Embed Size (px)
Citation preview

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Innovate vision solutions FROM EDGE TO CLOUDintel® distribution of openvino™ toolkit(Open Visual Inference & Neural Network Optimization)
Intel CEE Edge & IoT Developer Enabling(EIDE) May, 18, 2019
Includes Intel® Deep Learning Deployment Toolkit

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice2
My information
Zhou, zhaojing
Intel Computer Vison Application software engineer
Edge and IoT Developer Enabling (EIDE)
Email: [email protected]
Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
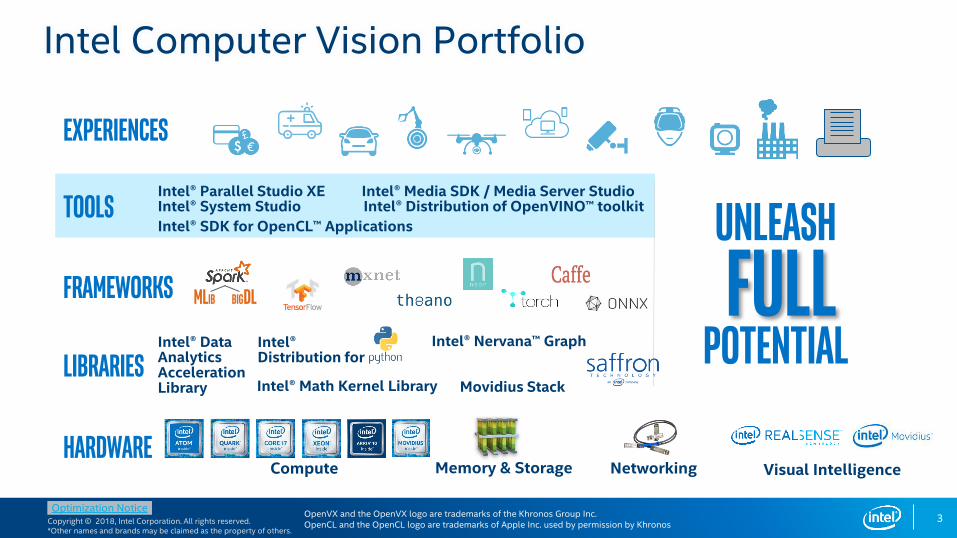
librariesIntel® Math Kernel Library
tools
Frameworks
Intel® Data Analytics Acceleration Library
hardwareMemory & Storage NetworkingCompute
Intel® Distribution for
Mlib BigDL
Intel® Nervana™ Graph
Intel Computer Vision Portfolio
experiences
Movidius Stack
Visual Intelligence
OpenVX and the OpenVX logo are trademarks of the Khronos Group Inc.OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos
Intel® Parallel Studio XE Intel® Media SDK / Media Server StudioIntel® System Studio Intel® Distribution of OpenVINO™ toolkit
Intel® SDK for OpenCL™ Applications
3

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice4
What’s Inside Intel® Distribution of OpenVINO™ toolkit
OpenVX and the OpenVX logo are trademarks of the Khronos Group Inc.OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos
Intel® Architecture-Based Platforms Support
OS Support CentOS* 7.4 (64 bit) Ubuntu* 16.04.3 LTS (64 bit) Microsoft Windows* 10 (64 bit) Yocto Project* version Poky Jethro v2.0.3 (64 bit) MacOS
Intel® Deep Learning Deployment Toolkit Traditional Computer Vision
Model Optimizer Convert & Optimize
Inference EngineOptimized InferenceIR
OpenCV* OpenVX*
Optimized Libraries & Code Samples
IR = Intermediate Representation file
For Intel® CPU & GPU/Intel® Processor Graphics
Increase Media/Video/Graphics Performance
Intel® Media SDKOpen Source version
OpenCL™ Drivers & Runtimes
For GPU/Intel® Processor Graphics
Optimize Intel® FPGA (Linux* only)
FPGA RunTime Environment(from Intel® FPGA SDK for OpenCL™)
Bitstreams
Code Samples
An open source version is available at 01.org/openvinotoolkit (some deep learning functions support Intel CPU/GPU only).
Tools & Libraries
Intel® Vision Accelerator Design Products &
Intel/Partner Developer Kits
20+ Pre-trained Models
Computer Vision Algorithms
Samples
Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
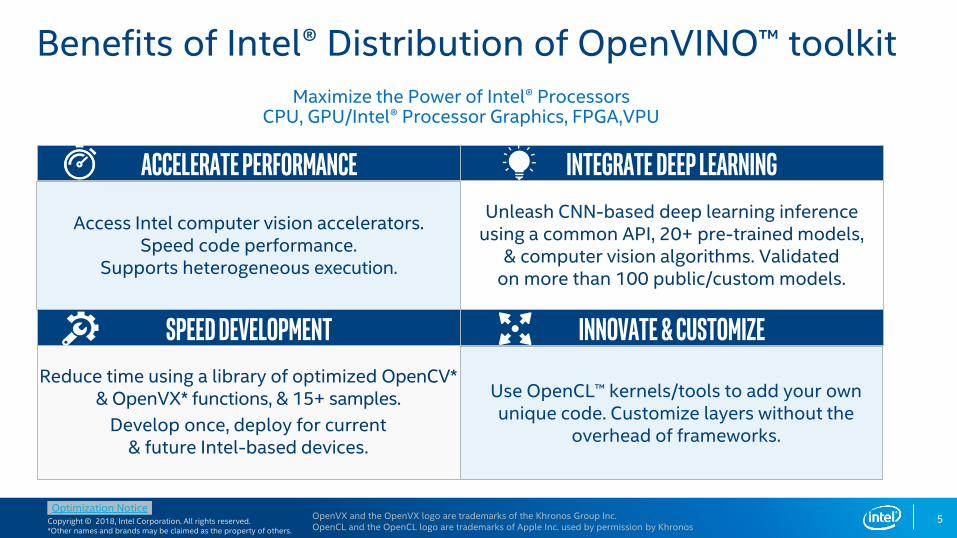
Unleash CNN-based deep learning inference using a common API, 20+ pre-trained models,
& computer vision algorithms. Validated on more than 100 public/custom models.
5
Benefits of Intel® Distribution of OpenVINO™ toolkit
Reduce time using a library of optimized OpenCV* & OpenVX* functions, & 15+ samples.
Develop once, deploy for current & future Intel-based devices.
Use OpenCL™ kernels/tools to add your own unique code. Customize layers without the
overhead of frameworks.
Access Intel computer vision accelerators. Speed code performance.
Supports heterogeneous execution.
Accelerate Performance
OpenVX and the OpenVX logo are trademarks of the Khronos Group Inc.OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos
Integrate Deep learning
Maximize the Power of Intel® ProcessorsCPU, GPU/Intel® Processor Graphics, FPGA,VPU
speed development Innovate & customize

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice6
OpenVINO™ ToolkitOpen source version
Provides flexibility and availability to the developer community to extend OpenVINO™ toolkit for custom needs
Components that are open sourced
‒ Deep Learning Deployment Toolkit with CPU, GPU & Heterogeneous pluginsgithub.com/opencv/dldt
‒ Open Model Zoo - includes pre-trained models, model downloader, demos and samples - github.com/opencv/open_model_zoo
See FAQ for key differences between OpenVINO™ Toolkit (open source) and Intel® Distribution of OpenVINO™ Toolkit (Intel version)
More details 01.org/openvinotoolkit

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice7
Quick Guide: What’s Inside the Intel Distribution vs Open Source version of OpenVINO™ toolkit
1Intel MKL is not open source but does provide the best performance2Refer to readme file for validated versions
Tool/ComponentIntel® Distribution of OpenVINO™ toolkit
OpenVINO™ toolkit (open source)
Open Source Directory
Installer (including necessary drivers) P
Intel® Deep Learning Deployment toolkit
Model Optimizer P P /opencv/dldt/tree/2018/model-optimizer
Inference Engine P P /opencv/dldt/tree/2018/inference-engine
Intel CPU plug-inP
(Intel® Math Kernel Library (Intel® MKL) only)1
P
(BLAS, Intel® MKL1, jit (Intel MKL))
/opencv/dldt/tree/2018/inference-engine
Intel GPU (Intel® Processor Graphics) plug-in P P /opencv/dldt/tree/2018/inference-engine
Heterogeneous plug-in P P /opencv/dldt/tree/2018/inference-engine
Intel GNA plug-in P
Intel® FPGA plug-in P
Intel® Neural Compute Stick (1 & 2) VPU plug-in P
Intel® Vision Accelerator based on Movidius plug-in P
30+ Pretrained Models - incl. Model Zoo (IR models that run in IE + open sources models)
P P https://github.com/opencv/open_model_zoo
Computer Vision Algorithms P
Samples (APIs) P P /opencv/dldt/tree/2018/inference-engine
Demos P P https://github.com/opencv/open_model_zoo
Traditional Computer Vision
OpenCV* P P https://github.com/opencv/opencv
OpenVX (with samples) P
Intel® Media SDK P P2 https://github.com/Intel-Media-SDK/MediaSDK
OpenCL™ Drivers & Runtimes P P2 https://github.com/intel/compute-runtime
FPGA RunTime Environment, Deep Learning Acceleration & Bitstreams (Linux* only)
P


Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice9
Intel® Deep Learning Deployment Toolkit For Deep Learning Inference
Caffe*
TensorFlow*
MxNet*.dataIR
IR
IR = Intermediate Representation format
Load, infer
CPU Plugin
GPU Plugin
FPGA Plugin
Myraid Plugin
Model Optimizer
Convert & Optimize
Model Optimizer
What it is: A python based tool to import trained models and convert them to Intermediate representation.
Why important: Optimizes for performance/space with conservative topology transformations; biggest boost is from conversion to data types matching hardware.
Inference Engine
What it is: High-level inference API
Why important: Interface is implemented as dynamically loaded plugins for each hardware type. Delivers best performance for each type without requiring users to implement and maintain multiple code pathways.
Trained Models
Inference Engine
Common API (C++ / Python)
Optimized cross-platform inference
OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos
GPU = Intel CPU with integrated graphics processing unit/Intel® Processor Graphics
Kaldi*
ONNX*
GNA Plugin
Extendibility C++
Extendibility OpenCL™
Extendibility OpenCL™

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice10
Improve Performance with Model Optimizer
Easy to use, Python*-based workflow does not require rebuilding frameworks.
Import Models from various supported frameworks - Caffe*, TensorFlow*, MXNet*, ONNX*, Kaldi*.
100+ models for Caffe, MXNet and TensorFlow validated. All public models on ONNX* model zoo supported.
With Kaldi support, the model optimizer extends inferencing for non-vision networks.
IR files for models using standard layers or user-provided custom layers do not require Caffe.
Fallback to original framework is possible in cases of unsupported layers, but requires original framework.
Trained Model
Model Optimizer
Analyze
Quantize
Optimize topology
Convert
Intermediate Representation (IR) file

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice11
Inference Engine Common API
Plu
g-I
n A
rch
ite
ctu
re
Inference Engine Runtime
Movidius API
Intel® Movidius™ Myriad™ 2
DLA
Intel® ProcessorGraphics (GPU)
CPU: Intel® Xeon®/Core™/Atom®
clDNN PluginIntel® Math Kernel
Library (MKLDNN)Plugin
OpenCL™Intrinsics
FPGA Plugin
Applications/Service
Intel® Arria 10 FPGA
Simple & Unified API for Inference across all Intel® architecture
Optimized inference on large IA hardware targets (CPU/GEN/FPGA)
Heterogeneity support allows execution of layers across hardware types
Asynchronous execution improves performance
Futureproof/scale your development for future Intel® processors
Transform Models & Data into Results & Intelligence
MovidiusPlugin
OpenVX and the OpenVX logo are trademarks of the Khronos Group Inc.OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos
GPU = Intel CPU with integrated graphics/Intel® Processor Graphics/GENGNA = Gaussian mixture model and Neural Network Accelerator
GNA API
Intel® GNA
GNA* Plugin
Optimal Model Performance Using the Inference Engine

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice12
OpenVINO™ toolkit includes optimized pre-trained models that can expedite development and improve deep learning inference on Intel® processors. Use these models for development and production deployment without the need to search for or to train your own models.
Speed Deployment with Intel Optimized Pre-trained Models
Intel Confidential
Age & Gender
Face Detection – standard & enhanced
Head Position
Human Detection – eye-level & high-angle detection
Detect People, Vehicles & Bikes
License Plate Detection: small & front facing
Vehicle Metadata
Human Pose Estimation
Vehicle Detection
Retail Environment
Pedestrian Detection
Pedestrian & Vehicle Detection
Person Attributes Recognition Crossroad
Emotion Recognition
Identify Someone from Different Videos – standard & enhanced
Facial Landmarks
Pre-Trained Models
Identify Roadside objects
Advanced Roadside Identification
Person Detection & Action Recognition
Person Re-identification – ultra small/ultra fast
Face Re-identification
Landmarks Regression
Smart Classroom Use Cases
Single image Super Resolution

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice13
Samples
Use Model Optimizer & Inference Engine for public models and Intel pretrained models.
Object Detection
Standard & Pipelined Image Classification
Security Barrier
Object Detection for Single Shot Multibox Detector (SSD) using Asynch API
Object Detection SSD
Neural Style Transfer
Hello Infer Classification
Interactive Face Detection
Image Segmentation
Validation Application
Multi-channel Face Detection
Save Time with Deep Learning Samples & Computer Vision Algorithms
Computer Vision Algorithms
Get started quickly with highly-optimized, ready-to-deploy, custom-built algorithms using Intel pretrained models.
Face Detector
Age & Gender Recognizer
Camera Tampering Detector
Emotions Recognizer
Person Re-identification
Crossroad Object Detector
License Plate Recognition
Vehicle Attributes Classification
Pedestrian Attributes Classification

14Intel Confidential

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice15
Intel® Deep Learning Deployment Toolkit For Deep Learning Inference
Caffe*
TensorFlow*
MxNet*.dataIR
IR
IR = Intermediate Representation format
Load, infer
CPU Plugin
GPU Plugin
FPGA Plugin
Myraid Plugin
Model Optimizer
Convert & Optimize
Model Optimizer
What it is: A python based tool to import trained models and convert them to Intermediate representation.
Why important: Optimizes for performance/space with conservative topology transformations; biggest boost is from conversion to data types matching hardware.
Inference Engine
What it is: High-level inference API
Why important: Interface is implemented as dynamically loaded plugins for each hardware type. Delivers best performance for each type without requiring users to implement and maintain multiple code pathways.
Trained Models
Inference Engine
Common API (C++ / Python)
Optimized cross-platform inference
OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos
GPU = Intel CPU with integrated graphics processing unit/Intel® Processor Graphics
Kaldi*
ONNX*
GNA Plugin
Extendibility C++
Extendibility OpenCL™
Extendibility OpenCL™

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice16
Configure the Model Optimizer
• To configure all three frameworks, go to the following directory:
<INSTALL_DIR>/deployment_tools/model_optimizer/install_prerequisites
• Run configuration script
• For Linux* OS: install_prerequisites.sh
• For Windows* OS: install_prerequisites.bat
Intel Confidential

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice17
Convert a Model to Intermediate Representation (IR)
• Use the mo.py script from the <INSTALL_DIR>/deployment_tools/model_optimizer directory
• The mo.py script is a universal entry point that can deduce the framework by a standard extension of the model file:• .caffemodel - Caffe models
• .pb - TensorFlow models
• .params - MXNet models
• .onnx - ONNX models
• .nnet - Kaldi models
• Use the --framework {tf,caffe,kaldi,onnx,mxnet} option to specify the framework type explicitly.
python3 mo.py --framework tf --input_model /user/models/model.pb
python3 mo.py --input_model /user/models/model.pb

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice18
Conversion Parameters
• Framework-Agnostic Parameters
• --input_model, --output_dir
• --input INPUT, --output OUTPUT, --input_shape
• --data_type {FP32, FP16}
• --reverse_input_channels
• --log_level {CRITICAL,ERROR,WARN,WARNING,INFO,DEBUG,NOTSET}
• --mean_values, --scale_values
• And more
• For framework-specific parameters and details, use mo.py -h

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice19
Some examples
• Launch the Model Optimizer for the Caffe bvlc_alexnet model with the output IR called result.* in the specified output_dir:
• Launch the Model Optimizer for the Caffe bvlc_alexnet model with multiple inputs with scale and mean values specified for the particular nodes:
• Launch the Model Optimizer for the Caffe bvlc_alexnet model with reversed input channels order, specified mean values to be used for the input image per channel, and specified data type for input tensor values
python3 mo.py --input_model bvlc_alexnet.caffemodel --model_name result --output_dir /../../models/
python3 mo.py --input_model bvlc_alexnet.caffemodel --input data,rois --mean_valuesdata[59,59,59] --scale_values rois[5,5,5]
python3 mo.py --input_model bvlc_alexnet.caffemodel --reverse_input_channels --mean_values data[255,255,255] --data_type FP16

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice20
What You Need to Know About Your Model
• Check whether layers in your model is supported/known by OpenVINO.
• The list of known layers of each framework is in OpenVINO reference manual.

21Intel Confidential
Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
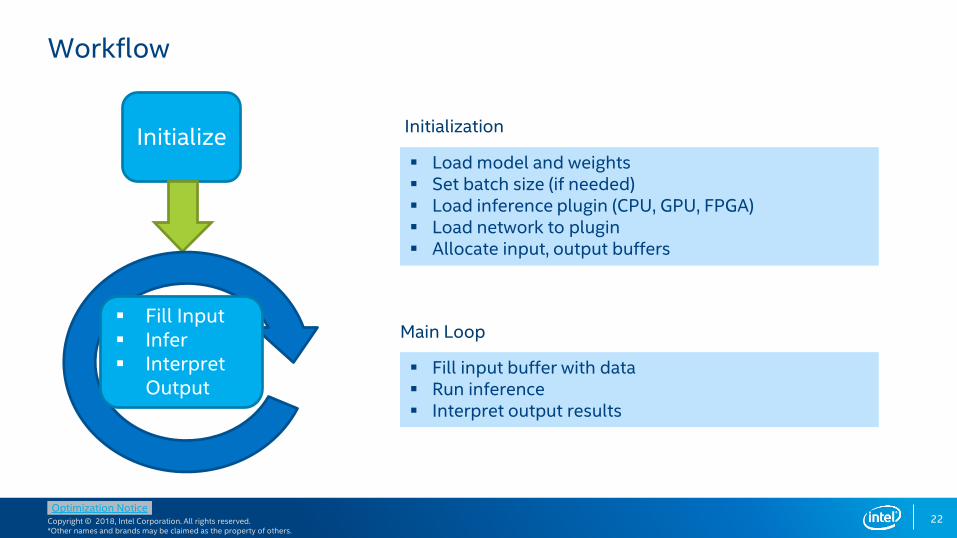
Workflow
Load model and weights Set batch size (if needed) Load inference plugin (CPU, GPU, FPGA) Load network to plugin Allocate input, output buffers
Fill input buffer with data Run inference Interpret output results
Initialization
Main Loop
Initialize
Fill Input Infer Interpret
Output
22

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Load model
• Every SDK sample has “-m” command-line option
• Classification sample support batches as “-b” (or via number of input images)

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Check the inputs/outputs are ok, set the data type/layout
Intel Confidential 24
/** map <string, info> about all inputs **/
InputsDataMap inputInfo = network.getInputsInfo();
if (inputInfo.size() != 1)
throw std::logic_error("Sample supports topologies only with 1 input");
auto inputInfoItem = *inputInfo.begin();
/** Precision and layout of input data provided by the user.
* This should be called before load of the network to the plugin **/
inputInfoItem.second->setPrecision(Precision::U8);
inputInfoItem.second->setLayout(Layout::NCHW);
//same checks/settings for the output(s)
…

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Load plugin and extensions
InferencePlugin plugin = PluginDispatcher({"../../../lib/intel64"}).getPluginByDevice(“CPU”);
• Every SDK sample has “–d” command-line option
// Loading default extensionsif (FLAGS_d.find("CPU") != std::string::npos) {
/** cpu_extensions library is compiled from "extension" folder custom MKLDNNPlugin layer implementations. These layers are useful for inferring custom topologies. **/plugin.AddExtension(std::make_shared<Extensions::Cpu::CpuExtensions>());
}
if (!FLAGS_l.empty()) {// CPU(MKLDNN) extensions are loaded as a shared libraryauto extension_ptr = make_so_pointer<IExtension>(FLAGS_l);plugin.AddExtension(extension_ptr);
}if (!FLAGS_c.empty()) {
// clDNN Extensions are loaded from an .xml description and OpenCL kernel filesplugin.SetConfig({{PluginConfigParams::KEY_CONFIG_FILE, FLAGS_c}});
}

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Load the network to the plugin and get the ExecutableNetwork// --------------------------- Loading model to the plugin ------------------------------------------
ExecutableNetwork executable_network = plugin.LoadNetwork(network, {});network = {}; //release the network datanetworkReader = {}; //release the network reader
…// --------------------------- Create infer request -------------------------------------------------
InferRequest infer_request = executable_network.CreateInferRequest();

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Populate input data/pre-process// --------------------------- Prepare input -------/for (const auto & item : inputInfo) {
/** getting input blob (by name) **/Blob::Ptr input = infer_request.GetBlob(item.first);
auto data = input->buffer().as<PrecisionTrait<Precision::U8>::value_type*>();…
Inferinfer_request.Infer();
Post-Process
const Blob::Ptr output_blob = infer_request.GetBlob(firstOutputName);auto output_data = output_blob->buffer().as<PrecisionTrait<Precision::FP32>::value_type*>();…Many output formats. Some examples:• Simple classification: an array of float confidence scores, # of elements=# of classes in the model• SSD: many “boxes” with a confidence score, label #, xmin,ymin, xmax,ymax

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice28
Use Asynchronous API
• Assuming Inference run on the GPU (orange) and other stages on CPU (white)
• Overall Pipeline will not be able to utilize the GPU and get to high frame rate.
• If next frame can start processing without waiting to previous inference to finish..

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Old-style API
Async API
Intel Confidential

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice30
for (int iter = 0; iter < FLAGS_ni; ++iter) {
auto t0 = Time::now();
infer_request.Infer();
}
inferRequests[0].StartAsync();
inferRequests[0].Wait(10000);
for (int iter = 0; iter < FLAGS_ni + FLAGS_nireq; ++iter) {
if (iter < FLAGS_ni) {
inferRequests[currentInfer].StartAsync();
}
inferRequests[prevInfer].Wait(10000);
currentInfer++;
if (currentInfer >= FLAGS_nireq) {
currentInfer = 0;
}
prevInfer++;
if (prevInfer >= FLAGS_nireq) {
prevInfer = 0;
}
}
Inference Engine Async API

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice 31
Hetero Plugin


Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Run Inference 1:Model
vehicle-license-plate-detection-barrier-0007
Detects Vehicles
Run Inference 2:Model
vehicle-attributes-recognition-barrier-0010
Classifies vehicle attributes
Run Inference 3:Model
license-plate-recognition-barrier-0001
Detects License Plates
Load Input Image(s)
Display Results
33

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice34
DecodePre-
Processing InferencePost-
Processing Encode
GPUCPU GPUCPU FPGA VPU GPUCPU
Intel® Media SDK
OpenCV*
Intel® DeepLearning
DeploymentToolkit
Intel Media SDK
Video input Video output with results annotated
End-to-End Vision Workflow
OpenCV*

+ Success Stories & More Resources

36Intel and the Intel logo are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others.© Intel Corporation OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos.
Optimization Notice
Optimize Vision/Smart Video Solutions from Edge to Cloud
Smart Cameras
Video Gateways
Data Center and Cloud
Clients
Intel® Software Tools Help Developers Accelerate, Innovate, and Differentiate
Speed Video Encode/Decode & Image Processing, CompressionIntel® Media Server Studio & Intel® Media SDK
Boost Performance, System Bring-up & Power Efficiency, Debug with Intel® System StudioAccelerate Data Center/Cloud Workloads with Intel® Parallel Studio XE
Accelerate Computer Vision Solutions, Integrate Deep Learning InferenceIntel® Distribution of OpenVINO™ toolkit
Customize Solutions, Optimize Compute, Heterogeneous ProgrammingIntel® SDK for OpenCL™ Applications & Intel® FPGA SDK for OpenCL™ software technology
Deliver Fast, Efficient, High Quality Video/Computer Vision Processing End to End
ACHIEVE
High Performance
Low Power Consumption
Programmability Across Hardware Blocks
Fast Time-to-Market

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice37
Call to Action, Resources
Download Free Intel® Distribution of OpenVINO™ toolkit
Get started quickly with:
Developer resources
Intel® Tech.Decoded online webinars, tool how-tos & quick tips
Hands-on developer workshops
Support
Connect with Intel engineers & computer vision experts at the public Community Forum
Select Intel customers may contact their Intel representative for issues beyond forum support.
https://software.intel.com/en-us/openvino-toolkit

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice38
Get the Most from Your Code with Intel® Tech.Decoded
Discover Intel’s vision for key development areas.
Big Picture Videos
Essential Webinars
Gain strategies, practices and tools to optimize application and solution performance.
Learn how to do specific programming tasks using Intel software tools.
How-to Videos & Articles
Visual Computing
Code Modernization
Systems & IoT
Data Science
Data Center & Cloud Computing
OVERALL DEVELOPMENT TOPICS
TechDecoded.intel.io - Put key optimization strategies into practice with Intel development tools.
4 Visionary videos
4 Webinars
12 How-to videos, articles
Intel® Distribution of OpenVINO™ toolkit

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization Notice39
Key Vision Solutions Optimized by Intel® Distribution of OpenVINO™ toolkit
Intel teamed with Philips to show that servers powered by Intel® Xeon® Scalable processors & Intel® Distribution of OpenVINO™ toolkit can efficiently perform deep learning inference on patients’ X-rays & computed tomography (CT) scans, without the need for accelerators. Achieved breakthrough performance for AI inferencing:
188x increase in throughput (images/sec) on Bone-age prediction model.
38x increase in throughput (images/sec) on Lung segmentation model.
“Intel®Xeon®Scalable processors and OpenVINO toolkit appears to be the right solution for medical imaging AI workloads. Our customers can use their existing hardware to its maximum potential, without having to complicate their infrastructure, while still aiming to achieve quality output resolution at exceptional speeds."— Vijayananda J., chief architect and fellow, Data Science and AI, Philips HealthSuite Insights, India
White Paper
Philips

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice Optimization Notice
40
The Intel® Distribution of OpenVINO™ toolkit helped GE deliver optimized inferencing to its deep learning image-classification solution. By bringing AI to its clinical diagnostic scanning, GE no longer needed an expensive 3rd party accelerator board, achieving:
5.9x inferencing performance above the target
14x inferencing speed over the baseline solution
Improved image quality, diagnostic capabilities, and clinical workflows
With the OpenVINO™ toolkit , we are now able to optimize inferencing across Intel® silicon, exceeding our throughput goals by almost 6x,” said David Chevalier, Principal Engineer for GE Healthcare. “We want to not only keep deployment costs down for our customers, but also offer a flexible, high-performance solution for a new era of smarter medical imaging. Our partnership with Intel allows us to bring the power of AI to clinical diagnostic scanning and other healthcare workflows in a cost-effective manner.”
GE Healthcare*5
Intel-GE Healthcare, Intel® Software Development Tools Optimize Deep Learning Performance for Healthcare Imaging
Key Vision Solutions Optimized by Intel® Distribution of OpenVINO™ toolkit

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice41
Success Stories/Case Studies
New!
New!
New!
New!
New!
New!Full Case Study list

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Technical Specifications - Intel® Distribution of OpenVINO™ toolkit Intel® Platforms Compatible Operating Systems
Target Solution
Platforms
CPU 6th-8th generation Intel® Xeon® & Core™ processors
Ubuntu* 16.04.3 LTS (64 bit) Microsoft Windows* 10 (64 bit) CentOS* 7.4 (64 bit)
Intel® Pentium® processor N4200/5, N3350/5, N3450/5 with Intel® HD Graphics Yocto Project* Poky Jethro v2.0.3 (64 bit)
Iris® Pro & Intel® HD Graphics 6th-8th generation Intel® Core™ processor with Intel® Iris™ Pro graphics & Intel® HD Graphics 6th-8th generation Intel® Xeon® processor with Intel® Iris™ Pro Graphics & Intel® HD Graphics
(excluding e5 product family, which does not have graphics1)
Ubuntu 16.04.3 LTS (64 bit) Windows 10 (64 bit) CentOS 7.4 (64 bit)
FPGA Intel® Arria® FPGA 10 GX development kit Intel® Programmable Acceleration Card with Intel® Arria® 10 GX FPGA operating systems OpenCV* & OpenVX* functions must be run against the CPU or Intel® Processor Graphics (GPU)
Ubuntu 16.04.3 LTS (64 bit) CentOS 7.4 (64 bit)
VPU Intel Movidius™ Neural Compute Stick Intel® Neural Compute Stick2
Ubuntu 16.04.3 LTS (64 bit) CentOS 7.4 (64 bit) Windows 10 (64 bit)
Intel® Vision Accelerator Design Products Intel® Vision Accelerator Design with Intel® Arria10 FPGA
Ubuntu 16.04.3 LTS (64 bit)
Development Platforms
6th
-8th
generation Intel® Core™ and Intel® Xeon® processors
Ubuntu* 16.04.3 LTS (64 bit) Windows® 10 (64 bit) CentOS* 7.4 (64 bit)
Additional Software
Requirements
Linux* build environment required components OpenCV 3.4 or higher GNU Compiler Collection (GCC) 3.4 or higher CMake* 2.8 or higher Python* 3.4 or higher
Microsoft Windows* build environment required components Intel® HD Graphics Driver (latest version)†
OpenCV 3.4 or higher Intel® C++ Compiler 2017 Update 4 CMake 2.8 or higher Python 3.4 or higher Microsoft Visual Studio* 2015
External Dependencies/Additional Software View Product Site, detailed System Requirements
421Graphics drivers are required only if you use Intel® Processor Graphics (GPU).

Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Legal Disclaimer & Optimization Notice
Optimization Notice
Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804
43
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
INFORMATION IN THIS DOCUMENT IS PROVIDED “AS IS”. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO THIS INFORMATION INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT.
Copyright © 2018, Intel Corporation. All rights reserved. Intel, Pentium, Xeon, Core, VTune, OpenVINO, and the Intel logo are trademarks of Intel Corporation in the U.S. and other countries.
OpenVX and the OpenVX logo are trademarks of the Khronos Group Inc.OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos


Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice45
My information
Zhou, zhaojing
Intel Computer Vison Application software engineerEdge and IoT Developer Enabling (EIDE)
Email: [email protected]


Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
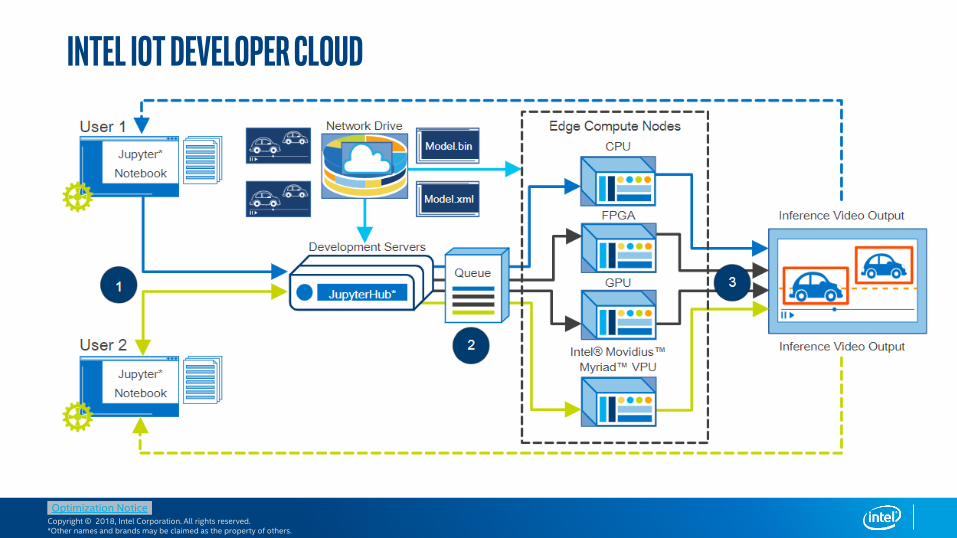
Easily evaluate the power of Intel’s heterogeneous edge compute processors: CPU, CPU with Integrated Graphics, FPGA,VPU
• Learn to develop vision inference solutionswith OpenVINO™ toolkit
• Get started with complete examples, modifyand upload your own models/workloads
• Evaluate and compare various IoT DeveloperKit offerings, software stacks and edge stacks
• Getting started immediately without waiting to buy edge hardware
Intel IoT Developer Cloud
KEY BENEFITS
CLOUD-BASED HETEROGENEOUSEDGE DEVELOPMENT ENVIRONMENT
Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
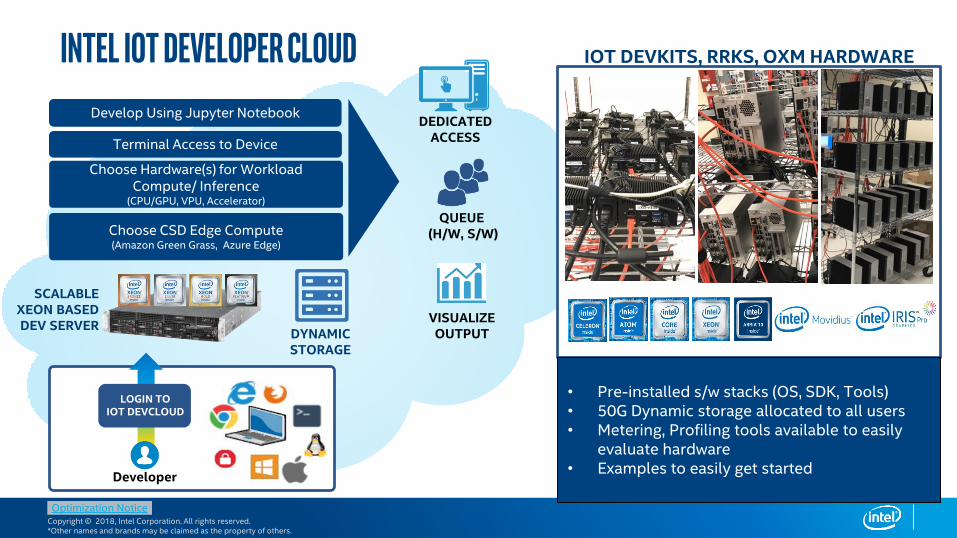
Intel IoT Developer Cloud
LOGIN TO IOT DEVCLOUD
Developer
SCALABLEXEON BASEDDEV SERVER
DYNAMIC STORAGE
IOT DEVKITS, RRKS, OXM HARDWARE
VISUALIZE OUTPUT
QUEUE(H/W, S/W)
• Pre-installed s/w stacks (OS, SDK, Tools)• 50G Dynamic storage allocated to all users• Metering, Profiling tools available to easily
evaluate hardware• Examples to easily get started
Choose CSD Edge Compute(Amazon Green Grass, Azure Edge)
Develop Using Jupyter Notebook
Terminal Access to Device
Choose Hardware(s) for Workload Compute/ Inference
(CPU/GPU, VPU, Accelerator)
DEDICATED ACCESS
Copyright © 2018, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
Optimization NoticeOptimization Notice
Intel IoT Developer Cloud





























