Embed Size (px)
Citation preview

http://parasol.tamu.edu
STAPL: A High Productivity Programming Infrastructure for
Parallel & Distributed Computing
Lawrence RauchwergerParasol Lab, Dept of Computer Science
Texas A&M University
http://parasol.tamu.edu/~rwerger/

Motivation
Parallel programming is Costly Parallel programs are not portable Scalability & Efficiency is (usually) poor Dynamic programs are even harder Small scale parallel machines:
ubiquitous

Our Approach: STAPL
STAPL: Parallel components library– Extensible, open ended– Parallel superset of STL – Sequential inter-operability
Layered architecture: User – Developer - Specialist– Extensible– Portable (only lowest layer needs to be specialized)
High Productivity Environment– components have (almost) sequential interfaces.

STAPL Specification
STL Philosophy Shared Object View
– User Layer: No explicit communication– Machine Layer: Architecture dependent code
Distributed Objects– no replication– no software coherence
Portable efficiency– Runtime System virtualizes underlying architecture.
Concurrency & Communication Layer– SPMD (for now) parallelism
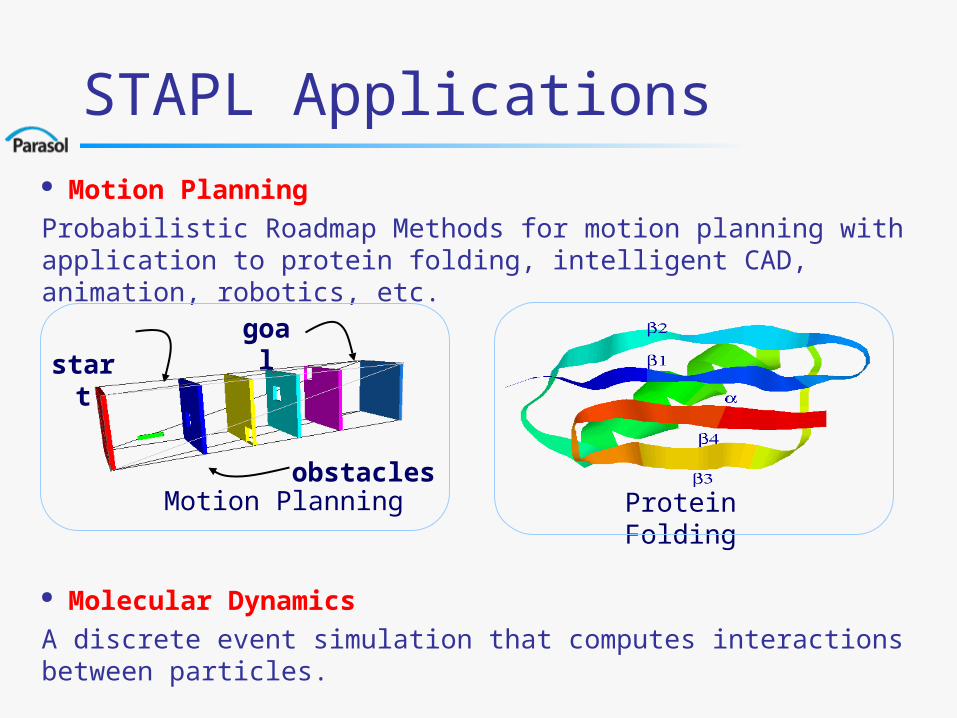
STAPL Applications Motion Planning
Probabilistic Roadmap Methods for motion planning with application to protein folding, intelligent CAD, animation, robotics, etc.
Molecular Dynamics
A discrete event simulation that computes interactions between particles.
startgoal
obstaclesMotion Planning Protein Folding
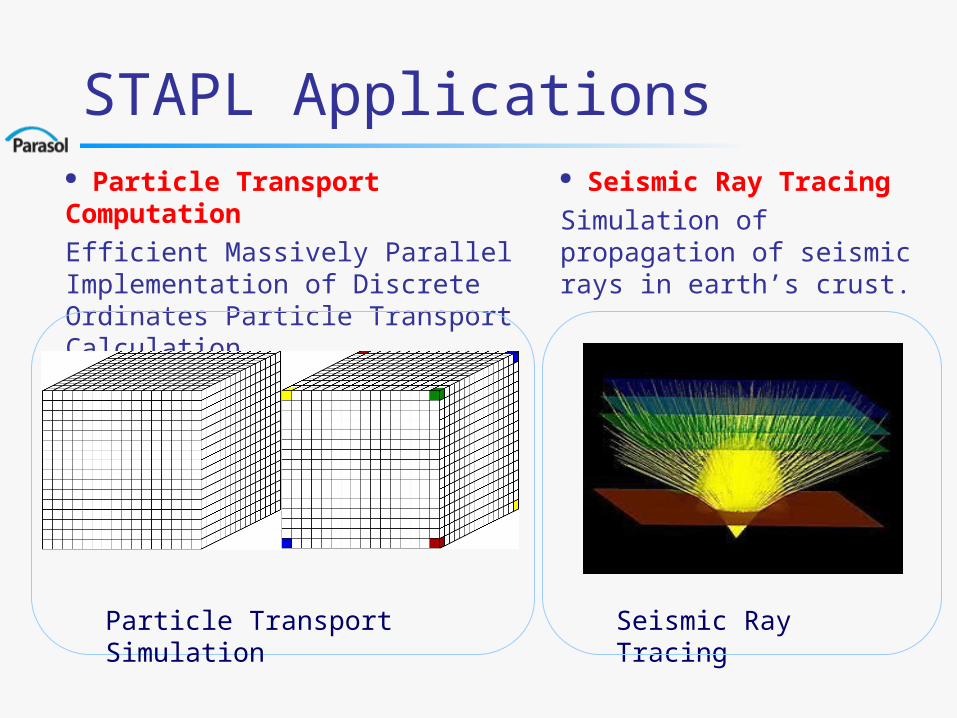
STAPL Applications Seismic Ray Tracing
Simulation of propagation of seismic rays in earth’s crust.
Particle Transport Computation
Efficient Massively Parallel Implementation of Discrete Ordinates Particle Transport Calculation.
Seismic Ray TracingParticle Transport Simulation
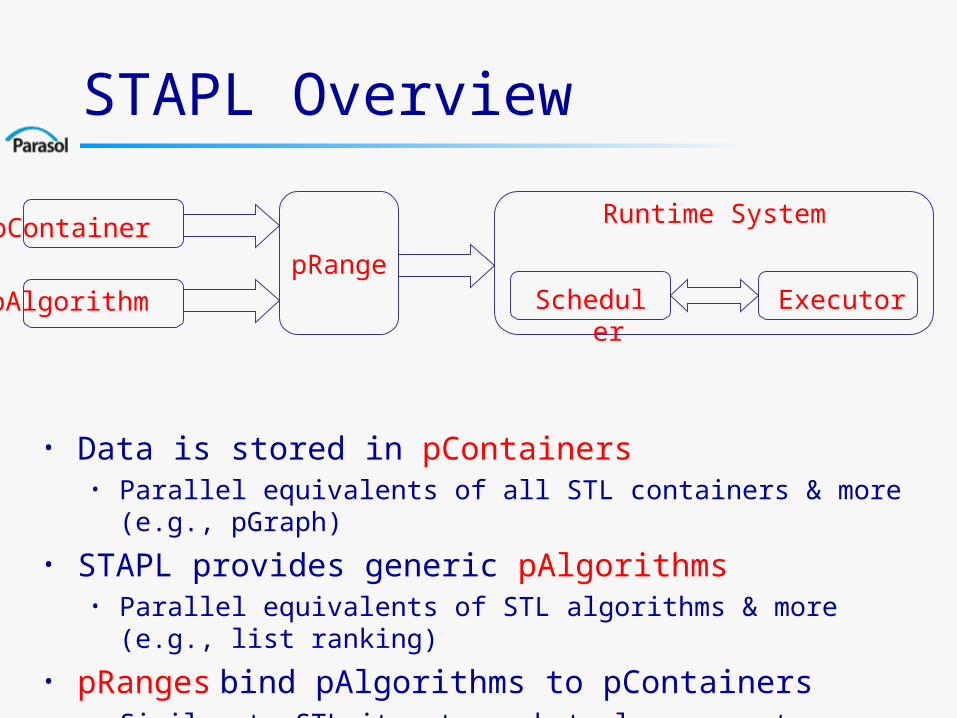
STAPL Overview
• Data is stored in pContainers• Parallel equivalents of all STL containers & more (e.g., pGraph)
• STAPL provides generic pAlgorithms• Parallel equivalents of STL algorithms & more (e.g., list ranking)
• pRanges bind pAlgorithms to pContainers• Similar to STL iterators, but also support parallelism
pContainer
pAlgorithmpRange
Runtime System
Scheduler Executor

STAPL Overview
pContainers pRange pAlgorithms RTS & ARMI Communication Infrastructure Applications using STAPL

pContainer Overview pContainer: A distributed (no replication) data structure with
parallel (thread-safe) methods
Ease of Use– Shared Object View– Handles data distribution and remote data access internally (no explicit
communication) Efficiency
– De-centralized distribution management– OO design to optimize specific containers– Minimum overhead over STL containers
Extendability– A set of base classes with basic functionality– New pContainers can be derived from Base classes with extended and
optimized functionality
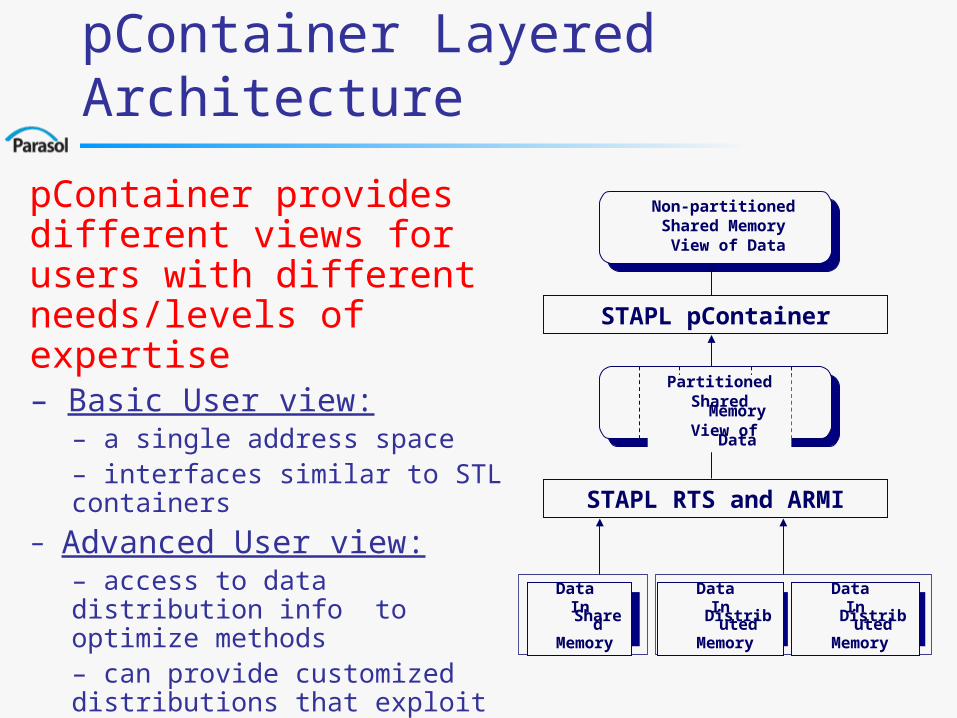
pContainer Layered Architecture
pContainer provides different views for users with different needs/levels of expertise– Basic User view:
– a single address space – interfaces similar to STL containers
– Advanced User view:– access to data distribution info to optimize methods– can provide customized distributions that exploit knowledge of application
Non-partitionedShared Memory
View of Data
STAPL pContainer
STAPL RTS and ARMI
Data In Shared Memory
Data In Distributed
Memory
Data In Distributed
Memory
PartitionedShared Memory
View of Data
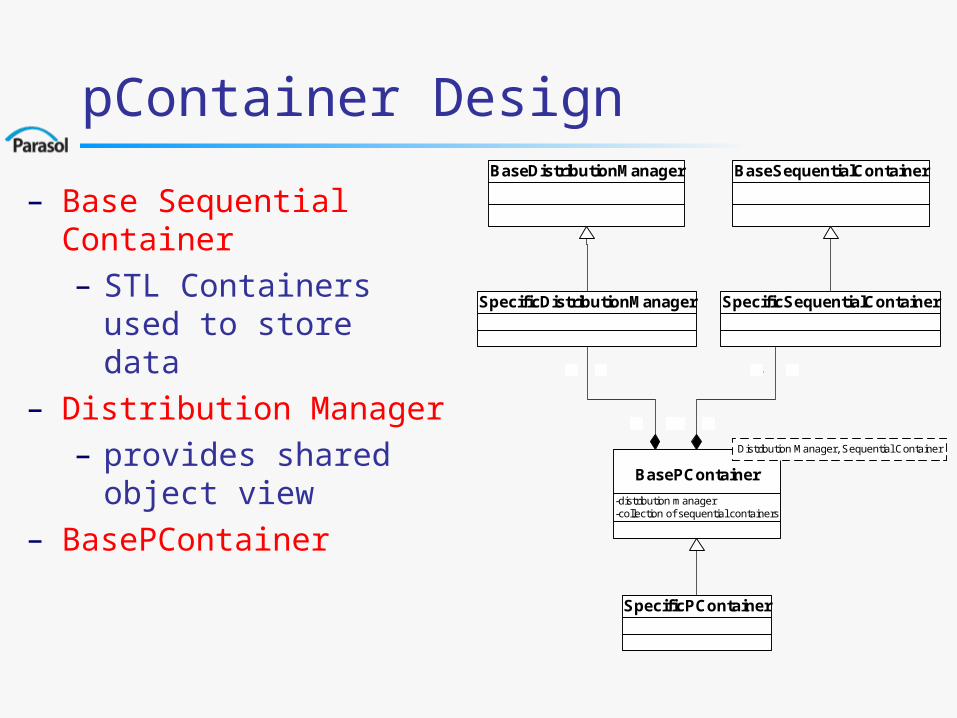
pContainer Design
– Base Sequential Container– STL Containers used to
store data– Distribution Manager
– provides shared object view
– BasePContainer-distribution manager-collection of sequential containers
BasePContainer
Distribution Manager, Sequential Container
BaseDistributionManager
SpecificDistributionManager
BaseSequentialContainer
SpecificSequentialContainer
SpecificPContainer
-1 1
-2 *
-3 1
-4 *

STAPL Overview
pContainers pRange pAlgorithms RTS & ARMI Communication Infrastructure Applications using STAPL

pRange Overview
Interface between pAlgorithms and pContainers– pAlgorithms expressed in terms of pRanges– pContainers provide pRanges– Similar to STL Iterator
Parallel programming support– Expression of computation as parallel task graph– Stores DDGs used in processing subranges
Less abstract than STL iterator– Access to pContainer methods
Expresses the Data—Task Parallelism Duality

pRange
View of a work space– Set of tasks in a parallel computation
Can be recursively partitioned into subranges – Defined on disjoint portions of the work space– Leaf subrange in the hierarchy
Represents a single task Smallest schedulable entity
Task:– Function object to apply
Using same function for all subranges results in SPMD– Description of the data to which function is applied
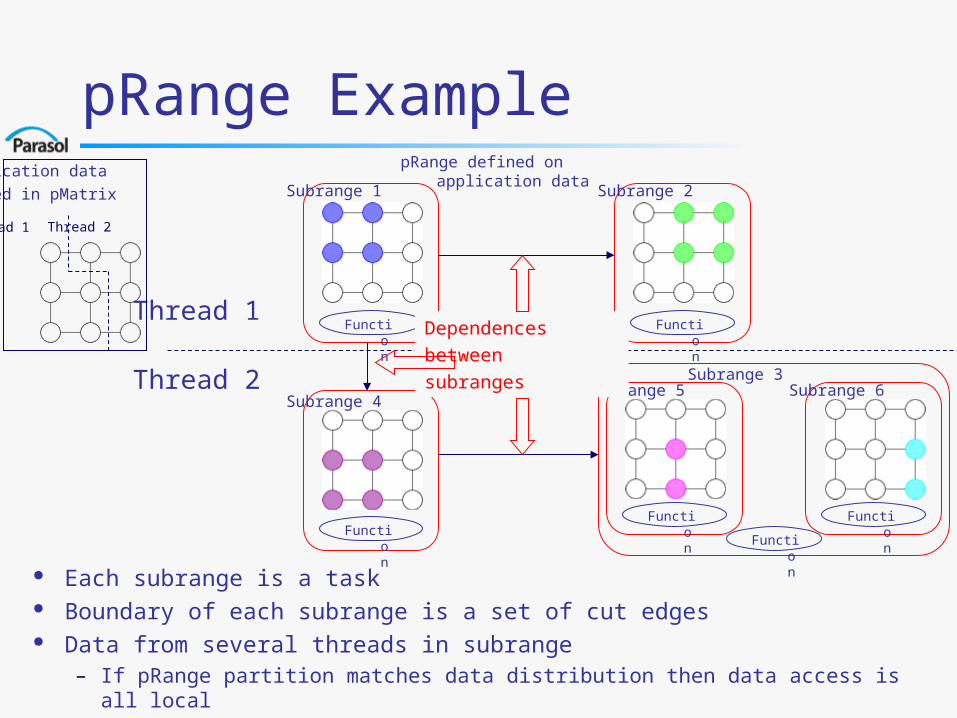
pRange Example
Each subrange is a task Boundary of each subrange is a set of cut edges Data from several threads in subrange
– If pRange partition matches data distribution then data access is all local
Application data
stored in pMatrix
Thread 1 Thread 2
Subrange 6Subrange 5Subrange 4
Subrange 1 Subrange 2
Subrange 3
FunctionFunction
FunctionFunction
FunctionFunction
Thread 1
Thread 2
Dependences
between
subranges
pRange defined on application data
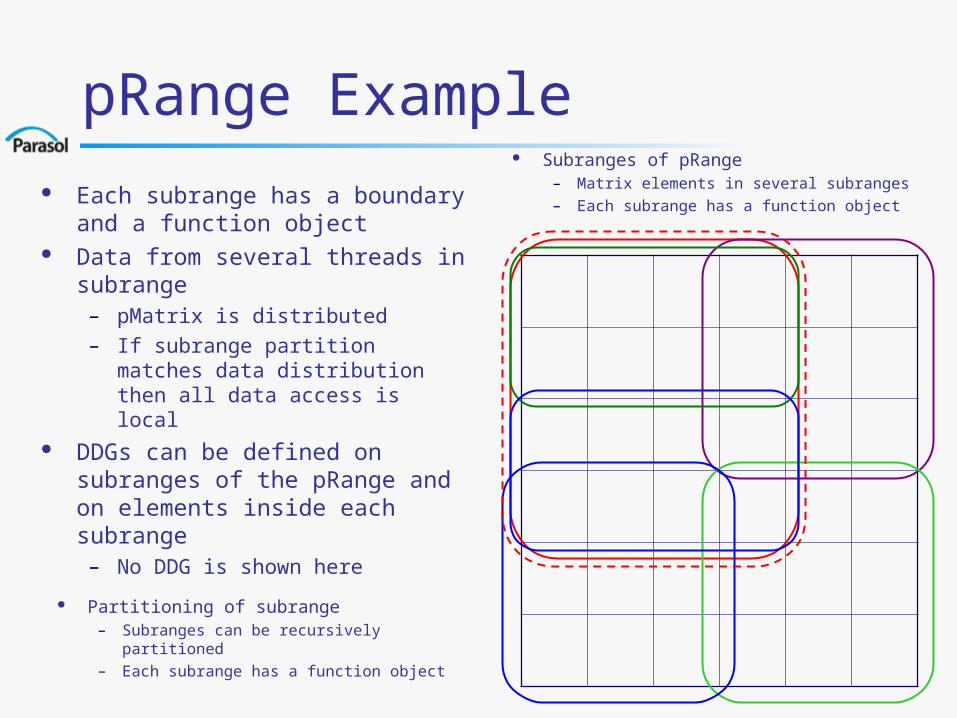
pRange Example
Each subrange has a boundary and a function object
Data from several threads in subrange
– pMatrix is distributed– If subrange partition matches data
distribution then all data access is local
DDGs can be defined on subranges of the pRange and on elements inside each subrange
– No DDG is shown here
Subranges of pRange– Matrix elements in several subranges
– Each subrange has a function object
Partitioning of subrange– Subranges can be recursively partitioned
– Each subrange has a function object

Overview
pContainers pRange pAlgorithms RTS & ARMI Communication Infrastructure Applications using STAPL

pAlgorithms
pAlgorithm is a set of parallel task objects– input for parallel tasks specified by the pRange– (Intermediate) results stored in pContainers– ARMI for communication between parallel tasks
pAlgorithms in STAPL– Parallel counterparts of STL algorithms provided in STAPL– STAPL contains additional parallel algorithms
List ranking Parallel Strongly Connected Components Parallel Euler Tour etc

Algorithm Adaptivity in STAPL
Problem: Parallel algorithms highly sensitive to:– Architecture – number of processors, memory
interconnection, cache, available resources, etc– Environment – thread management, memory
allocation, operating system policies, etc– Data Characteristics – input type, layout, etc
Solution: adaptively choose the best algorithm from a library of options at run-time
Adaptive Patterns ?
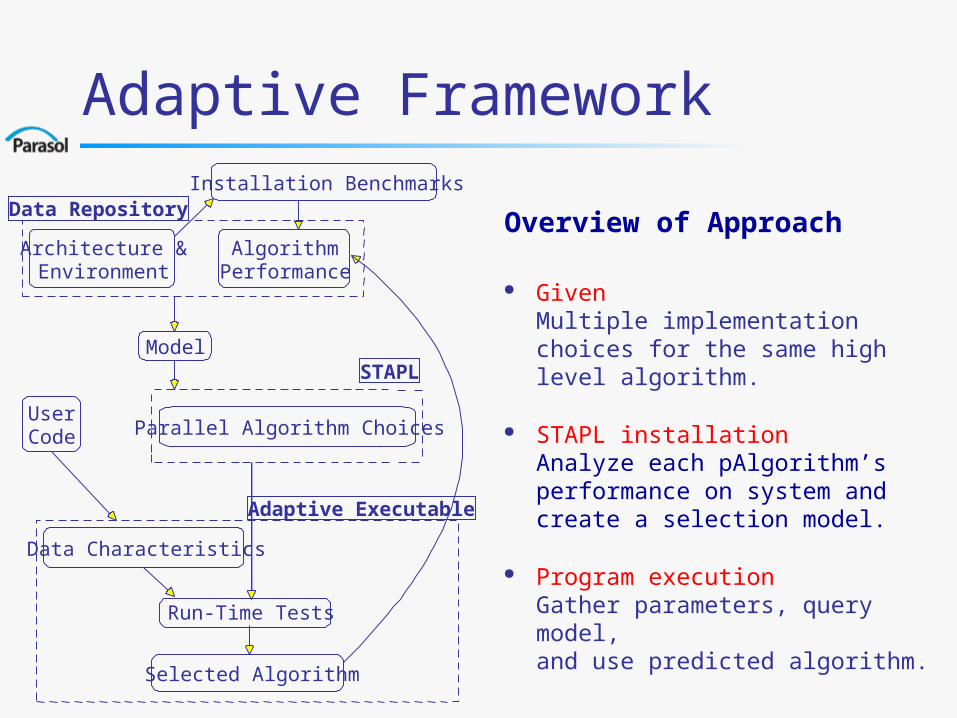
Adaptive Framework
Overview of Approach
GivenMultiple implementation choices for the same high level algorithm.
STAPL installationAnalyze each pAlgorithm’s performance on system and create a selection model.
Program executionGather parameters, query model, and use predicted algorithm.
Installation Benchmarks
Architecture &Environment
AlgorithmPerformance
Model
UserCode Parallel Algorithm Choices
Data Characteristics
Run-Time Tests
Selected Algorithm
Data Repository
STAPL
Adaptive Executable

Model generation
Installation Benchmarking– Determine parameters that may affect performance
(i.e., num procs, input size, algorithm specific…)– Run all algorithms on a sampling of instance space– Insert timings from runs into performance database
Create a Decision Model– Generic interface enables learners to compete
Currently: decision tree, neural net, Bayes naïve classifier Based on predicted accuracy (10-way validation test).
– “Winning” learner outputs query function in C++func* predict_pAlgorithm(attribute1, attributes2, ..)

Runtime Algorithm Selection
Gather parameters– Immediately available (e.g., num procs)– Computed (e.g., disorder estimate for sorting)
Query model and execute– Query function statically linked at compile time.
Current work: dynamic linking with online model refinement.

Experiments
Investigated two operations– Parallel Sorting– Parallel Matrix Multiplication
Three Platforms– 128 processor SGI Altix– 1152 nodes, dual processor Xeon Cluster– 68 nodes, 16 way IBM SMP Cluster

Parallel Sorting Algorithms
Sample Sort – Samples to define processor bucket thresholds– Scan and distribute elements to buckets– Each processor sort local elements
Radix Sort– Parallel version of linear time sequential approach. – Passes over data multiple times, each time considering r bits.
Column Sort– O(lg n) on running time– Requires 4 local sorts and 4 communication steps– Uses pMatrix data structure for workspace

Sorting Attributes
Attributes used to model sorting decision – Processor Count– Data Type– Input Size – Max Value
Smaller value ranges may favor radix sort by reducing required passes
– Presortedness Generate data by varying initial state (sorted,
random, reversed) and % displacement Quantify at runtime with normalized average
distance metric derived from input sampling

Training Set Creation
1000 Training inputs per platform by uniform random sampling of space defined below:
Parameter Value
Processors* 2, 4, 8, 16, 32, 64
Data Type int, double
Input Size (100K..20M)*P/sizeof(T)
Max Value N/1000, N/100, N/10, N, 3N, MAX_INT
Input Order sorted, reverse sorted, random
Displacement 0..20% of N**
*P = 64 linux cluster, frost
**only for sorted and reverse sorted

Model Error Rate Model accuracy with all training inputs is 94%, 98%
and 94% on Cluster, Altix, and SMP Cluster

Altix Cluster SMPCluster F(p, dist_norm) F(p, n, dt, dist_norm, max) F(p, n, dt, dist_norm, max)

Parallel Sorting: Experimental Results
Altix Model
Decision Tree
Validation (N=120M) on Altix
0Sorted
0.5ReversedRandom
Interpretation of dist_norm

Overview
pContainers pRange pAlgorithms RTS & ARMI Communication Infrastructure Applications using STAPL

Current Implementation Protocols
Shared-Memory (OpenMP/Pthreads)– shared request queues
Message Passing (MPI-1.1)– sends/receives
Mixed-Mode– combination of MPI with threads– flat view of parallelism (for now)
take advantage of shared-memory
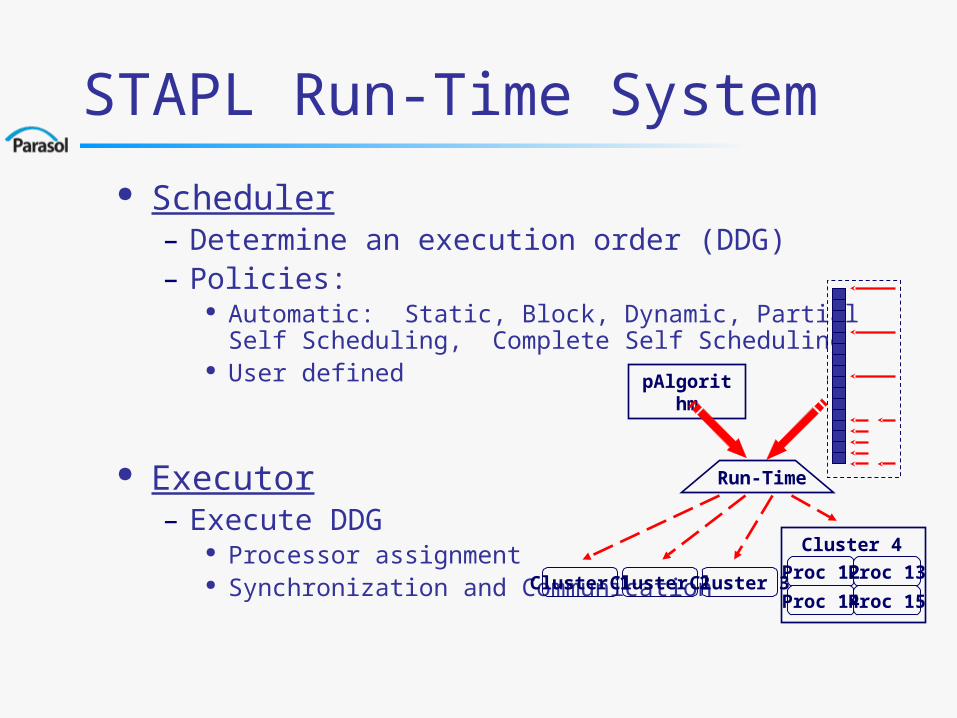
STAPL Run-Time System
Scheduler – Determine an execution order (DDG)– Policies:
Automatic: Static, Block, Dynamic, Partial Self Scheduling, Complete Self Scheduling
User defined
Executor– Execute DDG
Processor assignment Synchronization and Communication
Run-Time
Cluster 1Proc 12
Proc 14
Proc 13
Proc 15
Cluster 4
pAlgorithm
Cluster 2 Cluster 3

ARMI: STAPL Communication Infrastructure
ARMI: Adaptive Remote Method Invocation– abstraction of shared-memory and message passing
communication layer – programmer expresses fine-grain parallelism that
ARMI adaptively coarsens– support for sync, async, point-to-point and group
communication
ARMI can be as easy/natural as shared memory and as efficient as message passing

ARMI Communication Primitives
armi_sync– question: ask a thread something– blocking version
function doesn’t return until answer received from rmi
– non-blocking version function returns without answer program can poll with rtnHandle.ready() and then access armi’s return value with rtnHandle.value()
collective operations– armi_broadcast, armi_reduce, etc.– can adaptively set groups for communication– arguments always passed by value

ARMI Synchronization Primitives
armi_fence, armi_barrier– tree-based barrier– implements distributed termination algorithm to
ensure that all outstanding ARMI requests have been sent, received, and serviced
armi_wait– blocks until at least one (possibly more) ARMI
request is received and serviced armi_flush
– empties local send buffer, pushing outstanding ARMI requests to remote destinations

Overview
pContainers pRange pAlgorithms RTS & ARMI Communication Infrastructure Applications using STAPL

Particle TransportQ: What is the particle transport problem?
A: Particle transport is all about counting particles (such as neutrons). Given a physical volume we want to know how many particles there are and their locations, directions, and energies.
Q: Why is it an important problem?
A: Needed for the accurate simulation of complex physical systems such as nuclear reactions.Requires an estimated 50-80% of the total execution time in multi-physics simulations.
Particle Transport is an important problem.
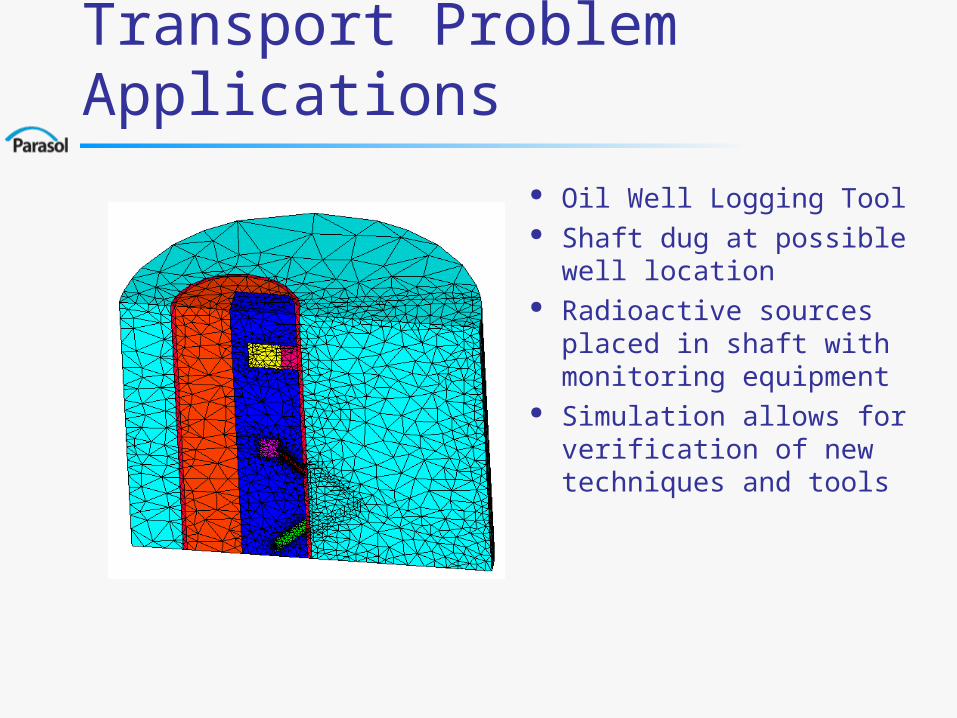
Transport Problem Applications
Oil Well Logging Tool Shaft dug at possible
well location Radioactive sources
placed in shaft with monitoring equipment
Simulation allows for verification of new techniques and tools

Discrete Ordinates MethodIterative method for solving the first-order form of the transport equation discretizes:
Algorithm:
• , the angular directions
for each direction in
• R, the spatial domain
for each grid cell in R
• E, the energy variable
for each energy group in E

Discrete Ordinates Method
. direction and groupenergy for
positionat flux for the solve We
particles. of source )( where
)()()(
,
,,,,
mg
r
rS
rSrr
gm
gmgmgtgmm
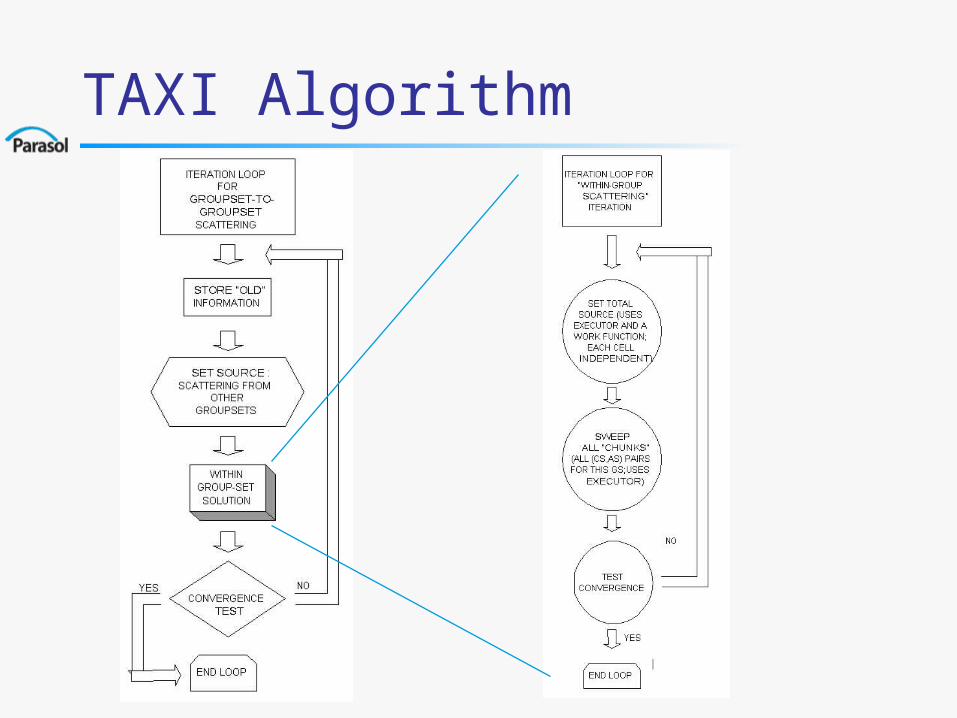
TAXI Algorithm

Transport Sweeps
Involves a sweep of the spatial grid for each direction in .
For orthogonal grids there are only eight distinct sweep orderings.
Note: A full transport sweep must process each direction.

Multiple Simultaneous Sweeps
One approach is to sequentially process each direction.
Another approach is to process each direction simultaneously.– Requires processors to
sequentially process each direction during the sweep.
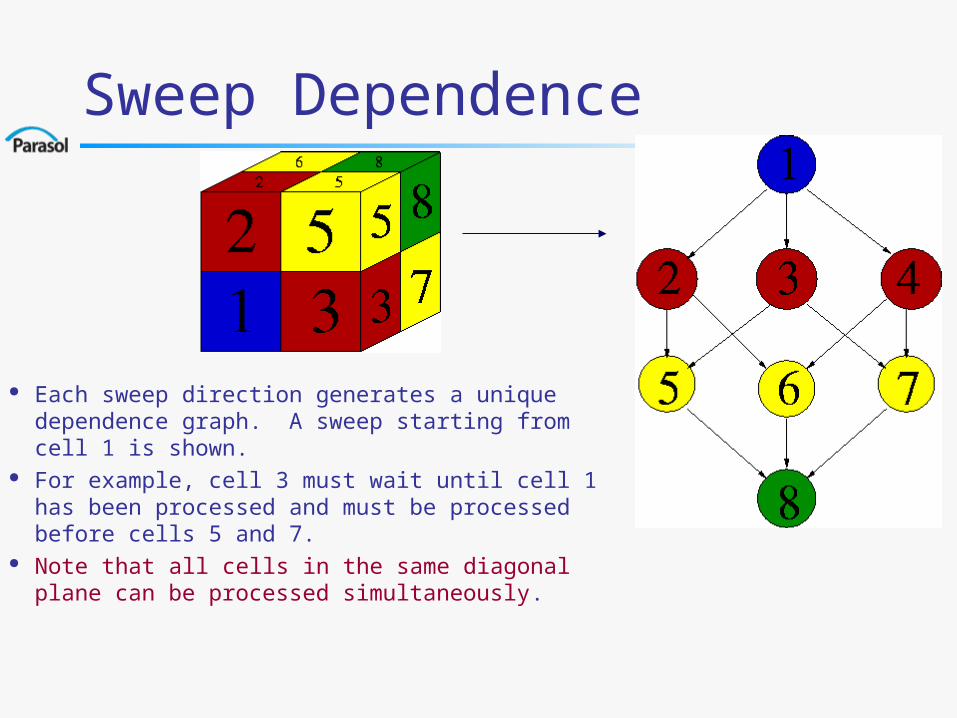
Sweep Dependence
Each sweep direction generates a unique dependence graph. A sweep starting from cell 1 is shown.
For example, cell 3 must wait until cell 1 has been processed and must be processed before cells 5 and 7.
Note that all cells in the same diagonal plane can be processed simultaneously.

pRange Dependence Graph
Numbers are cellset indices Colors indicate processors
angle-set A angle-set B angle-set C1
2 5
3 6
4 7
8
10 13
18 2112 15
14 1711
9
22 2516 19
26 2920 23
3024 27
28 31
32
4
3 8
2 7
1 6
5
11 16
19 249 14
15 2010
12
23 2813 18
27 3217 22
3121 26
25 30
29
32
31 28
30 27
29 26
25
23 20
15 1221 18
19 1622
24
11 817 14
7 413 10
39 6
5 2
1
29
30 25
31 26
32 27
28
22 17
14 924 19
18 1323
21
10 520 15
6 116 11
212 7
8 3
4
angle-set D

1
2 5
3 6
4 7
8
10 13
18 2112 15
14 1711
9
22 2516 19
26 2920 23
3024 27
28 31
32
angle-set A4
3 8
2 7
1 6
5
11 16
19 249 14
15 2010
12
23 2813 18
27 3217 22
3121 26
25 30
29
angle-set B
Adding a reflecting boundary32
31 28
30 27
29 26
25
23 20
15 1221 18
19 1622
24
11 817 14
7 413 10
39 6
5 2
1
angle-set C29
30 25
31 26
32 27
28
22 17
14 924 19
18 1323
21
10 520 15
6 116 11
212 7
8 3
4
angle-set D
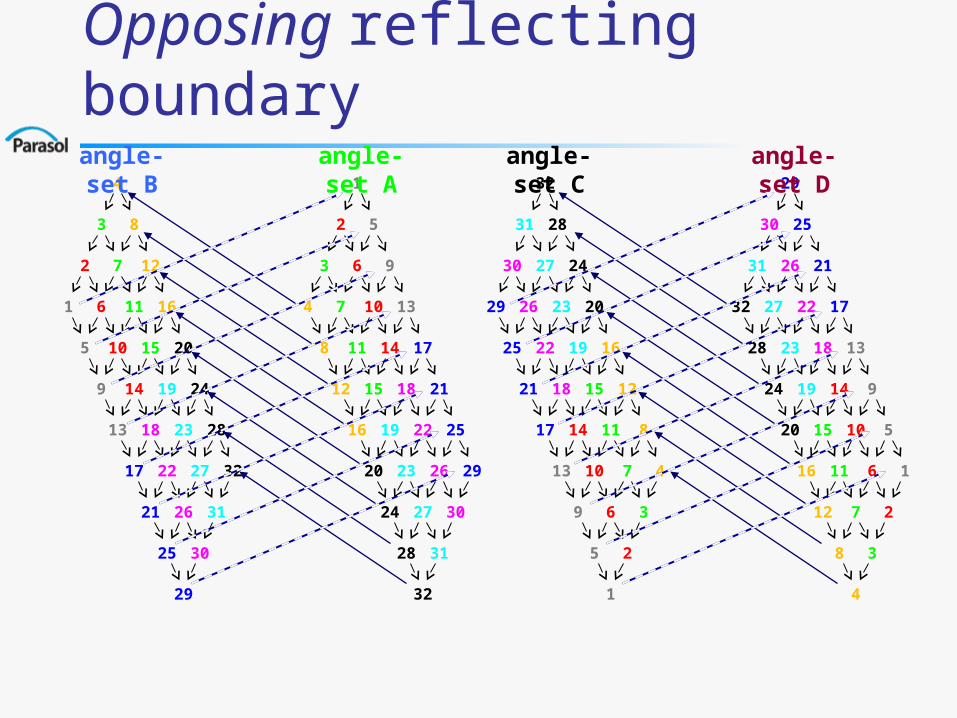
Opposing reflecting boundary1
2 5
3 6
4 7
8
10 13
18 2112 15
14 1711
9
22 2516 19
26 2920 23
3024 27
28 31
32
angle-set A4
3 8
2 7
1 6
5
11 16
19 249 14
15 2010
12
23 2813 18
27 3217 22
3121 26
25 30
29
angle-set B32
31 28
30 27
29 26
25
23 20
15 1221 18
19 1622
24
11 817 14
7 413 10
39 6
5 2
1
angle-set C29
30 25
31 26
32 27
28
22 17
14 924 19
18 1323
21
10 520 15
6 116 11
212 7
8 3
4
angle-set D
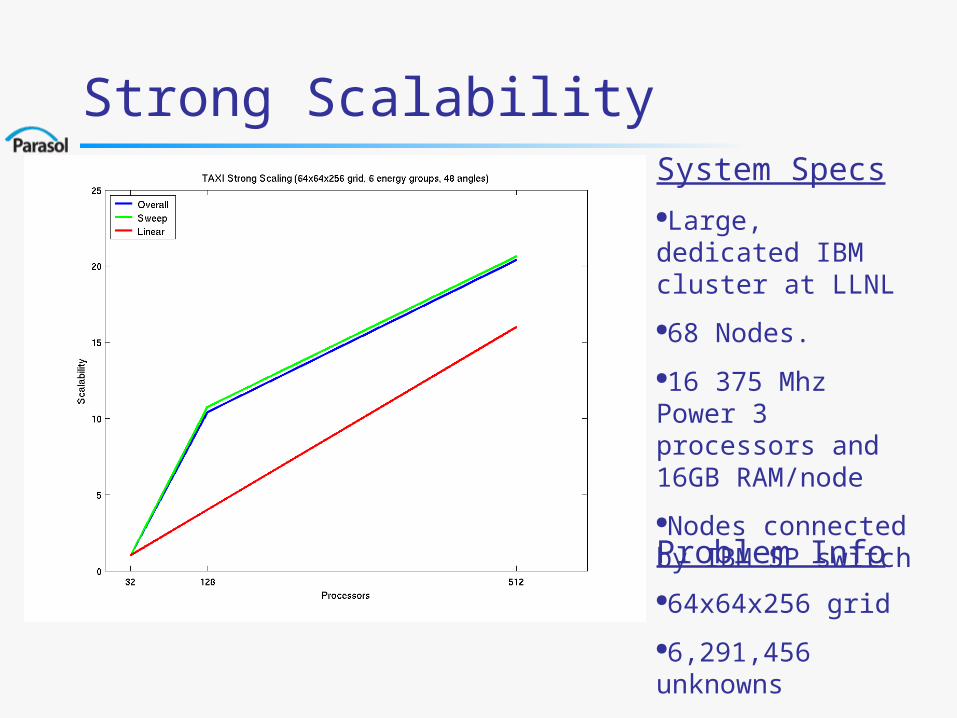
Strong ScalabilitySystem SpecsLarge, dedicated IBM cluster at LLNL
68 Nodes.
16 375 Mhz Power 3 processors and 16GB RAM/node
Nodes connected by IBM SP switch
Problem Info64x64x256 grid
6,291,456 unknowns

Work in Progress (Open Topics)
STAPL Algorithms STAPL Adaptive Containers ARMI v2 (multi-threaded, communication pattern library) STAPL RTS -- K42 Interface A Compiler for STAPL:
– A high level, source to source compiler– Understands STAPL blocks– Optimizes composition– Automates composition– Generates checkers for STAPL programs

References
[1] "STAPL: An Adaptive, Generic Parallel C++ Library", Ping An, Alin Jula, Silvius Rus, Steven Saunders, Tim Smith, Gabriel Tanase, Nathan Thomas, Nancy Amato and Lawrence Rauchwerger, 14th Workshop on Languages and Compilers for Parallel Computing (LCPC), Cumberland Falls, KY, August, 2001. [2] "ARMI: An Adaptive, Platform Independent Communication Library“, Steven Saunders and Lawrence Rauchwerger, ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), San Diego, CA, June, 2003. [3] "Finding Strongly Connected Components in Parallel in Particle Transport Sweeps", W. C. McLendon III, B. A. Hendrickson, S. J. Plimpton, and L. Rauchwerger, in Thirteenth ACM Symposium on Parallel Algorithms and Architectures (SPAA), Crete, Greece, July, 2001.[4] “A Framework for Adaptive Algorithm Selection in STAPL", N. Thomas, G. Tanase, O. Tkachyshyn, J. Perdue, N.M. Amato, L. Rauchwerger, in ACM SIGPLAN 2005 Symposium on Principles and Practice of Parallel Programming (PPOPP), Chicago, IL, June, 2005. (to appear)





























