Embed Size (px)
Citation preview

Hong JiangHong Jiang
((Yifeng Zhu, Xiao Qin, and David SwansonYifeng Zhu, Xiao Qin, and David Swanson))Department of Computer Science and EngineeringDepartment of Computer Science and Engineering
University of Nebraska – LincolnUniversity of Nebraska – LincolnApril 21, 2004April 21, 2004
AA Case Study of Parallel I/O for Biological Case Study of Parallel I/O for Biological Sequence Search on Linux ClustersSequence Search on Linux Clusters

Motivation (1): Cluster Computing Trends
Cluster computing is the fastest growing computing platform. 208 clusters were listed among the Top 500 by Dec. 2003. The power of cluster computing tends to be bounded by I/O

Motivation (2)
Biological sequence search is bounded by I/O– Databases are exploding in sizes– Growing at an exponential rate– Exceeding memory capacity and thrashing– Accelerating speed gap between CPU and I/O
database size
CP
U u
tili
zati
on %
performance in low memory
Goals– I/O characterization of biological search– Faster search by using parallel I/O– Using inexpensive Linux clusters– An inexpensive alternative to SAN or high end RAID

Talk Overview
Background: biological sequence search Parallel I/O implementation I/O characterizations Performance evaluation Conclusions

Biological Sequence Search
– Retrieving similar sequences from existing databases is important.– With new sequences, biologists are eager to find similarities.– Used in AIDS and cancer studies
Sequence Similarity Structural Similarity Functional Similarity
Unraveling life mystery by screening databases
databases homologous sequences
unknown sequences

BLAST: Basic Local Alignment Search Tool
Query: DNA Protein
Database: DNA Protein
BLAST– Most widely used similarity search tool– A family of sequence database search algorithms
1) Replicate database but split query sequence Examples: HT-BLAST, cBLAST, U. Iowa BLAST, TurboBLAST
2) Split database but replicate query sequence Examples: mpiBlast, TuboBlast, wuBLAST
Parallel BLAST– Sequence comparison is embarrassingly parallel– Divide and conquer

Large Biology Databases
Doubling every 14 months
— Public Domain• NCBI GenBank
26 million sequencesLargest database 8GBytes
• EMBL32 million sequences120 databases
– Commercial Domain• Celera Genomics• DoubleTwist• LabBook• Incyte Genomics
Challenge: databases are large.

Parallel I/O
disk
disk
disk
disk
Alleviate I/O Bottleneck in Clusters
The following data is measured on the PrairieFire Cluster at University of Nebraska:
PCI Bus264 MB/s=33Mhz*64 bits
W: 209 MB/s R: 236 MB/s
DiskW: 32 MB/s R: 26 MB/s
MemoryW: 592 MB/sR: 464 MB/sC: 316 MB/s
disk

Overview of CEFT-PVFS Motivations
– High throughput: exploit parallelism– High reliability:
Assume MTTF of a disk is 5 years,MTTF of PVFS = MTTF of 1 node ÷ 128 = 2
weeks Key features– Extension of PVFS– RAID-10 style fault tolerance– Free storage service, without any additional hardware costs– Pipelined duplication – “Lease” used to ensure consistency – Four write protocols to stride different balances between reliability and write throughput– Double parallelism for read operations– Skip hot spots for read
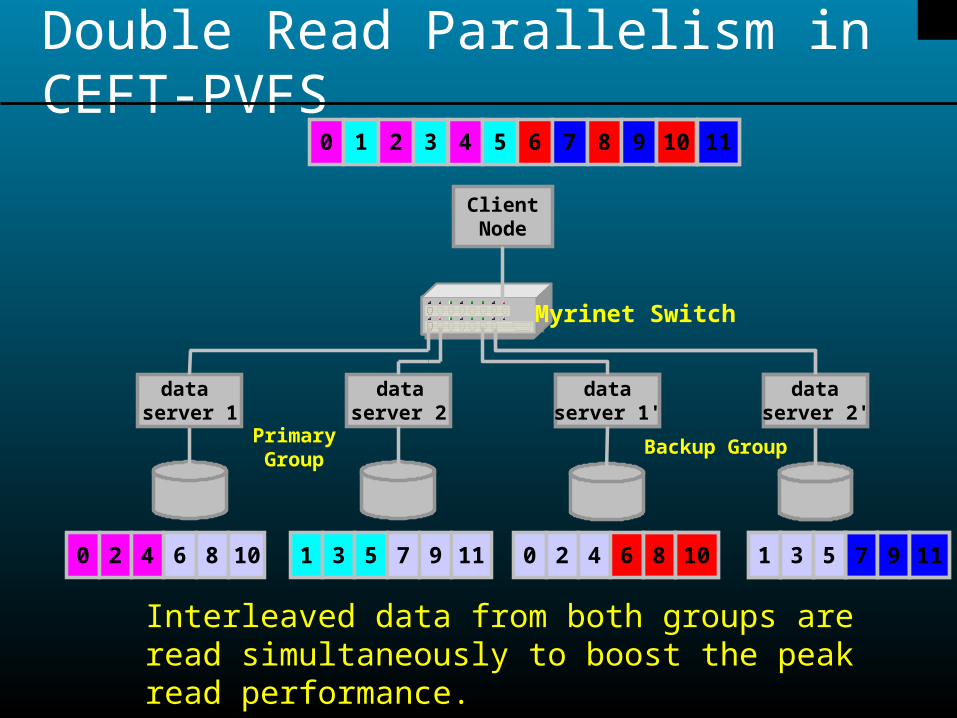
Double Read Parallelism in CEFT-PVFS0 1 2 3 4 5 6 7 8 9 10 11
ClientNode
dataserver 1'
dataserver 1
dataserver 2
dataserver 2'
PrimaryGroup
Backup Group
6 8 10 1 3 5 7 9 110 2 4 7 9 11 1 3 50 2 4 6 8 10
Myrinet Switch
Interleaved data from both groups are read simultaneously to boost the peak read performance.
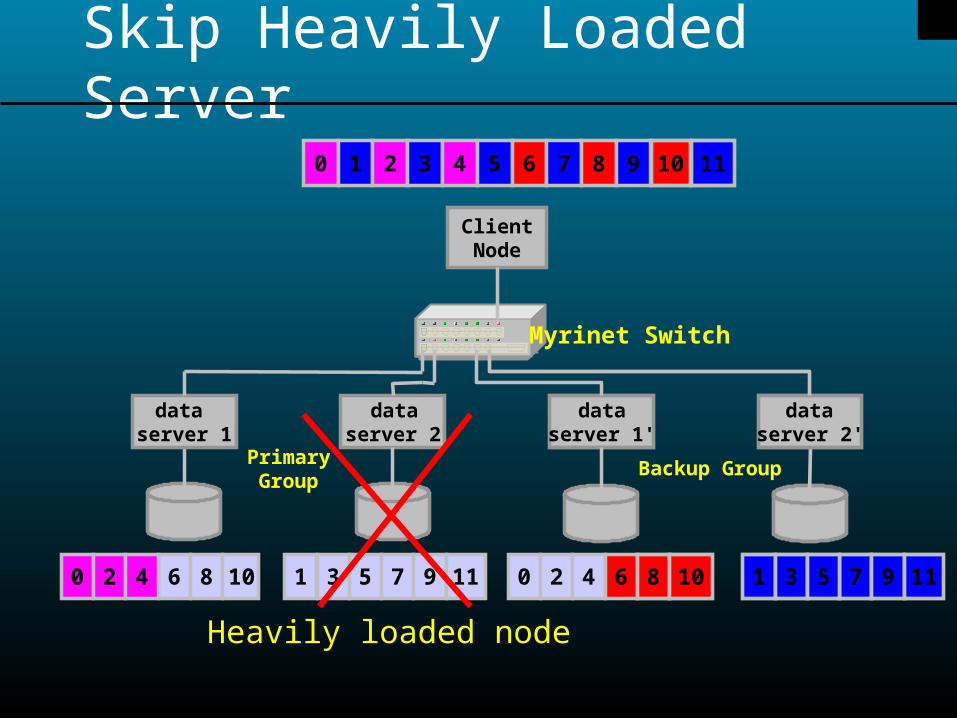
Skip Heavily Loaded Server
0 1 2 3 4 5 6 7 8 9 10 11
ClientNode
dataserver 1'
dataserver 1
dataserver 2
dataserver 2'
PrimaryGroup
Backup Group
6 8 10 1 3 5 7 9 110 2 4 7 9 11 1 3 50 2 4 6 8 10
Myrinet Switch
Heavily loaded node

Parallel BLAST over Parallel I/O
mpiBLAST
NCBI BLAST Lib
Parallel I/O Libs
Software stack
Avoid changing the search algorithms Minor modification to I/O interfaces of NCBI BLAST
For example:read(myfile, buffer, 10) pvfs_read(myfile, buffer, 10) ceft_pvfs_read(myfile, buffer, 10)
Arbitrarily choose mpiBLAST This scheme is general to any parallel blasts as long as they use NCBI BLAST ( This is true in most case. ☺)

Original mpiBLAST
Disk
CPU
Disk
CPU
Disk
CPU
Disk
CPU
Disk
CPU
mpiBLAST Master
mpiBLAST Worker
mpiBLAST Worker
mpiBLAST Worker
mpiBLAST Worker
Master splits database into segments Master assigns and copies segments to workers Worker searches its own disk using entire query
Switch

mpiBLAST over PVFS/CEFT-PVFS
Disk
CPU
Disk
CPU
Disk
CPU
Disk
CPU
Disk
CPU
mpiBLAST Master
mpiBLAST Worker
mpiBLAST Worker
mpiBLAST Worker
mpiBLAST Worker
MetadataServer
DataServer
DataServer
DataServer
DataServer
Database is striped over data servers; Parallel I/O services for each mpiBLAST worker. Fair comparisons:
Overlap servers and mpiBLASTs Do not count the copy time in original mpiBLAST
Switch

mpiBLAST over CEFT-PVFS with one hot spot skipped
Disk
CPU
Disk
CPU
Disk
CPU
Disk
CPU
Disk
CPU
mpiBLAST Master
mpiBLAST Worker
mpiBLAST Worker
mpiBLAST Worker
MetadataServer
DataServer 1
DataServer 2
DataServer 1’
DataServer 2’
Hot Spot
Double the degree of parallelism for reads Hot spot may exist since servers are not dedicated Exploit redundancy to avoid performance degradation
mpiBLAST Worker
Switch

Performance Measurement Environments
PrairieFire Cluster at UNL– Peak performance: 716 Gflops– 128 IDEs, 2.6 TeraBytes total capacity– 128 nodes, 256 processors– Myrinet and Fast Ethernet– Linux 2.4 and GM-1.5.1
Performance– TCP/IP: 112 MB/s– Disk writes: 32 MB/s– Disk reads: 26 MB/s

I/O Access Patterns Database: nt
– largest at NCBI web–1.76 million sequences, size 2.7 GBytes
Query sequence: subset of ecoli.nt (568 bytes)– Statistics shows typical query length within 300-600 bytes
8 mpiBLAST workers on 8 fragments
I/O patterns of a specific case: 8 workers and 8 fragments
– 90% are read operations.– Large reads and small writes– I/Os are out of phase gradually
Asynchronousness is great!!!

I/O Access Patterns (cont)
Read request size and number when the database fragment number changes from 5 to 30.
Focus attention on read operations due to their dominance. I/O patterns with 8 workers but different number of fragments
– Dominated by large reads.– 90% of all accessed data in databases are read by only 40% of the requests.
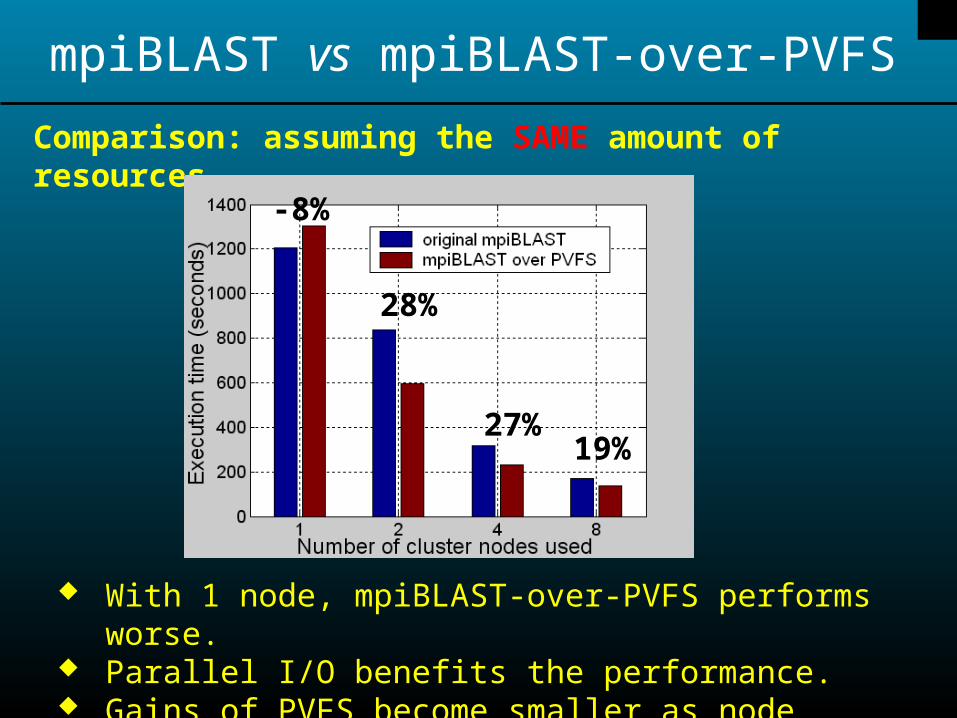
mpiBLAST vs mpiBLAST-over-PVFS
Comparison: assuming the SAME amount of resources
With 1 node, mpiBLAST-over-PVFS performs worse. Parallel I/O benefits the performance. Gains of PVFS become smaller as node number increases.
-8%
28%
27%19%
mpiBLAST vs mpiBLAST-over-PVFS (cont)
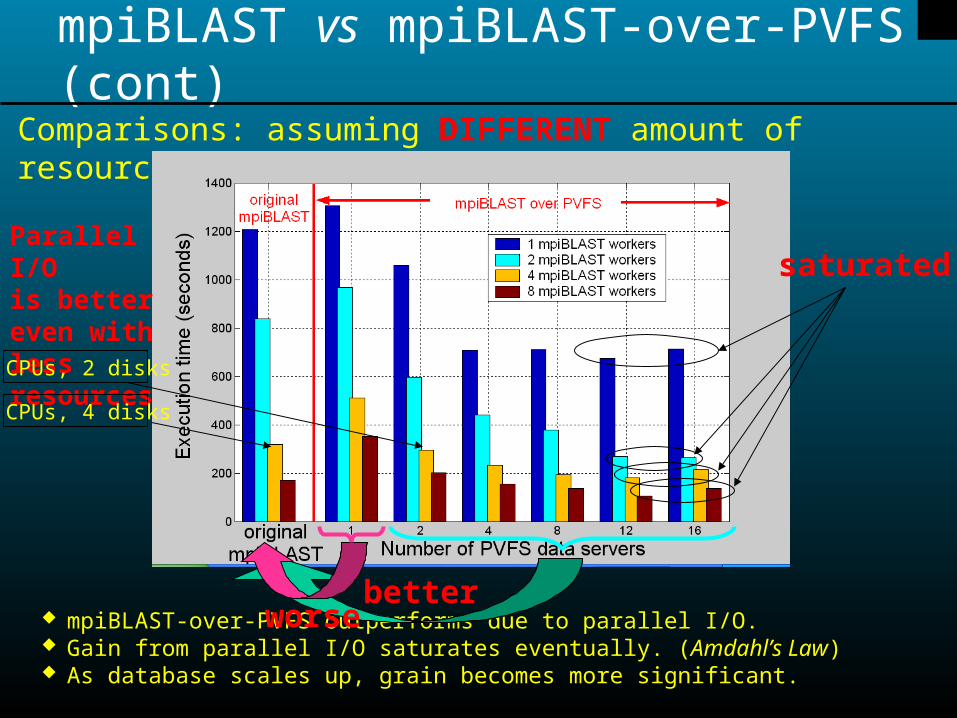
mpiBLAST-over-PVFS outperforms due to parallel I/O. Gain from parallel I/O saturates eventually. (Amdahl’s Law) As database scales up, grain becomes more significant.
Comparisons: assuming DIFFERENT amount of resources
better
saturated
worse
Parallel I/O is better even with less resources
4 CPUs, 4 disks
4 CPUs, 2 disks
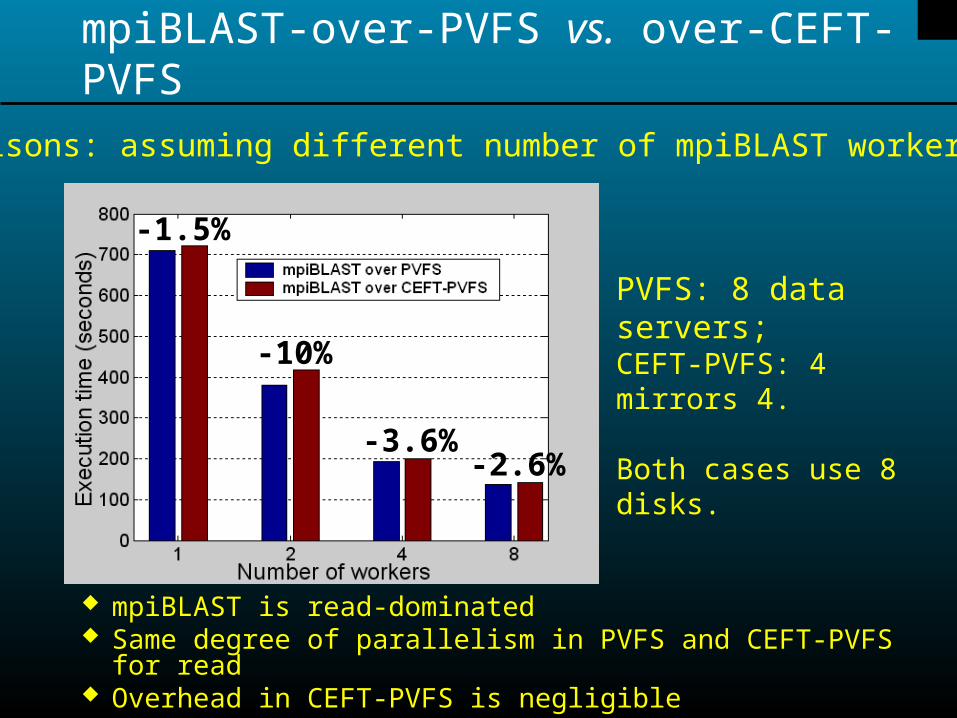
mpiBLAST-over-PVFS vs. over-CEFT-PVFS
mpiBLAST is read-dominated Same degree of parallelism in PVFS and CEFT-PVFS for read Overhead in CEFT-PVFS is negligible
PVFS: 8 data servers;CEFT-PVFS: 4 mirrors 4.
Both cases use 8 disks.
-1.5%
-10%
-3.6%-2.6%
Comparisons: assuming different number of mpiBLAST workers

mpiBLAST-over-PVFS vs over-CEFT-PVFS
Configuration: PVFS 8 servers, CEFT-PVFS: 4 mirrors 4 Stress disk on one data server by repeatedly appending data. While the original mpiBLAST and one over PVFS degraded by
10 and 21 folds, our approach degraded only by a factor of 2.
1. M = allocate(1 MBytes);2. Create a file named F;3. While(1)4. If(size(F) > 2 GB)5. Truncate F to zero byte;6. Else7. Synchronously append the 8. data in M to the end of F;9. End of if10. End of while
disk stress program
Comparisons when one disk is stressed.

Conclusions Clusters are effective computing platforms
for bioinformatics applications. A higher degree of I/O parallelism may not
lead to better performance unless I/O demand remains high (larger databases).
Doubling the degree of I/O parallelism for read operations provides CEFT-PVFS with a comparable read performance with PVFS.
Load balance in CEFT-PVFS is important and effective.

Thank you
Question?
http://rcf.unl.edu/~abacus