Embed Size (px)
Citation preview

© 2015 IBM Corporation
IBM Cognos – Dynamic Cubes

© 2015 IBM Corporation
Scope of Discussion
General Architecture
IBM OLAP technologies
2

© 2015 IBM Corporation
Elevator Pitch
In-memory OLAP cubes
High performance dimensional analytics over growing data volumes
Relational sources with star or snowflake schemas
Aggregate aware: database and/or memory based aggregates
Built-in aggregate optimization
Extends DQM in-memory caching of members, data, expressions, results, aggregates
Accessible by all IBM Cognos Interfaces
Included with Cognos Business Intelligence (no additional cost)

© 2015 IBM Corporation
ARCHITECTURE
Dynamic Cubes / IBM Cognos BI

© 2015 IBM Corporation
A Basic Conceptual View of a BI Stack
Presentation Layer
Application Layer
Data Layer

© 2015 IBM Corporation
Presentation Layer
Application Layer
Data Layer
… slightly more detail.
Aggregate
LayerSemantic Layer
© 2015 IBM Corporation
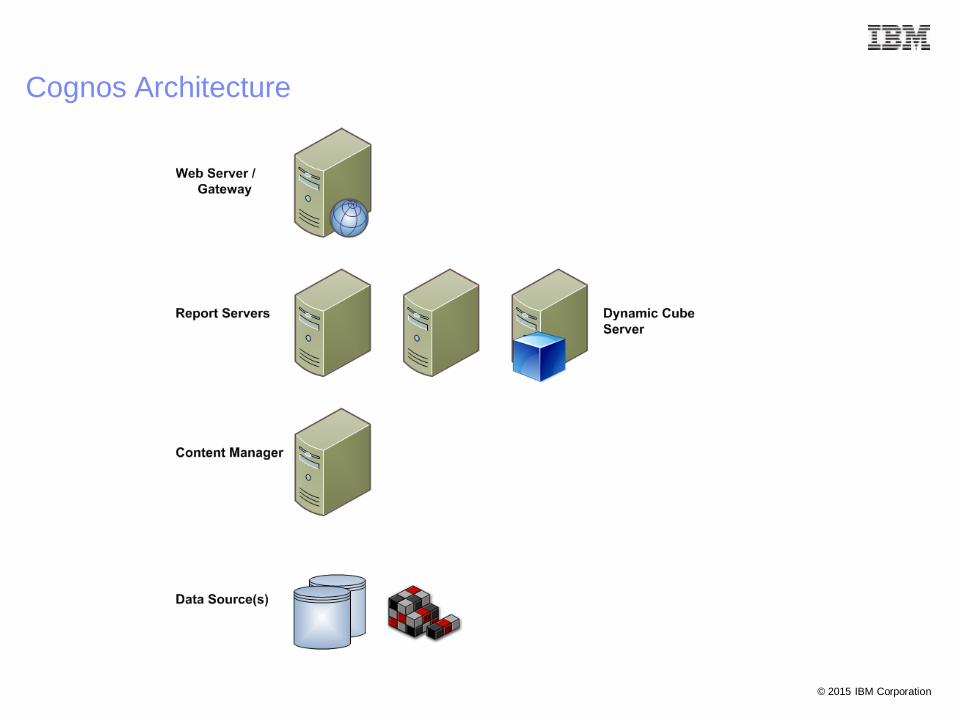
Cognos Architecture
© 2015 IBM Corporation
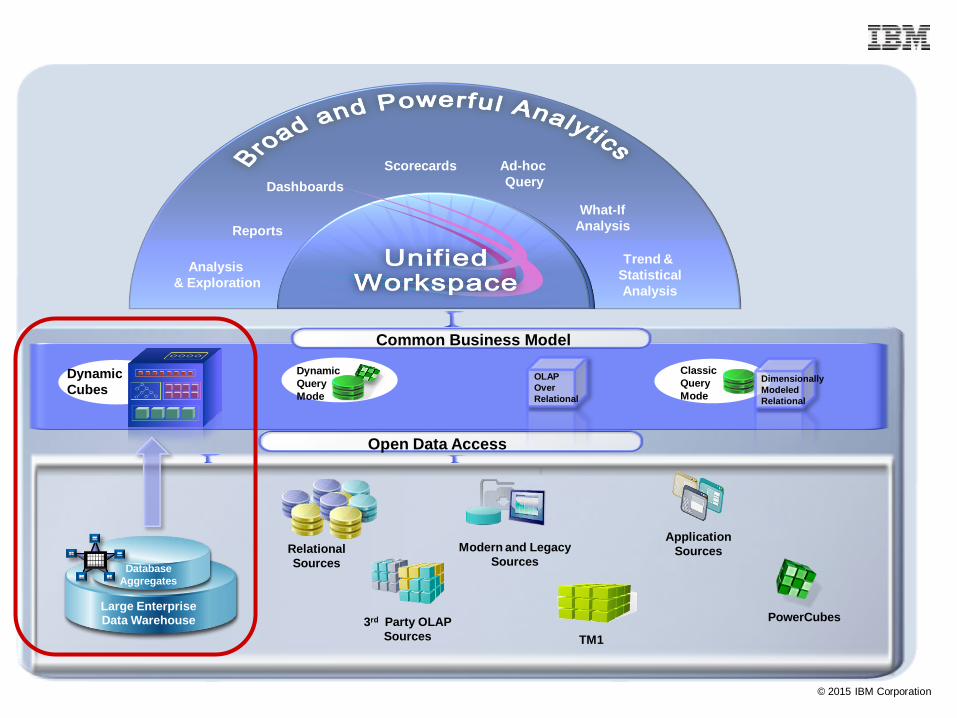
Modern and Legacy
Sources
Application
Sources
3rd Party OLAP
Sources
Relational
Sources
Dynamic
Query
Mode
Common Business Model
Classic
Query
Mode
Scorecards
Dashboards
Reports
Ad-hoc
Query
Analysis
& Exploration
Trend &
Statistical
Analysis
What-If
Analysis
PowerCubes
Open Data Access
OLAP
Over
Relational
Dimensionally
Modeled
Relational
Large Enterprise Data Warehouse
Database
Aggregates
Dynamic
Cubes
TM1
© 2015 IBM Corporation
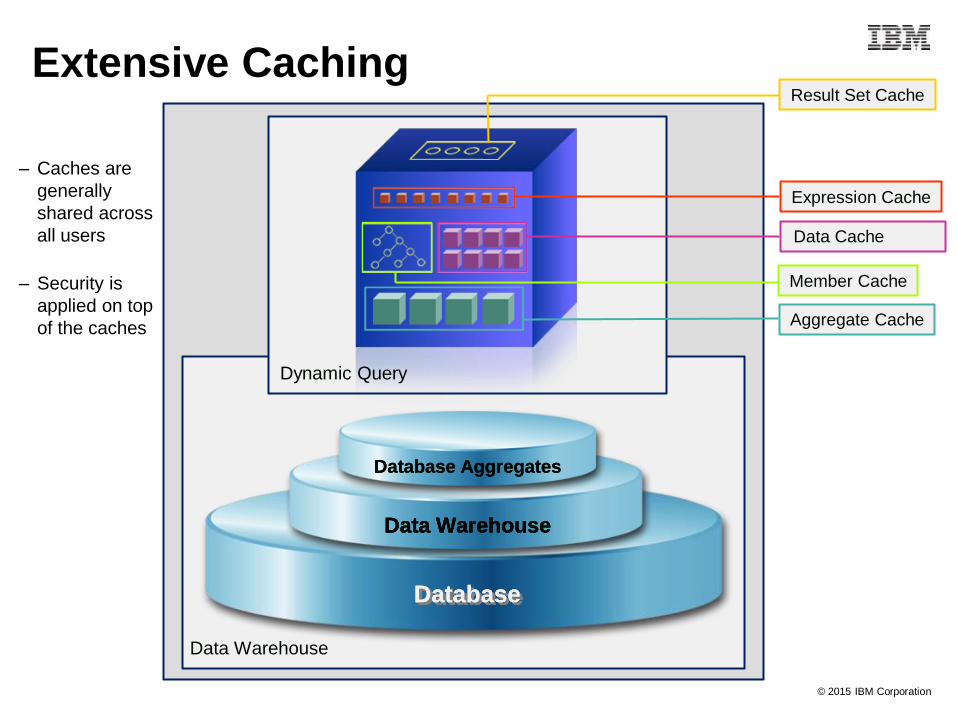
– Caches are
generally
shared across
all users
– Security is
applied on top
of the caches
Dynamic Query
Database
Data Warehouse
Database Aggregates
Result Set Cache
Expression Cache
Member Cache
Data Cache
Aggregate Cache
Database
Data Warehouse
Database Aggregates
Database
Data Warehouse
Data Warehouse
Extensive Caching
© 2015 IBM Corporation
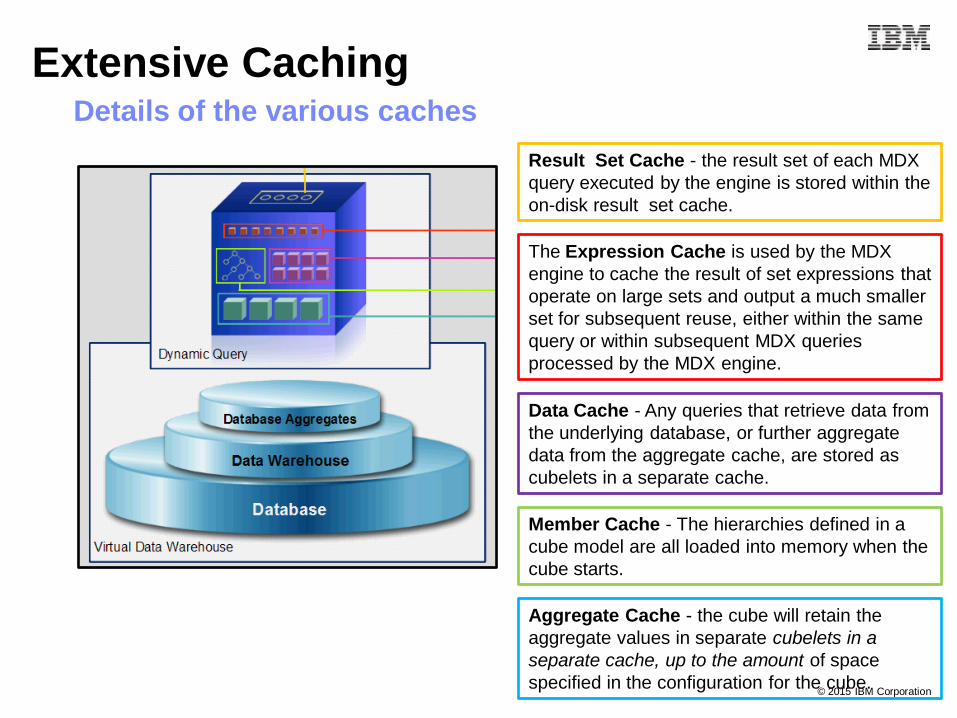
Details of the various caches
Member Cache - The hierarchies defined in a
cube model are all loaded into memory when the
cube starts.
Aggregate Cache - the cube will retain the
aggregate values in separate cubelets in a
separate cache, up to the amount of space
specified in the configuration for the cube.
Data Cache - Any queries that retrieve data from
the underlying database, or further aggregate
data from the aggregate cache, are stored as
cubelets in a separate cache.
Result Set Cache - the result set of each MDX
query executed by the engine is stored within the
on-disk result set cache.
The Expression Cache is used by the MDX
engine to cache the result of set expressions that
operate on large sets and output a much smaller
set for subsequent reuse, either within the same
query or within subsequent MDX queries
processed by the MDX engine.
Extensive Caching

© 2015 IBM Corporation
Virtual cube used as source for another
virtual cube
Combines cubes with common Time dimension
Virtual cubes combine two
cubes
Combines cubes with nearly identical
dimensions
Inventory
Sales
SalesInventory
Store
Sales
Web
Sales
Virtual Cubes
11
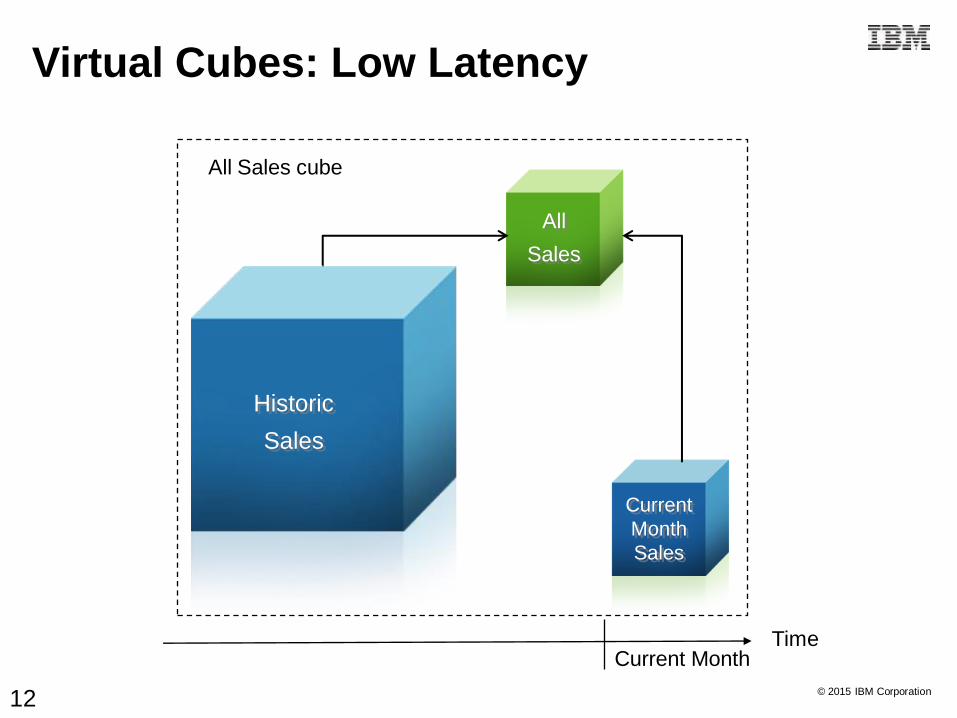
© 2015 IBM Corporation
TimeCurrent Month
All Sales cube
All
Sales
Current
Month
Sales
Historic
Sales
Virtual Cubes: Low Latency
12

© 2015 IBM Corporation
THE DC CYCLE
Soup to Nuts

© 2015 IBM Corporation
Interfaces Used
Developer/Administrator
Cube Designer
Cognos Administration Console
Dynamic Query Analyzer
End User
Workspace / Workspace Advanced
Any other
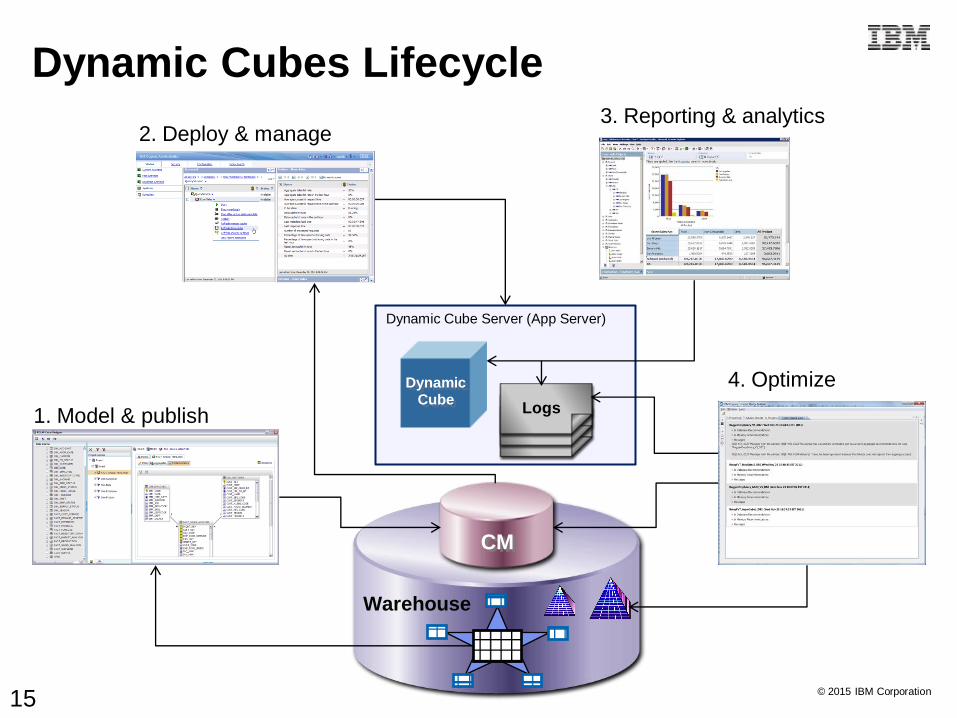
© 2015 IBM Corporation
1. Model & publish
2. Deploy & manage3. Reporting & analytics
4. Optimize
Dynamic Cube Server (App Server)
DynamicCube
Logs
CM
Warehouse
Dynamic Cubes Lifecycle
15

© 2015 IBM Corporation
Cube Designer
© 2015 IBM Corporation
Cognos Administration
© 2015 IBM Corporation
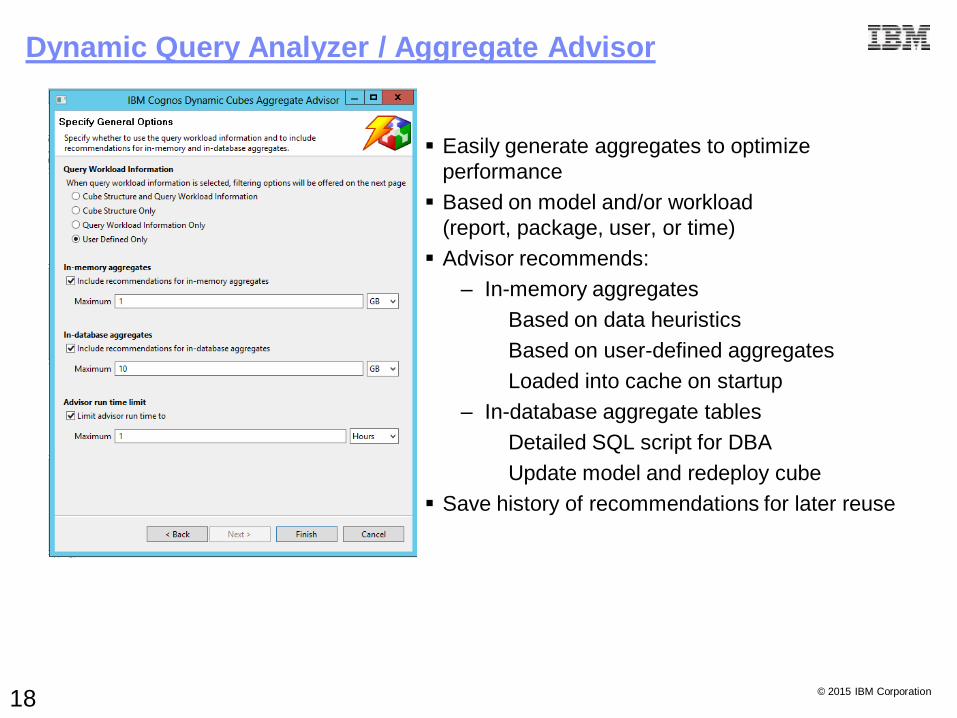
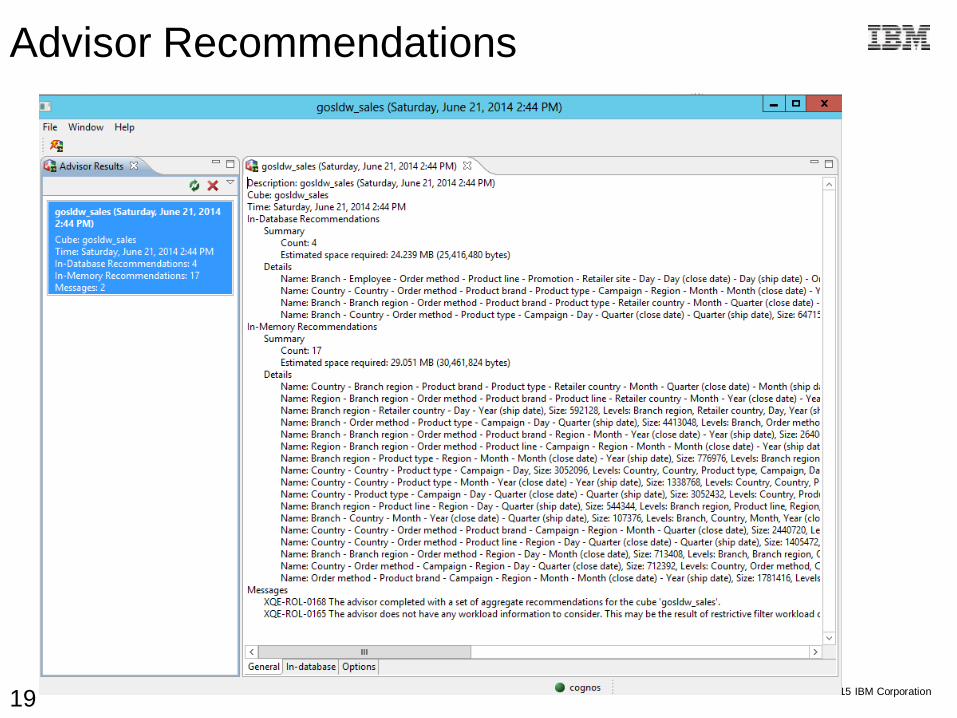
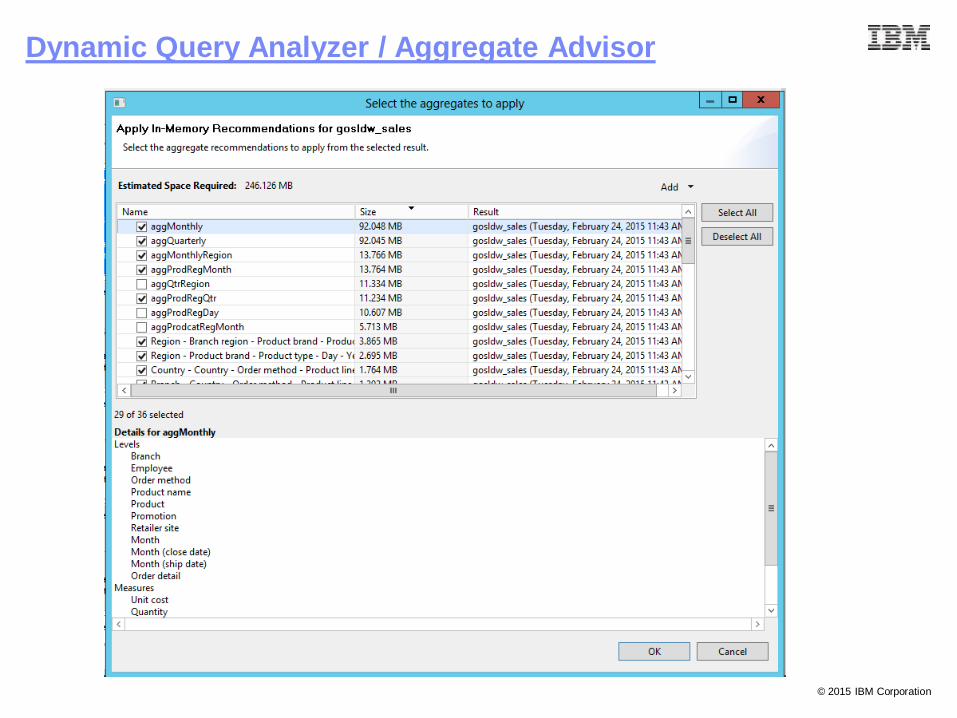
Easily generate aggregates to optimize
performance
Based on model and/or workload
(report, package, user, or time)
Advisor recommends:
– In-memory aggregates
Based on data heuristics
Based on user-defined aggregates
Loaded into cache on startup
– In-database aggregate tables
Detailed SQL script for DBA
Update model and redeploy cube
Save history of recommendations for later reuse
18
Dynamic Query Analyzer / Aggregate Advisor
© 2015 IBM Corporation
Advisor Recommendations
19
© 2015 IBM Corporation
Dynamic Query Analyzer / Aggregate Advisor
© 2015 IBM Corporation21
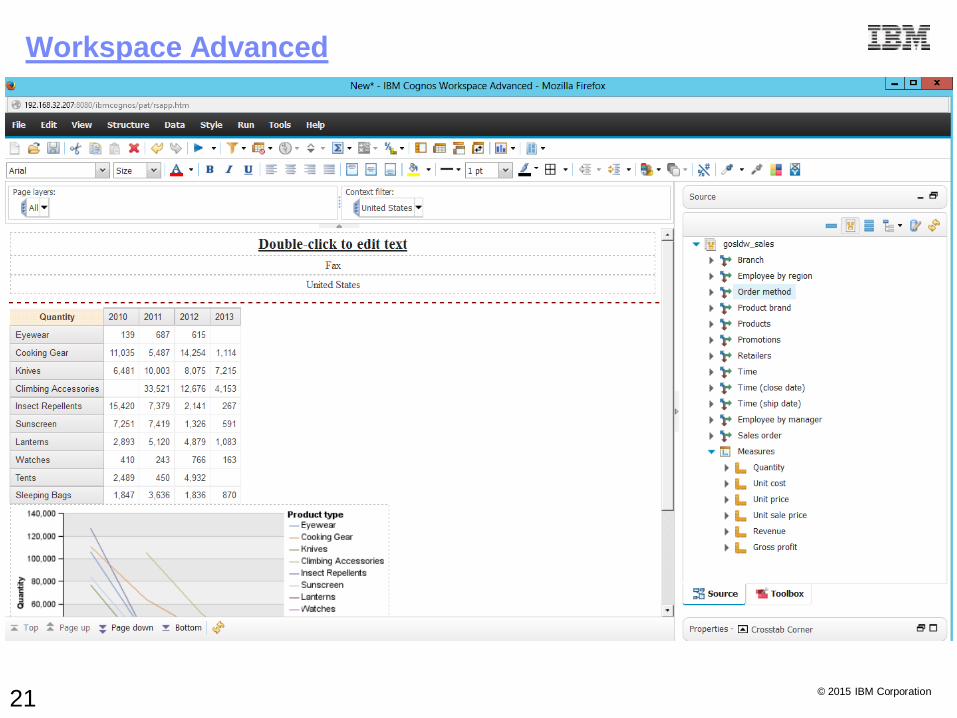
Workspace Advanced

© 2015 IBM Corporation
PARITY & NON-PARITY
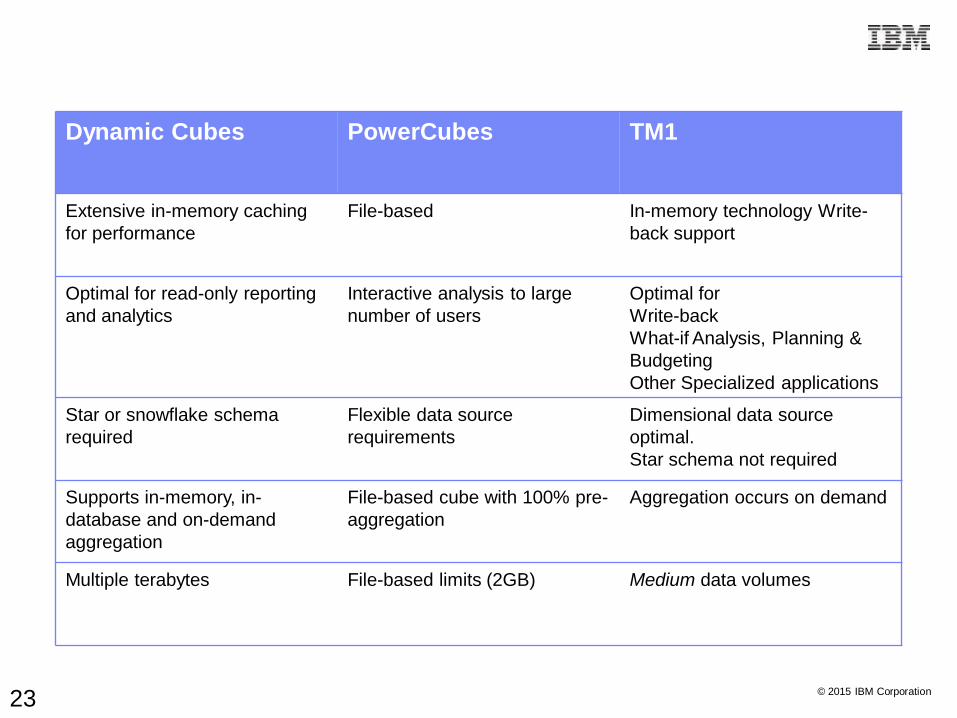
PowerCubes & Dynamic Cubes
© 2015 IBM Corporation23
Dynamic Cubes PowerCubes TM1
Extensive in-memory caching
for performance
File-based In-memory technology Write-
back support
Optimal for read-only reporting
and analytics
Interactive analysis to large
number of users
Optimal for
Write-back
What-if Analysis, Planning &
Budgeting
Other Specialized applications
Star or snowflake schema
required
Flexible data source
requirements
Dimensional data source
optimal.
Star schema not required
Supports in-memory, in-
database and on-demand
aggregation
File-based cube with 100% pre-
aggregation
Aggregation occurs on demand
Multiple terabytes File-based limits (2GB) Medium data volumes
© 2015 IBM Corporation
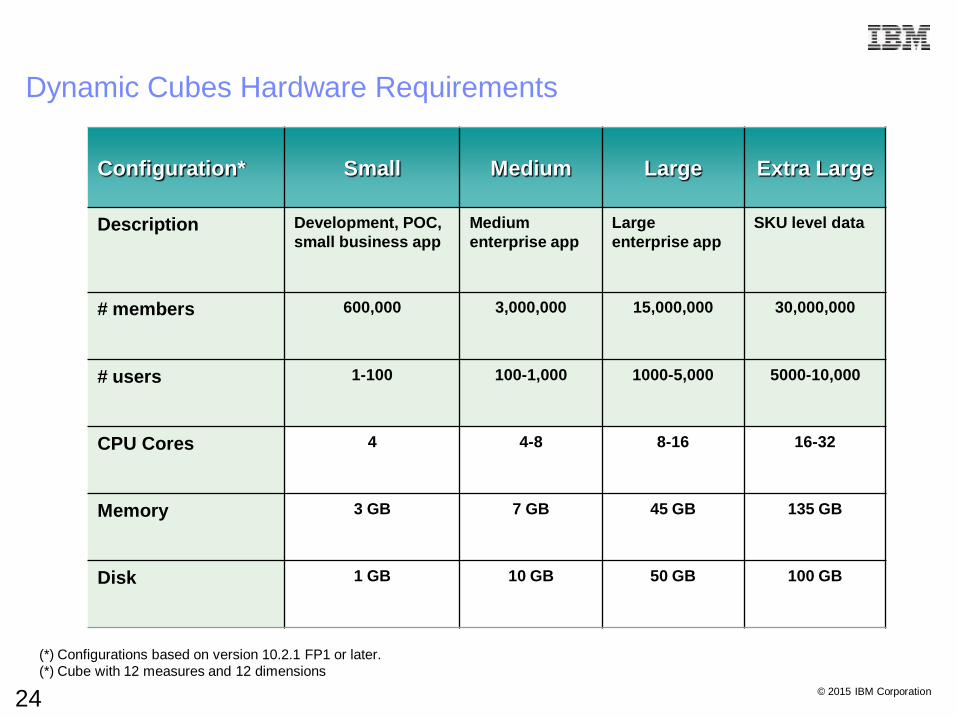
Dynamic Cubes Hardware Requirements
24
Configuration* Small Medium Large Extra Large
Description Development, POC,
small business app
Medium
enterprise app
Large
enterprise app
SKU level data
# members 600,000 3,000,000 15,000,000 30,000,000
# users 1-100 100-1,000 1000-5,000 5000-10,000
CPU Cores 4 4-8 8-16 16-32
Memory 3 GB 7 GB 45 GB 135 GB
Disk 1 GB 10 GB 50 GB 100 GB
(*) Configurations based on version 10.2.1 FP1 or later.
(*) Cube with 12 measures and 12 dimensions

© 2015 IBM Corporation
Dynamic Cubes - Summary
High Performance
– 80x improvement with aggregates*
– 80% queries under 3 seconds*
– Over 50% queries sub-second*
Growing Data Volumes
– In the labs testing with terabytes of
data
Flexible and Optimized
– Aggregate Advisor to easily create
optimized aggregates
Maximize Value of Data Warehouse
– Aggregate awareness to balance
load across app and DB tiers
25(*) Based on benchmarks conducted on IBM Labs.

© 2015 IBM Corporation
Demonstration:
26
• Explore the Cube Designer interface
• Explore dimension properties
• Explore cube properties
• Publish cube to Cognos Connection
• Use Dynamic cube in a report





























