Embed Size (px)
Citation preview

Human Activity Recognition: Group C | 1
Carnegie Mellon University - H. John Heinz III College
Human Activity Recognition
Data Mining Project
Karishma Agrawal, Shameel Abdul, Yash Thakur, Luis Carlos Leon Plata
1. Introduction
Human Activity Recognition (HAR) refers to the task of measuring the physical activity of a person
via the use of objective technology. This task is extremely challenging owing to the complexity and
diversity of human activities. It has been a longstanding goal of the medical research community.
Often external health sensors such as accelerometers have been used to track the activity, which is
followed by application of Machine Learning algorithms to successfully classify the activity.
2. Data
The data [1] provided for the HAR analysis consists of approximately 8 hours of accelerometer data
for 4 individuals. Each data point comprises of physical attributes of the subject, 3-axis readings
from 4 accelerometer and the corresponding physical activity as the class. This data was generated
by placing four accelerometer on different body parts, of four subjects, such as waist, left thigh, right
arm and right ankle. The readings were taken over a time window of 150ms and represented in
temporal sequence. The activity of each participant is categorized into 5 classes – standing, sitting,
walking, sitting down, and standing up.
3. Problem Statement
Our goal was to perform analysis on the given dataset and create a generalized classifier, which
would predict the user’s physical activity with sufficient confidence. Additionally, we had to focus on
detection of change point of the user’s physical task.
4. HAR Pipeline
Figure 1. Human Activity Recognition pipeline

Human Activity Recognition: Group C | 2
The task of human activity recognition begins with data collection. [2] However, the raw data in itself
is not representative enough to be used for carrying out the task of classification. Thus, we need to
prepare the data by cleaning it and carrying out various data preprocessing activities. The
preprocessed data still doesn’t capture the temporal nature of the task. Hence data segmentation
is performed to enhance the discriminative power of the data. Feature extraction, now, converts the
signals into the most relevant and powerful features which are unique for the activity at hand. Finally
classification algorithms can be trained on the refined data, and a reliable prediction model can be
created. [3]
5. Risks and Mitigation
The inherent diversity amongst humans increases the risks and the challenges of human activity
recognition. Described below are the risks that we have identified and our approach to tackle them.
5.1. Insufficient Data
The primary challenge we face is the lack of data. Our data set has readings for just four subjects.
This provides a biased representation of the population and hinders the generalization of the
classifier. To mitigate this risk, we used only the user independent features, such as the readings
from various accelerometer and ignored the user specific data such as their height, weight, BMI
etc.
5.2. Intra-Class Variability
Our challenge is to develop HAR models which are robust to the inherent intra-class variability.
[2] This is introduced in the data, because some activity may be performed differently by
different individuals. Moreover this may also occur in case of the activity being performed by
same subject, due to difference in their emotional and physical state, such as stress, fatigue etc.
To alleviate this liability, we have developed person-independent features such as the pitch of
accelerometer.
5.3. Inter-Class Similarity
This cases arises when the activities to be classified are physically different by give similar sensor
characteristics. [2] To reduce the effect of this risk, we have again increased the focus on feature
extraction to consider attributed which capture the maximum variance in the data.
5.4. Temporal Nature
Independently, the data points do not capture the chronological nature of the human activity.
Additionally, most of the classifiers consider each data point as independent point in the time
space. Since, temporal aspect of HAR carries the maximum discriminative information, we
carried out feature segmentation to ensure that the data itself represents the sequential nature
accurately.
5.5. Class Imbalance
When a certain activity occurs for a prolonged period with respect to others, it may end up
dominating the data space, creating imbalance in the class distribution. [2] This may increase
the chances of over-fitting the prediction model. Techniques like oversampling can be used
here, by replicating the records of the smaller class.
Human Activity Recognition: Group C | 3
6. Initial Analysis
6.1. Data Analysis
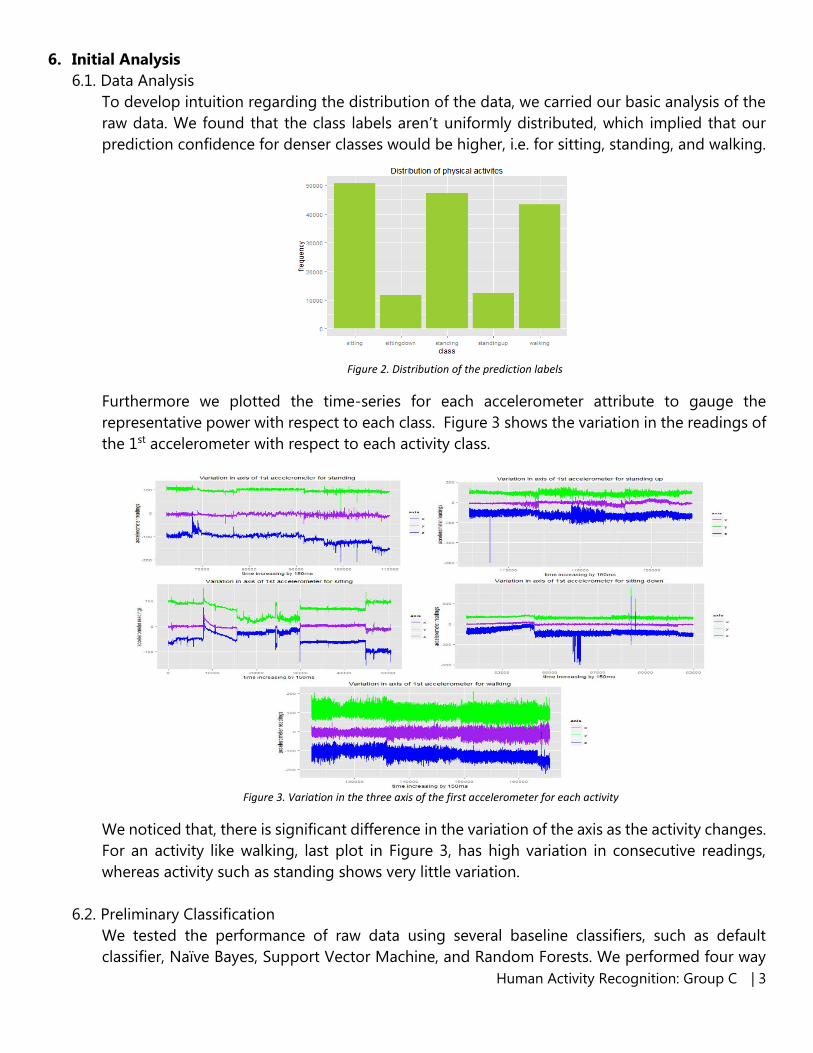
To develop intuition regarding the distribution of the data, we carried our basic analysis of the
raw data. We found that the class labels aren’t uniformly distributed, which implied that our
prediction confidence for denser classes would be higher, i.e. for sitting, standing, and walking.
Figure 2. Distribution of the prediction labels
Furthermore we plotted the time-series for each accelerometer attribute to gauge the
representative power with respect to each class. Figure 3 shows the variation in the readings of
the 1st accelerometer with respect to each activity class.
Figure 3. Variation in the three axis of the first accelerometer for each activity
We noticed that, there is significant difference in the variation of the axis as the activity changes.
For an activity like walking, last plot in Figure 3, has high variation in consecutive readings,
whereas activity such as standing shows very little variation.
6.2. Preliminary Classification
We tested the performance of raw data using several baseline classifiers, such as default
classifier, Naïve Bayes, Support Vector Machine, and Random Forests. We performed four way

Human Activity Recognition: Group C | 4
cross validation, wherein each user acted as test subject for one around. Our basic analysis
showed Naive Bayes as the best classifier, closely followed by Random Forest.
Figure 4. Accuracy obtained by various classifiers on raw data
Figure 5. Accuracy of Naive Bayes for all features vs. accelerometer features
Since the performance of Naïve Bayes was the best at this stage, we considered that, to find the
effect of subject’s physical attributes on the prediction capacity. As indicated in Figure 5.
Accuracy of Naive Bayes for all features vs. accelerometer features. We found that there was
slight increase in prediction power when only the accelerometer data is used. This strengthened
our conclusions, as we moved ahead.
7. Feature Engineering
Our preliminary analysis emphasizes on the dire need of new features. We transform the raw data
to a new feature space, where the classification task is better defined. This is an extremely crucial
step since the choice of our new features strongly influence the final prediction [4].

Human Activity Recognition: Group C | 5
7.1. Feature generation
To enhance the feature space, we calculated the pitch, roll and normal value for each of the
accelerometer using the following equations,
𝑝𝑖𝑡𝑐ℎ = atan(𝑦
√𝑥2+𝑧2) 𝑟𝑜𝑙𝑙 = atan(
−𝑥
𝑧) 𝑛𝑜𝑟𝑚 = √𝑥2 + 𝑦2 + 𝑧2
This increased the feature space from 12 attributes to 24 attributes.
7.2. Segmentation
For segmentation, our approach was to consider sliding windows [5], of various sizes, to
aggregate the data points within the window. This helps us capture the chronological variation
between the data points. Performing this activity, mitigates the risk that the classifier itself isn’t
temporal in nature.
Figure 6. Sliding Window
For our analysis, we considered both overlapping and non-overlapping sliding windows. We
found that the accuracy for prediction for non-overlapping windows is higher, however the
confidence interval is also wide. Here, if the window size is n, then the new data set would be
1/n the original data set. This increases the risks of over-fitting, due to decrease in training
points.
Next, we took overlapping windows, wherein though the size of dataset still reduces, it is greater
than 1/n. Also overlapping windows ensure that the transition of time is maintained and the
data points are not independent of each other.
We used mean and standard deviation as aggregation functions initially and performed
segmentation on raw dataset. This new dataset was then tested against Naïve Bayes and
Random Forest, the top two classifiers from our preliminary analysis.
Figure 7. Non-overlapping windows vs. overlapping window
In both the cases, we found the peak to be around window size of 13-14, i.e. 1.95s -2.10s. Further
to confirm our findings, we tested the overlapping window for newly generated features. Again,

Human Activity Recognition: Group C | 6
this time we considered the mean and variance for each attribute across the window. This time
we only considered Random Forest, since it had given us the best results in previous case.
Figure 8. Accuracy across different window sizes for Random Forest with new features
Finally, we concluded that window size of 14 gave us the best results. Next we moved on to
feature extraction.
7.3. Feature Extraction
Having multiple accelerometer increases redundancy in the data being observed. Thus, as the
first step of feature extraction we decided to test which accelerometers give us new information
and are relevant as opposed to the redundant ones. For carry out this analysis, we took all the
48 new features, and grouped them by the accelerometer number. [6] Then we performed the
performance test on the exhaustive combination of sensors using Random Forest.
Figure 9. Accuracy comparison for exhaustive combination set of sensors.
From the Figure 9, it is clear that if we were to consider single accelerometer then sensor 1, the
accelerometer placed on waist gives the best results. Also we find that the best results are obtained
using combination of sensor 1 and 3, i.e. ones placed on waist and right arm.
All our further analysis is carried by considered just the features corresponding to sensor 1 and 3. In
our next step to reduce the feature space, we carried our principle component analysis as well as
backward elimination of features.

Human Activity Recognition: Group C | 7
Figure 10. Feature space reduction using PCA and Backward Elimination
Initially we performed backward feature elimination and found that the accuracy peaked at feature
subset of size 11. The attributes in consideration at this point were, mean and variance of pitch and
normal of sensor 1 and 3 and the variance of roll of both sensor but mean of roll of only sensor 1.
To evaluate further, we decided to perform principle components analysis, to check if that yields
better performance. We found that even with PCA, the optimal number of components considered
would be 12.
Figure 11. Accuracy comparison for feature space reduction methods
As indicated in Figure 11, the accuracy obtained from PCA was slightly larger, however not
significant enough. This led to an executive decision to use backward elimination process, since it is
more intuitive as opposed to the black box structure of PCA.
8. Classification
Classification was a continuous ongoing process in our analysis. We performed 4-folds cross
validation to ensure that we were not over-fitting. Instead of typical 10-cross validation, we took 4-
folds by considering each subject as test case for one iteration and the remaining as training set.
While performing cross validation to retain the temporal aspect of the data, we did not randomize
our folds. In case of 10-folds, the accuracy of the classifier would increase, but that would be over-
fitting since a section of the test subject’s data would already be there in the training set.
Initially, we considered four classification methods for HAR analysis, however we kept on eliminating
them if there was no significant improvement in prediction power, with increasing complexity of
feature transformation.

Human Activity Recognition: Group C | 8
Figure 12, Figure 13 show the final comparison between the models generated by random forest for
raw attributed and processed final 11 attributes. They show the error rate of the models as well as
the variable importance plot. Model for these plots was trained using data from all the four subjects.
Figure 12. Error rate for Random Forest for raw features vs. final features
Figure 13. Variable Importance plot for Random Forest for raw vs. final features
9. Change Point Detection
Change point means whenever there is a significant change in the values of your temporal data then
some shift in class has occurred. We try to precisely identify that point. For our analysis, we
considered cumulative sum of the mean and variance of the attributes and tried to note a significant
change in their values. We have used the inbuilt R function CUSUM [7] for this purpose. We
constructed CUSUM charts which help us to detect deviations in the dataset. The change points are
represented by the shifts in the CUSUM charts. Periods where the CUSUM chart follows a relatively
straight path indicate a period where the average did not change.
As shown in the below Figure 14 a), the CUSUM chart was initially constructed with the raw data
which indicated shift in Sitting and Sitting Down and Standing Up. However, there were changes
detected when there was no shift in activity. The test was performed again including the newly
generated features such as pitch, roll and normal values for sensor 1 and 3 which is summarized in
Figure 14 b). As we can clearly notice, the CUSUM chart takes a sudden turn in direction and

Human Activity Recognition: Group C | 9
magnitude for the activities Standing, Standing up and walking. The significant change in the
cumulative sum of the mean and variance of the attributes is evident. Also, we were able to
determine this without any false values being generated. The minimum time taken for detection of
these change points detection does not vary much in either case. However, our confidence in
prediction increases significantly in case of new features.
Figure 14. CUSUM Charts for detecting Change Points

Human Activity Recognition: Group C | 10
10. Recommendations
If single sensor is to be used then, we would recommend that it should be placed on the waist.
However, we would also like to point out that our best results were obtained with combination of
two sensors, one placed at waist and other at right arm.
Additionally, we concluded that raw accelerometer data alone would not help us to build an accurate
prediction model. Thus, we recommend using the derived new features which improve the
classification confidence.
While there are other powerful classification methods available, we suggest application of Random
Forest for construction of prediction models since it turned out to be the best classifier for our
Human Activity Recognition dataset.
In addition to it, our change point analysis suggests that we could identify the activities standing,
standing up and walking with certainty. To enable detection for remaining activities, we believe
additional data points would be invaluable. Going forward, we also insist that the analysis should be
extended to wider set of audience to ensure the generalization of the classifiers.

Human Activity Recognition: Group C | 11
Appendix A
Table of Figures
FIGURE 1 HUMAN ACTIVITY RECOGNITION PIPELINE .............................................................................................................................................. 1
FIGURE 2. DISTRIBUTION OF THE PREDICTION LABELS ............................................................................................................................................. 3
FIGURE 3. VARIATION IN THE THREE AXIS OF THE FIRST ACCELEROMETER FOR EACH ACTIVITY .......................................................................................... 3
FIGURE 4. ACCURACY OBTAINED BY VARIOUS CLASSIFIERS ON RAW DATA ................................................................................................................... 4
FIGURE 5 ACCURACY OF NAIVE BAYES FOR ALL FEATURES VS. ACCELEROMETER FEATURES ............................................................................................. 4
FIGURE 6. SLIDING WINDOW ............................................................................................................................................................................ 5
FIGURE 7. NON-OVERLAPPING WINDOWS VS. OVERLAPPING WINDOW ...................................................................................................................... 5
FIGURE 8. ACCURACY ACROSS DIFFERENT WINDOW SIZES FOR RANDOM FOREST WITH NEW FEATURES ............................................................................ 6
FIGURE 9. ACCURACY COMPARISON FOR EXHAUSTIVE COMBINATION SET OF SENSORS. ................................................................................................. 6
FIGURE 10. FEATURE SPACE REDUCTION USING PCA AND BACKWARD ELIMINATION .................................................................................................... 7
FIGURE 11. ACCURACY COMPARISON FOR FEATURE SPACE REDUCTION METHODS ........................................................................................................ 7
FIGURE 12. ERROR RATE FOR RANDOM FOREST FOR RAW FEATURES VS. FINAL FEATURES .............................................................................................. 8
FIGURE 13. VARIABLE IMPORTANCE PLOT FOR RANDOM FOREST FOR RAW VS. FINAL FEATURES ..................................................................................... 8
FIGURE 14. CUSUM CHARTS FOR DETECTING CHANGE POINTS ............................................................................................................................... 9

Human Activity Recognition: Group C | 12
References
[1] W. Ugulino, D. Cardador, K. Vega, E. Velloso, R. Milidiu and H. Fuks, "Wearable Computing: Accelerometers' Data
Classification of Body Postures and Movements," in Proceedings of 21st Brazilian Symposium on Artificial
Intelligence. Advances in Artificial Intelligence - SBIA 2012, 2012.
[2] U. B. a. B. S. Andreas Bulling, "A Tutorial on Human Activity Recognition Using Body-worn Inertial," ACM Computing
Surveys (CSUR), 2014.
[3] D. T. G. Huynh, "Human Activity Recognition with Wearable Sensors," Doctoral dissertation, Technische Universität
Darmstadt, Darmstadt, 2008.
[4] O. a. D. M. a. P. H. a. P. A. a. R. I. Banos, "Daily living activity recognition based on statistical feature quality group
selection," Expert Systems with Applications, vol. 39, pp. 8013-8021, 2012.
[5] P. Maziewski, A. Kupryjanow, K. Kaszuba and A. Czyzewski, "Accelerometer signal pre-processing influence on
human activity recognition," in Signal Processing Algorithms, Architectures, Arrangements, and Applications
Conference Proceedings (SPA), Poznan, 2009.
[6] L. Atallah, B. Lo, R. King and G.-Z. Yang, "Sensor Positioning for Activity Recognition Using Wearable
Accelerometers," Biomedical Circuits and Systems, vol. 5, no. 4, pp. 320 - 329, 2011.
[7] D. W. A. Taylor, "Change-Point Analysis: A Powerful New Tool For Detecting Changes," [Online]. Available:
http://www.variation.com/cpa/tech/changepoint.html.



























