Embed Size (px)
Citation preview

Introduction to HPC Programming2. The IBM Blue Gene/P Supercomputer
Valentin Pavlov <[email protected]>

About these lectures
• This is the second of series of six introductory lecturesdiscussing the field of High-Performance Computing;
• The intended audience of the lectures are high-schoolstudents with some programming experience (preferrablyusing the C programming language) having interests inscientific studies, e.g. physics, chemistry, biology, etc.
• This lecture provides an overview of the IBM Blue Gene/Psupercomputer’s architecture, along with some practicaladvices about its usage.

What does “super-” mean?
• When talking about computers, the prefix “super-” does nothave the same meaning as when talking about people (e.g.Superman);
• The analogy is closer to that of a supermarket – a marketthat sells a lot of different articles;
• Thus, a supercomputer is not to be tought a priori as avery powerful computer, but simply as a collection of a lotof ordinary computers.

What does “super-” mean?
• Everyone with a spare several thousand euro can build anin-house supercomputer out of a lot of cheap components(think Raspberry Pi) which would in principle be not muchdifferent than high-end supercomputers, only slower.
• Most of the information in these lectures is applicable tosuch ad-hoc supercomputers, clusters, etc.
• In this lecture we’ll have a look at the architecture of a realsupercomputer, the IBM Blue Gene/P, and also discuss thedifferences with the new version of this architecture, IBMBlue Gene/Q.

IBM Blue Gene/P
• IBM Blue Gene/P is a modular hybrid parallel system.• Its basic module is called a “rack” and a certain
configuration can have from 1 to 72 racks.• In the full 72 racks configuration, the theoretical peak
performance of the system is around 1 PFLOPS;• Detailed information about system administration and
application programming of this machine is available onlinefrom the IBM RedBooks publication series, e.g.http://www.redbooks.ibm.com/abstracts/sg247287.html

The IBM Blue Gene/P @ NCSA, Sofia
• The Bulgarian Supercomputing Center in Sofia operatesand provides access to an IBM Blue Gene/P configurationthat consists of 2,048 Computing Nodes, having a total of8,192 PowerPC cores @ 850 MHz and 4TB of RAM;
• The connection of the Computing Nodes with the rest ofthe system is through 16 10 Gb/s channels;
• Its theoretical performance is 27.85 TFLOPS;• Its energy efficiency is 371.67 MFLOPS/W;• When it was put into operation in 2008, it was ranked
126-th in the world in the http://top500.org list.

Why a supercomputer?
• This supercomputer is not much different than a network of2,000 ordinary computers (cluster), or let’s say 40 differentclusters of 50 machines;
• So why bother with a supercomputer? Because it offersseveral distinctive advantages:
• Energy efficient – the maximum power consumption of thesystem at full utilization is 75 kWh; This might seem a lot,but is several times less than 2,000 ordinary computers.
• Small footprint – it fits in a small room, while 2,000 PCswould probably occupy a football stadium. 40 clusters of 50machines would occupy 40 different rooms.

Why a supercomputer?
• Transparent high-speed and highly available network –the mass of cables and devices that interconnect 2,000PCs would be a nightmarish mess;
• Standard programming interfaces (MPI and OpenMP) –the same would be used on clusters. So, a software for thecluster would work on the supercomputer, too (at least inprinciple);
• High scalability to thousands of cores – in the 40 differentclusters scenarios each cluster is small and cannot runextra large jobs;

Why a supercomputer?
• High availability at lower price – built as an integratedunit from the start, it breaks a lot less than 2,000 ordinarycomputers would. Moreover, it can be operated by a smallteam of staff, as opposed to 40 different teams in the manyclusters scenario.
• Better utilization, compared to the 40 clusters scenario.The centralized management allows different teams ofresearchers to use the processing power in a sharedresource manner, which would be very hard to do if theclusters were owned by different groups.
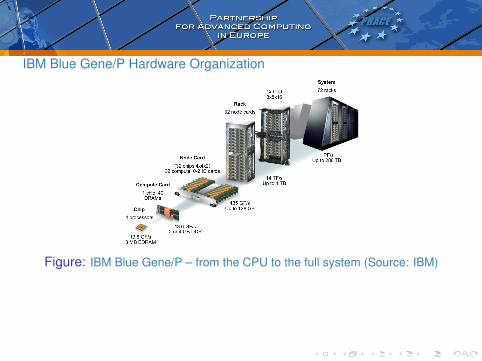
IBM Blue Gene/P Hardware Organization
Figure: IBM Blue Gene/P – from the CPU to the full system (Source: IBM)

Compute Nodes (CN)
• The processing power of the supercomputer stems fromthe multitude of Compute Nodes (CNs). There are 1,024CNs in a rack which totals to 73,728 CNs in a fullconfiguration.
• Each CN contains a quad-core PowerPC @ 850 MHz withdual FPU (called “double hummer”) and 2 GB RAM.
• Ideally, each core can process 4 instructions per cycle,thus performing at 850 × 4 = 3400 MFLOPS. Multiplied bythe number of cores, this brings the performance of asingle CN to 4 × 3.4 = 13.6 GFLOPS.

Compute Nodes (CN)• The theoretical performance of the whole system is thus
73728 × 13.6 = 1002700.8 GFLOPS= 1.0027008 PFLOPS
• Each CN has 4 cores and behave as a shared memorymachine with regards to the 2 GB of RAM on the node;
• The cores on one CN does not have access to the memoryof another CN, so the collection of CNs behave as adistributed memory machine;
• Thus, the machine has hybrid organization – distributedmemory between nodes and shared memory within thesame node.

Connectivity
• Each CN is directly connected to its immediate neighboursin all 3 directions;
• Communications between non-neighbouring nodes involveat least one node that apart from computation is alsoinvolved in forwarding network traffic, which brings down itsperformance.
• The whole system looks like a 3D MESH, but in order toreduce the amount of forwarding it can also be configuredas a 3D TORUS – a 4D figure in which the ends of themesh in each of the 3 directions are connected to eachother.

Connectivity
• The advantage of the torus is that it halves the amount offorwarding necessary, since the longest distance is nowhalf the number of nodes in each direction.
• The connectivity with the rest of the system is achivedthrough special Input/Output Nodes (IONs);
• Each Node Card (32 CNs) has 1 ION through which theCNs access shared disk storage and the rest of thecomponents of the system via 10 GB/s network;
• There are other specialized networks, e.g. for collectivecommunications, etc.

Supporting Hardware
• Apart from the racks containing the CNs, thesupercomputer configuration includes several othercomponents, the most important of them being:
• Front-End Nodes (FENs) – a collection of servers to whichthe users connect remotely using secure shell protocol. Inthe BGP configuration they are PowerPC 64bit machinesrunning SuSE Linux Enterprise Server 10 (SLES 10);
• Service Node (SN) – a backend service node that managesand orchestrates the work of the whole machine. It is offpremises for the end users and only administrators haveaccess to it;

Supporting Hardware
• File Servers (FS) – several servers that run distributed filesystem which is exported and seen by both the CNs andthe FENs. The home directories of the users are stored onthis distributed file system and this is where all input andoutput goes.
• Shared Storage library – disk enclosures containing thephysical HDDs over which the distributed file systemspans.

Software features—cross-compilation
• In contrast to some other supercomputers and clusters,Blue Gene has two distinct sets of computing devices:CNs—the actual work horses; and FENs—the machines towhich the users have direct access.
• CNs and FENs are not binary compatible—a program thatis compiled to run on the FEN cannot run on the CNs andvice versa.
• This puts the users in a situation in which they have tocompile their programs on the FEN (since they only haveaccess to it), but the programs must be able to run on theCNs. This is called cross-compilation.

Software features—batch execution
• Since cross-compiled programs cannot run on the FEN,users cannot execute them directly—they need some wayto post a program for execution.
• This is called batch job execution. The users prepare whatis called ’job control file’ (JCF) in which the specifics of thejob are stated and submit the job to a resource schedulerqueue. When the resource scheduler finds free resourcesthat can execute the job, it is sent to the correspondingCNs;
• Blue Gene/P uses TWS LoadLeveler (LL) as resourcescheduler;

Software features—batch execution• Important consequence of the batch execution is that
programs better not be interactive.• While it is possible to come up with some sophisticated
mechanism to wait on the queue and perform redirection inorder to allow interactivity, it is not desirable, since its onecannot predict exactly when the program will be run.
• And when it does run and waits for user input, and the useris not there, the CNs will idly waste time and power.
• Thus, all parameters of the programs must be passed viaconfiguration files, command line options or some otherway, but not via user interaction.

Partitions• The multitude of CNs is divided in “partitions” (or “blocks”)
and the smallest partition depends on the exact machineconfiguration, but is usually 32 nodes (on the machine inSofia the smallest partition is 128 nodes1);
• A partition that encompases 12 rack (512 CNs) is called
’midplane’ and is the smallest partition for which TORUSnetwork topology can be chosen;
• When LL starts a job, it dynamically creates acorrespondingly sized partition for it. After the jobterminates, the partition is destroyed.
1Which means that there are at most 16 simulateously running jobs on thismachine!

Resource Allocation
• LL does resource allocation. Its task is to maximize thenumber of executed jobs for minimum extent of time giventhe limited hardware resources.
• This is an optimization problem and is solved by heuristicmeans;
• In order to solve this problem LL needs to know the extentsof the jobs both in space (number of nodes) and in time(maximum execution time, called “wall clock limit”);

Constraints and prirotization
• In order to ensure fair usage of the resources, theadministrators can put constraints on the queue—e.g. auser can have no more than N running jobs and M jobs intotal in the queue;
• Apart from this, LL can dynamically assign a priority oneach job, based on things like job submition time, numberof jobs in the queue for the same user, last time a job wasrun by the same user, etc.
• The policy for these things is configured by the systemadministrators.

Execution modes• Each job must specify the execution mode in which to run.
The execution mode specifies the shared/distributedmemory configuration for cores inside each of the CNs inthe job’s partition.
• There are 3 available modes: VN, DUAL and SMP;• In VN mode each CN is viewed as a set of 4 different
CPUs, working in distributed memory fashion. Eachprocessor executes a separate copy of the parallelprogram, and the program cannot use threads. The RAMis divided into 4 blocks of 512 MB each and each core“sees” only its own block of RAM.

Execution modes
• In DUAL mode each CN is viewed as 2 sets of 2 cores.Each set of 2 cores runs one copy of the program, and thiscopy can spawn one worker thread in addition to themaster thread that is initially running. The RAM is dividedinto 2 blocks of 1 GB each and each set of 2 cores sees itsown block.
• This is a hybrid setting—the two threads running inside aset of cores work in shared memory fashion, while thedifferent sets of cores work in distributed memory fashion.

Execution modes
• In SMP mode each CN is viewed as 1 set of 4 cores. Thenode runs one copy of the program, and this copy canspawn three worker threads in addition to the masterthread that is initially running. The RAM is not divided andthe 4 cores see the whole 2 GB of RAM in a purely sharedmemory fashion.
• Again, this is a hybrid setting—the four threads runninginside a node work in shared memory fashion, while thedifferent nodes work in distributed memory fashion.

Execution modes—which one to use?
• In VN mode that partition looks like a purely distributedmemory machine, while in DUAL and SMP mode thepartition looks like a hybrid machine;
• It is much easier to program a distributed memory machinethan a hybrid one.
• Thus, VN mode is the easiest, but it has a giantdrawback—there are only 512 MB of RAM available toeach copy of the program.

Execution modes—which one to use?
• If you need more memory, you have to switch to DUAL orSMP mode.
• But then you also have to take into consideration the hybridnature of the machine and properly utilize the 4 threadsavailable to each copy of the program.
• Running single-threaded application in DUAL or SMPmode is enormous waste of resources!

Job submition
• Prepared jobs are run using the command llsubmit,which accepts as an argument the “job control file” (JCF),which describes the required resources, executable file, itsarguments and environment.
• Calling llsubmit puts the job in the queue of waiting jobs.This queue can be listed using the command llq
• A job can be cancelled by using llcancel and supplying itthe jobid as seen in the llq list.
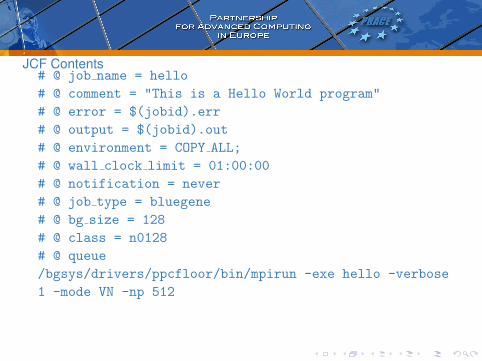
JCF Contents# @ job name = hello
# @ comment = "This is a Hello World program"
# @ error = $(jobid).err
# @ output = $(jobid).out
# @ environment = COPY ALL;
# @ wall clock limit = 01:00:00
# @ notification = never
# @ job type = bluegene
# @ bg size = 128
# @ class = n0128
# @ queue
/bgsys/drivers/ppcfloor/bin/mpirun -exe hello -verbose
1 -mode VN -np 512

Important directives in JCF• error = $(jobid).err
• output = $(jobid).out—These two directives specify aset of files to which the output of the job is redirected.
• Remember that jobs are not interactive and the usercannot see what would normally be seen on the screen ifthe program was run by itself.
• So the output that usually goes on the screen is stored inthe specified files: errors go in the first file and the regularoutput—in the second.
• LL replaces the text $(jobid) with the real ID assigned tothe job, so not to overwrite some previous output.

Important directives in JCF
• wall clock limit = 01:00:00
• bg size = 128
• The first directive provides the maximum extent of the jobin time (HH:MM:SS). If the job is not finished at the end ofthe specified period, it is killed by LL;
• The second directive provides the extent of the job inspace and gives the number of CNs required by the job.
• Remember that in order for LL to be able to solve theoptimization problem, it needs these two pieces of data.

Important directives in JCF• class = n0128
• The class of the job determines several importantparameters, among which:
• The maximum number of nodes that can be requested;• The maximal wall clock limit that can be specified;• The job priority—larger jobs have precedence over smaller
jobs and faster jobs have priority over slower ones;
• Administrators can put in place constraints in regards tothe number of simultaneously executing jobs of each class.
• The classes are different for each installation and theircharacteristics must be made available to the users insome documentation file.

Other supercomputers – Top 10 as of November 20121 Titan (USA) – 17 PFLOPS Cray XK72 Sequoia (USA) – 16 PFLOPS IBM Blue Gene/Q3 K Computer (Japan) – 10 PFLOPS, SPARC64-based4 Mira (USA) – 8 PFLOPS, Blue Gene/Q5 JUQUEEN (Germany) – 8 PFLOPS, Blue Gene/Q6 SuperMUC (Germany) – 2.8 PFLOPS, Intel iDataPlex7 Stampede (USA) – 2.6 PFLOPS, uses Intel Xeon Phi8 Tianhe-1A (China) – 2.5 PFLOPS, uses NVIDIA Tesla9 Fermi (Italy) – 1.7 PFLOPS Blue Gene/Q
10 DARPA Trial Subset (USA) – 1.5 PFLOPS POWER7-based

Blue Gene/Q• In the Top 10 list as of November 2012, 4 of the machines
are IBM Blue Gene/Q• Conceptionally it is very similar to IBM Blue Gene/P, but its
Compute Nodes are a lot more powerful;• Each compute node has 18 64-bit PowerPC cores @ 1.6
GHz (only 16 used for computation), 16 GB RAM and apeak performance of 20 PFLOPS;
• Important aspects as cross-compilation, batch jobsubmition, JCF file format, etc. are basically the same asthose in Blue Gene/P. The obvious difference is modespecification, since now VN, SMP and DUAL are obsoleteand the specification on the BG/Q is more flexible.





























