Embed Size (px)
Citation preview

How Machine Learning and AI can support the fight against COVID-19
Francesca Lazzeri, PhD
Principal Cloud Advocate Manager, Microsoft
@frlazzeri
Dmitry Soshnikov, PhD
Senior Cloud Advocate, Microsoft
@shwars

Problem
Around 30,000 scientific papers
related to COVID appear
monthly

CORD Papers Dataset
Data Source
https://allenai.org/data/cord-19
https://www.kaggle.com/allen-institute-for-ai/CORD-19-
research-challenge
CORD-19 Dataset
Contains over 400,000 scholarly articles about
COVID-19 and the coronavirus family of viruses
for use by the global research community
200,000 articles with full text

Natural Language Processing
Common tasks for NLP:
• Intent Classification
• Named Entity Recognition (NER)
• Keyword Extraction
• Text Summarization
• Question Answering
• Open Domain Question Answering
Language Models:
• Recurrent Neural Network (LSTM, GRU)
• Transformers
• GPT-2
• BERT
• Microsoft Turing-NLG
• GPT-3
Microsoft Learn Module:
Introduction to NLP with PyTorch
aka.ms/pytorch_nlp
docs.microsoft.com/en-us/learn/paths/pytorch-fundamentals/

How BERT Works (Simplified)
Masked Language Model + Next Sentence Prediction
During holidays, I like to ______ with my dog. It is so cute.
0.85 Play0.05 Sleep0.09 Fight
0.80 YES0.20 NO
BERT contains 345 million parameters => very difficult to train from scratch! In
most of the cases it makes sense to use pre-trained language model.
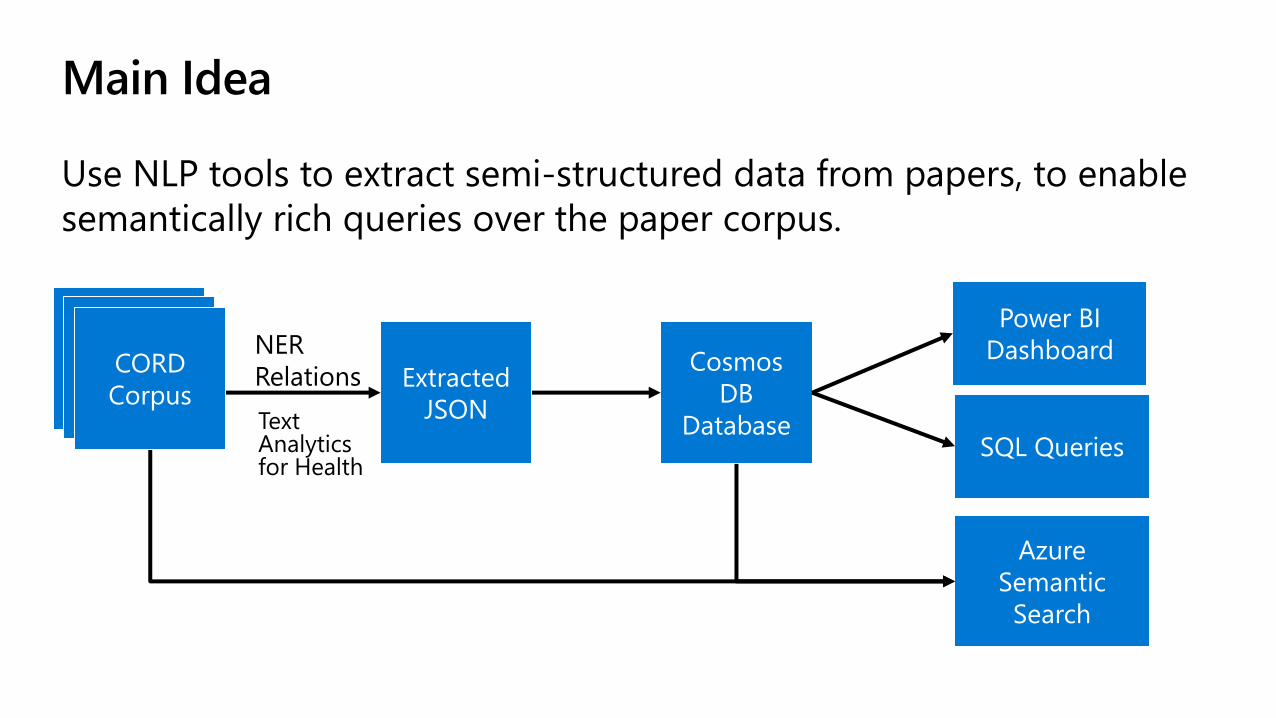
Main Idea
Use NLP tools to extract semi-structured data from papers, to enable
semantically rich queries over the paper corpus.
Extracted
JSON
Cosmos
DB
Database
Power BI
Dashboard
SQL Queries
Azure
Semantic
Search
NER
Relations
Text Analytics for Health
CORD
Corpus

Part 1: Extracting Entities and Relations
Base Language ModelDataset
Kaggle Medical NER:
• ~40 papers
• ~300 entities
Generic BC5CDR Dataset
• 1500 papers
• 5000 entities
• Disease / Chemical
Generic BERT Model
Pre-training BERT on Medical
texts
PubMedBERT pre-trained
model by Microsoft Research
Huggingface Transformer Library: https://huggingface.co/
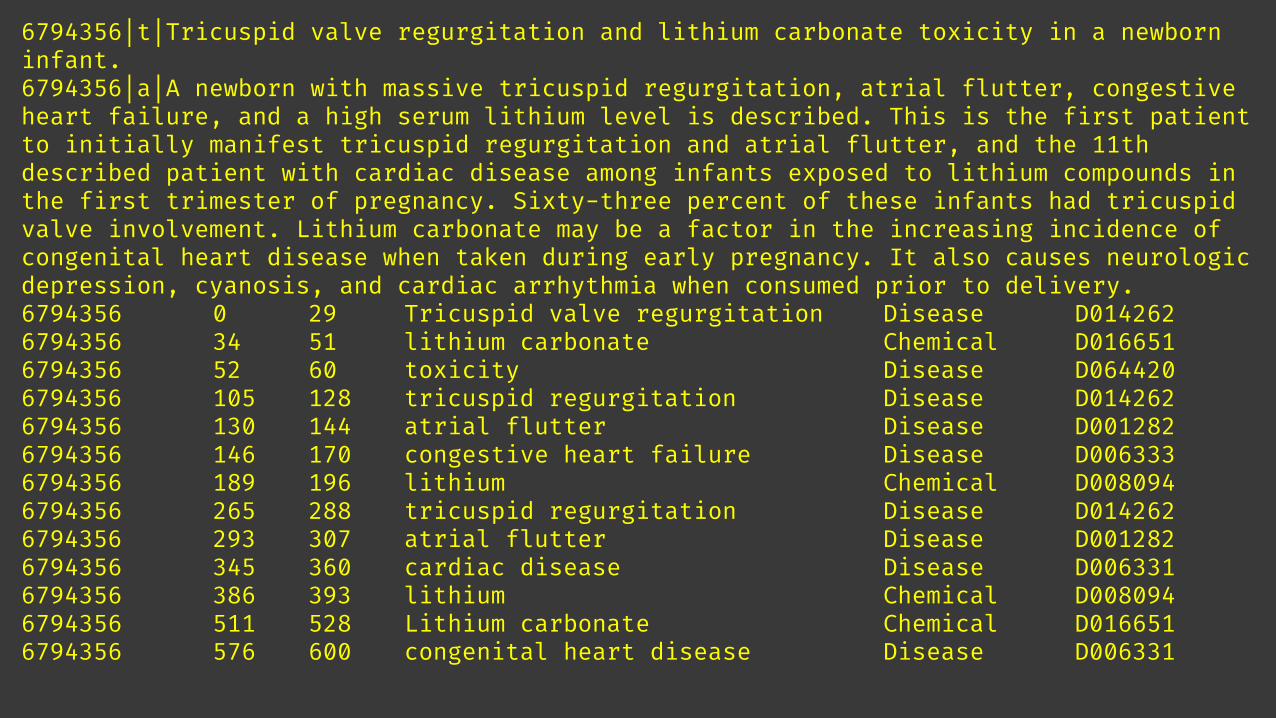
6794356|t|Tricuspid valve regurgitation and lithium carbonate toxicity in a newborninfant.6794356|a|A newborn with massive tricuspid regurgitation, atrial flutter, congestiveheart failure, and a high serum lithium level is described. This is the first patientto initially manifest tricuspid regurgitation and atrial flutter, and the 11th described patient with cardiac disease among infants exposed to lithium compounds inthe first trimester of pregnancy. Sixty-three percent of these infants had tricuspidvalve involvement. Lithium carbonate may be a factor in the increasing incidence ofcongenital heart disease when taken during early pregnancy. It also causes neurologicdepression, cyanosis, and cardiac arrhythmia when consumed prior to delivery.6794356 0 29 Tricuspid valve regurgitation Disease D0142626794356 34 51 lithium carbonate Chemical D0166516794356 52 60 toxicity Disease D0644206794356 105 128 tricuspid regurgitation Disease D0142626794356 130 144 atrial flutter Disease D0012826794356 146 170 congestive heart failure Disease D0063336794356 189 196 lithium Chemical D0080946794356 265 288 tricuspid regurgitation Disease D0142626794356 293 307 atrial flutter Disease D0012826794356 345 360 cardiac disease Disease D0063316794356 386 393 lithium Chemical D0080946794356 511 528 Lithium carbonate Chemical D0166516794356 576 600 congenital heart disease Disease D006331

NER as Token Classification
Tricuspid valve regurgitation and lithiumcarbonate toxicity in a newborn infant.
Tricuspid B-DISvalve I-DISregurgitationI-DISand Olithium B-CHEMcarbonate I-CHEMtoxicity B-DISin Oa Onewborn Oinfant O. O

PubMedBert, Microsoft Research
from transformers importAutoTokenizer, BertForTokenClassification,Trainer
mname = “microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract”
tokenizer = AutoTokenizer.from_pretrained(mname)
model = BertForTokenClassification.from_pretrained(mname,
num_labels=len(unique_tags))
trainer = Trainer(model=model,args=training_args, train_dataset=train_dataset, eval_dataset=val_dataset)
trainer.train()
Notebooks Automated ML UX Designer
Reproducibility Automation Deployment Re-training
CPU, GPU, FPGAs IoT Edge
Azure Machine LearningEnterprise grade service to build and deploy models at scale
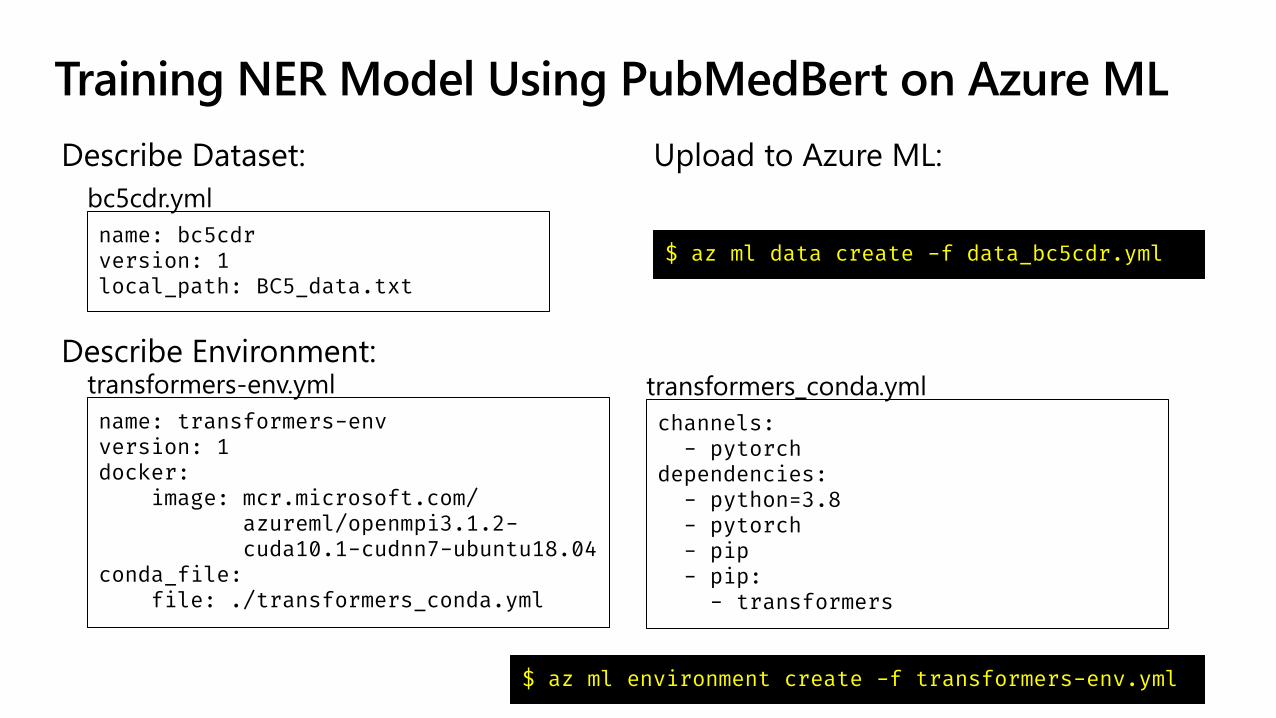
Training NER Model Using PubMedBert on Azure ML
Describe Dataset:
name: bc5cdrversion: 1local_path: BC5_data.txt
bc5cdr.yml
Upload to Azure ML:
$ az ml data create -f data_bc5cdr.yml
Describe Environment:
name: transformers-envversion: 1docker:
image: mcr.microsoft.com/azureml/openmpi3.1.2-cuda10.1-cudnn7-ubuntu18.04
conda_file: file: ./transformers_conda.yml
transformers-env.yml
channels:- pytorch
dependencies:- python=3.8- pytorch- pip- pip:
- transformers
transformers_conda.yml
$ az ml environment create -f transformers-env.yml

Training NER Model Using PubMedBert on Azure ML
Describe Experiment:
experiment_name: nertraincode:
local_path: .command: >-
pythontrain.py --data {inputs.corpus}
environment: azureml:transformers-env:1
compute:target: azureml:AzMLGPUCompute
inputs:corpus:
data: azureml:bc5cdr:1mode: download
job.yml
Create Compute:
$ az ml compute create –n AzMLGPUCompute--size Standard_NC6--max-node-count 2
Submit Job:
$ az ml job create –f job.yml

Result
• COVID-19 not recognized,
because dataset is old
• Some other categories would
be helpful (pharmacokinetics, biologic fluids, etc.)
• Common entities are also needed (quantity, temperature, etc.)
Get trained model:
$ az ml job download -n $ID--outputs

Text Analytics for Health (Preview)
Currently in Preview
Gated service, need to apply for usage
(apply at https://aka.ms/csgate)
Should not be implemented or deployed in any production use.
Can be used through Web API or Container Service
Supports: Named Entity Recognition (NER)
Relation Extraction
Entity Linking (Ontology Mapping)
Negation Detection

Entity Extraction+ Entity Linking, Negation Detection

Relation Extraction

Using Text Analytics for Health
Pip Install the Azure TextAnalytics SDK:
pip install azure.ai.textanalytics==5.1.0b5
from azure.core.credentials import AzureKeyCredentialfrom azure.ai.textanalytics import TextAnalyticsClient
client = TextAnalyticsClient(endpoint=endpoint,credential=AzureKeyCredential(key), api_version="v3.1-preview.3")
Create the client:
documents = ["I have not been administered any aspirin, just 300 mg or favipiravir daily."]poller = client.begin_analyze_healthcare_entities(documents)result = poller.result()
Do the call:

Analysis Result
I have not been administered any aspirin, just 300 mg or favipiravir
daily.
HealthcareEntity(text=300 mg, category=Dosage, subcategory=None, length=6, offset=47, confidence_score=1.0, data_sources=None, related_entities={HealthcareEntity(text=favipiravir, category=MedicationName, subcategory=None, length=11, offset=57, confidence_score=1.0, data_sources=[HealthcareEntityDataSource(entity_id=C1138226, name=UMLS), HealthcareEntityDataSource(entity_id=J05AX27, name=ATC), HealthcareEntityDataSource(entity_id=DB12466, name=DRUGBANK), HealthcareEntityDataSource(entity_id=398131, name=MEDCIN), HealthcareEntityDataSource(entity_id=C462182, name=MSH), HealthcareEntityDataSource(entity_id=C81605, name=NCI), HealthcareEntityDataSource(entity_id=EW5GL2X7E0, name=NCI_FDA)], related_entities={}): 'DosageOfMedication'})
aspirin (C0004057) [MedicationName]300 mg [Dosage] --DosageOfMedication--> favipiravir (C1138226) [MedicationName] favipiravir (C1138226) [MedicationName] daily [Frequency] --FrequencyOfMedication--> favipiravir (C1138226) [MedicationName]

Analyzing CORD Abstracts
• All abstracts contained in CSV metadata file
• Split 400k papers into chunks of 500• Id, Title, Journal, Authors, Publication Date
• Shuffle by date in order to get representative sample in each chunk
• Enrich each json file with text analytics data• Entities, Relations
• Parallel processing using Azure ML

Parallel Sweep Job in Azure ML
CORD Dataset
(metadata.csv)
Output
storage
(Database)Azure ML Cluster
experiment_name: cog-sweepalgorithm: gridtype: sweep_jobsearch_space:
number:type: choicevalues: [0, 1]
trial:command: >-
python process.py --number {search_space.number} --nodes 2--data {inputs.metacord}
inputs:metacord:
data: azureml:metacord:1mode: download
max_total_trials: 2max_concurrent_trials: 2timeout_minutes: 10000
$ az ml job create –f sweepjob.yml
…# Parse command-linedf = pd.read_csv(args.data)
for i,(id,x) in enumerate(df.iterrows()):if i%args.nodes == args.number:
# Process the record# Store the result
process.py

Results of Text Analytics Processing
{"gh690dai": {
"id": "gh690dai","title": "Beef and Pork Marketing Margins
and Price Spreads during COVID-19","authors": "Lusk, Jayson L.; Tonsor,
Glynn T.; Schulz, Lee L.","journal": "Appl Econ Perspect Policy","abstract": "...","publish_time": "2020-10-02","entities": [
{"offset": 0,"length": 16,"text": "COVID-19-related","category": "Diagnosis","confidenceScore": 0.79,"isNegated": false
},..]
"relations": [{
"relationType": "TimeOfTreatment","bidirectional": false,"source": {
"uri": "#/documents/0/entities/15","text": "previous year","category": "Time","isNegated": false,"offset": 704
},"target": {
"uri": "#/documents/0/entities/13","text": "beef","category": "TreatmentName","isNegated": false,"offset": 642
}}]},…

Storing Semi-Structured Data into Cosmos DB
Cosmos DB – NoSQL universal solution
Querying semi-structured data with SQL-like language
Paper
Paper
Entity
Entity
Rela
tion
Co
llect
ion
…
…

Cosmos DB & Azure Data Solutions
• Real-time access with fast read and write latencies globally, and throughput and consistency all backed by SLAs
• Multi-region writes and data distribution to any Azure region with the click of a button.
• Independently and elastically scale storage and throughput across any Azure region – even during unpredictable traffic
bursts – for unlimited scale worldwide.

Cosmos DB SQL Queries
Get mentioned dosages of a particular medication and papers they
are mentioned in
SELECT p.title, r.source.textFROM papers p JOIN r IN p.relationsWHERE r.relationType='DosageOfMedication’ AND CONTAINS(r.target.text,'hydro')

Further Exploration: Jupyter in Cosmos DB
SQL in Cosmos DB is somehow limited
Good strategy: make query in Cosmos DB, export to Pandas
Dataframe, final exploration in Python
Jupyter support is built into Cosmos DB
Makes exporting query results to DataFrame easy!
%%sql --database CORD --container Papers --output medsSELECT e.text, e.isNegated, p.title, p.publish_time,
ARRAY (SELECT VALUE l.id FROM l IN e.linksWHERE l.dataSource='UMLS')[0] AS umls_id
FROM papers pJOIN e IN p.entitiesWHERE e.category = 'MedicationName'

How Medication Strategies Change

Term relations

Term Relations
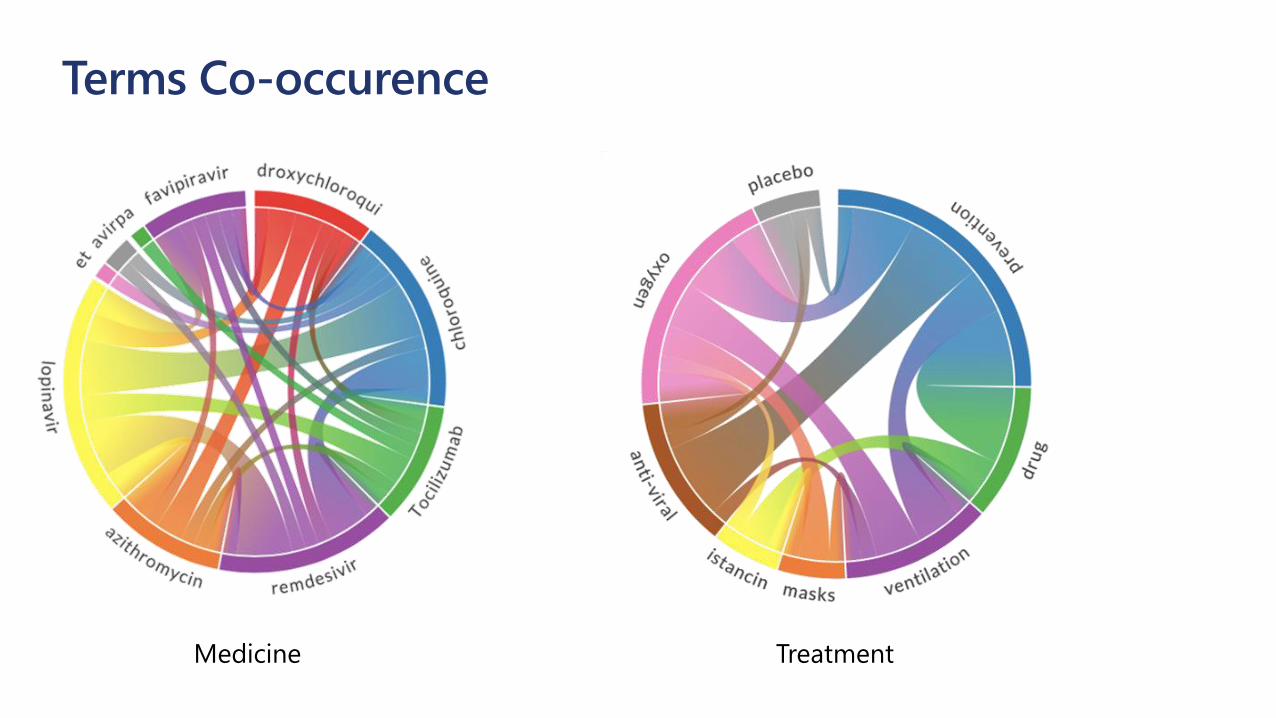
Terms Co-occurence
TreatmentMedicine

Power BI and No Code / Low Code Data Visualization
• Connect to data, including multiple data sources.
• Shape the data with queries that build insightful, compelling data
models.
• Use the data models to create visualizations and reports.
• Share your report files for others to leverage, build upon, and share.

Exploration: PowerBI

Exploration: PowerBI

Conclusions
Text Mining for Medical Texts can be very valuable resource
for gaining insights into large text corpus.❶
❷ A Range of Microsoft Technologies can be used to
effectively make this a reality:
• Azure ML for Custom NER training / Parallel Sweep Jobs
• Text Analytics for Health to do NER and ontology mapping
• Cosmos DB to store and query semi-structured data
• Power BI to explore the data interactively to gain insights
• Cosmos DB Jupyter Notebooks to do deep dive into the
data w/Python

Resources
• Article: https://soshnikov.com/science/analyzing-medical-papers-with-azure-and-text-
analytics-for-health/
• Text Analytics for Health
• Azure Machine Learning
• Cosmos DB
• Power BI
• Jupyter Notebooks on Azure Machine Learning
• MS LEARN

Feedback
Your feedback is important to us.
Don’t forget to rate and review the sessions.

Thank You!Francesca Lazzeri, PhD
Principal Cloud Advocate Manager, Microsoft
@frlazzeri
Dmitry Soshnikov, PhD
Senior Cloud Advocate, Microsoft
@shwars





























