Embed Size (px)
Citation preview

#IDUG
IBM DB2 BLU Acceleration A Primer for Sysadmins & DBAs
Olivier Bernin IBM
Session Code: <Insert Session Code> April 16th, 10:15 | Platform: DB2 LUW

#IDUG
Agenda
What is DB2 BLU Acceleration ?
Best Practices for Planning & Deploying Requirements & Configuration
Migrating an existing database to BLU
Loading data in BLU tables
Optimizing queries
Maintenance and monitoring
#IDUG
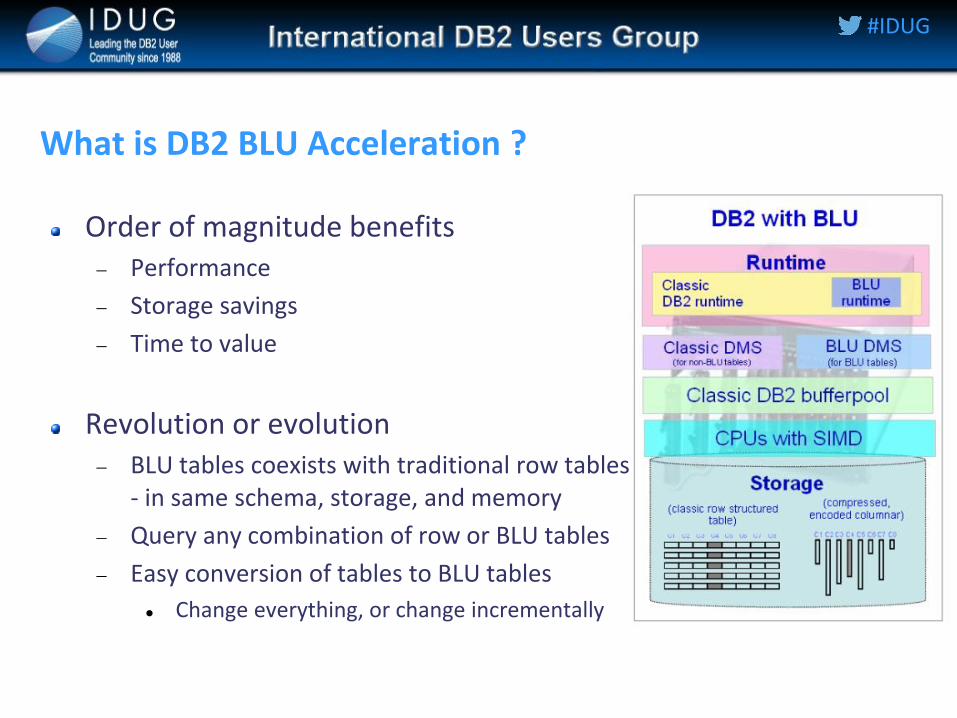
What is DB2 BLU Acceleration ?
Order of magnitude benefits Performance
Storage savings
Time to value
Revolution or evolution BLU tables coexists with traditional row tables
- in same schema, storage, and memory
Query any combination of row or BLU tables
Easy conversion of tables to BLU tables
Change everything, or change incrementally
#IDUG
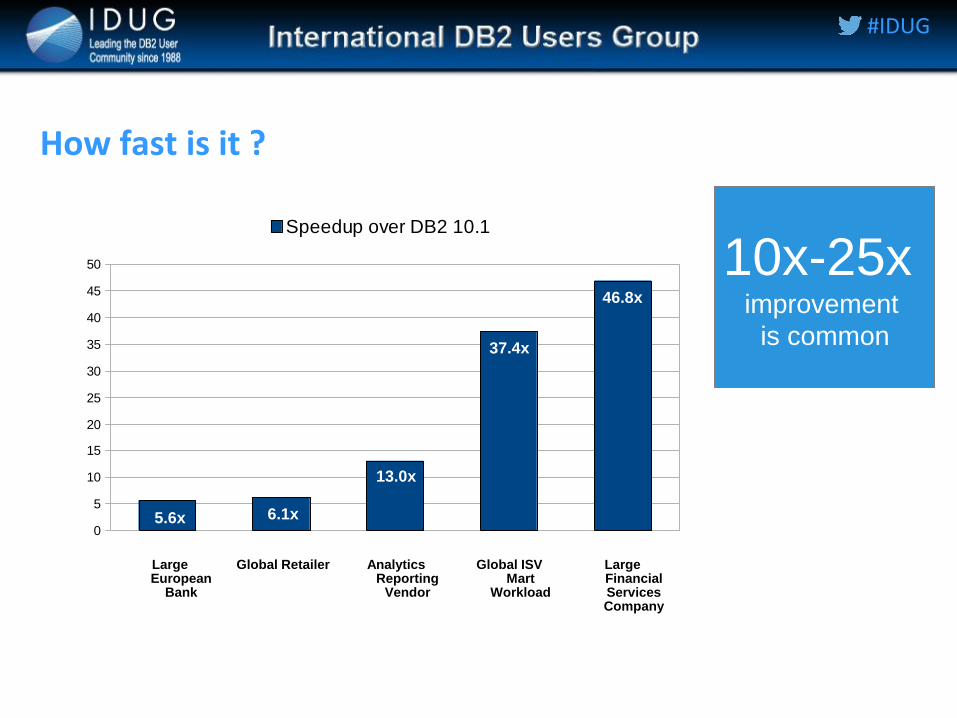
How fast is it ?
0
5
10
15
20
25
30
35
40
45
50
Speedup over DB2 10.1
10x-25x improvement
is common
Large Financial Services Company
Global ISV Mart
Workload
Analytics Reporting
Vendor
Global Retailer Large European
Bank
46.8x
37.4x
13.0x
6.1x 5.6x

#IDUG
Storage Savings
BLU data occupies substantially less space on disk ( ~10x) Superior compression
rate
Fewer objects required – no storage required for indexes, aggregates, etc
DB2 with BLU Accel.DB2 with BLU Accel.
#IDUG
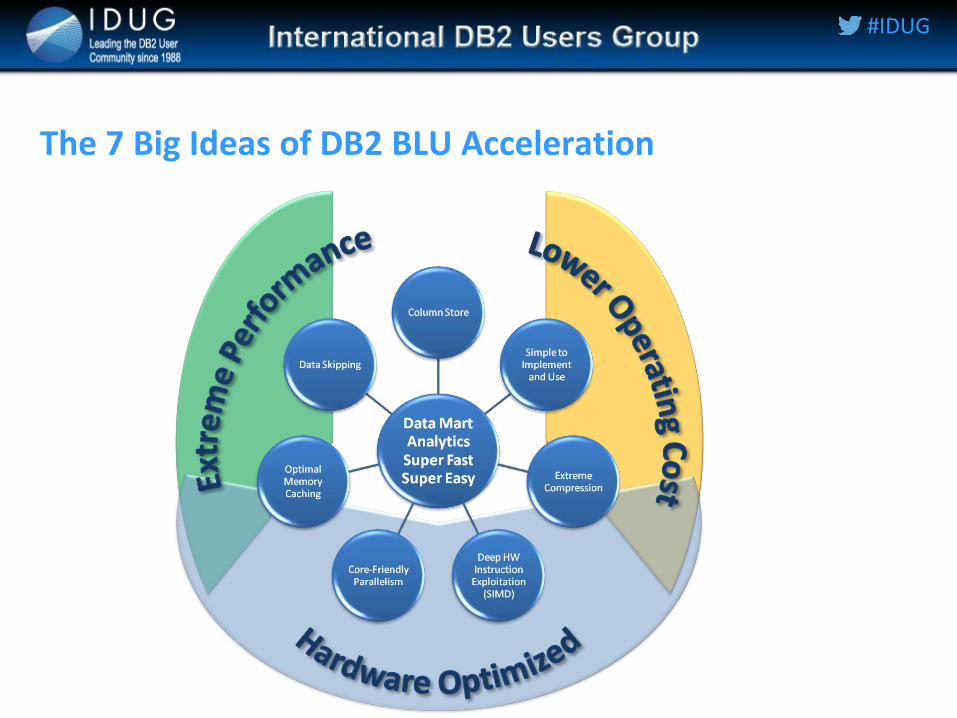
The 7 Big Ideas of DB2 BLU Acceleration

#IDUG
Column Store
Column organised data allow efficient selective loading of columns data required by heavy analytic workloads
Column 1 Column 3 Column 4 Column 5 Col
2
Row 1
Row 2
Row 3
Row n-1
Row n

#IDUG
Extreme and actionable compression
More frequent the value, the fewer bits it takes Fewer I/Os
Better memory utilization
Fewer CPU cycles to process
Compressed values do not need to be decompressed during evaluation Predicates (=, <, >, >=, <=, Between, etc), joins,
aggregations and more work directly on compressed values
LAST_NAME Encoding
Johnson
Johnson
Johnson
Johnson
Johnson
Johnson
Brown
Brown
Gilligan
Wong

#IDUG
Core Friendly Parallelism
Careful attention to physical attributes of the server Queries on BLU Acceleration tables automatically parallelized
Maximizes CPU cache, cacheline efficiency

#IDUG
Deep Hardware Instructions Exploitation
2005 Processor
Core
2010
2011
2012
2009
Compare = 2011 ? 2005
Processor Core
2010 2011 2012 2009
Instruction
Compare = 2011 ?
SIMD Instruction
2010 2011 2012 2009
2010 2011 2012 2009
2010 2011 2012 2009 Before BLU Acceleration One data operation required one CPU instruction to be executed
With BLU Acceleration Instructions executed on multiple data elements in a single CPU cycle (SIMD)
Dedicated single instructions applied to multiple data elements simultaneously: Predicate evaluation, joins, grouping, arithmetic

#IDUG
Data Skipping
Automatic detection of large sections of data that do not qualify for a query and can be ignored
Order of magnitude savings in all of I/O, RAM, and CPU

#IDUG
Putting it all together
The system: 32 cores, 10TB table with 100 columns, 10 years of data
The query: SELECT COUNT(*) from MYTABLE where YEAR = ‘2010’
The optimistic result: sub second 10TB query! Each CPU core examines the equivalent of just 8MB of data DATA
DATADATA
DATADATA
DATA
DATADATA
DATA
10TB data
DATA
1TB after storage savings
DATA
32MB linear scan
on each core
Scans as fast as 8MB
encoded and SIMD
DATA
Subsecond 10TB
query
DB2 WITH BLU ACCELERATION
10GB column
access
1GB after
data skipping

#IDUG
Simple to use
Same SQL, programming interface & administration tools
LOAD and then… run queries No indexes
No REORG (it’s automated)
No RUNSTATS (it’s automated)
No MDC or MQTs or Materialized Views
No partitioning
No statistical views
No optimizer hints

#IDUG
Hardware and Software requirements
BLU Acceleration supported on AIX & Linux
DB2 10.5 requirements
Operating System AIX Linux x86 (64 bits)
Minimum AIX 6.1 TL7 SP6 AIX 7.1 TL1 SP6
RHEL 5 SP 9 (10.5.1) RHEL 6 SLES 10 SP 4 SLES 11 SP 2
Recommended AIX 7.2 TL2 SP1 RHEL 6.3 SLES 11 SP2
Recommended Hardware
Power7 Intel Nehalem

#IDUG
Planning
Processor Cores 8 cores minimum
Latest processor: more L1 cache + leverage SIMD instructions
Memory 64 Gb
Rule of thumb for extension: number of cores x 8 Gb
Identifying workloads Analytics workload: grouping, aggregation, range scans ...
Flexibility to optimize at the table level (even in same tablespace & buffer pool)
Use Optim™ Query Workload Tuner

#IDUG
Configuration
One registry variable to rule them all: DB2_WORKLOAD=ANALYTICS
What does it do ? DFT_TABLE_ORG = COLUMN, PAGESIZE = 32 KB, DFT_EXTENT_SZ = 4,
DFT_DEGREE = ANY, AUTO_MAINT = ON, AUTO_REORG = ON
CATALOGCACHE_SZ, SORTHEAP, and SHEAPTHRES_SHR optimized for hardware
Enable Intraquery Parallelism for workload with MAXIMUM DEGREE set to DEFAULT
Enable concurrency control
If the Db already exists: db2 autoconfigure apply <db>

#IDUG
Memory allocation tuning
BLU Acceleration designed to effectively leverage large memory configuration
STMM on by default but not active for sort memory in BLU
Set instance level SHEAPTHRES = 0 Tracking of sort memory consumption at DB level using
SHEAPTHRES_SHR
Expected concurrency the main factor to consider for tuning
Planned concurrency Low ( < 20 requests) High ( > 20 requests)
SHEAPTHRES_SHR 40 % DATABASE_MEMORY
50 % DATABASE_MEMORY
SORTHEAP
SHEAPTHRES_SHR / 5
SHEAPTHRES_SHR / 20

#IDUG
Converting an existing database to use BLU
Set registry variable (DB2_WORKLOAD=ANALYTICS)
Run db2 autoconfigure apply <db>
If required, convert data & index table space from DMS to AUTOMATIC STORAGE Column organised tables can only be created in AUTOMATIC STORAGE
tablespace
Use db2convert tool to make existing tables to column-based db2convert -d <db> (all tables)
db2convert -d <db> -z <schema> -t <table> (single table)
Online (calls ADMIN_TABLE_MOVE behind the scenes)

#IDUG
A few things to know about db2convert
Automatically drops dependent objects (secondary indexes, etc ...)
Can be executed from Optim Data Studio “Migrate to Column Storage”
Use SYSTOOLS.ADMIN_MOVE_TABLE to check status
No “online” way to convert back from column to row based Unload / re-load
Perform a backup before converting
TABLEORG column of SYSCAT.TABLES shows organization of table 'R' for rows, 'C' for columns

#IDUG
Creating new column based tables
Column organized tables can only be created in Automatic Storage tablespaces
Specify the ORGANIZE BY ROW | COLUMN clause Alternatively, use the DB2_WORKLOAD=ANALYTICS or DFT_TABLE_ORG
variables
Not much else needed No compression, partitioning, indexes ...

#IDUG
Under the bonnet - Compression
2 Complementary compression methods Huffman compression & Prefix coding
Both method uses less bits for most frequent values → Space saving
Both method requires building a “dictionary” Maps “real” value to compressed one
One dictionary per column, also page level dictionary
Column dictionary built on initial load into the column … New “ANALYZE” phase of LOAD
Uses the utility heap ...
#IDUG
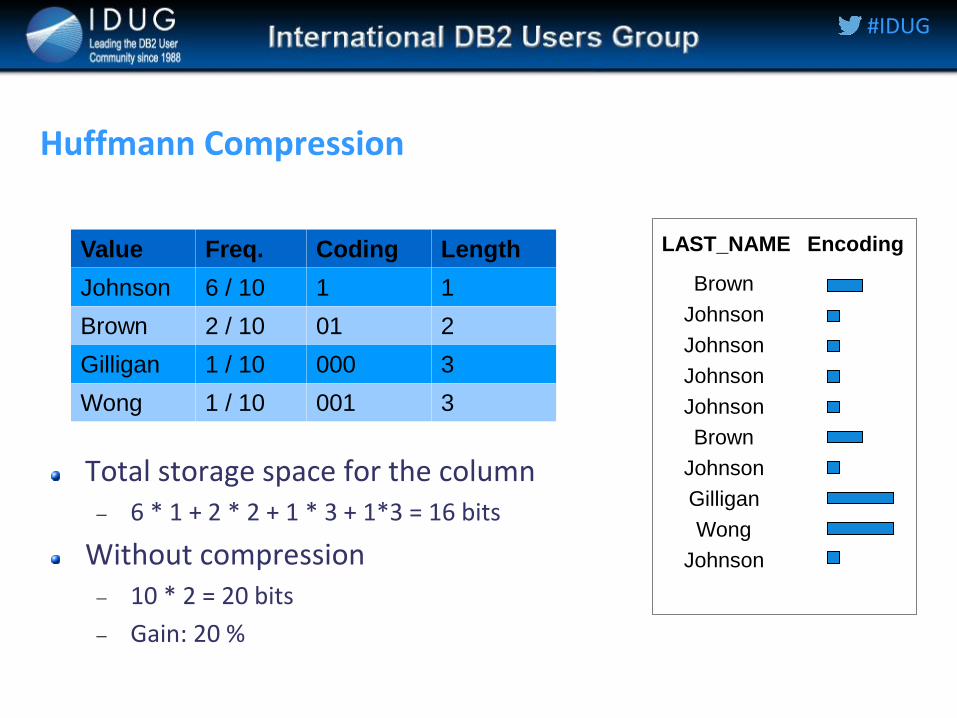
Huffmann Compression
Total storage space for the column 6 * 1 + 2 * 2 + 1 * 3 + 1*3 = 16 bits
Without compression 10 * 2 = 20 bits
Gain: 20 %
Value Freq. Coding Length
Johnson 6 / 10 1 1
Brown 2 / 10 01 2
Gilligan 1 / 10 000 3
Wong 1 / 10 001 3
LAST_NAME Encoding
Johnson
Johnson
Johnson
Johnson
Johnson
Johnson
Brown
Brown
Gilligan
Wong

#IDUG
Prefix Encoding
Compression of a first segment (“prefix”) of the data common to many values
Example: Jan1, Jan4, Feb3, Feb6, Jan2, etc ... Feb6 => “Feb” & “6”
Index for “Feb” is 01 – character “6” is 00110110b
Feb6 => 01 00110110
Length of prefix is know for a data set (column)
Value Index
Jan 00b
Feb 01b
Mar 10b
Apr 11b

#IDUG
Under the bonnet - Synopsis Tables
Data Skipping implemented using Synopsys Tables
One row for each 1024 rows of the table Kept up to date when IUD
Stores min & max values TSN S_DATE QTY
0 2005-03-01 176
2005-03-02 85
2005-03-02 267
2005-03-04 231
...
1023 ...
1024 2006-08-25
2007-09-14
2007-06-12
2047 ...
User table: SALES_COL
SYN130330165216275152_SALES_COL
TSNMIN TSNMAX S_DATEMIN S_DATEMAX ...
0 1023 2005-03-01 2006-10-17 ...
1024 2047 2006-08-25 2007-09-15 ...
...
TSN = Tuple Sequence Number

#IDUG
Best practices for loading data into BLU tables
Initially load a substantial & representative set of data Will allow to build an optimal compression dictionary
Set utility heap (UTIL_HEAP_SZ) appropriately Will allow to use more data to build the dictionary
Watch out if it's set to AUTOMATIC
When possible, sort the data before loading it Improves data skipping (hence performance)

#IDUG
Other remarks about loading data
The db2convert tool will use LOAD to create the dictionary under the cover
It is possible to manually reset the dictionary manually LOAD REPLACE RESETDICTIONARY | RESETDICTIONARYONLY
Monitoring the compression ratio PCTENCODED column in SYSCAT.COLUMNS catalog view
Indicates the percentage of values in the column that are compressed

#IDUG
Informational Constraints
Introduced with DB2 10.5, but not specific to BLU
Make Primary Key & Unique Constraint informational only Remove verification overhead, but still allow for optimization during
query rewriting or access plan generation
Less space - no uniqueness index
More speed - no index update on IUD
Add NOT ENFORCED clause
Rigorous ETL process required – uniqueness not enforced Default is to enforce constraint

#IDUG
Tuning queries on BLU tables – The CTQ operator
Row and column tables both natively supported by the engine Optimizer aware of both types and able to make relevant decisions
New operator introduced to mark transition between column & row organized data processing: CTQ All plan operations “below” the CTQ operator are column based
For column tables queries, good execution plan will maximize the amount of pressing below CTQ and minimize the amount of rows flowing through it

#IDUG
Maintenance
No RUNSTAT – automatic statistics collection enabled by default
REORG is automatic if DB2_WORKLOAD is set to ANALYTICS Otherwise, use REORG TABLE … RECLAIM EXTENT
Include sysnopsis table space reclaim
No partitioning, no MDC
No secondary optimization structures No indexes, MQTs, etc …
Backup & restore operations identical to row based table ones

#IDUG
Monitoring – What to watch
Adequate sort heap MON_GET_DATABASE.SORT_HEAP_ALLOCATED
MON_GET_DATABASE.SORT_SHRHEAP_ALLOCATED
MON_GET_DATABASE.SORT_SHRHEAP_TOP
Adequate table organization MON_GET_TABLE.NUM_COLUMNS_REFERENCED
MON_GET_TABLE.SECTION_EXEC_WITH_COL_REFERENCES
NUM_COLUMNS_REFERENCED / SECTION_EXEC_WITH_COL_REFERENCES => Avg number of columns accessed for the table
DB2 Monitoring extended for BLU: new column related metrics
Optim Query Workload Tuner as well ...

#IDUG
Olivier Bernin IBM [email protected]
Please fill out your session
evaluation before leaving!
Session 1 DB2 BLU Acceleration A Primer for Sysadmins & DBAs





























