Embed Size (px)
Citation preview

Implementation of a Resource-Aware, Data
Clustering Algorithm for the Sun SPOT
Distributed Query Processor (SSDQP)
Quincy Chi Kwan Tse (200310185) – 100%
contribution
Supervisor: Uwe Röhm
Submitted: 28 May 07

i
Title:
Implementation of a resource-aware, data clustering algorithm for the Sun SPOT Distributed
Query Processor
Author:
Quincy Tse
School of Information Technologies
Faculty of Engineering and Information Technologies
The University of Sydney
Australia
Abstract Wireless sensor network (WSN) nodes have very limited battery life. Therefore a current topic
in the research of WSN is to extend their operational life for as long as possible. In this
project, a resource-aware algorithm for clustering (aggregating) streaming data collected by
had been implemented into the School of Information Technologies’ WSN research project,
the Sun SPOT Distributed Query Processor (SSDQP). As part of this extension, a new
framework had been developed in order to cater for future implementations of different data
stream processing algorithms into SSDQP. A new mechanism was also developed to support
any resource-aware components implemented into SSDQP.
Acknowledgements I would like to take this opportunity to thank my supervisor for guiding me through the
project and keeping me on track. Without his guidance, I would probably have drifted to work
on some related but not assessable problem, and would never have got this finished.

ii
Table of Contents 1 Introduction..........................................................................................................................................1 1.1 Background...................................................................................................................................1 1.2 Related Work ...............................................................................................................................2 1.3 Organisation of the report .........................................................................................................3 2 System Design and Implementation..................................................................................................4 2.1 Original Design of SSDQP ..........................................................................................................4 2.2 System Design Extensions..........................................................................................................6 2.3 System Implementation .............................................................................................................7 3 Background on Tools and Concepts............................................................................................... 12 3.1 Artifacts used............................................................................................................................. 12 3.2 Coding Methods ........................................................................................................................ 13 3.3 Evaluation Methods ................................................................................................................. 14 4 User Operations ................................................................................................................................ 15 4.1 User Operations ........................................................................................................................ 15 4.2 Operational Scenarios .............................................................................................................. 16 5 Evaluation .......................................................................................................................................... 21 5.1 Tests for Correctness ............................................................................................................... 21 5.2 Tests for Performance............................................................................................................. 23 5.3 Limits on the Extension.......................................................................................................... 23 5.4 Evaluation of the Extension ................................................................................................... 24 6 Individual Reflections....................................................................................................................... 25 7 Conclusion ......................................................................................................................................... 27 8 Future Work ...................................................................................................................................... 28 9 References.......................................................................................................................................... 30
Table of Figures Figure 1 The version of Sun SPOT used (bSPOT) ...................................................................................1 Figure 2 The newer version of Sun SPOT (eSPOT) ................................................................................1 Figure 3 SSDQP Design (taken from [8]) .................................................................................................4 Figure 4 SSDQP Extensions (green – new addition, blue – modification) ............................................1 Figure 5 ERA Clustering algorithm ............................................................................................................1 Figure 6 Components of Sun SPOT (eSPOT) [13] .............................................................................. 12
List of Tables Table 1 BNF grammar definition for SSDQP query language at the start of the project...................1 Table 2 SSDQP Language extensions – the rest of Table 1 remained unmodified .............................8 Table 3 Specifications of the Sun SPOT (taken from [13]) ............................................................... 12 Table 4 Sample compiler results ............................................................................................................. 22

1
1 Introduction
1.1 Background
This project is part of the research conducted by the School of Information Technologies on
data processing in wireless sensor network. The objective for this project is to develop an
extension to the Sun SPOT Distributed Query Processor (SSDQP) in order to evaluate the
performance of the Enhanced Resource Aware (ERA) clustering algorithm proposed by Gaber
et al [4] in life operation of a typical wireless sensor network.
In implementing the ERA clustering algorithm, a number of supporting infrastructures have
been developed. These supporting infrastructures provide the capability to sense available
resources (CPU utilisation, free memory and remaining battery level) as well as to retrieve the
instantaneous state of an ERA cluster.
1.1.1 Wireless Sensor Networks
A wireless sensor network (WSN) is group of wirelessly connected, battery operated embedded
devices equipped with one or more sensors. Unlike other wireless networks, WSN is designed to
contain a large number of nodes that operate without operator intervention. Typically, these
devices are various types of environmental sensors capable of performing some calculations,
and are able to forward the measurements to a central location for further processing.
WSNs are relatively cheap to produce and deploy, and are typically used to monitor a large
area. Examples of WSN applications include collecting tidal data on a coastline, monitoring the
health of the Murray River and monitoring the stress on dam walls.
Due to the battery-operated nature of WSN nodes, resources at each node are very constrained.
Nodes have a very limited battery life. Consequently, the nodes’ processing power, radio
interface as well as memory have also been designed to be limited in order to conserve battery.
In addition, the radio interface was unreliable due to low transmission power and internal
antennae.
1.1.2 Enhanced Resource Aware Clustering
Studies [11] have identified that radio communication is the most energy-expensive operation
on a sensor node. The power used in transmitting one bit is enough to perform up to 1000 of
instructions [12]. In order to reduce the amount of data transmitting across the network, the
Enhanced Resource Aware (ERA) clustering algorithm [3], [4] had been designed to summarise
sensor data for storage and transmission.
The clustering algorithm in the ERA cluster summarises the sensed data by attempting to put
each measurement into an appropriate cluster. The most appropriate cluster is obtained by
selecting the cluster whose Manhattan distance to the measurement is the smallest and is below
a specified threshold. The use of the Manhattan distance allowed the clustering algorithm to
operate multi-dimensionally.
Since measurements on the environment tend to have quite a large temporal redundancy [3],
by locally summarising the measurements to value ranges (represented by the mean of the
measured values) and their respective frequencies (the number of measurements in each
“bucket”) over a period of time, the storage and transmission requirements can be greatly
reduced.

2
Figure 1 The version of Sun SPOT used
(bSPOT)
In addition, the ERA clustering algorithm also automatically adapts the processing to the
available resource level. Whenever the amount of free memory falls below a preset threshold,
the algorithm will increase the radius of each cluster (thus the range of values each cluster
contains) in order to discourage the formation of new clusters. It will also remove inactive and
outlier clusters.
1.1.3 Sun SPOT Distributed Query Processor
In addition to minimising energy use, flexibility and usability of a WSN is also important for
some applications. The Sun SPOT Distributed Query Processor (SSDQP) was developed to
address the usability of the WSN by providing a declarative query interface using a SQL-like
language to provide data abstraction. SSDQP also provides time synchronisation, in-network
processing, a remote multi-client GUI as well as a scheduling mechanism to enable multi-
tasking support [11].
Data abstraction allows users to easily specify the data to be gathered without the need to
instruct the WSN how to execute the query. The user specifies the data to be retrieved by
entering a SQL-like query into a GUI. The GUI then forwards the request to the host program
through a standard TCP/IP socket connection. This query is then parsed and compiled into a
high-level execution plan. Through the base station node connected to the host machine, this
execution plan is disseminated into the network. Each node then decides and schedules the
actual tasks to perform based on the received plan. The time-triggered scheduler in each node
will execute the tasks as scheduled and recurrent tasks will be rescheduled to run on the next
specified time.
By separating the GUI and the host program and communicating through TCP/IP, SSDQP
allows multiple users to access WSN resources remotely and concurrently. In addition, by
making the decision on the action to perform at the node, it allows for WSN with nodes that
have different capabilities and simplifies the deployment of new nodes into a WSN. Multi-
tasking is supported by compiling queries into tasks and scheduling them into the scheduler.
Multiple queries are compiled into separate tasks, allowing multiple queries to be issued to the
node concurrently.
SSDQP runs on WSN nodes called Sun SPOT, which are Java VM based devices. These devices
run Java natively, allowing programs written in the high-level language to be executed
relatively efficiently. The version of Sun SPOT used in SSDQP is the bSPOT (Figure 1). It is
intended that the code be ported across to the newer hardware called eSPOT (Figure 2) by July.
Further information on these devices is contained in section 3.1.1.2.
1.2 Related Work
There are a number of other research groups that are currently investigating different
approaches to minimise communications to increase the life of the sensor nodes. The concept
of resource aware clustering actually originated from Teng et al’s paper [10]. Other in-network
Figure 2 The newer version of Sun SPOT
(eSPOT)

3
clustering techniques like HEED [9] have also been developed. The majority of these proposals
are implemented on minimal sensor devices like MOTEs, which lacks the higher level
abstraction and libraries that are available in a virtual-machine based system.
In their paper, Madden et al [12] presented TinyDB, which is considered as the “gold standard”
in the field. TinyDB also uses an SQL-like language for declarative querying. The query is
parsed, compiled and optimised for overall power consumption, and are disseminated into the
network in binary format. Queries in TinyDB may iterate until a STOP QUERY command is
received by the node. TinyDB also provides event-based and life-time based queries in order to
minimise unnecessary transmission of intermediate results. Tiny DB provides stream
processing capabilities including sliding window aggregate as well as claiming to provide user-
defined aggregates. Resource optimisations in Tiny DB are primarily provided at the host when
compiling the query into the execution plan. In contrast, SSDQP concentrates on providing
dynamic resource adaptation on each node at runtime.
Mueller et al [1] have developed SwissQM, which utilise in-network aggregation to reduce data
sent. SwissQM essentially extends a Java opcode-based virtual machine with sensor and query
specific op-codes, running on top of TinyOS to provide higher level abstraction support.
SwissQM’s use of in-network clustering reduces data by eliminating spatial redundancies. It also
provides the ability for the nodes to accept macro-like programs in order to provide extra data
manipulation functionalities like aggregation operators. SwissQM compiles the query at the
host into VM code before disseminating to nodes. A time-trigger mechanism is not currently
supported.
In contrast, the ERA clustering algorithm aggregates the data collected in the node over a
period of time, thus exploiting the temporal redundancies that are inherent in the collected
data. The SSDQP extensions produced in this project also use a different concept to implement
new data manipulation functionalities. Instead of defining a new function that implements the
algorithm, it defines a special data storage container that implements the same interface as the
other data containers. This new container applies the aggregation algorithm either as new data
is added or as the stored data is retrieved (depending on the actual implementation). This allows
the intermediate states of the algorithm to be internalised, thus supporting multiple concurrent
queries that uses the same algorithm. Spatial redundancies can still be exploited by
implementing any other cluster-based routing schemes underneath the clustering application.
SSDQP also provides dynamic resource adaptation within the nodes through the use of a
resource monitor, which can alert resource-aware algorithms as resource level changes. In
addition, by implementing a task scheduler within SSDQP, multiple queries may be running on
the node concurrently, allowing the network to be used for multiple applications concurrently.
1.3 Organisation of the report
This report is divided into 8 chapters. The first chapter provides an introduction and the
background to the task, followed by a chapter about the background concepts and the tools used
in this project. Chapter 2 gives a general overview of the design of the extensions. The report
then provides a background on the tools used and concepts introduced in the system. The user
operations and usage scenarios are contained in Chapter 4 while a summary of the testing
procedures and the tests conducted are stated in Chapter 5. Chapter 6 presents a reflection on
the project, followed by the conclusion in Chapter 7. A suggestion on the future direction of
the project is presented in Chapter 8.

4
2 System Design and Implementation
2.1 Original Design of SSDQP
Initially, SSDQP contains 7 modules – Communication, Routing, Networking, Global Time
Synchronisation, Grammar, Sensing and the Scheduler modules [8]. Other than Communication
and Routing, all modules interact with the Scheduler for task scheduling. Most functions
performed in a node are packaged into “TaskSets”, which arrange the actions required
(“Tasks”) into an execution tree. New functionalities can be added by extending an appropriate
Task.
Figure 3 SSDQP Design (taken from [8])
2.1.1 Communication, Time Sync, Routing and Networking Modules
Together, these four modules handle all matters relating to the transmission and reception of
messages over the radio interface. Communication module deals with the various API calls in
order to receive and transmit messages, whereas the Routing module contains the routing
algorithm. The Networking module packages calls to these modules into Tasks and TaskSets
for scheduling.
Global Time Synchronisation module provides the singleton TimeKeeper class, allowing the
system clock to be adjusted, as well as the necessary TaskSets for processing time
synchronisation messages.
2.1.2 Grammar Module
The Grammar module is using recursive descent parsing. Two branches of the Grammar module
are used in the project – one branch for translating SQL queries into compact Tokens for
network transmission as well as defining the query plan, the other parses the Tokens on the
node and assembles a TaskSet for executing the specified query. The original query language is
defined in Table 1.
The current implementation of SSDQP uses a two-step process to interpret an SQL query into
a list of Tasks for the nodes to do. Step 1 is to rewrite the verbose SQL query into a shorter
network Tokens using the SQLParser and TokenCompiler classes in order to minimise network
transmission. Attribute names are translated to their numeric identifier in the host computer to
minimise communication cost. Step 2 is then to interpret the received Token string and
sequences a list of Tasks that are required to execute the query.

5
In order to extend the query language, new identifier token needs to be defined, as well as the
usage rules regarding the new syntax. Corresponding network Tokens and their syntax also
need to be defined. The parse is then updated to translate the new identifiers into the new
network tokens. New Tasks are also required to be defined in order to provide the
functionalities, and the parser on the node is then updated to produce the new execution tree.
2.1.3 Sensing Module
The sensing module deals with the acquisition and processing of sensor data. Not only does this
module contain code to access the node’s sensors, it also contains all the code needed for result
table operations.
For each sensor in the node, a SensorTask is created to activate and retrieve information from
that sensor. In order to allow a new sensor to be used in SSDQP, a new SensorTask needs to be
defined, with the eval() method overridden to return the sensor value. Since the sense() method
in SenseManager activates each sensor and arranges the values in a result Table, it also needs to
be updated such that it will activate the new sensor.
Result table operations are implemented in the “SSDQP Relational Database (srdb)” sub-
module. It defines the basic data container – the Table as well as a number of Tasks that
perform the operations.
<statement> ::= <maintenance> | <query> <maintenance> ::= <kill> | <sync> | <route> <kill> ::= “KILL” <number> <sync> ::= “SYNC” [<number>] <route> ::= “ROUTE” { <number> } <query> ::= “SELECT” <field> { “, ” <field> }
[ “WHERE” <condition> ] [ “GROUPBY” <attribute> ] [ “START” <starttime> ] [ “EPOCH” <verbosetime> ] [ “RUNCOUNT” <number> ]
<field> ::= <attribute> | <aggregation> <attribute> ::= “node” | “time” | “x” | “y” | “z” | “ temp” | “ light” | “sw1” | “ sw2” | “*” <aggregation> ::= <aggregator> “(” <attribute> “)” <aggregator> ::= “SUM” | “AVG” | “MAX”| “MIN” | “COUNT” <condition> ::= <comparison> [ <booleanop> <condition> ] <comparison> ::= <comparisonexpr> | <conditiongroup> <comparisonexpr> ::= <numericexpr> <comparator> <numericexpr> <conditiongroup> ::= “(” <condition> “)” <booleanop> ::= “AND” | “OR” <numericexpr> ::= <numericconst> { <numfunct> <numericconst> } <numericconst> ::= <field> | <number> <comparator> ::= “<” | “<=” | “=” | “>=” | “>” | “!=” <numfunct> ::= “*” | “/” | “+” | “-” <number> ::= any integer in the range !263 to 263 ! 1 <verbosetime> ::= <number> <timeunit> [ <verbosetime> ] <timeunit> ::= “hour” | “hours” | “h” | “minute” | “minutes” | “m” | “second” | “seconds” | “s” <starttime> ::= <fixedtime> | <relativetime> <fixedtime> ::= “AT” <statictime> <statictime> ::= <number> “:” <number> “:” <number> “ ” [ <date> ] <date> ::= <number> “.” <number> “.” <number> <relativetime> ::= “IN” ( <verbosetime> | <statictime> )
Table 0 BNF grammar definition for SSDQP query language at the start of the project

6
2.2 System Design Extensions
This project extends the existing SSDQP by incorporating the ERA clustering capability into
SSDQP. This extension is achieved by:
• Implementing “internal sensors” in order to provide a generic method of retrieving resource level. This is achieved by extending the Sensing module.
• Implementing a mechanism that monitors the current resource level and notifies any resource-aware components of any changes that have been detected. The Resource Monitor module was introduced into SSDQP to provide this functionality.
• Providing a generic mechanism to store intermediate results (buffered, or aggregated by some algorithm like ERA cluster), provided by the new Storage Point sub-module.
• Implementing the ERA clustering algorithm as prototyped. This is achieved by the new Clustering sub-module.
• Extending the query language in order for these new features to be used by the operator by
amending the Grammar module.
In addition, the start up routine was also updated in order for the Resource Monitoring module
to be started automatically.
2.2.1 Grammar Module
Amendments to the Grammar module are necessary in order to enable the new features to be
used in the query language. In this project, the existing module was extended to allow users to:
• specify any of the three new internal sensors (CPU idle time, free memory and battery level) to be used,
• specify whether to return the sensed data to the base station or to buffer them locally, • specify whether the buffered data should be summarised using the clustering algorithm, and • specify the source of the data to retrieve from (sensors or the buffered readings)
2.2.2 Sensing Module
The Sensing module was extended by adding new types of SensorTask to retrieve the current
battery level, free memory and the CPU utilisation. These tasks are invoked as the leaf node in
the recursive descent execution tree.
The Sensing module was also extended to allow buffers to be “sensed”. Future extensions to this
module (in conjunction with the Storage Point module) should create a new “Sensor” table, thus
removing this decision of where to sense for data by implicitly deciding the data source through
polymorphism.
Figure 4 SSDQP Extensions
(green – new addition, blue – modification)

7
2.2.3 Resource Monitor Module
The Resource Monitor module was added to the existing SSDQP project mainly for the use of
the resource-aware clustering algorithm that was integrated into this system in this project.
However, the module interface uses the well-known publisher-subscriber relationship,
implemented using Java call-back methods. This allows any other part of the SSDQP to
become resource-aware by subscribing to the Resource Monitor.
In order to reduce code redundancy and to fully utilise the scheduler for task scheduling, the
Resource Monitor module is designed as two separate parts: a Singleton Resource Table which is
a single-row Table that notifies all its subscribers whenever it is updated, and a periodic query
that sense the current resource level, and updates the Resource Table.
While these two parts are extremely simple to code (ResourceTable is a standard publisher in a
publisher-subscriber relationship, and the recurring query required no extra code – just a Token
string for the query that the Grammar module can easily decipher), they provide a trigger that
allows advanced resource-aware algorithms to be implemented into the various components of
the nodes.
2.2.4 Storage Point Sub-module
The Storage Point sub-module of the sensing module contains the code to define and retrieve
specific storage points for use as a buffer (clustering or otherwise).
This module contains only 1 class – StoragePoint. The StoragePoint class is a singleton class.
It basically creates storage locations (“pigeon holes”) for data storage. Each storage location is
identified internally by a location number.
The addLocation() method in the StoragePoint creates a new storage location to store data,
while the getLocation() method retrieves the Table currently stored in the specified location.
This Storage Point module is designed to be able to store any type of data Table. Aggregation
and other stream processes can be simplified by implementing them as a subtype of Table.
Using StoragePoint to store its intermediate states between invocations, the developer need
not worry about how these processes can be scheduled into the SSDQP.
2.2.5 Clustering Sub-module
This module contains all necessary code to perform the functions of the ERA clustering as
described in [2], [3].
This module contains 3 classes, of which only one (ERA_Cluster) is used externally by the rest
of the program. The ERA_Cluster is adapted from the original ERA_Cluster prototype, and
was made to become a type of data Table (which is used throughout the rest of SSDQP) by
implementing extra adapter methods. This allows the class to be stored in the Storage Point
module such that it is easy to access. This class enables resource awareness by registering itself
as a subscriber to the Resource Monitor module.
In order to use this module, a new Task was created in the Grammar module that will cause a
new cluster to be created when a clustering query is executed.
2.3 System Implementation
It should be noted that the modules described in this document does not directly corresponds to
the actual Java packages in the implementation. This document identifies the conceptual
modules is SSDQP and is in line with the original design as described in the original
documentation [8]. These modules may be separated into two or more Java packages in the

8
implementation of both the SSDQP and the extensions. This allows the programmers to
further restrict the namespace of the classes when implementing the design.
2.3.1 Grammar Module
Table 1 identifies the extensions made to the SSDQP query language to enable the new features
to be used.
<query> ::= “SELECT” <field> { “, ” <field> } [FROM <location>]
[INTO <location> [CLUSTER <radius>]] [ “WHERE” <condition> ]
[ “GROUPBY” <attribute> ] [ “START” <starttime> ]
[ “EPOCH” <verbosetime> ] [ “RUNCOUNT” <number> ]
<field> ::= <attribute> | <aggregation> <attribute> ::= “node” | “time” | “x” | “y” | “z” | “temp” | “light” | “sw1” | “sw2” | “battery” | “cpu” | “memory” | “*”
<location> ::= any alphanumeric string <radius> ::= <number>
Table 1 SSDQP Language extensions – the rest of Table 1 remained unmodified
To implement this change, step 1 of the query parsing process (translating to network Tokens)
was extended by first extending the language defining the Tokens. The Parser and the Compiler
were then extended to recognise the new syntax by adding new methods that deals with the new
syntax, and calling these new methods from the main Parser method.
Step 2 of the query parsing process (constructing an execution tree from network Tokens) was
extended by first creating the new Tasks that are required (for example, the Task to write data
to into a buffer, which was used in lieu of forwarding the results back to base station). The
TokenParser was then updated to recognise the new Token syntax and creates the new Tasks
as necessary. The use of the Composite design pattern and the recursive descent nature of the
task execution greatly simplified the amendments in this module.
2.3.2 Storage Point Sub-module
In order to conserve memory use and the amount of data transmitted across the network, the
Storage Point was designed to use integer identifiers to internally identify each storage point.
Currently the Storage Point is implemented as a hash table stored in RAM, mapping the
identifier to a type of the data Table. Internal implementation of the data Table is irrelevant
as it uses only the interface, thus allowing any specialised data Tables like the ERA Cluster to
be stored in addition to the standard buffer Tables. Future extensions to this module can easily
add support for the Storage Point to save its content to flash memory in order to protect
against any random node restarts.
However, the use of numeric identifier by users is both unintuitive and error prone. Therefore
the SQL query language uses an alphanumeric string to identify storage points.
In order for this to operate, a translator is required to translate the alphanumeric identifier to a
numeric identifier. The implementation of such a translator is simple and is based on HashMap.
There are two places where this translator could be placed – either in the host machine or on
the client. Since multiple clients may connect to the same host, identifier clashes may occur if
the translator is place in the clients. Therefore, the translator is placed in the host application
along with the translator for attribute names.
In the currently implementation, this translator is only stored in the host computer’s memory
and is therefore not persistent. In order to allow the host to be restarted without losing these
critical metadata, it is advised that future extensions to SSDQP enable this metadata table to be

9
dumped into persistent storage such that these metadata can be restored in the event of host
application restarting.
2.3.3 Sensing Module
The Sensing module was extended by adding three new SensorTasks to retrieve the resource
levels – CPUTask (CPU idle time), MemoryTask (free memory) and BatteryTask (remaining
battery level). Since the bSPOT hardware only support the calculation of free memory through
the standard JVM status methods, only MemoryTask was fully implemented. The remaining
Tasks are inserted into the system as dummy classes.
In order to determine whether the task require the activation of sensors or just reading from
buffer, the main sense() method was updated. The sense() method now defaults to retrieving
from buffer, unless the storage location indicates that it should be retrieved from the actual
sensors. This is an interim solution as a more elegant implementation is to implement the
sensing operation inside a “SensorTable” stored within the storage point. This allows the
program to implicitly perform the correct operation without checking the intention of the
query.
2.3.4 Resource Monitor Module
The Resource Monitor module was implemented as specified in section 2.2.3. In addition, a
new type of Task was also added to the Scheduler such that the run count (number of iterations
before terminating the task) is not decremented. This allows the recurrent monitoring task to
be able to run indefinitely.
2.3.5 Clustering Sub-module
As described in sections 1.1.2 and 2.2.5, the Clustering sub-module implements the ERA
Clustering algorithm in order to summarise measurements to value ranges and their frequencies.
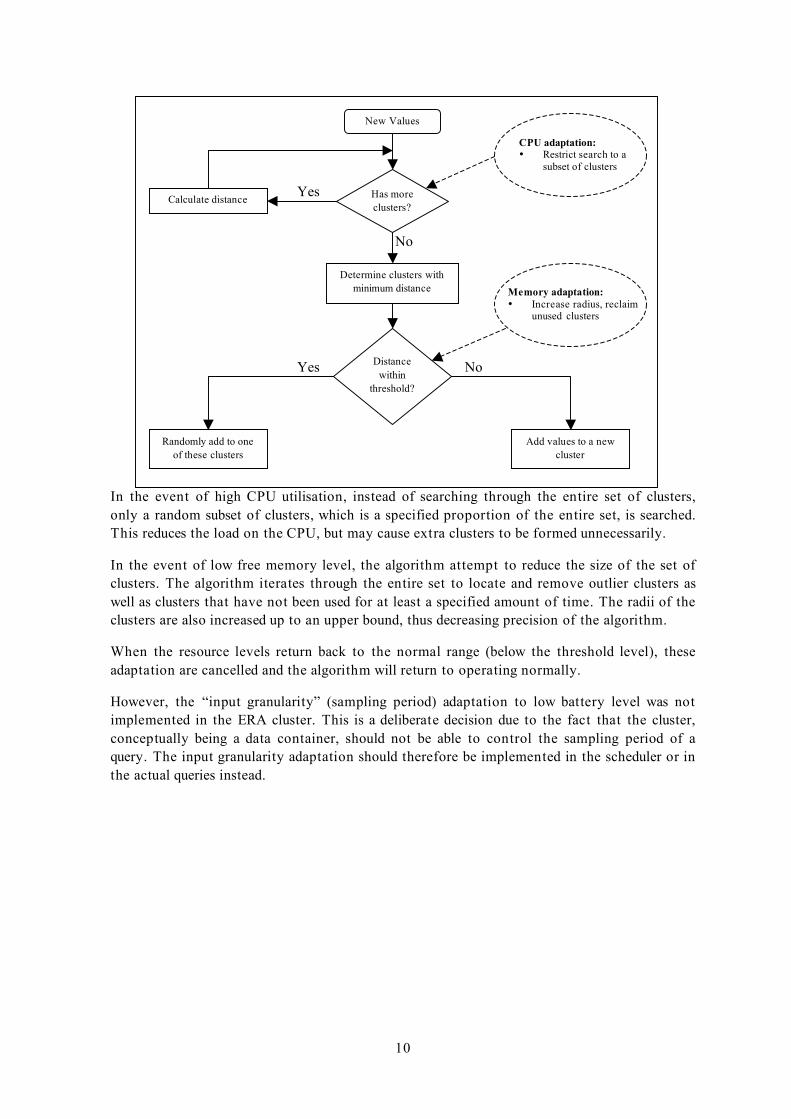
Figure 5 describes the operation of the algorithm as implemented in the Clustering sub-module.
When a new measurement is to be clustered, the algorithm searches through the set of all
clusters, calculating the Manhattan distance between the mean of each cluster and the new
measurement. If the measured values are within the specified threshold radius from the closest
cluster, then the measurement is added to that cluster by updating the mean of the cluster and
incrementing the count. If no such clusters are found, then a new cluster is established centred
at the measurement with the count set to 1. The use of Manhattan distance allows the
algorithm to apply in a multi-dimensional case, making the algorithm much more generic.
Resource adaptation in this sub-module is implemented by varying the “processing granularity”
(accuracy of the aggregation operation) and the “output granularity” (size – hence the
precision – of the clusters) as described in [4].
Figure 5 ERA Clustering algorithm
10
In the event of high CPU utilisation, instead of searching through the entire set of clusters,
only a random subset of clusters, which is a specified proportion of the entire set, is searched.
This reduces the load on the CPU, but may cause extra clusters to be formed unnecessarily.
In the event of low free memory level, the algorithm attempt to reduce the size of the set of
clusters. The algorithm iterates through the entire set to locate and remove outlier clusters as
well as clusters that have not been used for at least a specified amount of time. The radii of the
clusters are also increased up to an upper bound, thus decreasing precision of the algorithm.
When the resource levels return back to the normal range (below the threshold level), these
adaptation are cancelled and the algorithm will return to operating normally.
However, the “input granularity” (sampling period) adaptation to low battery level was not
implemented in the ERA cluster. This is a deliberate decision due to the fact that the cluster,
conceptually being a data container, should not be able to control the sampling period of a
query. The input granularity adaptation should therefore be implemented in the scheduler or in
the actual queries instead.
New Values
Has more
clusters? Calculate distance
Determine clusters with
minimum distance
Distance
within
threshold?
Randomly add to one
of these clusters
Add values to a new
cluster
Memory adaptation:
• Increase radius, reclaim unused clusters
CPU adaptation:
• Restrict search to a
subset of clusters
Yes
No
Yes No

11
2.3.6 Start-up Routine
The start-up routine that is executed by the sensor node when it is switch on was amended such
that the resource monitoring module is started at the first opportunity (as soon as the node is
synchronised with the network, which allows the exact system time to be determined for
scheduling purposes).

12
3 Background on Tools and Concepts
3.1 Artifacts used
3.1.1 Hardware
3.1.1.1 Development Platform
The hardware used in this project includes an Acer Aspire 3627WXMi laptop (1 GB DDR2
memory, 1.7GHz processor – can only run at 1.3GHz maximum, running Windows Vista
Business Edition). This computer is used due to budget constraints – the author cannot secure
funding from the School of Information Technologies to purchase a new personal computer
purely for this project.
3.1.1.2 Wireless Sensor Node
The sensor node used in this project is the beta-release Sun SPOT (bSPOT) (See Figure 1). This
node is used because this is the node the School of Information Technologies is currently
conducting research on. The most notable feature of this sensor node is that it runs Java as its
native programming language – “runs Java on bare metal”. This allows sophisticated algorithms
to be implemented on the sensors nodes easily. The specifications for a Sun SPOT device are
listed in Table 2 Specifications of the Sun SPOT.
Figure 6 Components of Sun SPOT (eSPOT) [13]
Sun SPOT Processor Board
• 180 MHz 32 bit ARM920T core - 512K RAM/4M Flash
• 2.4 GHz IEEE 802.15.4 radio with integrated antenna
• USB interface
• 3.7V rechargeable 720 mAh lithium-ion battery
• 32 uA deep sleep mode
General Purpose Sensor Board
• 2G/6G 3-axis accelerometer
• Temperature sensor
• Light sensor
• 8 tri-color LEDs
• 6 analog inputs
• 2 momentary switches
• 5 general purpose I/O pins and 4 high current output pins
Squawk Virtual Machine
• Fully capable J2ME CLDC 1.1 Java VM with OS
functionality
• VM executes directly out of flash memory
• Device drivers written in Java
• Automatic battery management
Developer Tools
• Use standard IDEs. e.g. NetBeans, to create Java code
• Integrates with J2SE applications
• Sun SPOT wired via USB to a computer acts as a base-station
Table 2 Specifications of the Sun SPOT (taken from [13])
3.1.2 Compilers and Language Tools
3.1.2.1 Programming Language - Java
SSDQP and its extensions are written entirely in Java. Java is used due to the native support for
the language by the sensor node. This greatly simplifies the development of new code for the
sensor nodes.
3.1.2.2 Java Compiler
The standard Java SE 1.60_01-b06 compiler was used to compile the project. This compiler
was used because it is the most current compiler for Java, and it maintains good backward

13
compatibility with previous versions of Java. The improved GUI API in Java SE 6.0 was also
used in the existing SSDQP project, and thus is a requirement in order to compile the existing
SSDQP code.
When this compiler is used to compile the code for deployment into the Sun SPOTs, the
source level” of the compiler is restricted to Java SE1.3 in order to maintain compatibility with
the Java (Squawk) Runtime used in the Sun SPOTs.
3.1.2.3 Sun SPOT Libraries and Deployment Tools
The Java (Squawk) library and the Sun SPOT libraries were used in this project as they are
required for compiling code that can be run on Sun SPOTs. The Sun SPOT libraries also allow
the software to interface with the Sun SPOT hardware on each node.
Ant is used both to compile, “suite” (collect all required class files and components of jar files
into an image file), deploy (write the image file to the node) as well as running the host
(computer-based base station logic), base station (a “tap” into the radio interface) and the
nodes. Ant is used as it is the default tool used by Sun SPOT, and it is easily configurable to the
project’s needs.
3.1.2.4 Source Code Repository
Subversion (SVN) was used to store the source code. A separate branch for this project was
created from the main SSDQP trunk in order to allow independent, concurrent development on
the SSDQP. SVN was used because it is a very common, fully featured source code versioning
tool, with many open-source add-ons to common IDEs.
3.1.2.5 Integrated Development Environment
Eclipse was used to write the source code for the project. Eclipse was used due to it being freely
available, and the author’s familiarity with the tool. Easy access to the source code repository
was enabled by using an open source add-on called Subclipse. This allows the repository to be
manipulated without escaping from the IDE.
3.2 Coding Methods
3.2.1 Design Approach
This project was developed using an object-oriented approach. This approach is used because
the chosen Wireless Sensor Node uses Java as its native language, and Java is designed for object
oriented programming. In addition, the polymorphism feature in object oriented design also
made the recursive descent parsing used extensively in the SSDQP easier. Polymorphism also
simplifies the coding required to extend the SSDQP.
3.2.2 Design Pattern
The Singleton pattern is used extensively through the project in order to minimise overhead in
creating new objects. Many classes used in this project require only one instance throughout the
process’s lifetime.
The Adapter is used in this project in order to couple the existing clustering prototype with
SSQDP. By using an adapter instead of implementing the algorithm from scratch, it minimises
the number errors that may occur from the implementation. This pattern allows the author to
isolate the problem, if exists, to the original implementation of the clustering algorithm.
The Composite design pattern is use primarily for the recursive descent parsing. It allows the
task to be decoupled into different stages for execution, simplifying the code.

14
The Command pattern is also used in this project, and is used as part of the parsing tree to
execute certain standard actions as required by the parsed query. This allows new actions to be
added into the SSDQP easily.
3.3 Evaluation Methods
In order to verify the software, tests are conducted at several level using different strategies.
Automated unit testing using JUnit had been used throughout the development in the project.
This allows code segments that are not performing in accordance with the specifications to be
detected early in the development stage and before deployment.
Scripted test cases were also used to test features of the program, sometimes requiring operator
intervention. In cases where the code being tested makes references to the configurations of
the node, which are unavailable in the desktop development platform, operator intervention is
required to skip certain lines of code. Commenting out the line and running the script would be
inappropriate as it may leave the system vulnerable to bugs if some commented out lines have
not been uncommented before deployment.
Human tests are used to test the operation of the program after the code had been deployed to
the nodes. This is required because the code is being run remotely and is not accessible by
debuggers. In order to test the implemented features, test queries are specially crafted to test
specific features both in isolation and in conjunction with other features.
Tests have not been conducted for the multi-hop scenarios (when a message is required to be
routed through intermediate nodes) due to the range required to sufficiently separate the nodes
to necessitate the multi-hop routing.

15
4 User Operations
4.1 User Operations
4.1.1 Returning the current battery level as a special type of “internal sensor”
4.1.1.1 Inputs
Specify the keyword “BATTERY” as part of the SELECT clause of the SQL statement:
SELECT BATTERY FROM sensors
Note that the “FROM sensor” clause is optional as it is the default location to retrieve data.
4.1.1.2 Expected Outcomes
The battery level of each sensor as a single column table
4.1.2 Returning the current amount of free memory as a special type of “internal
sensor”
4.1.2.1 Inputs
Specify the keyword “MEMORY” as part of the SELECT clause of the SQL statement:
SELECT MEMORY FROM sensors
Note that the “FROM sensor” clause is optional as it is the default location to retrieve data.
4.1.2.2 Expected Outcomes
The free memory of each sensor as a single column table
4.1.3 Returning the current CPU util isation as a special type of “internal sensor”
4.1.3.1 Inputs
Specify the keyword “CPU” as part of the SELECT clause of the SQL statement:
SELECT CPU FROM sensors
Note that the “FROM sensor” clause is optional as it is the default location to retrieve data.
4.1.3.2 Expected Outcomes
The CPU utilisation of each sensor as a single column table
4.1.4 Specifying the node to buffer the measured values instead of forward the
results
4.1.4.1 Inputs
Specify a buffer location to store the result as part of the query:
SELECT * INTO somewhere
4.1.4.2 Expected Outcomes
Nothing – Results should be buffered locally on each node instead of being returned to the user.

16
4.1.5 Specifying the node to retrieve data stored in a storage point (buffer or cluster)
4.1.5.1 Inputs
Submit a query to retrieve the data from the buffer:
SELECT * FROM somewhere
4.1.5.2 Expected Outcomes
The current content stored in the storage point.
4.1.6 Specify the node to return a clustered summary of the measured values
4.1.6.1 Inputs
The user specifies a clustering buffer to aggregate measured values, then retrieve data from the
clustering buffer:
SELECT * INTO somewhere CLUSTER <radius> (eg. SELECT * INTO somewhere
CLUSTER 5)
SELECT * FROM somewhere
4.1.6.2 Expected Outcomes
The summary of the sensor readings in a table containing the mean of each attribute for each
cluster, together with the number of elements in that cluster. A cluster is defined as a group of
measurements that are within a specified n-dimensional radius from the mean value as
calculated using the Manhattan distance formula.
4.1.7 Implement resource monitoring
4.1.7.1 Inputs
Nothing.
4.1.7.2 Expected Outcomes
Whenever the resource levels satisfy some critical conditions, the user may notice a change in
node performance in order to accommodate for the node condition. Refer to section 2.3.5 for
details on the adaptation implemented by the clustering algorithm.
4.2 Operational Scenarios
4.2.1 SSDQP setup (required before any requests may be made into the network)
Note: This guideline assumes that the relevant code had been compiled and deployed.
1. Attach the base station node to a free USB port on the base station.
2.
17
Start the base station node by typing “ant host-run” in a command prompt opened in the
SSDQP root directory
3.
Open another command prompt. Start the GUI by changing into the GUI directory and
type “ant run”.
4.
18
Connect to the base station node by setting the correct configuration and clicking
“Connect”.
5. Run the nodes by switching on the nodes. When the nodes start up, they will
automatically start the SSDQP.
6.
Build the routing tree by clicking “Build routing tree” and selecting the desired power
level.
7.
Synchronise node timers and start the resource monitor by clicking “Synchronise time”.
8. New queries may now be entered by clicking “Enter query”:
A new entry should be added for that task:
19
9. Return values (if any) can be viewed by double clicking on the query item.
(for the query “SELECT *”)
4.2.2 System Usage
Note: Since the GUI is not designed to work with the new extensions, the results retrieved may
not be able to be display in the Result Browser in the GUI. To observe these operations, one
currently needs to examine the debug output to see the returned table. This needs to be fixed in
any future extension as a priority.
4.2.2.1 Buffered Storage Point
In Step 8 described above in section 4.2.1, enter the query “SELECT * INTO blah EPOCH 5s
RUNCOUNT 10”. This will create a new query that is run every 5 seconds for 10 times, each
time storing all sensed values into the storage point called “blah”.
If the query “SELECT * FROM blah” is issued within 50s of the previous query, the previous
query will still be in progress and the node will return the results collected so far.
If the query “SELECT * FROM blah” is issued again after the first query had completed, it will
only return the results that had not previously been returned.
4.2.2.2 Resource Sensor
Enter the query “SELECT *” to retrieve the current measured values of all sensors. The
current battery level, percentage of CPU idle time and the percentage of free memory is
returned. Currently, the current battery level and the CPU idle time will always return 100%
due to the lack of hardware support for these features.

20
4.2.2.3 ERA Clustering
In Step 8 above, enter the query “SELECT light INTO blah2 CLUSTER 1 EPOCH 10s
RUNCOUNT 10”. This query requests the nodes to store the light sensor readings into the
clustering buffer called “blah2” every 10 seconds for 10 times. While the query is being
executed, vary the amount of light incident onto the sensor (note that readings are only taken
every 10 seconds). This allows the effect of the clustering algorithm to be observed. Please
note that variable cluster radius is not currently implemented as it was not implemented in the
original prototype. The radius field is included for future extension.
At any time, if the query “SELECT * FROM blah2” is issued, it will return the average value of
the clusters, and the number of items in each cluster at the point in time. Unlike the buffered
storage, the buffer is not reset every time the buffer is read, but will continue to aggregate.

21
5 Evaluation
5.1 Tests for Correctness
In order to verify the software correctness, tests are conducted at several levels using different
strategies.
Before tested on the actual nodes, unit tests are conducted on methods and classes to ensure
that these new additions/amendments will function as intended. These new additions /
amendments are then integrated into the SSDQP on the development platform, and unit tests
are conducted on the methods that will be using these changes. For some of these changes (for
example, changes to the parser), these unit tests needs to be stepped through manually since
the existing SSDQP code includes references to methods specific to the nodes and are not
available on the desktop, thus requiring human intervention to break from those routines.
After the code is unit tested as a whole, the new source code is then deployed to the sensor
nodes and acceptance tested. At this stage, since the code is now executing remotely and on a
reduced library, the author loses the ability to run/stop the process, and was unable to use
debuggers. Debugging of the code becomes difficult (for example, exceptions do not contain
reference to line numbers or method names when thrown).
Since the only interface that is available between any user (including the author) and the
process being tested is an outdated GUI that does not have scripting ability, only human tests
can be conducted. To conduct these tests, specially crafted queries designed to test a certain
feature are sent via the GUI, and the return values from the node is visually compared to an
expected range of values to determine the validity of the result.
The following sections explain the tests conducted for each addition/amendment as well as a
summary of the results obtained.
5.1.1 SQL Parser / Compiler
The SQL Parser and the Token Compiler sub-modules are pre-existing sub-modules developed
in SSDQP and extended in this project. The tests conducted test only for the correct operation
of the extended features.
The SQL Parser is responsible for the lexical analysis of a SQL query, and then decomposing
the query into a map of clauses. The Token Compiler is responsible for the construction of the
Token string that is sent across the radio interface based on the decomposed query.
Since these two sub-modules are never run in isolation, they were tested as a unit. In addition to
the normal JUnit tests, the two sub-modules are tested as a whole by using them to construct a
Token stream based on SQL queries that utilises the new features. The exceptions thrown are
monitored and the resultant Token string is compared to the expected values. Table 3 gives a
sample of the query strings and their expected compiler results.
It should be noted that in running these tests, operator intervention is required as the Token
Compiler requests the Sun SPOT framework to return a valid power level in order to construct
the network packet. Since unit tests bypass the Sun SPOT framework, the function call will
throw an exception. Therefore only the resultant Token string, not the actual packet is
checked for correctness. Correctness of the packet can be inferred if the Token Parser can
correctly read the packet.

22
SQL Query Token String
SELECT * FROM sensors D(M(C() E(0)))
SELECT * FROM resources D(M(C() E(1)))
SELECT BATTERY, CPU, MEMORY
D(M(C() P(E(0) 10 11 12)))
SELECT * INTO blah I(M(C() E(0)) 2)
SELECT * INTO blah CLUSTER
R(M(C() E(0)) 2)
SELECT * FROM blah D(M(C() E(2))) Table 3 Sample compiler results
The tests indicated that the extension to the grammar had been accurately implemented by
both the SQL Parser and Token Compiler.
5.1.2 Token Parser
Token Parse is responsible for creating the recursive descent execution tree from the Token
string embedded in the packet received. In addition to the JUnit tests, correct execution of the
parser is determined by using the parser to construct the execution tree for known valid Token
strings that uses the features added/changed in this project. Sub-tree containing the new/changed
features (not the whole tree) is then checked manually against the expected structure. Only the
sub-tree is verified as the correct operation of the existing code was assumed, and the new
features are implemented in a separate command object.
Tests indicated that the additional features enabled in the revised language can be constructed
into a proper execution tree.
5.1.3 Storage Point
Storage point module was comprehensively tested using JUnit on the desktop. No integration
test was possible without first deploying the code. The deployed code was tested as a part of the
integration test. SQL queries that write into and read from the storage points were used in the
final integration test.
JUnit tests indicated that the storage point is operation correctly.
5.1.4 Enhanced Resource Aware Cluster
The algorithm behind the Cluster (which was developed by another developer on a separate
project) was assumed to be correct by virtue of it being published in a conference. This project
extended the Cluster by creating an adapter for the Cluster such that it may be used as a storage
object – ie. a specialisation of the normal data table.
Only the adaptor methods have been tested, and were only tested to ensure the correct
methods and parameters have been passed. No tests have been conducted to verify the
implementation of the algorithm.
JUnit tests indicated that the adapter methods for the Cluster are operating correctly.
5.1.5 Resource Sensors
Resource sensors are new command objects that enables the “sensing” of the internal resource
level. Of the 3 sensors, 2 are dummy classes due to the fact that these resources cannot be
determined in bSPOTs (but can be determined in the newer eSPOTs). The remaining sensor,
free memory sensor cannot reliably be tested.
In order to qualitatively test the memory sensor, after the sensor had been deployed, a query
was issued to continuously add new entries to the buffer, while another query was issued to

23
retrieve the current battery level. The test showed that the memory level is consistent with the
aggressive use of memory by the other query.
5.1.6 Resource Monitor (Administrative Task)
Resource Monitor is a combination of a self-starting, recurring query and a publisher that
acknowledges the clusters whenever the resource level is updated. The self-starting nature of
the query was tested only in the final integration test. This is tested by issuing a query to
retrieve the stored resource level after the node had started up. If the query had not started, the
buffer would not have been initialised. The recurring nature was be tested by issuing the query
repeatedly in order to look for whether any change in the resource level can be detected.
The correctness of the publisher-subscriber interface was proven to be correct using code
tracing arguments. The actual operation is difficult to test due to the inability to efficiently
change the resource level of the node and the lack of clearly observable effects of the resource
adaptations.
5.1.7 Final Integration Test
The final integration test was conducted after all unit tests have been completed. It verifies the
correct operation of the system as a whole.
This test had revealed a possible bug that was not previously detected in the Clustering
prototype. It also found that the default “collection window” (time to wait for all children to
respond) may not be long enough.
5.2 Tests for Performance
In this experimental system, performance of the system is not currently a critical factor.
Therefore no explicit tests for performance have been conducted.
However, performance inefficiencies have been observed during the final integration test. It
was observed that the time required to execute a query is close to the 5 seconds collection
window. If multiple queries have been scheduled to run at times closed to each other, the
“processing” time may exceed the 5 seconds collection window at times, causing a nil return to
be interpreted by the host. It is suggested that the inefficiency may be due to the fact that all
sensors are polled for each sensing operation instead of activating only the required sensor.
5.3 Limits on the Extension
Currently the Storage Point extension is very primitive. Whenever a location is added using a
location number that is already in use, it assumes that the query wants to append the data in the
new table being added into the existing table. While this behaviour is useful for most
applications, if the type of the table (for example, clustering vs non-clustering) is different or
if the number of columns is different, it may produce unexpected results. The current
implementation is also unable to determine whether any storage location is disused and could
safely be reclaimed. This may lead to a type of “memory leak”.
The location number generator is also prone to overflowing as it has a finite length of an int
(32-bit).
The language extension, while operating correctly, produces a fair amount of useless tokens
(for example, the token for collecting children’s results when all data are buffered within the
nodes), taking up both transmission time and execution time.

24
5.4 Evaluation of the Extension
While some limits exist on the extension of the SSDQP, the extension can serve quite well as a
test bed system for the wireless sensor network research in the School of Information
Technologies. In addition to the planned features, this project also delivered a framework in
which future extensions and modifications can easily take place. The construction of the
Storage Point, and the concept of extending the basic Table to provide advanced
functionalities instead of forming a new operator for advanced features allows new data
aggregation and manipulation algorithms to be added to the SSDQP easily. However, the
current extensions may not be too useful in longer-running tests at this stage, mainly due to the
“memory leak” problem.

25
6 Individual Reflections Overall, the project provided an enjoyable yet valuable learning experience. In this project, the
author had been introduced to the researches into the active field of wireless sensor network. In
addition, the author was able to apply his knowledge gained in his undergraduate studies to
contribute into the ongoing research project. The project was completed without major
problems, but a number of issues did come up, mainly at the start and towards the end of the
project.
The author had found that the design of SSDQP is relatively extensible. The documentation
provided for the system adequately explains the process required to extend the system.
However, the documentation did not concisely describe the full implementation of a new
feature (from extending the query language, creating new network Tokens, to creating new
Tasks/TaskSets). These extensions have been documented, but they are scattered throughout
the document. In addition, there is a very steep learning curve for the developer to extend the
system. The developer must understand the full 2-stage execution process, from parsing the
query language to the final recursive descent execution of the Tasks by the scheduler.
While the author needed to interact with the Squawk Java SDK regularly, the author only
needed to call 4 commands through Ant (ant deploy, ant run, ant host-compile, ant host-run).
The author’s exposure to ant scripts greatly reduced the interactions needed as the author can
modify the standard script to minimise the action required. The author had also found that due
to the design of SSDQP, he did not need to deal with any of the Squawk API. However,
debugging software running on the nodes is found to be quite difficult, with the exception
messages only identify the class in which the exception was thrown, but not the actual method.
In terms of problems encountered, at the start of the project, miscommunication between the
author and the project supervisor delayed the actual start of the project. Initially, the author’s
understanding of the project was to extend the current SSDQP system by developing and
implementing a network-layer routing algorithm based on resource-aware clustering. Research
into that area was conducted with at least 5 paper referenced to ascertain the various
techniques used in WSN routing.
The exact nature of the task was not defined at the start of the project as the supervisor is
waiting for the code and documentation of the clustering algorithm to be submitted by the
author who was previously working on the prototype. This delayed that definition of the
project objectives.
In attempt to put the project back on schedule, specific objectives for the project were
discussed n the meeting prior to the report 1. In was then made clear that the intention of the
project was actually to extend SSDQP by implementing a resource-aware data clustering
algorithm for the efficient storage and transmission of collected data (not the formation of
network topologies). This misunderstanding required the first report to be rewritten (the
project plan needs to be overhauled), and more background research were needed as the
previous research is not too relevant to the task. However, this also gave the author the
opportunity to explore a different aspect of WSN which would otherwise not be investigated.
Towards the end of the project, it was noted that the specific requirements for the final report
and the demonstration had not been disclosed to the author, and the report is to be due with 2
weeks. This matter was raised with the project supervisor. However, 5 days before the report is
due, the report specification has yet to be disclosed. Using a guess-and-check method, the URL
for the 2003 SOFT3200 project website was discovered, with a report 3 specification sheet

26
(lecture 3) available. Since the UoS coordinator is the same and the specification for report 1 is
the same (albeit the name had changed and the dates were 3.5 years earlier), the author had
decided to write this report based on the specification for 2003.
In a follow up discussion with the supervisor, it was identified that the author had neglected to
follow up on the matter after initially raising the issue. This matter demonstrated to the author
the importance of following up on requests.
In summary, with the exception of some slight problems encountered, the programming
experience was challenging yet enjoyable. SSDQP was well designed and is quite easy to develop
in despite the steep learning curve. The Squawk Java SDK was quite simple to use but is slightly
difficult to debug in.

27
7 Conclusion In this project, the author has developed an extension to the SSDQP, a distributed query
processor for wireless sensor networks. The extension enables the system to aggregate
collected data using the Enhanced Resource Aware Clustering algorithm. In developing this
feature, several useful features have also been developed and used by the extension: the Storage
Point facility for each node, and the Resource Monitor.
The Storage Point extension provides a flexible framework for the implementation of stream
processing algorithms, using the concept of encapsulating the algorithm into the data container
instead of defining new operators. This framework enables the algorithms to operate with ad
hoc input of the data, and be able to display the “intermediate” (and instantaneous) state of the
operations. It also allows new algorithms to be easily implemented and possibly compared on
the nodes without returning the results to the base station for processing.
The mechanism to provide generic resource monitoring was also developed, enabling any
resource-aware algorithm to be implemented into SSDQP.

28
8 Future Work Since SSDQP is an ongoing experimental system, improvements to the system will constantly
be made. Some suggestions to future work include:
1. Update to the GUI to enable it to use and display the new features provided in this
project. This task should take no more than two weeks by one programmer.
2. Port the current SSDQP to the newer eSPOTs in order to take advantage of the newer
power management features. This may allow the currently unavailable features (battery
level detection and CPU utilisation) in this project to be used. This porting of the code
may take up to three weeks.
3. Optimisation to the grammar parsing in order to both reduce the overhead cost and
increase the readability of the code (current implementation had used a recursive
technique to solve an iterative problem). This task should take approximately two weeks.
4. Investigate the new ability to deploy code through the radio interface, enabled in the
eSPOTs. This task is quite open-ended, and a realistic forecast is not possible without
some initial investigation into this eSPOT capability.
5. Optimise how and when sensors are activated. The current system activates all sensors
before projecting the measurements collected into the set required whenever it needs to
sense any of the measurements, including internal measurements. A possible option is to
replace the current sense operation with a specialised buffered table, which checks the
timestamp of the existing data and determine whether to return (and buffer) a new
reading, or simply return the buffered value. This task is also quite open-ended, and a new
project may be able to be based on it, especially if this algorithm is to be made resource
aware.
6. Optimise the implementation of the ERA clustering algorithm such that an order list is
maintained in order to increase the efficiency of the insertion of new data. A possible
amendment is attached as a separate file with the corresponding mathematical proof.
7. Investigate whether the metadata on tables stored/returned from the nodes are adequate.
Currently, projection may not work as expected on buffer/clusters due to the tables not
matching the normal table, and the display of such tables are also difficult. One possible
solution would be to include an extra row of integers at the start of the result table to
denote the attributes being returned. This task may take up to three weeks for the
investigation, design and implementation of the solution.
8. Extend the Storage Point module by allowing the data stored in the node as well as the
metadata stored in the host application to be written to persistent storage. This extension
should take up to two weeks.
9. Develop and implement an algorithm to merge clusters returned from other nodes in
order to minimise network communication cost. This may require the returned table to be
identifiable as a cluster instead of a standard table in order to trigger the mechanism.
Language extensions may also be required for cases where the operator requires the
measurements to be associated to individual nodes.
This merging operation is also useful internally by the node as part of the adaptation to
reduced available memory. In some situations (like a slowly increasing value), the ERA

29
clustering algorithm may move a cluster to overlap with another cluster. While the
movement of any cluster is bounded (due to averaging), merging these clusters as a part of
the memory adaptation routine may be feasible if they overlaps by more than some
threshold amount.
10. Implement low battery (input granularity) adaptation. This adaptation described in [4],
but was unable to be implemented in the system due to the fact that the algorithm was
implemented in a data container and conceptually should not be able to alter the sampling
period of the queries that uses the container.
It is suggested that this adaptation be implemented in either the scheduler or the queries.
Implementing in the scheduler provides a global adaptation to all queries running on the
node, whereas implementing in the queries (specifically as either a separate Task or as a
parameter to the sensing Task) allows the operator to optionally disable low battery
adaptation for whatever reason.
Regardless of where this adaptation is implemented, synchronisation problems may occur
because the battery drain rate would be different across the network and the adaptation
modifies the frequency of the query. Therefore the design must be well thought through.
This adaptation could also be implemented in a special “sensor table” as described in
suggestion 5. This may be achieved by increasing the minimum sampling period. This
way, while the energy spent activating the sensor may be adapted, the adaptation does
not really change the input granularity, and would be less efficient than implementing in
the scheduler or the query. Any aggregating operators may also produce misleading results
(the effect is yet to be investigated).

30
9 References [1] Mueller R, Alonso G and Kossmann D, SwissQM: Next Generation Data Processing in Sensor
Networks, in the 3rd
Biennial Conference on Innovative Data Systems Research (CIDR), January 7-10, 2007, Asilomar, Califonia, USA
[2] Röhm U, Scholz B and Gaber M, Integration of Data Stream Clustering into a Query Processor Wireless Sensor Networks, in International Workshop on Data Intensive Sensor Networks 2007 (DISN’07), May 11, 2007, Mannheim, Germany
[3] Phung N, Gaber M and Röhm U, Resource-aware Online Data Mining in Wireless Sensor Networks, in the IEEE Symposium on Computational Intelligence and Data Mining (CIDM’07), April 1-5, 2007, Honolulu, Hawaii
[4] Gaber M and Yu P, “A Framework for Resource-aware Knowledge Discovery in Data Streams: A Holistic Approach with Its Application to Clustering”, in Proceedings of the ACM SAC ’06, Dijon, France : ACM Press, 206
[5] Scholz B, Gaber M, Dawborn T, Khoury R, and Tse E, Efficient time triggered query processing in wireless sensor networks, to appear in: Proceedings of the 2007 International Conference on Embedded Systems and Software (ICESS-07) to be held in Daegu, Korea, May 14-16. Springer Press, 2007.
[6] Röhm U, Sun SPOT Distributed Query Processor (SSDQP) website, http://www.cs.usyd.edu.au/~roehm/projects/SSDQP.html, last accessed 24 May 07
[7] Dawborn T, Khoury R and Tse E, SSDQP: Sun SPOT Distributed Query Processor Software Development Guide (distributed with SSDQP)
[8] Dawborn T, Khoury R and Tse E, SSDQP: Sun SPOT Distributed Query Processor System Design (distributed with SSDQP)
[9] Younis O and Fahmy S, “HEED: a hybrid, energy efficient, distributed clustering approach for ad hoc sensor networks” in Proceedings of the ACM SAC ’06. Dijon, France: ACM Press, 2006.
[10] Teng W-G, Chen M-S and Yu P S, “Resource-aware mining with variable granularities in data streams”, in SIAM SDM 2004, 2004
[11] Röhm U, Adaptive In-Network Query Processing for Data-Intensive Sensor Networks, presented in “Data From The Field” Workshop, University of Sydney, 24 May 2007
[12] Madden S, Franklin M, Hellerstein J and Hong W, The Design of an Acquisitional Query Processor for Sensor Networks, In the Proceedings of SIGMOD 2003, June 9-12, San Diego, USA
[13] Sun Microsystems, Inc., Project Sun SPOT Products website, http://www.sunspotworld.com/products/, last accessed 24 May 07

Appendix A. Mathematical proof for a proposed optimisation (Attached as PDF)



![Implementation of an Hierarchical Hybrid Intrusion ... · intrusion detection system [4] for WSN using the clustering algorithm, to reduce the information forwarded and decrease the](https://img.pdfslide.net/doc/110x75/5fc09764c1f8af7bb80a8951/implementation-of-an-hierarchical-hybrid-intrusion-intrusion-detection-system.jpg)

























