Embed Size (px)
Citation preview

Undefined 1 (2009) 1–5 1IOS Press
Transition of Legacy Systems to SemanticallyEnabled Applications: TAO Method andToolsHai H. Wanga,∗, Danica Damljanovicd, Terry Payneb, Nicholas Gibbinsc, and Kalina Bontchevada Aston University, Birmingham, UK, E-mail: [email protected] University of Liverpool Liverpool, UK, E-mail: [email protected] University of Southampton, UK, E-mail: [email protected] University of Sheffield, UK, E-mail: {D.Damljanovic, bontcheva}@dcs.shef.ac.uk
Abstract. Despite expectations being high, the industrial take-up ofSemantic Web technologies in developing services andapplications has been slower than expected. One of the main reasons is that many legacy systems have been developed withoutconsidering the potential of the Web in integrating services and sharing resources. Without a systematic methodology and propertool support, the migration from legacy systems to SemanticWeb Service-based systems can be a tedious and expensive process,which carries a significant risk of failure. There is an urgent need to provide strategies, allowing the migration of legacy systemsto Semantic Web Services platforms, and also tools to support such strategies. In this paper we propose a methodology andits tool support for transitioning these applications to Semantic Web Services, which allow users to migrate their applicationsto Semantic Web Services platforms automatically or semi-automatically. The transition of the GATE system is used as a casestudy.
Keywords: Semantic Web Services, Annotation
1. Introduction
Semantic Web (SW) and Semantic Web Service(SWS) technologies [19] have been recognised as verypromising emerging technologies that exhibit hugecommercial potential and have attracted significant at-tention from both industry and the research commu-nity [2]. Despite this promise, the resulting industrialtake-up of SW and SWS technologies has been slowerthan expected. This is mainly due to the fact that manylegacy systems have been developed without consid-ering the potential of the Web for integrating ser-vices and sharing resources. The migration of legacysystems into semantic-enabled environments involvesmany recursive operations that have to be executedwith rigour due to the magnitude of the investment in
* Corresponding author. E-mail: [email protected]
systems, and the technical complexity inherent in suchprojects. In this context, there are three main issuesto be considered, namely: 1)Web Accessibility, deal-ing with the transformation of components of a legacysystem that are exposed as Web services; 2)ServiceTransformation, where the exposed Web services aremapped to the corresponding Semantic Web Servicerepresentations; and 3)Semantic Annotation, wherethe service representations and software artefacts areannotated using the relevant domain ontology. Withouta systematic methodology and proper tool support, themigration from legacy systems to semantically enabledapplications could be a very tedious and expensive pro-cess, which carries a definite risk of failure. There isan urgent need to therefore provide strategies that sup-port the construction of ontologies which facilite themigration of legacy systems to Semantic Web Servicesplatforms, and also tools to support such strategies.
0000-0000/09/$00.00c© 2009 – IOS Press and the authors. All rights reserved

2 H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools
This paper reports on a new methodology and therelated tool support for addressing the above issues,which in turn could lead to an automatic platformtransformation. This work is part of theTransition-ing Applications to Ontologies (TAO)project1, whichwas part of the European Sixth Framework Program.In TAO, we created an open source infrastructure toaid transitioning of legacy applications to ontologies,through automatic ontology bootstrapping, semanticcontent augmentation, and generation of SemanticWeb service descriptions. The work is grounded in theTAO transitioning methodology and the tool –TAOSuite. In this way, TAO enables a much larger groupof companies to exploit semantics without having tore-implement their applications. All the related mate-rials about TAO (e.g., the TAO softwares, source code,manuals, demos and deliverables) are publicly avail-able athttp://www.tao-project.eu/.
The remainder of this paper is organised as follows.Section 2 presents a set of cookbook-style guidelinesfor the TAO methodology and the usage of the sup-porting tools. Section 3 discusses the evaluation of thework. Finally Section 4 and 5 present the related work,conclusions of this paper and future work.
2. Methodology cookbook, tool support and casestudy
The methodology presented in this section providesa detailed view of the important phases to be per-formed as part of the transition process of legacy sys-tems to semantic-enabled applications following theTAO scenario. It is fully supported by the TAO Suite,which is integrated from several software components.Figure 2 presents the architecture of the transition-ing environment. In it, theontology learning toolisused to derive an ontology from legacy applicationdocumentation (specifications, UML diagrams, codedocumentations, software manuals, including images).The content augmentation toolautomatically identi-fies key concepts within legacy contents, which cango beyond textual sources, and annotates them usingthe domain ontology concepts. The distributed hetero-geneous knowledge repositories are developed to ef-ficiently index, query, and retrieve legacy content (in-cluding code, documentation, transcripts taken fromdiscussion forums, etc), domain ontology and seman-
1http://www.tao-project.eu/
tic annotations. An Integrated Development Environ-ment (IDE) has been developed to provide an one-stoptransition support for users.
One important novelty for the TAO transitioningmethodology is that it provides a logical approach forconnecting the traditional ontology and service designthrough the following main points.
– Learning ontologies from service descriptions.In a normal ontology design lifecycle, theOn-tology Learningprocess attempts to automati-cally or semi-automatically derive a knowledgemodel from a document corpus. In our transition-ing methodology, we refine and extend this toemphasis the contribution made by the descrip-tion of a broader and more heterogeneous collec-tion of documentation resources that relate to ex-isting legacy applications (including applicationAPIs, developer documentation, SOA design doc-umentation, etc). We call this refinementService-Oriented Ontology Learning.
– Using domain ontologies to augment semanticcontent and service descriptions.The service an-notation process described in many existing SOAdesign methodologies refers to the description ofservices at the signature level in languages suchas WSDL. While these allow rudimentary ser-vice matchmaking and brokerage on the basis ofthe types of the inputs and outputs of a service,these types are typically expressed syntacticallyusing traditional data-types, rather than exploitinga semantically richer and more expressive repre-sentation grounded by an ontological characteri-sation of the relevant domain. Thus, these inter-faces need to be mapped to equivalent conceptswithin Semantic Web frameworks (such as OWL-S, WSMO or WS-WSDL) and annotated usingthe relevant domain ontologies.
In the next subsection, we present a set of cookbook-style guidelines for the usage of TAO tools. Note thatthis paper only focuses on the usage of TAO tools, dueto the limited space2.
To better illustrate the idea, we use as a case studythe transition of the GATE3 system to a collection ofsemantic-enhanced services. GATE is a leading open-source architecture and infrastructure for the building
2For more technical details on various tool components, please re-fer to the respective reports, which can be downloaded fromhttp://www.tao-project.eu/.
3http://gate.ac.uk

H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools 3
Collect
structure
docs for
the
legacy
app
Collect source
codes
Collect WSDL
definations
Collect APIs
Collect Database
schema
Collect XML
data
... ...
Service and content augmentation
Identify services
Identify other contents for annotating
Annotate services and other
contents using WP3
Load/import WSDL
or other resources
Load domain ontology
Start annotating
Manually
annotating
Save SA-WSDL and SA-Doc
into TAO repository
View and revise
annotations
Automatic
annotating
Ontology learning
Identify the text-mining instances
Assign textual document to
instances
Determining the structure
between instances
Transform content and
structure into feature vectors
Create Concept
(Unsupervised)
Manage concepts
Manage relations
Manage instances
Create Concept
(Supervised)
... ...
Identify structure and
content software
artefacts
Create domain
ontology from feature
vectors
Ensure the ontology is well-formed
Ensure the ontology has right formalism
Ensure the ontology is consisitant
Ensure the ontology is
contextually correct Design Ontology
Evaluate and refine Ontology
Document
Corpora
Save
corpora
into TAO
Repository
Collect
textual
docs
for
the
legacy
app
Collect reference
manuals
Collect source
code comments
Collect
annotator's guide
Collect user's guide
Collect forum
disucussion
... ...
Check if there already exists some ontolologies for the application domain
Domain
Ontology
Check if WSDL definitions exists?
WSDL Definitions
Documents for
annotating
Save
Ontology
into TAO
Repository
Evaluation and refine
service discriptions
SA-WSDL SA-Doc
No Yes
Save the ontologyno
Yes
Activity supported by HKS ) Activity supported by LATINO Activity supported by CA MANAGER
Evaluate and refine the domain Ontology
Ontology population
Fig. 1. Cookbook methodology overview.
and deployment ofHuman Language Technologyap-plications, used by thousands of users at hundreds ofsites. After many years of developing, revising and ex-tending, GATE developers and users find that it be-comes difficult to understand, maintain and extend thesystem in a systematic way, due the large amount ofheterogeneous information that cannot be accessed viaa unified interface [3].
The advantages of transitioning GATE to semantic-enhanced services are two-fold. Firstly, GATE compo-nents and services will be easier to discover and inte-grate within other applications due to the use of Se-mantic Web Service technology. Secondly, the transi-tion should facilitate better search results for queriesover a given GATE concept due to the enhancedknowledge based searches that span a broader set ofheterogeneous sources and corpora including the com-plete GATE document corpus, XML configurationfiles, video tutorials, screen shots, user discussion fo-rum, etc. The development team of GATE consists atpresent of over 15 people, but over the years morethan 30 people have been involved in the project. Tobe used for evaluating TAO tools, GATE exhibits all
the specific problems that large software architecturesencounter, which enables us to evaluate the methodol-ogy and tools intensively. Bontcheva et. al. [3] discussthe advantages and possibilities arising from buildingdomain ontology and application for semantic enrich-ment of software artefacts in the GATE case study.
2.1. Transitioning cookbook
The TAO methodology has three main phases: thedata acquisition phase, the ontology learning phase andthe semantic content and service augmentation phase.Each phase contains a set of tasks which may interactwith each other. Figure 1 presents a UML diagram thatillustrates the main transitioning process; details of themajor activities are presented below.
To transition a legacy application to a number ofsemantically enabled services, a software engineershould first check whether previously developed on-tologies exist for the application domain. Public on-tology search engines or ontology libraries may be

4 H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools
Existing Application Docs
Specifi-
cationsCode
APIs
Video
and Text
Manuals
...
Legacy Application Content
Content
Mgnt.
Systems
DBsService
Descript
-ion
...
Ontology Learning tool
Content Augment tool
Distributed Heterogeneous Knowledge Repository
Transition Support IDE
Application
Developer
Semantic Application Services
Fig. 2. Transitioning Process
used, such as Swoogle4 or SWSE5. If no such ontol-ogy is found, users have to derive the domain ontol-ogy from the legacy software. If a related ontologyis found, previous methodologies, such as the NEONmethodology6, could be used to directly adapt and ex-tend the discovered ontology. However, given past ex-perience in ontology development, these approachesare not ideal for many use cases. The main reason isthat in most cases, it is difficult to find an existing on-tology that is perfectly matched to the requirementsof annotating and describing legacy applications. Re-using complex domain ontologies built for the domainin similar projects could be a tedious task. The morecomplex an ontology, and the more tied it is to its orig-inal context of development and use, the less likely itwill fit another context. It can be as difficult and costlyto trim such ontologies in order to keep only the rele-vant parts as it is to re-build those parts completely.
Building domain ontologies with a “top-down” ap-proach as extensions of a “foundational ontology” isanother popular approach. Foundational ontologies areoften highly abstract, or include strong constraints thatare rarely part of the requirements of the target system.In the TAO approach, if a related ontology is found, itis saved into the knowledge store developed by TAOand used as training data for the ontology learning tooltogether with other software artefacts. For the GATE
4http://swoogle.umbc.edu5http://swse.deri.org6http://www.neon-project.org/
case study, the ontology was developed from scratchwith the assistance of the TAO tools.
2.1.1. Data acquisitionTo derive the domain ontology from a legacy appli-
cation using the TAO tools, users first need to collectrelevant resources about the legacy application.– Resources collection
In the TAO cookbook, we have identified variousdata sources which are commonly relevant to the de-scription of a legacy application, such as applicationsource code, APIs, and JavaDocs7. For the GATEcase study, the application’s Java source code and cor-responding JavaDoc files are identified and assem-bled8. These are then deposited in the the TAO reposi-tory [24] – a component of the TAO tools.– Save the resource corpora to the TAO Repository
The TAO repository [24] is a heterogeneous knowl-edge store designed and developed for efficient man-agement of different types of knowledge: unstructuredcontent (documents), structured data (databases), on-tologies, and semantic annotations, which augment thecontent with links to machine-interpretable metadata.The query and reasoning capabilities of this repositoryare based on the Ontology Representation and Data In-tegration (ORDI) framework [24].
7For more information about the potential data sources whichmaybe related to the description of legacy systems and their classifica-tion, please refer to the report [1].
8Those documents can be downloaded fromhttp://gate.ac.uk/download/index.html.

H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools 5
2.1.2. Ontology LearningThe process of ontology learning from software
artefacts is essentially one of discovering concepts andrelations from various learning resources identified inthe previous steps, including the source code, accom-panying documentation, and external sources (such asthe Web). Ontology learning is one of the most signif-icant approaches proposed to date for developing on-tologies from existing domain-related resources. Pre-viously, we have presented a detailed review of dif-ferent ontology learning approaches [1]. Gomez-Perezet. al. [9] also reviewed the major methods for semi-automatically building ontologies from texts.
Two learning components were used for ontologylearning within this case study:LATINO was used tobuild feature vectors from documentation; andOn-toGen, was used to build an ontology from the re-sulting feature vectors. LATINO9 is a general data-mining framework that unites text mining and linkanalysis for the purpose of (semi-automated) ontol-ogy construction. LATINO is novel with respect toother existing ontology learning methods in severalways. LATINO constructs the ontologies from implicitknowledge contained within the documents and datathat form the set of learning resources (identified inthe previous stages). Concepts and their inter/intro-relationships are selected and used in the ontology con-struction process. We introduce the term “applicationmining” to denote the process of extracting this knowl-edge from application-related resources. In addition,LATINO is not only limited to textual data sources;additional data resources that can be used for ontol-ogy learning, including structured documents such asdatabase schema, UML models, existing source code,APIs, etc., or textual documents that include require-ment documents, manuals, forum discussions etc.– Identify content and structure of software artefacts
To use LATINO, a selection of the learning re-sources relevant to the intended ontology (and thatwere identified in the previous data acquisition stage)should be selected. Given a concrete TAO scenario,the first question to be answered by a software engi-neer is – what are thetext-mining instances(i.e. piecesof data to be used for text-mining)10, in this partic-ular case. The user needs to study the data at hand
9http://www.tao-project.eu/researchanddevelopment/demosanddownloads/ontology-learning-software.html
10To avoid confusing the termINSTANCE in the text-mining sensewith the termINSTANCE from the ontological perspective, we will
and decide which data entities will play the role of in-stances in the transitioning process. It is impossibleto answer this question in general - it depends on theavailable sources. The cookbook offers users some po-tential choices including Java/C++ classes, methods,and database entities. In the GATE case study, the in-stances are all Java classes.
Next, we need to assign a textual document (de-scription) to each text-mining instance. This step is notobligatory, as there is no universal standard for whichtext should be included. However, it is important thatonly relevant elements of text are included to avoidthe text-mining algorithms generating poor or mislead-ing results. Users should develop several (reasonable)rules for what to include and what to leave out, andevaluate each of them in the given setting, choosingthe rule that will perform best. Some of the more com-monly used rules are given in the cookbook. Giventhat the GATE Java classes were used as text-mininginstances for the GATE case study, the assigned tex-tual documents included the Java classes’class com-ment, class name, field names, field comments, methodnamesandmethod comments.
The user may also identify any structural informa-tion evident from the data. This step is also not oblig-atory, provided that textual documents have been at-tached to the instances. The user should consider anykind of relationships between the instances (e.g. links,references, computed similarities, and so on). Notethat it is sometimes necessary to define the instancesin a way that makes it possible to exploit the rela-tionships between them. For Java/C++ classes, the po-tential links that can be extracted include inheritanceand interface implementation graphs, type referencegraphs, class and operation name similarity graphs,comment reference graphs, etc. After this step, the datapre-processing phase is complete. More informationabout those types of links and the different calculationsof link weight can be found in [11].– Creating feature vectors from contents and structures
The text-mining algorithms employed by LATINO(and also by many other data-mining tools) work withfeature vectors. Therefore, once the text-mining in-stances have been enriched with the textual docu-ments, they need to be converted into feature vectors.LATINO is able to compute the feature vectors from adocument network, based on the source code. In suchnetworks, classes generally contain methods that have
talk aboutTEXT-MINING INSTANCES to emphasise the text-miningcontext.

6 H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools
some return value which may in turn correspond to in-stances of another class. Comments within the sourcecode may also refer to other classes. For each of thesecases, a graph can be created, where vertices representJava classes and edges represent references betweenthese classes. This may result in the construction ofseveral graphs which all share the same set of vertices.Different weights (ranging from 0 to 1) are assignedto each graph. To help the user set the parameters,the TAO Suite application OntoSight [10] provides theuser with an insight into the resulting document net-works and semantic spaces via interactive visualisationtools. These feature vectors are further used as an inputfor OntoGen11 which is a semi-automatic data-drivenontology construction tool that creates suggestions fornew concepts for the ontology automatically. OntoGenis also integrated with LATINO and the TAO Suite.– Create domain ontology from feature vectors.
The most important step of ontology developmentis to identify the concepts in a domain. Using Onto-Gen, this can be performed by using either a fully au-tomated approach such as unsupervised learning (e.g.clustering), or a semi-automated supervised learning(e.g. classification) approach.
The main advantage of unsupervised methods is thatthey require very little input from the user. The unsu-pervised methods provide well-balanced suggestionsfor sub-concepts based on the instances and are alsogood for exploring the data. The supervised methodprovided by OntoGen, however, requires more input.The user has to initially identify the desired sub-concept, and then describe it through a query beforeengaging in a sequence of questions to clarify thatquery. This is intended for the cases where the userhas a clear idea of the desired sub-concept that shouldbe added to the ontology, but where this sub-conceptis not automatically discovered by the unsupervisedmethod. For the GATE case study, the unsupervisedapproach has proven to be sufficient for this learningtask, as there is little prior knowledge regarding the de-sired concepts for inclusion within the ontology. Fur-ther details on using OntoGen/LATINO can be foundin [11].
It is important to note that the automated meth-ods are not intended to extract the perfect ontology,they only offer support to domain experts in acquiringthis knowledge. This help is especially useful in situ-ations such as in the Gate scenario, where the knowl-
11http://ontogen.ijs.si/
edge is distributed across several documents. There-fore, the automatically acquired knowledge is post-edited, using an existing ontology editor, to remove ir-relevant concepts and add missed ones. This activityoccurs during theDesign Ontologystage within theTAO cookbook (as illustrated in Figure 1). Hence, on-tology learning tools are seen as a support for generat-ing ontologies, and using them makes sense only in thecontext of large legacy applications (i.e. where “thou-sands” of documents are used). These tools can of-fer guidance in these cases, when building ontologiesfrom scratch might be impractical.
After creating the domain ontology, it is savedwithin the TAO repository for later use. It is only nowpossible to augment the existing content of a legacyapplication (including any service definitions) seman-tically. We present the details in the following subsec-tion.
2.1.3. Service and content augmentationContent Augmentationis a specific metadata gener-
ation task that facilitates new information access meth-ods. It enriches the augmented text with semantic in-formation, linked to a given ontology, thus enablingsemantic-based search over the annotated content. Forlegacy software applications, the key parts are the ser-vice descriptions, software code and the documenta-tion. While there has been a significant body of re-search on semantic annotation of textual content (in thecontext of knowledge management applications), onlylimited attention has been paid to processing legacysoftware artefacts, and in general, to the problem ofsemantic-based software engineering. As part of theTAO Suite, a tool known as theKey Concept Iden-tification Tool (KCIT)was developed to assist usersin annotating heterogeneous software artefacts semi-automatically. In essence,KCIT is capable of perform-ing two tasks: 1)semantic annotation, whereby dif-ferent elements within a document (such as phrases,n-grams or terms) are identified using various infor-mation extraction techniques, and linked to conceptswithin an ontology; and 2)document query, wherebythe annotated documents are first stored within a per-sistent storage repository (i.e. the TAO Repository),and then retrieved using a relevance-query mechanismwhich exploits a selected set of semantic annotationsto find relevant documents, rathe than using keyword-lookup techniques. More information aboutKCIT canbe found at [5].

H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools 7
To useKCIT, we first need to identity which Webservices users want to provide, and also which types ofrelated content that need to be annotated.– Identify services and other content to be annotated.
The first step in creating a Web service is to designand implement the application that represents the Webservice. This step includes the design and coding of theservice implementation, and the verification of all ofits interfaces (to determine whether or not they workcorrectly). Once the Web service has been developed,the service interface definition can be generated fromthe implementation of the service (i.e. the service inter-face can be derived from the application’s ApplicationProgramming Interface (API)). Web service interfacesare usually described as WSDL documents that definethe interface and binding of the corresponding Webservice implementations. In this paper, we assume thatthe Web services and the corresponding WSDL defini-tions for a legacy application have already been devel-oped. As various methods and tools for wrapping theexisting functionalities of a legacy application as ser-vices currently exist [16,8], we focus here on assistingusers in the annotation of existing WSDL definitionsto generate SA-WSDL definitions12.– Annotate automatically and manually
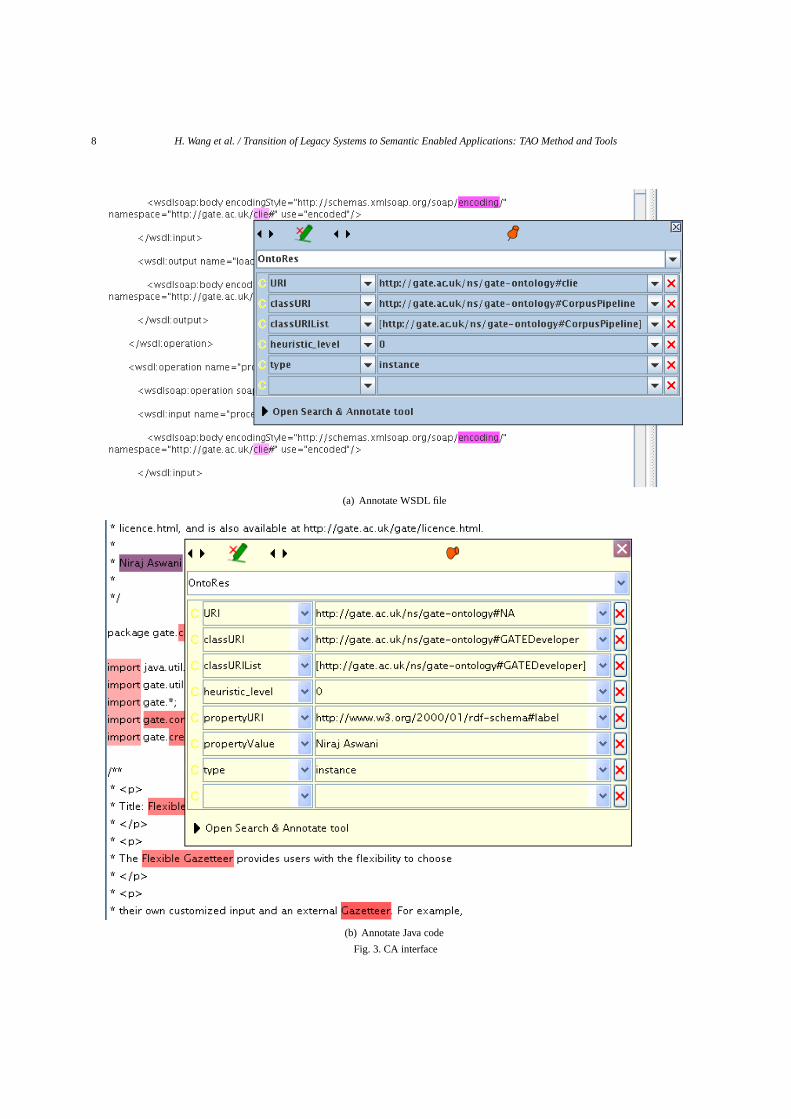
KCIT identifies key concepts from software-relatedlegacy content by preprocessing ontology lexicalisa-tions (e.g. replacing dashes and underlines with spaces,splitting camelCased words, etc.) and finally extract-ing the root from each ontology lexicalisation. It is thisroot that is matched against the roots of the words intext. Hence, KCIT performs more than an exact textmatch, like many other existing approaches. It can alsobe configured to better adopt different use cases. Forexample, when preparing a document such as WSDL,it can be configured so that the tags’ processing is en-abled. Users then just click a button and KCIT goesthrough the WSDL file or other legacy content and au-tomatically identifies the pieces of text or tag, whichare related to concepts or relations defined in the do-main ontology by using NLP techniques. After theprocess of automatic annotation is finished, users canvalidate results by visualising them (by using GATEGUI for example), correcting annotations if necessary,and adding new ones by manually selecting the textthey want to link to the relevant concept from the on-tology. Figure 3(a) shows an example of annotated
12Semantic Annotations for WSDL (SA-WSDL) [15] is the latestW3C recommendation for describing Semantic Web Services.
GATE WSDL file. We can see details of the high-lighted annotation over theclie string, where it showsthe instance URI (which refers toclie) and the clas-sURI (which refers to Corpus Pipeline). By automat-ically processing WSDL files using the TAO Suite,we produce the SWS descriptions represented usingSA-WSDL. The TAO Suite can also be used to an-notate other software artefacts including user guides,developer guides, forum posts, source code, etc. Fig-ure 3(b) shows the results of processing the GATEclassFlexibleGazetteer.java. The popup table de-picts annotation features created by KCIT for the an-notated term ‘Niraj Aswani’. From these features, itcan be concluded that this name is referring to a GATEdeveloper as, according to the features, this name is avalue (property-Value) of the property rdfs:label (prop-ertyURI) for an instance (type) that is of type GATEdeveloper (classURI). The automatically annotated re-sults could contain some flaws, and we need to ensurethat this semantic metadata is correctly asserted. TheTAO Suite allows domain experts to manually checkthe correctness of the annotations.– Storing and Querying Annotations
In order to access the semantic knowledge, the re-sulting annotation features, together with document-level metadata, are read and exported in a format whichcan be easily queried via a formal language such asSPARQL. More specifically, this extracted informationneeds to ‘connect’ a document with different ‘men-tions’ of the ontology resources inside the documents.For example, if a document contains mentions of theclass Sentence Splitter, the output should be mod-elled in a way that preserves this information duringquery time (i.e. the URLs of all documents mention-ing this class should be found easily). For this purpose,the PROTON Knowledge Management ontology13 hasbeen used in our repository, through which the infor-mation about the type and address of a document, theposition (the start and end offset) of a ‘mention’ withina document can be represented in a standard way.
The extracted annotations are stored in our OWL-compatible knowledge repository (OWLIM [14]), andaccessible for querying using formal SW query lan-guages (e.g. SPARQL). The exported annotations rep-resented using OWL are stored separately from the ac-tual GATE ontology (used for content augmentation).This way, we can easily keep the annotations and thetext syncronized.
13http://proton.semanticweb.org/2005/04/protonkm
8 H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools
(a) Annotate WSDL file
(b) Annotate Java code
Fig. 3. CA interface

H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools 9
Languages for querying OWL such as SPARQL,while having a strong expressive power, require de-tailed knowledge of their formal syntax and under-standing of ontologies. One of the ways to lower thelearning overhead and make semantic-based queriesmore straightforward is through text-based queries.In order to enable advanced semantic-based accessthrough text-based queries, aQuestion-based Inter-face to Ontologies– QuestIO has been developed andintegrated in the TAO Suite. QuestIO is a domain-independent system which translates text-based queriesinto the relevant SeRQL queries, executes them andpresents the results to the user. QuestIO first recog-nises key concepts inside the query, detects any poten-tial relations between them, and then creates the re-quired semantic query. An example query with resultsis shown in Figure 4; for the query ‘niraj’, a list of doc-uments mentioning this term is returned, among whichthe last link points to the documentation about Flexi-ble Gazetteer. This is inline with the Figure 3(b), fromwhich it can be concluded thatNiraj is the authorof the classFlexibleGazetteer.java. The advantageof the semantic query is that queries are observed asconcepts, rather than as a set of characters – as is thecase in traditional search engines. I.e.,Niraj, Niraj
Aswani, orNA (as initials) would all return the sameresults as soon as the ontology encodes that these termsrefer to the same concept.
3. Evaluation and discussion
3.1. Evaluation
Ontology Learning from Software Artefacts.Most ontology evaluation approaches that have beenproposed in the literature rely on the opinions andcommon sense of domain experts. For example, [18]proposed an approach whereby an expert ontology en-gineer was asked to model a gold standard for the taskand compare it with the generated ontology. Anotherstudy proposed that domain experts should use the on-tology in an application and then evaluate the results[21]. A set of ontology criteria have been designed[17], which need to be assessed manually by domainexperts, based on common sense and domain knowl-edge.
In our evaluation, we have used a combination ofthese approaches. After the ontology has been learnedfrom the software artefacts, we asked GATE devel-opers to refine it in order to create a gold standard
for the comparison. The final ontology with populatedinstances is available fromhttp://gate.ac.uk/ns/gate-kb.
A questionnaire was designed to collect the gen-eral opinion from engineers about the learned ontol-ogy. The feedback from experts is encouraging anddetails can be found in the reports [4,23]. To mea-sure the quality of the GATE ontology that is createdby the TAO method, we took a sample of 36 ques-tions collected at random from the GATE mailing listand measured what percentage can be answered us-ing the developed ontology. In these questions, numer-ous GATE users enquired about GATE modules, plug-ins, processing resources, and problems they encounterwhile using these components. After examining thesequestions, we identified that out of these 36 questions,61.1% (22 questions) were answerable: the GATE do-main ontology that was developed following the TAOmethodology contained the answers to these questions.The questions were mainly factual questions enquiringabout GATE components such asWhat are the runtimeparameters of the ANNIE POS Tagger?. The remain-ing 14 questions (38.9%) were unanswerable: the an-swer was not in the ontology/knowledge base. Most ofunanswerable questions tended to enquire about spe-cific features that were not included in user manualsand documentation, but were only known by experi-enced GATE developers. In additon, some questionsenquired about personal problems without enough ex-plicit information such asI cannot get Wordnet pluginto work.
Content Augmentation. To evaluate the CA com-ponent, we have selected 20 documents to serve as arepresentative corpus of GATE software artefacts, in-cluding forum posts, java classes, and the user man-ual. We have first manually annotated these documentsto create a gold standard corpus. Next, we ran KCITto automatically annotate these 20 artefacts, and thenwe compared the results using precision and recall;we have achieved an average precision of94.28% pre-cision and a recall of96.99%. For more informationabout this experience and the evaluation for other soft-ware components such asHeterogeneous KnowledgeStoreandQuestIO, please refer to the report [4].
User-centric Evaluation of the Transitioning Re-sults. In order to conduct a user-centric evaluation andinvestigate benefits of the TAO transitioning tools, wechose to test an integrated testbed containing user-understandable content. In other words, we asked agroup of GATE developers and users to carry out aset of tasks involving the source code, software doc-

10 H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools
Fig. 4. List of results for the query ‘niraj’
umentation, and other human-readable software arte-facts (e.g. to ‘Find which forum posts are related to theLearning PR’), excluding the semantically annotatedservices, as the latter are aimed at automatic processesand are hard to work with for non-specialists. How-ever, the same TAO tools can be used for discoveringsemantically annotated services. In fact, being able tohandle these diverse types of legacy services and datawith the same toolset was one of the original objectivesof the project.
The aim of this qualitative evaluation is to vali-date whether software developers, who are not experi-enced in Semantic Web technologies and formalisms,are able to find easily all information relevant to theirtasks by using the semantic-based testbed. This newsemantic-based system was evaluated with developersand users of the GATE open-source platform, in or-der to compare their working practices at present andwith the new technology. In a nutshell, we carried outa repeated measure: task-based evaluation design (also
called within-subjects design), i.e., the same users in-teract with our prototype (further referred asnew) andalso use their current working practices and tools (fur-ther referred astraditional), in order to complete agiven set of tasks.
From the study, we measured:
– Efficiency: time spent to complete the tasksusing the two approaches – traditional andnew. On average, it took46.61% longer to finishall the set tasks using the traditional methods incomparison to the new semantic-based prototype(107.1375 secondsvs. 157.075 seconds).
– Efficiency: the percentage of completed tasksusing the two approaches.Overall, the successrate for performing tasks using the prototype was152.11% better in comparison to the success rateusing the legacy system (0.355 in comparison to0.895, on a scale from 0 to 2).
– User satisfaction: the SUS questionnaire as astandard satisfaction measure.We chose the

H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools 11
SUS questionnaire as our principal measure ofsoftware usability because it is a de facto standardin this field. SUS scores range from 0 (very littlesatisfaction) to 100 (very high satisfaction). Totalscore in our evaluation was 69.38.
Detailed study results are in the report [4]. With re-gards to justification of using the TAO tools in com-parison to other available ones, we refer the reader to[20].
3.2. Impact and exploitation
The TAO method and tools offer a low-cost migra-tion path for legacy applications to knowledge tech-nologies and is accessible to both SMEs (which arecost sensitive) and large enterprises (with huge invest-ments in complex and critical IS). The results havebeen validated in two high-profile case studies: a com-prehensive open source platform (with thousands ofusers) and a data-intensive business process applica-tion (managing a multi-million business). More infor-mation about these case studies is in [5,6].
TAO project partners have obtained overe750,000in follow-up commercial funding from the Austriancompany Matrixware to apply two of the TAO toolsto the problem of Large-Scale Semantic Annotation ofPatents. The goal is to exploit this TAO technologyand annotate terabytes of data in several days of su-percomputer time. The TAO Suite is also now used bythe company behindhttp://videolectures.net for the automatic classification of video materialsposted to their web site.
TAO has delivered a series of tutorials focusedaround the TAO Suite and also organised an industry-oriented workshop in January 2009 which attractedstrong interest and produced very positive feedbackon the technological achievements of the project; onecompany commented that they had been waiting forsuch enabling technology for their business cases,and another company noted that it was the first timethat they had seen complementary solutions (ontol-ogy learning, content augmentation, knowledge stor-age and queries, WSDL annotations, SOA architectureetc.) harnessed together to facilitate the overall processof transitioning. In other words, from this external in-dustrial perspective, TAO has been successful in devel-oping and integrating the necessary enabling technolo-gies for transitioning legacy applications to ontologies,without making too rigid a stance on what softwarearchitectures or semantic service formalisms must beadopted.
3.3. License status and the latest development
The TAO Suite is open source and Eclipsed-basedand can be freely downloaded from the project’s website14. The ontology learning tool LATINO, the contentaugmentation tool KCIT and the knowledge store HKSare available under LGPL license.
The TAO project partners are currently maintain-ing and will further develop these software compo-nents. LATINO will be developed further by one ofthe TAO project partners (the Jozef Stefan Institute -JSI)15, as part of several ongoing EU projects. KCITand the other related components have been integratedinto GATE16, and are being further developed as partof the GATE development process. The latest versionof GATE 6.0 was released in November 2010 and anew release is planned for May 2011. HKS is furtherdeveloped as part of the OWLIM Semantic Repository(OWLIM)17 by Ontotext18.
4. Related work
A number of ontology-design methodologies thathave been proposed to date to guide the process ofontology development from scratch have been listedin a comprehensive survey in [13,9]. While [7] hasidentified seven of the most commonly used method-ologies for designing ontologies from scratch, [12,22]have outlined a set of principles and design criteria thathave been proved useful in developing domain ontolo-gies. During the last decade several ontology-learningsystems have been developed such as ASIUM, On-toLearn, Text2Onto, OntoGen, and others. Most ofthese systems depend on linguistic analysis and ma-chine learning algorithms to find potentially interest-ing concepts and relations between them.
Whilst several methodologies exist to develop do-main ontologies either from scratch or from text, thereis no widely accepted method for transitioning existingapplications to SOA based on domain ontologies. [16]proposed the use of black-box wrapping techniques tomigrate functionalities of existing Web applications totraditional Web services. In our methodology, the do-
14http://www.tao-project.eu/researchanddevelopment/demosanddownloads/tao-suite.html
15http://www.ijs.si/ijsw/JSI16http://gate.ac.uk/17http://www.ontotext.com/owlim/18http://www.ontotext.com/

12 H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools
main ontology plays a key role in the transition processas it contains all the semantics required for annotatingthe services of the new SOA. Our method and toolsare focused on legacy application transitioning. We usevarious kinds of function related resources to derivethe domain ontology. Since most existing applicationstend to have documentation describing their function-ality and APIs, it is possible to use automatic process-ing tools to abstract domain concepts from those termsused in such documentation and build the domain on-tology. Our methodology is also fully supported by anintegrated tool studio.
5. Conclusion and future work
A key requirement of transitioning applications toSemantic Web Services has promoted the urgent needof systematic methodologies and tools to assist themigration process. In this paper we present the TAOmethodology and tool suite for transitioning legacy ap-plications to SWS, which allows users to migrate theirapplications to SWS platform automatically or semi-automatically. In the future, more case studies will beapplied to further evaluate the system. We also plan tointegrate some third party tools to our framework, suchas WSDL generation tool, to make TAO Suite morecomplete and flexible.
References
[1] Florence Amardeilh, Bernard Vatant, Nicholas Gib-bins, Terry R. Payne, and Hai H.Wang. Sws boot-strapping methodology. Technical Report D1.2.2,TAO Project Deliverable, 2009. http://www.tao-project.eu/resources/publicdeliverables/d1-2-2.pdf.
[2] Grigoris Antoniou and Frank van Harmelen.A Semantic WebPrimer. MIT Press, Cambridge, MA, 2. edition, 2008.
[3] Kalina Bontcheva, Ian Roberts, Milan Agatonovic, JulienNioche, and James Sun. Case study 1: Requirement analysisand application of tao methodology in data intensive applica-tions. Technical Report D6.1, TAO Project Deliverable, 2007.http://www.gate.ac.uk/projects/tao/webpage/deliverables/d6-1.pdf.
[4] Damljanovic D. and Bontcheva K. Gate case study:Experiments and evaluation of testbed. TechnicalReport D6.4, TAO project, 2009. http://www.tao-project.eu/resources/publicdeliverables/d6-4.pdf.
[5] Damljanovic D., Bontcheva K., Tablan V., Roberts I.,Agatonovic M., Andrey S., and Sun J. Gate case study: Do-main ontology and semantic augmentation of legacy content.Technical Report D6.2, TAO project, 2008. http://www.tao-project.eu/resources/publicdeliverables/d6-2.pdf.
[6] Cerbah F. Case study 2: Domain ontology buildingand semantic augmentation of legacy content. Techni-cal Report D7.2, TAO project, 2008. http://www.tao-project.eu/resources/publicdeliverables/d7-2.pdf.
[7] Mariano Fernandez-Lopez, Asun Gomez-Perez, Jerome Eu-zenat, Aldo Gangemi, Y. Kalfoglou, D. Pisanelli, M. Schor-lemmer, G. Steve, Ljilajana Stojanovic, Gerd Stumme, andYork Sure. A survey on methodologies for developing,maintaining, integration, evaluation and reengineering ontolo-gies. Ontoweb deliverable, Universidad Politecnia de Madrid,2002. http://www.aifb.uni-karsruhe.de/WBS/ysu/publications/OntoWeb_Del_1-4.pdf.
[8] Gerald C. Gannod, Huimin Zhu, and Sudhakiran V. Mudiam.On-the-fly wrapping of web services to support dynamic inte-gration. InWCRE ’03: Proceedings of the 10th Working Con-ference on Reverse Engineering, page 175, Washington, DC,USA, 2003. IEEE Computer Society.
[9] Asunción Gómez-Pérez and David Manzano-Macho. Anoverview of methods and tools for ontology learning fromtexts.Knowl. Eng. Rev., 19(3):187–212, 2004.
[10] Miha Grcar. Ontology learning services library. Tech-nical Report D2.2.2, TAO Project Deliverable, 2008.http://www.gate.ac.uk/projects/tao/webpage/deliverables/d2-2-2.pdf.
[11] Miha Grcar, Dunja Mladenic, Marko Grobelnik, Blaz For-tuna, and Janez Brank. Ontology learning implementation.Technical Report D2.2, TAO Project Deliverable, 2007.http://www.gate.ac.uk/projects/tao/webpage/deliverables/d2-2.pdf.
[12] Thomas R. Gruber. A translation approach to portable ontologyspecifications.Knowl. Acquis., 5(2):199–220, 1993.
[13] Dean Jones, Trevor Bench-Capon, and Pepijn Visser. Method-ologies for ontology development. InProceedings ofIT&KNOWS Conference of the 15 th IFIP World ComputerCongress, pages 62–75. Chapman and Hall Ltd, 1998.
[14] Atanas Kiryakov, Damyan Ognyanov, and Dimitar Manov.Owlim – a pragmatic semantic repository for owl. InInt.Workshop on Scalable Semantic Web Knowledge Base Systems,pages 182–192, New York City, USA, 2005. Springer-Verlag.
[15] Holger Lausen and Joel Farrell. Semantic annotations forWSDL and XML schema. W3C recommendation, W3C, Au-gust 2007.
[16] Giusy Di Lorenzo, Anna Rita Fasolino, Lorenzo Melcarne,Porfirio Tramontana, and Valeria Vittorini. Turning web appli-cations into web services by wrapping techniques. InWCRE’07: Proceedings of the 14th Working Conference on ReverseEngineering, pages 199–208, Washington, DC, USA, 2007.IEEE Computer Society.
[17] A. Lozano-Tello and A. Gómez-Pérez. ONTOMETRIC: AMethod to Choose the Appropriate Ontology.Journal ofDatabase Management, 15(2), April-June 2004.
[18] Alexander Maedche and Steffen Staab. Measuring similar-ity between ontologies. InEKAW ’02: Proceedings of the13th International Conference on Knowledge Engineering andKnowledge Management. Ontologies and the Semantic Web,pages 251–263, London, UK, 2002. Springer-Verlag.
[19] Sheila A. McIlraith, Tran Cao Son, and Honglei Zeng. Seman-tic web services.IEEE Intelligent Systems, 16(2):46–53, 2001.
[20] Tomás Pariente, Germán Herrero, Danica Damljanovic, andFarid Cerbah. D1.3.2 case study reports on evaluating themethodology. Technical Report D1.3.2, TAO project, 2009.

H. Wang et al. / Transition of Legacy Systems to Semantic Enabled Applications: TAO Method and Tools 13
http://www.tao-project.eu/resources/publicdeliverables/d1-3-2-final.pdf.
[21] Robert Porzel and Rainer Malaka. A task-based approachforontology evaluation. InProceedings of ECAI 2004 Workshopon Ontology Learning and Population, Valencia, Spain, 2004.Springer-Verlag.
[22] Bill Swartout, Ramesh Patil, Kevin Knight, and Tom Russ. To-ward distributed use of large-scale ontologies. In10th Work-shop on Knowledge Acquisition, Canada, June 1996.
[23] Valentin Tablan, Danica Damljanovic, and Kalina Bontcheva.A natural language query interface to structured information.In Proceedings of the 5th European semantic web conferenceon The semantic web: research and applications, ESWC’08,pages 361–375, Berlin, Heidelberg, 2008. Springer-Verlag.
[24] Marinova Z. Heterogeneous knowledge store. Tech-nical Report D4.2, TAO Project Deliverable, 2008.http://www.gate.ac.uk/projects/tao/webpage/deliverables/d4-2.pdf.





























