Embed Size (px)
Citation preview

Ingeniería de SistemasData Analytics
Session 07 | ETLIntroduction to data types in DA
Loading processes
Bogotá. August 6, 2021

Contents• ETL - Loading data according to its structuring level
• Structured, semi-structured and unstructured data• Loading strategies according to the nature of the data
• Introduction to Data Warehouses• Introduction to Data Lakes

ETL: data loading according to data structuring level

ETL: Loading
• The loading process (within ETL) consists of storing the transformed data in its final representation (ready for data analysis) in the storage components of the target information system.
• There are two main methods for loading data into a warehouse:• Full load: Full data dump, takes place the first time a data source is loaded
at the destination.• Incremental load: Detected changes between the target and source data
are applied within some preset interval. • The last extraction date is logged so that only aggregated (or updated) data is
uploaded after the extraction. • There are two types of incremental loads, depending on the volume of the data:
• Incremental streaming load: suitable for small volumes of data• Batch loading: Suitable for large volumes of data

Structured Data Semi-structured Data Unstructured Data
Values are obtained/extracted by direct
addressing without any additional
processing for analysis. The data is
sorted within a formatted repository,
usually a database.
All data elements can be stored in SQL
tables (rows and columns). Relational
keys allow for simple query and preset
mapping.
Example: Relational data in SQL
databases, data warehouses, and data
marts.
Information that cannot be represented
by a relational database but exhibits
remarkable organizational properties.
Accessible through sequential or
hierarchical access to data elements.
Additional processing is required to
extract specific values from raw
representations.
Relational representations can be
"serialized" to achieve semi-structured
representations, which in turn reduces
storage requirements.
Example: JSON, XML.
Information without a predefined
homogeneous structure. There is no
data model, so it is not suitable for a
workflow based on relational
representations.
It is the most common approach in
recent computer systems and is the
most frequent choice for business
intelligence and Big Data applications.
Example: office documents, PDFs,
natural language records (BLOG and
microblogging posts), multimedia files,
logs, etc.
Data structuring levels

Loading strategies according to data nature
Structured Data
• Data warehouses • Usually, star or constellation schemas
• Datamarts are created to meet information requirements of different departments / units / analytic processes
• Datamarts also support analytical tasks. They usually use snowflake schemas
• One of the most used structures for rapid data analysis is the OLAP cube (online analytical processes).• Provides multidimensional analytical
queries quickly in a short time.
Semi-structured or unstructured data
• Mandatory when data is extracted from various types of sources (structured, semi-structured, unstructured)
• Storage approach: data lakes • Data is usually recorded as
information units (e.g. BLOB) along with structured tables (combined approaches), and is accessed according to the requirements of each operational or analytical process.

* Data Lake Vs Data Warehouse : Which one should you go for ? https://www.grazitti.com/blog/data-lake-vs-data-warehouse-which-one-should-you-go-for/
Data Warehouses vs. Data Lakes
The data is processed and organized in a single schema before being stored in a data warehouse.
The analysis is carried out on the prepared version of the data from the data warehouse
Raw and unstructured data is stored in a data lake.
The data contained in the data lake is selected and organized when required

Introduction to Data Warehouses
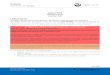
Workflow in data analytics: data warehouse scenario

Data warehouses - definitions
• Data warehouse: Integrated* and centralized data repository related to one specific aspect of the organization. Users can set parameters and criteria for assisted record grouping or classifying:
• Fact Table: main data related to the business logic.
• Dimension table: supporting data (e.g. additional details of records in the fact table, codes, dictionaries)
• Granularity: level of detail of the data contained in the warehouse, depending on the needs of the analytical process.
• Datamart: structure generated as a subset of a data warehouse, contains what is required by a specific aspect of the business logic, which is frequently used by both operational processes or data analytics.
* Data are acquired from multiple information systems

Star vs. Snowflake Schemas
• Star dimension tables are not normalized, snowflake dimension tables are normalized.
• Snowflake schemas will use less space to store dimension tables, but they are more complex.
• Star schemas relate the fact table to dimension tables, resulting in easier and faster SQL queries.
• Snowflake schemas do not have redundant data, so they are easier to maintain.
• Snowflake schemas have favorable characteristics for data warehouses, star schemas are better for datamarts with simple relationships.
Star Schema Snowflake Schema
• Another commonly used schema in data warehouses and datamarts is the of "constellation" (or "galaxy") scheme, which links multiple tables of facts in a more flexible fashion.

ETL: Loading into Data Warehouses Implementation Aspects
• The loading process is highly demanding in terms of both execution time and representation complexity, but it is critically important given it provides the actual input for the analysis processes.
• Loading of fact tables and dimension tables is quite similar in operational terms.
• However, dimension tables must be loaded before loading the fact tables, in order to preserve the consistency of the data model.

ETL: Data Warehouse Loading – Load Tasks
• Loading fact and dimension tables is not the last step in creating the database
• The structure of the data can be modified after loading without affecting the pattern of requests from end users
• These modifications are often called "graceful mods", and include:
• Adding a fact or dimension from an existing fact table of the same level of granularity
• Adding an attribute to a dimension
• Increase the granularity of existing dimension and fact tables

Introduction to Data Lakes

ELT worflows in large organizations
• Nowadays, more complex or larger systems integrate both data warehouses and data lakes as a required design pattern
• The content of the data warehouse is translated into the data lake by translating structured to semi-structured representations using formats such as JSON
• Process with data lakes:
• Extraction
• Loading (data lake)
• Transformation (according to user requirements)
• Loading (streaming vs. dataflow based on triggers or intervals)
• Example: Integration of services in Chicago using MongoDB: https://www.mongodb.com/customers/city-of-chicago
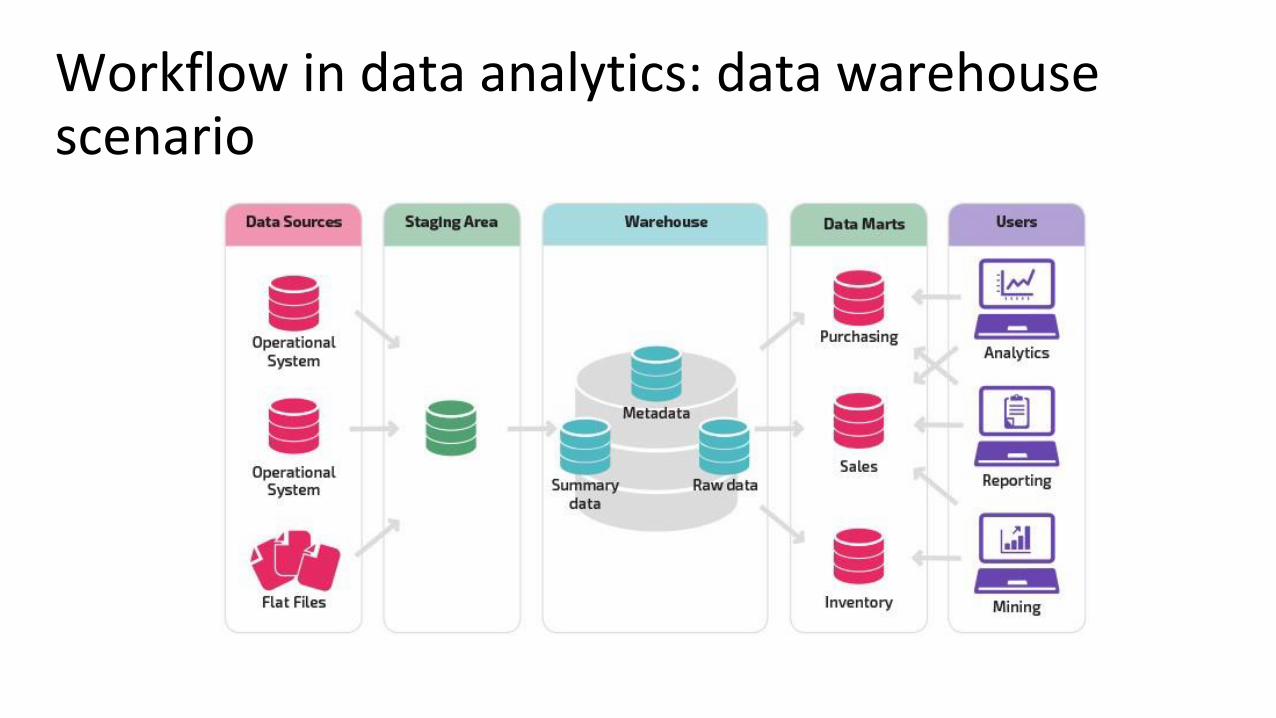
Data Lakes: definitions and reference architecture
https://www.dragon1.com/terms/data-lake-definition

Data Lakes: design and use case considerations
• A data lake is not a "data dump" • Therefore, the data must have an order, even if the underlying
information is semi-structured or unstructured
• This order is imposed by the business logic, and is also suggested by the data lake provider. Example: • Validation methods for files in the loading process
• Containers in Microsoft BLOB: • Data (RAW version)
• Valid (accepted records)
• Invalid (rejected records)

Commercial and open examples
Data Warehouses
• Teradata
• Oracle
• Amazon RedShift (Amazon Web Services)
• SQL Server (on Azure)
• Cloudera
• MarkLogic
• ...
Data Lakes
• Lago de Datos de IBM
• Azure Storage Services onAzure (Microsoft BLOB)
• MongoDB
• TIBCO
• Talend
• ...
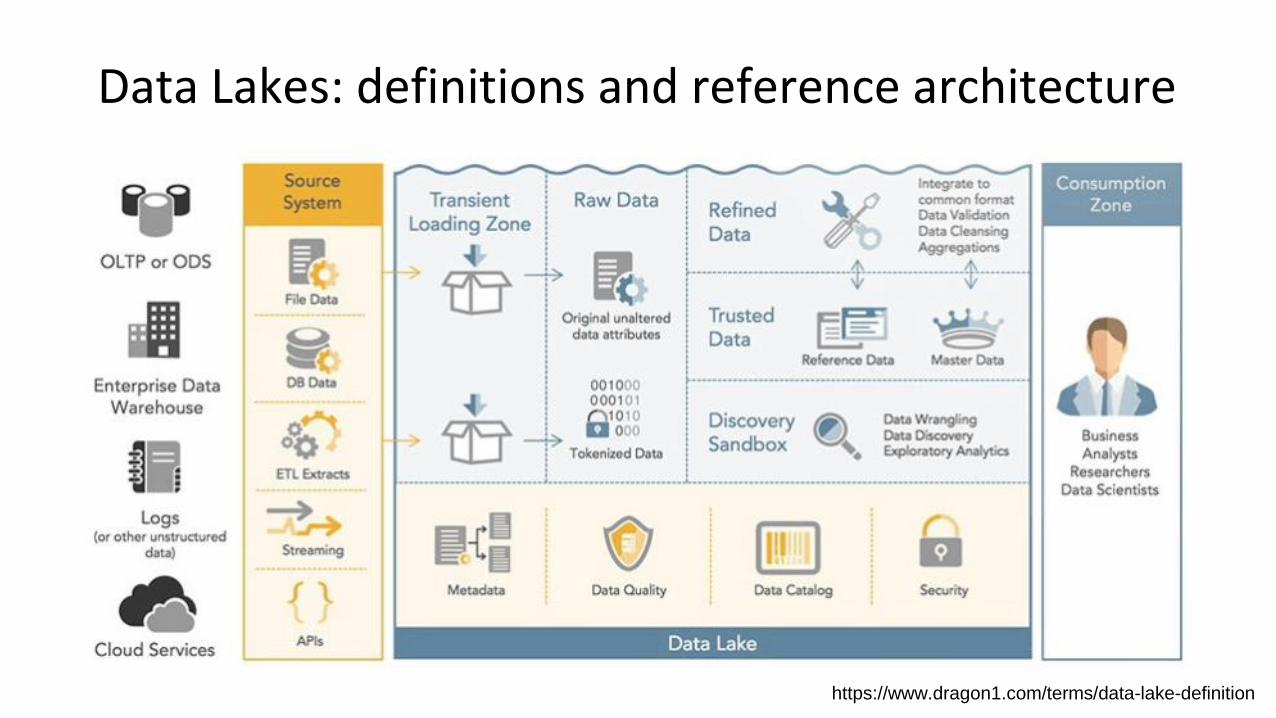
Structure of a data lake on Azure
• The structure of a data lake in Azure is pretty simple, and consists of:
• An Azure Storage Services Account
• A list of containers associated to the account
• A list of data pieces arranged as
• “Big large binary objects” (BLOBs)
• Tables
• Shared files (NFS, SMB)
• Queues


![Alexander Klein ETL meets Azure - sqlpass.de Data Lake Analytics U-SQL Azure Data Lake Analytics DotNet HDInsight[Hadoop] orAzure Batch. Azure Data Factory (ADF) ... Alexander Klein](https://img.pdfslide.net/doc/110x75/5ed51aa030f0eb5025593a3b/alexander-klein-etl-meets-azure-data-lake-analytics-u-sql-azure-data-lake-analytics.jpg)