Embed Size (px)
Citation preview

Universit�at HamburgFB Informatik
Information Retrieval Unterst�utzung zur
kooperativen Arbeit mit
Bibliographiedatenbanken
Anforderungsanalyse und Systementwurf am Beispiel des
BibTEX-Systems
Studienarbeit
eingereicht bei
Prof. Dr. J. W. SchmidtArbeitsbereich Softwaresysteme
Technische Universit�at Hamburg-Harburg
vonAndr�e Wittenburg
26. Juni 1998

Inhaltsverzeichnis
1 Einleitung und Motivation 2
2 BibTEX, eine kurze Einf�uhrung 52.1 BibTEX Klassen und Eintragstypen . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2 BibTEX Felder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3 Anforderungsanalyse 83.1 Aufgabenbeschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Systemvoraussetzungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.3 Anwendungsfallanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.4 Klassen und Dom�anen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.5 Merging-Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4 Information Retrieval 164.1 String Matching Methoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1.1 Edit Distance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174.1.2 Soundex und Phonix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.2 Bewertung von IR-Systemen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.2.1 Stoppwort-Elimination und Stammformreduktion . . . . . . . . . . . . . . . 204.2.2 Indexing in IR-Systemen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.3 Eine Fallstudie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5 Systementwurf 225.1 Tycoon-2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225.2 Structured Tycoon Markup Language - STML . . . . . . . . . . . . . . . . . . . . 235.3 Systemarchitektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.3.1 Verwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255.3.2 Applikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285.3.3 Pr�asentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
6 Zusammenfassung 35
7 Ausblick 37
Anhang 37
A BibTEX Eintragstypen 38
B BibTEX-Stildatei 40
C UML-Diagramme 43
II

D Systembeschreibung 46D.1 BibAlgo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46D.2 BibApplication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47D.3 BibCheckClass . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49D.4 BibCheck . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50D.5 BibEntry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51D.6 BibEntryClass . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51D.7 BibFile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51D.8 BibFileClass . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51D.9 BibMergeClass . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51D.10 BibMerge . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52D.11 BibParameter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52D.12 BibParameterClass . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52D.13 BibProcessor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53D.14 BibQuestionClass . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53D.15 BibQuestion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53D.16 BibRankedList . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54D.17 BibTriple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
III

Abbildungsverzeichnis
1.1 Teilergebnis der Suchanfrage: (latex) and(lamport) . . . . . . . . . . . . . . . . . . 3
2.1 ein- und ausgehende Dateien f�ur das BibTEX-System . . . . . . . . . . . . . . . . . 6
3.1 m�ogliche Ergebnismengen des Systems . . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Ablaufdiagramm der Anforderungsanalyse . . . . . . . . . . . . . . . . . . . . . . . 123.3 BibTEX-Dom�anen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.1 Rekurrenzgleichung f�ur Edit Distance . . . . . . . . . . . . . . . . . . . . . . . . . 184.2 Zusammenhang zwischen relevanten und gefundenen Objekten in IR-Systemen . . 19
5.1 Quelltext der Klassen MutableListClass und MutableList . . . . . . . . . . . . . . . 235.2 Beispiel einer STML-Seite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245.3 Schichtenmodell f�ur die Systemarchitektur . . . . . . . . . . . . . . . . . . . . . . . 255.4 Objekte einer BibTEX-Datei { Instanzendiagramm . . . . . . . . . . . . . . . . . . 265.5 aux -Datei zum Importieren der BibTEX-Dateien . . . . . . . . . . . . . . . . . . . 285.6 Bildschirmausschnitt - Hauptmen�u des BibTEX Merge-Tool . . . . . . . . . . . . . 335.7 Bildschirmausschnitt - Vergleichen zweier BibTEX-Eintr�age . . . . . . . . . . . . . 34
C.1 Use Case Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43C.2 Klassendiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44C.3 Ablaufdiagramm des Systementwurfs . . . . . . . . . . . . . . . . . . . . . . . . . . 45
1

Kapitel 1
Einleitung und Motivation
Ausgangspunkt f�ur diese Arbeit bildet folgendes Szenario:
Person A und Person B besitzen eine Datenbank, in der sie getrennt voneinander ihreLiteraturreferenzen verwalten. A und B m�ochten nun zusammen ein Paper schreibenund wollen dazu Ihre Literaturreferenzen abgleichen, um zu sehen, welche Quellenbeiden bekannt sind und welche der andere noch nicht kennt.
Im universit�aren Bereich ist f�ur die Archivierung von Literaturreferenzen das BibTEX-System weitverbreitet, so da� dieses System auf die obige Problemstellung hin genauer untersucht wird.
Einen Suchdienst im WWW bietet die Universit�at Karlsruhe unter folgender URL an:
liinwww.ira.uka.de/bibliography/
Hier haben die Benutzer die M�oglichkeit, ihre eigene BibTEX-Datei hinzuzuf�ugen und in denEintr�agen Anderer zu suchen. Mit der Zeit ist eine gro�e Datenbank aus den verschiedenstenBibTEX-Dateien entstanden.
Auf der Suche nach Eintr�agen zu Information Retrieval erh�alt man zwar eine Menge von Litera-turvorschl�agen, doch viele erscheinen mehrfach.Der Nachteil resultiert aus dem Verfahren, die verschiedenen Dateien zusammenzuf�uhren (mergen).Die einzelnen Eintr�age werden nicht miteinander verglichen, sondern nach Stichw�ortern durchsuchtund anschlie�end mit Angabe des Eigent�umers der BibTEX-Datei abgelegt.
Folgender Suchstring k�onnte als Anfrage gestellt werden:
(latex) and (lamport)
Einen Teil des Suchergebnisses sehen Sie in Abbildung 1.1.Wenn man aus dem Gesamtergebnisses die Duplikate eliminiert, so erh�alt man bei insgesamt 20Eintr�agen nur 6 verschiedene B�ucher.Die Felder einiger Eintr�age sind fast deckungsgleich (vgl. Eintr�age 4 und 5). Andere wiederumunterscheiden sich enorm (vgl. Eintr�age 1 und 6). Wenn man die einzelnen BibTEX Eintr�age ver-gleicht, so �ndet man keine zwei Eintr�age, in denen alle Felder den gleichen1 Inhalt haben.
1Gleich bezieht sich hier auf die Gleichheit jedes einzelnen Zeichens innerhalb der Felder.
2

KAPITEL 1. EINLEITUNG UND MOTIVATION 3
1.)
From Bibliography of the library of the Computer Science Department
at the University of Braunschweig, Germany (1986):
Leslie Lamport
LaTeX: A Document Preparation System - User's Guide & Reference
Manual
, Addison-Wesley, 1986.
2.)
From Peter B. Danzig's personal bibliographic collection:
Leslie Lamport
A Document Preparation System LATEX
, Addison-Wesley, 1986.
3.)
From Bibliography of the Signal Processing Group at
Rogaland University:
L. Lamport
LaTeXUser's Guide and Reference Manual
, Addison Wesley, 1986 or later.
4.)
From Bibliography on TeX and METAFONT:
Leslie Lamport
LaTeX--- A Document Preparation System---User's Guide
and Reference Manual
, p. xiv + 242, pub-AW, 1985.
5.)
From Bibliography of publications related to typesetting, primarily
computer-based typesetting:
Leslie Lamport
LaTeX: a document preparation system
, p. xiv + 242, pub-AW, 1986.
6.)
From Paolo Ciancarini's personal bibliography:
L. Lamport
LaTeX. User's Guide & Reference Manual.
, aw, 1986.
7.)
From Bibliography relating to algebra, program specification
and verification, and logic:
Leslie Lamport
\LaTeX User Guide and Reference Manual
, Addison-Wesley, 1985.
Abbildung 1.1: Teilergebnis der Suchanfrage: (latex) and(lamport)

KAPITEL 1. EINLEITUNG UND MOTIVATION 4
Es ergibt sich folgendes Problem:
� BibTEX-Datenbanken werden von unterschiedlichen Personen unabh�angig voneinander er-stellt.
� Zwei oder mehrere BibTEX-Datenbanken sollen zusammengef�uhrt werden.
� Semantische Duplikate sollen gefunden und gegebenenfalls eliminiert werden.
Da die Grundlage f�ur diese Arbeit das BibTEX-System ist, be�ndet sich in Kapitel 2 eine kurzeEinf�uhrung in den Aufbau und Strukturierung von BibTEX-Datenbanken.
Die Anforderungen an das System werden in Kapitel 3 beschrieben.
Doch welche M�oglichkeiten und Algorithmen bietet die Informatik, um L�osungsans�atze f�ur dasbeschriebene Problem zu �nden? Ans�atze hierzu bietet das Gebiet des Information Retrieval,welches sich unter anderem mit der inhaltlichen Suche in Texten, dem sogenannten Text Retrie-val, besch�aftigt. Welche Grundideen Information Retrieval beinhaltet, und einige L�osungsans�atze�nden sich in Kapitel 4.Den Systementwurf innerhalb einer objektorientierten Umgebung be�ndet sich in Kapitel 5.Die Zusammenfassung in Kapitel 6 enth�alt ein Resumee �uber die Implementationund die genutztenRessourcen. Abschlie�end werden im Ausblick m�ogliche Erweiterungen des Systems vorgestellt.

Kapitel 2
BibTEX, eine kurze Einf�uhrung
Das BibTEX-System soll die Erstellung von Literaturverzeichnissen in LATEX-Dokumenten erleich-tern und die Verwaltung von Literaturangaben unterst�utzen. Hierzu besitzt jeder Benutzer diesesSystems eine oder mehrere Literaturdateien, in denen er seine Literaturdaten verwaltet. Mit Hil-fe des ncite oder des nnocite-Befehls werden Literaturverweise zu einer LATEX-Datei hinzugef�ugt.BibTEX �ubernimmt dann anschlie�end aus der Hilfsdatei die entsprechenden Daten und erstellt dasLiteraturverzeichnis. Die Art des Aufbaus der einzelnen Eintr�age wird durch eine BibTEX-Stildateiangegeben.Innerhalb der Literaturdateien stehen eine Vielzahl von Eintr�agen. Ein Eintrag hat zum Beispielfolgende Form:
@Book{Lamport95,
author = "Leslie Lamport",
title = "Das LaTeX Handbuch",
pages = "325",
publisher = "Addison-Wesley",
year = "1995",
isbn = "3-89319-826-1",
price = "69,90"
}
Zu Beginn jedes Eintrags steht der Eintragstyp. In diesem Fall handelt es sich um den Typ book, wasdurch @Book de�niert wird. Lamport95 entspricht dem Schl�ussel, der in dem LATEX-Dokument aufdieses Buch referenziert. Dieser Eintrag enth�alt zus�atzlich sieben Felder, wobei author, title,
publisher und year zwingende Eintr�age sind. Die anderen Eintr�age werden vom BibTEX-Systemignoriert. Diese Zuordnung, die f�ur die standard Stildateien g�ultig ist, kann jedoch durch dieBibTEX-Stildatei beein u�t werden. Zus�atzlich gibt es noch optionale Eintr�age, die eine Ausgabeerzeugen (vgl. Abschnitt 2.1).Wichtig f�ur sp�atere Betrachtungen ist, da� BibTEX Gro�- und Kleinschreibung der Buchstaben imEintragstyp, im Schl�ussel und in den Feldnamen ignoriert, so da� ein Parser diese Zeichenkettengenerell in Kleinbuchstaben �ubersetzen k�onnte, ohne da� Information verloren geht. Des weiterenk�onnen statt der Anf�uhrungszeichen bei Feldern auch geschweifte Klammern verwendet werdenoder diese weggelassen werden, wenn es sich bei den Eintr�agen um Zahlen oder Makros handelt.
Wie BibTEX bestimmte Eintr�age in LATEX-Dokumenten darstellt, ist f�ur diese Arbeit nicht rele-vant, da dies durch die BibTEX-Stildatei beein u�t wird.
In Abbildung 2.1 sind die Dateien zu sehen, die f�ur das BibTEX-System eine Rolle spielen. Nach-folgend sind die Dateien beschrieben:
� aux -Datei:LATEX erzeugt diese Datei. Sie enth�alt alle Schl�ussel zu den gew�unschten Litraturreferenzenund Angaben �uber die zu benutzende Stildatei und BibTEX-Datei.
5

KAPITEL 2. BIBTEX, EINE KURZE EINF�UHRUNG 6
.bib(Literaturdatei)
.bst(Stildatei)
.aux(Hilfsdatei)
.bbl(Referenzdatei)
.blg(Protokolldatei)
BibTeX
Abbildung 2.1: ein- und ausgehende Dateien f�ur das BibTEX-System
� bst-Datei:Die BibTEX-Stildatei gibt an, wie die Ausgabe formatiert sein soll. Hierzu z�ahlt sowohl dieFormatierung der Eintr�age im Literaturverzeichnis, als auch die Angabe im Text.
� bib-Datei:Die Literaturdatei enth�alt alle Literaturreferenzen, die der Benutzer eingetragen hat.
� bbl-Datei:Die Referenzdatei enth�alt das fertige Literaturverzeichniss, das im Anschlu� vom LATEX-System genutzt werden kann.
� blg-Datei:Die Logdatei des BibTEX-Systems enth�alt alle Fehlermeldungen und Warnungen, die w�ah-rend des Aufrufs entstanden sind.
2.1 BibTEX Klassen und Eintragstypen
Wie bereits erw�ahnt, gibt es zu jedem Eintragstyp drei verschiedene Klassen von Feldern, die imfolgenden n�aher beschrieben werden:zwingendWenn ein Feld dieser Klasse ausgelassen wird, so erzeugt BibTEX beim �Ubersetzen eine Fehler-meldung. Diese kann jedoch ignoriert werden.optionalDiese Felder werden im Literaturverzeichnis in LATEX-Dokumenten ber�ucksichtigt und erzeugeneine Ausgabe.ignoriertBibTEX ignoriert diese Klasse von Feldern v�ollig. Ein Beispiel f�ur diese Klasse ist das Feld price.
Die Felder der Klasse ignoriert haben nicht automatisch einen niedrigeren Informationsgehalt alsoptionale Felder. Die ISBN ist bei keinem Eintragstyp ein zwingendes oder optionales Feld. Fallsjedoch zwei BibTEX-Eintr�age die gleiche ISBN haben, so ist die Wahrscheinlichkeit recht gro�,da� es sich um semantisch gleiche Eintr�age handelt. Allerdings gilt die Aussage, das die ISBN einignoriertes Feld ist, nur f�ur die Standard Stildateien des BibTEX-Systems. Verwendet man eineStildatei, die der Deutschen Industrie Norm (DIN) unterliegt, so ist die ISBN ein optionales Feldund erscheint in den Literaturverzeichnissen von LATEX-Dokumenten.Im Anhang A be�ndet sich eine Aufz�ahlung der BibTEX Eintragstypen, die in den standard Stil-dateien enthalten sind.

KAPITEL 2. BIBTEX, EINE KURZE EINF�UHRUNG 7
2.2 BibTEX Felder
Die von BibTEX unterst�utzten Felder sind:address, annote, author, booktitle, chapter, crossref, edition, editor,
howpublished, institution, journal, key, month, note, number, organization,
pages, publisher, school, series, title, type, volume, year
BibTEX erzeugt, beim Auslassen eines zwingenden Feldes nur eine Fehlermeldung, die jedochzu keinem Abbruch f�uhrt. Es ist somit nicht m�oglich anzunehmen, da� alle zwingenden Felderausgef�ullt sind.Die Felder key und crossref haben besondere Bedeutungen. Das key-Feld kann zur Formatierungverwendet werden und hat nichts mit dem Eintragsschl�ussel gemein. Das Feld crossref verweistauf einen anderen Eintrag innerhalb der BibTEX-Datei. Wenn ein BibTEX-Eintrag dieses Feldenth�alt, so werden alle nicht spezi�zierten Felder des Eintrages aus dem referenzierten Eintrag�ubernommen.Der Textteil eines Feldes ist generell mit geschweiften Klammern oder Anf�uhrungszeichen einge-fa�t. Es gibt desweiteren einige Regeln, wie die Eintr�age in spezi�schen F�allen auszusehen haben,jedoch f�uhrt auch diese Nichtbeachtung zu keiner Fehlermeldung, sondern nur zu schlecht forma-tierten Ausgaben.F�ur Namen gibt es zwei Arten der Darstellung:
"Donald E. Knuth" oder "Knuth, Donald E."
Allerdings sind die beiden folgenden Darstellungen nicht �aquivalent, da BibTEX in der erstenDarstellung "M�uller" als zweiten Vornamen interpretiert:
falsch:"Johannes M�uller Lotze" richtig:"M�uller Lotze, Johannes"
Um h�au�g benutzte Titel, Journale, etc. abzuk�urzen, k�onnen in der Literaturdatei Makros hinzu-gef�ugt werden:
@String{CACM = ''Communications of the ACM''}
Die Gro�- und Kleinschreibung des Makros ist unerheblich, so da� CACM und cacm die gleicheBedeutung haben. Das selbe gilt f�ur @String.
Folgende Schreibweisen sind somit �aquivalent:
journal = "Communications of the ACM"Journal = CACMJOURNAL = fCommunications of the ACMgjournal = Cacm
Eine ausf�uhrliche Einf�uhrung in BibTEX �ndet sich im LATEX-Handbuch[7] oder in der Dokumen-tation BibTEXing[11].

Kapitel 3
Anforderungsanalyse
Als Grundlage f�ur die Gliederung dieses Kapitels dient das Buch Objektorientierte Softwareent-wicklung mit der Uni�ed Modeling Language (UML) [10].In der Aufgabenbeschreibung in Kapitel 3.1 sollen die Aufgaben, die das System zu bew�altigen hat,kurz beschrieben werden. Das Kapitel 3.2 Systemvoraussetzungen soll die vorhandenen Resourcenund Systeme darlegen. Die einzelnen Anwendungsf�alle, die sich aus der Aufgabenbeschreibungergeben, �nden Sie in Kapitel 3.3. Hieraus lassen sich wiederum die ersten Klassen und einigeDom�anen identi�zieren (Kapitel 3.4). Zum Schlu� dieses Hauptkapitels werden im Kapitel 3.5 ei-nige Algorithmen beschrieben, die die Grundlage f�ur das Zusammenf�uhren von BibTEX-Eintr�agenbilden.
3.1 Aufgabenbeschreibung
Das zu entwickelnde System soll den Benutzer bei dem Zusammenf�uhren beziehungsweise Verglei-chen zweier BibTEX-Dateien unterst�utzen. Hierbei sollen semantisch gleiche Eintr�age vom Systemerkannt und gegebenenfalls unter Intervention des Benutzers zusammengef�uhrt werden. Die daraufaufbauenden Funktionen des Systems sind (vgl. Abbildung 3.1):
1. Union: In der Ergebnisdatei sollen alle Eintr�age enthalten sein, wobei die semantisch gleichenEintr�age nur einmal vorkommen sollen.
2. Intersection: Nur Eintr�age, die in beiden Dateien vorhanden sind, sollen in die Ergebnisdatei�ubernommen werden.
3. Minus: Es sollen nur Eintr�age der ersten (zweiten) Datei in die Ergebnisdatei �ubernommenwerden, die nicht in der zweiten (ersten) Datei enthalten sind.
4. Check : Aus der Datei selbst sollen semantische Duplikate herausge�ltert werden.
BA BA BA BA
Union Intersection A Minus B B Minus A Check
Abbildung 3.1: m�ogliche Ergebnismengen des Systems
Ist es dem System beim Vergleichen zweier Eintr�age nicht m�oglich, eine Entscheidung zu tre�en, sosoll der Benutzer intervenieren und die Entscheidung f�allen. Hierbei soll er entweder entscheiden,da� keine �Ubereinstimmung vorhanden ist oder das Aussehen des zusammengef�uhrten Eintragesbestimmen.
8

KAPITEL 3. ANFORDERUNGSANALYSE 9
Um die semantisch gleichen Eintr�age zu �nden, sollen Algorithmen des Information Retrievalgenutzt werden. Eine allgemeine Einf�uhrung und Literatur zu Information Retrieval folgen inKapitel 4.
3.2 Systemvoraussetzungen
Damit dies System m�oglichst plattformunabh�angig benutzt werden kann, wird das System in dasbestehende World-Wide-Web integriert und kann somit von jedem Rechner, der einen Internetzu-gang und einen WWW-Browser besitzt, genutzt werden. Allerdings ist die Voraussetzung f�ur denWWW-Browser die Unterst�utzung des Standards HTML 3.2 [12].
Als Programmiersprache wurde Tycoon-2 gew�ahlt. Zus�atzlich wird die Structured Tycoon MarkupLanguage (STML) zur dynamischen Generierung von HTML-Seiten genutzt, um einen interakti-ven Zugri� auf die Informationen des Objektspeichers �uber den WWW-Browser zu erlangen.Da Tycoon-2 zu diesem Zeitpunkt nur f�ur bestimmte Plattformen vorliegt, wird eine SUN Ultramit dem Betriebssystem Solaris 2.5.1 als Server dienen.
3.3 Anwendungsfallanalyse
Das Use Case Diagramm in Anhang C zeigt die m�oglichen Anwendungsf�alle und Aktionen desBenutzers. In Tabelle 3.1 werden die einzelnen Objekte (Anwendungsf�alle) und die Abh�angigkeitenzwischen ihnen dargestellt und genauer beschrieben.Um nun die einzelnen Anwendungsf�alle auf konkrete Aktionen im System abzubilden, ist in Tabel-le 3.2 eine Beschreibung der prim�aren Aktionen zwischen dem Benutzer und dem System zu sehen.
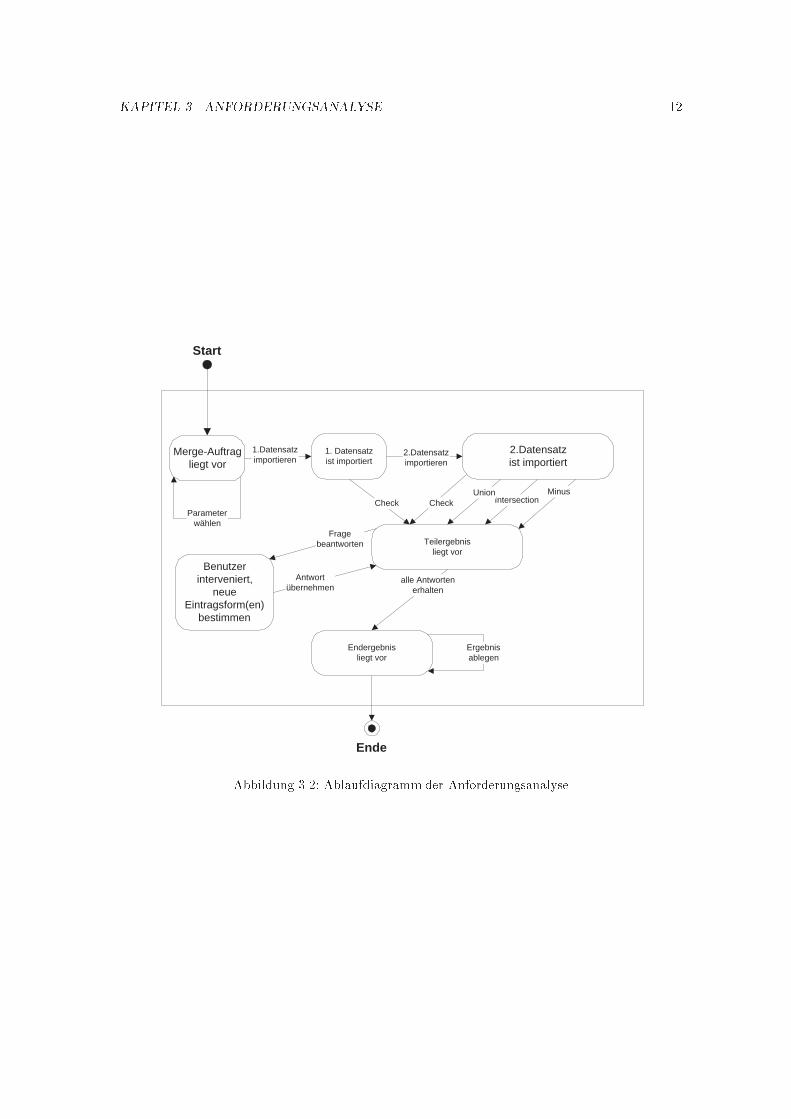
Das Ablaufdiagramm in Abbildung 3.2 zeigt die in Tabelle 3.2 diskutierten Aktionen in einemzeitlichen Ablauf, da die einzelnen Vorbedingungen f�ur bestimmte Aktionen innerhalb des Systemssonst nur schwer kenntlich zu machen sind.
3.4 Klassen und Dom�anen
In diesem Abschnitt werden Fachbegri�e, die sich w�ahrend der Analysephase ergeben haben, n�ahererl�autert und zu ersten Klassen ausgearbeitet. Ebenso werden die einzelnen Operationen auf dieeinzelnen Klassen abgebildet und eingebunden.Zun�achst ist der Begri� BibTEX-Eintrag sehr oft gefallen. Allgemein besteht ein BibTEX-Eintragaus einem Eintragstyp, einem Schl�ussel und einer Liste von Feldnamen und Werten (z.B.: author= "Leslie Lamport"). Eine BibTEX-Datei wiederum besitzt einen Dateinamen und eine Liste vonBibTEX-Eintr�agen. Zus�atzlich k�onnen in einer BibTEX-Datei benutzerde�nierte Makros enthaltensein, die aber bereits beim Importieren ber�ucksichtigt werden sollen.Die Parameter sind in diesem Kontext eine Liste von Parameternamen und Werten, wobei essysteminterne Parameternamen und Parameternamen aus BibTEX-Eintr�agen gibt. Genaueres zudiesen Parametern und ihrer Bedeutung folgt in Kapitel 5.
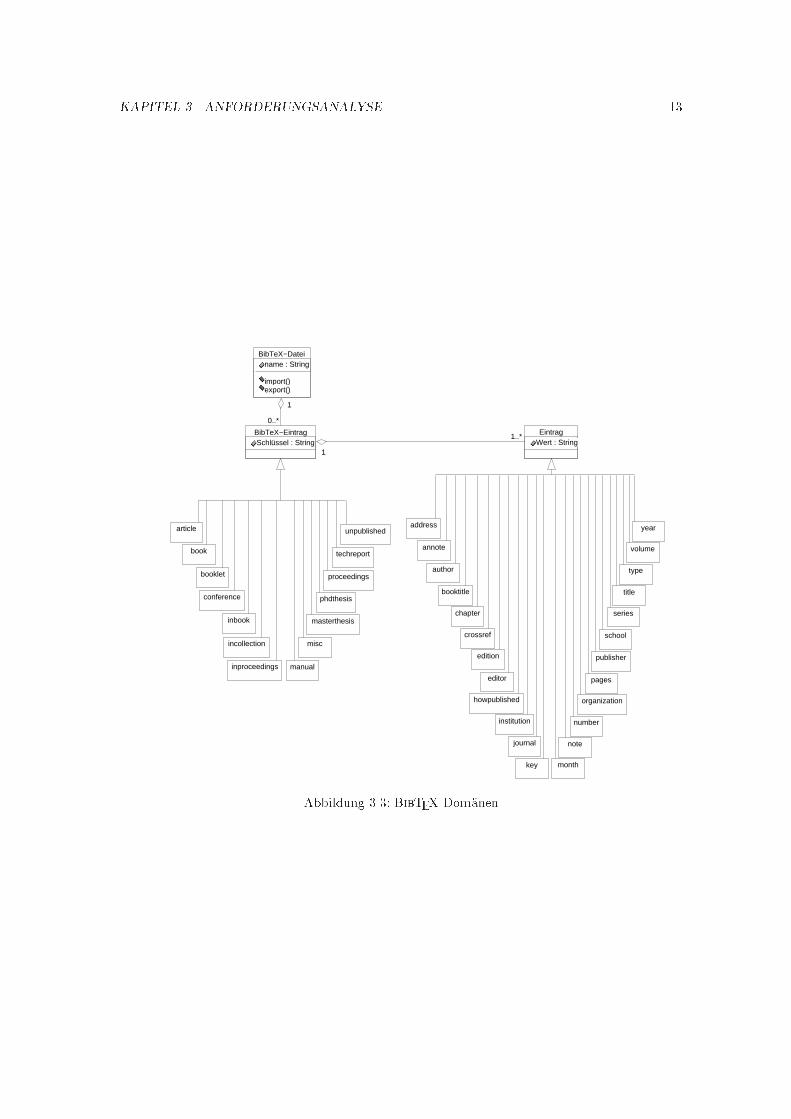
Die Begri�e BibTEX-Eintrag und BibTEX-Datei kann man bereits in ein Klassendiagramm abbil-den, welches in Abbildung 3.3 zu �nden ist. Zus�atzlich sind in diesem Diagrammdie Dom�anen derbeiden Klassen zu �nden.

KAPITEL 3. ANFORDERUNGSANALYSE 10
Use Case beteiligte Objekte Beschreibung
Bibliographiedatenbearbeiten
Benutzer, Eintr�agevergleichen
Der zentrale Use Case des Systems. Bibliographie-daten sollen mit Algorithmen und Unterst�utzungdes Benutzers bearbeitet werden.
Datenbestanderweitern
Bibliographiedatenbearbeiten
Eine der Funktionen, um Bibliographiedaten zubearbeiten. Entspricht der Funktion Union.
Dateien formatie-ren
Exportieren, Im-portieren
Um die BibTEX-Dateien f�ur das System lesbarzu machen, beziehungsweise Daten aus dem Sy-stem in eine Datei zu �ubertragen, durchlaufen dieBibTEX-Dateien einen Parser beziehungsweise Un-parser.
Eintr�age verglei-chen
Benutzer Der Benutzer mu� gegebenenfalls einzelne Ein-tr�age selbst vergleichen und Entscheidungenf�allen.
Exportieren Benutzer Damit die Daten aus dem System in eine BibTEX-Datei geschrieben werden k�onnen, mu� der Be-nutzer einen Dateinamen vergeben und die Dateieinen Unparser durchlaufen.
Importieren Benutzer Der Benutzer gibt die Dateinamen der zu bear-beitenden Dateien ein, damit diese f�ur das Systemsichtbar gemacht werden k�onnen.
Konsistentes Zu-sammenf�uhren
Bibliographiedatenbearbeiten
Eine der Funktionen, um Bibliographiedaten zubearbeiten. Entspricht der Funktion Intersection.
Parameter einstel-len
Benutzer Die Parameter sollen die Interaktionsm�oglichkei-ten zwischen dem System und dem Benutzerregeln und k�onnen somit durch den Benutzerver�andert werden.
Unterschiede �nden Bibliographiedatenbearbeiten
Eine der Funktionen, um Bibliographiedaten zubearbeiten. Entspricht der Funktion Minus.
Tabelle 3.1: Alphabetisch sortierte Au istung und Erkl�arung der einzelnen Use Cases

KAPITEL 3. ANFORDERUNGSANALYSE 11
EingehendesEreignis
Dateneingang(D), Vor-bedingung(V)
Erwartetes Verhalten Nach-bedingung
AusgehendeDaten
Benutzerm�ochte Datenimportieren
Dateiname(D)
Wenn die Datei in dem an-gegebenen Pfad existiert,wird die Datei ausgelesen.
Daten sind f�urdas Systemsichtbar
-keine-
Benutzerm�ochte Datenexportieren
Dateiname(D)
Die vom Benutzer aus-gew�ahlten Daten werdenin eine BibTEX-Datei ge-schrieben.
-keine- Daten liegenim BibTEX-Format vor
Parametereinstellen
-keine- Der Benutzer stellt nachseinen W�unschen die Pa-rameter f�ur das Bearbei-ten der Bibliographieda-ten ein.
Parameterge�andert
-keine-
Bibliographie-daten anzei-gen
Auswahl derDatei (D),Daten wurdenimportiert(V)
Die ausgew�ahlte Da-tei wird dem Benutzerangezeigt.
-keine- -keine-
Bibliographie-daten bear-beiten
Funktionw�ahlen (D),Daten wurdenimportiert(V)
Die gew�unschte Funkti-on wird vom System aus-gef�uhrt. Falls das Systemkeine eigene Entscheidungtre�en kann, so mu� derBenutzer die Eintr�age ver-gleichen, wobei das Sy-stem den Benutzer mit In-formationen �uber die Ein-tr�age unterst�utzen soll.
-keine- DistanzeneinzelnerBibTEX-Eintr�age,Endergebnis
Tabelle 3.2: Aktionen und Ereignisse des Systems
KAPITEL 3. ANFORDERUNGSANALYSE 12
Start
Ende
Merge-Auftragliegt vor
2.Datensatzist importiert
Benutzerinterveniert,
neueEintragsform(en)
bestimmen
1.Datensatzimportieren
Fragebeantworten
Antwortübernehmen
Endergebnisliegt vor
Teilergebnisliegt vor
alle Antwortenerhalten
IntersectionUnion Minus
CheckParameter
wählen
1. Datensatzist importiert
2.Datensatzimportieren
Check
Ergebnisablegen
Abbildung 3.2: Ablaufdiagramm der Anforderungsanalyse
KAPITEL 3. ANFORDERUNGSANALYSE 13
article
book
conference
inbook
booklet
incollection
inproceedings manual
masterthesis
misc
phdthesis
proceedings
techreport
unpublished
booktitle
chapter
crossref
edition
editor
howpublished
institution
journal
key
address
annote
author
1
BibTeX−Dateiname : String
import()export()
0..*
1
BibTeX−EintragSchlüssel : String
1
0..*
1..* EintragWert : String
1
1..*
month
note
publisher
type
pages
number
organization
volume
year
series
school
title
Abbildung 3.3: BibTEX-Dom�anen

KAPITEL 3. ANFORDERUNGSANALYSE 14
3.5 Merging-Algorithmen
Die zentrale Aufgabe des System soll es sein, BibTEX-Eintr�age zu vergleichen und gebenenfallszusammenzuf�uhren. Dieses Kapitel bildet die Grundlage f�ur diese beiden Operationen.Folgende Fragen sollen in diesem Kapitel beantwortet werden:
� Wie sollen zwei Eintr�age verglichen werden und was soll das Ergebnis dieses Vergleiches sein?
� Wann soll der Benutzer eingreifen und wie sollen die erw�ahnten Parameter genutzt werden?
� Welche Hilfsfunktionen werden ben�otigt, um die gew�unschten Funktionen durchf�uhren zuk�onnen?
� Gibt es Hilfsfunktionen, die bei mehreren oder gar allen Funkionen genutzt werden k�onnen?
Seien a; b; ai; : : : 2M Elemente einer beliebigen Menge M .
De�nition 3.1 probabilistische Distanz:
0 � a:= b � 1 ist eine probabilistische Distanz,wenn gilt: (a
:= a) = 1 (Re exivit�at),
und (a:= b) = (b
:= a) (Symmetrie),
und (a:= c) � (a
:= b) + (b
:= c) (Monotonie).
Die probabilistische Distanz a:= b zwischen zwei Elementen a und b Element der MengeM , gibt als
Ergebnis eine Wahrscheinlichkeit zur�uck, die die �Ahnlichkeit der beiden Elemente charakterisiert.Sei A eine Menge von Elementen, dann gilt:
8ai; aj; i 6= j : ai:= aj < 1:0
Sei R eine Menge von Tupeln fr0; r1; r2; : : : ; rng mit ri = (a; x) (a 2 A und x = [0; 1])
De�nition 3.2 probabilistischer Elementabgleich:
a _u ; = ? (3.1)
a _u f(b; 1:0)g [R = a (3.2)
a _u f(b1; x1); (b2; x2); : : : ; (bn; xn)g =
�?c(a; bi)
(3.3)
a _t ; = a (3.4)
a _t f(b; 1:0)g [R = ? (3.5)
a _t f(b1; x1); (b2; x2); : : : ; (bn; xn)g =
�?a
(3.6)
Die Funktionen cap( _u) und cup( _t) arbeiten grunds�atzlich auf einem Element vom Typ X undeiner Liste von Elementen vom Typ Y.In dieser Arbeit handelt es sich bei den Elementen des Typs X um einzelne BibTEX-Eintr�age. DieElemente des Typs Y bestehen aus einem Tupel mit einem BibTEX-Eintrag und einer Wahrschein-lichkeit.Ziel der Funktionen cap und cup ist es zu entscheiden, ob f�ur den Elementabgleich eine weitereFunktion hinzugezogen werden mu� oder ob durch die vorhandenen Angaben die Entscheidung�uber den Zusammenhang zweier Eintr�age getro�en werden kann.Die Funktion cap ist eine Hilfsfunktion f�ur die Funktion Intersection (Gleichung 3.7).
� Gleichung 3.1 beschreibt den Fall, da� das Element a mit keinem Element aus der Men-ge R �ubereinstimmt und nicht in die Ergebnismenge eingehen soll. Somit wird bottom(?)zur�uckgegeben.

KAPITEL 3. ANFORDERUNGSANALYSE 15
� Gleichung 3.2 beschreibt den Fall, da� die probabilistische Distanz zwischen a und einemElement b aus der Menge R 1:0 ist. Dieses Element a wird als Ergebnis zur�uckgegeben undgeht bei Intersection in die Ergebnismenge ein.
� Gleichung 3.3 beschreibt den Fall, da� es dem System nicht m�oglich ist �uber die Gleichheitdes Eintrages a und den Eintr�agen der Menge R zu entscheiden. Somit soll der Benutzerentscheiden, ob er bottom(?) oder neues Element c(a; bi) zur�uckgibt.
Die Funktion cup ist wiederum die Hilfsfunktion der Funktion Minus (Gleichung 3.8).
� Gleichung 3.4 beschreibt den Fall, da� kein Element mit a �ubereinstimmt und a bei Minusin die Ergebnismenge eingeht.
� Gleichung 3.5 beschreibt den Fall, da� ein Element der Menge Rmit einer Wahrscheinlichkeitvon 1:0 mit a �ubereinstimmt. Bei Minus geh�ort a somit nicht in die Ergebnismenge.
� Gleichung 3.6 entspricht Gleichung 3.3, jedoch soll der Benutzer bei Minus nur entscheiden,ob a in die Ergebnismenge �ubernommen wird oder nicht.
Die Gleichungen 3.1, 3.2, 3.4 und 3.5 k�onnen vollst�andig vom System bearbeitet werden.
De�nition 3.3 Intersection:
A _\B = f(a _uf(b; (a:= b)) j b 2 B; a
:= b � pg) j a 2 Ag; 0 � p � 1 (3.7)
Diese Funktion spiegelt eine der Funktionen des Systems wider, die bereits in Kapitel 3.1 beschrie-ben wurde. Es werden zwei Mengen von Elementen verglichen und eine Schnittmenge zur�uckgege-ben. Diese Schnittmenge soll mit Hilfe der Funktion cap erstellt werden, so da� alle semantischenDuplikate entfernt werden. Der Parameter p ist ein Schwellwert und soll vom Benutzer beein u�twerden. Wenn p nahe an 1 liegt, so wird der Benutzer selten gefragt werden. (Bei p nahe bei 0wird er h�au�g gefragt.)Es gilt: j A _\A j=j A j
De�nition 3.4 Minus:
A _nB = f(a _tf(b; (a:= b)) j b 2 B; a
:= b � pg) j a 2 Ag; 0 � p � 1 (3.8)
De�nition 3.5 Union:
A _[B = (A _\B) [ [A _n(A _\B)] [ [B _n(B _\A)] (3.9)
Genauso wie die Funktion Intersection entsprechen die Funktionen Minus und Union den zuvorbeschriebenen Systemfunktionen, auf denen das System beruht.

Kapitel 4
Information Retrieval
Ein Teilgebiet des Information Retrieval ist der Bereich des Textretrieval, den N. Fuhr [4] als
inhaltliche Suche in Texten
beschreibt.Hierbei ist die Quelle der Informationen und Daten zum Beispiel eine Literaturdatenbank, inwelcher der Anwender nach Quellen f�ur seine Studien sucht und seine Anfrage in einer nat�urlichenSprache eingibt. Das Problem an dieser Stelle ist, wie ein System diese Anfrage verstehen soll.Eine M�oglichkeit ist, nach der gesamten Eingabezeichenkette in der Datenbank zu suchen, eineandere nach jedem einzelnen Wort der Anfrage. Doch schon hier erkennt man, da� wohl beideMethoden nur teilweise zu einem erfolgreichen und befriedigenden Ergebnis f�uhren werden.Zum einen ist die Wahrscheinlichkeit, da� bei einer l�angeren Anfragezeichenkette genau dieseKonstellation der einzelnen Worte innerhalb des Textes eintritt, sehr gering, und die Anzahl dergefundenen Dokumente wird nicht sehr gro� sein. Wenn die Anfragezeichenkette jedoch sehr kurzsein sollte, so werden auch Dokumente gefunden, die nur am Rande Informationen zum gesuchtenThema enthalten. Falls man sich sogar innerhalb der Anfrage vertippt haben sollte oder durchmangelndes Wissen ein Schl�usselwort der Anfrage falsch geschrieben hat, so wird man von derAntwort des Systems stark entt�auscht sein.Bei der zweiten Methode treten ganz andere Probleme auf. Da man innerhalb der deutschen Spra-che oftmals W�orter wie \und, der, die ,das, ..." verwendet, wird man von einer Flut von Antworten�uberschwemmt werden, die �uberhaupt nichts mit der eigentlichen Themensuche zu tun hat. Desweiteren ist es sinnvoll, zu versuchen den Wortstamm der verbleibenden W�orter zu �nden, umdiesen in die Anfrage eingehen zu lassen. Somit wird bei einer Suchanfrage nach Handb�uchernauch Eintr�age die das Wort Handbuch enthalten, als Ergebnis zur�uckgegeben.
Wenn man eine Anfrage gegen�uber einem Information Retrieval System, wie oben beschrieben,stellt, so wird man keine exakte Antwort erhalten, sondern eine Liste von m�oglichen Ergebnissenbekommen. Hierbei ist es immer noch m�oglich, da� v�ollig irrelevante Dokumente gefunden wur-den, die zuf�allig diese Schl�usselw�orter enthielten, oder sogar die wichtigsten und besten Quellen�uberhaupt nicht als Ergebnis zur�uckgegeben werden.An dieser Stelle wird der Unterschied zu klassischen Anfragen gegen�uber Datenbank Systemensichtbar, die sich ausschlie�lich mit dem sogenannten Data Retrieval besch�aftigen. Einige Un-terschiede zwischen dem klassischen Data Retrieval und dem Information Retrieval hat Rijsber-gen [13] wie in Tabelle 4.1 dargestellt.
Den ersten Punkt der Tabelle, das Matching, habe ich bereits im Vorweg erl�autert.Bei DR-Systemen handelt es sich um deterministische Modelle, denn ein SQL-Statement wirdzum Beispiel immer eine eindeutige Antwort zur�uckgeben, wobei das Ergebnis dieser Anfrage dieBedingungen vollst�andig erf�ullen mu�. Innerhalb eines IR-Systems jedoch kann eine Antwort zumBeispiel mit der Wahrscheinlichkeit 0,66 der Anfrage entsprechen.
16

KAPITEL 4. INFORMATION RETRIEVAL 17
Data Retrieval (DR) Information Retrieval (IR)Matching exakt partiell, best matchModell deterministisch probabilistischAnfragesprache formal nat�urlichFragespezi�kation vollst�andig unvollst�andiggesuchte Objekte erf�ullende relevanteReaktion auf Datenfehler sensitiv nicht sensitiv
Tabelle 4.1: Data Retrieval vs. Information Retrieval
Die Anfragesprache f�ur DR-Systeme ist immer vorab durch eine Syntax de�niert, wogegen die An-frage gegen�uber einem IR-System ein beliebiger Text beziehungsweise Zeichenkette sein kann. EinBeispiel f�ur eine Anfrage gegen�uber einem DR-System k�onnte, wenn es SQL-Statements versteht,folgenderma�en aussehen:
select Fragen from Universum where Antwort = 42;
Bei einem IR-System k�onnte man diese Anfrage vielleicht wie folgt formulieren:
Suche alle Fragen des Universums, dessen Antwort \42" ist.
Da� die Fragespezi�kation eines IR-Systems unbegrenzt ist, h�angt mit der gro�en Variations-m�oglichkeit innerhalb der nat�urlichen Sprachen zusammen, so da� diese unvollst�andig ist.
Der Punkt gesuchte Objekte h�angt mit dem Matching zusammen, da die Antworten eines DR-Systems die Anfrage erf�ullen m�ussen und die eines IR-Systems die relevanten Objekte enthaltensollen, auch wenn sie die Anfrage nicht genau erf�ullen.Da� die Reaktion auf Datenfehler in DR-Systemen sensitiv ist, h�angt mit der formalen Anfra-gesprache zusammen. Wenn in der Anfrage gegen�uber dem SQL-System ein Fehler vorliegt undstatt 42 dort 44 steht, so wird ein falsches Ergebnis zur�uckkommen. Bei einem IR-Systems k�onntesich trotzdem eine �ahnliche Antwort ergeben, da diese von der Evaluation der \42" und derenBeachtung bei der Ergebnissuche abh�angt.
4.1 String Matching Methoden
Die unterschiedlichen Algorithmen des String Matching lassen sich in zwei Kategorien aufteilen.Zum einen gibt es Algorithmen, die sich ausschlie�lich mit den einzelnen Zeichen des String (Zei-chenkette) besch�aftigen und die Bedeutung dieser Zeichen au�er achtlassen. Zum anderen gibt esdie Kategorie des phonetischen String Matching. Hierbei werden die einzelnen Buchstaben des Al-phabets in Gruppen zusammengefa�t und den String in eine Zahlenkolonne �uberf�uhrt. Allerdingsz�ahlt man auch einige Algorithmen der ersten Kategorie zu den Algorithmen des phonetischenString Matching, da sich Worte, die �ahnlich geschrieben sind, auch �ahnlich anh�oren.Zus�atzlich kann man unterscheiden zwischen Algorithmen, die ein Ranking erm�oglichen bezie-hungsweise nicht erm�oglichen. Dies bedeutet, da� das System den einzelnen Ergebnissen einezus�atzliche Gewichtung beif�ugt und diese in eine Relation zueinander setzt.Eine Zusammenfassung verschiedener Algorithmen �nden Sie bei Zobel und Dart[16].
Aus beiden Kategorien �nden Sie in Kapitel 4.1.1 und Kapitel 4.1.2 exemplarische Beispiele.
4.1.1 Edit Distance
Dieser Algorithmus errechnet die Distanz1 zweier Strings zueinander, wobei man davon ausgeht,da� Strings, die sich �ahnlich anh�oren, auch �ahnlich geschrieben werden. Hierbei wird versucht,
1Diese Distanz ist nicht mit dem gebr�auchlichemBegri� Distanzma� innerhalb des IR zu verwechseln.

KAPITEL 4. INFORMATION RETRIEVAL 18
Code: 0 1 2 3 4 5 6Buchstabe: a e i o u y h w b p f v c g j k q s x z d t l m n r
Tabelle 4.2: Codierungstabelle f�ur Soundex
einen der beiden Eingabestrings in den anderen zu �uberf�uhren. Die verwendeten Operationen sindEinf�ugen, L�oschen und Ersetzen einzelner Charakters.Um die Distanz zweier Strings s und t mit den L�angen m und n zu bestimmen, benutzt man dieFunktion edit aus Abbildung 4.1 mit edit(m;n) auf. Die Hilfsfunktion r liefert den Wert 0, wennsi, wobei si das i-te Zeichen des Strings ist, und tj gleich sind, sonst 1.Die Distanz von Telefon und Telephon ist bei Edit Distance 2.Durch die R�uckgabe einer Zahl von Edit Distance erh�alt man zus�atzlich die M�oglichkeit, einRanking zu erstellen.
edit(0; 0) = 0
edit(i; 0) = i
edit(0; j) = j
edit(i; j) = min[ edit(i� 1; j) + 1;
edit(i; j � 1) + 1;
edit(i� 1; j � 1) + r(si; tj)]
Abbildung 4.1: Rekurrenzgleichung f�ur Edit Distance
4.1.2 Soundex und Phonix
Soundex ist einer der phonetischen Matching Algorithmen. Der Eingabestring wird in eine Zah-lenkolonne umgeformt, wobei das erste Zeichen unber�uhrt bleibt. Die Tabelle f�ur die Codierungbe�ndet sich in Tabelle 4.2.Der Algorithmus sieht folgenderma�en aus:
1. Ersetze alle Buchstaben au�er den ersten durch seinen phonetischen Code.
2. L�osche alle Nachbarn, die gleich sind.
3. L�osche alle Nullen aus dem codierten Wort (Eliminierung der Vokale)
4. Gebe die ersten vier Zeichen zur�uck.
Der String Telefon wird zum Beispiel reduziert zu T415 und Telephon ebenfalls zu T415. Aller-dings werden auch Strings, die v�ollig unterschiedlich klingen und keine gemeinsame Bedeutunghaben, als �ahnlich erkannt.Phonix ist eine Variation von Soundex. Die Kodierungstabelle ist leicht ver�andert, aber der ent-scheidende Unterschied ist, da� zu Beginn des Algorithmus einzelne Gruppen von Buchstabenumgesetzt werden. Zum Beispiel wird tjV, wobei V f�ur einen beliebigen Vokal steht, zu chVumgesetzt, wenn tj am Beginn eines Strings steht. Es gibt insgesamt 160 dieser Gruppen vonBuchstaben, die vorab ersetzt werden.
Die M�oglichkeit des Rankings entf�allt bei beiden Algorithmen, da die Antwort von Soundex undPhonix nur \�ahnlich" oder \nicht �ahnlich" ist.

KAPITEL 4. INFORMATION RETRIEVAL 19
4.2 Bewertung von IR-Systemen
Um die Antworten eines IR-Systems zu bewerten und somit seine Qualit�at zu beurteilen, mu�zuerst unter folgenden Gr�o�en unterschieden werden (vgl. Abbildung 4.2):
� Menge aller Objekten (ALL)
� Menge aller relevanten Objekte (REL)
� Menge aller gefundenen Objekte (GEF)
Die Menge der relevanten Objekte mu� bestimmt werden, indem sich der Benutzer alle Dokumenteselbst anschaut und f�ur jedes einzelne entscheidet, ob es relevant ist oder nicht. Ist dies m�oglich,so br�auchten wir gar kein IR-System.
Menge aller Objekte(ALL)
������������
������������
Menge allerrelevanten
Objekte(REL) ����������
����������
Menge allergefundenen
Objekte(GEF)�
�����
Abbildung 4.2: Zusammenhang zwischen relevanten und gefundenen Objekten in IR-Systemen
Es ergeben sich zus�atzlich die folgenden drei Gleichungen, die zur Beurteilung von IR-Systemenbeitragen:
� Precision: p = jREL\GEFjjGEFj
� Recall: r = jREL\GEFjjRELj
� Fallout: f = jGEF�RELjjALL�RELj
Precision ist hierbei der Anteil der gefundenen und relevanten Objekte an allen gefundenen Objek-ten. Recall wiederum bezeichnet den Anteil der tats�achlich gefundenen relevanten Objekte. Falloutgibt die F�ahigkeit eines Systems, irrelevante Objekte von der Antwortmenge fernzuhalten, wieder.
Precision zu bestimmen ist einfach, da der Benutzer nur alle Objekte der Antwortmenge durch-schauen mu� und diejenigen dabei aussortiert, die er f�ur irrelevant h�alt. Recall und Fallout setzenvoraus, da� man die Menge aller relevanten Objekte kennt, so da� dieser Wert zumeist nicht be-stimmbar ist, au�er man hat einen stark beschr�ankten Datenbestand und somit die M�oglichkeitalle Objekte einmal anzufassen.
Doch welche M�oglichkeiten hat man, um einen Text f�ur ein IR-System \verst�andlich" beziehungs-weise \lesbar" zu machen? Hierbei spielen zahlreiche Methoden eine Rolle, von denen an dieserStelle einige aufgef�uhrt werden sollen.

KAPITEL 4. INFORMATION RETRIEVAL 20
4.2.1 Stoppwort-Elimination und Stammformreduktion
Stoppw�orter haben generell keine Bedeutung f�ur den Inhalt und die Information eines Textes undwerden aus dem Text eliminiert. Hierbei handelt es sich vorrangig um Artikel, F�ullw�orter undKonjunktionen, deren Eliminierung einen Text um bis zu 50% schrumpfen lassen kann. Somit l�a�tsich der Text auf das Wesentliche reduzieren.Die Stammformreduktion wirft wesentlich gr�o�ere Probleme auf. Ein Beispiel aus der englischenSprache f�ur die Reduktion auf den Wortstamm ergibt sich bei der Endung ual. Bei factual gibt eskeine Probleme und der Wortstamm ist mit fact lokalisiert. Wenn es sich jedoch um equal handeltund man die Endung ual entfernt, so ist der Sinn dieses Wortes verloren. Zumeist gibt man eineuntere Schranke f�ur die L�ange nach der Reduktion an, so da� solche Probleme auf ein Minimumreduziert werden.
4.2.2 Indexing in IR-Systemen
Nach den zuvor beschriebenen Methoden erhalten wir einen Text, der nur noch die sogenanntenindex terms oder auch keywords enth�alt. Hieraus wird anschlie�end die sogenannte index languageentwickelt, die ein Objekt repr�asentieren soll.Es werden zwei Arten von index languages unterschieden:
� pre-coordinated: Bei dieser Variante charakterisiert eine Kombination von index terms eineKlasse von Objekten. Dies geschieht w�ahrend der Indexierung der Objekte zur sp�aterenVerarbeitung.
� post-coordinated: Erst w�ahrend der Anfrage an das IR-Systems wird eine Klasse von Ob-jekten ermittelt, deren index terms zu der gestellten Suchanfrage passen.
Bis zu diesem Zeitpunkt haben alle index terms die gleiche Gewichtung, doch manche repr�asen-tieren ein Objekt wom�oglich wesentlich besser als andere. Somit werden die einzelnen index termsnoch einer Gewichtung unterzogen, bei der zwei Faktoren eine Rollen spielen:
1. Exhaustivity (Ersch�opfung), gibt die Anzahl der Themen wieder, die ein index term enth�alt.
2. Speci�city (Genauigkeit), gibt die F�ahigkeit eines index term an, Themen des Objektes zubeschreiben.
Einige dieser beschriebenen Methoden �nden im nachfolgenden Anwendungsfall ihre Ber�ucksich-tigung. Diese Studie der University of Virginia [3] besch�aftigt sich mit der Suche in Literaturda-tenbanken und wird im folgenden vorgestellt.
4.3 Eine Fallstudie
Grundlage f�ur diese Studie ist die Literaturdatenbank Astrophysics Data System, in der versuchtwird, Eintr�age einer Institution zu �nden. Als Beispiel werden Artikel der
University of Virginia, Charlottesville, Virginia, US
gesucht. Hierbei sind im Vorweg per Hand identi�ziert, beziehungsweise durch menschliche Suche21 Varianten und Kombinationen gefunden worden, um Eintr�age dieser Institution zu beschreiben.Die Variationen ergeben sich sowohl durch Abk�urzungen von University und Virginia als auchdurch die unterschiedliche Anordnung und das Auslassen der einzelnen Teileintr�age. Beispielehierf�ur sind:
� Univ. of Virginia, VA, US
� Virginia, University

KAPITEL 4. INFORMATION RETRIEVAL 21
Au�erdem gibt es auch Rechtschreibfehler innerhalb der einzelnen Eintr�age, die die Suche nochweiter erschweren.Um nun m�oglichst viele Eintr�age zu �nden, die auf den Eingabestring passen, werden folgendeBearbeitungsschritte sequentiell durchgef�uhrt:
1. lexical cleanupDa sich viele Variationen durch die unterschiedliche Handhabe von Abk�urzungen und Akro-nymen ergeben, werden diese entweder durch ihre eigentliche Bedeutung (z.B.: VA durchVirginia) ersetzt oder vollst�andig entfernt. Um jedoch einen Informationsverlust weitestge-hend zu vermeiden, beschr�ankt man sich hierbei auf folgende Vorgehensweise:
(a) entferne US, U.S.A., etc. wenn diese am Ende vorkommen
(b) entferne US ZIP codes vom Ende
(c) entferne Abk�urzungen f�ur US-Bundesstaaten, die am Ende auftreten
(d) expandiere alle gew�ohnlichen Abk�urzungen f�ur University, Institute, etc.
(e) expandiere anwendungsbezogene Abk�urzungen und Akronyme
(f) entferne alle Staaten-Namen, die am Ende vorkommen
Diese Vorgehensweise ist allerdings nur auf diesen speziellen Kontext anzuwenden, da An-gaben �uber Staaten in vielen F�allen wichtige Angaben und wom�oglich der einzige Hinweissind. Somit m�u�te diese Vorgehensweise individuell auf die eigenen Algorithmen angepasstwerden, um nicht f�alschlicherweise Informationen zu verlieren. Allerdings ist das Expandie-ren von Abk�urzungen zu Beginn eines solchen Algorithmus sinnvoll, da keine Informationenverloren gehen. Eine Ausnahme ist jedoch folgendes Szenario:
Die beiden Strings \cacm" und \cacn" sollen verglichen werden. (Im zweiten Stringliegt ein Tippfehler vor.) Nun wird zun�achst versucht, alle Abk�urzungen und Akro-nyme zu expandieren. Bei \cacm" verl�auft dies erfolgreich, und wir erhalten \Com-munications of the ACM". F�ur das System scheint es jedoch, als wenn f�ur \cacn"keine Expansionsm�oglichkeit besteht, und somit bleibt der String bestehen. Wennman nun die beiden Strings vergleicht, so unterscheiden sie sich mehr voneinander,als vorher. Der Abstand der beiden Ausgangsstrings wird jedoch sehr gering sein,da sie sich nur an einer Stelle unterscheiden.
2. Edit distance clusteringNachdem die Abk�urzungen und Akronyme behandelt wurden, werden die einzelnen Stringsverglichen. Hierbei kommt der Algorithmus Edit Distance aus Kapitel 4.1 zum Zuge. Abeinem bestimmten Schwellwert wird nun angenommen, da� es sich um den gleichen Stringhandelt. Anschlie�end gruppiert man die Strings nach �Ubereinstimmung und nimmt alsrepr�asentatives Element jenes mit dem h�au�gsten Vorkommen in einer Gruppe. Die Wahldes Schwellwertes spielt in diesem Kontext eine wichtige Rolle, da bei einer falschen Wahlentweder semantisch gleiche Strings nicht erkannt oder unterschiedliche als gleich deklariertwerden.
3. Word-extraction and lexicographically sortZum Schlu� werden aus dem String die enthaltenen W�orter extrahiert. Die entstehende Listewird nun lexikographisch sortiert. Diese �Anderung ergibt f�ur diesen Kontext einen deutlichenFortschritt, da sowohl \Virginia, University", als auch \University, Virginia" gebr�auchlichsind.Dieses Verfahren k�onnte man auch bei Namen anwenden, denn je nach Gebrauch wird dieReihenfolge von Vornamen und Nachnamen vertauscht.

Kapitel 5
Systementwurf
Basis der Implementation stellen Tycoon-2 und STML dar (vgl. Abschnitt 5.1 und 5.2). Daserstellte System verwaltet BibTEX-Eintr�age (vgl. Kapitel 2), stellt Algorithmen auf den BibTEX-Eintr�agen zur Verf�ugung (vgl. Kapitel 3.5) und bietet eine gra�sche Benutzerober �ache (vgl. Ab-schnitt 5.3.3).
5.1 Tycoon-2
Bei Tycoon-2 [15] handelt es sich um den indirekten Nachfolger der Programmierumgebung Ty-coon [9]. Tycoon-2 ist jedoch im Gegensatz zu Tycoon vollst�andig objektorientiert [14]. Gemein-same Eigenschaften sind Persistenz und parametrischer Polymorphismus. Des weiteren erreichtTycoon-2 eine Plattformunabh�angigkeit, die mit der von JAVA [8] zu vergleichen ist.
In Tycoon-2 sind Klassen Objekte und verstehen somit Nachrichten, die �uber Methoden an siegeschickt werden. Diese Methoden be�nden sich in den sogenannten Metaklassen. Will man al-so Klassenobjekten Nachrichten schicken, so sind die zugeh�origen Methoden in der Metaklassezu �nden. Im allgemeinen werden Metaklassen mit der Endung class gekennzeichnet (vgl. Abbil-dung 5.1).
Um Typfehler und Meldungen wieMethod not understood zu vermeiden, gibt es einen Typechecker,der bereits beim �Ubersetzen Fehler im Code erkennt. Dies beinhaltet, da� der Typ jedes Objektesbereits zur �Ubersetzungszeit feststeht. Somit z�ahlt Tycoon-2 zu den strikt und statisch typisiertenSystemen, ebenso wie Tycoon.
Im Unterschied zu objektorientierten Sprachen wie Smalltalk [6] und JAVA [2] verf�ugt Tycoon-2�uber parametrischen Polymorphismus. Cardelli und Wegner [1] unterscheiden zwischen dem uni-versal und dem ad-hoc Polymorphismus, die sich wiederum aufspalten lassen.Tycoon-2 unterst�utzt jedoch keine der beiden Arten des ad-hoc Polymorphismus.1Universal Poly-morphismus unterteilt sich in parametric und inclusion Polymorphismus. Die Besonderheit beiminclusion Polymorphismus ist, da� ein Objekt zu mehreren Klassen geh�oren kann, so da� ein Ob-jekt sowohl der Klasse Person, also auch der Klasse Student angeh�oren kann und ein Objekt alle
1Der ad-hoc Polymorphismus spaltet sich auf in overloading und coercion Polymorphismus. Allgemein kann es
beim ad-hoc Polymorphismus eine Funktion geben, die auf unterschiedlichen Typen arbeitet und sich je nach Typ
des Objektes auch v�ollig unterschiedlich verh�alt.
Sollten zwei Methoden mit dem gleichen Namen existieren, die aber auf Objekten unterschiedlichen Typs arbeiten,
so kann beim overloading entschieden werden, welche Methode aufgerufen werden soll. Beim coercion wiederum
wird eine semantische Operation ben�otigt, um den Typ eines Objektes zu ver�andern, damit er mit den erwarteten
Typen einer Methode �ubereinstimmt.
Bei der Methode +, die in diesem Beispiel auf Objekten des Typs Real arbeiten soll, m�u�te beim Aufruf 5+6.0 das
Objekt 5 umgesetzt werden in ein Objekt des Typs Real.
22

KAPITEL 5. SYSTEMENTWURF 23
Methoden dieser beiden Klassen versteht.Beim parametrischen Polymorphismus besitzen Klassen und Methoden einen Typparameter �uberden der Typ der Argumente festgelegt wird. Ein Beispiel f�ur parametrischen Polymorphismus er-gibt sich, wenn man die parametrisierte Klasse MutableList aus Tycoon-2 benutzt (ein Objektder Klasse MutableList entspricht einer Liste im imperativen Sinne). Wenn zwei Objekte dieserKlasse erzeugt werden, eins mit dem Parameter Int und eins mit dem Parameter String, so sind dieMethoden, mit denen auf diesen Objekten gearbeitet wird, gleich, aber die Objekte k�onnen nichtaufeinander zugewiesen werden. In Abbildung 5.1 �nden Sie einen Ausschnitt des Quelltextes derKlasse MutableList und seiner Metaklasse MutableListClass.
class MutableListClass(E <:Object)
super AbstractListClass(E, MutableList(E))
metaclass MetaClass
public methods
new :MutableList(E)
{
EmptyList.new
}
...
: : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : :
class MutableList(E <:Object)
super AbstractList(E,MutableList(E)), MutableSequence(E)
public methods
asList :List(E)
{
self
}
...
Abbildung 5.1: Quelltext der Klassen MutableListClass und MutableList
5.2 Structured Tycoon Markup Language - STML
Bei der Structured Tycoon Markup Language (STML) handelt es sich genauso wie bei HTML umeine SGML. Das hei�t, da� ein STML-Dokument einen SGML konformen Aufbau besitzt.Eine vollst�andige Beschreibung der STML �nden Sie bei Gawecki und Wienberg [5].HTML biete keine M�oglichkeiten, WWW-Seiten dynamisch zu erstellen, so da� in Abh�angigkeitvon Abfragen oder Zust�anden bestimmter Objekte eine unterschiedliche Ausgabe entsteht. Dieeinzige M�oglichkeit, dies zu erreichen, besteht in der Nutzung des Common Gateway Interface(CGI) und Skriptsprachen (z.B. JavaScript).
Um dynamische WWW-Seiten mit Tycoon-2 zu erstellen, hat man die M�oglichkeit, �uber zus�atz-liche Steuerelemente HTML-Seiten zu erweitern (vgl. Abbildung 5.2). STML bietet folgende Er-weiterungen zu HTML:
� <if true='argument'>-<then>-<else>:
Entspricht dem if-then-else-Statement.
� <define>-<ref>-<apply>:
Durch <define> besteht die M�oglichkeit, Variablen mit Werten zu belegen oder Funktionenzu erzeugen. Mit <ref> greift man auf Variablen zu. Wenn man innerhalb des <define>

KAPITEL 5. SYSTEMENTWURF 24
Elements mit <fun> eine Funktion erzeugt, so ruft man diese mit <apply> auf.
� <send receiver='objekt' selector='method'>-<arg>:
Durch <send> kann man Objekten bestimmte Nachrichten schicken, die durch <arg> �uber-geben werden.
� Backquotes:Backquotes werden benutzt, um in HTML Attributen, wie zum Beispiel IMG="..." oderTYPE="...", Tycoon-2 Ausdr�ucke einzubetten.
� <tycoon>:
Innerhalb dieser Umgebung k�onnen vollst�andige Tycoon-2 Ausdr�ucke eingebettet werden.Hier k�onnen also sowohl Methodenaufrufe als auch Abfragen auftauchen.
Mit Hilfe des Tycoon Web Server ist es m�oglich, STML-Dokumente in HTML-Dokumente zu�ubersetzen. Hierzu wird zun�achst das STML-Dokument auf Fehler �uberpr�uft. Zum einen wirddie SGML-Konformit�at und zum anderen der enthaltene Tycoon-2 Code mit dem Typechecker�uberpr�uft.Mit Hilfe einer Applikationsklasse wird dem Tycoon Web Server die M�oglichkeit gegeben, aufausgew�ahlte Objekte der Anwendung zuzugreifen. Diese Applikationsklasse enth�alt insbesondereMethoden und Slots, die f�ur die Anwendung relevant sind. N�ahere Informationen �nden sich beiGawecki und Wienberg [5].
<!doctype stml system>
<stml processor=BibProcessor>
<TITLE>BibTeX-Merge-Tool</TITLE>
...
<BODY TEXT="#000000" BGCOLOR="#FFFFFF">
...
<FORM ACTION="question_end.stml">
<define name=output><fun param='zeile :BibTeXArray'>
<TR><TD BGCOLOR='`question.colourFirst`' VALIGN="MIDDLE">
<tycoon>out << zeile[0]</tycoon>
...
</fun></define>
<TABLE BORDER=1 WIDTH="100%" BGCOLOR="#CCCCCC">
<TR>...</TR>
<send receiver='table' selector='do'><arg><ref name=output></ref></send>
...
<TABLE>
<TR><TD ALIGN="CENTER" WIDTH="150">
<if true='nextButtonAppears'>
<B>nächster Eintrag</B><BR>
<A HREF='`"question_main.stml?number="+next`'>
<IMG BORDER=0 ALT="next" SRC="/icons/down.gif"></A>
<else>
</if>
...
</BODY>
Abbildung 5.2: Beispiel einer STML-Seite

KAPITEL 5. SYSTEMENTWURF 25
5.3 Systemarchitektur
- BibEntry, BibEntryClass- BibFile, BibFileClass
- BibProcessor- STML-Seiten
- BibParameter, BibParameterClass- BibRankedList- BibTriple- BibCheck, BibCheckClass- BibMerge, BibMergeClass- BibAlgo- BibQuestion, BibQuestionClass- BibApplication
VERWALTUNG
APPLIKATION
PRÄSENTATION
Abbildung 5.3: Schichtenmodell f�ur die Systemarchitektur
In Abbildung 5.3 sehen Sie die Gliederung des Unterkapitels Systemarchitektur. Im AbschnittVerwaltung (vgl. Kapitel 5.3.1) werden die Klassen beschrieben, die BibTEX-Dateien und BibTEX-Eintr�age repr�asentieren. Das Kapitel 5.3.2 enth�alt die Klassen, die f�ur die Verarbeitung der Datenzust�andig sind. Im Kapitel 5.3.3 werden die Komponenten f�ur die Pr�asentation beschrieben.
5.3.1 Verwaltung
Zur Verwaltung der Daten innerhalb des Systems dienen die Klassen BibEntry, die einen BibTEX-Eintrag, und BibFile, die eine BibTEX-Datei repr�asentiert (vgl. Abbildung 5.4).
BibEntry
Eine Instanz der Klasse BibEntry stellt einen BibTEX-Eintrag dar.Die Klasse BibEntry besitzt vier Slots. Die beiden �o�entlichen Slots type und key entsprechendem BibTEX-Eintragstyp und dem BibTEX-Schl�ussel. In Abbildung 3.3 der Anforderungsanalysesind Unterklassen f�ur die einzelnen Eintragstypen zu �nden. Jedoch ist es dem Benutzer m�oglich,eigene Eintragstypen zu de�nieren, so da� diese Klasse st�andig erweitert werden m�u�te. Um dieszu verhindern, wurde die Implementation �uber den Slot type gew�ahlt.Der dritte �o�entliche Slot �le dient als Informationsquelle, zu welcher BibTEX-Datei ein Eintraggeh�ort, da die einzelnen Dateien in der Pr�asentation farblich unterschiedlich dargestellt werden.Zwar kann man auch �uber die Objekte der Klasse BibFile heraus�nden, zu welcher BibTEX-Dateiein Eintrag geh�ort, doch aus Gr�unden der Performanz ist es sinnvoller, einem BibTEX-Eintragdiese Information mitzugeben.Der private Slot dict ist vom Typ Dictionary(String,String), wobei ein Dictionary aus einer Men-ge von (name, value)-Paaren besteht. Dieses Dictionary enth�alt die einzelnen BibTEX-Felder des

KAPITEL 5. SYSTEMENTWURF 26
BibTeX-Datei (mybib.bib):@Book{fowler97, author = "Martin Fowler", title = "UML Distilled", publisher = "Addison-Wesley", year = "1997", isbn = "0-201-32563-2", note = "Applying The Standard Object Modeling Language"
}
...
name := "mybib"
:BibFile
type := "book"key := "fowler97"file := "mybib"
:BibEntry dict :Dictionary(String, String)
.
.
.
.
.
[0] := "author"[1] := "title"[2] := "publisher"[3] := "year"[4] := "isbn"[5] := "note"
keys:MutableArray(String)
[0] := "Martin Fowler"[1] := "UML Distilled"[2] := "Addison-Wesley"[3] := "1997"[4] := "0-201-32563-2"[5] := "Applying TheStandard Object ModelingLanguage"
elements:MutableArray(String)
Abbildung 5.4: Objekte einer BibTEX-Datei { Instanzendiagramm

KAPITEL 5. SYSTEMENTWURF 27
Eintrags und kann mit den Methoden der Klasse bearbeitet werden. Die einzelnen Methoden die-ser Klasse delegieren die Nachrichten an die Methoden der Klasse Dictionary weiter.Auf Grund dieser De�nition sind die einzelnen BibTEX-Felder Objekte der Klasse String. Prinzi-piell w�are es zum Beispiel auch m�oglich, eine Klasse author und title zu bilden. Jedoch k�onnenBibTEX-Datenbanken beliebige Feldnamen enthalten, so da� das System f�ur jeden Benutzer gege-benenfalls erweitert werden m�u�te. Da dies aber nicht sinnvoll erscheint, wird an dieser Stelle aufdie Unterscheidung der einzelnen Feldtypen verzichtet und erst beim Vergleichen zweier Eintr�agediese Unterscheidung herbeigef�uhrt.Die Methode keysAndElementsDoSorted ist eine Erweiterung der Methode keysAndElementsDo(sequentielle Bearbeitung von einem Dictionary), wobei die einzelnen Felder alphabetisch sortiertabgearbeitet werden. Dies ist f�ur die Pr�asentation wichtig, damit die Ausgabe der einzelnen Feldereines BibTEX-Eintrags nicht durch die Speicherung innerhalb der Hash-Tabellen beein u�t wird,sondern diese alphabetisch sortiert ausgegeben werden k�onnen.Die zugeh�orige Metaklasse BibEntryClass enth�alt zum einen die Methode new, die als Eingabe kei-ne Parameter erwartet, und zum anderen newWith, bei der der Typ, Schl�ussel und das zugeh�origeFile als Parameter beim Aufruf �ubergeben werden.
BibFile
Ein BibFile entspricht einer BibTEX-Datei mit Eintr�agen (BibEntry).Der �o�entliche Slot name speichert den Namen des entsprechenden Objektes. Dieser entsprichtim allgemeinen dem Dateinamen. Der private Slot list ist vom Typ List(BibEntry) und entsprichtder Aggregation aus Abbildung 3.3. Somit besteht eine BibTEX-Datei f�ur das System aus einemNamen und einer Liste von BibTEX-Eintr�agen.In einer BibTEX-Datei k�onnten allerdings auch noch Makros enthalten sein. Doch diese werdenbeim Importieren bereits auf die einzelnen BibTEX-Eintr�age angewendet und m�ussen somit nichtgespeichert werden.
1. Importieren von Daten (import(�leName :String) :Bool)Die Methode import liest eine BibTEX-Datei ein. Hierzu werden folgende Schritte durch-gef�uhrt:
(a) Der Slot name des Objektes wird mit dem mitgelieferten Parameter �leName belegt.
(b) Das Programm BibTEX wird mit der aux -Datei, die von der Methode selbst erzeugtwird, aufgerufen (Abbildung 5.5). Innerhalb der aux -Datei wird die BibTEX-Stildateimerge verwendet (vgl. Anhang B). Der Parameter f�ur bibdata wird durch den Parameter�leName der import-Methode ersetzt.Durch den Aufruf von BibTEX entsteht eine tempor�are Datei tmp.bbl, die in BNF-Notation folgendes Aussehen hat:
fbibtex type:type@%key of entry: keyf@%�eld name:�eld valueg@%g
Durch den Aufruf des Programms BibTEX werden alle Feldnamen (z.B. ISBN, Author)in Kleinbuchstaben �ubersetzt und alle Makros aus der Stildatei und der BibTEX-Dateiexpandiert. Falls bestimmte Felder und Eintragstypen nicht in der Stildatei enthaltensind, so mu� diese erweitert werden, da diese Felder sonst verloren gehen.
(c) Die tempor�are Datei tmp.bbl wird gelesen und mit Hilfe eines Scanners, der den re-gul�aren Ausdruck, den man aus der obigen BNF-Notation erh�alt, f�ur die Datei kennt,werden die einzelnen BibTEX-Eintr�age als Elemente in den Slot list des Objektes ein-gef�ugt.
2. Exportieren von Daten (export(:String) :Bool)Hierzu dient die Methode export, die die in dem Objekt enthaltenen Daten in eine Dateischreibt. Als Parameter erh�alt diese Methode den Dateinamen, der gegebenenfalls von dem

KAPITEL 5. SYSTEMENTWURF 28
\relax
\citation{*}
\bibstyle{merge}
\bibdata{``fileName''}
Abbildung 5.5: aux -Datei zum Importieren der BibTEX-Dateien
im Slot name gespeicherten Wert abweichen kann.Die einzelnen BibTEX-Eintr�age, die in dem Slot list gespeichert sind, werden zum Expor-tieren vorab alphabetisch sortiert und dann in die Datei geschrieben. Das Aussehen dereinzelnen BibTEX-Eintr�age entspricht dem in Kapitel 1 beschriebenen BibTEX-Format.
3. Integrit�atspr�ufung eines BibFile-Objektes (checkIntegrity() :BibEntry)Da beim Mergen der Dateien nicht auf die Schl�ussel der einzelnen BibTEX-Eintr�age geachtetwird, ist es m�oglich, da� mehrere verschiedene BibTEX-Eintr�age den gleichen Schl�ussel er-halten haben. Um diesen Mangel zu beseitigen, wird dem entsprechenden Objekt, das beimMergen entstanden ist, die Nachricht checkIntegrity geschickt. Diese parameterlose Methodeliefert entweder nil oder einen BibTEX-Eintrag zur�uck. Wird nil zur�uckgegeben, so liegenkeine Integrit�atsprobleme vor. Wird jedoch ein BibTEX-Eintrag zur�uckgegeben, so sollte mananschlie�end diesem Objekt der Klasse BibEntry die Nachricht changeKey(:String, :BibEn-try) schicken. Die Parameter sind der BibTEX-Eintrag und der neue Eintragsschl�ussel f�urdieses Objekt.
5.3.2 Applikation
F�ur die Verarbeitung der Daten, die in den Objekten der Klassen BibFile und BibEntry enthaltensind, dienen die Klassen, die in diesem Unterkapitel beschrieben werden. Sie �ubernehmen dasMergen von BibTEX-Datens�atzen und das Vergleichen einzelner Eintr�age.
BibParameter
Die Klasse BibParameter ist eine einfache Struktur und enth�alt nur den privaten Slot param, dersich von der parametrisierten Klasse Dictionary ableitet und vom Typ Dictionary(String,Real) ist.Allerdings spielen die Objekte dieser Klasse eine wichtige Rolle beim Vergleichen zweier BibTEX-Eintr�age.Innerhalb des Systems gibt es folgende vorde�nierte Parameter:
� Upper CUT : Falls die Wahrscheinlichkeit (im Folgenden mit p bezeichnet), mit der zweiBibTEX-Eintr�age �ubereinstimmen, gr�o�er als der Upper CUT ist, so nimmt das System au-tomatisch an, da� diese beiden BibTEX-Eintr�age gleich sind.Dieser Wert sollte nahe bei 1 liegen, da ein zu niedriger Upper CUT dazu f�uhrt, da� Eintr�ageals gleich angenommen werden, die dies m�oglicherweise gar nicht sind.
� CUT Point : Wenn gilt CUT Point < p < Upper CUT, so stellt dies f�ur das System einenicht l�osbare Aufgabe dar, und der Benutzer mu� intervenieren, um die BibTEX-Eintr�age zuvergleichen.Der CUT Point mu� auf jeden Fall kleiner sein als der Upper CUT. Sollte der Benutzerjedoch versuchen dies zu �andern, so ber�ucksichtigt das System zun�achst den CUT Pointund benutzt anschlie�end den Upper CUT, um die Ergebnismenge weiterzuverarbeiten.Ein Wert zwischen 0,6 und 0,8 hat sich f�ur diesen Parameter als g�unstig erwiesen. Sollten die�Ahnlichkeitsalgorithmen noch einmal verfeinert werden, so k�onnte man diesen Wert weitererh�ohen.

KAPITEL 5. SYSTEMENTWURF 29
Durch diese Parameter erh�alt der Benutzer die M�oglichkeit, in die Systemabl�aufe einzugreifen.Setzt er zum Beispiel den CUT Point sehr hoch, so wird der Benutzer bei den gleichen Dateienseltener intervenieren m�ussen, als wenn der CUT Point sehr niedrig gew�ahlt wurde.
Zus�atzlich gibt es noch zwei Parameter, die den Informationsgehalt des Eintragstyps und des Ein-tragsschl�ussels widerspiegeln. Diese beiden Parameter sind vorde�niert, da jeder BibTEX-Eintragdiese Informationen enth�alt. Hierbei bedeutet ein Wert nahe bei 1, da� beim Vergleichen zweierBibTEX-Eintr�age dieses Feld besonders stark gewichtet werden soll. Liegt der Wert nahe bei 0,so gilt das entsprechende Gegenteil. Die systeminternen Bezeichnungen f�ur diese Parameter sindBibTeX Typ und BibTeX Key. F�ur den Parameter BibTeX Typ scheint ein Wert um 0,4 sinnvoll.Bei dem Parameter BibTeX Key sollte man jedoch einen Wert nahe bei oder gleich 0 w�ahlen,da im allgemeinen jeder Benutzer seine eigenen Konventionen besitzt, um seine Eintragsschl�usselsinnvoll zu belegen.Des weiteren werden nach dem Importieren einer BibTEX-Datei alle Datens�atze auf neue Eintrags-felder durchsucht und diese zu dem Slot param hinzugef�ugt. Somit sind nach dem Importierenzweier BibTEX-Dateien alle Eintragsfelder, die mindestens einmal in einer der beiden Dateien vor-kamen, genau einem Parameter im Slot param zugeordnet. Die Werte dieser Parameter haben diegleiche Bedeutung, wie die des BibTeX Typ und BibTeX Key. Also bedeutet auch hier ein Wertnahe bei 1, da� dieses Feld stark gewichtet werden soll.
BibCheck
Die Methoden und Slots dieser Klasse und ihrer Metaklasse BibCheckClass unterst�utzen die Funk-tion Check (vgl. Kapitel 3.1).
Die Methoden der Metaklasse BibCheckClass:
� compareBibFile(:BibFile, :BibParameter) :MutableList(BibRankedList)Innerhalb dieser Methode werden die einzelnen Objekte der Klasse BibEntry mit Hilfe derMethode compareBibEntries wechselseitig verglichen.
� compareBibEntries(:BibEntry, :BibEntry, :BibParameter) :BibTripleAus dem mitgelieferten Objekt der Klasse BibParameter werden die n�otigen Parameterherausgezogen. Hierzu z�ahlen zun�achst die vorde�nierten Parameter BibTeX Key und Bib-TeX Typ. Zus�atzlich werden Eintragsfelder gesucht, die in beiden BibTEX-Eintr�agen vor-kommen. Zu diesen Eintragsfeldern werden die entsprechenden Parameter ausgelesen undgespeichert. Anschlie�end werden die einzelnen Parameter normalisiert, damit anschlie�enddie Summe der ben�otigten Parameter 1 ergibt.Nun werden die einzelnen Dom�anen des BibTEX-Eintrags identi�ziert und die Inhalte derBibTEX-Felder mit den entsprechenden Algorithmen verglichen. Abschlie�end k�onnen dieseErgebnisse mit dem entsprechenden Parameter multipliziert und aufsummiert werden. EinBeispiel folgt bei der Beschreibung der Klasse BibAlgo.
Die Methoden der Klasse BibCheck :
� cleanUp() :VoidDer Slot result enth�alt nach Ausf�uhrung der new-Methode bereits ein Zwischenergebnis.Dieses Zwischenergebnis wird weiter bearbeitet, um die einzelnen BibTEX-Eintr�age entwederin den Slot newBibFile oder questions zu schreiben. Hierzu wird die Liste des Slots resultsequentiell abgearbeitet. Wenn man ein Objekt dieser Liste betrachtet, so geh�ort es der KlasseBibRankedList an. Also enth�alt es einen BibEntry und eine Liste von BibTriple. Sollte dieseListe leer sein, so konnte das System keinen Eintrag entdecken, der mit diesem Eintrag desObjektes �ubereinstimmt. Also kann dieser Eintrag in dem Slot newBibFile abgelegt werden.Sollte die Liste nicht leer sein und die Wahrscheinlichkeiten innerhalb der Objekte KlasseBibTriple kleiner sein als der upperCut und gr�o�er als der cutPoint, so wird der Eintrag in

KAPITEL 5. SYSTEMENTWURF 30
dem Slot questions verschoben. Sollte eine Wahrscheinlichkeit gr�o�er als der upperCut sein,so wird nur der entsprechende Eintrag in newBibFile �ubernommen und der andere gel�oscht.Sind alle Wahrscheinlichkeiten kleiner als der cutPoint, so wird der Eintrag in newBibFileabgelegt.
� addEmptyElementsFromBibFile(:MutableList(BibRankedList)) :MutableList(BibRankedList)Durch das Ver�andern des Slots questions kann eine RankedList entstehen, dessen Felder zumTeil leer geworden sind, so da� die Elemente in den Slot newBibFile geschrieben werdenk�onnen.
BibAlgo
Diese Klasse enth�alt alle Methoden, mit denen einzelne Felder der BibTEX-Eintr�age verglichenwerden. Will man die Algorithmen verbessern, so hat dies in dieser Klasse zu geschehen. Fallsman zus�atzlich einzelne Dom�anen der BibTEX-Eintr�age noch weiter unterscheiden will, so mu�man die compareBibEntries-Methode der Klassen BibCheckClass und BibMergeClass ebenfallserweitern.
Als kurzes Anwendungsbeispiel werden die beiden folgenden BibTEX-Eintr�age mit den implemen-tierten Algorithmen verglichen. Es liegen zus�atzlich die folgenden Parameter vor, wobei die Wertein Klammern bereits normalisiert sind:
Parameter WertUpper Cut 0:99Cut Point 0:7BibTeX Key 0:0 (0:0)BibTeX Typ 0:4 (0:129)author 0:8 (0:258)title 0:7 (0:226)publisher 0:5 (0:161)year 0:3 (0:097)isbn 0:4 (0:129)note 0:3
Erster Eintrag:
@Book{fowler97,
author = "Martin Fowler",
title = "UML Distilled",
publisher = "Addison-Wesley",
year = "1997",
isbn = "0-201-32563-2",
note = "Applying The Standard Object Modeling Language"
}
Zweiter Eintrag:
@Book{uml_fowler97,
author = "Fowler, Martin",
title = "UML-Distilled",
publisher = "Addison",
year = "1996",
isbn = "0-201-32563-2",
}

KAPITEL 5. SYSTEMENTWURF 31
In beiden Eintr�agen kommen die Felder BibTeX Key, BibTeX Typ, author, title, publisher, yearund isbn vor. Somit sind nur diese Felder f�ur die Normalisierung der Parameter relevant.Die einzelnen Distanzen der Felder ergeben sich wie folgt:
� BibTeX Key = 4=12 (Die Distanz der Strings wird �uber Edit Distance errechnet und durchdie L�ange dividiert.)
� BibTeX Typ =0:0 (Die Eintragstypen sind gleich)
� author = 0:0 (Die beiden Felder werden vom System als gleich erkannt.)
� title = 1=13 ({ siehe BibTeX Key {)
� publisher = 7=15 ({ siehe BibTeX Key {)
� year = 0:5 ({ siehe distanceYear im Anhang D {)
� isbn = 0:0
Nun ergibt sich folgende Gleichung:
d = 4=12�0:0+0:0�0:129+0:0�0:258+1=13�0:226+7=15�0:168+0:5�0:097+0:0�0:129 = 0:144
Daraus ergibt sich die Wahrscheinlichkeit p = 1� d = 0:856.
5.3.3 Pr�asentation
Die Pr�asentation �ndet auf einemWWW-Browser statt. Somit m�ussen die Daten, die der Benutzererh�alt, �uber die STML-Seiten aufgearbeitet werden.
BibProcessor
Bei jedem Http-Request wird ein neues Prozessor Objekt erzeugt, das unter anderem spezi�scheDaten der Anfrage und einen Verweis auf die Applikation enth�alt. Durch Festlegen der parametri-sierten Superklasse HtmlFormProcessor, welche als Parameter stets die Applikationsklasse erh�alt,ist der Verweis auf die Applikation gegeben.Der BibProcessor erbt vom HtmlFormProcessor, so da� auch die Form-Felder der HTML-Seitenbeachtet werden. Zus�atzlich enth�alt er die Methode printReal, damit Zahlen der Klasse Real nichtnur in wissenschaftlicher Notation, sondern auch als Gleitkommadarstellung ausgegeben werdenk�onnen.
STML-Seiten
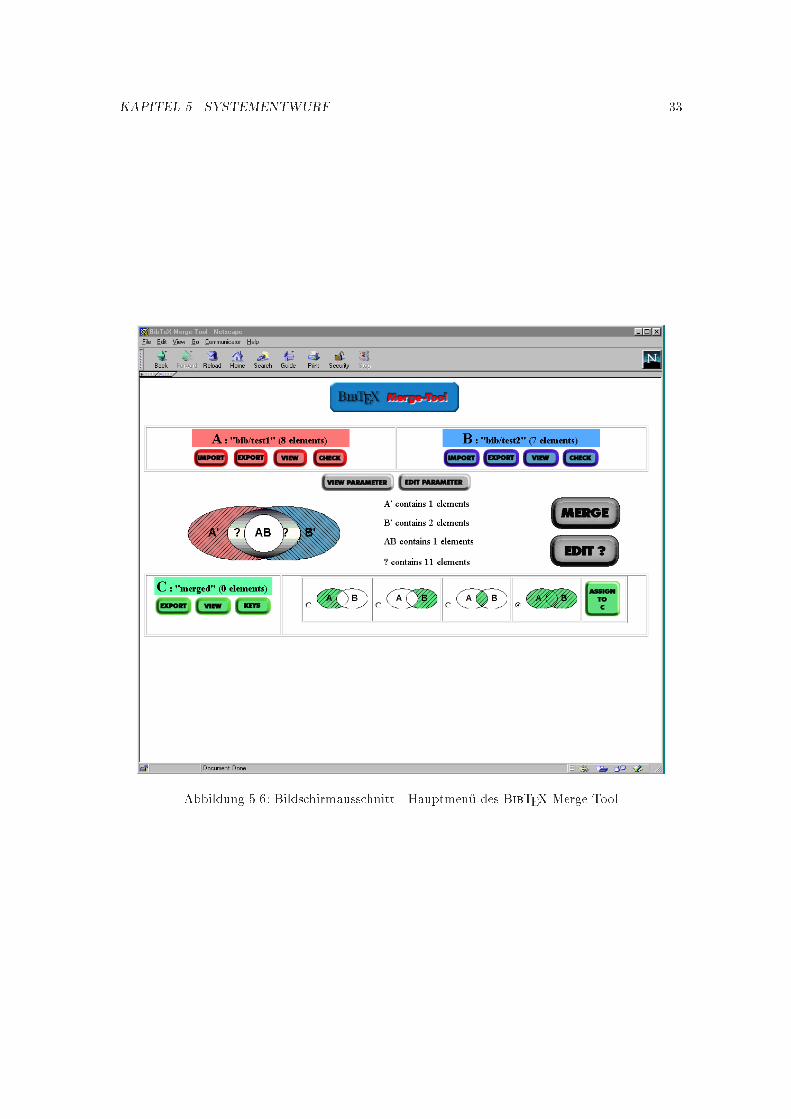
Einen Bildschirmausschnitt des Hauptmen�us �nden Sie in Abbildung 5.6. Hierin enthalten ist auchdas zentrale Mengendiagramm f�ur die Applikation.
In diesem Mengendiagramm sind die folgenden vier Mengen enthalten:
� A' und B' :Die Menge A' (B' ) enth�alt alle Elemente, die in dem Slot newBibFileA (newBibFileB)enthalten sind, also alle Elemente, zu denen es keinen semantisch gleichen Eintrag aus B (A)gibt.
� AB :Die Menge AB wiederum enth�alt die Eintr�age, zu denen es semantisch gleiche in beidenMengen gibt. Diese Elemente sind in dem Slot newBibFileAB gespeichert.

KAPITEL 5. SYSTEMENTWURF 32
� ? :Hierin sind alle Elemente enthalten, die nicht eindeutig zugeordnet werden k�onnen. Durchdie Intervention des Benutzers werden diese Elemente entweder nach A', B' oder AB ver-schoben. Sollten zwei Eintr�age gleich sein, so wird entweder ein neuer Eintrag erstellt odereiner von beiden �ubernommen und der Eintrag in AB hinzugef�ugt. Anderenfalls wird derEintrag je nach Zugeh�origkeit in die Menge A' oder B' verschoben.
Wie aus Abbildung 5.6 zu entnehmen ist, wurden bereits BibTEX-Dateien importiert. Die jeweiligeAnzahl der enthaltenen Elemente steht hinter dem Dateinamen in Klammern.Auch die Merge-Funktion wurde �uber die entsprechende Funktion angesto�en, da den einzelnenMengen bereits Elemente zugeordnet worden sind. Die Anzahl der Elemente, die in den einzelnenMengen enthalten sind, stehen in der Mitte des Bildschirmausschnittes.Die Funktion \EDIT PARAMETER" sollte vor den Funktionen \MERGE" und \CHECK" aus-gef�uhrt werden, damit die benutzerde�nierten Parameter bei beiden Operationen zum Tragenkommen.�Uber die Funktion \EDIT ?" m�u�te der Benutzer nun die o�enen Fragen beantworten, damitdie derzeit 11 Elemente der Menge ? in die entsprechenden Mengen verschoben werden k�onnen,beziehungsweise neue Eintr�age entstehen.�Uber die Funktion \ASSIGN TO C" wird die entsprechende Funktion ausgew�ahlt. Dies ist zwarauch m�oglich, wenn die Menge ? nicht leer ist, doch der Benutzer mu� bedenken, da� ihm Eintr�ageverloren gehen, wenn er diese Operation ausf�uhrt, bevor er alle o�enen Fragen beantwortet hat.Hinter der Funktion \CHECK" verbirgt sich die entsprechende Check-Funktion des Systems. Jenachdem bei welcher Menge die Funktion aufgerufen wird, wird die Methode Check der Applika-tion mit dem richtigen Parameter aufgerufen. Die Funktion \KEYS" wiederum st�o�t die MethodecheckIntegrity an und �uberpr�uft die Ergebnismenge auf eventuelle Integrit�atsprobleme.
In Abbildung 5.7 sehen Sie den Bildschirmausschnitt, den der Benutzer erh�alt, wenn er zwei Ein-tr�age miteinander vergleichen soll.In diesem Fall hat das System zwei Eintr�age gefunden, die mit dem Eintrag aus der ersten Spalte�ubereinstimmen k�onnten. �Uber die Funktion n�achster Eintrag unter der Tabelle erh�alt der Benut-zer den zweiten Eintrag.Die Wahrscheinlichkeit p = 0:97065 ist der vom System errechnete Wert.�Uber die Funktion \->" hat der Benutzer die M�oglichkeit, den Feldinhalt direkt in das entspre-chende Formfeld in der rechten Spalte zu �ubertragen. Hierzu verbirgt sich hinter der Funktion eineJavaScript-Methode.Sollte die gerade angezeigten Eintr�age �ubereinstimmen, so mu� der Benutzer den neuen Eintragerstellen und mit \YES" best�atigen. Stimmen keine der vorgeschlagenen Eintr�age �uberein, soverneint er entsprechend �uber die \NO"-Funktion.
KAPITEL 5. SYSTEMENTWURF 33
Abbildung 5.6: Bildschirmausschnitt - Hauptmen�u des BibTEX Merge-Tool

KAPITEL 5. SYSTEMENTWURF 34
Abbildung 5.7: Bildschirmausschnitt - Vergleichen zweier BibTEX-Eintr�age

Kapitel 6
Zusammenfassung
Ausgangspunkt dieser Arbeit bildet die Aufgabenstellung, mehrere BibTEX-Datenbanken zu ver-gleichen und zusammenzuf�uhren. In der Anforderungsanalyse werden die dom�anenspezi�schen An-forderungen f�ur das Zusammenf�uhren von BibTEX-Eintr�agen analysiert. Insbesondere �nden Me-thoden des Information Retrieval ihre Anwendung, um die �Ahnlichkeiten von BibTEX-Eintr�agenfestzustellen. Die Implementierung eines Prototypen greift auf Tycoon-2 als Implementierungs-sprache und STML zur Visualisierung zur�uck.
Nach der Implementierung des ersten Prototypen ergaben sich einige neue Gesichtspunkte, so da�von dem Ablaufdiagramm (Abbildung 3.2) der Anforderungsanalyse abgewichen wurde. Das Ab-laufdiagramm der zweiten Iteration �nden Sie im Anhang C.Zu diesem Entschlu� f�uhrte die Tatsache, da� die Funktionen des Systems und seine Leistungbisher vor dem Benutzer total verborgen blieben. Die M�oglichkeiten der qualitativen Analyse wa-ren ebenso stark eingeschr�ankt. Zus�atzlich sollte dem Benutzer die M�oglichkeit gegeben werden,verschiedene Ergebnismengen zu erhalten, ohne die gesamte Prozedur zu wiederholen.In dem Prototyp war es ebenso nicht m�oglich, w�ahrend der Benutzerintervention abzubrechen,falls es dem Benutzer zu viele Fragen sind, die ihm das System stellt. Jetzt kann dies ohne Ergeb-nisverlust und mit der Option den Vorgang fortzusetzen durchgef�uhrt werden.
Die Anforderungsanalyse und der Systementwurf beschr�anken sich in dieser Arbeit ausschlie�lichauf das in Kapitel 2 beschriebene BibTEX-System. Die in Kapitel 4 beschriebenen Algorithmenzur �Ahnlichkeits�ndung lassen sich jedoch auf viele Datenbanken ausweiten.W�ahrend der Anforderungsanalyse hat sich herausgestellt, da� man die speziellen Dom�anen ei-nes Systems im Vorweg identi�zieren mu�, da es sonst f�ur Information Retrieval Systeme nichtm�oglich ist, ausreichende Informationen aus den Daten zu ziehen. Es gibt zwar bereist kommerziel-le Systeme, die versuchen, Information Retrieval auf bestehende Datenbanksysteme anzuwenden,doch diese gehen von sehr allgemeinen Annahmen aus, so da� auch hier eine Verbesserung durchSpezi�kation der individuellen Dom�anen zu erwarten ist.
W�ahrend der Test-Phase des Systems haben die verwendeten Algorithmen, speziell der Edit Di-stance, sehr gute Ergebnisse gezeigt. Voraussetzung hierf�ur war jedoch, da� inbesondere die Feldereines BibTEX-Eintrags sinnvoll ausgef�ullt sind. Sollten zum Beispiel Felder, dessen Inhalt demBenutzer nicht bekannt ist, mit Fragezeichen ausgef�ullt sein, so sinkt die vom System errechneteWahrscheinlichkeit vehement. Dies k�onnte jedoch durch Erweiterung der Algorithmen umgangenwerden. Felder vom Typ ISBN k�onnten zum Beispiel als eine Zahlenkolonne mit Trennzeichen in-terpretiert werden und somit k�onnte bei fehlerhafter Belegung eine Ausnahmebehandlung erfolgen.
Insgesamt sollte es sich bei dieser Anwendung um ein generisches System handeln, das stetig erwei-tert wird. Speziell die BibTEX-Felder der einzelnen Benutzer sollten st�andig hinzugef�ugt werden.Somit k�onnen auch die Algorithmen erweitert werden, da auch die Dom�anen erweitert werden.
35

KAPITEL 6. ZUSAMMENFASSUNG 36
Um die BibTEX-Felder der einzelnen Benutzer zu erg�anzen mu� die Stildatei (Anhang B) erweitertwerden, da das System durch diese Datei die Daten importiert.Um die Algorithmen zu erweitern beziehungsweise zu verfeinern mu� in der Klasse BibAlgo dieentsprechende �Anderung vorgenommen werden. Falls neue Dom�anen und Eintragstypen hinzu-kommen, so m�ussen diese zus�atzlich in der Methode compareBibEntries der Klassen BibCheckund BibMerge bekanntgemacht werden.
F�ur mich pers�onlich war es das erste Projekt in der objektorientierten Welt, so da� es im Nach-hinein scheint, da� man durch eine ausf�uhrlichere und tiefgehendere Anforderungsanalyse bessereErgebnisse erzielen k�onnte.

Kapitel 7
Ausblick
W�ahrend der Implementation und Test-Phase des Systems haben sich bereits Ver�anderungengegen�uber der Anforderungsanalyse ergeben, so da� ein Teil der urspr�unglichen Ideen verworfenwurde.Doch wie kann man dieses System noch erweitern?Die Ober �ache kann durch die STML-Seiten weiter verfeinert werden. Auch die Anbindung einesJAVA-Applets ist denkbar. Sollen andere Systeme verwendet werden oder das System durch ex-terne Systeme angesto�en werden, so m�usste man die Ober �ache dahingehend erweitern.Auch die Personalisierung von BibTEX-Daten ist denkbar, so da� der Benutzer selektiert, welcheBibTEX-Eintr�age beim Mergen ber�ucksichtigt werden sollen.Des weiteren k�onnte man vom Benutzer zus�atzliche Eingaben erwarten. Wenn der Benutzer dieverwendeten Sprachen eingeben w�urde, so k�onnte man phonetische Algorithmen wie Phonix oderSoundex verwenden, die zus�atzliche Ergebnisse liefern.
Innerhalb der Applikation k�onnte man die Algorithmen verbessern. Inbesondere die Performanzdes Systems ist noch verbesserungsf�ahig, da der Edit Distance momentan sehr oft Verwendung�ndet und dieser eine mittlere Komplexit�at von �(nm) besitzt. Doch gerade dieser Algorithmusf�uhrt zu den guten Ergebnissen.Auch eine Datenbank zur phonetischen Suche, die st�andig erweitert werden k�onnte, kann eingebun-den werden. Ebenso k�onnen Fingerprints, die den einzelnen BibTEX-Eintr�agen angeh�angt werden,helfen den Benutzer zu entlasten. Sollte ein Benutzer seinen Datenbestand stetig erweitern wollen,so w�urden Antworten, die schon einmal gemacht wurden, als bekannt erkannt werden und Fragenvom Benutzer ferngehalten.
Die Verwaltung der Daten k�onnte durch einen eigene Parser verbessert werden, der auch Makrosmit importiert. Somit kann der Benutzer seine selbst de�nierten Makros weiterbenutzen.
37

Anhang A
BibTEX Eintragstypen
Die folgende Aufz�ahlung enth�alt alle Eintragstypen und Felder, die in den standard Stildateienvorde�niert sind:
� articlezwingend: author, title, journal, year
optional: volume, number, pages, month, note
� bookzwingend: author oder editor, title, publisher, year
optional: volume oder number, series, address, edition, month, note
� bookletzwingend: titleoptional: author, howpublished, address, month, year, note
� conferenceentspricht inproceedings
� inbookzwingend: author oder editor, title, chapter und/oder pages, publisher,year
optional: volume oder number, series, type, address, edition, month, note
� incollectionzwingend: author, title, booktitle, publisher, year
optional: editor, volume oder number, series, type, chapter, pages,
address, edition, month, note
� inproceedingszwingend: author, title, booktitle, year
optional: editor, volume oder number, series, pages, address, month,
organization, publisher, note
� manualzwingend: titleoptional: author, organization, address, edition, month, year, note
� masterthesiszwingend: author, title, school, year
optional: type, address, month, note
� misczwingend: keineoptional: author, title, howpublished, month, year, note
38

ANHANG A. BIBTEX EINTRAGSTYPEN 39
� phdthesiszwingend: author, title, school, year
optional: type, address, month, note
� proceedingszwingend: title, year
optional: editor, volume oder number, series, address, month, organization,
publisher, note
� techreportzwingend: author, title, institution, year
optional: type, number, address, month, note
� unpublishedzwingend: author, title, note
optional: month, year
Zus�atzlich gibt es noch ein optionales key-Feld, welches zur Sortierung verwendet wird, doch keinenweiteren Regeln unterliegt! Dieses Feld steht in keinem Zusammenhang mit dem Eintragsschl�ussel,wird jedoch oft mit diesem verwechselt.

Anhang B
BibTEX-Stildatei
%% *** BibTeX-MergeTool ***
%% Ausgabe: bibtex_type: (type)@%key_of_entry: (key){@%(field): (entry)}@&
ENTRY
{ address
author
booktitle
chapter
edition
editor
howpublished
institution
isbn
journal
key
month
note
number
organization
pages
price
publisher
school
series
title
type
volume
year
}
{}
{ label }
FUNCTION {output}
{
duplicate$ empty$
'pop$
'write$
if$
"@%" write$
40

ANHANG B. BIBTEX-STILDATEI 41
}
FUNCTION {output.bibitem}
{
"key_of_entry: " write$
cite$ write$
"@%" write$
""
}
FUNCTION {fin.entry}
{
duplicate$ empty$
'pop$
'write$
if$
"@&" write$
newline$
}
% Ausgabe der Felder
FUNCTION {print.fields}
{
output.bibitem
"address: " write$ address output
"author: " write$ author output
"booktitle: " write$ booktitle output
"chapter: " write$ chapter output
"edition: " write$ edition output
"editor: " write$ editor output
"howpublished: " write$ howpublished output
"institution: " write$ institution output
"isbn: " write$ isbn output
"journal: " write$ journal output
"key: " write$ key output
"month: " write$ month output
"note: " write$ note output
"number: " write$ number output
"organization: " write$ organization output
"pages: " write$ pages output
"price: " write$ price output
"publisher: " write$ publisher output
"school: " write$ school output
"series: " write$ series output
"title: " write$ title output
"type: " write$ type output
"volume: " write$ volume output
"year: " write$ year output
fin.entry
}
FUNCTION {article} {"bibtex_type: article@%" write$ print.fields}

ANHANG B. BIBTEX-STILDATEI 42
FUNCTION {book} {"bibtex_type: book@%" write$ print.fields}
FUNCTION {booklet} {"bibtex_type: booklet@%" write$ print.fields}
FUNCTION {conference} {"bibtex_type: conference@%" write$ print.fields}
FUNCTION {inbook} {"bibtex_type: inbook@%" write$ print.fields}
FUNCTION {incollection} {"bibtex_type: incollection@%" write$ print.fields}
FUNCTION {inproceedings} {"bibtex_type: inproceedings@%" write$ print.fields}
FUNCTION {manual} {"bibtex_type: manual@%" write$ print.fields}
FUNCTION {mastersthesis} {"bibtex_type: mastersthesis@%" write$ print.fields}
FUNCTION {misc} {"bibtex_type: misc@%" write$ print.fields}
FUNCTION {phdthesis} {"bibtex_type: phdthesis@%" write$ print.fields}
FUNCTION {proceedings} {"bibtex_type: proceedings@%" write$ print.fields}
FUNCTION {techreport} {"bibtex_type: techreport@%" write$ print.fields}
FUNCTION {unpublished} {"bibtex_type: unpublished@%" write$ print.fields}
FUNCTION {default.type} {"bibtex_type: unknown@%" write$ print.fields}
% Macros:
MACRO {jan} {"Januar"}
MACRO {feb} {"Februar"}
MACRO {mar} {"Maerz"}
MACRO {apr} {"April"}
MACRO {may} {"Mai"}
MACRO {jun} {"Juni"}
MACRO {jul} {"Juli"}
MACRO {aug} {"August"}
MACRO {sep} {"September"}
MACRO {oct} {"Oktober"}
MACRO {nov} {"November"}
MACRO {dec} {"Dezember"}
MACRO {acmcs} {"ACM Computing Surveys"}
MACRO {acta} {"Acta Informatica"}
MACRO {cacm} {"Communications of the ACM"}
MACRO {ibmjrd} {"IBM Journal of Research and Development"}
MACRO {ibmsj} {"IBM Systems Journal"}
MACRO {ieeese} {"IEEE Transactions on Software Engineering"}
MACRO {ieeetc} {"IEEE Transactions on Computers"}
MACRO {ieeetcad} {"IEEE Transactions on Computer-Aided Design of Integrated Circuits"}
MACRO {ipl} {"Information Processing Letters"}
MACRO {jacm} {"Journal of the ACM"}
MACRO {jcss} {"Journal of Computer and System Sciences"}
MACRO {scp} {"Science of Computer Programming"}
MACRO {sicomp} {"SIAM Journal on Computing"}
MACRO {tocs} {"ACM Transactions on Computer Systems"}
MACRO {tods} {"ACM Transactions on Database Systems"}
MACRO {tog} {"ACM Transactions on Graphics"}
MACRO {toms} {"ACM Transactions on Mathematical Software"}
MACRO {toois} {"ACM Transactions on Office Information Systems"}
MACRO {toplas} {"ACM Transactions on Programming Languages and Systems"}
MACRO {tcs} {"Theoretical Computer Science"}
% Ausfuehren :
READ
ITERATE {call.type$}

Anhang C
UML-Diagramme
BibTeX−Merge−Tool
Unterschiedefinden
konsistentesZusammenführen
Datenbestanderweitern
Parametereinstellen
Einträgevergleichen
Bibliographiedatenbearbeiten
<<extends>>
<<extends>>
<<extends>>
<<uses>>
Importieren
Benutzer
Dateien formatieren
<<uses>>
Exportieren
<<uses>>
Abbildung C.1: Use Case Modell
43
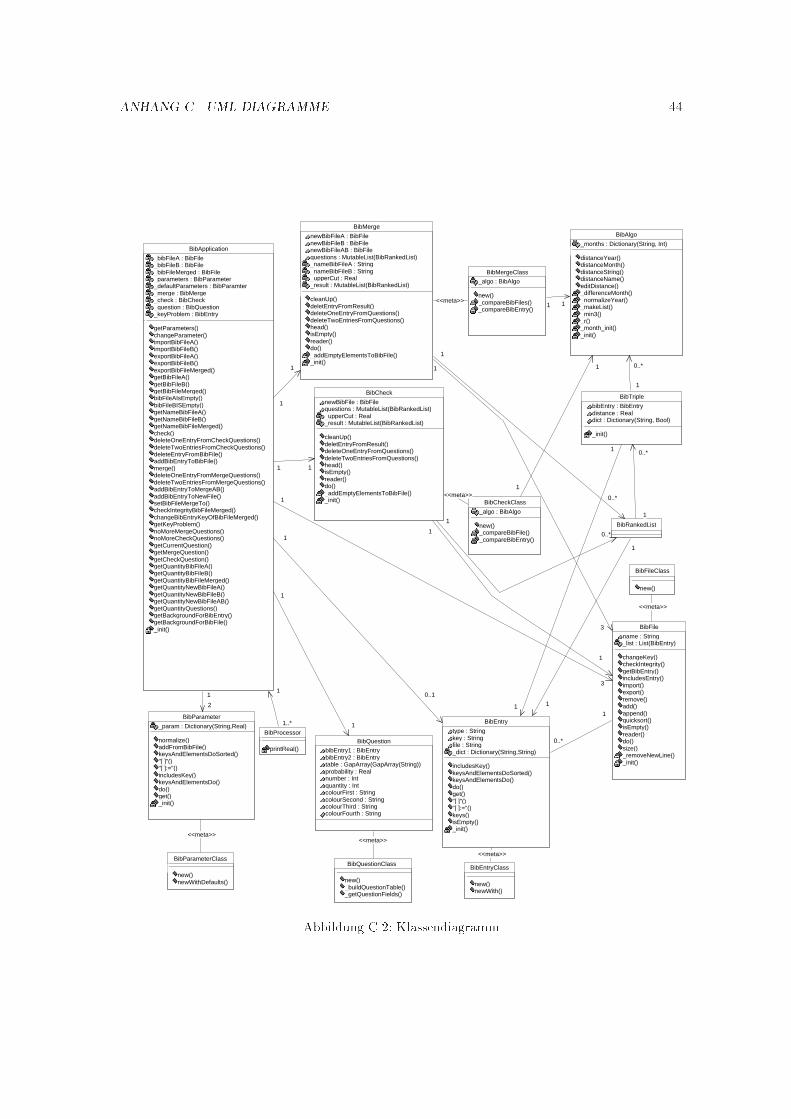
ANHANG C. UML-DIAGRAMME 44
11
1
1
0..*
BibAlgo
_months : Dictionary(String, Int)
distanceYear()distanceMonth()distanceString()distanceName()editDistance()_differenceMonth()_normalizeYear()_makeList()_min3()_r()_month_init()_init()
1
0..*
1
BibMergeClass
_algo : BibAlgo
new()_compareBibFiles()_compareBibEntry()
11
0..*
1
BibCheckClass
_algo : BibAlgo
new()_compareBibFile()_compareBibEntry()
1
1
0..*
1
BibQuestionClass
new()_buildQuestionTable()_getQuestionFields()
BibParameterClass
new()newWithDefaults()
BibFileClass
new()
3
1
1
1
BibEntryClass
new()newWith()
0..*
11
1
BibTriple
bibEntry : BibEntrydistance : Realdict : Dictionary(String, Bool)
_init()
0..*
1
1
1
BibRankedList
0..*
1
1
BibMerge
newBibFileA : BibFilenewBibFileB : BibFilenewBibFileAB : BibFilequestions : MutableList(BibRankedList)_nameBibFileA : String_nameBibFileB : String_upperCut : Real_result : MutableList(BibRankedList)
cleanUp()deletEntryFromResult()deleteOneEntryFromQuestions()deleteTwoEntriesFromQuestions()head()isEmpty()reader()do()_addEmptyElementsToBibFile()_init()
<<meta>>
0..*
1
1
1
BibCheck
newBibFile : BibFilequestions : MutableList(BibRankedList)_upperCut : Real_result : MutableList(BibRankedList)
cleanUp()deletEntryFromResult()deleteOneEntryFromQuestions()deleteTwoEntriesFromQuestions()head()isEmpty()reader()do()_addEmptyElementsToBibFile()_init()
<<meta>>
0..*
1
1
1
BibQuestion
bibEntry1 : BibEntrybibEntry2 : BibEntrytable : GapArray(GapArray(String))probability : Realnumber : Intquantity : IntcolourFirst : StringcolourSecond : StringcolourThird : StringcolourFourth : String
<<meta>>
1
2
BibParameter
_param : Dictionary(String,Real)
normalize()addFromBibFile()keysAndElementsDoSorted()"[ ]"()"[ ]:="()includesKey()keysAndElementsDo()do()get()_init()
<<meta>>
11
1..*
BibProcessor
printReal()
3
BibFile
name : String_list : List(BibEntry)
changeKey()checkIntegrity()getBibEntry()includesEntry()import()export()remove()add()append()quicksort()isEmpty()reader()do()size()_removeNewLine()_init()
<<meta>>
3
1
1
1
1
0..1
BibEntry
type : Stringkey : Stringfile : String_dict : Dictionary(String,String)
includesKey()keysAndElementsDoSorted()keysAndElementsDo()do()get()"[ ]"()"[ ]:="()keys()isEmpty()_init()
<<meta>>
0..*
11
1
1
1
1
BibApplication
_bibFileA : BibFile_bibFileB : BibFile_bibFileMerged : BibFile_parameters : BibParameter_defaultParameters : BibParamter_merge : BibMerge_check : BibCheck_question : BibQuestion_keyProblem : BibEntry
getParameters()changeParameter()importBibFileA()importBibFileB()exportBibFileA()exportBibFileB()exportBibFileMerged()getBibFileA()getBibFileB()getBibFileMerged()bibFileAIsEmpty()bibFileBISEmpty()getNameBibFileA()getNameBibFileB()getNameBibFileMerged()check()deleteOneEntryFromCheckQuestions()deleteTwoEntriesFromCheckQuestions()deleteEntryFromBibFile()addBibEntryToBibFile()merge()deleteOneEntryFromMergeQuestions()deleteTwoEntriesFromMergeQuestions()addBibEntryToMergeAB()addBibEntryToNewFile()setBibFileMergeTo()checkIntegrityBibFileMerged()changeBibEntryKeyOfBibFileMerged()getKeyProblem()noMoreMergeQuestions()noMoreCheckQuestions()getCurrentQuestion()getMergeQuestion()getCheckQuestion()getQuantityBibFileA()getQuantityBibFileB()getQuantityBibFileMerged()getQuantityNewBibFileA()getQuantityNewBibFileB()getQuantityNewBibFileAB()getQuantityQuestions()getBackgroundForBibEntry()getBackgroundForBibFile()_init()
1
1
11
1
1
2
11
1..*
3
1
0..1
1
Abbildung C.2: Klassendiagramm
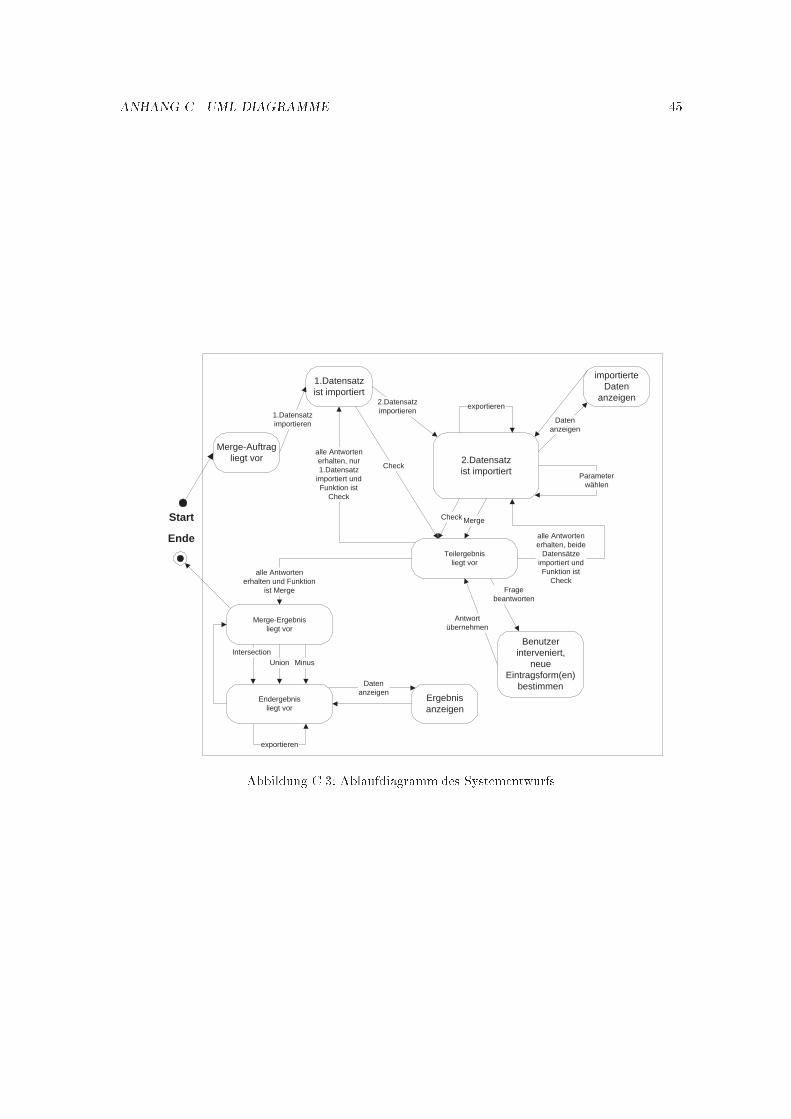
ANHANG C. UML-DIAGRAMME 45
Start
Ende
Merge-Auftragliegt vor 2.Datensatz
ist importiert
importierteDaten
anzeigen2.Datensatzimportieren
Datenanzeigen
Ergebnisanzeigen
Datenanzeigen
Merge-Ergebnisliegt vor
Teilergebnisliegt vor
IntersectionUnion Minus
Merge
Benutzerinterveniert,
neueEintragsform(en)
bestimmen
Fragebeantworten
Antwortübernehmen
Check
alle Antwortenerhalten und Funktion
ist Merge
Endergebnisliegt vor
exportieren
exportieren
1.Datensatzist importiert
1.Datensatzimportieren
CheckParameter
wählen
alle Antwortenerhalten, nur1.Datensatz
importiert undFunktion ist
Check
alle Antwortenerhalten, beide
Datensätzeimportiert undFunktion ist
Check
Abbildung C.3: Ablaufdiagramm des Systementwurfs

Anhang D
Systembeschreibung
D.1 BibAlgo
{ siehe auch Kapitel 5.3.2 {
Slots
� months :Dictionary(String,Int)Durch die Methode months init wird dieses Dictionary mit Werten belegt. Es enth�alt an-schlie�end, f�ur die verschiedenen M�oglichkeiten einen Monat abzuk�urzen, die entsprechendeZahl. Ebenso sind f�ur die englische Sprache alle Monate enthalten, um auch dies zu ber�uck-sichtigen. F�ur den Monat Oktober sind zum Beispiel folgende Eintr�age enthalten:
oktober, october, oct, okt, 10
Methoden
� distanceYear(:String, :String):Um zwei Jahresangaben zu vergleichen, werden diese zun�achst durch die Methode norma-lizeYear in zwei Integers �ubersetzt. Anschlie�end werden die beiden Zahlen miteinanderverglichen. Sollten die beiden Zahlen gleich sein, so wird die Distanz 0:0 zur�uckgegeben. Istdie Di�erenz 1, so wird 0:5 und bei einer Di�erenz von 2 wird 0:8 zur�uckgegeben. Ansonstenist die Distanz gleich 1.
� distanceMonth(:String, :String) :RealDiese Methode nutzt den privaten Slot months, um einen Integer f�ur die Monatsangabezu erhalten. Allerdings werden beide Strings zuvor in Kleinbuchstaben �uberf�uhrt. Die vonder Methode di�erenceMonth zur�uckgegebene Distanz wird genauso wie bei distanceYearinterpretiert.
� distanceString(:String, :String) :RealMit Hilfe der Methode editDistance wird zun�achst berechnet, an wie vielen Stellen sichdie beiden Strings unterscheiden. Das Ergebnis wird durch die L�ange des l�angeren Stringsdividiert und als Ergebnis zur�uckgegeben.
� distanceName(:String, :String) :RealIn Kapitel 4.3 wurden Ans�atze beschrieben, um aus einem String m�oglichst viele Informa-tionen zu erhalten. An dieser Stelle wird ein Teil dieser Ideen verwendet. Die beiden Stringswerden mit der Methode makeList in Teilstrings zerlegt. Die zur�uckgegebene Liste wirdnun sequentiell abgearbeitet und die einzelnen Teilstrings mit der Methode editDistanceverglichen. Die Summe der Unterschiede wird wiederum durch die Gesamtl�ange dividiert.
46

ANHANG D. SYSTEMBESCHREIBUNG 47
� editDistance(:String, :String) :IntDie Funktionsweise dieser Methode ist bereits in Kapitel 4.1.1 beschrieben worden. DieHilfsfunktion r entspricht der dort beschriebenen Funktion r.
� di�erenceMonth(:String, :String) :IntDurch Zugri� auf den Slot dict werden die beiden Strings verglichen und die Di�erenz alsInteger zur�uckgegeben.
� normalizeYear(:String) :IntF�ur Jahreszahlen existieren im allgemeinen zwei Konventionen. Zum einen \1998" und zumanderen \98". Diese Methode gibt f�ur beide Darstellungen die Zahl \98" zur�uck.
� makeList(:String) :MutableList(String)Der String, den diese Methode erh�alt, wird auf Leerzeichen, Kommata und Semikolonsdurchsucht. Jedesmal wenn eines dieser Zeichen auftritt, wird der vordere Teil des Stringabgeschnitten und zu der Ergebnisliste hinzugef�ugt.
� months init() :VoidBeim erzeugen eines Objektes dieser Klasse wird automatisch diese Methode ausgef�uhrt undder Slot mit den beschriebenen Werten belegt.
D.2 BibApplication
Diese Klasse enth�alt alle Methoden, die die Applikation ben�otigt, um die STML-Seiten mit denn�otigen Informationen zu versorgen, um daraus den HTML-Output zu generieren. Diese Methodenwerden somit direkt aus den einzelnen STML-Seiten aufgerufen.
Slots
� bibFileA :BibFile, bibFileB :BibFile und bibFileMerged :BibFileDie Slots bibFileA und bibFileB nehmen die importierten Daten aus den beiden BibTEX-Dateien auf. Der Slot bibFileMerged soll das Endergebnis beinhalten.
� defaultParameters :BibParameter und parameters :BibParameterDer Slot defaultParameters wird bereits beim Initialisieren mit den Werten aus der Da-tei \parameter.txt" gespeist. Bei jedem Importieren von Daten werden die entsprechendenParameter aus diesem Slot ausgelesen. Der Slot parameters kann vom Benutzer angepa�twerden. Er enth�alt nur die Parameter, die tats�achlich f�ur die beiden BibTEX-Dateien ben�otigtwerden.
� merge :BibMerge und check :BibCheckUmdie Zwischenergebnisse und die einzelnen RankedLists zwischenzuspeichern, werden beimAufruf der Methoden merge beziehungsweise check diese Slots als Pu�er ben�otigt. Aus ihnenwerden ebenfalls die einzelnen Fragen bei Bedarf herausgezogen.
� question :BibQuestionDer Slot question speichert die aktuelle Frage, die der Benutzer gerade beantworten soll.
� keyProblem :BibEntryDie Methode checkIntegrity, die ein Objekt der Klasse BibFile bekommt, gibt als Ergebnisein Objekt der Klasse BibEntry zur�uck. Dieses Objekt mu� kurzfristig zwischengespeichertwerden, um nach Intervention des Benutzers den Schl�ussel dieses Objektes zu �andern.

ANHANG D. SYSTEMBESCHREIBUNG 48
Methoden
Da diese Klasse eine F�ulle von Methoden besitzt, werden die Methoden mit geringer Funktiona-lit�at nicht aufgef�uhrt. Hierzu z�ahlt zum Beispiel die Methode bibFileAISEmpty, die die Liste desObjektes auf isEmpty abfragt. Eine vollst�andige Au istung der Methoden enth�alt das Klassendia-gramm in Anhang C.Die gro�e Anzahl von Methoden kommt durch die Kapselung der Anwendung zustande, da inner-halb der STML-Seiten m�oglichst geringe Funktionalit�at vorhanden sein soll. Des weiteren wurdens�amtliche zu speichernde Objekte in privaten Slots aufgehoben, damit nur die vorde�nierten Me-thoden auf sie zugreifen k�onnen.
� getParameters() :BibParameter und changeParameter(:String, :Real) :VoidZum �Andern und Anzeigen der Parameter greifen diese Methoden auf den privaten Slotparameters zu. Die Methode ChangeParameter �andert einen Eintrag im Dictionary.
� importBibFileA(:String) :Bool und importBibFileB(:String) :BoolDiese Methoden schicken an den jeweiligen Slot ( bibFileA oder bibFileB) die Nachricht newund anschlie�end import.
� exportBibFileA(:String) :Bool, exportBibFileB(:String) :Bool undexportBibFileMerged(:String) :BoolGenauso wie die vorigen Methoden leiten auch diese Methoden ihre Nachricht an die ent-sprechenden Slots weiter.
� getBibFileA() :Reader(BibEntry), getBibFileB() :Reader(BibEntry) undgetBibFileMerged() :Reader(BibEntry)Zum Anzeigen der Daten in den Slots wird auch hier nur die entsprechende Nachricht an dieeinzelnen Slots weitergeleitet.
� check (:String) :Void und merge() :VoidDa check auf den beiden Slots bibFileA und bibFileB getrennt ausgef�uhrt wird, ben�otigtcheck noch den Dateinamen, �uber den das Objekt identi�ziert wird, als Parameter. Anson-sten enthalten auch diese Methoden keine eigene Funktionalit�at, sondern rufen nur mit denentsprechenden Objekten die n�otigen Methoden auf.
� deleteOneEntryFromCheckQuestions(:BibEntry) :Void unddeleteOneEntryFromMergeQuestions(:BibEntry) :VoidSollte der Benutzer entschieden haben, da� das System eine Gleichheit erkannt hat, die garkeine darstellt, so mu� dieser Eintrag aus dem Fragenkatalog gel�oscht werden. Dies ist f�ur diebeiden Vorg�angeMerge und Check �aquivalent und unterscheidet sich nur in dem betro�enenSlot.
� deleteTwoEntriesFromCheckQuestions(:BibEntry, :BibEntry) :Void unddeleteTwoEntriesFromMergeQuestions(:BibEntry, :BibEntry) :VoidIm Gegensatz zum vorherigen Fall wird diese Methode ben�otigt, wenn der Benutzer zweiEintr�age als gleich erkannt hat. Nachdem der neue Eintrag erstellt wurde, m�ussen die beidenalten gel�oscht werden.
� deleteEntryFromBibFile(:BibEntry) :Void und addBibEntryToFile(:BibEntry) :VoidBeimCheck-Vorgang ist es notwendig, wenn der Benutzer entschieden hat, da� zwei Eintr�agetats�achlich gleich sind, da� die beiden alten Eintr�age aus dem Datenbestand gel�oscht werdenund der neue hinzugef�ugt wird.
� addBibEntryToMergeAB(:BibEntry) :Void und addBibEntryToNewFile(:BibEntry) :VoidBeim Merge-Vorgang m�ussen die Eintr�age im Gegensatz zum Check-Vorgang nie gel�oschtwerden, da die entsprechenden Eintr�age noch gar nicht in der Ergebnismenge vorhanden sind.Allerdings mu� bei der Entscheidung des Benutzers, da� das System f�alschlicherweise eine

ANHANG D. SYSTEMBESCHREIBUNG 49
�Ubereinstimmung erkannt hat, dieser Eintrag in die entsprechende Ergebnismenge eingef�ugtwerden. Diese Ergebnismengen sind in dem Objekt der Klasse BibMerge als �o�entliche Slotsenthalten (newBibFileA,newBibFileB und newBibFileAB).
� setBibFileMergedTo(:String) :VoidJe nach ausgew�ahlter Operation (A Minus B, B Minus A, Intersection oder Union) m�ussendie einzelnen Ergebnismengen des Slots merge miteinander verkn�upft werden.
� checkIntegrityBibFileMerged() :BibEntryUm nach doppelten Eintragsschl�usseln zu suchen, wird diese Methode angesto�en. Die Sucheerfolgt auf dem Slot bibFileMerged.
� changeBibEntryKeyOfBibFileMerged(:String) :VoidFalls ein doppelter Eintragsschl�ussel in den Daten des Slot bibFileMerged gefunden wurde,so wird der BibTEX-Eintrag, der im Slot keyProblem gespeichert wurde, mit dem neuenEintragsschl�ussel versehen.
� getKeyProblem() :BibEntryDiese Methode gibt den BibTEX-Eintrag, der in dem Slot keyProblem enthalten ist, zur�uck.
� noMoreMergeQuestions() :Bool und noMoreCheckQuestions() :BoolWenn der Fragenkatalog des Merge- beziehungsweise Check-Vorganges leer ist, so gibt dieseMethode \true" zur�uck.
� getCurrentQuestion() :BibQuestionGibt die aktuelle Frage zur�uck, die der Benutzer beantworten soll.
� getMergeQuestion(:Int) :BibQuestion und getCheckQuestion(:Int) :BibQuestionFalls das System mehrere Eintr�age gefunden hat, mit denen ein BibTEX-Eintrag �ubereinstim-men kann, so wird durch den Parameter festgelegt, welche der Benutzer auf seinen Bildschirmbekommt.
� Die nachfolgenden Methoden geben f�ur die Pr�asentation die Anzahl der Elemente in denjeweiligen Mengen zur�uck
{ getQuantityBibFileA() :Int
{ getQuantityBibFileB() :Int
{ getQuantityBibFileMerged() :Int
{ getQuantityNewBibFileA() :Int
{ getQuantityNewBibFileB() :Int
{ getQuantityNewBibFileAB() :Int
{ getQuantityQuestions() :Int
� getBackgroundForBibEntry(:BibEntry) :String undgetBackgroundForBibFile(:String) :StringDiese beiden Methoden geben als RGB-Code die Farbgestaltung eines Objektes der KlasseBibEntry oder BibFile zur�uck.
D.3 BibCheckClass
Slots
� algo :BibAlgoUm einzelne Objekte der Klasse BibEntry zu vergleichen werden Algorithmen ben�otigt, diein den Methoden der Klasse BibAlgo enthalten sind.

ANHANG D. SYSTEMBESCHREIBUNG 50
Methoden
� new(:BibFile, :BibParameter) :BibCheckWie bei jeder new-Methode wird das Objekt der entsprechenden Klasse initialisiert. Zus�atz-lich wird der Slot result mit dem Ergebnis der angesto�enen Methode compareBibFilebelegt, und in dem Slot upperCut wird der entsprechende Wert aus dem Objekt der KlasseBibParameter gespeichert.
� compareBibFile(:BibFile, :BibParameter) :MutableList(BibRankedList){ siehe Kapitel 5.3.2 {
� compareBibEntries(:BibEntry, :BibEntry, :BibParameter) :BibTriple{ siehe Kapitel 5.3.2 {
D.4 BibCheck
Slots
� newBibFile :BibFileNach dem Aufruf der Methode cleanUp entsteht in diesem Slot das neue Objekt, das alsErgebnis der Systemfunktion Check zur�uckgegeben wird. Durch Intervention des Benutzerskommen ebenso nach und nach Elemente aus dem Slot questions hinzu.
� questions :BibQuestionSollten beim Aufruf der Methode cleanUp nicht alle BibTEX-Eintr�age eindeutig abgearbeitetwerden k�onnen, so werden diese Eintr�age mit zus�atzlichen Informationen als o�ene Fragenin diesem Slot abgelegt.
� result :MutableList(BibRankedList)Dieser Slot wird, wie bereits beschrieben, beim Aufruf der new-Methode der Metaklassebelegt. Hierin be�ndet sich das Zwischenergebnis der Check-Funktion.
� upperCut :RealAuch dieser Slot wird beim Aufruf der new-Methode der Metaklasse belegt. Die Bedeutungdieses Slots wurde bereits bei der Beschreibung der Klasse BibParameter gekl�art.
Methoden
� cleanUp() :Void{ siehe Kapitel 5.3.2 {
� deleteEntryFromResult(:BibEntry) :VoidFalls der eben erw�ahnte Fall eintreten sollte und zwei Eintr�age mit einer Wahrscheinlichkeit�ubereinstimmen, die gr�o�er ist als der upperCut, so l�oscht diese Methode die �uber �ussigenEintr�age.
� deleteOneEntryFromQuestions(:BibEntry) :VoidSollte der Benutzer eine o�ene Frage beantwortet haben, so kann dieser Eintrag aus deno�enen Fragen, also aus dem Slot questions, gel�oscht werden. Hierbei m�ussen allerdings alleObjekte des Slots questions bearbeitet werden, da dieser Eintrag aus s�amtlichen RankedListsebenso verschwinden mu�. Hierdurch k�onnte eine RankedList leer geworden sein, so da� dieMethode addEmptyElementsToBibFile ausgef�uhrt wird.
� deleteTwoEntriesFromQuestions(:BibEntry, :BibEntry) :VoidDiese Methode verh�alt sich �aquivalent zu deleteOneEntryFromQuestions. Sie besitzt ihre

ANHANG D. SYSTEMBESCHREIBUNG 51
Berechtigung in der Tatsache, da� am Schlu� beider Methoden zus�atzlich einmal die Metho-de addEmptyElementsToBibFile aufgerufen wird. W�urde man die Methode deleteOneEn-tryFromQuestions zweimal hintereinander ausf�uhren, so w�urde wom�oglich der Eintrag, dereigentlich beim zweiten Aufruf gel�oscht werden soll, durch die Methode addEmptyElements-ToBibFile in den Slot newBibFile geschrieben werden.
� addEmptyElementsFromBibFile(:MutableList(BibRankedList)) :MutableList(BibRankedList){ siehe Kapitel 5.3.2 {
D.5 BibEntry
{ siehe Kapitel 5.3.1 {
D.6 BibEntryClass
{ siehe Kapitel 5.3.1 {
D.7 BibFile
{ siehe Kapitel 5.3.1 {
D.8 BibFileClass
{ siehe Kapitel 5.3.1 {
D.9 BibMergeClass
Slots
� algo :BibAlgo{ siehe BibCheckClass {
Methoden
� new(:BibFile, :BibFile, :BibParameter) :BibMergeDie Funktionsweise ist sehr �ahnlich zur new-Methode der Klasse BibCheckClass. Jedoch wirdnicht die Methode compareBibFile angesto�en, sondern compareBibFiles, die auf zwei Ob-jekten der Klasse BibFile arbeitet. Zus�atzlich werden noch die beiden Slots nameBibFileAund nameBibFileB mit den entsprechenden Attributen der beiden mitgelieferten Objektebelegt.
� compareBibFiles(:BibFile, :BibFile :BibParameter) :MutableList(BibRankedList)Die Struktur entspricht der Methode compareBibFile, jedoch wird hier nicht ein Objekt derKlasse BibFile mit sich selbst verglichen, sondern ein Objekt mit einem anderen.
� compareBibEntries(:BibEntry, :BibEntry, :BibParameter) :BibTriple{ siehe BibCheckClass {

ANHANG D. SYSTEMBESCHREIBUNG 52
D.10 BibMerge
Diese Klasse und seine Metaklasse BibMergeClass unterst�utzen die Funktionen Union, Intersecti-on und Minus.
Slots
� newBibFileA :BibFile, newBibFileB :BibFile und newBibFileAB :BibFileIm Gegensatz zu BibCheck entstehen bei den Funktionen Union, Intersection und Minusdrei Ergebnismengen. Diese drei Ergebnismengen spiegeln sich in diesen Slots wieder. EinMengendiagrammzur Erkl�arung des Zusammenhanges dieser drei Slots folgt in Kapitel 5.3.3,da diese Mengen insbesondere f�ur die Pr�asentation eine Rolle spielen.
� questions :BibQuestion{ siehe BibCheck {
� result :MutableList(BibRankedList){ siehe BibCheck {
� upperCut :Real{ siehe BibCheck {
� nameBibFileA und nameBibFileBUm einzelne Eintr�age in die jeweiligen Slots richtig zuzuordnen, werden die Namen derbeiden BibTEX-Dateien ben�otigt. Diese beiden Slots werden bereits durch die new-Methodeder Metaklasse mit ihren Werten belegt.
Methoden
� cleanUp() :VoidDie Funktion dieser Methode entspricht der namensgleichen aus der Klasse BibCheck. Jedochm�ussen die einzelnen Eintr�age nicht nur einem einzigen Slot newBibFile, sondern je nachSituation den drei Slots newBibFileA, newBibFileB oder newBibFileAB zugeordnet werden.
� deleteEntryFromResult(:BibEntry) :Void{ siehe BibCheck {
� deleteOneEntryFromQuestions(:BibEntry) :Void{ siehe BibCheck {
� deleteTwoEntriesFromQuestions(:BibEntry, :BibEntry) :Void{ siehe BibCheck {
� addEmptyElementsFromBibFile(:MutableList(BibRankedList)) :MutableList(BibRankedListGenauso wie die Methode cleanUp mu�te diese Methode nur an die drei Slots angepa�twerden. Ansonsten funktioniert sie genauso wie die namensgleiche Methode aus BibCheck.
D.11 BibParameter
{ siehe Kapitel 5.3.2 {
D.12 BibParameterClass
{ siehe Kapitel 5.3.2 {

ANHANG D. SYSTEMBESCHREIBUNG 53
D.13 BibProcessor
{ siehe Kapitel 5.3.3 {
D.14 BibQuestionClass
Methoden
� new(:BibRankedList, :Int, :String, :String) :BibQuestionDie beiden Strings enthalten die jeweiligen Namen der beiden BibTEX-Dateien. Dies ist indiesem Kontext f�ur die farbige Gestaltung wichtig, da die Eintr�age beider Dateien farblichvoneinander zu unterscheiden sein sollen.Da das System zu einem Eintrag mehrere m�ogliche �Ubereinstimmungen gefunden habenkann, wird in Abh�angigkeit von der Zahl vom Typ Int der entsprechende BibTEX-Eintragaufbereitet. Allerdings k�onnen nie zwei oder mehr Eintr�age einer Datei mit einem Eintragder anderen Datei �ubereinstimmen. Dies verbietet zum einen die Vorbedingung aus der An-forderungsanalyse und zum anderen sollen diese Elemente bereits durch die Check-Funktionherausge�ltert worden sein.Das Objekt der Klasse BibRankedList ist der Informationstr�ager. Sie enth�alt sowohl diebeiden BibTEX-Eintr�age als auch die Wahrscheinlichkeiten, mit denen Sie �ubereinstimmen.
� buildQuestionTable(:Pair(:BibEntry, :BibTriple):GapArray(GapArray(String))Diese Methode wird innerhalb der new-Methode aufgerufen. Diese Methode liefert eine Ta-belle zur�uck, die vier Spalten besitzt.In der ersten Spalte stehen alle Feldnamen der beiden BibTEX-Eintr�age. Die Spalten zweiund drei enthalten die beiden BibTEX-Eintr�age selbst. Sollte ein Feld in einem der beidenBibTEX-Eintr�age nicht vorhanden sein, so bleibt die entsprechende Zelle leer. In der viertenSpalte werden nur die Zellen ausgef�ullt, bei denen die Felder der beiden BibTEX-Eintr�ageexakt gleich waren. Dies soll sp�ater dem Benutzer die Arbeit erleichtern, und er soll Unter-schiede schneller �nden.
� getQuestionFields(:BibEntry, :BibEntry):GapArray(String)Die Methode buildQuestionTable ben�otigt alle Felder der beiden BibTEX-Eintr�age. Hier-zu wird diese Methode aufgerufen, um Funktionalit�at zu kapseln und �Ubersichtlichkeit zugewinnen.
D.15 BibQuestion
Ein Objekt dieser Klasse soll alle Informationen enthalten, die ben�otigt werden, um den Benutzer�uber die Gleichheit zweier BibTEX-Eintr�age entscheiden zu lassen.Hierzu mu� die Information, die in einem Objekt der Klasse BibRankedList enthalten ist, so auf-gearbeitet werden, da� sie pr�asentationsf�ahig ist.
Slots
� bibEntry1 :BibEntry und bibEntry2 :BibEntryDie beiden Slots enthalten die Objekte, die vom Benutzer verglichen werden sollen.
� table :GapArray(GapArray(String))Diese Array-Struktur enth�alt die Tabelle, die durch die Methode buildQuestionTable be-rechnet wurde. Der Benutzer erh�alt diese Tabelle auf den Bildschirm.

ANHANG D. SYSTEMBESCHREIBUNG 54
� probability :RealDie Wahrscheinlichkeit, mit der die beiden BibTEX-Eintr�age aus den beiden Slots bibEntry1und bibEntry2 �ubereinstimmen.
� number :IntWie bereits erw�ahnt, kann das System zu einem BibTEX-Eintrag mehrere �Ubereinstimmun-gen erkannt haben. Diese Zahl spiegelt die n-te Alternative wieder. Diese Zahl kann niemalsgr�o�er als quantity werden.
� quantity :IntDie Anzahl der m�oglichen �Ubereinstimmungen, die ein System erkannt hat.
� colourFirst :String, colourSecond, colourThird und colourFourthDie einzelnen Farben der Spalten f�ur die Tabelle in dem Slot table. Allerdings sind colourFirstund colourFourth unver�anderlich. ColourSecond und colourThird h�angen jedoch davon ab,aus welcher BibTEX-Datei der entsprechende Eintrag stammt.
D.16 BibRankedList
RankedLists sind eines der h�au�gsten Ergebnisse von Information Retrieval Systemen. Hierbeiwird eine Liste als Ergebnis zur�uckgeliefert, in der jedes Element einen Wert besitzt, so da� dieeinzelnen Elemente durch diesen Wert in eine Relation gesetzt werden k�onnen.Ein Objekt der Klasse BibRankedList besitzt ein Objekt vom Typ BibEntry und eine Liste vonObjekten der Klasse BibTriple. Diese Liste entspricht einer erweiterten RankedList.
D.17 BibTriple
Diese Klasse spiegelte das Ergebnis eines Vergleiches zweier Objekte der Klasse BibEntry wieder.Wenn ein Objekt A mit einem Objekt B verglichen wird, so wird das Ergebnis in einem Objektder Klasse BibTriple gespeichert. Die beiden Slots bibEntry und distance enthalten das Objekt Bund die Distanz, die das Ergebnis des Vergleiches ist.Zus�atzlich wird f�ur die sp�atere Pr�asentation die Information ben�otigt, ob zwei Felder mit einerWahrscheinlichkeit von 1 �ubereinstimmen. Diese Information wird in dem Slot dict gespeichert.

Literaturverzeichnis
[1] Cardelli, Luca ; Wegner, Peter: On Understanding Types, Data Abstraction, and Poly-morphism. In: Computing Surveys (1985)
[2] Eckel, Bruce: Thinking in JAVA. erste. Prentice Hall, 1998
[3] French, James ; Powell, Allison ; Schulmann, Eric ; Pfaltz, John: Automating theConstruction of Authority Files in Digital Libraries: A Case Study. In: Research and AdvancedTechnology for Digital Libraries, Springer, 1997. { ISBN 3{540{63554{8
[4] Fuhr, Norbert: Information Retrieval / Universit�at Dortmund. 1996. { Forschungsbericht
[5] Gawecki, Andreas ;Wienberg, Axel: STML Developer's Guide. Higher-Order GmbH, 1997
[6] Goldberg, Adele ; Robson, David: Smalltalk-80: The Language and its Implementation.Addison-Wesley, 1985
[7] Lamport, Leslie: Das LaTeX Handbuch. erste. Addison-Wesley, 1995. { ISBN 3{89319{826{1
[8] Lindholm, Tim ; Yellin, Frank: The Java Virtual Machine Speci�cation. Addison Wesley,1996
[9] Matthes, Florian: Persistente Objektsysteme: Integrierte Datenbankentwicklung und Pro-grammerstellung . Springer Verlag, 1993
[10] Oestereich, Bernd: Objektorientierte Softwareentwicklung mit der UML. erste. Oldenburg,1997. { ISBN 3{486{24319{5
[11] Patashnik, Oren: BibTeXing / Stanford University. 1988. { Forschungsbericht
[12] Ragett, Dave: HTML 3.2 Reference Speci�cation / W3C. www.w3.org, 1997. { Forschungs-bericht
[13] van Rijsbergen, C.J.: Information Retrieval / University of Glasgow. 1996. { Forschungs-bericht
[14] Sebesta, R. W.: Concepts of Programming Languages. Benjamin/Cummings, 1989
[15] Wahlen, Jens: Entwurf einer objekt-orientierten Sprache mit statischer Typisierung unterBeachtung kommerzieller Relevanz , Universit�at Hamburg, Fachbereich Informatik, Diplom-arbeit, 1998
[16] Zobel, Justin ; Dart, Philip: Phonetic String Matching: Lessons from Information Retrieval/ University of Melbourne. 1996. { Forschungsbericht
55












![Stabilisierung von pharmazeutischen Proteinlösungen … · Ausbeuten möglich waren und körperfremde Proteine vom Körper als Fremdproteine erkannt und eliminiert werden [2]. Die](https://img.pdfslide.net/doc/110x75/5b9f804309d3f25b318d3012/stabilisierung-von-pharmazeutischen-proteinloesungen-ausbeuten-moeglich-waren.jpg)
![trtr trn tru tr[] ujosephschwartzdermatology.com/wp-content/uploads/... · trtr UEI trtr E] utr E] Y-ES tr tr B D tr tr tr tr tr NO tr EI tr u u u EI E tr OlherSystemic: Diobetes](https://img.pdfslide.net/doc/110x75/5f655dabeca5702d4204d061/trtr-trn-tru-tr-ujosep-trtr-uei-trtr-e-utr-e-y-es-tr-tr-b-d-tr-tr-tr-tr-tr-no.jpg)



![Revision and Exam Tips - New SMART website · =====trtrt]=-tr-trtrtrtrtrtr-tr F 1F]ilflfrritfltrft tr-trtr=tr tr=tr==tr tr-tlF-lflft 71 trtr=trtrtr=tr trtrtrtrtr=trtr trtrtrtrtr==tr](https://img.pdfslide.net/doc/110x75/5ed679a2e7ed90307a0783ea/revision-and-exam-tips-new-smart-trtrt-tr-trtrtrtrtrtr-tr-f-1filflfrritfltrft.jpg)











