Embed Size (px)
Citation preview

Influence at Scale: Distributed Computation of Complex Contagion in Networks
JOEL OREN, UNIVERSITY OF TORONTO
JOINT WORK WITH YARON SINGER (HARVARD) & BRENDAN LUCIER (MSR)

Efficient Influence Estimation in Massive Social Networks
• Given a model for influence spread, how do we compute the influence of a group of “initial adopters”?
• Common approaches: • Polytime methods such as Monte-Carlo (sampling) based
methods, (Kempe et al.2003),• Elementary matrix-product methods work. (Even-Dar & Shapira
2011).
• This talk: scaling to Massive social networks: are these satisfying approaches?
2

Influence Estimation for Massive Social Networks
• General question: what is the information cost of theoretical methods for estimating properties of large graphs?1. How much of the graph do we need to
examine? (query complexity).2. How much information do we need to
store throughout the execution?
• Can we get provably efficient estimation using distributed methods? How applicable is the MapReduce paradigm?
𝐺3

Influence Estimation: Context and Related Work
• Analysis of massive graphs:1. Single machine systems: Cassovary (Twitter), Ligra, SNAP.2. Distributed: Hadoop/MapReduce, Spark/GraphX, Giraph, GraphLab.
• Ongoing: efficient algorithms that adhere to a computational paradigm inspired by MapReduce (Karloff et al. 2010):• Connectivity, MST’s, counting triangle, edge covers, matching …
• Influence diffusion: models have been proposed since the 1960’s. Kempe et al. (2003,2005) studied the algorithmic problem of selecting the most influential. • Influence can be estimated with samples.
4

The Independent Cascade Model
• Introduced by Kempe et al. (2003).
•The model: 1. Input: An edge-weighted directed graph p), set of
initial infected seeds .2. Write for set of infected nodes at step .3. At every synchronous step , every newly infected
node infects neighbor independently w.p. . 𝑏
𝑎
𝑥
𝑐 𝑑
𝑆0𝑝𝑥𝑏
𝑝𝑥𝑎𝑝𝑏𝑑𝑝𝑏𝑐
𝑝𝑑𝑎
5

Estimating Influence under the Independent Cascade Model
• For seed set , expected number of infected nodes at the end.
• Monte Carlo sampling (Kempe et al. 2003): 1. Sample instances of the process.2. Take mean # of infected nodes.Q1: How much local information (e.g., neighborhoods) do we need to consider?
• Q2: How scalable is this?• Samples may require lots of space (high
influence).• Run in parallel on multiple machines.
𝑏
𝑎
𝑥
𝑐 𝑑
𝑝𝑥𝑏
𝑝𝑥𝑎𝑝𝑏𝑑𝑝𝑏𝑐
𝑝𝑑𝑎
𝑏
𝑎
𝑥
𝑐 𝑑
𝑏
𝑎
𝑥
𝑐 𝑑
𝑏
𝑎
𝑥
𝑐 𝑑
6

Q1: What is the complexity of Contagion?
• Link-server model: we have access to a server. For query , returns out-neighborhood of with respective edge-probabilities.
• The information need of estimation: How many queries do we need to provide a constant factor approximation of ?
• Implication: in worst case, need knowledge about a large portion of the graph.
Theorem: (informal) Obtaining an -approximation (or better) of with probability , requires queries.
7

The Algorithmic Framework: the MRC Model
• We know we need queries total, which is a lot for massive networks – maybe we can achieve scalability via parallelization. For this, we’ll turn to the MapReduce model.
• The parallel computation paradigm: MRC Model (Karloff et al.2010).
• Synchronous round computation on on tuples. On every round:•Map: apply local transformation on tuples in a streaming fashion.• Reduce: do polytime computation on aggregates of tuples with the same key.
• MRC model constraints: – number of input tuples; – const fraction.• # of machines: .• space per machine.• Up to rounds, for some .
8

Q2: Scalability of Influence Estimation for Massive Graphs
• Approach: repeatedly sample the process, but now run many samples in parallel (recall: at most samples are needed in total)
•Recall: we can estimate by sampling poly(n) instances of the process.
• Challenge 1: A single sample: may require memory too big for MRC.
• Challenge 2: Many samples may be required too many for MRC
• Synchronous round approach: multiple samples per machine, over multiple rounds.
• How can we assign samples to machines, and avoid consuming too much memory when samples are too large?
13
13
13
13
13
Θ(1
𝑛−1)
1
1
111
1
1
9
𝑆0

An MRC Algorithm for Influence Estimation
• Goal: design an efficient, MRC algorithm for approximating with high confidence.
•Theorem: We can give a -approximations with rounds.
• Approach: take a modular approach:• Layer 1: sampling bounded instances. Take samples,
and cap infection at nodes.• Layer 2: approximate integral of infection distribution
CDF: for a guess , use capped samples to determine whether the true influence is greater than .
◦ Layer 3: in descending order, iterate over logarithmically many guesses stop when we verify the true influence is greater than the guess.
Sample Oracle
𝐿 ,𝑡
fraction of samples reached nodes.
1−𝐹 (𝐼 )
𝐼𝜏𝜏 ′
10

Layer 1: Bounded Parallel Sampling
• In parallel: for take samples of influence process. Terminate a sample if nodes reached.• Perform multiple (bounded) BFS, 1 layer at a time. • # of rounds – linear in diameter of the graph.
•Map: node-level infections. Reduce: aggregate results.•Challenge: handling the case where the influence jumps from less than t to much larger than t in a single round.•Can plug-in alternative reachability algorithm.
𝑝𝑺𝒕( 𝒋)
𝑺𝒕(𝒊)
11
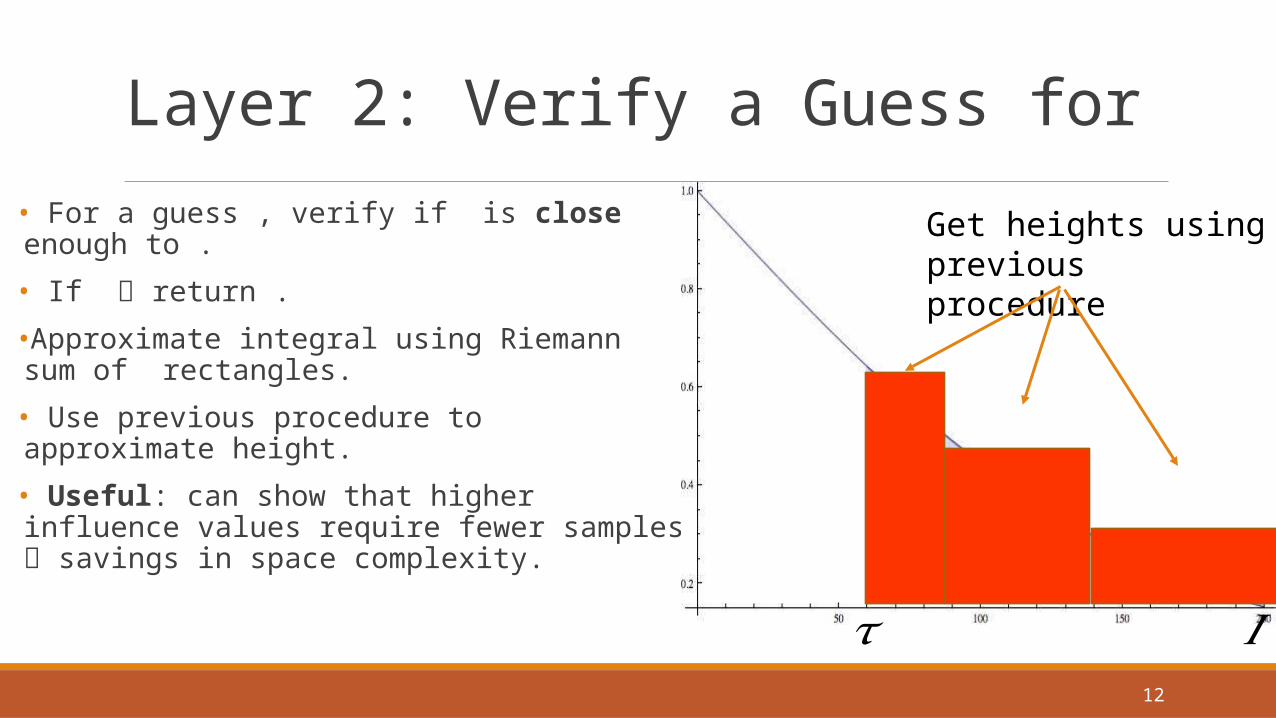
Layer 2: Verify a Guess for
• For a guess , verify if is close enough to .
• If return .
•Approximate integral using Riemann sum of rectangles.
• Use previous procedure to approximate height.
• Useful: can show that higher influence values require fewer samples savings in space complexity.
𝜏 𝐼
Get heights using previous procedure
12

Top Layer: InfEst – Top-Down Iteration over Guesses
• Iterate over guesses.
• At each iteration:• Scale down .• VerifyGuess() – if returned True, return
value close enough to . Total: many rounds; Sublinear # of tuples per machine throughout.
Approximation ratio: 𝜏
VerifyGuess(𝑓 (𝑆0)
𝜏
FalseTrue
13

Empirical Testing: Running Time• Benchmark: the standard Monte Carlo algorithm: sample influence times.
• Approximate Monte Carlo: take linear number of samples.
•Results: InfEst scales well.• Larger seed-sets Monte Carlo takes longer.
InfEst
Approx-MC
MC
14

Empirical Testing: Approximation
• We measured the approximation ratio of InfEst for different scaling factors (determine the decrease, and how many rectangles in the Riemann sum).
• Recall: is controlling the maximum error, and not the average error.
15

Summary• Influence estimation: polynomial time computation in theory; in practice, sampling is very time and space consuming.
• Recent parallel computing frameworks offer a way to alleviate such issues.
• We designed an algorithmic approach for estimating influence in MapReduce fashion that scales to massive networks.
• Next steps:1. Other influence models: may require different approaches.2. Influence maximization: how to pick so as to maximize . The hope: use our
approach as a stepping stone.
16

17
THANK YOU

![Competitive Contagion in Networksmkearns/papers/CompetitiveContagionG… · and Tardos [19, 20]; Mossel and Roch [21]; Borodin, Filmus, and Oren [8]; Chasparis and Shamma [9]; Carnes](https://img.pdfslide.net/doc/110x75/5f37e36ecf3fac4c505e176d/competitive-contagion-in-networks-mkearnspaperscompetitivecontagiong-and-tardos.jpg)

![שמאות isa[1] - לשכת שמאי מקרקעין · Yam Spector Gil Sitton Golan Vakrat Roni Cohen Yaron Parienti Yaniv Cachlon Gnad Gelbaum Hanan Binsky Yossi Almoznino Oren](https://img.pdfslide.net/doc/110x75/5ae8b6907f8b9a087790166a/-isa1-spector-gil-sitton-golan-vakrat.jpg)