Embed Size (px)
Citation preview

Information Retrieval on the Web – Page 1
Information retrieval on the WebTools & algorithmic issues
Andrei Broder & Monika HenzingerCompaq Systems Research Center
November 1998
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,19982
Systems Research Center
What is this talk about?
l Topic:
– Algorithms for retrieving information on the Webl Non-Topics:
– Algorithmic issues in classic information retrieval (IR),e.g. stemming
– String algorithms, e.g. approximate matching– Other algorithmic issues related to the Web:
• networking & routing• cacheing• security• e-commerce

Information Retrieval on the Web – Page 2
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,19983
Systems Research Center
Preliminaries
l Each Web page has a unique URL
http://theory.stanford.edu/~focs98/tutorials.html
l (Hyper) link = pointer from one page to another, loadssecond page if clicked on
l In this talk: document = (Web) page
Accessprotocol
Host name =Domain name
Page name
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,19984
Systems Research Center
princess diana
Engine 1 Engine 2 Engine 3
Relevant butlow quality
Not relevantindex pollution
Example of a query
Relevant andhigh quality

Information Retrieval on the Web – Page 3
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,19985
Systems Research Center
Open problems
Outline
l Classic IR vs. Web IR
l Some IR tools specific to the Web
For each type
– Examples
– Algorithmic issues
l Conclusions
Details on - Ranking - Duplicate elimination - Measuring the Web
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,19986
Systems Research Center
Classic IR
l Input: Document collection
l Goal: Retrieve documents or text with information
content that is relevant to user’s information need
l Two aspects:
1. Processing the collection
2. Processing queries (searching)
l Reference Texts: SW’97, BF’92

Information Retrieval on the Web – Page 4
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,19987
Systems Research Center
Determining query results
“model” = strategy for determining which documents to returnl Logical model: String matches plus AND, OR, NOTl Vector model:
– Documents and query represented as vector of terms– Vector entry i = weight of term i = function of
frequencies within document and within collection– Similarity of document & query = cosine of angle of their
vectors– Query result: documents ordered by similarity
l Other models used in IR but not discussed here:– Probabilistic model– Cognitive model– …
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,19988
Systems Research Center
IR on the Web
l Input:The publicly accessible Webl Goal: Retrieve high quality pages that are relevant to
user’s need– Static (files: text, audio, … )– Dynamically generated on request: mostly data base
accessl Two aspects:
1. Processing and representing the collection• Gathering the static pages• “Learning” about the dynamic pages
2. Processing queries (searching)

Information Retrieval on the Web – Page 5
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,19989
Systems Research Center
What’s different about the Web?Pages
l Bulk …………………… 350 M (7/98); grows at 20M/monthl Lack of stability……….. Estimates: 1%/day -- 1%/weekl Heterogeneity
– Type of documents .. Text, pictures, audio, scripts,…– Quality ……………… From dreck to FOCS papers …– Language ………….. 100+
l Duplication– Syntactic……………. 30% (near) duplicates– Semantic……………. ??
l Non-running text……… many home pages, bookmarks, ...
l High linkage…………… ≥ 8 links/page in the average
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199810
Systems Research Center
Typical home page: non-runningtext

Information Retrieval on the Web – Page 6
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199811
Systems Research Center
The big challenge
Meet the user needs given
the heterogeneity of Web pages
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199812
Systems Research Center
What’s different about the Web?Users
l Make poor queries– Short (2.35 terms avg)– Imprecise terms– Sub-optimal syntax
(80% queries withoutoperator)
– Low effortl Wide variance in
– Needs– Expectations– Knowledge– Bandwidth
l Specific behavior– 85% look over one result
screen only– 78% of queries are not
modified– Follow links– See various user studies
in CHI, Hypertext, SIGIR,etc.
Information Retrieval on the Web – Page 7
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199813
Systems Research Center
The bigger challenge
Meet the user needs given
the heterogeneity of Web pagesand
the poorly made queries.
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199814
Systems Research Center
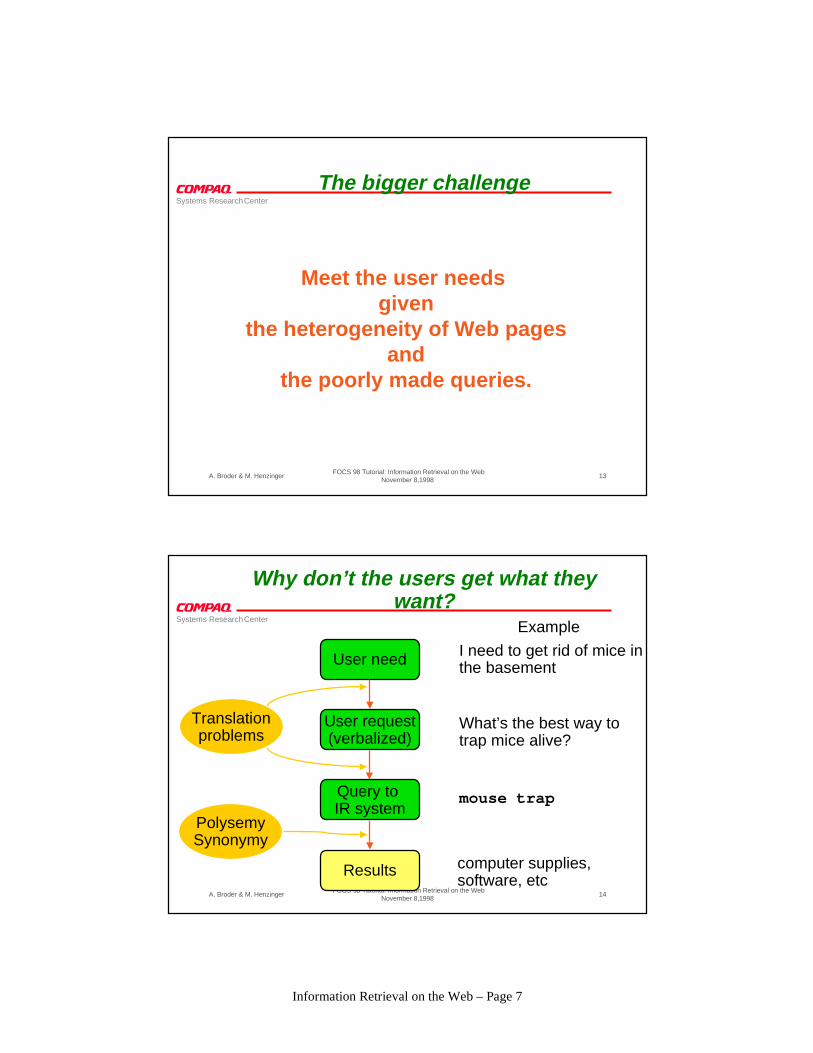
Why don’t the users get what theywant?
I need to get rid of mice inthe basement
What’s the best way to trap mice alive?
mouse trap
User request(verbalized)
Query to IR system
Translationproblems
Example
User need
Results
PolysemySynonymy
computer supplies,software, etc

Information Retrieval on the Web – Page 8
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199815
Systems Research Center
AltaVista output: mouse trap
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199816
Systems Research Center
AltaVista output: mice trap

Information Retrieval on the Web – Page 9
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199817
Systems Research Center
The bright side: Web advantages vs. classic IR
Collection/toolsl Redundancyl Hyperlinksl Statistics
– Easy to gather– Large sample sizes
l Interactivity (make theusers explain what theywant)
Userl Many tools availablel Personalizationl Timelinessl Interactivity (refine the
query if needed)
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199818
Systems Research Center
Quantifying the quality of results
l How to evaluate different strategies?
l How to compare different search engines?

Information Retrieval on the Web – Page 10
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199819
Systems Research Center
Classic evaluation of IR systems
l Precision: % of returnedpages that are relevant.
l Recall: % of relevantpages that are returned.
l Precision at 10: % of top10 pages that are relevant(“ranking quality”)
l …
We start from a human made relevance judgementfor each (query, page) pair and compute:
Relevantpages
Returnedpages
All pages
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199820
Systems Research Center
Evaluation in the Web context
l Quality of pages varies widely
l Relevance is not enough
l We need both relevance and high quality = value ofpage.

Information Retrieval on the Web – Page 11
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199821
Systems Research Center
Web IR tools
l General-purpose search engines:
– direct: AltaVista, Excite, Infoseek, Lycos, HotBot, ….
– Indirect (Meta-search): MetaCrawler, DogPile,AskJeeves, …
l Hierarchical directories: Yahoo!, all portals.
l Specialized search engines:
– Home page finder: Ahoy
– Shopping robots: Jango, Junglee,…
– Applet finders
Database mostly built
by hand
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199822
Systems Research Center
Web IR tools (cont...)
l Search-by-example: Netscape’s “What’s related”,Excite’s “More like this”, …
l Collaborative filtering: Firefly, GAB, …l Notification systems: Clipping services
l Meta-information:– Web statistics:
size, number of domains, geography, ….– Usage statistics– Query log statistics– …

Information Retrieval on the Web – Page 12
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199823
Systems Research Center
General purpose search engines
l Search engines’ components:
– Spider = Crawler -- collects the documents
– Indexer -- process and represents the data
– Search interface -- answers queries
l Example: AltaVista as of 7/98
– Collects ~ 170,000,000 pages.
– Indexes ~ 125,000,000 pages = 700 GB of text.
– Roughly 35% of the entire indexable Web.
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199824
Systems Research Center
Algorithmic issues related tosearch engines
l Collectingdocuments– Priority– Load
balancing• Internal• External
– Trapavoidance
– ...
l Processing andrepresenting thedata– Query-
independentranking
– Graphrepresentation
– Index building– Duplicate
elimination– Categorization– …
l Processingqueries– Query-
dependentranking
– Duplicateelimination
– Queryrefinement
– Clustering– ...

Information Retrieval on the Web – Page 13
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199825
Systems Research Center
Ranking
l Goal: order the answers to a query in decreasing orderof value– Query-independent: assign an intrinsic value to a
document, regardless of the actual query– Query-dependent: value is determined only wrt a
particular query.– Mixed: combination of both valuations.
l Examples– Query-independent: length, vocabulary, publication
data, number of citations (indegree), etc.– Query-dependent: cosine measure
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199826
Systems Research Center
Some ranking criteria
l Content-based techniques (variant of term vector modelor probabilistic model)
l Ad-hoc factors (anti-porn heuristics, publication/locationdata, ...)
l Human annotationsl Connectivity-based techniques
– Query-independent (PageRank [PBMW’98, BP’98],indegree [CK’97], …)
– Query-dependent (HITS [K’98], …)

Information Retrieval on the Web – Page 14
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998
Systems Research Center
Connectivity analysis
l Idea: Mine hyperlink information of the Web
l Assumptions:
– Links often connect related pages
– A link between pages is a recommendation
l Classic IR work (citations = links) a.k.a. “Bibliometrics”[K’63, G’72, S’73, …]
l Many Web related papers build on this idea [PPR’96,AMM’97, S’97, CK’97, K’98, BP’98,…]
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199828
Systems Research Center
Graph representation for the Web
l Node for each page u
l Directed edge (u,v) if page u contains a hyperlink to
page v.

Information Retrieval on the Web – Page 15
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199829
Systems Research Center
Query-independent connectivitybased ranking: PageRank [BP’98]
l Consider a random Web surfer:
– Jumps to random page with probability ε– With probability 1-ε, follows a random hyperlink of the
current pagel Transition probability matrix is
where U is the uniform distribution and A is adjacencymatrix (normalized)
l Query-independent rank = stationary probability for thisMarkov chain.
l Used in GOOGLE! http://google.stanford.edu/
AU ×−+× )1( εε
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199830
Systems Research Center
Output from Google! princess diana

Information Retrieval on the Web – Page 16
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199831
Systems Research Center
Output from Google!: jobs
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199832
Systems Research Center
Query Results= Start Set Forward SetBack Set
Query-dependent ranking:the neighborhood graph
An edge for each hyperlink, but no edges within the same host
Result1
Result2
Resultn
f1
f2
fs
...
b1
b2
bm
… ...
l Subgraph associated to each query

Information Retrieval on the Web – Page 17
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199833
Systems Research Center
HITS [K’98]
l Goal: Given a query find:
– Good sources of content (authorities)
– Good sources of links (hubs)
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199834
Systems Research Center
l Authority comes from in-edges.Being a good hub comes from out-edges.
l Better authority comes from in-edges from good hubs.Being a better hub comes from out-edges to goodauthorities.
Intuition

Information Retrieval on the Web – Page 18
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199835
Systems Research Center
Repeat until HUB and AUTH converge:
Normalize HUB and AUTH
HUB[v] := Σ AUTH[ui] for all ui with Edge(v, ui)
AUTH[v] := Σ HUB[wi] for all wi with Edge(wi, v)
HITS details
w1
wk
......Aw2
u1
uk
u2......
H
v
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199836
Systems Research Center
J
JJ
JJJ
JJJ
Output from HITS: jobs(start set from AltaVista)

Information Retrieval on the Web – Page 19
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199837
Systems Research Center
Problems & solutions
Author A Author B1/3
1/3
1/3
l Some edges are “wrong” -- not arecommendation:– multiple edges from same author– automatically generated– spam, etc.
Solution: Weight edges to limit influence
l Topic drift– Query: jaguar AND cars
Result: pages about cars in general
Solution: Analyze content and assign topicscores to nodes
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199838
Systems Research Center
Repeat until HUB and AUTH converge:
Normalize HUB and AUTH
HUB[v] := Σ AUTH[ui] TopicScore[ui] weight[v,ui]
for all ui with Edge(v, ui)
AUTH[v] := Σ HUB[wi] TopicScore[wi] weight[wi,v]
for all wi with Edge(wi, v)
Modified HITS algorithms [CDRRGK’98, BH’98, CDGKRRT’98]

Information Retrieval on the Web – Page 20
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199839
Systems Research Center
User study [BH’98]
Valuable pages within 10 top answers (averaged over 28 topics)
012345
6789
10
Authorities Hubs
Val
uabl
e pa
ges
with
in to
p 10
Original
EdgeWeighting
EW +ContentAnalysis
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199840
Systems Research Center
Open problems
l Compare performance of query-dependent and query-
independent connectivity analysis
l Exploit order of links on the page (see e.g.
[CDGKRRT’98])
l Both Google! and HITS compute principal eigenvector.
What about non-principal eigenvector? ([K’98])
l Derive other graphs from the hyperlink structure …

Information Retrieval on the Web – Page 21
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199841
Systems Research Center
More on graph representation
l Graphs derived from the hyperlink structure of the Web:– Node =page– Edge (u,v) iff pages u and v are related in a specific
way (directed or not)l Examples of edges:
– iff u has hyperlink to v– iff there exists a page w pointing to both u and v– iff u is often retrieved within x seconds after v– …
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199842
Systems Research Center
Graph representation usage
l Ranking algorithms
– PageRank
– HITS
– …
l Market research
– Lycos “LinkAlert”
l Categorization of Webpages
– [CDI’98]
l Visualization/Navigation
– Mapuccino [MJSUZB’97]
– Microsoft’s Site Mappingtool
– …
l Structured Web query tools
– WebSQL [AMM’97]
– WebQuery [CK’97]

Information Retrieval on the Web – Page 22
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199843
Systems Research Center
Example: SRC Connectivity Server[BBHKV’98]
Directed edges = Hyperlinksl Goal: Support two basic operations for all URLs
collected by AltaVista– InEdges(URL u, int k)
• Return k URLs pointing to u– OutEdges(URL u, int k)
• Return k URLs that u points tol Difficulties:
– Memory usage (~180 M nodes, 1B edges)– Preprocessing time (days …)– Query time (~ 0.0001s/result URL)
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998
Systems Research Center
www.foobar.com/www.foobar.com/gandalf.htmwww.foograb.com/
0 www.foobar.com/ 115 gandalf.htm 267 grab.com/ 41
Original text Delta Encoding
gandalf.htm 15
size of shared prefix
26
Node ID
URL database
Sorted list of URLs is 8.7 GB (≈ 48 bytes/URL)Å Delta encoding reduces it to 3.8 GB (≈ 21 bytes/URL)
Information Retrieval on the Web – Page 23
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199845
Systems Research Center
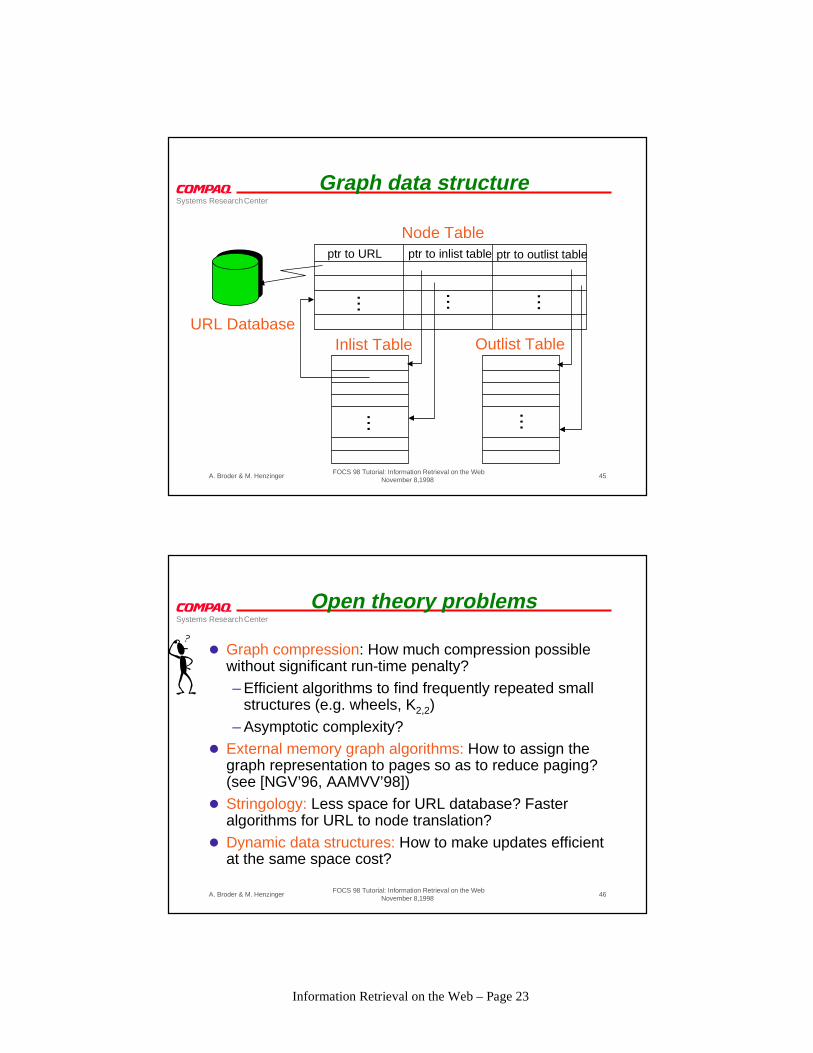
...
Graph data structure
ptr to outlist tableptr to inlist tableptr to URL
Node Table
URL DatabaseInlist Table Outlist Table
...
......
...
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199846
Systems Research Center
Open theory problems
l Graph compression: How much compression possiblewithout significant run-time penalty?– Efficient algorithms to find frequently repeated small
structures (e.g. wheels, K2,2)– Asymptotic complexity?
l External memory graph algorithms: How to assign thegraph representation to pages so as to reduce paging?(see [NGV’96, AAMVV’98])
l Stringology: Less space for URL database? Fasteralgorithms for URL to node translation?
l Dynamic data structures: How to make updates efficientat the same space cost?

Information Retrieval on the Web – Page 24
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199847
Systems Research Center
Algorithmic issues related tosearch engines
l Collectingdocuments– Priority– Load
balancing• Internal• External
– Trapavoidance
– ...
l Processing andrepresenting thedataáQuery-
independentranking
áGraphrepresentation
– Index building– Duplicate
elimination– Categorization– …
l ProcessingqueriesáQuery-
dependentranking
– Duplicateelimination
– Queryrefinement
– Clustering– ...
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199848
Systems Research Center
performance
l Indexes about 0.8TB of text
l Every word is indexed! (No stop words.)
l About 37 million queries on weekdays
l Mean response time = 0.6 sec (elapsed Palo Alto time)
l Median response time, as observed in NJ = 0.9 sec[LG’98b]

Information Retrieval on the Web – Page 25
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199849
Systems Research Center
Why is AltaVista so fast?
l Conceptually simple algorithms
l Good algorithms engineering
l Good software engineering
l Lots of fast hardware, lots of RAM
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199850
Systems Research Center
AltaVista search index
l View all documents as concatenated into one document(Special token to separate original documents)
l Basic data structure: flat inverted file [See e.g. BF’92]
– Store for each word, a delta-encoded list of alllocations where word occurs
– Order words lexicographically and compresscommon word prefixes
l ⇒ Size of full-text index ≈ 30% of input size

Information Retrieval on the Web – Page 26
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199851
Systems Research Center
Operations
l Extended Boolean model:– matches: exact, prefix, phrase– operators: AND, OR, AND NOT, NEAR
l To support this: only one abstract data type Index Stream Reader (ISR) = the ordered list of
locations that match a given query. For a given ISR:
• loc(): return current location• next(): advance to next location
• seek(int k): advance to first location ≥ k
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199852
Systems Research Center
Translating a query into an ISR
Each query is decomposed into these elementaryoperations:
CREATE: WORD → ISR ...……….. Create a list
OR: ISR × ISR → ISR ...…………… Merge lists
AND NOT: ISR × ISR → ISR ...…… Intersect lists
AND: ISR × ISR → ISR ...…………………."
NEAR: ISR × ISR → ISR ...………………. "
PHRASE: ISR × ISR × … × ISR→ ISR …. "
The final resulting ISR is translated back into list ofdocuments and ranked

Information Retrieval on the Web – Page 27
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199853
Systems Research Center
Hardware
The search happens on
l ~ 20 64-bit machines
l Typical configuration
– 10 CPU each (625 MHz)
– 12 GB RAM
– 300 GB RAID
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199854
Systems Research Center
Reasons for duplicate filtering
l Proliferation of almost but not quite equal documents onthe Web:
– Legitimate: Mirrors, local copies, updates, etc.
– Malicious: Spammers, spider traps, dynamic URLs
– Mistaken: Spider errors
l Costs:
– RAM and disks
– Unhappy users
l Approximately 30% of the pages on the Web are (near)duplicates. [BGMZ’97,SG’98]

Information Retrieval on the Web – Page 28
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998
Systems Research Center
Basic mechanism needed
l Must filter both duplicate and near-duplicate documents
l Computing pair-wise edit distance would take forever
l Preferably to store only a short sketch for each
document.
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998
Systems Research Center
The basics of a solution
[B’97],[BGMZ’97],[B’98]
1. Reduce the problem to a set intersection problem
2. Estimate intersections by sampling minima.
Information Retrieval on the Web – Page 29
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199857
Systems Research Center
D
a rose is a rose is a rosea rose is a rose is a rose is a rose is a rose is a rose is a rose
FingerprintShinglingSet of 64 bit
fingerprints
Set of shingles
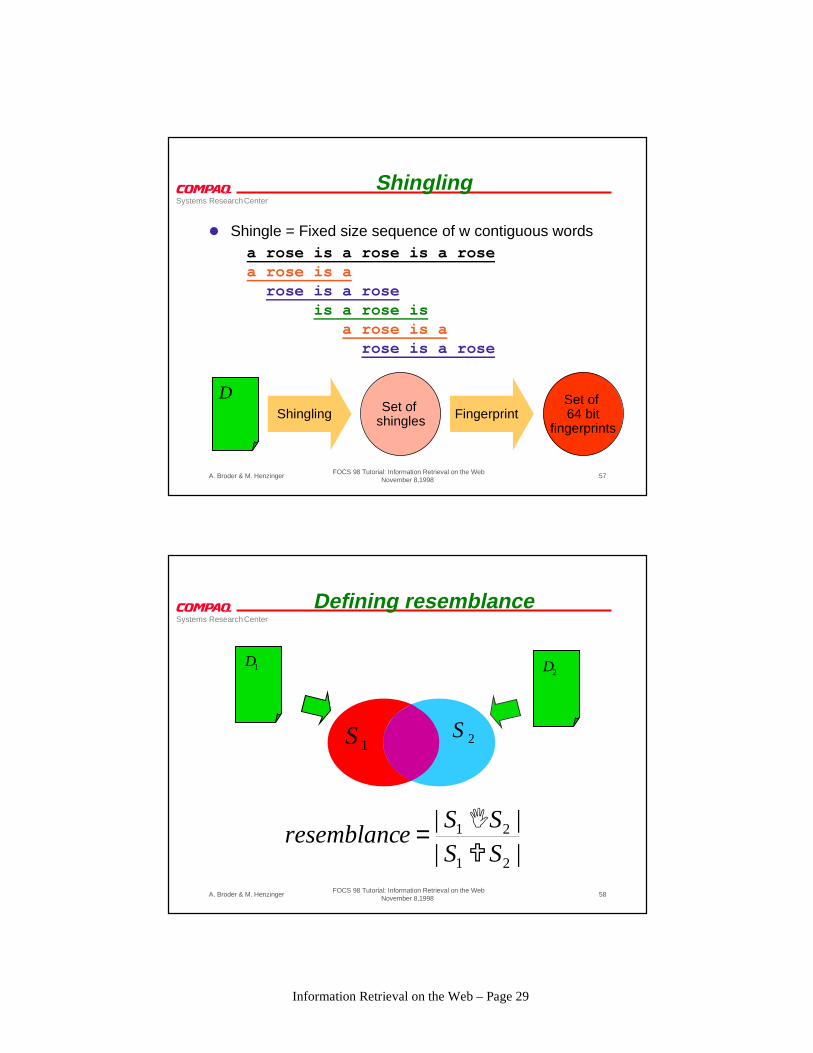
Shingling
l Shingle = Fixed size sequence of w contiguous words
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199858
Systems Research Center
Defining resemblance
1D2D
||
||eresemblanc
21
21
SS
SS
U
I=
||||
21
21
SSSS
eresemblancUI=
1S 2S

Information Retrieval on the Web – Page 30
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199859
Systems Research Center
l Apply a random permutation σ to the set [0..264]
l Crucial fact
Let
Sampling minima
||||
)Pr(21
21
SSSS
UI== βα
))(min())(min( 21 SS σβσα ==
1S2S
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998
Systems Research Center
Implementation
l Choose a set of t random permutations of U
l For each document keep a sketch S(D) consisting of tminima = samples
l Estimate resemblance of A and B by counting commonsamples
l The permutations should be from a min-wiseindependent family of permutations. See [BCFM’97] forthe theory of mwi permutations.

Information Retrieval on the Web – Page 31
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998
Systems Research Center
If we need only high resemblance
Sketch 1:
Sketch 2:
l Divide sketch into k groups of s samples (t = k * s)
l Fingerprint each group ⇒ feature
l Two documents are fungible if they have more
than r common features.
l WantFungibility ⇔ Resemblance above fixed threshold ρ
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998
Systems Research Center
Real implementation
l ρ = 90%. In a 1000 word page with shingle length = 8this corresponds to
• Delete a paragraph of about 50-60 words.
• Change 5-6 random words.
l Sketch size t = 84, divide into k = 6 groups of s = 14samples
l 8 bytes fingerprints → we store only 6 x 8 =
48 bytes/documentl Threshold r = 2
Information Retrieval on the Web – Page 32
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199863
Systems Research Center
Probability that two documents aredeemed fungible
Two documents with resemblance ρl Using the full sketch
l Using features
( ) iksisk
ri i
kP
−⋅
=
−
= ∑ ρρ 1
( ) iskisk
ti i
skP −⋅
⋅
=
−
⋅
= ∑ ρρ 1
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998
Systems Research Center
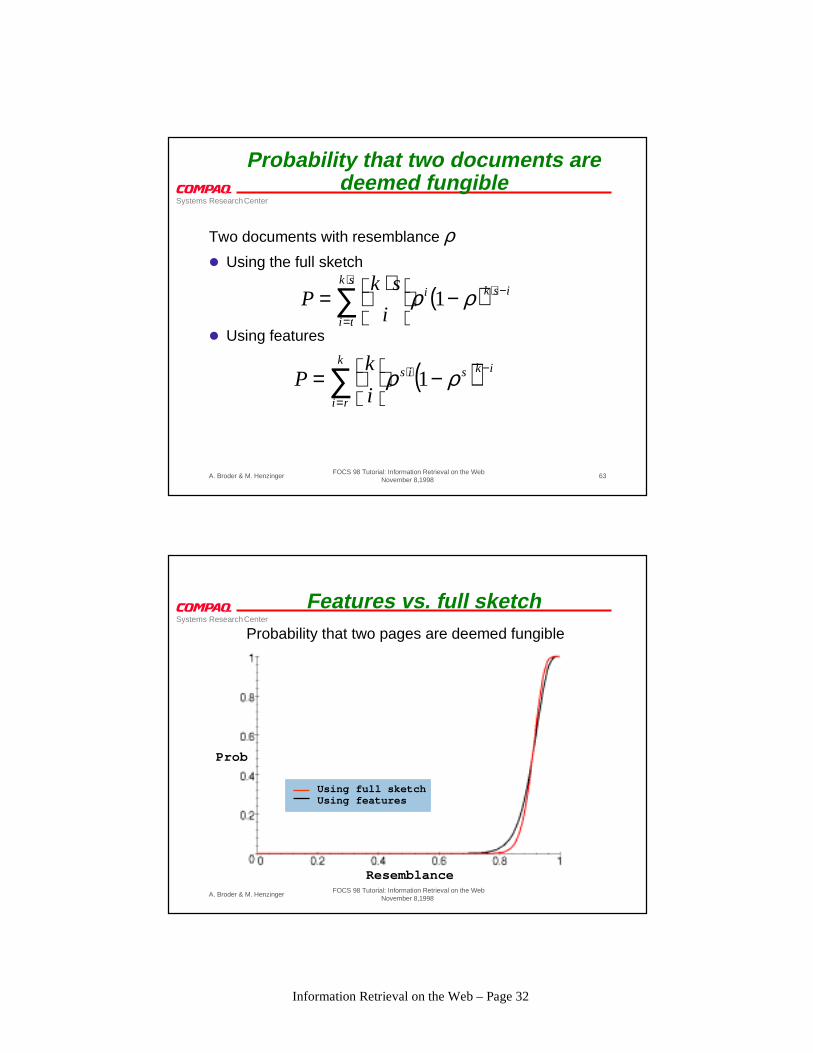
Features vs. full sketch
Prob
Resemblance
Probability that two pages are deemed fungible
Using full sketchUsing features

Information Retrieval on the Web – Page 33
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199865
Systems Research Center
Related work
l Similarity detection [M’94, BDG’95, SG’95, H’96,
BGMZ’97]
l Mathematics of resemblance [B’97, B’98]
l Min-wise independent permutations [BCFM’97, BCM’98]
l Duplication on the Web [SG’98]
l Efficient ways of finding data base elements that share
many attributes. [FSGMU’98]
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199866
Systems Research Center
Open problems
l Best way of grouping samples for a given thresholdand/or for multiple thresholds?
l Efficient ways to find in a data base pairs of records thatshare many attributes. Best approach?
l Min-wise independent permutations -- lots of openquestions.
l Connections with the Hamming distance nearestneighbor problem. (See [IM’98]).
l Other applications possible (images, sounds, ...) -- needtranslation into set intersection problem.
Information Retrieval on the Web – Page 34
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199867
Systems Research Center
Algorithmic issues related tosearch engines
l Collectingdocuments– Priority– Load
balancing• Internal• External
– Trapavoidance
– ...
l Processing andrepresenting thedataáQuery-
independentranking
áGraphrepresentation
áIndex buildingáDuplicate
elimination– Categorization– …
l ProcessingqueriesáQuery-
dependentranking
áDuplicateelimination
– Queryrefinement
– Clustering– ...
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199868
Systems Research Center
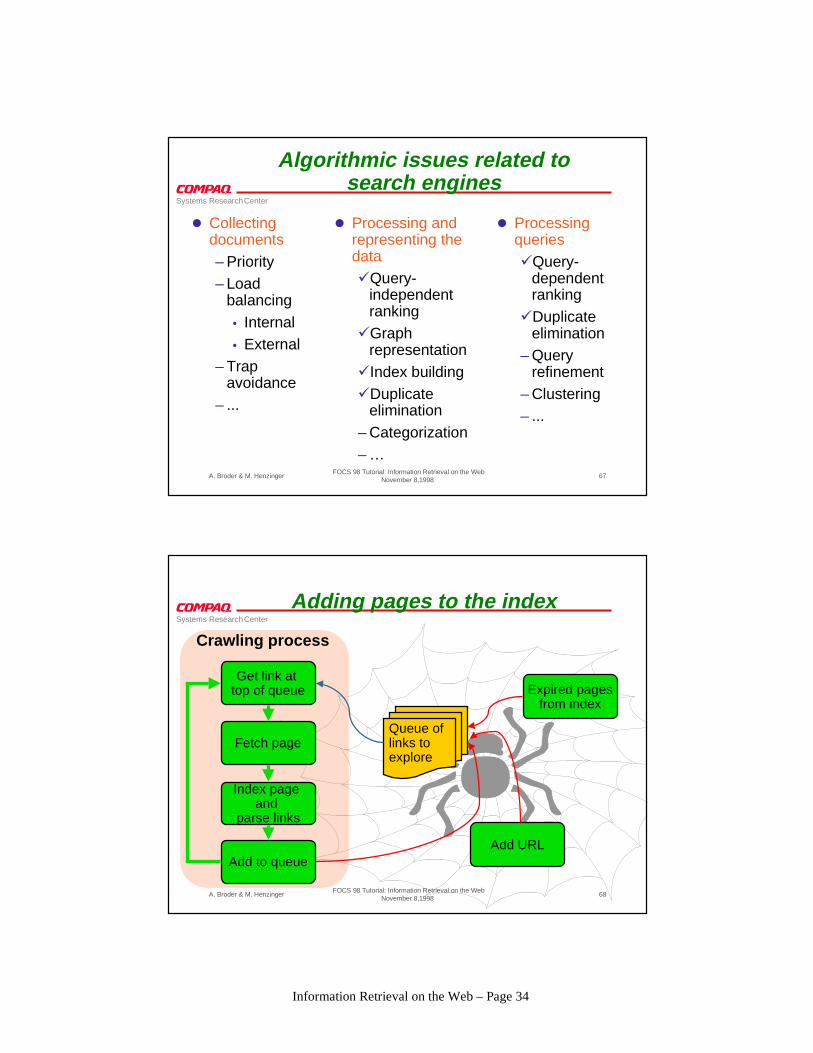
Adding pages to the index
Queue of links to explore
Expired pagesfrom index
Add URL
Get link at top of queue
Fetch page
Add to queue
Index page and
parse links
Crawling process

Information Retrieval on the Web – Page 35
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199869
Systems Research Center
Queuing discipline
l Standard graph exploration:– Random– BFS– DFS (+ depth limits)
l Goal: get “best” pages for a given index size– Priority based on query-independent ranking– Visit the page that has the highest potential
PageRank [CGP’98]l Goal: keep index fresh
– Priority based on rate of change [CLW’97]
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199870
Systems Research Center
Load balancing
l Internal -- can not handle too much retrieved datasimultaneously, but– Response time is unpredictable– Size of answers is unpredictable– There are additional system constraints (# threads, #
open connections, etc.)l External
– Should not overload any server or connection– A well-connected crawler can saturate the entire
outside bandwidth of some small countries– Any queuing discipline must be acceptable to the
community

Information Retrieval on the Web – Page 36
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199871
Systems Research Center
Web IR Tools
á General-purpose search enginesl Hierarchical directories
– Automatic categorizationl Specialized search engines
(dealing with heterogeneous data sources)– Shopping robots– Home page finder [SLE’97]– Applet finders– …
l Search-by-examplel Collaborative filteringl Notification systemsl Meta-information
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199872
Systems Research Center
Dealing with heterogeneoussources
l Modern life problem:
Hot issue in current data base research
Red hot issue in the industry.
l Examples– Inter-business e-commerce e.g. www.industry.net
– Meta search engines
– Shopping robots
l Issues
– Determining relevant sources -- the “identification” problem
– Merging the results -- the “fusion” problem
Given information sources with various capabilities, query all of them and combine the output.

Information Retrieval on the Web – Page 37
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199873
Systems Research Center
Standards and tools
l Some standards:– STARTS → Stanford Protocol Proposal for [distributed]
Internet Retrieval and Search– EDI → Electronic Data Interchange– XML → Extensible Markup Language
• http://www.w3.org/TR/1998/REC-xml-19980210
• http://www.oasis-open.org/cover/sgml-xml.html
l Some tools:– WebL → scripting language for automating tasks on the
Web• http://www.research.digital.com/SRC/WebL
– WebSQL → SQL like query language [M’96, AMM’97]
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199874
Systems Research Center
Example: a shopping robot
l Input: A product description in some formFind: Merchants for that product on the Web
l Jango [DEW’97]– preprocessing: Store vendor URLs in database;
learn for each vendor:• the URL of the search form• how to fill in the search form and• how the answer is returned
– request processing: fill out form at every vendor andtest whether the result is a success
– range of products is predetermined

Information Retrieval on the Web – Page 38
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199875
Systems Research Center
Jango input example
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199876
Systems Research Center
Jango output

Information Retrieval on the Web – Page 39
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199877
Systems Research Center
Direct query to K&L Wine
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199878
Systems Research Center
What price decadence?

Information Retrieval on the Web – Page 40
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199879
Systems Research Center
Open problems
l Going beyond the lowest common capabilityl Learning problem: automatic understanding of new
interfacesl Efficient ways to determine which DB is relevant to a
particular queryl “Partial knowledge indexing”: indexer has limited access
to the full DB
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199880
Systems Research Center
Web IR Tools
á General-purpose search enginesá Hierarchical directoriesá Specialized search engines
(dealing with heterogeneous data sources)l Search-by-examplel Collaborative filteringl Notification systemsl Meta-information

Information Retrieval on the Web – Page 41
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199881
Systems Research Center
Search-by-example
l Given: set S of URLsl Find: URLs of similar pagesl Algorithms:
– Connectivity-based: build graph consisting ofneighborhood of S and run HITS [K’98]
– Usage based: related pages are pages visitedfrequently after S [Netscape “What’s related”]
– Query refinement [Excite’s “More like this”]
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199882
Systems Research Center
Netscape example
Information Retrieval on the Web – Page 42
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199883
Systems Research Center
Web IR Tools
á General-purpose search engines:á Hierarchical directoriesá Specialized search engines:á Search-by-examplel Collaborative filteringl Notification systemsl Meta-information
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199884
Systems Research Center
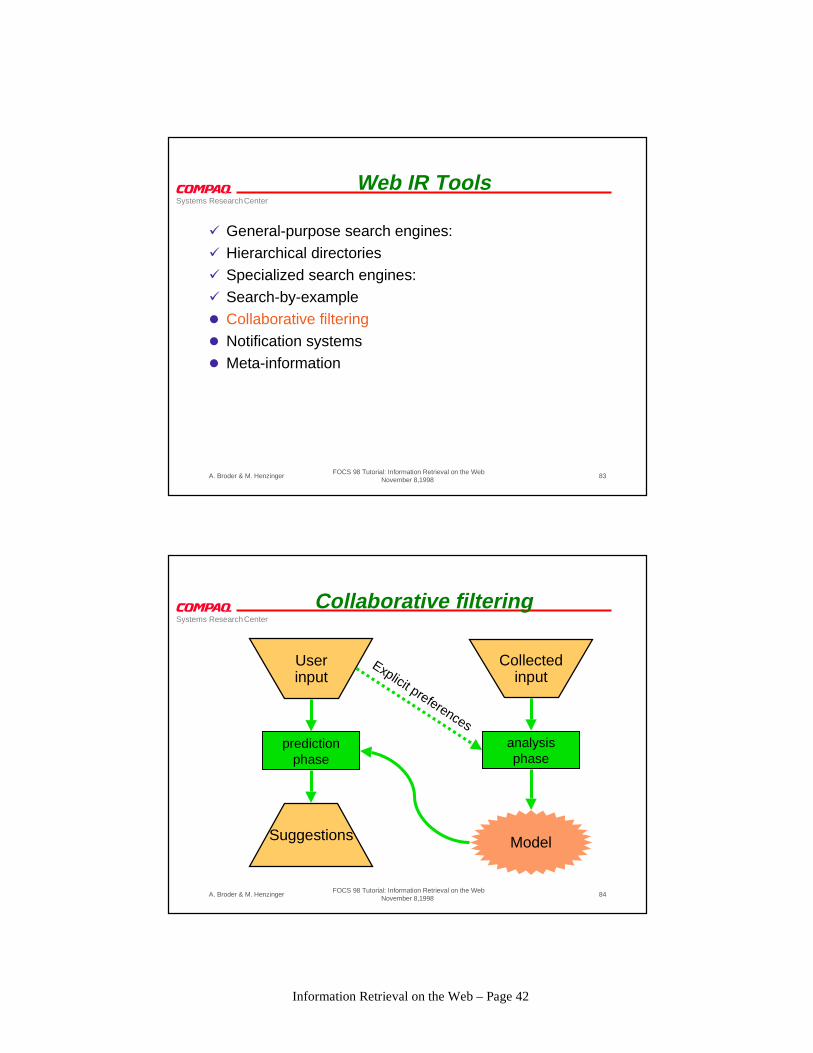
Collaborative filtering
Suggestions
predictionphase
Userinput
analysisphase
Model
Collectedinput
Explicit preferences

Information Retrieval on the Web – Page 43
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199885
Systems Research Center
Lots of projects
l Collaborative filtering seldom used in classic IR, bigrevival on the Web. Projects:
– PHOAKS -- ATT labs → Web pages recommendationbased on Usenet postings
– Firefly -- MIT → share profiles without infringing privacy
– GAB -- Bellcore → Web browsing
– Grouplens -- U. Minnesota → Usenet newsgroups
– EachToEach -- Compaq SRC → rating movies
– …
See http://sims.berkeley.edu/resources/collab/
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199886
Systems Research Center
Why do we care?
l The ranking schemes that we discussed are also a formof collaborative ranking!
– Connectivity = people vote with their links
– Usage = people vote with their clicks
l These schemes are used only for a global model building.Can it be combined with per-user data?Ideas:
– Consider the graph induced by the user’s bookmarks.
– Profile the user -- see www.globalbrain.net
– Deal with privacy concerns!

Information Retrieval on the Web – Page 44
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199887
Systems Research Center
Web IR Tools
á General-purpose search engines:á Hierarchical directoriesá Specialized search engines:á Search-by-exampleá Collaborative filteringl Meta-information
– Web Statistics: Size, Growth, ...– Usage Statistic– Query Log Statistics
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199888
Systems Research Center
Size of the Web
l How big is the Web?
l How fast does the Webgrow?
l What is the proportion ofpages in French, XML,Postscript, etc. ?
l How do various searchengines compare?
Arachnometry: The art and science of measuring theworld wide Web, in particular the coverage of varioussearch engines.

Information Retrieval on the Web – Page 45
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199889
Systems Research Center
Comparing Search EngineCoverage
l Naïve Approaches– Get a list of URLs from each search engine and
compare• Not practical or reliable.
– Result Set Size Comparison• Reported sizes are approximate.
– …l Better Approach
– Statistical Sampling
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199890
Systems Research Center
URL sampling
l Ideal strategy: Generate a random URL and check forcontainment in each index.
l Random URLs are hard to generate:– Random walks methods
• Graph is directed• Stationary distribution is non-uniform• Must prove rapid mixing.
– Pages in cache, query logs [LG’98a], etc.• Correlated to the interests of a particular group of
users.l A simple way: collect all pages on the Web and pick one
at random.

Information Retrieval on the Web – Page 46
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199891
Systems Research Center
Sampling via queries [BB’98]
l Search engines have the best crawlers -- why not
exploit them?
l Method:
– Sample from each engine in turn
– Estimate the relative sizes of two search engines
– Compute absolute sizes from a reference point
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199892
Systems Research Center
|A ∩ B| ≈ (1/2) * |A|
|A ∩ B| ≈ (1/6) * |B|
∴ |B| ≈ 3 * |A|
Select pages randomly fromA (resp. B)
Check if page contained inB (resp. A)
Two steps: (i) Selecting (ii) Checking
Estimate relative sizes

Information Retrieval on the Web – Page 47
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199893
Systems Research Center
Selecting a random page
l Generate random query
– Build a lexicon of words that occur on the Web
– Combine random words from lexicon to form queries
l Get the first 100 query results from engine A
l Select a random page out of the set
l Distribution is biased -- the conjecture is that
where p(D) is the probability that D is picked by this scheme
||||
~)(
)(
ABA
Dp
Dp
AD
BAD ∩
∑∑
∈
∩∈
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199894
Systems Research Center
Checking if an engine has a pagel Create a “unique query” for the page:
– Use 8 rare words.– E.g., for the Systems Research Center Home Page:
Information Retrieval on the Web – Page 48
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199895
Systems Research Center
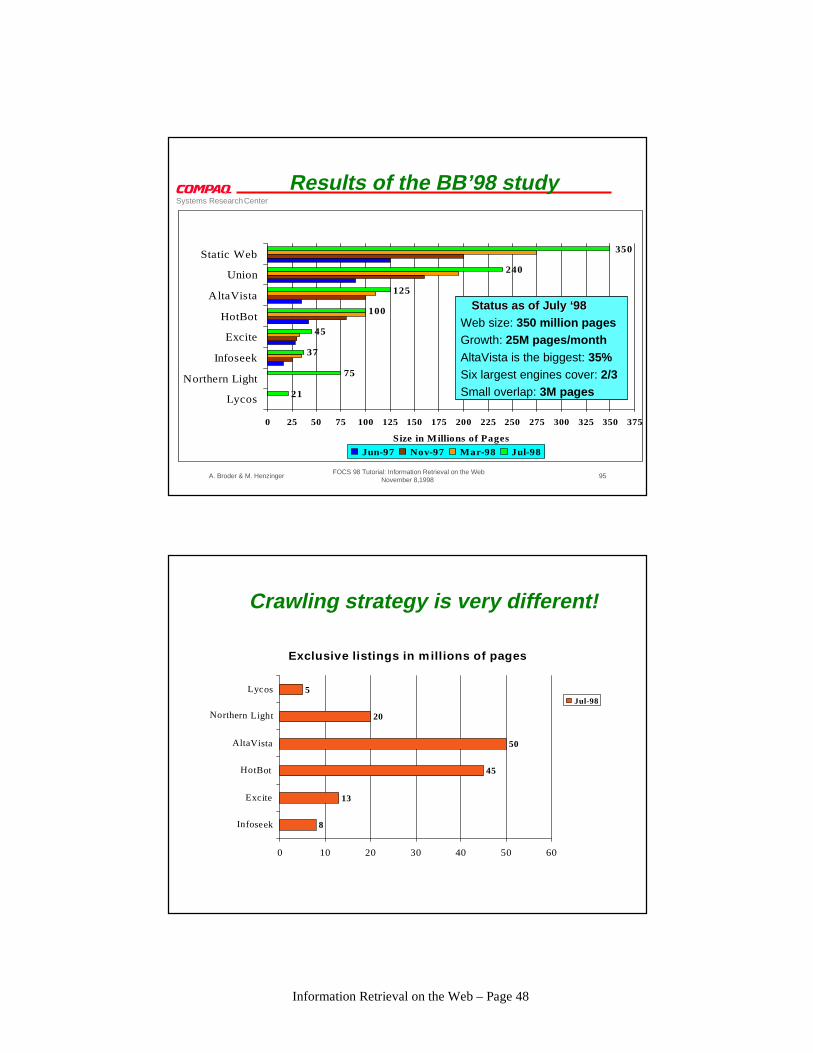
Results of the BB’98 study
21
75
37
45
100
125
240
350
0 25 50 75 100 125 150 175 200 225 250 275 300 325 350 375
Lycos
Northern Light
Infoseek
Excite
HotBot
AltaVista
Union
Static Web
Size in Millions of Pages
Jun-97 Nov-97 Mar-98 Jul-98
Status as of July ‘98Status as of July ‘98Web size: 350 million pagesGrowth: 25M pages/monthAltaVista is the biggest: 35%Six largest engines cover: 2/3Small overlap: 3M pages
Crawling strategy is very different!
Exclusive listings in millions of pages
8
13
45
50
20
5
0 10 20 30 40 50 60
Infoseek
Excite
HotBot
AltaVista
Northern Light
LycosJul-98

Information Retrieval on the Web – Page 49
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199897
Systems Research Center
Open problems
l Random page generation via random walksl Better “sampling via queries” methodl Cryptography based approach: want random pages
from each engine but no cheating! (page should bechosen u.a.r. from the actual index)– Each search engine can commit to the set of pages it
has without revealing it– Need to ensure that this set is the same as the set
actually indexed– Need efficient oblivious protocol to obtain random
page from search engine– See [NP‘98] for possible solution
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199898
Systems Research Center
How often do people view a page?
l Problems:– Web caches interfere with click counting– cheating pays (advertisers pay by the click)
l Solutions:– naïve: forces caches to re-fetch for every click.
• Lots of traffic, annoyed Web users– extend HTML with counters [ML’97]
• requires compliance, down caches falsify results.– use sampling [P’97]
• force refetches on random days• force refetches for random users and IP addresses
– cryptographic audit bureaus [NP’98a]l Commercial providers: 100hot, Media Matrix, Relevant
Knowledge, …

Information Retrieval on the Web – Page 50
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,199899
Systems Research Center
Query Log Statistics [SHMM’98]
request = new queries or new result screen of old querysession = a series of requests by one user close together
in timel analyzed ~1B AltaVista requests consisting of:
– ~840 000 000 non-empty requests– ~575 000 000 non-empty queries– ~153 000 000 unique non-empty queries– ~285 000 000 user sessions
l average number of terms: 2.35 (max 393)l average number of operators: 0.41l 78% of sessions -- only 1 query askedl 64% of queries occur only once
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998100
Systems Research Center
Lots of things we didn’t eventouch...
l Clustering = group similar items (documents or queries)together ↔ unsupervised learning
l Categorization = assign items to predefined categories↔ supervised learning
l Classic IR issues that are not substantially different inthe Web context:– Latent semantic indexing -- associate “concepts” to
queries and documents and match on concepts– Summarization: abstract the most important parts of
text content. (See [TS’98] for the Web context)l Many others …

Information Retrieval on the Web – Page 51
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998101
Systems Research Center
Final conclusionsl We talked mostly about IR methods and tools that
– take advantage of the Web particularities– mitigate some of the difficulties
l Web IR offers plenty of interesting problems… … but not on a silver platterl Almost every area of algorithms research is relevant:
l Great need for algorithms engineering
data structures
random walks
learning
stringology
cryptography
compression
graph algorithm
external memoryalgorithms
on-linescheduling
load balancing
etc
A. Broder & M. Henzinger FOCS 98 Tutorial: Information Retrieval on the Web
November 8,1998102
Systems Research Center
Thanks!
l Krishna Bharat
l Moses Charikar
l Edith Cohen
l Jeff Dean
l Uri Feige
l Puneet Kumar
l Hannes Marais
l Michael Mitzenmacher
l Prabhakar Raghavan
l Lyle Ramshaw























