Embed Size (px)
Citation preview

Université des Sciences et Technologies de LilleU.F.R. de Mathématiques Pures et Appliquées
M306 : Intégration et ProbabilitésElémentaires
Notes de cours par Clément Boulonne
L3 Mathématiques 2008 - 2009

Table des matières
1 Dénombrer et sommer 51.1 Dénombrabilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.1.2 Ensembles dénombrables . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.1.3 Ensembles non dénombrables . . . . . . . . . . . . . . . . . . . . . . . . 9
1.2 Sommabilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.2.1 Motivations, rappels sur les séries . . . . . . . . . . . . . . . . . . . . . . 101.2.2 Familles sommables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3 Series doubles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2 Evénements et Probabilités 212.1 Notions de mesure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.2 Probabilités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.2.1 Vocabulaire probabiliste . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.2.2 Probabilité comme mesure . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.3 Exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.3.1 Ω fini ou dénombrable . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.3.2 Du fini à l’infini non dénombrable . . . . . . . . . . . . . . . . . . . . . . 282.3.3 Le cas Ω = R, F = B(R) . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.3.4 Probabilité uniforme / conditionnelle . . . . . . . . . . . . . . . . . . . . 31
2.4 Probabilité conditionnelle et indépendance . . . . . . . . . . . . . . . . . . . . . 322.4.1 Probabilité conditionnelle . . . . . . . . . . . . . . . . . . . . . . . . . . 332.4.2 Indépendance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3 Variables aléatoires réelles 363.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.2 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.2.2 Loi d’une variable aléatoire . . . . . . . . . . . . . . . . . . . . . . . . . 383.2.3 Fonctions de répartition . . . . . . . . . . . . . . . . . . . . . . . . . . . 383.2.4 Variables aléatoires indépendantes . . . . . . . . . . . . . . . . . . . . . . 39
3.3 Variables aléatoires discrètes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.3.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.3.2 Lois discrètes classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.4 Lois à densité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.4.1 Définitions et propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.4.2 Lois à densité classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2

3
4 Espérance d’une variable aléatoire 504.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 504.2 Espérence de variables aléatoires réelles positives . . . . . . . . . . . . . . . . . . 51
4.2.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 514.2.2 Exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.2.3 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.3 Espérance d’une variable aléatoire réelle . . . . . . . . . . . . . . . . . . . . . . 594.3.1 Définitions et généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.3.2 Propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.4 Moments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 634.4.1 h-moments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 634.4.2 Moments d’ordre r . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 664.4.3 Variance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5 Vecteurs aléatoires et indépendance 685.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 685.2 Vecteurs aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.2.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 685.2.2 Vecteurs aléatoires discrets . . . . . . . . . . . . . . . . . . . . . . . . . . 695.2.3 Vecteurs aléatoires à densité . . . . . . . . . . . . . . . . . . . . . . . . . 705.2.4 h-moments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.2.5 Covariance et variance d’une somme . . . . . . . . . . . . . . . . . . . . 73
5.3 Indépendance de variables et vecteurs aléatoires . . . . . . . . . . . . . . . . . . 755.3.1 Suites indépendantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 755.3.2 Composantes indépendantes . . . . . . . . . . . . . . . . . . . . . . . . . 755.3.3 Loi d’une somme de variables aléatoires indépendantes . . . . . . . . . . 775.3.4 Indépendance et espérance de produit . . . . . . . . . . . . . . . . . . . . 795.3.5 Indépendance, variance et covariance . . . . . . . . . . . . . . . . . . . . 80
5.4 Vecteurs aléatoires gaussiens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 815.4.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81

Références
Certaines parties du cours ont été recopiées des polycopiés de cours suivant :1) Ch. Suquet, Introduction au Calcul des Probabilités, 2007-20082) Ch. Suquet, Intégration et Probabilités Elémentaires, 2008-2009
Les cours sont téléchargeables sur le site IPEIS (Intégration, Probabilités Elémentaires etInitiation à la Statistique) de l’Université Lille 1.
4

Chapitre 1
Dénombrer et sommer
1.1 Dénombrabilité
1.1.1 MotivationDéfinition 1.1.1. Soit E un ensemble non vide, on dit que E est fini si il existe n ∈ N∗ telque E est en bijection avec 1, ..., n. n est unique et card(E) = n.
Problème. Soit E =]0, 1[ et F =]1,+∞[ deux ensembles infinies. E et F contiennent-ils"autant" d’éléments ?
Y-a-t-il "autant" de droites en dessous et au dessus de la diagonale ?
Définition 1.1.2. E est infini s’il existe une injection de N dans E.
Définition 1.1.3. Deux ensembles ont le même cardinal (fini ou infini) s’ils sont en bijection.
1.1.2 Ensembles dénombrablesDéfinition 1.1.4. Un ensemble E est dit dénombrable s’il existe une bijection de E sur N, auplus dénombrable s’il est fini ou dénombrable.
Exemple 1.1.1. • N est dénombrable.• 2N est dénombrable car :
f : N → 2Nn 7→ 2n est une bijection
5

6 Chapitre 1. Dénombrer et sommer
• N2 est dénombrable. On construit :
f : N2 → N(i, j) ∈ N 7→ (i+j)(i+j+1)
2 + j
Sur l’axe des abscisses, on a :n−1∑k=0
(k + 1) = n(n+ 1)2 = (i+ j)(i+ j + 1)
2 (1.1)
et pour un point quelconque, on ajoute à (1.1) la valeur j. On démontre que f est bijective.Soit l ∈ N, on veut (i, j) ∈ N2 tel que f(i, j) = l, la suite
(n(n+1)
2
)n∈N
est strictementcroissante, il existe un unique 1 n = n(l) tel que :
n(n+ 1)2 ≤ l <
(n+ 1)(n+ 2)2
alors on définit :j = l − n(n+ 1)
2et i = n− j. On peut vérifier que f(i, j) = l 2.
Proposition 1.1.1. Toute partie infinie d’un ensemble dénombrable est dénombrable.
Démonstration. Soit E un ensemble dénombrable et A une partie infinie de E.• Si E = N, on a A ⊂ N. Comme A est une partie non vide de N, on a un plus petit élémentpour a0. On définit donc a0 = mina ∈ A. On définit par récurrence :
ak = minA\a0, a1, ..., ak−1 car A\a0, a1, ..., ak−1 est non vide car A est infinie
On a ainsi :f : N → A
n 7→ an
f est bijective car :– f est injective car f strictement croissante.– f est surjective car si m ∈ A et n = card(a ∈ A, a < m = a0, ..., an−1 alorsf(n) = m.
1prouve l’injectivité2prouve la surjectivité

Chapitre 1. Dénombrer et sommer 7
• Si E quelconque, alors il existe g : E → N. On a : A ⊂ E, on définit alors g = g|A : A→ N.g(A) est une partie infinie de N donc elle est dénombrable donc il existe une bijectionh : g(A)→ N. On a ainsi :
h g : A→ N bijection
donc A est dénombrable.
Conséquence (Contraposée de la Proposition 1.1.1.). Si A est une partie infinie non dénom-brable d’un ensemble E alors E est non dénombrable.
Proposition 1.1.2. Un ensemble E est au plus dénombrable si et seulement il existe uneinjection de E dans N.
Démonstration. (⇐) ϕ : E → N injective. On a ϕ(E) ⊂ N• si ϕ(E) est fini alors E est fini.• si ϕ(E) est infini, d’après la Proposition 1.1.1., ϕ(E) est une partie infinie de N doncdénombrable. Donc : il existe ψ : ϕ(E)→ N bijective. On regarde ψ ϕ : E → N et ona que ψ ϕ est bijective.
Proposition 1.1.3. Le produit cartésien d’une famille finie d’ensembles au plus dénombrablesnon vide est au plus dénombrable. Ce produit est dénombrable dès qu’un ensemble de cettefamille est dénombrable.
Démonstration. Soit E1, ..., Ek la famille finie des ensembles au plus dénombrables et on note
E = E1 × E2 × ...× Ek = (x1, ..., xk), xi ∈ Ei, 1 ≤ i ≤ k
• E1 = E2 = ... = Ek = N, Nk est dénombrable. Par récurrence, on vérifie cette proposition :
(Pk) : il existe ϕk : Nk → Nk+1 bijective
Initialsation : ϕ1 : N→ N2 a été construit dans l’Exemple 1.1.1..Héréditié : si on a vérifie (Pk) est vérifie pour k ∈ N∗, c’est-à-dire :
ϕk = Nk → Nk+1 bijective
on définit :ϕk+1 : Nk+1 → Nk+2
(n,m) 7→ (ϕk(n),m) pour n ∈ Nk, m ∈ N
On vérifie que ϕk+1 est bijective. Ainsi ∀k ∈ N, on a vérifié la validité de (Pk). On a ainsi :
ϕk−1 ϕk−2 ... ϕ1 : N→ Nk bijective
car tous les ϕk sont bijectives. Donc Nk est dénombrable.• Cas général : soit 1 ≤ i ≤ k, on définit :
fi : Ei → N injective
et :f : E → Nk
(x1, ..., xk) 7→ (f1(x1), ..., fk(xk))

8 Chapitre 1. Dénombrer et sommer
f est injective car si x, x′ ∈ E tel que f(x) = f(x′), on aura :
(f1(x′1), ..., fk(x′k)) = (f1(x1), ..., fk(xk))
⇔ ∀i ∈ 1, ..., k, fi(x′i) = fi(xi)⇒ x′i = xi
3 donc x = x′. On définit :
f : E →︸︷︷︸injective
Nk ϕk−→︸︷︷︸surjective
N
On a ainsi :ϕk f : E → N injective
donc E est au plus dénombrable.
Exemple 1.1.2. Q est dénombrable car il s’injecte dans N∗×Z par l’unicité de la décompositionx ∈ Q, il existe un unique couple (p, q) ∈ Z× N∗ tel que :
x = p
q, PGCD(p, q) = 1
Or : Z × N∗ est dénombrable ⇒ Q est au plus dénombrable. N ⊂ Q ⇒ Q est infini doncdénombrable.
Proposition 1.1.4. Soit J un ensemble d’indices au plus dénombrable et (Aj)j∈J des ensemblesau plus dénombrables alors A =
⋃j∈J
Aj est au plus dénombrable.
Démonstration. Soit J = j0, j1, ..., jn, ... un ensemble non vide. Soit fj : Aj → N injective.On construit une suite (A′j)j∈J d’ensembles deux à deux disjoints tel que :
A =⋃j∈J
A′j
On a ainsi :A′j0 = Aj0 , A
′j1 = Aj0\Aj0
∀k ⊂ N, A′jk = Ajk
k−1⋃i=0
Aji
On montre que les (A′jk)k∈N sont disjoitns. On prend x ∈ A′jk ∩ A′jlpour k < l. Donc :
x ∈ A′jl = A′jl\(l−1⋃i=0
Aji
)
donc x 6∈l−1⋃i=0
Aji , en particulier : x 6∈ Ajk . Or x ∈ A′jk ⊂ Ajk impossible. Donc : A′jl ∩ A′jk
= ∅.
On montre ensuite que :A =
∞⋃k=0
Ajk
En particulier : ⋃k∈N
Ajk =⋃k∈N
A′jk
3par injectivité des fi

Chapitre 1. Dénombrer et sommer 9
• A′jk ⊂ Ajk ⇒⋃k∈N
A′jk ⊂⋃k∈N
Ajk = A
• On montre que A ⊂⋃k∈N
A′jk . Soit x ∈ A =⋃k∈N
Ajk et soit l = l(x) = mink ∈ N, x ∈
Ajk ⇒ x ∈ Ajl et x ∈⋃k∈N
Ajk .
On construit fj : Aj → N injective et f : A → J × N. Soit x ∈ A. Comme A =⋃j∈J
A′j et A′j
disjoint, il existe j = j(x) unique tel que x ∈ A′j(x) :
f(x) = (j(x), fj(x)(x))
f est injective car si f(x) = f(x′) alors (j(x), fj(x)(x)) = (j(x′), fj(x′)(x′)) ⇒ j(x) = j(x′) =j et fj(x) = fj(x′) 4 ⇒ x = x′.
On a que : J×N est dénombrable et f : A→ J×N injective donc A est au plus dénombrable.
Exemple 1.1.3. L’ensemble des points de discontinuités d’une fonction réglée sur [a, b] est auplus dénombrable.Rappel. f : [a, b]→ R est dite réglée si elle est limite uniforme de fonction en escalier sur [a, b].fn : [a, b]→ R. On note :• Dn : l’ensemble des points de discontinuité de fn (Dn fini)• Df : l’ensemble des points de discontinuité de f .
On a ainsi :Df ⊂
⋃n∈N
Dn
est au plus dénombrable (par la Proposition 1.1.4.).
1.1.3 Ensembles non dénombrablesProposition 1.1.5. L’ensemble 0, 1N (ensembles des suites à valeurs dans 0, 1) est infininon dénombrable.
Démonstration. Supposons qu’il soit dénombrable après 0, 1N = xn, n ∈ N. On a donc :
xn = xn0 , xn1 , ..., xnk , ... = (xnk)k∈N
On note :yik = 1− xik
et on construit :yn = y00 , y11 , ..., ynn , ...
et on voit que yn+1 6= xi,∀i ∈ 1, ..., n et yn ∈ 0, 1N. Contradiction !
4fj injective

10 Chapitre 1. Dénombrer et sommer
Proposition 1.1.6. Les ensembles suivants sont infinies et non dénombrables :1) P(N) (ensemble des parties de N).2) le segment [0, 1]3) R,C,Rd,Cd
Démonstration. 1) Soit :ϕ : P(N) → 0, 1N
A 7→ 1(A)tel que : (xi)i∈N :
xi =
1 si i ∈ A0 sinon
On a ϕ est bijective :ϕ−1(x) = i ∈ N tel que xi = 1
2) Soit :f : 0, 1N → [0, 1]
(xk)k∈N 7→∞∑k=0
xk3k+1
• f(x) ∈ [0, 1] et f(x) ≥ 0 car xk3n+1 ≥ 0 :
f(x) =∞∑k=0
xk3n+1 ≤
∞∑k=0
13k+1 = 1
31
1− 13
= 12
• Soit x, x′ ∈ 0, 1N tel que x 6= x′, x = (xk)k∈N, x′ = (x′k)k∈N et l = mink ∈ N, xk 6= x′k.On suppose xk = 1 et x′k = 0. On regarde f(x)− f ′(x) :
xl − x′l3k+1 −
∞∑k=l+1
xk − x′k3n+1 (∗)
Or : xk − x′k ≥ −1, donc :
−∞∑
k=l−1
xk − x′k3n+1 ≥ −
∞∑k=l+1
13n+1 = 1
3l+2 ×32 = −1
21
3l+1
Donc :(∗) = 1
3l+1 −12
13l+1 = 1
21
3l+1 > 0
⇒ f(x) 6= f(x′) donc f injective. Donc f(0, 1N) est une partie infinie non dénombrablede [0, 1].
– Construire une bijection de ]a, b[ dans R.
1.2 Sommabilité1.2.1 Motivations, rappels sur les sériesTrois notions de convergence de série
Rappel. Soit (un)n∈N, un ∈ R ou C :

Chapitre 1. Dénombrer et sommer 11
• convergence de série : convergence des sommes partielles.• convergence absolue : convergence de
∞∑n=0|un|.
• convergence commutative : si ∀f : N→ N bijective, on a :∞∑n=0
uf(n) converge.
Proposition 1.2.1.
convergence absoluem
convergence commutative
⇒ convergence
Exemple 1.2.1 (Convergence ; Convergence commutative ou absolue). Soit :
un = (−1)nn+ 1
On a : ∞∑n=0
(−1)nn+ 1
convergente mais elle n’est pas absolument convergente ou commutativement convergente caron peut construire f : N→ N tel que :
∞∑k=0
uf(n)
diverge. On a :
0 1 2 3 4 5 6 7 8 9 ...+ − + − + − + − + − ...
f(0) = 0 f(1) = 1 f(2) = 2 f(3) = 3 f(4) = 5 f(5) = 4 f(6) = 7 f(7) = 9 f(8) = 11 f(9) = 13 ...+ − + − + − − + − − ...
A l’étape : p : 1 > 0, 2p−1 < 0. Donc :+∞∑n=0
uf(n) diverge
Remarque. Séries à termes positifs : Sn =n∑k=0
admet toujours une limite dans R+ donc ∑+∞k=0 uk
a une sens dans R+.
Notation. •∞∑k=0
uk a un sens si convergence.
•∑k∈N
uk a un sens si l’ordre ne compte pas (convergence commutative).
1.2.2 Familles sommablesNotation. Soit (ui)i∈I avec I un ensemble d’indices infini et ui ∈ R ou C (ou plus généralementdans un espace vectoriel normé et complet E 5). On notera :
SK =∑i∈K
ui
si K ⊂ I fini.5mais il faudra remplacer | · | par ‖ · ‖

12 Chapitre 1. Dénombrer et sommer
Définition et propriétés
Définition 1.2.1. La famille (ui)i∈I est sommable de somme S, si ∀ε > 0, ∃J fini ⊂ I tel que∀K fini tel que J ⊂ K ⊂ I, on a : |S − SK | < ε.
Remarque. Si I = N et (ui)i∈N sommable alors la série∞∑i=0
ui est convergente car ∃J fini ⊂ N
tel que en posant N = max J alors :
∀n ≥ N,n∑i=0
ui = SK
et K = 0, ..., n ⊃ 0, ..., N ⊃ J .Attention ! La réciproque est fausse. On peut prendre uk = (−1)k
k+1 qui n’est pas une sériesommable.Propriété 1.2.2 (Unicité de la somme). La somme S d’une famille sommable est unique.Démonstration. (ui)i∈I est sommable de somme S et S ′ :
∀ε > 0 :
∃J fini ⊂ I tel que ∀K fini ⊃ J, |S − SK | < ε
∃J ′ fini ⊂ I tel que ∀K fini ⊃ J ′, |S ′ − SK | < ε(∗)
|S − S ′| ≤ |S − SK |+ |SK − S ′| ≤ 2ε (∀ε > 0)⇒ S = S ′
Propriété 1.2.3 (Invariance par permutation). Si ϕ : I → I est bijective et (ui)i∈I est som-mable de somme S alors (uϕ(i))i∈I est sommable de somme SDémonstration. On veut montrer que ∀ε > 0, ∃J ′ fini ⊂ I, ∀K ′ ⊃ J ′ avec K ′ fini, on a :∣∣∣∣∣∣
∑i∈K′
uϕ(i) − S
∣∣∣∣∣∣ < ε
or : ∑i∈K′
uϕ(i) =∑
l∈ϕ(K′)ul = Sϕ(K′)
On pose J ′ = ϕ−1(J), ∀K ′ fini ⊃ J ′, ϕ(K ′) ⊃ ϕ(J ′) = J . Donc : |Sϕ(K′) − S| < ε.
Remarque. Si I = N et (ui)i∈N est sommable alors la série ∑ui est commutativement conver-gente.Propriété 1.2.4 (Sommabilité et dénombrabilité). Si (ui)i∈I est sommable alors I ′ = i ∈I, ui 6= 0 est dénombrable.Démonstration. ∀n ∈ N∗, ∃Jn fini ⊂ I, ∀Kn ⊃ Jn, on ait |S − SKn| < 1
n. On pose :
H =⋃n∈N∗
Jn
H est dénombrable et on démontre que H = I ′. Soit i0 6∈ H, ∀n ∈ N, Kn = Jn ∪ i0. Alors :
|SJn − ui0 − S| <1n
d’où :|ui0| < |SJn + ui0 − S|︸ ︷︷ ︸
<1/n
+ |SJn − S|︸ ︷︷ ︸<1/n
<2n
⇒ ui0 = 0.

Chapitre 1. Dénombrer et sommer 13
Propriété 1.2.5 (Linéarité de la somme). (ui)i∈I et (u′i)i∈I deux familles sommales de sommesrespectives S et S ′ alors la famille (aui + bu′i)i∈I est sommable de somme aS + bS ′.
Lien avec les séries
Theorème 1.2.6. Si I est dénombrable alors on a équivalence entre :a) (ui) est sommable de somme S.
b) ∀f : N→ I bijection, la série+∞∑k=0
uf(k) est convergente.
Démonstration. a)⇒ b) Soit f : N→ I bijective. On veut montrer que :
∀ε > 0, ∃N ∈ N tel que ∀n ≥ N,
∣∣∣∣∣n∑k=0
uf(k) − S∣∣∣∣∣ < ε
On a :n∑k=0
uf(k) = SK
où K = f(0, ..., n). Il suffit de prendre N = max f−1(J)b)⇒ a) (par contraposée). On suppose que :
∃ε > 0, ∀J fini ⊂ I, ∃K fini ⊃ J vérifiant |S − SK | ≥ ε
On construit une suite (Kn)n∈N tel que :• Kn fini, ∀n ∈ N.• Kn ⊂ Kn+1, ∀n ∈ N.•⋃n∈N
Kn = I
• |S − SKn| ≥ εOn prend : ϕ : N→ I bijection.Etape 0 : on pose J0 = ϕ(0) alors il existe K0 fini ⊃ J0 tel que |SK0 − S| ≥ ε.Etape 1 : on prend k1 = maxϕ−1(K0)+ 1, J1 = ϕ(0, ..., k1) et il existe K1 fini ⊃ J1tel que |SK1 − S| ≥ ε. On a que J1 ! K0....Etape p : kp = maxϕ−1(Kp−1) + 1, Jp = ϕ(0, ..., kp) ! Kp−1. ∃Kp fini ⊃ Jp tel que|Skp − S| ≥ ε.On a ainsi : k0 < k1 < ... < kp suite strictement croissante. Si i ∈ I, ϕ−1(i) ≤ kn. Elletend vers +∞ pour un certain n⇒ i ∈ ϕ(0, ..., kn) = Jn ⊂ Kn.On a aussi : mn = card(Kn)− 1. On construit une bijection entre :
fn : mn−1 + 1, ...,mn → Kn\Kn−1
où mn−1 + 1, ...,mn et Kn\Kn−1 deux ensembles finis de même cardinal.
f : N→ I
tel que f |0,...,m0 = f0 et f |mn−1+1,...,mn = fn alors :
SKn =∑i∈Kn
ui =mn∑k=0
uf(k)

14 Chapitre 1. Dénombrer et sommer
et : ∣∣∣∣∣mn∑k=0
uf(k) − S∣∣∣∣∣ ≥ ε
pour une sous-suite (mn)n∈N strictement croissante. La série+∞∑k=0
uf(k) ne converge pas vers
S.
Cas particulier des familles des réels positifs
Proposition 1.2.7. Si (ui)i∈I est une famille de réels positifs :
a) Si M := supK fini ⊂I
SK < +∞ alors la famille (ui)i∈I est sommable de somme S.
b) Réciproquement, si la famille (ui)i∈I est sommable de somme S alors M := supK fini ⊂I
SK <
+∞
Démonstration. a)∀ε > 0, ∃J fini ⊂ I tel que M − ε < SJ ≤M
donc ∀K fini ⊃ J , Sk ≥ SJ donc M − ε < SJ ≤ SK ≤M donc |M − SK | < ε.
b)M = sup
K fini ⊂ISK = sup
K fini ⊃JSK ∀J fini ⊂ I
car :• sup
K fini ⊃JSK ≤ sup
K finiSK
• K fini ⊂ I. On a : SK ≤ SK∪J ≤ supK′ fini ⊃J
SK′ . Donc : supK fini
SK ≤ supK′ fini ⊃J
SK′ .
Donc :∀ε > 0, ∃J fini ⊂ I tel que ∀K fini ⊃ J ; SK ∈]S − ε, S + ε[
⇒M ∈]S − ε, S + ε[,∀ε > 0⇒M = S.
Remarque. Si I = N, sommabilité des (ui)i∈N ⇔ convergence de la série+∞∑i=0
ui en prenant
M = supK fini ⊂N
SK = supn∈N
n∑i=0
ui.
Proposition 1.2.8 (Principe de comparaison). (ui)i∈I et (vi)i∈I deux familles des réels positifstel que ui ≤ vi, ∀i ∈ I :• Si (vi)i∈I est sommable alors (ui)i∈I est sommable.• Si (ui)i∈I n’est pas sommable alors (vi)i∈I n’est pas sommable.
Remarque.∑i∈I
ui a toujours un sens dans R+,∑i∈I
= supK fini ⊂I
SK ∈ R+ si ui ≥ 0, ∀i ∈ I.

Chapitre 1. Dénombrer et sommer 15
Critère de Cauchy
Définition 1.2.2. (ui)i∈I vérifie le critère de Cauchy si :
∀ε > 0, ∃J fini ⊂ I tel que ∀K fini ⊂ I\J, |Sk| < ε (C)
Remarque. Si I = N, (C) implique le critère de Cauhy (C ′) pour les séries. Si J fini ⊂ N,N = max J , J ⊂ 0, ..., N alors q > p ≥ N , K = p+ 1, ..., q alors :
|SK | =
∣∣∣∣∣∣q∑
i=p+1ui
∣∣∣∣∣∣ < ε
Theorème 1.2.9. (ui)i∈I est sommable si et seulement si elle vérifie le critère de Cauchy.
Démonstration. Sommabilité ⇒ (C) :
∀ε > 0, ∃J fini ⊂ I tel que ∀K fini ⊃ J, |SK − S| < ε
Soit H ⊂ I\J , donc :
|SH | = |SJ∪H − SJ | ≤ |SJ∪H − S|+ |S − SJ | ≤ 2ε
(C)⇒ Sommabilité : On peut montrer que I ′ = i ∈ I, ui 6= 0 est au plus dénombrable.• I ′ fini ⇒ (ui)i∈I sommable.• I ′ infini, dénombrable.
1) On peut trouver f : N→ I ′ une bijection et on pose : vk = uf(k). On montre ainsique : ∑∞n=0 vk est convergente.
∀ε > 0, ∃J fini ⊂ I ′, ∀K fini ⊂ I\J, |SK | < ε∣∣∣∣∣∣q∑
k=p+1vk
∣∣∣∣∣∣ ≤ ε
Il suffit de prendre mε = max f−1(J) + 1. ∀p, q : mε ≤ p < q. On aura :∣∣∣∣∣∣q∑
k=p+1vk
∣∣∣∣∣∣ =∣∣∣∣∣∣
q∑k=p+1
uf(k)
∣∣∣∣∣∣ = |Sf(p+1,...,q)| < ε
Donc : ∑ vk converge vers S.2) On montre que (ui)i∈I est sommable de somme S avec S = ∑+∞
k=0 uf(k). Soit J ′ =f(0, ...,mε) avec mε = max f−1(J)+1. On montre que ∀K fini ⊃ J ′, |S−SK | ≤ε. On prend SK\J ′ + SJ ′ :
|S − SK | ≤ |S − SJ ′ |+ |SK\J ′ ⇔ |S − SK | ≤∣∣∣∣∣S −
mε∑k=0
uf(k)
∣∣∣∣∣︸ ︷︷ ︸|∑+∞
k=mε+1 uf(k)≤ε
+ |SK\J ′ |︸ ︷︷ ︸≤ε(C)
Corollaire. Si (ui)i∈I est absolument sommable alors (ui)i∈I est sommable.

16 Chapitre 1. Dénombrer et sommer
Démonstration. Critère de Cauchy :
∀ε > 0, ∃J fini ⊂ I, ∀K fini ⊂ I\J,∑i∈K|ui| ≤ ε
L’inégalité triangulaire nous dit que :∣∣∣∣∣∑i∈K
ui
∣∣∣∣∣ ≤∑i∈K|ui| ≤ ε
Proposition 1.2.10. Soit I dénombrable, si ui (avec i ∈ I) est à valeurs dans R ou C ou dansun espace vectoriel normé complet, on a l’équivalence :(1) (ui)i∈I est sommable(2) (ui)i∈I est absolument sommable(3) (uf(k))k∈N est commutativement convergente pour f : N→ I bijective.
Corollaire. Soit (ui)i∈I une famille sommble :(a) Pour tout ensemble L ⊂ I (fini ou infini), (ui)i∈L est sommable et on note SL sa somme.(b) ∀ε > 0, ∃J fini ⊂ I, ∀K fini ⊃ J , |S − SK | ≤ ε et si L ⊃ J est infini alors |S − SL| ≤ ε.
(c) Si L1, ..., Ln sont deux à deux disjoints de I et si L =n⋃i=1
Li alors SL =n∑i=1
SLi.
Démonstration. (a) ∀ε > 0, ∃J fini ⊂ I tel que ∀K fini : K ⊂ I\J , |SK | ≤ ε. En posantJ ′ = J ∩ L fini ⊂ L alors ∀K ′ fini ⊂ L\J ′ alors |SK′| ≤ ε car K ′ ⊂ I\J .
(b)|S − SL| ≤ |S − SK | ≤ |SK − SL|
alors ∀n ∈ N, ∃Jn fini ⊂ L tel que ∀Kn fini , Jn ⊂ Kn ⊂ L, on a :
|SL − SKn| ≤1n
On pose : K ′n = Jn ∪ J fini ⊂ L, d’où :
|S − SL| ≤ |S − SK′n|︸ ︷︷ ︸≤ε
+ |SK′n − SL|︸ ︷︷ ︸≤1/n
≤ ε+ 1n≤ ε pour n→ +∞
(c) ∀i ∈ 1, ..., n, ∀ε > 0, ∃Ji fini ⊂ Li tel que ∀K fini Ji ⊂ K ⊂ Li :
|SLi − SK | ≤ ε
En posant J = J1 ∪ ... ∪ Jn et soit K fini tel que J ⊂ K ⊂ L :
K =n⋃i=1︸︷︷︸
disjointe
(K ∩ Li)
SK =n∑i=1
SKi

Chapitre 1. Dénombrer et sommer 17
où Ki = K ∩ Li, K ⊃ J où K ∩ Li ⊃ Ji = J ∩ Li :∣∣∣∣∣∣∣∣n∑i=1
SLi︸︷︷︸(a)
−SK
∣∣∣∣∣∣∣∣ ≤n∑i=1|SLi − SKi | ≤ nε
car Ji ⊃ Ki︸︷︷︸fini
⊂ Li.∑ni=1 SLi est la somme de la famille (ui)i∈L, c’est-à-dire :
SK =∞∑i=1
SLi
Theorème 1.2.11 (Principe de sommation par paquets). Soit (ui)i∈I une famille sommablede somme S et (Iα)α∈A une partition de I alors :
∑i∈I
ui =∑α∈A
∑i∈Iα
ui
Remarque. D’après (a) du Corollaire précédent : (ui)i∈Iα est sommable de somme notée SIα ,∀α ∈ A⇒ la famille (SIα)α∈A est sommable.
Démonstration. On veut montrer que : ∀ε > 0, ∃B fini ⊂ A tel que ∀C fini B ⊂ C ⊂ A :∣∣∣∣∣∑α∈C
SIα − S∣∣∣∣∣ ≤ ε d’après (c) du Corollaire
Si C est fini : ∑α∈C
SIα = S⋃α∈C Iα
=∑i∈IC
ui
où IC =⋃α∈C
Iα.
∀ε > 0, ∃J fini ⊂ I, ∀Kfini (ou non : (b)) ⊃ J, |S − SK | ≤ ε (∗)
. Soit :B = α ∈ A tel que Iα ∩ J 6= ∅
∀i ∈ J , ∃!α(i) ∈ A tel que i ∈ Iα(i) tel que B = α(i), i ∈ J ⇒ B est fini et si C fini ⊃ Balors : ∑
α∈CSIα = SIC
et :IC =
⋃α∈C
Iα ⊃⋃α∈B
Iα = IB ⊃ J
on applique (∗) à K (infini). K = IC .
Remarque. (Iα)α∈A une partition de I tel que (ui)i∈Iα est sommable, ∀α ∈ A et (SIα)α∈A estsommable n’implique pas la sommabilité des (ui)i∈I .
Exemple 1.2.2. I = Z, Ik = k,−k, uk = k, ∀k ∈ Z.

18 Chapitre 1. Dénombrer et sommer
Theorème 1.2.12. Soit (ui)i∈I une famille tel que ui ∈ R+, ∀i ∈ I et soit (Iα)α∈A une partitionde I. On a alors l’inégalité dans R+ :
∑i∈I
ui =∑α∈A
∑i∈Iα
ui
Remarque. On a : R+ = R+ ∪ +∞ :
x+ (+∞) = (+∞) + x = (+∞) (∀x ∈ R+) (+∞) + (+∞) = (+∞)
Démonstration. On note : ∑i∈I
ui = supK fini ⊂I
SK = M
M ′ = supB fini ⊂A
SIB
où IB = ⋃α∈B Iα et :
SIB =∑i∈IB
ui =∑α∈B
SIα
– Si K fini ⊂ I alors ∃B fini ⊂ A tel que K ⊂ IB :
B = α(k), k ∈ K = α ∈ A tel que K ∩ Iα 6= ∅
où ∀k ∈ K, ∃α(k) ∈ A tel que Iα(k). On a : SK ≤ SIB donc M ≤M ′.–
SIB = supL fini ⊂IB
SL ≤M
∀B fini ⊂ A⇒M ′ ≤M .
1.3 Series doublesCas particulier où I = N2, (uk,l)(k,l)∈N2 une famille à valeurs R, C ou un espace vectoriel
normé complet.
Définition 1.3.1. La série double de terme général (uk,l)(k,l)∈N2 est dite convergente (resp. ab-solument convergente) si et seulement si la famille (uk,l)(k,l)∈N2 est sommable (resp. absolumentsommable). La somme S de la famille est appelée somme de la série double :
S =∑
(k,l)∈N2
uk,l
Définition 1.3.2. (uk,l)(k,l)∈N2 est convergente si et seulement si (|uk,l|)(k,l)∈N2 est convergente.
Proposition 1.3.1. (uk,l)(k,l)∈N2 est convergente si et seulements si les suites suivantes sontbornées :• Tn =
∑(k,l)∈N2 ; k+l≤n
|uk,l|
• T ′n =∑
(k,l)∈N2 ;max(k,l)≤n|uk,l|

Chapitre 1. Dénombrer et sommer 19
Démonstration. (uk,l)(k,l)∈N2 est sommable si et seulement si (|uk,l|)(k,l)∈N2 est sommable si etseulement :
supK fini ⊂N2
∑(k,l)∈K
|uk,l| < +∞
Reste à montrer que :
supK fini ⊂N2
∑(k,l)∈K
|uk,l| = supK=0,...,n2,n∈N
∑(k,l)∈K
|uk,l| = supn∈N
Tn
Theorème 1.3.2 (Interversion des sommations). (a) si uk,l ∈ R+, ∀(k, l) ∈ N2 alors :
∑(k,l)∈N2
uk,l =+∞∑k=0
(+∞∑l=0
uk,l
)=∞∑l=0
( ∞∑k=0
uk,l
)(∗)
(∗) est valable dans R+.
(b) Si la série double∑
(k,l)∈N2
uk,l est convergente alors ∀k ∈ N, la série (simple)+∞∑l=0
uk,l et
∀l ∈ N, la série (simple)∞∑k=0
uk,l converge et :
∑(k,l)∈N2
uk,l =+∞∑k=0
(+∞∑l=0
uk,l
)=∞∑l=0
( ∞∑k=0
uk,l
)(∗)
On a ainsi :N2 =
⋃k∈N
(k × N)︸ ︷︷ ︸Ik
=⋃j∈N
(N× j)︸ ︷︷ ︸Ij
Démonstration. Principe de sommation par paquets.
Remarque. En pratique, on vérifie la convergence de (uk,l)(k,l)∈N2 en montrant que :
∑(k,l)∈N2
|uk,l| =∞∑k=0
( ∞∑l=0|uk,l|
)=∞∑l=0
( ∞∑k=0|uk,l|
)< +∞
Cas particulier : produit de séries
Theorème 1.3.3 (Séries produits). Si (uk)k∈N et (vk)k∈N deux séries absolument convergentesalors la série double de terme général si (ukvl)(k,l)∈N est convergente et on a :
S =∑
(k,l)∈N2
ukvl =( ∞∑k=0
uk
)( ∞∑l=0
vl
)=∑n∈N
∑k+l=n
ukvl
Démonstration.
T ′n =∑
(k,l)∈0,...,n2
|ukvl| =∞∑l=0
(n∑k=0|ukvl|
)=∞∑l=0
(|vl|
n∑k=0|uk|
)
=(
n∑k=0|uk|
)(n∑l=0|vl|)≤( ∞∑k=0|uk|
)( ∞∑l=0|vl|)

20 Chapitre 1. Dénombrer et sommer
donc (uk,l) est convergente. Principe de sommation par paquets :
∑(k,l)∈N2
uk,l =∞∑k=0
( ∞∑l=0
ukvl
)
=∞∑k=0
(uk∞∑l=0
vl
)=( ∞∑l=0
vl
)( ∞∑k=0
uk
)∑
(k,l)∈N2
ukvl =∑n∈N
∑(k,l)∈In
ukvl︸ ︷︷ ︸=∑n
k=0 ukvn−k

Chapitre 2
Evénements et Probabilités
2.1 Notions de mesureLa notion de mesure englobe la notion de grandeurs géométriques (longueur, aire, volume),
physiques (masse) et probabilités. On va définir une fonction m d’un ensemble A vers R+ telqu’elle satisfait les conditions suivantes :a) croissance : si A ⊂ B, m(A) ≤ m(B).b) additivité : si A ∩ B = ∅, m(A ∪ B) = m(A) + m(B), sous réserve que m(A), m(B) et
m(A ∪B) soient définies.On peut étendre l’additivité sur des suites finies A1, ..., An tel quem(A1∪...∪An) = m(A1)+...+m(An) si les Ai sont deux à deux disjoints (ceci n’est pas forcément vrai pour des suites infinies).Mais des fois, m(A) n’est pas clairement définis. On va pour cela voir quelques définitions.
Définition 2.1.1 (Tribu). Une famille F de parties de Ω est appelée tribu (ou σ-algèbre) surΩ si elle :a) possède l’ensemble vide : ∅ ∈ Fb) est stable par passage au complémentaire : ∀A ∈ F , AC ∈ F .c) est stable par union dénombrable : (∀i ∈ N∗, Ai ∈ F)⇒ ⋃
i∈N∗ Ai ∈ F .
Définition 2.1.2 (Mesure). Soit F une tribu sur Ω. On appelle mesure positive sur (Ω,F) uneapplication :
m : F → [0,+∞]vérifiant :a) m(∅) = 0b) m est σ-additive : pour toute suite (Ai)i∈N∗ d’éléments de F deux à deux disjoints :
m
⋃i∈N∗
Ai
=∞∑i=1
m(Ai)
Remarque. La réunion des Ai est invariante par permutation sur les indices et chaque Ai est àson tour union dénombrable d’ensembles Bi,j ∈ F (j ∈ N∗ deux à deux, on a clairement :⋃
i∈N∗Ai =
⋃i∈N∗
⋃j∈N∗
Bi,j =⋃
(i,j)∈N∗2Bi,j
Exemple 2.1.1. 1) La plus petite tribu sur Ω est F = Ω, ∅
21
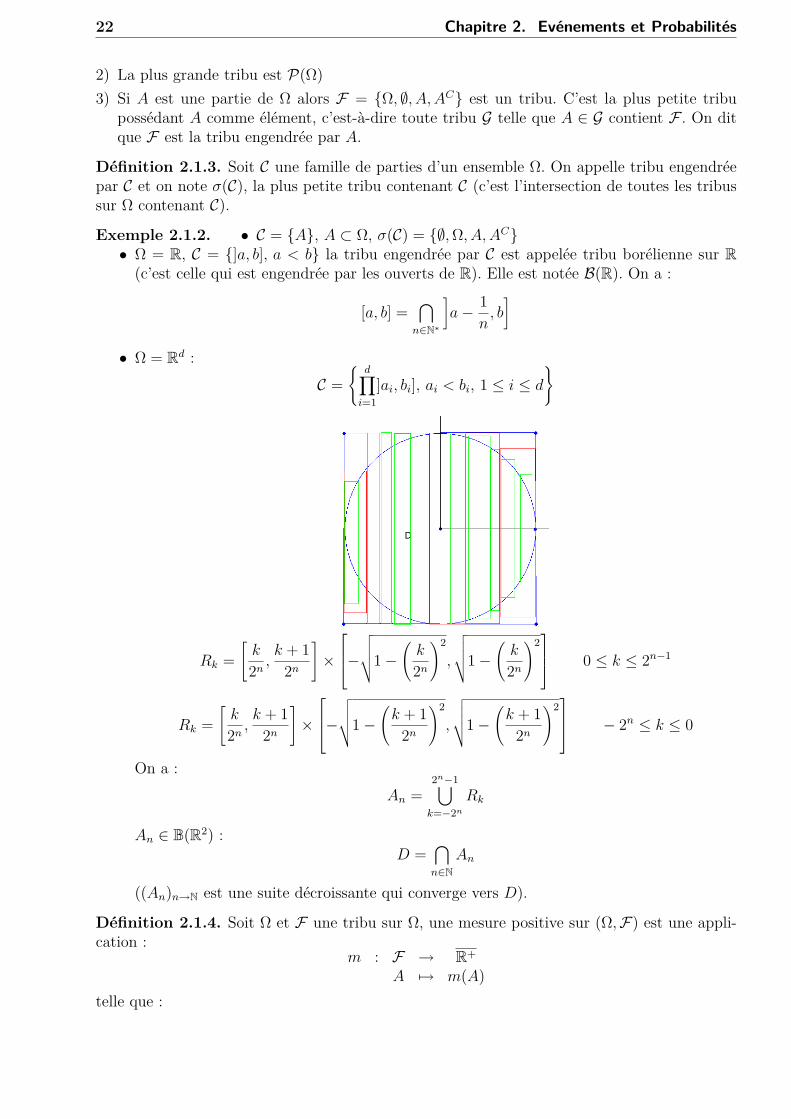
22 Chapitre 2. Evénements et Probabilités
2) La plus grande tribu est P(Ω)3) Si A est une partie de Ω alors F = Ω, ∅, A,AC est un tribu. C’est la plus petite tribu
possédant A comme élément, c’est-à-dire toute tribu G telle que A ∈ G contient F . On ditque F est la tribu engendrée par A.
Définition 2.1.3. Soit C une famille de parties d’un ensemble Ω. On appelle tribu engendréepar C et on note σ(C), la plus petite tribu contenant C (c’est l’intersection de toutes les tribussur Ω contenant C).
Exemple 2.1.2. • C = A, A ⊂ Ω, σ(C) = ∅,Ω, A,AC• Ω = R, C = ]a, b], a < b la tribu engendrée par C est appelée tribu borélienne sur R(c’est celle qui est engendrée par les ouverts de R). Elle est notée B(R). On a :
[a, b] =⋂n∈N∗
]a− 1
n, b]
• Ω = Rd :C =
d∏i=1
]ai, bi], ai < bi, 1 ≤ i ≤ d
Rk =[k
2n ,k + 12n
]×
−√√√√1−
(k
2n
)2
,
√√√√1−(k
2n
)2 0 ≤ k ≤ 2n−1
Rk =[k
2n ,k + 12n
]×
−√√√√1−
(k + 12n
)2
,
√√√√1−(k + 12n
)2 − 2n ≤ k ≤ 0
On a :An =
2n−1⋃k=−2n
Rk
An ∈ B(R2) :D =
⋂n∈N
An
((An)n→N est une suite décroissante qui converge vers D).
Définition 2.1.4. Soit Ω et F une tribu sur Ω, une mesure positive sur (Ω,F) est une appli-cation :
m : F → R+
A 7→ m(A)telle que :

Chapitre 2. Evénements et Probabilités 23
a) m(∅) = 0
b) si (An)n∈N est une suite d’éléments disjoints de F alors m⋃n∈N
An
=∑n∈N
m(A).
Remarque.∑n∈N
m(An) a une sens dans R+.
Définition 2.1.5. Une mesure m sur (Ω,F) est dite :a) discrète si il existe A au plus dénombrable tel que m(Ω\A) = 0 (c’est le cas si Ω est au plus
dénombrable)b) diffuse ou continue si ∀ω ∈ Ω, ω ∈ F et m(ω) = 0c) finie si m(Ω) < +∞
Exemple 2.1.3. 1) (Ω,F), ω0 ∈ Ω :
m(A) =
1 si ω0 ∈ A0 sinon
m est appelée mesure de Dirac en ω0, elle est notée δω0 et elle est finie et discrète. On peutvérifier que c’est bien une mesure.
2) mesure ponctuelle sur (Ω,F) : (ωi)i∈I une famille au plus dénombrable de Ω, (ai)i∈I unefamille de réels positifs.
m =∑i∈I
aiδωi m(A) =∑i∈I
aiδωi(A) ∀A ∈ F
Cette mesure est discrète. On montre que c’est une mesure :a) m(∅) = 0.b) (An)n∈N 2 à 2 disjoints :
m
⋃n∈N
An
=∑i∈I
ai δωi
⋃n∈N
An
︸ ︷︷ ︸=∑
n∈N δωi (An)
=∑i∈I
ai∑n∈N
δωi(An)
=∑n∈N
∑i∈I
aiδωi(An) =∑n∈N
m(An)
Toute mesure sur un ensemble Ω au plus dénombrable est une mesure ponctuelle : Ω =ωi, i ∈ I avec I au plus dénombrable
m =∑i∈I
aiδωi
où ai = m(ωi).Cas particulier : ai = 1, ∀i ∈ I : mesure de comptage sur (Ω,P(Ω))
m(A) =
card(A) si A est fini+∞ si A est infini

24 Chapitre 2. Evénements et Probabilités
3) Mesure de Lebesgue (Existence admise) : sur (R,B(R)), il existe une unique mesure λ telleque :
λ(]a, b]) = b− a ∀(a, b) ∈ R2, a < b
sur (Rd,B(Rd), il existe une unique mesure λd telle que :
λd
(d∏i=1
]ai, bi])
=d∏i=1
(bi − ai) pour ai < bi, i ≤ i ≤ d
La mesure de Lesbegue généralise la notion de longueur pour d = 1, d’aire pour d = 2, devolume pour d = 3.Propriétés :(1) ∀x ∈ Rd, λd(x) = 0 (λd est diffuse) car, pour d = 1 1, :
x =⋂n∈N∗
]x− 1
n, x]
On a aussi : A ∪B ⇒ m(A) ≤ m(B). Donc :
λd(x) ≤ λd
(]x− 1
n, x])
︸ ︷︷ ︸1/n
∀n ∈ N∗
Si A ∈ B(Rd) est au plus dénombrable alors λd(A) = 0 car A =⋃x∈Ax
(2) λd est invariant par translation : si A ∈ B(Rd) et c ∈ Rd alors tc(A) = A+ c ∈ B(Rd) etλd(tc(A)) = λd(A).
(3) λd par isométrie (de Rd) 2.(4) si h est une homothétie de Rd (h : x 7→ cx pour c ∈ R) alors ∀B ∈ B(Rd), h(B) ∈ B(Rd)
et λd(h(B)) = |c|dλd(B).(5) Si E est un sous-espace affine de Rd alors λd(E) = 0.(6)
λd
(d∏i=1
[ai, bi])
= λd
(d∏i=1
]ai, bi])
4) Mesure de Lebesgue-Stieljes sur (R,B(R)), soit F une fonction croissante sur R et continueà droite alors il exsite une unique mesure µF sur (R,B(R)) tel que :
µF (]a, b]) = F (b)− F (a) a < b
Si F = id, on obtient la mesure de Lebesgue.
2.2 Probabilités2.2.1 Vocabulaire probabilisteDéfinition 2.2.1. Une expérience aléatoire est l’ensemble des résultats possibles sur une ex-périence dont on ne connait pas à l’avance ces résultats. L’ensemble des résultats possibles estdécrit par l’ensemble Ω.
1on peut génraliser pour d > 1 en utilisant le produit2symétries, rotations ...

Chapitre 2. Evénements et Probabilités 25
Exemple 2.2.1. • – On lance une pièce : Ω = p, f– On lance deux pièces : Ω = p, f2 = (p, p), (p, f), (f, p), (f, f)– On lance n pièces : Ω = p, fn, card(Ω) = 2n• Nombre d’appels téléphoniques sur un standard :– Ω = N pour un jour.– Ω = N7 pour 7 jours.• Flèche sur une cible : Ω = D, un résultat est un point du disque.• Trajectoire d’un objet sur une surface : Ω = f : I → R2 = C0(I,R2)
Définition 2.2.2. F est l’ensemble des événements observables. On a :• ∅ = événement impossible• Ω = événement certain• ω = événement élémentaire• A ∈ F , B ∈ F , A ∩ B = ∅ : on dit que A et B sont deux événements impossibles ouincompatibles.• AC = événement contraire•⋃i∈IAi : "au moins un des Ai se réalise"
•⋂i∈IAi : "tous les Ai se réalisent"
2.2.2 Probabilité comme mesureDéfinition 2.2.3. Soit (Ω,F) un espace probabilisable, une probabilité P sur (Ω,F) est unemesure de masse 3 totale 1. Autrement dit :
P : F → [0, 1]A 7→ P (A)
telle que :a) P (Ω) = 1b) si (An)n∈N est une suite dénombrable d’événements deux à deux disjoints alors :
P
⋃n∈N
An
=∑n∈N
P (An)
Définition 2.2.4. (Ω,F , P ) est un espace de probabilité.
Propriété 2.2.1. (1) P (∅) = 0(2) ∀n ∈ N∗, A1, ..., An dans F disjoints alors :
P
(n⋃i=1
Ai
)=
n∑i=1
P (Ai)
(3) A ∈ F , P (AC) = 1− P (A)(4) A ∈ F , B ∈ F , A ⊂ B, P (A) ≤ P (B).(5) A ∈ F , B ∈ F , A ⊂ B, P (A ∪B) = P (A) + P (B)− P (A ∩B)(6) continuité séquentiellement monotone :
3c’est-à-dire que P (Ω) = 1

26 Chapitre 2. Evénements et Probabilités
a) (Bn)n∈N une suite croissante d’événéments de F qui converge vers B 4, alors :
P (B) = limn→+∞
P (Bn)
b) Si (Cn)n∈N une suite décroissante d’événements de F qui converge vers C 5 alots :
P (C) = limn→+∞
P (Cn)
(7) Si (An) est une suite quelconque de Fa)
P
(n⋃i=1
Ai
)≤
n∑i=1
P (Ai)
b)
P
⋃n∈N
An
≤ ∑n∈N
P (An)
Démonstration de la continuité séquentielle. a) Soit B =⋂n∈N
Bn.
On pose :• A0 = B0• A1 = B1\B0• A2 = B2\B1• Ak = Bk\Bk+1, ∀k ∈ N∗• les (An)n∈N sont disjoints car soit ω ∈ Ai = Bi\Bi−1 ⊂ B alors i ≤ j − 1, Bi ⊂ Bj−1 doncω ∈ Bj−1 ce qui contredit ω ∈ Aj = Bj\Bj−1.•⋃n∈N
Bn =⋃n∈N
An
On a ainsi :
P (B) = P
⋃n∈N
An
=∑n∈N
P (An) = limn→+∞
n∑k=1
P (Ak)
or :n∑k=1
P (Ak) = P
(n⋃k=1
Ak
)= P (B0 ∪ (B1\B0) ∪ (B2\B1) ∪ ... ∪ (Bn\Bn−1)) = P (Bn)
b) Passage au complémentaire en possant Bn = CCn .
4Mathématiquement :
Bn ⊂ Bn+1 ∀n ∈ N⋃n∈N Bn = B
5Mathématiquement :
Cn+1 ⊂ Cn ∀n ∈ N⋂n∈N Cn = C

Chapitre 2. Evénements et Probabilités 27
Démonstration de la propriété (7) de la Propriété 2.2.1.
P
⋃n∈N
An
≤ ∑n∈N
P (An)
Bn =n⋃k=0
Ak
suite croissante de F ⋃n∈N
Bn =⋃n∈N
An
Donc :
P
⋃n∈N
An
= P
⋃n∈N
Bn
(6)= limn∈+∞
P (Bn)
or :P (Bn) = P
(n⋃k=0
Ak
)≤
n∑k=0
P (Ak)R+
≤+∞∑k=0
P (Ak)
Proposition 2.2.2 (Formule de Poincarré). Soit A1, ..., An n évémenements de F :
P
(n⋃i=1
Ai
)=
n∑i=1
P (Ai) +n∑k=2
(−1)k+1 ∑1≤i1<...<ik≤n
P (Ai1 ∩ ... ∩ Aik)
=n∑k=1
(−1)k+1 ∑1≤i1<...<ik≤n
P (Ai1 ∩ ... ∩ Aik)
2.3 Exemples
2.3.1 Ω fini ou dénombrable• Ω = ωi, i ∈ I, I fini ou dénombrable. On a ainsi : F = P(Ω) si Ω est fini, card(F) =
2card(Ω). Si Ω est infini dénombrable, F est infini et dénombrable.• P est une mesure ponctuelle :
P =∑i∈I
piδωi où pi = P (ωi)
et :P (A) =
∑i:ωi∈A
pi
Donc : ∑i∈I
pi = 1
• Cas particulier : l’équiprobabilité sur Ω fini et ∀i ∈ I fini, pi = p alors p = 1card(Ω) et
∀A ∈ P(Ω), P (A) = card(A)card(Ω)

28 Chapitre 2. Evénements et Probabilités
• Exemples concrets : Problème des anniversaires : "Soit n étudiants pris au hasard :
Ω = 1, ..., 365n
On a que ω = ω1, ..., ωn est un événement élémentaire si ωi = numéro du jour anniver-saire du ième étudiant (1 ≤ i ≤ n), ω ∈ 1, ..., 365. Quelle est la probabilité pour quedeux étudiants aient leur anniversaire le même jour ? On introduit A = ω = (ω1, ..., ωn) ∈Ω tel que ∃i 6= j, ωi = ωj et AC = ω = (ω1, ..., ωn) ∈ Ω, ∀i 6= j, ωi 6= ωj. On a ainsi :
P (AC) = card(AC)card(Ω) = 365× 364× ...× (365− n+ 1)
365n
On en déduit que :
P (A) = 1− P (AC) = 365× 364× ...× (365− n+ 1)365n
• Ω = N, F = P(N, loi de Poisson de paramètre λ > 0 qu’on note Pois(λ) :
P (n) = λn
n! e−λ ∀n ∈ N
• Ω = N∗, F = P(N∗), loi géométrique de paramètre p ∈]0, 1[ :
P (n) = p(1− p)n−1
2.3.2 Du fini à l’infini non dénombrableExemple du schéma "succès-echec"
a) Cas fini : on définit n épreuves avec chacune deux issues possibles(1) Succès avec probabilité p (p ∈]0, 1[)(0) Echec avec probabilité 1− pOn a : Ωn = 0, 1n muni de P(Ωn).
Ωn = (ω1, ..., ωn), ωi ∈ 0, 1, 1 ≤ i ≤ n
ωi = résultat de la i-ème épreuve
On prend :
Pn(ω1, ..., ωn) =n∏i=1
pωi(1− p)1−ωi = pk(ω)(1− p)n−k(ω)
où :k(ω) =
n∑i=1
ωi (nombre de succès lors des n épreuves)
On peut vérifier que : ∑ω∈Ωn
Pn(ω) = 1
b) Cas infini : suite infinie de telles épreuves :
Ω = 0, 1N∗ = ω = (ωi)i∈N∗ , ωi ∈ 0, 1, ∀i ∈ N∗

Chapitre 2. Evénements et Probabilités 29
– On définit d’abord une tribu F . Soit n fixé, tous les éléments qui dépendent des n premièresépreuves doivent être dans F . On a : Ωn = 0, 1n, Ω′n+1 = 0, 1Nn avec Nn = k ∈ N, k >n.
Fn = A× Ω′n+1, A ∈ P(Ωn)
On peut vérifier que Fn est une tribu. On veut que F contiennent tous les Fn, c’est-à-dire :
C :=⋃n∈N∗Fn ⊂ F
Remarque.⋃n∈N∗
n’est pas une tribu.
Exemple 2.3.1. Soit A = "au moins un succès" et An = "au moins un succès avant n".On a ainsi : ⋃
n∈N∗An
An ∈ Fn donc An ∈⋃k∈N∗Fk mais
⋃n∈N∗
An 6∈⋃k∈N∗Fk. On prend donc F = σ(C) tribu
engendrée par C.– On définit ensuite P sur (Ω,F), on sait que si A′ = A× Ω′n+1 ∈ Fn alors :
P (A′) = Pn(A) =∑
(ω1,...,ωn)∈Ap∑n
i=1 ωi(1− p)n−∑n
i=1 ωi
où Pn(A) est une probabilité sur Ωn. P (A′) permet de définr P sur C :
Fn ⊂ Fn+1
si B′ = B × Ω′n+1 ∈ Fn alors B′ = B × 0, 1 × Ω′n+2 ∈ Fn+1.
P (B′) = Pn+1(B × 0, 1) =∑
(ω1,...,ωn+1)∈B×0,1p∑n+1
i=1 ωi(1− p)n+1−∑n+1
i=1 ωi
= ∑
(ω1,...,ωn)∈Bp∑n
i=1 ωi(1− p)n−∑n
i=1 ωi
(1− p)
+ p
∑(ω1,...,ωn)∈B
p∑n
i=1 ωi(1− p)n−∑n
i=1 ωi
= Pn(B)
On admet qu’on peut étendre P en une probabilité sur F = σ(C).Exemple 2.3.2. A = "au moins 1 succès" :
A =⋃n∈N∗
An ∈ F
An ⊂ An+1 (propriété de continuité monotone séquentielle), P (A) = limn→+∞
P (An) = 1 .On a :
P (An) = 1− P (ACn ) = 1− (1− p)n
Remarque. AC = "avoir que des echecs" = (ωi)i∈N, ωi = 0, ∀i ∈ N contient un seulélément : P (AC) = 0.

30 Chapitre 2. Evénements et Probabilités
2.3.3 Le cas Ω = R, F = B(R)Soit P une probbilité sur (R,B(R)) :
Définition 2.3.1. La fonction de répartition de P est l’application :
F : R → [0, 1]x 7→ P (]−∞, x])
Propriété 2.3.1. (1) F est croissante, continue à droite, limité à gauche.(2) lim
x→−∞F (x) = 0 et lim
x→+∞F (x) = 1
(3) ∀x ∈ R, P (x)) = F (x) − F (x−) avec F (x−) = limt→x,t<x
F (t) et x ∈ R, P (x) 6= 0 estau plus dénombrable
(4) F caractérise P (admis)
Démonstration. 1) • x ≤ x′ alors ]−∞, x] ⊂]−∞, x′]⇒ F (x) ≤ F (x′).•⋂n∈N
]−∞, x− 1/n] ∈]−∞, x]⇒ F (x) = limn→+∞
F (x+ 1n
) = F (x+)
2) ⋂n∈N∗
]−∞, n] = ∅ ⇒ 0 = limn→+∞
F (−n) (car F strictement décroissante)
⋃n∈N∗
]−∞, n] = R⇒ 1 = limn→+∞
F (n) (car F strictement croissante)
3) On a :x =
⋂n∈N∗
]x− 1
n, x]
strictement décroissante et ]x− 1n, x] =]−∞, x]\]−∞, x− 1
n:
P(]x− 1
n, x])
= F (x)− F (x− 1n
)
P (x) = limn→+∞
(F (x)− F (x− 1
n))
= F (x)− F (x−)
(Px)x∈R est une famille sommable :
SK =∑x∈K
P (x) = P (K) ≤ 1 ∀K ⊂ R, K fini
donc :sup
K fini ⊂RSK ≤ 1
en particulier, il est fini et la famille est sommable.
Chapitre 2. Evénements et Probabilités 31
Remarque. On a :R =
⋃x∈Rx
mais :P (R) 6=
∑x∈R
P (x)
Theorème 2.3.2 (Admis). Si F est une fonction croissante, continue à droite et telle que :
limx→−∞
F (x) = 0 limx→+∞
F (x) = 1
alors il existe une unique probabilité sur (R,B(R)) telle que P (]a, b]) = F (b)− F (a).
Remarque. – P (]a, b[) = F (b−)− F (a)– P ([a, b]) = F (b)− F (a−)– P (]b,+∞[) = 1− F (b)– P ([b,+∞[) = 1− F (b−)
2.3.4 Probabilité uniforme / conditionnelleSoit m une mesure sur (Ω,F) et soit B ∈ F tel que m(B) > 0 alors :
mB : F → [0, 1]A 7→ mB(A) = m(A∩B)
m(B)
définit une probabilité sur (Ω,F).
Application 2.3.1. Probabilité uniforme sur un borélien, m = λd : mesure de Lebesgue sur(Rd,B(Rd)) :
∀A ∈ B(Rd) P (A) = λd(A ∩B)λd(B)
(si B ∈ B(Rd), λd(B) > 0) est appelé probabilité uniformé sur B.
Exemple 2.3.3. 1) Probabilité uniforme sur [a, b] sur (R,B(R)) :
P (A) = λ(A ∩ [a, b])b− a
F (x) = P (]−∞, x]) = P (]−∞, x] ∩ [a, b])b− a
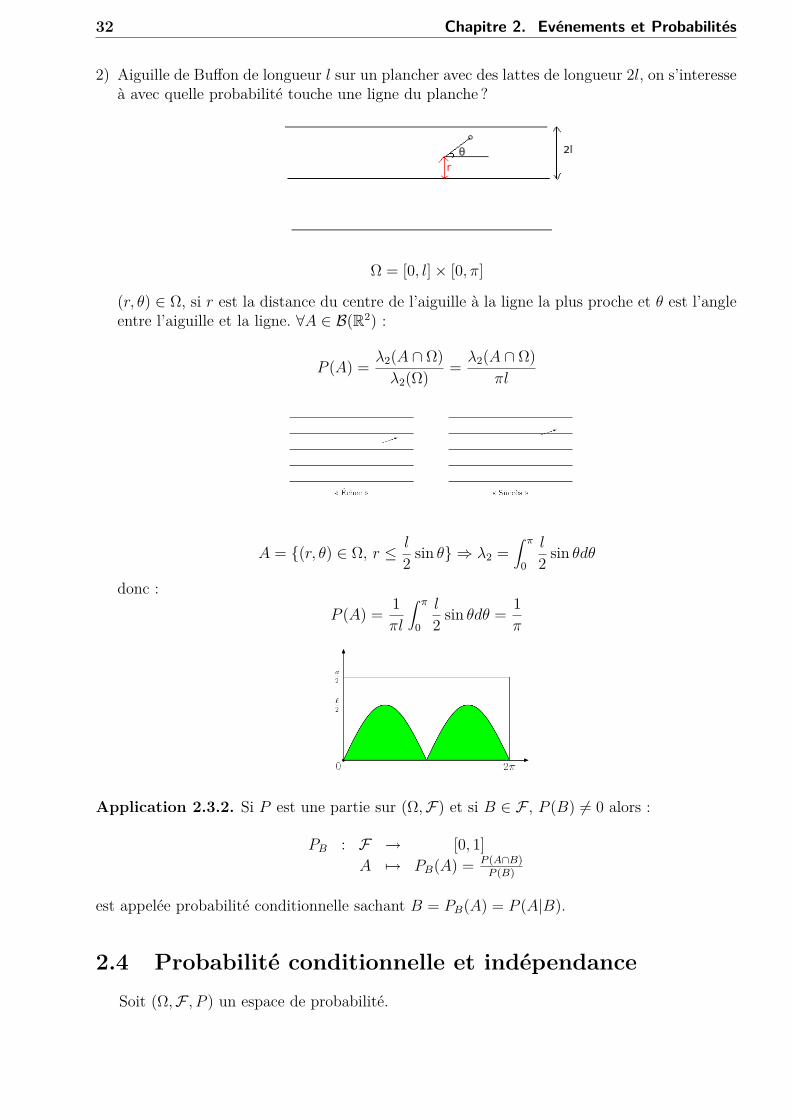
32 Chapitre 2. Evénements et Probabilités
2) Aiguille de Buffon de longueur l sur un plancher avec des lattes de longueur 2l, on s’interesseà avec quelle probabilité touche une ligne du planche ?
Ω = [0, l]× [0, π]
(r, θ) ∈ Ω, si r est la distance du centre de l’aiguille à la ligne la plus proche et θ est l’angleentre l’aiguille et la ligne. ∀A ∈ B(R2) :
P (A) = λ2(A ∩ Ω)λ2(Ω) = λ2(A ∩ Ω)
πl
A = (r, θ) ∈ Ω, r ≤ l
2 sin θ ⇒ λ2 =∫ π
0
l
2 sin θdθ
donc :P (A) = 1
πl
∫ π
0
l
2 sin θdθ = 1π
Application 2.3.2. Si P est une partie sur (Ω,F) et si B ∈ F , P (B) 6= 0 alors :
PB : F → [0, 1]A 7→ PB(A) = P (A∩B)
P (B)
est appelée probabilité conditionnelle sachant B = PB(A) = P (A|B).
2.4 Probabilité conditionnelle et indépendanceSoit (Ω,F , P ) un espace de probabilité.

Chapitre 2. Evénements et Probabilités 33
2.4.1 Probabilité conditionnelleExemple 2.4.1.
Ω = (F, F ); (F,G); (G,F ); (G,G)la réalisation d’un événement H modifie la probabilité de la réalisation de A.
H = "avoir une fille" = (F, F ); (F,G); (G,F )
A = "avoir un garçon"Si on sait que la famille contient une fille, la probabilité que l’autra ait un garçon est de 2
3 .
P (A|H) = P (A ∩H)P (H) = 2/4
3/4 = 23
Propriété 2.4.1. H, P (H) > 0 :1)
PH : F → [0, 1]A 7→ PH(A) = P (A∩H)
P (H) = P (A|H)
est une probabilité sur (Ω,F) :
PH(AC) = 1− PH(A)
PH(Ω) = 1
2) Régle de conditionnement successif : si A1, ..., An, n éléments de F tel que P (A1∩...∩An−1) 6=0 alors :
P (A1 ∩ ... ∩ An) = P (A1)P (A2|A1)P (A3|A1 ∩ A2)...P (An|A1 ∩ ... ∩ An−1)
3) Formule de Bayes : (Hi)i∈I une famille d’événements disjoints au plus dénombrable tel queP (Hi) 6= 0 (∀i ∈ I) et A ∈ F :
P (Hj|A) = P (A|Hj)P (Hj)∑i∈I P (A|Hi)P (Hi)
Exemple 2.4.2. Lors du partiel, on donne un QCM avec m choix possibles. p désigne laprobabilité de connaître son cours et ainsi de répondre corectement sinon on répond au hasard.Si l’étudiant repond correctement, quelle est la probabilité qu’il connaisse son cours ? On désigneles événements suivants :
R = "l’étudiant répond correctement"

34 Chapitre 2. Evénements et Probabilités
H = "l’étudiant répond au hasard"
C = "l’étudiant connait son cours" = HC
On a ainsi :P (R|C) = 1, P (R|H) = 1
m, P (C) = p
on veut connaître P (C|R) :
P (C|R) = P (R|C)P (C)P (R|C)P (C) + P (R|H)P (H) = p
p+ 1m
(1− p) = mp
m(p− 1) + 1
2.4.2 IndépendanceDe deux événements
Définition 2.4.1. A et B sont deux événements indépendants si :
P (A ∩B) = P (A)P (B)
Remarque. 1) si 0 < P (B) < 1 alors A et B indépendants ⇔ P (A|B) = P (A|BC)(= P (A)).2) Deux événements incompatibles de probabilité non nule ne sont pas indépendants.
Indépendance mutuelle
Exemple 2.4.3.A = "l’ainé est une fille" P (A) = 1/2
B = "le cadet est un garçon" P (B) = 1/2
C = "les enfants ont le même sexe" P (C) = 1/2
On a :A et B indépendants car P (A ∩B) = P ((F,G)) = 1
4 = P (A)P (B)
A et C indépendants
B et C indépendants
A, B et C sont indépendants deux à deux mais :
P (C|A ∩B) = 0
La probabilité de C est modifié si A et B sont réalisés. A, B et C ne sont pas mutuellementindépendants.

Chapitre 2. Evénements et Probabilités 35
Définition 2.4.2. A, B et C sont (mutuellement) indépendants si :
P (A ∩B) = P (A)P (B)
P (A ∩ C) = P (A)P (C)
P (B ∩ C) = P (B)P (C)
et :P (A ∩B ∩ C) = P (A)P (B)P (C)
Définition 2.4.3. Une suite (An)n∈N∗ d’événements est constituée d’événements indépendantssi toute sous famille finie est constituée d’événements indépendants.
∀I ⊂ N∗, I fini, P(⋂i∈IAi
)=∏i∈IP (Ai)
Définition 2.4.4 (Epreuves indépendantes répétées). Des épreuves répétées sont dites indé-pendantes si toute famille d’événements (An)n∈N∗ tel que An ne dépend que du résultat de lan-ième épreuve est une famille d’événements indépendants.
Exemple 2.4.4 (Le schéma "succès-echec"). Soit :
Ω = 0, 1N∗
Si = "succès à la i-ème épreuve"
Les (Si)i∈N∗ sont indépendants et P (Si) = p. Si on note :
An = "au moins un succès avant la n-ième épreuve"
ACn = "aucun succès avant la n-ième épreuve" =n⋂i=1
SCi
Alors :P (An) = 1− P (ACn ) = 1− (1− p)n
Soit :
Bn,k = "exactement k succès avant la n-ième épreuve" =⋃
I⊂1,..,n,card(I)=k︸ ︷︷ ︸union disjointe
(⋂i∈ISi
)∩
⋂i∈1,...,n\I
SCi
︸ ︷︷ ︸
de probabilité pk(1−p)n−k
P (Bn,k) =∑
I∈1,...,n,card(I)=kpk(1− p)n−k = Ck
npk(1− p)n−k

Chapitre 3
Variables aléatoires réelles
3.1 IntroductionOn s’intéresse à une fonction des événements élémentaires (ω).
Exemple 3.1.1. Dans le cas de la somme des deux dés :
Ω = 1, ..., 62, ω = (i, j)
avec i (respectivement j) est le résultat du dé bleu (respectivement rouge). P équiprobabilitésur (Ω,P(Ω)). On introduit la fonction :
X : Ω → Ω′(i, j) 7→ i+ j
avec Ω′ = 2, ..., 122 = X(Ω), i + j est la somme des 2 chiffres i, j obtenus. On veut savoirP (A2) tel que :
A2 = "la somme des 2 dés soit 2" = (i, j) ∈ Ω, i+j = 2 = (i, j) ∈ Ω, X(i, j) = 2 = X−1(2) = (1, 1)
Donc :P (A2) = PX(2) = P (X = 2) = P (X−1(2)) = 1
36De même pour P (A3) :
A3 = "la somme des 2 dés soit 3" = (i, j) ∈ Ω, X(i, j) = 3 = X−1(3) = (2, 1), (1, 2)
Donc :P (A3) = PX(3) = P (X = 3) = P (X−1(3)) = 2
36Plus généralement, pour 2 ≤ k ≤ 12 :
P (X = k) =
k−136 si k ≤ 7
13−k36 si k > 7
L’applicationX transporte la probabilité P sur (Ω,P(Ω)) en une probabilité PX sur (Ω′,P(Ω′)).
∀B ∈ P(Ω′) :PX(B) = P (X−1(B)) = P (X ∈ B)
avec :X−1(B) = ω ∈ Ω, X(ω) ∈ B
image réciproque de l’ensemble B par X.
36

Chapitre 3. Variables aléatoires réelles 37
Définition 3.1.1. Soit deux espaces (Ω1,F1) et (Ω2,F2) et X une application de Ω1 dans Ω2,on dit que X est F1 −F2 mesurable si ∀B ∈ F2, X−1(B) ∈ F1.
La notion de mesurabilité est conservée par composition : somme, produit...
3.2 GénéralitésSoit (Ω,F , P ) un espace de probabilité.
3.2.1 DéfinitionsDéfinition 3.2.1. Une application X de Ω dans R est une variable aléatoire si c’est uneapplication F − B(F) mesurable, c’est-à-dire :
∀B ∈ B, X−1(B) ∈ F (∗)
Remarque. •
X−1(⋃i∈IBi
)=⋃i∈IX−1(Bi)
X−1(⋂i∈IBi
)=⋂i∈IX−1(Bi)
X−1(AC) = (X−1(A))C
• Comme B(R) est engendré par ]a, b], (a, b) ∈ R2 ou ] −∞, x], x ∈ R, pour vérifier(∗), il suffit :
∀x ∈ R, X−1(]−∞, x]) ∈ F• Si X est une variable aléatoire alors Y = X2 est une variable aléatoire.
Y −1(]−∞, x]) = Y ≤ x = X2 ≤ x =
∅ si x < 0−√x ≤ X ≤
√x = X−1([−
√x,√x]) si x > 0
• De même pour Z = 1X
avec ∀ω ∈ Ω, X(ω) 6= 0.
1X≤ x⇔
1 ≤ xX et X > 01 ≥ xX et X < 0
Z−1(]−∞, x]) = 1X≤ x
=
X ≤ 0 si x = 0(
X ≤ 1x
∩ X > 0
)∪(X ≥ 1
2
∩ X < 0
)=
1x≤ X < 0
si x < 0(
X ≤ 1x
∩ X < 0
)∪(X ≥ 1
2
∩ X > 0
)= X < 0 ∪
X ≥ 1
2
si x > 0
• Si X est une variable aléatoire et g : R→ R une application B(R)−B(R) mesurable alorsY = g(X) est mesurable car :
Y −1(B) = g(X) ∈ B = X ∈ g−1(B)︸ ︷︷ ︸B(R)
︸ ︷︷ ︸F

38 Chapitre 3. Variables aléatoires réelles
3.2.2 Loi d’une variable aléatoireDéfinition 3.2.2. Soit X : Ω→ R est une variable aléatoire alors l’application PX = P X−1
sur B(R) définie par :PX : B(R) → [0, 1]
B 7→ PX(B)
où PX(B) = P (X−1(B)) = P (X ∈ B est une probabilité sur (R,B(R)) appelée loi de X (sousP ).
Remarque. X−1(B) ∈ F donc PX est bien définie.
Démonstration. • PX(R) = P (X ∈ R) = P (ω ∈ Ω, X(ω) ∈ R) = P (Ω) = 1• (Bn)n∈N une famille de boréliens de R disjoints 2 à 2 :
PX
⋃n∈N
Bn
= P
X−1
⋃n∈N
Bn
= P
⋃n∈N
X−1(Bn)︸ ︷︷ ︸disjoints
=∑n∈N
P (X−1(Bn)) =∑n∈N
PX(Bn)
Remarque. Deux variables aléatoires X et Y définies sur (Ω,F) peuvent avoir la même loi (sousP ) sans être égale.
Exemple 3.2.1. X(i, j) = i résultat du dé bleuY (i, j) = j résultat du dé rouge
X et Y ont la même loi :P (X = Y ) = 1
6
Définition 3.2.3. Soit H ∈ F tel que P (H) > 0 alors loi de X sous PH est appelée loiconditionnelle de X sachant H.
PX|H : B(R) → [0, 1]B 7→ PX|H(B) = P (X ∈ B|H)
3.2.3 Fonctions de répartitionDéfinition 3.2.4. Soit X une variable aléatoire réelle sur Ω alors la fonction de répartition deX est celle de PX , c’est-à-dire c’est l’application :
FX : R → [0, 1]x 7→ PX(]−∞, x]) = P (X ≤ x)
Remarque. Si FX = FY alors X et Y ont la même loi.
Exemple 3.2.2. X(i, j) = i+ j

Chapitre 3. Variables aléatoires réelles 39
3.2.4 Variables aléatoires indépendantesDéfinition 3.2.5. n variables réelles X1, ..., Xn définies sur (Ω,F , P ) sont indépendantes si∀Ai ∈ B(R), ∀i ∈ 1, .., n :
P
(n⋂i=1Xi ∈ Ai
)=
n∏i=1
P (Xi ∈ Ai)
Exemple 3.2.3.X(i, j) = i
Y (i, j) = jsont indépendantes (il suffit de le vérifier pour A = i et
B = j).
3.3 Variables aléatoires discrètes(Ω,F , P ) est un espace de probabilité, X : Ω → R une variable aléatoire réelle dont la loi
est notée PX .
3.3.1 GénéralitésDéfinition 3.3.1. X est discrète si X(Ω) est au plus dénombrable.
Remarque. Si X est discrète alors sa loi PX est discrète : il existe A ∈ B(R) tel que PX(R\A) =0⇔ PX(A) = 1.
Si PX est une loi discrète alors :
PX =∑x∈A
pxδx avec px = P (X = x) = PX(x)
A est au plus dénombrable et PX(A) = 1.
Fonctions de répartition :
FX(x) = PX(]−∞, x]) =∑
y∈A,y≤xPy

40 Chapitre 3. Variables aléatoires réelles
Si A = xk, k ∈ I, I fini ou I = N alors :
FX(x) =∑
xk∈A,xk≤xpxk =
∑k∈I
pxk 1[xk,+∞[(x)︸ ︷︷ ︸δxk (]−∞,x])
Si de plus, xk ≤ xk+1 alors FX est constante sur l’intervalle [xk, xk+1[.
Proposition 3.3.1. La loi de X est discrète si la somme du saut de sa fonction de répatitionFX vaut 1.
Démonstration. En effet, il existe A au plus dénombrable :
PX(A) = 1 =∑x∈A
PX(x) (∗)=∑x∈A
(FX(x+)− FX(x−)) = 1
Réciproquement, FX admet un nombre au plus dénombrable de discontinuité, on la note A :
⇒ PX(A) = 1(via (∗))
3.3.2 Lois discrètes classiques(1) Loi de Bernouilli : X suit la loi de Bernouilli de paramètre p ∈ [0, 1], X ∼ Bern(p) si :
PX = pδ1 + (1− p)δ0
P (X = 1) = p P (X = 0) = 1− pExemple 3.3.1. Si A ∈ F alors X = 1A suit une loi de Bernouilli : X ∼ Bern(P (A)).
(2) Loi uniforme sur x1, ..., xn : X ∼ Unif(x1, ..., xn) si :
PX =n∑i=1
1nδxi
∀i ∈ 1, ..., n :P (X = xi) = 1
n
Exemple 3.3.2. X(i, j) = i, X ∼ Unif(1, ..., 6).

Chapitre 3. Variables aléatoires réelles 41
(3) Loi binomiale de paramètres n ∈ N∗ et p ∈ [0, 1] : X ∼ Bin(n, p) si :
PX =n∑k=0
Cknp
k(1− p)n−kδi
P (X = k) = Cknp
k(1− p)n−k
C’est la loi du nombre de succès dans une suite de n épreuves indépendantes avec 2 issuespossibles :• succès de probabilité p• échec de probabilité 1− pExemple 3.3.3. Xi = 1Ai , (Ai)i∈1,...,n forme une famille de n variables aléatoires indé-pendants de même probabilité p :
Sn =n∑i=1
Xi
c’est la somme de n variables aléatoires de loi de Bern(p) indépendantes.
Sn = Bin(n, p)
(4) Loi hypergéométrique :Soit une population de N personnes tel que :M personnes votent pour A
N −M personnes votent pour B
On fait un sondage de n personnes et on regarde X le nombre de personnes parmi les npersonnes qui votent pour A.
P (X = k) = CkMC
n−kN−M
CnN
pour
0 ≤ k ≤M
0 ≤ n− k ≤ N −M
On dit que : X ∼ Hyp(N,M, n).Proposition 3.3.2. Si M(n)
N−−−−→N→+∞
p et si XN ∼ Hyp(N,M(n), n) alors ∀k ∈ 0, ..., n :
limN→+∞
P (XN = k) = P (X = k) = Cknp
k(1− p)n−p si X ∼ Bin(n, p)
(5) Loi géométrique de paramètre p ∈ [0, 1] sur N∗ : X ∼ Geo(p) si :
PX =+∞∑k=1
p(1− p)k−1δk
∀k ∈ N :P (X = k) = p(1− p)k−1
C’est la loi d’apparition du premier succès dans une suite infinie d’épreuves indépendantesayant deux issues possibles :• succès p• échec 1− pRemarque. P (X > n) = (1− p)n

42 Chapitre 3. Variables aléatoires réelles
(6) Loi de Poisson de paramètre α > 0 : X ∼ Pois(α) si :
PX =∑k∈N
αk
k! e−αδk
Autrement dit :∀k ∈ N, P (X = k) = αk
ke−α
Proposition 3.3.3. Si (pn)n∈N∗ est une suite dans ]0, 1[ tel que npn → α quand n→ +∞alors ∀k ∈ N :
limn→+∞
Cknp
kn(1− pn)n−k = αk
k! e−α
Si Xn ∼ Bin(n, pn) et X ∼ Pois(α) alors :
∀k ∈ N, limn→+∞
P (Xn = k) = P (X = k)
(on dit que Xn converge en loi vers X).
Démonstration. Voir M206 partie Probabilités
Conséquence. Si "n grand et np petit" alors si X ∼ Bin(n, p), on peut approcher P (X = k)par P (Y = k) où Y ∼ Pois(np).Caractère universel : La loi de Poisson peut modéliser :– Nombre de numéros sur un standard téléphonique– Accidents d’avion– ...
3.4 Lois à densité(Ω,F , P ) espace de probabilités. X est une variable aléatoire réelles sur Ω de loi PX .
3.4.1 Définitions et propriétésDéfinition 3.4.1. Une densité f est une fonction à valeurs dans R+ telle que :1) f est définie sur R\K où K fini à valeurs positives ou vide.2) f est localement Riemann-intégrable sur R\K.3) L’intégrale généralisée :
I =∫ +∞
−∞f(t)dt
est convergente et I = 1.
Remarque. Si f est définie, positive sur ]a, b[ tel que∫ ba f(t)dt = 1 alors on peut définir g(t) =
f(t)1]a,b[(t) qui est une densité sur R.
Exemple 3.4.1.g(t) = 1
2√t1]0,1[(t)
Chapitre 3. Variables aléatoires réelles 43
Définition 3.4.2. On dit que la loi de X a pour densité F sous P si :
P (X ∈]a, b]) =∫ b
af(t)dt pour tout a ≤ b
Remarque. Il n’y a pas d’unicité de la densité.Mais :
Lemme 3.4.1. Si X et Y ont pour densité respective f et g tel que ∃t0 ∈ R :• f(t0) 6= g(t0)• f et g sont continues en t0.
alors X et Y n’ont pas la même loi.
Démonstration.
Soit ε > 0 :∃α1 > 0 tel que ∀x ∈]t0 − α1, t0 + α1[= I1, f(t) ≤ f(t0) + ε
∃α2 > 0 tel que ∀x ∈]t0 − α2, t0 + α2[= I2, g(t) ≥ g(t0)− εε est tel que f(t0) + ε < g(t0)− ε alors [a, b] = I1 ∩ I2.
∀t ∈ [a, b] : f(t) ≤ f(t0) + ε < g(t0)− ε ≤ g(t)
alors :∫ b
af(t)dt ≤ (b− a)(f(t0) + ε) < (b− a)(g(t0)− ε) ≤
∫ b
ag(t)dt⇒ P (X ∈]a, b]) < P (Y ∈]a, b])

44 Chapitre 3. Variables aléatoires réelles
Proposition 3.4.2 (Fonction de répartition). Si X a pour denstité f alors sa fonction derépartition F vérifie :(1) F (x) =
∫+∞−∞ f(t)dt, ∀x ∈ R.
(2) F est continue.(3) si f est continue en t0 alors F est dérivable en t0 et F ′(t0) = f(t0).
Démonstration. (1) x ∈ R :
P (X ∈]−∞, x]) =∫ x
−nf(t)dt − n ≤ x
⋃n∈N
]− n, x] =]−∞, x] union croissante
donc :PX(]−∞, x]) = lim
n→+∞PX(]− n, x]) = lim
n→+∞
∫ x
−nf(t)dt =
∫ x
−∞f(t)dt
(2) Soit x0 ∈ R, on veut démontrer :
limx→x0,x<x0
F (x) = F (x0)
∃a ∈ R tel que f est intégrable sur [a, x] ⊂ [a, x0[. On a :
P (X ∈ [a, x]) =∫ x
af(t)dt = F (x)− F (a)
limx→x0,x<x0
∫ x
af(x) =
∫ x0
af(t)dt︸ ︷︷ ︸
int. déf ou gén. conv en x0
= F (x0)− F (a)
donc limx→x0,x<x0
F (x) = F (x0)
(3) f continue en t0 :
|F (t0 + h)− F (t0)− f(t0)h| =∣∣∣∣∣∫ t0+h
t0f(t)dt−
∫ t0+h
t0f(t0)dt
∣∣∣∣∣=∣∣∣∣∣∫ t0+h
t0(f(t)− f(t0))dt
∣∣∣∣∣ (∗)≤∫ t0+h
t0|f(t)− f(t0)|dt
Si h < 0, (∗) devient :≤∫ t0
t0+h|f(t)− f(t0)|dt
La continuité de f en t0 implique :
∀ε > 0, ∃δ > 0 tel que si |t− t0| < δ ⇒ |f(t)− f(t0)| ≤ ε
On prend |h| < δ :
⇒ |F (t0 + h)− F (t0)− hf(t0)| ≤ ε|h| ⇒∣∣∣∣∣F (t0 + h)− F (t0)
h− f(t0)
∣∣∣∣∣ ≤ ε
donc : F ′(t0) = f(t0).
Remarque. Si FX est une fonction à densité réelle continue alors X n’est pas nécessairement àdensité.

Chapitre 3. Variables aléatoires réelles 45
Theorème 3.4.3. Si FX est une fonction à densité réelle C1 par morceaux, c’est-à-dire FX estcontinue sur R, dérivable sur R\a1, ..., an et à dérivée continue sur chaque intervalle ]ai, ai+1[pour 0 ≤ i ≤ n et tel que a0 = −∞, ai < ai+1 (∀i ∈ 0, ..., n), an+1 = +∞, de dérivée f(définie sur Ra1, ..., an) alors X est a densité f .
Démonstration. Si f est continue sur ]ai, ai+1[ alors elle admet des primitives de la forme :
H(x) =∫ x
αf(t)dt+ c où α ∈]ai, ai+1[
et F est une primitive de f ⇒ c = F (α) :
F (x)− F (α) =∫ x
αf(t)dt
∀[a, b] ⊂]ai, ai+1[ :
FX(b)− FX(a) =∫ b
af(t)dt⇒ P (X ∈]a, b]) =
∫ b
af(t)dt
sinon on utilise la relation de Chasles pour les intégrales généralisées.
Remarque. Si X est à densité alors P (X = x) = 0, ∀x ∈ R.
P (X ∈]a, b]) = P (x ∈ [a, b]) = P (X ∈ [a, b[) =∫ b
af(t)dt
3.4.2 Lois à densité classiques(1) Loi uniforme sur un intervalle [a, b] (a < b) : X ∈ Unif([a, b]) si ∀I ∈ B(R) :
P (X ∈ I) = λ1(I ∩ [a, b])b− a
(PX est la probabilité uniforme sur [a, b])
Sa fonction de répartition F :
F (x) = λ1(]−∞, x] ∩ [a, b])b− a
=
0 si −∞ < x < ax−ax−b si a ≤ x < b
1 si b ≤ x < +∞
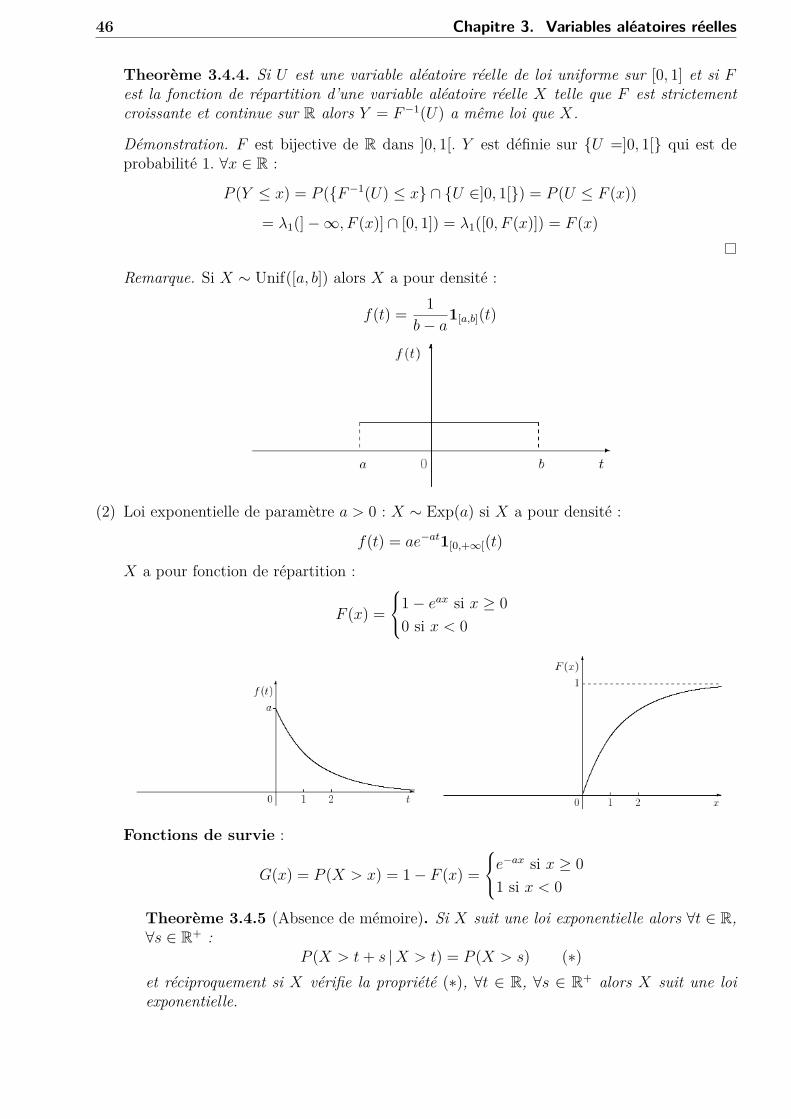
46 Chapitre 3. Variables aléatoires réelles
Theorème 3.4.4. Si U est une variable aléatoire réelle de loi uniforme sur [0, 1] et si Fest la fonction de répartition d’une variable aléatoire réelle X telle que F est strictementcroissante et continue sur R alors Y = F−1(U) a même loi que X.
Démonstration. F est bijective de R dans ]0, 1[. Y est définie sur U =]0, 1[ qui est deprobabilité 1. ∀x ∈ R :
P (Y ≤ x) = P (F−1(U) ≤ x ∩ U ∈]0, 1[) = P (U ≤ F (x))
= λ1(]−∞, F (x)] ∩ [0, 1]) = λ1([0, F (x)]) = F (x)
Remarque. Si X ∼ Unif([a, b]) alors X a pour densité :
f(t) = 1b− a
1[a,b](t)
(2) Loi exponentielle de paramètre a > 0 : X ∼ Exp(a) si X a pour densité :
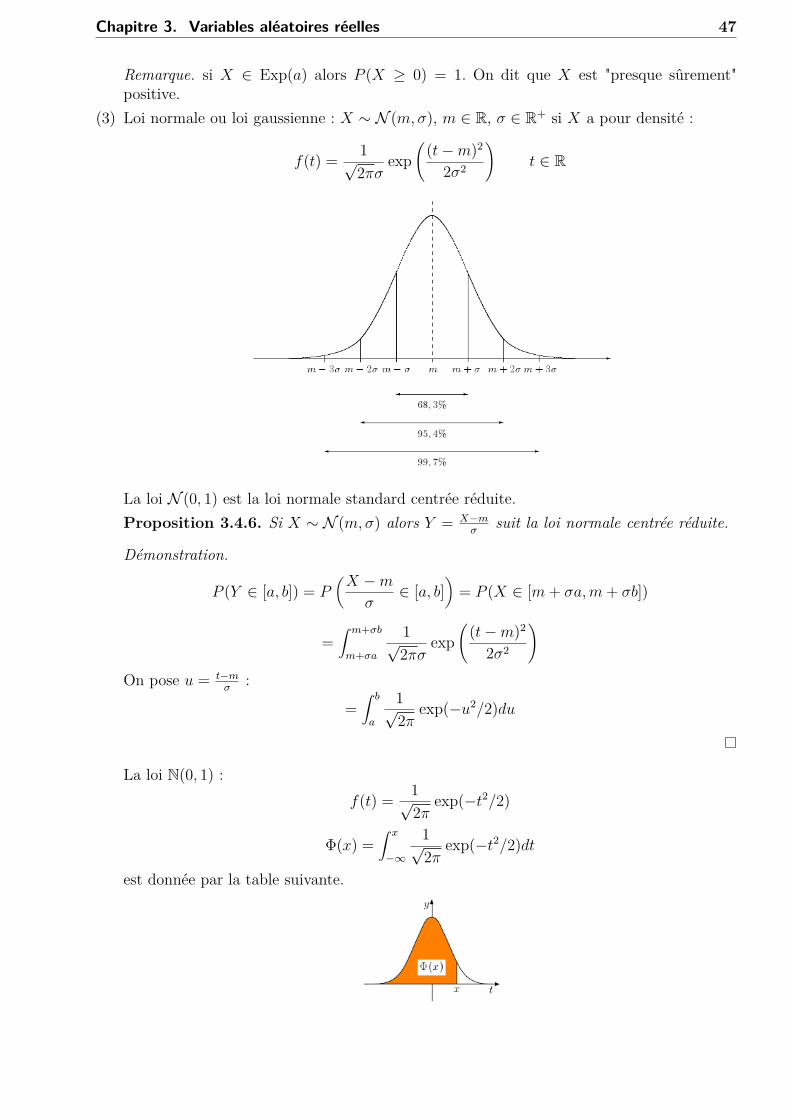
f(t) = ae−at1[0,+∞[(t)
X a pour fonction de répartition :
F (x) =
1− eax si x ≥ 00 si x < 0
Fonctions de survie :
G(x) = P (X > x) = 1− F (x) =
e−ax si x ≥ 01 si x < 0
Theorème 3.4.5 (Absence de mémoire). Si X suit une loi exponentielle alors ∀t ∈ R,∀s ∈ R+ :
P (X > t+ s |X > t) = P (X > s) (∗)et réciproquement si X vérifie la propriété (∗), ∀t ∈ R, ∀s ∈ R+ alors X suit une loiexponentielle.
Chapitre 3. Variables aléatoires réelles 47
Remarque. si X ∈ Exp(a) alors P (X ≥ 0) = 1. On dit que X est "presque sûrement"positive.
(3) Loi normale ou loi gaussienne : X ∼ N (m,σ), m ∈ R, σ ∈ R+ si X a pour densité :
f(t) = 1√2πσ
exp(
(t−m)2
2σ2
)t ∈ R
La loi N (0, 1) est la loi normale standard centrée réduite.Proposition 3.4.6. Si X ∼ N (m,σ) alors Y = X−m
σsuit la loi normale centrée réduite.
Démonstration.
P (Y ∈ [a, b]) = P(X −mσ
∈ [a, b])
= P (X ∈ [m+ σa,m+ σb])
=∫ m+σb
m+σa
1√2πσ
exp(
(t−m)2
2σ2
)On pose u = t−m
σ:
=∫ b
a
1√2π
exp(−u2/2)du
La loi N(0, 1) :f(t) = 1√
2πexp(−t2/2)
Φ(x) =∫ x
−∞
1√2π
exp(−t2/2)dt
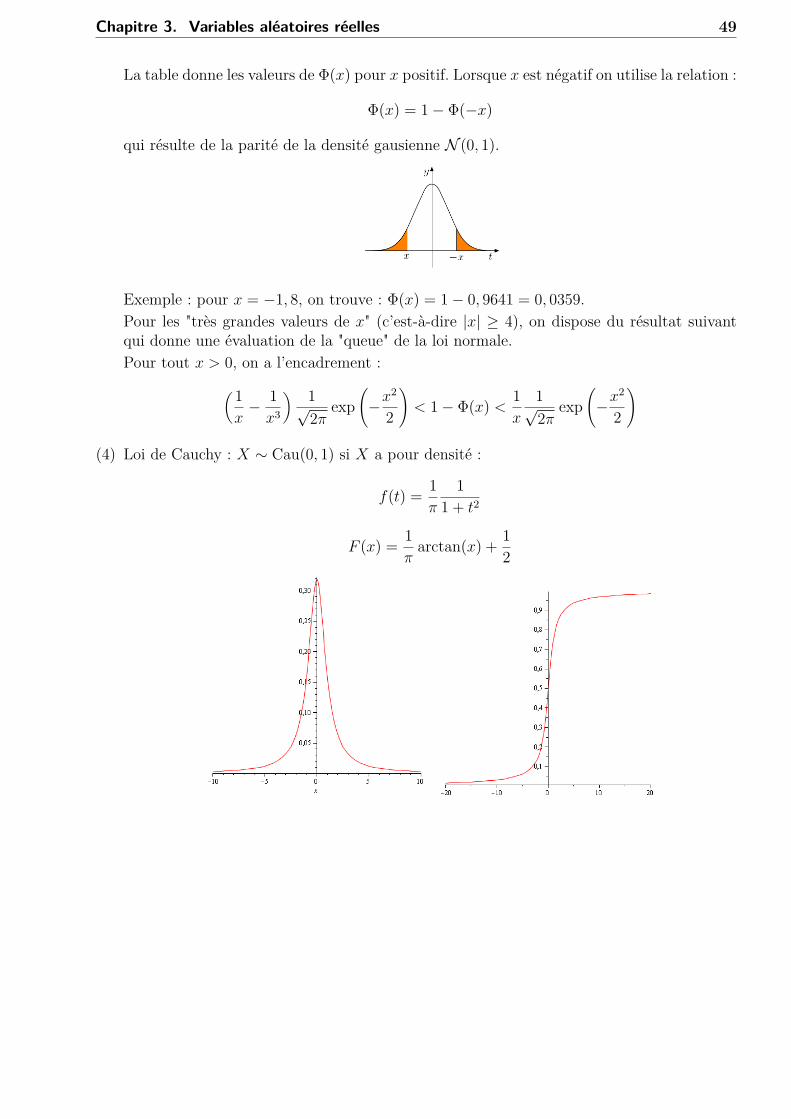
est donnée par la table suivante.
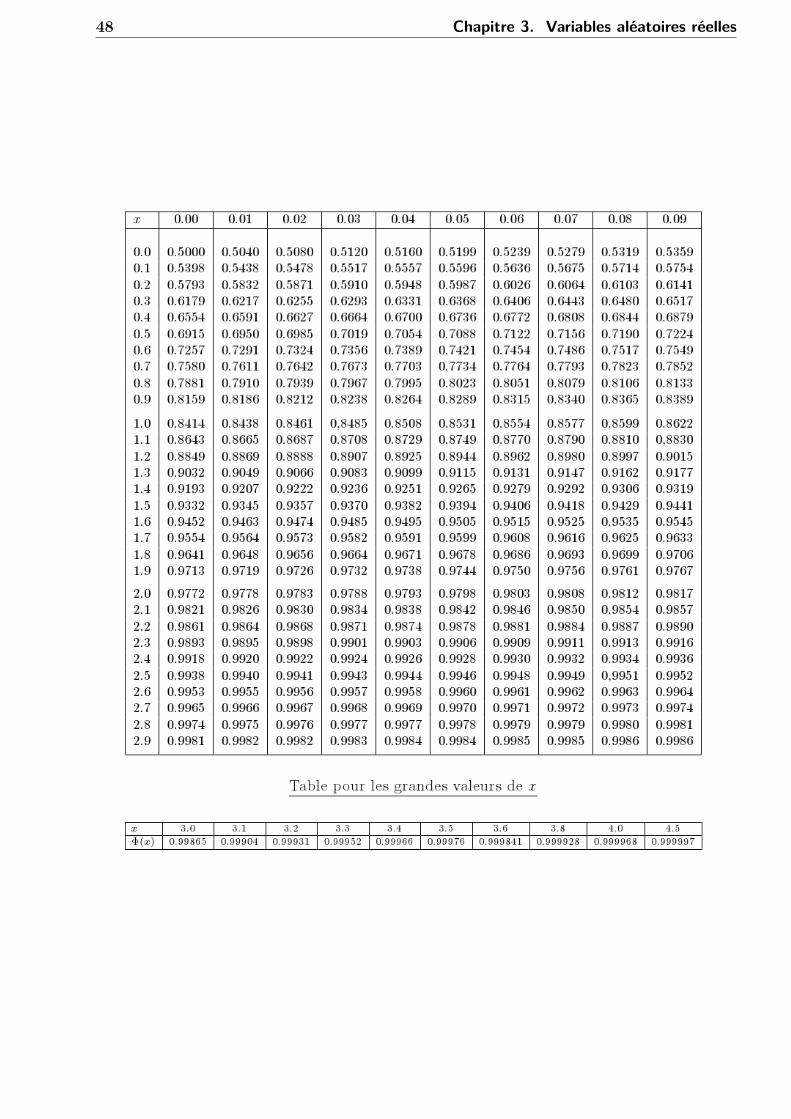
48 Chapitre 3. Variables aléatoires réelles
Chapitre 3. Variables aléatoires réelles 49
La table donne les valeurs de Φ(x) pour x positif. Lorsque x est négatif on utilise la relation :
Φ(x) = 1− Φ(−x)
qui résulte de la parité de la densité gausienne N (0, 1).
Exemple : pour x = −1, 8, on trouve : Φ(x) = 1− 0, 9641 = 0, 0359.Pour les "très grandes valeurs de x" (c’est-à-dire |x| ≥ 4), on dispose du résultat suivantqui donne une évaluation de la "queue" de la loi normale.Pour tout x > 0, on a l’encadrement :
(1x− 1x3
) 1√2π
exp(−x
2
2
)< 1− Φ(x) < 1
x
1√2π
exp(−x
2
2
)
(4) Loi de Cauchy : X ∼ Cau(0, 1) si X a pour densité :
f(t) = 1π
11 + t2
F (x) = 1π
arctan(x) + 12
Chapitre 4
Espérance d’une variable aléatoire
4.1 IntroductionSoit X une variable aléatoire discrète à valeurs dans X(Ω) = xi, i ∈ I avec I est au plus
dénombrable. La valeur moyenne de X est donnée par son espérance :E(X) =
∑i∈I
xiP (X = xi).
Si I est fini, E(X) est bien définie. Si I est dénombrable, E(X) est bien définie si la famillexiP (X = xi), i ∈ I est sommable ou bien si I = N, E(X) est bien définie si
+∞∑i=0|xi|P (X = xi) < +∞.
Donc, dans le cas discret,E(X) =
∑x∈X(Ω)
xP (X = x) (∗)
mais dans le cas à densité, on a besoin de calculer une intégrale car P (X = x) = 0, ∀x ∈ R(voir la remarque de la section 3.4.1). Donc
E(X) =∫
Rxf(x)dx. (∗∗)
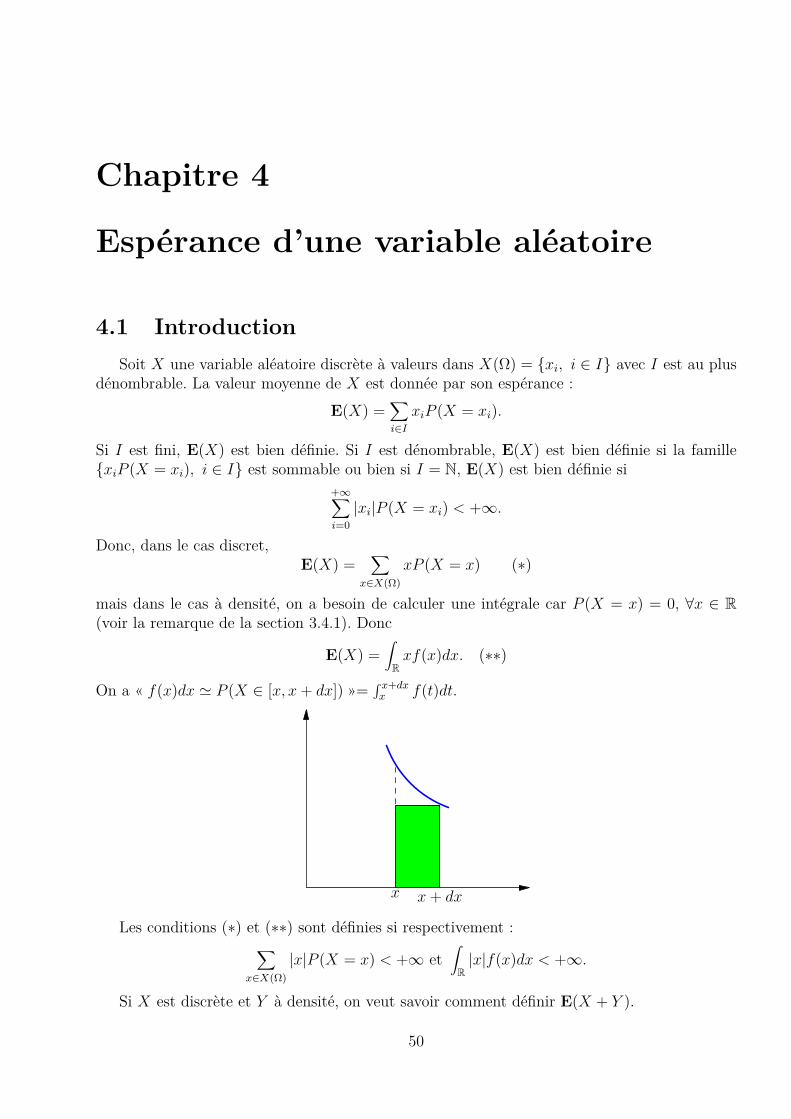
On a « f(x)dx ' P (X ∈ [x, x+ dx]) »=∫ x+dxx f(t)dt.
x x + dx
Les conditions (∗) et (∗∗) sont définies si respectivement :∑x∈X(Ω)
|x|P (X = x) < +∞ et∫
R|x|f(x)dx < +∞.
Si X est discrète et Y à densité, on veut savoir comment définir E(X + Y ).
50
Chapitre 4. Espérance d’une variable aléatoire 51
1.∫ΩX(ω)dP (ω). C’est l’intégrale de Lebesgue mais ce n’est pas dans le programme ducours (voir M304).
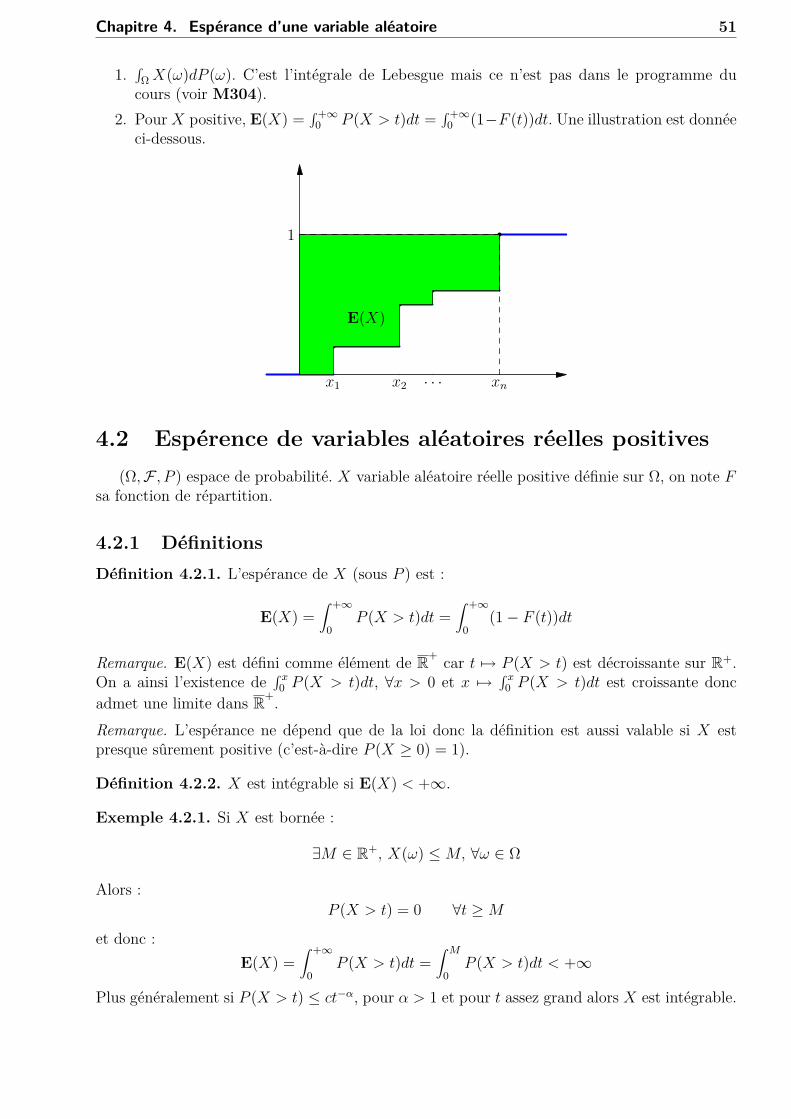
2. Pour X positive, E(X) =∫+∞0 P (X > t)dt =
∫+∞0 (1−F (t))dt. Une illustration est donnée
ci-dessous.
x1
1
x2 · · · xn
E(X)
4.2 Espérence de variables aléatoires réelles positives(Ω,F , P ) espace de probabilité. X variable aléatoire réelle positive définie sur Ω, on note F
sa fonction de répartition.
4.2.1 DéfinitionsDéfinition 4.2.1. L’espérance de X (sous P ) est :
E(X) =∫ +∞
0P (X > t)dt =
∫ +∞
0(1− F (t))dt
Remarque. E(X) est défini comme élément de R+ car t 7→ P (X > t) est décroissante sur R+.On a ainsi l’existence de
∫ x0 P (X > t)dt, ∀x > 0 et x 7→
∫ x0 P (X > t)dt est croissante donc
admet une limite dans R+.Remarque. L’espérance ne dépend que de la loi donc la définition est aussi valable si X estpresque sûrement positive (c’est-à-dire P (X ≥ 0) = 1).
Définition 4.2.2. X est intégrable si E(X) < +∞.
Exemple 4.2.1. Si X est bornée :
∃M ∈ R+, X(ω) ≤M, ∀ω ∈ Ω
Alors :P (X > t) = 0 ∀t ≥M
et donc :E(X) =
∫ +∞
0P (X > t)dt =
∫ M
0P (X > t)dt < +∞
Plus généralement si P (X > t) ≤ ct−α, pour α > 1 et pour t assez grand alors X est intégrable.
52 Chapitre 4. Espérance d’une variable aléatoire
4.2.2 ExemplesEspérance d’une constante (positive)
X(ω) = c, ∀ω ∈ Ω :
On a ainsi : E(X) = c (valable aussi si P (X = c) = 1.
Espérence d’une indicatrice
X = 1A, A ∈ F , X ∼ Bern(p) avec p = P (A) :
On a ainsi : E(X) = P (A).Remarque. Si X ∼ Bern(p) alors E(X) = p.
Espérence d’une variable aléatoire étagée positive
Définition 4.2.3. X est une variable aléatoire étagée si X(Ω) est fini.
Proposition 4.2.1. Si X est une varible aléatoire étagée positive. On note X(Ω) = xk, 1 ≤k ≤ n. Alors :
E(X) =n∑k=1
xkP (X = xk)
Démonstration. Soit :X =
n∑k=1
xk1Ak
avec :Ak = X−1(xk) = ω ∈ Ω, X(ω) = xk
On définit :PX =
n∑k=1
pkδxk avec pk = P (Ak) = P (X = xk)
On a :E(X) =
∫ +∞
0P (X > t)dt

Chapitre 4. Espérance d’une variable aléatoire 53
Ainsi :P (X > t) = PX(]t,+∞[) =
n∑k=1
pkδxk(]t,+∞[)
avec :
δxk(]t,+∞[) =
1 si xk ∈]t,+∞[0sinon
= 1]−∞,xk[(t)
P (X > t) =n∑k=1
pk1]−∞,xk[(t)
On a ainsi :
E(X) =∫ +∞
0P (X > t)dt =
∫ +∞
0
(n∑k=1
pk1[0,xk[(t))dt =
n∑k=1
(∫ +∞
0pk1[0,xk[(t)dt
)=
n∑k=1
pkxk
et finalement :E(X) =
n∑k=1
xkP (X = xk)
Espérance d’une variable aléatoire X positive à densité
Proposition 4.2.2. Si X est positive et a pour densité f alors :
E(X) =∫ +∞
0xf(x)dx ∈ R+
Démonstration.P (X > t) =
∫ +∞
tf(x)dx =
∫ +∞
0f(x)1[t,+∞[(x)dx
On a ainsi :
E(X) =∫ +∞
0
(∫ +∞
0f(x)1[t,+∞[(t)dx
)dt
FT=∫ +∞
0
(∫ +∞
0f(x)1[t,+∞[(x)dt
)dx
=∫ +∞
0f(x)
(∫ +∞
01[0,x](t)dt
)dx =
∫ +∞
0xf(x)dx
4.2.3 PropriétésProposition 4.2.3. Si X est une variable positive et c ∈ R+ alors :
E(cX) = cE(X)
Démonstration. 1) c = 0 évident.2) si c > 0 :
E(cX) =∫ +∞
0P (cX > t)dt =
∫ +∞
0P (X > t/c)
On pose : u = tc
E(cX) = c∫ +∞
0P (X > u)du = cE(X)
54 Chapitre 4. Espérance d’une variable aléatoire
Croissance de l’espérance
Proposition 4.2.4 (Croissance de l’espérance). Si X et Y sont deux variables aléatoires posi-tives définies sur Ω tel que X ≤ Y (∀ω ∈ Ω, X(ω) ≤ Y (ω)) alors E(X) ≤ E(Y ).Démonstration.
E(X) =∫ +∞
0P (X > t)dt
On a l’inclusion X > t ⊂ Y > t ainsi P (X > t) ≤ P (Y > t) et :
E(X)dans R+
≤∫ +∞
0P (Y > t)dt = E(Y )
Conséquence. Si X ≤ Y :• Si Y est intégrable alors X est intégrable.• Si X n’est pas intégrable alors X n’est pas intégrable.
Approximation d’une variable aléatoire positive par une suite croissante de va-riables aléatoires étagées positives
Soit X une variable aléatoire.
Xn étagée tel que la suite (Xn)n∈N est croissante. On a :
Xn(ω) = Xn+1(ω) ∀ω ∈ Ω
La suite (Xn) converge simplement vers X.
Xn(ω) =
n si X(ω) ≥ n
k2−n si k2−n ≤ X(ω) ≤ (k + 1)2n et 0 ≤ k ≤ n2−n − 1
Xn =n2n∑k=0
k2−n1Ak,n
On a : Ak,n = X−1([k2−n, (k + 1)2−n[) pour 0 ≤ k ≤ 2n − 1 et An2n,n = X−1[n,+∞[. Ainsi(Ak,n)0≤k≤2n forment une partition de Ω. Ak,n ∈ F car X est F −B(R) mesurable donc Xn estune variable aléatoire qui prend un nombre fini de valeurs (n2n+1). A ω fixé, Xn(ω) ≤ Xn+1(ω).Soit n0 = [X(ω)] 1 :
1[x] est la partie entière x

Chapitre 4. Espérance d’une variable aléatoire 55
• n ≤ n0 :X(ω) ≥ n0 ≥ n⇒ Xn(ω) = n
• n > n0 :Xn(ω) = maxl2−n, l2−n ≤ X(ω) = k(n, ω)2−n
avec k(n, ω) = [2nX(ω)] :– n ≤ n+ 1 ≤ n0 :
Xn(ω) = n ≤ Xn+1(ω) = n+ 1– n0 < n ≤ n+ 1 :
Xn(ω) = k(n, ω)2−n = 2k(n, ω)2−(n+1) ≤ X(ω)
car soit :k(n+ 1, ω) = maxl tel que l2−(n+1) ≤ X(ω)
ainsi2k(n, ω) ≤ k(n+ 1, ω)⇒ Xn(ω) ≤ Xn+1(ω)
avec :Xn+1(ω) = k(n+ 1, ω)2−(n+1)
– Xn0(ω) ≤ Xn0+1(ω) :
Xn0(ω) = n0 = 2n0+1n02−(n0+1) ≤ Xn0+1(ω)
On a :2n0+1n0 ≤ k(n0 + 1, ω)
et :Xn0+1(ω) = k(n0 + 1, ω)2−(n0+1)
⇒ (Xn(ω) = k2−n).– Si n > n0 alors :
k2−n ≤ X(ω) < (k+1)2−n ⇒ Xn(ω) ≤ X(ω) ≤ Xn(ω)+2−n ⇒ 0 ≤ X(ω)−Xn(ω) ≤ 2−n
Lemme 4.2.5. Si Xn converge en croissant vers X alors P (Xn > t) converge en croissant versP (X > t) quand n→ +∞ (à t ≥ 0 fixé).
Démonstration. Xn ≤ Xn+1 et Xn > t ⊂ Xn+1 > t donc P (Xn > t) ≤ P (Xn+1 > t) doncP (Xn > t)n∈N est croissante. Soit An = Xn > t donc :
A =+∞⋃n=0
An = X > t
car :– si ω ∈ A alors ∃n ∈ N tel que Xn(ω) > t. Or X(ω) ≥ Xn(ω) donc X(ω) > t donc :A ⊂ X > t
– si ω ∈ X > t, X(ω) > t :
∀ε > 0, ∃n0 ∈ N, ∀n ≥ n0, X(ω)− ε ≤ Xn(ω) ≤ X(ω)
On prend ε = X(ω) − t > 0 ⇒ à partir de n0 = n0(t, ω), Xn(ω) > t, ω ∈ An. Donc∀n ≥ n0, ω ∈ A. Cela implique que X > t ⊂ A.

56 Chapitre 4. Espérance d’une variable aléatoire
⇒ P (A) = limn→+∞
P (An)⇔ P (X > t) = limn→+∞
P (Xn > t)
Theorème 4.2.6 (Beppo-Levi). Soit (Xn)n∈N une suite croissante de variables aléatoires po-sitives qui converge simplement vers X alors :
limn→+∞
E(Xn) = E(X)
Démonstration. On se base sur le théorème suivant :
Theorème 4.2.7. Si (fn)n∈N est une suite de fonctions qui sont décroissantes, qui convergesimplement vers f alors : ∫ b
afn(t)dt −−−−→
n→+∞
∫ b
af(t)dt
fn(t) = P (Xn > t) est une suite de fonctions décroissantes (en t). On a ainsi avec le lemmefn(t)→ f(t) = P (X > t) quand n→ +∞ :
∫ b
0fn(t)dt −−−−→
n→+∞
∫ b
0f(t)dt, ∀b ∈ R+∗
∫ b
0P (Xn > t)dt −−−−→
n→+∞
∫ b
0P (X > t)dt, ∀b ∈ R+∗
– si X est intégrable :
∀ε > 0 tel que∫ +∞
bP (X > t)dt < ε
On a : P (Xn > t) ≤ P (X > t) :
0 ≤ E(X)− E(Xn) =∫ +∞
0P (X > t)dt−
∫ +∞
0P (Xn > t)dt
=∫ b
0P (X > t)dt−
∫ b
0P (Xn > t)dt︸ ︷︷ ︸
≤ε pour n assez grand
+∫ +∞
bP (X > t)dt−
∫ +∞
bP (Xn > t)dt︸ ︷︷ ︸
≤ε
≤ 2ε
– si X n’est pas intégrable : ∀A > 0, ∃b ∈ R+∗ tel que :∫ b
0P (X > t)dt ≥ A
A partir d’un certain rang n0 = n0(A) :
∫ b
0P (Xn > t)dt ≥
∫ b
0P (X > t)dt− A
2 ≥A
2
Cela veut dire que :lim
n→+∞E(Xn) = +∞ = E(X)

Chapitre 4. Espérance d’une variable aléatoire 57
Additivité de l’espérance
Theorème 4.2.8. Si X et Y sont deux variables aléatoires positives définies sur Ω alors :
E(X + Y ) = E(X) + E(Y )
Démonstration. – Si Xn et Yn sont étagées (positives) alors E(Xn + Yn) = E(Xn) + E(Yn).– SiX et Y sont quelconques (positives) alors il existe (Xn)n∈N tel que chaqueXn soit étagéeet Xn(ω) converge en croissant sur X(ω), ∀ω ∈ Ω et il existe (Yn)n∈N tel que chaque Ynsoit étagée et Yn(ω) converge en croissant sur Y (ω), ∀ω ∈ Ω alors Zn(ω) := Xn(ω)+Yn(ω)converge simplement en croissant vers Z(ω) := X(ω) + Y (ω) (Zn est étagée). D’après lethéorème de Beppo-Levi : E(Zn) → E(Z) avec n → +∞, cela implique E(Xn) + E(Yn).On réapplique le théorème de Beppo-Levi :
E(Xn) + E(Yn) −−−−→n→+∞
E(X) + E(Y ) = E(X + Y )
Corollaire (Inversion séries-espérance). Si (Xn)n∈N est une suite de variables aléatoires posi-tives et si :
S(ω) =+∞∑n=0
Xn(ω) fini
alors S est une variable aléatoire positive sur (Ω,F) et :
E(S) =+∞∑n=0
E(Xn)
Démonstration.S = lim
n→+∞Sn
où :Sn =
n∑k=1
Xk et (Sn)n∈N est croissante
Beppo-Levi nous dit que :lim
n→+∞E(Sn) = E(S)
et par linéarité :E(Sn) =
n∑k=1
E(Xk)
Corollaire (Espérance d’une variable positive discrète). Si X est une variable aléatoire positivediscrète alors :
E(X) =∑
x∈X(Ω)xP (X = x) dans R+
Démonstration. Si X(Ω) est fini, X étagée, si X(Ω) est dénombrable :
X =+∞∑k=0
xk1Ak
Ak = X = xk = X−1(xk)
E(X) =+∞∑k=0
E(xk1Ak) =+∞∑k=0
xkP (Ak) =+∞∑k=0
xkP (X = xk)
58 Chapitre 4. Espérance d’une variable aléatoire
Inégalité de Markov
Lemme 4.2.9. X variable aléatoire positive :
E(X) =∫ +∞
0P (X > t)dt =
∫ +∞
0P (X ≥ t)dt
Démonstration.I =
∫ +∞
0P (X > t)dt J =
∫ +∞
0P (X ≥ t)dt
– P (X ≥ t) ≥ P (X > t) car X > t ⊂ X ≥ t ⇒ J ≥ I.–
J =∫ +∞
0P (X ≥ t)dt =
∫ +∞
−εP (X ≥ s+ε)ds =
∫ 0
−εP (X ≥ s+ ε)︸ ︷︷ ︸
≤1
ds
︸ ︷︷ ︸≤ε
+∫ +∞
0P (X ≥ s+ ε)ds︸ ︷︷ ︸
≤P (X>s)︸ ︷︷ ︸≤I
≤ I+ε
Donc J ≤ I ⇒ J = I.
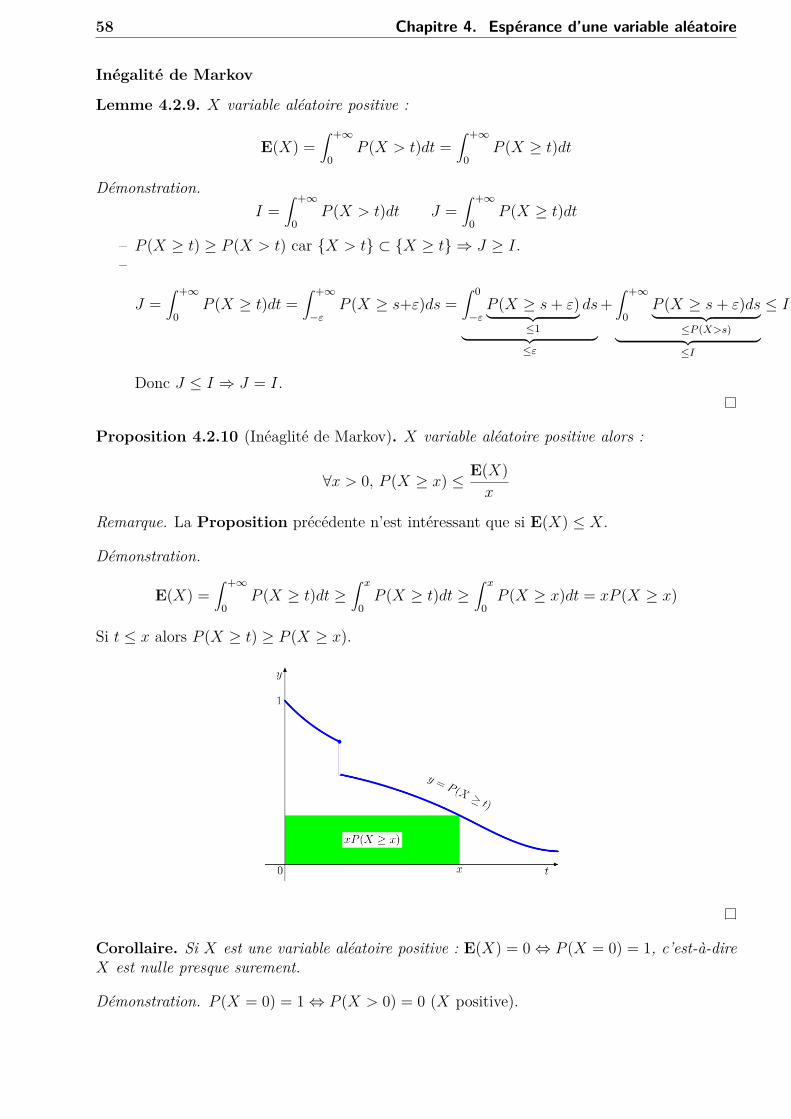
Proposition 4.2.10 (Inéaglité de Markov). X variable aléatoire positive alors :
∀x > 0, P (X ≥ x) ≤ E(X)x
Remarque. La Proposition précédente n’est intéressant que si E(X) ≤ X.
Démonstration.
E(X) =∫ +∞
0P (X ≥ t)dt ≥
∫ x
0P (X ≥ t)dt ≥
∫ x
0P (X ≥ x)dt = xP (X ≥ x)
Si t ≤ x alors P (X ≥ t) ≥ P (X ≥ x).
Corollaire. Si X est une variable aléatoire positive : E(X) = 0⇔ P (X = 0) = 1, c’est-à-direX est nulle presque surement.
Démonstration. P (X = 0) = 1⇔ P (X > 0) = 0 (X positive).
Chapitre 4. Espérance d’une variable aléatoire 59
∗ si P (X > 0) = 0 alors ∀t ∈ R+, P (X > t) = 0 donc :
E(X) =∫ +∞
0P (X > t)dt = 0
∗ si E(X) = 0 alors :
X > 0 =⋃n∈N∗
X >
1n
P (X > 0) = limn→+∞
P (X > 1/n)
P (X > 1/n) = E(X)1/n = 0
∀n ∈ N∗, P (X > 1/n) = 0⇒ P (X > 0)
Donc : P (X > x) ≤ E(X)x
.
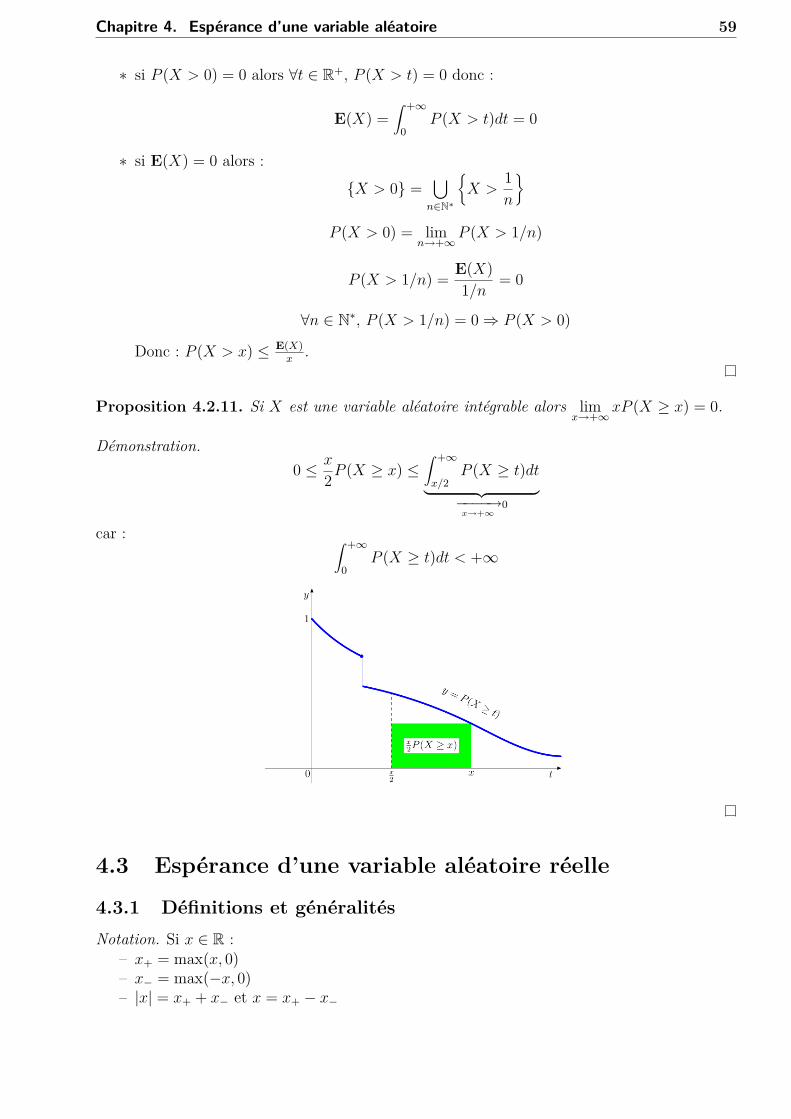
Proposition 4.2.11. Si X est une variable aléatoire intégrable alors limx→+∞
xP (X ≥ x) = 0.
Démonstration.0 ≤ x
2P (X ≥ x) ≤∫ +∞
x/2P (X ≥ t)dt︸ ︷︷ ︸−−−−→x→+∞
0
car : ∫ +∞
0P (X ≥ t)dt < +∞
4.3 Espérance d’une variable aléatoire réelle
4.3.1 Définitions et généralitésNotation. Si x ∈ R :
– x+ = max(x, 0)– x− = max(−x, 0)– |x| = x+ + x− et x = x+ − x−
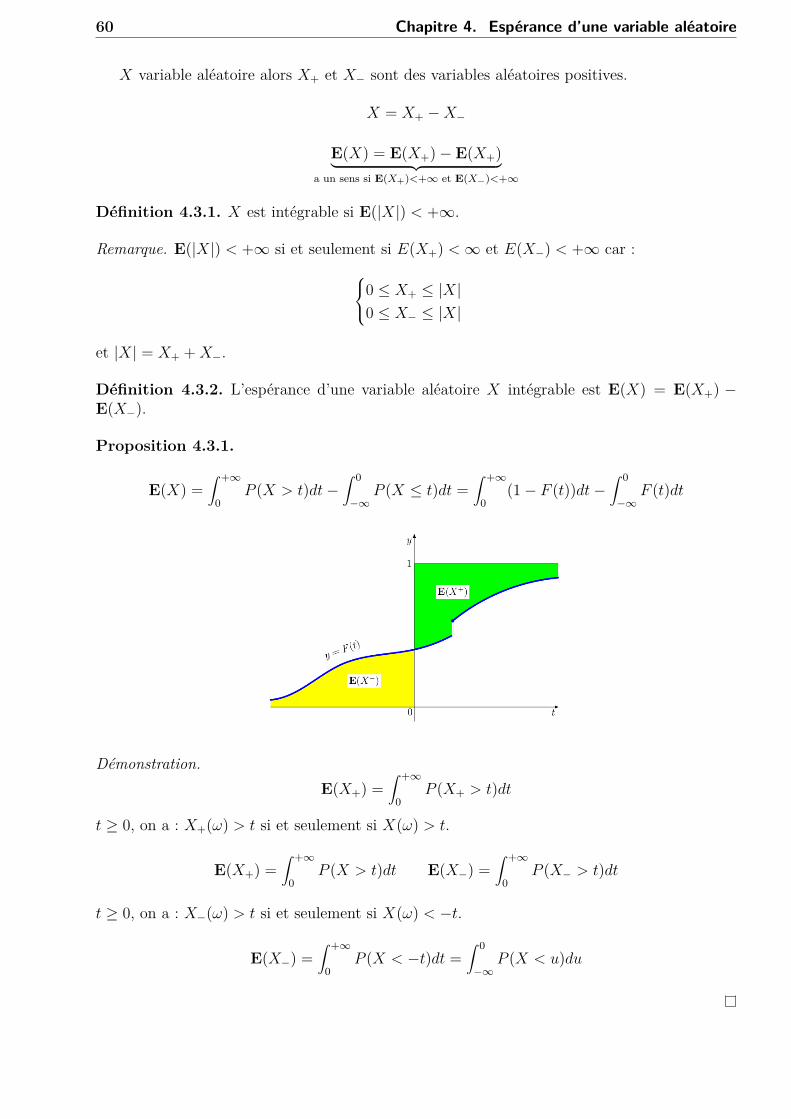
60 Chapitre 4. Espérance d’une variable aléatoire
X variable aléatoire alors X+ et X− sont des variables aléatoires positives.
X = X+ −X−
E(X) = E(X+)− E(X+)︸ ︷︷ ︸a un sens si E(X+)<+∞ et E(X−)<+∞
Définition 4.3.1. X est intégrable si E(|X|) < +∞.
Remarque. E(|X|) < +∞ si et seulement si E(X+) <∞ et E(X−) < +∞ car :0 ≤ X+ ≤ |X|0 ≤ X− ≤ |X|
et |X| = X+ +X−.
Définition 4.3.2. L’espérance d’une variable aléatoire X intégrable est E(X) = E(X+) −E(X−).
Proposition 4.3.1.
E(X) =∫ +∞
0P (X > t)dt−
∫ 0
−∞P (X ≤ t)dt =
∫ +∞
0(1− F (t))dt−
∫ 0
−∞F (t)dt
Démonstration.E(X+) =
∫ +∞
0P (X+ > t)dt
t ≥ 0, on a : X+(ω) > t si et seulement si X(ω) > t.
E(X+) =∫ +∞
0P (X > t)dt E(X−) =
∫ +∞
0P (X− > t)dt
t ≥ 0, on a : X−(ω) > t si et seulement si X(ω) < −t.
E(X−) =∫ +∞
0P (X < −t)dt =
∫ 0
−∞P (X < u)du

Chapitre 4. Espérance d’une variable aléatoire 61
Cas d’une varialble discrète
Proposition 4.3.2. Soit X une variable aléatoire discrète alors X est intégrable si et seulementsi : ∑
x∈X(Ω)|x|P (X = x) < +∞
et dans ce cas :E(X) =
∑x∈X(Ω)
xP (X = x)
Remarque. C’est encore valable si la loi de X est discrète (en remplaçant X(Ω) par A =xP (X = x) 6= 0, P (A) = 1.
Démonstration.
X+(Ω) = X+(ω), ω ∈ Ω =
= X(Ω)∩]0,+∞[X(Ω)∩]0,+∞[︸ ︷︷ ︸
B
∪0
est au plus dénombrable. X+ est discrète si :
E(X+) =∑x∈B
xP (X = x)
Si X(Ω)∩]−∞, 0] 6= ∅ alors :
X−(Ω) = X−(ω), ω ∈ Ω =
−X(Ω)∩]−∞, 0]︸ ︷︷ ︸
B′
si X(Ω)∩]0,+∞[= ∅
−B′ ∪ 0 si X(Ω)∩]0,+∞[ 6= ∅
E(X−) =∑
x∈X−(Ω)xP (X− = x) =
∑x∈−B′
xP (X− = x) = −∑−x∈B′
(−x)P (X = −x)
= −∑x∈B′
xP (X = x) =∑x∈B′|x|P (X = x)
E(|X|) = E(X+) + E(X−) =∑
x∈B′∪B|x|P (X = x) =
∑x∈X(Ω)
|x|P (X = x)
On a :B′ ∪B = X(Ω) (B ∩B′ = ∅)
Si E(|X|) < +∞ et :
E(X) = E(X+)−E(X−) =∑x∈B
xP (X = x)+∑x∈B′
xP (X = x) =∑
x∈B∪B′xP (X = x) =
∑x∈X(Ω)
xP (X = x)
Remarque. A savoir : espérance des variables aléatoires discrètes "classiques".

62 Chapitre 4. Espérance d’une variable aléatoire
Cas d’une variable aléatoire à densité
Proposition 4.3.3. Si X a pour densité f (sous P ) alors X est intégrable si et seulement si :∫ +∞
−∞|x|f(x)dx < +∞
et dans ce cas :E(X) =
∫ +∞
−∞xf(x)dx
Démonstration.
E(X+) =∫ +∞
0P (X+ > t)dt =
∫ +∞
0P (X > t)dt =
∫ +∞
0
∫ +∞
tf(x)dxdt
=∫ +∞
0
∫ +∞
0f(x)1[0,x](t)dtdx =
∫ +∞
0xf(x)dx
E(X−) =∫ +∞
0P (X− > t)dt =
∫ +∞
0P (X < −t)dt =
∫ 0
−∞P (X < t)dt
=∫ 0
−∞
∫ t
−∞f(x)dxdt =
∫ 0
−∞
∫ 0
−∞f(x)1[x,0](t)dtdx = −
∫ 0
−∞f(x)dx
E(|X|) = E(X+) + E(X−) =∫ +∞
0xf(x)dx =
∫ 0
−∞(−x)f(x)dx =
∫ +∞
−∞|x|f(x)dx
et si l’intégrale est convergente alors :
E(X) = E(X+)− E(X−) =∫ +∞
0xf(x)dx−
∫ 0
−∞(−x)f(x)dx =
∫ +∞
−∞xf(x)dx
4.3.2 PropriétésProposition 4.3.4 (Linéarité). 1) si X et Y sont définies sur (Ω,F , P ) et intégrables alors
E(X + Y ) = E(X) + E(Y ).2) si c ∈ R et X intégrable alors E(cX) = cE(X).Remarque. L1(Ω,F , P ) : l’ensemble des variables réelles intégrables.
Démonstration. 1. Z = X + Y– |Z| ≤ |X|+ |Y | donc :
E([Z[) ≤ E(|X|+ |Y |) = E(|X|) + E(|Y |) < +∞
⇒ Z intégrable.– Z = Z+ − Z− = X+ −X− + Y+ − Y−
Z+ +X− + Y−︸ ︷︷ ︸v.a positive
= Z− +X+ + Y+︸ ︷︷ ︸v.a positive
E(Z+ +X− + Y−) = E(Z− +X+ + Y+)Linéarité de l’espérance de variables aléatoires positives :
E(Z+) + E(X−) + E(Y−) = E(Z−) + E(X+) + E(Y+)
E(Z) = E(Z+)− E(Z−) = E(X+)− E(X−) + E(Y−)− E(Y−) = E(X) + E(Y )

Chapitre 4. Espérance d’une variable aléatoire 63
2. |cX| = c|X| donc E(|cX|) < +∞ si et seulement si E(|X|) < +∞.
E(cX) = E((cX)+)− E((cX)−)
c > 0(cX+) = cX+ c(X−) = cX−
E(cX) = cE(X+)− cE(X−) = cE(X)
c ≤ 0(cX)+(ω) = cX(ω) = −cX−(ω) si cX(ω) ≥ 0⇒ X(ω) ≤ 0
(cX)+ = −cX−
(cX)−(ω) = −cX(ω) = −cX+(ω) si cX(ω) ≤ 0⇒ X(ω) ≥ 0
E(cX) = E((−c)X−)− E((−c)X+) = −cE(X−) + cE(X+) = cE(X)
Proposition 4.3.5. 1) Si X et Y sont dans L1(Ω,F , P ) et si X ≤ Y alors E(X) ≤ E(Y ).2) Si X est intégrable alors |E(X)| ≤ E(|X|).
Démonstration. 1) X ≤ Y alors Z = Y −X ≥ 0 donc :– Z est intégrable– E(Z) ≥ 0Par linéarité E(Z) = E(Y )− E(X)⇒ E(Y ) ≥ E(X).
2) −|X| ≤ X ≤ |X| par 1) :
E(−|X|) = −E(|X|) ≤ E(X) ≤ E(|X|)
4.4 Moments
4.4.1 h-momentsBut. Si h : R→ R borélienne (B(R)−B(R) mesurable) et X une variable aléatoire réelle sur
(Ω,F , P ) alors h(X) est une variable aléatoire réelle et on veut calculer E(h(X)) sans calculerla loi de h(X) donc à partir de la loi de X uniquement.
X discrète
Proposition 4.4.1. Si X est une variable aléatoire discrète et h : R→ R borélienne alors :
E(X) =∑
x∈X(Ω)|h(x)|P (X = x)
et si E(|h(X)|) < +∞ alors :
E(h(X)) =∑
x∈X(Ω)h(x)P (X = x)

64 Chapitre 4. Espérance d’une variable aléatoire
Remarque. La Proposition 4.4.1 reste encore valable si la loi de X est discrète en remplaçantX(Ω) par :
A = x ∈ R, P (X = x) > 0
Démonstration. • On pose Y = |h(X)|, on a que Y est une variable aléatoire et Y estdiscrète car :
Y (Ω) = |h|(X(ω)), ω ∈ Ωest au plus dénombrable.
E(Y ) =∑
y∈Y (Ω)yP (Y = y)
Pour y ∈ Y (Ω), on pose :
By = x ∈ X(Ω), |h(x)| = y ⊂ X(Ω)
donc est au plus dénombrable et non vide.
Y = y =⋃x∈ByX = x (disjointe)
∑y∈Y (Ω)
yP (Y = y) =∑
y∈Y (Ω)y∑x∈By
P (X = x) =∑
y∈Y (Ω)
∑x∈By|h(x)|P (X = x) (∗)
Par le principe de sommation par paquets :
(∗) =∑
x∈X(Ω)|h(x)|P (X = x)
• si∑
x∈X(Ω)|h(x)|P (X = x) < +∞ alors la famille h(x)P (X = x)x∈XΩ) est sommable et
on conclut par principe de sommation par paquets :
E(h(X)) =∑
x∈X(Ω)h(x)P (X = x)
X à densité f
Définition 4.4.1. h : [a, b] → R est une fonction réglée si h est limite uniforme de fonctionsen escaliers.
On peut montrer que le nombre de points de discontinuité d’une fonction réglée est au plusdénombrable.
Exemple 4.4.1. Les1) fonctions en escaliers2) fonctions monotones, différences de fonctions monotones3) fonctions continuessur [a, b] sont des fonctions réglées.
Remarque. h réglée sur [a, b] alors h est Riemann-intégrable sur [a, b] et h est bornée sur [a, b].De plus h admet une limite à droite et une limite à gauche en tous points de [a, b].

Chapitre 4. Espérance d’une variable aléatoire 65
Proposition 4.4.2. Si X est une variable aléatoire réelle de densité f sur R et si h est unefonction réglée sur tout intervalle [a, b] ⊂ R alors :
E(|h(X)|) =∫ ∞−∞|h(x)|f(x)dx
si E(|h(X)|) < +∞ alors :
E(h(X)) =∫ +∞
−∞h(x)f(x)dx
Démonstration. 1) h est une fonction en escalier sur [a, b] positive. a = x0 < x1 < ... < xn = b :
h(x) =n−1∑k=0
ak1]xk,xk+1[ +n∑k=0
bk1xk
h(X) =n−1∑k=0
ak1X−1(]xk,xk+1[) +n∑k=0
bk1X=xn
E(h(X)) =n−1∑k=0
akE(1X−1(]xk,xk+1[))+n∑k=0
bkE(1X=xn) =n−1∑k=0
akP (X ∈]xk, xk+1[)+n∑k=0
bkP (X = xn)
=n−1∑k=0
ak
∫ xk+1
xk
f(x)dx =∫ +∞
−∞
∑ak1]xk,xk+1[(x)f(x)dx =
∫ +∞
−∞h(x)f(x)dx
2) h fonction positive réglée sur [a, b] et nulle en dehors, h est limite uniforme de fonctions ensecaliers (ϕn)n∈N∗ .
h(X) = ϕn(X)︸ ︷︷ ︸intégrable
+h(X)− ϕn(X)︸ ︷︷ ︸(∗)
(∗) : ∀ε > 0,∃Nε∆ ∈ N tel que ∀n ≥ Nε, |h(X)− ϕn(X)| < ε
∀n > Nε, E(h(X)) = E(ϕn(X)) + E(h(X)− ϕn(X))
|E(h(X))− E(ϕn(X))| = |E(h(X)− ϕn(X))| ≤ E(|h(X)− ϕn(X)|) ≤ ε
Par 1) :
E(ϕn(X)) =∫ +∞
−∞ϕn(x)f(x)dx =
∫ b
aϕn(x)f(x)dx ?−−−−→
n→+∞
∫ b
ah(x)f(x)dx
f intégrable sur tout intervalle I ⊂ R\K (K est un ensemble fini de points de R) :∫Iϕn(x)f(x)dx −−−−→
n→+∞
∫h(x)f(x)dx
Par passage à la limite aux bornes :∫ b
aϕn(x)f(x)dx −−−−→
n→+∞
∫ b
ah(x)f(x)dx
donc :E(X) =
∫ b
ah(x)f(x)dx =
∫ +∞
−∞h(x)f(x)dx

66 Chapitre 4. Espérance d’une variable aléatoire
3) h fonction positive réglée sur tout intervalle [a, b] ⊂ R. On pose :
hn(x) = h(x)1[−n,n](x)
(hn(X))n∈N∗ est une suite croissante de variables aléatoires qui converge simplement versh(X). On applique le théorème de Beppo-Levi :
E(hn(X)) −−−−→n→+∞
E(h(X))
Par 2) :
E(hn(X)) =∫ +∞
−∞hn(x)f(x)dx =
∫ n
−nhn(x)f(x)dx −−−→
n→∞
∫ +∞
−∞h(x)f(x)dx
Donc :E(h(X)) =
∫ +∞
−∞h(x)f(x)dx
4) h est de signe quelconque. On considère |h| et on refait le 3) et ensuite on décompose :
h(x) = h+(x)− h−(x)
4.4.2 Moments d’ordre rC’est la cas particulier où h(x) = xr, r ∈ R+.
Définition 4.4.2. Soit r ∈ R+, on appelle moment absolue d’ordre r, E(|X|r) et si E(|X|r) <∞ alors X admet un mombre d’ordre r, E(Xr).
Remarque. 1) si X discrète :
E(|X|r) =∑
x∈X(Ω)|x|rP (X = x)
et si E(|X|r) < +∞ :E(Xr) =
∑x∈X(Ω)
xrP (X = x)
2) X à densité f :E(|X|r) =
∫ +∞
−∞|x|rf(x)dx
si E(|X|r) < +∞ :E(Xr) =
∫ +∞
−∞xrf(x)dx
Proposition 4.4.3. Si X admet un moment d’ordre r, ∀p ∈ [0, r], X admet un moment d’ordrer.
Démonstration.E(|X|p) = E(|X|p1|X|≤1)︸ ︷︷ ︸
E(1X≤1)︸ ︷︷ ︸|X|≤1⇒|X|p≤1
+ E(|X|p1|X|>1)︸ ︷︷ ︸≤ E(|X|r1|X|>1)︸ ︷︷ ︸|X|>1⇒|X|p≤|X|r

Chapitre 4. Espérance d’une variable aléatoire 67
Proposition 4.4.4. ∀t > 0, ∀r > 0 :
P (|X| ≥ t) ≤ E(|X|r)tr
Démonstration. On utilise l’inégalité de Markov :
P (|X| ≥ t) = P (|X|r ≥ tr) ≤ E(|X|r)tr
4.4.3 VarianceSoit r = 2 et X une variable aléatoire réelle :
Définition 4.4.3. Si X admet un moment d’ordre 2 alors on appelle variance de X :
Var(X) = E((X − E(X))2)
et l’écart-type de X, σ(X) =√
Var(X).
Remarque. Si E(X2) < +∞ alors E(X) < +∞ donc m = E(X) est bien définie :
(X − E(X))2 < 2(X2 +m2)
est bien intégrable.
Proposition 4.4.5 (Formule de Koeing). Si X a un moment d’ordre 2 :
Var(X) = E(X2)− (E(X))2
Démonstration. En notant m = E(X) :
(X − E(X))2 = X2 − 2mX +m2
Var(X) = E(X)2 − 2mE(X)︸ ︷︷ ︸m
+m2 = E(X)2 −m2
Conséquence. Var(X) ≥ 0⇒ E(X)2 ≤ E(X2)⇒ |E(X)| ≤√
E(X2) (Cauchy-Schwartz)
Propriété 4.4.6. Si X a un moment d’ordre 2 :1) Var(aX + b) = a2 Var(X) et σ(aX + b) = |a|σ(X).2) Var(X) = 0⇔ X = c presque surement.3) Inégalité de Tchebytchev :
P (|X − E(X)| ≥ t) ≤ Var(X)t2
Démonstration. 2) E((X −E(X))2) = 0⇔ (X −E(X))2 = 0 presque surement ⇔ P (X =E(X)) = 1.
1) Utilisation de l’inégalité de Markov.

Chapitre 5
Vecteurs aléatoires et indépendance
5.1 IntroductionSoit :
X : Ω,F) → (Rd,B(Rd)X(ω) 7→ (X1(ω), ..., Xd(ω)
La connaissance individuelle des lois des Xi ne suffit pas à connaître la loi du vecteur X.Exemple 5.1.1. Considérons un ensemble de 10 coureurs de fond, chacun muni d’un dossardnuméroté de 1 à 10. Si on les rassemble sur une même piste pour une épreuve de 5000 métres, onpeut représenter le résultat de la course par le vecteur (X1, ..., X10) où Xi désigne le temps mispar le coureur numéroté i pour parcourir les 5000 mètres. Cette expérience n’est pas équivalenteà faire courir isolément un 5000 mètres à chacun des 10 coureurs sur des stades séparés. Ladifférence ici vient de la compétition, de la tactique de course...
5.2 Vecteurs aléatoires5.2.1 GénéralitésDéfinition 5.2.1. X : (Ω,F) → (Rd,B(Rd)) est un vecteur aléatoire si c’est une applicationF − B(Rd) mesurable.Définition 5.2.2. Si X un vecteur aléatoire sur (Ω,F) à valeurs dans Rd alors sa loi est laprobabilité PX , sur (Rd,B(Rd)) définie par :
P : B(Rd) → [0, 1]B 7→ PX(B) = P (X ∈ B)
PX(B) = P (ω ∈ Ω, X(ω) ∈ B) = P (X−1(B))Proposition 5.2.1. Si X = (X1, ..., Xd) est un vecteur aléatoire sur (Ω,F , P ) alors chaque Xi
(1 ≤ i ≤ d) est une variable réelle et la loi de Xi est appelée ième loi marginale de X. De plus :∀B ∈ B(R) :
PXi(B) = P (Xi ∈ B) = P ((X1, ..., Xi−1) ∈ Ri−1, Xi ∈ B, (Xi+1, ..., Xd) ∈ Rd−i) = PX(Ri−1×B×Rd−i)
Démonstration. Xi = Πi X tel que :Πi : Rd → R
(x1, ..., xd) 7→ xi
Πi : B(Rd)− B(Rd) mesurable donc Xi est F − B(R) mesurable.
68
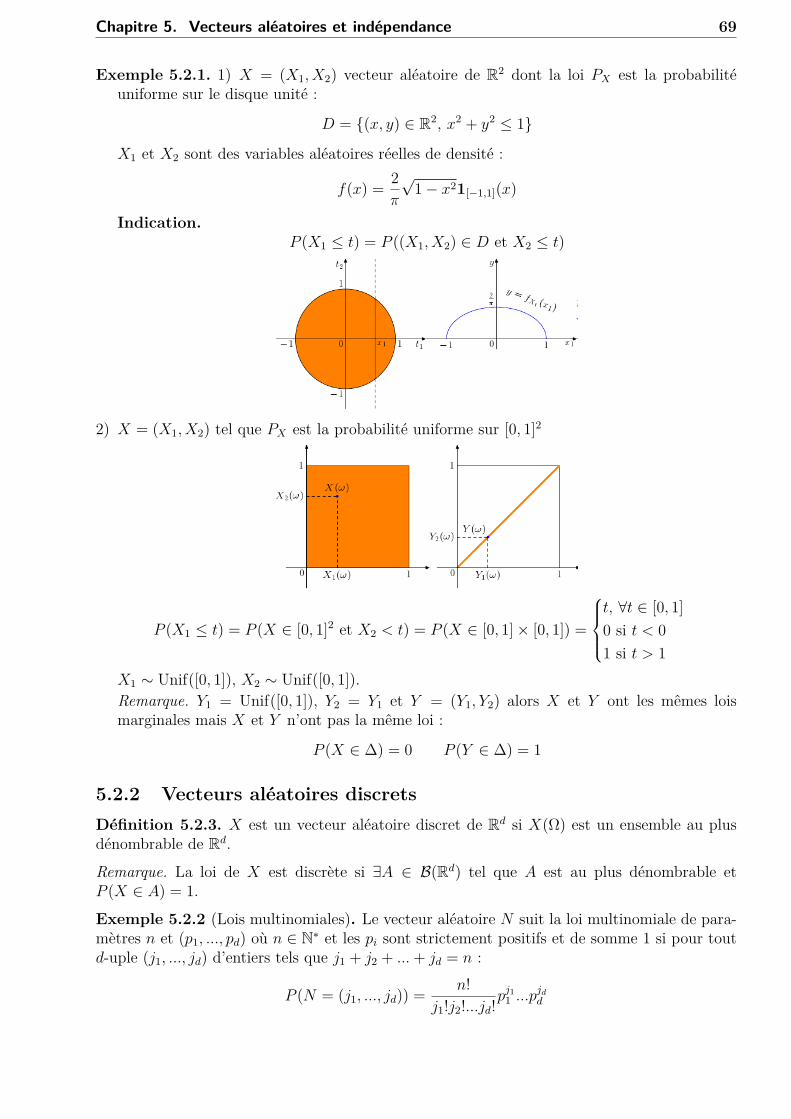
Chapitre 5. Vecteurs aléatoires et indépendance 69
Exemple 5.2.1. 1) X = (X1, X2) vecteur aléatoire de R2 dont la loi PX est la probabilitéuniforme sur le disque unité :
D = (x, y) ∈ R2, x2 + y2 ≤ 1
X1 et X2 sont des variables aléatoires réelles de densité :
f(x) = 2π
√1− x21[−1,1](x)
Indication.P (X1 ≤ t) = P ((X1, X2) ∈ D et X2 ≤ t)
2) X = (X1, X2) tel que PX est la probabilité uniforme sur [0, 1]2
P (X1 ≤ t) = P (X ∈ [0, 1]2 et X2 < t) = P (X ∈ [0, 1]× [0, 1]) =
t, ∀t ∈ [0, 1]0 si t < 01 si t > 1
X1 ∼ Unif([0, 1]), X2 ∼ Unif([0, 1]).Remarque. Y1 = Unif([0, 1]), Y2 = Y1 et Y = (Y1, Y2) alors X et Y ont les mêmes loismarginales mais X et Y n’ont pas la même loi :
P (X ∈ ∆) = 0 P (Y ∈ ∆) = 1
5.2.2 Vecteurs aléatoires discretsDéfinition 5.2.3. X est un vecteur aléatoire discret de Rd si X(Ω) est un ensemble au plusdénombrable de Rd.
Remarque. La loi de X est discrète si ∃A ∈ B(Rd) tel que A est au plus dénombrable etP (X ∈ A) = 1.
Exemple 5.2.2 (Lois multinomiales). Le vecteur aléatoire N suit la loi multinomiale de para-mètres n et (p1, ..., pd) où n ∈ N∗ et les pi sont strictement positifs et de somme 1 si pour toutd-uple (j1, ..., jd) d’entiers tels que j1 + j2 + ...+ jd = n :
P (N = (j1, ..., jd)) = n!j1!j2!...jd!
pj11 ...pjdd

70 Chapitre 5. Vecteurs aléatoires et indépendance
Ici l’ensemble N(Ω) = (j1, ..., jd) ∈ Nd, j1 + ...+ jd = n est fini et on vérifie grâce à la formuledu multinôme que :
∑x∈N(Ω)
P (N = x) =∑
j1+...+jd=n
n!j1!j2!...jd!
pj11 pj22 ...p
jdd = (p1 + ...+ pd)n = 1n = 1
La loi multinomiale est celle du vecteur des résultats d’une suite d’épreuves répétées indépen-dantes ayant chacune d issues possibles respectives p1, ...pd. Par exemple, considérons 20 tiraged’une boule avec remise dans une urne contenant 1 boule bleue, 3 jaunes, 4 rouges et 2 vertes.Notons N = (N1, N2, N3, N4) où Ni est le nombre de boules de la couleur i en numérotant lescouleurs par ordre alphabétique (b,j,r,v). On a (p1, p2, p3, p4) =
(110 ,
310 ,
410 ,
210
). La probabilité
d’obtenir en 20 tirages 3 bleues, 5 jaunes, 10 rouges et 2 vertes est :
P (N = (3, 5, 10, 2)) = 20!3!5!10!2!
( 110
)3 ( 310
)5 ( 410
)10 ( 210
)2' 0, 004745
5.2.3 Vecteurs aléatoires à densitéDéfinition 5.2.4. Une densité f sur Rd est une fonction f à valeurs dans R+ tel que :a) f est définie sur Rd\H où H est une union finie (éventuellement vide) d’hyperplans.b) f est localement Riemann-intégrable.c)∫Rd f(t)dt est convergente et : ∫
Rdf(t1, ..., td)dt1...dtd = 1
Définition 5.2.5. Un vecteur aléatoire X à valeurs dans Rd a pour densité f sur Rd si pourtout pavé C = ∏d
i=1[ai, bi] :
P (X ∈ C) =∫Cf(t)dt =
∫Cf(t1, ..., td)dt1...dtd
Exemple 5.2.3. B ∈ B(Rd) (avec λd(B) 6= 0), X suit la loi uniforme sur B c’est-à-dire PXprobabilité uniforme sur B :
∀C ∈ B(Rd), PX(C) = P (X ∈ C) = λd(B ∩ C)λd(B)
X a pour densité :
PX(C) = 1λd(B)
∫B∩C
dt1...dtd = 1λd(B)
∫Rd
1B∩C(t1, ..., td)dt1...dtd
= 1λd(B)
∫Rd
1B(t1, ..., td)1C(t1, ..., td)dt1...dtd =∫C
1λd(B)1B(t1, ..., td)︸ ︷︷ ︸
f(t1,...,td)
dt1...dtd
X a pour densité f = 1λd
(B)1B.
Proposition 5.2.2. Si X a pour densité f sur Rd, X = (X1, ..., Xd) alors ses marginales Xi,1 ≤ i ≤ d ont pour densité :
f(u) =∫
Ri−1×Rd−if(t1, ..., ti−1, u, ti+1, ..., td)dt1...dti−1dti+1...dtd
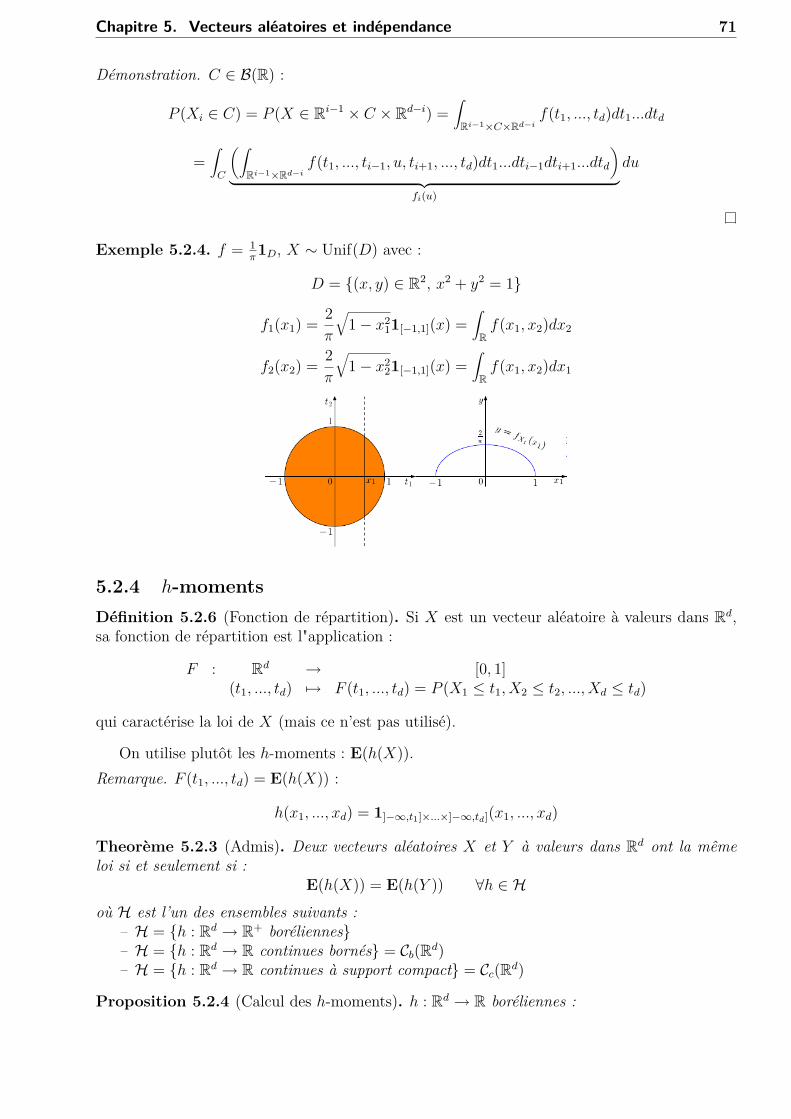
Chapitre 5. Vecteurs aléatoires et indépendance 71
Démonstration. C ∈ B(R) :
P (Xi ∈ C) = P (X ∈ Ri−1 × C × Rd−i) =∫
Ri−1×C×Rd−if(t1, ..., td)dt1...dtd
=∫C
(∫Ri−1×Rd−i
f(t1, ..., ti−1, u, ti+1, ..., td)dt1...dti−1dti+1...dtd
)︸ ︷︷ ︸
fi(u)
du
Exemple 5.2.4. f = 1π1D, X ∼ Unif(D) avec :
D = (x, y) ∈ R2, x2 + y2 = 1
f1(x1) = 2π
√1− x2
11[−1,1](x) =∫
Rf(x1, x2)dx2
f2(x2) = 2π
√1− x2
21[−1,1](x) =∫
Rf(x1, x2)dx1
5.2.4 h-momentsDéfinition 5.2.6 (Fonction de répartition). Si X est un vecteur aléatoire à valeurs dans Rd,sa fonction de répartition est l"application :
F : Rd → [0, 1](t1, ..., td) 7→ F (t1, ..., td) = P (X1 ≤ t1, X2 ≤ t2, ..., Xd ≤ td)
qui caractérise la loi de X (mais ce n’est pas utilisé).
On utilise plutôt les h-moments : E(h(X)).Remarque. F (t1, ..., td) = E(h(X)) :
h(x1, ..., xd) = 1]−∞,t1]×...×]−∞,td](x1, ..., xd)
Theorème 5.2.3 (Admis). Deux vecteurs aléatoires X et Y à valeurs dans Rd ont la mêmeloi si et seulement si :
E(h(X)) = E(h(Y )) ∀h ∈ H
où H est l’un des ensembles suivants :– H = h : Rd → R+ boréliennes– H = h : Rd → R continues bornés = Cb(Rd)– H = h : Rd → R continues à support compact = Cc(Rd)
Proposition 5.2.4 (Calcul des h-moments). h : Rd → R boréliennes :

72 Chapitre 5. Vecteurs aléatoires et indépendance
1) si X est un vecteur aléatoire discret et si :
E(|h(X)|) =∑
x∈X(Ω)|h(x)|P (X = x) < +∞
alors :
E(h(X)) =∑
x∈X(Ω)h(x)P (X = x) =
∑(x1,...,xd)∈X(Ω)
h(x1, ..., xd)P (X = (x1, ..., xd))
2) si X est un vecteur aléatoire de densité f sur Rd et si :
E(|h(X)|) =∫
Rd|h(x)|f(x)dx < +∞
alors :E(h(X)) =
∫Rdh(x)f(x)dx =
∫Rdh(x1, ..., xd)f(x1, ..., xd)dx1...dxd
Proposition 5.2.5 (Loi d’un vecteur image). Soit X un vecteur aléatoire à valeurs dans Rd
de densité fX tel que P (X ∈ D) = 1 où D ⊂ Rd un ouvert. Soit g!D → Rd injective tel queg(D) = D′ et g est de classe C1 alors le vecteur Y = g(X) a pour densité fY :
fY = (fX g−1)× | Jac(g−1)|1′D
Rappel.
Jacϕ = det[∂ϕi
∂xj
]1≤i≤d,1≤j≤d
Démonstration. Changement de variables dans Rd :
ϕ : D′ → D C1-difféomorphisme∫Dh(x1, ..., xd)dx1...dxd =
∫D′h ϕ(x1, ..., xd)| Jac(ϕ)|(x1, ..., xd)dx1...dxd
h est continue bornée de Rd dans R :
E(h(Y )) = E(h g(X)) =∫Dh g(x1, ..., xd)f(x1, ..., xd)dx1...dxd (∗)
ϕ = g−1 : D′ → D
(∗) =∫D′h g(g−1(x1, ..., xd)| Jac(g−1)|(x1, ..., xd)fX(g−1(x1, ..., xd))dx1...dxd
=∫D′h(x1, ..., xd)| Jac(g−1)|(x1, ..., xd)fX(g−1(x1, ..., xd))dx1...dxd
On pose (y1, ..., yd) = g(x1, ..., xd) :
=∫
Rdh(y1, ..., yd)fy(y1, ..., yd)dy1...dyd
On peut vérifier que fY est une densité sur Rd.
Remarque.Jac(g−1)(y) = 1
Jac(g)(g−1(y))

Chapitre 5. Vecteurs aléatoires et indépendance 73
Application 5.2.1. Cas où g est linéaire c’est-à-dire :
g = (g1, ..., gd) gi(x1, ..., xd) =d∑j=1
ajxj
On a aussi :Jac(g) = 1
det(G) avec G =[(aij)1≤i≤d,1≤j≤d
]
fY (g1, ..., gd) = fX(g−1(y1, ..., yd))1
| det(G)|
5.2.5 Covariance et variance d’une sommeCovariance
Définition 5.2.7. Soit X et Y variables réelles définies sur (Ω,F , P ) ayant des momentsd’ordre 2 alors la covariance de X, Y est :
Cov(X, Y ) = E[(X − E(X))(Y − E(Y ))]
Cov(X, Y ) est bien définie car si X et Y sont des moments d’ordre 2 alors XY est intégrableet on a, grâce à l’inégalité de Cauchy-Schwartz :
|E(XY )| ≤√
E(X2)√
E(Y 2)
Démonstration de l’inégalité de Cauchy-Schwartz. 1) |XY | ≤ 12X
2 + 12Y
2
2) |XY | ≤ θ2X
2 + 12θY
2 (θ > 0) car θX2 − 2|XY |+ 1θY 2 = (
√θX − 1√
θY )2.
En particulier |XY | est intégrable :
E(|XY |) ≤ θ
2E(X2) + 12θE(Y 2) ≤ min
θ>0
θ
2E(X2) + 12θE(Y 2)
︸ ︷︷ ︸
g(θ)
g′(θ) = 12E(X2)− 1
2θ2 E(Y 2)
g′(θ) = 0⇔ θ =
√√√√E(Y 2)E(X2) E(X2) 6= 0, E(Y 2) 6= 0
si E(Y 2) = 0 alors P (X = 0) = 1 et donc P (XY = 0) = 1 et Cauchy-Schwartz est vérifié.
Remarque. Cas d’égalité ⇔ ∃(a, b) ∈ R2 non tous nuls tel que aX + bY = 0 presque sûrement.
Proposition 5.2.6.Cov(X, Y ) = E[(X − E(X))(Y − E(Y ))]
1) Cov(X, Y ) = Cov(Y,X)2) Cov(aX + b, cY + d) = acCov(X, Y )3) |Cov(X, Y )| ≤ σ1(X)σ(Y ) (CS)Si Cov(X, Y ) = 0, on dit que X et Y sont non correlées.
1On rappelle que σ est l’écart type d’une variable aléatoire

74 Chapitre 5. Vecteurs aléatoires et indépendance
Définition 5.2.8. SiX et Y sont des variables aléatoires sur le même espace ayant des momentsd’ordre 2 et non constant presque sûrement alors le coefficient de corrélation ρ(X, Y ) est définide la manière suivante :
ρ(X, Y ) = Cov(X, Y )σ(X)σ(Y )
Proposition 5.2.7. 1) |ρ(X, Y )| ≤ 12) ρ est maximal si Y est une fonction affine de X : Y = aX + b
Proposition 5.2.8.Cov(X, Y ) = E(XY )− E(X)E(Y )
Démonstration.
E[(X − E(X))(Y − E(Y ))] = E(XY − E(X)Y − E(Y )X + E(XY ))
= E(XY )− E(X)E(Y )− E(X)E(Y ) + E(X)E(Y )
Proposition 5.2.9 (Calcul de Cov(X, Y )). 1) X et Y discret :
Cov(X, Y ) =∑
x∈X(Ω),y∈Y (Ω)xyP (X = x, Y = y)−
∑x∈X(Ω)
xP (X = x) ∑
y∈Y (Ω)yP (Y = y)
2) (X, Y ) à densité f sur R2 (f1, 1ère marginale et f2, 2ème marginale) :
Cov(X, Y ) =∫
R2xyf(x, y)dxdy −
∫Rxf1(x)dx
∫Ryf2(y)dy
Variance d’une somme
Proposition 5.2.10. Soit X1, ..., Xn n variables aléatoires réelles définies sur le même espaceayant des moments d’ordre 2 alors :
Var(X1 + ...+Xn) =∑
1≤i,j≤nCov(X1, Xj)
=n∑i=1
Var(Xi) +∑
1≤i,j≤n,i6=jCov(Xi, Xj) =
n∑i=1
Var(Xi) + 2∑
1≤i,j≤nCov(Xi, Xj)
Démonstration.
Var(X1 + ...+Xn) = E[(X1 + ...Xn)(E(X1) + ...E(Xn))]
= E ∑
1≤i,j≤n(Xi − E(Xi))(Xj − E(Xj))
=∑
1≤i,j≤nCov(Xi, Xj)

Chapitre 5. Vecteurs aléatoires et indépendance 75
5.3 Indépendance de variables et vecteurs aléatoires5.3.1 Suites indépendantesDéfinition 5.3.1. n variables aléatoires X1, ..., Xn définies sur le même espace sont indépen-dants si ∀Bi ∈ B(R), ∀i ∈ 1, ..., n :
P (X1 ∈ B1, ..., Xn ∈ Bn) = P (X1 ∈ B1)...P (Xn ∈ Bn)
Remarque. On peut se contenter de prendre Bi = [ai, bi].
Définition 5.3.2. Xi : Ω → Rdi , 1 ≤ i ≤ n, les n vecteurs aléatoires X1, ..., Xn sont indépen-dants si ∀Bi ∈ B(Rdi), ∀i ∈ 1, ..., n :
P (X1 ∈ B1, ..., Xn ∈ Bn) = P (X1 ∈ B1)...P (Xn ∈ Bn)
Exemple 5.3.1 (hérédité de l’indépendance). Soient 5 variables aléatoires X1, .., X5 indépen-dantes et
Y1 = X1 + 2X2 Y2 = (exp(X3),√|X5|) Y3 = (X4, X
24 , X
34 )
alors : Y1, Y2, Y3 sont des vecteurs aléatoires indépendants.
Proposition 5.3.1. Soient n variables aléatoires X1, ..., Xn définies sur le même espace etindépendantes et :
1, ..., n =k⋃i=1
Il
avec comme conditions :1) Il ∩ Il′ 6= ∅ si l 6= l′
2) Il 6= ∅On pose pour 1 ≤ l ≤ k :
– ml = card IL– hl : Rml → Rdl
– Zl = hl((Xi)i∈Il) vecteurs à valeurs dans Rd
alors les vecteurs Z1, ..., Zk sont indépendants.
Corollaire. 1 < m0 < m1 < ... < mk = n, X1, ..., Xn indépendants :
Yl = (Xml + 1, ..., Xml+1) pour 0 ≤ l ≤ k − 1
Y0, ..., Yk−1 sont des vecteurs indépendants.
Définition 5.3.3. Xi : Ω→ Rd, i ∈ N, la suite (Xi)i∈N est une suite de vecteurs indépendants.Si ∀K ⊂ N fini, les vecteurs (Xi)i∈K est une suite de vecteurs indépendants.
5.3.2 Composantes indépendantesCas discret
Proposition 5.3.2. Le vecteur aléatoire discret (X1, ..., Xd) a des composantes indépendantessi et seulement si :
∀(x1, ..., xd) ∈ X(Ω) P (X1 = x1, ..., Xd = xd) =d∏i=1
P (Xi = xi)

76 Chapitre 5. Vecteurs aléatoires et indépendance
Démonstration. (⇒) Clair en prenant Bi = xi.(⇐) B = B1 × ...×Bd. On veut montrer que :
PX(B) = P (X ∈ B) =d∏i=1
PXi(Bi) =d∏i=1
P (Xi ∈ Bi)
X(Ω) est au plus dénombrable : X(Ω) ⊂ X1(Ω) × ... × Xd(Ω) = E. Si x ∈ E\X(Ω),P (X = X) = 0 :
P (X ∈ B1 × ...×Bd) =∑
x∈B1×...×BdP (X = x) =
∑x∈B1×...×Bd∩E
P (X = x) (∗)
B1 × ...×Bd ∩ E = B1 ∩X1(Ω)× ...×Bd ∩Xd(Ω)(∗) =
∑x1∈B1∩X1(Ω),...,xd∈Bd∩Xd(Ω)
P (X1 = x1, ..., Xd = xd) =∑
P (X1 = x1)...P (Xd = xd)
=n∏i=1
∑xi∈Bi∩Xi(Ω)
P (Xi = xi) =d∏i=1
P (Xi ∈ Bi ∩Xi(Ω)) =d∏i=1
P (X ∈ Bi)
Cas des vecteurs aléatoires à densité
Notation. Si f1, ..., fd sont des fonctions de R dans R, on définit
f1 ⊗ ...⊗ fd : Rd → R(x1, ..., xd) 7→ f1(x1)...fd(xd)
(appelé produit tensoriel de fi).
Proposition 5.3.3. Soit (X1, ..., Xd) un vecteur aléatoire de Rd.a) si les (Xi)1≤i≤d sont indépendantes et de densité respective fi (1 ≤ i ≤ d) alors le vecteur
(X1, ..., Xd) a pour densité f1 ⊗ ...⊗ fd.b) si le vecteur (X1, ..., Xd) a pour densité f1⊗...⊗fd où les (fi)1≤i≤d sont des fonctions positives
définies sur R\Ki où Ki est un ensemble fini de points alors ∀i ∈ 1, ..., d il existe ci > 0tel que Xi a pour densité cifi, de plus, les (Xi)1≤i≤d sont indépendantes et ∏d
i=1 ci = 1.
Démonstration. a) C = ∏di=1]ai, bi] ∈ B(Rd) :
P (X ∈ C) = P ((X1, ..., Xd) ∈d∏i=1
]ai, bi]) = P (X1 ∈]a1, b1], ..., Xd ∈]ad, bd]) = P (X1 ∈]a1, b1])...P (Xd ∈]ad, bd])
=∫ b1
a1f(x1)dx1 × ...×
∫ bd
ad
fd(xd)dxd =∫Cf1(x1)...fd(xd)dx1...dxd
b) loi marginale : soit ]a, b] ⊂ R
P (Xi ∈]a, b]) =∫
Ri−1×]a,b]×Rd−if1(x1)...fd(xd)dx1...dxd
=∫ b
a
(∫Ri−1×Rd−i
f1(x1)...fi−1(xi−1)fi+1(xi+1)dx1...dxi−1dxi+1...dxd
)︸ ︷︷ ︸
cifi(xi)dxi
=∫ b
af(xi)dxi avec f = cifi

Chapitre 5. Vecteurs aléatoires et indépendance 77
Indépendance : C = ∏di=1]ai, bi] :
P (X ∈ C) =∫Cf1(x1)...fd(xd)dx1...dxd =
d∏i=1
∫ bi
aifi(xi)dxi
d∏i=1
P (Xi ∈]ai, bi]) =d∏i=1
∫ bi
aicifi(xi)dxi =
(d∏i=1
ci
)d∏i=1
∫ bi
aifi(xi)dxi
En prenant Cn = ∏di=1]− n, n], n ∈ N et en faisant tendre n vers +∞, avec la propriété de
continuité sequentielle monotone d’une probabilité ⇒ ∏di=1 ci = 1.
Exemple 5.3.2. 1) Xi ∼ N (0, σi), 1 ≤ i ≤ d, (Xi) indépendants alors (X1, ..., Xd) a pourdensité :
f(x1, ..., xd) = 1(√
2π)dσ1...σdexp
(− x2
12σ2
1
)... exp
(− x2
d
2σ2d
)C’est un cas particulier du vecteur gaussien.
2) Si (X, Y ) a pour densité :
f(x, y) = 1√2π3
e−y/2
(1 + x2)√y1]0,+∞[(y)
X a pour densité :fX = 1
π
11 + x2 sur R
Y a pour densité :fY = 1√
2πye−y/21]0,+∞[(y)
On peut montrer que Y a même loi que Z2 avec Z ∼ N (0, 1) : loi du χ2(1) (loi du chi-deuxa 1 degré de liberté).
5.3.3 Loi d’une somme de variables aléatoires indépendantesX et Y deux variables aléatoires définies sur (Ω,F , P ) :
Z = Σ(X, Y ) = X + Y
Pour connaître la loi de Z, il faut connaître la loi du couple. C’est le cas si X et Y sontindépendantes et quand on connait la loi de X et Y .
Cas où X et Y sont discrètes
Proposition 5.3.4. Si X, Y discrètes indépendantes alors Z = X +Y est discrète et sa lo iestdonnée par ∀z ∈ Z(Ω) :
P (Z = z) =∑
x∈X(Ω)P (Y = z − x)P (X = x) =
∑y∈Y (Ω)
P (X = z − y)P (Y = y)
Démonstration. –Σ : X(Ω)× Y (Ω) → Z(Ω)
(x, y) 7→ x+ y
Z(Ω) est l’image par une application surjective d’un ensemble au plus dénombrable ⇒Z(Ω) est au plus dénombrable.

78 Chapitre 5. Vecteurs aléatoires et indépendance
– ∀z ∈ Z(Ω), on cherche à calculer P (Z = z). X = xx∈X(Ω) forme une partition de Ω.
Z = z =⋃
x∈X(Ω)Z = z ∩ X = x =
⋃x∈X(Ω)
X + Y = Z et X = x
=⋃
x∈X(Ω)Y = z − x et X = x (union disjointe dénombrable)
∀z ∈ Z(Ω) :
P (Z = z) =∑
x∈X(Ω)P (Y = z − x,X = x) indép.=
∑x∈X(Ω)
P (Y = z − x)P (X = x)
Exemple 5.3.3. En exercice, on peut montrer que si :
X = Pois(α), Y = Pois(β), X et Y indépendantes
alors X + Y ∼ Pois(α + β).
Cas où X et Y à densité
Proposition 5.3.5. Si X, Y ont pour densité respectives f et g et sont indépendantes alorsZ = X + Y a pour densité le produit de convolution de f par g noté f ∗ g définit sur R par :
f ∗ g(s) =∫
Rf(s− t)g(t)dt =
∫Rf(t)g(s− t)dt ∀s ∈ R
Démonstration. h continue bornée sur R. On veut montrer que :
E(h(Z)) =∫
Rh(s)f ∗ g(s)ds
On a que :E(h(Z)) = E(h Σ(X, Y )) =
∫R2h(x+ y)f(x)g(y)dxdy
(X, Y ) a pour densité f ⊗ g. On fait le changement de variables suivant :– (s, t) = (x+ y, y)– (x, y) = (s− t, t)
On a ainsi que Jac = 1. Ainsi :
E(h(Z)) =∫
R2h(s)f(s− t)g(t)dsdt =
∫Rh(s)
(∫Rf(s− t)g(t)dt
)︸ ︷︷ ︸
f∗g(s)
ds
Remarque. En prenant h ≡ 1 : ∫Rf ∗ g(s)ds = 1
Exemple 5.3.4. 1) X ∼ χ2(1) et Y ∼ χ2(1) de desnité :
f(t) = 1√2πt
e−t/21]0,+∞[(t)dt
et indépendantes alors X + Y a pour densité :
f ∗ f(s) = 12e−s/21]0,+∞[(t)dt
C’est la loi de Z21 + Z2
2 où Z1 ∼ N (0, 1) et Z2 ∼ N (0, 1) et Z1 indépendants.
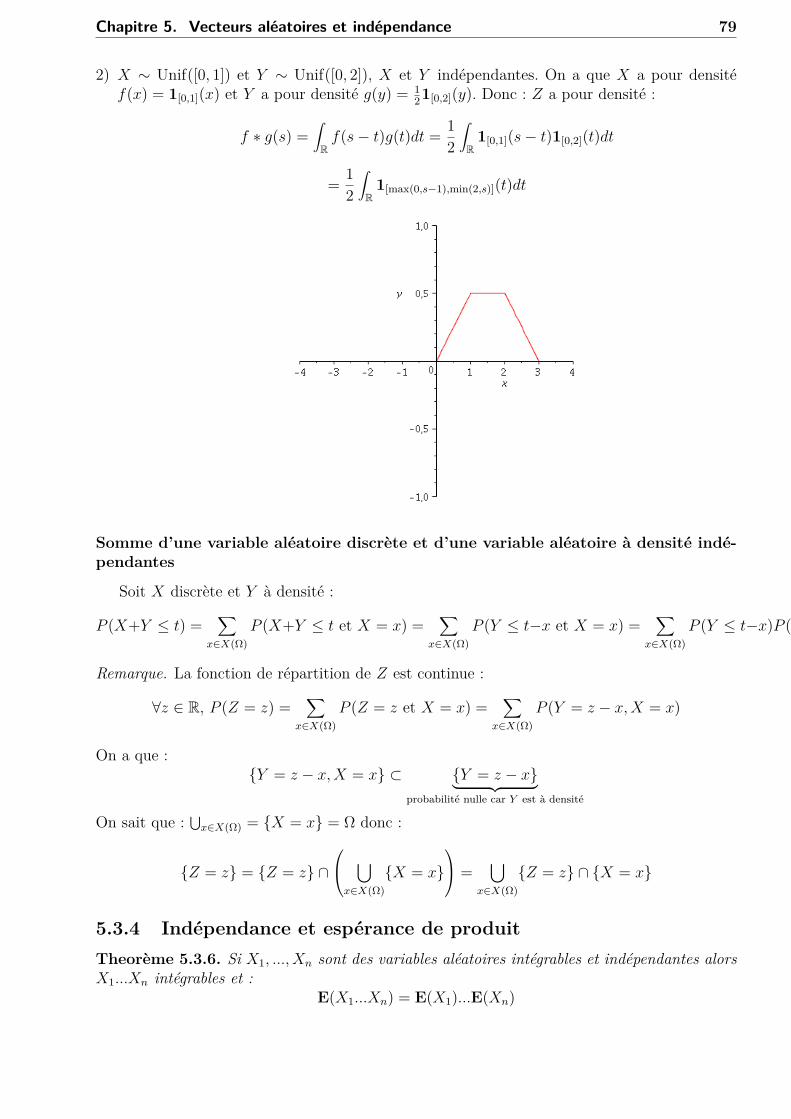
Chapitre 5. Vecteurs aléatoires et indépendance 79
2) X ∼ Unif([0, 1]) et Y ∼ Unif([0, 2]), X et Y indépendantes. On a que X a pour densitéf(x) = 1[0,1](x) et Y a pour densité g(y) = 1
21[0,2](y). Donc : Z a pour densité :
f ∗ g(s) =∫
Rf(s− t)g(t)dt = 1
2
∫R
1[0,1](s− t)1[0,2](t)dt
= 12
∫R
1[max(0,s−1),min(2,s)](t)dt
Somme d’une variable aléatoire discrète et d’une variable aléatoire à densité indé-pendantes
Soit X discrète et Y à densité :
P (X+Y ≤ t) =∑
x∈X(Ω)P (X+Y ≤ t et X = x) =
∑x∈X(Ω)
P (Y ≤ t−x et X = x) =∑
x∈X(Ω)P (Y ≤ t−x)P (X = x)
Remarque. La fonction de répartition de Z est continue :
∀z ∈ R, P (Z = z) =∑
x∈X(Ω)P (Z = z et X = x) =
∑x∈X(Ω)
P (Y = z − x,X = x)
On a que :Y = z − x,X = x ⊂ Y = z − x︸ ︷︷ ︸
probabilité nulle car Y est à densité
On sait que : ⋃x∈X(Ω) = X = x = Ω donc :
Z = z = Z = z ∩
⋃x∈X(Ω)
X = x
=⋃
x∈X(Ω)Z = z ∩ X = x
5.3.4 Indépendance et espérance de produitTheorème 5.3.6. Si X1, ..., Xn sont des variables aléatoires intégrables et indépendantes alorsX1...Xn intégrables et :
E(X1...Xn) = E(X1)...E(Xn)

80 Chapitre 5. Vecteurs aléatoires et indépendance
Corollaire. Xi : Ω → Rdi vecteur aléatoire, 1 ≤ i ≤ n, hi : Rdi → R fonctions boréliennes telque hi(Xi) est variable aléatoire intégrable alors h1(X1)...hn(Xn) est intégrable et :
E(h1(X1)...hn(Xn)) = E(h1(X1))...E(hn(Xn))
Démonstration du Théorème 5.3.6. On se ramène à n = 2 (+ reccurence) :1) Fonctions indicatrices : X1 = 1A1 , X2 = 1A2 . X1, X2 indépendants⇒ A1 et A2 indpéndants.
X1 ×X2 = 1A1 ∩ 1A2 = 1A1∩A2
E(X1X2) = E(1A1∩A2) = P (A1∩A2) = P (X1 = 1, X2 = 1) = P (X1 = 1)P (X2 = 1) = E(X1)E(X2)
2) Pour des variables aléatoires étagées positives. Soient :
X1 =l∑
k=1a1,k1A1,k , X2 =
n∑k=1
a2,k1A2,k
avec :A1,k = X1 = a1,k A2,k = X2 = a2,k
et X1, X2 indépendants. On vérifie que E(X1X2) = E(X1)E(X2) en utilisant :
E(1A1,k1A2,k′ ) = E(1A1,k)E(1A2,k′ )
puis la linéarité de l’espérance.3) Pour des variables aléatoires positives : par Beppo-Levi
X1 = limn→+∞
X1,n
X2 = limn→+∞
X2,n
limite croissante de variable aléatoires étagées
Remarque. X1,n = hn(X1) et X2,n = hn(X2) où hn(x) = minn, 2−n[2nx]. On a indépen-dance de X1,n et X2,n :
E(X1,n, X2,n) = E(X1,n)E(X2,n)
+ passage à la limite par Beppo-Levi4) Pour des variables quelconques intégrables :
X1 = X+1 −X−1 X2 = X+
2 −X−2
X1X2 = X+1 X
+2 −X+
1 X−2 −X−1 X+
2 +X−1 X−2
5.3.5 Indépendance, variance et covarianceProposition 5.3.7. 1) Si X et Y sont définies sur le même espace et sont indépendantes et
de carré intégrable alors Cov(X, Y ) = 0.2) Si X1, ..., Xn sont n variables aléatoires définies sur le même espace, de carré intégrable et
indépendantes alors :
Var(X1 + ...+Xn) =n∑i=1
Var(Xi)

Chapitre 5. Vecteurs aléatoires et indépendance 81
Rappel.Cov(X, Y ) = E((X − E(X))(Y − E(Y ))) = E(XY )− E(X)E(Y )
Attention :. X, Y indépendantes → X, Y non correlées mais la réciproque est fausse.
Exemple 5.3.5. X ∼ N (0, 1) et P (Y = 1) = P (Y = −1) = 1/2. Soit Z = XY . On peut montrerque Z ∼ N (0, 1)2
E(XZ) = E(X2Y ) = E(X2)E(Y ) = 0 et E(X) = E(Z) = 0
Donc : X et Z sont non correlées (Cov(X,Z) = 0) mais X et Y ne sont pas indépendantes.Par exemple, on peut voir que :
P (X > 1, Z ≤ 1) 6= P (X > 1)P (Z ≤ 1)
5.4 Vecteurs aléatoires gaussiens5.4.1 DéfinitionsDéfinition 5.4.1. X = (X1, ..., Xd) est un vecteur gaussien de Rd si pour toute forme linéaireu, u(X) est une variable aléatoire gaussienne. C’est-à-dire ∀(a1, ..., ad) ∈ Rd, a1X1 + ...+ adXd
est gaussienne.
Remarque. Une variable aléatoire constante presque sûrement est une variable aléatoire de loigaussienne N (m, 0).Conséquence. Si X = (X1, ..., Xd) est un vecteur guassien alors chaque Xi est gaussienne(prendre ui : (x1, ..., xd)→ xi).Attention :. La réciproque est fausse. On prend le même exemple que Exemple 5.3. : X ∼N (0, 1), Z ∼ N (0, 1) mais (X,Z) n’est pas un vecteur gaussien. En effet :
X + Z = X + Y X = (1 + Y )X
P (X + Z = 0) = P ((1 + Y )X = 0) = P (1 + Y = 0) = 1/2
⇒ X + Z n’est pas à densité donc non gausienne.
2Indication :
P (Z ≤ t) = P (XY ≤ t) = P (−X ≤ t et Y = −1) + P (X ≤ t et Y = 1)





























