Embed Size (px)
Citation preview

Journal of Information Assurance and Security 1 (2006) 59–77
Integrating Intelligent Anomaly Detection Agents into
Distributed Monitoring Systems
German Florez-Larrahondo, Zhen Liu, Yoginder S. Dandass, Susan M. Bridges, and Rayford Vaughn
Department of Computer Science and EngineeringMississippi State UniversityMississippi State, MS 39762
{gf24,zliu,yogi,bridges,vaughn}@cse.msstate.edu
Abstract: High-performance computing clusters have be-
come critical computing resources in many sensitive and/oreconomically important areas. Anomalies in such systems canbe caused by activities such as user misbehavior, intrusions,corrupted data, deadlocks, and failure of cluster components.Effective detection of these anomalies has become a high pri-ority because of the need to guarantee security, privacy andreliability. This paper describes the integration of intelligentanomaly agents and traditional monitoring systems for high-performance distributed systems. The intelligent agents pre-sented in this study employ machine learning techniques todevelop profiles of normal behavior as seen in sequences ofoperating system calls (kernel-level monitoring) and functioncalls (user-level monitoring) generated by an application. TheGanglia monitoring system was used as a test bed for inte-gration case studies. Mechanisms provided by Ganglia makeit relatively easy to integrate anomaly detection systems andto visualize the output of the agents. The results provideddemonstrate that the integrated intelligent agents can detectthe execution of unauthorized applications and network faultsthat are not obvious in the standard output of traditionalmonitoring systems. Hidden Markov models working in userspace and neural network models working in kernel space areshown to be effective. Simultaneous monitoring in both userspace and kernel space is also demonstrated.
Keywords: anomaly detection, performance monitoring,hidden Markov models, artificial neural networks.
1 Introduction
In April 2004, several academic supercomputing laboratorieswere targeted by “unsophisticated” attackers who logged intothe system using compromised accounts. After the incidentwas noticed (in some cases several weeks after the intru-sions had taken place) at least one supercomputing centerreported that the attackers were executing distributed ver-sions of well-known password cracking tools such as “Johnthe Ripper,” using standard MPI (Message Passing Inter-face) applications [1]. Even if the latest operating system
patches are installed, the best commercial and open sourcefirewalls are in place, and traditional intrusion detection sys-tems are deployed, this type of unauthorized action can beconcealed. Additionally, previous research by the authors hasdemonstrated several specific attack techniques against high-performance clusters. These attacks, while not yet reportedin general use, have been implemented in research environ-ments and shown to perturb normal operations in a clusterof Linux workstations [2–4]. Application-specific anomaly de-tection systems hold the promise of detecting such attacks.
These are a few examples of the lack of protection insensitive distributed systems where a wide variety of inter-networked computational resources are combined. Often, inorder to contain costs, commercial off-the shelf (COTS) com-ponents are used and these typically provide sparse moni-toring mechanisms. Furthermore, despite careful monitoringof the software development process, flaws in the design andimplementation of COTS systems create opportunities for un-expected system failures, user misbehavior and computer at-tacks.
In the not-too-distant future, it is likely that high-performance clusters will be employed in safety critical envi-ronments such as the dashboards of automobiles where theywill facilitate drive-by-wire applications, in the nose-cones ofanti-missile missiles where they will control targeting maneu-vers, and in the cockpits of high-performance aircraft wherethey will handle various avionics applications [3]. Typically,such systems will mostly consist of a static suite of softwareapplications exhibiting regular behavior that can be charac-terized and monitored. Furthermore, corrective, perfective,and adaptive maintenance will be performed on the softwareover time, increasing the risk of introducing malicious ex-ploits. Detecting anomalies and reporting them quickly willbe an essential requirement in these systems.
The Center for Computer Security Research at MississippiState University (http://www.cse.msstate.edu/ ~security) hasbeen working on the problem of anomaly detection in high-performance computer environments by using machine learn-ing techniques to build intelligent anomaly detection agents
Received December 27, 2005 1554-1010 $03.50 c© Dynamic Publishers, Inc.

60 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
[2–6]. Lightweight detection systems with high accuracy havebeen successfully implemented, but several issues related toscalability and usability remain. In previous work with agent-based detectors in high-performance clusters of workstations,the authors used a centralized collection scheme in order togather the results of the anomaly detection systems runningon each node of the distributed system. The central host dis-plays the status of the cluster system. However, when thenumber of nodes in the cluster is large, communication withthis central host becomes a bottleneck. Therefore, alterna-tive scalable solutions are required. Furthermore, determin-ing how to meaningfully convey the voluminous output fromthe various distributed anomaly detectors to the system ad-ministrator is an additional challenge.
Several distributed cluster monitoring systems are avail-able in the high-performance computing community that dis-play cluster status and performance information to systemadministrators. Therefore, a natural extension of previousresearch is the integration of intelligent anomaly detectionagents (IADAs) into traditional cluster monitoring systems.This paper describes the integration of two IADAs into theGanglia distributed monitoring system (developed by Massie,Chun and Culler at the University of California, Berkeley [7]).Ganglia is open-source, can be compiled for a wide varietyof Unix/Linux flavors, provides detailed documentation, andhas been used successfully by more than 500 cluster and gridinstallations around the world. Furthermore, the GangliaPHP-based web front end provides an effective mechanismfor visualizing the overall status of the distributed system.This display mechanism can be leveraged for displaying thebehavior of parallel applications as reported by the IADAs.
2 Related Work
Verifying a program’s behavior by analyzing the processes,methods, tasks, and function calls that a program executeshas been an active field of research. Forrest and Longstaff[8] authored one of the first research papers on the analy-sis of system calls. An extended overview of their work isdescribed in [9]. Other anomaly detection algorithms in-clude the EMERALD system [10], Somayaji’s pH [11] andEschenauer’s ImSafe [12]. Warrender, Forrest and Pearlmut-ter [13] performed a comparison of different algorithms thatperformed anomaly detection of privileged UNIX programsusing system calls. In their previous work, the authors havesuccessfully applied different artificial neural networks andboosting algorithms for detecting anomalies in well-known se-quential UNIX applications and in parallel applications exe-cuting on high-performance clusters of workstations [14,15].
Markov processes are widely used to model systems interms of state transitions. Some detection algorithms that ex-ploit the Markov property implement hidden Markov models(HMM), Markov chains, and sparse Markov trees. Lane [16]used HMMs to profile user identities for the anomaly detec-tion task. An open problem with this profiling technique isthe selection of appropriate and effective model parameters.Other experiments performed by Warrender, Forrest, andPearlmutter [13] compared an HMM with algorithms such ass-tide and RIPPER for anomaly detection using sequences ofsystem calls. They concluded that the hidden Markov modelexhibited the best performance but was also the most com-putationally expensive of all the models considered.
A number of applications have been implemented to gatherdata from the execution of parallel programs in a cluster ofworkstations, but none were developed with anomaly detec-tion as an objective. Some examples include the automaticcounter profiler [17] and the Umpire manager [18].
Several monitoring tools have been published and usedsuccessfully in real-world distributed environments. As anexample, PerfMC, the monitoring system created by Mar-zolla [19], implements a performance monitoring systems fora large computing cluster. Some of the metrics collected byPerfMC are available space on /tmp, /var and /usr, cachedmemory, available free memory and total swap, among oth-ers. Lyu and Mendiratta [20] use resource monitoring forreliability analysis of a cluster architecture in their RCC (Re-liable Clustered Computing) system and present a Markovreliability model for software fault tolerance. Augerat, Mar-tin and Stein [21] implement a scalable monitoring tool thatuses bwatch, a Tcl/Tk script designed to watch the load andmemory usage of Beowulf clusters.
Parmon, another example of a cluster-monitoring tool forBeowulf clusters, was designed and implemented by Buyya[22]. It monitors system resources utilization, process activ-ities, system log activities, and selected kernel activities foreach node in a distributed system. This performance moni-toring system is based on a client-server model in which nodesto be monitored act as servers and monitoring nodes act asclients. Performance information is collected and stored in aParmon-server and a GUI based client is responsible for datavisualization.
Finally, Supermon [23] a research project conducted at LosAlamos National Laboratory, consists of three distinct com-ponents: a loadable kernel module providing performance in-formation about each node, a single-host data server (mon)and a data concentrator (Supermon) that summarizes perfor-mance information from many nodes into a single data sam-ple. Supermon uses a data exchange protocol consisting ofdata in s-expressions format introduced originally as part ofthe LISP programming language. The simple and recursiveform of s-expressions allows Supermon to encode arbitrarilycomplex data. Unlike Parmon, Supermon provides an archi-tecture to collect and represent performance information froma distributed system, but it does not provide a graphical userinterface for visualization of the overall status of the system.
3 Ganglia: A Distributed Monitoring
System
The authors selected Ganglia as the test platform for inte-grating IADAs into a distributed monitoring system becauseGanglia is open-source, is supported on many commonly usedplatforms, provides for easy integration of new componentsfor monitoring and visualization, and is widely used in thecluster computing community [7].
Ganglia was developed by Massie, Chun, and Culler atthe University of California, Berkeley [7] as a scalable dis-tributed monitoring system for high-performance computingsystems. This system is able to collect between 28 and 37different built-in and user-defined metrics “which capture ar-bitrary application-specific state” [7]. Ganglia is based on ahierarchical design targeted at federations of clusters, wherea multicast-based listen/announce protocol is used to mon-itor state within clusters and a hierarchy tree of point-to-

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 61
Figure 1: The Ganglia architecture (Taken from Massie, Chunand Culler [7])
point connections among representative cluster nodes is usedto federate clusters and aggregate their state. Membership ismaintained by using the reception of a heartbeat from a nodesignaling the node’s availability. Each node monitors its localresources and sends multicast packets containing monitoringdata to a well-known multicast address whenever significantupdates occur. Thus, all nodes always have an approximateview of the entire cluster’s state, and this state is easily re-constructed after crash recovery.
Ganglia uses the RRDtool (Round Robin Database) tostore and visualize historical monitoring information, XML(Extensible Markup Language) for data representation, andXDR (External Data Representation standard) for compactdata transport.
Figure 1 (taken from [7]) shows the basic software archi-tecture of Ganglia. Ganglia uses two daemons, gmond andgmetad. The former monitors single nodes, whereas the lat-ter integrates data from multiple clusters. Because the ex-periments reported in this paper were conducted on a singleLinux cluster, the set of Ganglia metrics reported in this pa-per were collected from gmond.
4 Anomaly Detection
An anomaly detection system learns a baseline-model from aset of observations of a computer system operating under nor-mal conditions and recognizes unusual and potentially dan-gerous events in the system. Any deviation from the set ofnormal patterns is considered an anomalous event. This workassumes an environment where the application base is welldefined, but the user-base may not be. Therefore, patternsof usage are expected to emerge that can be used to detectirregularities in the execution of parallel programs. Theseirregularities include user misbehavior, intrusions, corrupteddata, deadlocks, and failure of cluster components.
Current monitoring systems such as Ganglia are able todetect some of these irregularities by testing individual ser-vices with simple message exchanges among the cluster com-ponents. Other configuration management systems providemethods for configuration and for prevention of errors in acluster. However, no single system can find all possible er-rors, misconfigurations, and runtime irregularities. Further-more, traditional monitoring systems typically cannot provide
Figure 2: A sequence of events produced over time
useful information about the status of specific distributed ap-plications because they show the overall status of the wholesystem.
An application-specific anomaly detection system can pro-vide a qualitative measure of the execution of a job that an-swers the question “is the parallel program being executed cor-rectly?” Detection of anomalous program execution can alsoplay an important role in providing the inner layers of protec-tion in defense-in-depth security architectures. For example,many cluster computer installations typically enforce tight au-thorization and authentication policies at the head node whileleaving the compute nodes relatively less secure. This is be-cause only the head node is accesible from outside the cluster;the compute nodes are not directly connected to an exter-nal network. However, this security configuration renders thecluster vulnerable to misuse by insiders and by outsiders whohave compromised the passwords of legitimate users. Addi-tionally, application-specific anomaly detection can also beused to enhance the security of systems in which classes ofusers, as opposed to individual users, are permitted to submitjobs. In such systems, profiling behaviour of users may be oflimited use for anomaly detection.
Anomaly detection generally consists of the following threephases:
1. Samples of sequences of normal events in the system arecollected, generating a set of observations. The discreteevents generated by the application being monitored in-clude operating system calls (low level information, knownas kernel-level monitoring) and/or application library func-tion calls (high-level information, known as user-level mon-itoring).
2. Machine learning algorithms are applied to the dataset col-lected in the previous step. In the experiments conductedfor this paper, the profiles were acquired using artificialneural networks and Hidden Markov models. In each nodeof the cluster, the profile of the application is used as theinput to an IADA.
3. New sequences of events in the system are collected, andthe intelligent anomaly detection agents determine in real-time if the sequence of events is sufficiently similar to theprofile. If the application is not behaving as expected, acounter of anomalies is increased and reported to the Gan-glia database.
5 Intelligent Anomaly Detection Agents
A problem of interest in many domains is the characterizationof signals produced by a real-world process in terms of simplemodels. Such models can provide an abstract description ofthe process and can be embedded in practical systems to aidin complex decision problems [24].
This research deals specifically with discrete-valued signals,where the stream of events being monitored is categorical,(i.e. it can be divided into finite groups). Examples of cate-gorical variables include DNA bases, operating system (OS)

62 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
Figure 3: Average number of false positives detected in 60test instances of FFT
commands typed by a user on a console, computer securityaudit events, and network requests among many others.
Previous research in the area of anomaly detection in com-plex software applications [3, 4] has demonstrated that ar-tificial neural networks (ANNs) and hidden Markov mod-els (HMMs) outperform simpler deterministic algorithms foranomaly detection when the amount of training data is lim-ited. When learning the behavior of a parallel implementa-tion of the Fast Fourier Transform (FFT ), for example, ex-periments were conducted to determine the number of train-ing samples (sequences of library function calls generated bythe application) required to completely describe the program.Figure 3 contrasts the number of training samples required bythe ANN and the HMM with the number of samples requiredby a deterministic algorithm to model this scientific applica-tion. Details of this experiment can be found in [3,4]. Clearly,the deterministic algorithm achieves a high accuracy (i.e. lownumber of false positives) with a large number of samples,but the ANN and the HMM perform better with less train-ing data. In a system where it is difficult or expensive togather large sets of training data and where the total numberof samples from the event source that needs to be providedis difficult to determine, traditional deterministic algorithmsare not appropriate.
The intelligent agents integrated into the Ganglia monitor-ing system are implemented as artificial neural networks andhidden Markov models. A brief discussion of the use of thesemachine learning techniques for solving the anomaly detec-tion problem is presented in the next section.
5.1 Artificial Neural Network
The use of artificial neural networks (ANNs) for construct-ing classifiers has become popular in recent years. Comparedwith other approaches for classifier construction (e.g. tem-plate matching, statistical analysis, and rule-based decisiontrees) neural network models have the advantages of havingrelatively low dependence on domain specific knowledge andthe availability of efficient learning algorithms.
5.1.0.0.1 Description An artificial neural network iscomposed of simple processing units and weighted connec-tions between the units that are used to determine how muchone unit will affect another. In this work, a feed-forward neu-
Figure 4: A two-layer feed-forward network
ral network is used to build the model of normal programbehavior. The feed-forward network consists of three types ofunits: input units, hidden units, and output units. By assign-ing a value to each input unit and allowing the activations topropagate through the network, a neural network performs afunctional mapping from one set of values (assigned to theinput units) to another set of values (appearing in the out-put units). The mapping function is stored in the weights ofthe network. An example of a two-layer feed-forward neuralnetwork with six input units, four hidden units and a singleoutput unit can be seen in Figure 4.
5.1.0.0.2 The Backpropagation Algorithm Thetraining of artificial neural networks for anomaly detectioninvolves the use of both normal and anomalous data. Theexperiments described in this paper use normal data collectedfrom audit data and anomalous data generated by randomlyinjecting artificial anomalies into normal data. Anomalieswere spread throughout the training space to the extent pos-sible. The network weights were initialized to random valuesprior to training. A traditional backpropagation algorithmwas used to find an optimal set of weights to describe the setof subsequences of calls issued by an application.
The backpropagation algorithm can be seen as a gradientdescent method in weight space where the goal is to min-imize the error propagated throughout the network by theinput nodes and hidden nodes (See Figure 5). The error ofthe network is defined as the difference between the expectedoutput (i.e. normal or anomalous subsequence of calls) andthe output node. The key of the backpropagation algorithmis to “assess the blame for an error and divide it among thecontributing weights” [25, p.579].
In order to build the lightweight detection system requiredfor high performance cluster monitoring, computational over-head must be reduced as much as possible without compro-mising the accuracy of the detector (a fundamental designobjective). Moreover, in Linux kernel programming, the stan-dard C math library cannot be accessed. Therefore, a simpleactivation function that retains accuracy and reduces compu-tation is needed. In order to reduce computational require-ments, the standard sigmoid function (1) can be modified assuggested by Tveter [26]. This simple sigmoid function isgiven in (2) and its derivative is presented in (3).
ystd =1
1 + e−x(1)
y =x2
1 + |x|+ 0.5 (2)

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 63
Figure 5: The backpropagation algorithm as a gradient de-scent search in weight space. The training error is minimizedwith respect to the set of weights W1 and W2
y′ =
1
2(1 + |x|)2(3)
5.1.0.0.3 The Online Detection Algorithm with
ANNs The main goal of the ANN-based anomaly detec-tor described in this paper is to determine whether an inputsub-sequence of calls is anomalous or normal. Therefore, asliding window is used to divide a trace into a set of smallsub-sequences. As an example, assume the following trace:
execve, brk, open, fstat, mmap, close, open, mmap, munmap
Processing this trace with a window size of 4 yields the followsubsequences:
position 3 position 2 position 1 currentexecve
execve brkexecve brk open
execve brk open fstatbrk open fstat mmapopen fstat mmap closefstat mmap close openmmap close open mmapclose open mmap munmap
Each system call is represented by a binary number and thebinary representations of the calls in a window are concate-nated to yield an input vector. A single output node is usedto indicate the status of the input sub-sequence. A value of 0indicates a normal subsequence and a value of 1 indicates ananomalous subsequence. Because researchers have reportedthat anomalous sequences in operating system calls tend tooccur in clusters [27,28], a scheme called maxburstcounter [29]was implemented. In this scheme, a counter of anomalies isincremented every time an anomalous call is found. Con-versely, the counter is decremented at a slow rate when theapplication is behaving as expected. The two fundamentalassumptions of this method are as follows:
1. An anomalous sequence seen long ago should have only asmall effect on classification of the entire trace.
2. Although anomalous sequences tend to occur locally, theyare not necessarily consecutive.
The main advantage of using maxburstcounter is that it allowsfor anomalous behavior that occasionally occurs during nor-mal system operation, while simultaneously, it is sufficiently
sensitive to detect the temporally co-located anomalies thatoccur when a program is being misused. This mechanism issimilar to the leaky bucket method of Ghosh et al. [27]andthe LFC method by Somayaji [11]. However, it is much lesscomputationally expensive than these methods and enablesthe monitoring of a large number of operating system calls.
5.2 Discrete Hidden Markov Model
Discrete hidden Markov models are useful for anomaly de-tection because “...when the observations are categorical innature, and when the observations are quantitative but fairlysmall, it is necessary to use models which respect the discretenature of the data” [30, p.3]. This section introduces a briefdescription of stationary discrete first order hidden Markovmodels. For a more complete description of HMMs refer tothe work of Rabiner [24] and MacDonald and Zucchini [30]among others.
5.2.0.0.4 Description Consider a system with N statesSi, Sj , Sk..., where each state represents some physical (ob-servable) event. Employing Rabiner’s notation, let the ac-tual state at time t be qt. By assuming a discrete first orderMarkov chain, the probability that qt = Si, for some state Si,is given by
P [qt = Si|qt−1 = Sj , qt−2 = Sk, ...] = P [qt = Si|qt−1 = Sj ](4)
Furthermore, assuming a stationary process, it is not neces-sary to keep track of the time t to compute transition proba-bilities, and therefore
P [qt = Si|qt−1 = Sj ] = aij , 1 ≤ i, j ≤ N (5)
This system is considered to be an “observable” first-orderMarkov model because each state is associated with one (andonly one) observable event and the history of previous tran-sitions is summarized in the last transition. Such a Markovchain can be seen as a finite state automata (FSA) with proba-bilistic transitions. An nth-order Markov chain can always beconverted into an equivalent first-order Markov chain givena large state space [31]. In contrast, in a hidden Markovmodel, a state cannot be observed directly, since each stateoutputs different symbols with some probability distributionB. Therefore, a hidden Markov model is a doubly stochasticprocess, where the states represent an unobservable conditionof the system [32]. Because this work deals with “discrete”HMMs, the output probability distribution is discrete. Theelements of a discrete HMM λ = (A, B, π), are described asfollows:
1. N, the number of states,
2. M, the number of distinct observation symbols per state(the alphabet size),
3. A, the state transition probability distribution,
4. B, the observation symbol probability distribution, and
5. π, the initial state distribution.
5.2.0.0.5 The Baum-Welch Algorithm The Baum-Welch algorithm is an expectation maximization (EM) tech-nique that is generally used to train the transition and symbolprobabilities of an HMM utilizing the concept of forward andbackward probabilities [24]. The forward procedure finds theprobability of the partial observation sequence from the first

64 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
event to some event O(t) at time t, whereas the backwardprocedure finds the probability of the partial observation fromO(t+1) to the last event in the sequence.
The forward variable corresponds to the probability of thepartial observation sequence O up to time t and state Si attime t, given the model λ. It is defined as
αt(i) = P (O1O2...Ot, qt = Si|λ) (6)
and can be computed by induction, knowing that
α1(i) = πibi(O1), 1 ≤ i ≤ N (7)
and
αt+1 =
[
N∑
i=1
αt(i)aij
]
bj(Ot+1). (8)
This variable can be used as an efficient estimate (in O(N2T )time) of the likelihood that the observation O is generated bythe model λ:
P (O|λ) =
N∑
i=1
αT (i). (9)
Note that P (O|λ) can also be computed in O(TNT ) timeby summing the probability of occurrence of the observationsO1O2...Oτ for each hidden state sequence q1q2...qτ from theset Q of all possible hidden state sequences:
P (O|λ) =∑
Q
P (O|Q, λ)P (Q|λ) (10)
which yields
P (O|λ) =∑
q1,q2,...qτ
πq1bq1(O1)aq1q2bq2(O2)...aqτ−1qτbqτ
(Oτ ).
(11)On the other hand, the backward variable is the probability
of the partial observation from t+1 to the last event, giventhe state Si at time t and the model λ. It is defined as
βt(i) = P (Ot+1Ot+2...OT |qt = Si, λ) (12)
and can also be computed by induction, using the fact that
βT (i) = 1, 1 ≤ i ≤ N (13)
and
βt(i) =N
∑
j=1
aijbj(Ot+1)βt+1(j). (14)
The Baum-Welch algorithm updates the model λ (M-step)using the probability of being in state Si at time t and stateSj at time t+1, given the model and the observations. Thisvariable, ξt(i, j) can be seen as an efficient auxiliary variablefor the E-step of the algorithm and is given by:
ξt(i, j) =αt(i)aijbj(Ot+1)βt+1(j)
∑N
i=1
∑N
j=1αt(i)aijbj(Ot+1)βt+1(j)
. (15)
Given ξt(i, j) , the probability of being in state Si at time tgiven the model and observation sequence can be estimatedas:
γt(i) =∑
j=1
ξ(i, j). (16)
The initial state distribution can be computed as the expectedfrequency of being in state Si at time t = 1 as:
πi = γ1(i). (17)
The state transition probability distribution is given by theexpected number of transitions from the state Si to state Sj
divided by the expected number of transitions from state Si:
aij =
∑
t=1ξt(i, j)
∑
t=1γt(i)
. (18)
The observation symbol probability distribution can be com-puted as the expected number of times state j occurred andthe symbol vk was observed, divided by the expected numberof occurrences of the state j:
bi(k) =
∑
t=1
s.t. Ot=vk
γt(j)∑
t=1γt(j)
. (19)
A new estimator ξt(i, j) can be computed using πi, aij andbi(k). This process is repeated several times until some limit-ing point is reached. It has been proven by Baum et al. thatthis process leads to an increase in the likelihood P (O|λ) [24].It is important to observe, however, that the maximum-likelihood procedure only results in a local maxima. Thetime and space complexity of the Baum-Welch algorithm isO(N2T ).
5.2.0.0.6 The Threshold-Based Online Detection
with HMMs Given a sequence of events O and a modelλ = (A, B, π), the following algorithm for detection of singleanomalies was implemented:
1. Initialize the counter of anomalies, C = 0.
2. For each event Ot (0 ≤ t < TO)
(a) For each state Sj that can be reached from the previousstate, i.e. if the probability aij of moving to the currentstate from some state Si is greater than the threshold θA
• If the probability of producing the symbol Ot in thecurrent state, bj(Ot), is less than a user threshold θB ,then the event is considered anomalous, and C = C+1.
• Otherwise, repeat step 2.
(b) If Ot could not be produced by any state then C = C+1.
3. Output C.
6 Integration of Intelligent Anomaly De-
tection Agents into Ganglia
An event-driven system architecture has been chosen wherespecific sensors collect information every time a discrete eventis generated. Sequences of those events are used for train-ing the intelligent agents. In this research, the set of dis-crete events considered corresponds to the application li-brary function calls and/or operating system calls issued bya UNIX/Linux parallel application.
6.1 Operating System Calls (Kernel-levelMonitoring)
System call interfaces are the application programmer inter-faces (APIs) through which the operating system kernel pro-vides low-level operations (such as memory allocation, fileaccess, and network transfers) to the user space applications.For Linux, this interface is wrapped by the GNU standard Clibrary (libc) so that C programmers can have a common stan-dard interface. Although user space applications usually uti-lize low-level operations through library function calls, some

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 65
applications and attacks can bypass the libc interface and in-voke system calls directly [2].
Several mechanisms can be used to obtain system call in-formation. The current implementation uses a loadable ker-nel module (LKM) because of the flexibility, efficiency andcompatibility this approach provides. LKMs are used by theLinux kernel and many other UNIX-like systems as well asMicrosoft Windows to expand their functionality. An LKMcan access all the variables in the kernel. This method is moreflexible than the methods based on kernel patching becauseit does not require changes to the kernel source code. A priv-ileged user can load or unload the LKM during runtime. Thedisadvantage is that an attacker can install malicious codeinto the kernel before the tool is loaded. This weakness canbe resolved by adding the tool into a startup script.
Extensions that use kernel level interposition have a broadrange of capabilities. For example, extensions “...can pro-vide security guarantees (for example, patching security flawsor providing access control lists), modify data (transparentlycompressing or encrypting files), re-route events (sendingevents across the network for distributed systems extensions),or inspect events and data (tracing, logging)” [33, p.1]. Theprimary advantage of this method is that it cannot be by-passed. All programs must use the system call interface toaccess the low-level functionality implemented by the kernel.Another advantage is it does not require modification of theapplication code. Only the kernel needs to be changed. Thedisadvantage is that a security hole in the monitor program ismuch more dangerous than with other methods. It can causethe system to crash or to grant root privilege.
It is interesting to note here that fundamental design ob-jectives in early attempts to develop secure operating systemsrequired the security mechanisms to be tightly coupled at thekernel level, and to be non-bypassable, tamper proof, andverifiably correct [34]. Those same characteristics should beincluded in any secure low-level monitoring system.
6.2 Library Function Calls (User-levelMonitoring)
A software application issues calls to the operating systemto perform a wide variety of functions such as I/O access,memory requests, and network management. However, manyapplication programmer interfaces (APIs) do not make useof system calls, mainly for performance reasons or becauseno privileged resources need to be manipulated. A typicalexample is the set of functions such as cos, sin or tan fromthe standard mathematical library of C.
Linux provides a large collection of mechanisms to trapsystem and function calls from any process in user-mode. Forinstance, in order to monitor kernel calls, the OS provides thetools strace, trace and truss [35], but these tools only recordkernel level functions, and the trap mechanism produces toomuch overhead [36]. However, another method that has beenwidely used for implementing performance and monitoringtools is library interposition.
The link editor (ld) in a Linux operating system buildsdynamically linked executables by default. Building “incom-plete” executables, the link editor allows the incorporation ofdifferent objects in real time. Communication between themain program and the objects is done by shared memory op-erations. Such (shared) objects are called dynamic libraries:
“A dynamic library consists of a set of variables and functionswhich are compiled and linked together with the assumptionthat they will be shared by multiple processes simultaneouslyand not redundantly copied into each application” [36, p.1].
In the Linux system, the link editor uses theLD PRELOAD environment variable to search for the user’sdynamic libraries. Using this feature, the operating systemgives the user the option of interposing a new library. In-terposition is “the process of placing a new or different li-brary function between the application and its reference to alibrary function” [36]. Thus, the library interposition tech-nique allows interception of the function calls without themodification or recompilation of the dynamically linked tar-get program. By default, C compilers in Linux use dynamiclinking. Furthermore, “most parts of the Linux libc packageare under the Library GNU Public License, though some areunder a special exception copyright like crt0.o. For commer-cial binary distributions this means a restriction that forbidsstatically linked executables” [37].
The user functions (i.e., the functions inside the interposi-tion library with the same prototype as the “real” ones) areable to check, record and even modify the arguments and theresponse of the original function call. Other advantages in-clude the capability to profile a subset of the library ratherthan the entire library, the ability to generate levels of pro-filing, and provision of control over nesting levels inside thelibrary [36].
The main disadvantage of the interposition library tech-nique is that it can be bypassed by calling functions at a lowerlevel (for instance, executing system call interruptions) [38].Also, as explained above, the process of searching the symboltable in the new interposition library and the allocation ofmemory increases the execution time of the target process.
The libraries to be profiled are defined by the system ad-ministrator using a configuration file and template like theone depicted in Figure 6. The source code needed to inter-cept function calls from any dynamic library is generated au-tomatically.
6.3 System Architecture
Figure 7 contrasts the mechanisms used to collect and analyzeoperating system calls and library function calls issued by adynamically linked program. The output of the detectors issent to the Ganglia monitoring system via the interface gmet-ric. Four important characteristics of the system should benoted. First, operating system calls describe low-level accessof the application and cannot be bypassed by a malicious user.In contrast, application library function calls represent high-level information about the application and can be bypassed.Second, monitoring of function calls is more efficient thanmonitoring of system calls, because the number of operatingsystem calls greatly outnumbers the number of function calls.Third, root access is needed to monitor system calls becausethe system call wrapper must be executed as a part of thekernel. In contrast, function calls can be monitored in userspace, and root access is not required. Finally, although ourcurrent experiments only collect calls from the libraries libcand libmpipro, other dynamic libraries can be easily includedin the detection scheme.

66 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
Figure 7: Architectures used to monitor system calls (in kernel space) and function calls (in user space)
Figure 6: Template to intercept any C function
7 Experiments
7.1 DatasetFive MPI (Message Passing Interface) parallel applicationswritten in C were selected for the test cases. These wereexecuted on a small cluster with Linux RedHat 7.1 (kernel2.4.2). The cluster contains one head node able to compileand launch the parallel programs and eight computing nodes.The head node is a four-CPU SMP computer and the othernodes are dual-CPU SMP computers. The machines are fullyconnected with Ethernet and Giganet switches and the MPIenvironment used in all the experiments was MPI/Pro 1.5.Only the head node can be accessed from the Internet.
The following applications were selected to test the inte-gration of the intelligent anomaly detectors with Ganglia: animplementation of the Fast Fourier Transform (FFT) [39],an NPB benchmark based on a bucket sort (IS) [40], animplementation of the LU Factorization method for solvingsystems of linear equations (LU), a modified version of LL-Cbench from the MPBench benchmarks suite (LL) [41], andthe Network Protocol Independent Performance Evaluator(NETIPPE) [42]. Training and test data for the anomalydetectors were generated by executing each program fifteentimes with different input parameters and collecting both thesequence of function calls and system calls issued by eachexecutable in each of the four nodes of the cluster. As an ex-ample, when executing FFT, a total of 60 function-call tracefiles and 60 system-call trace files were created.
Previous research by Tan and Maxion [43] among othershave demonstrated that the intrinsic structure of the data,as measured by conditional entropy, affects the performanceof anomaly detection algorithms. Entropy is associated withthe level of uncertainty or randomness in the sequence of ob-servations. Because entropy has no upper bound, a relativeentropy is often used where a minimum value of 0 means thatthe sequence is completely predictable and a maximum valueof 1 indicates that the sequence is completely random. Of par-ticular interest is the sequential dependence of the data wheresome events precede others. This property can be measuredas the conditional relative entropy (CRE) of the source. Sup-pose X and Y are two random variables. Knowing the con-ditional probability distribution P (Y |X), the CRE can becomputed as
CRE =−
∑
xP (x)
∑
yP (y|x) log P (y|x)
MaximumEntropy(20)

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 67
where MaximumEntropy is the entropy of a theoreticalsource in which all symbols have the same probability.P (Y |X) can be defined as a matrix M , in which the rowsrepresent the current symbol and the columns represent thenext symbol in the sequence: The value of M(x, y) is theconditional probability P (Y = y|X = x).
Figure 8 shows the conditional relative entropy for eachprogram. An important conclusion is that the CRE of thefunction call sequences varies from 0.05 to almost 0.35, in-dicating that some of the programs are highly deterministic(such as NETPIPE), but others exhibit more complex behav-ior. In contrast, the CRE of the system call datasets for allthe applications shows far less variation for all values (in therange 0.25 - 0.3).
Since the system call traces record more detailed events foreach program operation (such as I/O transactions or memoryallocation), the number of calls invoked by a program is quitelarge and, as indicated by the CRE values, the sequences ofcalls show less organization than is often seen with functioncalls. This can make it more difficult to accurately model thebehavior of the program. For example, consider the systemcalls generated by high-level function calls such as MPI Sendand MPI Recv. Both calls will make use of similar low-levelsystem requests for operations such as memory allocation, in-put/output device control and timestamps. Figure 9 presentshistograms of the frequency of different calls (both systemcalls and function calls) observed for 20 samples of FFT andLU. It is difficult to differentiate the behavior of the two pro-grams based on system call logs, but in the function call logs,there are library function calls that are executed exclusivelyby one of the programs and not the other.
It is also important to observe the difference in the totalnumber of library function calls and operating system callsissued by the applications. A summary of the average num-ber of calls issued by each application is shown in Figure 10.Clearly, the number of system calls is substantially greaterthan the total number of function calls for most of the ap-plications. This may affect both the performance and accu-racy of the intelligent detection systems. For a comparisonof accuracy and overhead between user-level and kernel-levelmonitoring refer to the author’s previous work [3, 4].
7.2 Configuring the Intelligent DetectionAgents
In all of the experiments reported in this paper, ANN-baseddetectors were used for kernel-level monitoring, and HMM-based detectors were used for user-level monitoring. Eachtype of model has a different set of parameters that must bedetermined.
An appropriate number of states for the hidden Markovmodel must be estimated from the training dataset in orderto generate high-quality profiles for the parallel applications.If an HMM has fewer states than needed, or if the topol-ogy is not adequate, the estimation algorithm will generate asuboptimal model. For example, Figure 11 shows the aver-age Baum-Welch likelihood estimation of five HMMs from 60samples of sequences of library calls for FFT using differentnumbers of states. The y-axis shows the log of the probabilityof the sequence being generated by each of the models (thehighest point on this axis corresponds to a probability of 1,i.e. exact match between the 60 logs of function calls and
Figure 10: Average number of calls for each MPI application.
Figure 11: Baum-Welch estimation of 60-function call logs forFFT
the HMMs). This graph shows that there is a large improve-ment in the likelihood by using 16 states but little additionalimprovement using 32 states. In the experiments reportedin this paper, HMMs with 16 states were used and up to 20iterations of the Baum-Welch algorithm were allowed in train-ing. Also, the empirical thresholds θA = θB = 0 have beenselected for the online detection algorithm with the HMM.
The number of hidden nodes and number of epochs in-fluence the classification performance of neural networks. Afive-fold cross-validation technique was used to select the bestnumber of hidden nodes and the most appropriate number ofepochs to prevent overfitting. Results of this experiment re-sulted in the selection of 32 hidden nodes. The number ofepochs was controlled to prevent memorization (and there-fore lack of generalization) of the patterns. The subsequencelength (window size) of the input examples for the feed-forward network was set to six.
7.3 Monitoring of Applications
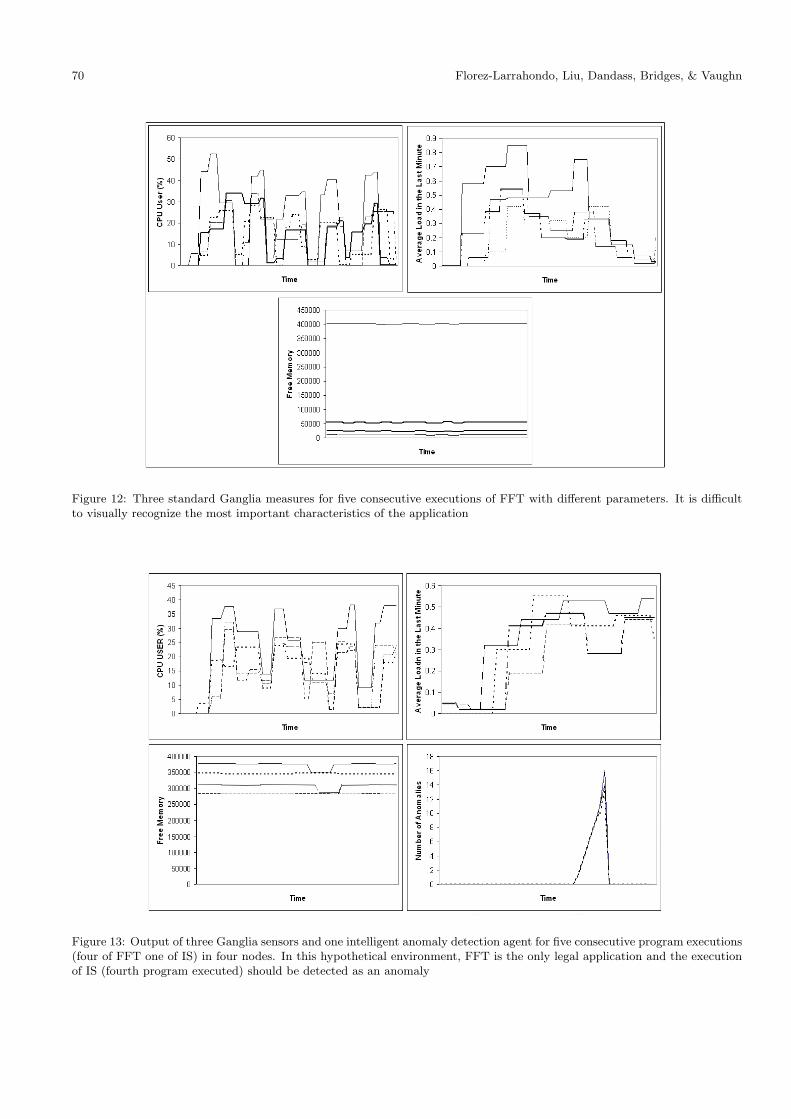
Figure 12 shows the percentage of CPU time spent by userprocesses, the average load for the last one minute, and theamount of free memory of four nodes in the cluster, whenfive FFT applications with different parameters were exe-cuted consecutively. This data was collected by pulling data

68 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
Figure 8: Conditional Relative Entropy of Training Data
Figure 9: Frequency of calls issued by 20 samples of FFT and LU

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 69
from gmond every five seconds by executing the command tel-net localhost 8649 and parsing the corresponding XML file.These results demonstrate that although Ganglia monitoringis useful for determining the overall status of the distributedsystem, it can be misleading when it is used to monitor aparticular parallel application. For example, the execution ofa parallel program with different input data and parameterswill result in very skewed values for CPU usage times, andtherefore, it is difficult to summarize this feature using simplestatistical properties such as mean and variance. The prob-lem of profiling applications with traditional Ganglia metricsis even more difficult when the application makes use of ran-domized algorithms. Because most of the sensors used inGanglia are time-driven (i.e a snapshot of the sensor is takenat a given time period), creating a useful model of the sensorfor a complex distributed application can be a difficult task.
An experiment was conducted to demonstrate the addeddetection capability provided by our intelligent sensors. Con-sider a hypothetical distributed environment where a singleapplication is allowed to execute. Any other program is con-sidered to be anomalous even if it has been launched by anauthorized user. Figure 13 shows three standard Ganglia met-rics along with the output of one intelligent anomaly detectionagent (an HMM analyzing library function calls) for a hypo-thetical environment where the application FFT is the onlyone allowed to run. In this particular example, four FFTprograms were launched with different parameters along withone IS program used to simulate the execution of an unautho-rized program. A system administrator can easily recognizewhen a user is misusing the system by looking at the outputof the intelligent anomaly detector. Note that in this exampleone can observe a small reduction in the amount of availablememory that indicates the existence of potential anomaliesin the system. However, this reduction in free memory couldalso be attributed to other factors such as incorrect argumentsfor the program or a small input dataset.
7.4 Integrating Anomaly Detection withthe Ganglia Front End
Previous experimental results demonstrated that the outputof an anomaly detection system can help a system admin-istrator determine when an application is not behaving asexpected. The next step is the integration of the detectorsinto the Ganglia framework. This is easily accomplished byusing the gmetric interface and by modifying the PHP sourceof the Ganglia front end. Three test cases were conductedto demonstrate the capabilities of the system with intelligentanomaly detection agents integrated into the Ganglia moni-toring system. The first test case shows how the execution ofan unauthorized program can be detected using the integratedsystem. The second test case shows how the integrated sys-tem can be used to recognize network or software faults in thesystem. The third test case demonstrates simultaneous use ofuser-level and kernel-level monitoring for detecting anomalies.
Case Study 1. Detection of Unauthorized Applications: Atest environment was created where it was assumed that onlyone application (IS) is authorized to run and the execution ofother programs such as LL, FFT, LU and NETPIPE shouldbe detected as anomalies. Figure 14 shows the output ofGanglia from the most recent 10 minutes of activity in thecluster when both legal and illegal programs have been exe-
cuted. Note that the figure shows the output of the user-levelmonitoring as AD FC (i.e., anomaly detection with functioncalls in the Ganglia framework) for six computing nodes, aswell as four standard Ganglia metrics such as CPU Load andbandwidth usage. As was demonstrated previously, it is diffi-cult to determine whether unauthorized applications are be-ing executed in the cluster using only the traditional Gangliametrics. On the other hand, the six anomaly detectors shownin Figure 14 (each one monitoring a single node in the cluster)alert the system administrator of suspicious activity in nodes1, 2, 6 and 7. Furthermore, the figure indicates that someunauthorized applications were executed in four nodes, whilesome other unauthorized applications employed only nodes 1and 2.
Similar techniques can be applied on a distributed systemin order to detect exploitation of computer resources by ma-licious users who are attempting to gain access to sensitiveinformation or to perform distributed network attacks. Theattack on academic supercomputing laboratories using sim-ple MPI applications reported in 2004 [1] is an example ofthe type of attack that requires more sophisticated sensorsthan those provided by firewalls and traditional intrusion de-tection systems.
Case Study 2. Fault Tolerance and Detection: Software andhardware faults are likely to occur during long-running jobs ina cluster with several individual nodes. Several approaches forthe development of fault-tolerant distributed applications areknown (see for example the previous work on fault tolerance inMPI programs [44,45]). A simple mechanism that checks thereturn status of MPI functions was implemented. If the returncode is not equal to MPI SUCCESS, an error is reported toa log via the standard C function fwrite.
In this particular scenario, an interposition library was cre-ated to simulate anomalies in the network interface whenthe application LLCbench was executed five times, with a0.001 probability of error for the functions MPI Send andMPI Recv. This is an example of fault injection and simula-tion of attacks described in previous work [3,4]. Every time afault is reported via the fwrite call by a parallel program, theintelligent agents detect the change in the sequence of obser-vations and inform Ganglia that the counter of anomalies hasbeen increased. Figure 15 shows the output of the anomalydetectors in the Ganglia front end. The intelligent detectionagents integrated in the Ganglia front end clearly provide asimple way to visualize system faults. Again, these faults aredifficult to detect using the standard Ganglia metrics.
Note that although fault detection is not widely used inMPI programs, similar catch-throw mechanisms often occurin high-quality software. Therefore, recognizing a change inthe sequence of discrete events can still be used as a meansof detecting faults.
Case Study 3. Simultaneous Detection of Anomalies inUser Space and Kernel Space: The author’s previous workconducted experiments to compare the accuracy in the detec-tion and the overhead produced by the intelligent detectionagents [3, 4] . However, the behavior of distributed applica-tions when both systems are simultaneously used to detectanomalies in real-time has not been observed before. Figure16 shows the detection of network faults in a single node ofthe cluster when both user-level monitoring and kernel-levelmonitoring are enabled.
70 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
Figure 12: Three standard Ganglia measures for five consecutive executions of FFT with different parameters. It is difficultto visually recognize the most important characteristics of the application
Figure 13: Output of three Ganglia sensors and one intelligent anomaly detection agent for five consecutive program executions(four of FFT one of IS) in four nodes. In this hypothetical environment, FFT is the only legal application and the executionof IS (fourth program executed) should be detected as an anomaly

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 71
Figure 14: Detection of unauthorized applications using the Ganglia front end enhanced with an intelligent anomaly detector(AD FC)
Figure 15: Detection of network faults using the Ganglia front end enhanced with an intelligent anomaly detector (AD FC)

72 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
Figure 16: Simultaneous detection of network faults in a single cluster node for the previous 10 minutes using the HMM-baseddetector and the ANN-based detector. The outputs in the first row correspond to user-level monitoring (AD FC ) and thekernel-level monitoring (AD SC ). Four built-in Ganglia metrics are also shown.
One of the problems encountered when executing both sys-tems at the same time is contamination of the system callsequences by calls made by the user level monitoring system.Every operating system call issued by the user space monitor-ing system is recorded by the kernel space monitoring system.Therefore, even if an MPI application is behaving as expected(and the user-level monitoring system reports 0 anomalies),the kernel-level detection system will detect changes in the se-quence of operating system calls and report these as anoma-lies. To solve this problem, a new system call exclusivelyexecuted by the user-level monitoring system that acts as aflag to temporarily deactivate the detection of system callswas created. Although this naive solution allows observationof the behavior of both systems in a research environment, itis not an adequate solution for real-world systems because itcan create a security vulnerability. Further research is neededto develop better mechanisms for allowing the simultaneousexecution of the two levels of detection in real-time includingstudies of the security, scalability and performance of suchmechanisms.
7.5 Limitations of Anomaly Detection withSequences of Discrete Events
The fundamental assumption of this work is that high-qualityprofiles (artificial neural networks or hidden Markov models)can be used to discriminate between normal and suspiciousexecutions of a distributed application. However, there aresituations in which this assumption may not hold. For ex-ample, when the behavior of legal applications is quite variedresulting in a complex model, it may not be possible to de-tect the execution of illegal applications with simple behav-ior that is a subset of the behavior of the legal application.This phenomenon was observed in our experiments when we
used one application as the “legal” application. When themodel of the legal application was run against sequences ofsystem calls from other applications that should have beendetected as anomalies, it was not always possible to detectthe anomalies. Figure 17 shows the results of such an exper-iment in which HMM profiles were created using five differ-ent programs. Each profile was run with system calls result-ing from running the other applications and the percentageof anomalous function calls (i.e., y-axis) was computed witheach profile. The programs run were (FFT, IS, LU, LL andNETPIPE). Points on the x-axis represent executions of dif-ferent instances of each program. When the profile for oneprogram is used, the system calls from all other programsshould be flagged as anomalous. From the figure it is clearthat most of the profiles are able to discriminate normal be-havior (i.e. the intelligent agents output 0% anomalies whenthe parallel program being executed has the same behavioras the profile of such a program) from suspicious activitiesin the system. However, when NETPIPE is the “anomalousapplication”, only the profiles obtained from sampling FFTand IS detect it as anomalous. NETPIPE is an example ofa highly deterministic benchmark application where a largeportion of the computation consists of calls to the functionsMPI Send (send a message to a specific node) and MPI Recv(receive a message). These sequences of calls are also likely tooccur in the other applications. Figure 18 repeats the sameexperiment with the ANN-based detector monitoring operat-ing system calls. It is important to observe that the largedifference in the scale of the x-axis for Figures 17 and 18 isdue to the large number of operating system calls executedby the applications.

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 73
Figure 17: The percentage of anomalous function calls de-tected for each application execution by the HMM-based de-tector monitoring library function calls for a given profile isplotted for a work session consisting of the consecutive exe-cution of several MPI programs.
Figure 18: The percentage of anomalous function calls de-tected per application execution by the ANN-based detectormonitoring operating system calls for a given profile is plottedfor a work session consisting of the consecutive execution ofseveral MPI programs.
8 Conclusions and Future Work
The central focus of the research reported in this paper isthe integration of intelligent anomaly agents and high perfor-mance monitoring systems. An event-driven system architec-ture is used in which sensors collect information every timea discrete event is generated. The intelligent agents used forthis study use machine learning techniques to develop pro-files of normal behavior as seen in the sequences of operatingsystem calls generated by an application and the sequence offunction calls. The intelligent agents are able to flag anoma-lies that are difficult to detect in traditional monitoring sys-tems, while the monitoring systems provide the frameworkneeded for communication and visualization of system status.The Ganglia monitoring system was used as a test bed forintegration case studies. Mechanisms provided by Gangliamake it relatively easy to integrate the new detectors into thesystem and to visualize the results of these detectors. The ex-perimental results demonstrate that the integrated intelligentagents can detect the execution of unauthorized applicationsand faults that are not obvious in the standard output fromthe monitoring system. Both hidden Markov models workingin user space and neural network models working in kernelspace are shown to be effective. Simultaneous monitoring inboth user space and kernel space is also demonstrated.
The research reported in this paper provides preliminaryevidence that intelligent anomaly detectors can be effectivelyintegrated in a high performance monitoring system. Our sys-tem can also be used to detect anomalies in general purposesystems because we use standard Linux libraries and the Gan-glia framework. However the system may suffer from a largenumber of false positives in general environments because itbecomes difficult to collect an adequate set of samples to trainthe models.
A number of research issues remain. More effective meth-ods are needed for resolving conflicts encountered during si-multaneous user and kernel space monitoring. Studies need tobe conducted in order to determine the performance penaltyincurred by the anomaly detectors and to determine scalabil-ity of the system.
Also, although previous work has shown that the anomalydetectors have small overheads [3,4], the authors are currentlyinvestigating the use of reconfigurable co-processors to reducethis overhead further. Research also needs to be conducted inthe use of extended models that are able to monitor a set ofattributes of the calls such as return value or call parameters.This kind of model can potentially provide more informationabout the expected behavior of an application.
Future work also includes the study of incremental al-gorithms able to estimate the parameters and topology ofHMMs to reduce the space complexity from O(N2T ) toO(N2). Such an algorithm will provide a mechanism for learn-ing directly from the sequence of calls generated by the appli-cations without the need to store and transfer large amountsof data and can be modified to handle non-stationary distri-butions, providing a solution for the problem of concept drift.Furthermore, in the case that it is necessary to avoid contam-inating the model with outliers (elements in the dataset thatdo not seem consistent with past observations, including per-haps system anomalies), the incremental learning algorithmcan decide whether a observation needs to be included in themodel or not.

74 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
Finally, a related issue in high-performance cluster mon-itoring is the fusion of monitoring results by disparate sen-sors in a highly efficient and accurate manner. Experimentalwork in this area includes the use of fuzzy cognitive maps(FCMs) as the technical basis for a fusion engine. The inter-ested reader is invited to review Siraj’s work [5, 6].
Acknowledgment
This work was supported by the Naval Research, contractN00014-01-0678; the Army Research Laboratory, contractDAAD17-01-C-0011; and the National Science Foundation,contract CCR-0098024, 98-1849 and 99-88524. We also thankthe members of the Center for Computer Security Research(CCSR) at Mississippi State University.
References
[1] R. Lemos, Academics search forclues after supercomputer attacks,http://news.zdnet.co.uk/internet/security/0,39020375,39152264,00.htm (April 2004).
[2] M. Torres, R. Vaughn, S. Bridges, G. Florez, Z. Liu,Attacking a high performance computer cluster, in: Pro-ceedings of the 15th Annual Canadian Information Tech-nology Security Symposium, Ottawa, Canada, 2003.
[3] G. Florez, Z. Liu, S. Bridges, A. Skjellum, R. Vaughn,Lightweight monitoring of MPI programs in real-time,Concurrency and Computation: Practice and Experience17 (3) (2005) 1547–1578.
[4] G. Florez, Z. Liu, S. Bridges, A. Skjellum, R. Vaughn,Detecting anomalies in high-performance parallel pro-grams, Journal of Digital Information Management 2 (2)(2004) 44–47.
[5] A. Siraj, S. Bridges, , R. Vaughn, Fuzzy cognitive mapsfor decision support in an intelligent intrusion detectionsystem, in: International Fuzzy Systems Association/North American Fuzzy Information Processing Society(IFSA/NAFIPS) Conference on Soft Computing, Van-couver, Canada, 2001.
[6] A. Siraj, R. B. Vaughn, S. M. Bridges, Decision makingfor network health assessment in an intelligent intrusiondetection system architecture, International Journal ofInformation Technology and Decision Making 3 (2).
[7] M. L. Massie, B. N. Chun, D. E. Culler, TheGanglia distributed monitoring system: De-sign, implementation, and experience, Ac-cepted for publication in Parallel Computing,http://ganglia.sourceforge.net/talks/parallelcomputing/ganglia-twocol.pdf (2004).
[8] S. Forrest, S. A. Hofmeyr, A. Somayaji, T. A. Longstaff,A sense of self for unix processes, in: Proceedings ofthe 1996 IEEE Symposium on Security and Privacy, LosAlamitos, CA, 1996, pp. 120–128.
[9] H. Steven A, S. Forrest, A. Somayaji, Intrusion detectionusing sequences of system calls, Journal Of ComputerSecurity 6 (3) (1998) 151–180.
[10] P. A. Porras, P. G. Neumman, Emerald: Event monitor-ing enabling responses to anomalous live disturbances,
in: Proceedings of the 20th National Information Sys-tems Security Conference, 1997.
[11] A. Somayaji, Operating system stability and securitythrough process homeostasis, Ph.D. thesis, The Univer-sity of New Mexico, Albuquerque, New Mexico (July2002).
[12] L. Eschenaur, Imsafe: Immune secu-rity architecture, World Wide Web,http://imsafe.sourceforge.net/inside.htm (2001).
[13] C. Warrender, S. Forrest, B. A. Pearlmutter, Detectingintrusions using system calls: Alternative data Models,in: Proceedings of the IEEE Symposium on Security andPrivacy, 1999, pp. 133–145.
[14] G. Florez, Analyzing system call sequences with Ad-aboost, in: Proceedings of the 2002 International Con-ference on Artificial Intelligence and Applications (AIA),Malaga, Spain, 2002.
[15] Z. Liu, G. Florez, S. Bridges, A comparison of input rep-resentations in neural networks: A case study in intru-sion detection, in: Proceedings of the 2002 InternationalJoint Conference on Neural Networks (ICJNN’02), Hon-olulu, Hawaii, 2002.
[16] T. Lane, Hidden Markov Models for human/computerinterface modeling, in: IJCAI-99 Workshop on LearningAbout Users, 1999, pp. 35–44.
[17] R. Rabenseifner, Automatic MPI counting profiling, in:Proceedings of the 42nd Cray User Group Conference,CUG SUMMIT 2000, 2000.
[18] J. S. Vetter, B. R. de Supinski, Dynamic software test-ing of MPI applications with Umpire, in: SC2000: HighPerformance Networking and Computing Conference,ACM/IEEE, 2000.
[19] M. Marzolla, A performance monitoring system for largecomputing clusters, in: Proceedings of the Eleventh Eu-romicro Conference on Distributed and Network-BasedProcessing, Genova, Italy, 2003, pp. 393–400.
[20] M. Lyu, V. Mendiratta, Software fault tolerance in aclustered architecture: Techniques and reliability mod-eling, in: Proceedings 1999 IEEE Aerospace Conference,Snowmass, Colorado, 1999, pp. 141–150, vol.5.
[21] C. M. P. Augerat, B. Stein, Scalable monitoring and con-figuration tools for grids and clusters, in: Proceedings ofthe 10th Euromicro Workshop on Parallel, Distributedand Network-based Processing, Canary Islands, Spain,2002.
[22] R. Buyya, Parmon: A portable and scalable monitoringsystem for clusters, Software: Practice and Experience30 (7) (2000) 723–739.
[23] M. Sottile, R. Minnich, Supermon: A high-speed clus-ter monitoring system, in: Proceedings of Cluster 2002,2002.
[24] L. Rabiner, A tutorial on Hidden Markov Models andselected applications in speech recognition, in: Proceed-ings of the IEEE, Vol. 77 of 2, 1989, pp. 257–286.
[25] S. Russel, P. Norvig, Artificial Intelligence: A ModernApproach, Prentice Hall, 1995.

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 75
[26] D. R. Tveter, Backpropagator’s review,http://www.dontveter.com/bpr/bpr.html (August2002).
[27] A. K. Ghosh, A. Schwartzbard, M. Schatz, Learning pro-gram behavior profiles for intrusion detection, in: Pro-ceedings of the 1st USENIX Workshop on Intrusion De-tection and Network Monitoring, Santa Clara, Califor-nia, 1999, pp. 51–62.
[28] W. Lee, S. Stolfo, Data mining approaches for intrusiondetection, in: Proceedings of the 7th USENIX SecuritySymposium, San Antonio, Texas, 1998, pp. 79–94.
[29] Z. Liu, S. Bridges, R. Vaughn, Classification of anoma-lies traces of privileges and parallel programs by neuralnetworks, in: Proceedings of the 2003 FUZZIEEE Con-ference, St. Louis, MO, 2003.
[30] I. MacDonald, W. Zucchini, Hidden Markov and OtherModels for Discrete-valued Time Series, Monographson Statistics and Applied Probability, Chapman andHALL/CRC, 1997.
[31] J. Bilmes, What HMMs can do, Tech. Rep. UWEETR-2002-0003, Department of Electrical Engineering, Uni-versity of Washington (January 2002).
[32] G. Sun, H. Chen, Y. Lee, C. Giles, Recurrent neuralnetworks, Hidden Markov Models and stochastic gram-mars, in: Proceedings of International Joint Conferenceon Neural Networks, San Diego,CA, 1990, pp. 729–734.
[33] T. Mitchem, R. Lu, , R. O’Brien, Using kernel hyper-visors to secure applications, in: Proceedings of AnnualComputer Security Application Conference, San Diego,California, 1997, pp. 175–181.
[34] Department of Defense, Trusted Computing systemsEvaluation Criteria, DoD Standard 5200.28 (1985).
[35] B. Kuperman, E. Spafford, Generation of applicationlevel audit data via library interposition, Technical Re-port TR 99-11, COAST laboratory, Purdue University(1998).
[36] T. W. Curry, Profiling and tracing dynamic library usagevia interposition, in: Proceedings of the USENIX 1994summer conference, 1994.
[37] S. Goldt, S. van der Meer, S. Burkett, M. Welsh,The linux programmer’s guide, World Wide Web,http://ibiblio.org/mdw/LDP/lpg/node5.html (1995).
[38] K. Jain, R. Sekar, User-level infrastructure for systemcall interposition: A platform for intrusion detection andconfinement, in: Proceedings of the Network and Dis-tributed Systems Security, 2000, pp. 19–34.
[39] M. Frigo, S. Jhonson, Discrete fourier transformation,Wolrd Wide Web, http://www.fftw.org (2003).
[40] M. Yarrow, Nas parallel benchmarks suite 2.3 - is, Tech.rep., NASA Ames Research Center, Moffett Field, CA(1995).
[41] P. Mucci, Llcbench (low-level characterizationbenchmarks) home page, World Wide Web,http://icl.cs.utk.edu/projects/llcbench/ (July 2000).
[42] Q. Snell, A. Mukler, J. Gustafson, Netpipe: Networkprotocol independent performance evaluator, in: Pro-ceedings of the IASTED International Conference on In-telligent Information Management and Systems, 1996,http://www.scl.ameslab.gov/netpipe.
[43] K. Tan, R. Maxion, Determining the operational limitsof an anomaly-based intrusion detector, IEEE Journalon Selected Areas in Communications, Special Issue onDesign and Analysis Techniques for Security Assurance21 (1) (2003) 96–110.
[44] R. Batchu, Y. S. Dandass, A. Skjellum, M. Bed-dhu, MPI/FT: A model-based approach to low-overhead fault-tolerant message-passing middleware,Cluster Computing 7 (4) (2004) 303–315.
[45] W. Gropp, E. Lusk, Fault tolerance in MPI programs, in:Proceedings of the Cluster Computing and Grid SystemsConference, 2002.
Author Biographies
German Florez-Larrahondo Dr. Florez-Larrahondo wasborn in Bogota, Colombia. He received a Bachelor degreein Systems Engineering from the Universidad Nacional deColombia, as well as an MS and Ph.D. in Computer Sci-ence from Mississippi State University. His major researchareas include machine learning, computer security and high-performance computing. Dr. Florez-Larrahondo currentlyworks for Verari Systems Software designing middleware forhigh-performance applications.
Zhen Liu Dr. Liu was born in Beijing, China. He receivedhis Bachelor degree in computer science at the University ofScience and Technology of China in 2000, and his MS andPh.D. in computer science from Mississippi State Universityin 2003 and 2005 respectively. His major research areas arecomputer security, intrusion detection, and machine learning.Dr. Liu currently works for Microsoft.
Yoginder S. Dandass Dr. Dandass is an Assistant Pro-fessor of Computer Science and Engineering at MississippiState University. He received his Ph.D. in Computer Sciencefrom Mississippi State University in 2003 with an emphasis inhigh-performance computing. His research interests includehigh-performance computing, real-time systems, and recon-figurable computing. From 1997 to 2003, he was a researchassociate at Mississippi State. He also has over eight yearsof experience as an IT consultant prior to joining MississippiState.
Susan M. Bridges Dr. Bridges is a professor of computerscience and engineering at Mississippi State University. Shereceived her B.S. in botany from the University of Arkansasin 1969, an M.S. in biology from the University of Missis-sippi in 1975, an M.C.S. in computer science from MississippiState University in 1983, and her Ph.D. in computer sciencefrom the University of Alabama in Huntsville in 1989. Herresearch interests are in machine learning and data miningwith applications in computer security and bioinformatics
Rayford Vaughn Dr. Vaughn received his Ph.D. fromKansas State University, Manhattan Kansas (USA) in 1988in the area of computer science with an emphasis in computer

76 Florez-Larrahondo, Liu, Dandass, Bridges, & Vaughn
security. He joined Mississippi State University in 1997 as afaculty member. Prior to joining the University, he completeda twenty-six year career in the Army where he commanded theArmy’s largest software development organization and cre-ated the Pentagon agency that today centrally manages allPentagon IT support. He is currently the Billie J. Ball Pro-fessor of Computer Science and Engineering and teaches andconducts research in the areas of Software Engineering and In-formation Security. Dr. Vaughn has over 70 publications tohis credit and is an active contributor to software engineeringand information security conferences and journals.
.

Integrating Intelligent Anomaly Detection Agents into Distributed Monitoring Systems 77
.





























