Embed Size (px)
Citation preview

Internet Server ClustersInternet Server Clusters
Jeff Chase
Duke University, Department of Computer Science
CPS 212: Distributed Information Systems

Using Clusters for Scalable ServicesUsing Clusters for Scalable Services
Clusters are a common vehicle for improving scalability and availability at a single service site in the network.
Are network services the “Killer App” for clusters?
• incremental scalability
just wheel in another box...
• excellent price/performance
high-end PCs are commodities: high-volume, low margins
• fault-tolerance
“simply a matter of software”
• high-speed cluster interconnects are on the market
SANs + Gigabit Ethernet...
cluster nodes can coordinate to serve requests w/ low latency
• “shared nothing”

[Fox/Brewer]: SNS, TACC, and All That[Fox/Brewer]: SNS, TACC, and All That
[Fox/Brewer97] proposes a cluster-based reusable software infrastructure for scalable network services (“SNS”), such as:
• TranSend: scalable, active proxy middleware for the Web
think of it as a dial-up ISP in a box, in use at Berkeley
distills/transforms pages based on user request profiles
• Inktomi/HotBot search engine
core technology for Inktomi Inc., today with $15B market cap.
“bringing parallel computing technology to the Internet”
Potential services are based on Transformation, Aggregation, Caching, and Customization (TACC), built above SNS.

TACCTACC
Vision: deliver “the content you want” by viewing HTML content as a dynamic, mutable medium.
1. Transform Internet content according to:
• network and client needs/limitations
e.g., on-the-fly compression/distillation [ASPLOS96], packaging Web pages for PalmPilots, encryption, etc.
• directed by user profile database
2. Aggregate content from different back-end services or resources.
3. Cache content to reduce cost/latency of delivery.
4. Customize (see Transform)
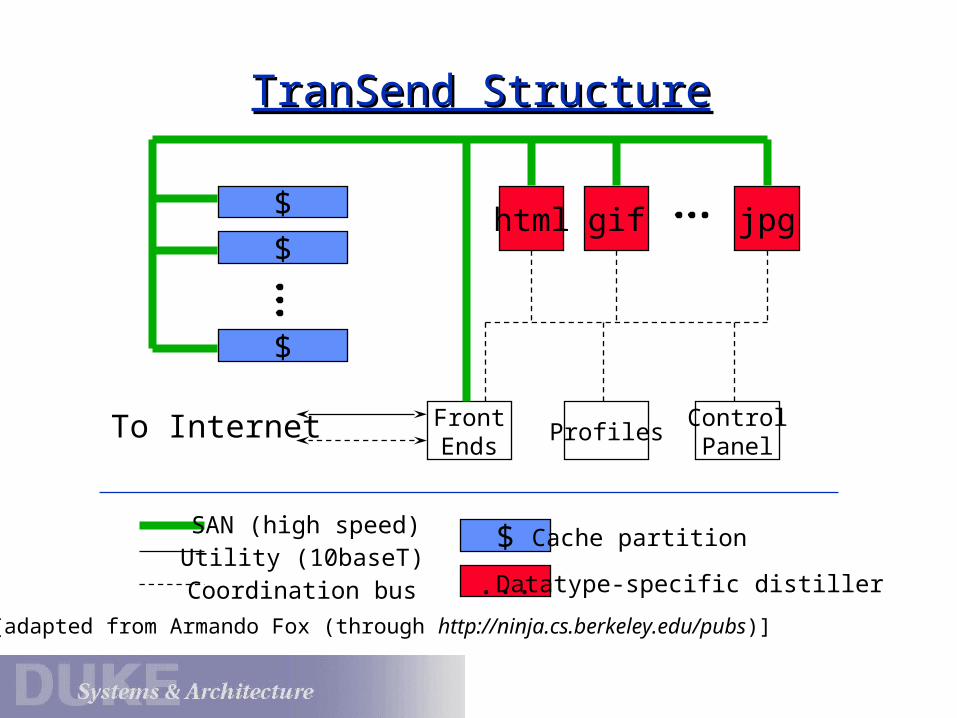
TranSend StructureTranSend Structure
$
$
$
FrontEnds
ProfilesControlPanel
html gif jpg
To Internet
SAN (high speed)Utility (10baseT)Coordination bus
$ Cache partition
... Datatype-specific distiller
[adapted from Armando Fox (through http://ninja.cs.berkeley.edu/pubs)]

SNS/TACC PhilosophySNS/TACC Philosophy
1. Specify services by plugging generic programs into the TACC framework, and compose them as needed.
sort of like CGI with pipes
run by long-lived worker processes that serve request queues
allows multiple languages, etc.
2. Worker processes in the TACC framework are loosely coordinated, independent, and stateless.
ACID vs. BASE
serve independent requests from multiple users
narrow view of a “service”: one-shot readonly requests, and stale data is OK
3. Handle bursts with designated overflow pool of machines.
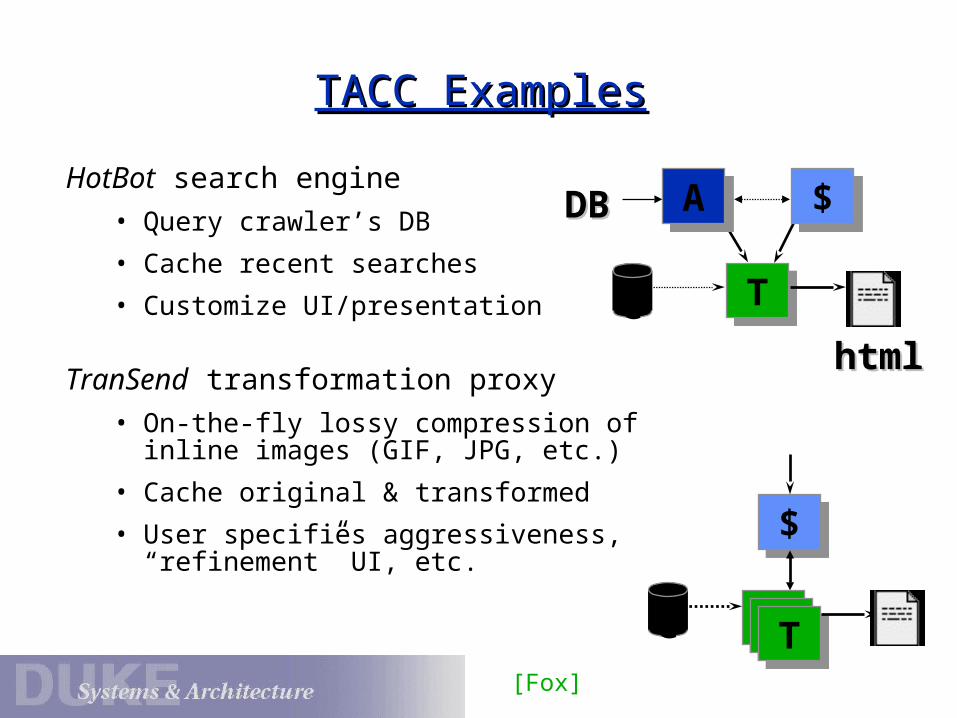
TACC ExamplesTACC Examples
HotBot search engine
• Query crawler’s DB
• Cache recent searches
• Customize UI/presentation
TranSend transformation proxy
• On-the-fly lossy compression of inline images (GIF, JPG, etc.)
• Cache original & transformed
• User specifies aggressiveness, “refinement” UI, etc.
C TT
$$AA
TT
$$
C
DBDB
htmlhtml
[Fox]

(Worker) Ignorance Is Bliss(Worker) Ignorance Is Bliss
What workers don’t need to know
• Data sources/sinks
• User customization (key/value pairs)
• Access to cache
• Communication with other workers by name
Common case: stateless workers
C, Perl, Java supported
• Recompilation often unnecessary
• Useful tasks possible in <10 lines of (buggy) Perl
[Fox]

QuestionsQuestions
1. What are the research contributions of the paper?system architecture decouples SNS concerns from content
TACC programming model composes stateless worker modules
validation using two real services, with measurements
How is this different from clusters for parallel computing?
2. How is this different from clusters for parallel computing?
3. What are the barriers to scale in SNS/TACC?
4. How are requests distributed to caches, FEs, workers?
5. What can we learn from the quantitative results?
6. What about services that allow client requests to update shared data?e.g., message boards, calendars, mail,

SNS/TACC Functional IssuesSNS/TACC Functional Issues
1. What about fault-tolerance?
• Service restrictions allow simple, low-cost mechanisms.
Primary/backup process replication is not necessary with BASE model and stateless workers.
• Uses a process-peer approach to restart failed processes.
Processes monitor each other’s health and restart if necessary.
Workers and manager find each other with “beacons” on well-known ports.
2. Load balancing?
• Manager gathers load info and distributes to front-ends.
• How are incoming requests distributed to front-ends?

Porcupine: A Highly Available Porcupine: A Highly Available Cluster-based Mail ServiceCluster-based Mail Service
Yasushi Saito
Brian Bershad
Hank Levy
University of Washington Department of Computer Science and Engineering,
Seattle, WA
http://porcupine.cs.washington.edu/
[Saito]

Why Email?Why Email?
Mail is importantReal demand
Mail is hard
Write intensive
Low locality
Mail is easy
Well-defined API
Large parallelism
Weak consistency
[Saito]
How much of Porcupine isreusable to other services?
Can we use the SNS/TACCframework for this?

GoalsGoals
Use commodity hardware to build a large, scalable mail service
Three facets of scalability ...
Performance: Linear increase with cluster size
Manageability: React to changes automatically
Availability: Survive failures gracefully
[Saito]
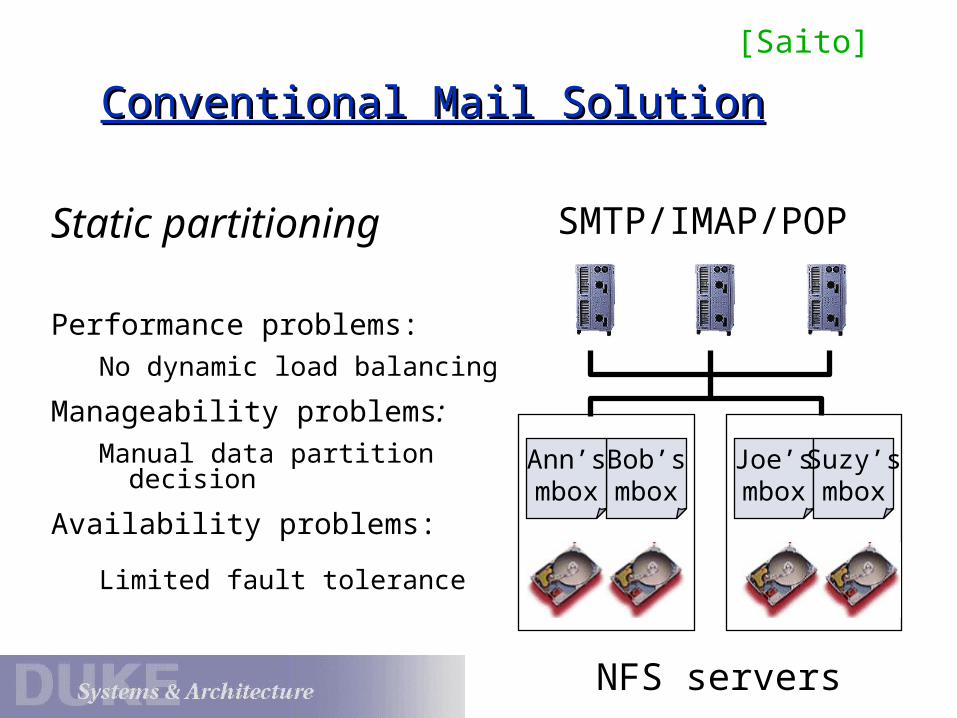
Conventional Mail SolutionConventional Mail Solution
Static partitioning
Performance problems:
No dynamic load balancing
Manageability problems:
Manual data partition decision
Availability problems:
Limited fault tolerance
SMTP/IMAP/POP
Bob’smbox
Ann’smbox
Joe’smbox
Suzy’smbox
NFS servers
[Saito]
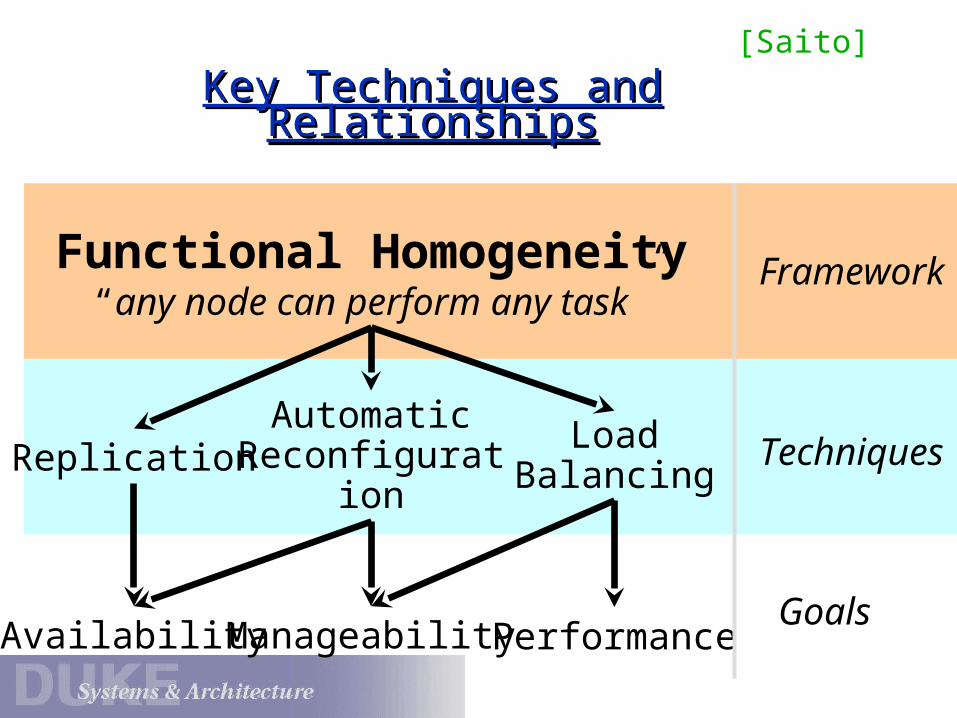
Key Techniques and RelationshipsKey Techniques and Relationships
Functional Homogeneity“any node can perform any task”
AutomaticReconfiguration
Load BalancingReplication
Manageability PerformanceAvailability
Framework
Techniques
Goals
[Saito]
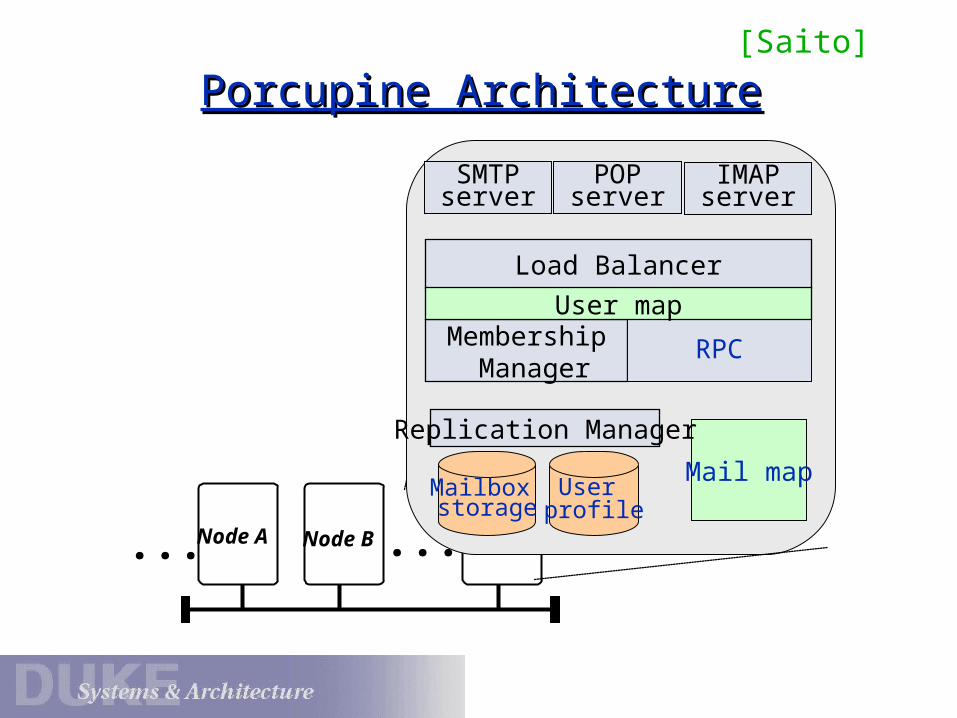
Porcupine ArchitecturePorcupine Architecture
Node A ...Node B Node Z...
SMTPserver
POPserver
IMAPserver
Mail mapMailbox storage
User profile
Replication Manager
Membership Manager
RPC
Load Balancer
User map
[Saito]
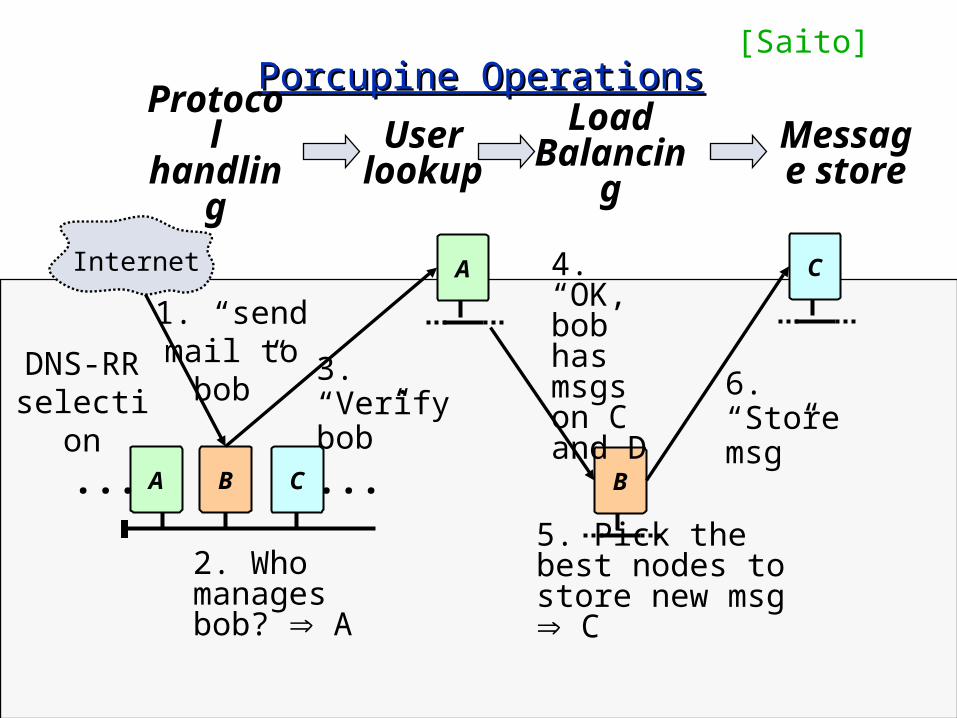
Porcupine OperationsPorcupine Operations
Internet
A B...
A
1. “send mail to bob”
2. Who manages bob? A
3. “Verify bob”
5. Pick the best nodes to store new msg C
DNS-RR selection
4. “OK, bob has msgs on C and D 6. “Store
msg”B
C
Protocol handling
User lookup
Load Balancing
Message store
...C
[Saito]
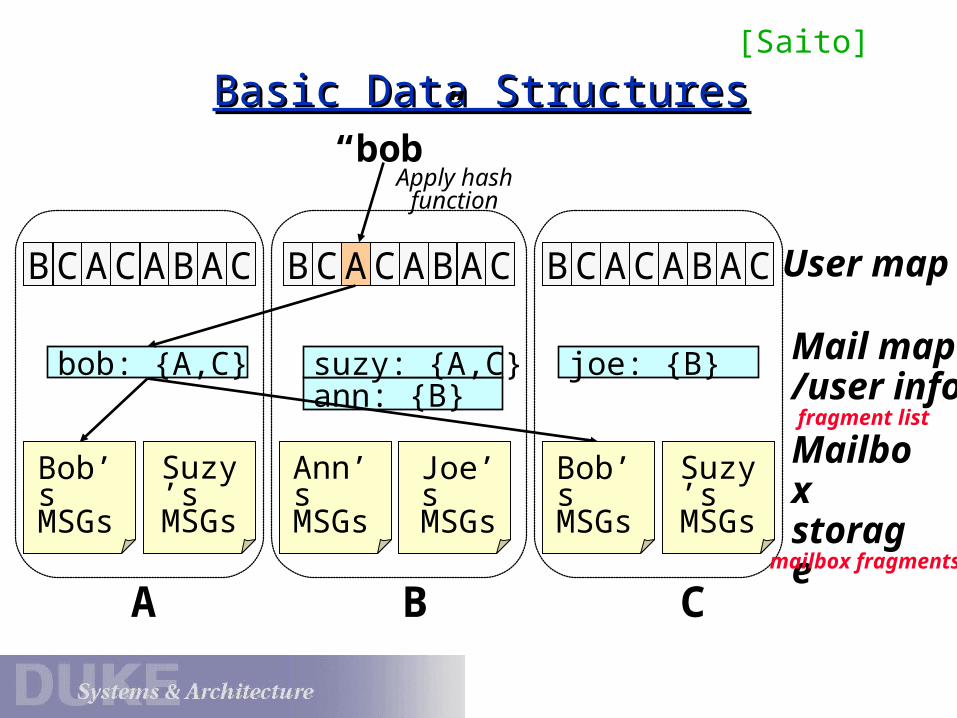
Basic Data StructuresBasic Data Structures“bob”
BCACABAC
bob: {A,C}ann: {B}
BCACABAC
suzy: {A,C} joe: {B}
BCACABAC
Apply hash function
User map
Mail map/user info
Mailbox storage
A B C
Bob’s MSGs
Suzy’s MSGs
Bob’s MSGs
Joe’s MSGs
Ann’s MSGs
Suzy’s MSGs
[Saito]
fragment list
mailbox fragments

Porcupine AdvantagesPorcupine Advantages
Advantages:
Optimal resource utilization
Automatic reconfiguration and task re-distribution upon node failure/recovery
Fine-grain load balancing
Results:
Better Availability
Better Manageability
Better Performance
[Saito]

AvailabilityAvailability
Goals:Maintain function after failuresReact quickly to changes regardless of cluster sizeGraceful performance degradation / improvement
Strategy: Two complementary mechanisms
Hard state: email messages, user profile Optimistic fine-grain replication
Soft state: user map, mail map Reconstruction after membership change
[Saito]
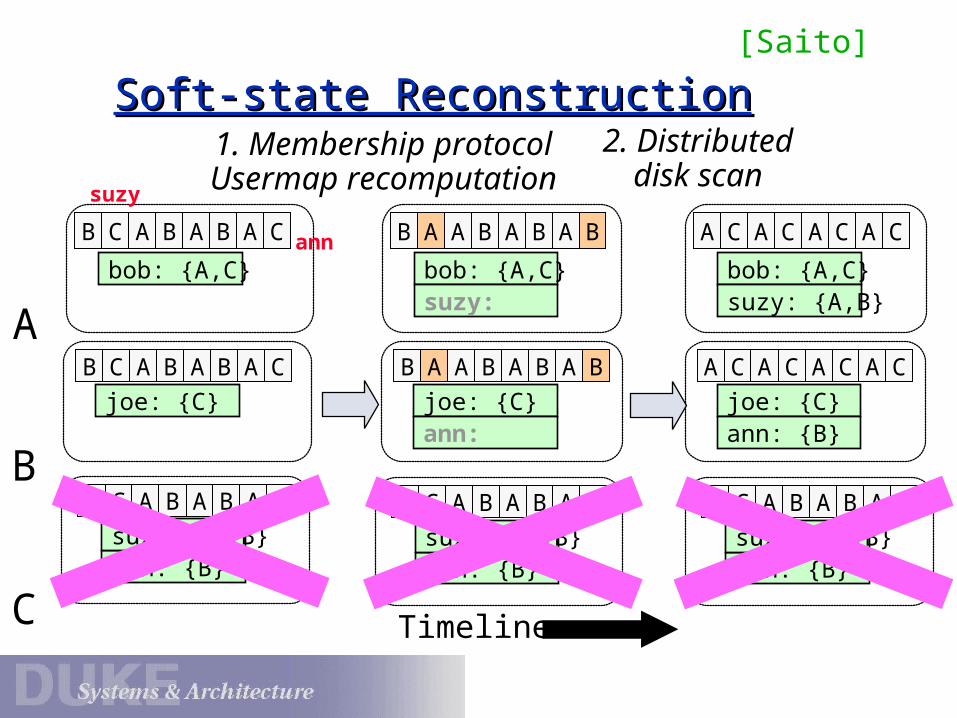
Soft-state ReconstructionSoft-state Reconstruction
B C A B A B A C
bob: {A,C}
joe: {C}
B C A B A B A C
B A A B A B A B
bob: {A,C}
joe: {C}
B A A B A B A B
A C A C A C A C
bob: {A,C}
joe: {C}
A C A C A C A C
suzy: {A,B}
ann: {B}
1. Membership protocolUsermap recomputation
2. Distributed disk scan
suzy:
ann:
Timeline
A
B
ann: {B}
B C A B A B A C
suzy: {A,B}
Cann: {B}
B C A B A B A C
suzy: {A,B}ann: {B}
B C A B A B A C
suzy: {A,B}
[Saito]
suzy
ann
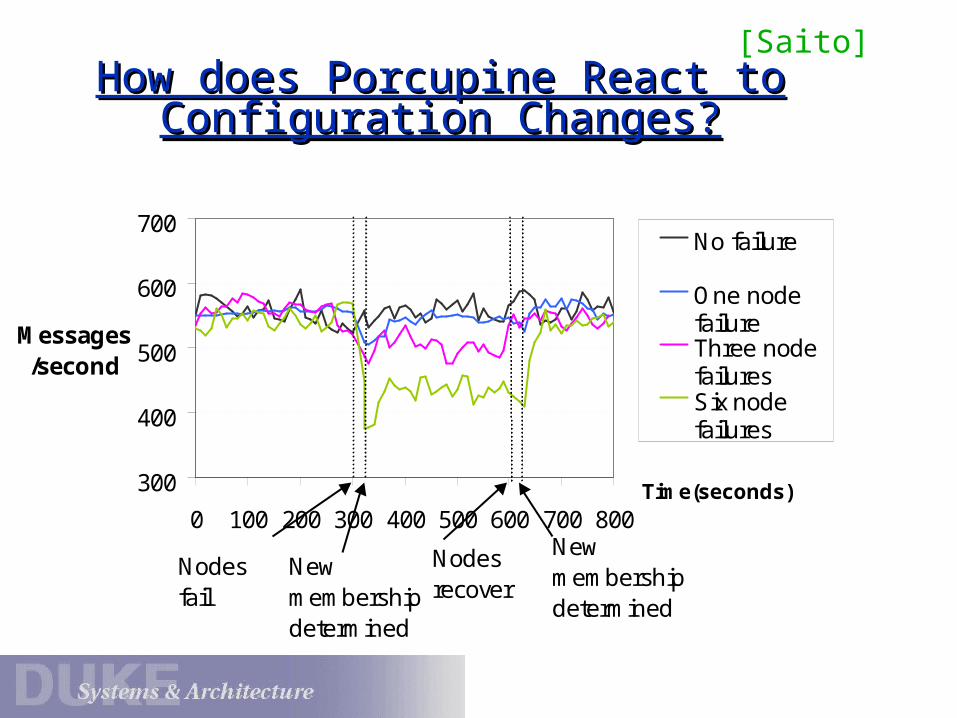
How does Porcupine React to How does Porcupine React to Configuration Changes?Configuration Changes?
300
400
500
600
700
0 100 200 300 400 500 600 700 800Time(seconds)
Messages/second
No failure
One nodefailureThree nodefailuresSix nodefailures
Nodes fail
New membership determined
Nodes recover
New membership determined
[Saito]

Hard-state ReplicationHard-state Replication
Goals:
Keep serving hard state after failures
Handle unusual failure modes
Strategy: Exploit Internet semantics
Optimistic, eventually consistent replication
Per-message, per-user-profile replication
Efficient during normal operation
Small window of inconsistency
[Saito]
How will Porcupine behave in a partition failure?

More on Porcupine ReplicationMore on Porcupine Replication
To add/delete/modify a message:• Find and update any replica of the mailbox fragment.
Do whatever it takes: make a new fragment if necessary...pick a new replica if chosen replica does not respond.
• Replica asynchronously transmits updates to other fragment replicas.
continuous reconciling of replica states
• Log/force pending update state, and target nodes to receive update.
on recovery, continue transmitting updates where you left off
• Order updates by loosely synchronized physical clocks.
Clock skew should be less than the inter-arrival gap for a sequence of order-dependent requests...use nodeID to break ties.
• How many node failures can Porcupine survive? What happens if nodes fail “forever”?
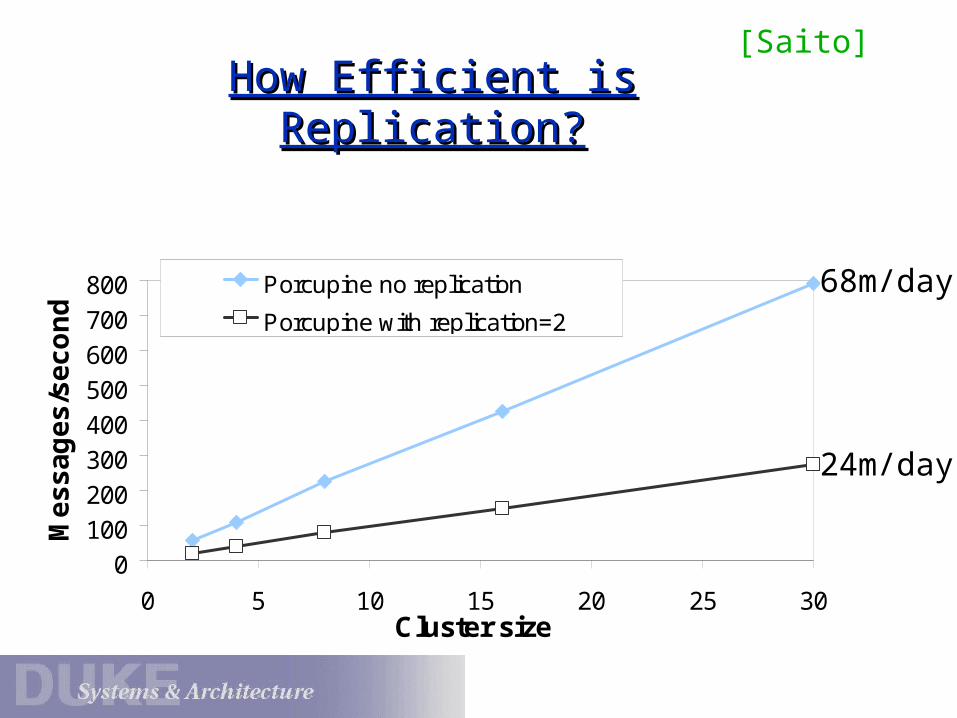
How Efficient is Replication?How Efficient is Replication?
0
100
200
300
400
500
600
700
800
0 5 10 15 20 25 30Cluster size
Me
ss
ag
es
/se
co
nd
Porcupine no replication
Porcupine with replication=2
68m/day
24m/day
[Saito]
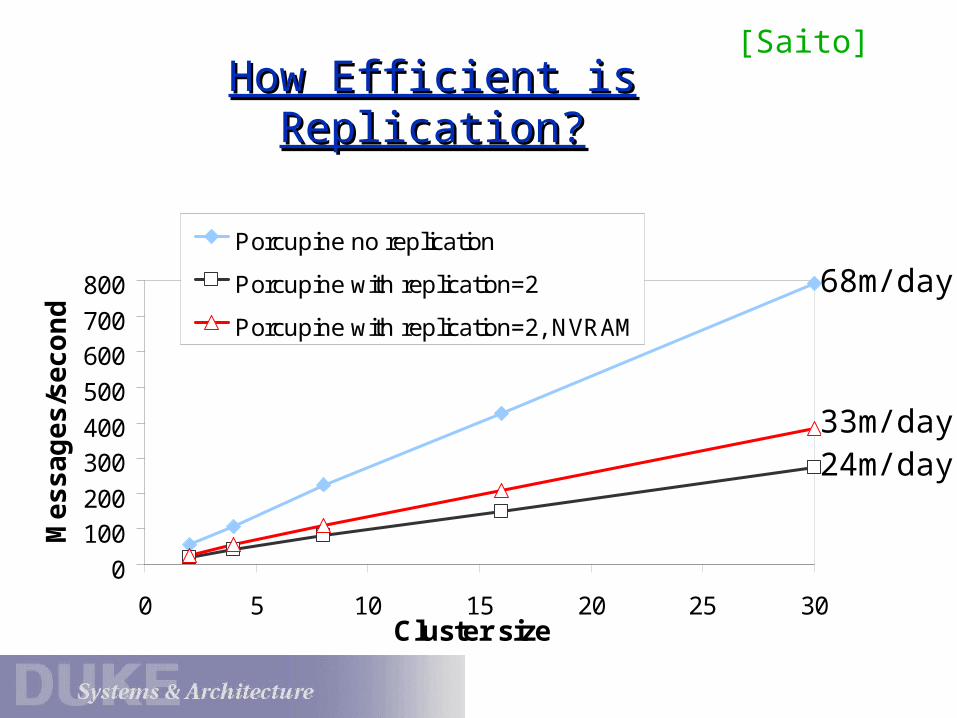
How Efficient is Replication?How Efficient is Replication?
0
100
200
300
400
500
600
700
800
0 5 10 15 20 25 30Cluster size
Me
ss
ag
es
/se
co
nd
Porcupine no replication
Porcupine with replication=2
Porcupine with replication=2, NVRAM
68m/day
24m/day33m/day
[Saito]

Load balancing: Deciding where to store messagesLoad balancing: Deciding where to store messages
Goals:
Handle skewed workload well
Support hardware heterogeneity
No voodoo parameter tuning
Strategy: Spread-based load balancing
Spread: soft limit on # of nodes per mailbox
Large spread better load balance
Small spread better affinity
Load balanced within spread
Use # of pending I/O requests as the load measure
[Saito]

QuestionsQuestions• How to select the front-end node to handle the request? Does it
matter which one we choose?
• Don’t we already know how to build big mail servers? (e.g., Earthlink, Christenson USITS97) Why do we need Porcupine?
• What properties of the mail “data model” allow this approach, with weaker consistency guarantees than a database?
• How does the system leverage/exploit the weaker semantics?
• Can the architecture accommodate new features, e.g., Pachyderm-like storage/indexing of large mail collections?
• Could I run Porcupine on the same cluster with other applications?
• Could this have been built on Microsoft’s MSCS? How much application effort would have been saved?

Clusters: A Broader ViewClusters: A Broader View
MSCS (“Wolfpack”) is designed as basic infrastructure for commercial applications on clusters.
• “A cluster service is a package of fault-tolerance primitives.”
• Service handles startup, resource migration, failover, restart.
• But: apps may need to be “cluster-aware”.
Apps must participate in recovery of their internal state.
Use facilities for logging, checkpointing, replication, etc.
• Service and node OS supports uniform naming and virtual environments.
Preserve continuity of access to migrated resources.
Preserve continuity of the environment for migrated resources.

Wolfpack: ResourcesWolfpack: Resources
• The components of a cluster are nodes and resources.
Shared nothing: each resource is owned by exactly one node.
• Resources may be physical or logical.
Disks, servers, databases, mailbox fragments, IP addresses,...
• Resources have types, attributes, and expected behavior.
• (Logical) resources are aggregated in resource groups.
Each resource is assigned to at most one group.
• Some resources/groups depend on other resources/groups.
Admin-installed registry lists resources and dependency tree.
• Resources can fail.
cluster service/resource managers detect failures.
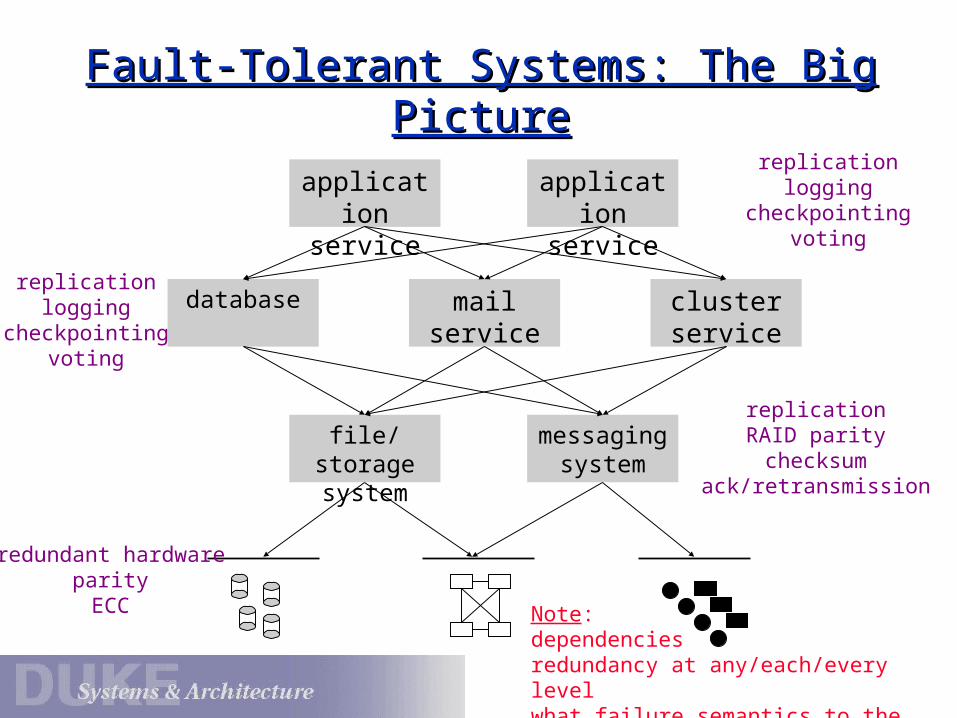
Fault-Tolerant Systems: The Big PictureFault-Tolerant Systems: The Big Picture
messaging system
file/storage system
database mail service cluster service
application service
application service
redundant hardwareparityECC
replicationRAID parity
checksumack/retransmission
replicationlogging
checkpointingvoting
replicationlogging
checkpointingvoting
Note:dependenciesredundancy at any/each/every levelwhat failure semantics to the level above?

Wolfpack: Resource Placement and MigrationWolfpack: Resource Placement and Migration
The cluster service detects component failures and responds by restarting resources or migrating resource groups.
• Restart resource in place if possible...
• ...else find another appropriate node and migrate/restart.
Ideally, migration/restart/failover is transparent.
• Logical resources (processes) execute in virtual environments.
uniform name space for files, registry, OS objects (NT mods)
• Node physical clocks are loosely synchronized, with clock drift less than minimal time for recovery/migration/restart.
guarantees migrated resource sees monotonically increasing clocks
• Route resource requests to the node hosting the resource.
• Is the failure visible to other resources that depend on the resource?

Membership 101Membership 101
Cluster nodes must agree on the set of cluster members (the view).
• distribute resource ownership effectively
shift resources on node failures or additions
• eliminate dangerous/expensive interactions with faulty nodes
• “keep everyone in the loop” on updates and events
e.g., multicast groups and group communication
The literature on group membership is tangled up with the problem of ordered multicast (e.g., “CATOCS”).
• What are the ordering guarantees for message delivery, especially with respect to membership changes?
• Ordered group communication is controversial, but everyone needs a solution for the separate but related membership problem.

Failure DetectorsFailure Detectors
First problem: how to detect that a member has failed?
• pings, timeouts, beacons, heartbeats
• recovery notifications
“I was gone for awhile, but now I’m back.”
Is the failure detector accurate?
Is the failure detector live?
In an asynchronous system, it is possible for a failure detector to be accurate or live, but not both.
• As it turns out, it is impossible for an asynchronous system to agree on anything with accuracy and liveness!
• But this is academic...

Failure Detectors in Real SystemsFailure Detectors in Real Systems
Common solution: • Use a failure detector that is live but not accurate.
Assume bounded processing delays and delivery times.
Timeout with multiple retries detects failure accurately with high probability.
If a “failed” site turns out to be alive, then kill it (fencing).
• Use a recovery detector that is accurate but not live.
“I’m back....hey, did anyone hear me?”
What do we assume about communication failures?How much pinging is enough?
1-to-N, N-to-N, ring?
What about network partitions?

Membership ServiceMembership Service
Second problem: How to propagate knowledge of failure/recovery events to other nodes?
• Surviving nodes should agree on the new view (regrouping).
• Convergence should be rapid.
• The regrouping protocol should itself be tolerant of message drops, message reorderings, and failures.
liveness and accuracy again
• The regrouping protocol should be scalable.
• The protocol should handle network partitions.
• Behavior of the messaging system (e.g., group multicast) across membership changes must be well-specified and understood.

Example: WombatExample: Wombat
• Wombat is a new membership protocol, an outgrowth of Porcupine.
Gretta Bartels, University of Washington, Duke ‘98
• Wombat is empirically more efficient/scalable than competing algorithms such as Three Round.
• But: Wombat makes no guarantees about the relative ordering of membership events and messages.
Adherents of group communication would not accept it as a “real” membership protocol.
• Wombat’s assumptions have not been formally defined, and its properties have not been proven.
If you can’t prove that it works, you can’t believe that it works.
• Disclaimer: Wombat is a promising work in progress.

Wombat BasicsWombat Basics
ping
ping
leader
minions
Nodes are ranked by unique IDs.
Node IDs are permanent.
Node i pings predecessor(i).
The highest-ranked node is the leader.
All other nodes are minions.
The leader periodically broadcasts its view to all known minions.
physical broadcast
Minions adopt the leader’s view.
determine pred from leader’s view

Node Arrival/Recovery in WombatNode Arrival/Recovery in Wombat
If node i joins the cluster:
1. i waits for the leader’s next beacon.
2. i detects that the leader’s view does not include i.
3. i notifies the leader.
4. The leader updates its view.
5. The leader broadcasts its new view.
6. Minions adopt the leader’s view.
“I’m here too.”
i

Node Failure in WombatNode Failure in Wombat
If a node fails:
1. Its successor notifies the leader.
2. The leader updates its view.
3. The leader broadcasts its view.
4. Minions adopt the leader’s new view.
5. Life goes on.
X
“Node i has failed.”
i

Leader Failure in WombatLeader Failure in Wombat
If the leader fails:
1. Successor detects the failure.
2. Successor knows that the failed node was the leader.
3. Successor broadcasts as leader.
4. Minions adopt the new leader’s view.
5. Life goes on.
X “I am in control.”

Multiple Failures in WombatMultiple Failures in Wombat
If the leader and its successor(s) fail(s), the next ranking node must assume command on its own.
1. Each node has a broadcast timer; if the timer goes off, broadcast as leader.
2. Each node’s timer is set by its rank.
if i< j then timer(i)<timer(j)
3. Reset timer on each beacon.
4. Leader’s timer value is adaptive.
Go faster if things are changing.
X
“I must be in control.”
X

Suppressing False LeadersSuppressing False Leaders
If a node falsely broadcasts as leader:
1. All nodes that know of a better leader recognize the usurper as such.
2. The real leader recognizes that it is a better leader than the usurper.
3. The real leader broadcasts the union of its view and the usurper’s view.
4. The usurper shuts up and adopts the real leader’s view.
What if the “real leader” is dead?
X
“I must be in control.”
“I don’t think so.”

Partitions in WombatPartitions in WombatpartitionleaderIf a network failure partitions the
cluster:
1. The old partition continues.
2. The leader of the new partition eventually broadcasts its view.
3. Minions accept the new leader’s view. partition
leader
notion

Healing a PartitionHealing a Partitiondominating
leaderWhen the partition heals, either:
1. The dominating partition leader hears a false broadcast, and...
2. ...corrects it by broadcasting the union of the views.
- or -
1. The dominating partition leader broadcasts first, and...
2. ...minions respond “I’m here”.
partitionleader

Wombat: WrinklesWombat: Wrinkles
1. What are the assumptions about:• network?• clocks?
2. Are these reasonable/realistic assumptions?
3. How to ensure a single cluster view in the event of a partition?
4. How long does it take for the view to converge after a partition?
5. How do we start a cluster? What if a node starts or recovers but never receives a beacon?
6. What about the ordering of messages and membership events?
7. How do minions come to accept a new leader?
8. What about “message storms”?



















![18-4masglp.olemiss.edu/Water Log PDF/18-4.pdfcob-qoza_T ZApg1J cg1crqgg1JB cps cps aorupgw glgccgq co nag g rg4 cps cps g aorupgw co pgbgug]lxgq upla ÀggL' cps cowbg1JÀ pgcaug cps](https://img.pdfslide.net/doc/110x75/5e2f59f63318b957b5481e92/18-log-pdf18-4pdf-cob-qozat-zapg1j-cg1crqgg1jb-cps-cps-aorupgw-glgccgq-co-nag.jpg)









