Embed Size (px)
Citation preview

Improved Single and Multiple ApproximateString Matching
Kimmo Fredriksson
Department of Computer Science, University of Joensuu, Finland
Gonzalo Navarro
Department of Computer Science, University of Chile
CPM’04 – p.1/26

The Problem Setting & Complexity
� Given text
����� � � and pattern
� ��� � � over some finitealphabet
of size , find the approximateoccurrences of
�
from
�
, allowing at most
�
differences (edit operations).
� Exact matching (single pattern) lower bound:� �� ��� ��� � � � � character comparisons (Yao, 79).
� Approximate matcing lower bound:� �� ��� � � ��� � � � � � (Chang & Marr, 94).
� We will search simultaneously a set� � � ���! ��"! # # # �%$ &of ' patterns.
� � �� ��� � � �(� ' � � � � � lower bound for ' patterns(Fredriksson & Navarro, 2003)
CPM’04 – p.2/26

Previous work
� Only a few algorithms exist for multipatternapproximate searching under the
�differences
model.
� Naïve approach: search the ' patterns separately,using any of the single pattern search algorithms.
� (Muth & Manber, 1996):� � '� � � �
average timealgorithm using
� � " ' � space. The algorithm isbased on hashing, and works only for
� � �
.
� (Baeza-Yates & Navarro, 1997):
� Partitioning into exact search:
� �� �
on average(
� ' � � preprocessing), but can be improved to
� � ��� � � ' � � � � � � . Works for
� � � � � � � � � � ' � � .
� Other less interesting ones. CPM’04 – p.3/26

Previous work
� (Fredriksson & Navarro, 2003): The firstaverage-optimal algorithm.
� average-optimal
� �� ��� ��� � � ' � � � � � up to errorlevel
� � � � � ��
.
� linear
� �� �
on average up to error level� � � � � ��
.
� (Hyyrö, Fredriksson & Navarro, 2004):
� �� � ' �� � � � �� �
worst case for short patterns,where � is the number of bits in machine word.
CPM’04 – p.4/26

This work
� We have improved the (optimal) algorithm of(Fredriksson & Navarro, 2003)
� Faster in practice, and...
� ...allows error levels up to� � � � � ��
.
� Our algorithm runs in
� �� �� ��� � ' � � � � � averagetime, which is optimal.
� Preprocessing time is� ' � � � � � , and the
algorithm needs� ' � �
space, where
� � � � � � � ' � � � .
� The fastest algorithm in practice for intermediate� � � and small .
CPM’04 – p.5/26

The method in brief:
� The algorithm is based on thepreprocessing/filtering/verification paradigm.
� The preprocessing phase generates all �
stringsof lenght
�
, and computes their minimum distanceover the set of patterns.
� The filtering phase searches (approximately) text
�
-grams from the patterns, using the precomputeddistance table, accumulating the differences.
� The verification phase uses dynamic programmingalgorithm, and is applied to each patternseparately.
CPM’04 – p.6/26

Preprocessing
� Build a table
�
as follows:
1. Choose a number
�
in the range� � � � � � �
2. For every string
�
of length�
(�
–gram), searchfor
�
in
� ��� �
3. Store in
� � � �
the smallest number of differencesneeded to match
�
inside
�
(a number between0 and
�
).
� �
requires space for �
entries and can becomputed in
� ' � � � � � time.
CPM’04 – p.7/26

Filtering
� Any occurrence is at least � � �
characters long
�
use a sliding window of � � �
characters over
�
� Invariant: all occurreces starting before thewindow are already reported.
� Read
�
-grams
� � � " # # # ��from the text window,
from right to left:
T: S3 S2 S1
text window m−k characters
� Any occurrence starting at the beginning of thewindow must contain all the
�
-grams read.
CPM’04 – p.8/26

Filtering
� Accumulate a sum of necessary differences:
� � �� �� �
� � � � �
.
� If � becomes � �
for some (i.e. the smallest) �,then no occurrence can contain the
�
-grams�� �# # # � � " � � �
�
slide the window past the first character of
� �
.
E.g.
� � � � � � � � � " � � �:
new window position
T:
S3 S2 S1
text window m−k characters
T:
CPM’04 – p.9/26

Verification
� If �
� �
, then the window might contain anoccurrence
�
the occurrence can be �� �
characters long, soverify the area
���� � � � � � ��� � , where�
is the startingposition of the window
T: S3 S2 S1
text window m−k characters
verification area m+k characters
� The verification is done for each of the ' patterns,using standard dynamic programming algorithm.
CPM’04 – p.10/26

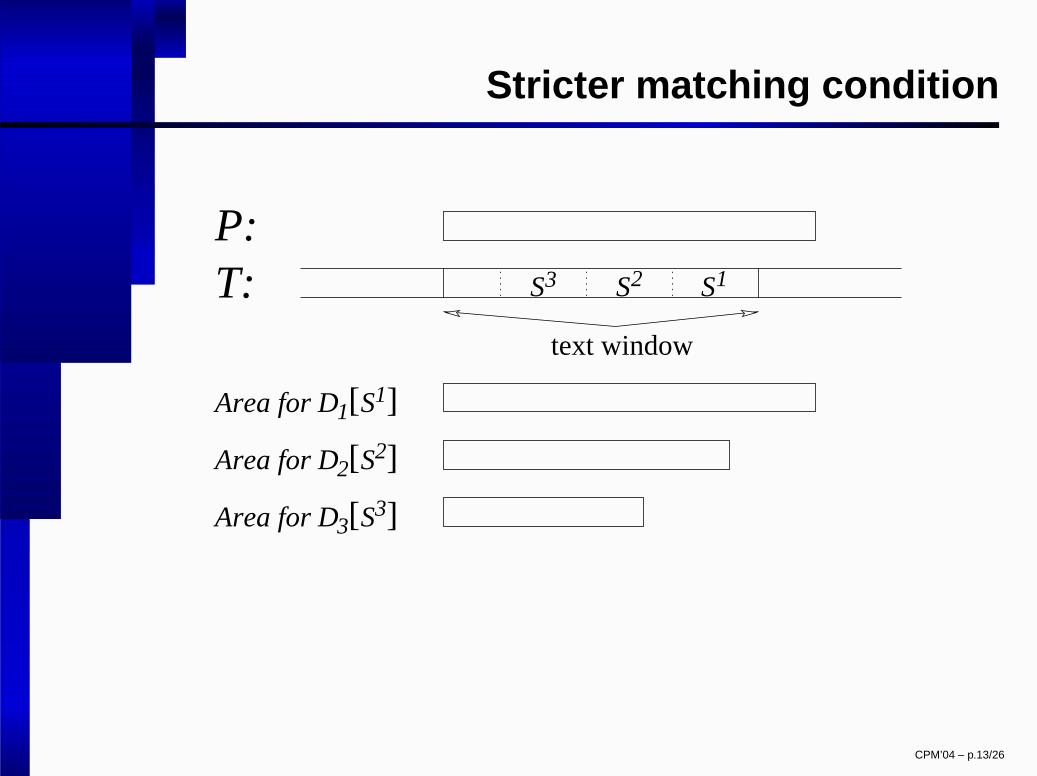
Stricter matching condition
� Our basic algorithm: text
�
-grams can matchanywhere inside the patterns.
�
If � � �
, then we know that no occurrence cancontain the
�
-grams
� � �# # # � � �in any position.
� The matching area can be made smaller withoutlosing this property.
CPM’04 – p.11/26

Stricter matching condition
� Consider an approximate occurrence of� " � � �
inside the pattern.
� � "
cannot be closer than
�
positions from theend of the pattern.
�
For
� "
precompute a table
� " , which considersits best match in the area
� ��� � � �� � rather than����� � � �.
� In general, for� �preprocess a table
� �, usingthe area
� ��� � � �� � �� � � �
� Compute � as
� � � � � � � � � �
CPM’04 – p.12/26
Stricter matching condition
T:P:
text window
Area for 1 S[ ]D
Area for 2 S[ ]D
Area for 3 S[ ]D
1
2
3
S3 S2 S1
CPM’04 – p.13/26

Stricter matching condition
� � � � � � � � � � �
for any � and
�
�
the smallest � that permits shifting the window isnever smaller than for the basic method.
�
this variant never examines more
�
-grams, verifiesmore windows, nor shifts less.
� Drawback: needs more space and preprocessingeffort
�
Can be slower in practice.
� The matching condition can be made even stricter
� Work less per window...
� ...but the shift can be smaller. CPM’04 – p.14/26

Analysis
� It can be shown that the basic algorithm hasoptimal average case complexity
� �� �� ��� ��� ' � � � � � .This holds for
� � � � � � � � � � � � .
� The worst case complexity can be made
� �� � ' �� �
(filtering � verification).
� The preprocessing cost is
� � � ' � � � � � �
, and itrequires
� � � ' " � � � � �space.
� Since the algorithm with the stricter matchingcondition is never worse than the basic version, itis also optimal.
CPM’04 – p.15/26

Analysis
� For a single pattern our complexity is the same asthe algorithm of Chang & Marr, i.e.
� �� �� ��� �(� � � � � � ...
� ...but our filter works up to
� � � � � �� � � � � � ,whereas the filter of Chang & Marr works only upto
� � � � � �� � � � � � .
CPM’04 – p.16/26

Experimental results
� Implementation in C, compiled using icc 7.1with full optimizations, run in a 2GHZ Pentium 4,with 512MB RAM, running Linux 2.4.18.
� Experiments for alphabet sizes � �
(DNA) and � � �
(proteins), both random and real texts.
� Text lengths were 64Mb, and patterns 64characters.
� In the implementation we used several practicalimprovements described in (Fredriksson &Navarro, 2003)
� Bit-parallel counters
� Hierarchical / bit-parallel verificationCPM’04 – p.17/26

Experimental results
� We used
� � �
for DNA, and
� � �
for proteins.
� the maximum values we can use in practice,otherwise the preprocessing cost becomes toohigh.
� Analytical results:
� � � � �# # # � �
for DNA, and
� � �# # # � �
for proteins(depending on ').
�
Altought our algorithms are fast, in practice theycannot cope with as high difference ratios aspredicted by the analysis.
CPM’04 – p.18/26

Experimental results
� Comparison against:
CM: Our previous optimal filtering algorithmLT: Our previous linear time filterEXP: Partitioning into exact searchMM: Muth & Manber algorithm, works only for
� � �
ABNDM: Approximate BNDM algorithm, a singlepattern approximate search algorithm extendingclassical BDM.
BPM: Bit-parallel Myers, currently the bestnon-filtering algorithm for single patterns.
CPM’04 – p.19/26
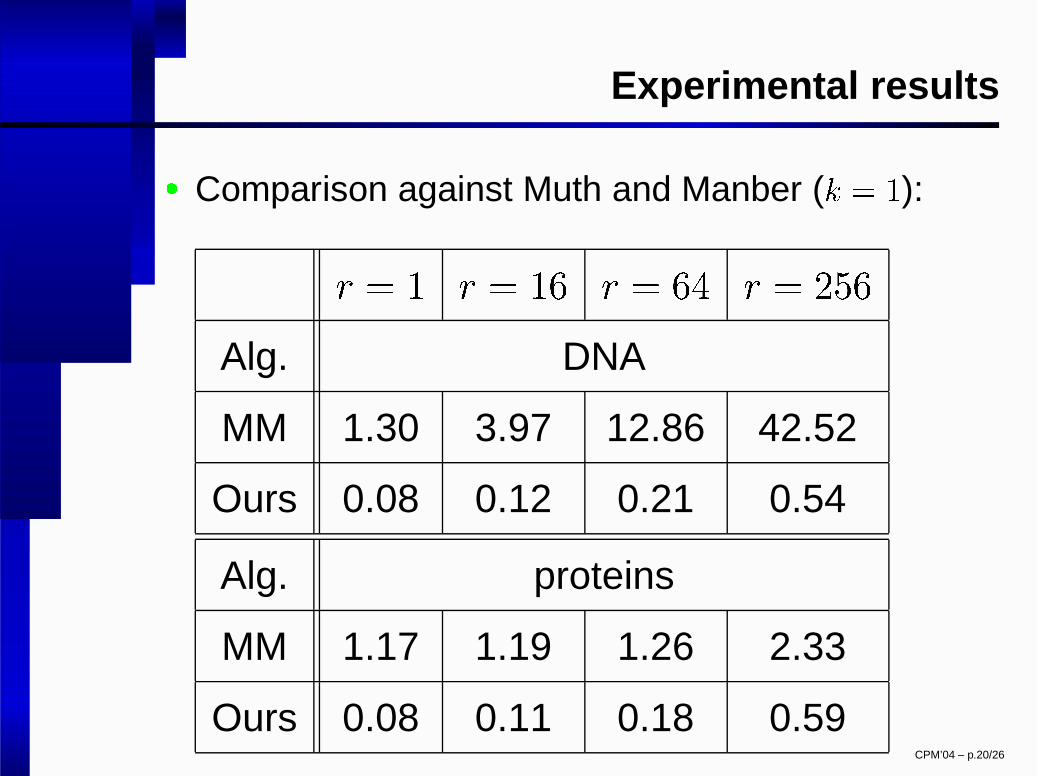
Experimental results
� Comparison against Muth and Manber (� � �
):
� � � � � �� � � � � � � �� �
Alg. DNA
MM 1.30 3.97 12.86 42.52
Ours 0.08 0.12 0.21 0.54
Alg. proteins
MM 1.17 1.19 1.26 2.33
Ours 0.08 0.11 0.18 0.59CPM’04 – p.20/26
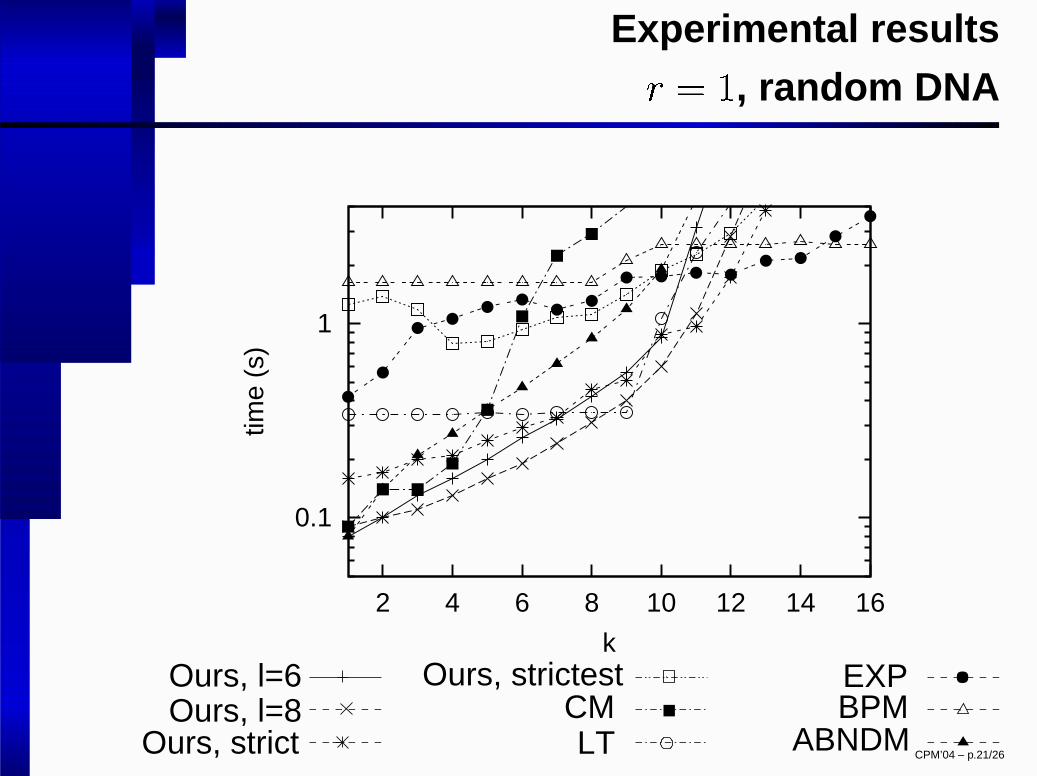
Experimental results
� � �
, random DNA
0.1
1
2 4 6 8 10 12 14 16
time
(s)
kOurs, l=6Ours, l=8
Ours, strict
Ours, strictestCMLT
EXPBPM
ABNDMCPM’04 – p.21/26

Experimental results
� � � �
, random DNA
0.1
1
10
100
2 4 6 8 10 12 14
time
(s)
kOurs, l=6Ours, l=8
Ours, strict
Ours, strictestCMLT
EXPBPM
ABNDMCPM’04 – p.22/26
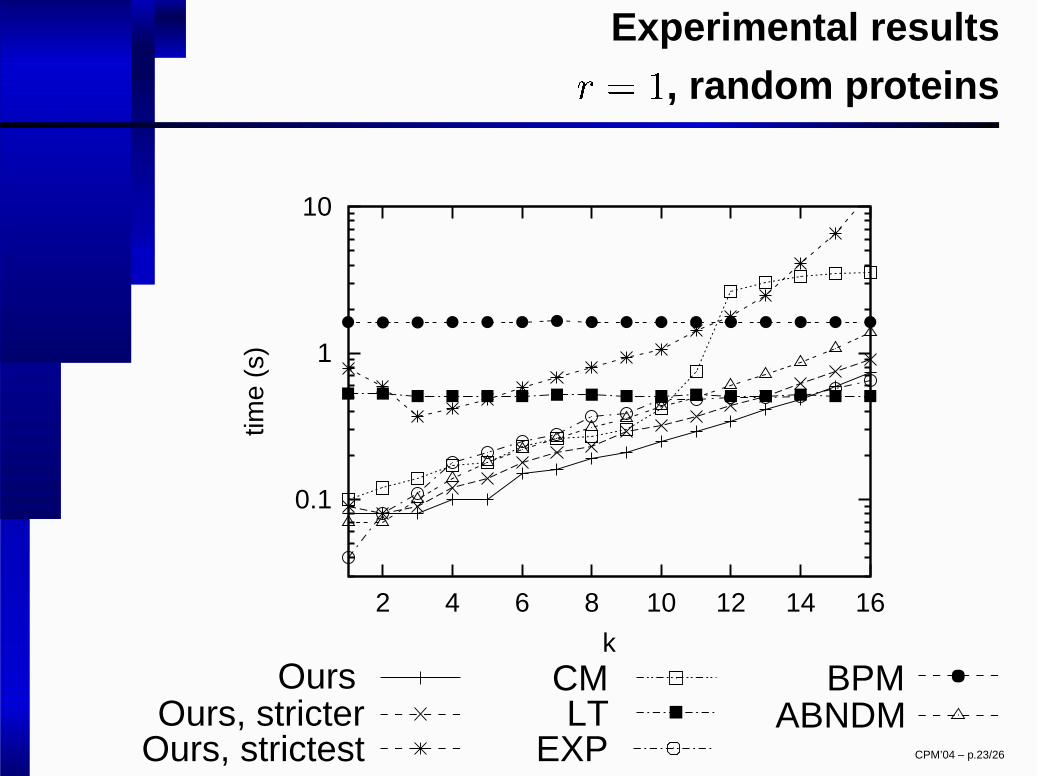
Experimental results
� � �
, random proteins
0.1
1
10
2 4 6 8 10 12 14 16
time
(s)
kOurs
Ours, stricterOurs, strictest
CMLT
EXP
BPM ABNDM
CPM’04 – p.23/26
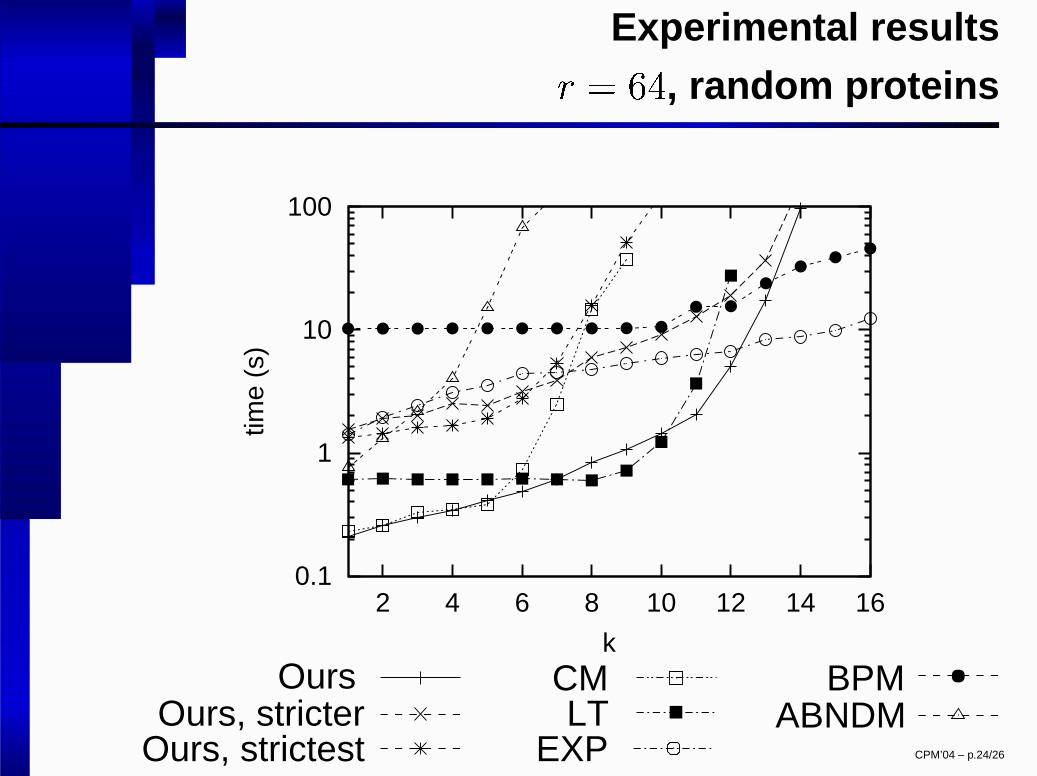
Experimental results
� � � �
, random proteins
0.1
1
10
100
2 4 6 8 10 12 14 16
time
(s)
kOurs
Ours, stricterOurs, strictest
CMLT
EXP
BPM ABNDM
CPM’04 – p.24/26
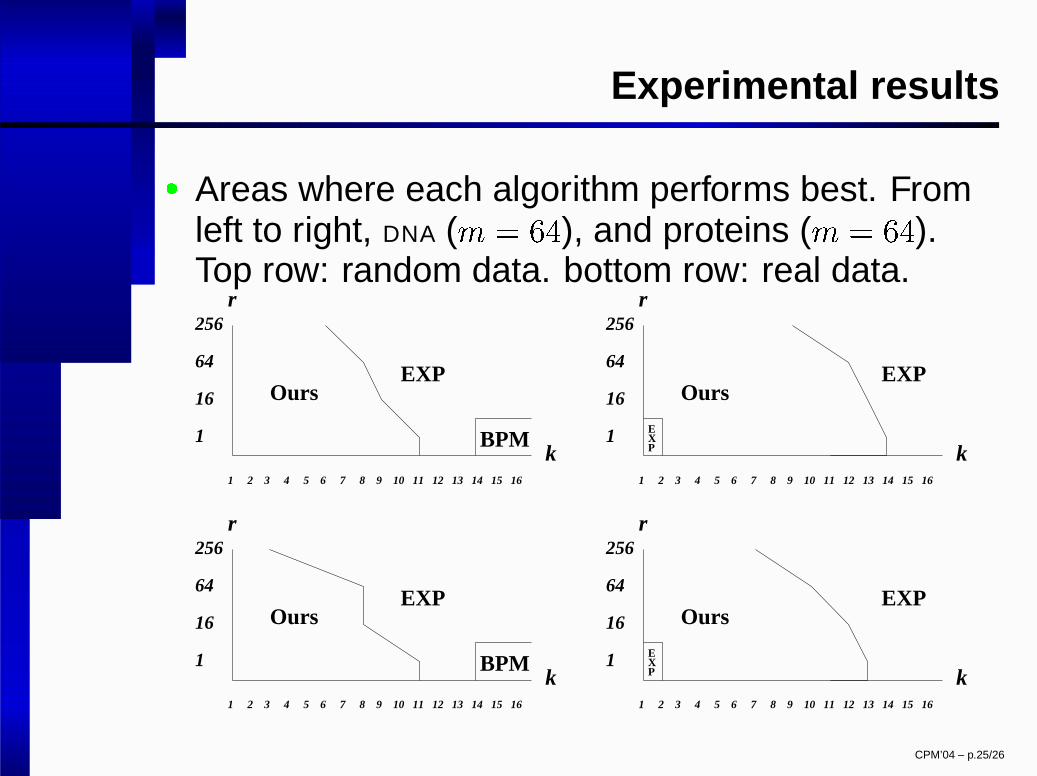
Experimental results
� Areas where each algorithm performs best. Fromleft to right, DNA ( � � � �
), and proteins ( � � � �
).Top row: random data. bottom row: real data.
256
64
16
1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
BPM
OursEXP
k
r
256
64
16
1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
BPM
OursEXP
k
r
256
64
16
1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Ours
k
r
EXP
256
64
16
1
Ours
k
r
EXP
P
EX
EXP
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
CPM’04 – p.25/26

Conclusions
� Our new algorithm becomes the fastest for low
�
.
� The larger ', the smaller
�
values are tolerated.
� When applied to just one pattern, our algorithmbecomes the fastest for low difference ratios.
� Our basic algorithm usually beats the extensions.
� True only if we use the same parameter
�
forboth algorithms.
� For limited memory we can use the strictermatching condition with smaller
�
, and beat thebasic algorithm
� Our algorithm would be favored on even longertexts (relative preprocessing cost decreases).
CPM’04 – p.26/26









![ACCURACY OF APPROXIMATE STRING JOINS USING GRAMS … · ACCURACY OF APPROXIMATE STRING JOINS USING GRAMS Oktie Hassanzadeh ... Variable-length grams [VGRAM-VLDB’07] ... Stsalney](https://img.pdfslide.net/doc/110x75/5ae6bb517f8b9ae1578e140c/accuracy-of-approximate-string-joins-using-grams-of-approximate-string-joins.jpg)



















