Embed Size (px)
Citation preview

Internet Traffic Filtering System based on Data
Mining Approach
Vladimir MaslyakovComputer Science Department of
Lomonosov Moscow State University

Plan
• Actuality• Current Approaches• Our Approach• Results

Actuality
1. About 30% of its work time knowledge workers spend on personal usage: surfing Internet, chatting, entertaining, etc*
2. Only 40% of organizations use some software to control Internet traffic
3. 90% of organizations would like to use some sort of software to control Internet traffic**
* Dan Malachowski (2005, July 11) Salary.com “Wasting Time at Work Costing Companies Billions” ** Karl Donert, Sara Carro Martinez (2002, December 23) “End-user Requirements: Final Report”

Goals
• to prevent access to unwanted content. A common scenario for schools and libraries;
• to detect harmful content (viruses, spam, trojans, etc) or links to such content;
• to detect possible intrusion threats or suspicious traffic;
• to reduce number of leakages of confidential information;
• to prevent unwanted usage of Internet during working time.

Problems
Modern Internet:1. is HUGE2. is constantly changing (in size and
content)3. mostly consists of dynamic resourcesOrganizations want:1. to be independent of knowledge bases
from third-party companies2. a good precision of filtering with minimum
number of errors3. maximum performance with minimum
resources

Requirements
• the ability to process and filter information online, which means that end users should not experience significant delays because of traffic filtering;
• high precision of filtering (low rates of false-positive and false-negative errors);
• the ability to process dynamic content; • the ability to adapt to new types of resources and
filter resources using its content as well as its metadata;
• scalability, the ability to be installed in organizations of different scale.

Desirable features
• Independence of language of Internet resources
• Configurability and ability to adapt to specific organization needs
• Ability to analyze traffic transparently to end users

Plan
• Actuality• Current Approaches• Our Approach• Results
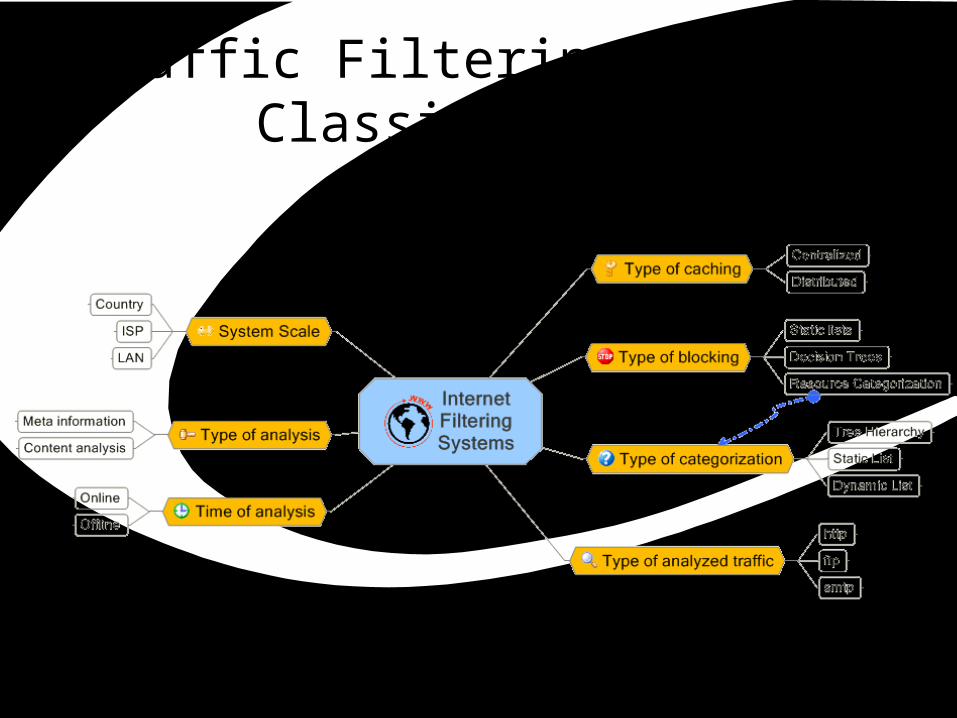
Traffic Filtering Systems Classification

Characteristics
• speed of filtering (kbytes/sec);• false-positive errors, cases when system
forbids access to legal resource (%);• false-negative errors, cases when system
allows access to forbidden resource (%);• precision of filtering, ratio of correctly
allowed and correctly forbidden resources to the total number of analyzed resources (%).

Problems
• There is no benchmarks and methodologies for testing Internet Traffic Filtering Software
• There is even no datasets on which tests could be performed

Signature Approach
• Bring signature database of analyzed resources to up-to-date state.
• Process requests from users in real-time.
• If Internet resource A is marked as harmful, access to the resource is forbidden.
But Content at the update stage and content at the stage of analysis could be different!

Advantages of Signature Approach
• The signature database is usually centralized and is maintained by some organization
• Content analysis is often not used at all => very good speed
• Human experts precision is very good (>95%)

Disadvantages of Signature Approach
• speed and precision of analysis significantly depends on quality of centralized knowledge base
• analysis of Internet resources without using its content or poor precision of content analysis
• inability to add new types and categories of resources

Other drawbacks of modern solutions
• inability to personalize traffic• inability to analyze resources in
different languages• inability to analyze dynamic content
online• outdated databases• etc

Plan
• Actuality• Current Approaches• Our Approach• Results

Architecture

Components of System
• Cache Proxy Server (Squid with ICAP support)
• Java-based Kernel with built-in ICAP client
• Java-based Decision Making Module• C++-based Parser (antlr)• C++-based Classifier (Perceptron, SVM)• XML-RPC for interoperability between
different components (apache xml-rpc)

Data Mining Approach• A fully automatic process of training on test data.• All requests are identified and transparently redirected
from cache proxy server to the kernel of the system.• Kernel saves all information about the requested
resource and the request’s author.• Parser tokenizes html content and extracts all the
links• Classifier assigns categories to requested resource,
based on output of parser, and returns results to Decision Making Module
• Decision Making Module decides whether to allow or forbid current resource to user, basing on classification labels, resource metadata and user rights.

Additional features
• Analysis of resource in offline using robot to extract information about hyperlinks => higher precision
• Ability to make incrementive learning of algorithm
• Ability to parse using n-gramm methods => independence of language (payback - lower precision)
• User identification by ip address

Advantages of Data Mining Approach
• necessary speed of analysis (decimal fractions of a second);
• necessary precision of analysis (more than 90% with 1% of false-positive errors);
• adaptation and self-learning, which will allow to adapt to specific organization needs;
• scalability of result system, which will allow to deploy system in organizations of different scale;
• autonomy from external knowledge bases and human experts.

Disadvantages of Data Mining Approach
• higher rate of false-positive errors than signature approach
• necessity of training data

Future Plans
• to develop rdf knowledge base of users, statistics and resources (based on HP Jena or Protégé)
• to enhance identification algorithms (SSO and LDAP support)
• to enhance decision making strategies (bayesian networks or svm)
• to implement more sophisticated user rights system

Plan
• Actuality• Current Approaches• Our Approach• Results

What we have
• A developed prototype• Pentium III 550 Mhz with 384 Mbs of RAM• Debian 4.0 Etch• Java 1.5.0• Tomcat 5.0• Gcc 4.1.2• Some other third-party libraries (antlr
2.7.7, apache xml-rpc 3.0, berkeley db 4.5.20, etc)

Training Corpus
• Bank Research Corpus• 11 themes (Java, Visual Basic,
Astronomy, …)• 11000 documents, 1000 for each
theme

Results
• Training average speed: 1.3 seconds per document – ln(n)
• Average Download Speed: 2 seconds • Parsing & Classification average
speed: 0.6 seconds – n• Accuracy: ~90%• False-positive errors: ~1-2%

Thank You!Q & A




























