Embed Size (px)
Citation preview

IS1200 DatorteknikIS1500 Datorteknik och komponenter
Hemlaboration Cache
Cacheminnen2011-08-30
Kursdeltagarens namn: .................................................................................................................
Datum: .............................. Godkänd av (assistentens signatur): ...............................................
IS1200/IS1500 Hemlab cache: Cacheminnen sida 1

Målsättning med hemlaborationen
När du har redovisat den här hemlaborationen kommer du att kunna:
•Allmänt beskriva och motivera hur cacheminnen påverkar prestanda för olika datorprogram.
•Beskriva och motivera hur ändringar i cacheminnets parametrar kan påverka prestanda för ett visst program.
•Föreslå och motivera hur program kan ändras för att ge högre prestanda i datorsystem med cacheminnen.
Förkunskaper
Innan du genomför den här hemlaborationen måste du kunna:
•Läsa och skriva program i språket C, på en nivå som motsvar godkänd hemlaboration 1 (om C).
•Förklara grundläggande principer hos cacheminnen, på en nivå motsvarande kapitel 6 i Mats Brorssons bok Datorsystem.
•Förstå och gärna förklara konstruktions-principer hos cacheminnen, på en nivå motsvarande cacheminnesdelen av F Lundevalls kompendium Cacheminne och adressöversättning.
Kompendiet Cacheminne och adressöversätt-ning är mer omfattande och detaljerat än kapitel 6 i Mats Brorssons bok. Den som har läst, förstått och kan tillämpa innehållet i kompendiets cacheminnesdel behöver inte läsa kapitel 6 i boken.
Tekniska krav
Den här hemlaborationen använder en annan programvara än övriga laborationer i kursen.
Programvaran kräver tillgång till en person-dator med Microsoft Windows. Den är testad med Windows 98 och Windows XP, samt med Ubuntu 10.04 LTS (kräver Wine).
Frågor
Vi i kursteamet svarar gärna på frågor om du undrar över något när du arbetar med hem-laborationen! E-postadress: [email protected] [email protected]åda adresserna fungerar. Välj helst den som stämmer med kurskoden för den kurs du läser.
Se också kursens webbplats.
Redovisning av hemlaborationen
Bokför alla ändringar i programfiler, cacheminnesinställningar och resultat från varje provkörning! Vid redovisningen ska du kunna beskriva och förklara alla resul-tat. Om någon dokumentation saknas så krävs komplettering och ny redovisning.
Om det är några enstaka resultat som du inte har lyckats förstå eller förklara så har du möjlighet att be assistenten förklara för dig.
Vid redovisningen ställer assistenten flera frågor än dem som finns med här i lab-PM. En viktig fråga, som assistenten kan ställa ofta, är frågan "Varför?"
När Du vid redovisningstillfället uppvisar tillräckliga kunskaper bokförs din laboration som godkänd. Om du inte kan visa att du förstått allt, eller inte har utfört alla moment, eller saknar dokumentation, eller har hunnit glömma viktiga kunskaper, så får du göra om redovisningen vid ett senare tillfälle. Inför det senare tillfället kompletterar du förstås provkörningar och dokumentation, och repeterar allt så att du har det aktuellt vid redovisningen.
Redovisning ska göras ensam eller i grupp om 2 personer. Vid redovisning i grupp bedöms kunskaperna individuellt. Om bara en av gruppmedlemmarna har tillräckliga kunskaper så blir bara den medlemmen godkänd.
Gör pappersutskrifter! Laborations-redovisningen genomförs utan dator.
Se till att ha dina utskrifter väl organi-serade, så att du hinner klart redovisningen på utsatt tid. Annars får du göra om redovisningen vid ett senare tillfälle.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 2

Programvara
Programvaran har två delar: MipsIT Studio, som används för att redigera och kompilera program, samt Mips Simulator, som är själva simulatorn. Du hämtar och installerar programvaran enligt instruktionerna på kursens webbsidor om labben:
www.ict.kth.se/courses/IS1500/2010/labcache/
MipsIT Studio
Obs! Meddelandet Failed to open COM port är ofarligt. Klicka bara OK.
När du vill kompilera ett program i C-kod för att köra det i simulatorn gör du följande.
Skapa ett Projekt (New → Project) markerat som C(minimal)/Assembler, och därefter en fil (New → File) markerad som C-file. Nu kan du klippa-och-klistra in en programfil från detta lab-PM eller från webben. Använd filen:
www.ict.kth.se/courses/IS1500/2010/labcache/strcpy.c
Därefter kan du kompilera med Build → Rebuild all. Då skapas en fil som kan köras i Mips-simulatorn. En genväg för att kompilera är att trycka på funktionsknapp F7.
Du kan studera Mips-assemblerkoden från kompilatorn, med Build → View Assembler.
När du vill simulera programmet startar du Mips-simulatorn. Växla sedan tillbaka till MipsIT Studio och gör Build → Upload to simulator. En genväg är att trycka på F5.
Sedan kan du studera innehåll och beteenden i Instruktions- och Data-cache. Klickar du på rutorna märkta I-cache respektive D-cache, så får du fram en grafisk bild som visar konfigur-ation och innehåll i respektive cacheminne.
I Mips-simulatorn kan du ändra konfiguration för cacheminnena och primärminnet genom att välja Edit → Cache/Mem Config.
I laborationen ingår att studera hur utseendet på cachen förändras då du ändrar konfigurationsparametrarna.
Simulatorn
Simulatorn är en programdriven cacheminnes-simulator, som kör program kompilerade till
Mips-kod. "Programdriven" betyder att Mips-instruktionerna tolkas och utförs i simulatorn, och att läsningar och skrivningar till cache-minnena simuleras under programkörningen.
Att simulatorn kör Mips-programkod betyder inte att du måste skriva program i Mips-assembler. MipsIT Studio innehåller en C-kompilator som producerar Mips-kod.
De C-program som ska köras begränsas av att simulatorn inte har något operativsystem, men hemlaborationen är speciellt konstruerad för att detta inte ska ge problem.
Viktiga tips för hela labben
På många ställen finns prickade rader för svar på frågorna. Vi rekommenderar att du skriver ut lab-PM på papper, och skriver svaren på de prickade raderna. Då hittar du snabbt rätt svar på redovisningen. Gör extra anteckningar om motiveringar och förklaringar.
Ibland saknas prickade rader. Då är svaret mer komplicerat än vad som brukar få plats på en prickad rad. Använd ett separat papper.
I en del fall är förväntade resultat tryckta med fetstil i lab-PM. Om dina resultat inte stämmer med det förtryckta värdet så måste du under-söka vad som har blivit fel. Förslag på åtgärder är:
Skapa ett nytt projekt och se till att välja "C(minimal)/Assembler". Skulle du råka välja något av de andra alternativen så får du fel resultat. Skapa i så fall ett nytt projekt och gör om simuleringen med det nya projektet.
Var noga med att ställa in optimeringsgraden enligt anvisningarna för varje uppgift. Om du behöver starta om MipsIT Studio så måste du göra om inställningarna efter varje omstart.
Vi rekommenderar att du återställer simulatorn med menyvalet Cpu – Reset före varje ny kör-ning. Kom ihåg att kontrollera cache- och minneskonfigurationerna innan varje körning.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 3

Inledning
För att en dator ska gå snabbt måste alla komponenterna i datorn gå tillräckligt fort. Är någon del långsammare än de andra så skapar den delen problem, och blir det som begränsar totalprestandan hos systemet.
Prestanda hos processorer har under perioden 1980–2000 ökat exponentiellt. Primärminnet har under samma period växt exponentiellt i storlek, men hastigheten bara har ökat linjärt.
Idag är hastighetsskillnaden mellan processor och huvudminne mycket stor. Det problemet kan angripas på flera sätt.
Ett sätt skulle vara att helt enkelt använda supersnabba minneskretsar som primärminne. Det är dock mycket dyrt och energislukande.
Tidigare användes denna metod av ett fåtal superdatortillverkare. Idag skulle den leda till nya svåra flaskhalsar, eftersom det energi-slukande minnet måste placeras långt från processorn för att kunna kylas ordentligt. Men med stort avstånd så tar det lång tid att flytta data mellan minne och processor, och prestandavinsten uteblir.
Ett bättre sätt att angripa problemet är att använda cacheminne. Detta är idag en standardlösning som används i alla datorer som är byggda för snabb programkörning.
Det är värt att notera, att datorer i inbyggda system (embedded systems) bara behöver vara tillräckligt snabba för att klara systemets uppgift. I sådana system är cacheminnen i vissa fall onödiga.
Lokalitet
Cacheminnen utnyttjar lokalitet i program, för att snabba upp huvuddelen av de läsningar och skrivningar som görs mot minnet. En minnes-läsning eller skrivning kallas ofta för referens. Därför talar man ibland om referenslokalitet.
Den som konstruerar en ny dator studerar beteendet hos viktiga program, bland annat de testprogram som marknadsförarna ska använda för att hävda att datorn är snabb, och anpassar cacheminnena så att programexekveringen går fort utan att datorn blir för dyr.
Ett annat sätt att få program att gå fort är den omvända metoden: studera hur cacheminnena fungerar och anpassa sitt program så att det utnyttjar cacheminnena på bästa sätt.
I den här hemlaborationen ska du få möjlighet att prova på båda vägarna.
En av grundidéerna med cacheminnen är att de vanligtvis ger bra effekt utan ändringar i programmen. Att anpassa sina program till cacheminnena är alltså ett nischområde, men när det behövs kan prestandaförbättringen vara dramatisk.
Låt oss repetera de båda typerna av lokalitet.
● Lokalitet i tiden: om en minnescell just har lästs eller skrivits, så läser eller skriver programmet troligen snart precis samma minnescell igen. Detta kallas också temporal lokalitet, eller re-use.
● Lokalitet i rummet: om en minnescell just har lästs eller skrivits, så läser eller skriver programmet troligen snart en annan minnescell med näraliggande adress. Detta kallas också spatial lokalitet, eller bara locality.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 4

Byte-adresserat minne och cacheminne
I simulatorns minne innehåller en byte 8 bitar, och varje byte har en egen adress. Så fungerar de flesta nya datorer idag.
Instruktionerna till en Mips-processor är alltid 4 byte långa, det vill säga 32 bitar. Om första instruktionen finns på adress 0 och är 4 byte lång, så finns nästa instruktion på adress 4. Sedan följer instruktioner på adresserna 8, 12, 16, 20 och så vidare. Se figuren.
Adresserna för instruktioner är alltså alltid jämnt delbara med 4. Det gör att instruktionsadresserna alltid har 0:or i de båda minst signifikanta bitarna, alltså längst till höger.
Ett minne blir enklare att konstruera om det bara behöver hantera hela ord. Därför byggs instruktionscacheminnet i Mips-datorer för att alltid hantera hela 4-bytes ord .
Ett ord börjar alltid på en adress som är jämnt delbar med 4, och sådana adresser slutar ju med två binära 0:or. Av samma orsak innehåller alltid programräknaren (Program Counter, PC), alltid adresser som är jämnt delbara med 4 (och slutar med två binära 0:or).
Instruktionscacheminnet konstrueras alltså med förutsättningen att de två minst signifikanta adressbitarna är noll. Då behöver cacheminnet inte använda de båda bitarna.
För säkerhets skull kan det vara bra om cacheminnet kollar att de två minst signifikanta adressbitarna verkligen är nollställda. Detta görs i de flesta datorer. Ett undantag är Nios II, där processorn i vissa konfigurationer ignorerar bitarnas värden och alltid arbetar som om de var nollställda.
Mats Brorssons bok Datorsystem tar inte upp de här detaljerna om hur byte-adressering påverkar cache-minnet. Du kan i stället läsa om det i kompendiet Cacheminnen och adress-översättning.
Mips-simulatorn särbehandlar de två minst signifikanta adressbitarna, och förutsätter att de är nollställda.
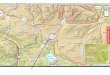
Figur 2 visar ett direktmappat cache-minne med storlek 64 byte (16 ord) och blockstorlek 8 byte per block (2 ord per block).
IS1200/IS1500 Hemlab cache: Cacheminnen sida 5
Figur 2. Cacheminne (bild från simulatorn).
giltigbit(valid-bit)
väljer rad i cacheminnet
adressetikett
de 2 minst signifikanta adressbitarna ska vara noll
väljer ordinom raden
jämförare
OCH-grind
Figur 1. 4-bytes instruktioner i byte-adresserat minne.
1 byte(8 bitar)
......
adress...
......
000000000...0 0000 0000
0...0 0000 0001
0...0 0000 0010
0...0 0000 0011
0...0 0000 0100
0...0 0000 0101
0...0 0000 0110
000000000...0 0000 0111
0...0 0000 1000
0...0 0000 1001
0...0 0000 1010
0...0 0000 1011
0...0 0000 1100
0...0 0000 1101
0...0 0000 1110
0...0 0000 1111
000000000...0 0001 0000
0...0 0001 0001
eninstruk-
tion
nästainstruk-
tion
eninstruk-
tiontill
ännu eninstruk-
tion
och såvidare
1 byte(8 bitar)
......
adress...
......
000000000...0 0000 0000
0...0 0000 0001
0...0 0000 0010
0...0 0000 0011
0...0 0000 0100
0...0 0000 0101
0...0 0000 0110
000000000...0 0000 0111
0...0 0000 1000
0...0 0000 1001
0...0 0000 1010
0...0 0000 1011
0...0 0000 1100
0...0 0000 1101
0...0 0000 1110
0...0 0000 1111
000000000...0 0001 0000
0...0 0001 0001
eninstruk-
tion
nästainstruk-
tion
eninstruk-
tiontill
ännu eninstruk-
tion
och såvidare

LaborationsuppgifterLäs hela lab-PM innan du börjar!
Uppgift 1. Längd, bredd, höjd hos olika cacheminnen
Starta simulatorn. Välj Edit → Cache/Mem Config och studera de inställningar som finns för I-cache, D-cache och Memory.
Figur 3 till höger visar ett cacheminne med standardinställningarna. Det är direktmappat, med storlek 16 ord (64 byte) och blockstorlek 2 ord per block (8 byte per block).
Svara på följande frågor. Vid redovisningen ska du kunna förklara och motivera svaren i detalj. Du kan också få nya, liknande frågor vid redovisningen.
1 ord är 4 bytes, det vill säga 32 bitar, i simulatorn.
Fråga 1.1. Hur många bitars adress krävs (till exempel i Program Counter) i en byte-adresserad dator med ett RAM-minne som är 512 Mbyte stort?
............................................................
Fråga 1.2. Förklara i vilka fält adressen delas och hur många bitar som ingår i varje fält, för ett direktmappat cache-minne med storlek 16 kbyte (16384 byte) och blockstorlek 2 ord. Ange också namnet på varje fält. Figur 4 visar ett exempel på hur en fältindelning kan se ut.
Fråga 1.3. Utgå från figur 3. Den visar ett direktmappat cacheminne med storlek 16 ord (64 byte) och blockstorlek 2 ord per block (8 byte per block). I vilka fält delas adressen och hur många bitar ingår i varje fält?
Fråga 1.4. Utgå från figur 3. Hur ändras cache-minnets utseende om du ökar cacheminnesstorleken (Size) från 16 ord till 32 ord och hur påverkas fältindelningen i adressen?
Fråga 1.5. Utgå från figur 3. Hur ändras cache-minnets utseende om du ökar blockstorleken (Block size) från 2 ord per block till 4 ord per block, och hur påverkas fältindelningen i adressen?
Fråga 1.6. Utgå från figur 3. Hur ändras cacheminnets utseende om du ändrar från associativitet 1 (direktmappat cacheminne) till associativitet 2, och hur påverkas fältindelningen i adressen?
IS1200/IS1500 Hemlab cache: Cacheminnen sida 6
Figur 4. Exempel på fältindelning av den adress som kommer från CPU:n.
Bilden saknar namn och storlekar på fälten.
Exempel på fältindelning, här med 3 fält
Adress från CPU:n (32 bitar)
Figur 3. Cacheminne (bild från simulatorn).

Cache miss penalty
Tidsförlusten för en miss i ett cache-minne (cache miss penalty) anges ofta som hur många extra CPU-klockcykler det tar att läsa/skriva huvud-minnet. Standardvärdet för denna "kostnad" är i Mips-simulatorn satt till 50 klockcykler per ord.
Här följer en beskrivning av hur man kan räkna fram ett mer realistiskt värde på miss penalty, vid olika klockfrekvenser hos processor och minnesbuss.
Som exempel väljer vi CPU-frekvens 2 GHz, och minnesklockfrekvens 200 MHz.
Vidare förutsätter vi att varje minnesreferens görs som en burst (skur), med 4 stycken över-föringar av 4-bytes data, det vill säga 4 × 32 bits data.
Orsaken till att överföringen görs som burst är att överföringen har en viss uppstartstid. Att läsa eller skriva ett enda ord (4 byte) i primär-minnet tar 3 busscykler. Om man i stället läser en skur, så tar första ordet 3 busscykler och de följande orden 1 busscykel var.
När CPU/cacheminne läser 4 ord i taget så blir alltså totaltiden 3 + 1 + 1 + 1 busscykler. Detta brukar betecknas 3-1-1-1.
Referensmönster 3-1-1-1 betyder alltså att den första referensen tar 3 busscykler och att efterföljande 3 referenser tar vardera 1 ytterligare busscykel.
I vårt exempel är CPU:n 10 gånger så snabb som minnesbussen. Att referera 4 × 4 bytes tar då 30+10+10+10 = 60 CPU-cykler.
Vid en läs-miss som leder till att cacheminnet hämtar ett block på 4 ord (16 bytes), så blir alltså miss penalty 60 CPU-cykler. Med lite tur så kommer det i framtiden att göras referenser till andra ord/bytes inom detta block, och då ger de referenserna träffar i cachen.
Tyvärr tar inte simulatorn någon hänsyn till att den första referensen i ett block tar längre tid. Det går inte att ställa in 30 + 10 i simulatorn.
För att få riktiga värden vid simuleringen måste du räkna ut medelvärdet av miss penalty. Det medelvärdet ställer du in som access time i simulatorn.
Om totaltiden för att hämta 4 ord är 60 CPU-cykler som i exemplet, så är genomsnittstiden per ord 15 cykler. 15 cykler är alltså den access time som ska anges i simulatorn när blockstorleken är 4 ord.
Read och Write ska ha samma access time.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 7
Figur 5. Cache miss penalty när blockstorleken är 4 ord (16 byte).

Uppgift 2. Instruktions- och datacacheminnen
Simulatorn förstår alltså inte resonemangen om burst-referenser med mera. I simulatorn ställer du in en access time som sedan gäller för alla ord.
Därför behöver du ändra access time när du ändrar blockstorleken. Se till att access time motsvarar genomsnittstiden enligt resone-manget här.
Simulatorn klarar att man har olika block-storlek för datacacheminne (D-cache) och instruktionscacheminne (I-cache).
Tyvärr går det inte att ha olika access time för D-cache och I-cache. Det gör att simuleringen inte kan ge helt korrekta värden på körtiden (execution time) när blockstorleken är olika för data- och instruktionscacheminnena.
För att felet vid dina mätningar ska bli så litet som möjligt ska du ställa in access time i simulatorn efter det cacheminne som gör flest referenser (läsningar och/eller skrivningar) till primärminnet.
I simulatorn kan du göra en provkörning, och studera antalet missar (miss count) för
instruktions- och datacacheminnena. Det cacheminne som har högst värde på miss count kommer att påverka körtiden mest.
Miss count multiplicerad med miss penalty ger ju den totala extratid som det aktuella cacheminnet (I eller D) har använt till hämt-ningar från det långsamma primärminnet.
Fråga 2.1. Vilket cacheminne används oftast, instruktionscacheminnet eller data-cacheminnet?
............................................................
Fråga 2.2. Anta att du ska göra en simulering där instruktions- och datacacheminne har olika blockstorlek. Du gör en provkörning och ser att båda har 50% hit-rate. Vilket cacheminne ska styra din inställning av miss penalty?
............................................................
Fråga 2.3. Varför har datacacheminnet (D-cache) en write-policy, men inte instruktionscacheminnet?
Ledning till alla tre frågorna: vilket cache-minne används vid Fetch, och vilket används när Load och Store utförs?
IS1200/IS1500 Hemlab cache: Cacheminnen sida 8
Figur 6. Cache miss penalty när blockstorleken är 2 ord (8 byte).

CPI, Cycles Per Instruction
Här nedanför ser du simulatorns standardinställningar för I-cache och D-cache.
Du når de här inställningarna i simulatorn med Edit – Cache/Mem Config.
Associativitetstalet kallas i simulatorn för Blocks in sets. Utbytespolicyn (Replacement policy) spelar ingen roll så länge associativitetstalet är 1, det vill säga när cacheminnet är direktmappat.
Standardinställningarna för primärminnet visas här nedanför till höger.
Standardinställningarna i simulatorn ger inte så bra prestanda. Du har redan gjort provkörningar. Räkna fram CPI, Cycles Per Instruction:
CPI=cycle count
hit countmiss count
Lågt CPI betyder bättre prestanda, så länge klockfrekvensen är konstant.
En Mips-processor kan hämta och utföra en instruktion varje klockcykel. Det betyder att processorn har CPI = 1.
Ska vi vara noga så tar hoppinstruktioner 2 cykler, vilket höjer det genomsnittliga CPI-värdet till cirka 1,2.
Beräkna det CPI-värde du fått vid provkörningen. Har du använt standardinställningarna så blir CPI-värdet mycket högre än 1,2. I nästa uppgift ska vi studera detta lite närmare.
Påminnelse: Read och Write ska ha samma access time.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 9
Figur 7. Standardinställningarna för instruktions- och datacacheminnena i simulatorn.
Figur 8. Standardinställningar, primärminne.

Tidslinje – ett sätt att analysera prestanda för cacheminnen
Tidslinjen är ett verktyg för analys av cacheminnesprestanda. Med en tidslinje kan du för hand ta fram exakt vilka referenser ett visst program kommer att göra till cacheminnena. Det gör det möjligt att exakt beräkna den hit rate programmet bör ha.
Om de simulerade värdena inte stämmer med de beräknade, så finns en felkälla någonstans. Simuleringen kan vara fel, till exempel för att någon kompilator- eller simulator-inställning inte är som den ska vara. Beräkningen kan också vara fel, till exempel på grund av misstag i analysen av vilka referenser som blir träff och vilka som blir miss.
När du har ställt upp tidslinjen analyserar du hur cacheminnet kommer att reagera på varje referens. Eftersom cacheminnets beteende beror på tidigare händelser så är det viktigt att ta händelserna i den ordning de verkligen inträffar.
Som exempel studerar vi tidslinjen i figuren här ovanför. Fetch betyder att en instruktion hämtas.
Vi antar att instruktionscacheminnet är tomt när vårt exempel börjar. Då kommer den första hän-delsen på tidslinjen, Fetch från adress 0, att medföra miss i cacheminnet. Vi bokför detta i tidslinjen.
Miss innebär att cacheminnet inte har den information som CPU:n begärt. Cacheminnet kan alltså inte leverera informationen till CPU:n. Då startar cacheminnet en hämtning från primärminnet.
Hur mycket cacheminnet hämtar från primärminnet beror på blockstorleken. Vid miss på grund av läsning, som det är fråga om här, så hämtar alla cacheminnen alltid ett helt block.
Anta att blockstorleken är 8 byte (2 ord). Cacheminnet hämtar alla bytes i blocket, och med 8 bytes blockstorlek är det de bytes som har binär adress från och med xxx...x000 till och med xxx...x111. Gå gärna tillbaka till figur 1, så ser du att cacheminnet i så fall hämtar två instruktioner: den instruktion som orsakade missen (på adress 0), och så den instruktion som ligger intill (på adress 4).
Nästa referens är Fetch från adress 4. Den informationen har redan hämtats till cacheminnet, vid missen alldeles nyss. Vi får alltså en träff.
Referensen därefter är Fetch från adress 8. Med blockstorleken 2 ord så ingår inte adress 8 i det block som just hämtades. Adress 8 är aldrig hämtad till cacheminnet, och vi får en miss.
Vi fortsätter tidslinjen tills vi är säkra på att vi sett hela referensmönstret. Slutar vi för tidigt finns ju risk att vi använder fel värden i vår beräkning.
I det här fallet bör vi fortsätta tills vi har fyllt drygt två block. Vi ser att programmets förväntade hit rate i instruktionscacheminnet är 50%.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 10
Figur 9. Exempel på ofullständig tidslinje för instruktionscacheminne (I-cache).Programmet i detta exempel har inga hoppinstruktioner, utan består enbart av "rak" kod.
tid
Fetch, adress 0
Fetch, adress 4
Fetch, adress 8
Fetch, adress 12
Fetch, adress 16
Fetch, adress 20
Fetch, adress 24
Figur 10. Tidslinjen, när resultatet från de första fem referenserna har fyllts i.
tid
Fetch, adress 0
MISS
Fetch, adress 4
TRÄFF
Fetch, adress 8
MISS
Fetch, adress 12
TRÄFF
Fetch, adress 16
MISS
Fetch, adress 20
Fetch, adress 24

Placering av information i cacheminnet
För att veta vilka referenser som ger träff och vilka som ger miss, så måste vi beräkna vilken information som placeras på vilken rad i cache-minnet. Som exempel använder vi programmet här till vänster.
Vi studerar en I-cache med storlek 64 byte (16 ord), blockstorlek 8 byte (2 ord) och tvåvägsassociativitet (blocks in set = 2). Se figuren ovan.
Först av allt ska CPU:n hämta instruktionen på adress 0. Indexdelen av adressen är noll. Därför används rad 0, som är den översta raden i cacheminnet. Översta raden är markerad i figuren.
Cacheminnet är till en början tomt. Det blir miss och cachen ska hämta in ett block. Båda blocken på översta raden är lediga (eftersom cachen är tom). Då spelar det ingen roll om vi placerar blocket i vänster eller höger halva av cacheminnet. Vi väljer den vänstra halvan.
Vid miss hämtas alltid ett helt block, alltså två instruktioner: den på adress 0 och den på adress 4. Sedan hämtas instruktionen på adress 4. Det blir en träff.
Instruktionen call f1 hoppar till adress 36. Där ska alltså nästa instruktion hämtas. Binär form av talet 36 är 0...0 001 00 1 00. Indexbitarna är 00, så vi undersöker översta raden i cacheminnet.
I vänstra halvan finns information från adress 0. Alla bitar i adressetiketten (tag) är nollställda. Det stämmer inte med motsvarande del av adress 36: 0...0 001. Ingen träff i den halvan alltså.
I högra halvan av översta raden är det tomt, så där blir det inte heller träff. Nu har vi undersökt hela raden och inte hittat det vi sökte. Vi har en miss, och måste hämta från primärminnet.
Eftersom indexbitarna är noll så ska informationen placeras på översta raden i cacheminnet. Som tur är finns ett ledigt block där: det högra. Cacheminnet hämtar alltid ett helt block vid miss, med binära adresser från och med xxx...x000 till och med xxx...x111, det vill säga instruktionerna på adress 32 och 36.
Nu innehåller cacheminnet den information som visas i figuren här till höger.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 11
Figur 11. Ett program i primärminnet.
Figur 12. Tvåvägsassociativt cacheminne, med storlek 64 byte (16 ord) och blockstorlek 8 byte (2 ord). Adressens fältindelning förklaras uppe till höger.
27 bit tag2 bit index1 bit ordval2 bit byte-i-ord 0
1 ord
(4 byte)
...
4
8
12
16
20
24
28
32
36
40
44
48
52
56
60
64
call f1
call f1
...
L: ...
...
call f1
...
br L
...
f1: ...
...
nop
...
...
ret
Figur 13. Innehåll i cacheminnet efter de tre första referenserna.
0...0 00 L: ... call f1 0...0 01 nop f1: ...

Uppgift 3. Provkörning av ett enkelt program: string-copy
I den här uppgiften ska du provköra programmet strcpy.c, som visas här nedanför. Du kan hämta programtexten på kursens webbsidor om labben:
http://www.ict.kth.se/courses/IS1500/2010/labcache/
strcpy.c1 /* strcpy.c */23 #include <stdio.h>4 #include <idt_entrypt.h>56 /* C stringcopy */78 static void str_cpy( char *to, const char *from)9 {10 while( *from)11 {12 *to++ = *from++;13 }14 *to = '\0';15 }1617 int main()18 {19 static char* hello = "Hello World!";20 static char to[4711] = "blaha blaj blurk bletch";21 int Time;2223 printf("Strangen hello ser ut sa har: %s\n", hello);24 flush_cache(); /* toem cache-minnet */25 timer_start(); /* nollstall tidmatning */2627 str_cpy( to, hello);2829 Time = timer_stop(); /* las av tiden */30 printf("Time to copy: %d\n",Time);31 printf("Och kopian sa har: %s\n", to);32 }
Kompilering av strcpy.c
För programmet strcpy.c ska du ha kompileringsinställningen Optimization level: Default.
Vid behov ändrar du i MipsIT Studio, under Project – Settings – Compile/Assemble.
Simulering
Starta simulatorn och ladda programmet till simulatorn. Provkör programmet.
Klicka sedan på rutan I-Cache, så att instruk-tionscacheminnesfönstret öppnas. Summan av
Hit Count och Miss Count anger antalet instruktioner som hämtats och utförts.
Ändra textsträngen hello i programmet. Ta bort eller lägg till ett eller ett par tecken så att strängen får en lite annan längd.
Kompilera, återställ simulatorn, ladda upp programmet, provkör.
Skillnaden i antalet utförda instruktioner beror på att loopen i funktionen str_cpy körs olika antal varv för olika längder på strängen.
Fråga 3.1. Exakt hur många instruktioner körs i ett varv i loopen?............................................................
IS1200/IS1500 Hemlab cache: Cacheminnen sida 12

Uppgift 4. Mer om string-copy
Kom ihåg: Optimization level: Default.
I-cache disabled, D-cache dis-abled och miss penalty disabled
Återställ simulatorn och gör följande cache-inställningar. Se till att kryssrutorna Disable och Disable penalty är ikryssade, för både in-struktions- och datacacheminnena. Inställning-arna för primärminnet behöver inte ändras.
Gör en provkörning.
Fråga 4.1. Hur lång tid tog programmet enligt utskriften Time to copy?
............................................................
Fråga 4.2. Hur många cykler tog programmet enligt simulatorns Cycle count?
............................................................
Fråga 4.3. Varför blev värdena olika? Båda anger antalet cykler.
I-cache enabled, D-cache enabled och miss penalty enabled
Återställ simulatorn och se till att I-cache och D-cache är enabled. Ställ in en rimlig access time för primärminnet. Låt de andra paramet-rarna ha standardvärdena. Gör en provkörning.
Fråga 4.4. Vilket värde valde du på access time?....................
Fråga 4.5. Hur många cykler tog programmet enligt simulatorns Cycle count?
............................................................
Fråga 4.6. Hur många instruktioner utfördes?
...........................................................
Fråga 4.7. Vilken hit rate fick du i instruk-tionscacheminnet?
............................................................
Fråga 4.8. Vad blev CPI?............................................................
Fråga 4.9. Varför blir det så dålig hit rate i instruktionscacheminnet?
Variera parametrar för I-cachen
Försök förbättra prestanda genom att ändra parametervärden för instruktionscacheminnet.Kan du genom att ändra någon parameter få kortare körtid (mindre cycle count) på grund av förbättrad hit rate i I-cachen?
Fråga 4.10. Provkör systematiskt. Bokför i tabellen här nedanför, eller i en likadan tabell på separat papper. Förklara resultaten vid redovisningen.
Size (antal ord)
Block size
(ord)
Associativitet (blocks in sets)
Access time
Cycle count
CPI I-cache hit rate
I-cache miss count
D-cache hit rate
D-cache miss count
16 2 1
32 2 1
16 4 1
16 2 2
IS1200/IS1500 Hemlab cache: Cacheminnen sida 13

Uppgift 5. Matris-addition
Studera programmet matris.c som visas här nedanför. Du kan hämta programtexten på kursens webbsidor om labben:
http://www.ict.kth.se/courses/IS1500/2010/labcache/
För programmet matris.c ska du ha kompileringsinställningen Optimization level: 3 (High). Vid behov ändrar du i MipsIT Studio, under Project – Settings – Compile/Assemble.
1 /* matris.c */2 #include <stdio.h>3 #include <idt_entrypt.h>45 #define MATRIXSIZE 166 #define MATRIXSIZE_ROWS 167 #define MATRIXSIZE_COLS 1689 /*10 * addera two matriser11 */12 void matrisadd( int res[MATRIXSIZE_ROWS][MATRIXSIZE_COLS],13 int a[MATRIXSIZE_ROWS][MATRIXSIZE_COLS],14 int b[MATRIXSIZE_ROWS][MATRIXSIZE_COLS] )15 {16 int i,j;1718 for(j=0; j < MATRIXSIZE; ++j) /* variera kolumn-index */19 for(i=0; i < MATRIXSIZE; ++i) /* variera rad-index */20 res[i][j] = a[i][j] + b[i][j];21 }2223 int main()24 {25 static int a[MATRIXSIZE_ROWS][MATRIXSIZE_COLS];26 static int b[MATRIXSIZE_ROWS][MATRIXSIZE_COLS];27 static int res[MATRIXSIZE_ROWS][MATRIXSIZE_COLS];28 int i,j, Time;2930 /*31 * initiera matris a och b32 */33 for( i=0; i<MATRIXSIZE; ++i)34 for( j=0; j<MATRIXSIZE; ++j)35 {36 a[i][j] = i+j;37 b[i][j] = i-j;38 }3940 flush_cache(); /* toem cachen */41 timer_start(); /* nollstall tidmatning */4243 matrisadd( res, a, b);4445 Time = timer_stop(); /* las av tiden */46 printf("Time: %d\n",Time);47 }
Påminnelse: för matris.c ska du ha kompileringsinställningen Optimization level: 3 (High).
IS1200/IS1500 Hemlab cache: Cacheminnen sida 14

De tre matrisernas placering i primärminnet
Programmet matris.c gör beräkningar på matriser. Varje matris innehåller ett antal matriselement, och varje matriselement består av ett heltal. Ett heltal är 4 byte stort i simulatorn.
Kompilatorn placerar matriserna omedelbart efter varandra i primärminnet, som figuren till höger visar.
Inom varje matris placeras matriselementen radvis, helt enligt definitionen av programmeringsspråket C. Index för några av matriselementen finns angivna i figuren till höger.
Addition av matriser
Figuren här nedanför visar en principskiss över addition av matriser. Matriserna lagras radvis i primärminnet.
Fråga 5.1. Vilket index, radnummer eller kolumnnummer, är det som ska variera i inre loopen för att programmet ska referera närliggande adresser i primärminnet?
IS1200/IS1500 Hemlab cache: Cacheminnen sida 15
Figur 14. De tre matrisernas placering i primärminnet.
adress 0
a[0][2]
a[0][0]
a[0][1]
a[0][15]
a[1][0]a[1][1]
1 ord
(4 byte)
......
a[15][15]b[0][0]
b[0][1]
...
b[15][15]
res[0][0]
res[0][1]
...
res[15][15]
...
a[1][15]a[2][0]
...
Figur 15. Elementen i en matris M lagras radvis i primärminnet. Ett element väljs ut med uttrycket
M[radnummer][kolumnnummer].
rad i
kolumn j
res[i][j]
= +
Addition av matriserFör varje i och j utförs:
res[i][j] = a[i][j] + a[i][j]
a[i][j] b[i][j]

En första provkörning av matris.c
Se till att kompileringsinställningen för optimering är 3 (High).
Kompilera.
Återställ simulatorn. Ställ in de värden som anges här nedanför.
I-cache
Size: 32 ord (ej standardvärde). Block size: 2 ord. Blocks in sets (associativitet): 1.
D-cache
Size: 16 ord. Block size: 2 ord. Blocks in sets (associativitet): 1. Write policy: Write back (ej standardvärde).
Minnet
Fråga 5.2. Vilken access time valde du? .............................................
Varning för cycle count!
Det finns en viktig brist hos simulatorn. Värdena för cycle count som visas tillsammans med I-cache och D-cache har bara 5 siffror.
De visar fel om det behövs fler siffror än 5.
För att få riktiga värden, använd View – I-cache Stats, eller View – D-cache Stats. Båda visar rätt antal clock cycles.
Fråga 5.3. Hur många cykler tog programmet enligt simulatorns antal clock cycles? ..........
Fråga 5.4. Hur många instruk-tioner utfördes? ...................................
Fråga 5.5. Vilken hit rate fick dui instruktionscacheminnet (I-cache)? ............................................
Fråga 5.6. Vilken hit rate fick du i datacacheminnet (D-cache)? .........................................
Fråga 5.7. Varför blir det så bra hit rate i instruktionscacheminnet?
Variera parametrar för I-cachen
Försök nu förbättra prestanda genom att ändra parametervärden för instruktionscacheminnet. Kan du genom att ändra någon parameter få kortare körtid (mindre cycle count) på grund av förbättrad hit rate i I-cachen?
Fråga 5.8. Provkör systematiskt. Bokför i tabellen, eller i en likadan tabell på separat papper. Förklara resultaten vid redovisningen.
Size (antal ord)
Block size
(ord)
Associativitet (blocks in sets)
Access time
Cycle count
CPI I-cache hit rate
I-cache miss count
D-cache hit rate
D-cache miss count
32 2 1
64 2 1
32 4 1
32 2 2
IS1200/IS1500 Hemlab cache: Cacheminnen sida 16

Matris-addition program-version 1 (originalversion från lab-PM)
Instruktionscacheminnet (I-cache) ska alltid ha följande värden:Size = 32 ord; Block size = 2 ord; Blocks in sets = 1 (det vill säga direktmappat).
Var noga med att datacacheminnet alltid har Write policy = Write back.
Variera D-cache-storlek (size) för programversion 1
Prova olika storlekar på datacacheminnet, från 16 till 1024 ord. Låt Block size = 2 ord, och Blocks in sets (associativiteten) = 1. Ange access time här: ...................
Size 16 32 64 128 256 512 1024
Hit rate högst 3 %
Cycle count
Fråga 5.9. Förklara de värden du fått på hit rate och körtid.
Fråga 5.10. Varför blir det så dåligt ända tills storleken når 512 ord?
Variera D-cache-associativitet (blocks in sets) för programversion 1
Prova olika associativitet (blocks in sets) för D-cachen, från 1 till 4. Låt Size = 128 ord, och Block size = 4 ord. Välj LRU som utbytespolicy (replacement policy). Ange access time här: ......
Associativitet 1 2 4
Hit rate högst 3 %
Cycle count
Fråga 5.11. Förklara de värden du fått på hit rate och körtid.
Fråga 5.12. Det första matriselement som hämtas in till D-cachen är a[0][0]. För associativitetstalen 1 och 4, analysera fram och förklara i detalj vilket element i vilken matris som skriver över a[0][0] i D-cachen.
Variera D-cache-blockstorlek (block size) för programversion 1
Prova olika blockstorlek för D-cachen, från 1 till 4. Låt Size = 128 ord, och Blocks in sets (associativiteten) = 1..
Block size 1 2 4
Access time
Hit rate högst 3 %
Cycle count
Fråga 5.13. Förklara de värden du fått på hit rate och körtid.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 17

Matris-addition program-version 2 (med inre och yttre loop växlade)
Du ska nu ändra programmet på följande sätt. I funktionen matrisadd finns ett loop-nest bestående av två slingor (loopar) i varandra.
Program-version 1 (originalversion från lab-PM) ser ut så här:
for(j=0; j < MATRIXSIZE; ++j) /* variera kolumn-index */ for(i=0; i < MATRIXSIZE; ++i) /* variera rad-index */ res[i][j] = a[i][j] + b[i][j];
Du ska byta plats på de två raderna med for, så att programmet gör samma beräkningar fast i en annan ordning. I det nya programmet ser de tre raderna i ut så här:
for(i=0; i < MATRIXSIZE; ++i) /* variera rad-index */ for(j=0; j < MATRIXSIZE; ++j) /* variera kolumn-index */ res[i][j] = a[i][j] + b[i][j];
Instruktionscacheminnet (I-cache) ska alltid ha följande värden:Size = 32 ord; Block size = 2 ord; Blocks in sets = 1 (det vill säga direktmappat).
Var noga med att datacacheminnet alltid har Write policy = Write back.
Variera utbytespolicy (replacement policy) för D-cache för programversion 2
Använd följande värden för datacacheminnet (D-cache). Låt storleken (size) = 32 ord (128 byte), Block size = 8 ord (32 byte), och Blocks in sets (associativiteten) = 4. Ange access time här: ........
Utbytespolicy Random FIFO LRU
Hit rate
Cycle count
Fråga 5.14. I vilka fält delas adressen, och hur många bitar ingår i varje fält, när det cacheminne som ingår i den här uppgiften ska adresseras?
Fråga 5.15. Varför blir värdena på hit rate och körtid lika för FIFO och LRU?
Fråga 5.16. Förklara varför värdet på hit rate för LRU blev just det värde du fick. Kunde värdet lika gärna ha varit 5% högre eller lägre? Varför, eller varför inte?
IS1200/IS1500 Hemlab cache: Cacheminnen sida 18
Figur 16 (samma som figur 4). Exempel på fältindelning av adressen från CPU:n.
Exempel på fältindelning, här med 3 fält
Adress från CPU:n (32 bitar)

Matris-addition program-version 2 (fortsättning)
Instruktionscacheminnet (I-cache) ska alltid ha följande värden:Size = 32 ord; Block size = 2 ord; Blocks in sets = 1 (det vill säga direktmappat).
Var noga med att datacacheminnet alltid har Write policy = Write back.
Variera D-cache-storlek (size) för programversion 2
Prova olika storlekar på datacacheminnet, från 16 till 1024 ord. Låt Block size = 2 ord, och Blocks in sets (associativiteten) = 1. Ange access time här: ...................
Size 16 32 64 128 256 512 1024
Hit rate högst 3 %
Cycle count
Fråga 5.17. Förklara de värden du fått på hit rate och körtid.
Fråga 5.18. Varför blir det så dåligt ända tills storleken når en viss gräns?
Variera D-cache-associativitet (blocks in sets) för programversion 2
Prova olika associativitet (blocks in sets) för D-cachen, från 1 till 4. Låt Size = 128 ord, och Block size = 4 ord. Välj LRU som utbytespolicy (replacement policy). Ange access time här: ......
Associativitet 1 2 4
Hit rate högst 3 %
Cycle count
Fråga 5.19. Förklara de värden du fått på hit rate och körtid.
Fråga 5.20. Det första matriselement som hämtas in till D-cachen är a[0][0]. För associativitetstal 4, analysera fram och förklara i detalj vilket element i vilken matris som skriver över a[0][0] i D-cachen.
Variera D-cache-blockstorlek (block size) för programversion 2
Prova olika blockstorlek för D-cachen, från 1 till 4. Låt Size = 128 ord, och Blocks in sets (associativiteten) = 1..
Block size 1 2 4
Access time
Hit rate högst 3 %
Cycle count
Fråga 5.21. Förklara de värden du fått på hit rate och körtid.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 19

Matris-addition program-version 3 (med inre och yttre loop växlade, och med konstanten MATRIXSIZE_ROWS ändrad till 17)
Utgå från programversion 2. Kontrollera att looparna i funktionen matrisadd ser ut så här:
for(i=0; i < MATRIXSIZE; ++i) /* variera rad-index */ for(j=0; j < MATRIXSIZE; ++j) /* variera kolumn-index */ res[i][j] = a[i][j] + b[i][j];
Ändra nu konstanten MATRIXSIZE_ROWS från 16 till 17.
Fråga 5.22. När MATRIXSIZE_ROWS ändras från 16 till 17, så blir det ju flera matriselement i varje matris. Markera i figuren här intill var de nya matris-elementen placeras i datorns primärminne. Motivera.
Fråga 5.23. Förklara vilken påverkan de nya matriselementen kan förväntas få på programkörningen.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 20
Figur 17 (samma som figur 11). De tre matrisernas placering i
primärminnet.
adress 0
a[0][2]
a[0][0]
a[0][1]
a[0][15]
a[1][0]
a[1][1]
1 ord
(4 byte)
......
a[15][15]
b[0][0]
b[0][1]
...
b[15][15]
res[0][0]res[0][1]
...
res[15][15]
...
a[1][15]
a[2][0]
...

Matris-addition program-version 3 (fortsättning)
Instruktionscacheminnet (I-cache) ska alltid ha följande värden:Size = 32 ord; Block size = 2 ord; Blocks in sets = 1 (det vill säga direktmappat).
Var noga med att datacacheminnet alltid har Write policy = Write back.
Variera D-cache-storlek (size) för programversion 3
Prova olika storlekar på datacacheminnet, från 16 till 1024 ord. Låt Block size = 2 ord, och Blocks in sets (associativiteten) = 1. Ange access time här: ...................
Size 16 32 64 128 256 512 1024
Hit rate högst 3 %
Cycle count
Fråga 5.24. Förklara de värden du fått på hit rate och körtid.
Fråga 5.25. Nu har vi ju förbättrat programmet på två olika sätt. Varför blir det ändå så dålig hit rate när storleken är 16 ord?
Variera D-cache-associativitet (blocks in sets) för programversion 3
Prova olika associativitet (blocks in sets) för D-cachen, från 1 till 4. Låt Size = 128 ord, och Block size = 4 ord. Välj LRU som utbytespolicy (replacement policy). Ange access time här: ......
Associativitet 1 2 4
Hit rate
Cycle count
Fråga 5.26. Förklara de värden du fått på hit rate och körtid.
Variera D-cache-blockstorlek (block size) för programversion 3
Prova olika blockstorlek för D-cachen, från 1 till 8. Låt Size = 128 ord, och Blocks in sets (associativiteten) = 1..
Block size 1 2 4 8
Access time
Hit rate
Cycle count
Fråga 5.27. Förklara de värden du fått på hit rate och körtid.
IS1200/IS1500 Hemlab cache: Cacheminnen sida 21

Här följer ett urklipp/avskrift av optimerad MIPS-kod för inre och yttre loop.
for(i=0; i < MATRIXSIZE; i++) /* variera rad-index */ for(j=0; j < MATRIXSIZE; j++) /* variera kolumn-index */ res[i][j] = a[i][j] + b[i][j];
1 move $11,$0 ;i=02 la $10,b.5 ;reg10 pekar på matris b3 la $9,a.4 ;reg9 pekar på matris a4 la $8,res.6 ;reg8 pekar på matris res5 $L38: move $7,$0 ;j=06 move $6,$8 ;reg6 pekar på res[i,j]7 move $5,$10 ;reg5 pekar på b[i,j]8 move $4,$9 ;reg4 pekar på a[i,j]9 $L42: lw $3,0($5) ;reg 3 innehåller nu a[i,j]10 addu $5,$5,4 ;peka ut nästa radelement i a11 lw $2,0($4) ;reg 2 innehåller nu b[i,j]12 addu $4,$4,4 ;peka ut nästa radelement i b13 addu $7,$7,1 ;j++14 addu $2,$2,$3 ;reg2 = a[i,j] + b[i.j]15 sw $2,0($6) ;skriv till res [i,j]16 slt $2,$7,16 ;reg2 :=1 om i<1617 bne $2,$0,$L42 ;hoppa om i<16, samt i hoppluckan...18 addu $6,$6,4 ;peka ut nästa radelement i res19 addu $10,$10,64 ;byt rad i b20 addu $9,$9,64 ;byt rad i a21 addu $11,$11,1 ;i++22 slt $2,$11,16 ;reg2 :=1 om i<1623 bne $2,$0,$L38 ;hoppa om i<1624 addu $8,$8,64 ;byt rad i res (i hopplucka)
IS1200/IS1500 Hemlab cache: Cacheminnen sida 22










![Analytic Hierarchy Process – en kritisk genomgång726909/FULLTEXT01.pdfAHP [3], och det exemplifieras delvis med hjälp av programvaran Expert Choice . I AHP skapar beslutsfattaren](https://img.pdfslide.net/doc/110x75/6098a755de50ee1ef643bd20/analytic-hierarchy-process-a-en-kritisk-genomgng-726909fulltext01pdf-ahp-3.jpg)