Embed Size (px)
Citation preview

Agenda
• Why do we need many core platforms ?
• Single-thread optimization
• Parallelization
• Conclusions

Why do we need
many core platforms ?
Why many-core platforms ?
• Von Neumann architecture (1945)
• Moore’s law (1965)“The number of transistors in a dense integrated circuit double approximately every two years”
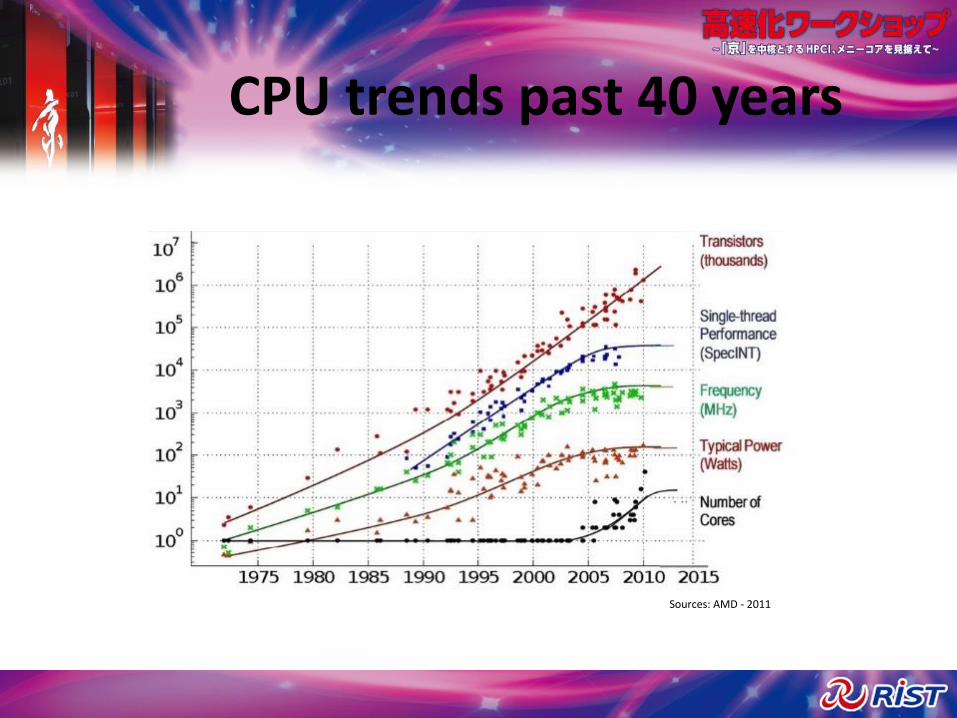
CPU trends past 40 years
Sources: AMD - 2011

The “free lunch” is over
• Back in the days, Moore’s law meant the processor frequency doubled every two years
• Memory bandwidth increased too
upgrading hardware was enough to increase
application performance
• Processor frequency cannot increase any more (physical, power and thermal constraints)
• More transistors means more and more capable cores
• Memory bandwidth and cache size keeps increasing
• Memory bandwidth and cache size per core tends to decrease

The road to exascale
• Exascale supercomputer using evolved technology would be– too expensive
– too power hungry ( > 100 MW, acceptable is < 20 MW)
• Disruptive technology is needed– FPGA ?
– GPU ?
– Many core ?

Disruptive technologyis needed for exascale
• Good compromise between absolute performance, performance per Watt, cost and programmability
• Many core is a popular option, easy programming is an important factor– Sunway TaihuLight (RISC - #1 on Top500)– KNL (x86_64 - #5 and #6 on Top500)– Post K (ARMv8)

Challenges
• More, and more capable but slower cores
• Good algorithm is critical
• Parallelism is no more an option– Instruction level parallelism (vectorization)
– Block level parallelism (MPI and/or OpenMP)
• Hierarchical memory
• Hyperthreading
• Code modernization is mandatory

Manycore tuning challenges
“With great computational power comes great algorithmic responsibility”
David E. Keyes (KAUST)

Single-thread optimization

Single thread optimization
Maximum single thread performance can only be achieved with optimized code that fully exploits all the hardware features :
– Vectorization (Instruction Level Parallelism)
– use of all the Floating Points units (FMA)
– Maximize FLOP vs BYTES
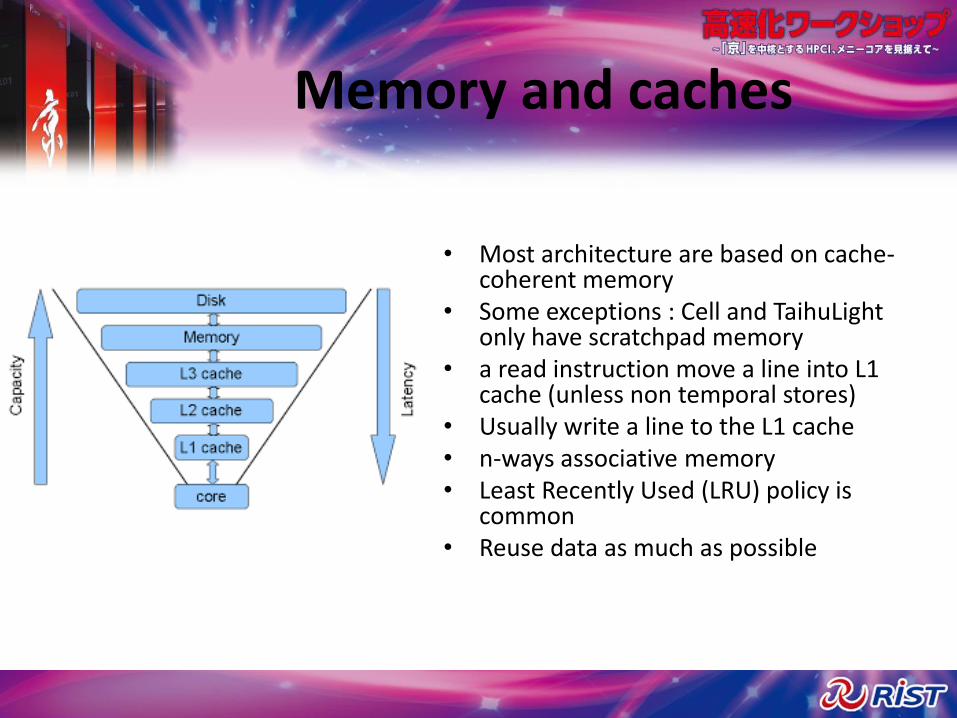
Memory and caches
• Most architecture are based on cache-coherent memory
• Some exceptions : Cell and TaihuLightonly have scratchpad memory
• a read instruction move a line into L1 cache (unless non temporal stores)
• Usually write a line to the L1 cache• n-ways associative memory• Least Recently Used (LRU) policy is
common• Reuse data as much as possible
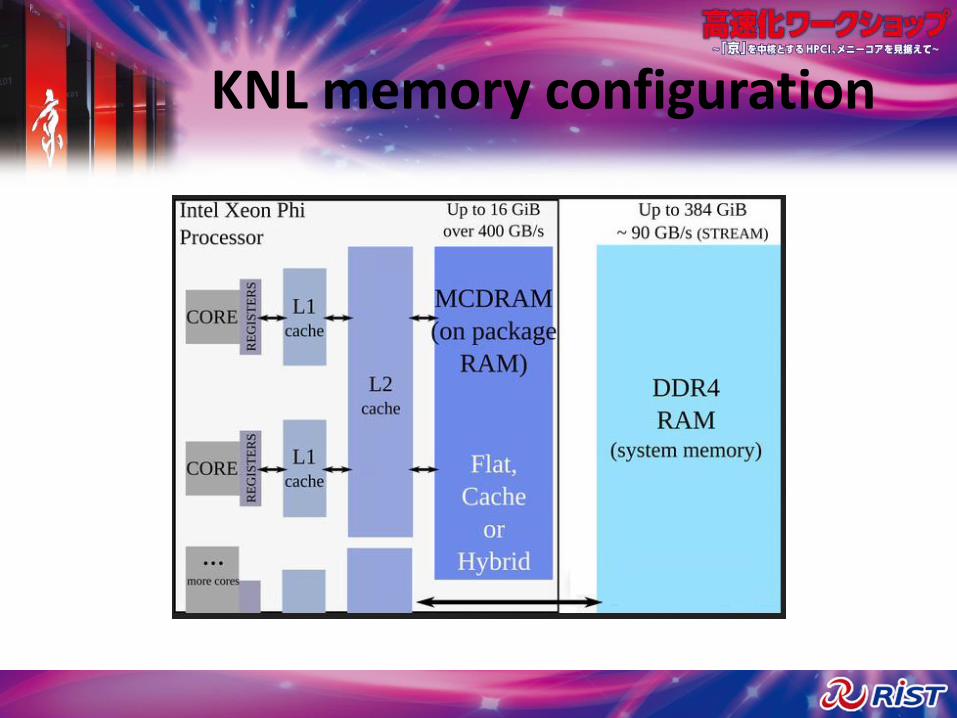
KNL memory configuration

Vectorization
Scalar(one instruction produces one result)
SIMD processing(one instruction can produce multiple results)

When vectorize ?
• Vectorization can be seen as instruction level parallelism
• Loop carried dependence prevent vectorization#define N 1024
double a[N][N];
for (i=1; i<n; i++)
for (j=1; j< n; j++)
a[i][j] = a[i][j-1] + 1;
#define N 1024
double a[N][N];
for (i=1; i<n; i++)
for (j=1; j< n; j++)
a[i][j] = a[i-1][j] + 1;
• loop carried on for j loop
• no loop-carried dependence in for i loop
• no loop-carried dependence in for j loop
• loop-carried dependence in for i loop

Compilers are conservative
• If there might be some dependences, the compiler will not vectorize
• Compiler generated vectorization report are very valuable
• Developer knows best, if there is no dependence, then tell the compiler
– Compiler specific pragma
– Standard OpenMP 4 simd directive

Vectorized loop internals
• Aligned memory accesses are more efficient
• A loop is made of 3 phases– Peeling (scalar) so aligned access can
be used in the main body– Main body (vectorized) with only
aligned access– Remainder (scalar) aligned access but
not a full vector
• Align data and inform the compiler to get rid of loop peeling (directive or compiler option)

#define N 1020
double a[N], b[N], c[N];
for (int i=0; i<N; i++)
a[i] = b[i] + c[i];
#define N 1020
double a[N], b[N];
double sum = 0;
for (int i=0; i<N; i++)
sum += a[i] * b[i];
If 512 bits vectors, bump N to 1024 to get rid of the remainder
If 512 bits vectors, bump N to 1024 and zero a[1020:1023] and b[1020:1023] to get rid of the remainder
Vectorized loop internals
integer, parameter :: N=1020, M=512
double precision :: a(N,M), b(N,M), c(N,M)
do j=1,M
do i=1,N
a(i,j) = b(i,j) + c(i,j)
end do
end do
If 512 bits vectors, bump N to 1024 to get rid of the remainder in the innermost loop
#define N 1024
typedef struct {
double x;
double y;
double z;
} point;
point p[N];
/* x-translation */
for (int i=0; i<N; i++)
p[i].x += 1.0;
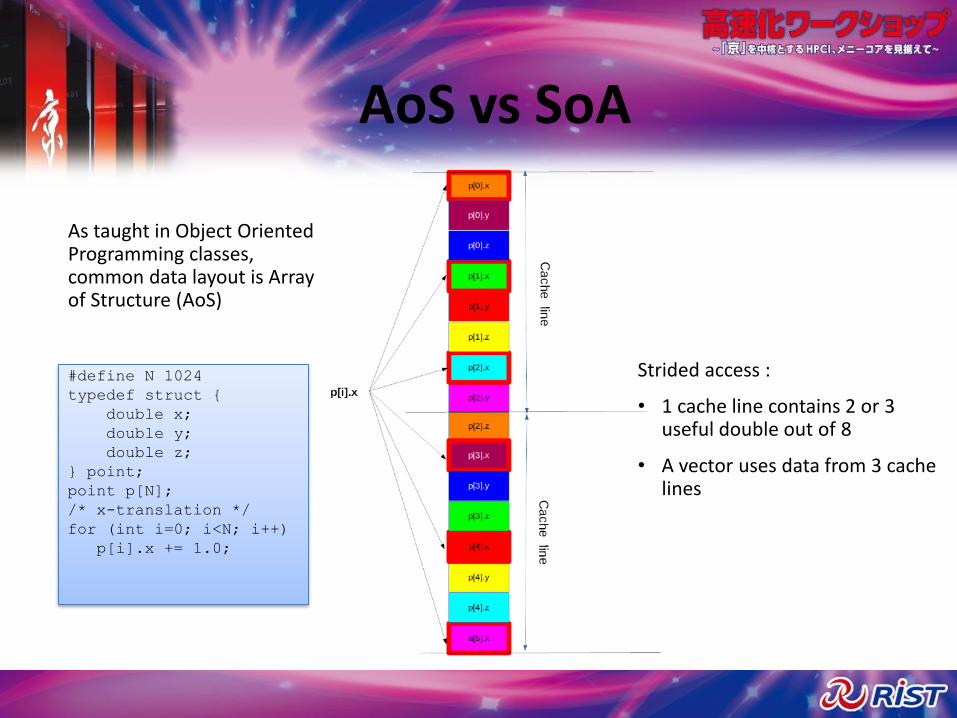
AoS vs SoA
Strided access :
• 1 cache line contains 2 or 3 useful double out of 8
• A vector uses data from 3 cache lines
As taught in Object Oriented Programming classes, common data layout is Array of Structure (AoS)
#define N 1024
typedef struct {
double x[N];
double y[N];
double z[N];
} points;
points p;
/* x-translation */
for (int i=0; i<N; i++)
p.x[i] += 1.0;
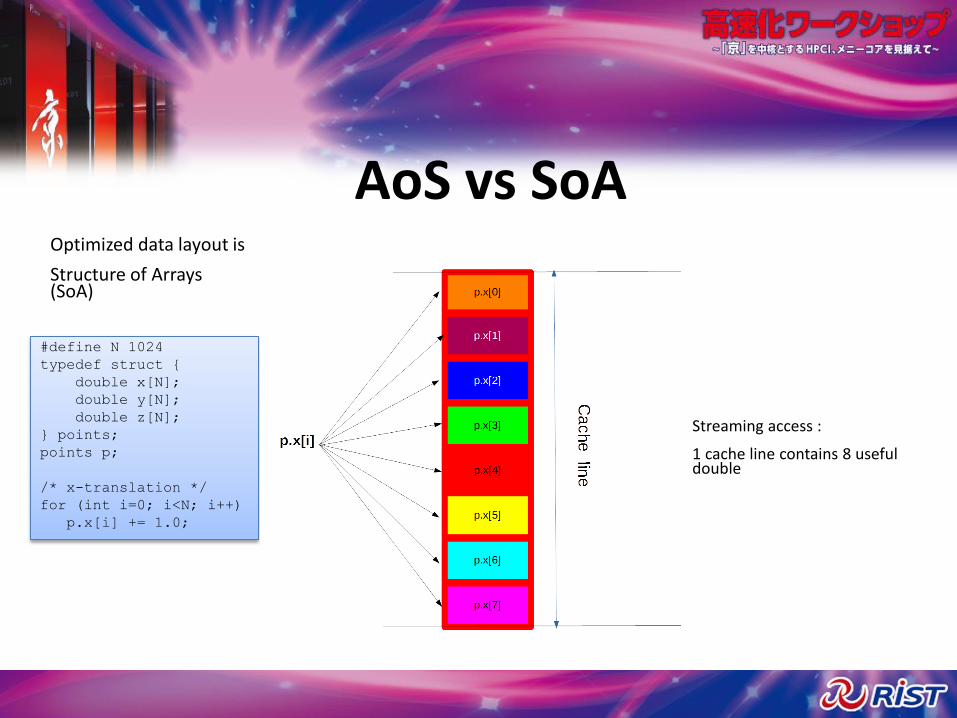
AoS vs SoA
Streaming access :
1 cache line contains 8 useful double
Optimized data layout is
Structure of Arrays (SoA)

Indirect access
#define N 1024
double * a;
int * indixes;
for (int i=0; i<N; i++)
a[indixes[i]]] += 1.0;
• Data must be gathered/scattered from/to several cache lines
• Hardware support is available
• In the general case, vectorization is incorrect !

Indirect access and collisions
#define N 1024
double * a;
int * indixes;
for (int i=0; i<N; i++)
a[indixes[i]]] += 1.0;
• If no conflict can occur, then compiler must be informed vectorization is safe
• Hardware support might be available for collision detection (AVX512-CD)

KNL High Bandwidth Memory
• KNL comes with 16 GB of MCDRAM / High Bandwidth Memory (HBM)
• Memory mode can be selected at boot time (and ideally on a per-job basis)– Flat : NUMA node with 16 GB of HBM and
standard memory
– Cache : only standard memory, HBM is transparently used as a L3 cache
– Hybrid (one portion is used as cache, the other as scratchpad)

KNL flat mode
# use only HBM
$ numactl –m 1 a.out
# try HBM first, fallback to standard memory
$ numactl –preferred=1 a.out
• Command line
• Fortran directive
real(r8), allocatable :: a(:)
!dir$ attributes fastmem, align:64 :: a
allocate(a)
$ export AUTO_HBW_SIZE=min_size[:max_size]
$ LD_PRELOAD=libautohbw.so a.out
#include <hbwmalloc.h>
double * d = hbw_malloc(N*sizeof(double));
• Autohbw library
• Memkind library
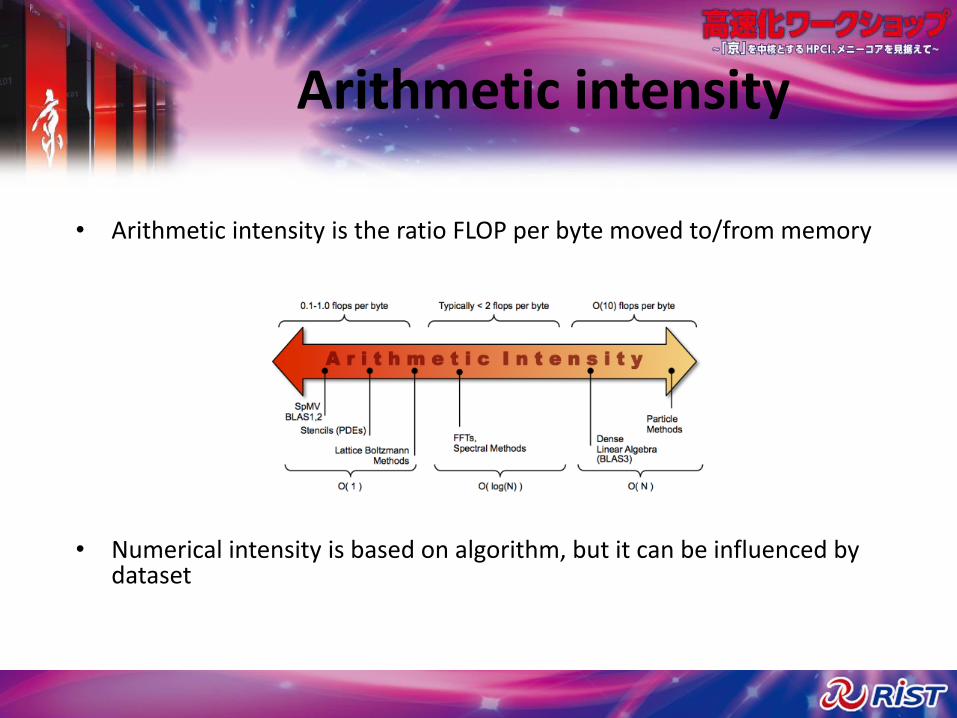
Arithmetic intensity
• Arithmetic intensity is the ratio FLOP per byte moved to/from memory
• Numerical intensity is based on algorithm, but it can be influenced by dataset
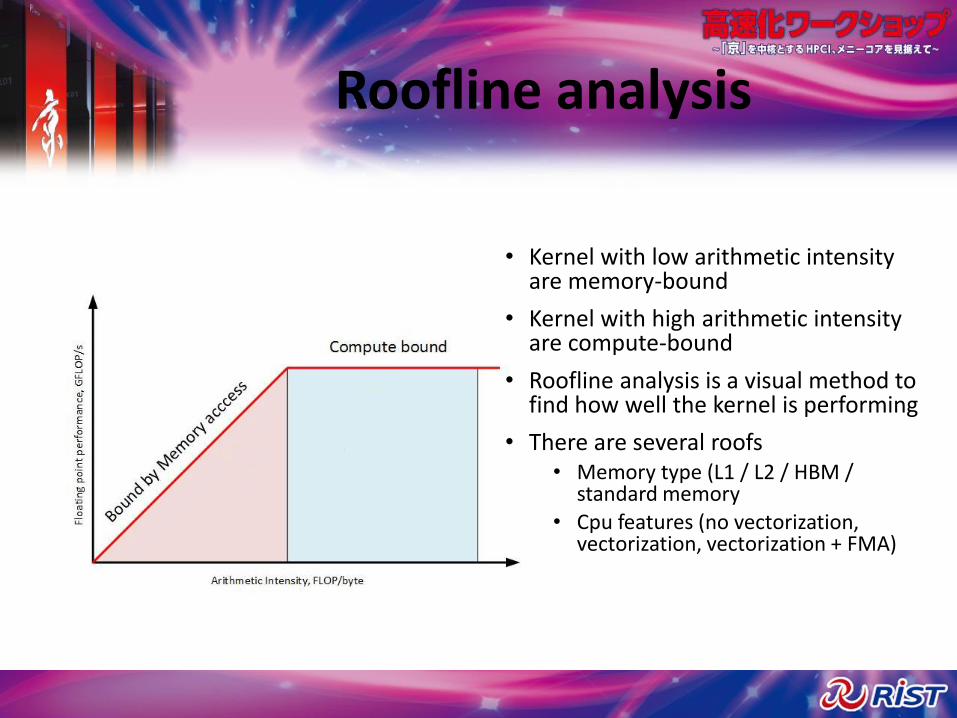
Roofline analysis
• Kernel with low arithmetic intensity are memory-bound
• Kernel with high arithmetic intensity are compute-bound
• Roofline analysis is a visual method to find how well the kernel is performing
• There are several roofs• Memory type (L1 / L2 / HBM /
standard memory• Cpu features (no vectorization,
vectorization, vectorization + FMA)

Roofline analysisw/ Intel Advisor 2017
• Roofline model has to be built once per processor
• Vendor knows best
• Process fully automated from Advisor 2017 Update 2

False sharing
• Different data from the same cache line is used on different processors
• Excessive time is spent ensuring cache coherency
• Re-organize data so per thread data does not share any cache line (padding)
double local_value[NUM_THREADS];
#pragma omp parallel
{
int me = omp_get_thread_num();
local_value[me] = func(me);
}
typedef struct {
double value;
double[7] padding;
} local_data;

n-way associative cache
Since cache is not fully associative, all cache might not be used

Parallelization

Parallelization• “Free lunch” is over, more cores are needed to
keep application performances
• A lot more cores are available and must be effectively used to achieve greater performance
• Parallelization is now mandatory

Performance scaling
• Strong scaling
“how the solution time varies with the number of processors for a fixed total problem size ?”
Ideally, adding processors decreases the time to solution.
• Weak scaling
“how the solution time varies with the number of processors for a fixed problem size per processor”
Ideally, the time to solution remains constant.
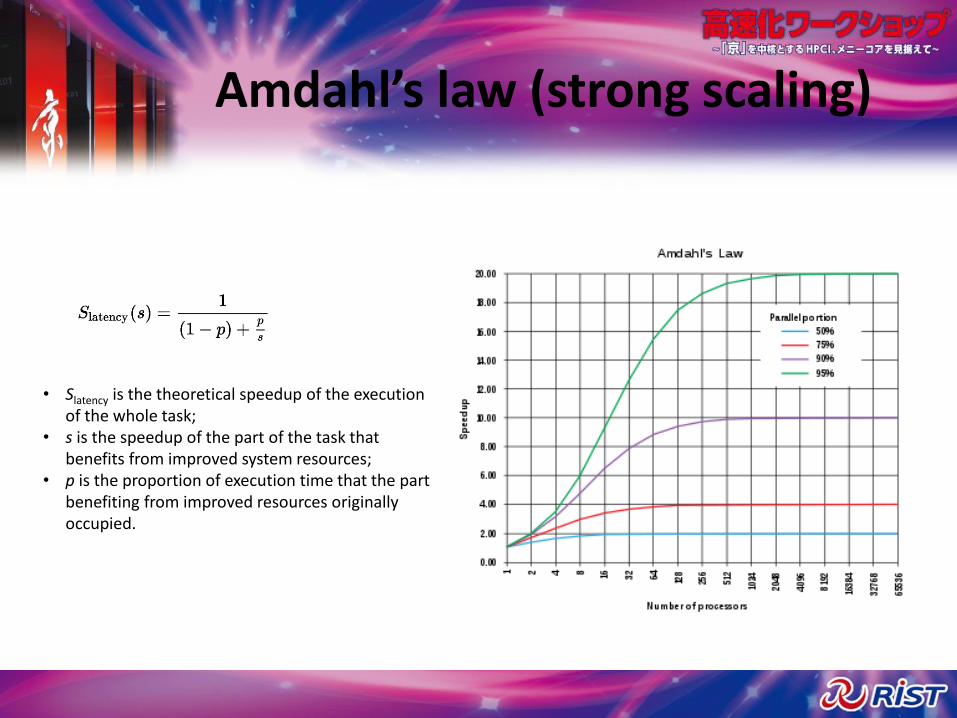
Amdahl’s law (strong scaling)
• Slatency is the theoretical speedup of the execution of the whole task;
• s is the speedup of the part of the task that benefits from improved system resources;
• p is the proportion of execution time that the part benefiting from improved resources originally occupied.
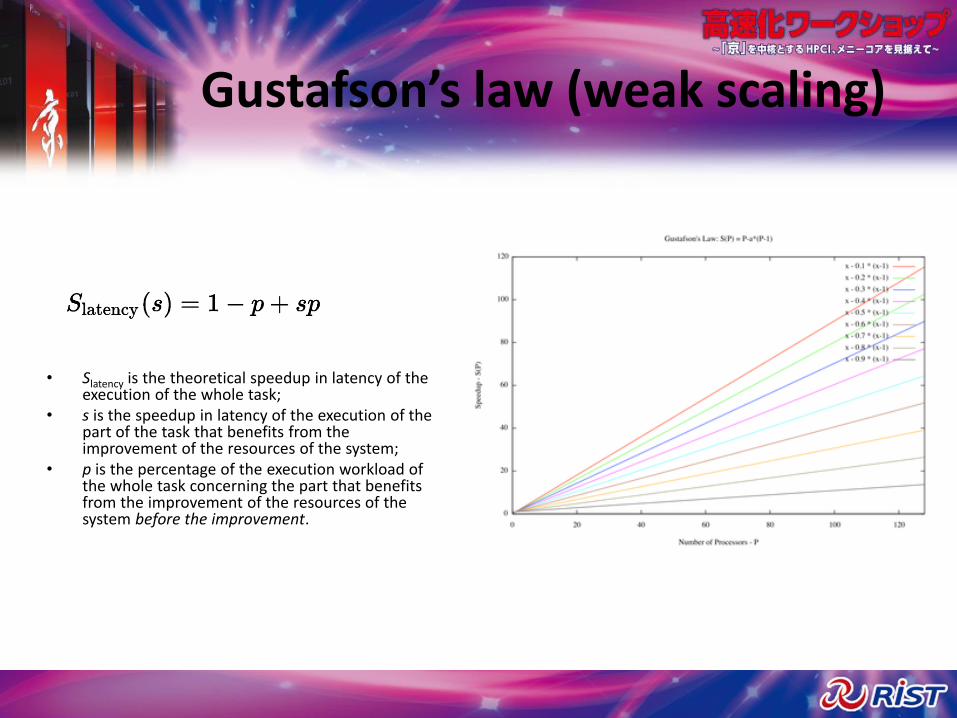
Gustafson’s law (weak scaling)
• Slatency is the theoretical speedup in latency of the execution of the whole task;
• s is the speedup in latency of the execution of the part of the task that benefits from the improvement of the resources of the system;
• p is the percentage of the execution workload of the whole task concerning the part that benefits from the improvement of the resources of the system before the improvement.

At a glance
• Amdahl’s law
“we are fundamentally limited by the serial fraction”
• Gustafson’s law
“we need larger problems for larger numbers CPUs”
“whilst we are still limited by the serial fraction, it becomes less important”

Parallelization models• MPI is the de facto standard for inter process
communication• Flat MPI is sometimes a good option, but beware
of memory and wire-up overhead• MPI+X is the general paradigm• X is for intra node communications and can be
– OpenMP– Pthreads– PGAS (OpenSHMEM, Co-arrays, …)– MPI (!)

OpenMP• OpenMP is a common parallelization
paradigm used on shared memory node
• OpenMP is a set of directives to enable parallelization
#define N 1024
double a[N], b[N], c[N];
for (int i=0; i<N; i++)
a[i] = b[i] + c[i];
#define N 1024
double a[N], b[N], c[N];
#pragma omp parallel for
for (int i=0; i<N; i++)
a[i] = b[i] + c[i];

OpenMP limitations• Most OpenMP parallelization focus only on loops• OpenMP has an overhead (thread creation,
synchronization, reduction)• OpenMP was designed when memory was flat,
today NUMA is very common.• NUMA makes performance models hard to build• OpenMP is generally best within a NUMA node• “natural” when iterations are independent• MPI communications within an OpenMP region is
“not natural”

Hyperthreading• A KNL core consists of 4 hardware threads
• Hardware threads share resources (cache, FPU, …)
• When a hardware thread is waiting for memory, an other hardware thread can be scheduled to perform some computation
• 2 hardware threads are enough to achieve maximum performances (4 on KNC)
• Best is to experiment with 1 and 2 threads per core, and choose the fastest option
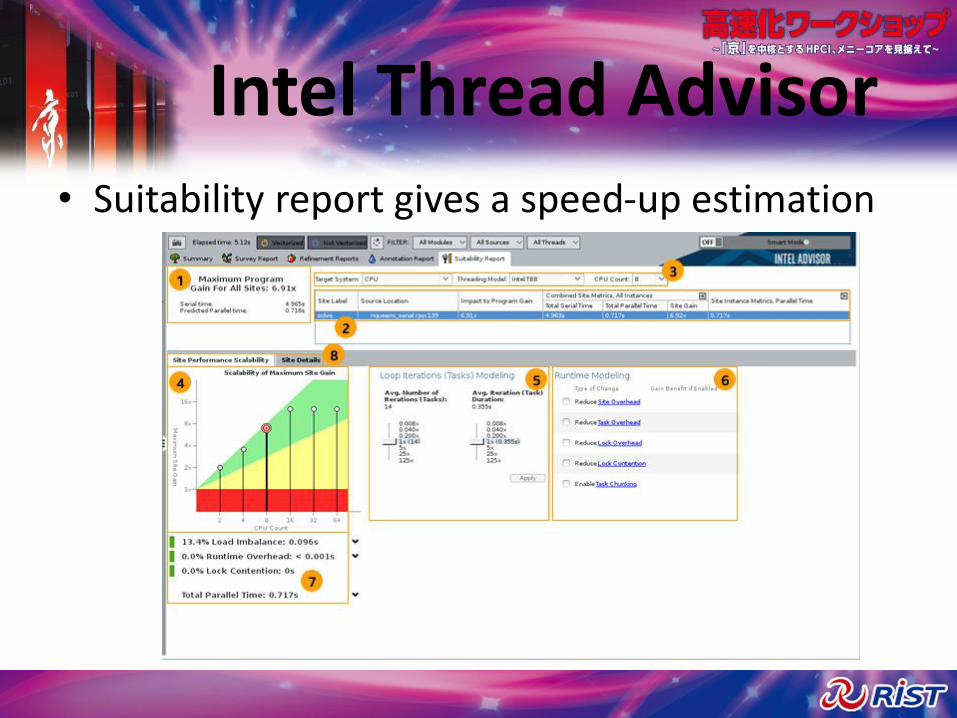
Intel Thread Advisor• Suitability report gives a speed-up estimation

Intel Thread Advisor• Dependency analysis help predicting parallel
data sharing problems (very slow, and only on annotated loops)

KNL cluster modes• KNL cluster mode is selected at boot time (BIOS parameter)• KNL modes influence cache coherency wiring and topology
presented to the application. Commonly used modes are :– Alltoall– Quadrant– SNC-4– SNC-2
• Using the most appropriate mode is critical to achieve optimal performances
• The “best” mode depends on application and parallelization model
• Hopefully, KNL cluster mode can be selected on a per job basis

KNL Cluster modes• All2all/Quadrant (1 socket, 68 cores)
• SNC2 (2 sockets, 34+34 cores)
• SNC4 (4 sockets, 18+18+16+16 cores)

KNL cluster modes• Rules of thumb
– AlltoAll : do not use it !
– SNC-4: 4 NUMA nodes, generally best with a multiple of 4 MPI tasks per node. Note 34 tiles do not split evenly into 4 quadrants !
– SNC-2: 2 NUMA nodes, generally best with a multiple of 2 MPI tasks per node
– Quadrant: flat memory, to be used if SNC-4/2 is not a fit

Problem sizing on KNL• KNL has both ECC (standard) and MCDRAM
(High Bandwidth) memory
• MCDRAM can be configured as cache or scratchpad
• Impact of performance can be significant
• If your app is cache-friendly, weak scale using all available memory
• If your app is not cache-friendly, it might be more effective to weak scale using only HBM

Is your app-cache friendly ?
• In flat mode
– Run with HBM only
– Run with standard memory only
• In cache mode
– Increase dataset size to use all available memory
Measure the drop in performance (if any) when using all the memory in cache mode

Conclusions

Conclusions• Moore’s law is yet still valid
– It used to mean “free-lunch”
– It now means “more cores” and more complex architectures, and that comes with new challenges
• Vectorization and parallelization are mandatory
• Tools are available to help
• We can help you too !

Questions ?
• Regarding this presentation
• Need help with your research






























