Embed Size (px)
Citation preview

David Wild – I533 2006. Page 1 Indiana University School of
David [email protected]
http://www.informatics.indiana.edu/djwild
Chemical Informatics tools, services
and workflows

David Wild – I533 2006. Page 2 Indiana University School of
Outline
• Chemical Informatics software packages available at IU
• Open source software • The need for integration & innovation• Pipelines, workflows and web services

David Wild – I533 2006. Page 3 Indiana University School of
Software at IUB Informatics
• Spotfire DecisionSite• ChemTK• ArgusLab• BCI software – cluster analysis, fingerprints,
Markush• OpenEye software – 3D conformer, docking• Chemaxon• gNova CHORD• Chemoinformatics programming toolkits
– Daylight, BCI, OpenEye

David Wild – I533 2006. Page 4 Indiana University School of
Open Source / Free Software
• Blue Obelisk - http://wiki.cubic.uni-koeln.de/dokuwiki/doku.php
• InChI - http://www.iupac.org/inchi/ • JMOL – http://jmol.sourceforge.net• FROWNS - http://frowns.sourceforge.net/• OpenBabel - http://openbabel.sourceforge.net/• CML - http://cml.sourceforge.net/• CDK - http://almost.cubic.uni-koeln.de/cdk/• MMTK -
http://starship.python.net/crew/hinsen/MMTK/

David Wild – I533 2006. Page 5 Indiana University School of
The need for integration
• Research computing is currently very fragmented• Existing approaches do not scale up to the amount of data now
common• Many chemical informatics tools are obscure, difficult to use and
access• Scientists’ questions are not that complex, but finding the answers
is currently very time consuming and/or complex (for a human)– “has anybody patented this chemical structure I just made?”– “can I get hold of a compound that might bind to the active site of this
protein I just resolved?”– “which compounds in this series are least likely to exhibit toxic
effects?”• Answers are often “stale” after a short period of time – questions
need to be re-answered as new information is generated• Almost all available systems are passive, and follow the
(web) browsing model• There tends to be one interface for every data source
(or encompassing just a few)

David Wild – I533 2006. Page 6 Indiana University School of
Oracle Database (HTS)
Compounds were tested against related assays and showed activity, including
selectivity within target families
Oracle Database (Genomics)
? None of these compounds have been tested in a
microarray assay
Computation
The information in the structures and known activity data is good enough to create
a QSAR model with a confidence of 75%
External Database (Patent)
Some structures with a similarity > 0.75 to these
appear to be covered by a patent held by a competitor
Computation
All the compounds pass the Lipinksi Rule of Five and
toxicity filters
Excel Spreadsheet (Toxicity)
One of the compounds was previously tested for
toxicology and was found to have no liver toxicity
Word Document (Chemistry)
Several of the compounds had been followed up in a
previous project, and solubility problems prevented further
development
Journal Article
A recent journal article reported the effectiveness of some compounds in a related series against a target in the same family
Word Document (Marketing)
A report by a team in Marketing casts doubt on
whether the market for this target is big enough to make development cost-effective
SCIENTIST
“These compounds look promising from their HTS results. Should I commit some
chemistry resources to following them up?”
?

David Wild – I533 2006. Page 7 Indiana University School of
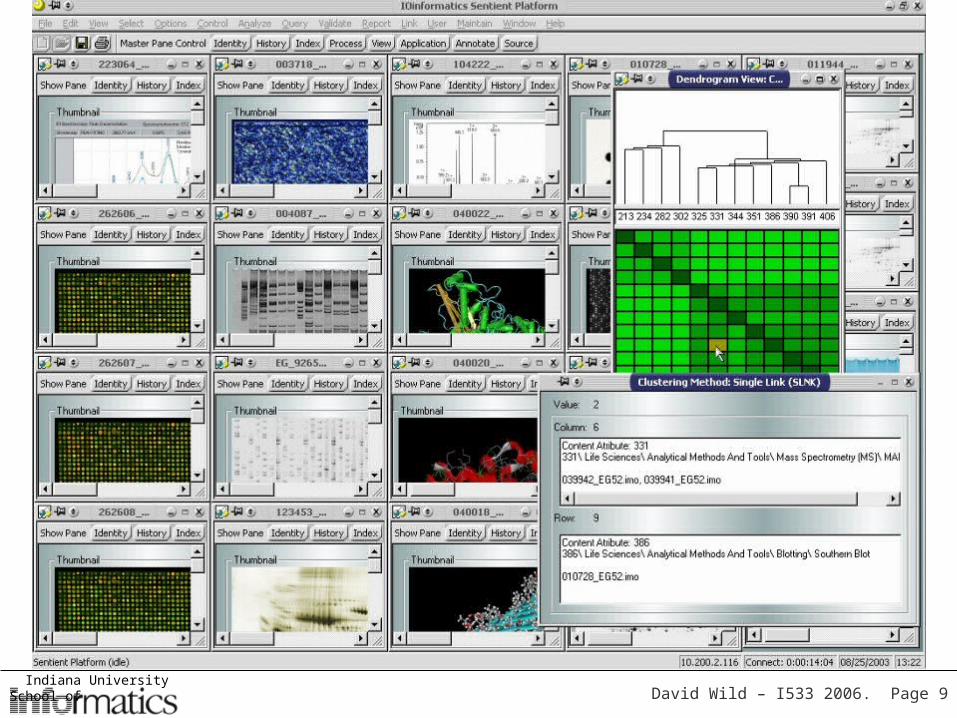
Pipelining and workflow tools
• These tools permit applications to be “piped” together or connected in “workflows” where the output of one program can be given as input to another program (or script)
• Graphical front ends are replacing scripting – e.g. PERL, Python, etc
• Available graphical tools– Scitegic Pipeline Pilot - http://www.scitegic.com– Inforsense KDE - http://www.inforsense.com/– Taverna – http://taverna.sourceforge.net– IO-Informatics Sentient – http://www.io-informatics.com
• Find their real power in a web services environment

David Wild – I533 2006. Page 8 Indiana University School of
David Wild – I533 2006. Page 9 Indiana University School of

David Wild – I533 2006. Page 10 Indiana University School of

David Wild – I533 2006. Page 11 Indiana University School of
Web Services
• Semantic Web – “Next Big Thing”– Encode semantics in web pages (XML)– Describes services as well as information (SOAP, WSDL,
UDDI)– Computation detached from interface– Note seeping through to general web usage
• http://www.google.com/apis/• http://www.amazon.com/webservices
• eScience (UK)– £200m over 2001-2006 period– http://www.rcuk.ac.uk/escience/
• Cyber Infrastructure / Grid (US)– Semantic Web Health Care & Life Sciences Research
Group - http://www.w3.org/2001/sw/hcls/

David Wild – I533 2006. Page 12 Indiana University School of
CICC-related projects
• Formal CICC projects1. Innovative cross-screen analysis of NIH DTP Human Tumor Cell
Line Data – innovative scientific analysis of NIH HTS data2. Development of cheminformatics web services and use cases in
Taverna – web service & workflow infrastructure3. Development of a novel interface for the analysis of PubChem
HTS data – tools for interacting with lots of complex data4. A structure storage and searching system for Distributed Drug
Discovery – innovative kinds of chemical databases
• Other, related projects– Fast clustering of very large datasets using Linux clusters– Smart client for mining drug discovery data (Microsoft
supported)

David Wild – I533 2006. Page 13 Indiana University School of
PROJECT 4Experimental
Databases
PROJECT 2Web services& workflows PROJECT 1
Innovative cross-screenanalysis ofHTS data
PROJECT 3Visualization, navigation
& analysis tools forHTS data
SMART CLIENTSmart interfaces (incl.NLP, RSS, agents, etc)
SMART CLIENTGeneral drug discovery
web services& workflows SMART CLIENT
Smart interfaces (incl.NLP, RSS, agents, etc)
FAST PARALLELCLUSTERING
Using DivKmeans& AVIDD

David Wild – I533 2006. Page 14 Indiana University School of
Desired outcomes by Summer 2006
• A chemical informatics web service infrastructure running at IU• Several Taverna workflows that use these and other web
services, and which demonstrate that the infrastructure can be used to perform complex, relevant operations on PubChem data
• Demonstrated scientific results with the NIH DTP data• An established Distributed Drug Discovery database linked with
PubChem, that shows that our techniques together with PubChem can be employed in ways which benefit humanity in general
• A sandbox PubChem copy with improved functionality and architecture
• One or more novel visualization tools for PubChem data• Demonstrate the feasibility of fast, accurate clustering of very
large datasets (including the whole of PubChem) using the AVIDD Linux Cluster and a parallelized clustering algorithm (DivKmeans)
• Show that .NET and Java-based web services can work well together in a common infrastructure
• Demonstrate the feasibility of a natural language or other straightforward interface for scientists to express their information needs

David Wild – I533 2006. Page 15 Indiana University School of
NIH DatabaseService
PostgreSQLCHORD
FingerprintGenerator
BCI Makebits
ClusterAnalysis
BCI Divkmeans TableManagement
VoTables
PlotVisualizer
VoPlot
DockingSelector
Script
2D-3D
OpenEye OMEGA
Docking
OpenEye FRED
3D Visualizer
JMOL
Cluster the compounds in the NIH DTP database by chemical structure, then
choose representative compounds from the clusters and dock them into
PDB protein files of interest
SMILES + ID
Fingerprints
PDB DatabaseService
SMILES + ID + Data
ClusterMembership
SMILES + ID + + Cluster # + Data
SMILES + ID
MOL File
PDB Structure +
Box
Docked Complex

David Wild – I533 2006. Page 16 Indiana University School of
“However large an array of facts, however rapidly they accumulate,it is possible to keep them in order and to extract from
time to time digests containing the most generally significantinformation, while indicating how to find those items of
specialized interest. To do so, however, requires the willand the means”
“[we need to] get the best information in the minimum quantityin the shortest time, from the people who are producing theinformation to the people who want it, whether they know they
want it or not”
J.D. Bernal, quoted in Murray-Rust et. al., Org. Biomol. Chem., 2004, 2, 3192-3203

David Wild – I533 2006. Page 17 Indiana University School of
“Smart Client” for drug discovery
An open-source prototype that implements a new model of data mining that would, on request, “push” relevant information to pharmaceutical scientists in response to previously-defined straightforward expressions of needs, rather than relying on them stumbling upon the right information using traditional “browsing” models.
… using workflows and web services

David Wild – I533 2006. Page 18 Indiana University School of

David Wild – I533 2006. Page 19 Indiana University School of

David Wild – I533 2006. Page 20 Indiana University School of
Onlinedatabase
(e.g. PubChem)
Localdatabase
3D DockingTool
2D-3Dconverter
3Dvisualizer
UDDI
New Structure Service
Search online databasesfor recent structures
Search local databasesfor recent structures
Merge Results
AGENT / SMART CLIENT
Parse requestSelect appropriate use cases
and/or web service(s)Schedule as necessary
Request from Human Interface
WSDLSOAP
atomic services
aggregate services
USE-CASE SCRIPT
Invoke New Structure ServiceConvert structures to 3DDock results & protein file
Extract any hitsReturn links for visualization

David Wild – I533 2006. Page 21 Indiana University School of
Prototype development plan
• Develop a handful of use-cases based around industry/academia scientists
• Build 5-6 data / computation sources (e.g. enumeration, property calculation, structure database) that can fulfill the use cases
• Build WSDL and SOAP web services around the data sources that can be accessed from Taverna
• Develop workflows in Taverna (see taverna.sourceforge.net) • Publish web services in UDDI• Encode use-cases into scripts• Build Intelligent Agent / Smart Client node that can match user
needs with scripts & web services using workflows• Develop browser interface through Contextual Inquiry/Usability
Studies• Consider mapping to a Natural Language Interface

David Wild – I533 2006. Page 22 Indiana University School of
Use Case #1Are there any good ligands for my
target?• A chemist is working on a project involving a
particular protein target, and wants to know:– Any newly published compounds which might fit the
protein receptor site– Any published 3D structures of the protein or of protein-
ligand complexes– Any interactions of compounds with other proteins– Any information published on the protein target

David Wild – I533 2006. Page 23 Indiana University School of
Use Case #1Are there any good ligands for my
target?• A chemist is working on a project involving a
particular protein target, and wants to know:– Any newly published compounds which might fit the
protein receptor site gNova / PostgreSQL, PubChem search, FRED Docking
– Any published 3D structures of the protein or of protein-ligand complexes PDB search
– Any interactions of compounds with other proteins gNova / PostgreSQL, PubChem search
– Any information published on the protein target Journal text search

David Wild – I533 2006. Page 24 Indiana University School of
Use Case #2Who else is working on these
structures?• A chemist is working on a chemical series for a
particular project and wants to know:– If anyone publishes anything using the same or related
compounds– Any new compounds added to the corporate collection
which are similar or related – If any patents are submitted that might overlap the
compounds he is working on– Any pharmacological or toxicological results for those or
related compounds– The results for any other projects for which those
compounds were screened

David Wild – I533 2006. Page 25 Indiana University School of
Use Case #2Who else is working on these
structures?• A chemist is working on a chemical series for a
particular project and wants to know:– If anyone publishes anything using the same or related
compounds ~ PubChem search– Any new compounds added to the corporate collection
which are similar or related gNova CHORD / PostgreSQL– If any patents are submitted that might overlap the
compounds he is working on ~ BCI Markush handling software
– Any pharmacological or toxicological results for those or related compounds gNova CHORD / PostgreSQL, MiToolkit
– The results for any other projects for which those compounds were screened gNova CHORD / PostgreSQL, PubChem search

David Wild – I533 2006. Page 26 Indiana University School of
Priorities for web service development
• Search of PubChem– Wrap around HTTP or SOAP request
• Search of local gNova / PostgreSQL database– Wrap around application
• Molecular docking with OpenEye FRED– Wrap around application
• Property calculation with Molinspiration MiTools– Wrap around application
• PDB Search– Already implemented as EMBL web service
• BCI Markush search– Wrap around application
• Fast clustering of large datasets– Wrap around grid-based application
• Visualizations of datasets– Client and service development – VisualiSAR, Spotfire

David Wild – I533 2006. Page 27 Indiana University School of
Use Case - CICCWhich of these hits should I follow up?
• An MLI HTS experiment has produced 10,000 possible hits out of a screening set of 2m compounds. A chemist at another laboratory wants to know if there are any interesting active series she might want to pursue, based on:– Structure-activity relationships– Chemical and pharmacokinetic properties– Compound history– Patentability– Toxicity– Synthetic feasibility

David Wild – I533 2006. Page 28 Indiana University School of
Use Case – ECCRWhich of these hits should I follow up?
• An HTS experiment has produced 10,000 possible hits out of a screening set of 2m compounds. A chemist on the project wants to know what the most promising series of compounds for follow-up are, based on:– Series selection cluster analysis– Structure-activity relationships modal fingerprints/stigmata– Chemical and pharmacokinetic properties mitools,
chemaxon– Compound history gNova / PostgreSQL– Patentability BCI Markush handling software– Toxicity– Synthetic feasibility– + requires visualization tools!

David Wild – I533 2006. Page 29 Indiana University School of
Technology
• Perl SOAP::Lite – Will be used for initial web service development– Doesn’t really implement WSDL & UDDI
• Apache Axis & Tomcat– Deploy WSDL for web services
• BPEL4WS – Business Process Execution Language– For aggregation of web services– http://www-128.ibm.com/developerworks/library/
specification/ws-bpel/
• Microsoft .NET & C#

David Wild – I533 2006. Page 30 Indiana University School of
Current activities
• Core activities– Development of use-cases– Development of initial web services (Perl SOAP::Lite)– Use of Taverna to prototype use-case scripts
• Basic research on future components– Organizing large amounts of chemical information
for human consumption• Development of very fast parallel clustering techniques –
to be exposed as web services– Selection of interface-level tools for basic interaction
• Chemical structure drawing, display• Investigation of email, NLP, RSS, and browser interfaces
– Interface-level tools for visualization, navigation and analysis
• Cluster and dataset visualization, natural language interfaces)

David Wild – I533 2006. Page 31 Indiana University School of
Cluster Analysis and Chemical Informatics
• Used for organizing datasets into chemical series, to build predictive models, or to select representative compounds
• Organizational usage has not been as well studies as the other two, but see– Wild, D.J., Blankley, C.J. Comparison of 2D Fingerprint Types and
Hierarchy Level Selection Methods for Structural Grouping using Wards Clustering, Journal of Chemical Information and Computer Sciences., 2000, 40, 155-162.
• Essentially helping large datasets become manageable• Methods used:
– Jarvis-Patrick and variants• O(N2), single partition
– Ward’s method• Hierarchical, regarded as best, but at least O(N2)
– K-means• < O(N2), requires set no of clusters, a little “messy”
– Sphere-exclusion (Butina)• Fast, simple, similar to JP
– Kohonen network• Clusters arranged in 2D grid, ideal for visualization

David Wild – I533 2006. Page 32 Indiana University School of
Limitations of Ward’s method forlarge datasets (>1m)
• Best algorithms have O(N2) time requirement (RNN)
• Requires random access to fingerprints– hence substantial memory requirements (O(N))
• Problem of selection of best partition– can select desired number of clusters
• Easily hit 4GB memory addressing limit on 32 bit machines– Approximately 2m compounds

David Wild – I533 2006. Page 33 Indiana University School of
Scaling up clustering methods
• Parallelisation– Clustering algorithms can be adapted for multiple
processors– Some algorithms more appropriate than others for
particular architectures– Ward’s has been parallelized for shared memory
machines, but overhead considerable
• New methods and algorithms– Divisive (“bisecting”) K-means method– Hierarchical Divisive– Approx. O(NlogN)

David Wild – I533 2006. Page 34 Indiana University School of
Divisive K-means Clustering
• New hierarchical divisive method – Hierarchy built from top down, instead of bottom up– Divide complete dataset into two clusters– Continue dividing until all items are singletons– Each binary division done using K-means method– Originally proposed for document clustering
• “Bisecting K-means”– Steinbach, Karypis and Kumar (Univ. Minnesota)
http://www-users.cs.umn.edu/~karypis/publications/Papers/PDF/doccluster.pdf
– Found to be more effective than agglomerative methods– Forms more uniformly-sized clusters at given level

David Wild – I533 2006. Page 35 Indiana University School of
BCI Divkmeans
• Several options for detailed operation– Selection of next cluster for division– size, variance, diameter– affects selection of partitions from hierarchy, not shape of
hierarchy
• Options within each K-means division step – distance measure– choice of seeds– batch-mode or continuous update of centroids– termination criterion
• Have developed parallel version for Linux clusters / grids in conjunction with BCI
• For more information, see Barnard and Engels talks at: http://cisrg.shef.ac.uk/shef2004/conference.htm

David Wild – I533 2006. Page 36 Indiana University School of
Comparative execution timesNCI subsets, 2.2 GHz Intel Celeron processor
7h 27m
3h 06m
2h 25m
44m
0
5000
10000
15000
20000
25000
30000
0 20000 40000 60000 80000 100000 120000Number of Structures in Clustered Set
Exe
cutio
n T
ime
(s)
Wards
K-means
Divisive K-means
Parallel Divisive Kmeans (4-node)

David Wild – I533 2006. Page 37 Indiana University School of
Clustering a 1 million compound dataset
on a 2.2 GHz Celeron Desktop Machine
Method Time * Memory Usage
K-Means(10,000 clusters)
3½ days 95 MB
Divisive K-means 7 days 65 MB
Divisive K-means(Parallel, 4 machinesincl. 1.7 GHz Pentium M)
16½ hours
~ 50 MB
* Time for a single run may vary due to different selection of seeds. Runtimes can be shortened e.g. by using a max. number of iterations or a % relocation cutoff.
Results from AVIDD clusters & Teragrid coming soon….

David Wild – I533 2006. Page 38 Indiana University School of
Divisive Kmeans: Conclusions
• Much faster than Ward’s, speed comparable to K-means, suitable for very large datasets (millions) – Time requirements approximately O(N log N)– Current implementation can cluster 1m compounds in under
a week on a low-power desktop PC– Cluster 1m compounds in a few hours with a 4-node parallel
Linux cluster
• Better balance of cluster sizes than Wards or Kmeans• Visual inspection of clusters suggests better assembly of
compound series than other methods• Better clustering of actives together than previously-
studied methods• Memory requirements minimal• Experiments using AVIDD cluster and Teragrid
forthcoming(50+ nodes)

David Wild – I533 2006. Page 39 Indiana University School of
Visualization & interface level tools
• No matter how clever the smarts underneath, the overriding factor in usefulness will be the quality of scientists’ interaction with the system
• Contextual Design, Interaction Design (Cooper) and Usability Studies have proven effective in designing the right interfaces for the right peoplein chemical informatics [collaboration with HCI?]
• Possibility of multiple interfaces for different people groups(Cooper’s “primary personas”)
• Don’t assume the browser interface – email / NLP ?• Start with the basics
– 2D chemical structure drawing (input)– Visualization of large numbers of chemical structures in 2D– 3D chemical structure visualization
• Planning on evaluation of NLP, email, RSS, etc. as well asbrowser-based interfaces

David Wild – I533 2006. Page 40 Indiana University School of
Usability of 2D structure drawing tools
• Key difference between “sequential” and “random” drawers
• Huge difference in intuitiveness• Key factor how badly you can mess things up• Marvin Sketch ≈ JME > ChemDraw >> ISIS Draw

David Wild – I533 2006. Page 41 Indiana University School of
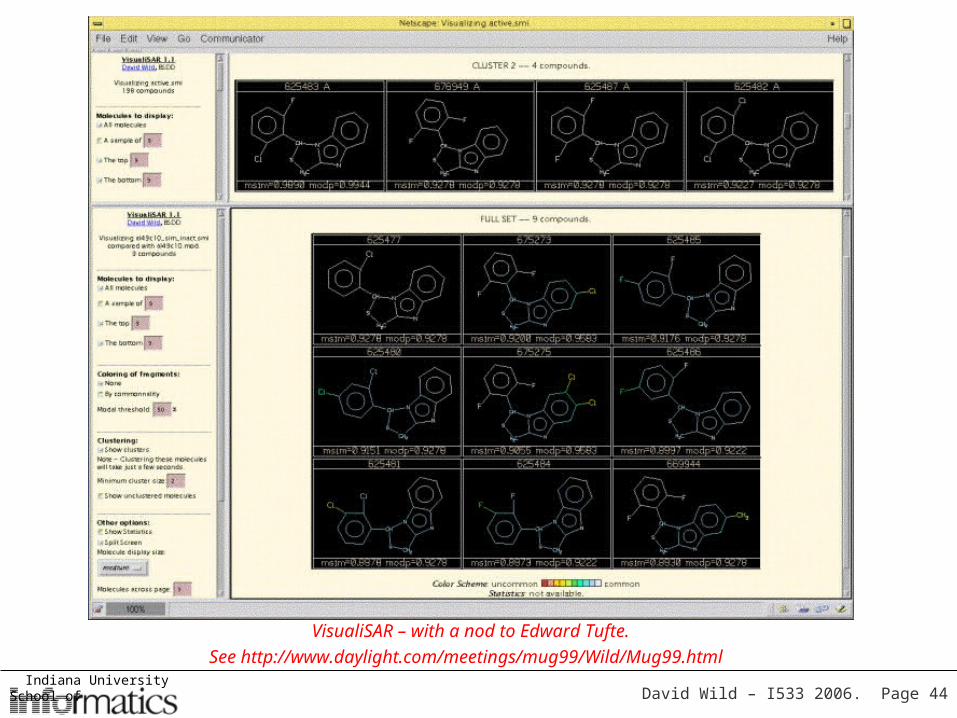
Visualization methods for datasets &
clusters• Partitions– Spreadsheets– Enhanced Spreadsheets– 2D or 3D plots
• Hierarchies– Dendograms– Tree Maps– Hyperbolic Maps

David Wild – I533 2006. Page 42 Indiana University School of

David Wild – I533 2006. Page 43 Indiana University School of
David Wild – I533 2006. Page 44 Indiana University School of
VisualiSAR – with a nod to Edward Tufte.See http://www.daylight.com/meetings/mug99/Wild/Mug99.html

David Wild – I533 2006. Page 45 Indiana University School of
Tree Maps – very Tufte-esque

David Wild – I533 2006. Page 46 Indiana University School of
3D Visualization - JMOL
Open Source, very flexible, works in a web service environment: jmol.sourceforge.net

David Wild – I533 2006. Page 47 Indiana University School of
Conclusions so far
• Effective exploitation of large volumes and diverse sources of chemical information is a critical problem to solve, with a potential huge impact on the drug discovery process
• Most information needs of chemists and drug discovery scientists are conceptually straightforward, but complex (for them) to implement
• All of the technology is now in place to implement may of these information need “use-cases”: the four level model using service-oriented architectures together with smart clients look like a neat way of doing this
• The aggregation and interface levels offer the most challenges• In conjunction with grid computing, rapid and effective organization and
visualization of large chemical datasets is feasible in a web service environment
• Some pieces are missing:– Chemical structure search of journals (wait for InChI)– Automated patent searching– Effective dataset organization– Effective interfaces, especially visualization of large numbers of 2D structures
(we’re working on it!)





























