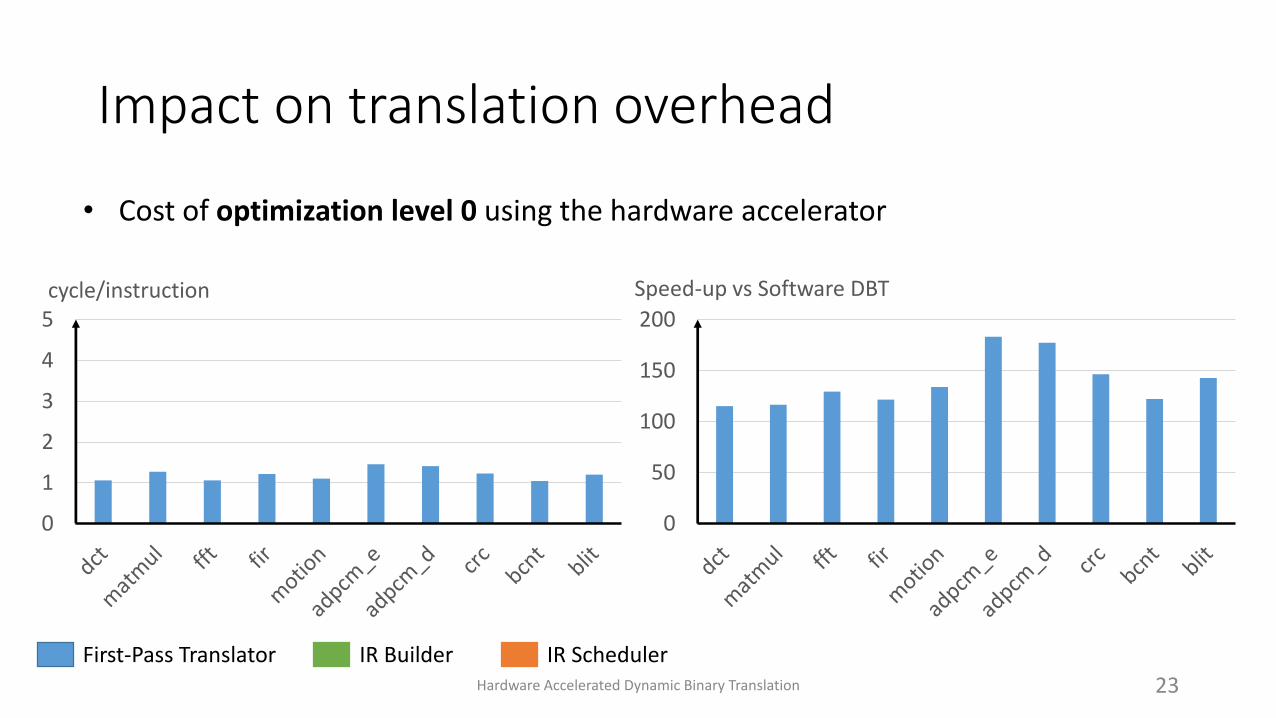
Impact on translation overhead
0
1
2
3
4
5cycle/instruction
0
50
100
150
200
Speed-up vs Software DBT
First-Pass Translator IR Builder IR Scheduler
23
• Cost of optimization level 0 using the hardware accelerator
Hardware Accelerated Dynamic Binary Translation

Impact on translation overhead
14 15 13 14 13 13 13 13 12 1337
144
61
132106 112 106 116
60
105
0
50
100
150
200
cycle/instruction
05
10152025303540
Speed-up vs Software DBT
First-Pass Translator IR Builder IR Scheduler
24
• Cost of optimization level 1 using the hardware accelerator
Hardware Accelerated Dynamic Binary Translation

Impact on area/resource cost
19 220
6 3007 626
779
5 019
0
5000
10000
15000
20000
25000
VLIW DBTProcessor
IRScheduler
First-PassTranslator
IR Builder
NAND equivalent gates
25
Overhead from Hybrid-DBT
• Resource usage for all our platform components • ASIC 65nm
Hardware Accelerated Dynamic Binary Translation

Performance results• Comparison against OoO architectures
• Compare area, power consumption and performance with BOOM
26HW/SW Dynamic Compilation for Adaptive Embedded Systems
0
500
1000
1500
2000
BOOM VLIW4
Power Consumption (mW)
5x
0
0,1
0,2
0,3
0,4
0,5
adpcm dec g721 dec g721 enc matmul
Speed-up OoO vs VLIW
Stay at opt level 0

Conclusion
• Presentation of Hybrid-DBT framework• Hardware accelerated DBT
• Open-source DBT framework RISC-V to VLIW
• Tested FPGA prototype
• Sources are available on GitHub: https://github.com/srokicki/HybridDBT
27
HardwareAccelerators
VLI
WBinaries(RISC-V)
VLIWBinaries
Dynamic BinaryTranslation
Hardware Accelerated Dynamic Binary Translation

28
GPU-style SIMT execution assembles vector instructions across threads of SPMD applications
Alternative to vector processing based on scalar ISA
Simty: proof of concept for SIMT on general-purpose binariesRuns the RISC-V instruction set (RV32I), no modificationWritten in synthesizable VHDLWarp size and warp count adjustable at synthesis time10-stage in-order pipeline
More details on https://team.inria.fr/pacap/simty/ !!
Scales up to 2048 threads per core with 64 warps × 32 threads
Simty: a synthesizable SIMT CPU

Questions
https://github.com/srokicki/HybridDBT
https://team.inria.fr/pacap/simty/
29
?Hardware Accelerated Dynamic Binary Translation

30
FPGA synthesis of Simty
• Up to 2048 threads per core: 64 warps × 32 threads• Sweet spot: 8x8 to 32x16
Overhead of per-PC control is easily amortized
Logic area (LEs) Memory area (M9Ks) Frequency (MHz)
Latency hiding
multithreading depth
Throughput
SIMD width
On Altera Cyclone IV




























