Embed Size (px)
Citation preview

R.Marti
6 Text-basiertesInformationRetrieval
Informationssysteme für Ingenieure (ISI)
Herbstsemester 2016

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 2
ZieldesKapitels
• KenntnisderMethodenzumAuffindenrelevanterText-DokumenteineinergrossenSammlungvonText-DokumentenaufgrundeinesInformationsbedürfnisses,d.h.,einerAnfrage,diemeistnurdurchAngabeeinigerwenigerWortegestelltwird.
Dazugehörenetwa:– AufbaueinerIndex-Struktur(ausEffizienzgründen)
– BehandlungvonSynonymen
– BehandlungverschiedenerFlexionsformenvonWorten
– RangierungderAntwortengemässeinemGütekriterium
GrundfürdieVermittlungdiesesStoffs
• DerEinbezugunstrukturierterDatenwirdimmerwichtiger– EsgibtdeutlichmehrunstrukturierteDatenalsstrukturierteDaten,
undausunstrukturiertenDatenkönnenzusätzlicheErkenntissegewonnenwerden.DiesisteinerderwesentlichenFaktorenfürdiemomentane"BigData"Hysterie.

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 3
StrukturierteundunstrukturierteDaten
• strukturierteDatenDatenineinerfestvorgegebenenStruktur,demSchema,welchesdieDatenbeschreibt.DerSchema-EntwurferfordertvorgängigeAnalyse.➛ relationale(undobjektorientierte)Datenbanken
• unstrukturierteDatenDaten,diekeineexpliziteStrukturbesitzen,d.h.vorgängignichtinhaltlichanalysiertwurden.(EsgibtimpliziteStrukturen– z.B.GrammatikregelnnatürlicherSprachefürText,MengevonPixelnu.ä.fürMultimedia)➛ Unicode/ASCII Text,weitereText-Formate(z.B.Word,RTF,evt.PDF) ; Bitmaps,mitTextund/oderBildern(FormatewieJPEG,GIF,TIFF,evt.PDF);
Audio-Dateien(MP3,WAV,…);FilmealsSequenzenvonBitmaps
• semi-strukturierteDatenDaten,dieteilweiseirregulärebzw.unvollständigeStrukturenaufweisen,diesichöftersundaufunvorhersehbareArtändernkönnen.EinSchemakannevt.ausspeziellenAnnotationenindenDaten(sog."markup")synthetisiertwerden.➛ XMLDatensammlungen (siehespäter)

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 4
Wasist InformationRetieval?
DefinitionausChristopherD.Manning,Prabhakar Raghavan,HinrichSchütze,Introduction to InformationRetrieval,CambridgeUniversityPress.2008
sieheauch:http://nlp.stanford.edu/IR-book/
Informationretrieval(IR) isfinding material(usuallydocuments)
ofanunstructured nature(usuallytext)thatsatisfiesaninformation
need fromwithinlargecollections (usuallystoredoncomputers).
Beispielvon"sound-based"InformationRetrieval:shazam– ErkennenvonMusikStücken

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 5
GeschichtlicheEntwicklung
• AnfängedesText-basiertenIRinspäten50-erJahren(IBM,Rand,Lockheed),G.Salton (Cornell)inden60-erJahren
• UrsprünglichprimärfürBibliothekareund"Informationsspezialisten":AuffindennützlicherDokumentein(homogener)Dokumentensammlung
– Bibliotheken
– Gesetzessammlungen
– SammlungenvonFachartikeln(z.B.inMedizin,Chemie,Rechtusw.)
• neueForschungsimpulsedieEntwicklungdesWorldWide Web
– Hypertext/Hypermedia(WebseitenalsKnoten,LinksalsKanteneinesGraphs)
– grosseMengevonsehrheterogenenDokumenten(bezügl.Grösse,Fachgebiet,Qualität,Sprache,geographischerVerteilung)
• DigitalLibraries:Scanning derBücherbestehenderBibliotheken
• NeuereAnwendungen:EntdeckenvonDuplikaten,Plagiaten

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 6
Datenbanksystemevs.InformationRetrievalSysteme
Datenbank-Anfragen InformationRetrieval
gewünschteObjekte(Datensätze) gewünschteObjekte(Dokumente)exaktspezifiziert vagespezifiziert
meistreicht eineeinzigeAnfrage oftmehrere Anfragen(z.B.sukzessivesEinengen)
Antwort:vollständigeMenge Antwort:RanglistederallerResultate(Datensätze) wichtigstenResultate(Dokumente)
ModifikationderDatenbank ModifikationderDokumentsammlung
potentiell häufig tendentiellseltenhoch-paralleleINSERTs,UPDATEs, periodischesHinzufügen("append")DELETEs[nebenLesen(SELECTs)] [nebenLesen]

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 7
Fokus:Text
• imfolgendenbeschränkenwirunsaufSucheinText-Dokumenten,allenfallsmitFormatierungoderanderenMetadaten(Markup)versehen
• ungefährerPlatzbedarffür1A4SeiteText- alsBitmap ~8400KByte(beiAuflösungvon300dpi)- alskomprimierteBitmap ~100KByte- alsUnicode/ASCII-Text 3– 10KByte
• Text,derinFormvonBitmapsvorliegt,musszuerstmitOCR(Optical Character Recognition)Methodenerkanntwerden
• eingebetteteBilder(Vektorgraphik,Bitmaps)werdenignoriertkönntenmitMetadaten – Daten,dieDatenbeschreiben– gefundenwerden

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 8
Boole'schesModell
Boole'sches RetrievalaufeinerDokumentsammlung D
• AnfragenMengevonWörtern (bzw.Termen)T
• AntwortenDieTeilmengeR derMengeallerDokumente D,inwelchenalleTerme derAnfrageT (mindestenseinmal)vorkommen
• BeispielAnfrage:T = { 'Brutus' ,'Caesar' }Dokumentsammlung D :DieWerkevonShakespeare
• MöglicheLösung (sofern jedes Werk inseparater Datei):Dateiennach Zeichenketten 'Brutus' und'Caesar' absuchen,danach Werkezurückgeben,indenen diebeiden Begriffe vorkommen.BeigrossenDokumentsammlungenundgrossenDokumentenlangsam.
adapted from C. Manning CS276A Course

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti
'Antho
ny&Cleop
atra'
'Juliu
sCaesar'
'The
Tem
pest'
'Ham
let'
'Othello'
...
ç Dokumente
'Anthony' 1 1 0 0 0 ...
'Brutus' 1 1 0 1 0 ...
'Caesar' 1 1 0 1 1 ...
'Calpurnia' 0 1 0 0 0 ...
'Cleopatra' 1 0 0 0 0 ...
... ... ... ... ... ... ...
é
Terme
9
HilfsstrukturzurBeschleunigungvonIRAnfragen
© C. Manning CS276A Course
Term-DokumentMatrix
1 fallsdasDokument denTerm enthält(z.B.'Julius Caesar' enthält 'Calpurnia'),
0 sonst

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti
'Antho
ny&Cleop
atra'
'Juliu
sCaesar'
'The
Tem
pest'
'Ham
let'
'Othello'
...
'Anthony' 1 1 0 0 0 ...
'Brutus' 1 1 0 1 0 ... ç BitVektor
'Caesar' 1 1 0 1 1 ... ç BitVektor
'Calpurnia' 0 1 0 0 0 ...
'Cleopatra' 1 0 0 0 0 ...
... ... ... ... ... ... ...
é é é
Res. Res. Res.
10
BestimmenderResultat-DokumenteviaHilfsstruktur
© C. Manning CS276A Course
Term-DokumentMatrix Anfrage
• Dokumente,welchedieTerme'Brutus' und'Caesar' enthalten
Resultat
• logischesand derBit-Vektorenfür'Brutus','Caesar'
• 11010 and 11011 =11010.
• Resultat-Dokumente:- 'Anthony&Cleopatra'- 'JuliusCaesar'- 'Hamlet'

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 11
Finden relevanter Textstellen inResultat-Dokumenten
'Antony and Cleopatra' Act III, Scene iiAgrippa [Aside to DOMITIUS ENOBARBUS]:
Why, Enobarbus,When Antony found Julius Caesar dead,He cried almost to roaring; and he weptWhen at Philippi he found Brutus slain.
'Hamlet' Act III, Scene iiLord Polonius:
I did enact Julius Caesar I was killed i' the Capitol;Brutus killed me.
© C. Manning CS276A Course

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 12
ProblememitgrossenTextsammlungen:GrössederMatrix
• Annahmen
– 1MioDokumente,mit jeca.1000Termen,total1Mia(109)Terme
– durchschnittl.6Zeichen (Byte)proTerm(inkl.Leerzeichen &Interpunktion)ergibt ca.6GByte für ganze Sammlung
– 500'000 verschiedene Terme unter den1MiaTermen
• Problem
– 500'000× 1'000'000 Matrixhat5·1011 Positionen
– nur 1Mia(109)Positionen haben eine 1als EintragÞMatrixsehr dünn besiedelt
• Bessere Repräsentation
– Speichere Positionen,dieeine 1habensog.invertierter Index
© C. Manning CS276A Course

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti
proTermt :
speicherestatt Bit-Vektor
ListederDocIDs(Nummern der Dokumente),indenen derTermt vorkommt
Invertierter Index
Brutus 1 2 4 …
Caesar 1 2 4 5 …
Calpurnia 2 …
Invertierter Index(Beispiel)
ß im Mittel ca 8kByte
total1MiaTerme500'000verschiedeneTerme4Byte(=32bit)proDocId
13
'Antho
ny&Cleop
atra'
'Juliu
sCaesar'
'The
Tem
pest'
'Ham
let'
'Othello'
...
çDokumente(1'000'000Stk)
1 2 3 4 5 ... ç DocID
'Brutus' 1 1 0 1 0 ...
'Caesar' 1 1 0 1 1 ... LängeBit-Vektor:
'Calpurnia' 0 1 0 0 0 ... ca.122kByte
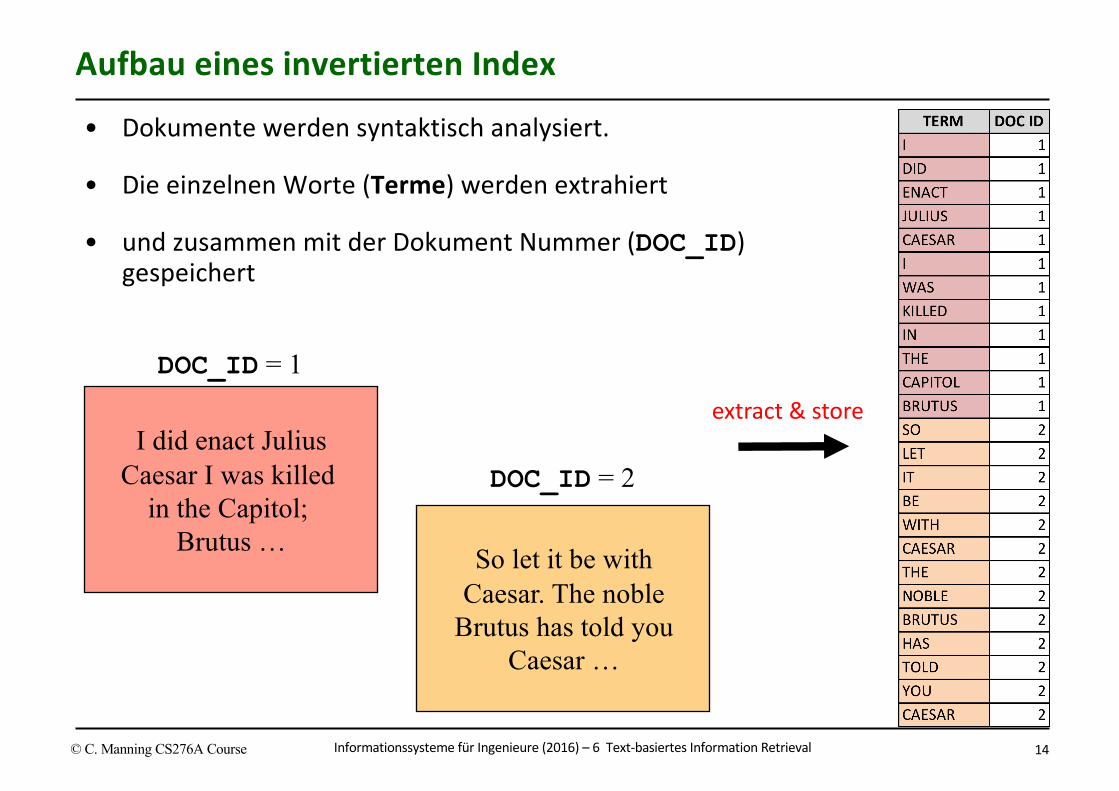
InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 14
• Dokumentewerdensyntaktischanalysiert.
• DieeinzelnenWorte(Terme)werdenextrahiert
• undzusammenmitderDokumentNummer(DOC_ID)gespeichert
I did enact JuliusCaesar I was killed
in the Capitol; Brutus …
DOC_ID = 1
So let it be withCaesar. The noble
Brutus has told youCaesar …
DOC_ID = 2
AufbaueinesinvertiertenIndex
© C. Manning CS276A Course
extract&store
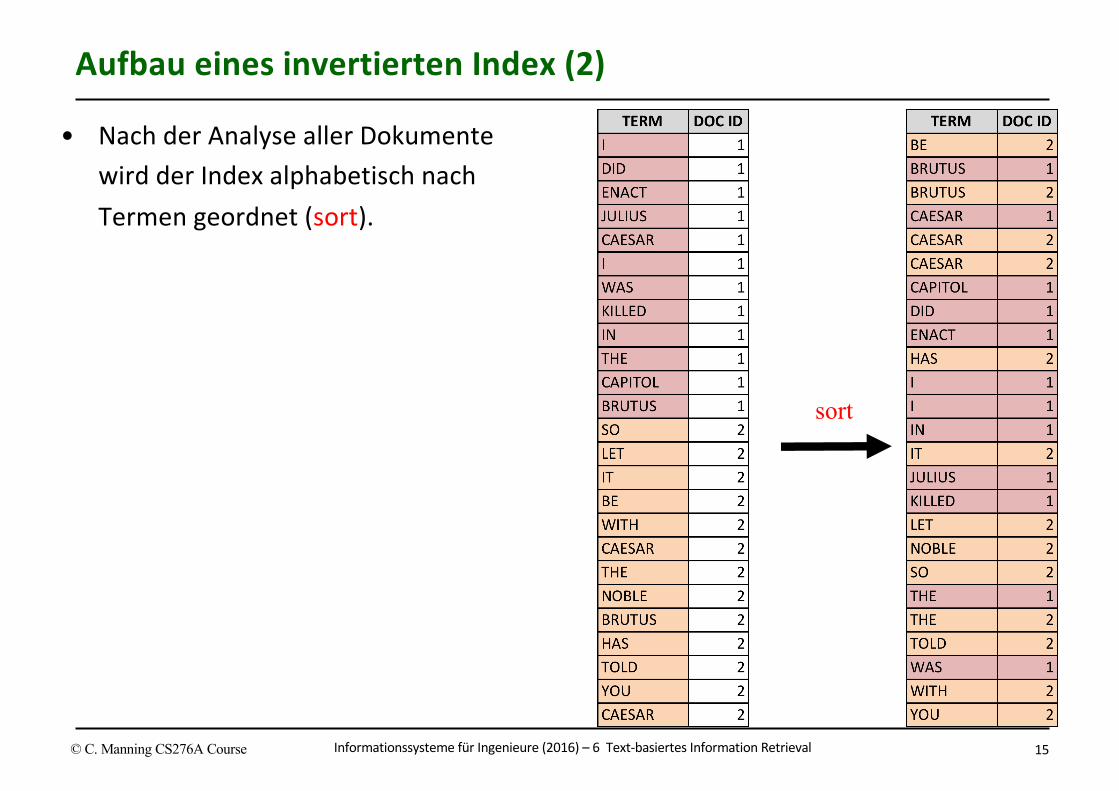
InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 15
• NachderAnalyseallerDokumentewirdderIndexalphabetischnachTermengeordnet(sort).
AufbaueinesinvertiertenIndex(2)
© C. Manning CS276A Course
sort

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 16
• Mehrfach-Einträge eines Termsim gleichen Dokument werdenverschmolzen (merge)undmitihrer HäufigkeitimjeweiligenDokument(derTermFrequency,TF)versehen.
AufbaueinesinvertiertenIndex(3)
© C. Manning CS276A Course
merge

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 17
• DieDaten werden normalerweiseaufgeteilt
• ineinen Dictionary,wennmöglichimHauptspeicher,mitDocumentFrequency(DF)(AnzahlDoksindenenTermvorkommt)undeinerListevonDoc_IDs(DOCS)
• inPostings,meistaufDiskmitStartpositionenderTerme(FST_POS)
AufbaueinesinvertiertenIndex(4)
© C. Manning CS276A Course

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 18
VorteilederIndexierung
• IndexierungerlaubteffizientesSuchenvonDokumentenmitpassendenTermen
• OperatorenAND,OR undNOT könnendirektausDictionaryabgelesenwerden(stattBit-weiseOperationenaufBit-VektoreninTerm-DokumentMatrix)
• EinOperator NEAR (Term1 NEAR Term2)kannmitHilfederPositionenimDokumentrealisiertwerden

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 19
ProblememitBool’schemRetrieval
Probleme
• dieAntwortmengeistnichtgemäss(geschätzter)RelevanzgeordnetsondernnacheinemKriteriumwiePublikationsdatum(odersogargarnicht)
• alleTermeeinerFragewerdengleichgewichtet,obwohlinvielenFälleneinzelneTermebesserdiskriminierenalsandere
Þ Entwicklungdessog.Vektorraum-Modells(folgendeSeiten)sowieanderer,z.B.probabilistischer,Modelle

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 20
Vektorraummodell:RankingderResultate
Grundidee
Gegeben
• N Textdokumente,jedesdurcheinenVektordj (1 £ j £ N) repräsentiert
• Anfrageq einesBenutzers,ebenfallsdurcheinenVektorrepräsentiert
Gesucht
• geordneteListe(rankedlist)vonk Dokumentendj (1 £ j £ k £ N),welchedieAnfrageq "möglichstgut"erfüllen.
FürdasRankingeinerAntwortdj bezüglicheinerAnfrageq wirdeineÄhnlichkeit(similarity)desDokuments dj zurAnfrage q, sim(q, dj) ,berechnet.

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 21
Dokument- undAnfrage-Vektoren
EinDokumentmitDOC_ID j wirddurcheinenVektordj = < d1 j , d2 j , ... , dM, j > repräsentiert,wobei
• Indexi ,1 £ i £ M füreineninderDokumenten-SammlungvorkommendenTermsteht,
• Wertdi j füreinGewichtdesTermsi imDokumentmitDOC_ID j steht,z.B.derTerm-FrequenzdesTermsi imDokumentmitDOC_ID j .
EineAnfrage,bestehendauseinigenbekannten(allenfallsauchunbekannten)TermenwirdebenfallsalsDokumentaufgefasst,wobeifürdenVektorq = < q1 , q2 , ... , qM , ... >üblicherweisegilt:
• Wertqi = 1 fallsderTermi inderAnfragevorkommt,und0 sonst

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 22
Dokument- undAnfrage-Vektoren(Beispiel)
Dokumente (d1, d2)
• 'Anthony & Cleopatra' (DOC_ID = 1)
• 'Julius Caesar' (DOC_ID = 2)
Anfrage q
• { 'Brutus', 'Caesar' }

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 23
DokumenteimVektorraum(Beispiel)
©[Manning&Schütze1999](Fig.15.3)
d1: 7 × CAR, 1 × INSURANCE
Koordinaten: 71
CAR
INSURANCE
d2: 1 × CAR, 7 × INSURANCE
Koordinaten: 17
d3: 4 × CAR, 3 × INSURANCE
Koordinaten: 43
d4: 8 × CAR, 6 × INSURANCE
Koordinaten: 86d1
d2
d3
d4
1
1

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 24
ÄhnlichkeitvonDokumentvektoren
MassfürÄhnlichkeit zweierVektorenimn-dimensionalenRaum
CosinusdesWinkelszwischenAnfrageq undDokumentdj
wobeiqi bzw.dij dieHäufigkeitdesTermsi inderAnfrageq bzw.imDokumentdj repräsentieren(diesog.termfrequency,dij := tfij)
åå
å
==
=
×
=×
×==
n
iij
n
ii
n
iiji
dq
dqsim
1
2
1
2
1),cos(:),(j
jjj dq
dqdqdq

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 25
ÄhnlichkeitvonDokumentenzuAnfrage(Beispiel)
©[Manning&Schütze1999](Fig.15.3)
CAR
INSURANCE
q d1
d2
d3
d4
11q =
71d1 =
17d2 =
43d3 =
86d4 =
Anfrage:‘CARINSURANCE’
1
dij := tfij
1

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 26
DämpfungderTerm-Gewichtung
• Erfahrung:n-facheHäufigkeiteinesTermsi ineinemDokumentj(tfij = n)erhöhtRelevanzdesTermszwar,abernichtumFaktorn
Þ Term-Frequenztfij wirdgedämpft,z.B.ineinerderfolgenden3Arten
(1)
wij := (2)
(3)
dij := wij
îíì
=>+)0(0)0(log1
ij
ijij
tftftf
)1log( ijtf+
ijtf
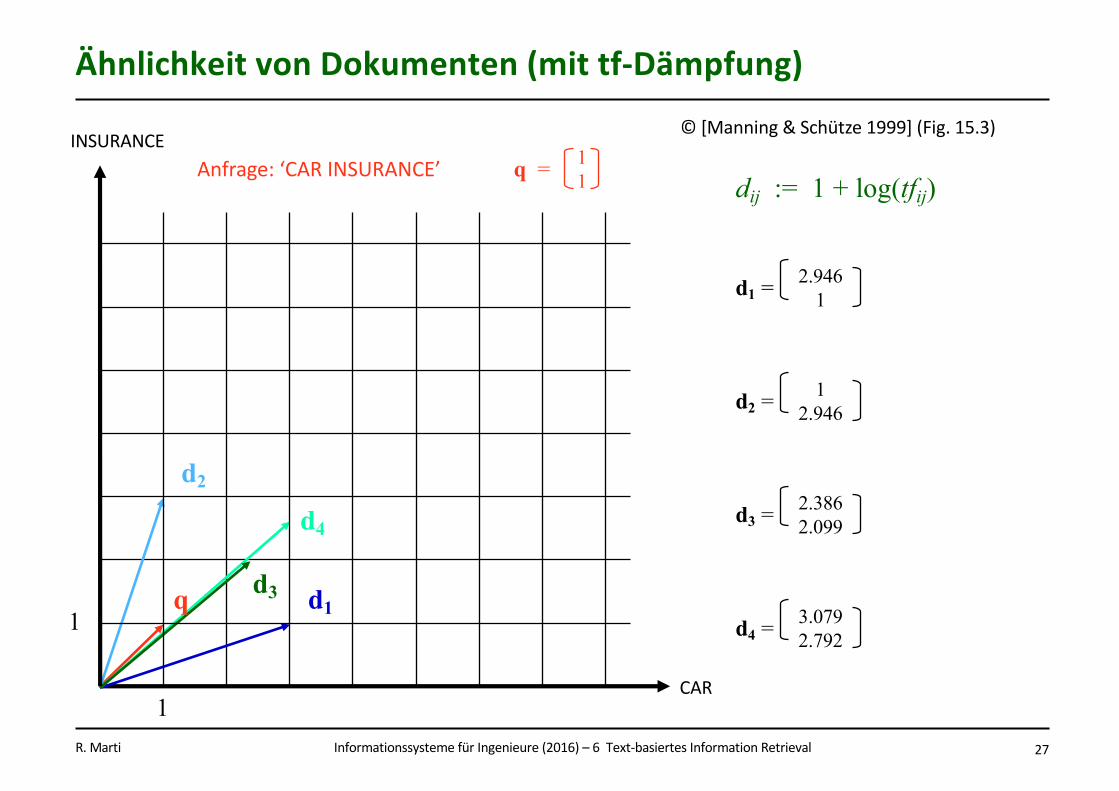
InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 27
ÄhnlichkeitvonDokumenten(mittf-Dämpfung)
©[Manning&Schütze1999](Fig.15.3)
q d1
d2
d3
d4
2.9461d1 =
12.946d2 =
2.3862.099d3 =
3.0792.792d4 =
dij := 1 + log(tfij)
1
1CAR
INSURANCE11q =Anfrage:‘CARINSURANCE’

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 28
Term-GewichtungmitInverseDocumentFrequency
• ZusätzlicheIdee:EinTerm,derinwenigenDokumentenvorkommt,"diskriminiertbesser",d.h.,einsolcherTermsollteeinhöheresGewichtbekommenÞ MultiplikationdesTermgewichtsmitdersog.inversedocumentfrequency(idf)
N + 1idfi := log ¾¾¾
dfi + 1N:totaleAnzahlDokumente;dfi:AnzahlDokumentemitTermi
dij := wij · idfi
0 20 40 60 80 1000
1
2
3
4
df
idfi
dfi
idfi in Abhängigkeit von dfi
(Annahme: totale Anzahl Dokumente N = 100)
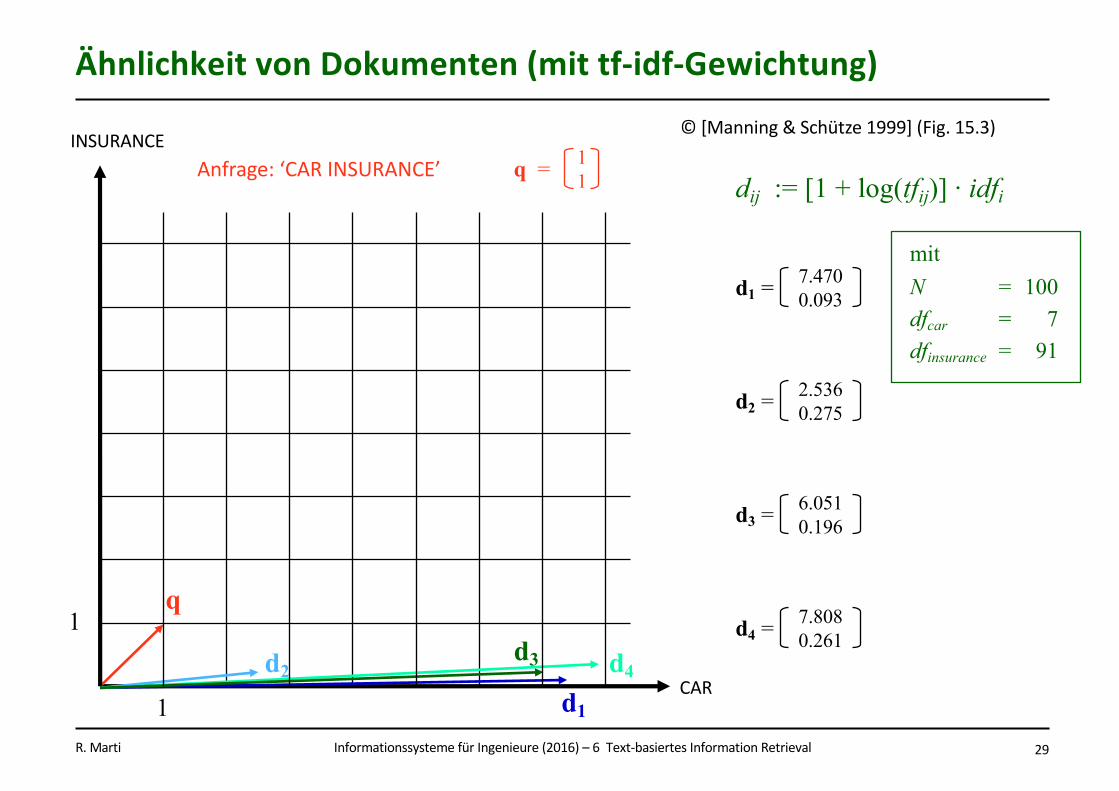
InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 29
ÄhnlichkeitvonDokumenten(mittf-idf-Gewichtung)
©[Manning&Schütze1999](Fig.15.3)
q
d1
d2d3 d4
7.4700.093d1 =
2.5360.275d2 =
6.0510.196d3 =
7.8080.261d4 =
dij := [1 + log(tfij)] · idfi
mitN = 100dfcar = 7dfinsurance = 91
1
1CAR
INSURANCE11q =Anfrage:‘CARINSURANCE’

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 30
Mögliches Preprocessing:Ebenen der Sprachverarbeitung
Ebenen Methoden,dieinIRverwendetwerden
1. phonetischeEbeneKlangeinzelnerBuchstaben/Silben(Phoneme)
2. phonologischeEbeneZusammensetzungvonPhonemenzuWörtern
3. lexikalischeEbene à spellchecking,MengederWörterinSprache(Vokabular,Lexikon) stopwordremoval,
synonymexpansion
4. morphologischeEbene à stemmingFlexionen,Vor- &Nachsilben,Zusammensetzungen
5. syntaktischeEbeneZusammensetzungvonWörternzuSätzen(Grammatik)
6. semantischeEbeneBedeutungvonWörternundSätzen

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 31
EliminationvonStopwörtern
Stopwort
• Wort,dasausdemVokabularfürdieIndizierungentferntwird.
• TypischerweiseWörtermitgeringerAussagekraft.Die200–300häufigstenWörterineinerKollektionvonDokumentensindmeistens(abernichtimmer)solchemitgeringerAussagekraft.
• AngenehmerNebeneffekt(vgl.folgendeSeite):DieEliminationvonStopwörternmachtdasRetrievaleffizienterdaDictionary undPostings Filekleinerwerden.
• AsmallstoplistforEnglish
a also an and as at be but by can could do for from go have he her here his how i if in into it its my of on or our say she that the their there therefore they this these those through to until we what when where which while who with would you your

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 32
InvertierterIndexohneStopwörter
© C. Manning CS276A Course
removestopwords

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 33
GesetzvonZipf
Seif dieHäufigkeiteinesWortsineinemText,r die„Rangierung“desWortsgemässHäufigkeit.
Danngilt f ~ (1/r) bzw.f · r = k (k eineKonstante)
Beispiel„TomSawyer“: Word f r f · rthe 3332 1 3332and 2972 2 5944a 1775 3 5235he 877 10 8770but 410 20 8400there 222 40 8880about 158 60 9480never 124 80 9920two 104 100 10400turned 51 200 10200name 21 400 8400group 13 600 7800friends 10 800 8000family 8 1000 8000brushed 4 2000 8000

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 34
GesetzvonZipf:Beispiel“Browncorpus”
©[Manning&Schütze1999](Fig.1.1)

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 35
ThesauriundSynonym-Expansion
• TermeinderAnfragekönnenverschiedenvonTermeninDokumentensein,obwohlsiedasgleiche(odereinähnliches)Konzeptbezeichnen
• Beispiel(adaptiertvon[Jackson&Moulinier 2002]):- Anfrage:„seller of complete e-mail solutions for cell phones“- Dokument:„Gizmotron is a leading vendor of comprehensive electronicmessaging services for mobile devices“
• möglicheLösung:- VerwendungeinesThesaurus,derfürjedenTermSynonymesowieallgemeinere undspeziellereTermeenthält- beiAnfragewerdenautomatischSynonymeundevt.weitereTermehinzugefügt
• Problem:zwarwerdenoftmehrDokumentezurückgeliefert(bessere➛Ausbeute),darunteraberauchetlichefalsche(schlechtere➛Präzision),weilz.B.- device einÜberbegriff vonphone ist- cell etlicheandereBedeutungenhat(Gefängniszelle,Keimzelle)

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 36
"SpellChecking"etc.
• HinzufügenvonähnlichenSchreibweisen derTermeinderAnfrage,z.B.alleTermemiteinerEditier-Distanz£ 2
Editier- bzw.Levenshtein-Distanzzwischen2Stringss undt:AnzahlderZeichen,dieinStrings eingefügt,gelöschtoderüberschriebenwerdenmüssen,umdenStringt zuerhalten
• Soundex-Algorithmus(insbesonderefürNamen):AbbildeneinesStringsaufeinen“charakteristischen”4-ZeichenString
• Wildcards/RegularExpressions

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 37
RückführungaufdenWortstamm(Stemming)
• vieleWörterexistiereninverschiedenenFlexionsformen,z.B.- Substantive:Singular/Plural,Deklination- Verben:Singular/Plural,Konjugation,Zeitformen,Partizipformen- AdjektiveundAdverben:Steigerungsformen
• Wortreduktion(RückführungaufWortstamm,engl.Stemming)verbessertdie➛ Ausbeute(s.spätereFolienzumThema"MessungderEffektivitätvonIRMethoden")
Beispiel:
• Anfrage:“hash functions using dynamic hash tables.”
• Dokument:“W. Litwin: Linear Hashing: A New Tool for File and Table Addressing. Linear hashing is a hashing in which the address space may grow and shrink dynamically. A file or table may then support any number of insertions and deletions without access or memory load performance deterioration.”

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 38
Porter’sStemmingAlgorithmus: Definitionen
• KonsonantBuchstaben ausser A,E,I,OundUsowie Ynach einem Konsonanten(inTOYist Ydemnach ein Konsonant,inLOVELYein Vokal)
• Vokal:Buchstabe,der kein Konsonant ist
• Notation:c steht für Konsonant,c für nichtleere Folge vonKonsonantenv steht für Vokal,v für nichtleere Folge vonVokalen
• Jedes Wort hatdemnach eine der folgenden Formen:cvcv ...ccvcv ... vvcvc ... cvcvc ... v
• abgekürzte Form[c]vcvc ...[v]bzw.[c](vc)m[v].
Grossbuchstaben stehen für sich selbst
Kleinbuchstaben stehen für Klassen von Buchstaben
Achtung:Der Porter-Algorithmusproduziert nicht immerkorrekte Wortstämme

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 39
PorterAlgorithmus:Grundidee,Notation
• EliminationvonSuffixenwirdinRegelnfolgenderFormangegeben:(condition)S1 ® S2.
• Bedeutung:Falls
– WortmitSuffixS1 endet
– WortstammvorS1 Bedingungcondition erfüllt
dannwirdS1 durchS2 ersetzt.
• BedingungwirdoftmitAnzahlVokal-Konsonant-Folgen (m)ausgedrückt,z.B.(m >0)EMENT ® e. (e stehtfürdenleerenString)
MitdieserRegelwirdz.B.REPLACEMENT aufREPLACabgebildet(m =2).
• WeiteremöglicheBedingungensinddiefolgenden:
– (*S) WortstammendetmitdemStringS
– (*v*) WortstammenthälteinenVokal
– (*o) Wortstammendetmitcvc,wobeiderzweiteKonsonantc Ï {W,X,Y}
– (*d) WortstammendetmitzweiidentischenKonsonanten

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 40
PorterAlgorithmus– Schritt1:Plurale,Partizipien• 1a SSES® SS caresses® caress
IES® I ponies® ponities® ti
SS® SS caress® caressS®e cats® cat
• 1b (m>0)EED® EE feed® feedagreed® agree
(*v*)ED®e plastered® plasterbled® bled
(*v*)ING®e motoring®motorsing® sing
• Ifsecondorthirdoftherulesin1bissuccessful,thefollowingisdone:AT® ATE conflat(ed)® conflateBL® BLE troubl(ed)® troubleIZ® IZE siz(ed)® size(*dandnot(*Lor*Sor*Z))® singleletter hopp(ing)® hop
tann(ed)® tanfall(ing)® fallhiss(ing)® hissfizz(ed)® fizz
(m=1and*o)® E fail(ing)® failfil(ing)® file
• 1c (*v*)Y® I happy® happisky® sky

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 41
PorterAlgorithmus– Schritt2
• 2 (m>0)ATIONAL® ATE relational® relate(m>0)TIONAL® TION conditional® condition
rational® rational(m>0)ENCI® ENCE valenci® valence(m>0)ANCI® ANCE hesitanci® hesitance(m>0)IZER® IZE digitizer® digitize(m>0)ABLI® ABLE conformabli® conformable(m>0)ALLI® AL radicalli® radical(m>0)ENTLI® ENT differentli® different(m>0)ELI® E vileli® vile(m>0)OUSLI® OUS analogousli® analogous(m>0)IZATION® IZE vietnamization® vietnamize(m>0)ATION® ATE predication® predicate(m>0)ATOR® ATE operator® operate(m>0)ALISM® AL feudalism® feudal(m>0)IVENESS® IVE decisiveness® decisive(m>0)FULNESS® FUL hopefulness® hopeful(m>0)OUSNESS® OUS callousness® callous(m>0)ALITI® AL formaliti® formal(m>0)IVITI® IVE sensitiviti® sensitive(m>0)BILITI® BLE sensibiliti® sensible

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 42
PorterAlgorithmus– Schritte3und4• 3 (m>0)ICATE® IC triplicate® triplic
(m>0)ATIVE® formative® form(m>0)ALIZE® AL formalize® formal(m>0)ICITI® IC electriciti® electric(m>0)ICAL® IC electrical® electric(m>0)FUL®e hopeful® hope(m>0)NESS®e goodness® good
• 4 (m>1)AL®e revival® reviv(m>1)ANCE®e allowance® allow(m>1)ENCE®e inference® infer(m>1)ER®e airliner® airlin(m>1)IC®e gyroscopic® gyroscop(m>1)ABLE®e adjustable® adjust(m>1)IBLE®e defensible® defens(m>1)ANT®e irritant® irrit(m>1)EMENT®e replacement® replac(m>1)MENT®e adjustment® adjust(m>1)ENT®e dependent® depend(m>1and(*Sor*T))ION®e adoption® adopt(m>1)OU®e homologou® homolog(m>1)ISM®e communism® commun(m>1)ATE®e activate® activ(m>1)ITI®e angulariti® angular(m>1)OUS®e homologous® homolog(m>1)IVE®e effective® effect(m>1)IZE®e bowdlerize® bowdler

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 43
PorterAlgorithmus– Schritt5sowieeinigeBeispiele
• 5a (m>1)E®e probate® probatrate® rate
(m=1andnot*o)E®e cease® ceas
• 5b (m >1and*dand*L)® singleletter controll® controlroll® roll
• DerAlgorithmusistbestrebt,einSuffixnichtzueliminieren,fallsderverbleibendeWortstammzukurzwird.DieLängedesWorstammswirddurchdasMassm ausgedrückt.DafürgibteskeinelinguistischeBasis.Eswurdeeinfachgestgestellt,dassdasMassm einguterIndikatordafürist,obeinSuffixeliminiertwerdensollodernicht..
• KomplexeSuffixewerdenSchrittumSchritteliminiertGENERALIZATIONS ® GENERALIZATION(Schritt1),
® GENERALIZE(Schritt2),® GENERAL(Schritt3),® GENER(Schritt4).
• OSCILLATORS ® OSCILLATOR(Schritt1),® OSCILLATE(Schritt2),® OSCILL(Schritt4),® OSCIL(Schritt5).

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 44
EffektivitätvonInformationRetrievalMethoden
• Basis:RelevanzvonDokumentenbezüglichmehrererAnfragen.
FüreinebestimmteAnfrageq werdenfolgendeMengendefiniert:
Aq : DieMengedervonderAnfrageq gefundenenDokumente.
Rq : DieMengeallerrelevantenDokumenteinderDokumenten-SammlungD bezüglichderAnfrageq .
• Problem:BestimmungvonRq ,d.h.derjenigenDokumentedj∈ D ,diebezüglichAnfrageq relevantsind(insbesonderewenndj ∉ Aq )?⇒ Test-Kollektion,mitbekanntenDokumentenundbekanntenAnfragen
Aq Rq
D
⊕⊕⊖
⊖
⊕ True Positive
⊕ False Positive
⊖ True Negative
⊖ False Negative

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 45
TraditionelleMassefürEffektivität vonIR-Methoden
• Ausbeute (recall)fürAnfrageq :
DieAusbeuteistderQuotientderAnzahlgefundenerrelevanterDokumentezurAnzahlallerrelevanten Dokumente.
• Präzision (precision)fürAnfrageq :
DiePräzisionistderQuotientderAnzahlgefundenerrelevanterDokumentezurAnzahldergefundenen Dokumente.
• EineAusbeutevon1istleichtzuerreichen.- Wie?- WasbedeutetdasfürdiePräzision?
Aq∩RqRq
Aq∩RqAq

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 46
Precision-RecallDiagramme

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 47
ÄhnlicheDokumentebzw.Texte
• ManchmalsollennichtnotwendigerweiseinhaltlichähnlicheDokumentegefundenwerden(semantischeÄhnlichkeit),sondernreintextuellähnlicheDokumente(VorkommenähnlicherTextkettenbzw.Strings).
• PlagiateTexte(Informations-Artikel,Bücher,wissenschaftlicheArbieten),indenensubstantielleTeileauseinem(odermehreren)anderenTextenstammen(ohnedassdiesdurchZitateoffengelegtwurde).
• VariantenvonWebSeiten(MirrorPages)WebPagespopulärerSiteswerdenteilweiserepliziert("gespiegelt"),umdenLoadaufverschiedeneServerszuverteilen.
• Entity Resolution(auchDeduplikation)EinProzessumzubestimmen,obverschiedeneReferenzenaufEntitätenderrealenWeltdasgleicheObjektbezeichnen,oderverschiedene.EinesolcheReferenzaufeineEntitätbestehtauseinemStringineinemDokumentoderauseinerMengevonAttributwerten(vgl.SchlüsselkandidatinrelationalenDBs).

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 48
Deduplikation:EntdeckungvonDuplikaten
• EntdeckungvonDuplikaten(DuplicateDetection,auchFuzzy Matching,Approximate Matching)entscheidet,obzweiverschiedeneaberähnlicheDaten-Repräsentationen einerEntitätderrealenWeltalsäquivalentbetrachtetwerdensollten.
• Ingredienzen:
• MessenderÄhnlichkeitvon (oderallenfallsderDistanzzwischen)zweiDaten-Repräsentationen,mitSchwellwert,derdie Gleichheitzweier Repräsentationenakzeptiert oder verwirft⇒ Effektivität
• Algorithmus,umingrossemDatenvolumenDuplikate zuentdecken⇒ Effizienz
• KombinationderverschiedenenDaten-Repräsentationen vonDuplikatenineineeinzige"kanonische"Daten-Repräsentation
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 49
GründefürAuftretenvonDuplikaten
• DuplikateinnerhalbeinerDatenquelle (Datenbank,Dok.Sammlung)
• unbeabsichtigteTippfehler
• schwierigeWörter(Eigennnamen)/fehlendeOrthographie-Kenntnisse
• falschausgesprochene/verstandeneWörter
• FehlerinOutputvonOCR(OpticalCharacter Recognition)Software
• verschiedeneZeitpunktederEingabe(etwabeiNamensänderungen)
• Duplikate,dieausverschiedenenDatenquellenstammen
• verschiedeneDB-Schemas,Format-Konventionen,Datenbedüfrnisse,Formulierungen
• verschiedene Zeitpunkte der Eingabe(etwabeiNamensänderungen)
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 50
TypischeAnwendungenfürDeduplikaten
• CustomerDataIntegration(CDI)als Basis fürCustomerRelationshipManagement(CRM)
• GrosseFirmenhabenoft verschiedeneVerkaufskanäle,e.g.physischeFilialen,Online Verkauf(WebSite),Telefon- unde-mail Hotlines.
• VerkäufesowieReklamationen,RückvergütungenetcüberdieseKanälemüssendemrichtigenKundenzugewiesenwerden,umderenProfitabilitätundKaufgewohnheitenzuanalysieren.
• WisenschaftlicheDatenbanken
• WissenschaftlicheExperimente /Beobachtungen generierengrosseDatenmengen (z.B.HumanGenome Project,Umwelt-Forschung,Astronomie).
• DieAggregationvonMessungenausverschiedenenQuellenhilft,dieWiederholungteurerExperimentezureduzieren/vermeiden.
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 51
Deduplikation:EinBeispiel
• Beispiel:InformationenüberKinofilme
TabelleMovies
• WelchessinddieKandidatenfürDeduplikation:- DatensätzeeinerTabelle?- NeuineineTabelleeinzufügendeDatensätze?
• IdentifikationderEntitäten:DieAttribute,welcheeineEntitätidentifizieren(normalerweise"natürliche"Identifikationsattribute)und/oderweitere"charakterisierende"Attribute.
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 52
Deduplikation:EineDefinition
Seien c1 , c2 zweiKandidatenfürDeduplikation,sim(c1, c2) einÄhnlichkeitsmass,q einSchwellwertüberdem c1 undc2 als gleichbetrachtetwerden
GesuchtwerdenallePaare(c1, c2) ,fürwelchegilt:sim(c1, c2) > q undc1 ≠ c2
• ZweimöglicheFehler:
• False Negatives:verschiedeneRepräsentationeneinereinzigenEntität,dieinkorrektalsverschiedeneEntitätenbetrachtetwerden
• False Positives:verschiedeneEntitäten,dieinkorrektalseineeinzigeEntitätbetrachtetwerden
• Problem:sim(c1, c2) ist normalerweisenicht transitiv
⇒ sim(c1, c2) > q ∧ sim(c2, c3) > q ⇏ sim(c1, c3) > q
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 53
ProblememitTransitivität– einBeispiel
Annahme:sim(c1, c2) berechnesichauseinerSummefolgenderTeile:- 10 beigleichemNamen(Attributname)- je1beigleichemWertinanderemAttribut(street, phone)
2Datensätze werdenalsDuplikatebetrachtetfallssim(c1, c2) > 10
#1 name = 'Mary Smith', street = '123 Oak', phone = '555-1234'#2 name = 'Mary Smith', street = '456 Elm', phone = '555-1234'#3 name = 'Mary Smith', street = '456 Elm', phone = null
• Esgilt:- #2istDuplikatvon #1:sim(c1, c2) = 10 + 1 = 11 > 10- #3istDuplikatvon #2:sim(c2, c3) = 10 + 1 = 11 > 10- aber:#3istkein Duplikatvon#1:sim(c1, c3) = 10
FüreineÄquivalenzrelation ~müsstedieTransitivitätgelten:c1 ~ c2 ∧ c2 ~ c3 ⇒ c1 ~ c3
vgl. Talburt 2011

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 54
KomplexitätderDeduplikation
• IneinerMengevonn Daten-sätzenbenötigtDeduplikationn× (n−1) / 2 AufrufederFunktion sim(c1, c2)
⇒ Quadratische Komplexität,d.h.,O(n2)
• Dieskannevt.etwasvermindertwerden,z.B.durchSortierenderDatensätzegemässAttributen,dieinsim(c1, c2)benötigtwerden.
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 55
ÄhnlichkeitgegenüberDistanz
Definitionen
• Einenormalisierte Ähnlichkeitsfunktion sim(c1, c2) ist1 füreinenexakten Matchund0 füreinentotalenMismatch.
• EinenormalisierteDistanzfunktion dist(c1, c2) ist0 füreinenexakten Match und1 füreinentotalenMismatch.
• Falls sim(c1, c2) eine normalisierte Ähnlichkeitsfunktionist,dist(c1, c2) eine normalisierte Distanzfunktionist,dist(c1, c2) = 1 − sim(c1, c2) gilt,undq einSchwellwertist,
dann bedeutetsowohl sim(c1, c2) > q wieauch dist(c1, c2) ≤ q dassc1 und c2 alsgleichbetrachtetwerden.
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 56
VerschiedeneTypenvonÄhnlichkeitsmassen
• Token-basierte Ähnlichkeit:verwendetexakte Matches zwischen"natürlichen"TeilenvonBeschreibungenvonEntitäten,z.B.- verschiedenedurchBlanksetcgetrennteTermeeinesDokuments- "ganze"DatenwerteinverschiedenenAttributeneinesDatensatzes
• String-basierte Ähnlichkeit:verwendetapproximativeMatches zwischenStrings,welche Entitätenbeschreiben,oftmitDistanzfunktion(z.B.Editier-Distanz)
• HybriderAnsatz:verwendetapproximativeMatches korrespondierenderTokens ausBeschreibungenvonEntitäten
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 57
Jaccard Koeffizient
• Token-basierter Ansatz
• Seiens, t zweiStringsbestehenausmehrerenToken (bzw. WertenmehrererAttribute)
• Seien S resp.T dieMengenderTokens inString s resp.t
• DieJaccard Ähnlichkeit(derJaccardKoeffizient)für Strings s undt ist
• Beispiel:s = ′Thomas Sean Connery′ => S = { ′Connery′, ′Sean′, ′Thomas′ } t = ′Sir Sean Connery′ => T = { ′Connery′, ′Sean′, ′Sir′ }=> S ∩ T = { ′Connery′, ′Sean′ } => | S ∩ T | = 2=> S∪ T = { ′Connery′, ′Sean′, ′Sir′, ′Thomas′ } => | S∪ T | = 4=> JaccardSim(s, t) = 0.5
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 58
Ähnlichkeitbasierendaufq-Grammen
• Token-basierter Ansatz
• q-Gramme (auchn- und k-Gramme,Englischq-grams)sindTokens bestehendausq aufeinanderfolgendenZeicheneinesStrings
• DerString s wirdals Menge S allermöglichenq-Grammedargestellt.DerString t wirdals Menge T allermöglichenq-Grammedargestellt.DanachwirddieJaccard-ÄhnlichkeitderMengenS undT ermittelt.
• Beispiel: s = ′Henri Waternoose′ und t = ′Henry Waternose′ (mit q = 3)
• 3-Grammefür s: S = { ′##H′, ′#He′, ′Hen′, ... , ′i W′, ... , ′oos′, ′ose′, ′se#′, ′e##′ } 3-Grammefür t: T = { ′##H′, ′#He′, ′Hen′, ... , ′y W′, ... , ′nos′, ′ose′, ′se#′, ′e##′ }
• DieJaccard-Ähnlichkeitist 13/22 = 0.59 (Esentstehen22Trigramme,vondenen13inbeidenMengenauftreten.)
vgl. Naumann/Herschel 2010

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 59
Edit-Distanzen– insbesondereLevenshtein Distanz
• EineEditDistanzzwischenzweiStringss1 und s2 istdieminimaleAnzahlvonEditier-Operationendies1 in s2 überführen.
• VerschiedeneVariantenderEdit-DistanzunterscheidensichdurchdiezulässigenEditier-Operationen (sowiedieKosten dieserOperationen).
• Levenshtein Distanz:DiezulässigenEditier-Operationen sindinsert,delete,sowiereplace einesZeichens(jeweilsmitKosten1proOperation).
• Levenshtein Distanzdog-do: 1
• Levenshtein Distanzcat-cart: 1
• Levenshtein Distanzcat-cut: 1
• Levenshtein Distanz cat-act: 2 ( ‘c‘ → ‘a‘ , ‘a‘ → ‘c‘ )
vgl. Manning et al 2008

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 60
AlgorithmuszurBerechnungderLevenshtein Distanz
vgl. Manning et al 2008

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 61
BerechnungderLevenshtein Distanz:Beispiel
• Distanzzwischen'cats' und 'fast'
vgl. Manning et al 2008

InformationssystemefürIngenieure(2016)– 6Text-basiertesInformationRetrievalR.Marti 62
Zusammenfassung
• ImText-InformationRetrievalwerdenpassendeDokumenteaufgrundderAngabeeinigerWörterbzw.Termegesucht
• Boole‘schesRetrieval:GibtalleDokumentezurück,indenendieTermevorkommen
• Vektorraum-Modell:DokumentewerdenalshochdimensionalerVektorrepräsentiert,wobeidieimDokumentvorkommentenTerme(allenfallsmitAusnahmesog.Stoppwörter)einGewichterhalten,dasvonderAnzahlVorkommendesTermsimDokument(sowieallenfallsinallenDokumenten)bestimmtwird:TF-IDF Gewichtung
• Dokumenteund/oderAnfragenwerdenoft“vorbearbeitet“,etwadurch
– EliminationvonStoppwörtern
– StemmingderTerme
– Synonym-ExpansioninderAnfrage
• EntityResolution:Entdecken,ob(leicht)erschiedeneZeichenketten/Datensatz-Formatediegleiche„realworld“Entitätbezeichnenkönnten





























