Embed Size (px)
Citation preview
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 1 of 124
SmartMiner
Quick Start
Common Operation Pages
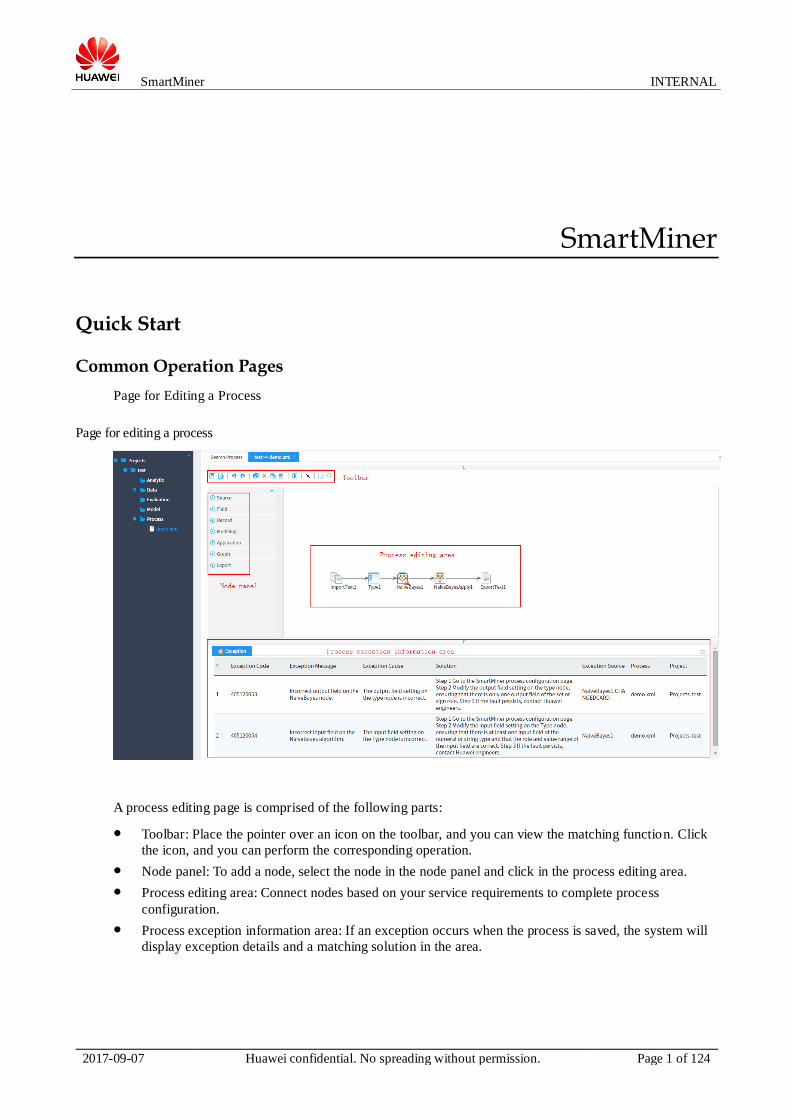
Page for Editing a Process
Page for editing a process
A process editing page is comprised of the following parts:
Toolbar: Place the pointer over an icon on the toolbar, and you can view the matching function. Click
the icon, and you can perform the corresponding operation.
Node panel: To add a node, select the node in the node panel and click in the process editing area.
Process editing area: Connect nodes based on your service requirements to complete process
configuration.
Process exception information area: If an exception occurs when the process is saved, the system will
display exception details and a matching solution in the area.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 2 of 124
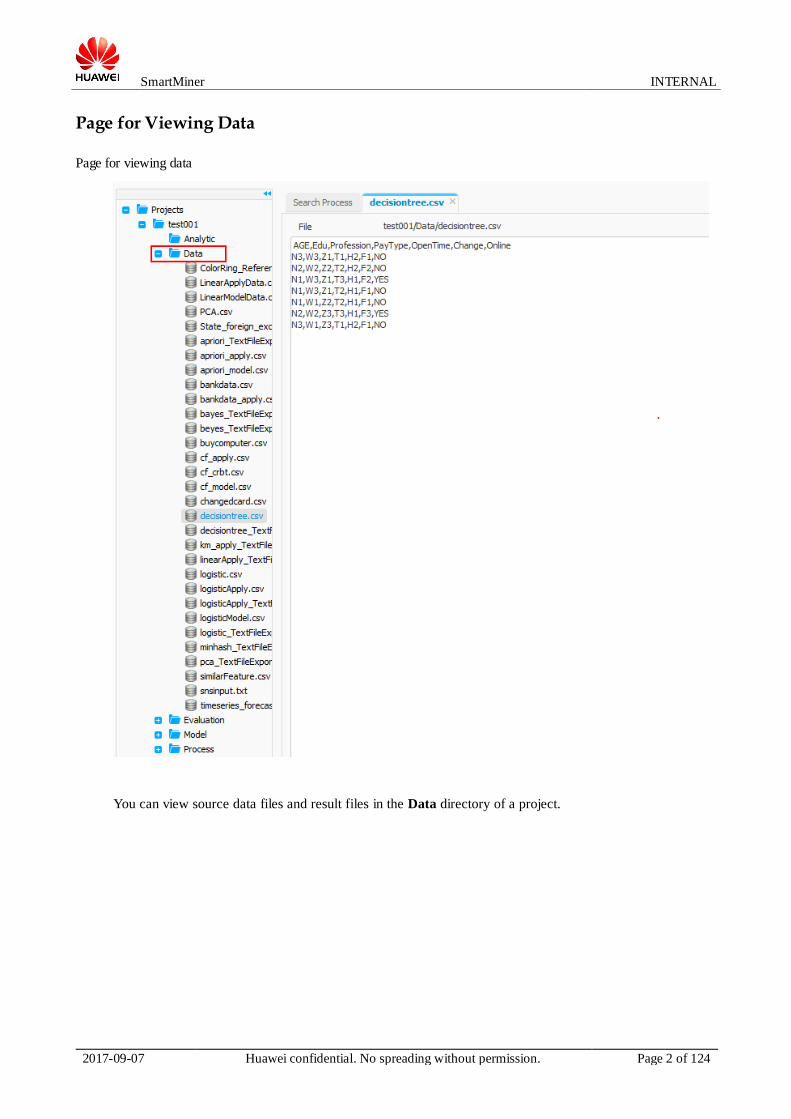
Page for Viewing Data
Page for viewing data
You can view source data files and result files in the Data directory of a project.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 3 of 124
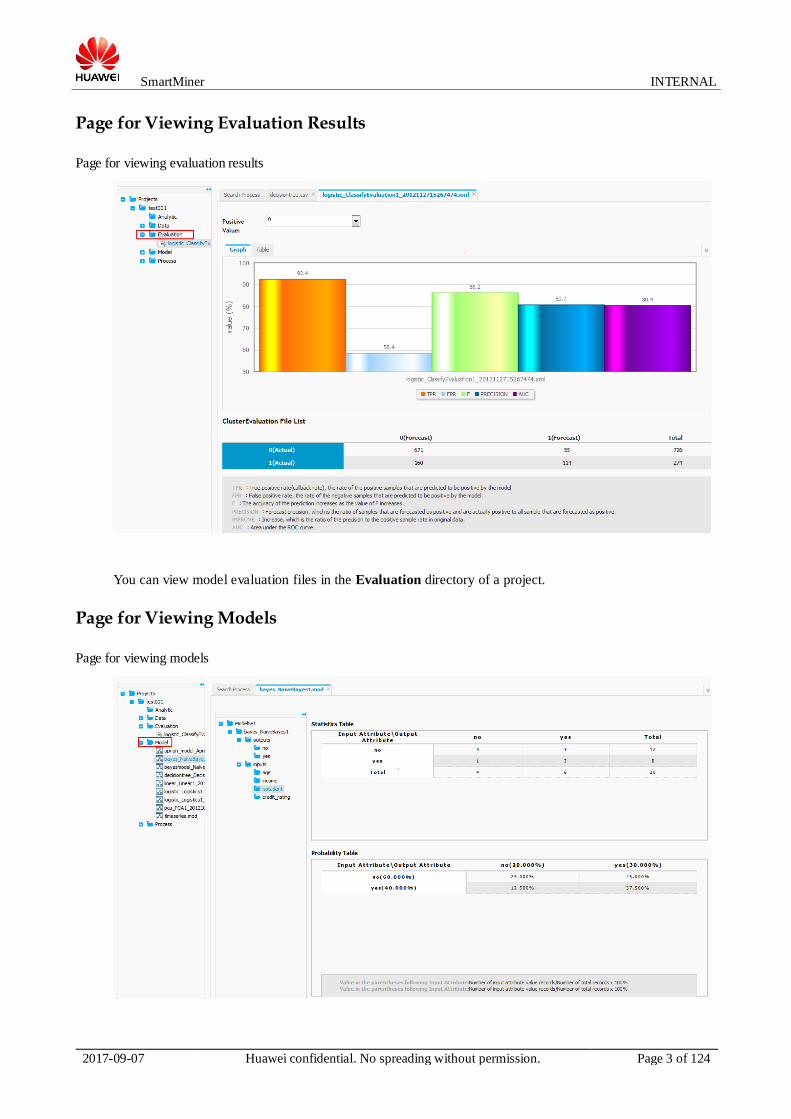
Page for Viewing Evaluation Results
Page for viewing evaluation results
You can view model evaluation files in the Evaluation directory of a project.
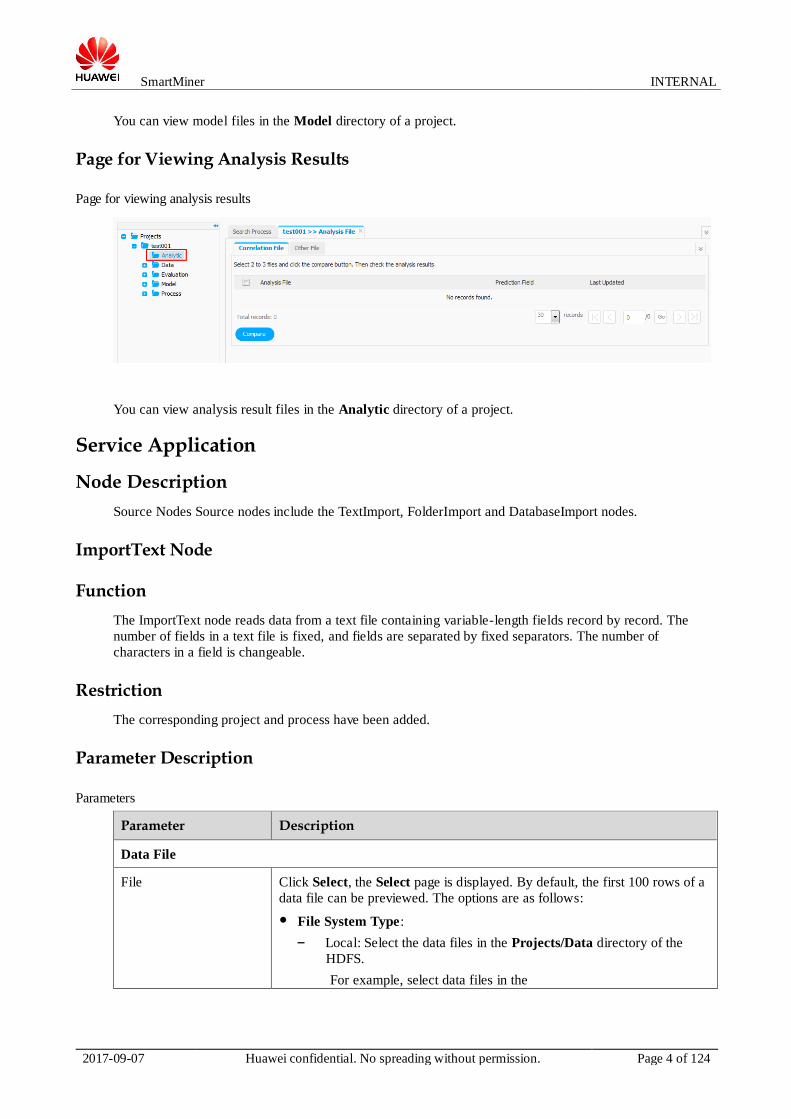
Page for Viewing Models
Page for viewing models
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 4 of 124
You can view model files in the Model directory of a project.
Page for Viewing Analysis Results
Page for viewing analysis results
You can view analysis result files in the Analytic directory of a project.
Service Application
Node Description
Source Nodes Source nodes include the TextImport, FolderImport and DatabaseImport nodes.
ImportText Node
Function
The ImportText node reads data from a text file containing variable-length fields record by record. The
number of fields in a text file is fixed, and fields are separated by fixed separators. The number of
characters in a field is changeable.
Restriction
The corresponding project and process have been added.
Parameter Description
Parameters
Parameter Description
Data File
File Click Select, the Select page is displayed. By default, the first 100 rows of a
data file can be previewed. The options are as follows:
● File System Type:
– Local: Select the data files in the Projects/Data directory of the
HDFS.
For example, select data files in the
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 5 of 124
Parameter Description
${smart_project_home_dir}/Projects/ONE/Data/ directory.
${smart_project_home_dir}: set the parameter in the
${SmartMiner_HOME}/conf/smartminer.properties file.
ONE: project name.
– HDFS: Select a data file from the Hadoop distributed file system
(HDFS).
NOTE
If the file system is HDFS, the ImportText node exports files from each project directory in /smartminer/inputdir of the HDFS to the mapping project directories in /smartminer/outputdir.
You can configure the directory by setting the following parameters in ${SmartMiner_HOME}/conf/smartminer.properties as a SmartMiner user. Restart the SmartMiner for the settings to take effect.
smart_hdfs_input_dir=/smartminer/inputdir
smart_hdfs_output_dir=/smartminer/inputdir
– FTP: Select a data file from the FTP server.
NOTE
You need to enable the FTP service before selecting a data file. For details, see Configuring the FTP Service.
● File: Enter a file name in the text box and click Query. All files that
meet the search criteria are displayed on the page. By default, all files are
selected. A file name can contain an expression, for example,
sm_user_retain_#date(yyyyMMddHHmmss)#.csv.
File Uploads a local file to the node server.
Read field names from
the file
Specifies whether to read field names. The parameter is selected by default.
● If the parameter is selected, the TextImport node will read the first row of
the text file as field names.
● If the parameter is not selected, the TextImport node will generate field
names automatically, for example, FIELD1 and FIELD2.
Metadata
Field Name Field name in a data file.
● If the TextImport node reads field names, the first row in the data file is
read as field names.
● If the TextImport node does not read field names, the node generates
field names automatically.
Filter
NOTE
After the field name is modified, the mapping field names on subsequent nodes also need to be modified.
Click Export, and the system will export a metadata file that contains values of the fieldName, dataType, and format fields.
Click Restore, and metadata, such as fieldName and dataType, will be restored to its factory default.
Select a Metadata File Select a metadata file and click Import, and the system will import values of
the New Field, DataType, and Format fields. If the TextImport node has a

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 6 of 124
Parameter Description
different number of fields from the metadata file, the system notifies you
that the number of fields in the TextImport node does not match that in the
metadata file.
● If the TextImport node has more fields than the metadata file, the system
notifies you that the number of fields in the TextImport node does not
match that in the metadata file after reading the file.
● If the TextImport node has fewer fields than the metadata file, the system
notifies you that the number of fields in the TextImport node does not
match that in the metadata file after setting the ImportText node with the
imported data.
ImportFeatureLibrary Node
Function
The ImportFeatureLibrary node combines corresponding fields in feature files based on a specified
prediction field and multiple specified feature fields to generate sample data required for data mining. Files
involved in field combination must have the same primary key, for example, user ID. Invalid data is filtered
out during field combination.
Restriction The corresponding project and process have been added.
Feature files and features have been created.
Parameter Description
Parameters
Parameter Description
Prediction Field You can set the forecast field in either of the
following ways:
● Click the text box:
– Click Select Field: select a field in the
feature list on the page that is displayed.
– Click Customize Field: select a field in
the feature list as a reference field, and
then customize a forecast field based on
the expression.
● Click Importing External Tag Data. The data
to be imported must have two fields: primary
key and forecast field.
Input Field Click the text box and select input fields on the
page that is displayed.
● On the Input Field tab page, you can query
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 7 of 124
Parameter Description
features in the feature query area. The query
results are displayed in a list. Features selected
as input fields are displayed in a list at the
bottom of the tab page.
● On the Auto tab page, you can configure
analysis counters and click Recommendation
Similarity. The system then automatically
analyzes the correlation between the prediction
field and input fields, selects features based on
the correlation evaluation counter threshold,
and displays the selected features in a feature
list. Features selected on the Auto and Input
Field tab pages are combined.
Prediction Periods The default value is 1. The value of this parameter
must be equal to or less than the value of
Maximum storage duration (months) minus one.
For example, if the maximum storage duration is
three months, the maximum value of this
parameter is 2.
Sampling Conditions Click the text box. The page for editing feature
conditions is displayed.
Sampling Periods The default value is 1. The value of this parameter
must be equal to or less than the value of
Maximum storage duration (months) minus the
maximum value of Prediction Periods. For
example, if the maximum storage duration is three
months and the maximum value of Prediction
Periods is 2, the value of the parameter is 1.
Input Sampling After you click Month, the input month source
and forecast month source of the combined sample
data are displayed at the bottom of the page.
ImportFolder Node
Function
The ImportFolder node imports folders and displays folder and text information.
Restriction
The corresponding project and process have been added.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 8 of 124
Parameter Description
Parameters
Parameter Description
File Folder Selects a folder where the file to be uploaded is
located.
NOTE
If FTP is used to upload folders, set the encoding code for FTP uploading to the same value on the Linux server. If the encoding codes are different, Chinese characters in folder or file names are displayed as garbled characters.
Folder Displays details about a selected folde.
Character Set Encoding method of a data file. The default value
is UTF-8.
ImportDatabase Node
Function
The ImportDatabase node extracts data from database tables and views.
Restriction The corresponding project and process have been added.
The corresponding database has been configured and the database can be connected successfully.
Parameter Description
Parameters
Parameter Description
Data Source
Database Database name. Select a currently available
database from the drop-down list box. Oracle and
DB2 databases are supported.
Schema Table mode in the database. The default value of
the table mode is the name of the created schema.
For example, if database user U1 creates tables T1
and T2 and user U2 creates table T3 in the
database, the options of the table mode in the
database are U1 and U2. When you select a mode,
only the tables of the selected mode are displayed.
Table Database table name. Select a value from the
drop-down list box.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 9 of 124
Parameter Description
Select condition Criteria for filtering extracted data, which is similar
to the where expression in a SQL statement.
NOTE
The criteria does not need to contain the keyword where.
Sample The default value is No.
Indicates whether to extract 2 million records when
the number of records exceeds 2 million. When the
total number of records is less than 2 million, all
records are extracted.
Meta Data
NOTE
After the field name is modified, the data on the following nodes also needs to be modified.
Delimiter
NOTE
The delimiter for separating data stored when a process is executed is set on this tab page. The delimiter cannot be a special character that exists in the stored data.
Field Nodes
A Field node bins, partitions, fills, or filters source data.
1.1.1.1 Type Node
Function
The Type node specifies the data role, direction, and missing value for each field in a data set, and verifies
that field types are valid.
Restriction
The Type node follows a ImportText, ImportFeatureLibrary, ImportFolder, or ImportDatabase node or
Application node.
Parameter Description
Parameters
Parameter Description
Read Value Reads the values of Role and Value Range from the
data audit file.
Clear Clears the values of Role and Value Range.
Role Role type.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 10 of 124
Parameter Description
The options are as follows:
● No: The value type is not specified.
● Range: Specifies a value range, for example, 0 to
100. The range can be an integer, real number, or
date/time range.
● Sign: The value has only two options, for
example, 0 and 1, or y and n.
● Set: The value has multiple options, for example,
high, middle, and low, or type1, type2, and type3.
Value Range Value range. Set this parameter when Role is not set
to No.
● If Role is Range, the following parameters are
required:
– Lower Limit: lower limit of a range
– Upper Limit: upper limit of a range
● If Role is Sign, the following parameters are
required:
– Flag Value 1: use the first value
– Flag Value 2: use the second value
● If Role is Set, set the Set Value parameter. You
can click New to add options.
Default Value Default value used for replacement. When Check is
Modify and data is missing or out of range, the data
is replaced with the parameter value.
Check Checks all values in a field to verify that all values
are correct. Using this method, you can manage the
data sets and reduce the data sizes conveniently.
The options are as follows:
● Close: Not check a field. This value is the default
value.
● Modify: Check all values in a field and correct
incorrect values. If the default value is not set,
values will be modified according to the following
rules:
– For a field of the Set role, the method
changes all unknown values to the first value
in the data set.
– For a field of the Sign role, the method
changes all unknown values to the first value
in the data set.
– For a field of the Range role, the method
changes values greater than the upper limit to
the upper limit, changes value less than the
lower limit to the lower limit, and changes

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 11 of 124
Parameter Description
null values to the middle value in the range.
● Discard: Check all values in a field and delete
incorrect values.
Anonymize Specifies whether to anonymize a field. For example,
sensitive customer information displayed in models
need to be anonymized in actual use to protect
privacy.
The options are as follows:
● Yes: Replace values in a field based on the field
type. The replacement complies with the
following rules:
– For a field of the Range role, the range is
changed to another range to anonymize
sensitive data. The replacement rule is as
follows: Final value = Conversion factor x
Actual value + Offset. The default conversion
factor is 3 and default offset is 9.
– For a field of the Sign or Set role, values in
the field are changed to the following
character string:
– prefix_Sn: prefix is a character string defined
by users. The default value is anon. n is an
integer greater than 0. Therefore, by default,
unique values in a field is changed to values
such as anon_S1 and anon_S2 in sequence.
– For a field of other roles, values in the field
are changed to the following character string:
prefix_S0: prefix is a character string defined
by users. The default value is anon.
● No: Not anonymize a field.
● Define: Customize a field. When the option is
selected, you can customize a value to replace
sensitive data.
Direct Field direction that specifies the role of a field during
the modeling process, for example, an input field or
an output field.
The options are as follows:
● No: ignore the field
● Primary key: primary key field
● Input: self-learning input field (forecast variable
field)
● Output: self-leaning output field or object (field to
be forecasted)
● Two-way: input/output field to be used by the
Apriori node. Other modeling nodes will ignore

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 12 of 124
Parameter Description
the field.
● Partition: field to be partitioned into samples for
training, test, and verification
NOTE
When the value of Direct is Partition, you should choose Sign of Role. The relationship between Default Value and Partition is:
● Flag Value 1:Training Partition
● Flag Value 2:Tset Partition
Bin Node
Function
The Bin node divides the attribute value range of fields of the Range role into segments and assigns a value
to each segment. This reduces the number of attribute values. The Bin node can create a field of the Set role
based on one or more values of range segments. For example, the node can change the customer income
range into a set of income groups or a set of differences from the average income.
Restriction
The node must follow a source node (ImportText, ImportFeatureLibrary or ImportDatabase) and a Type
node.
Parameter Description
Parameters
Parameter Description
Fixed width Fixed binning width.
The maximum and minimum values in a data set
are calculated. Then the binning method is defined
based on the minimum and maximum values and
Bin width.
For example, if the minimum value is 10, the
maximum value is 30, and Fixed width is 10, the
range is binned into [10,20) and [20,30].
Width or Amount This parameter is valid only when Binning Type
is set to Fixed width.
● Bin width: binning width. The default value is
10.
● Number of bins: number of bins. The default
value is 10 and the value cannot exceed 100.
Fixed depth Bins a range at a fixed depth.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 13 of 124
Parameter Description
The number of values in a data set is calculated
and values are sorted in ascending order. Then data
is binned based on the value of Bin depth, that is,
the number of values in a set.
Depth or Amount This parameter is valid only when Binning Type
is set to Fixed depth.
● Bin depth: binning depth. The default value is
10.
● Number of bins: number of bins. The default
value is 10.
Standard Deviation Bins data based on the standard deviation. Values
are compared with the standard deviation and
binned based on the differences.
Offset Bins data based on the average value and
deviation. This parameter is valid only when
Binning Type is set to Standard Deviation.
The options are as follows:
● +/- 1 Standard Deviation. The range is as
follows:
– [-∞,average value - deviation)
– [average value - deviation,average value +
deviation)
– [average value + deviation,+∞]
● +/-2 Standard Deviation. The range is as
follows:
– [-∞,average value - 2 x deviation)
– [average value - 2 x deviation,average
value - deviation)
– [average value - deviation,average value +
deviation)
– [average value + deviation,average value +
2 x deviation)
– [average value +2 x deviation,+∞]
● +/-3 Standard Deviation. The range is as
follows:
– [-∞, average value - 3 x deviation)
– [average value - 3 x deviation,average
value - 2 x deviation)
– [average value - 2 x deviation,average
value - deviation)
– [average value - deviation,average value +
deviation)
– [average value + deviation,average value +
2 x deviation)

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 14 of 124
Parameter Description
– [average value + 2 x deviation,average
value + 3 x deviation)
– [average value +3 x deviation,+∞]
Frequency Bins data based on the frequency of each value.
Frequency Range List Enter a list of integers separated with commas (,),
for example, a1,a2,a3,...an.an cannot exceed
999999999, and n must be an integer less than 10.
Example: 2,4,5
Gain Ratio of the difference between the type
distribution of input attributes (for example, B) and
the corresponding type distribution of output
attributes (for example, A) to B. As a result, the
gain expression is as follows:
p=(A-B)/B
When the method is used, you need to configure a
field whose Role is Set or Sign and Direct is
Output.
Binning Number Beforehand Number of bins for pre-binning specified fields.
Irregular Binning Threshold If the value of Gain is less than the value of
Irregular Binning Threshold, records that exceed
the threshold are put into the irregular bin. The
default value is 0.2.
Partition Node
Function
The Partition node generates partition fields. It partitions data into subsets and samples for the training and
test phases in the modeling process. During the modeling process, a sample is used to generate a model and
another sample is used to test the model. In this way, the system can check the forecast accuracy deviation
of the model on large size data sets similar to the data samples.
The Partition node generates fields of the Sign role. Only fields of the Sign role can be defined as partition
fields on the Type node.
Restriction
The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a Type
node.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 15 of 124
Parameter Description
Parameters
Parameter Description
Partition Type ● Random: separate data to training partition and
testing partition according to the rate you
entered.
● Stratified: separate the data to some floors, then
separate the data from every floor to training
partition and testing partition according to the
rate you entered.
● Condition: separate data using expressions.
Stratified Field Field based on which data is separated to multiple
floors in stratified partitioning.
Partition Field Partition field name. The value must be unique in
the data sets.
Training Data Rate Percentage of a training data set to the input data
set. The default value is 0.5
NOTE
The sum of Training Data Rate and Test Data Rate cannot exceed 1.
If the sum is less than 1, the system will discard records that are not contained in the two sets. For example, if a user has 10 million records, and Training Data Rate and Test Data Rate are 0.05 and 0.1 respectively, after the partition node is executed, about 0.5 million training records and 1 million test records are generated and other records are discarded.
Training Data Partition Condition Click the text box. The dialog box is displayed for
you to configure the partition condition for training
data.
Training Data Flag Flag of a training data set. The default value is 1,
unchangeable.
Test Data Rate Percentage of a test data set to the input data set.
The default value is 0.5.
Test Data Partition Condition Click the text box. The dialog box is displayed for
you to configure the partition condition for test
data.
NOTE
The partition condition for training data and that for test data cannot be both empty. If one of them is empty, the two partition conditions are complementary by default.
If a data record meets both the partition conditions for training data and test data, it will be used as training data.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 16 of 124
Parameter Description
Test Data Flag Flag of a test data set. The default value is 2,
unchangeable.
Fill Node
Function
The Fill node replaces the field values in the input data set.
Restriction
The node must follow a source node (ImportText, ImportFeatureLibrary or ImportDatabase) and a Type
node.
Parameter Description
Parameters
Parameter Description
Value Range Value range. By default, the setting on the Type node is used. You need to change the
parameter value after Conversion setting is complete.
Conversion
Setting
Conversion type. Click Configure. Then the Conversion Setting Window page is
displayed.
Conversion types include missing, exception, data normalization, function, expression,
and virtual variable. The conversion types that can be used for data of the set type
include missing, expression, and virtual variable. The conversion types that can be used
for data of the value type include missing, exception, data normalization, function, and
expression. Multiple conversion types can be used for a same attribute at the same time.
The system will execute the conversion in the sequence that the types are configured.
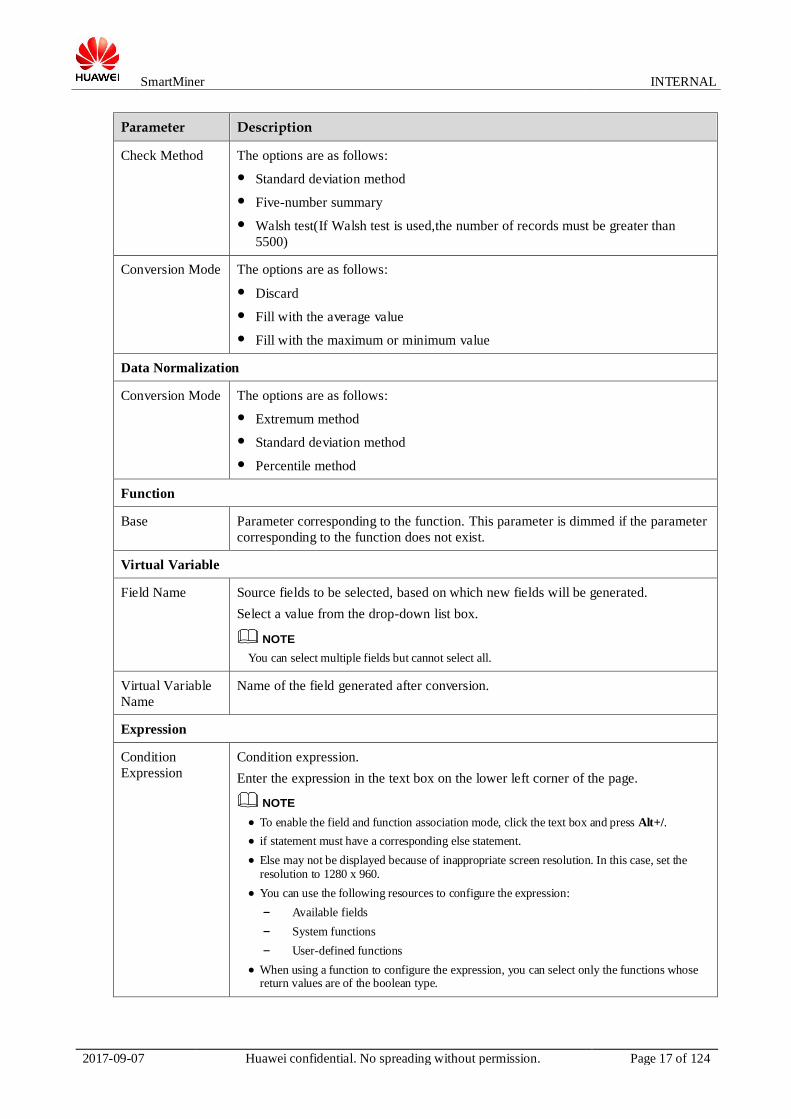
0 describes the parameters on the Conversion Setting Window page.
Conversion setting page
Parameter Description
Missing
Conversion Mode The options are as follows:
● Fill with the cumulative rate: Select this option for fields of the range type.
● Fill with the modal number: Select this option for fields of the set type.
Exception
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 17 of 124
Parameter Description
Check Method The options are as follows:
● Standard deviation method
● Five-number summary
● Walsh test(If Walsh test is used,the number of records must be greater than
5500)
Conversion Mode The options are as follows:
● Discard
● Fill with the average value
● Fill with the maximum or minimum value
Data Normalization
Conversion Mode The options are as follows:
● Extremum method
● Standard deviation method
● Percentile method
Function
Base Parameter corresponding to the function. This parameter is dimmed if the parameter
corresponding to the function does not exist.
Virtual Variable
Field Name Source fields to be selected, based on which new fields will be generated.
Select a value from the drop-down list box.
NOTE
You can select multiple fields but cannot select all.
Virtual Variable
Name
Name of the field generated after conversion.
Expression
Condition
Expression
Condition expression.
Enter the expression in the text box on the lower left corner of the page.
NOTE
To enable the field and function association mode, click the text box and press Alt+/.
if statement must have a corresponding else statement.
Else may not be displayed because of inappropriate screen resolution. In this case, set the resolution to 1280 x 960.
You can use the following resources to configure the expression:
– Available fields
– System functions
– User-defined functions
When using a function to configure the expression, you can select only the functions whose return values are of the boolean type.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 18 of 124
Filter Node
Function
The Filter node filters fields based on the correlation information of the analysis field and the forecast field
or filters specified fields.
Correlation filtering indicates that fields are filtered based on Error Decrease Rate in the analysis field
and the forecast field. The system retains fields whose Error Decrease Rate is greater than a specified
threshold according to the configured Max. Number of Retained Fields. This method is used when a large
amount of data needs to be filtered.
Users can also filter fields manually. The filtering effect of this method is similar to that of Filter on the
TextImport node.
Restriction
The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node.
To filter fields by correlation, you need to use Correlate to analyze the correlation of the source data.
Parameter Description
Parameters
Parameter Description
Threshold Value threshold of Error Decrease Rate. This
parameter is valid only when a correlation analysis
file is selected by clicking the Select Correlation
Analysis File button.
When you click Filter, the system will filter out all
fields whose Error Decrease Rate is less than the
threshold.
Max.Retained Fields Maximum number of fields that are retained after
correlation filtering. This parameter is valid only
when a correlation analysis file is selected by
clicking the Select Correlation Analysis File
button. When you click Filter, the system will sort
fields by Error Decrease Rate in descending
order and retain the first Max.Retained Fields
fields.
Field Field to search.
Filtering Field Filtering field.
If you use the correlation filtering method, the
system automatically selects filtering fields when
you press Filter. To deselect all filtering fields,
click Reset.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 19 of 124
Record Nodes
A Recode node samples or selects source data.
1.1.1.1 Sampling Node
Function
The Sampling node can extract samples from records for analysis. The Sampling node has the following
advantages:
You can evaluate models based on sample analysis results to improve model performance. Models
improved based on sample analysis results can generate accurate forecast results. In addition,
improved models can provide more methods that can further improve the models.
The Sampling node can extract records that share specified features, for example, all items in a
shopping cart or all attributes of related objects.
The node can randomly extract samples in a specified unit or with a specified attribute and check them.
In this way, service quality is verified, fraud is prevented, and security is ensured.
NOTE If you only need to partition data into a training data set and a test data set, use the Partition node.
The Sampling node supports the following sampling modes:
Random: The Sampling node extracts data at a specified ratio. For example, if a user has 10 million
records and the sampling ratio is 0.5, the node will extract 5 million records.
Equidistant: The Sampling node extracts a record from every N records. For example, if a user has 10
thousand records, N is 10, and the maximum sample size is 100, the Sampling node will extract 100
records.
Cluster: The Sampling node extracts records from a group with a specified field at a specified ratio.
For example, if the sampling field is school and the sampling ratio is 0.5, the Sampling node will
extract 50% of the records from the school group.
You can set multiple sampling fields, and the node will extract records across the specified groups.
For example, field A and field B are specified, and the sampling ratio is 0.5. Field A is of the Set role,
and the options are a and b. Field B is a string character, and the options are c and d. Then the
Sampling node will extract all data from two of the following sets:
− a,c
− b,c
− a,d
− b,d
Stratified: The Sampling node extracts records at a specified ratio from each sampling group specified
by a sampling field.
For example, field A and field B are specified, and the extraction ratio is 0.5. Field A is of the Set role,
and the options are a and b. Field B is a string character, and the options are c and d. Then the
Sampling node will extract 50% records from each of the following sets:
− a,c
− b,c
− a,d
− b,d
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 20 of 124
Balance: Balance sampling balances discrete fields. The Sampling node returns the extracted records
to the input data sets for next sampling, so that the value types in the final extracted records are
balanced.
Restriction
The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a Type
node.
Parameter Description
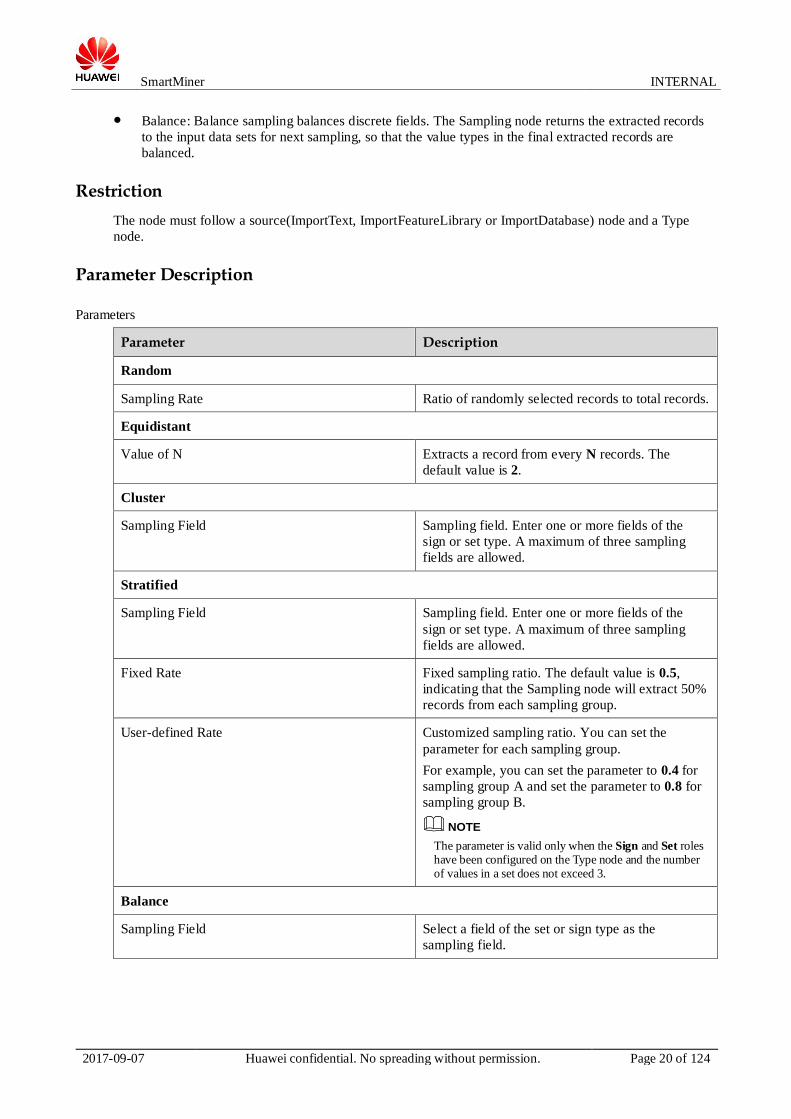
Parameters
Parameter Description
Random
Sampling Rate Ratio of randomly selected records to total records.
Equidistant
Value of N Extracts a record from every N records. The
default value is 2.
Cluster
Sampling Field Sampling field. Enter one or more fields of the
sign or set type. A maximum of three sampling
fields are allowed.
Stratified
Sampling Field Sampling field. Enter one or more fields of the
sign or set type. A maximum of three sampling
fields are allowed.
Fixed Rate Fixed sampling ratio. The default value is 0.5,
indicating that the Sampling node will extract 50%
records from each sampling group.
User-defined Rate Customized sampling ratio. You can set the
parameter for each sampling group.
For example, you can set the parameter to 0.4 for
sampling group A and set the parameter to 0.8 for
sampling group B.
NOTE
The parameter is valid only when the Sign and Set roles have been configured on the Type node and the number of values in a set does not exceed 3.
Balance
Sampling Field Select a field of the set or sign type as the
sampling field.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 21 of 124
Select Node
Function
The Select node selects records with a specified feature, for example, Salary>2000, from data streams.
Restriction
The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a Type
node.
Parameter Description
Parameters
Parameter Description
Edit Expression
NOTE To enable the field and function association mode, click the text box and press Alt+/.
Verify Authenticates the selected expression type and entered expression.
Click the check button.
SelectFeature Node
Function
The SelectFeature node filters out invalid or indistinct attributes based on filter criteria.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The SelectFeature node cannot be configured in a process that contains the Bin node. The
SelectFeature node can only be used for Naive Bayes models.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 22 of 124
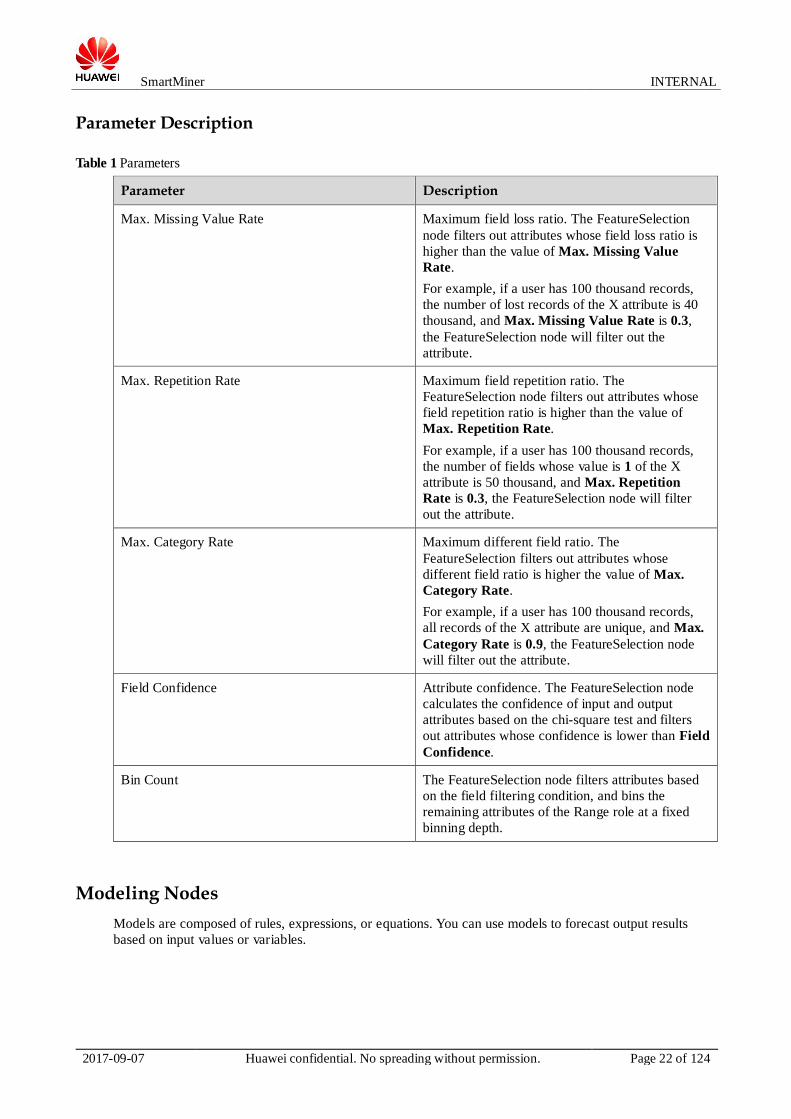
Parameter Description
Table 1 Parameters
Parameter Description
Max. Missing Value Rate Maximum field loss ratio. The FeatureSelection
node filters out attributes whose field loss ratio is
higher than the value of Max. Missing Value
Rate.
For example, if a user has 100 thousand records,
the number of lost records of the X attribute is 40
thousand, and Max. Missing Value Rate is 0.3,
the FeatureSelection node will filter out the
attribute.
Max. Repetition Rate Maximum field repetition ratio. The
FeatureSelection node filters out attributes whose
field repetition ratio is higher than the value of
Max. Repetition Rate.
For example, if a user has 100 thousand records,
the number of fields whose value is 1 of the X
attribute is 50 thousand, and Max. Repetition
Rate is 0.3, the FeatureSelection node will filter
out the attribute.
Max. Category Rate Maximum different field ratio. The
FeatureSelection filters out attributes whose
different field ratio is higher the value of Max.
Category Rate.
For example, if a user has 100 thousand records,
all records of the X attribute are unique, and Max.
Category Rate is 0.9, the FeatureSelection node
will filter out the attribute.
Field Confidence Attribute confidence. The FeatureSelection node
calculates the confidence of input and output
attributes based on the chi-square test and filters
out attributes whose confidence is lower than Field
Confidence.
Bin Count The FeatureSelection node filters attributes based
on the field filtering condition, and bins the
remaining attributes of the Range role at a fixed
binning depth.
Modeling Nodes
Models are composed of rules, expressions, or equations. You can use models to forecast output results
based on input values or variables.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 23 of 124
1.1.1.1 NaiveBayes Node
Function
NaiveBayes classifier is a classification method in statistics. The NaiveBayes node forecasts the class
membership probabilities, for example, the probability that a sample belongs to a specified class.
The NaiveBayes node can build models to forecast event probability by analyzing event attributes based on
the system's cognition towards reality and obtained records.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the NaiveBayes node must meet the following conditions:
− The node must contain a minimum of one input field and only one output field.
− For input fields, Role must be Sign, Set, or Range.
− For the output field, Role must be Sign or Set.
The computing framework (Hadoop or Spark) on which the NaiveBayes node runs can be configured
in the ${SmartMiner_HOME}/conf/smartminer.spark.nodes file. Parameters in Precision
Improving Method vary depending on the selected computing framework. For details about the
parameters, see Parameter Description.
An example of the configuration file is as follows:
NaiveBeyes=hadoop //The node runs on the Hadoop framework.
NaiveBeyes=spark //The node runs on the Spark framework.
Model Input Example
USER_ID,SERV_NUMBER,STATIS_DATE,AREA_CODE, ...,OUT
001,18936897385,20100606,0371,...,yes
002,18936897386,20100607,0371,...,no
Fields are separated by commas (,).
On the Type node:
USER_ID: Primary key
Modeling feature field: Input
Forecast field: Output
The role and value range of each field need to be configured.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 24 of 124
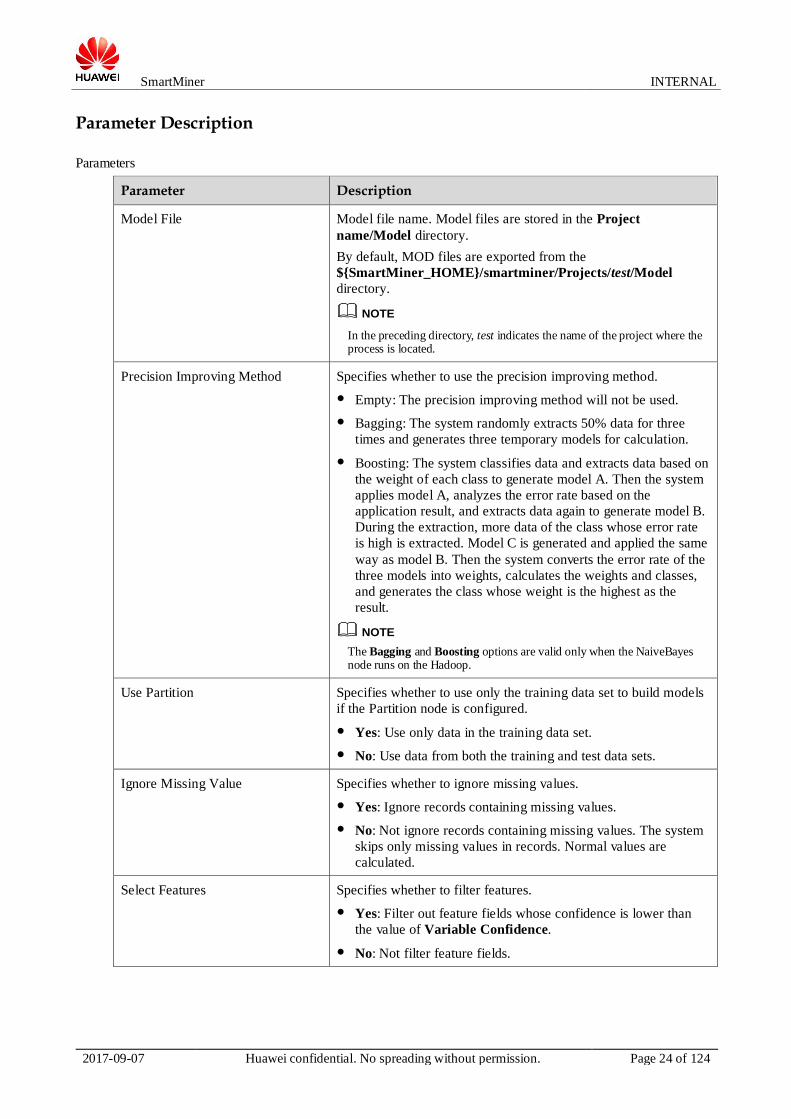
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Precision Improving Method Specifies whether to use the precision improving method.
● Empty: The precision improving method will not be used.
● Bagging: The system randomly extracts 50% data for three
times and generates three temporary models for calculation.
● Boosting: The system classifies data and extracts data based on
the weight of each class to generate model A. Then the system
applies model A, analyzes the error rate based on the
application result, and extracts data again to generate model B.
During the extraction, more data of the class whose error rate
is high is extracted. Model C is generated and applied the same
way as model B. Then the system converts the error rate of the
three models into weights, calculates the weights and classes,
and generates the class whose weight is the highest as the
result.
NOTE
The Bagging and Boosting options are valid only when the NaiveBayes node runs on the Hadoop.
Use Partition Specifies whether to use only the training data set to build models
if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from both the training and test data sets.
Ignore Missing Value Specifies whether to ignore missing values.
● Yes: Ignore records containing missing values.
● No: Not ignore records containing missing values. The system
skips only missing values in records. Normal values are
calculated.
Select Features Specifies whether to filter features.
● Yes: Filter out feature fields whose confidence is lower than
the value of Variable Confidence.
● No: Not filter feature fields.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 25 of 124
Parameter Description
Variable Confidence Confidence value. The fields whose confidence is lower than this
parameter value will be filtered out. The default value is 0.95.
NOTE
When the value of Select Features is yes, you should configure this parameter.
Visualization Input and output attributes of the model
Click the NaiveBayes model file. The tree structure of the NaiveBayes model is displayed, including
the input and output attributes of the model, as shown in 0
NaiveBayes model file structure
NOTE If Bagging and Boosting are used, the SmartMiner will generate multiple models. The model structure tree displays multiple models, among which the root node is ModelSet, the Boosting model weight is calculated based on the error rate, and the default Bagging model weight is 1.
Input attribute node information
− When the inputs attribute node of the set type is clicked, the statistics table and probability table
are displayed to the right of the structure tree, as shown in 0.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 26 of 124
Set type
− When the inputs attribute node of the range type is clicked, the average table and deviation table
are displayed to the right of the structure tree, as shown in 0.
Range type
DecisionTree Node
Function
The DecisionTree node can develop a classification system. Using this system, you can forecast results or
classify records based on predefined decision policies.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the DecisionTree node must meet the following conditions:
− The process must contain one input field and one output field.
− For the input field, Role must be Sign, Set, or Range. The number of set value types cannot exceed
10.
− For the output field, Role must be Sign or Set.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 27 of 124
Model Input Example
USER_ID,SERV_NUMBER,STATIS_DATE,AREA_CODE, ...,OUT
001,18936897385,20100606,0371,...,yes
002,18936897386,20100607,0371,...,no
Fields are separated by commas (,).
On the Type node:
ID: Primary Key
Modeling feature field: Input
Forecast field: Output
The role and value range of each field need to be configured.
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Precision Improving Method Specifies whether to use the precision improving method.
● Empty: The precision improving method will not be used.
● Bagging: The system randomly extracts 50% data for three
times and generates three temporary models for calculation.
● Boosting: The system classifies data and extracts data based on
the weight of each class to generate model A. Then the system
applies model A, analyzes the error rate based on the
application result, and extracts data again to generate model B.
During the extraction, more data of the class whose error rate
is high is extracted. Model C is generated and applied the same
way as model B. Then the system converts the error rate of the
three models into weights, calculates the weights and classes,
and generates the class whose weight is the highest as the
result.
Select Attribute Method NOTE
If this parameter is set to Gini or F-Score and the role of the input fields is Set, the number of set value types cannot exceed 10. If input fields of the set type must be used, a data processing node is required to process the fields first. For example, you can use a Filler node to combine data or convert a set to multiple fields.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 28 of 124
Parameter Description
Use Partition Specifies whether to use only the training data set to build models
if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from both the training and test data sets.
Ignore Missing Value Specifies whether to ignore missing values.
● Yes: Ignore records containing missing values.
● No: Not ignore records containing missing values.
Use Pruned Branch Specifies whether to enable the pruned branch function. When the
function is enabled, the system does not analyze attributes that
cannot affect decision results.
● Yes: Enable the pruned branch function. Set the parameter to
Yes when the training data set contains abnormal data or when
data amount in the training data set is too small to generate
practical functions.
● No: Disable the pruned branch function.
Prune Confidence Factor Prune confidence factor for pruning a field. The value must be
greater than 0 and less than 1. The system ignores fields whose
confidence is lower than Prune Confidence Factor.
NOTE
This parameter is valid only when Use Pruned Branch is set to Yes.
Min. Leaf Nodes Minimum number of records on a leaf node. Set the parameter to a
positive integer. The default value is 2. The system ignores
attributes whose number of fields is less than Min. Leaf Nodes.
NOTE
It is recommended that you use the value obtained by dividing the number of records in the raining data set by 2L. L indicates the number of input fields in the training data set.
Visualization Model Structure
Click the DecisionTree model file. The system displays information about the model, in which, the
model structure is displayed on the left.
NOTE When viewing the DecisionTree model for the first time, the model structure tree on the left displays a maximum of
10,000 nodes. You can click the structure tree to display the hidden nodes.
If Bagging and Boosting are used, the SmartMiner will generate multiple models. The structure tree displays multiple models, among which the root node is ModelSet, the Boosting model weight is calculated based on the error rate, and the default Bagging model weight is 1.
Node information
The information about the node is displayed on the right, as shown in 0.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 29 of 124
DecisionTree model file information
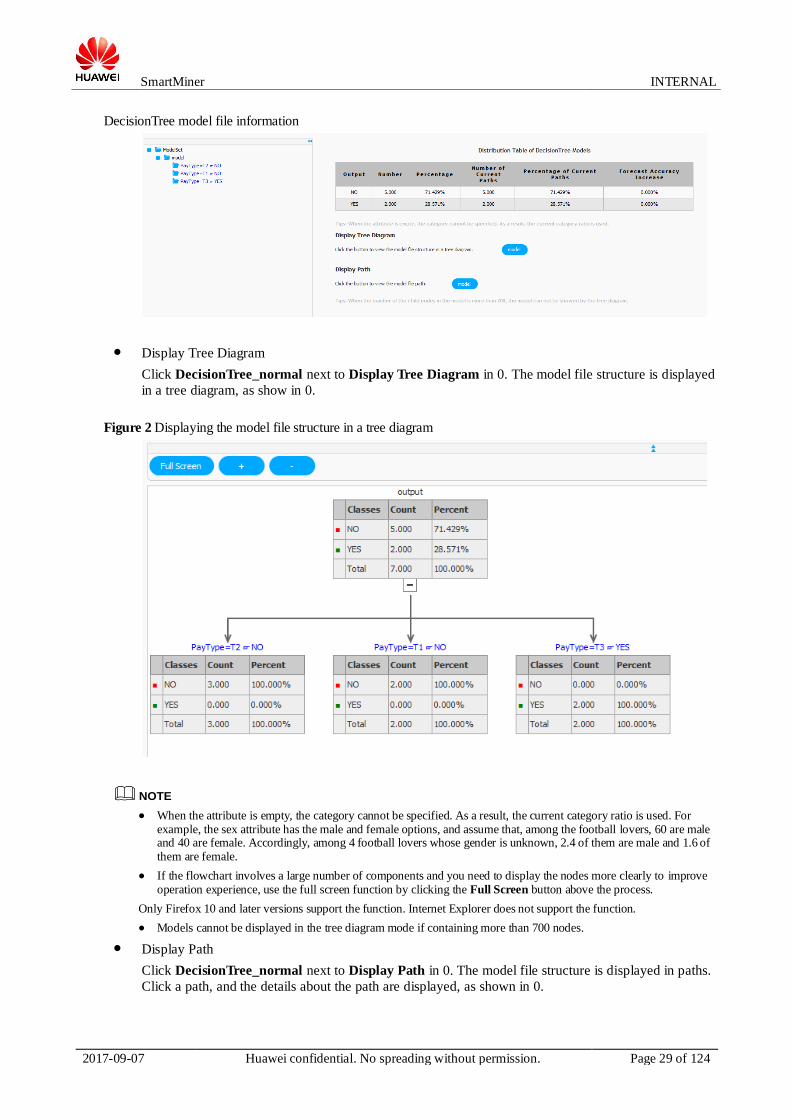
Display Tree Diagram
Click DecisionTree_normal next to Display Tree Diagram in 0. The model file structure is displayed
in a tree diagram, as show in 0.
Figure 2 Displaying the model file structure in a tree diagram
NOTE When the attribute is empty, the category cannot be specified. As a result, the current category ratio is used. For
example, the sex attribute has the male and female options, and assume that, among the football lovers, 60 are male and 40 are female. Accordingly, among 4 football lovers whose gender is unknown, 2.4 of them are male and 1.6 of them are female.
If the flowchart involves a large number of components and you need to display the nodes more clearly to improve operation experience, use the full screen function by clicking the Full Screen button above the process.
Only Firefox 10 and later versions support the function. Internet Explorer does not support the function.
Models cannot be displayed in the tree diagram mode if containing more than 700 nodes.
Display Path
Click DecisionTree_normal next to Display Path in 0. The model file structure is displayed in paths.
Click a path, and the details about the path are displayed, as shown in 0.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 30 of 124
Figure 3 Displaying the model file structure in path
Logistics Node
Function
The Logistics node determines the cause-effect relationships between variables, sets up regression models,
and checks the correlations between symptoms and the correlation directions and levels.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the Logistics node must meet the following conditions:
The process must contain only one output field and one or more input fields.
If the input field is of the character string type, the field must be of Sign, Range or Set role. If the
input field is of the numeral type, you do not need to set the Role parameter.
The output fields must be of Sign role.
The computing framework (Hadoop or Spark) on which the Logistics node runs can be configured in
the ${SmartMiner_HOME}/conf/smartminer.spark.nodes file. Parameters to be configured vary
depending on the selected computing framework. For details about the parameters, see Parameter
Description.
An example of the configuration file is as follows:
Logistics=hadoop //The node runs on the Hadoop framework.
Logistics=spark //The node runs on the Spark framework.
Model Input Example
USER_ID,SERV_NUMBER,STATIS_DATE,AREA_CODE, ...,OUT
001,18936897385,20100606,0371,...,yes
002,18936897386,20100607,0371,...,no
Fields are separated by commas (,).
On the Type node:

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 31 of 124
ID: Primary Key
Modeling feature field: Input
Forecast field: Output
The role and value range of each field need to be configured. For output fields, Role must be set to
Sign.
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the
Project name/Model directory.
Precision Improving Method Specifies whether to use the precision improving
method. The options are as follows:
● Empty: The precision improving method will
not be used.
● Bagging: The system randomly extracts 50%
data for three times and generates three
temporary models for calculation.
● Boosting: The system classifies data and
extracts data based on the weight of each class
to generate model A. Then the system applies
model A, analyzes the error rate based on the
application result, and extracts data again to
generate model B. During the extraction, more
data of the class whose error rate is high is
extracted. Model C is generated and applied the
same way as model B. Then the system
converts the error rate of the three models into
weights, calculates the weights and classes, and
generates the class whose weight is the highest
as the result.
NOTE
The Bagging and Boosting options are valid only when the Logistics node runs on the Hadoop.
Use Partition Specifies whether to use only the training data set
to build models if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from both the training and test
data sets.
Max. Iterations Maximum number of iteration times during the
computing process.
Iteration End Threshold The parameter is valid only when the Logistics
node runs on the Hadoop.
Specifies the threshold for stopping iteration. An
iteration process ends if the coefficient change of
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 32 of 124
Parameter Description
the iteration algorithm is less than the value of this
parameter twice.
Select Features The parameter is valid only when the Logistics
node runs on the Hadoop.
Specifies whether to select features. You can use
the parameter to define feature selection criteria
based on the probability associated with fields.
Include Significance Threshold The parameter is valid only when the Logistics
node runs on the Hadoop.
This parameter is valid only when Select Features
is set to Select Features. The default value is 0.05.
In the model iteration process, the ¦Α value of the
chi-squared distribution is used to display the
associated confidence of the statistical probability.
When ¦Α is less than the value of Include
Significance Threshold, the system adds the field
to the model.
Exclude Significance Threshold The parameter is valid only when the Logistics
node runs on the Hadoop.
This parameter is valid only when Select Features
is set to Select Features. The default value is 0.1.
In the model iteration process, the ¦Α value of the
chi-squared distribution is used to display the
associated confidence of the statistical probability.
When ¦Α is greater than the value of Exclude
Significance Threshold, the system deletes the
field.
NOTE
The value of Include Significance Threshold must be less than the value of Exclude Significance Threshold.
Step Size The parameter is valid only when the Logistics
node runs on the Spark.
Specifies the coefficient weight change of each
iteration.
Regularization The parameter is valid only when the Logistics
node runs on the Spark.
Regularization refers to a process of introducing
additional information to solve an ill-posed
problem or to prevent overfitting. In linear algebra,
ill-posed problems are defined by a group of linear
algebraic equations and the linear algebraic
equations come from ill-posed inverse problems
that have large condition numbers. Large condition
numbers will seriously affect the computing result
due to rounding errors or other errors.
Regularization parameters are used to define

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 33 of 124
Parameter Description
parameter conversion of linear equations.
Mini Batch Fraction The parameter is valid only when the Logistics
node runs on the Spark.
Defines an iteration factor (proportion of samples
used for computing for each iteration).
Include Constant Specifies whether the model contains constants.
Base Category Model forecast field. The value is the same as that
of the output field on the Type node.
This parameter is valid only when Include
Constant is set to Yes.
Visualization
Click the Logistics model file. The system displays the model information, as shown in 0. The structure tree
is displayed on the left, indicating the attributes and values. The significance of the attributes is displayed
on the right.
Logistics model file information
NOTE If Bagging and Boosting are used, the SmartMiner will generate multiple models. The model structure tree displays multiple models, among which the root node is ModelSet, the Boosting model weight is calculated based on the error rate, and the default Bagging model weight is 1.
Kmeans Node
Function
The Kmeans node groups data sets into different cluster centers (or clusters). This method defines a fixed
number of clusters, classifies records to clusters in iteration mode, and adjusts the cluster center until the
model can no longer be optimized.
The Kmeans node is a non-monitoring learning mechanism. It finds hidden patterns behind input data sets
instead of forecasts results.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 34 of 124
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The data mining process in which the Kmeans node is configured must contain a minimum of one
input field. You need to set the role and range for the input fields.
Model Input Example
id,age,sex,children
ID12101,48,FEMALE,1
ID12102,40,MALE,3
ID12103,51,FEMALE,0
ID12104,23,FEMALE,3
ID12105,57,FEMALE,0
Fields are separated by commas (,).
On the Type node, Direction of ID is set to Primary Key, and Direction for other fields is set to Input.
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Max.Iterations Maximum number of iteration times for the Kmeans modeling.
Use Partition Specifies whether to use only the training data set to build models
if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Visualization View the overall table.
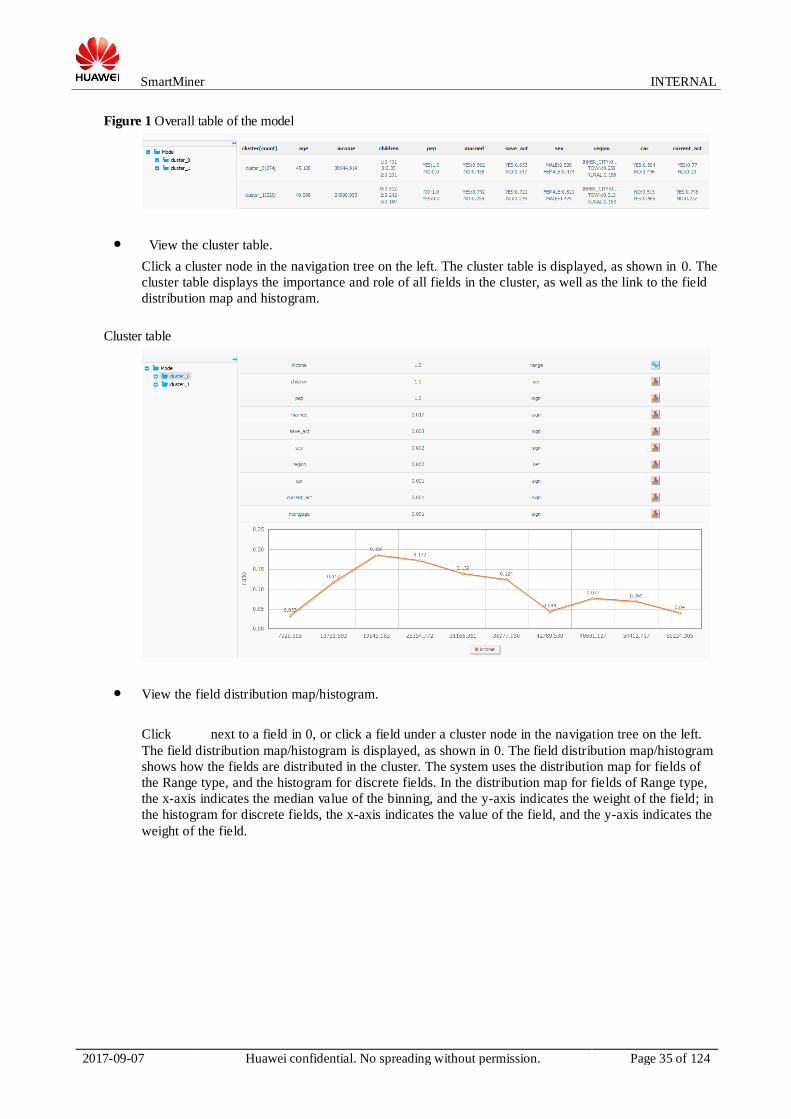
Click the Kmeans model file. The overall table is displayed, as shown in 0. The overall table shows all
the clusters and their input fields. The value of a field of the Range type is the average value of this
field in the cluster to which it belongs. For a discrete field, only three values of the highest weight are
displayed, by weight in descending order. A maximum of 10 fields are displayed and sorted by
importance in descending order. If fields have the same importance, they are sorted by index ID in
ascending order.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 35 of 124
Figure 1 Overall table of the model
View the cluster table.
Click a cluster node in the navigation tree on the left. The cluster table is displayed, as shown in 0. The
cluster table displays the importance and role of all fields in the cluster, as well as the link to the field
distribution map and histogram.
Cluster table
View the field distribution map/histogram.
Click next to a field in 0, or click a field under a cluster node in the navigation tree on the left.
The field distribution map/histogram is displayed, as shown in 0. The field distribution map/histogram
shows how the fields are distributed in the cluster. The system uses the distribution map for fields of
the Range type, and the histogram for discrete fields. In the distribution map for fields of Range type,
the x-axis indicates the median value of the binning, and the y-axis indicates the weight of the field; in
the histogram for discrete fields, the x-axis indicates the value of the field, and the y-axis indicates the
weight of the field.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 36 of 124
Attribute distribution map
EM Node
Function
The EM node groups data sets into different cluster centers (or clusters). The EM node assumes that the
sample complies with multidimensional normal distribution and analyzes hidden classifications of the
sample using the expectation maximization method to implement automatic clustering. This method defines
a fixed number of clusters, calculates the probability that each record belongs to a cluster, and updates the
probability iteratively until the probability change is less than the preset Iteration End Threshold or the
Maximum number of iteration times is achieved.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The data mining process that contains an EM node must comply with the following requirements: the
process contains at least one input field, the input data must be of the numeric type (data of the string
type is not supported), and the role and value range of the input data must be set.
Model Input Example
5.1,3.5,1.4,0.2
4.9,3.0,1.4,0.2
4.7,3.2,1.3,0.2
4.6,3.1,1.5,0.2
5.0,3.6,1.4,0.2
5.4,3.9,1.7,0.4
4.6,3.4,1.4,0.3
5.0,3.4,1.5,0.2
4.4,2.9,1.4,0.2
4.9,3.1,1.5,0.1
5.4,3.7,1.5,0.2
4.8,3.4,1.6,0.2
4.8,3.0,1.4,0.1
4.3,3.0,1.1,0.1
5.8,4.0,1.2,0.2
......
The input fields are a set of IRIS data, indicating the calyx length, calyx width, petal length, and petal width
of the flower-de-luce respectively. The fields are separated by the commas (,).
On the Type node, Direction of all fields is set to Input.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 37 of 124
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Cluster Name Prefix Name prefix of a clustering field. This field is displayed in the
output result as a new field.
Cluster Count Defines the number of clustering results in the output result.
For example, if this parameter is set to 5, Cluster_0-Cluster_4
will be generated in the clustering result.
Iteration Times Maximum number of iteration times for the EM modeling
algorithm. The model training ends when the number of iteration
times reaches the value of Iteration Times.
The value ranges from 1 to 100.
Default value: 20
Iteration End Threshold Iteration end threshold. If the maximum likelihood estimate
between two iterations is less than the value of this parameter, the
iteration ends.
If the parameter value is between 1.0E-1 and 1.0E-5, the
clustering calculation result precision increases sequentially.
Both Iteration End Threshold and Iteration Times can be used
to end iterations. If the input data is multidimensional or high
clustering precision is required, you are advised to increase the
value of Iteration Times.
Use Partition Specifies whether to use only the training data set to build models
if the Partition node is configured.
The options are as follows:
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Default value: No
Retain Only Elements on Diagonal
Line
Specifies whether to retain only the elements on the diagonal line
in the covariance matrix calculated in the iteration process.
The options are as follows:
● Yes: Retain only the elements on the diagonal line.
Convergence is fast.
● No: Retain all elements. Convergence is slow.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 38 of 124
Parameter Description
Default value: Yes
Output Result Example
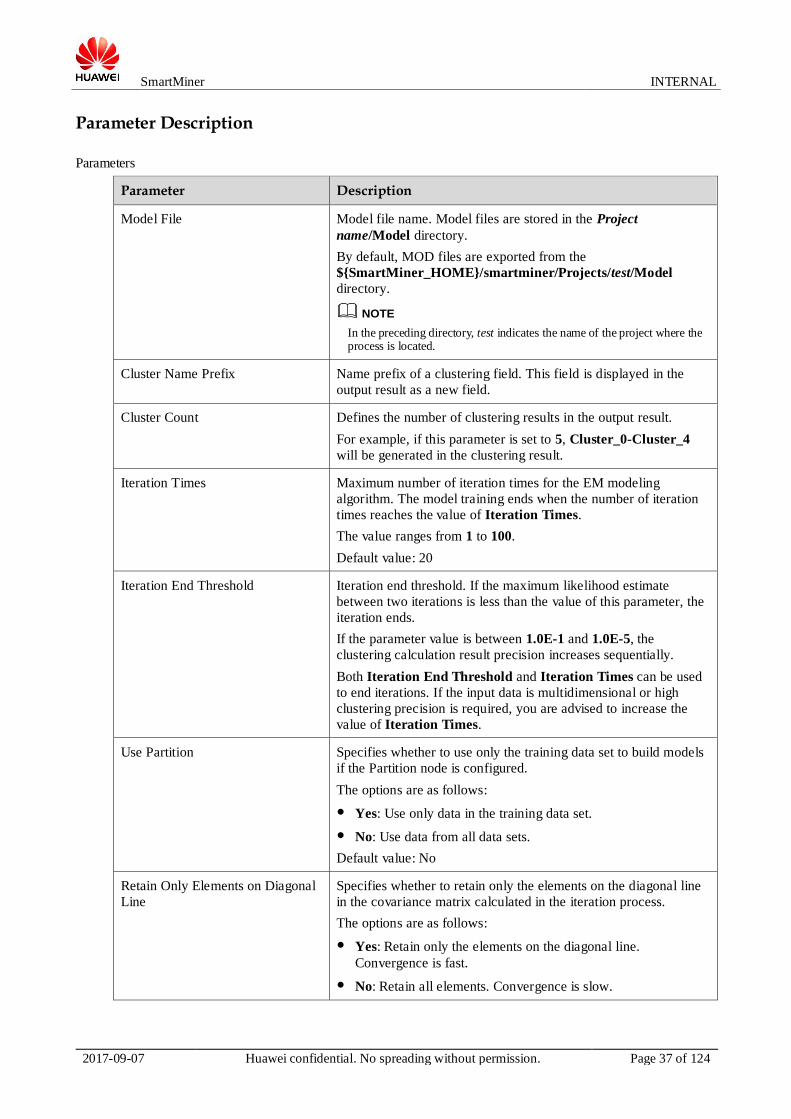
Model Input Example shows the input text, and 0 describes the process configuration.
EM node process
0 shows the configuration of the Segment node.
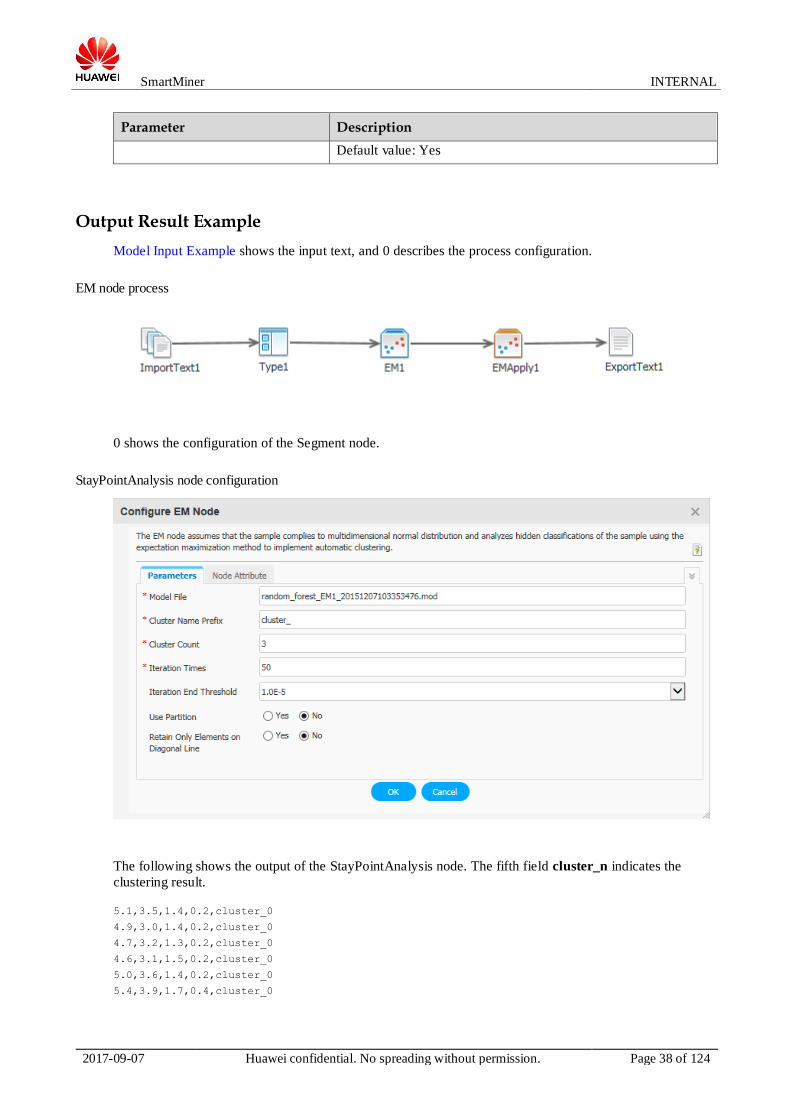
StayPointAnalysis node configuration
The following shows the output of the StayPointAnalysis node. The fifth field cluster_n indicates the
clustering result.
5.1,3.5,1.4,0.2,cluster_0
4.9,3.0,1.4,0.2,cluster_0
4.7,3.2,1.3,0.2,cluster_0
4.6,3.1,1.5,0.2,cluster_0
5.0,3.6,1.4,0.2,cluster_0
5.4,3.9,1.7,0.4,cluster_0

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 39 of 124
4.6,3.4,1.4,0.3,cluster_2
5.0,3.4,1.5,0.2,cluster_0
4.4,2.9,1.4,0.2,cluster_2
4.9,3.1,1.5,0.1,cluster_0
5.4,3.7,1.5,0.2,cluster_0
4.8,3.4,1.6,0.2,cluster_0
4.8,3.0,1.4,0.1,cluster_0
4.3,3.0,1.1,0.1,cluster_2
5.8,4.0,1.2,0.2,cluster_0
......
Apriori Node
Function
The Apriori node analyzes and mines data associations to obtain valuable information for the decision
process.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
If the data format is of sparse matrix on the Apriori node, the node must comply with the following
rules:
− In any of the following scenarios:
At least one input field and one outfield
At least one input field and one bidirectional field
At least one output field and one bidirectional field
All bidirectional fields
− Input and output fields are of the integer type.
− Input and output fields are of the Sign role, and the value options are 0 and 1.
If the data format is Key-Value pairs on the Apriori node, the node must comply with the following
rules:
One key field and one bidirectional field in the condition of model node, one key field and one input
field or bidirectional field in Apply Node.
Model Input Example 1 (Sparse Matrix)
cardid,fruitveg,freshmeat,dairy,cannedveg,cannedmeat,frozenmeal,beer,wine,softdrink,fish,confe
ctionery
39808,0,1,1,0,0,0,0,0,0,0,1
67362,0,1,0,0,0,0,0,0,0,0,1
10872,0,0,0,1,0,1,1,0,0,1,0
Fields are separated by commas (,).
On the Type node:
The Direction parameter for cardid is set to None, and the Direction for other fields is set to
Two-way.
The role and value range of each field need to be configured.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 40 of 124
Model Input Example 1 (Key-Value Pair)
cardid,goods
39808,freshmeat
39808,dairy
39808,confectionery
67362,freshmeat
67362,confectionery
10872,cannedveg
10872,frozenmeal
10872,beer
10872,fish
28935,fruitveg
28935,frozenmeal
41792,fruitveg
41792,fish
Fields are separated by commas (,).
On the Type node:
cardid: Primary Key
goods: Two-way
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Use Partition Specifies whether to use only the training data set to build models
if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from both the training and test data sets.
Min. Support Support degree for retaining a rule in the rule set. Support degree
indicates the percentage of records whose conditions are true in
the training data set. If the rule you have obtained is applicable to
data subsets of a small size, increase the value of the parameter.
Min. Confidence Minimum confidence of records forecasted by a rule. Confidence
indicates the percentage of true results forecasted by a rule to the
total forecast results. The SmartMiner discards rules whose
confidence is lower than Min. Rule Confidence. If you have
obtained too may rules, increase the value of the parameter. If you
have obtained few rules, decrease the value of the parameter.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 41 of 124
Parameter Description
Max. Antecedents Maximum input records of a rule. You can use the parameter
along with efficient index modes to reduce the search scope based
on the information theory.
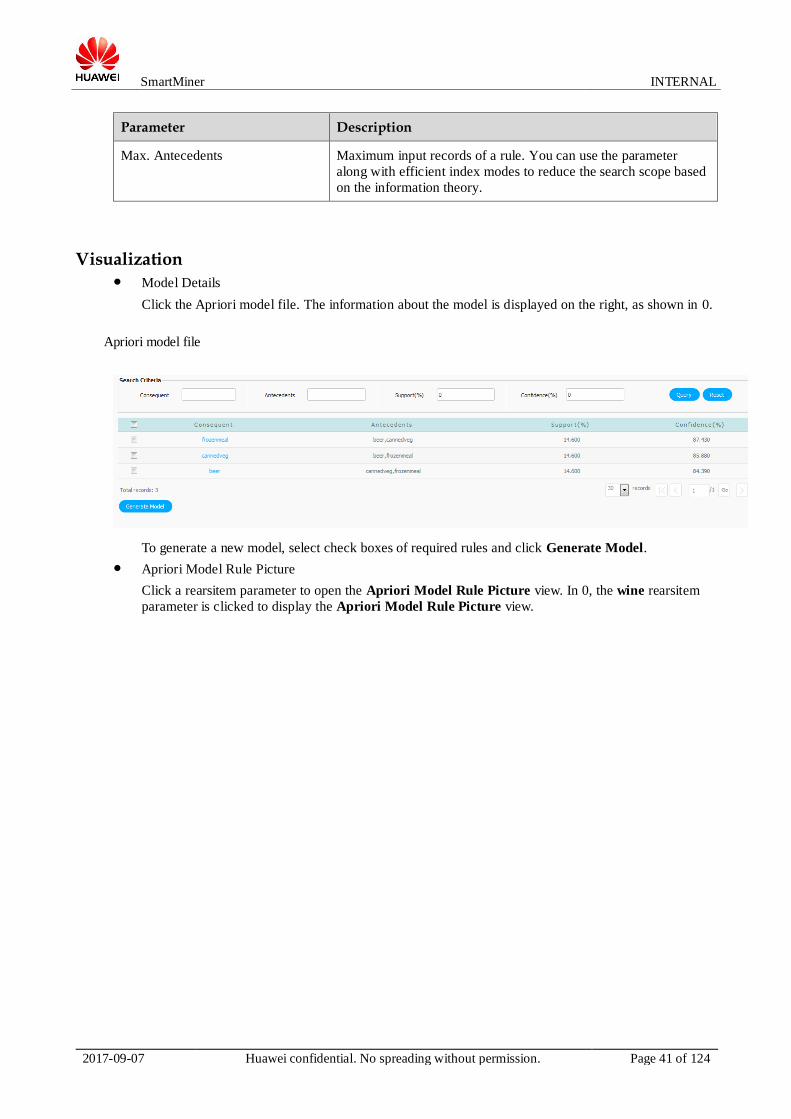
Visualization Model Details
Click the Apriori model file. The information about the model is displayed on the right, as shown in 0.
Apriori model file
To generate a new model, select check boxes of required rules and click Generate Model.
Apriori Model Rule Picture
Click a rearsitem parameter to open the Apriori Model Rule Picture view. In 0, the wine rearsitem
parameter is clicked to display the Apriori Model Rule Picture view.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 42 of 124
Apriori Model Rule Picture
Click or right-click, and hold down and move the mouse to form a rectangle that can cross the selected
connection line. Then the correlation information between the two parameters is displayed, as shown
in 0.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 43 of 124
Correlation information
TimeSeries Node
Function
The TimeSeries node finds rules in sequence data, that is, a trend that the data changes over time to forecast
the future value.
The time series modeling mode assumes that history repeats itself. Therefore, decisions applicable to future
events can be made by analyzing historical records. For example, to forecast the sales volume of next year,
you can use the SmartMiner to find the trend that the sales volume changes over time by analyzing the sales
volume of the past few years. A time sequence is a set of records obtained at scheduled times.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the TimeSeries node must meet the following conditions:
− The process must contain only one input field and only one output field, and the fields must be of
the value type.
− The input field must be arithmetic series.
− The process cannot have missing value in output or input field.
Model Input Example
YEAR,GDP,AVR_GDP,POPULATION,AVR_WAGE,CS_INDEX
1990,18547.9,1634,212548,2140,103.1

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 44 of 124
1991,21617.9,1879,201548,2340,103.4
1992,26638.1,2287,198452,2711,106.4
1993,34634.4,2939,178456,3371,114.7
1994,46759.4,3923,165874,4538,124.1
1995,58478.1,4854,154846,5500,117.1
1996,67884.6,5576,141548,6210,108.3
1997,74462.6,6054,130254,6470,102.8
Fields are separated by commas (,).
On the Type node:
YEAR: Input
GDP: Output
Other fields: None
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project name/Model
directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Variable Confidence Confidence interval of the autocorrelation between the forecasted
value and residual. The default value is 95.
ACF and PACF Delay Time delay in the autocorrelation and partial autocorrelation
coefficient. This parameter is used to evaluate models. The default
value is 24.
Test Outlier Specifies whether to detect outliers. The options are as follows:
● Yes: Detect outliers automatically based on data types.
● No: Not detect or build models for outliers. The value is the
default value.
MinHash Node
Function
The MinHash node analyzes the similarity between two data sets quickly.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 45 of 124
The data mining process in which the MinHash node is configured must contain only one primary key
field and only one input field.
Model Input Example
phone_num,color_ring
13978965412,A
13978965412,B
13978965412,C
13978965412,D
13978965412,E
13945632178,A
13945632178,B
13945632178,D
Fields are separated by commas (,).
On the Type node:
phone_num: Primary Key
color_ring: Input
Parameter Description
Parameters
Parameter Description
Min. Items Minimum number of data entries in a data primary
key or field. The default value is 5, indicating that
a primary key or field contains a minimum of five
data entries.
Min. Cluster Elements Minimum number of data subsets on a cluster. The
default value is 5, indicating that a cluster contains
a minimum of 5 subsets.
Linear Node
Function
The Linear node determines the cause-effect relationships between variables, sets up regression models,
and checks the correlations between symptoms and the correlation directions and levels.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node, and cannot follow a Bin node.
A data mining process containing the Linear node must meet the following conditions:
− The Type node must contain only one output field and one or more input fields.
− If the input field is of the character string type, the field must be of Sign or Set role. If the input
field is of the numeral type, you do not need to set the Role parameter.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 46 of 124
− The output fields must be of Range role.
− The Linear node must contain a maximum of one partition field.
Model Input Example
id,AD,RD,commission,GDP,VOS
2012,1302,1851,723,57080,4970
2011,1204,1704,675,26461.5,4521
2010,1105,1557,629,48235.1,4124
2009,1002,1404,576,49495.9,3692
2008,903,1255,523,31377,3269
2007,802,1109,475,23339.1,2846
Fields are separated by commas (,).
On the Type node:
id: Primary Key
AD, RD, commission, and GDP: Input
VOS: Output; Role must be set to Range.
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project name/Model
directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Use Partition Specifies whether to use only the training data set to build models if
the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Select Feature Specifies whether to select features. You can use the parameter to
define feature selection criteria based on the probability associated
with fields.
Threshold for Including
Significance
This parameter is valid only when Select Feature is set to Yes. The
default value is 0.05.
When the probability of a field is less than the value of Threshold
for Including Significance, the system adds the field to the model.
Threshold for Excluding
Significance
This parameter is valid only when Select Feature is set to Yes. The
default value is 0.1.
When the probability of a field is greater than the value of
Threshold for Excluding Significance, the system deletes the

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 47 of 124
Parameter Description
field.
NOTE The value of Threshold for Including Significance must be less than the value of Threshold for Excluding Significance.
Include Constant Specifies whether the model contains constants.
Visualization
Click the Linear model file. Information about the model is displayed, as shown in 0. The structure tree is
displayed on the left, indicating the attributes and values of the model, and the significance of attributes is
displayed in a column bar on the right.
Linear model file information
NOTE If Bagging and Boosting are used, the SmartMiner will generate multiple models. The model structure tree displays multiple models, among which the root node is ModelSet, the Boosting model weight is calculated based on the error rate, and the default Bagging model weight is 1.
GBDT Node
Function
The GBDT algorithm is an iterative DecisionTree algorithm. It consists of multiple decision trees. The
regression trees from each iteration are merged based on their weights. The algorithm is used to solve
regression and dichotomy problems.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the GBDT node must meet the following conditions:
− The Type node must contain at least one input field of the numeral or string type, and the Role
must be Sign, Set, or Range.
− The Type node must contain only one output field, and the Role must be Sign or Range.
The GBDT node follows a Type, Binning, Partition, Filler, Filter, Sampling or Select node, and is
followed by a GBDTApply, TextFileExport or DataBaseExport node.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 48 of 124
Model Input Example
range1,set1,sign1,output
10,AA,yes,-3.9
21,BB,yes,6.9
5,AA,yes,5
7,CC,yes,6
8.6,BB,no,9
35,CC,no,12
Fields are separated by commas (,).
On the Type node:
range1, set1, and sign1: Input
output: Output
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Tree Depth Maximum layer of nodes (root node excluded) in a decision tree,
that is, depth of a decision tree.
The value ranges from 1 to 8.
Default value: 5
Step (Decrease) It determines the merging weight of each decision tree.
The value ranges from 0.01 to 1.
Default value: 1
Round It determines the max number of the decision trees.
Default value: 3
Use Partitioned Specifies whether to use only the training data set to build models
if the Partition node is configured.
The options are as follows:
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Default value: No

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 49 of 124
PCA Node
Function
The PCA node transforms multiple indexes to few comprehensive indexes that are not correlated.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The PCA node can contain only fields of the value type. To generate the model for factor analysis or
principal component analysis, one or more input fields are required. The node ignores output,
bidirectional, and nondirectional fields.
Model Input Example
ID,FIELD1,FIELD2,FIELD3,FIELD4,FIELD5,FIELD6,FIELD7,FIELD8
1,40.4,24.7,7.2,6.1,8.3,8.7,2.442,20
2,25,12.7,11.2,11,12.9,20.2,3.542,9.1
3,13.2,3.3,3.9,4.3,4.4,5.5,0.578,3.6
4,22.3,6.7,5.6,3.7,6,7.4,0.176,7.3
5,34.3,11.8,7.1,7.1,8,8.9,1.726,27.5
6,35.6,12.5,16.4,16.7,22.8,29.3,3.017,26.6
Fields are separated by commas (,).
On the Type node, Direction of ID is set to None, and Direction and Role of other fields are set to Input
and Range respectively.
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
Use Partition Specifies whether to use only the training data set to build models
if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Extract Principal Component By Method for specifying the number of principal components and
extracting principal component factors from input fields.
The options are as follows:
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 50 of 124
Parameter Description
● By Component Count
This method retains a specified number of factors or
components sorted by feature value in descending order. By
default, the node retains five factors or components with the
highest feature values.
● By Min. Eigen
Feature values measure a factor's or component's capability for
describing the deviation of the input field set. This method
retains factors or components whose feature value is greater
than the specified threshold. Ensure that the threshold is not
too large to retain any principal component. The default feature
value threshold is 1.
Rotation Method You can rotate the retained factor set to improve the practicability
of the factors and make the factors easier to describe.
The options are as follows:
● Do not rotate: default value
● Varimax: This method minimizes the number of fields that are
overloaded for each factor, which facilitates the description of
the factor.
● Quartimax: This method minimizes the number of factors for
describing a field.
● Equamax: This method combines the Varimax and
Quartimax methods
NOTE
To rotate principal factors is to perform orthogonal transformation for changing the linear coefficient of principal factors. In this way, the relationships between principal factors and original factors are clearer, but the analysis results are not affected.
CF Node
Function
The CF node analyzes the similarity between users or items, and provides personalized offers to users
based on the similarities.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The data mining process in which the CF node is configured must contain only one primary key field
and a minimum of one input field.
The computing framework (Hadoop or Spark) on which the CF node runs can be configured in the
${SmartMiner_HOME}/conf/smartminer.spark.nodes file. Parameters in Similarity Parameters
vary depending on the selected computing framework. For details about the parameters, see

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 51 of 124
Parameter Description. If the CF runs on the Spark, Harden Trust is not supported for Calculate
Similarity By user.
An example of the configuration file is as follows:
#[Parameter Group]: nodes implementation way
#[Parameter]: CF
#[Description]: CF node implementation way.
#[SetGuide]: Set this parameter based on the way to implement CF node.
#[Default]: hadoop
#[Range]: hadoop
CF=hadoop //The node runs on the Hadoop framework.
CF=spark //The node runs on the Spark framework.
Model Input Example 1 (Item Similarity)
ID,POINT,THINGS
1001,5.2,shoes
1001,7,football
1001,9,mineralwater
1002,7.3,basketball
1002,5.5,shoes
Fields are separated by commas (,).
On the Type node:
− ID: Primary Key
− POINT: Input
− THINGS: Input
On the CF node:
− Calculate Similarity: By item
− Item field: THINGS
− Rating field: POINT
Model Input Example 1 (User Similarity)
user,item,score
uu1,ii1,5
uu1,ii4,4
uu2,ii1,3
uu2,ii2,2
Fields are separated by commas (,).
On the Type node:
− user: Primary Key
− score: Input
On the Type node:
− Calculate Similarity: By user
− Item field: item
− Rating field: score
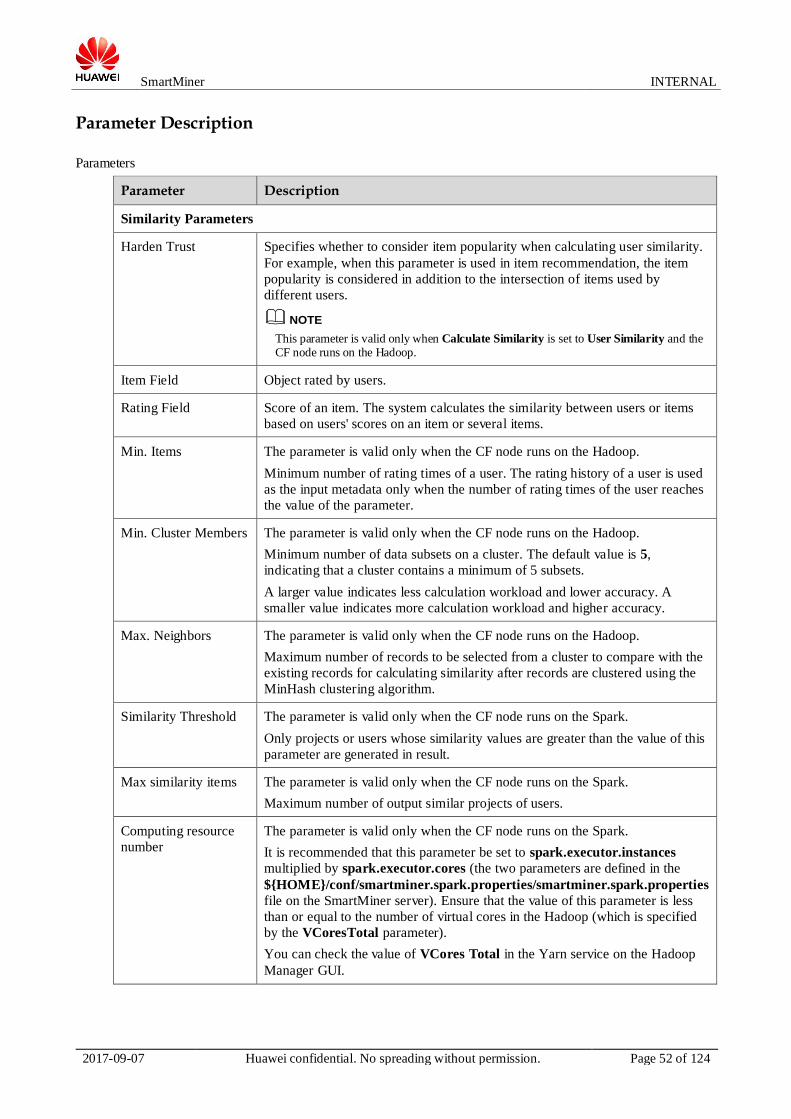
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 52 of 124
Parameter Description
Parameters
Parameter Description
Similarity Parameters
Harden Trust Specifies whether to consider item popularity when calculating user similarity.
For example, when this parameter is used in item recommendation, the item
popularity is considered in addition to the intersection of items used by
different users.
NOTE
This parameter is valid only when Calculate Similarity is set to User Similarity and the CF node runs on the Hadoop.
Item Field Object rated by users.
Rating Field Score of an item. The system calculates the similarity between users or items
based on users' scores on an item or several items.
Min. Items The parameter is valid only when the CF node runs on the Hadoop.
Minimum number of rating times of a user. The rating history of a user is used
as the input metadata only when the number of rating times of the user reaches
the value of the parameter.
Min. Cluster Members The parameter is valid only when the CF node runs on the Hadoop.
Minimum number of data subsets on a cluster. The default value is 5,
indicating that a cluster contains a minimum of 5 subsets.
A larger value indicates less calculation workload and lower accuracy. A
smaller value indicates more calculation workload and higher accuracy.
Max. Neighbors The parameter is valid only when the CF node runs on the Hadoop.
Maximum number of records to be selected from a cluster to compare with the
existing records for calculating similarity after records are clustered using the
MinHash clustering algorithm.
Similarity Threshold The parameter is valid only when the CF node runs on the Spark.
Only projects or users whose similarity values are greater than the value of this
parameter are generated in result.
Max similarity items The parameter is valid only when the CF node runs on the Spark.
Maximum number of output similar projects of users.
Computing resource
number
The parameter is valid only when the CF node runs on the Spark.
It is recommended that this parameter be set to spark.executor.instances
multiplied by spark.executor.cores (the two parameters are defined in the
${HOME}/conf/smartminer.spark.properties/smartminer.spark.properties
file on the SmartMiner server). Ensure that the value of this parameter is less
than or equal to the number of virtual cores in the Hadoop (which is specified
by the VCoresTotal parameter).
You can check the value of VCores Total in the Yarn service on the Hadoop
Manager GUI.
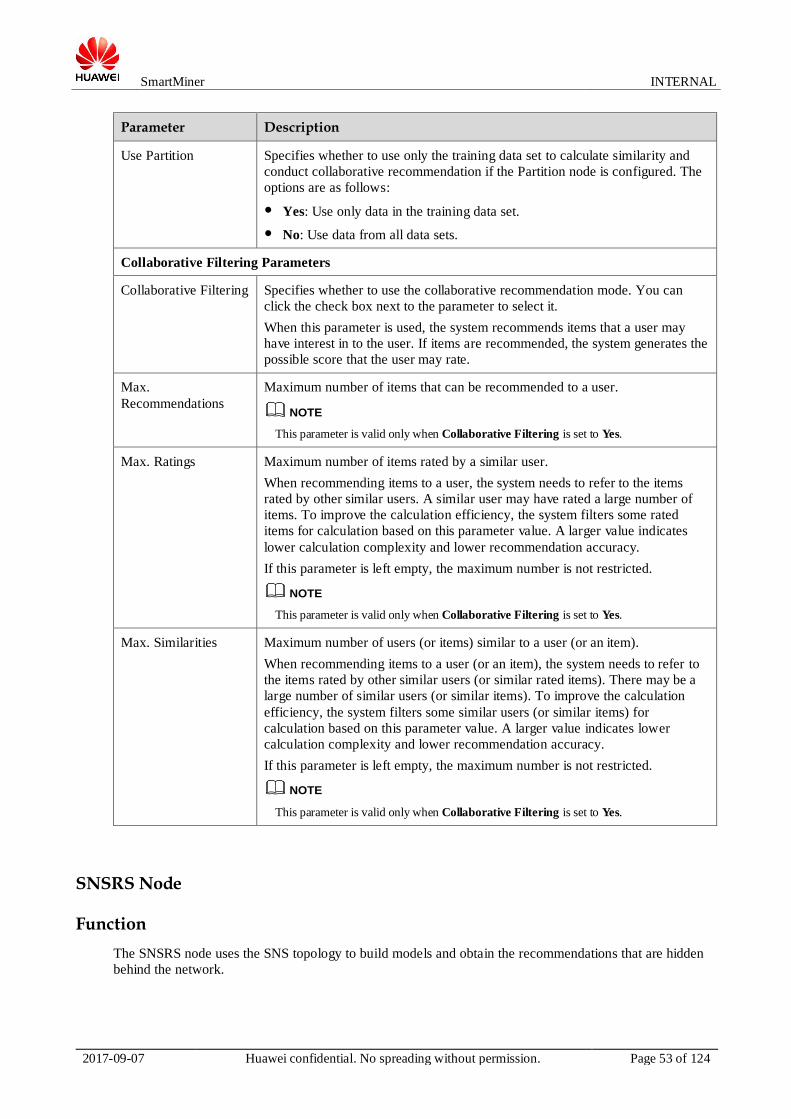
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 53 of 124
Parameter Description
Use Partition Specifies whether to use only the training data set to calculate similarity and
conduct collaborative recommendation if the Partition node is configured. The
options are as follows:
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Collaborative Filtering Parameters
Collaborative Filtering Specifies whether to use the collaborative recommendation mode. You can
click the check box next to the parameter to select it.
When this parameter is used, the system recommends items that a user may
have interest in to the user. If items are recommended, the system generates the
possible score that the user may rate.
Max.
Recommendations
Maximum number of items that can be recommended to a user.
NOTE This parameter is valid only when Collaborative Filtering is set to Yes.
Max. Ratings Maximum number of items rated by a similar user.
When recommending items to a user, the system needs to refer to the items
rated by other similar users. A similar user may have rated a large number of
items. To improve the calculation efficiency, the system filters some rated
items for calculation based on this parameter value. A larger value indicates
lower calculation complexity and lower recommendation accuracy.
If this parameter is left empty, the maximum number is not restricted.
NOTE This parameter is valid only when Collaborative Filtering is set to Yes.
Max. Similarities Maximum number of users (or items) similar to a user (or an item).
When recommending items to a user (or an item), the system needs to refer to
the items rated by other similar users (or similar rated items). There may be a
large number of similar users (or similar items). To improve the calculation
efficiency, the system filters some similar users (or similar items) for
calculation based on this parameter value. A larger value indicates lower
calculation complexity and lower recommendation accuracy.
If this parameter is left empty, the maximum number is not restricted.
NOTE
This parameter is valid only when Collaborative Filtering is set to Yes.
SNSRS Node
Function
The SNSRS node uses the SNS topology to build models and obtain the recommendations that are hidden
behind the network.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 54 of 124
Restriction The node must follow a source (TextImport, ImportFeatureLibrary or DatabaseImport) node and a
Type node.
The SNSRS node must contain a minimum of one input field that functions as the user field and a
minimum of one input field that functions as the item field.
Model Input Example 1 (Heat Spreading)
A,B
U1,I2
U1,I3
U2,I2
U2,I4
U2,I5
U3,I3
Fields are separated by commas (,).
On the Type node, Direction of all fields is set to Input.
On the SNSRS node:
− ITSF
− User field: A
− Item field: B
− Recommendation algorithm: HeatSpreading
Model Input Example 1 (Probability Spreading)
A,B
U1,I2
U1,I3
U2,I2
U2,I4
U2,I5
U3,I3
Fields are separated by commas (,).
On the Type node, Direction of all fields is set to Input.
On the SNSRS node:
− User field: A
− Item field: B
− Recommendation algorithm: ProbabilitySpreading

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 55 of 124
Parameter Description
Parameters
Parameter Description
Recommendation Algorithm Recommendation algorithm. The options are as follows:
● HeatSpreading
Heat of an item indicates users' acceptance degree
towards the item. The heat of rated items is 1 and that of
unrated items is 0. Heat is spread from high heat to low
heat. In the spreading process, the system spreads heat
from rated items to users and then to unrated items.
Unrated items with higher heat are recommended first.
● ProbabilitySpreading
Probability indicates the likelihood that a user accepts an
item. The probability of rated items is 1. Assume that
probability can be spread on the SNS network. In the
spreading process, the system spreads probability from
rated items to users and then to unrated items. Unrated
items with higher probability are recommended first.
Constringency Factor Constringency factor. A greater Lambda value indicates a
higher probability for recommending unpopular items.
Use Partition Specifies whether to use only the training data set to build
models if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
PersonalTag Node
Function
The PersonalTag node analyzes the initial preferences, preview history, and features of previewed contents
of users, and recommends offers to users accordingly.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The data mining process in which the PersonalTag node is configured must contain a minimum of
three input fields.
Model Input Example
USER;MOVIE;SCORE;ITEM1;ITEM2;ITEM3
U1;M1;5;I11|I12;I21|I22|I23;I31
U1;M2;4;I11;I21|I23;I32|I33
U2;M3;4;I12|I13;I22|I23;I31|I32
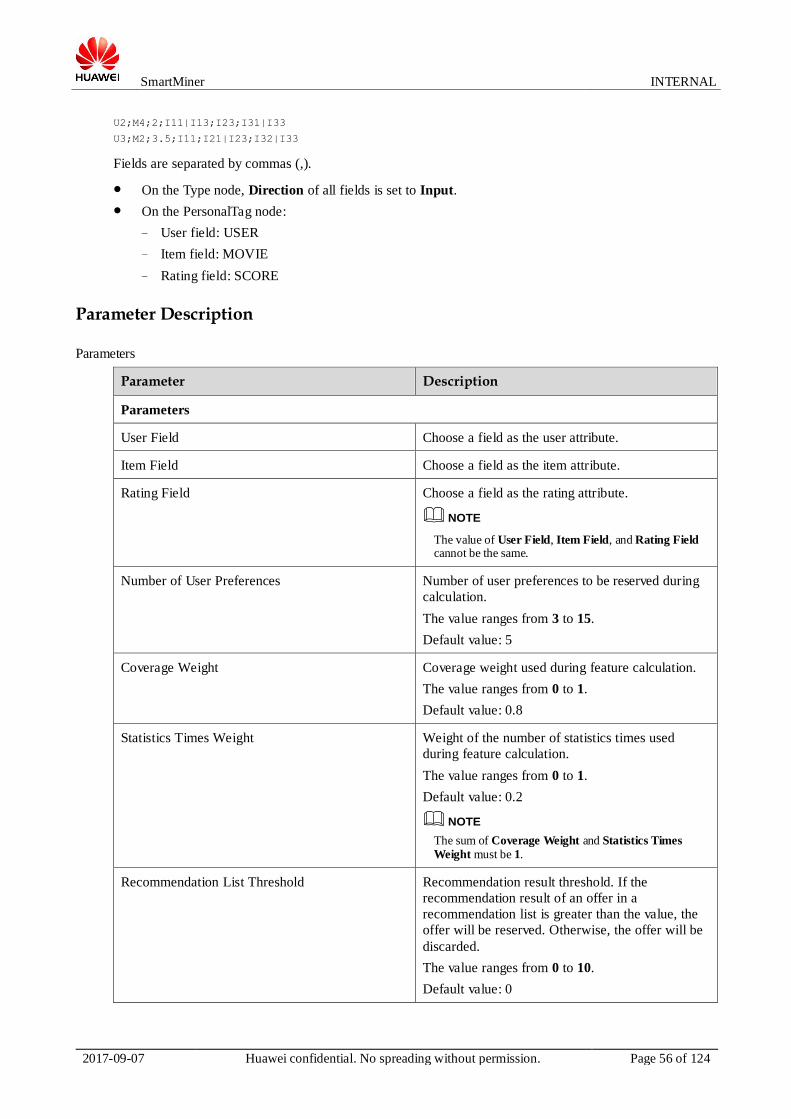
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 56 of 124
U2;M4;2;I11|I13;I23;I31|I33
U3;M2;3.5;I11;I21|I23;I32|I33
Fields are separated by commas (,).
On the Type node, Direction of all fields is set to Input.
On the PersonalTag node:
− User field: USER
− Item field: MOVIE
− Rating field: SCORE
Parameter Description
Parameters
Parameter Description
Parameters
User Field Choose a field as the user attribute.
Item Field Choose a field as the item attribute.
Rating Field Choose a field as the rating attribute.
NOTE
The value of User Field, Item Field, and Rating Field cannot be the same.
Number of User Preferences Number of user preferences to be reserved during
calculation.
The value ranges from 3 to 15.
Default value: 5
Coverage Weight Coverage weight used during feature calculation.
The value ranges from 0 to 1.
Default value: 0.8
Statistics Times Weight Weight of the number of statistics times used
during feature calculation.
The value ranges from 0 to 1.
Default value: 0.2
NOTE
The sum of Coverage Weight and Statistics Times
Weight must be 1.
Recommendation List Threshold Recommendation result threshold. If the
recommendation result of an offer in a
recommendation list is greater than the value, the
offer will be reserved. Otherwise, the offer will be
discarded.
The value ranges from 0 to 10.
Default value: 0
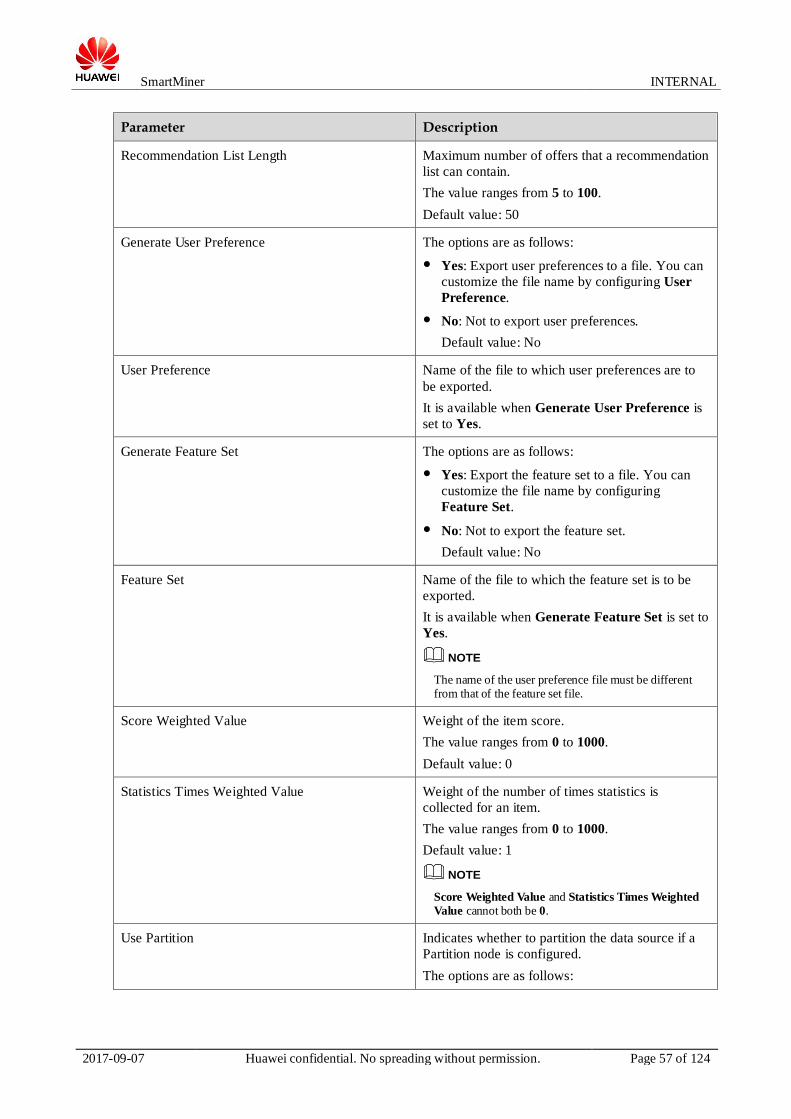
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 57 of 124
Parameter Description
Recommendation List Length Maximum number of offers that a recommendation
list can contain.
The value ranges from 5 to 100.
Default value: 50
Generate User Preference The options are as follows:
● Yes: Export user preferences to a file. You can
customize the file name by configuring User
Preference.
● No: Not to export user preferences.
Default value: No
User Preference Name of the file to which user preferences are to
be exported.
It is available when Generate User Preference is
set to Yes.
Generate Feature Set The options are as follows:
● Yes: Export the feature set to a file. You can
customize the file name by configuring
Feature Set.
● No: Not to export the feature set.
Default value: No
Feature Set Name of the file to which the feature set is to be
exported.
It is available when Generate Feature Set is set to
Yes.
NOTE
The name of the user preference file must be different from that of the feature set file.
Score Weighted Value Weight of the item score.
The value ranges from 0 to 1000.
Default value: 0
Statistics Times Weighted Value Weight of the number of times statistics is
collected for an item.
The value ranges from 0 to 1000.
Default value: 1
NOTE
Score Weighted Value and Statistics Times Weighted
Value cannot both be 0.
Use Partition Indicates whether to partition the data source if a
Partition node is configured.
The options are as follows:

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 58 of 124
Parameter Description
● Yes: partition the data source into the training
data set for recommendation and the test data
set for evaluation.
● No: not partition the data source and use full
data for recommendation and evaluation.
Default value: No
Multi-Attribute Configuration
NOTE At least one Multi-Attribute needs to be configured.
Contain Multiple Values The options are as follows:
● Yes: The attribute contains multiple values.
● No: The attribute contains only one value.
Weight The weight of the field.
The value ranges from 0 to 100.
Default value: 1
NOTE
The weights of the fields cannot be all 0.
Multi-Attribute Separator Separator for separating multiple values in an
attribute.
NOTE The value of Multi-Attribute Separator cannot be the same as that used on the source node.
DiscriminationTree Node
Function
The Discrimination node provides recommendations to new users based on the existing user group
information as follows: The system asks a new user questions, uses the answers to find a matching user
group for this user, and recommend preferences of the user group to the user. (A recommendation can be a
movie that has the highest score or is most frequently watched.)
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The data mining process in which the PersonalTag node is configured must contain a minimum of
three input fields.
Model Input Example
USER,MOVIE,SCORE
U1,M29,2
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 59 of 124
U1,M10,2
U1,M1,5
U1,M27,4
U1,M16,1
U1,M20,2
Fields are separated by commas (,).
On the Type node, Direction of all fields is set to Input.
On the Discrimination node:
− User field: USER
− Item field: MOVIE
− Rating field: SCORE
Parameter Description
Parameters
Parameter Description
User Field Choose a field as the user attribute.
Item Field Choose a field as the item attribute.
Rating Field Choose a field as the rating attribute.
NOTE
The value of User Field, Item Field, and Rating Field cannot be the same.
Tree Count Number of Discrimination trees, for example, the
number of questions displayed to users in one
round.
Height Depth of a Discrimination tree, for example, the
number of rounds in which questions are displayed
to users.
Min. Records on Leaf Node Minimum number of records that is required in a
leaf node. If the number of records is less than the
value of this parameter, no more leaf nodes will be
created.
Preference Threshold User preference threshold. Items with a value
greater than the threshold will be considered as
user preferences.
Score Pruning Coefficient Formula correction value introduced in case that
there are few rating records for an item in a leaf
node. The value 0 indicates no correction will be
made. A greater threshold indicates a more
obvious correction will be made to the
recommendation rating.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 60 of 124
Parameter Description
Recommendation Novelty Threshold Formula correction value introduced to improve
recommendation novelty. The value 0 indicates no
correction will be made. A greater threshold
indicates a more obvious correction will be made
to the recommendation rating.
Use Partition Indicates whether to partition the data source if a
Partition node is configured.
The options are as follows:
● Yes: partition the data source into the training
data set for recommendation and the test data
set for evaluation.
● No: not partition the data source and use full
data for recommendation and evaluation.
Recommendation List Length Max number of recommendations that will be
provided to a user.
SimilarFeature Node
Function
The SimilarFeature node calculates the similarity of contents based on the features and the feature weight.
This node supports incremental feature similarity calculation. After a full calculation, you can import only
new, deleted, and updated records, and then the system can calculate feature similarities based on only the
imported records and combine the calculation result with the last analysis result. This function can save
computing resources because it does not calculate the similarities between existing records.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The data mining process in which the SimilarFeature node is configured must contain only one
primary key field and a minimum of one input field.
The analysis result is exported using the ExportText node.
In the incremental calculation mode, the BDI is required. After a full analysis, the BDI periodically
loads incremental data and invokes the SmartMiner for incremental analysis.
In the incremental calculation mode, the input data must contain a flag field that indicates data
resetting, creation, update, or deletion. This field can be user-defined. On the Type node, you must
comply with the following rules when defining the field:
− Set Role of the field to Set, and values of the set must contain r (resetting), n (creation), u (update),
and d (deletion).
− Set Direction of the field to Input.
Model Input Example (Full Calculation Mode)
TONEID,SINGER,SINGERSEX,TONELANGUAGE,TONEINFO,PRICE

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 61 of 124
77954,Football Songs,1,2,HipHop,50
64089,alfasuarawuolorunninbe,1,2,gospel,50
64120,raskimono,1,2,raggae,50
78601,Soule Baba,2,2,Naija,50
Fields are separated by commas (,).
On the Type node, Direction of TONEID is set to Primary Key, and Direction for other fields is set to
Input.
Model Input Example (Incremental Calculation Mode)
The following shows the initial full input data:
TONEID,SINGER,SINGERSEX,TONELANGUAGE,TONEINFO,PRICE,SIGN
1,Nubia,2,2,HipHop,50,r
2,Usher,2,2,HipHop,50,r
3,Benie Man,2,2,HipHop,50,r
In the data, SIGN is the flag field. It can be left empty for full data import. The default value of SIGN is r
by default.
Feature similarity modeling process
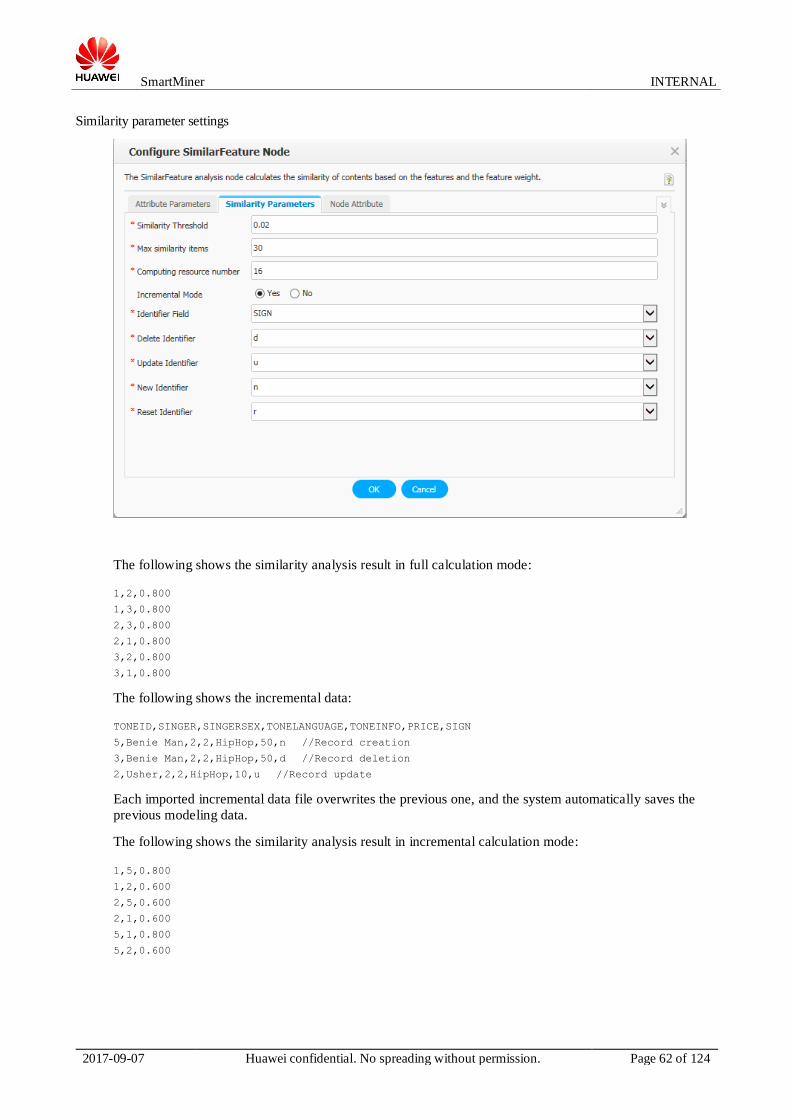
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 62 of 124
Similarity parameter settings
The following shows the similarity analysis result in full calculation mode:
1,2,0.800
1,3,0.800
2,3,0.800
2,1,0.800
3,2,0.800
3,1,0.800
The following shows the incremental data:
TONEID,SINGER,SINGERSEX,TONELANGUAGE,TONEINFO,PRICE,SIGN
5,Benie Man,2,2,HipHop,50,n //Record creation
3,Benie Man,2,2,HipHop,50,d //Record deletion
2,Usher,2,2,HipHop,10,u //Record update
Each imported incremental data file overwrites the previous one, and the system automatically saves the
previous modeling data.
The following shows the similarity analysis result in incremental calculation mode:
1,5,0.800
1,2,0.600
2,5,0.600
2,1,0.600
5,1,0.800
5,2,0.600
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 63 of 124
Parameter Description
Parameters
Parameter Description
Attribute Parameters
Multi-Value Indicates whether a field can contain multiple values. For example, the SINGER
field of a song can have multiple values.
Weight Field weight. A field with a larger weight has greater impact on the similarity
results.
Multi-Value
Separator
Separator used to separate values of a field if the field has multiple values. For
example, Tom;Anna, which indicates that the values of SINGER are separated by
semicolons (;).
Similarity Parameters (Hadoop-based)
Min. Cluster
Members
Minimum number of data subsets on a cluster. The default value is 5, indicating
that a cluster contains a minimum of 5 subsets.
A larger value indicates less calculation workload and lower accuracy. A smaller
value indicates more calculation workload and higher accuracy.
Max. Neighbors Maximum number of records to be selected from a cluster to compare with the
existing records for calculating similarity after records are clustered using the
MinHash clustering algorithm.
Number of Hash
Functions
Number of Hash functions required for the similarity calculation.
The value of the parameter ranges from 1 to 100.
The default value is 20.
Number of Hash
Function Values
Number of items to be compared between two objects. If the items are the same, the
two objects are similar. The greater the parameter value is, the lower the similarity
probability is.
The value of the parameter ranges from 1 to 100.
The default value is 2.
NOTE Number of Hash Functions cannot be greater than Number of Hash Function Values.
Similarity Parameters (Spark-based)
Similarity
Threshold
Threshold lower than which similarities are not displayed in the analysis result.
If there is a large amount of input data and the calculated similarities are low, set
this parameter to a smaller value to increase the number of records in the generated
analysis result.
Max similarity
items
Maximum number of similarity records in the analysis result that contains
similarities in ascending order.
Computing
resource number
It is recommended that this parameter be set to spark.executor.instances
multiplied by spark.executor.cores (the two parameters are defined in the
${HOME}/conf/smartminer.spark.properties/smartminer.spark.properties file
on the SmartMiner server). Ensure that the value of this parameter is less than or

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 64 of 124
Parameter Description
equal to the number of virtual cores in the Hadoop (which is specified by the
VCoresTotal parameter).
You can check the value of VCores Total in the Yarn service on the Hadoop
Manager GUI.
Incremental Mode Indicates whether to use the incremental calculation mode. If this parameter is set
to No, the full calculation mode is used by default and the input data does not need
to contain a flag field.
Identifier Field Specifies a flag field. This parameter is valid only when Incremental Mode is set
to Yes. The SmartMiner automatically reads the field whose Role is set to Set on
the Type node.
Delete Identifier Specifies the identifiers. This parameter is valid only when Incremental Mode is
set to Yes. The SmartMiner automatically reads the values of the field whose Role
is set to Set on the Type node. Update Identifier
New Identifier
Reset Identifier
FullConnected Node
Function
The FullConnected node is used to find fully connected submaps for home networks.
Restriction The node must follow a source (TextImport, ImportFeatureLibrary or DatabaseImport) node and a
Type node.
The data mining process in which the FullConnected node is configured must contain a minimum of
two input fields.
Model Input Example
USER LUSER
A B,C,D,E,F,H
B A,D,E,G,H
C A,E,F,G,H
D A,B,F,G,H
E A,B,C,F,H
F A,C,D,E
G B,C,D,H
H A,B,C,D,E,G1
Fields are separated by commas (,).
On the Type node, Direction of all fields is set to Input.
On the FullConnected node:
− Vertex field: USER

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 65 of 124
− Neighboring field: LUSER
− Neighbor separator: ,
Parameter Description
Parameters
Parameter Description
Convert to Undirected Figure Whether to use the bidirectional data transmission
mode. A bidirectional relationship example is as
follows: A and B have called each other.
Vertex Field Vertex field to be analyzed. In a fully connected
map, every two vertex fields are connected. For
example, if field A, B, C, and D are all vertex
fields, the data format is as follows:
● A|B;C;D
● B|B;C;D
● C|B;C;D
● D|B;C;D
NOTE
In the preceding format, the field before | is a vertex field, fields after | are neighboring fields, and ; is a neighboring field separator.
Neighbor Field Neighboring field of a vertex field. A vertex may
have multiple neighboring fields. Therefore,
Neighboring Field may contain multiple values.
Max. Full Connections Maximum number of vertex fields. In a fully
connected map, every two records are connected.
The parameter specifies the number of vertex
fields in a fully connected map.
TextClassify Node
Function
The TextClassify node segments text and forecasts its classification.
Restriction The node must follow a ImportFolder node and a Type node.
Generally, the TextClassify node follows the FolderImport node. If the TextClassify node follows
another node, it must contain the CATALOG, SUBCATALOG, FILENAME, and CONTENT input
fields.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 66 of 124
Model Input Example
The process of using the TextClassify node is: import a directory -> use a Type node to process data ->
classify text.
You can upload a directory to the Data directory of the corresponding project, for example,
/homedcp01/autoTest/Projects/TextClassify_mod/Data/classify/mine.app.TextClassify.functiona.027.txt,
, and then select the corresponding directory on the ImportFolder node.
Parameter Description
Parameters
Parameter Description
Model File Model file name. Model files are stored in the
Project name/Model directory.
Use Partition Specifies whether to use only the training data set
to build models if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Text Type Text format.
NOTE Text of the Wed type only supports web pages using the WAP protocol
SPA Node
Function
The SPA node expands influence and identifies users based on the SNS network.
You can use the SPA node to forecast results by classification, for example, customer loss probability and
whether a customer will accept an offer. For example, if the system wants to forecast customer loss
probability, it defines some lost customers on the SNE network, and finds the influence the lost customers
have on other customers based on their call frequency and duration. Then the system calculates the
customer loss probability based on the obtained data and iteratively expands the calculated probability
through the influence spreading expression until the probability seldom changes.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The SPA node must contain a minimum of three input fields that function as analysis fields.
Model Input Example
A,B,C

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 67 of 124
a,y,b|1
b,n,f|1;e|5
c,n,e|1
d,y,
e,n,
f,y,e|1;d|1;g|1
g,n,d|1
Fields are separated by commas (,).
On the Type node, Direction of all fields is set to Input.
On the SAP node:
− Vertex field: A
− Type field: B
− Neighbor field: C
− Separator between neighboring fields: ;
− Separator between neighboring weights: |
Parameter Description
Parameters
Parameter Description
Input/Output Parameters
Vertex Field Vertex field to be analyzed. In a fully connected
map, every two vertex fields are connected. For
example, if field A, B, C, and D are all vertex
fields, the data format is as follows:
● A|B;C;D
● B|B;C;D
● C|B;C;D
● D|B;C;D
NOTE
In the preceding format, the field before | is a vertex field, fields after | are neighboring fields, and ; is a neighboring field separator.
Neighbor Field Neighboring field of a vertex field. A vertex may
have multiple neighboring fields. Therefore,
Neighbor Field may contain multiple values.
Neighbor Separator Separator between neighboring fields.
Neighbor Contain Weight Specifies whether neighboring fields contain
weight. The options are as follows:
● Yes
Read neighboring fields in the
V1|weight1|V2|weight2|V3|weight3 format.
● No

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 68 of 124
Parameter Description
Read neighboring fields in the V1|V2|V3
format. The weight is set to 1.
Neighbor Weight Separator Neighboring field weight separator. The value
cannot be the same as the field separator or the
value of NNeighbor Separator.
This parameter is valid only when Neighbor
Contain Weight is set to Yes.
Type Field User type field, for example, a field that indicates
whether a user is online or offline.
Predict Type Forecast type. For example, if the options of Type
Field are A and B, and the value of Predict Type
is B, the SmartMiner will forecast the probability
of the event that A is changed into B.
Use Partition Specifies whether to use only the training data set
to build models if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Generate Forecast Record Specifies whether to generate records of the
forecast type. For example, if the options of Type
Field are A and B, and the value B indicates the
forecast type, this parameter specifies whether to
generate records whose Type Field is B.
Algorithm Parameters
Spreading Factor Percentage of spread influence to the original
influence. A smaller Spreading Factor value
indicates greater influence on the vertexes around
the influence source, and a larger Spreading
Factor value indicates a larger influence scope.
End Threshold Spread end threshold. If the accepted influence is
lower than the threshold, the spreading operation
ends. A smaller End Threshold value indicates a
larger influence scope.
Classification Threshold Forecast result classification threshold. If the final
influence is higher than the threshold, the system
forecasts records as the forecast type. Therefore, a
smaller Classification Threshold value indicates
that more records are forecasted as the forecast
type.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 69 of 124
OverlapNeighbour Node
Function
The OverlapNeighbour node finds node pairs that have overlapping neighboring points.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The data mining process in which the OverlapNeighbour node is configured must contain a minimum
of three input fields.
Model Input Example 1 (The Neighbor Field Contains No Coefficient)
User Type Neighbor
A TYPE1 B|C|D|E|F
B TYPE1 A|D|E|G
Fields are separated by commas (,). The values of the neighbor field are separated by vertical bars (|).
On the Type node, Direction of all fields is set to Input. The roles and value ranges of all fields do not
need to be configured.
On the OverlapNeighbor node:
− Vertex field: User
− Type field: Type
− Neighbor field: Neighbor
− Neighbor field separator: |
− Neighbor field coefficient: No
Model Input Example 2 (The Neighbor Field Contains Coefficient)
User Type Neighbor
A TYPE1 B,5|C,10|D,15|E,20|F,5
B TYPE1 A,5|D,10|E,15|G,20
Fields are separated by commas (,). The values of the neighbor field are separated by vertical bars (|). The
neighboring field and its coefficient are separated by comma (,).
On the Type node, Direction of all fields is set to Input. The roles and value ranges of all fields do not
need to be configured.
On the OverlapNeighbor node:
− Vertex field: User
− Type field: Type
− Neighbor field: Neighbor
− Neighbor field separator: |
− Neighbor field coefficient: Yes
− Coefficient separator: ,
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 70 of 124
Parameter Description
Parameters
Parameter Description
Convert to Undirected Graph Whether to use the bidirectional data transmission
mode. A bidirectional relationship example is as
follows: A and B have called each other. This parameter
is used to set the data transmission mode to
bidirectional.
Vertex Field Vertex field to be analyzed. In a fully connected map,
every two vertex fields are connected. For example, if
field A, B, C, and D are all vertex fields, the data format
is as follows:
● A|B;C;D
● B|B;C;D
● C|B;C;D
● D|B;C;D
NOTE
In the preceding format, the field before | is a vertex field, fields after | are neighboring fields, and ; is a neighboring field separator.
Neighbor Field Neighboring field of a vertex field. A vertex may have
multiple neighboring fields. Therefore, Neighboring
Field may contain multiple values.
Vertex Type Specifies whether vertex fields are of a same type. For
example, if two vertex fields share a neighboring field
in a batch of data, the vertex fields are of a same type.
● Different Type
Scenario: Assume that a mobile phone user whose
number is A subscribed to a new package and
changed the mobile number to B in October, and
consumption data of number B is generated in
November. The SmartMiner analyzes the data of
number A in October and the data of number B in
November and finds that contacts of number A and
B overlap. As a result, the system can draw the
conclusion that number A and number B belong to a
same user. In this case, a mobile number is a vertex
field and the vertex fields are of different types.
● Same Type
Scenario: The SmartMiner analyzes a batch of data
and finds that the contacts of mobile number E and F
overlap. As a result, the system can draw the
conclusion that the user of number E may be an
acquaintance to the user of number F, and the
service side can recommend F as a friend to E. In
this case, a mobile number is a vertex field and the

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 71 of 124
Parameter Description
vertex fields are of a same type.
Min. Overlapping Neighbors Minimum number of overlapping neighbors. When the
number of overlapping neighbors between two nodes
reaches the value of Min. Overlapping Neighbors, the
fields are similar nodes.
SparseLinear Node
Function
The SparseLinear node supports a large number of features, precisely analyzes multi-dimensional data, and
builds models.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the SparseLinear node must meet the following conditions:
− The process contains a minimum of two input fields and only one output field.
− The input fields cannot be of the time, date, or timestamp type. If an input field is of the character
string type, the corresponding Role cannot be set to Range.
− For output fields, Role must be set to Sign.
Model Input Example
ID,UserID,Age,ARPU,Tags,Sex,Is,ItemID,Type,Score
1,user123,28,20.3,China|Huawei1|Huawei2|Huawei3|Huawei4,male,Y,item1234,MI|Honor,1
2,user456,30,30.3,China|Huawei,female,Y,item7890,MI|Honor,1
3,user123,28,20.3,China|ZTE,male,N,item1235,MI|Apple,0
4,user789,27,20.3,China|Huawei,male,Y,item8888,MI|Honor,1
5,user100,15,22.3,China|Huawei,female,Y,item1234,MI|Honor,0
6,user101,16,21.3,China|Huawei,female,Y,item1234,MI|Honor,0
7,user102,18,31.3,China|Ericsson,female,N,item1234,MI|Samsung,0
Fields are separated by commas (,).
On the Type node, Direction of ID is set to Primary Key, Direction of Score is set to Output, and
Direction of other fields is set to Input.
Parameter Description
Parameters
Parameter Description
Parameters

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 72 of 124
Parameter Description
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE In the preceding directory, test indicates the name of the project where the process is located.
Use Partition Specifies whether to use only the training data set to build models
if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from all data sets.
Split Set into Multiple Columns Specifies whether to convert a field of the set type into multiple
fields.
Support Multiple Values Specifies whether the source data can be multi-value data.
Base Category Reference value of the model forecast field, which is one of the
flag values of modeling node output fields.
Advanced Parameters
Advanced Parameters Algorithms for SparseLinear modeling. Currently, only the
LBFGS algorithm is supported.
RandomForest Node
Function
The RandomForest node supports a large number of features and builds multiple decision tree models to
abstract classification rules through random sampling, which avoids overfitting caused by the use of a
single decision tree.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the RandomForest node must meet the following conditions:
− The process contains a minimum of one input field and only one output field.
− If the input fields are of the character type, Role must be set to Sign, Set, or Range. If the input
fields are of the number type, Role does not need to be set.
− For output fields, Role must be set to Sign or Set.
Model Input Example
id,sign1,set1,rangei1,rangef2,string1,rangei3,rangef4,string2,sign2,set2,sign3,set3
0,0,b,-474,7600.86,DJPVBH,-148,3299.60,JPVBHN,no,1,0,b
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 73 of 124
1,1,b,114,4083.32,PVBHNT,219,8399.50,QWCIOU,no,2,1,b
2,1,c,282,2765.76,SYEKQW,-37,1875.44,EKQWCI,yes,1,0,b
3,0,a,75,7768.26,GMSYEK,10,1717.19,SYEKQW,no,2,0,c
4,1,c,443,9209.32,GMSYEK,100,6838.23,LRXDJP,no,3,1,c
Fields are separated by commas (,).
On the Type node, Direction of ID is set to Primary Key, and Direction for other fields is set to Input.
Parameter Description
Parameters
Parameter Description
Parameters
Model File Model file name. Model files are stored in the Project
name/Model directory.
By default, MOD files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Model
directory.
NOTE In the preceding directory, test indicates the name of the project where the process is located.
Number of Trees Number of decision tree submodels required during modeling.
Maximum Number of Bin Maximum number of bins for a feature during extraction.
Default value: 32
Maximum Number of Feature Maximum number of features required for building each decision
tree submodel.
Default value: 5
NOTE During sample extraction, sampling without replacement is used.
Maximum Number of Tree Depth Maximum layer of nodes in a decision tree.
Default value: 10
Use Partition Specifies whether to use only the training data set to build models
if the Partition node is configured.
● Yes: Use only data in the training data set.
● No: Use data from both the training and test data sets.
Min. Leaf Nodes NOTE It is recommended that you use the value obtained by dividing the number of records in the training data set by 2 to the power of L, in which L indicates the number of input fields in the training data set.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 74 of 124
PageRank Node
Function
The PageRank algorithm measures node importance. For example, it measures the importance of website
pages and ranks them by importance.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the PageRank node must meet the following conditions:
− The process must contain a minimum of three input fields.
− The Role field does not need to be configured.
− The data type of a start point and an end point can be integer, real, or string character; a weight can
be of the integer or real type.
Model Input Example
Start,End,Weight
A,B,10
B,A,10
A,C,20
C,A,20
A,D,30
D,A,30
Fields are separated by commas (,).
On the Type node, Direction of all fields is set to Input.
Parameter Description
Parameters
Parameter Description
Start Point Start point of an edge.
End Point End point of an edge.
Weight Weight of an edge.
Iteration Times Maximum number of iteration times for the
PageRank modeling algorithm. The model training
ends when the number of iteration times reaches
the value of Iteration Times.
Spreading Propagation Factor Percentage of spread influence to the original
influence. A smaller Spread Factor value
indicates greater influence on the vertexes around
the influence source, and a larger Spread Factor
value indicates a larger influence scope.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 75 of 124
Parameter Description
Iteration End Threshold Minimum change value of a PageRank value. The
iteration ends when the change value of a
PageRank value is less than the value specified by
this parameter
LDA Node
Function
Latent Dirichlet Allocation (LDA) is a way of automatically discovering themes in a large number of files
and predicting the generation of a theme model. LDA can also find categories that users prefer and
recommend by category.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
A data mining process containing the LDA node must meet the following conditions:
− Ensuring that word fields of the data type fields of the metadata on the source node are of the
character, floating point, or integer type and value fields are of the integer or floating point type.
− The process must contain a minimum of three input fields.
− The Role field does not need to be configured.
Model Input Example
document,word,score
1,1,3
1,2,3
1,3,3
1,4,3
1,5,3
1,6,3
Fields are separated by commas (,).
On the Type node, Direction of all fields is set to Input.
Parameter Description
Parameters
Parameter Description
Document Document used to build an LDA model. Example:
papers (during paper clustering)
Word Word used to build an LDA model. Example: a
word in a paper

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 76 of 124
Parameter Description
Score Score used to build an LDA model. Example: the
number of times that a word appears in a paper
Iteration Times Maximum number of iteration times for the LDA
modeling algorithm. The model training ends
when the number of iteration times reaches the
value of Iteration Times.
Number of Themes Number of clusters that the LDA model classifies
documents into.
Recommend Specifies whether to use an LDA model for user
clustering and content recommendation.
Application Nodes
Application nodes correspond to modeling nodes. You are advised to place an Export node after an
Application node to check the application result.
1.1.1.1 NaiveBayesApply Node
Function
The NaiveBayesApply node uses models generated on the NaiveBayes node to forecast sample
classification based on test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The NaiveBayes model file exists.
Parameter Description
Parameters
Parameter Description
Positive Value Customer care type. For example, in a customer
model, the loss of a customer is marked as a
positive value and the retaining of a customer is
marked as a negative value.
Select a value of the sign role from the drop-down
list box.
NOTE
This parameter is available only when the output field is of the sign role.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 77 of 124
Parameter Description
Positive Value Rate Threshold Used for changing the default threshold in the
algorithm. A type is regarded as positive only
when the rate of the type exceeds the threshold.
Enter a real number ranging from 0 to 1.
NOTE This parameter is available only when the output field is of the sign role.
Use Partition Specifies whether to use only the test data set to
build models if the Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
DecisionTreeApply Node
Function
The DecisionTreeApply node uses models generated on the DecisionTree node to forecast sample
classification based on test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The DecisionTree model file exists.
Parameter Description
Parameters
Parameter Description
Positive Value Customer care type. For example, in a customer
model, the loss of a customer is marked as a
positive value and the retaining of a customer is
marked as a negative value.
Select a value of the sign role from the drop-down
list box.
NOTE
This parameter is available only when the output field is of the sign role.
Positive Value Rate Threshold Used for changing the default threshold in the
algorithm. A type is regarded as positive only
when the rate of the type exceeds the threshold.
Enter a real number ranging from 0 to 1.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 78 of 124
Parameter Description
NOTE This parameter is available only when the output field is of the sign role.
Use Partition Specifies whether to use only the test data set to
build models if the Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
LogisticsApply Node
Function
he LogisticsApply node uses models generated on the Logistics node to forecast sample classification
based on test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node, and can not follow a Binning node.
The Logistics model file exists.
Parameter Description
Parameters
Parameter Description
Positive Value Customer care type. For example, in a customer
model, the loss of a customer is marked as a
positive value and the retaining of a customer is
marked as a negative value.
Select a value of the sign role from the drop-down
list box.
NOTE This parameter is available only when the output field is of the sign role.
Positive Value Rate Threshold Used for changing the default threshold in the
algorithm. A type is regarded as positive only
when the rate of the type exceeds the threshold.
Enter a real number ranging from 0 to 1.
NOTE
This parameter is available only when the output field is of the sign role.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 79 of 124
Parameter Description
Use Partition Specifies whether to use only the test data set to
build models if the Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
LinearApply Node
Function
The LinearApply node uses models generated on the Linear node to forecast sample classification based on
test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node, and can not follow a Binning node.
The Linear model file exists.
Parameter Description
Parameters
Parameter Description
Use Partition Specifies whether to use only the test data set to
build models if the Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
GBDTApply Node
Function
The GBDTApply node uses models generated on the GBDT node to forecast values of specified output
fields and sample classification based on test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The corresponding GBDT model file exists.
The GBDTApply node follows a Type, Binning, Partition, Filler, Filter, Sampling, Select or GBDT
node, and is followed by a NumericalEvaluation, ClassifyEvaluation, ExportText or ExportDataBase
node.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 80 of 124
Parameter Description
Parameters
Parameter Description
Positive Value Customer care type. For example, in a customer
model, the loss of a customer is marked as a
positive value and the retaining of a customer is
marked as a negative value.
Select a value of the sign role from the drop-down
list box.
NOTE
This parameter is available only when the output field is of the sign role.
Positive Value Rate Threshold Used for changing the default threshold in the
algorithm. A type is regarded as positive only
when the rate of the type exceeds the threshold.
Enter a real number ranging from 0 to 1.
NOTE This parameter is available only when the output field is of the sign role.
Use Partition Specifies whether to use only the test data set if the
Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
KmeansApply Node
Function
The KmeansApply node uses models generated on the Kmeans node to forecast sample classification based
on test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The Kmeans model file exists.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 81 of 124
Parameter Description
Parameters
Parameter Description
Use Partition Specifies whether to use only the test data set to build models if the
Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
Generate Distance Field Specifies whether to generate a distance field.
● Yes: Generate a distance field that records the distance between a
record and its cluster centers.
● No: Not generate a distance field.
EMApply Node
Function
The EMApply node uses model files generated on the EM node to forecast sample classification based on
test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The corresponding EM model file exists.
The EMApply node follows an EM or Type node, and is followed by a ExportText, ExportDatabase or
ClusterEvaluation node.
Parameter Description
Parameters
Parameter Description
Use Partition Specifies whether to use only the test data set if the Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
Generate Rate
Field
Specifies whether to generate a probability field.
● Yes: Generate a rate field, which specifies the probability that a record belongs
to a forecast cluster.
● No: Not to generate a rate field.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 82 of 124
AprioriApply Node
Function
The AprioriApply node uses models generated on the Apriori node to forecast sample classification based
on test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The Apriori model file exists.
Parameter Description
Parameters
Parameter Description
Data Format Data format. The format is inherited from the
Apriori model. The Sparse Matrix and
Key-Value pairs formats are available.
Use Partition Specifies whether to use only the test data set to
build models if the Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
TimeSeriesApply Node
Function
The TimeSeriesApply node uses models generated on the TimeSeries node to forecast results in the next
period based on test sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The TimeSeries model file exists.
Parameter Description
Parameters
Parameter Description
Time Points to Predict Number of time points in the next period to forecast results.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 83 of 124
PCAApply Node
Function
The PCAApply node uses models generated on the PCA node to extract principal components from test
sample data.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The PCA model file exists.
Parameter Description
Parameters
Parameter Description
Use Partition Specifies whether to use only the test data set to
build models if the Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
TextClassifyApply Node
Function
The TextClassifyApply node uses models generated on the TextClassify node to forecast sample
classification based on test sample data.
Restriction The node must follow a FolderImport node and a Type node.
The TextClassify model file exists.
Parameter Description
Parameters
Parameter Description
Text Type Data file text type.
NOTE Text of the Wed type only supports web pages using the WAP protocol.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 84 of 124
Parameter Description
Use Partition Specifies whether to use only the test data set to
build models if the Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from both the training and test
data sets.
SparseLinearApply Node
Function
The SparseLinearApply node uses models generated on the SparseLinear node to forecast sample
classification or recommend based on test sample data.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The corresponding SparseLinear model file exists.
Parameter Description
Parameters
Parameter Description
Model File Name Select a model file to be applied.
Use Partition Specifies whether to use only the test data set if the
Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
Generate Recommendation List Specifies whether to generate a recommendation
list.
Use Full Recommendation Specifies whether to use full recommendation.
User Field User attribute. For example, in the event that
Henry goes to the supermarket to buy coke, Henry
is the value of this parameter.
Item Field Item attribute. For example, in the event that
Henry goes to the supermarket to buy coke, coke is
the value of this parameter.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 85 of 124
Parameter Description
Recommendation Coefficient Threshold Recommendation result threshold. If the
recommendation result of an offer in a
recommendation list is greater than the value, the
offer will be reserved. Otherwise, the offer will be
discarded.
Max. Recommendations Maximum number of items that a recommendation
list can contain.
RandomForestApply Node
Function
The RandomForestApply Node uses the model file generated by the RandomForest Node to predict the
sample classification.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The corresponding RandomForest model file exists.
Parameter Description
Parameters
Parameter Description
Model File Select a model file to be applied.
Maximum Number of Feature Maximum number of features required for building
each decision tree submodel.
Default value: 5
Use Partition Specifies whether to use only the test data set if the
Partition node is configured.
● Yes: Use only data in the test data set.
● No: Use data from all data sets.
Generate Primary Key Only Specifies whether to generate the primary key only.
Graph Nodes
A Graph node collects data feature values and evaluates the model application result.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 86 of 124
1.1.1.1 ClassifyEvaluation Node
Function
The ClassifyEvaluation node checks the forecast accuracy of NaiveBayes, DecisionTree, Logistics and
GBDT models by analyzing data generated during the model application.
Restriction The value set of the evaluation field on the ClassifyEvaluation node must be the same as that of the
output field in the modeling process. If null values exist, the system discards the values.
For non-third-party data evaluation, the ClassifyEvaluation node follows a NaiveBayesApply,
DecisionTreeApply, LogisticsApply, and GBDTApply node.
For third-party data evaluation, the ClassifyEvaluation node follows a Type node.
Parameter Description
Parameters
Parameter Description
Evaluation File Name Exported evaluation file name. Evaluation files are stored in
the Project name/Evaluation directory.
Evaluation Field Name of the field to evaluate. Evaluation Field is an actual
field.
Prediction Field Algorithm forecast result.
NOTE
This parameter
r is not displayed for non-third-party data evaluation.
Visualization
Click the ClassifyEvaluation file. The system displays the classify evaluation information, as shown in
Figure.
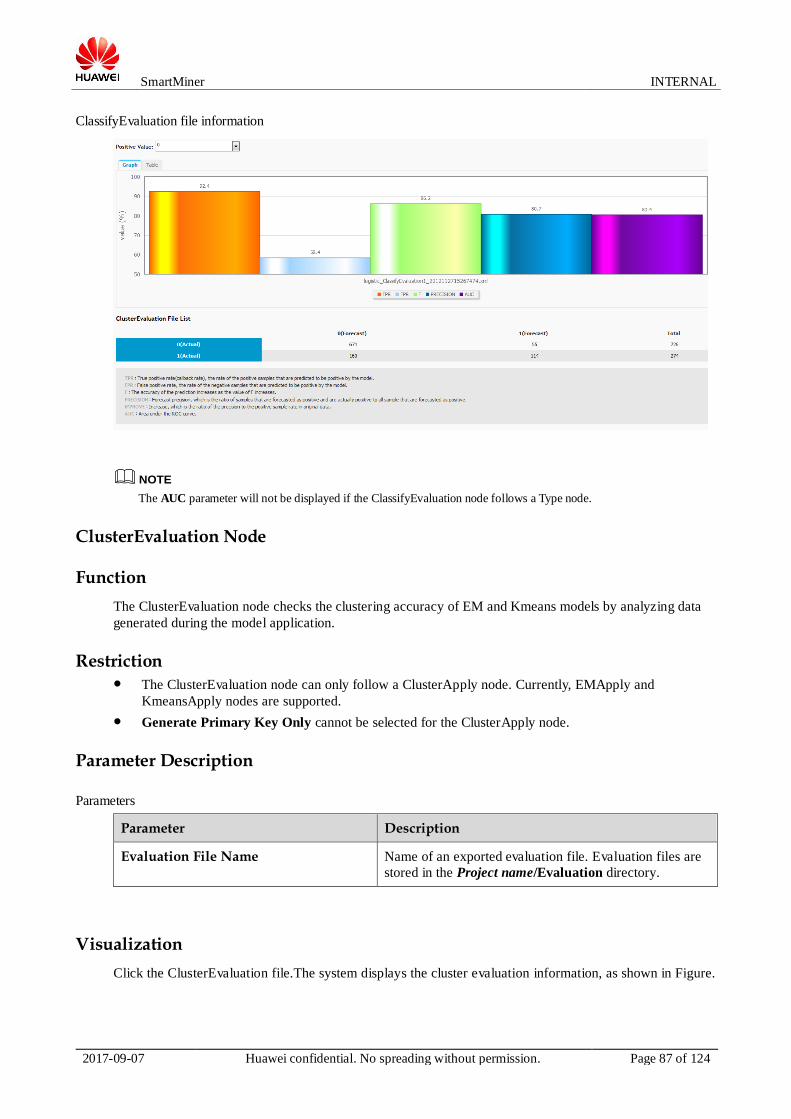
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 87 of 124
ClassifyEvaluation file information
NOTE The AUC parameter will not be displayed if the ClassifyEvaluation node follows a Type node.
ClusterEvaluation Node
Function
The ClusterEvaluation node checks the clustering accuracy of EM and Kmeans models by analyzing data
generated during the model application.
Restriction The ClusterEvaluation node can only follow a ClusterApply node. Currently, EMApply and
KmeansApply nodes are supported.
Generate Primary Key Only cannot be selected for the ClusterApply node.
Parameter Description
Parameters
Parameter Description
Evaluation File Name Name of an exported evaluation file. Evaluation files are
stored in the Project name/Evaluation directory.
Visualization
Click the ClusterEvaluation file.The system displays the cluster evaluation information, as shown in Figure.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 88 of 124
ClusterEvaluation file information
NumericalEvaluation Node
Function
The NumericalEvaluation node checks the forecast accuracy of Linear and GBDT models by analyzing
data generated during the model application. The NumericalEvaluation node supports third-party data
evaluation.
Restriction For non-third-party data evaluation, the NumericalEvaluation node follows a LinearApply node.
For third-party data evaluation, the NumericalEvaluation node follows a Type node. The Type node
must be configured with a minimum of two input fields of the Range type.
Parameter Description
Parameters
Parameter Description
Evaluation File Name of the evaluation file that is generated.
Evaluation files are stored in the Project
name/Evaluation directory.
Evaluation Field Field to be evaluated. It is an actual field.
Prediction Field Forecast result of the algorithms.
NOTE This parameter is not displayed for non-third-party data evaluation.
Model Verification Counter Mode for verifying the application result.
The options are as follows:
● Error Rate
● Pearson
● Anova
● Kolmogorov-Smirnov
Residual Differences between the actual value and
forecasted value, including differences in the basic
and advanced statistics items.
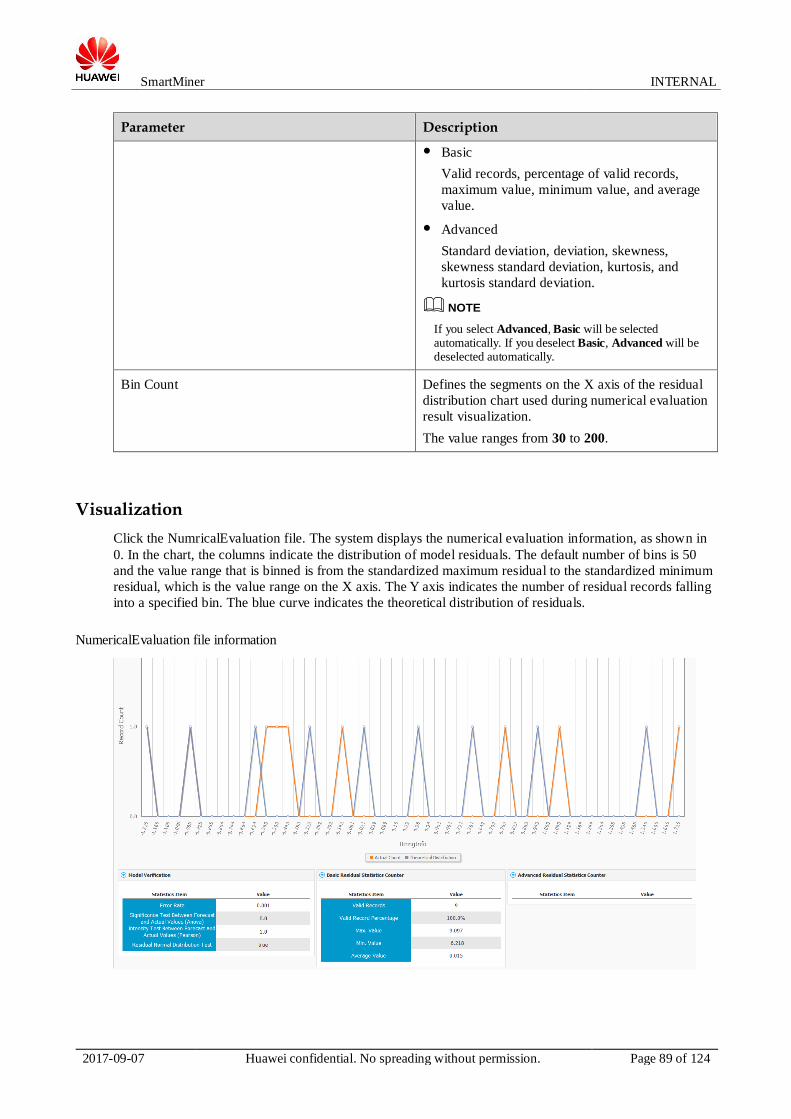
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 89 of 124
Parameter Description
● Basic
Valid records, percentage of valid records,
maximum value, minimum value, and average
value.
● Advanced
Standard deviation, deviation, skewness,
skewness standard deviation, kurtosis, and
kurtosis standard deviation.
NOTE If you select Advanced, Basic will be selected automatically. If you deselect Basic, Advanced will be deselected automatically.
Bin Count Defines the segments on the X axis of the residual
distribution chart used during numerical evaluation
result visualization.
The value ranges from 30 to 200.
Visualization
Click the NumricalEvaluation file. The system displays the numerical evaluation information, as shown in
0. In the chart, the columns indicate the distribution of model residuals. The default number of bins is 50
and the value range that is binned is from the standardized maximum residual to the standardized minimum
residual, which is the value range on the X axis. The Y axis indicates the number of residual records falling
into a specified bin. The blue curve indicates the theoretical distribution of residuals.
NumericalEvaluation file information

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 90 of 124
RecommenderEvaluation Node
Function
The RecommenderEvaluation node analyzes model application data generated by the CF, SNSRS,
PersonalTag nodes, DiscriminationTree Node and SparseLinear Node to evaluate the rating counter,
classification counter, coverage, accuracy, variety, and novelty.
Restriction For non-third-party data evaluation, the RecommenderEvaluation node follows a CF, SNSRS,
PersonalTag nodes, DiscriminationTree Node and SparseLinear Node.
For third-party data evaluation, the RecommenderEvaluation node follows a Type node.
Parameter Description
Parameters
Parameter Description
Evaluation File Exported evaluation file name. Evaluation files are
stored in the Project name/Evaluation directory.
Rating Indicator Rating indicator to be calculated. Select rating
indicators by clicking the check boxes. The options
are as follows:
● MAE: A smaller value indicates more accurate
scores.
● MSE: A smaller value indicates more accurate
scores.
● RMS error: A smaller value indicates more
accurate scores.
● Distance-Based mean evaluation counter: A
smaller value indicates more accurate scores.
Classification Counter Classification indicator to be calculated. Select
classification indicators by clicking the check
boxes. The options are as follows:
● Accuracy: A larger value indicates better
recommendation effects.
● Callback Rate: A larger value indicates better
recommendation effects.
● Average Recommended Length: It displays
the average value of all the users' actual
recommended lengths.
Coverage Coverage to be calculated. Select coverage by
clicking the check boxes. The options are as
follows:
● Product Coverage: A larger value indicates
higher product coverage.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 91 of 124
Parameter Description
● User Coverage: A larger value indicates higher
user coverage.
NOTE This parameter is not displayed for third-party data evaluation.
Variety Variety to be calculated. Select variety by clicking
the check boxes. The options are as follows:
Mean Hamming distance: A larger value
indicates higher variety.
Novelty Novelty to be calculated. Select novelty by
clicking the check boxes. The options are as
follows:
Mean degree: A smaller value indicates higher
novelty.
Recommendation Algorithm Type The parameter value automatically inherits the
setting from the upper-level node and cannot be
changed.
NOTE This parameter is not displayed for third-party data evaluation.
User Field ● For non-third-party data evaluation, the
parameter value automatically inherits the
setting from the upper-level node and cannot be
changed.
● For third-party data evaluation, select a value
from the drop-down list box.
Item Field ● For non-third-party data evaluation, the
parameter value automatically inherits the
setting from the upper-level node and cannot be
changed.
● For third-party data evaluation, select a value
from the drop-down list box.
Rating Field ● For non-third-party data evaluation, if the
prepositional node does not have rating fields,
this parameter is not displayed, otherwise, this
parameter value automatically inherits the
setting from the upper-level node and cannot be
changed.
● For third-party data evaluation, select a value
from the drop-down list box.
Use Partition ● For non-third-party data evaluation, the
parameter value automatically inherits the
setting from the upper-level node and cannot be
changed.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 92 of 124
Parameter Description
● This parameter is not displayed for third-party
data evaluation.
Visualization
You can find the evaluation files generated by the RecommenderEvaluation node in the Project
name/Evaluation directory, as shown in Figure.
Personalized recommendation evaluation files
DataAudit Node
Function
The DataAudit calculates statistics such as roles, ranges, and minimum/maximum values for fields and
generates evaluation files in the Analytic directory.
Restriction
the DataAudit node can be connected to source(ImportText, ImportFeatureLibrary or ImportDatabase) node
or data preprocessing node.
Parameter Description
Parameters
Parameter Description
DataAudit File Exported evaluation file name. Evaluation files are
stored in the Project name/Analytic directory.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 93 of 124
Parameter Description
Overlay Field Overlay field to be calculated. The DataAudit node
calculates the correlation between the analysis and
overlay fields, correlation verification statistics,
and the degree of freedom of correlation
verification statistics.
Statistics Grade Statistics grade.
The options are as follows:
● Base
Basic statistics, such as roles, ranges, and
minimum/maximum values of fields.
● Advance
Advanced statistics, such as correlation,
covariance, standard deviation, and deviation
between the analysis and overlay fields.
Visualization Scenario
Assume that the DataAudit node needs to calculate the basic and advanced statistics for the ID, AGE,
SEX, REGIONand INCOME fields in a batch of user data.
Visualization Result
The DataAudit node will generate data audit files in the Project name/Analytic directory, as shown in
0 and 0.
− The Base Statistics tab page is displayed as follows:
Base Statistics
− The Advance Statistics tab page is displayed as follows:

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 94 of 124
Advance Statistics
Statistics Node
Function
The Statistics calculates statistics such as counts, means, minimum/maximum values, and sums for fields of
the value type and generates statistics files in the Analytic directory.
Restriction the Statistics node can be connected to source(ImportText, ImportFeatureLibrary or ImportDatabase)
node or data preprocessing node.
The system calculates the correlation counters between Statistics Field and Correlated Field only
when Correlated Field is set and the Variance, Satandard Deviation or SEM statistical item is
selected.
The values of Statistics Field and Correlated Field must be of the numeral type.
Parameter Description
Parameters
Parameter Description
Statistics File Exported evaluation file name. Evaluation files are
stored in the Preject name/Analytic directory.
Correlated Field Correlated field between which and the statistics
field the correlation is to be calculated.
Visualization Scenario
Assume that the Statistics node needs to calculate the statistics of the smoking field and the
correlation between the smoking and isill fields in a batch of user data.
Visualization Result=
The Statistics node will generate statistics files in the Project name/Analytic directory as shown in
Figure.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 95 of 124
Figure Statistics
Mean Node
Function
The Mean node compares the means between group fields and test fields, or between other correlated field
pairs to check whether remarkable differentials exist.
Restriction The node must follow a source(ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The node can follow a data preprocessing node.
Parameter Description
Parameters
Parameter Description
Means Comparison File Exported evaluation file name. Evaluation files are stored in
the Project name/Analytic directory.
Compare Type Mean comparison mode.
The options are as follows:
● Between groups
Grouping Field: Group data based on the group field.
Test Fields: Calculate mean-related statistics by group.
● Between field pairs
Calculate statistics for the means for the fields in a field
pair and the mean difference between the fields in the pair.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 96 of 124
Visualization Scenario 1
Assume that the Mean node needs to calculate the statistics for the means of the RANGE1 fields
grouped by the SET1 field in a batch of user data. The Mean node will generate mean comparison
files in the Project name/Analytic directory, as shown in Figure.
Figure Between groups
Scenario 2
Assume that the Mean node needs to calculate the statistics for the means of the RANGE1 and
OUTPUT fields. The Mean node will generate mean comparison files in the Project name/Analytic
directory, as shown in Figure.
Figure Between field pairs
Distribution Node
Function
The distribution node collects statistics on field value distribution.
Restriction The node must follow a source (ImportText, ImportFeatureLibrary or ImportDatabase) node and a
Type node.
The node can follow a data preprocessing node except the FeatureSelection node.
Parameter Description
Parameters
Parameter Description
Display Style Data distribution display mode. The options are as
follows:
● Graph
Displays data distribution in graphs.
● Data File
Displays the number of each field in exported data

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 97 of 124
Parameter Description
files.
NOTE If you want to use this mode, configure the TextFileExport node before the Distribution node.
Distribution Graph Name Name of the data distribution graph file.
NOTE When the Graph display mode is selected, data distribution
files are stored in the Analytic directory.
When the Data File display mode is selected, exported files are stored in the Data directory.
Analysis Field Field to be analyzed. For example, you can click
Settings, and set Analysis Field to Age.
Exchange Field Field to be evaluated. For example, if you want to analyze
the gender distribution by age segment and view the
distribution information in a graph, you can set Exchange
Field to Gender.
Details Analysis field details. The parameter is valid only when
Display Style is set to Graph.
Analysis field details include:
● Numbers per Segment
If the analysis field is of the Range role, you need to
set the parameter. The default value is 25. For
example, if you set Analysis Field to Age, Age ranges
from 1 to 100, and Numbers per Segment is 25,
gender distribution is displayed by age segment such
as 1 to 4, 5 to 8, and 9 to 12.
● Title
Distribution graph title.
● X-axis
Title of the X axis in the distribution graph. The title is
the same as the value of Analysis Field.
● Y-axis
Title of the Y axis in the distribution graph. The
default value is COUNT.
Delete Deletes an analysis field.
Visualization Scenario
Assume that you want to view the gender distribution by age segment in a batch of user data
containing the Age and Sex fields.
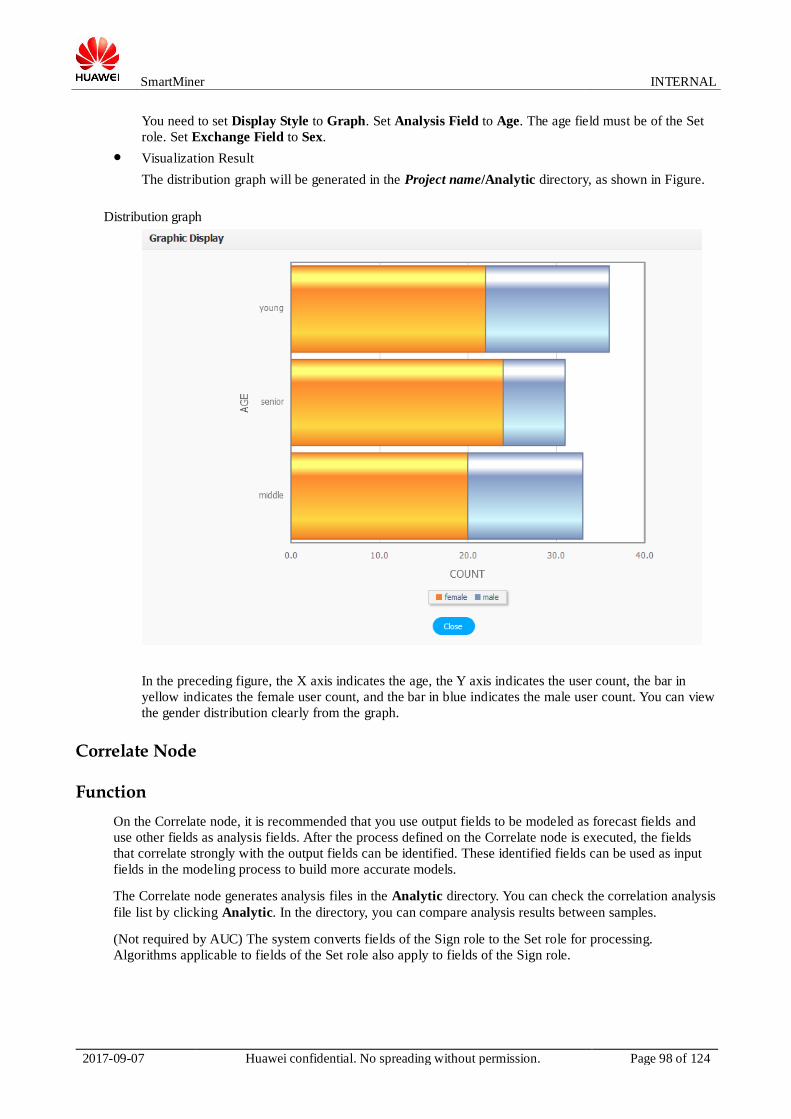
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 98 of 124
You need to set Display Style to Graph. Set Analysis Field to Age. The age field must be of the Set
role. Set Exchange Field to Sex.
Visualization Result
The distribution graph will be generated in the Project name/Analytic directory, as shown in Figure.
Distribution graph
In the preceding figure, the X axis indicates the age, the Y axis indicates the user count, the bar in
yellow indicates the female user count, and the bar in blue indicates the male user count. You can view
the gender distribution clearly from the graph.
Correlate Node
Function
On the Correlate node, it is recommended that you use output fields to be modeled as forecast fields and
use other fields as analysis fields. After the process defined on the Correlate node is executed, the fields
that correlate strongly with the output fields can be identified. These identified fields can be used as input
fields in the modeling process to build more accurate models.
The Correlate node generates analysis files in the Analytic directory. You can check the correlation analysis
file list by clicking Analytic. In the directory, you can compare analysis results between samples.
(Not required by AUC) The system converts fields of the Sign role to the Set role for processing.
Algorithms applicable to fields of the Set role also apply to fields of the Sign role.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 99 of 124
Restriction The Correlate node can be connected to a source node (ImportText, ImportFeatureLibrary or
ImportDatabase) or data preprocessing node.
The Data Type of the field cannot be Time, Date, or Timestamp.
Parameter Description
Parameters
Parameter Description
Correlate File Exported analysis file name. Analysis files are
stored in the Project name/Analytic directory.
Prediction Field Forecast field. Select an option from the
drop-down list box.
The parameter value cannot be the same as the
value of Analysis Field.
Correlation Significance Counter You can use the Chi-square test and Anova test to
analyze the correlation between fields. 0 describes
the calculation of the counters.
Correlation Strength Counter Error decrease rate, including five counters. The
parameter indicates the forecast error rate that can
be decreased when the value of Prediction Field is
forecasted based on a given Analysis Field value.
0 describes the calculation of the four counters.
NOTE When the system calculates the Pearson correlation
coefficient between two fields, it also generates the distance between them, which also indicates the correlation between the two fields. You can select a counter to calculate the preceding information based on the field value type.
The difference between significance analysis and strength analysis is that the former calculates qualitative correlation between fields and the later calculates quantitative correlation between fields.
Correlation counter calculation description
Distance Analysis Role Prediction Field Role Field Type
Chi-squared Set Set Integer, real, and string
Anova Set Range Integer, real, and string
Range Set
Tau Set and Range Set Integer, real, and string
Eta Set Range Integer, real, and string
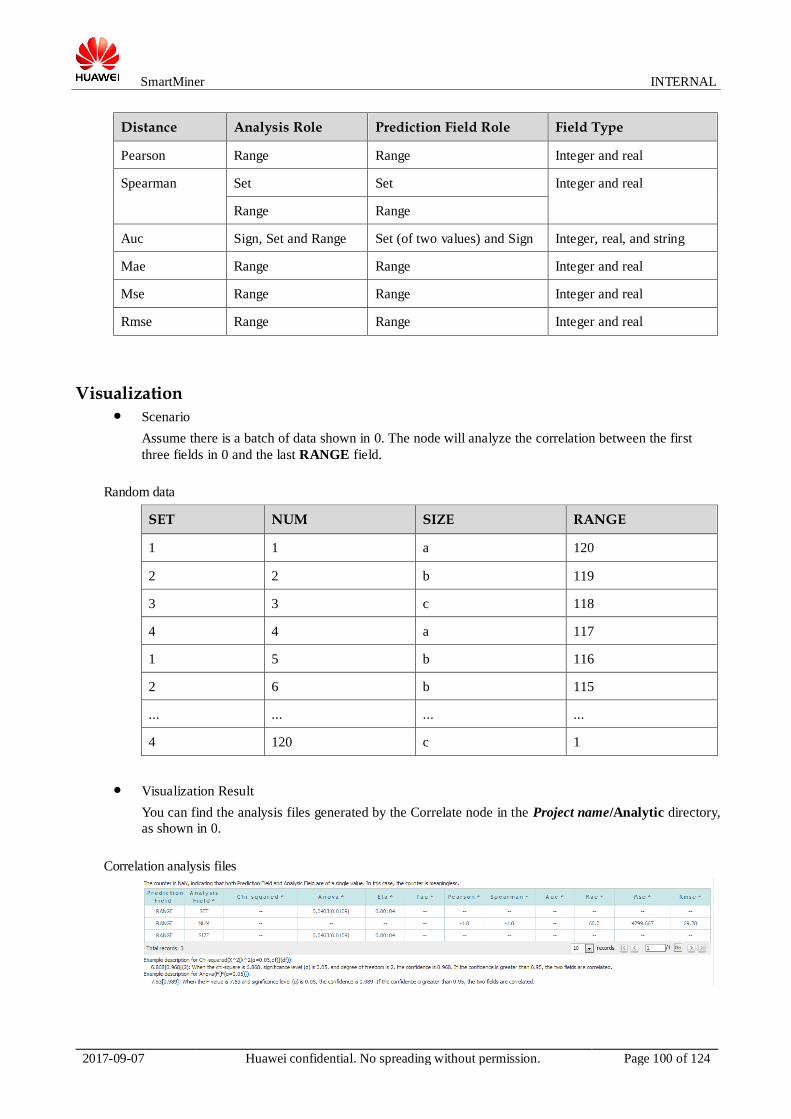
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 100 of 124
Distance Analysis Role Prediction Field Role Field Type
Pearson Range Range Integer and real
Spearman Set Set Integer and real
Range Range
Auc Sign, Set and Range Set (of two values) and Sign Integer, real, and string
Mae Range Range Integer and real
Mse Range Range Integer and real
Rmse Range Range Integer and real
Visualization Scenario
Assume there is a batch of data shown in 0. The node will analyze the correlation between the first
three fields in 0 and the last RANGE field.
Random data
SET NUM SIZE RANGE
1 1 a 120
2 2 b 119
3 3 c 118
4 4 a 117
1 5 b 116
2 6 b 115
... ... ... ...
4 120 c 1
Visualization Result
You can find the analysis files generated by the Correlate node in the Project name/Analytic directory,
as shown in 0.
Correlation analysis files

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 101 of 124
Export Nodes
An Export node can export processed data into a file or a table in the database.
1.1.1.1 ExportText Node
Function
The ExportText node exports data or models generated by other nodes.
Restriction The node must follow a ImportText, ImportFeatureLibrary or ImportDatabase Node and a Type node.
Related data has been imported.
Parameter Description
Parameters
Parameter Description
File System Type File system to store exported text files.
The options are as follows:
● Local
● HDFS
● FTP
NOTE You need to enable the FTP service before selecting a data file. For details, see Configuring the FTP Service.
File to Export Exported file name. Expressions are supported, for example,
sm_user_retain_#date(yyyyMMddHHmmss)#.csv.
Exported files are stored in the Project name/Data directory. By
default, CSV files are exported from the
${SmartMiner_HOME}/smartminer/Projects/test/Data directory.
NOTE
In the preceding directory, test indicates the name of the project where the process is located.
ExportDatabase Node
Function
The ExportDatabase node writes data to the database.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 102 of 124
Restriction The ExportDatabase node follows a PCAFactor node and a PCAFactor model exists.
The ExportDatabase cannot follow an SNSRS, FullConnected, OverlapNeighbor node, or
DiscriminationTree node.
The ExportDatabase cannot follow a TextClassifyApply node.
Parameter Description
Parameters
Parameter Description
Database Database name. Select a currently available database from the
drop-down list box. Oracle and DB2 databases are supported.
Schema Table mode in the database. The default value of the table mode is
the name of the created schema. Select a value from the drop-down
list box.
For example, if database user U1 creates tables T1 and T2 and user
U2 creates table T3 in the database, the options of the table mode in
the database are U1 and U2. When you select a mode, only the tables
of the selected mode are displayed.
Table Database table name. Select a value from the drop-down list box.
Load Type Mode for loading data.
The options are as follows:
● Insert
Data is inserted into the database.
● Update
Existing data in the database is updated. You can search for a
record in the database by keyword. If the record exists, the system
updates the record. If the record does not exist, no operation will
be performed.
● Replace
All records in a table are replaced.
● Update or insert
You can search for a record in the database by keyword. If the
record exists, the system updates the record. If the record does not
exist, the record is inserted into the database.
Target Field Name of a field in the database.
Data Type Type of a field in the database.
Source Field Field that matches a field in the database.
Key Field Specifies whether a field is a key field. Records of the same key field
will be updated, and records of different key fields will not be
updated.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 103 of 124
NLP
NLP is short for Natural Language Processing. The NLP node provides various text information mining
functions.
1.1.1.1 Segment
Function
Chinese segmentation refers to the process of dividing written Chinese text into meaningful words based on
specific rules, that is, converting the original unstructured text into structured information that computers
can process.
Algorithms on the Segment node are based on the Ansj framework, which is the Java version of the
ICTCLAS (Institute of Computing Technology, Chinese Lexical Analysis System). The SmartMiner has
implemented the parallel computing capability for segmentation, improving the segmentation speed and
accuracy.
Restriction The node must follow an ImportText node and a Type node.
The Type node must have at least two input fields: Primary Key and Input.
The segmentation result is exported using the ExportText node.
Model Input Example
The following input text is movie comments from a video website:
In the input text, you can use id and review_content as input fields. Set Direction of id to Primary Key,
and set Direction of review_content to Input.
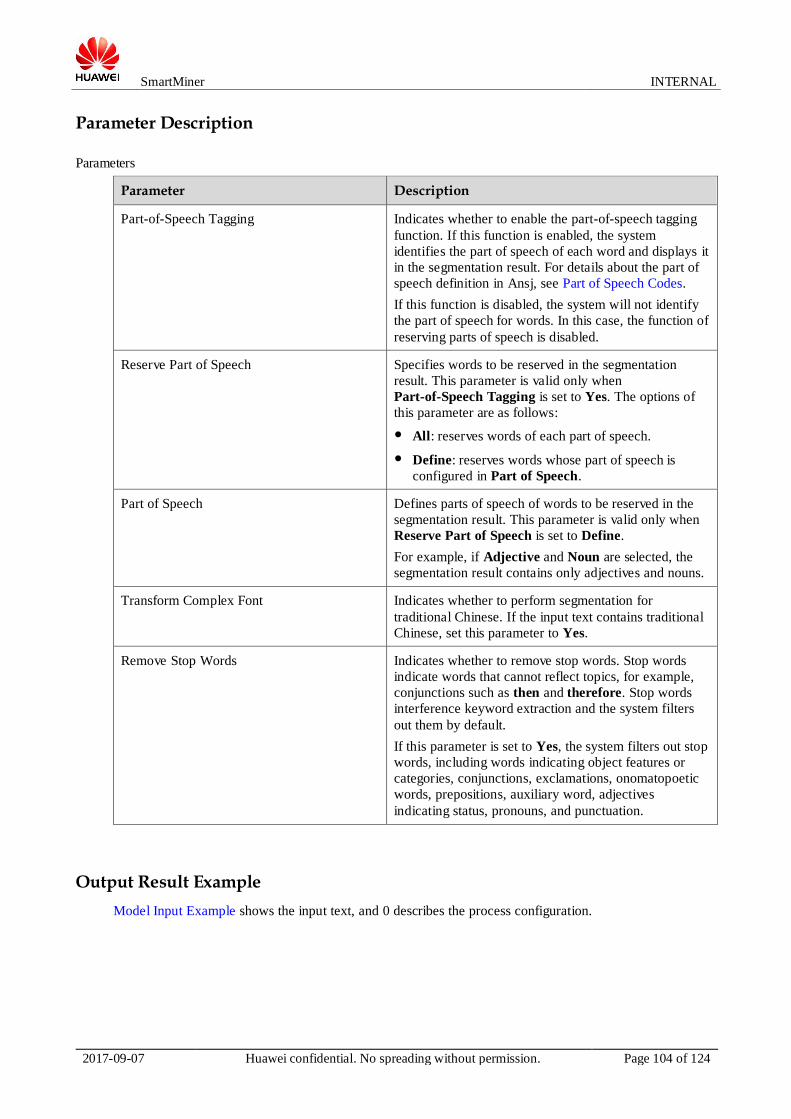
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 104 of 124
Parameter Description
Parameters
Parameter Description
Part-of-Speech Tagging Indicates whether to enable the part-of-speech tagging
function. If this function is enabled, the system
identifies the part of speech of each word and displays it
in the segmentation result. For details about the part of
speech definition in Ansj, see Part of Speech Codes.
If this function is disabled, the system will not identify
the part of speech for words. In this case, the function of
reserving parts of speech is disabled.
Reserve Part of Speech Specifies words to be reserved in the segmentation
result. This parameter is valid only when
Part-of-Speech Tagging is set to Yes. The options of
this parameter are as follows:
● All: reserves words of each part of speech.
● Define: reserves words whose part of speech is
configured in Part of Speech.
Part of Speech Defines parts of speech of words to be reserved in the
segmentation result. This parameter is valid only when
Reserve Part of Speech is set to Define.
For example, if Adjective and Noun are selected, the
segmentation result contains only adjectives and nouns.
Transform Complex Font Indicates whether to perform segmentation for
traditional Chinese. If the input text contains traditional
Chinese, set this parameter to Yes.
Remove Stop Words Indicates whether to remove stop words. Stop words
indicate words that cannot reflect topics, for example,
conjunctions such as then and therefore. Stop words
interference keyword extraction and the system filters
out them by default.
If this parameter is set to Yes, the system filters out stop
words, including words indicating object features or
categories, conjunctions, exclamations, onomatopoetic
words, prepositions, auxiliary word, adjectives
indicating status, pronouns, and punctuation.
Output Result Example
Model Input Example shows the input text, and 0 describes the process configuration.
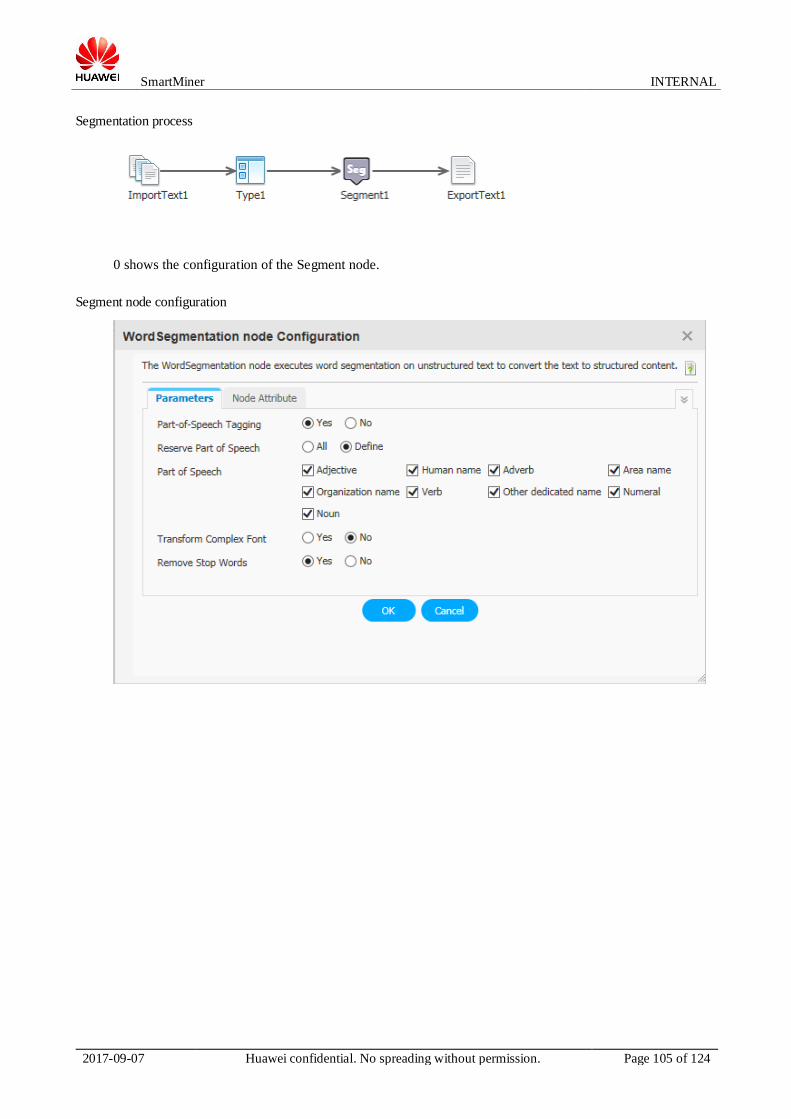
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 105 of 124
Segmentation process
0 shows the configuration of the Segment node.
Segment node configuration

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 106 of 124
The following shows the segmentation result:
User-defined Dictionary
You can replace user-defined dictionaries in directories on the SmartMiner server. 0 describes the
directories.
NOTE Back up the original file before replacing a user-defined dictionary file.
User-defined dictionary directories
Dictionary File Directory Format Description
default.dic ${HOME}/data/nlp/
ansj/custom
Word Part of Speech Frequency
For example:
Longguan station n 2
Longyu nz 2
Hengda nt 20
Defines service-related
feature words that users
concern with. If the
segmentation result
does not contain the
words, they can be
added to the
user-defined dictionary.
newWordFilter.dic ${HOME}/data/nlp/
ansj/stopword
Stop word 1
Stop word 2
...
Defines stop words to
be filtered out.
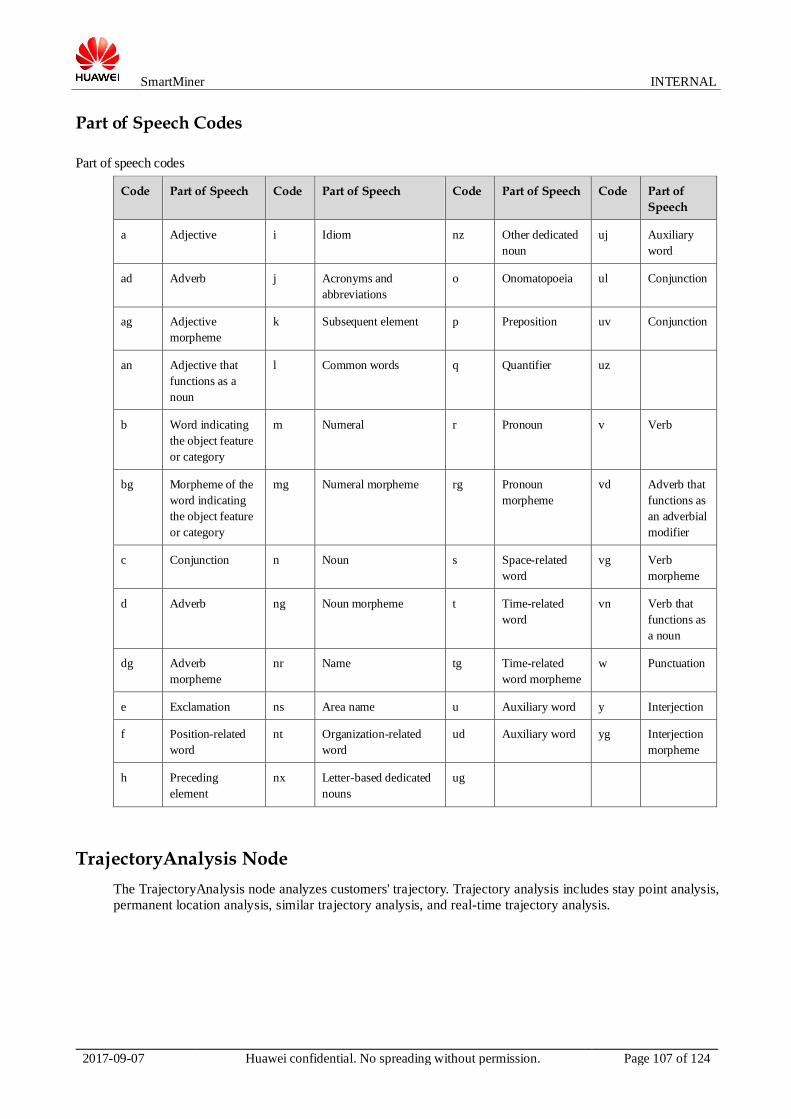
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 107 of 124
Part of Speech Codes
Part of speech codes
Code Part of Speech Code Part of Speech Code Part of Speech Code Part of
Speech
a Adjective i Idiom nz Other dedicated
noun
uj Auxiliary
word
ad Adverb j Acronyms and
abbreviations
o Onomatopoeia ul Conjunction
ag Adjective
morpheme
k Subsequent element p Preposition uv Conjunction
an Adjective that
functions as a
noun
l Common words q Quantifier uz
b Word indicating
the object feature
or category
m Numeral r Pronoun v Verb
bg Morpheme of the
word indicating
the object feature
or category
mg Numeral morpheme rg Pronoun
morpheme
vd Adverb that
functions as
an adverbial
modifier
c Conjunction n Noun s Space-related
word
vg Verb
morpheme
d Adverb ng Noun morpheme t Time-related
word
vn Verb that
functions as
a noun
dg Adverb
morpheme
nr Name tg Time-related
word morpheme
w Punctuation
e Exclamation ns Area name u Auxiliary word y Interjection
f Position-related
word
nt Organization-related
word
ud Auxiliary word yg Interjection
morpheme
h Preceding
element
nx Letter-based dedicated
nouns
ug
TrajectoryAnalysis Node
The TrajectoryAnalysis node analyzes customers' trajectory. Trajectory analysis includes stay point analysis,
permanent location analysis, similar trajectory analysis, and real-time trajectory analysis.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 108 of 124
1.1.1.1 StayPointAnalysis Node
Function
In a trajectory, some points denote locations where people have stayed for a while, such as the shopping
malls, tourist attractions, or gas stations. These kinds of points are called stay points. There are two types of
stay points. One is a single point location, such as Stay Point 1 in Figure. This situation is very rare,
because a user's positioning device usually generates different readings even in the same location. The other,
such as Stay Point 2, is more generally observed in trajectories, representing the places where people move
around. The clustering algorithm of the StayPointAnalysis node can calculate the longitude and latitude of
the stay points.
Stay point examples
Restriction The node must follow an ImportText node and a Type node.
The input fields of the node must include User ID, BTS ID, Timestamp, Longitude, and Latitude.
The stay point analysis result is exported using the ExportText node.
Model Input Example
The input text is a user' trajectory.
User_id,BTS_id,Timestamp,Longitude,Latitude
user1,BS1,1431000000,120.0000,30.0000
user1,BS2,1431000100,120.0030,30.0040
user1,BS3,1431002100,120.0030,30.0000
user1,BS4,1431002110,120.0230,30.0000
user1,BS5,1431002210,120.0030,30.0010
user1,BS6,1431002212,120.0040,30.0030
user1,BS7,1431003212,120.0100,30.0100
user1,BS8,1431003312,120.1000,30.1000
user1,BS9,1431003412,120.0100,30.0100
user1,BS10,1431006000,120.0100,30.0100
user1,BS12,1431007000,120.0140,30.0130
user2,BS9,1431003412,120.0100,30.0100
user2,BS10,1431004000,120.0100,30.0100
user2,BS11,1431004100,120.0140,30.0130
user3,BS9,1431003412,120.0100,30.0100
user3,BS10,1431006000,120.0100,30.0100
user3,BS11,1431007000,120.0140,30.0130
user4,BS12,1431001412,120.0101,30.0101
user4,BS12,1431003412,120.0101,30.0101
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 109 of 124
user4,BS13,1431003482,120.0400,30.0400
user4,BS13,1431003562,120.0400,30.0400
user4,BS14,1431003632,120.0400,30.0400
In the preceding information, Direction of the User_id, BTS_id, Timestamp, Longitude, and Latitude
fields on the Type node must be set to Input.
Parameter Description
Parameters
Parameter Description
User ID Maps the field name of an input field. For example, this parameter can
be set to User_id or Field0 for User ID (the headers of the input file
are not read).
The five fields record users' trajectories. Each record in the input file
indicates that a BTS (specified by BTS_ID) obtains a user's (specified
by User_ID) longitude and latitude (specified by Longitude and
Latitude respectively) at a specific time (specified by Timestamp).
BTS ID
Timestamp
Longitude
Latitude
Tolerance Distance (m) Tolerance distance. If the distance between two stay points is shorter
than the value of this parameter, the system considers that the two stay
points are the same stay point.
Min Time Span (h) Minimum time span for stay point detection. If the duration that a user
stays at a location is longer than or equal the value of this parameter,
the system considers the location as the stay point.
Speed Threshold (m/s) Threshold of users' moving speed between two stay points. If a user's
moving speed is faster than the value of this parameter, the system
considers that the two stay points are abnormal points. Abnormal stay
points are removed from the output data.
Abnormal points contain error data or data that is not applicable to
analysis scenarios. For example, to obtain the stay points when users
walk or drive a car, set this parameter to 50 m/s (180 km/s).
Max BTS Distance (m) Maximum distance between two adjacent BTSs.
● If BTSs are used to collect information for calculating users'
location information, the value of this parameter must be greater
than the value of Tolerance Distance (m).
● If BTSs are not used to collect information for calculating users'
location information, this parameter can be set to the value of
Tolerance Distance (m)
Output Result Example
Model Input Example shows the input text, and Figure describes the process configuration.
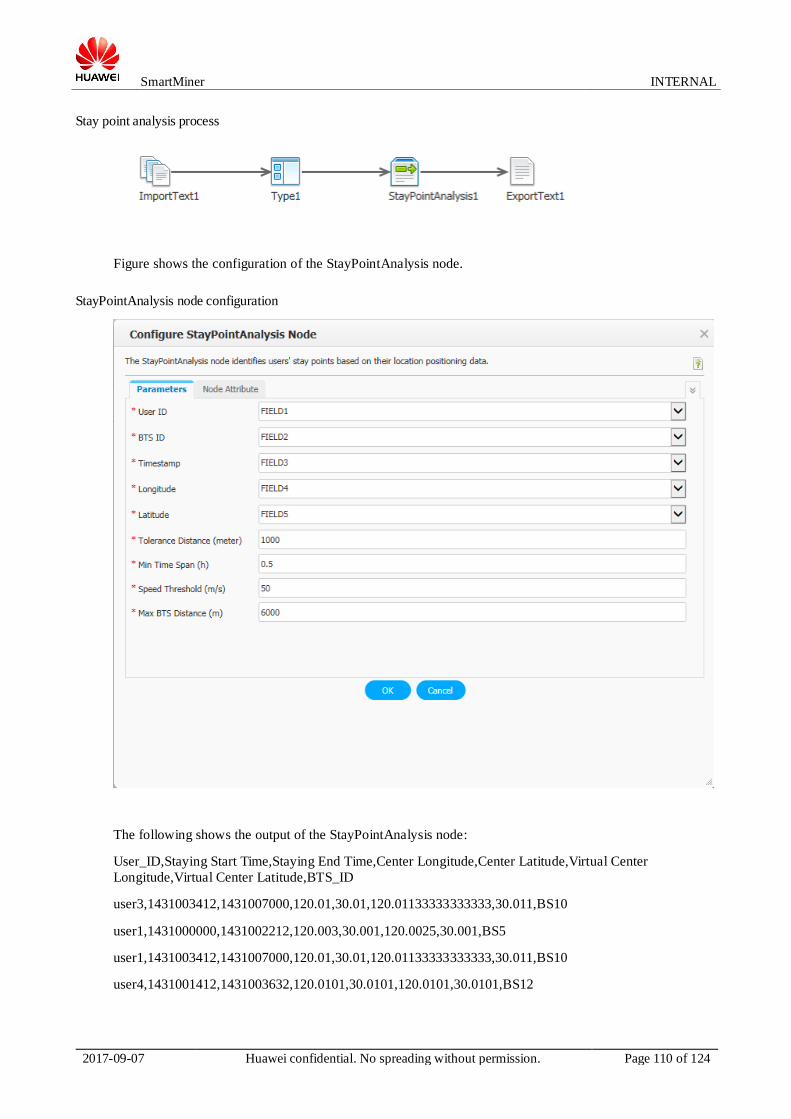
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 110 of 124
Stay point analysis process
Figure shows the configuration of the StayPointAnalysis node.
StayPointAnalysis node configuration
The following shows the output of the StayPointAnalysis node:
User_ID,Staying Start Time,Staying End Time,Center Longitude,Center Latitude,Virtual Center
Longitude,Virtual Center Latitude,BTS_ID
user3,1431003412,1431007000,120.01,30.01,120.01133333333333,30.011,BS10
user1,1431000000,1431002212,120.003,30.001,120.0025,30.001,BS5
user1,1431003412,1431007000,120.01,30.01,120.01133333333333,30.011,BS10
user4,1431001412,1431003632,120.0101,30.0101,120.0101,30.0101,BS12

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 111 of 124
In the preceding information:
The Virtual Center Longitude and Virtual Center Latitude fields indicate the longitude and latitude
of the center of the range where users stay respectively. The Center Longitude and Center Latitude
fields indicate the longitude and latitude of the BTS nearest to the virtual center respectively.
Each record in the output indicates that a user (specified by User_ID) stays at a virtual center
(specified by Virtual Center Latitude and Virtual Center Longitude) for a period (specified by
Staying Start Time and Staying End Time).
Points That You Might Be Interested In
Cascading Models
Function
If you want to build a model after it is applied, you do not have to import source data again. Instead, use an
Application node (TextClassifyApply node excluded) as the source node in the new modeling process. The
Application node can be followed by a Type, DataAudit, Statistics, GraphVisualize, Correlate, or Filter
node.
Process Instance
Process instance
Several fields will be created after the Application node is executed, and these fields will be displayed in
the nodes cascaded to the Application node, such as the Type and DataAudit nodes. In this example, the
FORCAST_CATEGORY, PROB_yes, and PROB_no fields are created after the NaiveBayesApply node
is executed. Of the fields, yes and no are two options of an output field.
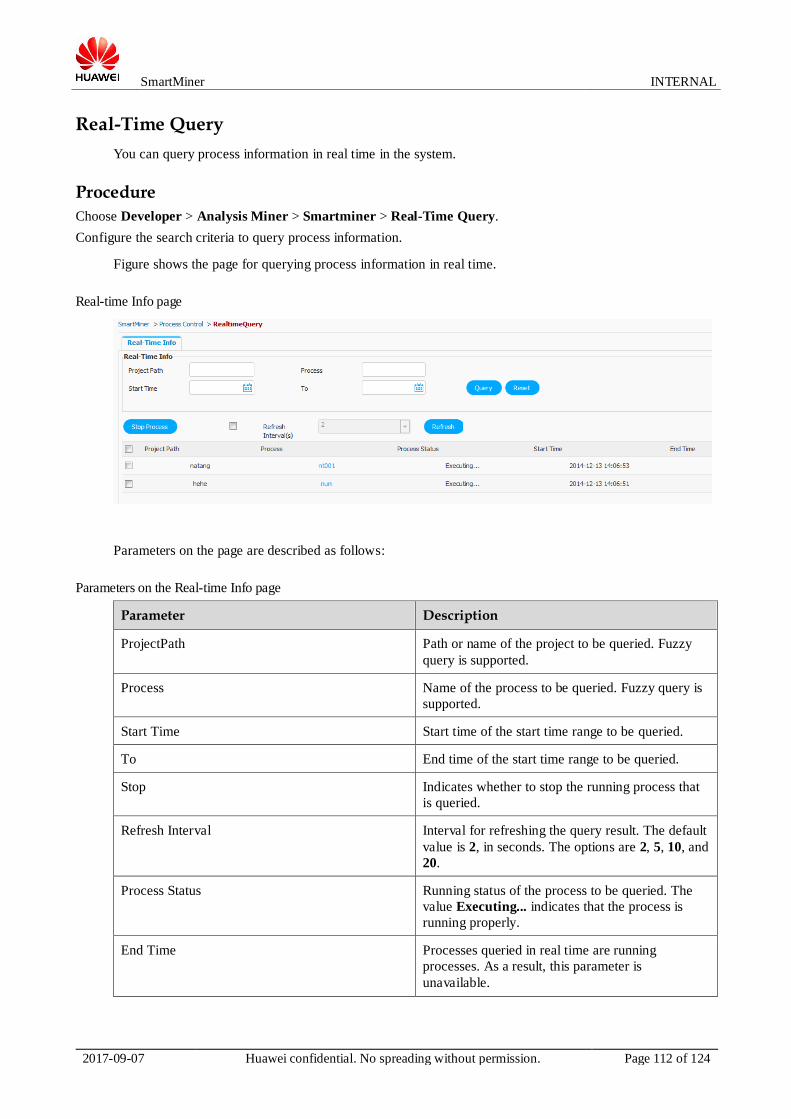
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 112 of 124
Real-Time Query
You can query process information in real time in the system.
Procedure
Choose Developer > Analysis Miner > Smartminer > Real-Time Query.
Configure the search criteria to query process information.
Figure shows the page for querying process information in real time.
Real-time Info page
Parameters on the page are described as follows:
Parameters on the Real-time Info page
Parameter Description
ProjectPath Path or name of the project to be queried. Fuzzy
query is supported.
Process Name of the process to be queried. Fuzzy query is
supported.
Start Time Start time of the start time range to be queried.
To End time of the start time range to be queried.
Stop Indicates whether to stop the running process that
is queried.
Refresh Interval Interval for refreshing the query result. The default
value is 2, in seconds. The options are 2, 5, 10, and
20.
Process Status Running status of the process to be queried. The
value Executing... indicates that the process is
running properly.
End Time Processes queried in real time are running
processes. As a result, this parameter is
unavailable.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 113 of 124
History Query
You can query historical process information in the system.
Procedure
Choose Developer > Analysis Miner > Smartminer > History Query.
Configure the search criteria to query process information.
Figure shows the page for querying historical process information.
Historical Info page
Parameters on the page are described as follows:
Parameters on the Historical Info page
Parameter Description
ProjectPath Path or name of the project to be queried. Fuzzy
query is supported.
Process Name of the process to be queried. Fuzzy query is
supported.
Process Status Status of the process to be queried. The options are
as follows:
● Executing...
● Completed
● Stopped
● Failed
● Stopping...
Start Time Start time of the process start time range to be
queried.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 114 of 124
Parameter Description
To End time of the process start time range to be
queried.
End Time Start time of the process termination time range to
be queried.
To End time of the process termination time range to
be queried.
Process Status Running status of the process to be queried.
Start Time Start time of the process to be queried.
End Time End time of the process to be queried.
Configuring the FTP Service
To select files from the FTP server, you need to enable the FTP service.
Procedure
Modify the ${HOME}/conf/smartminer.properties file of the SmartMiner user.
A configuration example is as follows:
smart_ftp_ip=10.41.28.33
smart_ftp_port=22
smart_ftp_username=username
smart_ftp_input_dir=/home/ftphome
smart_ftp_output_dir=/home/username
smart_ftp_keytype=0
smart_ftp_password=ytpnga9zY0GwAy/G0mP6FA==
smart_ftp_keypath=
smart_ftp_passphrase=
Parameter Description and Setting
smart_ftp_ip IP address of the FTP server.
smart_ftp_port SSH port number on the FTP server. The 22 port is used by
default. That is, the SFTP protocol is used to connect to the
FTP service.
smart_ftp_username User name for logging in to the FTP server.
smart_ftp_input_dir Directory on the FTP server where the file to be read is
located. The directory must start with a slash (/).
smart_ftp_output_dir Directory on the FTP server to which a file is to be
exported. The directory must start with a slash (/).
smart_ftp_keytype Key type.
● 0: password
● 1: private key

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 115 of 124
Parameter Description and Setting
smart_ftp_password If the password mode is used, use the script in the
${HOME}/tools/interactive_encrypt.sh directory of the
SmartMiner user to encrypt the password.
smart_ftp_keypath If the private key mode is used, set the full path for the
private key file.
smart_ftp_passphrase If the private key mode is used, you need to encrypt the
private key file. The encryption method is the same as that
of the password mode.
Run the restart-ide.sh commands to restart the SmartMiner for the settings to take effect.
Importing and Exporting a Project
You can import or export a project package in the SmartMiner console.
Context
Project importing and exporting share one temporary file storage directory. You can customize the
temporary file storage directory by configuring smart_temp_dir in
${HOME}/conf/smartminer.properties.
Importing a Project
Right-click Project in the navigation tree on the left and choose Import.
The dialog box shown in Figure is displayed.
Importing a project
Click to select a package to import.
NOTE The size of the package cannot exceed 100 MB. If the name of the package to import already exists in the destination directory, change it.
Click Import.
Exporting a Project
1. Right-click Project in the navigation tree on the left and choose Export.
The dialog box shown in Figure is displayed.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 116 of 124
Exporting a project
Select the data file to be exported, Click Export.
The system generates a project package. The name format of the project package is project
name_timestamp.zip, and the format of the timestamp is YYYYMMDDHHMMSSMMM. After the
project package is compressed, the temporary file will be deleted automatically, and a dialog box is
displayed for the users to export the project package.
NOTE The size of the package cannot exceed 200 MB.
Feature Management
1.1.1.1 Managing Features Files
You can configure files used for creating features on the SmartMiner GUI.
Prerequisites
A feature file has been uploaded to the HDFS.
Procedure
Choose Developer > Analysis Miner > Smartminer > Data Files.
Right-click a directory in the navigation tree on the left and choose Create File from the shortcut menu.
The dialog box for adding a feature file is displayed.
Set the parameters.
0 describes the parameters.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 117 of 124
Parameters
Parameter Description
File ID The description of the file.
File Type The default value is HDFS.
File Path Directory where a feature file is stored.
Replace the last part of the path that indicates the
month with an asterisk (*), for example,
/DataStoreage4Feature/Customer/u2f2/*
File Name Name of the feature file to be added. You can click
Obtain File Fields to obtain fields in the feature
file and then select a primary key. Sample data
extraction indicates the process of an
ImportFeatureLibary node combines forecast fields
and input fields of the same primary key.
Corresponding Primary Key Primary key of the feature file to be added.
Object Type Object type associated with the feature file to be
added.
NOTE The file separator must be consistent with the actual file separator.
Files referenced by features cannot be deleted.
Managing Features
You can create, import, and export features on the SmartMiner GUI.
Prerequisites
A feature file has been defined.
Context The following two parameters need to be added to the
${SmartMiner_HOME}/conf/smartminer.properties file:
smart_feature_maxstoremonth=12
smart_feature_data_rootpath=hdfs://133.34.223.46:8920
The preceding configuration indicates that the maximum data storage duration is 12 months and data
is stored in the HDFS.
Feature data is stored by month with the same data view. A large data file can be divided in to multiple
small files by user and feature. Currently, a large file can be divided into multiple small files by user
for features. All small files use the same primary key, for example, user ID.
A small file contains only data, and the file name is in userfeature_part*_part* format, in which the
first part* indicates the user division index and the second part* indicates the feature division index.
For example, a large file that contains features of 1,000,000 users (including the age and gender). The
large file can be divided into the following files:

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 118 of 124
− userfeature-part1-part1: stores the age information of 500,000 users; userfeature-part2-part1:
stores the age information of another 500,000 users. The common file name is
userfeature-part?-part1.
− userfeature-part1-part2: stores the gender information of 500,000 users;
userfeature-part2-part2: stores the gender information of another 500,000 users. The common
file name is userfeature-part?-part2.
Field name information is saved in a header file that contains only one line. The header file name is in
userfeature_part*.head format. Small files for a feature shares one header file.
Creating a Feature
Choose Developer > Analysis Miner > Smartminer > Feature Manager.
Click Create Feature.
The dialog box for creating a feature is displayed.
Set the parameters.
0 describes the parameters.
Parameters
Parameter Description
Feature ID File ID. You can click Verify Uniqueness to check whether a feature
ID is unique.
Statistics Period The default value is Month. Currently, the parameter can only be set to
Month.
Associated File File referenced by the feature to be created.
File Fields Fields used for creating features in a feature file.
Value Type Data type of the file field.
Value Range Value range of the data type of the primary key.
● If Value Type is set to Range, Lower Limit and Upper Limit
need to be set.
● If Value Type is set to Sign, Flag Value 1 and Flag Value 2 need
to be set.
● If Value Type is set to Set, Value Range does not need to be set.
Click OK.
The newly created feature is displayed in the feature list.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 119 of 124
NOTE A field of a file can be used to create only one feature.
Only enabled features can be used to abstract sample data.
Features referenced by an ImportFeatureLibrary node cannot be deleted.
Importing Features
1. Right-click the root directory in the navigation tree on the left and choose Import Feature from the
shortcut menu.
Click and select the feature package to be uploaded.
Click Import.
NOTE The feature package to be uploaded cannot exceed 100 MB.
Exporting Features
1. Right-click the directory from which features need to be exported in the navigation tree on the left and
choose Export Feature from the shortcut menu.
Click Export.
NOTE Information including file definition (file and field definitions included), category directory definition, and feature definition is exported to a package.
Other Common Operations
Click to delete a feature.
Click
to edit a feature.
Click to view details of a feature.
Click to enable a feature.
Click to disable a feature.
Model Management
1.1.1.1 Creating a Theme
A theme is a specific service topic for example, the deregistration analysis theme. A theme can contain
multiple data mining models created based on the same target.
SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 120 of 124
Procedure
Choose Developer > Analysis Miner > Smartminer > Model Manager.
Right-click the root node of the navigation tree on the left and choose Create Theme from the shortcut menu.
The dialog box for creating a theme is displayed.
Set the parameters.
0 describes the parameters.
Parameters
Parameter Description
Theme ID Theme ID. You can click Verify Uniqueness to
check the uniqueness of a theme ID.
Theme Name Theme name.
Theme Category Theme category. Currently, the following theme
categories are supported: Value forecast,
classification, and clustering.
Evaluation Interval Interval between executions of the theme
evaluation scheduled task.
● When Scheduling Type is None, scheduled
task is not need to set.
● When Scheduling Type is Update
Interval,Second is need to set.
● When Scheduling Type is Every Day, Hour
and Minute are need to set.
● When Scheduling Type is Every Month,
Date, Hour and Minute are need to set.
Evaluation Timeout Interval (minutes) Timeout interval of the theme evaluation
scheduled task.
Application Interval Interval between executions of the theme
application scheduled task.
● When Scheduling Type is None, scheduled
task is not need to set.
● When Scheduling Type is Update
Interval,Second is need to set.
● When Scheduling Type is Every Day, Hour
and Minute are need to set.
● When Scheduling Type is Every Month,
Date, Hour and Minute are need to set.
Application Timeout Interval (minutes) Timeout interval of the theme application
scheduled task.
Evaluation Counter Evaluation counter of a theme. You can click the
entry box and select theme evaluation counters in

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 121 of 124
Parameter Description
the dialog box that is displayed.
Threshold Evaluation counter threshold.
Click OK.
The newly created theme is displayed in the navigation tree on the left.
Follow-up Procedure
After a theme is created, you can perform the following operations:
1. Click the theme to view theme details. The theme details are displayed on the right of the page.
Right-click the theme and choose Import Model from the shortcut menu to import a model. For details about how
to import a model, see Importing a Model.
Delete the theme.
a Suspend all models under the theme.
b Delete all models under the theme.
c Suspend the theme.
d Delete the theme.
Importing a Model
After a theme is created, you can import a model under the theme. During model import, you need to
specify a model file and a process file and an evaluation file that are associated with the model.
Procedure
Right-click a theme and choose Import Model from the shortcut menu.
Enter basic information, including model ID and name.
Click OK.
Select a model file, process file, and an evaluation file.
Click Next.
Configure a data source.
For details about how to configure a data source, see ImportText Node.
Click Next.
Configure fields.
For details about how to configure fields, see Creating an Auto Theme Process.
Click Complete.
NOTE
You can import multiple models for a theme. After the models are configured, the SmartMiner automatically and periodically evaluates the models based on the scheduled task configured in the associated theme, and selects and executes the optimal model.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 122 of 124
FAQs
Predictive Analytics Module Fault Diagnosis Methods
Symptom
Common failure symptoms are as follows:
Failed to jump to the SmartMiner GUI from the Portal.
Failed to execute processes.
Operations performed on the GUI cannot be submitted.
Possible Causes
Common fault causes
Symptom Possible Cause
Failed to access the SmartMiner GUI. ● The SmartMiner cannot be started because the
startup port is occupied.
● The SmartMiner service has not been registered
to the SLB.
Failed to execute processes. ● The flow configuration is incorrect:
– The data field types are different from the
actual types.
– The data input and output types do not
meet the modeling requirements.
● The communication between systems is
abnormal:
– The IP address used for communication
between the SmartMiner and Hadoop is
not in the SmartMiner whitelist.
– At the site, the IP address segment of the
management plane is separated from that
of the services plane. The IP address used
for communication between the
SmartMiner and Hadoop is an IP address
of the management plane and cannot
communicate with the services plane.
– The communication between the
DataNode in the Hadoop and the Hadoop
cluster is faulty.
● The database is abnormal. The metadata
database is locked and the SmartMiner cannot
read data from and write data to the database.
● The system resource is insufficient. The
memory and kernel resources of the Hadoop
cluster is not sufficient for the execution of

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 123 of 124
Symptom Possible Cause
processes.
Operations performed on the GUI cannot be
submitted.
The browser is not compatible.
Failure to Access the SmartMiner GUI
1. Log in to the SLB and check whether the SmartMiner service has been correctly registered.
Choose Monitor > Servers. Normally, a SmartMiner node is online.
If no node is online, view the tomcat startup and stopping logs of the SmartMiner to check whether the
SmartMiner is normally started.
Check the startup and stop information in the Tomcat startup and stopping log to check whether the SmartMiner is
properly started.
a Log in to the SmartMiner server as the SmartMiner installation user.
b View the tomcat startup and stopping logs ${HOME}/tomcat/logs/catalina.out to check the port
number is occupied.
If the logs indicate that the SmartMiner is not properly started and the port number is occupied,
port already exits.
Change the port number in the ${HOME}/conf/universe.config.properties file to an idle port
number.
http_port=9380
https_port=9343
Restart the SmartMiner for the configuration to take effect.
% stop_all.sh
% start_all.sh
If the password of the Oracle database is changed recently, check whether the Oracle database password in the
SmartMiner has been changed accordingly.
For details about how to change the password in the SmartMiner configuration file, see
Maintenance > Password Change > Changing Oracle Database User Passwords in the product
documentation.
SmartMiner Process Execution Failure
1. Check whether the data field types are different from the actual ones.
Click the faulty node in a process and modify the node configuration according to the error code and
rectification suggestion.
Check whether the data input and output types do not meet the modeling requirements.
Verify the configuration of the Type node. For details about the model input data type requirements,
see chapter "Operation" in the product documentation.
If no, modify the input data and configuration of the Type node based on the requirements.
View the process execution information in the ${HOME}/logs/debug/smartminer_debug.log file:
− Check whether the Hadoop node whose IP address is in the error logs can properly communicate
with the Hadoop cluster.
Log in to the FusionInsight Manager and check the node connection status.
− Check whether the Hadoop IP address in the error logs belongs to the management plane.

SmartMiner INTERNAL
2017-09-07 Huawei confidential. No spreading without permission. Page 124 of 124
If yes, change the JobHistory address in the smartminer.hadoop.properties to the IP address on
the service plane and restart the SmartMiner service for the modification to take effect.
− Check whether the Hadoop IP address in the error logs has been added to the /etc/hosts on the
SmartMiner server. All IP addresses that need to communicate with the SmartMiner must be added
to the file.
Log in to the HOM JobHistory page and check whether any jobs failed to be executed. Diagnose the fault based
on the error information and rectify the fault.
The URL of the JobHistory monitoring page is http://IP address:Port number/jobhistory.
In the URL:
− IP address: Set it to the IP address of the JobHistory Server node.
− Port number: Set it to the port number configured during the installation.
Set the memory and kernel count required for node execution to smaller values in the SmartMiner configuration
file and execute the process again.
Modify the ${HOME}/conf/smartminer.hadoop.properties file based on the running Hadoop node,
and modify the ${HOME}/conf/smartminer.spark.properties file based on the running Spark node.
Failure to Submit Operations on the GUI
Configure browser compatibility. For details, see Operation > Unified Analytics Runtime Platform >
System Management > Getting Started > Basic Operations > Configuring the Browser in the product
documentation.
If the fault persists, collect the SmartMiner fault information and contact Huawei technical support. For
details about how to collect fault information, see Fault Information Collection.





























