Embed Size (px)
Citation preview

IRLecture 1

Information Retrieval Information retrieval is concerned with
representing, searching, and manipulating large collections of electronic text and other human-language data.
Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).

1. Basic techniques (Boolean Retrieval)2. Searching, browsing, ranking, retrieval3. Indexing algorithms and data structures
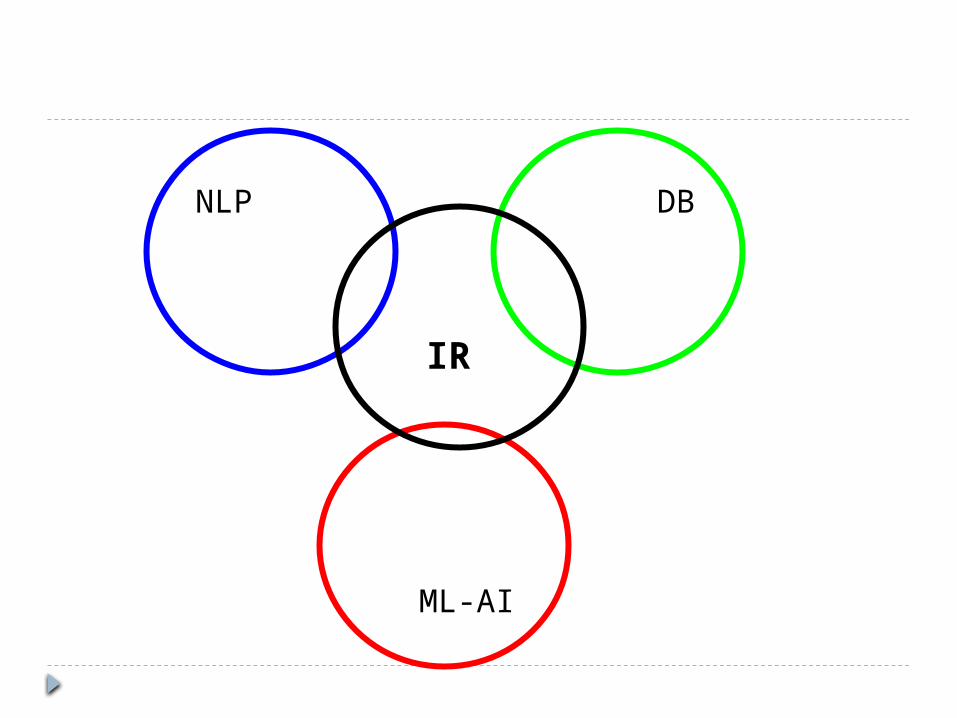
NLP DB
ML-AI
IR

Database Management Library and Information Science Artificial Intelligence Natural Language Processing Machine Learning

Database Management
Focused on structured data stored in relational tables rather than free-form text.
Focused on efficient processing of well-defined queries in a formal language (SQL).
Clearer semantics for both data and queries.
Recent move towards semi-structured data (XML) brings it closer to IR.

Library and Information Science
Focused on the human user aspects of information retrieval (human-computer interaction, user interface, visualization).
Concerned with effective categorization of human knowledge.
Concerned with citation analysis and bibliometrics (structure of information).
Recent work on digital libraries brings it closer to CS & IR.

Artificial Intelligence
Focused on the representation of knowledge, reasoning, and intelligent action.
Formalisms for representing knowledge and queries: First-order Predicate Logic Bayesian Networks
Recent work on web ontologies and intelligent information agents brings it closer to IR.

Natural Language Processing Focused on the syntactic, semantic, and
pragmatic analysis of natural language text and discourse.
Ability to analyze syntax (phrase structure) and semantics could allow retrieval based on meaning rather than keywords.

Natural Language Processing:IR Directions Methods for determining the sense of an
ambiguous word based on context (word sense disambiguation).
Methods for identifying specific pieces of information in a document (information extraction).
Methods for answering specific NL questions from document corpora.

Machine Learning
Focused on the development of computational systems that improve their performance with experience.
Automated classification of examples based on learning concepts from labeled training examples (supervised learning).
Automated methods for clustering unlabeled examples into meaningful groups (unsupervised learning).

Machine Learning:IR Directions
Text Categorization Automatic hierarchical classification (Yahoo). Adaptive filtering/routing/recommending. Automated spam filtering.
Text Clustering Clustering of IR query results. Automatic formation of hierarchies (Yahoo).
Learning for Information Extraction Text Mining

Information Retrieval The indexing and retrieval of textual
documents. Searching for pages on the World Wide Web is
the most recent and widely used application. Concerned firstly with retrieving relevant
documents to a query. Concerned secondly with retrieving from large
sets of documents efficiently.

Information Retrieval SystemsGiven:
A corpus of textual natural-language documents. A user query in the form of a textual string.
Find: A ranked set of documents that are relevant to the query.
Most IR systems share a basic architecture and organizations. (adapted to the requirements of specific applications)
Like any technical field, IR has its own jargon.
Next page illustrates the major components in an IR system.

IRSystem
Query String
Documentcorpus
RankedDocuments
1. Doc12. Doc23. Doc3 . .
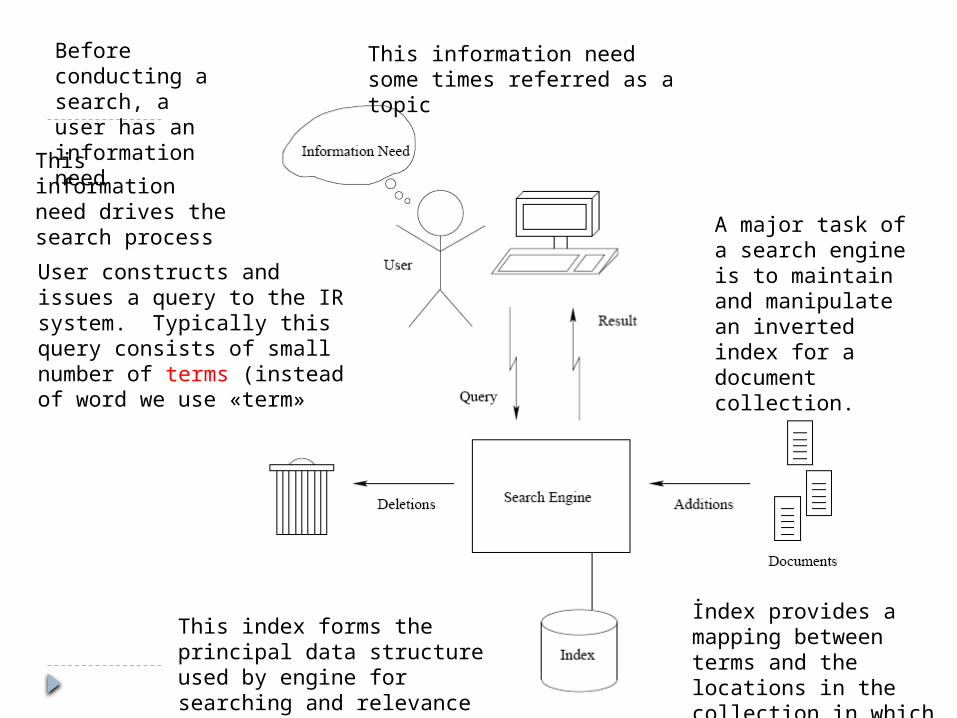
Before conducting a search, a user has an information need
This information need drives the search process
This information need some times referred as a topic
User constructs and issues a query to the IR system. Typically this query consists of small number of terms (instead of word we use «term»
A major task of a search engine is to maintain and manipulate an inverted index for a document collection.
This index forms the principal data structure used by engine for searching and relevance ranking.
İndex provides a mapping between terms and the locations in the collection in which they occure.

Relevance Relevance is a subjective judgment and may
include: Being on the proper subject. Being timely (recent information). Being authoritative (from a trusted source). Satisfying the goals of the user and his/her
intended use of the information (information need).
Simplest notion of relevance is that the query string appears verbatim in the document.
Slightly less strict notion is that the words in the query appear frequently in the document, in any order (bag of words).

Problems May not retrieve relevant documents that
include synonymous terms. “restaurant” vs. “café” “Turkey” vs. “TR”
May retrieve irrelevant documents that include ambiguous terms. “bat” (baseball vs. mammal) “Apple” (company vs. fruit) “bit” (unit of data vs. act of eating)For instance, the word "bank" has several distinct lexical definitions, including "financial institution" and "edge of a river".
19
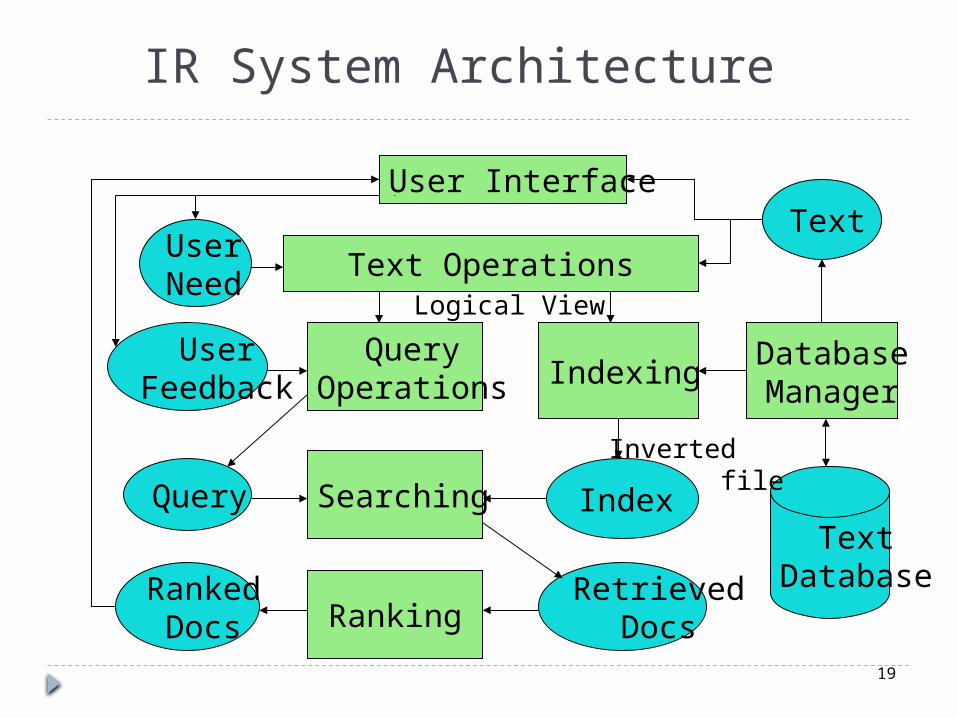
IR System Architecture
TextDatabase
DatabaseManager
Indexing
Index
QueryOperations
Searching
RankingRanked
Docs
UserFeedback
Text Operations
User Interface
RetrievedDocs
UserNeed
Text
Query
Logical View
Inverted file

IR Components Text Operations forms index words (tokens).
Stopword removal Stemming
Indexing constructs an inverted index of word to document pointers.
Searching retrieves documents that contain a given query token from the inverted index.
Ranking scores all retrieved documents according to a relevance metric.

IR Components User Interface manages interaction with the
user: Query input and document output. Relevance feedback. Visualization of results.
Query Operations transform the query to improve retrieval: Query expansion using a thesaurus.
Query transformation using relevance feedback.

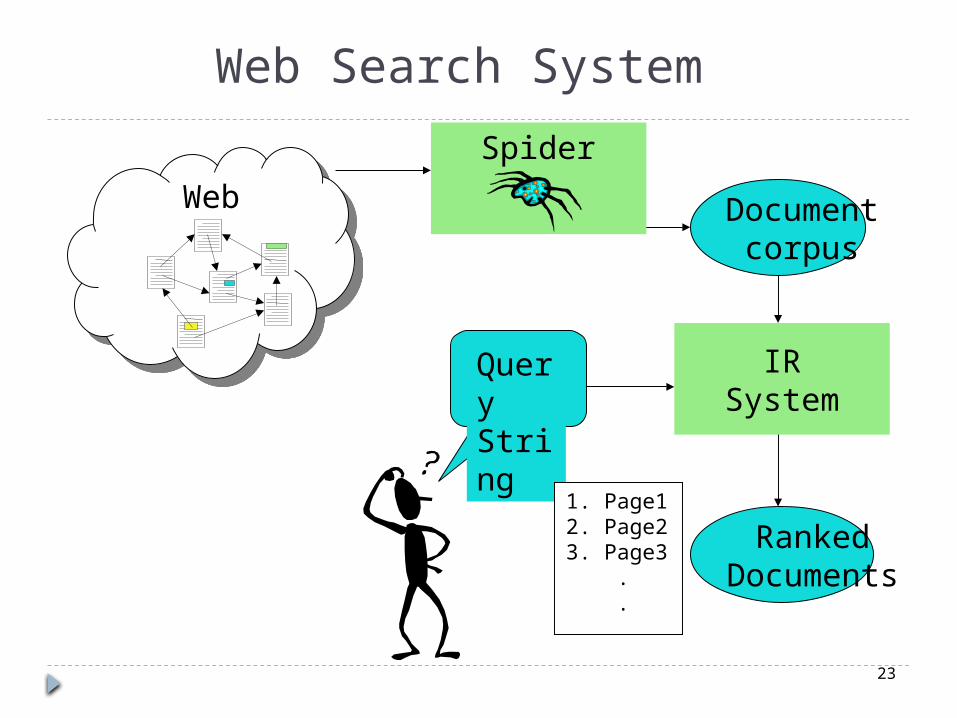
Web Search Application of IR to HTML documents on the
World Wide Web. Differences:
Must assemble document corpus by spidering the web.
Can exploit the structural layout information in HTML (XML).
Documents change uncontrollably. Can exploit the link structure of the web.
23
Web Search System
Query String
IRSystem
RankedDocuments
1. Page12. Page23. Page3 . .
Documentcorpus
Web
Spider

Other IR-Related Tasks Automated document categorization Information filtering (spam filtering) Information routing Automated document clustering Recommending information or products Information extraction Information integration Question answering

25
History of IR 1940-50’s:
World War II denoted the official formation of Information Representation and Retrieval. Because of war, a massive number of technical reports and documents were produced to record the research and development activities surrounding weaponary production.

26
History of IR 1960-70’s:
Initial exploration of text retrieval systems for “small” corpora of scientific abstracts, and law and business documents.
Development of the basic Boolean and vector-space models of retrieval.
Prof. Salton and his students at Cornell University are the leading researchers in the area.

27
IR History Continued 1980’s:
Large document database systems, many run by companies: Lexis-Nexis (On April 2, 1973, LEXIS launched publicly,
offering full-text searching of all Ohio and New York cases)
Dialog (manual to computerized information retrieval) MEDLINE ((Medical Literature Analysis and Retrieval
System)

28
IR History Continued 1990’s: Networked Era
Searching FTPable documents on the Internet Archie WAIS
Searching the World Wide Web Lycos Yahoo Altavista

29
IR History Continued 1990’s continued:
Organized Competitions NIST TREC (Text REtrieval Conference (TREC) is an on-
going series of workshops focusing on a list of different information retrieval (IR) research areas, or tracks.)
Recommender Systems Ringo Amazon
Automated Text Categorization & Clustering

30
Recent IR History 2000’s
Link analysis for Web Search Google (page rank)
Automated Information Extraction Whizbang (Build Highly Structured Topic-Specific/Data-
Centric Databases) (White Paper, Information Extraction and Text Classification” via WhizBang! Corp)
Burning Glass (Burning Glass’s technology for reading, understanding, and cataloging information directly from free text resumes and job postings is truly state-of-the-art)
Question Answering TREC Q/A track (Question answering systems return an
actual answer, rather than a ranked list of documents, in response to a question.)

31
Recent IR History 2000’s continued:
Multimedia IR Image Video Audio and music
Cross-Language IR DARPA Tides (Translingual Information Detection,
Extraction and Summarization) Document Summarization

An example information retrieval problem
A fat book which many people own is Shakespeare’s Collected Works. Suppose you wanted to determine which plays of Shakespeare contain the words Brutus AND Caesar AND NOT Calpurnia.
One way to do that is to start at the beginning and to read through all the text, noting for each play whether it contains Brutus and Caesar and excluding it from consideration if it contains Calpurnia.
The simplest form of document retrieval is for a computer to do this sort of linear scan through documents.

This process is commonly referred to as grepping.
Grepping through text can be a very effective process, especially given the speed of modern computers
With modern computers, for simple querying of modest collections (the size of Shakespeare’s Collected Works is a bit under one million words of text in total), you really need nothing more.
But for many purposes, you do need more:
To process large document collections quickly. The amount of online data has grown at least as quickly as the speed of computers, and we would now like to be able to search collections that total in the order of billions to trillions of words.
To allow more flexible matching operations. For example, it is impractical to perform the query Romans NEAR countrymen with grep, where NEAR might be defined as “within 5 words” or “within the same sentence”.
To allow ranked retrieval: in many cases you want the best answer to an information need among many documents that contain certain words.

Indexing The way to avoid linearly scanning the texts
for each query is to index the documents in advance.

Basics of the Boolean Retrieval ModelTerm-document incidence
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 1 1 0 0 0 1
Brutus 1 1 0 1 0 0
Caesar 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0
Cleopatra 1 0 0 0 0 0
mercy 1 0 1 1 1 1
worser 1 0 1 1 1 0
Entry is 1 if term occurs. Example: Calpurnia occurs in Julius Caesar.Entry is 0 if term doesn’t occur. Example: Calpurnia doesn’t occur in The tempest.

Basics of the Boolean Retrieval Model
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 1 1 0 0 0 1
Brutus 1 1 0 1 0 0
Caesar 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0
Cleopatra 1 0 0 0 0 0
mercy 1 0 1 1 1 1
worser 1 0 1 1 1 0
Entry is 1 if term occurs. Example: Calpurnia occurs in Julius Caesar.Entry is 0 if term doesn’t occur. Example: Calpurnia doesn’t occur in The tempest.

So we have a 0/1 vector for each term. To answer the query Brutus and Caesar and
not Calpurnia:
Take the vectors for Brutus, Caesar, and CalpurniaComplement the vector of CalpurniaDo a (bitwise) and on the three vectors110100 and 110111 and 101111 = 100100
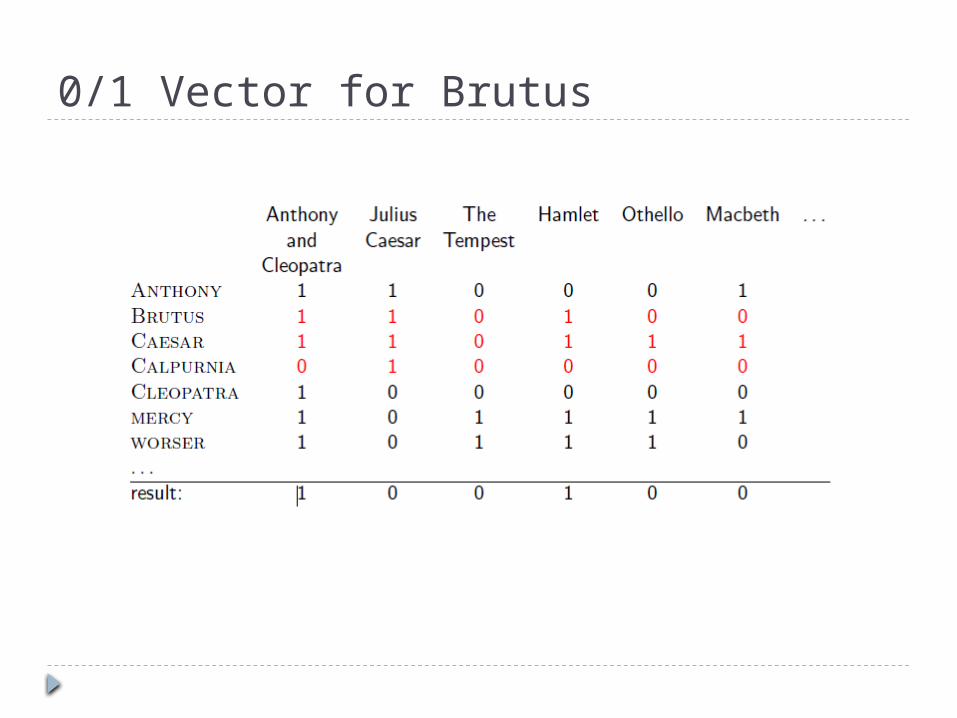
0/1 Vector for Brutus

Answers to query
Antony and Cleopatra, Act III, Scene iiAgrippa [Aside to DOMITIUS ENOBARBUS]: Why, Enobarbus,
When Antony found Julius Caesar dead,
He cried almost to roaring; and he wept
When at Philippi he found Brutus slain.
Hamlet, Act III, Scene iiLord Polonius:
I did enact Julius Caesar I was killed i' the
Capitol; Brutus killed me.

Bigger collections Consider N = 10^6 documents, each with
about 1000 tokens ⇒ total of 10^9 tokensOn average 6 bytes per token, including spaces and punctuation ⇒ size of document collection is
about 6 ・ 10^9 = 6 GB
Assume there are M = 500,000 distinct terms in the collection M = 500,000 × 10^6 = half a trillion 0s and
1s.

But the matrix has no more than one billion 1s.
Matrix is extremely sparse.
What is a better representations?
We only record the 1s.

Inverted index
For each term t, we must store a list of all documents that contain t. Identify each by a docID, a document serial
number Can we use fixed-size arrays for this?Brutus
Calpurnia
Caesar
1 2 4 5 6 16 57 132
1 2 4 11 31 45173
2 31
What happens if the word Caesar is added to document 14?
174
54101
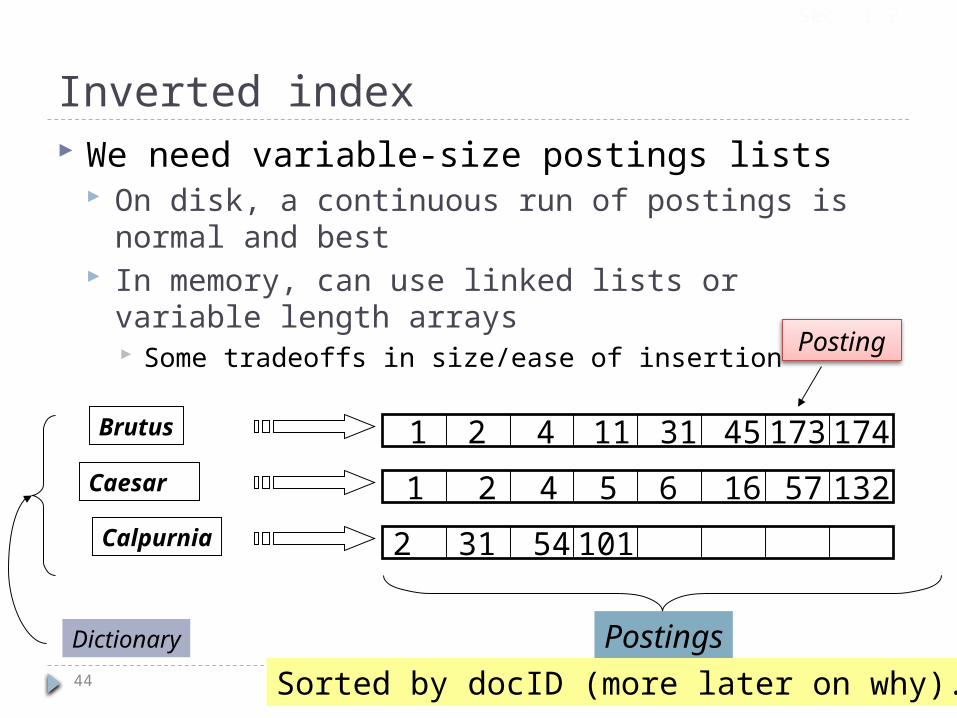
Inverted index We need variable-size postings lists
On disk, a continuous run of postings is normal and best
In memory, can use linked lists or variable length arrays Some tradeoffs in size/ease of insertion
44
Dictionary Postings
Sorted by docID (more later on why).
Posting
Sec. 1.2
Brutus
Calpurnia
Caesar 1 2 4 5 6 16 57 132
1 2 4 11 31 45173
2 31
174
54101

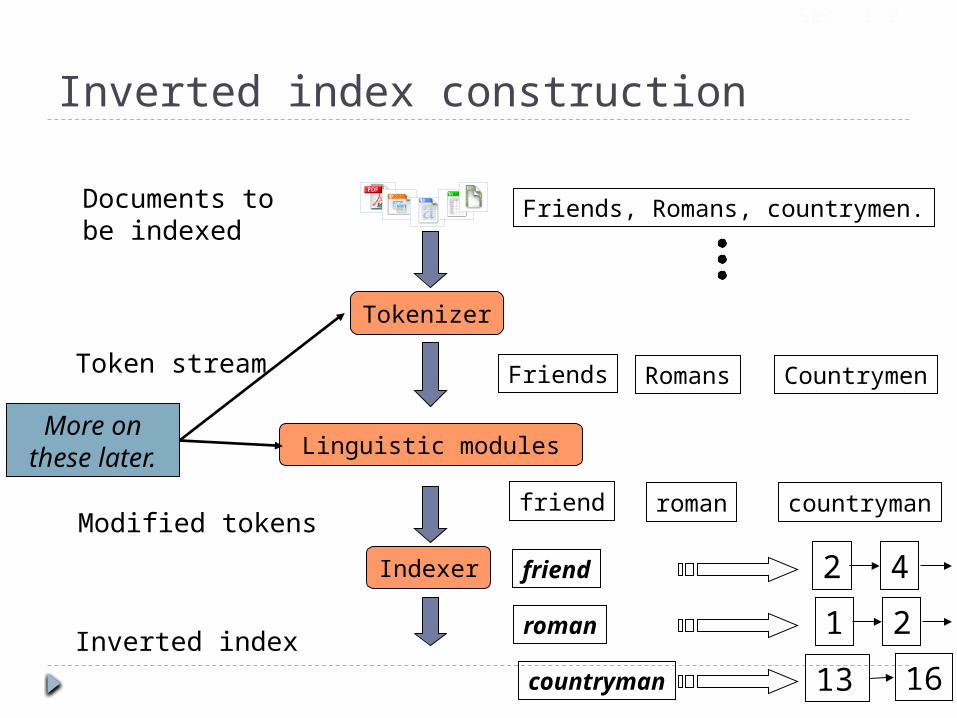
Tokenizer
Token stream Friends Romans Countrymen
Inverted index construction
Linguistic modules
Modified tokensfriend roman countryman
Indexer
Inverted index
friend
roman
countryman
2 4
2
13 16
1
More onthese later.
Documents tobe indexed
Friends, Romans, countrymen.
Sec. 1.2

Tokenization and preprocessing
Doc 1. I did enact Julius Caesar: Iwas killed i’ the Capitol; Brutus killedme.Doc 2. So let it be with Caesar. Thenoble Brutus hath told you Caesarwas ambitious:
Doc 1. i did enact julius caesar i waskilled i’ the capitol brutus killed meDoc 2. so let it be with caesar thenoble brutus hath told you caesar wasambitious

Indexer steps: Token sequence
Doc 1. i did enact julius caesar i waskilled i’ the capitol brutus killed me
Doc 2. so let it be with caesar thenoble brutus hath told you caesar wasambitious
Sequence of (Modified token, Document ID) pairs.
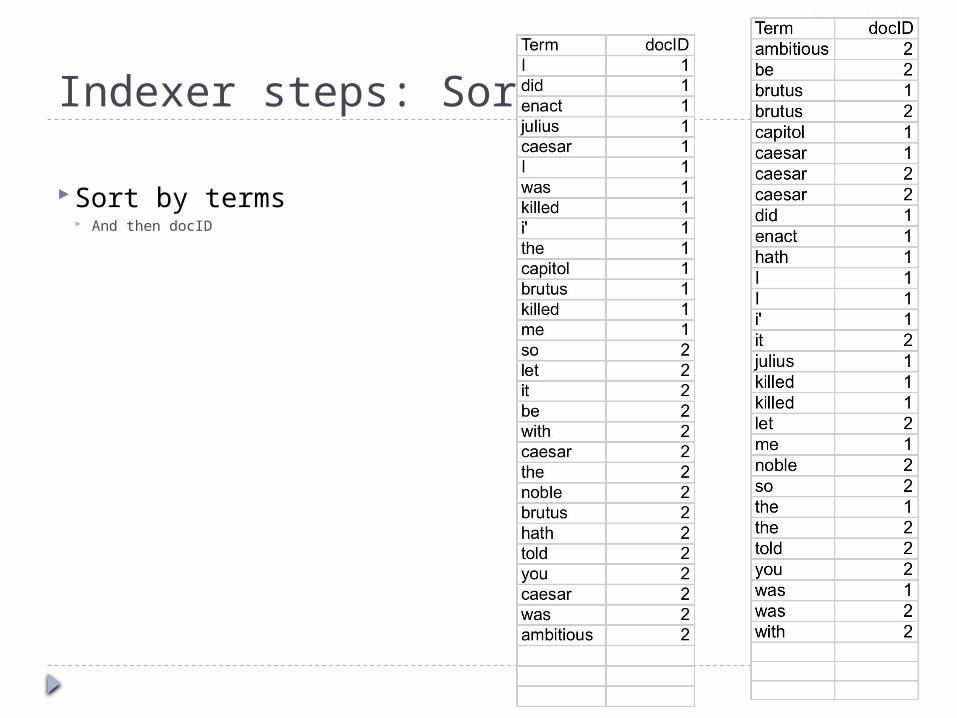
Indexer steps: Sort
Sort by terms And then docID
Sec. 1.2

Indexer steps: Dictionary & Postings
Multiple term entries in a single document are merged.
Split into Dictionary and Postings
Doc. frequency information is added.
Why frequency?Will discuss later.
Sec. 1.2
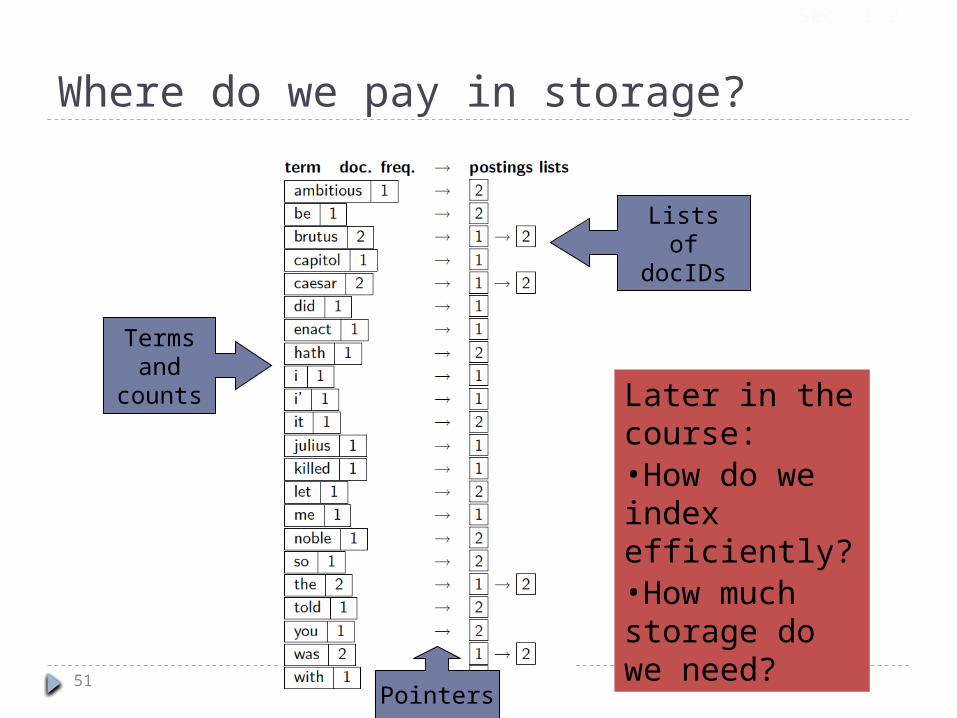
Where do we pay in storage?
51Pointers
Terms and
counts Later in the course:•How do we index efficiently?•How much storage do we need?
Sec. 1.2
Lists of docIDs

The index we just built How do we process a query?
Later - what kinds of queries can we process?
52
Sec. 1.3

Query processing: AND Consider processing the query:Brutus AND Caesar Locate Brutus in the Dictionary;
Retrieve its postings. Locate Caesar in the Dictionary;
Retrieve its postings. “Merge” the two postings:
53
128
34
2 4 8 16 32 64
1 2 3 5 8 13
21
Brutus
Caesar
Sec. 1.3

The merge Walk through the two postings
simultaneously, in time linear in the total number of postings entries
54
34
1282 4 8 16 32 64
1 2 3 5 8 13 21
128
34
2 4 8 16 32 64
1 2 3 5 8 13 21
Brutus
Caesar2 8
If list lengths are x and y, merge takes O(x+y) operations.Crucial: postings sorted by docID.
Sec. 1.3

Intersecting two postings lists(a “merge” algorithm)
55

Boolean queries: Exact match
The Boolean retrieval model is being able to ask a query that is a Boolean expression: Boolean Queries use AND, OR and NOT to join
query terms Views each document as a set of words Is precise: document matches condition or not.
Perhaps the simplest model to build an IR system on
Primary commercial retrieval tool for 3 decades.
Many search systems you still use are Boolean: Email, library catalog, Mac OS X Spotlight
56
Sec. 1.3




























