Embed Size (px)
Citation preview

How to Turbocharge Network ThroughputTony AmiesRSM Partners
Tuesday 1st NovemberSession EC
TriassicPeriod
JurassicPeriod
CretaceousPeriod
CenzoicEra
NetworkSysProgPeriod
Architect Period
RSMEra
Director &Consultant
Period
IBMEra
IMSProgEra
NetworkConsultant
Period
Now245 million years ago
Bio …
Started Work as an IMS DB/DC Programmer
New Millennium

• Typical Datacentre Connections• Key Considerations to Improve Performance• Some of the available options
– Hipersockets– Dynamic XCF– SMC-R – SMC-D
• Performance Comparisons
Agenda
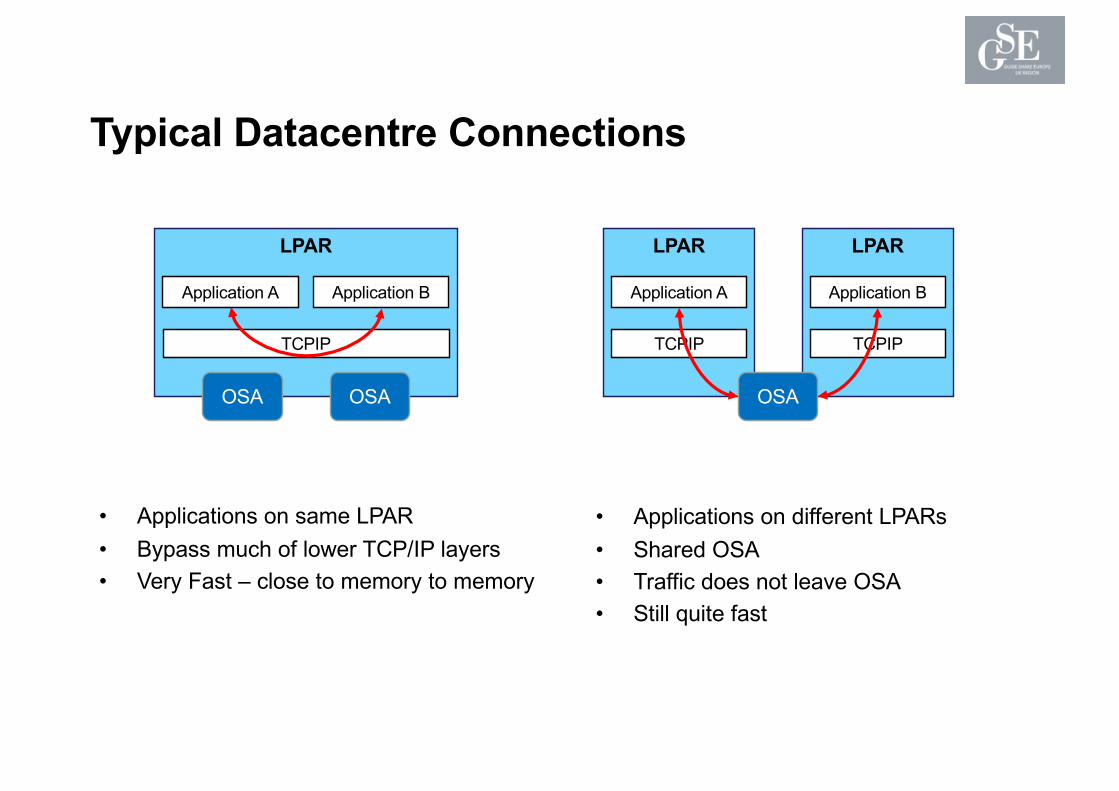
Typical Datacentre Connections
LPAR
Application A Application B
TCPIP
OSA OSA
• Applications on same LPAR• Bypass much of lower TCP/IP layers• Very Fast – close to memory to memory
LPAR
Application A
TCPIP
LPAR
Application B
TCPIP
OSA
• Applications on different LPARs• Shared OSA• Traffic does not leave OSA• Still quite fast
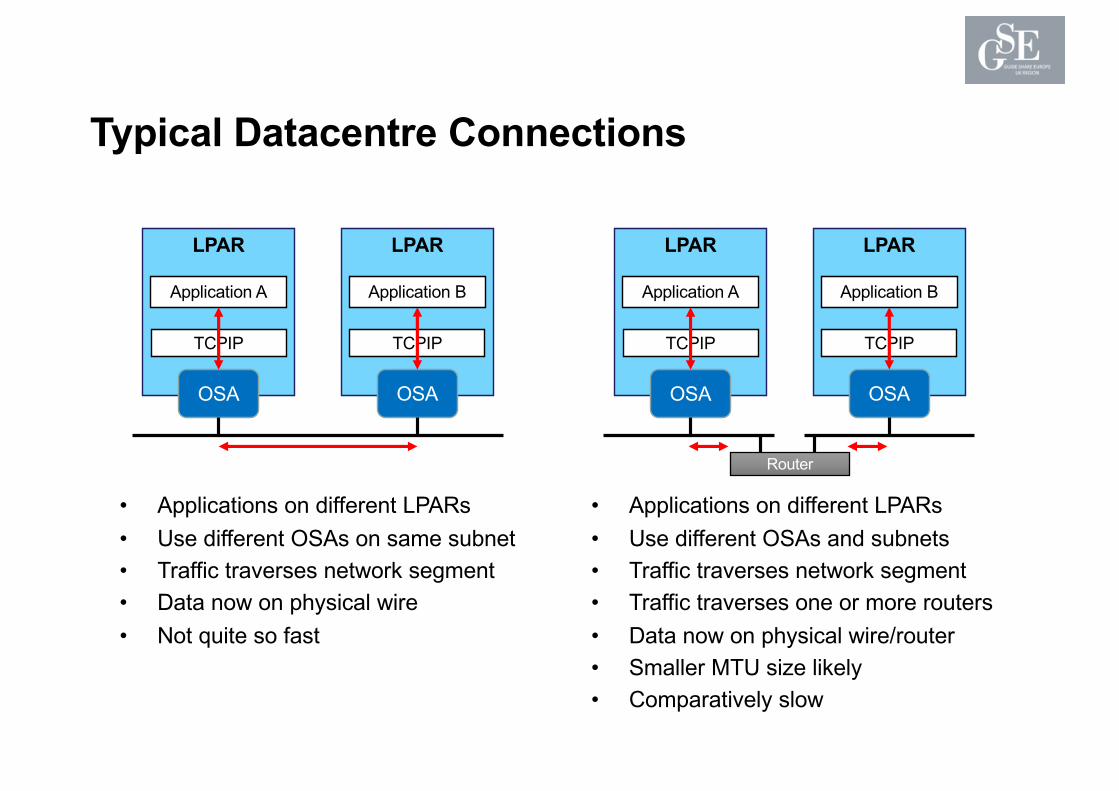
Typical Datacentre Connections
• Applications on different LPARs• Use different OSAs on same subnet• Traffic traverses network segment• Data now on physical wire• Not quite so fast
LPAR
Application A
TCPIP
LPAR
Application B
TCPIP
OSA OSA
LPAR
Application A
TCPIP
LPAR
Application B
TCPIP
OSA OSA
Router
• Applications on different LPARs• Use different OSAs and subnets• Traffic traverses network segment• Traffic traverses one or more routers• Data now on physical wire/router• Smaller MTU size likely• Comparatively slow
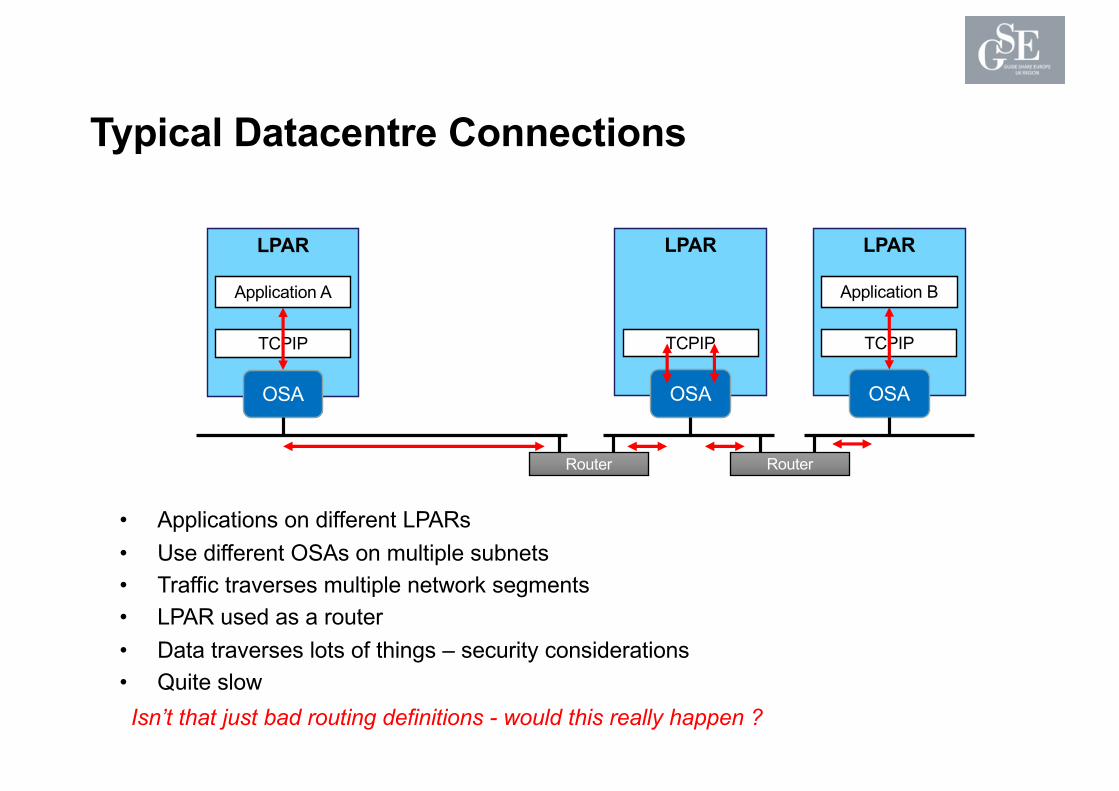
Typical Datacentre Connections
• Applications on different LPARs• Use different OSAs on multiple subnets• Traffic traverses multiple network segments• LPAR used as a router• Data traverses lots of things – security considerations• Quite slow
LPAR
Application A
TCPIP
OSA
LPAR
TCPIP
LPAR
Application B
TCPIP
OSA OSA
RouterRouter
Isn’t that just bad routing definitions - would this really happen ?
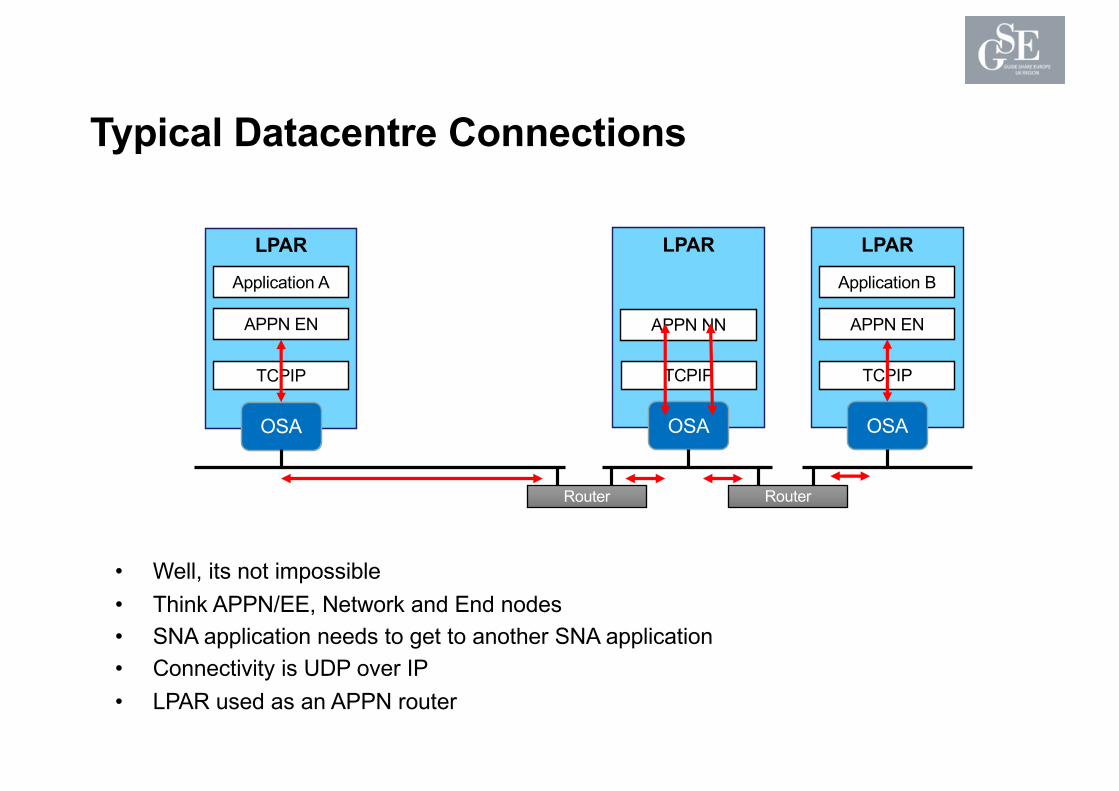
Typical Datacentre Connections
• Well, its not impossible• Think APPN/EE, Network and End nodes• SNA application needs to get to another SNA application• Connectivity is UDP over IP• LPAR used as an APPN router
LPAR
APPN EN
TCPIP
OSA
LPAR
TCPIP
LPAR
TCPIP
OSA OSA
RouterRouter
APPN NN APPN EN
Application A Application B

• Which applications need to communicate• Are the LPARs hosting these in same CPC/CEC• Are the LPARs hosting these in same Sysplex• Are there zLinux or zVM LPARs involved• What z hardware do these run on• z/OS (and zVM) Version• Security considerations (Firewall, PCI compliance)• Traffic footprint
– TCP or UDP– Streaming or interactive– Typical message sizes and volumes (MTU sizes)
• Budget
Considerations for improving performance

• Optional Technologies– Hipersockets– Dynamic XCF– SMC-R– SMC-D
• All of these– Could potentially improve performance
• But not all are– Supported in different CPC/Sysplex combinations– Supported by all hardware– Supported by all operating systems– Supported by all applications– Supported by all security compliances– Supported by your accountant
Turbocharging Options

Hipersockets
• High speed communication between LPARs – Within the same CPC/CEC
• Internal Queued Direct I/O (iQDIO)– Based on QDIO Architecture
• Communication via shared memory– High speed, low latency
• Multiple Operating System Support– z/OS, zLinux, z/VM and even z/VSE
• Transparent to applications• No additional hardware or software required (aka free!)• Easy to configure• Large MTU capability (up to 56K)
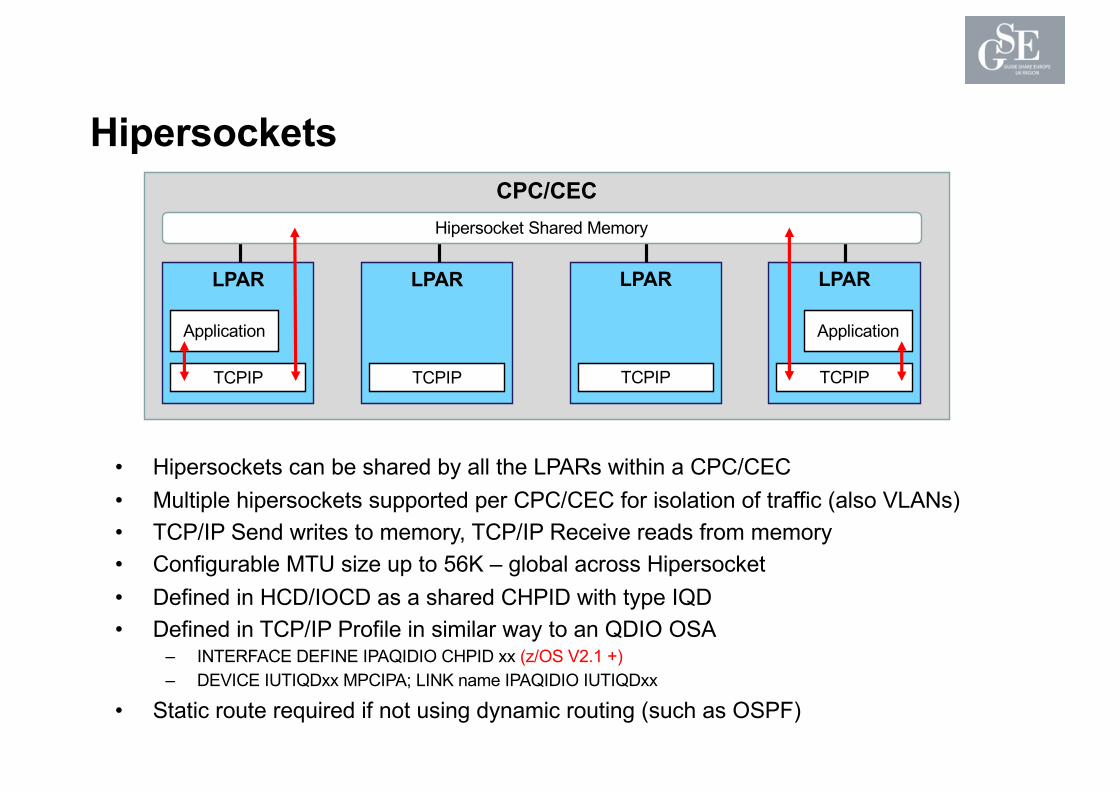
CPC/CEC
Hipersockets
• Hipersockets can be shared by all the LPARs within a CPC/CEC• Multiple hipersockets supported per CPC/CEC for isolation of traffic (also VLANs)• TCP/IP Send writes to memory, TCP/IP Receive reads from memory• Configurable MTU size up to 56K – global across Hipersocket• Defined in HCD/IOCD as a shared CHPID with type IQD • Defined in TCP/IP Profile in similar way to an QDIO OSA
– INTERFACE DEFINE IPAQIDIO CHPID xx (z/OS V2.1 +)– DEVICE IUTIQDxx MPCIPA; LINK name IPAQIDIO IUTIQDxx
• Static route required if not using dynamic routing (such as OSPF)
LPAR
Application
TCPIP
LPAR
TCPIP
LPAR
TCPIP
LPAR
TCPIP
Application
Hipersocket Shared Memory
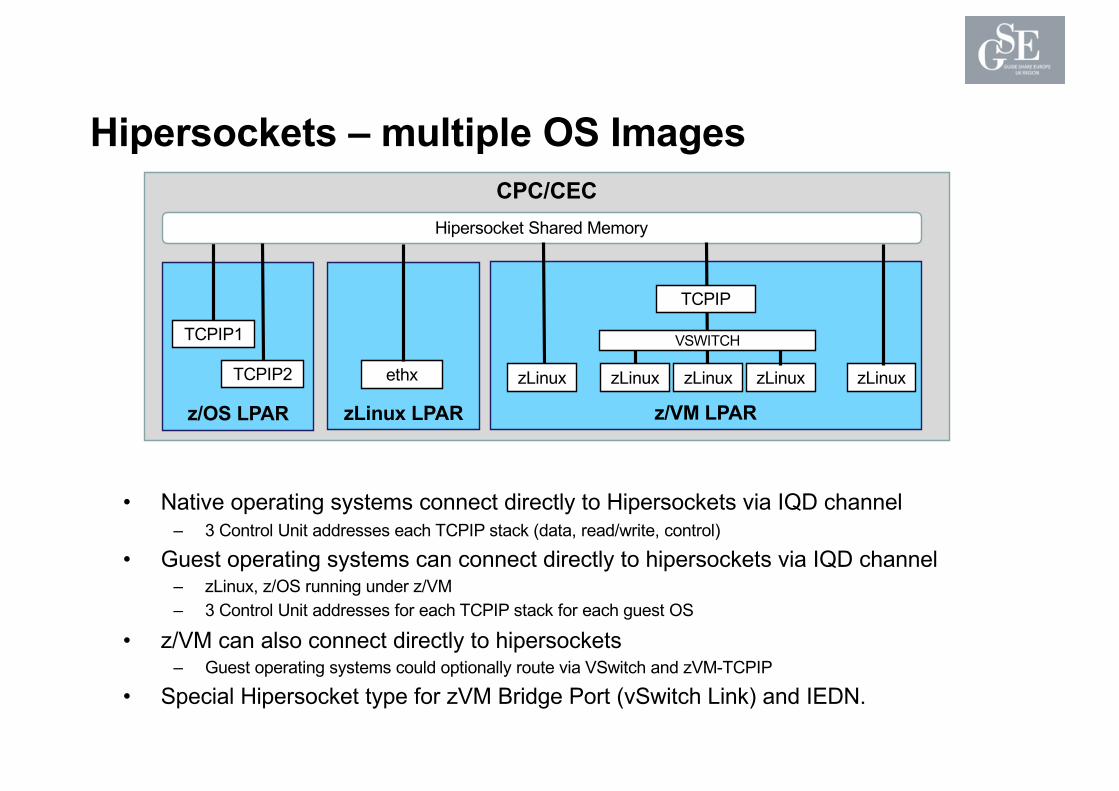
CPC/CEC
Hipersockets – multiple OS Images
• Native operating systems connect directly to Hipersockets via IQD channel– 3 Control Unit addresses each TCPIP stack (data, read/write, control)
• Guest operating systems can connect directly to hipersockets via IQD channel– zLinux, z/OS running under z/VM– 3 Control Unit addresses for each TCPIP stack for each guest OS
• z/VM can also connect directly to hipersockets– Guest operating systems could optionally route via VSwitch and zVM-TCPIP
• Special Hipersocket type for zVM Bridge Port (vSwitch Link) and IEDN.
z/OS LPAR zLinux LPAR z/VM LPAR
Hipersocket Shared Memory
zLinux
TCPIP1
TCPIP2 zLinuxzLinux zLinux zLinux
TCPIP
VSWITCH
ethx

Hipersockets – additional technologies
• Multi-write capability – CPU reduction– Multiple buffers written to hipersockets in single write operation– Processing can be offloaded to zIIP– Supported on z10+ and z/OS 1.10+
• Completion Queues– Queue mechanism if target system for data is saturated
• Hipersocket data sent synchronously if target has available buffers• Hipersocket data queued and sent asynchronously if target has no buffers
– Supported on z196+ and z/OS 1.13+ • QDIO Accelerator
– When LPAR used as a router for traffic arriving via OSA– Processing of first packet determines forwarding via hipersockets– Subsequent packets routed down at DLC layer, bypassing TCPIP

Dynamic XCF
• High speed communication between LPARs – Within the same SYSPLEX
• Communication via XCF transport– VTAM/TCPIP create an XCF “data” group– High speed, low latency
• Single Operating System Support– z/OS only
• Provides a logical LAN between TCPIP instances• Transparent to applications• No additional hardware or software required (aka free)
– Assuming Sysplex and Coupling Facility implemented
• Very easy to configure
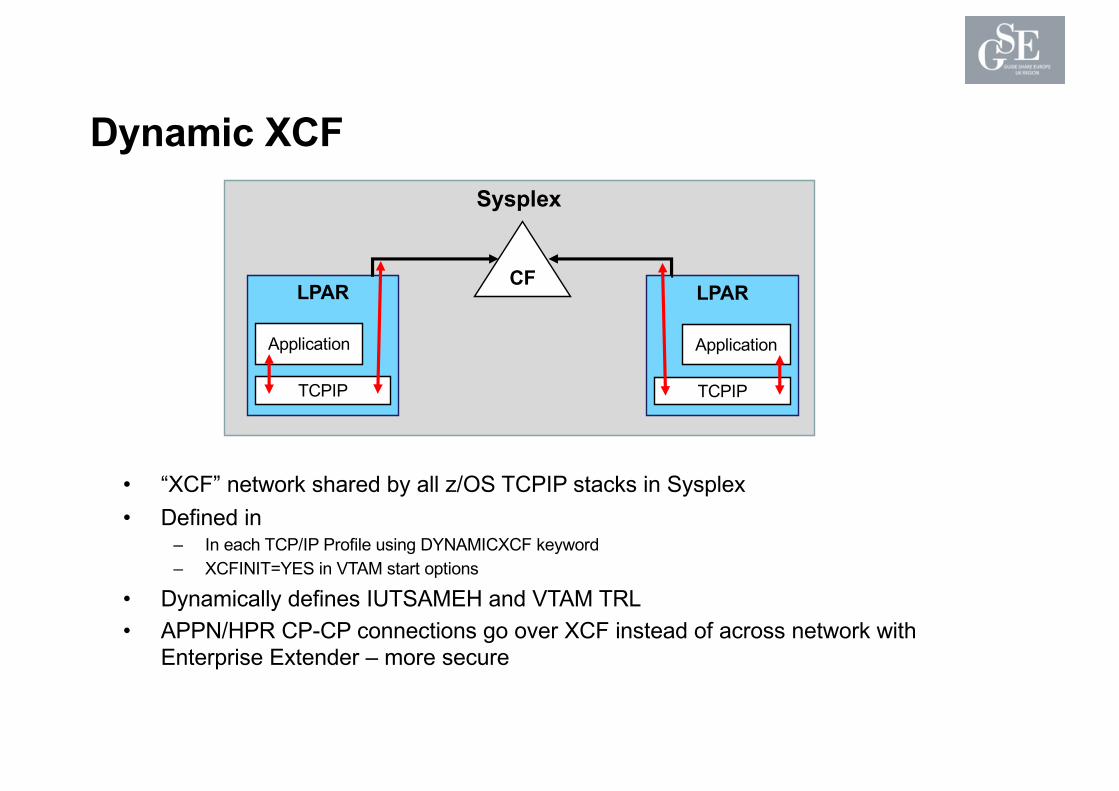
Sysplex
Dynamic XCF
• “XCF” network shared by all z/OS TCPIP stacks in Sysplex• Defined in
– In each TCP/IP Profile using DYNAMICXCF keyword– XCFINIT=YES in VTAM start options
• Dynamically defines IUTSAMEH and VTAM TRL• APPN/HPR CP-CP connections go over XCF instead of across network with
Enterprise Extender – more secure
LPAR
Application
TCPIP
LPAR
TCPIP
Application
CF
SysplexCEC CEC
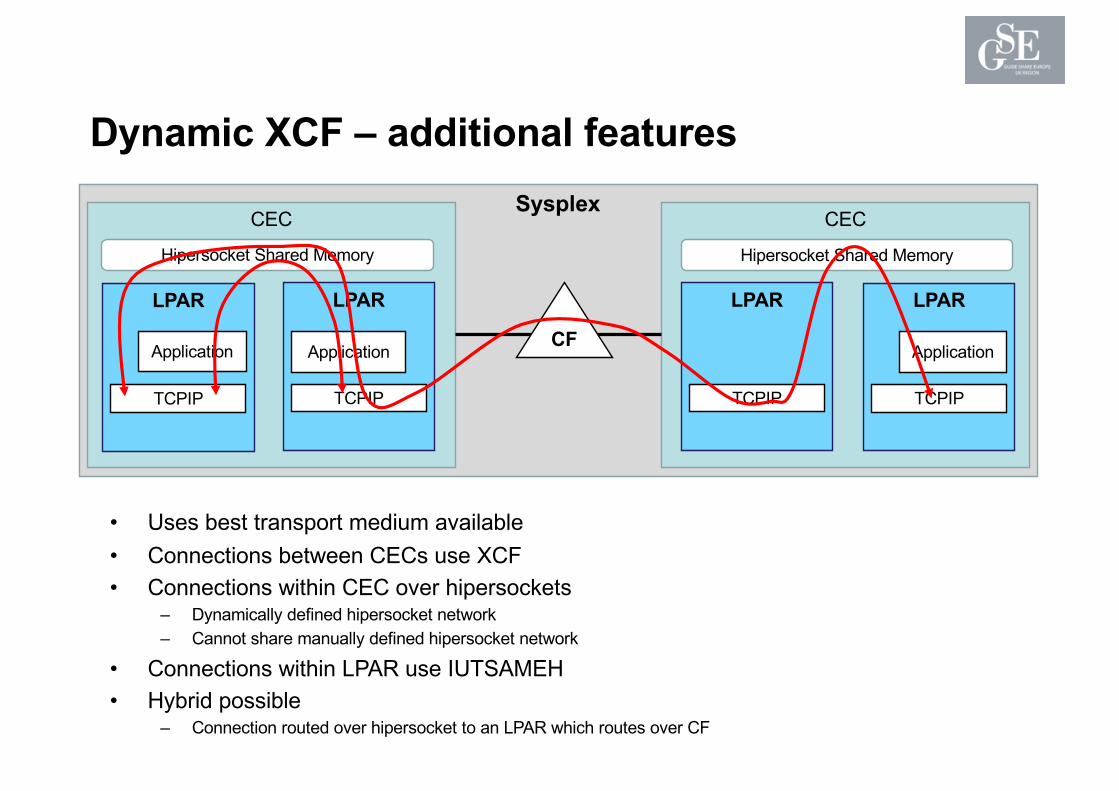
Dynamic XCF – additional features
• Uses best transport medium available• Connections between CECs use XCF• Connections within CEC over hipersockets
– Dynamically defined hipersocket network– Cannot share manually defined hipersocket network
• Connections within LPAR use IUTSAMEH• Hybrid possible
– Connection routed over hipersocket to an LPAR which routes over CF
LPAR
TCPIP
LPAR
TCPIP
Application
Hipersocket Shared Memory
LPAR
TCPIP
LPAR
TCPIP
Application CF
Hipersocket Shared Memory
Application

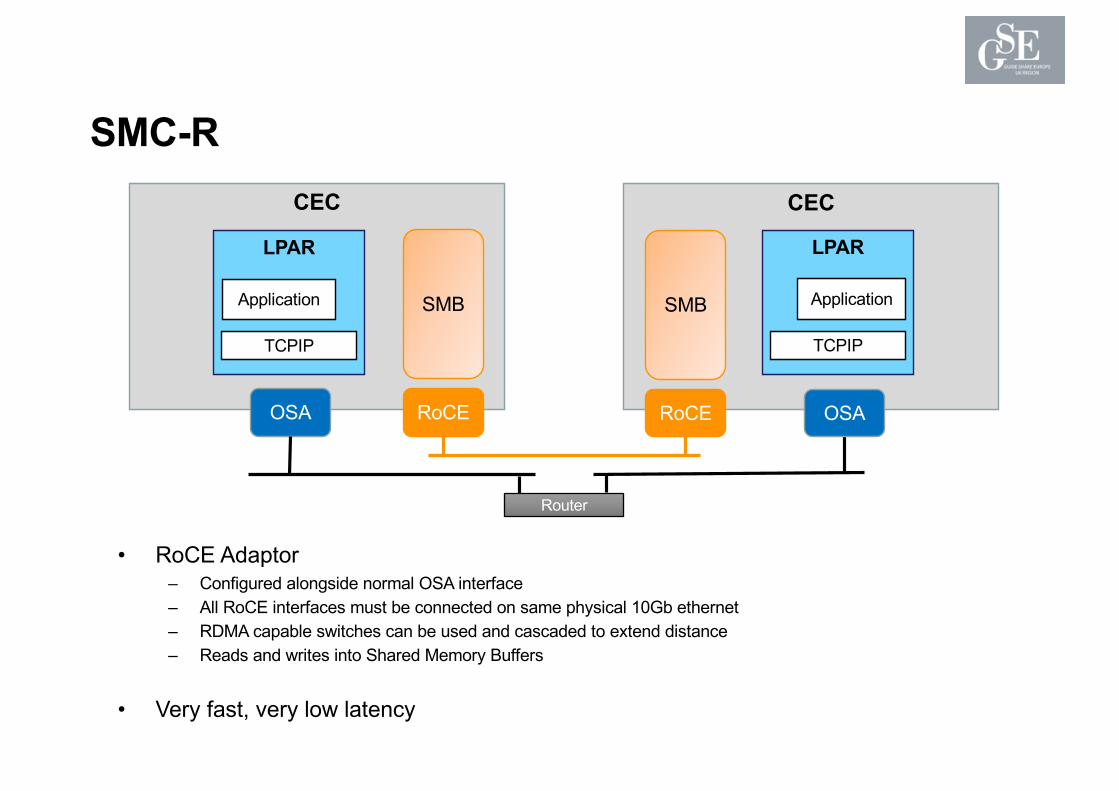
SMC-R• Acronyms rule!
– RDMA : Remote Direct Memory Access– SMC-R : Shared Memory Communications over RDMA– RNIC : RDMA Network Interface Card– RoCE : RDMA over Converged Ethernet (“Rocky”)– RMB : RDMA Remote Memory Buffers
• RDMA– Direct read/write to/from memory– Memory area registered for RDMA use (RMBs)– No CPU cycles required for I/O– TCP/IP processing mainly bypassed - CPU used for interrupt to TCP/IP API
• RoCE (“Rocky”)– New hardware adapter– One or more in each CEC – sharable between LPARs (only on Z13)

SMC-R continued• Very high speed communication between LPARs
– In different CECs– Over distance 300m-600m (extendable to KM with cascaded switches)– Up to 100KM+ with multiplexers typically used for GDPS
• Transparent to applications – TCP only• Still requires “normal” OSA connectivity in parallel• MTU size 1K, 2K and up to 4K in z/OS 2.2• Failover capability back to OSA transport• Security Considerations
– SMC-R traffic flows over ethernet wire– Cannot be routed, single switched network– Cannot support/traverse firewalls– Could compromise security rules or PCI compliance
SMC-R
• RoCE Adaptor– Configured alongside normal OSA interface– All RoCE interfaces must be connected on same physical 10Gb ethernet– RDMA capable switches can be used and cascaded to extend distance– Reads and writes into Shared Memory Buffers
• Very fast, very low latency
CEC
LPAR
TCPIP
Application
OSA RoCE
Router
CEC
LPAR
TCPIP
Application
OSARoCE
SMBSMB
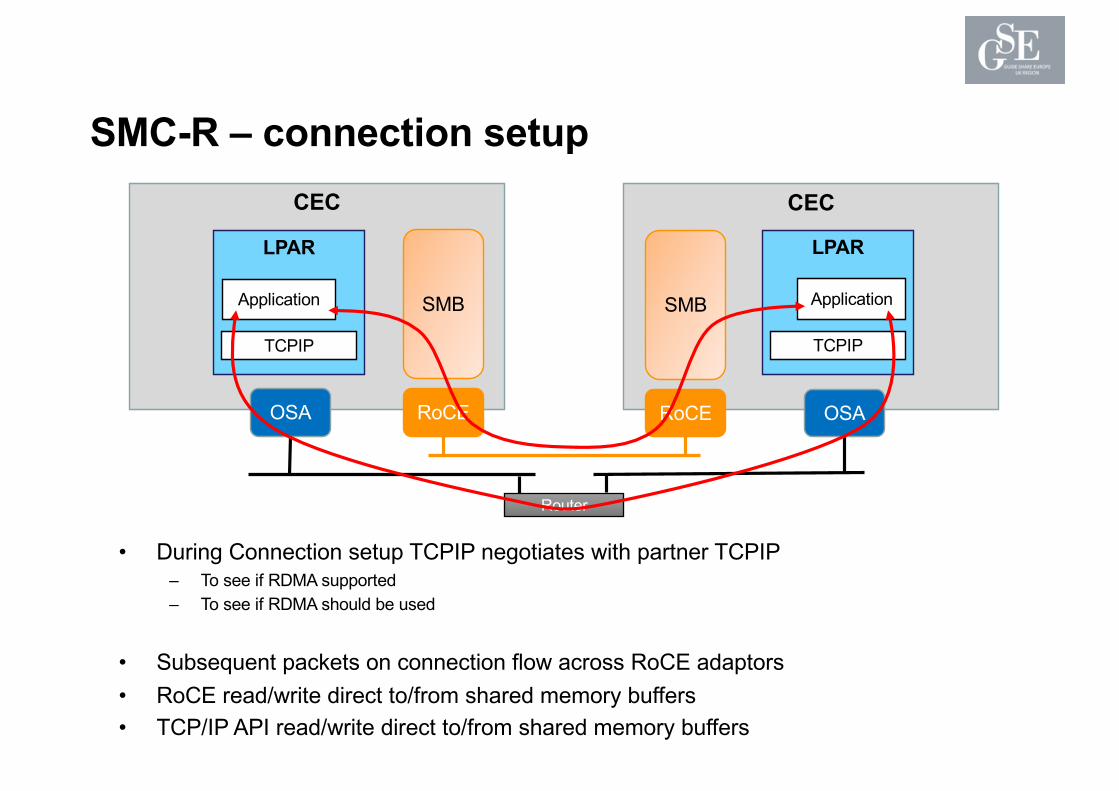
SMC-R – connection setupCEC
LPAR
TCPIP
Application
OSA RoCE
Router
CEC
LPAR
TCPIP
Application
OSARoCE
SMBSMB
• During Connection setup TCPIP negotiates with partner TCPIP– To see if RDMA supported– To see if RDMA should be used
• Subsequent packets on connection flow across RoCE adaptors• RoCE read/write direct to/from shared memory buffers • TCP/IP API read/write direct to/from shared memory buffers

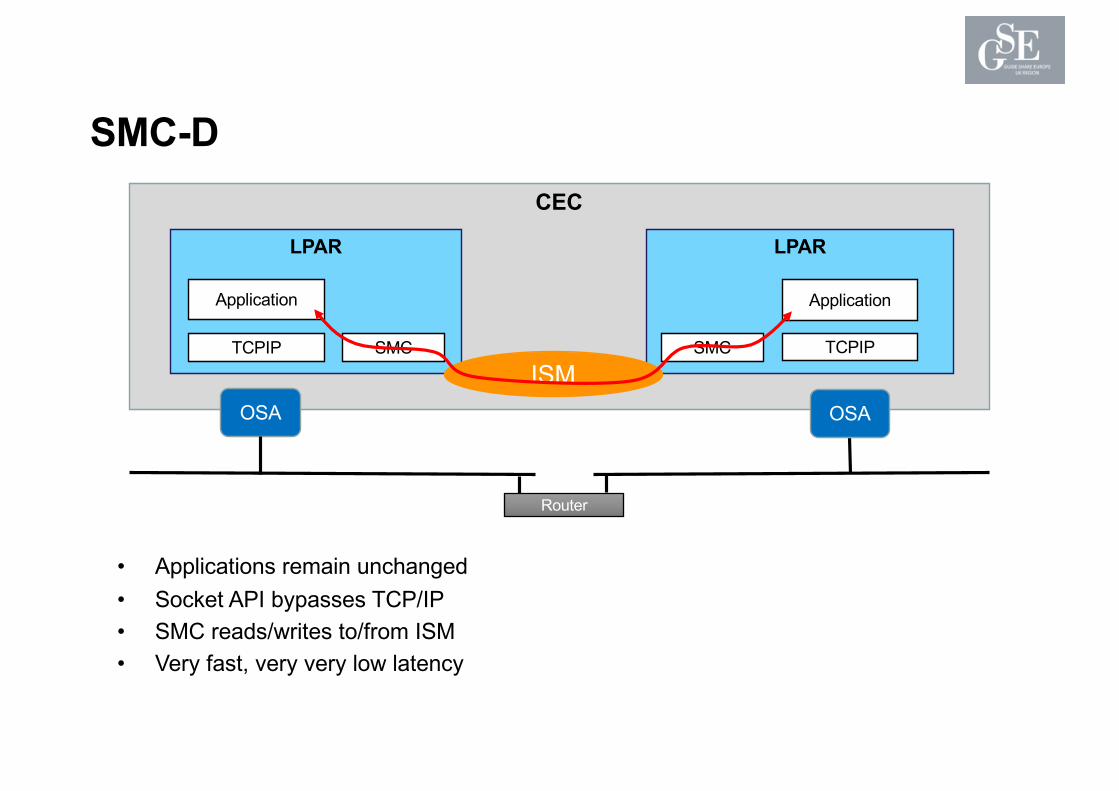
SMC-D• More Acronyms!
– SMC-D : Shared Memory Communications Direct Memory Access over ISM– ISM : Internal Shared Memory
• ISM– New virtual vPCI network adapter defined in IOCDS, similar to IQD– No hardware, just System Z firmware– Similar technology to RDMA
• Very high speed communication between LPARs– Within same CEC – so similar to hipersockets– Also similar to SMC-R, but without hardware or network infrastructure
• Transparent to applications• Requires “normal” TCPIP connectivity in parallel• Fastest possible communication within a CEC
– And no additional hardware/software required .. other than a Z13.
SMC-D
• Applications remain unchanged• Socket API bypasses TCP/IP• SMC reads/writes to/from ISM• Very fast, very very low latency
CEC
LPAR
TCPIP
Application
OSA
Router
LPAR
TCPIP
Application
OSA
SMC
ISMSMC
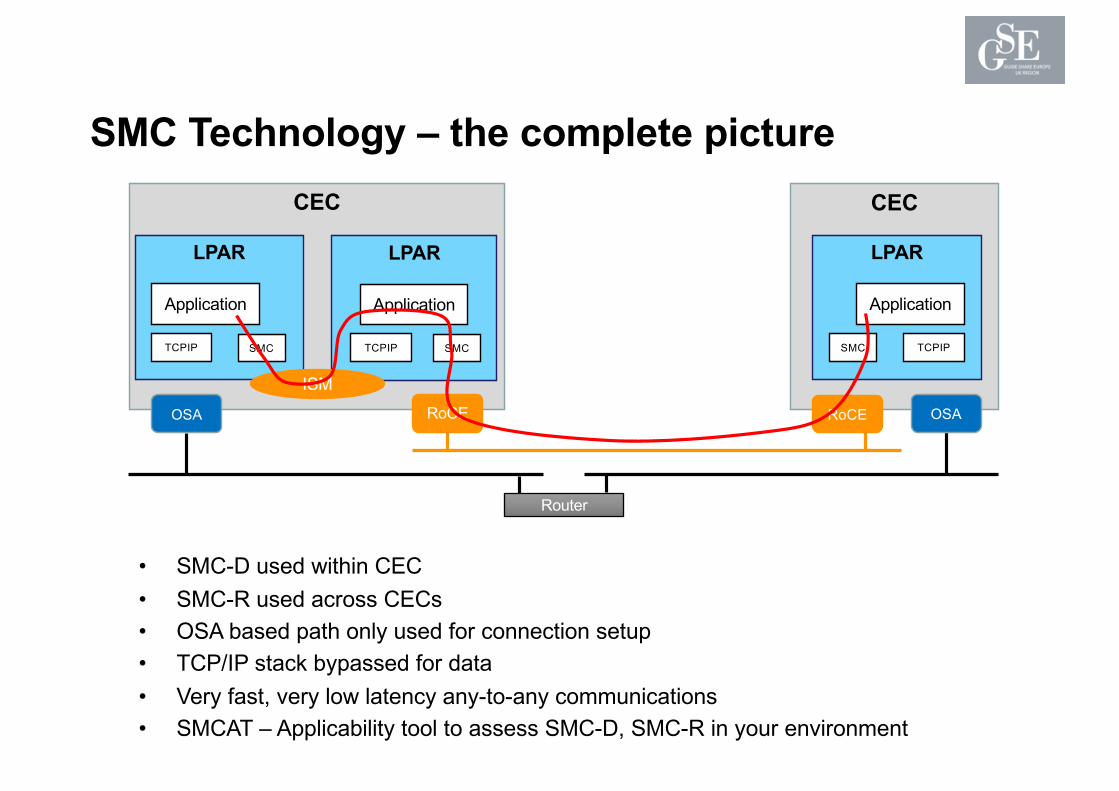
SMC Technology – the complete picture
• SMC-D used within CEC• SMC-R used across CECs• OSA based path only used for connection setup• TCP/IP stack bypassed for data• Very fast, very low latency any-to-any communications• SMCAT – Applicability tool to assess SMC-D, SMC-R in your environment
CEC
Router
CEC
LPAR
Application
RoCE
LPAR
SMC
Application
LPAR
Application
RoCE
TCPIP SMCTCPIP SMC TCPIP
ISM
OSA OSA

Performance comparisons • Relative performance varies depending on many factors• Traffic Type
– Request/Response– Streaming
• Message Sizes• Availability of other resources• But in summary:
– New shared memory communications provide ultimate performance – but you need a Z13 for SMC-D and RoCE adapters for SMC-R
– Hipersockets are the best alternative within a CEC, and no H/W or S/W costs.– DynamicXCF a good alternative within a Sysplex, especially when combined with
hipersockets, and no H/W or S/W costs.
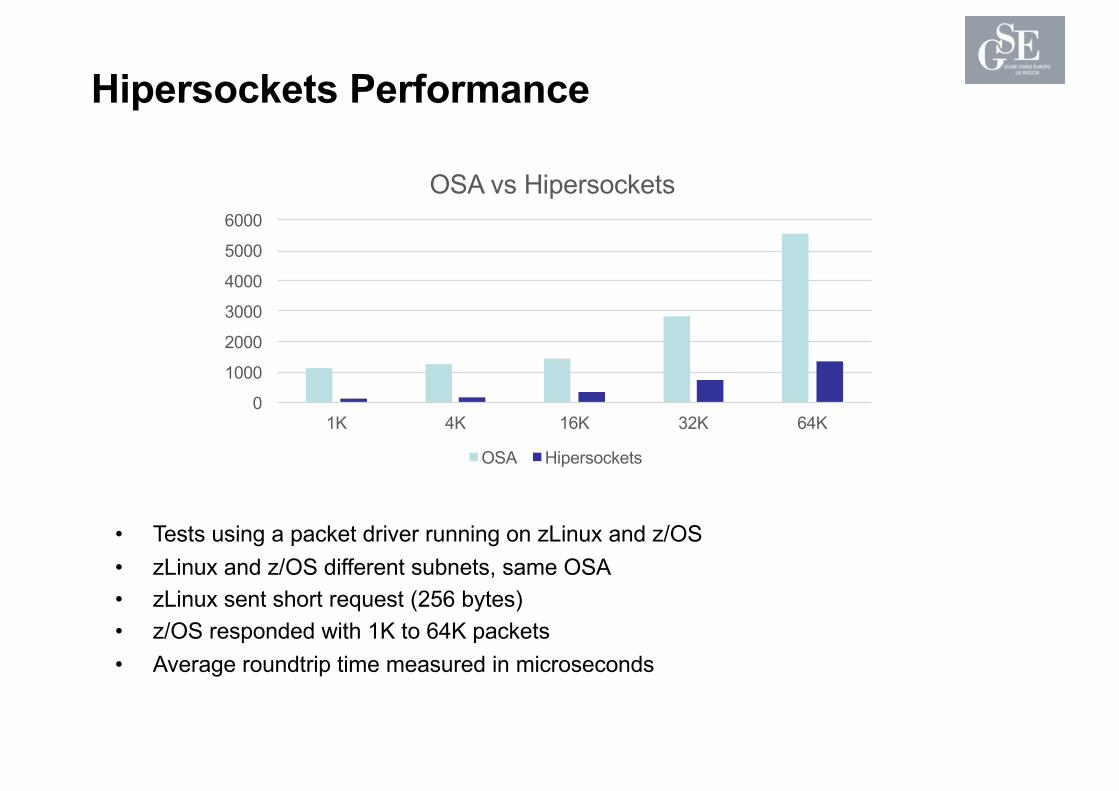
0
1000
2000
3000
4000
5000
6000
1K 4K 16K 32K 64K
OSA vs Hipersockets
OSA Hipersockets
Hipersockets Performance
• Tests using a packet driver running on zLinux and z/OS• zLinux and z/OS different subnets, same OSA• zLinux sent short request (256 bytes)• z/OS responded with 1K to 64K packets• Average roundtrip time measured in microseconds
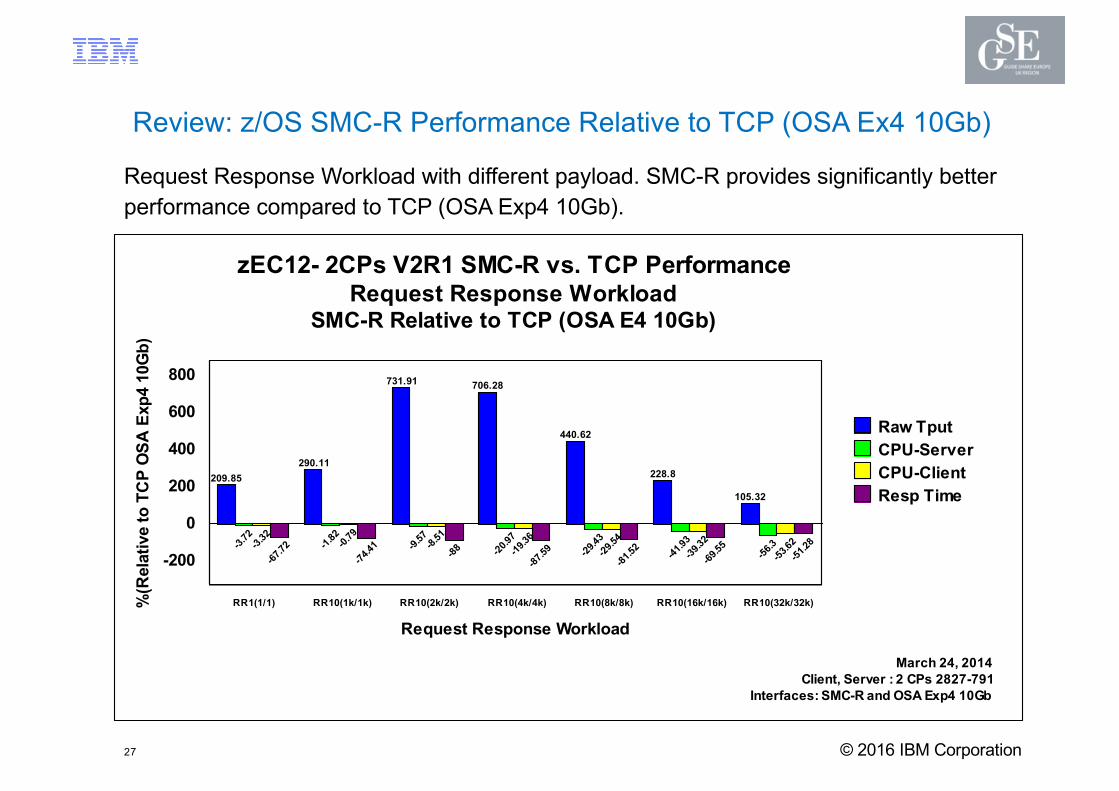
27
Review: z/OS SMC-R Performance Relative to TCP (OSA Ex4 10Gb)
Request Response Workload with different payload. SMC-R provides significantly better performance compared to TCP (OSA Exp4 10Gb).
-67.72
-74.41 -88
-87.59
-81.52
-69.55 -51
.28-3.32 -0.
79-8.
51
-19.36
-29.54
-39.32
-53.62-3.
72-1.
82-9.
57-20
.97-29
.43-41
.93-56
.3
209.85290.11
731.91 706.28
440.62
228.8
105.32
RR1(1/1) RR10(1k/1k) RR10(2k/2k) RR10(4k/4k) RR10(8k/8k) RR10(16k/16k) RR10(32k/32k)
Request Response Workload
-200
0
200
400
600
800
%(R
elat
ive
to T
CP
OSA
Exp
4 10
Gb)
Raw TputCPU-ServerCPU-ClientResp Time
March 24, 2014Client, Server : 2 CPs 2827-791
Interfaces: SMC-R and OSA Exp4 10Gb
zEC12- 2CPs V2R1 SMC-R vs. TCP Performance Request Response Workload
SMC-R Relative to TCP (OSA E4 10Gb)
© 2016 IBM Corporation
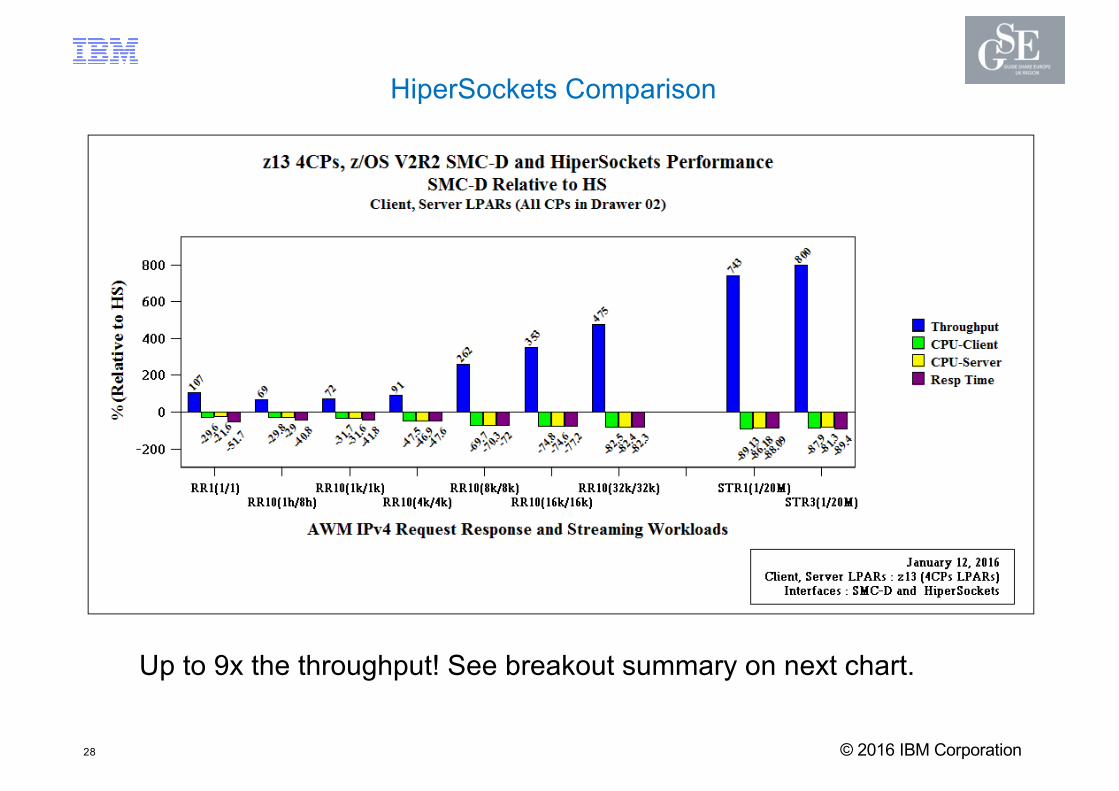
HiperSockets Comparison
Up to 9x the throughput! See breakout summary on next chart.
28 © 2016 IBM Corporation

SMC-D / ISM to HiperSockets Summary Highlights§ Request/Response Summary for Workloads with 1k/1k – 4k/4k Payloads:
– Latency: Up to 48% reduction in latency– Throughput: Up to 91% increase in throughput– CPU cost: Up to 47% reduction in network related CPU cost
§ Request/Response Summary for Workloads with 8k/8k – 32k/32k Payloads: – Latency: Up to 82% reduction in latency– Throughput: Up to 475% (~6x) increase in throughput– CPU cost: Up to 82% reduction in network related CPU cost
§ Streaming Workload:
– Latency: Up to 89% reduction in latency– Throughput: Up to 800% (~9x) increase in throughput– CPU cost: Up to 89% reduction in network related CPU cost
29 © 2016 IBM Corporation
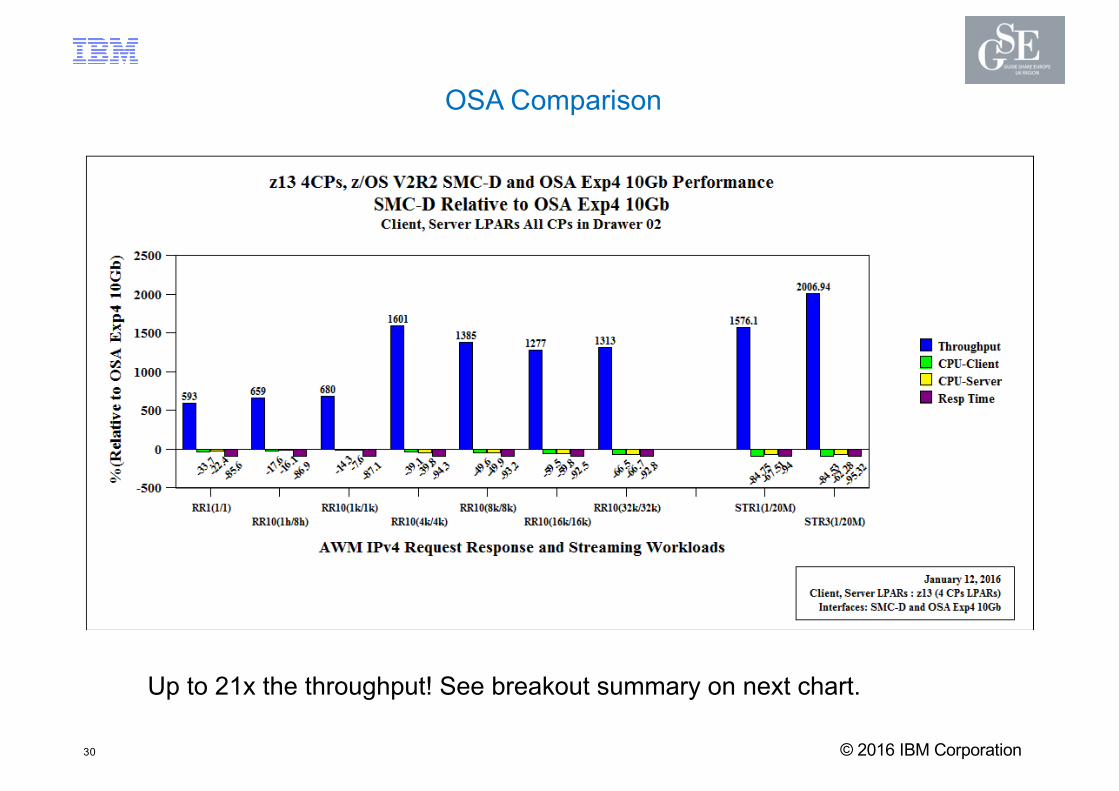
Up to 21x the throughput! See breakout summary on next chart.
30
OSA Comparison
© 2016 IBM Corporation

SMC-D / ISM to OSA Summary Highlights
§ Request/Response Summary for Workloads with 1k/1k – 4k/4k Payloads:
– Latency: Up to 94% reduction in latency– Throughput: Up to 1601% (~17x) increase in throughput– CPU cost: Up to 40% reduction in network related CPU cost
§ Request/Response Summary for Workloads with 8k/8k – 32k/32k Payloads: – Latency: Up to 93% reduction in latency– Throughput: Up to 1313% (~14x) increase in throughput– CPU cost: Up to 67% reduction in network related CPU cost
§ Streaming Workload:
– Latency: Up to 95% reduction in latency– Throughput: Up to 2001% (~21x) increase in throughput– CPU cost: Up to 85% reduction in network related CPU cost
§ FTP:– For Binary Get and Put:
• Up to 58% lower (receive side) CPU cost and• Up to 26% lower (send side) CPU cost and equivalent throughput
31
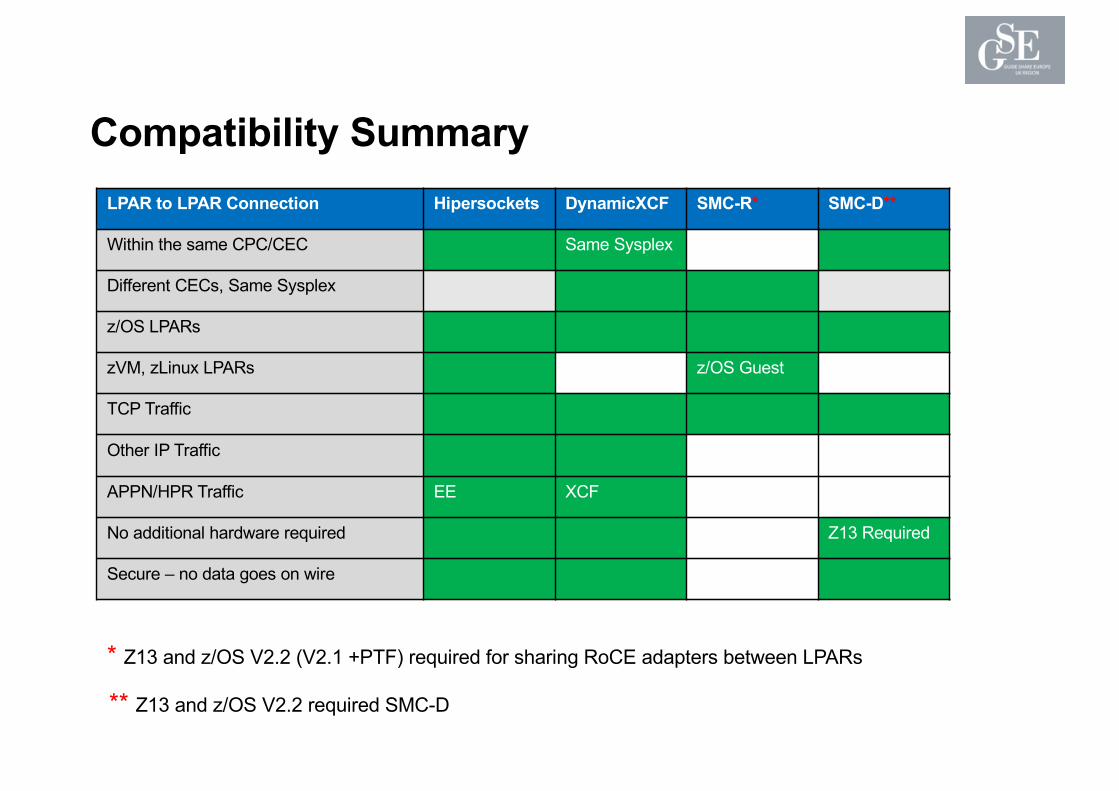
Compatibility SummaryLPAR to LPAR Connection Hipersockets DynamicXCF SMC-R* SMC-D**
Within the same CPC/CEC Same Sysplex
Different CECs, Same Sysplex
z/OS LPARs
zVM, zLinux LPARs z/OS Guest
TCP Traffic
Other IP Traffic
APPN/HPR Traffic EE XCF
No additional hardware required Z13 Required
Secure – no data goes on wire
* Z13 and z/OS V2.2 (V2.1 +PTF) required for sharing RoCE adapters between LPARs
** Z13 and z/OS V2.2 required SMC-D
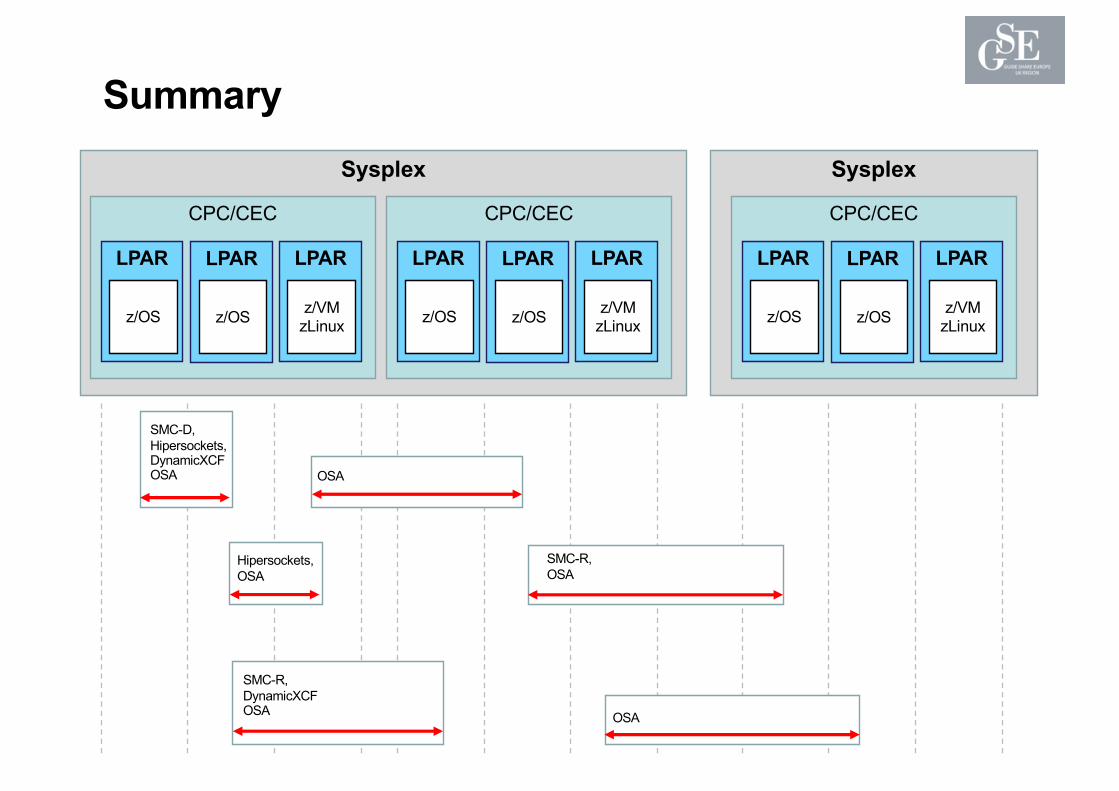
SummarySysplex Sysplex
CPC/CEC
LPAR
z/OS
LPAR
z/OS
LPAR
z/VMzLinux
CPC/CEC
LPAR
z/OS
LPAR
z/OS
LPAR
z/VMzLinux
CPC/CEC
LPAR
z/OS
LPAR
z/OS
LPAR
z/VMzLinux
SMC-D, Hipersockets,DynamicXCFOSA
Hipersockets,OSA
OSA
SMC-R,DynamicXCFOSA OSA
SMC-R,OSA

Session feedback
• Please submit your feedback at
http://conferences.gse.org.uk/2016/feedback/EC
• Session is EC





























