Embed Size (px)
Citation preview

High-dimensional covariance matrix estimationwith applications in finance and genomic studies
Esa Ollila
Department of Signal Processing and AcousticsAalto University, Finland
Nov 12, 2018, ML coffee seminar

New Book! Published November 2018 by CambridgeUniversity Press
Covers robust methods for
1 sparse regression
2 covariance estimation
3 bootstrap-based statistical inference
4 tensor data analysis
5 filtering
6 spectrum estimation
7 . . .
Includes real-life applications and dataanalysis.
Matlab RobustSP Toolbox:https://github.com/RobustSP/toolbox
Robust Statistics for Signal Processing
Abdelhak M. Zoubir, Visa Koivunen, Esa Ollila and Michael Muma
Zoubir, Koivunen, O
llila and Mum
aRobust Statistics for Signal Processing

Covariance estimation problem
x : p-variate (centered) random vector (p large)
x1, . . . ,xn i.i.d. realizations of x.
Problem: Find an estimate Σ of the pos. def. covariance matrix
Σ = E[(x− µ)(x− µ)>
]∈ Sp×p++
where µ = E[x].The sample covariance matrix (SCM),
S =1
n− 1
n∑
i=1
(xi − x)(xi − x)>,
is the most commonly used estimator of Σ.
Challenges in HD:
1 Insufficient sample support (ISS) case: p > n.=⇒ S is singular (non-invertible).
2 Low sample support (LSS) (i.e., p of the same magnitude as n)=⇒ estimate Σ has a lot of error.
3 Outliers or heavy-tailed non-Gaussian data1/28

Covariance estimation problem
x : p-variate (centered) random vector (p large)
x1, . . . ,xn i.i.d. realizations of x.
Problem: Find an estimate Σ of the pos. def. covariance matrix
Σ = E[(x− µ)(x− µ)>
]∈ Sp×p++
where µ = E[x].The sample covariance matrix (SCM),
S =1
n− 1
n∑
i=1
(xi − x)(xi − x)>,
is the most commonly used estimator of Σ.
Challenges in HD:
1 Insufficient sample support (ISS) case: p > n.=⇒ S is singular (non-invertible).
2 Low sample support (LSS) (i.e., p of the same magnitude as n)=⇒ estimate Σ has a lot of error.
3 Outliers or heavy-tailed non-Gaussian data1/28
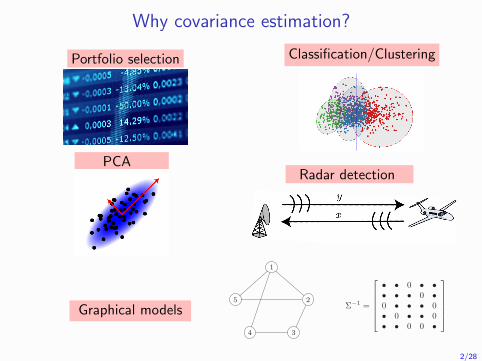
Why covariance estimation?
Portfolio selection Classification/ClusteringThe Most Important Applications
graphical models clustering/discriminant analysis
PCAradar detection
Ilya Soloveychik (HUJI) Robust Covariance Estimation 15 / 47
PCA
The Most Important Applications
graphical models clustering/discriminant analysis
PCA radar detection
Ilya Soloveychik (HUJI) Robust Covariance Estimation 15 / 47
Radar detection
Graphical models
Gaussian graphical model
n-dimensional Gaussian vector
x = (x1, . . . , xn) ∼ N (0,Σ)
xi, xj are conditionally independent (given the rest of x) if
(Σ−1)ij = 0
modeled as undirected graph with n nodes; arc i, j is absent if (Σ−1)ij = 0
1
2
34
5Σ−1 =
• • 0 • •• • • 0 •0 • • • 0• 0 • • 0• • 0 0 •
12/28

Bias-variance trade-off
Any estimator Σ ∈ Sp×p++ of Σ verifies
MSE(Σ) , E[‖Σ−Σ‖2F
](‖A‖2F = tr(A2))
= var(Σ) + bias2(Σ)
Since S is unbiased, bias2(S) = ‖E[S]−Σ‖2F = 0, one has that
MSE(S) = var(S)
but var(S) can be very large when n ≈ p.
3 Use an estimator Σ = Sβ that shrinks S towards a structure (e.g., ascaled identity matrix) using a tuning (shrinkage) parameter β
MSE(Σ) can be reduced by introducing some bias.Positive definiteness of Σ can be ensured.
3/28

Bias-variance trade-off
Any estimator Σ ∈ Sp×p++ of Σ verifies
MSE(Σ) , E[‖Σ−Σ‖2F
](‖A‖2F = tr(A2))
= var(Σ) + bias2(Σ)
Since S is unbiased, bias2(S) = ‖E[S]−Σ‖2F = 0, one has that
MSE(S) = var(S)
but var(S) can be very large when n ≈ p.
3 Use an estimator Σ = Sβ that shrinks S towards a structure (e.g., ascaled identity matrix) using a tuning (shrinkage) parameter β
MSE(Σ) can be reduced by introducing some bias.Positive definiteness of Σ can be ensured.
3/28

Regularized SCM (RSCM) a la Ledoit and Wolf:
Sβ = βS + (1− β)[tr(S)/p]I,
where β ∈ [0, 1) denotes the shrinkage (regularization) parameter.
0 0.05 0.1 0.15
0.26
0.28
0.3
β
Nor
mal
ized
MS
E
Regularized SCM (RSCM) a la Ledoit and Wolf:
Sβ = βS + (1− β)[tr(S)/p]I
where β ∈ [0, 1) denotes the shrinkage (regularization) parameter.
0 0.05 0.1 0.15
0.26
0.28
0.3
β
Nor
mal
ized
MS
E
NMSE; Theory; Ell1; Ell2; LW4/30
4/28

References
Optimal shrinkage covariance matrix estimationunder random sampling from elliptical distribu-tions arXiv:1808.10188 [stat.ME], August 2018.
MATLAB® toolbox: http://users.spa.aalto.
fi/esollila/regscm/ joint work withElias Raninen
Compressive regularized discriminant analysis ofhigh-dimensional data with applications to mi-croarray studies, Proc. ICASSP’18, Calgary,Canada, 2017, pp. 4204 –4208.
R-package: compressiveRDA @ https://github.
com/mntabassm/compressiveRDAjoint work withM.N. Tabassum
5/28

1 Portfolio optimization
2 Ell-RSCM estimators
3 Estimates of oracle parameter
4 Compressive Regularized Discriminant Analysis

Modern portfolio theory (MPT)
Mathematical framework by Markowitz [1952, 1959] for portfolioallocations that balances the return-risk tradeoff. MPT furtherdeveloped by Tobin [1958], Sharpe [1964], Malkiel and Fama [1970]∗
A portfolio consist of p assets, e.g.:
- equity securities (stocks), market indexes- fixed-income securities (e.g., government or corporate bonds)- currencies (exchange rates),- . . .
To use MPT one needs to estimate the mean vector µ and thecovariance matrix Σ of asset returns.
7 often p, the number of assets is larger (or of similar magnitude) to n,the number of historical returns.
∗Nobel price recipients: James Tobin (1981), Harry Markovitz (1990) and Willian F.
Sharpe (1990), and Eugene F. Fama (2013)
6/28

Basic definitions
Portfolio weight at (discrete) time index t:
wt = (wt,1, . . . , wt,p)> s.t. 1>wt = 1
Let Ci,t > 0 be the price of the ith asset
The net return of the ith asset over one interval is
ri,t =Ci,t − Ci,t−1
Ci,t−1=
Ci,tCi,t−1
− 1 ∈ [−1,∞)
Single period net returns of p assets form a p-variate vector
rt = (r1,t, . . . , rp,t)>
The portfolio net return at time t+ 1 is
Rt+1 = w>t rt+1 =
p∑
i=1
wi,tri,t+1
7/28

Assume historical returns {rt}nt=1 are i.i.d., so that
µ = E[rt] and Σ = E[(rt − µt)(rt − µt)
>]
holds for all t (so drop the index t from subscript).
Let r denote the (random) vector of returns. Two key statistics ofportfolio return R = w>r are
mean return E[R] = w>µ
variance (risk) var(R) = w>Σw.
Global minimum variance portfolio (GMVP) allocation strategy:
minimizew∈Rp
w>Σw subject to 1>w = 1.
⇒ wo =Σ−11
1>Σ−11.
8/28

S&P 500 and Nasdaq-100 indexes for year 2017
01-03 03-16 05-26 08-08 10-18 12-29
2300
2400
2500
2600
S&P 500 index prices
01-03 03-16 05-26 08-08 10-18 12-29
5000
5500
6000
6500NASDAQ-100 prices
01-03 03-16 05-26 08-08 10-18 12-29
-0.02
-0.01
0
0.01
0.02
NASDAQ-100 daily net returns
01-03 03-16 05-26 08-08 10-18 12-29
-0.02
-0.01
0
0.01
0.02
S&P 500 daily net returns
9/28

Are historical returns Gaussian?
-0.02 -0.015 -0.01 -0.005 0 0.005 0.01 0.015
-0.03
-0.02
-0.01
0
0.01
0.02
0.03
Scatter plots and estimated 99%,95% and 50% tolerance ellipses:
inside the 50% ellipse: 65.6% of returns
inside the 95% ellipse: 95.6% of returns
S&P 500
-4 -2 0 2
0
0.1
0.2
0.3
0.4
0.5
0.6NASDAQ-100
-4 -2 0 2 4
0
0.1
0.2
0.3
0.4
0.5
0.6N(0,1) sample
-2 -1 0 1 2
0
0.1
0.2
0.3
0.4
0.5
0.6
10/28

And stocks are unpredictable...
TECH stocks (Facebook, Apple, Amazon, Microsoft, Google) droppeddrastically (in seconds) due to ”fat finger” or automated trade.
...and there is that guy in the white house
Dow Jones Industrial Average:
11/28

And stocks are unpredictable...
TECH stocks (Facebook, Apple, Amazon, Microsoft, Google) droppeddrastically (in seconds) due to ”fat finger” or automated trade.
...and there is that guy in the white house
Dow Jones Industrial Average:
11/28

And stocks are unpredictable...
TECH stocks (Facebook, Apple, Amazon, Microsoft, Google) droppeddrastically (in seconds) due to ”fat finger” or automated trade.
...and there is that guy in the white house
Dow Jones Industrial Average:
11/28

Stock data analysis
We apply GMVP to stock data set consitsing of daily net returnscomputed from divident adjusted daily closing prices.
Data sets
• p = 45 stocks in Hang Seng Index (HSI), 1/2010 - 12/2011.
• p = 396 stocks in S&P500, 1/2016 - 4/2018.
Sliding window method
• At day t, we use the previous n days to estimate Σ and w.
• portfolio returns are then computed for the following 20 days.
• Window is shifted 20 trading days forward, new allocations andportfolio returns for another 20 days are computed.
12/28

HSI (Jan/2010 - Dec/2011)
50 100 150 200n (window length)
0.12
0.122
0.124
0.126
0.128
annu
aliz
ed re
aliz
ed ri
sk
Ell1-RSCM
Ell2-RSCM
LW-RSCM
150 200 250
n (window length)
0.75
0.8
0.85
0.9
0.95
shin
kage
par
amet
er
Ell1-RSCM
Ell2-RSCM
LW-RSCM
SP500 (Jan/2016 - Apr/2018)
70 120 170 220 270n (window length)
0.075
0.078
0.081
0.084
0.087
annu
aliz
ed re
aliz
ed ri
sk
Ell1-RSCM
Ell2-RSCM
LW-RSCM
100 150 200 250 300
n (window length)
0.5
0.6
0.7
0.8
0.9
shrin
kage
par
amet
er
Ell1-RSCM
Ell2-RSCM
LW-RSCM
13/28

1 Portfolio optimization
2 Ell-RSCM estimators
3 Estimates of oracle parameter
4 Compressive Regularized Discriminant Analysis

Regularized SCM and MMSE estimator
Problem: We consider an estimator Sβ,α = βS + αI, where theweight (shrinkage) parameters are determined by solving
(αo, βo) = argminα,β>0
{E[∥∥βS + αI−Σ
∥∥2F
]},
7 (αo, βo) will depend on true unknown Σ ⇒ need to estimate (αo, βo)
How to estimate (αo, βo)?
Ledoit and Wolf [2004] (no assumptions on x ∼ F )Chen et al. [2010] (assumes Gaussianity)
⇒ we avoid strict assumptions, and simply assume that data is sampledfrom an unspecified elliptically symmetric distribution.
14/28

Important statistics
Scale measure:
η =tr(Σ)
p= mean of eigenvalues
Sphericity measure:
γ =p tr(Σ2)
tr(Σ)2
=mean of (eigenvalue)2
(mean of eigenvalues)2
γ ∈ [1, p], and
• γ = 1 iff Σ ∝ I• γ = p iff rank(Σ) = 1.
15/28

Optimal shrinkage parameters
Define normalized MSE of SCM S as
NMSE(S) =E[‖S−Σ
∥∥2F
]
‖Σ‖2F
Result 1
Assume finite 4th-order moments.
Optimal shrinkage parameters:
βo =(γ − 1)
(γ − 1) + γ ·NMSE(S)
αo = (1− βo)η.
and note that βo ∈ [0, 1).
⇒ one may use α0 = (1− β0)tr(S)
pand simply find an estimate β0 of β0
16/28

Elliptically symmetric distributions
x ∼ Ep(µ,Σ, g), when its pdf is of the form:
f(x) ∝ ·|Σ|−1/2g([x− µ]>Σ−1[x− µ]
)
where g : [0,∞)→ [0,∞) is the density generator:
Gaussian distribution : x ∼ Np(µ,Σ): g(t) = exp(−t/2).t-distribution with ν > 4 dof: x ∼ tν(0,Σ), g(t) = . . .
Throughout, we assume finite 4th-order moments.
We also need to introduce the elliptical kurtosis parameter [Muirhead, 1982]:
κ =E[‖Σ−1/2(x− µ)‖4]
p(p+ 2)− 1
=1
3· {kurtosis of xi}
17/28

Elliptically symmetric distributions
x ∼ Ep(µ,Σ, g), when its pdf is of the form:
f(x) ∝ ·|Σ|−1/2g([x− µ]>Σ−1[x− µ]
)
where g : [0,∞)→ [0,∞) is the density generator:
Gaussian distribution : x ∼ Np(µ,Σ): g(t) = exp(−t/2).t-distribution with ν > 4 dof: x ∼ tν(0,Σ), g(t) = . . .
Throughout, we assume finite 4th-order moments.
We also need to introduce the elliptical kurtosis parameter [Muirhead, 1982]:
κ =E[‖Σ−1/2(x− µ)‖4]
p(p+ 2)− 1
=1
3· {kurtosis of xi}
17/28

Result 2
Optimal shrinkage parameter when x ∼ Ep(µ,Σ, g) is
βEllo =γ − 1
γ − 1 + κ(2γ + p)/n+ (γ + p)/(n− 1)
γ := sphericity =p tr(Σ2)
tr(Σ)2κ := elliptical kurtosis
Note: βEllo = βEllo (γ, κ) depends on unknown γ and κ.
Proof: Use Result 1 and the results:
MSE(S) = E[‖S−Σ
∥∥2F
]= tr{cov(vec(S))},
cov(vec(S)) =( 1
n− 1+κ
n
)(I + Kp)(Σ⊗Σ) +
κ
nvec(Σ)vec(Σ)>,
where Kp is a commutation matrix (Kpvec(A) = vec(A>)).
18/28

Result 2
Optimal shrinkage parameter when x ∼ Ep(µ,Σ, g) is
βEllo =γ − 1
γ − 1 + κ(2γ + p)/n+ (γ + p)/(n− 1)
γ := sphericity =p tr(Σ2)
tr(Σ)2κ := elliptical kurtosis
Note: βEllo = βEllo (γ, κ) depends on unknown γ and κ.
Proof: Use Result 1 and the results:
MSE(S) = E[‖S−Σ
∥∥2F
]= tr{cov(vec(S))},
cov(vec(S)) =( 1
n− 1+κ
n
)(I + Kp)(Σ⊗Σ) +
κ
nvec(Σ)vec(Σ)>,
where Kp is a commutation matrix (Kpvec(A) = vec(A>)).
18/28

Result 2
Optimal shrinkage parameter when x ∼ Ep(µ,Σ, g) is
βEllo =γ − 1
γ − 1 + κ(2γ + p)/n+ (γ + p)/(n− 1)
γ := sphericity =p tr(Σ2)
tr(Σ)2κ := elliptical kurtosis
Note: βEllo = βEllo (γ, κ) depends on unknown γ and κ.
Proof: Use Result 1 and the results:
MSE(S) = E[‖S−Σ
∥∥2F
]= tr{cov(vec(S))},
cov(vec(S)) =( 1
n− 1+κ
n
)(I + Kp)(Σ⊗Σ) +
κ
nvec(Σ)vec(Σ)>,
where Kp is a commutation matrix (Kpvec(A) = vec(A>)).
18/28

1 Portfolio optimization
2 Ell-RSCM estimators
3 Estimates of oracle parameter
4 Compressive Regularized Discriminant Analysis

Estimation of oracle shrinkage parameter
Ell-RSCM estimator is defined as
Sβ = βS + (1− β)[tr(S)/p]I
where
β = βEllo (γ, κ)
=γ − 1
γ − 1 + κ(2γ + p)/n+ (γ + p)/(n− 1)
A consistent estimator of κ = 13 × { kurtosis of xi} is easy to find:
κ =1
3× average of sample kurtosis of x1, . . . , xp
Next we consider two different estimates for sphericity γ.
19/28

Ell1-estimator of sphericity γ
Sample sign covariance matrix [Visuri et al., 2000] is defined as
Ssgn =1
n
n∑
i=1
(xi − µ)(xi − µ)>
‖xi − µ‖2 ,
where µ = argminµ
n∑
i=1
‖xi − µ‖
[Zhang and Wiesel, 2016] proposed a sphericity statistic
γEll1 = p tr(S2sgn
)− p
n
and showed that γEll1 → γ under the random matrix theory regime:
n, p→∞ andp
n→ c0, 0 < c0 <∞.
Ell1-RSCM estimator uses β = βo(κ, γEll1).
20/28

Ell2-estimator of sphericity γ
Consider the statistic:
ϑ = bn
(tr(S2)
p− an
p
n
[tr(S)
p
]2),
where
bn =(κ+ n)(n− 1)2
(n− 2)(3κ(n− 1) + n(n+ 1))& an =
n
n+ κ
(n
n− 1+ κ
)
Note: For large n: ϑ ≈ tr(S2)
p− (1 + κ)
p
n
[tr(S)
p
]2.
Result 4 (holds for any n and p)
E[ϑ] =tr(Σ2)
p= mean of (eigenvalues)2
⇒ tr(S2)
p6→ tr(Σ2)
punless
p
n→ 0 as p, n→∞
21/28

Ell2-estimator of sphericity γ
Consider the statistic:
ϑ = bn
(tr(S2)
p− an
p
n
[tr(S)
p
]2),
where
bn =(κ+ n)(n− 1)2
(n− 2)(3κ(n− 1) + n(n+ 1))& an =
n
n+ κ
(n
n− 1+ κ
)
Note: For large n: ϑ ≈ tr(S2)
p− (1 + κ)
p
n
[tr(S)
p
]2.
Result 4 (holds for any n and p)
E[ϑ] =tr(Σ2)
p= mean of (eigenvalues)2
⇒ tr(S2)
p6→ tr(Σ2)
punless
p
n→ 0 as p, n→∞
21/28

Ell2-estimator of sphericity γ
Consider the statistic:
ϑ = bn
(tr(S2)
p− an
p
n
[tr(S)
p
]2),
where
bn =(κ+ n)(n− 1)2
(n− 2)(3κ(n− 1) + n(n+ 1))& an =
n
n+ κ
(n
n− 1+ κ
)
Note: For large n: ϑ ≈ tr(S2)
p− (1 + κ)
p
n
[tr(S)
p
]2.
Result 4 (holds for any n and p)
E[ϑ] =tr(Σ2)
p= mean of (eigenvalues)2
⇒ tr(S2)
p6→ tr(Σ2)
punless
p
n→ 0 as p, n→∞
21/28

The sphericity measure
γ =mean of (eigenvalues)2
(mean of eigenvalues)2
can be estimated by
γEll2 =ϑ
[tr(S)/p]2
= bn
(p tr(S2)
tr(S)2− an
p
n
)
where an = an(κ) and bn = bn(κ).
Ell2-RSCM estimator uses β = βo(κ, γEll2).
22/28

1 Portfolio optimization
2 Ell-RSCM estimators
3 Estimates of oracle parameter
4 Compressive Regularized Discriminant Analysis

Microarray data analysis (MDA)
Inferring large-scale covariance matrices from sparse genomic data isan ubiquitous problem in bioinformatics.
microarrays measure the expression of genes(which genes are expressed and to whatextent) in a given organism.
A challenging framework:
I p = # genesI n =
∑Gg=1( # of obs. in class g)
I G = # of classes
Microarrays
Microarray
• Physically: a glass slide
Microarray
Feature / probe
oligo / cDNA
Collection of features / probes
Dataset n p G Disease/organism
Su et al. 102 5,565 4 Multiple mammalian tissuesYeoh et al. 248 12,625 6 Acute lymphoblastic leukemiaRamaswamy et al. 190 16,063 14 Cancer
Table 1. Example of real data sets used in our analysis23/28

Goals:
Assign x ∈ Rp to a correct class (out of G distinct classes).
Reduce # of features without sacrificing the classification accuracy.
Giordano et al. BMC Bioinformatics 2018, 19(Suppl 2):48 Page 42 of 54
model [4], and smoke exposure [5–7]. Several works pro-pose the use of transcriptome-based exposure responsesignatures, computed by processing gene expression data(RNA/DNA microarray), to develop toxicant exposureprediction models [8–10]. In most of these approaches,gene signatures are identified by differential expression,using statistical tests involving case and control popula-tions. Due to inter-individual variations present in humanpopulations, observed gene sets could result in not-robustsignatures. Indeed, robust signatures should maintainhigh specificity and sensitivity across independent sub-ject cohorts, laboratories, and nucleic acid extractionmethods.
In the present work we propose a methodology, as wellas an experimental pipeline, for finding gene signaturesfor tobacco smoke exposure characterization and pre-diction. Our approach integrates different gene selectionmechanisms, whose results are studied and compared toextract gene signatures more robust than those producedby a single methodology. In particular, the consideredgene selection methods are based on a regression method(LASSO-LARS), a recursive elimination by support vec-tor machines (RFE-SVM), and a feature selection by anensemble of decision trees (Extra-Trees). While recentworks start employing machine learning techniquesfor gene selection [11–13], the novelty of this work isto employ and merge the results from different geneselection methods, which are not limited to statisticalanalysis ones.
The sbv IMPROVER project [14] is a collaborative effortled and funded by Philip Morris International Researchand Development which focuses on the verification ofmethods and concepts in systems biology research withinan industrial framework. sbv IMPROVER project hasrecently proposed the SysTox Computational Challenge[15] aiming at exploiting crowdsourcing as a pertinentapproach to identify and verify chemical cigarette smok-ing exposure response markers from human whole bloodgene expression data. The aim is to leverage these mark-ers as a signature in computational models for predictiveclassification of new blood samples as part of the smokingexposed or non-exposed groups (see Fig. 1). In this appli-cation domain we investigated our methodology for geneexpression data processing and selection as a machinelearning problem of feature selection/reduction in a dataspace with high dimensionality (in the order of thou-sands of variables). In this context, we demonstrate howthe blood gene signatures we found with our methodol-ogy have large overlaps with those found by other relatedworks. In addition we identified new genes which are notmentioned in literature as possible biomarkers for tobaccosmoke exposure. The functional annotation and termsenrichment analysis, together with toxicogenomics anal-ysis (chemical-gene-disease-pathway association studies),showed that the expression levels of these new genes areaffected by smoke exposure. In addition, based on oursignatures we obtained higher performances in terms ofarea under precision-recall curve (AUPR) and matthews
Fig. 1 SysTox challenge workflow. First stage (up row): gene selection (signature) from the gene expression data from humans blood samples of thetraining dataset. Second stage (bottom row): develop inductive prediction models bases on training data from gene signature and provideclassification results on testing datasetFigure from Giordano et al. [2018]
24/28

Benchmark methods:
nearest shrunken centroid [Tibshirani et al., 2002]
shrunken centroids regularized discriminant analysis [Guo et al., 2007].
Our method, compressive regularized discriminant analysis (CRDA):
3 can be used as fast and accurate gene selection method andclassification tool in MDA
3 provides fewer misclassification errors than its competitors while atthe same time achieving accurate feature elimination.
25/28

Compressive Regularized Discriminant Analysis (CRDA)
Classify x ∈ Rp to class g = argmaxg dg(x), where
d(x) =(d1(x), . . . , dg(x), . . . , dG(x)
)
= x>B − 1
2diag
(M>B
),
where M =(x1 . . . xG
), where xg is the sample mean of class g, and
B = HK(S−1β
M, q)
hard-thresholding operator HK(·, q) Ell2-RSCM estimator Sβ
HK(B, q) retains the elements of the K rows of B that possesslargest `q norm and set elements of the other rows to zero.
I Regularization parameter is K (for a fixed `q-norm q ∈ {1, 2,∞}).Our default choice for q is q =∞.
26/28

●
●
●
● ●
● ●
●
●
●
CR
DA
(KU
B)
CR
DA
(KC
V)
SP
CA
LDA
PLD
AS
CR
DA
NS
CD
QD
AD
LDA
varS
elR
Flin
−SV
MC
RD
A(K
UB)
CR
DA
(KC
V)
SP
CA
LDA
PLD
AS
CR
DA
NS
CD
QD
AD
LDA
varS
elR
Flin
−SV
MC
RD
A(K
UB)
CR
DA
(KC
V)
SP
CA
LDA
PLD
AS
CR
DA
NS
CD
QD
AD
LDA
varS
elR
Flin
−SV
M
0.00
0.25
0.50
0.75
1.00
Methods
Rat
eTest Error Rate (TER)Su Yeoh Ramaswamy ● Su Yeoh Ramaswamy
Feature Selection Rate (FSR)
Classification results for data sets of Table 1. Results are averaged over 10training-to-test set splits (using 60%-to-40% ratio).
Benefits of CRDA:
performs effectivegene selection
a) accurateclassification
b) very fast tocompute
c)
27/28

Thank you!
28/28

ReferencesYilun Chen, Ami Wiesel, Yonina C Eldar, and Alfred O Hero. Shrinkage algorithms for
mmse covariance estimation. IEEE Trans. Signal Process., 58(10):5016–5029, 2010.Maurizio Giordano, Kumar Parijat Tripathi, and Mario Rosario Guarracino. Ensemble of
rankers for efficient gene signature extraction in smoke exposure classification. BMCbioinformatics, 19(2):48, 2018.
Yaqian Guo, Trevor Hastie, and Robert Tibshirani. Regularized linear discriminantanalysis and its application in microarrays. Biostatistics, 8(1):86–100, 2007.
Olivier Ledoit and Michael Wolf. A well-conditioned estimator for large-dimensionalcovariance matrices. Journal of multivariate analysis, 88(2):365–411, 2004.
Burton G Malkiel and Eugene F Fama. Efficient capital markets: A review of theory andempirical work. The journal of Finance, 25(2):383–417, 1970.
Harry Markowitz. Portfolio selection. The journal of finance, 7(1):77–91, 1952.Harry Markowitz. Portfolio Selection, Efficent Diversification of Investments. J. Wiley,
1959.R. J. Muirhead. Aspects of Multivariate Statistical Theory. Wiley, New York, 1982. 704
pages.William F Sharpe. Capital asset prices: A theory of market equilibrium under conditions
of risk. The journal of finance, 19(3):425–442, 1964.Robert Tibshirani, Trevor Hastie, Balasubramanian Narasimhan, and Gilbert Chu.
Diagnosis of multiple cancer types by shrunken centroids of gene expression.Proceedings of the National Academy of Sciences, 99(10):6567–6572, 2002.
James Tobin. Liquidity preference as behavior towards risk. The review of economicstudies, 25(2):65–86, 1958.
S. Visuri, V. Koivunen, and H. Oja. Sign and rank covariance matrices. J. Statist.Plann. Inference, 91:557–575, 2000.
Teng Zhang and Ami Wiesel. Automatic diagonal loading for tyler’s robust covarianceestimator. In IEEE Statistical Signal Processing Workshop (SSP’16), pages 1–5, 2016.




























