Embed Size (px)
Citation preview

The Migration Prefetcher:Anticipating Data Promotion in Dynamic NUCA
Caches
Javier Lira (Intel-UPC, Spain) Timothy M. Jones (U. of Cambridge, UK)
[email protected] [email protected]
Carlos Molina (URV, Spain) Antonio González (Intel-UPC, Spain)
[email protected] [email protected]
HiPEAC 2012, Paris (France) – January 23, 2012
2
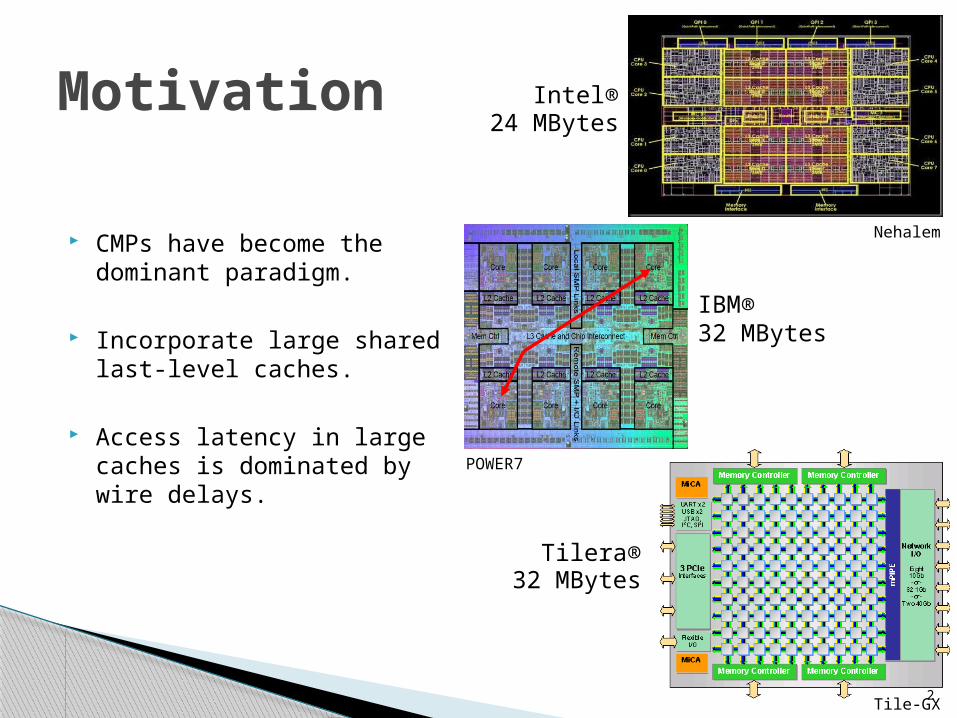
CMPs have become the dominant paradigm.
Incorporate large shared last-level caches.
Access latency in large caches is dominated by wire delays.
Motivation24 MBytes
Intel®
32 MBytesIBM®
32 MBytesTilera®
Nehalem
POWER7
Tile-GX
3
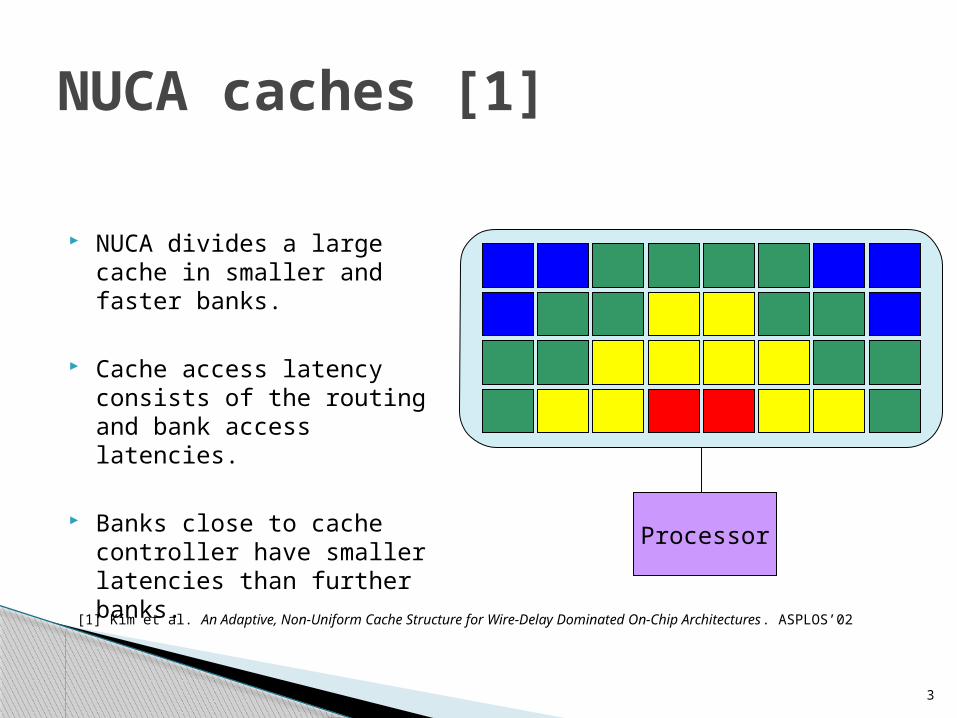
NUCA divides a large cache in smaller and faster banks.
Cache access latency consists of the routing and bank access latencies.
Banks close to cache controller have smaller latencies than further banks.
NUCA caches [1]
Processor
[1] Kim et al. An Adaptive, Non-Uniform Cache Structure for Wire-Delay Dominated On-Chip Architectures. ASPLOS’02

Data can be mapped in multiple banks. Migration allows data to adapt to application’s behaviour.
4
Dynamic NUCA
S-NUCA D-NUCA
Migration movements are effective, but about 50% of hits still happen in non-optimal banks.

5
Introduction
Methodology
The Migration Prefetcher
Analysis of results
Conclusions
Outline
6
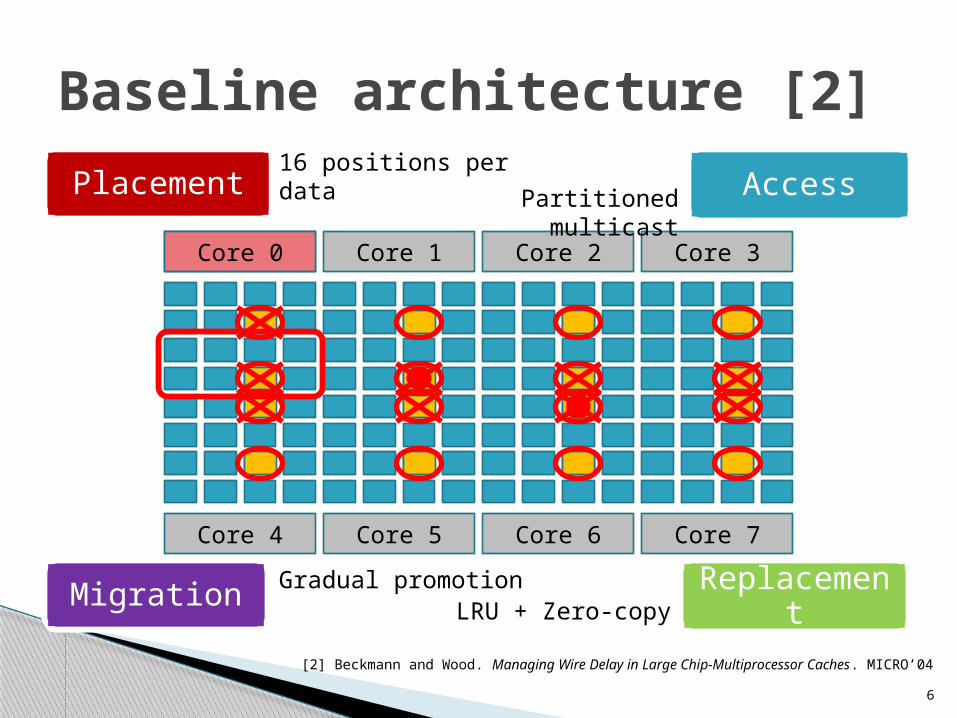
Baseline architecture [2]
Migration
Placement Access
Replacement
Placement Access
Migration Replacement
Core 0 Core 1 Core 2 Core 3
Core 4 Core 5 Core 6 Core 7
16 positions per data
Partitioned multicast
Gradual promotionLRU + Zero-copy
Core 0
[2] Beckmann and Wood. Managing Wire Delay in Large Chip-Multiprocessor Caches. MICRO’04
7
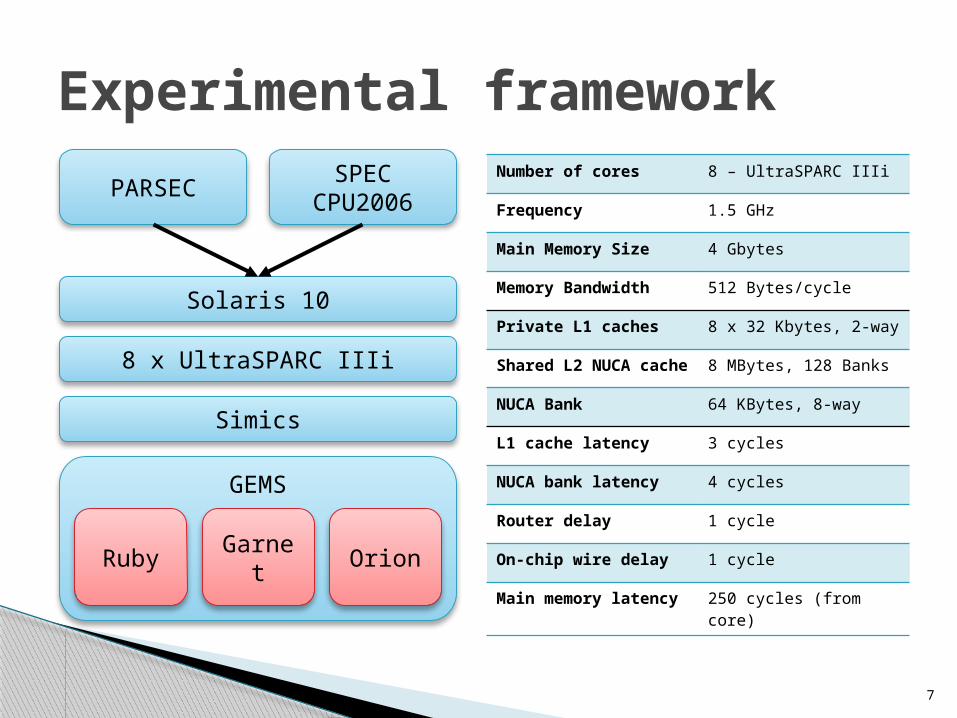
Number of cores 8 – UltraSPARC IIIi
Frequency 1.5 GHz
Main Memory Size 4 Gbytes
Memory Bandwidth 512 Bytes/cycle
Private L1 caches 8 x 32 Kbytes, 2-way
Shared L2 NUCA cache
8 MBytes, 128 Banks
NUCA Bank 64 KBytes, 8-way
L1 cache latency 3 cycles
NUCA bank latency 4 cycles
Router delay 1 cycle
On-chip wire delay 1 cycle
Main memory latency
250 cycles (from core)
Experimental framework
GEMS
Simics
Solaris 10
PARSECSPEC
CPU2006
8 x UltraSPARC IIIi
Ruby Garnet Orion

8
Introduction
Methodology
The Migration Prefetcher
Analysis of results
Conclusions
Outline
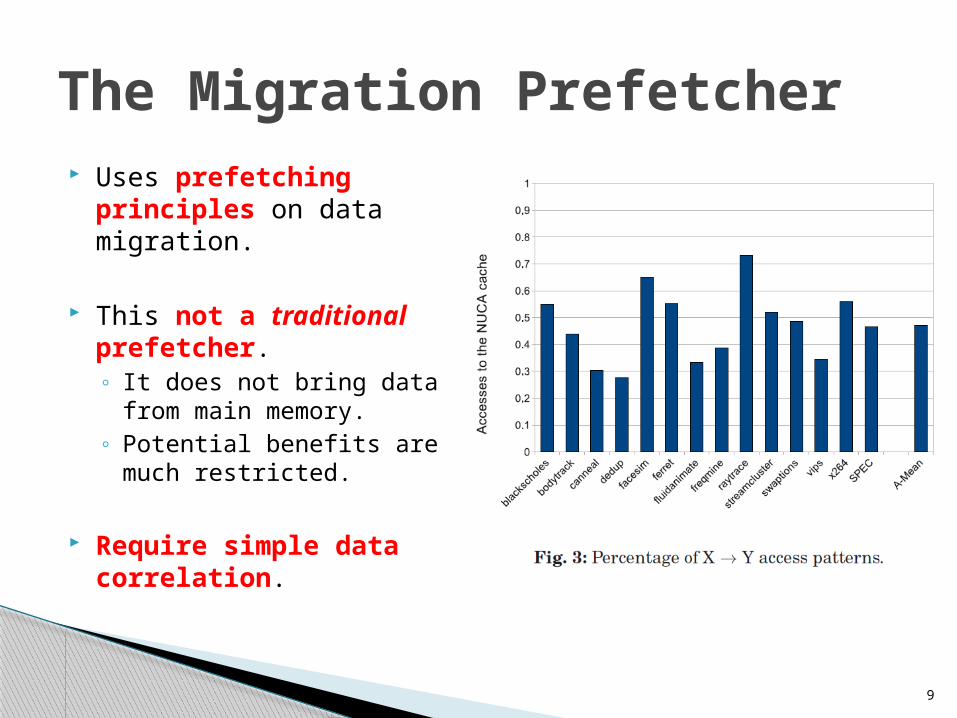
Uses prefetching principles on data migration.
This not a traditional prefetcher.◦ It does not bring data from
main memory.◦ Potential benefits are much
restricted.
Require simple data correlation.
9
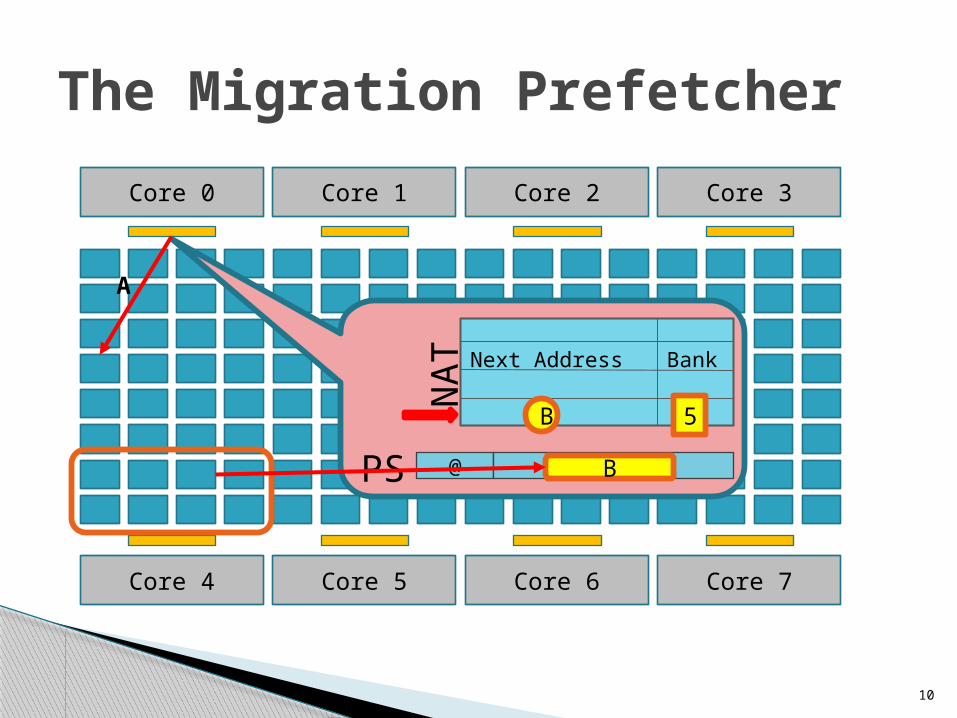
The Migration Prefetcher
10
The Migration Prefetcher
Core 0 Core 1 Core 2 Core 3
Core 4 Core 5 Core 6 Core 7
Next Address Bank
@ Data blockN
ATPS
B 5
A
B
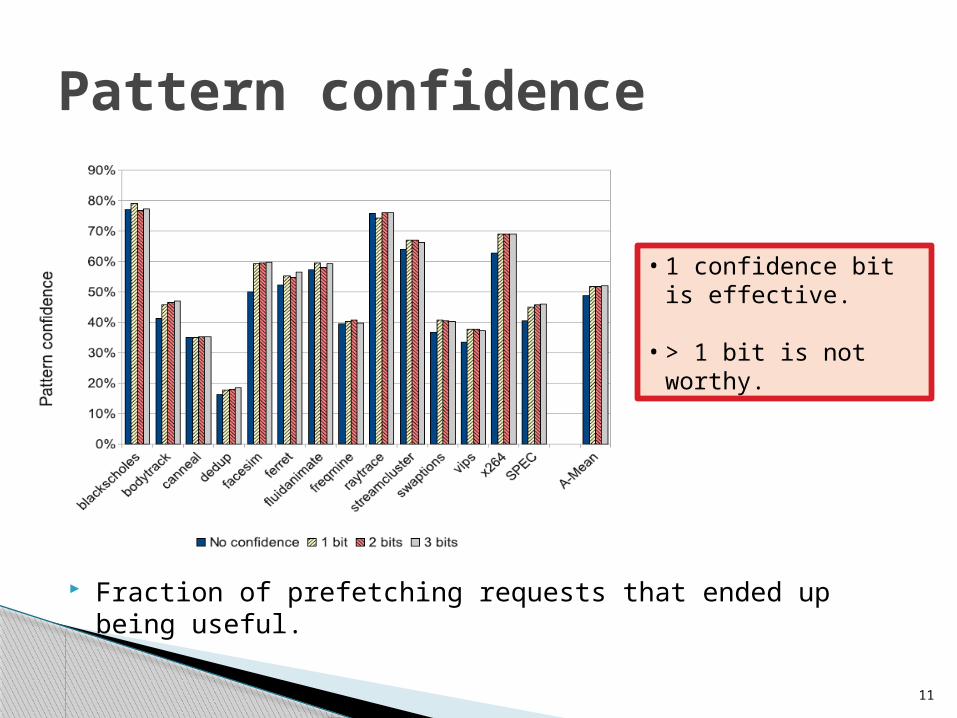
Fraction of prefetching requests that ended up being useful.
11
Pattern confidence
• 1 confidence bit is effective.
• > 1 bit is not worthy.
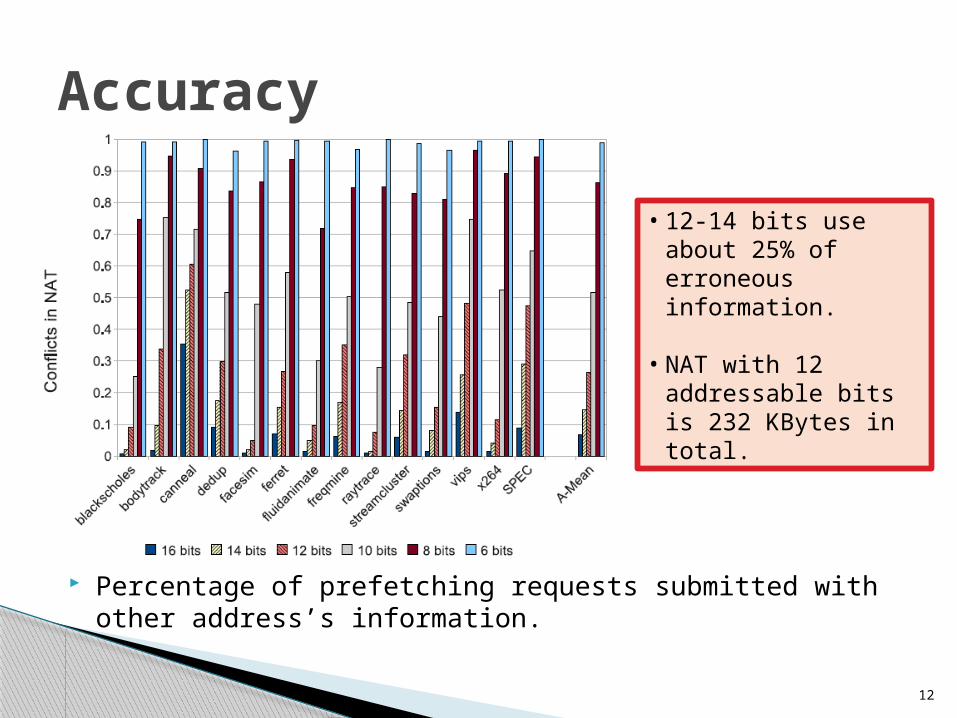
Percentage of prefetching requests submitted with other address’s information.
12
Accuracy
• 12-14 bits use about 25% of erroneous information.
• NAT with 12 addressable bits is 232 KBytes in total.
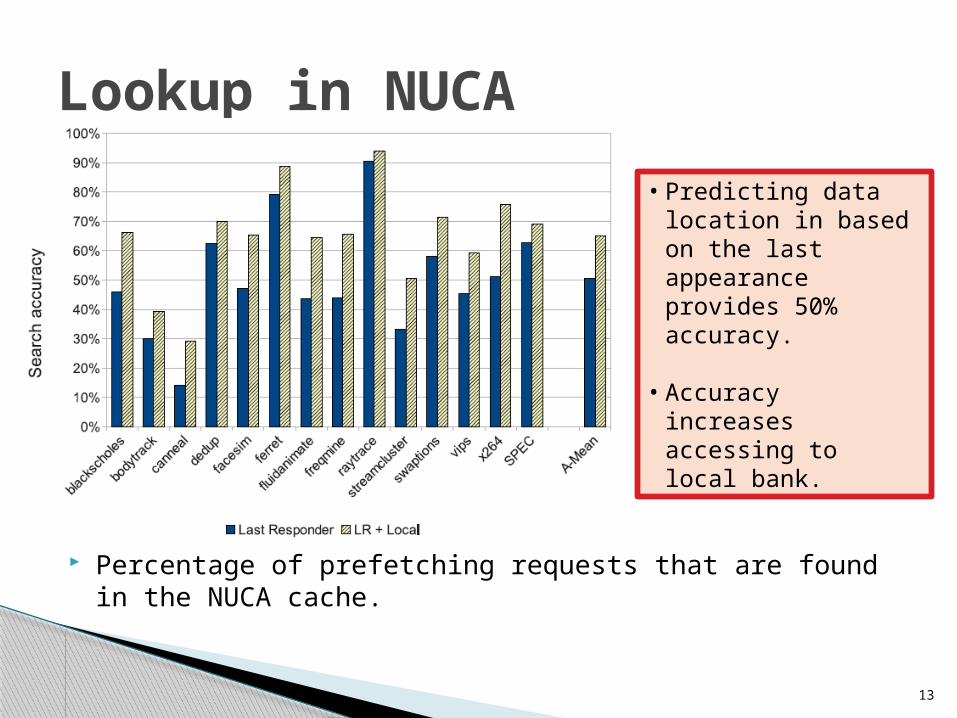
Percentage of prefetching requests that are found in the NUCA cache.
13
Lookup in NUCA
• Predicting data location in based on the last appearance provides 50% accuracy.
• Accuracy increases accessing to local bank.

The realistic Migration Prefetcher uses:◦ 1-bit confidence for data patterns.◦ A NAT with 12 addressable bits
(29KBytes/table).◦ Last responder + Local as search scheme.
Total hardware overhead is 264 KBytes. Latency: 2 cycles.
14
Tuning the prefetcher

15
Introduction
Methodology
The Migration Prefetcher
Analysis of results
Conclusions
Outline
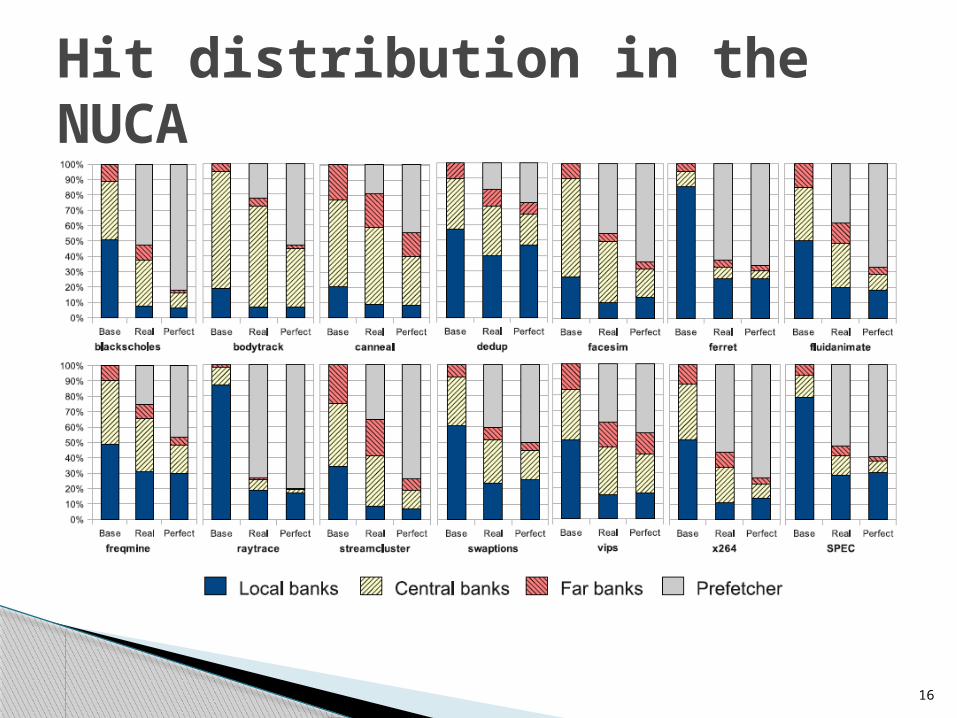
16
Hit distribution in the NUCA
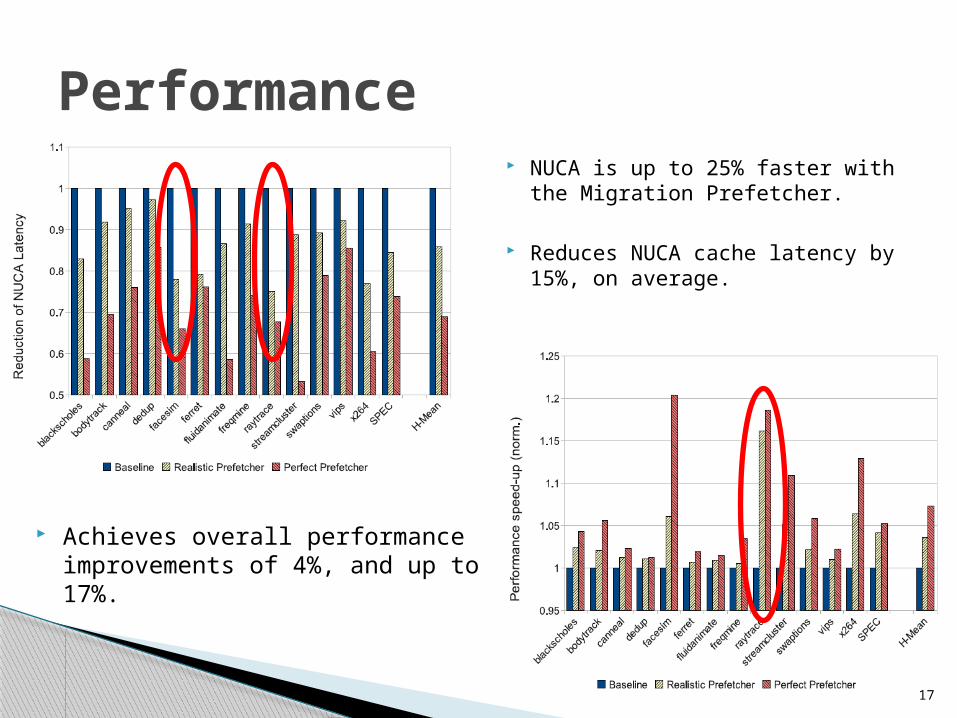
17
Achieves overall performance improvements of 4%, and up to 17%.
NUCA is up to 25% faster with the Migration Prefetcher.
Reduces NUCA cache latency by 15%, on average.
Performance
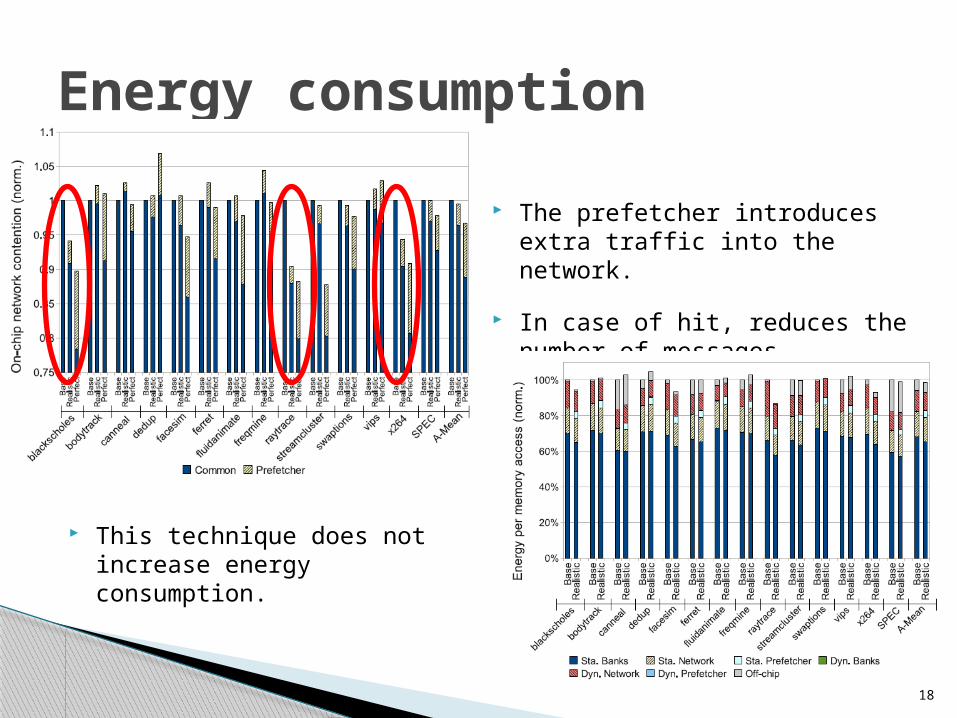
18
This technique does not increase energy consumption.
The prefetcher introduces extra traffic into the network.
In case of hit, reduces the number of messages significantly.
Energy consumption

19
Introduction
Methodology
The Migration Prefetcher
Analysis of results
Conclusions
Outline

20
Existing migration techniques effectively concentrate most accessed data to banks that are close to the cores.
About 50% of hits in NUCA are in non-optimal banks.
The Migration Prefetcher anticipates migrations based on the past.
It reduces the average NUCA latency by 15%.
Outperforms the baseline configuration by 4%, on average, and does not increase energy consumption.
Conclusions

The Migration Prefetcher:Anticipating Data Promotion in Dynamic NUCA
Caches
Questions?
HiPEAC 2012, Paris (France) – January 23, 2012





























