Embed Size (px)
Citation preview

Innovative Analytics for Traditional, Social, and Text Data Dr. Gerald Fahner, Senior Director Analytic Science, FICO

Big Data – the Fuel “is high-volume, high-velocity and high-variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making.”
Gartner
Machine Learning - the Engine “is a scientific discipline that explores the construction and study of algorithms that can learn from data. Such algorithms operate by building a model from example inputs and using that to make predictions or decisions, rather than following strictly static program instructions. Machine learning is closely related to and often overlaps with computational statistics; a discipline that also specializes in prediction-making.”
Wikipedia
Hot Trends in Predictive Analytics

Big Data and Machine Learning can help you to
Predict consumer behavior more accurately
To unlock this value requires domain expertise to build
Comprehensible models for justifiable decisions
Big data-driven
learning
Domain expertise
Deeper Insights - Stronger Predictions – Better Decisions
Balance Number Crunching With Expertise Domain Expert – the Driver

Informing Origination Risk Score Development by Machine Learning
Improving Insurance Fraud Model With Social Network Variables
Evaluating Predictive Power of Text Data for a Peer Lending Network
Case Studies
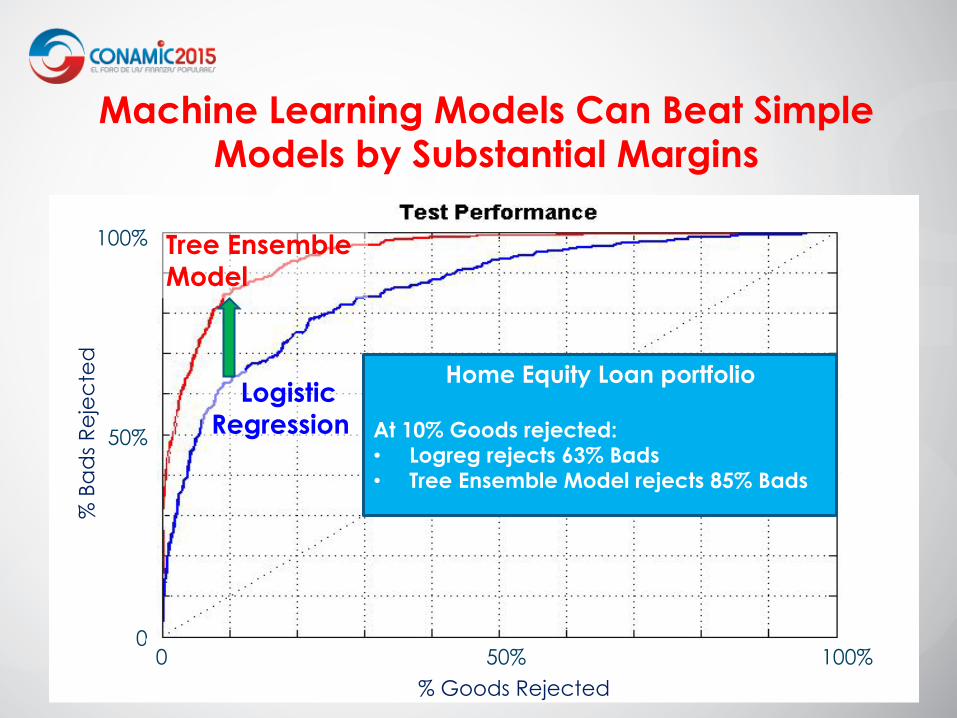
Tree Ensemble Model
Logistic Regression
100%
50%
0
% B
ad
s R
eje
cte
d
0 50% 100% % Goods Rejected
Home Equity Loan portfolio
At 10% Goods rejected: • Logreg rejects 63% Bads • Tree Ensemble Model rejects 85% Bads
Machine Learning Models Can Beat Simple Models by Substantial Margins

Training Data Prediction Function
Predictors
Ou
tco
me
s
Tree 1
Tree 2
Tree 200
Combine predictions
from 200 trees
Tree Ensemble Model
Predictors
Random Forest
Gradient Boosting
?
Scored!
New case
Sco
re
Anatomy of a Tree Ensemble Model

-2-1
01
2
-2-1
01
2-10
-5
0
5
10
Noisy training samples
Predictive relationship from which data were generated (“ground truth”)
Ou
tco
me
s
Predictors
Demonstration Problem

Tree 1
Weighted Average
-2-1
01
2
-2-1
01
2-10
-5
0
5
10
Stochastic Gradient Boosting 1’st Tree

Tree 1
Tree 5 Weighted Average
-2-1
01
2
-2-1
01
2-10
-5
0
5
10
Stochastic Gradient Boosting 5 Trees

Tree 1
Tree 200
Weighted Average
-2-1
01
2
-2-1
01
2-10
-5
0
5
10
Stochastic Gradient Boosting 200 Trees

2
11
1
3 2
5 11
7
1
3 2
5 11
7
1
2
11
1
3 2
5 11
7
1
3
5
7
1
3 2
5 11
7
3
5
7
1
3 2
5 11
7
1
3 2
5 11
7
1
3 2
5 11
7
1
3 2
5 11
7
6
4 10
12 13 6
8 9
4
13 6
8 9
8 9
4
13 6
8 9 8 9
4 10
12 13
10
12 13 6
8 9
4 10
12 13 6
8 9
10
12 4 10
12 13 6
10
12
4 10
12 13 6
8 9
4 10
12 13 6
8 9
4 10
12 13 6
8 9
Direct Inspection Yields a Black Box

DEBTINC 1.00 DELINQ 0.49 VALUE 0.45 CLAGE 0.40 DEROG 0.34 LOAN 0.25 CLNO 0.24 MORTDUE 0.23 NINQ 0.23 JOB 0.20 YOJ 0.20 REASON 0.07
Variable Importance Relative to most
important variable
Interaction Test Statistics Whether a variable interacts
with other variables
DEBTINC 0.029 VALUE 0.022 CLNO 0.014 CLAGE 0.013 DELINQ 0.010 YOJ 0.008 MORTDUE 0.007 LOAN 0.007 DEROG 0.006 JOB 0.006
Useful Diagnostic Information

Input/Output Simulation Create Deeps Insight Into Black Box
x1
)...( 1121 Pxxx
Condition values of all other predictors to data
Black box model (already trained)
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2 -8 -6 -4 -2 0 2 4 6 8
Sweep through range of Score as
function of
?

Non-intuitive Associations Can Lead to Unjustifiable Credit Decisions
Associa'on … (a,er controlling for all else) … Could lead to decision
Loan Applica'on: Consumers with 10% debt ra4o have lower risk score than consumers with 30% debt ra4o
Applicant is rejected because her debt ra4o is not high enough(!?)
Mortgage Lending: Consumers without previous mortgage have lower risk score than consumers with previous mortgage
Applicant can’t get a mortgage because he doesn’t have a mortgage(!?)
Practical Pitfalls Hindering Deployment of Machine Learning Models

PROS
Highly accurate fit to data
Discovery of unexpected associa4ons
Automated, produc4ve analysis
CONS
Hard to impose domain exper4se
Vulnerable to data limita4ons
May capture non-‐intui4ve associa4ons
Pros and Cons of Machine Learning Models for Credit Scoring
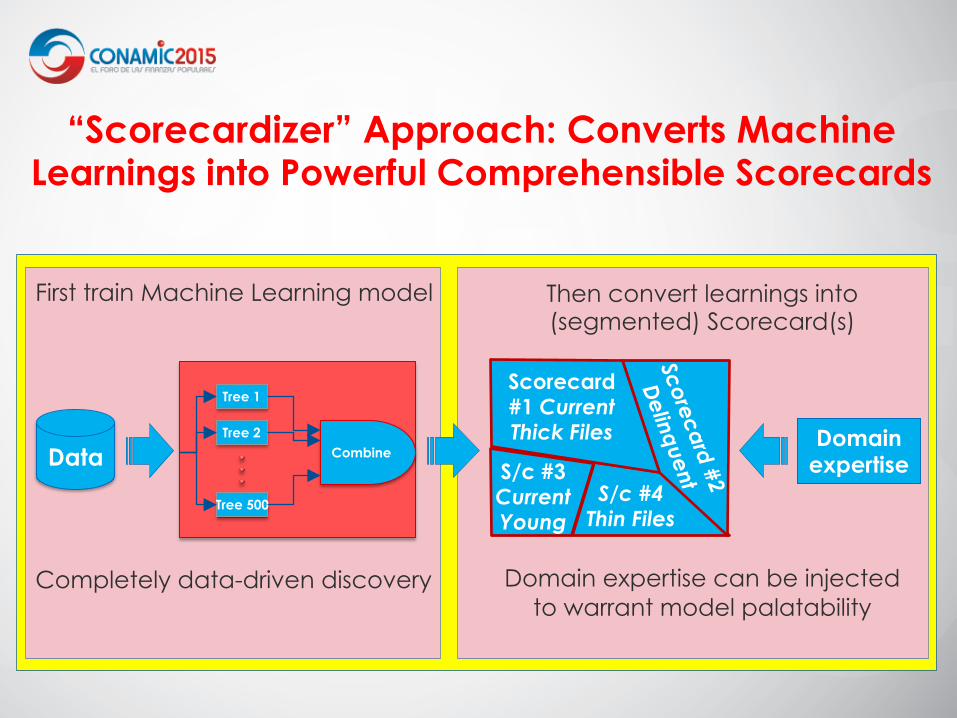
Then convert learnings into (segmented) Scorecard(s)
Domain expertise can be injected to warrant model palatability
First train Machine Learning model Completely data-driven discovery
Tree 1
Tree 2
Tree 500
Combine
Scorecard #1 Current Thick Files
S/c #4 Thin Files
S/c #3 Current Young
Domain expertise
“Scorecardizer” Approach: Converts Machine Learnings into Powerful Comprehensible Scorecards
Data

• In well-defined domains (e.g. credit scoring), can codify expertise
• Scorecardizer hooks into a database of expert rules, which enables fully automatic construction of palatable models – Manual refinement of the “end product” by domain experts is
still possible before deployment
Some examples of codified expertise
• Everything else equal:
– Score must not increase with higher Debt Ratio
– Score must not decrease with Applicant Age above 60 years
– For current accounts, a history of delinquency is bad
– For 2-cycle delinquents, history of mild delinquency can be good (these have shown their capacity to recover)
Can We Automate Expertise?

100
50
0
% B
ads
Rej
ecte
d
S/c #1 S/c #2 S/c #3 S/c #4 S/c #5
Scorecard segmentation discovered by Scorecardizer
Age of oldest credit line
Value of Current Property
5-fold cross-validated AUC
Tree Ensemble: incomprehensible 0.96
Scorecardizer: 5 comprehensible segmented scorecards
0.94
Single comprehensible scorecard 0.91
Results for Home Equity Loan Portfolio
0 50 100 % Goods Rejected

Informing Origination Risk Score Development by Machine Learning
Improving Insurance Fraud Model With Social Network Variables
Evaluating Predictive Power of Text Data for a Peer Lending Network
Case Studies

Florida $1 Million in
worker’s compensation fraud ring
New York $279 Million in
insurance fraud ring
20
Insurance Fraud and Networks

Predicting Fraud with Traditional and Network Data
Age Income Credit Score
Fraud
Adam 21 7,000 680 0
Beth 36 3,200 744 0
Carl 62 9,000 803 1
Dave 32 4,250 713 0
Eva 49 800 720 0
Customer-specific predictors
Traditional fraud score
Adam
Eva
Carl
Beth
Dave
Money transfer connection Similar address connection
Network variables
Predict
Combine

22
Enhancing Data with Network Variables
Age Income Credit Score
Adam 21 7,000 680
Beth 36 3,200 744
Carl 62 9,000 803
Dave 32 4,250 713
Eva 49 800 720
Avg. Age of Connections
# Money Transfers in Network per Month
Fraud
23 2 0
45 3 0
21 7 1
37 3 0
55 4 0
Variables derived from network • Graph algorithms • Feature generation • Feature evaluation • Feature selection

0
10
20
30
40
50
60
70
80
90
100
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
% D
ete
cte
d
% Reviewed
Boosting Auto Insurance Fraud Detection with Network Information
After adding network variables
Traditional variables only
+14%

24
Variable Importance Top 10 Variables
Rank Variable Name
1 Car Model
2 Total Paid Amount in Network
3 Policy Holder Occupation
4 Pre-accident Vehicle Value
5 Total # Payments in Network
6 # Phantom Vehicles in Network
7 ZIP Code of Policy Holder
8 Size of Network
9 Repairable Flag
10 Type of Accident
Network Variables

Informing Origination Risk Score Development by Machine Learning
Improving Insurance Fraud Model With Social Network Variables
Evaluating Predictive Power of Text Data for a Peer Lending Network
Case Studies

Call center records, claims, public records, collector notes, emails, blogs, social data, freeform comments, reviews, webpages, product descriptions,
transcribed phone calls, news articles…
Is there predictive value? How can we leverage it for comprehensible
models and justifiable decisions?
Semantic Scorecards & Topic Analysis
Ubiquitous Text Data Can Be Predictive and Yield New Insights

Hi, thanks for considering my request. I’m a student in Southern California. I have a great credit score. I will use this loan to pay my rent, books and tuition expenses. I’ve secured a part time job. My federal loans take care of all the rest. Thanks! Last summer we’ve extended our business for second-hand furniture into Southern Florida. We’ve been growing nice there. We need $4,000 to do enlarge showroom. Expecting to double sales thereafter. Sincerely, D.J. I need this loan to pay off higher rate credit card debt - fixed rate at 15%, that’s the only card I use.
Structured origination information
Generate traditional variables Extract keywords and topics
“Semantic Scorecard”: Combine traditional variables and text-based features in a comprehensible model
Prospect ID #5340164: “I need this loan to pay off higher rate credit card debt - fixed rate at 15%, that’s the only card I use”
Origination Risk for Peer-to-Peer Lending Network
Associated Loan Descriptions

Predictive Value of Text Data
Winner: Regular and text data Runner-up: Regular data only For comparison: Text data only
0 100
% Goods Rejected
100
0
% B
ads
Rej
ecte
d

Traditional variables (black) Keywords indicating elevated risk (red) Keywords indicating reduced risk (green)
Rank Variable Name
1 Credit Bureau Grade 2 Inquiries During Last 6 Months 3 Monthly Income 4 Months Since Last Record 5 need 6 Revolving Credit Balance 7 baby 8 Loan Purpose 9 business
10 would 11 Revolving Line Utilization 12 qualify 13 Length of Employment 14 sincerely 15 credit
Rank Variable Name
16 provided 17 sales 18 job 19 open 20 stable 21 payday 22 card 23 www 24 Open Credit Lines 25 Total Credit Lines 26 shop
Top Predictors From Automatic Variable Selection Lead to Unjustifiable Decisions

debt, free, consolidating, consolidated, card, credit, revolving, paying, payoff, sooner, quicker, clear, accumulated,
accrued, completely, …
business, equipment, sales, capital, store, marketing, experience, location, expand,
owner, retail, advertising, partner, inventory, products, profit, shop, restaurant, ...
Reduced risk topic: “Credit card consolidation”
Elevated risk topic: “Business-related items”
Gained New Insights Into Risk Topics Results Using “Latent Dirichlet Allocation”

• Machine learning, text- and social network analytics can yield deeper insights and stronger predictions, by combining traditional and novel data sources.
• Yet to make more profitable and justifiable decisions requires careful results interpretation and robust, explainable models.
• Domain expertise, combined with special methods and tools supporting interpretation, are of utmost importance for harnessing the potential of big data and machine learning.
Discussion





























