Embed Size (px)
Citation preview

www.huawei.com
Improve the Fault Management
Capability of IP Networks
XiangPing Wu ([email protected])
Sean Xuewen Gong ([email protected])
For IEEE CQR 2009

Content
• Introduction
• Challenges
• Why are IP Networks not Reliable?
• Current State of Fault Management Capability of IP
Networks
• The Requirement for Recovery
• The Typical Solutions
• Conclusions

HUAWEI TECHNOLOGIES CO., LTD. Page 3
Introduction
� All services will be based on IP technology
� Service control will be mainly handled by IMS (SIP signaling)
� Packet transport will be used for all network traffic
� There will be many access types supporting IP connectivity.
Future Networks will be All-IP, Converged networks:
All IP detail in Each Network Layer
IP
SIP Signaling HTTP
NG-WDM/OTN
IP Etherne
t
…Voice Video Data APPs
…
IP
Voice Video Data APPs
Core Network
Bearer
Terminal
Services
IP Infrastructure
NG-WDM/OTN
TV Voice BB Mobile ...
IP

HUAWEI TECHNOLOGIES CO., LTD. Page 4
Challenges
� When migrating to ALL-IP, Converged networks from legacy
networks, the operators are concerning about:
� Can the future networks be as reliable as legacy networks?
� … and can do so at the low cost of ownership?
� Rule of thumb for Carrier-
Grade Telecom Network:
� 50-ms recovery time, and
� Five 9s of availability

HUAWEI TECHNOLOGIES CO., LTD. Page 5
Why are IP Networks not Reliable?
New Security Threats
Poor Fault Management Capability
•Fault detection mechanisms in IP are relatively slow, usually in seconds;
•Fault recovery time depends on the re-convergence time for IP networks,
usually in minutes, will be worse for lager-scale networks;
•Edge effects of network recovery, such as, route flapping and black hole,
will also impact the stability of IP networks;
•Degradation or QoS/QoE detection is still a challenging problem for IP
Networks.
• IP network is an Open and Distributed architecture, is prone to being
attacked from inside and outside, such as, DoS/DDoS, and virus.
• Although new security mechanisms make the networks more robust to
attacks, attack means themselves are also retrofitting
Complexity Makes IP Networks Configuration Prone to Errors
• Consistency of neighboring routers
• Complex configuration options
•Rapid changes to the network
• Limited configuration tools

HUAWEI TECHNOLOGIES CO., LTD.
Fault Management Capability of IP Networks -Concept of Fault Management
� Detection. A fault is found, but determination of the
failed component is not made
� Diagnosis. The determination of which component
has failed
� Isolation. Ensuring a fault does not cause a system
failure (isolation does not necessarily make the
system function correctly)
� Recovery. Restoring system to expected behavior
� Repair. Restoring a system to full capability
including all redundancy
� Notification. Between each step above, there is
notification of the fault to the next step or steps in
the process.
RecoveryRecovery
DetectionDetection
DiagnoseDiagnose
IsolationIsolation
RepairRepair
Notific
ation
Notific
ation
From the view of Fast Service Recovery, the steps of Detection
and Recovery are of most importance.

HUAWEI TECHNOLOGIES CO., LTD. Page 7
Fault Management Capability of IP Networks -Detection
� Longer Fault Detection Time Compared to Legacy Networks
� SONET/SDH are synchronous technologies, faults can be detected
within 50 ms;
� IP is an asynchronous technology, it detects fault using Keep-alive or
Hello mechanisms embedded in the protocols.
� For OSPF and IS-IS, keep-alive or hello packets are sent every 3 seconds,
and a fault is detected when consecutive 3 packets are lost by default,
which means the fault detection time will be 9 seconds by default.
� Reducing keep-alive or hello transmission time arbitrarily might result in the
problem of route flapping.
� Another challenge for IP networks is the detection of
degradation or QoS attributes, such as, packet loss, delay,
and jitter.
HUAWEI TECHNOLOGIES CO., LTD. Page 8
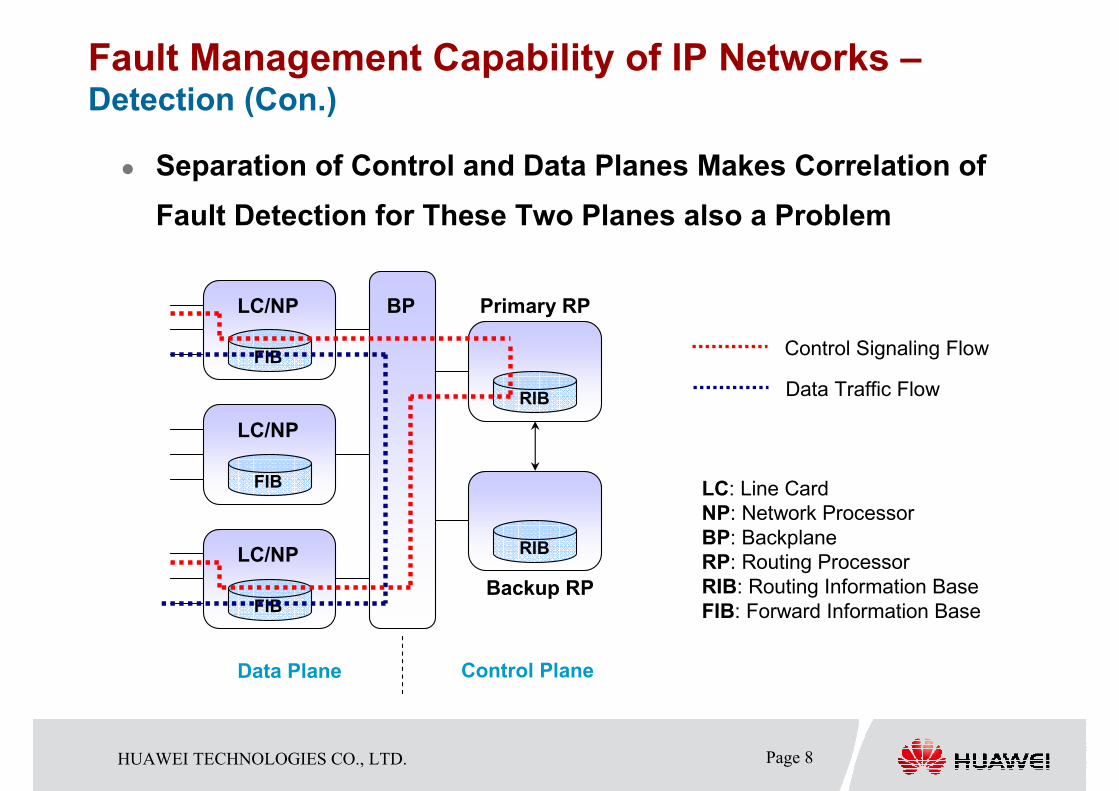
Fault Management Capability of IP Networks –Detection (Con.)
� Separation of Control and Data Planes Makes Correlation of
Fault Detection for These Two Planes also a Problem
FIB
LC/NP
FIB
FIB
RIB
Primary RP
RIB
LC/NP
LC/NP
Backup RP
BP
Data Plane Control Plane
LC: Line Card
NP: Network Processor
BP: Backplane
RP: Routing Processor
RIB: Routing Information Base
FIB: Forward Information Base
Control Signaling Flow
Data Traffic Flow

HUAWEI TECHNOLOGIES CO., LTD. Page 9
Fault Management Capability of IP Networks –Recovery
� Fault recovery time of IP networks depends on the re-
convergence time of networks, which afterwards depends on
the size and topology of Networks
� Basically, this time can be relatively LONG.
� In some networks, link and node faults can be
troubleshot very quickly when incorporating the
recovery capabilities of IP layer and
transmission layer
� But the fact is, it still CAN NOT meet the rule of thumb
requirements of Carrier-Grade Reliability

HUAWEI TECHNOLOGIES CO., LTD. Page 10
The Requirement for Recovery
� Is 50 ms of Recovery NECESSARY for IP Networks?
� If NOT, How Long is Required?
IP over Optical
� According to testing results, 1 ~ 2
seconds of interrupt of signaling has
no impact on dialogues
� The story is totally different for voice
flows, see the table below.
� Protection time for IP carrier networks
should not be faster than optical
transmission networks;
� From the viewpoints of operating and
billing, the protection time for IP carrier
networks has to be equivalent to TDM
Signaling vs. Voice Flow
Recovery Time Impact on Voice Service
< 50 ms No impact
50~200 ms Connection loss probability is less than 5%, which has no impact on signaling
>2 s (Connection
loss threshold)
Voice session and dedicated line connection are interrupted
From above, the recovery time for IP networks should be within 50 ~ 500 ms

HUAWEI TECHNOLOGIES CO., LTD.
Case for Example-
Reliability of VPN with enhanced VPN FRR
� The commonly used protection techniques
nowadays focuses on the protection of nodes
and links in the core layer, and do not get the
PE involved.
� Keep-alive of BGP is used to detect the faults
on PE nodes, the time is above 3 seconds.
� After that, the end-to-end route/LSP re-
convergence is needed for service recovery,
the time of which depends on the quantity of
the routes and hops in carrier networks.
� The whole protection process will last about 5
seconds.
� The fault detection time for typical networks is less than 200 ms
� The re-convergence time for PE nodes only depends on the fault detection time of remote PE nodes and
the time needed for state update in forward engine, but has nothing to do with the quantity of VPN route.
The new VPN FRR protection:
• With End-to-end view, based on service-Impact centralized analysis,
identify WHAT, and find out HOW.
• Innovation and/or optimization for solutions

HUAWEI TECHNOLOGIES CO., LTD. Page 12
Conclusions
� All-IP is the inevitable trend for future networks and services .
� Reliability will be the foundation for ALL-IP to come true.
� Fault management capability is one of the most important features to
achieve acceptable IP network reliability, especially from the view of service
protection and recovery, the capabilities of fault Detection and Recovery are
the keys for success.
� Current IP networks have some inherent deficiencies in their fault detection
and recovery capabilities, which can not meet the requirements of carrier-
grade reliability.
� We has developed some solutions to improve the fault management
capability of IP networks. These solutions can make the IP networks real
carrier-grade, and meet the requirements from operators around the world.

HUAWEI TECHNOLOGIES CO., LTD. Page 13
Questions?

















![ARTICLE IN PRESS · 2017. 6. 14. · Our implementation uses the User Level Fault Mitigation MPI (MPI-ULFM) [7], a fault tolerance capability proposed for the MPI standard that enables](https://img.pdfslide.net/doc/110x75/60820fa192cbdc3e3f19a905/article-in-press-2017-6-14-our-implementation-uses-the-user-level-fault-mitigation.jpg)











