Embed Size (px)
DESCRIPTION
Improving the performance of personal name disambiguation using web directories. Quang Minh Vu, Atsuhiro Takasu, Jun Adachi IPM, 2008 Presented by Hung-Yi Cai 2010/09/01. Outlines. Motivation Objectives Methodology Experiments Conclusions Comments. Motivation. - PowerPoint PPT Presentation
Citation preview

Intelligent Database Systems Lab
國立雲林科技大學National Yunlin University of Science and Technology
1
Improving the performance of personal name disambiguation using web directories
Quang Minh Vu, Atsuhiro Takasu, Jun AdachiIPM, 2008
Presented by Hung-Yi Cai2010/09/01

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.
2
Outlines
Motivation Objectives Methodology Experiments Conclusions Comments

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Motivation
Searching for information about a person on the internet is an increasing requirement in information retrieval.
Search results returned from search engines for a personal name query often contain documents relevant to several people because a name is usually shared by several people.
Due to this name ambiguity problem, users have to manually investigate the result documents to filter out people in whom they have no interest.
3
Intelligent Database Systems Lab
N.Y.U.S.T.
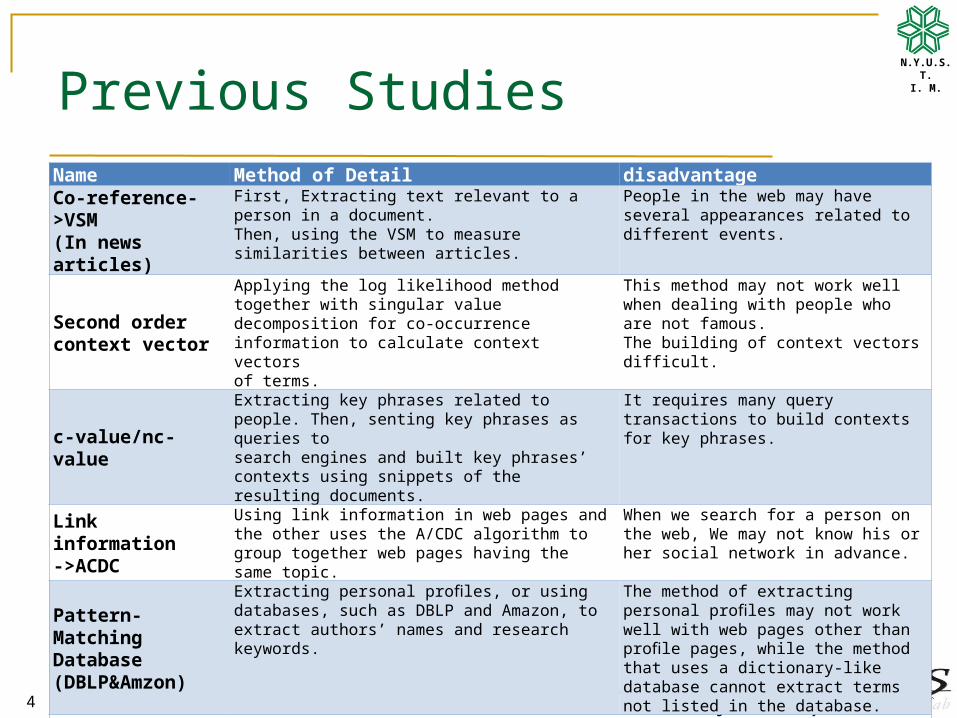
I. M.Previous Studies
4
Name Method of Detail disadvantage
Co-reference->VSM(In news articles)
First, Extracting text relevant to a person in a document. Then, using the VSM to measure similarities between articles.
People in the web may have several appearances related to different events.
Second order context vector
Applying the log likelihood method together with singular value decomposition for co-occurrence information to calculate context vectorsof terms.
This method may not work well when dealing with people who are not famous.The building of context vectors difficult.
c-value/nc-value
Extracting key phrases related to people. Then, senting key phrases as queries tosearch engines and built key phrases’ contexts using snippets of the resulting documents.
It requires many query transactions to build contexts for key phrases.
Link information->ACDC
Using link information in web pages and the other uses the A/CDC algorithm to group together web pages having the same topic.
When we search for a person on the web, We may not know his or her social network in advance.
Pattern-MatchingDatabase(DBLP&Amzon)
Extracting personal profiles, or using databases, such as DBLP and Amazon, to extract authors’ names and research keywords.
The method of extracting personal profiles may not work well with web pages other than profile pages, while the method that uses a dictionary-like database cannot extract terms not listed in the database.
Natural language-processing
Extracting named entities in documents. Because web documents contain much noisy information, the extraction of named entities may not work well.

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Objectives
Propose Similarity via Knowledge Base (SKB) that uses web directories to improve the disambiguating performance in Name Disambiguation System (NDS).
SKB can be divided into two components:─ Using web directories as a knowledge base to find common
contexts by TF-IDF in documents.─ Then, using the common contexts measure to determine
document similarities.
5

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.TF-IDF
6
Term weights are calculated using the terms’ occurrences in the document concerned and in a set of documents.─ Tf (t, doc) is the number of times term t appears in the
document doc.

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Methodology
In SKB, using web directories to measures features of terms in a document.1) Measurement of term weights using a knowledge base
A knowledge base Modification of term weight in documents Modification of term weight in directories
2) Measurement of document similarities Find directories close in topic with the document Measure document similarities
7

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Name Disambiguation System
The operational details are as follows:1) Preprocessing documents
2) Calculation of document similarities
3) Discrimination by reranking documents
8

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Experiments
Step 1. Data Sets─ Documents of people─ Creation of pseudo namesake document sets and real
namesake document sets
9

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Experiments
Step 2. Web directory structures
10

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Experiments
Step 3. Baseline methods─ Comparing SKB with two conventional methods:
VSM: Calculating the weight of these terms by TF-IDF Building the feature vectors of documents
NER: Extracting the entity names in the documents by LingPipe
software Using these names to construct feature vectors of the documents
(the constituents of vectors were binary values)
11

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Experiments
Step 4. Evaluation metrics─ We recorded the precision values at 11 recall points:
0%, 10%, ... ,90%, and 100% and denoted these as P(doci, 0%), P(doci, 10%), ... , P(doci, 90%) and P(doci, 100%), respectively.
12

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.
Step 5. Experimental results─ The overall performance for each method
In this experiment, we set the window size n = 50 and the number of representative directories k = 20. We set the frequency document ratio threshold for SKB2 r = 5.
Experiments
13
Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Experiments
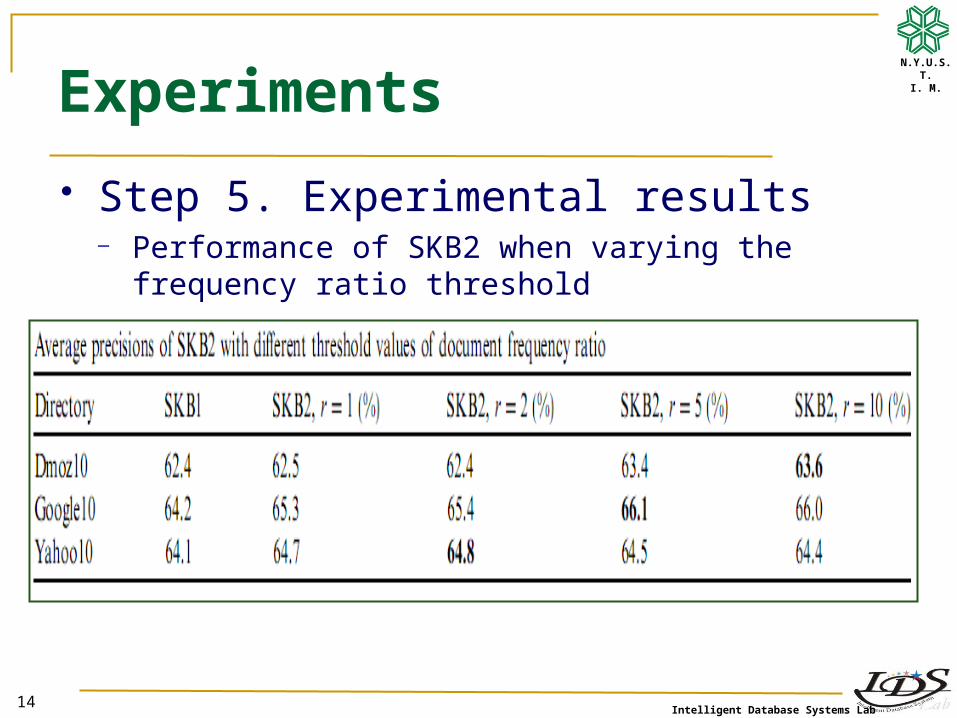
Step 5. Experimental results─ Performance of SKB2 when varying the frequency ratio
threshold
14
Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Experiments
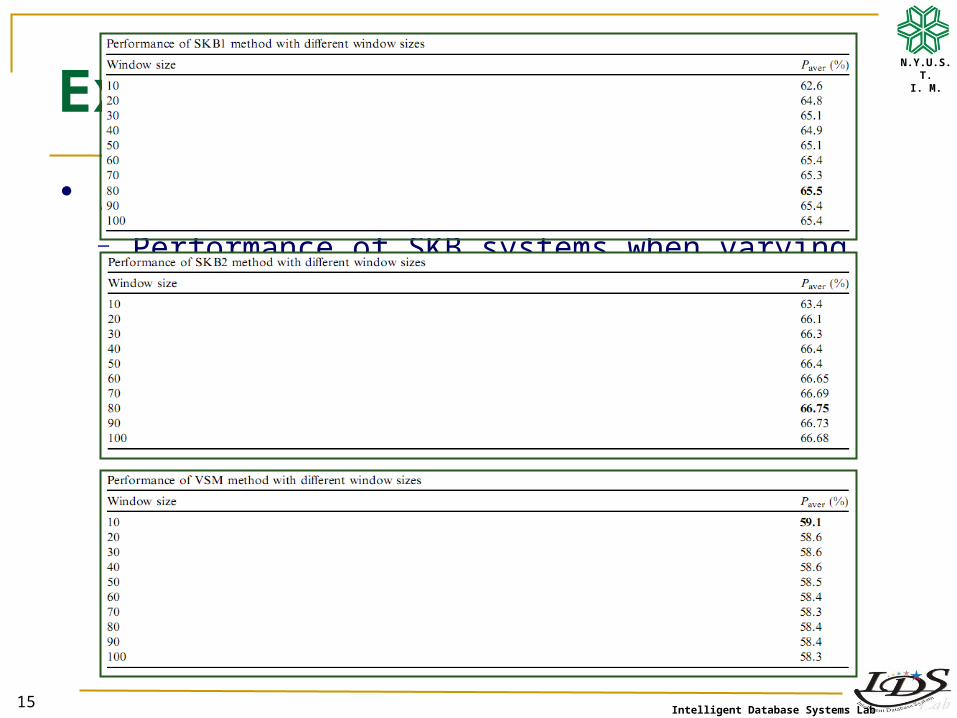
Step 5. Experimental results─ Performance of SKB systems when varying the window size
15

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Experiments
Step 5. Experimental results─ Performance of SKBs when varying the number of
representative directories
16
Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.Experiments
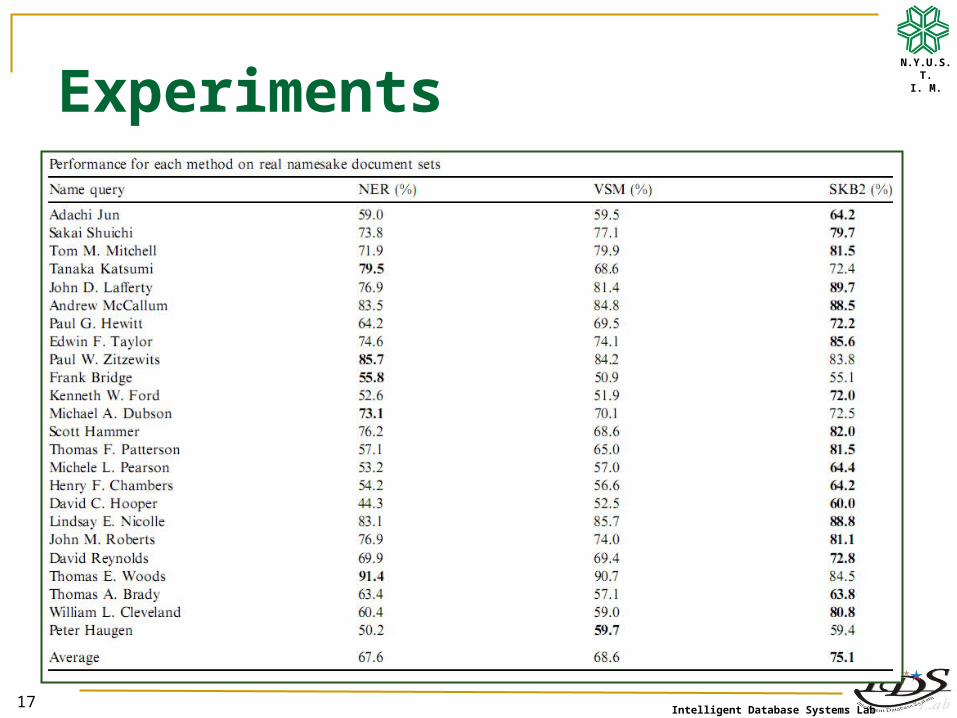
Step 5. Experimental results─ Performance for each method on real namesake document sets
17

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.
18
Conclusions
Disambiguation of people will be a trend in web search, and we propose a new method that uses web directories as a knowledge base to improve the disambiguation performance.
The experimental results showed a significant improvement with our system over the other methods, and we also verified the robustness of our methods experimentally with di erent ffweb directory structures and with di erent ffparameter values.

Intelligent Database Systems Lab
N.Y.U.S.T.
I. M.
19
Comments
Advantages─ Just requiring little preparation─ Broad range of people
Shortages─ Cost of computation is proportional─ Some mistake
Applications─ Information retrieval





























