Embed Size (px)
Citation preview

IIIT
Hyd
erab
ad
Word Hashing for Efficient Search in Document Image Collections
Anand Kumar
Advisors:Dr. C. V. JawaharIIIT Hyderabad
Dr. R. ManmathaUniversity of Massachusetts, Amherst, USA

IIIT
Hyd
erab
ad
Overview
• Introduction• The problem• Previous work• Contributions• Searching in document images• Annotation for retrieval• Summary• Future work

IIIT
Hyd
erab
ad
Introduction
Database
Documents
Processing Input Query
Image Matching
Retrieved Documents
NOT the text (ASCII) words.
Scanning
Matching images of words,

IIIT
Hyd
erab
ad
Challenges
• Direct matching of images is an expensive process.• Represent word images as feature vectors and match.
– Representation should capture the characteristics (mainly content) of words.
• On every query, searching in large word image database by matching is time consuming.
• The scalability issues arise with the increase in size of the document image collection.

IIIT
Hyd
erab
ad
Basic Directions of Solution
• Convert the images into text using recognizers and build index using text search methods.– If the converted text has errors, will the text search
methods deliver the expected performance?TextDatabase
Documents
Optical Character Recognition (OCR)
Input Query
Text Search Engine
Retrieved Documents
Scanning

IIIT
Hyd
erab
ad
Basic Directions of Solution
• Group similar words in the document image collection and annotate (label with text) the groups.
• Apply text search methods for accessing the documents.– Is it possible to annotate large groups of words found
in a large collection of document images?
Database
Documents
Processing Input Query
Text Search Engine
Retrieved Documents
Scanning
Annotate Words

IIIT
Hyd
erab
ad
The Problem
• Building an index using matching or other existing methods is not scalable for even moderate collections.
• Given a large collection of document images, how to search efficiently for similar words so that queries are answered quickly (in milli seconds)?

IIIT
Hyd
erab
ad
Previous Work
• Recognition based methods– Chan et al. use bi-gram letter transition model for recognition of words.– BYBLOS system uses similar approach for line recognition.
• The recognizers may fail in presence of degradations.• There are no good recognizers and language modeling
approaches for Indian languages.
Jim Chan, Celal Ziftci, and David A. Forsyth. “Searching Online Arabic Documents”. In Proc. of Conference on Computer Vision and Pattern Recognition (CVPR) (2), pages 1455-1462, 2006.
Zhidong Lu, Richard Schwartz, Premkumar Natarajan, Issam Bazzi, and John Makhoul. “Advances in the BBN BYBLOS OCR System”. In Proc. of International Conference on Document Analysis and Recognition (ICDAR), pages 337-340, 1999.
U. Pal and B.B. Chaudhuri. “Indian Script Character Recognition: A Survey”. Pattern Recognition, 37:1887-1899, 2004.

IIIT
Hyd
erab
ad
Previous Work
• Recognition free methods– Word spotting in handwritten documents
• Words are clustered and the clusters are annotated to enable search.• Dynamic time warping (DTW) is used for matching words.• George Washington’s handwritten documents.
– Similar approach for printed Indian language documents.– Word spotting in Ottoman documents
• Successive pruning stages eliminate wrong words.
Toni M. Rath and R. Manmatha. “Word Image Matching Using Dynamic Time Warping”. In Proc. of Conference on Computer Vision and Pattern Recognition (CVPR)(2), pages 521-527, 2003.
A. Balasubramanian, M. Meshesha, and C. V. Jawahar. “Retrieval from Document Image Collections”. In International Workshop on Document Analysis Systems (DAS), pages 1-12, 2006.
Esra Ataer and Pinar Duygulu. “Retrieval of Ottoman documents”. In Multimedia Information Retrieval (MIR) workshop, pages 155-162, 2006.

IIIT
Hyd
erab
ad
Contribution of This Work
• Data is processed quickly using the proposed technique to help search efficiently in large collection.
• Effect of word image representation and document types on the proposed technique are analyzed.
• Scalability of the proposed method is demonstrated on a collection of Kalidasa’s books.
• The group of similar words retrieved using the proposed approach are labeled (automatically) for annotation based access to documents.
• A method to improve the automatic word labeling (annotation) accuracy is presented.

IIIT
Hyd
erab
ad
Overview
• Introduction• The problem• Previous work• Contributions• Searching in document images
– Word image representation– Similarity search– Content sensitive hashing– Fitting in retrieval system– Experimental results
• Annotation for retrieval• Summary• Future work

IIIT
Hyd
erab
ad
Word Image Representation
• Profile Features– Ink transitions
• Number of black to white pixel transitions in the image row or column. Calculated for both rows and columns.
– Projection profiles• Sum over the pixel values of a column

IIIT
Hyd
erab
ad
Word Image Representation
• Profile Features– Upper word profiles
• Black pixel distance from top boundary of the image.
– Lower word profiles • Black pixel distance from
bottom of the image.
– If no pixel is found in a column, the value is taken as height of the image.

IIIT
Hyd
erab
ad
Word Image Representation
• Region based moments• Central moments• Discrete Fourier Transform
(DFT) coefficients.– Projection and word profile
features are segmented vertically into four equal parts.
– 1D Fourier transform of the segmented profile features is obtained.
– n=4 real parts and last n-1=3 imaginary parts of the DFT are taken as features.
– Total 84 Fourier coefficients are taken from each image.
3 x (7 x 4) = 84features x (coefficients x segments) = total coefficients for every image

IIIT
Hyd
erab
ad
Similarity search
• Given word image representations as vectors (points) in some space,– We need to search for similar vectors (points) i.e., nearest neighbor search
(NNS).• k-d tree, B-tree or R-tree can be used for the NNS.• How to handle the slight differences in the representation of
similar words?– Approximate nearest neighbor search has to be carried out.
• Since the representations are in high dimension (more than 84 in our case), traditional way of searching is inefficient.– Locality sensitive hashing (LSH) is an approximate nearest neighbor
search method for sub-linear time complexity.
Rudolf Bayer and E. McCreight. “Organization and Maintenance of Large Ordered Indexes”. Acta Informatica, 1(3):173-189, 1972.
Jon Louis Bentley. “Multidimensional Binary Search Trees Used for Associative Searching”. Communications of the ACM, 18(9):509-517, 1975.Sunil Arya and David M. Mount. “Approximate Nearest Neighbor Queries in Fixed Dimensions”. In
SODA '93. pages 271-280, 1993.M. Datar, N. Immorlica, P. Indyk, and V. S. Mirrokni. “Locality-Sensitive Hashing Scheme Based on p-Stable Distributions”. In ACM SOCG, pages 253-262, 2004.

IIIT
Hyd
erab
ad
Content Sensitive Hashing
• A similarity search problem in which it is not necessary to find exact answer; instead determine approximate answer.
• The key idea is:– To hash points using several hash functions so as to ensure
that for each function the probability of collision is much higher for objects which are close to each other than for those which are far apart.
• When a query point is given,– Hash the query point and retrieve elements stored in buckets
containing that point.

IIIT
Hyd
erab
ad
Content Sensitive Hashing
• Hashing Technique– Given: set P of n points and number of hash tables L.
for each hash table Ti, i = 1,…,L
for each point pj, j=1,…n
store pj on bucket gi(pj) of hash table Ti.
– where gi(p), i=1,…,L is hash function of table Ti
• Hash function can be combination of other functions.• Some Examples:
– g(v1,…,vk) = a1.v1+…+ak.vk mod Mwhere M is hash table size and a1,…,ak are random numbers from interval [0…M-1]
– g(p) = h1(p),…,hk(p)where hi(p) = (ai.p+bi)/w, ai is a d dimensional vector
– gL(p) = v1(p)…vL(p)v(p) = Unaryc(x1)…Unaryc(xd).Unaryc(x) = x 1s followed by c-x 0svi(p) => select some bits from v(p), i = 1..L

IIIT
Hyd
erab
ad
Content Sensitive Hashing
• Querying– To process a query q
• we search all indices of g1(q),…,gL(q) and collect all points from L indices of hash tables.
• Linear search on the collected points.
• Output points within distance R from query.
Let n is the size of data and B is the bucket size.
If p1 is the probability that a point is found and p2 is probability that a point is found in given radius r.
log (1/p1)
log (1/p2)ρ = L = (n / B)
ρ

IIIT
Hyd
erab
ad
Content Sensitive Hashing
• Example– Let, p={1,3,2}, q={1,2,3}, r={3,1,1}, s={2,1,1} are d=3 dimensional points
and c=3 is max value in the dimensions.
– v(p) = Unaryc(x1)…Unaryc(xd).– Unaryc(x) = x 1s followed by c-x 0s– v(p) = v(1,3,2) = 100 111 110– A new dimensions d’ = cd = 9 is obtained i.e., a set I = {1,2,3,4,5,6,7,8,9}.– Let number of hash tables L=2, and I1={1,5,6}, I2={2,3,7,9} be L subsets
from of I.
– Hash function is gL(p) = v1(p)…vL(p)– vi(p) => select Ii bits from v(p), i = 1…L
Unary(1) = 100 Unary(3) = 111 Unary(2) = 110

IIIT
Hyd
erab
ad
Content Sensitive Hashing
• Example– v(p) = v(1,3,2) = 100 111 110– g1(p) = 111, g2(p) = 0010. (7, 2)
– v(q) = v(1,2,3) = 100 110 111– g1(q) = 110, g2(q) = 0011. (6, 3)
– v(r) = v(3,1,1) = 111 100 100– g1(r) = 100, g2(r) = 1110. (4, 13)
– Query s = {2,1,1}– v(s) = 110 100 100– g1(s) = 100, g2(s) = 1010. (4, 10)– Resulting point is r
I1={1,5,6} and I2={2,3,7,9}
v(p) = v(1,3,2) = 100 111 110
g1(p) = 1 1 1
IIIT
Hyd
erab
ad
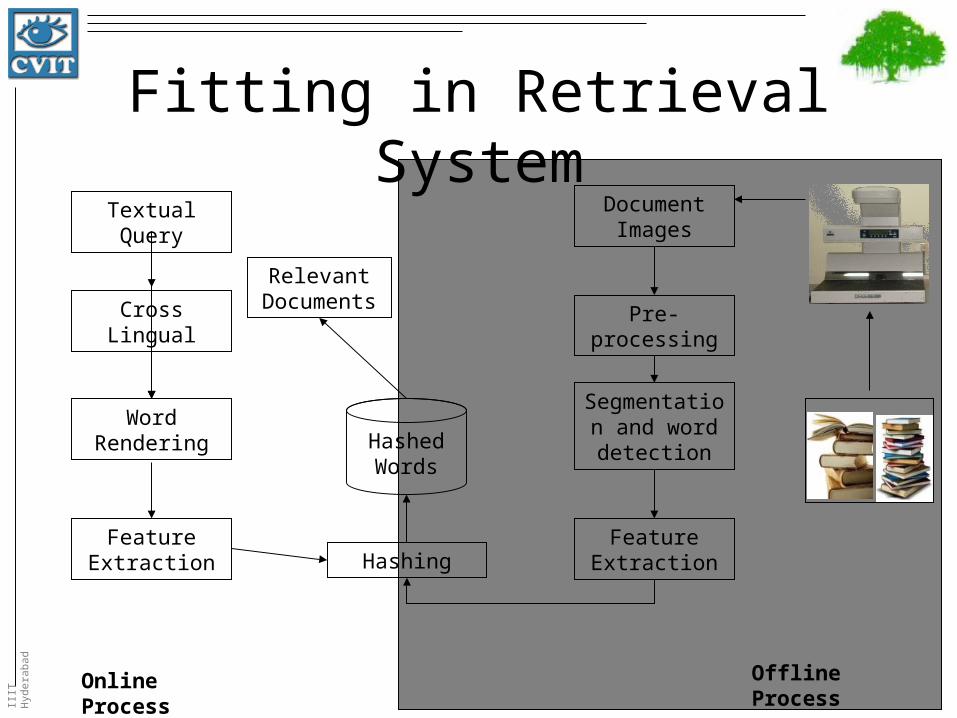
Fitting in Retrieval SystemDocument
Images
Pre-processing
Segmentation and word detection
Feature ExtractionHashing
Feature Extraction
Word Rendering
Textual Query
Relevant Documents
HashedWords
Cross Lingual
Offline ProcessOnline Process
IIIT
Hyd
erab
ad
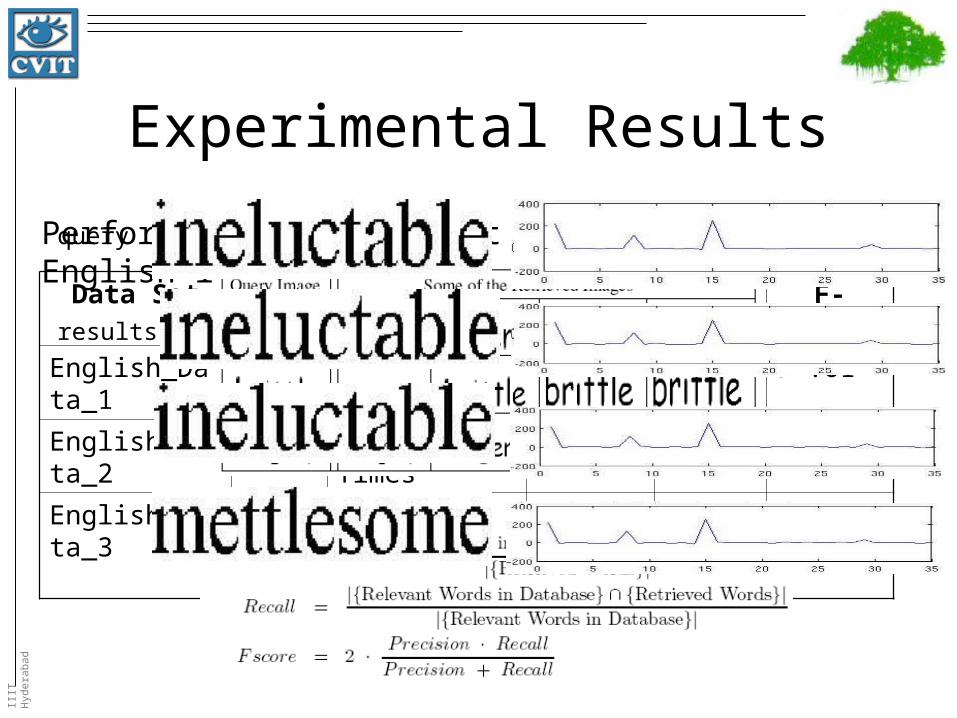
Data Set Size Font Precision Recall F-Score
English_Data_1 2200 Times 97.23 98.00 97.61
English_Data_2 3520 Arial and Times 94.45 96.80 95.61
English_Data_3 7920 Arial, Comic and Times
63.70 56.47 59.87
Performance on different data sets of English language
Experimental Results
query
results
IIIT
Hyd
erab
ad
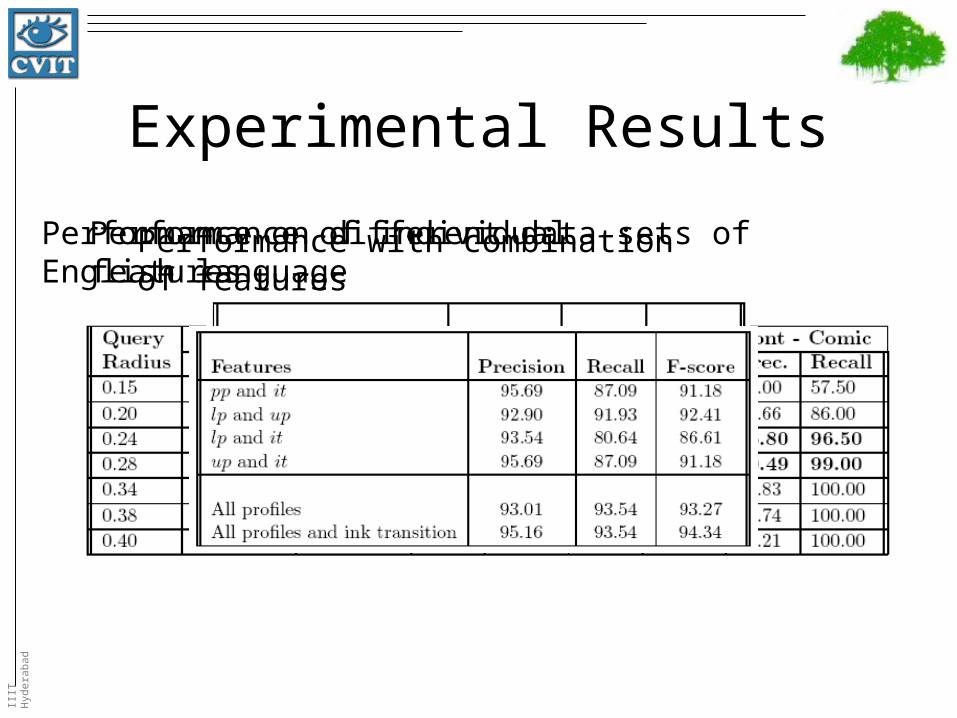
Experimental Results
Performance on different data sets of English languagePerformance with combination of featuresPerformance of individual features
IIIT
Hyd
erab
ad
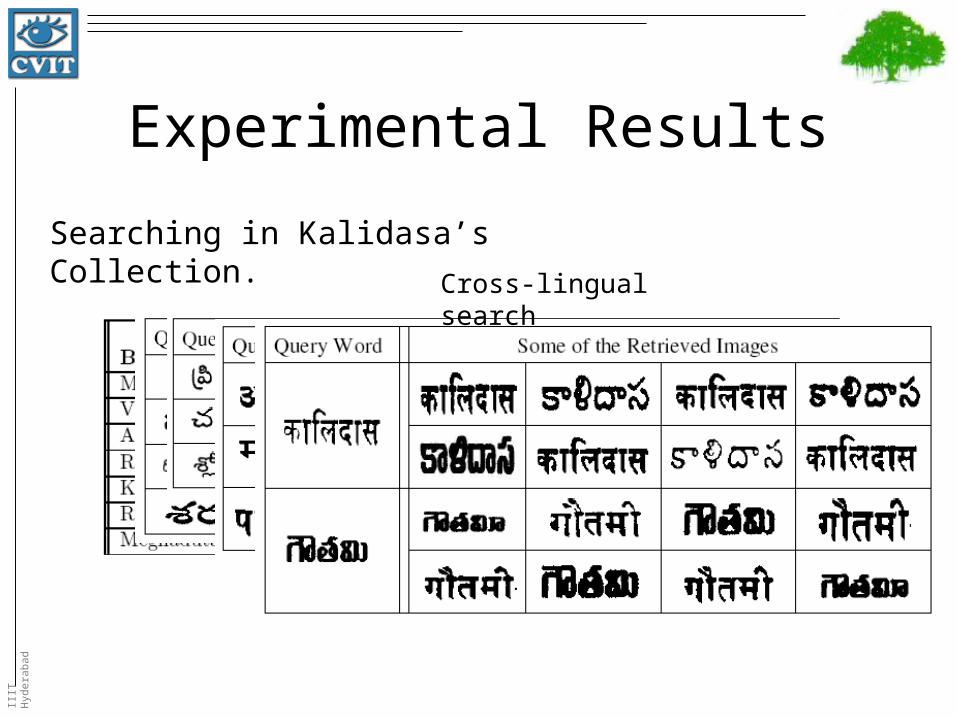
Experimental Results
Searching in Kalidasa’s Collection.
Cross-lingual search

IIIT
Hyd
erab
ad
Experimental Results
Searching in Kalidasa’s Collection.
Comparison with Dynamic Time Warping based NNS

IIIT
Hyd
erab
ad
Overview
• Introduction• The problem• Previous work• Contributions• Searching in document images• Annotation for retrieval
– Annotation based search– Annotation correction– Experimental results
• Summary• Future work

IIIT
Hyd
erab
ad
Annotation for Retrieval
• Annotation is the process of identifying objects in images and labeling with meaningful description.
• Search is easy and efficient in annotated document images.
• Challenges– Recognition for annotation may be inaccurate.– Manual annotation is impractical
vijayavaaDa paalakulu maarinaa konni
Labeling word segments with corresponding text words.

IIIT
Hyd
erab
ad
Annotation for Retrieval
• Can we use image search to speed up annotation and increase accuracy?– Image search produces clusters of similar words.– A single representative is required to annotate words
of the whole cluster.– Cluster of recognized words can be obtained to get
the representative.– The cluster information can be used to obtain correct
annotation of the cluster.

IIIT
Hyd
erab
ad
Annotation Based SearchDocument
Images
Pre-processing
Segmentation and word detection
Feature ExtractionHashing
Textual Query
Text Search Engine
Cluster of Word Images
Relevant Documents
HashedWords
Word Annotation by Recognition
Offline ProcessOnline Process

IIIT
Hyd
erab
ad
Annotation CorrectionCorrection by Majority Voting
ambiderous
anbiderous
ambidextrous
ambidextro4s
ambidextrous
ambidextrous
abidextro4s
ambideous
ambiderous
ambidextrous ambidextro4s ambidextrous ambidextrous ab idex tro4s ambiderous an biderous ambiderous ambideous
ambidextrous
Final word
Word length = 12
Ordered words
Text words of clusterWord image cluster
recognition
What if too
erroneous?

IIIT
Hyd
erab
ad
Annotation Correction
• Input: Cluster C of words.• Output: Representative word WR for C
1. S = Sort C based on string length2. Get M = {S | for all A, B in S edit distance of A and B is less than half of the
lengths of A and B}
3. If l is the length of most of the strings (majority) the cluster representative WR has length l.
4. For each character i = 1,…,l do– Get all k words of length l– Find majority of characters for position i of WR
Correction by Majority Voting

IIIT
Hyd
erab
ad
Annotation CorrectionCorrection by Alignment
ambidextrous
ambidextro4s
ambidextrous
abidextro4s
ambiderous
a m b i d e x t r o u s
a b i d e x t r o 4 s
a m b i d e r o u s
a m b i d e x t r o u s
a m b i d e x t r o 4 s
a m b i d e x t r o u s
Final word
Aligned wordsText words of cluster
a m b i d e x t r o 4 s
Word obtained by majority voting

IIIT
Hyd
erab
ad
Annotation Correction
• Input: Cluster C of Wi = 1,…,n words• Output: Cluster representative WR of C
• for each i = 1,…,n do– for each j = 1,…,n do
• if j ≠ i then do– Align word Wi and Wj
– Record errors Ek, k = 1,…,m in Wi
– Record possible correction Gp, p = 1,…,q for Ek from Wj
• end if– end for– Find correction Ch = Gp by majority voting– Correct Ek with Ch
– O ← O U Wi
• end for• Find correct word WR from the alignments O with majority voting.
Correction by Alignment
IIIT
Hyd
erab
ad
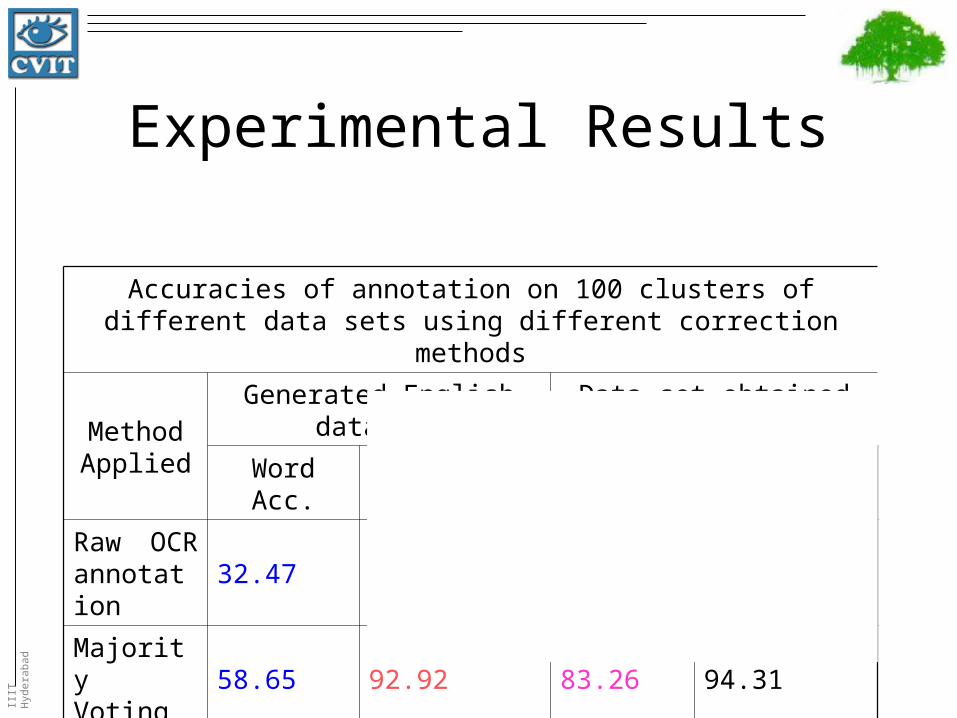
Experimental Results
Accuracies of annotation on 100 clusters of different data sets using different correction methods
Method Applied
Generated English data set Data set obtained from book
Word Acc. Character Acc. Word Acc. Character Acc.
Raw OCR annotation
32.47 69.59 82.71 93.78
Majority Voting
58.65 92.92 83.26 94.31
String Alignment
78.85 94.5 86.45 95.98

IIIT
Hyd
erab
ad
Experimental Results
Effect of cluster size on the retrieval performance

IIIT
Hyd
erab
ad
Summary
• Direct hashing of the word features eliminates costly processing before building an index.
• Query results can be obtained in milliseconds using the content sensitive hashing (CSH).
• Scalability of the proposed method is demonstrated on a collection of Kalidasa’s books.
• Two methods to improve the automatic word labeling (annotation) accuracy are presented.
• Demonstrated annotation based retrieval technique using the automatic annotations of document images.

IIIT
Hyd
erab
ad
Future Work
• Indexing of documents images in different fonts.• Searching in Multi-lingual documents is one of the
challenging tasks.– Many Indian language documents are translated to other
languages.• Usage of cluster information
– for improving the accuracy of character recognizers.• Annotation becomes difficult in presence of errors in
every recognized word of a cluster.– Need to explore new techniques for annotation

IIIT
Hyd
erab
ad
Related Publications
• Anand Kumar, C.V.Jawahar and R. Manmatha. "Efficient Search in Document Image Collections". Asian Conference on Computer Vision (ACCV), pages 586-595, November 18-22, 2007, Tokyo, Japan.
• C.V.Jawahar and Anand Kumar. "Content Level Annotation of Large Collection of Printed Document Images". International Conference on Document Analysis and Recognition (ICDAR), pages 799-803, September 23-26, 2007, Brazil.
• Anand Kumar, A. Balasubramanian, Anoop M. Namboodiri and C.V. Jawahar. "Model-Based Annotation of Online Handwritten Datasets", International Workshop on Frontiers in Handwriting Recognition (IWFHR), October 23-26, 2006, La Baule, France.

IIIT
Hyd
erab
ad
Thank You
Questions ?
IIIT
Hyd
erab
ad
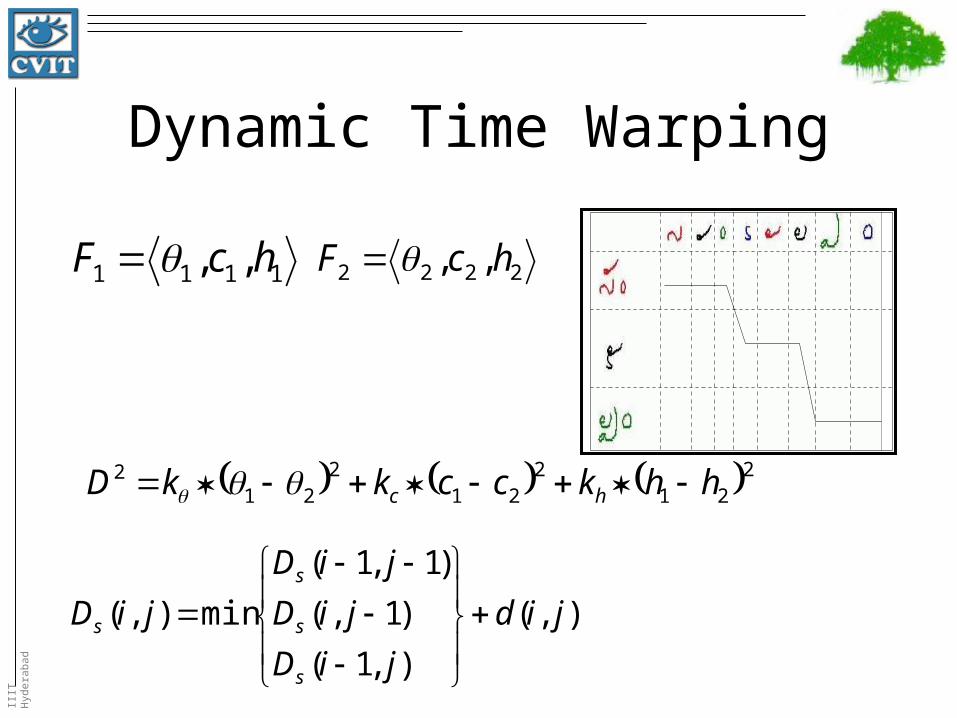
Dynamic Time Warping
),(
),1(
)1,(
)1,1(
min),( jid
jiD
jiD
jiD
jiD
s
s
s
s
2222 ,, hcF
221
221
221
2 hhkcckkD hc
1111 ,, hcF

IIIT
Hyd
erab
ad
Partial Matching





























