Embed Size (px)
Citation preview

How do we know what works?
Robert Coe
ResearchEd, London, 5 Sept 2015

∂
2

∂
How do we know what works?
Progress in evidence-based education Defining ‘what works’ The case for RCTs Some standard objections When ‘what works’ doesn’t work Practical implications
3

∂
4

∂
How far have we come?
1999
Very few UK education researchers who had done RCTs
Dominant view: you can’t (or shouldn’t) do RCTs in education
Very limited policy interest in robust evaluation
2015
Growing, sustainable body of UK researchers with education RCT expertise
EEF funding changed those views
Policy interest excellent in parts
5

∂
To claim something ‘works’ Is there a choice between two (or more)
plausible options?– Well-defined (inc how to implement)– Repeatable, generalisable, transferable– Feasible, acceptable, equipoise
Can we agree what outcome(s) are important?– Value judgements resolved or explicit– Valid measurement process
Is there rigorous systematic evidence to support one choice?– Systematic review– Overall average difference & ‘moderators’
6

∂
7

∂
In a ‘research-based’ profession:
Professionals would, for some decisions they need to take, be able to access and understand high-quality evidence that particular courses of action would be likely to lead to better outcomes than others.
Coe 2015
8
Professionals would, for the majority of decisions they need to take, be able to find and access credible research studies that provided evidence that particular courses of action that would, implemented as directed, be substantially more likely to lead to better outcomes than others.
Wiliam (2014)
∂
9

∂
From Corder et al (2015)International Journal of Behavioral Nutrition and Physical Activity
Appropriately cautious claims:– “An extra hour of screen time was associated with
9.3(−14·3,-4·3) fewer [GCSE] points” – “it would be impossible to tell whether reductions in
screen time caused an increase in academic performance without a randomised controlled trial”
But also some implicit causal claims– “Screen time was associated with lower academic
performance, suggesting that strategies to limit screen behaviours among adolescents may benefit academic performance”
10

∂
Media quotes But even if pupils spent more time studying,
more time spent watching TV or online, still harmed their results, the analysis suggested.
"We believe that programmes aimed at reducing screen time could have important benefits for teenagers' exam grades, as well as their health," said Dr Van Sluijs
“We found that TV viewing, computer games and internet use were detrimental to academic performance”
11

∂
Is screen time the cause of poorer GCSEs? A statistical association can be evidence for causal
relationship – if other explanations for the relationship have been systematically
generated, tested and discredited– Eg smoking and cancer
But even high correlations, sophisticated models and ‘strong’ controls do not guarantee this– Coe (2009) “What appeared to the original researchers to be
substantial and unequivocal causal effects were reduced to tiny and uncertain differences when the effects of plausible unobserved differences were taken into account.”
In this study– No control for any prior cognitive measure – Weak control for SES (IMD from LSOAs)– Many obvious alternative explanations
12

∂
Is screen time the cause of poorer GCSEs?
It is a meaningless question:– What are the well-defined, feasible, repeatable
options for action?
A question you could answer:– Does intervention X to reduce the time 14-year-
olds spend on non-educational screen time lead to increases in their GCSEs?
Related questions– Does X actually reduce screen time?– What support factors are required for it to work?– Does it work more/less with some groups?
13

Is the RCT a gold standard?
14

∂
Claim: If you do A, it will improve BEvidence: We did A and it improved B
1. Would B have improved anyway? (counterfactual)
2. Was it really A? (attribution)
3. Did B really improve? (interpretation)
4. Will it work again for me? (generalisation)

∂
1. Would B have improved anyway? (counterfactual)
Was there an equivalent, randomly allocated comparison group?– Randomisation done properly?– Beware attrition
Was there a comparison group, equivalent on observed measures?– Quality of the measures?– Quantity of the measures (inc repeated measures)?– Unobserved differences (eg enthusiasm, choice)?
Was there a non-equivalent comparison group?– Select an overlapping subset (propensity score matching)– Statistical ‘control’ is problematic
If no direct comparison: impossible to interpret

∂
2. Was it really A? (attribution)
Could the process of being observed or involved in an experiment have caused it (reactivity/Hawthorne effects)?
Could the involvement of the researcher or developer be a factor?
Contamination: what did control group do? Did they actually do A (faithfully)? Did other things change?

∂
3. Did B really improve? (interpretation)
Was the measure of B adequate?– Validity of measure (biased, unreliable, misinterpreted)– Too narrow/broad– Ceiling/floor effects– Un-blinded judgements
Was the ‘post-test’ timing too soon/late? Any attrition? (missing data, lost persons, units) Could it have been just chance? (statistical significance) Was the reporting comprehensive and unbiased?
– data dredging – selective reporting – publication bias

∂
4. Will it work again for me? (generalisation)
Representativeness– Context (including support factors)– Population (achieved, not just intended)
Intervention not specified or replicable Will it still work at a large scale?

∂
Claim: If you do A, it will improve BEvidence: We did A and it improved B
1. Would B have improved anyway? (counterfactual)
2. Was it really A? (attribution)
3. Did B really improve? (interpretation)
4. Will it work again for me? (generalisation)
Does RCT help?

∂
Some standard objections to RCTs
Causation– Social world is too complex / Humans are free agents
Values– Positivism requires objective, value-free stance
Generalisation– Every context is unique
Too hard– Problems with RCTs: clustering, power, file-drawer,
wrong questions, moderators, wrong outcomes, etc
Not my thing
21

When ‘what works’ doesn’t work …
22
∂
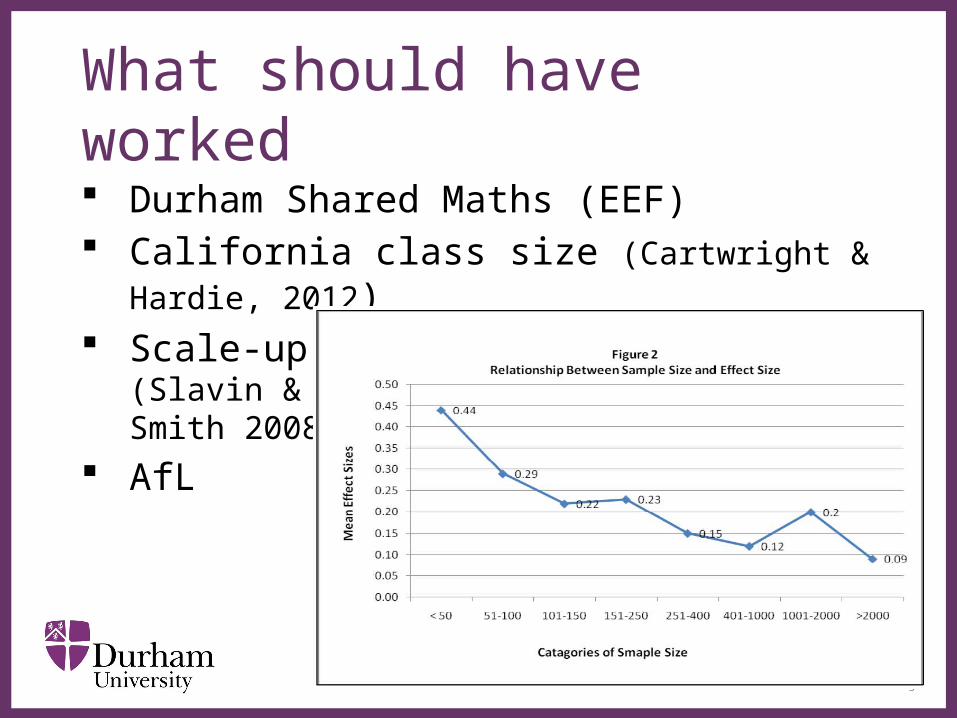
What should have worked Durham Shared Maths (EEF) California class size (Cartwright & Hardie, 2012) Scale-up
(Slavin & Smith 2008)
AfL
23

∂
What should you do? Don’t ignore the evidence just because it is
imperfect: understand the limitations and help to improve it
Simple, superficial knowledge of research evidence may not improve decision making: deep, integrated understanding is required
Routinely monitor the effectiveness of your practice
Evaluate the impact of any changes you make
24
See @LeadingLearner ‘Four Aces’ from rEdScot: Experience, Data, Feedback, Research





























