Embed Size (px)
Citation preview

Nau: Game Theory 1
Introduction to Game Theory
7. Repeated Games
Dana Nau University of Maryland

Nau: Game Theory 2 Repeated Stag Hunt
Repeated Games Used by game theorists, economists, social and behavioral scientists
as highly simplified models of various real-world situations
Roshambo
Iterated Chicken Game Repeated
Matching Pennies
Iterated Prisoner’s Dilemma Repeated Ultimatum Game
Iterated Battle of the Sexes

Nau: Game Theory 3
Finitely Repeated Games In repeated games, some game G is played
multiple times by the same set of agents G is called the stage game
• Usually (but not always), G is a normal-form game
Each occurrence of G is called an iteration or a round
Usually each agent knows what all the agents did in the previous iterations, but not what they’re doing in the current iteration
Thus, an imperfect-information game with perfect recall
Usually each agent’s payoff function is additive
Agent 1: Agent 2:
C
C D
C Round 1:
Round 2:
Prisoner’s Dilemma:
3+0 = 3 3+5 = 5 Total payoff:
2 1
C D
C 3, 3 0, 5 D 5, 0 1, 1
Iterated Prisoner’s Dilemma, with 2 iterations:
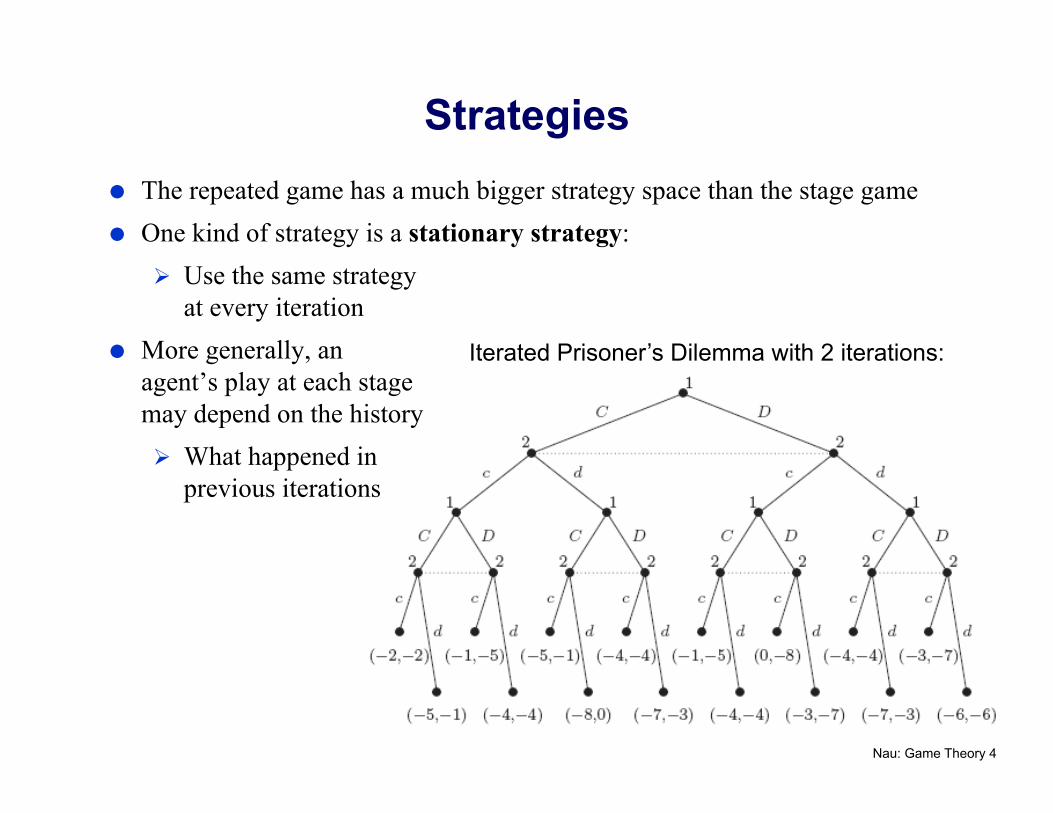
Nau: Game Theory 4
Iterated Prisoner’s Dilemma with 2 iterations:
Strategies The repeated game has a much bigger strategy space than the stage game One kind of strategy is a stationary strategy:
Use the same strategy at every iteration
More generally, an agent’s play at each stage may depend on the history What happened in
previous iterations

Nau: Game Theory 5
Backward Induction If the number of iterations is finite and known, we can use backward
induction to get a subgame-perfect equilibrium
Example: finitely many repetitions of the Prisoner’s Dilemma In the last round,
the dominant strategy is D That’s common knowledge So in the 2nd-to-last round,
D also is the dominant strategy … The SPE is (D,D) on every round
As with the Centipede game, this argument is vulnerable to both empirical and theoretical criticisms
Agent 1: Agent 2:
D
D D
D Round 1:
Round 2:
D
D D
D Round 3:
Round 4:

Nau: Game Theory 6
Backward Induction when G is 0-sum As before, backward induction works much better in zero-sum games
In the last round, equilibrium is the minimax profile • Each agent uses his/her minimax strategy
That’s common knowledge So in the 2nd-to-last round, it
again is the minimax strategies …
The SPE is (D,D) on every round

Nau: Game Theory 7
An infinitely repeated game in extensive form would be an infinite tree
Payoffs can’t be attached to any terminal nodes Payoffs can’t be the sums of the payoffs in the stage games (generally infinite)
Two common ways around this problem Let r (1)
i , r (2)i , … be an infinite sequence of payoffs for agent i
Agent i’s average reward is
Agent i’s future discounted reward is the discounted sum of the payoffs, i.e.,
where β (with 0 ≤ β ≤ 1) is a constant called the discount factor
Two ways to interpret the discount factor:
1. The agent cares more about the preset than the future 2. The agent cares about the future, but the game ends at any round with
probability 1 − β
Infinitely Repeated Games
€
limk→∞
rij( ) / k
j=1
k∑
€
β jrij( )
j=1
∞
∑
Nau: Game Theory 8
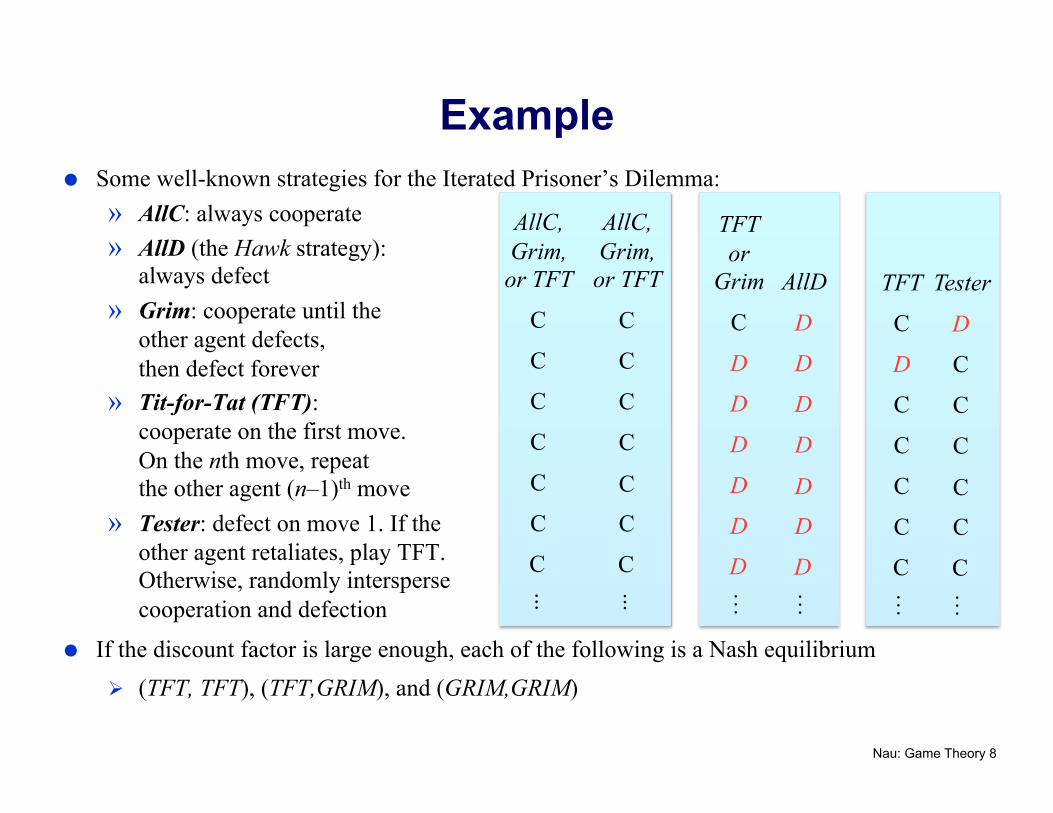
Example Some well-known strategies for the Iterated Prisoner’s Dilemma:
» AllC: always cooperate » AllD (the Hawk strategy):
always defect » Grim: cooperate until the
other agent defects, then defect forever
» Tit-for-Tat (TFT): cooperate on the first move. On the nth move, repeat the other agent (n–1)th move
» Tester: defect on move 1. If the other agent retaliates, play TFT. Otherwise, randomly intersperse cooperation and defection
If the discount factor is large enough, each of the following is a Nash equilibrium (TFT, TFT), (TFT,GRIM), and (GRIM,GRIM)
C C
TFT Tester
C
C
C
C
C
C
…
…
D
C
D
C
C
C
D D
TFT or
Grim AllD
C
D
D
D
D
D
…
…
D
D
D
D D
D
C C
AllC, Grim,
or TFT
AllC, Grim,
or TFT
C
C
C
C
C
C ...
...
C
C
C
C
C
C

Nau: Game Theory 9
Equilibrium Payoffs for Repeated Games There’s a “folk theorem” that tells what the possible equilibrium payoffs
are in repeated games It says roughly the following:
In an infinitely repeated game whose stage game is G, there is a Nash equilibrium whose average payoffs are (p1, p2, …, pn)
if and only if G has a mixed-strategy profile (s1, s2, …, sn) with the following
property: • For each i, si’s payoff would be ≥ pi if the other agents used
minimax strategies against i

Nau: Game Theory 10
Proof and Examples The proof proceeds in 2 parts:
Use the definitions of minimax and best-response to show that in every equilibrium, an agent’s average payoff ≥ the agent’s minimax value
Show how to construct an equilibrium that gives each agent i the average payoff pi, given certain constraints on (p1, p2, …, pn)
• In this equilibrium, the agents cycle in lock-step through a sequence of game outcomes that achieve (p1, p2, …, pn)
• If any agent i deviates, then the others punish i forever, by playing their minimax strategies against i
There’s a large family of such theorems, for various conditions on the game
D D
Agent 1 Agent 2
D
D
D
D
D
D
…
…
C
C
C
D D
C
Example 2: IPD with
(p1, p2) = (2.5,2.5)
D C
Grim Other agent
C
C
C
C
C
C
…
…
C
C
C
D D
C
Example 1: IPD with
(p1, p2) = (3,3)
C D C D

Nau: Game Theory 11
Zero-Sum Repeated Games For two-player zero-sum repeated games, the folk theorem is still true, but it
becomes vacuous
Suppose we iterate a two-player zero-sum game G Let V be the value of G (from the Minimax Theorem)
If agent 2 uses a minimax strategy against 1, then 1’s maximum payoff is V • Thus max value for p1 is V, so min value for p2 is –V
If agent 1 uses a minimax strategy against 2, then 2’s maximum payoff is –V
• Thus max value for p2 is –V, so min value for p1 is V
Thus in the iterated game, the only Nash-equilibrium payoff profile is (V,–V) The only way to get this is if each agent always plays his/her minimax strategy
• If agent 1 plays a non-minimax strategy s1 and agent 2 plays his/her best response, 2’s expected payoff will be higher than –V

Nau: Game Theory 12
Nash equilibrium for the stage game: choose randomly, P=1/3 for each move
Nash equilibrium for the repeated game: always choose randomly, P=1/3 for each move
Expected payoff = 0
Let’s see how that works out in practice …
A1 A2
Rock Paper Scissors
Rock 0, 0 –1, 1 1, –1 Paper 1, –1 0, 0 –1, 1
Scissors –1, 1 1, –1 0, 0
Roshambo (Rock, Paper, Scissors)

Nau: Game Theory 13
1999 international roshambo programming competition
www.cs.ualberta.ca/~darse/rsbpc1.html Round-robin tournament:
• 55 programs, 1000 iterations for each pair of programs
• Lowest possible score = –55000, highest possible score = 55000
Average over 25 tournaments:
• Highest score (Iocaine Powder): 13038 • Lowest score (Cheesebot): –36006
Very different from the game-theoretic prediction
A1 A2
Rock Paper Scissors
Rock 0, 0 –1, 1 1, –1 Paper 1, –1 0, 0 –1, 1
Scissors –1, 1 1, –1 0, 0
Roshambo (Rock, Paper, Scissors)

Nau: Game Theory 14
A Nash equilibrium strategy is best for you if the other agents also use their Nash equilibrium strategies
In many cases, the other agents won’t use Nash equilibrium strategies If you can forecast their actions accurately, you may be able to do
much better than the Nash equilibrium strategy
Why won’t the other agents use their Nash equilibrium strategies? Because they may be trying to forecast your actions too
Something analogous can happen in non-zero-sum games

Nau: Game Theory 15
Multiple iterations of the Prisoner’s Dilemma
Widely used to study the emergence of cooperative behavior among agents
e.g., Axelrod (1984), The Evolution of Cooperation Axelrod ran a famous set of tournaments
People contributed strategies encoded as computer programs
Axelrod played them against each other
Iterated Prisoner’s Dilemma
If I defect now, he might punish me by defecting next time
Nash equilibrium
P2 P1
Cooperate Defect
Cooperate 3, 3 0, 5 Defect 5, 0 1, 1
Prisoner’s Dilemma
Nau: Game Theory 16
C C
TFT TFT C
C C
C C
C
…
…
C
C
C
C C
C
C C
TFT Grim C
C C
C C
C
…
…
C
C
C
C C
C
C C
TFT Tester C
C C
C C
C
…
…
D
C
D
C C
C
D D
TFT AllD C
D D
D D
D
…
…
D
D
D
D D
D
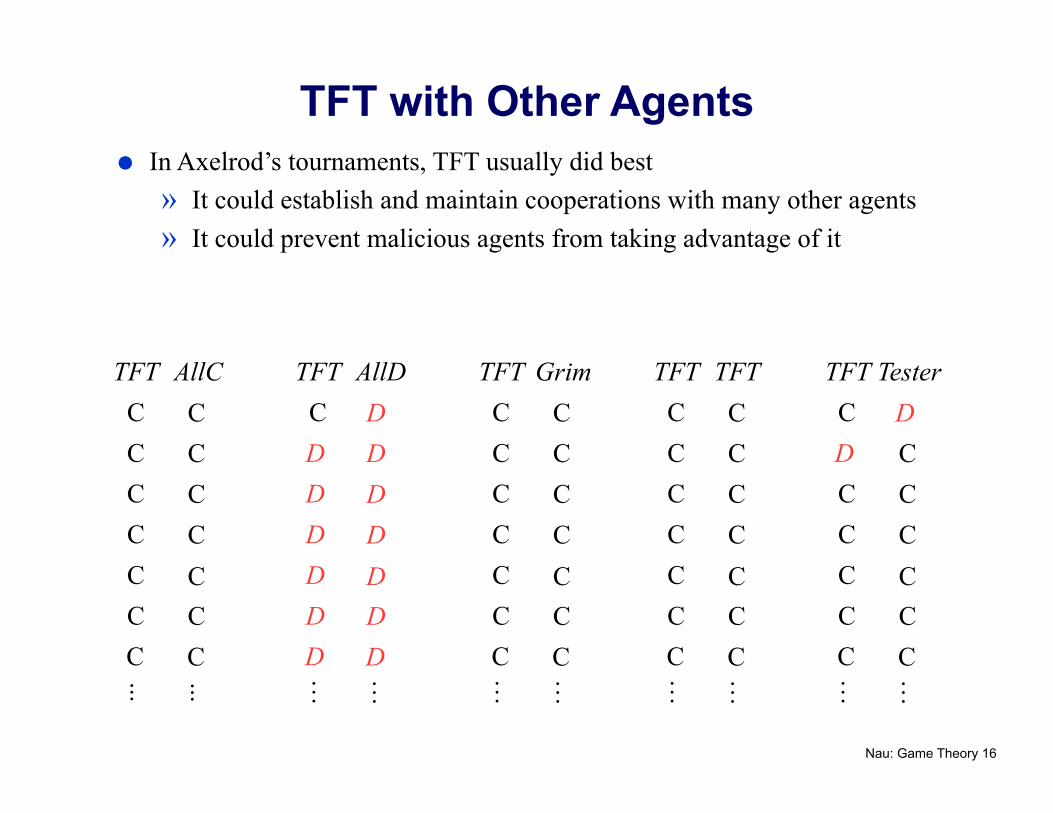
TFT with Other Agents In Axelrod’s tournaments, TFT usually did best
» It could establish and maintain cooperations with many other agents » It could prevent malicious agents from taking advantage of it
C C
TFT AllC C
C C
C C
C
...
...
C
C
C
C C
C
Nau: Game Theory 17
Example: A real-world example of the IPD, described in Axelrod’s book:
World War I trench warfare
Incentive to cooperate:
If I attack the other side, then they’ll retaliate and I’ll get hurt If I don’t attack, maybe they won’t either
Result: evolution of cooperation Although the two infantries were supposed to be enemies, they
avoided attacking each other
Nau: Game Theory 18
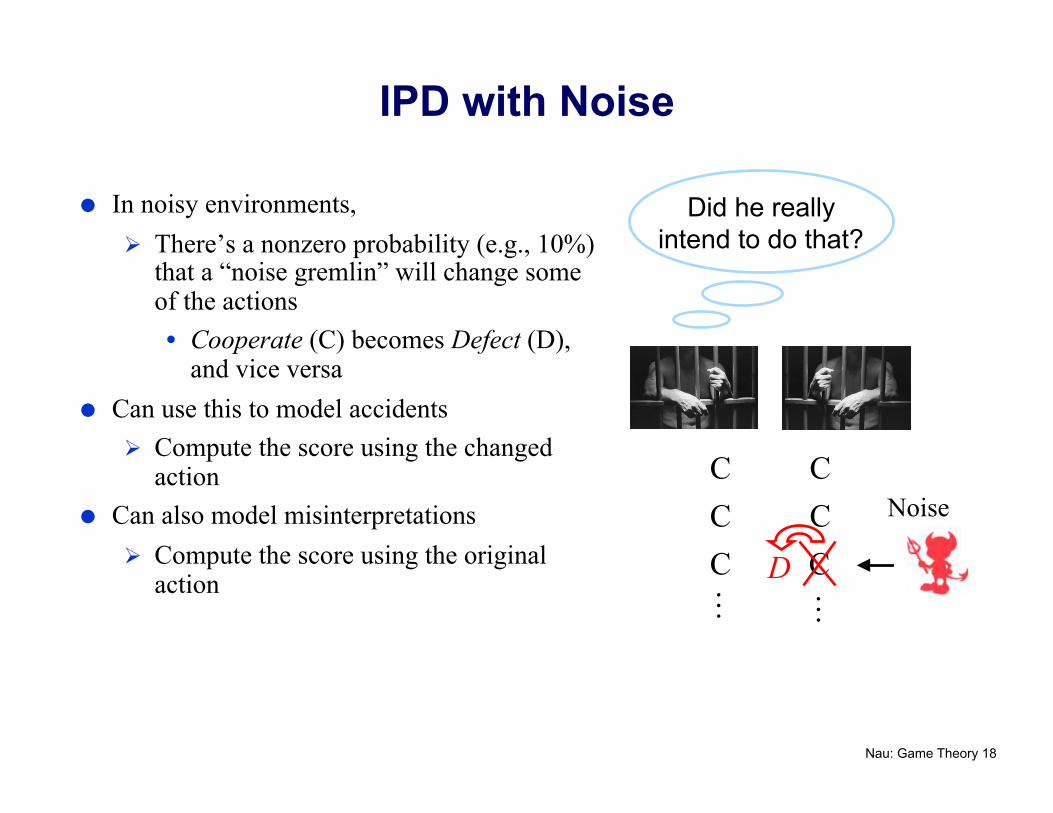
IPD with Noise
In noisy environments, There’s a nonzero probability (e.g., 10%)
that a “noise gremlin” will change some of the actions • Cooperate (C) becomes Defect (D),
and vice versa Can use this to model accidents
Compute the score using the changed action
Can also model misinterpretations Compute the score using the original
action
C C C C C D …
…
C
Noise
Did he really intend to do that?

Nau: Game Theory 19
Example of Noise
Story from a British army officer in World War I: I was having tea with A Company when we heard a lot of shouting and went
out to investigate. We found our men and the Germans standing on their respective parapets. Suddenly a salvo arrived but did no damage. Naturally both sides got down and our men started swearing at the Germans, when all at once a brave German got onto his parapet and shouted out: “We are very sorry about that; we hope no one was hurt. It is not our fault. It is that damned Prussian artillery.”
The salvo wasn’t the German infantry’s intention They didn’t expect it nor desire it

Nau: Game Theory 20
Consider two agents who both use TFT
One accident or misinterpretation can cause a long string of retaliations
C D
C C C
C C
C C
C
. . .
. . .
C
D
C
D D
D C
Noise"
Retaliation
Retaliation
Retaliation
Retaliation
Noise Makes it Difficult to Maintain Cooperation

Nau: Game Theory 21
Some Strategies for the Noisy IPD Principle: be more forgiving in the face of defections
Tit-For-Two-Tats (TFTT) » Retaliate only if the other agent defects twice in a row
• Can tolerate isolated instances of defections, but susceptible to exploitation of its generosity
• Beaten by the TESTER strategy I described earlier Generous Tit-For-Tat (GTFT)
» Forgive randomly: small probability of cooperation if the other agent defects » Better than TFTT at avoiding exploitation, but worse at maintaining cooperation
Pavlov » Win-Stay, Lose-Shift
• Repeat previous move if I earn 3 or 5 points in the previous iteration • Reverse previous move if I earn 0 or 1 points in the previous iteration
» Thus if the other agent defects continuously, Pavlov will alternatively cooperate and defect

Nau: Game Theory 22
Discussion The British army officer’s story:
a German shouted, ``We are very sorry about that; we hope no one was hurt. It is not our fault. It is that damned Prussian artillery.”
The apology avoided a conflict It was convincing because it was consistent with the German infantry’s
past behavior The British had ample evidence that the German infantry wanted to
keep the peace
If you can tell which actions are affected by noise, you can avoid reacting to the noise
IPD agents often behave deterministically For others to cooperate with you it helps if you’re predictable
This makes it feasible to build a model from observed behavior

Nau: Game Theory 23
The DBS Agent Work by my recent PhD graduate, Tsz-Chiu Au
Now a postdoc at University of Texas
From the other agent’s recent behavior, build a model π of the other agent’s strategy
Use the model to filter noise Use the model to help plan our next move Au & Nau. Accident or intention:
That is the question (in the iterated prisoner’s dilemma). AAMAS, 2006.
Au & Nau. Is it accidental or intentional? A symbolic approach to the noisy iterated prisoner’s dilemma. In G. Kendall (ed.), The Iterated Prisoners Dilemma: 20 Years On. World Scientific, 2007.

Nau: Game Theory 24
Modeling the other agent A set of rules of the following form
if our last move was m and their last move was m' then P[their next move will be C]
Four rules: one for each of (C,C), (C,D), (D,C), and (D,D) For example, TFT can be described as
(C,C) ⇒ 1, (C, D) ⇒ 1, (D, C ) ⇒ 0, (D, D) ⇒ 0
How to get the probabilities? One way: look at the agent’s behavior in the recent past
During the last k iterations, What fraction of the time did the other agent cooperate at iteration j
when the agents’ moves were (x,y) at iteration j–1?

Nau: Game Theory 25
Modeling the other agent π can only model a very small set of strategies It doesn’t even model the Grim strategy correctly:
If Grim defects, it may be defecting because of something that happened many moves ago
But we’re not trying to model an agent’s entire strategy, just its recent behavior
If an agent’s behavior changes, then the probabilities in π will change e.g., after Grim defects a few times, the rules will give a very low
probability of it cooperating again

Nau: Game Theory 26
Noise Filtering
C C
C C C
C C
C C
C
: :
C
C
C
C
So I won’t retaliate here. I think these defections are actually noise
D C
D C
Suppose the applicable rule is deterministic P[their next move will be C] = 0 or 1
If the other agent’s next move isn’t what the rule predicts, then Assume the
observed action is noise
Behave as if the action were what the rule predicted
The other agent cooperates when I do

Nau: Game Theory 27
Change of Behavior Anomalies in observed behavior can be due
either to noise or to a genuine change of behavior
Changes of behavior occur because The other agent can change its strategy
anytime E.g., if noise affects one of Agent 1’s
actions, this may trigger a change in Agent 2’s behavior • Agent 1 does not know this
How to distinguish noise from a real change of behavior?
C C
C
C
C D
C D
: :
C
C
C
D
D
D
These moves are not noise
D
:
:
I am Grim. If you ever betray me, I will never forgive you.

Nau: Game Theory 28
Detection of a Change of Behavior
C C C
C C D
C D
: :
C
C
C
The defections might be accidents, so I shouldn’t lose my temper too soon
D
D D D
D I think the other agent’s has really changed, so I’ll change mine too
Temporary tolerance: When we observe unexpected
behavior from the other agent Don’t immediately decide
whether it’s noise or a real change of behavior
Instead, defer judgment for a few iterations
If the anomaly persists, then recompute π based on the other agent’s recent behavior
The other agent cooperates when I do
Nau: Game Theory 29
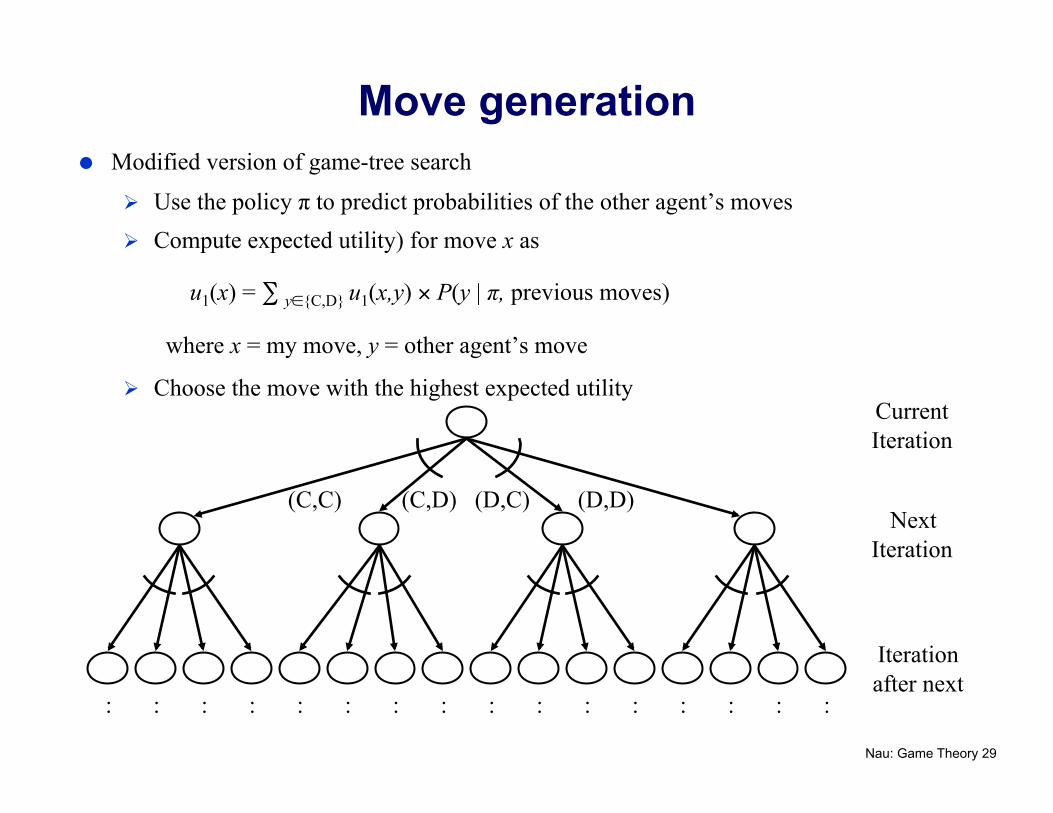
Move generation Modified version of game-tree search
Use the policy π to predict probabilities of the other agent’s moves Compute expected utility) for move x as
u1(x) = ∑ y∈{C,D} u1(x,y) × P(y | π, previous moves)
where x = my move, y = other agent’s move
Choose the move with the highest expected utility Current Iteration
Next Iteration
Iteration after next
: : : : : : : : : : : : : : : :
(C,C) (C,D) (D,C) (D,D)
Nau: Game Theory 30
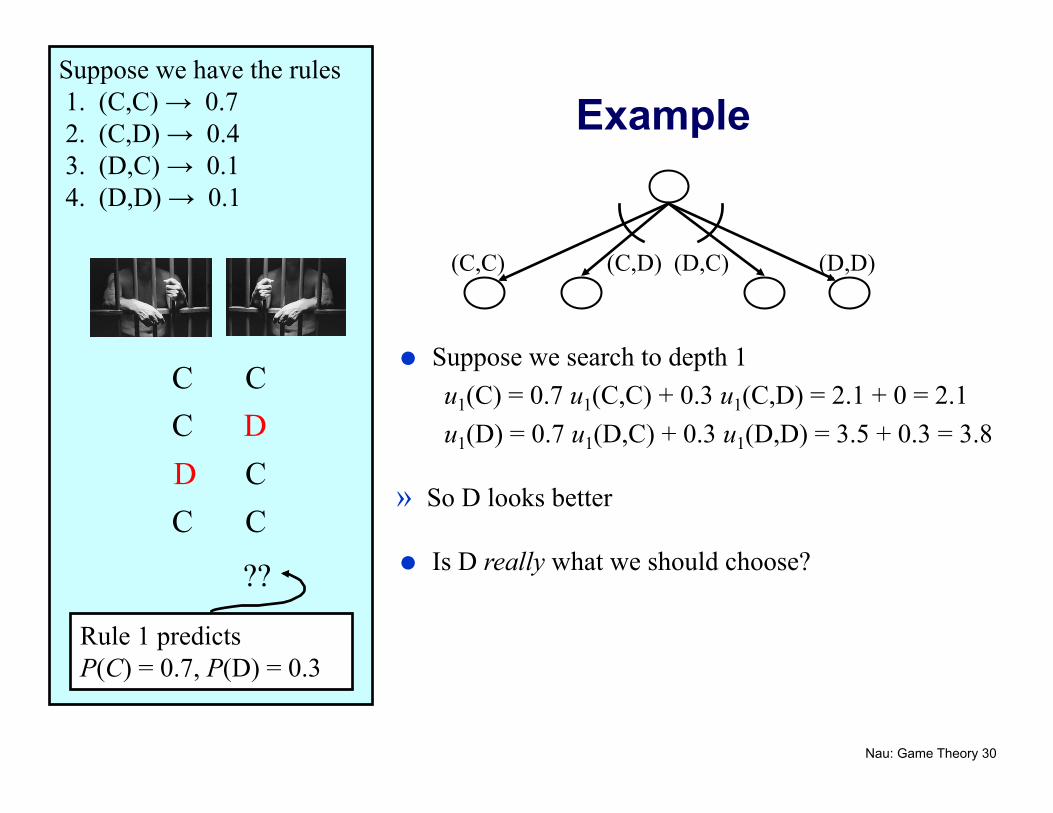
Suppose we have the rules 1. (C,C) → 0.7 2. (C,D) → 0.4 3. (D,C) → 0.1 4. (D,D) → 0.1
C C C
C C C
D D
??
Rule 1 predicts P(C) = 0.7, P(D) = 0.3
(C,C) (C,D) (D,C) (D,D)
Example
Suppose we search to depth 1 u1(C) = 0.7 u1(C,C) + 0.3 u1(C,D) = 2.1 + 0 = 2.1 u1(D) = 0.7 u1(D,C) + 0.3 u1(D,D) = 3.5 + 0.3 = 3.8
» So D looks better
Is D really what we should choose?
Nau: Game Theory 31
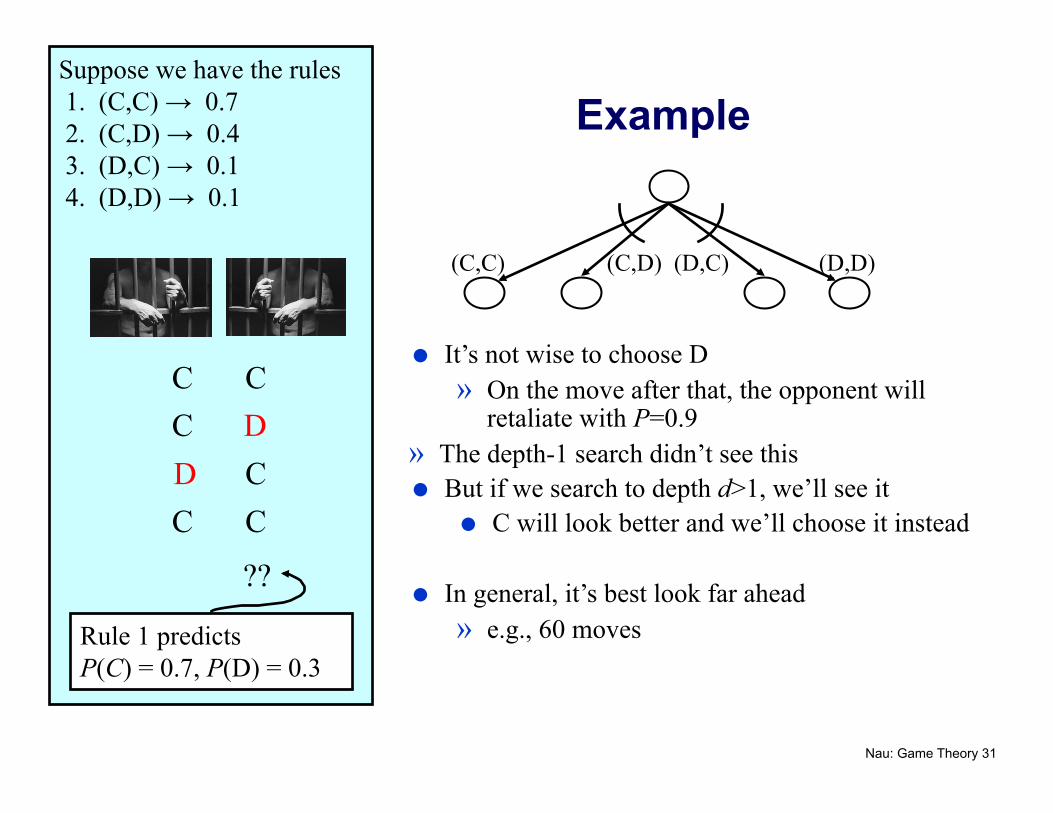
Suppose we have the rules 1. (C,C) → 0.7 2. (C,D) → 0.4 3. (D,C) → 0.1 4. (D,D) → 0.1
C C C
C C C
D D
??
Rule 1 predicts P(C) = 0.7, P(D) = 0.3
(C,C) (C,D) (D,C) (D,D)
Example
It’s not wise to choose D » On the move after that, the opponent will
retaliate with P=0.9 » The depth-1 search didn’t see this But if we search to depth d>1, we’ll see it
C will look better and we’ll choose it instead
In general, it’s best look far ahead » e.g., 60 moves
Nau: Game Theory 32
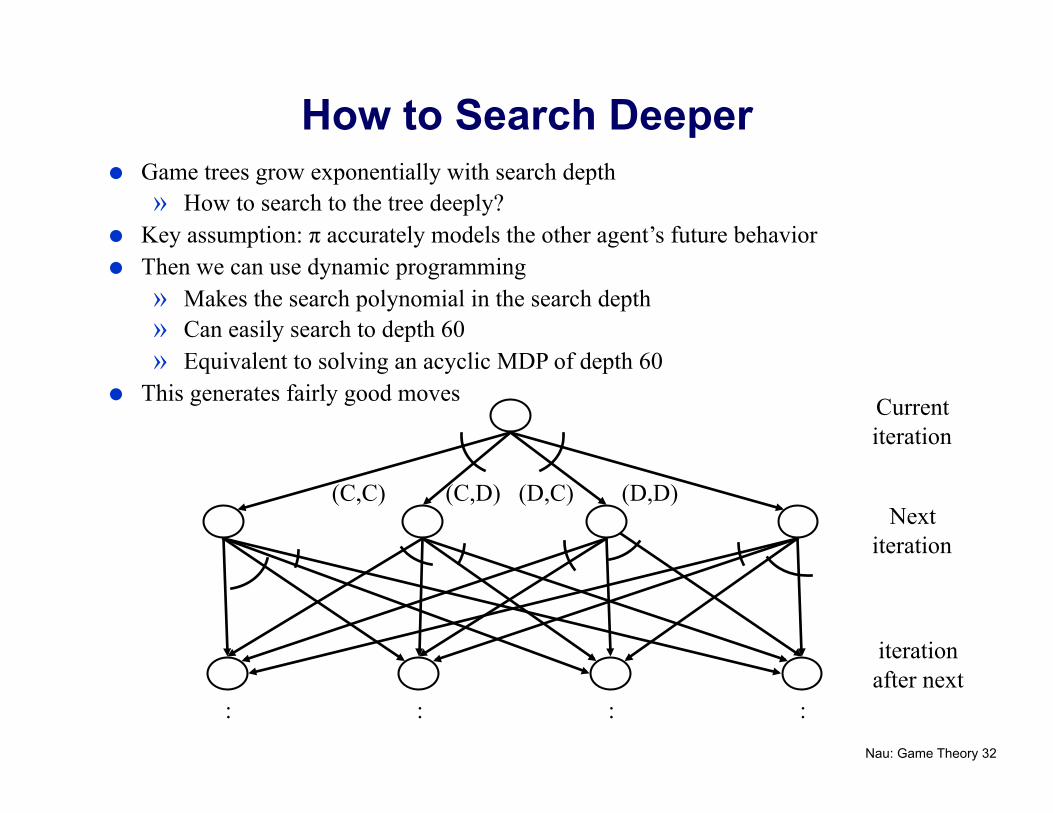
How to Search Deeper Game trees grow exponentially with search depth
» How to search to the tree deeply? Key assumption: π accurately models the other agent’s future behavior Then we can use dynamic programming
» Makes the search polynomial in the search depth » Can easily search to depth 60 » Equivalent to solving an acyclic MDP of depth 60
This generates fairly good moves Current iteration
Next iteration
iteration after next
: : : :
(C,C) (C,D) (D,C) (D,D)

Nau: Game Theory 33
http://www.prisoners-dilemma.com
Category 2: IPD with noise 165 programs participated
DBS dominated the top 10 places
Two agents scored higher than DBS They both used
master-and-slaves strategies
20th Anniversary IPD Competition

Nau: Game Theory 34
Master & Slaves Strategy Each participant could submit up to 20 programs
Some submitted programs that could recognize each other (by communicating pre-arranged sequences of Cs and Ds)
The 20 programs worked as a team • 1 master, 19 slaves
When a slave plays with its master
• Slave cooperates, master defects => maximizes the master’s payoff
When a slave plays with an agent not in its team
• It defects
=> minimizes the other agent’s payoff
… and they beat up everyone else
My goons give me all their money …

Nau: Game Theory 35
Comparison Analysis
Each master-slaves team’s average score was much lower than DBS’s If BWIN and IMM01 had each been restricted to ≤ 10 slaves,
DBS would have placed 1st Without any slaves, BWIN and IMM01 would have done badly
In contrast, DBS had no slaves DBS established cooperation
with many other agents DBS did this despite the noise,
because it filtered out the noise

Nau: Game Theory 36
Summary Finitely repeated games – backward induction
Infinitely repeated games average reward, future discounted reward
equilibrium payoffs Non-equilibrium strategies
opponent modeling in roshambo
iterated prisoner’s dilemma with noise • opponent models based on observed behavior
• detection and removal of noise • game-tree search against the opponent model
20th anniversary IPD competition





























