Embed Size (px)
Citation preview

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1
Generative Adversarial Reward Learning forGeneralized Behavior Tendency Inference
Xiaocong Chen, Lina Yao, Member, IEEE, Xianzhi Wang, Member, IEEE, Aixin Sun, Member, IEEE,Wenjie Zhang, Member, IEEE, Quan Z. Sheng, Member, IEEE
Abstract—Recent advances in reinforcement learning have inspired increasing interest in learning user modeling adaptively throughdynamic interactions, e.g., in reinforcement learning based recommender systems. Reward function is crucial for most of reinforcementlearning applications as it can provide the guideline about the optimization. However, current reinforcement-learning-based methodsrely on manually-defined reward functions, which cannot adapt to dynamic and noisy environments. Besides, they generally usetask-specific reward functions that sacrifice generalization ability. We propose a generative inverse reinforcement learning for userbehavioral preference modelling, to address the above issues. Instead of using predefined reward functions, our model canautomatically learn the rewards from user’s actions based on discriminative actor-critic network and Wasserstein GAN. Our modelprovides a general way of characterizing and explaining underlying behavioral tendencies, and our experiments show our methodoutperforms state-of-the-art methods in a variety of scenarios, namely traffic signal control, online recommender systems, andscanpath prediction.
Index Terms—Inverse Reinforcement Learning, Behavioral Tendency Modeling, Adversarial Training, Generative Model
F
1 INTRODUCTION
B EHAVIOR modeling provides a footprint about user’sbehaviors and preferences. It is a cornerstone of di-
verse downstream applications that support personalizedservices and predictive decision-making, such as human-robot interactions, recommender systems, and intelligenttransportation systems. Recommender systems generallyuse users’ past activities to predict their future interest[1], [2], [3]; past studies integrate demographic informationwith user’s long-term interest on personalized tasks [4],[5], [6], [7]. In human-robot interaction, a robot learnsfrom user behaviors to predict user’s activities and providenecessary support [8]. Multimodal probabilistic models [9]and teacher-student network [10] are often used to predictuser’s intention for traffic prediction or object segmentation.Travel behavior analysis ; it is a typical task in smart-cityapplications [11], [12].
Traditional methods learn static behavioral tendenciesvia modeling user’s historical activities with items as afeature space [13] or a user-item matrix [14]. In contrast,reinforcement learning shows advantages in learning user’spreference or behavioral tendency through dynamic interac-tions between agent and environment. It has attracted lots ofresearch interests in recommendation systems [6], intentionprediction [15], traffic control [16], and human-robot inter-action domains [17]. Reinforcement learning covers severalcategories of methods, such as value-based methods, policy-
• X. Chen, L. Yao and W. Zhang are with the School of Computer Scienceand Engineering, University of New South Wales, Sydney, NSW, 2052,Australia.E-mail: {xiaocong.chen, lina.yao, wenjie.zhang}@unsw.edu.au
• X. Wang is with School of Computer Science, University of TechnologySydney, Sydney, NSW, 2007, Australia.
• A. Sun is with Nanyang Technological University, Singapore.• Q. Sheng is with Department of Computing, Macquarie University,
Sydney, NSW, 2109, Australia.
based methods, and hybrid methods. All these methodsuse the accumulated reward during a long term to indicateuser’s activities. The reward function is manually definedand requires extensive effort to contemplate potential fac-tors.
In general, user’s activities are noisy, occasionally con-taminated by imperfect user behaviors and thus may notalways reveal user’s interest or intention. For example, inonline shopping, a user may follow a clear logic to buy itemsand randomly add additional items because of promotionor discounts. This makes it difficult to define an accuratereward function because the noises also affect the fulfillmentof task goals in reinforcement learning. Another challengelies in the common practice of adding task-specific termsto the reward function to cope with different tasks. Cur-rent studies usually require manually adjusting the rewardfunction to model user’s profiles [2], [18], [19]. Manualadjustment tends to produce imperfect results because it isunrealistic to consider all reward function possibilities, notto mention designing reward functions for new tasks.
A better way to determine the reward function is to learnit automatically through dynamic agent-environment in-teractions. Inverse reinforcement learning recently emergesas an appealing solution, which learns reward functionlearning from demonstrations in a few scenarios [20]. How-ever, inverse reinforcement learning faces two challengesfor user behavior modeling. First, it requires a repeated,computational expensive reinforcement learning process toapply a learned reward function [21]; second, given anexpert policy, there could be countless reward functionsfor choice, making the selection of reward function difficultand the optimization computationally expensive. The onlyrecommendation model [22] that adopts improved inversereinforcement learning simply skips the repeated reinforce-ment learning process; thus, it is hard to converge as it
arX
iv:2
105.
0082
2v2
[cs
.LG
] 5
May
202
1

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 2
lacks sampling efficiency and training stability; furthermore,the model only works for recommender systems and lacksgeneralization ability.
With such existing challenges, manually designed re-ward function has less feasibility and generalizability. More-over, [22] employs inverse reinforcement learning to learnthe reward from demonstration which still suffers the un-defined problem due to the nature of the logarithm. Torelieve this, we manipulate the function by adding an extralearnable term to avoid such a problem. In addition, existingworks do not consider the absorbing state problem suchthat agents will stop learning once the absorbing states arereached. The major reason why is that agent will receivezero rewards in absorbing states and may lead to a sub-optimal policy.
In this paper, we aim to construct user models directlyfrom an array of various demonstrations efficiently andadaptively, based on a generalized inverse reinforcementlearning method. Learning from demonstrations not onlyavoids the need for inferring a reward function but alsoreduces computational complexity. To this end, we proposea new model that employs a generative adversarial strategyto generate candidate reward functions and to approximatethe true reward. We use the new model as a general way ofcharacterizing and explaining tendencies in user behaviors.In summary, we make the following contributions:
• We propose a new inverse reinforcement-learning-based method to capture user’s behavioral tenden-cies. To the best of our knowledge, this is the firstwork to formulate user’s behavioral tendency usinginverse reinforcement learning.
• We design a novel stabilized sample-efficient dis-criminative actor-critic network with WassersteinGAN to implement the proposed framework. Ourframework is off-policy and can reduce interactionsbetween system and environment to improve effi-ciency. Besides, we integrate a learnable term intoour reward function to increase the capability of ourmethod.
• Our extensive experiments demonstrate the general-ization ability and feasibility of our approach in threedifferent scenarios. We use visualization to show theexplainability of our method.
2 PROBLEM FORMULATION AND PRELIMINARY
Behavioral tendency refers to user’s preferences at a certaintimestamp and is usually hard to be evaluated directly. Thecommon way to evaluate behavioral tendencies is to exam-ine how well the actions taken out of the learned behavioraltendencies match the real actions taken by the user. It issimilar to reinforcement learning’s decision-making process,where the agent figures out an optimal policy π such thateach action of it could achieve a good reward.
In this work, we define behavioral tendencies modelingas an optimal policy finding problem. Given a set of usersU = {u0, u1, · · · , un}, a set of items O = {o0, o1, · · · , om}and user’s demographic information D = {d0, d1, · · · , dn}.We first define the Markov Decision Process (MDP) as atuple (S,A,P,R, γ), where S is the state space (i.e., the
combination of the subset of O, subset of U and its cor-responding D). A is the action space, which includes allpossible agent’s decisions,R is a set of rewards received foreach action a ∈ A, P is a set of state transition probability,and γ is the discount factor used to balance the futurereward and the current reward. The policy can be definedas π : S → A—given a state s ∈ S , π will return anaction a ∈ A so as to maximize the reward. However, itis unrealistic to find a universal reward function for user be-havioral tendency, which is highly task-dependent. Hence,we employ Inverse reinforcement learning (IRL) to learna policy π from the demonstration from expert policy πE ,which always results in user’s true behavior. We formulatethe IRL process using a uniform cost function c(s, a) [20]:
minimizeπ
maxc∈C
Eπ[c(s, a)]− EπE [c(s, a)] (1)
The cost function class C is restricted to convex sets de-fined by the linear combination of a few basis functions{f1, f2, · · · , fk}. Hence, given a state-action pair (s, a), thecorresponding feature vector can be represented as f(s, a) =[f1(s, a), f2(s, a), · · · , fk(s, a)]. Eπ[c(s, a)] is defined as (onγ-discounted infinite horizon):
Eπ[c(s, a)] = E[∞∑t=0
γtc(st, at)] (2)
According to Eq.(1), the cost function class C is convexsets, which have two different formats: linear format [23]and convex format [24], respectively:
Cl ={∑
i
wifi : ‖w‖2 ≤ 1}
(3)
Cc ={∑
i
wifi :∑i
wi = 1,∀i s.t. wi ≥ 0}
(4)
The corresponding objective functions are as follows:
‖Eπ[f(s, a)]− EπE [f(s, a)]‖2 (5)Eπ[fj(s, a)]− EπE [fj(s, a)] (6)
Eq.(5) is known as feature expectation matching [23],which aims to minimize the l2 distance between the state-action pairs that are generated by learned policy π and ex-pert policy πE . Eq.(6) aims to minimize the function fj suchthat the worst-case should achieve a higher value [25]. SinceEq.(1 suffers the feature ambiguity problem, we introduceγ-discounted causal entropy [26] (shown below) to relievethe problem:
H(π) ,Eπ[− log π(a|s)] = Est,at∼π[−∞∑t=0
γt log π(at|st)]
(7)
As such, Eq.(1) can be written by using the γ-discountedcausal entropy as:
minimizeπ
−H(π)− EπE [c(s, a)] + maxc∈C
Eπ[c(s, a)] (8)
Suppose Π is the policy set. We define the loss func-tion c(s, a) to ensure the expert policy receives the lowestcost while all the other learned policies get higher costs.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 3
FC
FC FC
FC
FC
FCFC
FC
GAE GAE
... ...
Expected State-Action PairsLearned State-Action Pairs
......
Real World Tasks Expert Action
...
......
Our Model
1
2
3
45
6
7
8
FC
FC
FC
FC Softmax
FC
FC
FC
FC Softmax
Policy ActionState Value Fully-Connected
Layer
Urban MobilityManagement
Recommender System
Scanpath Prediction
Environment-System Interaction
Legend
PPO Update
Fig. 1: Overall structure of the proposed framework. The left-hand side provides three example environments from top tobottom: urban mobility management, recommender system and scanpath prediction. The proposed model will interact withthe environment to achieve the corresponding state representations for current task. The expert actions will be achievedsimultaneously and feed into our model to participate the training procedure of the discriminator.
Referring to Eq.(8), the maximum causal entropy inversereinforcement learning [27] works as follows:
maximizec∈C
(minπ∈Π−H(π) + Eπ[c(s, a)])− EπE [c(s, a)] (9)
Then, the policy set Π can be obtained via policy genera-tion. Policy generation is the problem of matching two occu-pancy measures and can be solved by training a GenerativeAdversarial Network (GAN) [28]. The occupancy measureρ for policy π can be defined as:
ρπ(s, a) = π(s|a)∞∑t=0
γtP (st = s|π) (10)
We adopts GAIL [21] and make an analogy from the occu-pancy matching to distribution matching to bridge inversereinforcement learning and GAN. A GA regularizer is de-signed to restrict the entropy function:
ψGA(c(s, a)) =
{EπE [−c(s, a)− log(1− exp(c(s, a)))] c < 0
∞ c ≥ 0
(11)
The GA regularizer enables us to measure the differencebetween the π and πE directly without the reward function:
ψGA(ρπ − ρπE ) = maxD∈(0,1)S×A
Eπ[logD(s, a)]
+EπE [log(1−D(s, a))] (12)
The loss function from the discriminator D is definedas c(s, a) in Eq.(9); it uses negative log loss (commonly usedfor binary classification) to distinguish the policies π and πEvia state-action pairs. The optimal of Eq.(12) is equivalenceto the Jensen-Shannon divergence [29]:
DJS(ρπ, ρπE ) = DKL(ρπ‖(ρπ + ρπE )/2)+
DKL(ρπE‖(ρπ + ρπE )/2) (13)
Finally, we rewrite inverse reinforcement learning bysubstituting the GA regularizer into Eq.(8):
minimizeπ
−λH(π) + ψGA(ρπ − ρπE )︸ ︷︷ ︸DJS(ρπ,ρπE )
(14)
where λ is a factor with λ ≥ 0. Eq.(14) has the same goalas the GAN, i.e., finding the squared metric between distri-butions. Eq.(14) can be further extended into the following,which serves as the objective function for GAIL:
minimizeπ
−λH(π) + ψGA(ρπ − ρπE ) ≡ minπ
maxDLD
LD = Eπ[logD(s, a)] + EπE [log(1−D(s, a))]− λH(π)(15)
We summarized all the notations used in this paper inTable 1.
3 METHODOLOGY
The overall structure of our proposed method (shown inFig. 1) consists of three components: policy and reward

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 4
TABLE 1: Main notations
Symbols MeaningU Set of usersO Set of itemsR Set of rewards receivedD Set of demographic information| · | Number of unique elements in ·γ Discount Factor
H(π) γ-discounted casual entropyE Expectationρ Occupancy MeasureSt State space at timestamp tat Action space at timestamp tπ PolicyπE Expert PolicyD Discriminator
DKL Kullback–Leibler divergenceDJS Jensen-Shannon divergence·‖· Divergence
learning, stabilized sample efficient discriminative actor-critic network, and its optimization. Policy and rewardlearning aims to solve the reward bias and the absorbingstate problem by introducing a learnable reward functionand environment feedback. The stabilized actor-critic net-work aims to improve the training stability and sampleefficiency for the ex sting methods. Optimization refers tothe method to optimize the policy and the algorithms totrain the overall approach.
3.1 Policy and Reward Learning
We consider behavioral tendencies inference as an agentpolicy learning problem and an agent policy as the ab-straction of user’s behavioral tendencies. Policy learningaims to make the learned policy π and expert policy πE .We define the occupancy measure ρ in Eq.(10) and solvepolicy learning as a occupancy measure based distributionmatching problem [23]. To this end, we define a rewardfunction below to determine the performance in existingmethods:
r(s, a) = log(D(s, a))− log(1−D(s, a)) (16)
[30] design a dynamic robust disentangled reward functionfor the approximation by introducing the future state s′.
r′(s, a) = log(D(s, a, s′))− log(1−D(s, a, s′)) (17)
The reward function defined in Eq.(16) is not robustfor dynamic environments. Although Eq.(17) improves itby assigning positive and negative rewards for each timestep to empower the agent to fit into different scenarios,both Eq.(16) and Eq.(17) have the absorbing state problem,i.e., the agent will receive no reward at the end of eachepisode, leading to sub-optimal policies [31]. Specifically, in-stead of exploring more policies, the reward function r(s, a)will assign a negative reward bias for the discriminator todistinguish samples from the generated policies and expertpolicies at the beginning of the learning process. Since theagent aims to avoid the negative penalty, the zero rewardmay lead to early stops.
Moreover, the above two reward functions are moresuitable for survival or exploration tasks rather than the goalof this study. For survival tasks, the reward used on GAIL
is logD(s, a), which is always negative because D(s, a)(∈ [0, 1]) encourages agent to end current episode to stopmore negative rewards. For exploration tasks, the rewardfunction is − log(1−D(s, a)), it is always positive and mayresult in the agent to loop in the environment to collect morerewards.
We add a bias term to the reward function r(s, a), asdefined by either Eq.(16) or Eq.(17) to overcome the rewardbias. In addition, we introduce a new reward given byenvironment re for reward shaping. Finally, we have thefollowing:
rn(s, a) = λi
(r(s, a) +
∞∑t=T+1
γt−T r(sa, ·))
+ re (18)
where r(sa, ·) is a learnable reward function, which is train-able during the training process. We also add a dimensionto indicate whether the current state is an absorbing stateor not (denoted by 1 or 0, respectively). Besides, we simplysample the reward from the replay buffer, considering thebias term is unstable in practice.
3.2 Stabilized Sample Efficient Discriminative Actor-Critic Network
The stabilized sample efficient discriminative actor-criticnetwork aims to enable the agent to learn the policy ef-ficiently. We take a variant of the actor-critic network,advantage actor-critic network [32], as the backbone of ourapproach. In this network, the actor uses policy gradientand the critic’s feedback to update the policy, and thecritic uses Q-learning to evaluate the policy and providesfeedback [33].
Given the state space at timestamp t, the environmentdetermines a state st, which contains user’s recent interestand demographic information embedded, via the actor-network [34], [35]. The actor-network feeds the state st toa network that has four fully-connected layers with ReLUas the activation function. The final layer of the networkoutputs a policy function π, which is parameterized by θ.Then, the critic network takes two inputs: the trajectory(st, at), and the current policy πθt from the actor-network.We concatenate the state-action pair (st, at) and feed it intoa network with four fully-connected layers (with ReLU asthe activation function) and a softmax layer. The output ofthe critic-network is a value V (st, at) ∈ IR to be used foroptimization (to be introduced later).
The discriminator D is the key component of our ap-proach. To build an end-to-end model that better approxi-mates the expert policy πE , we parameterize the policy withπθ and clip the discriminator’s output so that D : S × A →(0, 1) with weight w. The loss function of D is denoted byLD. Besides, we use Adam [36] to optimize weight w (theoptimization for θ will be introduced later). We considerthe discriminator D as a local cost function provider toguide the policy update. During the minimization of theloss function LD, i.e., finding a point (π,D) for it, the policywill move toward expect-like regions (divided by D) in thelatent space.
Like many other networks, Actor-critic network alsosuffers the sample inefficiency problem [37], i.e., the agent

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 5
has to conduct sampling from the expert policy distribu-tion, given the significant number of agent-environmentinteractions needed to learn the expert policy during thetraining process. In this regard, we use an off-policy re-inforcement learning algorithm (instead of on-policy rein-forcement learning algorithms) to reduce interactions withthe environment. In particular, we introduce a replay bufferR to store previous state-action pairs; when training dis-criminator we sample the transition from the replay bufferR in off-policy learning (instead of sampling trajectoriesfrom a policy directly). We thereby define the loss functionas follows:
LD = ER[logD(s, a)] + EπE [log(1−D(s, a))]− λH(π)(19)
Eq.(19) matches the occupancy measures between theexpert and the distribution induced by R. Instead of com-paring the latest trained policy π and expert policy πE , itcomprises a mixture of all policy distributions that appearedduring training. Considering off-policy learning has differ-ent expectation from on-policy learning, we use importancesampling on the replay buffer to balance it.
LD = ER[ρπθ (s, a)
ρR(s, a)logD(s, a)
]+ EπE [log(1−D(s, a))]− λH(π) (20)
Considering GAN has the training instability prob-lem [38], we employ the Wasserstein GAN [39] to improvethe discriminator’s performance. While a normal GAN min-imizes JS-Divergence cannot measure the distance betweentwo distributions, Wasserstein GANs uses the EM-distanceand Kantorovich-Rubinstein duality to resolve the prob-lem [40].
Eπ[logD(s, a)]− EπE [log(D(s, a))]
+ EπE [(‖∇D(s, a)‖ − 1)2] (21)
We further use gradient penalty to improve the trainingfor Wasserstein GANs [39], given the gradient penalty canimprove training stability for JS-Divergence-based GANs[41]. We thereby obtain the final loss function as follows:
LD = ER[ρπθ (s, a)
ρR(s, a)logD(s, a)
]+ EπE [log(1−D(s, a))]
−λH(π) + EπE [(‖∇D(s, a)‖ − 1)2](22)
3.3 OptimizationWe conduct a joint training process on the policy network(i.e., the actor-critic network) and the discriminator. We pa-rameterize the policy network with policy parameter θ andupdate it using trust region policy optimization (TRPO) [42]based on the discriminator. TRPO introduces a trust regionby restricting the agent’s step size to ensure a new policy isbetter than the old one. We formulate the TRPO problem asfollows:
maxθ
1
T
T∑t=0
[πθ(at|st)πθold(at|st)
At
]subject to Dθold
KL (πθold , πθ) ≤ η (23)
where An is the advantage function calculated by General-ized Advantage Estimation (GAE) [43]. GAE is describedas follows:
At =∞∑l=0
(γλg)lδVt+l
where δVt+l = −V (st) +∞∑l=0
γlrt+l (24)
where rt+l is the test reward for l-step’s at timestamp t, asdefined on Eq.(18). Considering the high computation loadof updating TRPO via optimizing Eq.(23), we update thepolicy using a simpler optimization method called ProximalPolicy Optimization (PPO) [44], which has an objectivefunction below:
Eτ∼πold
[ T∑t=0
min( πθ(at|st)πθold(at|st)
At,
clip( πθ(at|st)πθold(at|st)
, 1− ε, 1 + ε)At)]
(25)
where ε is the clipping parameter representing the max-imum percentage of change that can be made by eachupdate.
The overall training procedure is illustrated in Algorithm1, which involves the training of both the discriminator andthe actor-critic network. For the discriminator, we use Admaas the optimizer to find the gradient for Eq.(22) for weightw at step i:
Eπ[∇w log(Dw(s, a))] + EπE [∇w log(1−Dw(s, a))]
+EπE [(‖∇wD(s, a)‖ − 1)2 (26)
4 EXPERIMENTS
We evaluate the proposed framework and demonstrateits generalization capability by conducting experiments inthree different environments: Traffic Control, Recommenda-tion System, and Scanpath Prediction. Our model is imple-mented in Pytorch [45] and all experiments are conductedon a server with 6 NVIDIA TITAN X Pascal GPUs, 2NVIDIA TITAN RTX with 768 GB memory.
4.1 Urban Mobility ManagementIn the traffic control scenario, the agent is required tocontrol cars to conduct a certain task. The objective is tominimize the total waiting time in the trip.
4.1.1 Simulation of Urban Mobility
Traffic signal control is critical to effective mobilitymanagement in modern cities. To apply our model tothis context, we use the Simulation of Urban MObility(SUMO) [46] library, a microscopic, space-continuous,and time-discrete traffic flow simulation tool, to test themethod’s performance. The agent controls traffic signals,and a car may take three actions facing traffic lights:go straight, turn left, or turn right, depending on user’spreference. We design a simple two-way road network
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 6
1 5 10 15 20Time Step ('000 s)
0
1000
2000
3000
4000
5000
6000
7000
Tota
l Wai
ting
Tim
e (s
)
OursexpertQ-Learning
Deep Q-LearningSARSAA2C
(a) Total waiting time with 95% confi-dence interval
1 250 500 750 1000 1250 1500 1750 2000Iteration
0.0
0.2
0.4
0.6
0.8
1.0
CTR
ExpertOursIRecGAN
KGRLGAUMPGCR
(b) CTR with 95% confidence interval
0 1 2 3 4 5 6Number of Fixations Made to Target
0.0
0.2
0.4
0.6
0.8
1.0
Cum
ulat
ive
Prob
abilit
y
OursHumanIRLBC_LSTM
BC_CNNFixDetector
(c) Cumulative probability comparisonfor selected baseline methods
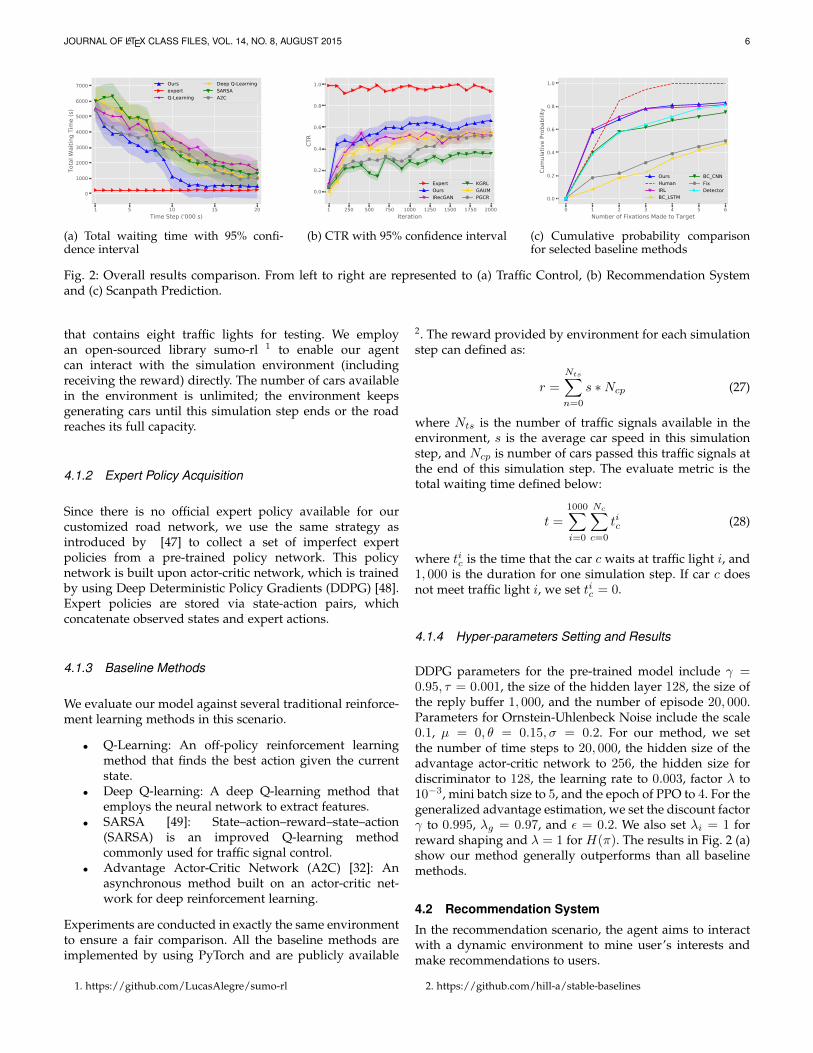
Fig. 2: Overall results comparison. From left to right are represented to (a) Traffic Control, (b) Recommendation Systemand (c) Scanpath Prediction.
that contains eight traffic lights for testing. We employan open-sourced library sumo-rl 1 to enable our agentcan interact with the simulation environment (includingreceiving the reward) directly. The number of cars availablein the environment is unlimited; the environment keepsgenerating cars until this simulation step ends or the roadreaches its full capacity.
4.1.2 Expert Policy Acquisition
Since there is no official expert policy available for ourcustomized road network, we use the same strategy asintroduced by [47] to collect a set of imperfect expertpolicies from a pre-trained policy network. This policynetwork is built upon actor-critic network, which is trainedby using Deep Deterministic Policy Gradients (DDPG) [48].Expert policies are stored via state-action pairs, whichconcatenate observed states and expert actions.
4.1.3 Baseline Methods
We evaluate our model against several traditional reinforce-ment learning methods in this scenario.
• Q-Learning: An off-policy reinforcement learningmethod that finds the best action given the currentstate.
• Deep Q-learning: A deep Q-learning method thatemploys the neural network to extract features.
• SARSA [49]: State–action–reward–state–action(SARSA) is an improved Q-learning methodcommonly used for traffic signal control.
• Advantage Actor-Critic Network (A2C) [32]: Anasynchronous method built on an actor-critic net-work for deep reinforcement learning.
Experiments are conducted in exactly the same environmentto ensure a fair comparison. All the baseline methods areimplemented by using PyTorch and are publicly available
1. https://github.com/LucasAlegre/sumo-rl
2. The reward provided by environment for each simulationstep can defined as:
r =Nts∑n=0
s ∗Ncp (27)
where Nts is the number of traffic signals available in theenvironment, s is the average car speed in this simulationstep, and Ncp is number of cars passed this traffic signals atthe end of this simulation step. The evaluate metric is thetotal waiting time defined below:
t =1000∑i=0
Nc∑c=0
tic (28)
where tic is the time that the car c waits at traffic light i, and1, 000 is the duration for one simulation step. If car c doesnot meet traffic light i, we set tic = 0.
4.1.4 Hyper-parameters Setting and Results
DDPG parameters for the pre-trained model include γ =0.95, τ = 0.001, the size of the hidden layer 128, the size ofthe reply buffer 1, 000, and the number of episode 20, 000.Parameters for Ornstein-Uhlenbeck Noise include the scale0.1, µ = 0, θ = 0.15, σ = 0.2. For our method, we setthe number of time steps to 20, 000, the hidden size of theadvantage actor-critic network to 256, the hidden size fordiscriminator to 128, the learning rate to 0.003, factor λ to10−3, mini batch size to 5, and the epoch of PPO to 4. For thegeneralized advantage estimation, we set the discount factorγ to 0.995, λg = 0.97, and ε = 0.2. We also set λi = 1 forreward shaping and λ = 1 for H(π). The results in Fig. 2 (a)show our method generally outperforms than all baselinemethods.
4.2 Recommendation System
In the recommendation scenario, the agent aims to interactwith a dynamic environment to mine user’s interests andmake recommendations to users.
2. https://github.com/hill-a/stable-baselines

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 7
Algorithm 1: Training algorithm for our modelinput: Expert replay buffer RE , Initialize Policy
Replay Buffer R,Initialize policy parameterθ0, clipping parameter ε
1 Function Absorbing(τ) is2 if sT is a absorbing state then3 {sT , aT , ·, s′T } ← {sT , aT , ·, sa};4 τ ← τ ∪ {sa, ·, ·, sa};5 end6 return τ ;7 end8 for τ = {st, at, ·, s′t}Tt=1 ∈ RE do9 τ ← Absorbing(τ );
10 end11 R ← ∅ ;12 for i = 1, 2, · · · do13 Sampling trajectories τ = {st, at, ·, s′t}Tt=1 ∼ πθi ;14 R ← R∪ Absorbing(τ ) ;15 for j = 1, · · · , |τ | do16 {st, at, ·, ·}Bt=1 ∼ R, {s′t, a′t, ·, ·}Bt=1 ∼ RE ;17 Update the parameter wi by gradient on
Eq.(26) ;18 end19 for j = 1, · · · , |τ | do20 {st, at, ·, ·}Bt=1 ∼ R;21 for b = 1, · · · , B do22 r = log(Dwi(sb, ab))− log(1−Dwi(sb, ab))
;23 Calculate the reshape reward r′ by Eq.(18)
;24 (sb, ab, ·, s′b)← (sb, ab, r
′, s′b) ;25 end26 for k = 0, 1, · · · do27 Get the trajectories (s, a) on policy
πθ = π(θk) ;28 Estimate advantage At using Eq.(24);29 Compute the Policy Update
θk+1 = arg maxθ
Eq.(25)
By taking K step of minibatch SGD (viaAdma)
30 end31 θi ← θK ;32 end33 end
4.2.1 VirtualTB
We use an open-source online recommendation platform,VirtualTB [50], to test the performance of the proposedmethods in a recommendation system. VirtualTB is a dy-namic environment built on OpenAI Gym3 to test ourmethod’s feasibility on recommendation tasks. VirtualTBemploys a customized agent to interact with it and achievesthe corresponding rewards. It can also generate severalcustomers with different preferences during the agent-
3. https://gym.openai.com/
Algorithm 2: PPO Updateinput: Initialize policy parameter θ0, clipping
parameter ε1 for k = 0, 1, · · · do2 Get the trajectories (s, a) on policy πθ = π(θk) ;3 Estimate advantage At using Eq.(24);4 Compute the Policy Update
θk+1 = arg maxθ
Eq.(25)
By taking K step of minibatch SGD (via Adma)5 end6 θi ← θK ;
environment interaction. In VirtualTB, each customer has11 static attributes encoded into an 88-dimensional spacewith binary values as the demographic information. Thecustomers have multiple dynamic interests, which are en-coded into a 3-dimensional space and may change overthe interaction process. Each item has several attributes(e.g., price and sales volume), which are encoded into a 27-dimensional space. We use CTR as the evaluation metricbecause the gym environment can only provide rewards asfeedback. CTR is defined as follows:
CTR =repisode
10 ∗Nstep(29)
where repisode is the reward that the agent receives at eachepisode. At each episode, the agent may take Nstep stepsand receive a maximum reward of 10 per step.
4.2.2 Baseline Methods
We evaluate our model against four state-of-the-art methodscovering methods based on deep Q-learning, policy gradi-ent, and actor-critic networks.
• IRecGAN [51]: An online recommendation methodthat employs reinforcement learning and GAN.
• PGCR [52]: A policy-Gradient-based method for con-textual recommendation.
• GAUM [53]: A deep Q-learning based method thatemploys GAN and cascade Q-learning for recom-mendation.
• KGRL [34]: An Actor-Critic-based method for inter-active recommendation, a variant of online recom-mendation.
Note that GAUM and PGCR are not designed for onlinerecommendation, and KGRL requires a knowledge graph—which is unavailable to the gym environment—as the sideinformation, . Hence, we only keep the network structureof those networks when testing them on the VirtualTBplatform.
4.2.3 Hyper-parameters Setting and Results
The hyper-parameters are set in a similar way as in the

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 8
traffic signals control. We set the number of episodes to200, 000 for both the pre-trained policy network and ourmethod. To ease comparison, we configure each iterationto contain 100 episodes. The results in Fig. 2 (b) showour method outperform all state-of-the-art methods. KGRL’spoor performance may be partially caused by its reliance onknowledge graph, which is unavailable in our experiments.
4.3 Scanpath Prediction
Scanpath prediction is a type of goal-directed humanintention prediction problem [15]. Take the last task in Fig. 1for example. Given a few objects, a user may first look atitem 1, then follows the item numbers annotated in thefigure, and finally reaches item 8. The task aims to predictuser’s intention (i.e., item 8), given the start item (i.e., item1).
4.3.1 Experimental Setup
We follow the same experimental setup as [15] and con-duct all experiments on a public COCO-18 Search dataset4.We replace the fully-connected layer in actor-network withCNN to achieve the best performance of our method onimages. The critic-network has a new structure with twoCNN layers followed by two fully-connected layers. Thediscriminator contains all CNN layers with a softmax layeras output. We also resize the input image from the originalsize of 1680 × 1050 into 320 × 512 and construct the stateby using the contextual beliefs calculated from a Panoptic-FPN with a backbone network (ResNet-50-FPN) pretrainedon COCO2017.
4.3.2 Baseline Methods
We compare our method with several baseline methods,including simple CNN based methods, behavior-cloningbased methods, and inverse reinforcement-learning-basedmethod.
• Detector: A simple CNN to predict the location of atarget item.
• Fixation heuristics [15]: A method similar to Detectorbut using the fixation to predict the location of atarget item.
• BC-CNN [54]: A behavior-cloning method that usesCNN as the basic layer structure.
• BC-LSTM [55]: A behavior-cloning method that usesLSTM as the basic layer structure.
• IRL [15]: A state-of-the-art inverse reinforcement-learning-based method for scanpath prediction.
Experiments are conducted under the same conditions toensure fairness.
4. https://saliency.tuebingen.ai/datasets/COCO-Search18/index new.html
4.3.3 Performance Comparison
The hyper-parameters settings are the same as those usedfor the recommendation task. We also use the same evalu-ation metrics as used in [15] to evaluate the performance:cumulative probability, probability mismatch, and scanpathratio. The results in Fig. 2(c) show the cumulative probabil-ity of the gaze landing on the target after first six fixations.We report the probability mismatch and scanpath ratio intable 2.
TABLE 2: Results comparison for selected methods on prob-ability mismatch and scanpath ratio
Probability Mismatch ↓ Scanpath Ratio↑Human n.a. 0.862Detector 1.166 0.687BC-CNN 1.328 0.706BC-LSTM 3.497 0.406Fixation 3.046 0.545
IRL 0.987 0.862Ours 0.961 0.881
4.4 Evaluation on Explainability
Explainability plays a crucial role on the understandingof the decision-making process. By visualizing the learnedreward map, we show in this experiment our model canprovide a certain level of interpretability. We evaluate theexplanability for our model in the scanpath prediction sce-nario. Fig. 4 shows that the reward maps recovered by theour model depend heavily on the category of the searchtarget. In the first image, the highest reward is assigned tothe piazza when drinking beers. Similarly, the searching ofroad signal on the road, the stop signal get almost all of thereward while the car get only a few.
4.5 Ablation Study
We test using three different optimization strategies (DDPG,Adaptive KL Penalty Coefficient and Twin Delayed DDPG)to update the policy parameter θ. (TD3) [56]. The AdaptiveKL Penalty Coefficient is defined as:
L(θ) = Et[πθ′(at|st)πθ(at|st)
At − βKL[πθ(·|st), πθ′(·|st)]]
(30)
where the β will be adjust dynamically by the following,{β ← β/2 d < dtarget ∗ 1.5
β ← β ∗ 2 d >= dtarget ∗ 1.5(31)
where d = Et[KL[πθold(·|st), πθ(·|st)]]
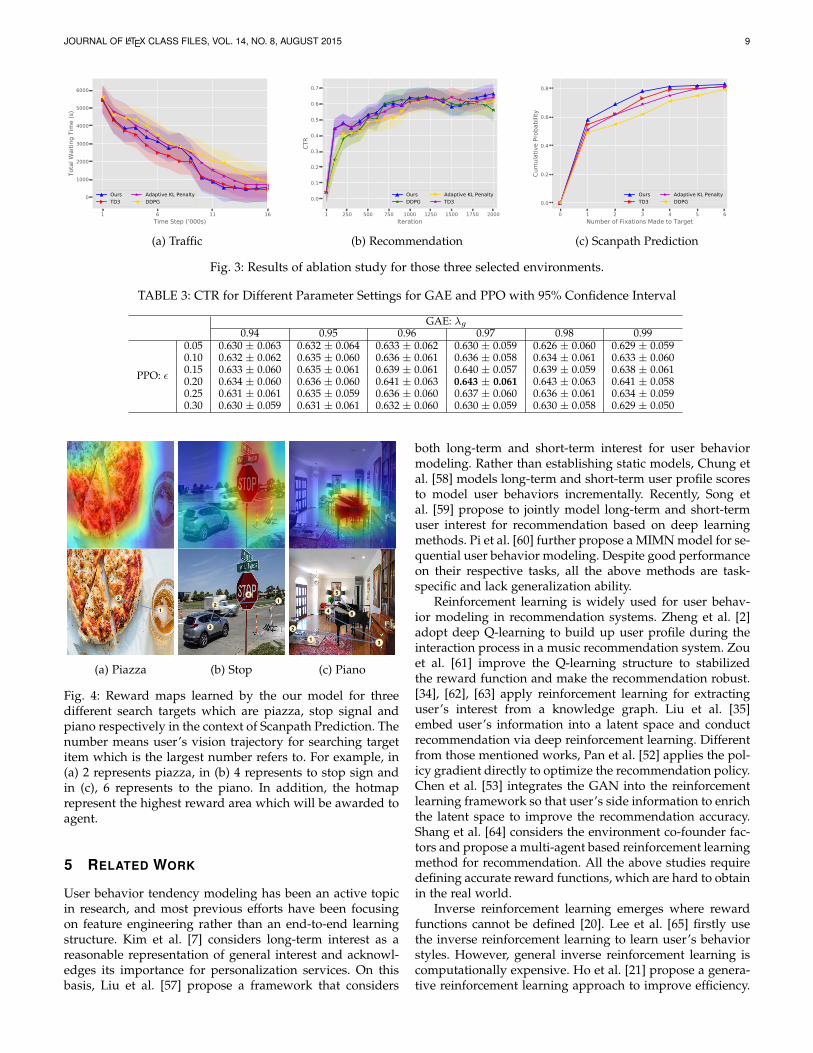
We empirically choose coefficient 1.5 and 2 and select totalwaiting time, CTR, and cumulative probability as the eval-uation metrics to compare the three optimization strategiesfor traffic signal control, recommendation system, and scan-path prediction, respectively. The results (shown in Fig. 3)show our optimization method achieve a similar result asTD3 on all the three tasks but is better than TD3 on therecommendation task. Hence, we want to conduct a furtherstep about the parameter selection about the PPO and GAEwhich can be found on Table 3.
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 9
1 6 11 16Time Step ('000s)
0
1000
2000
3000
4000
5000
6000
Tota
l Wai
ting
Tim
e (s
)
OursTD3
Adaptive KL PenaltyDDPG
(a) Traffic
1 250 500 750 1000 1250 1500 1750 2000Iteration
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
CTR
OursDDPG
Adaptive KL PenaltyTD3
(b) Recommendation
0 1 2 3 4 5 6Number of Fixations Made to Target
0.0
0.2
0.4
0.6
0.8
Cum
ulat
ive
Prob
abilit
y
OursTD3
Adaptive KL PenaltyDDPG
(c) Scanpath Prediction
Fig. 3: Results of ablation study for those three selected environments.
TABLE 3: CTR for Different Parameter Settings for GAE and PPO with 95% Confidence Interval
GAE: λg0.94 0.95 0.96 0.97 0.98 0.99
PPO: ε
0.05 0.630 ± 0.063 0.632 ± 0.064 0.633 ± 0.062 0.630 ± 0.059 0.626 ± 0.060 0.629 ± 0.0590.10 0.632 ± 0.062 0.635 ± 0.060 0.636 ± 0.061 0.636 ± 0.058 0.634 ± 0.061 0.633 ± 0.0600.15 0.633 ± 0.060 0.635 ± 0.061 0.639 ± 0.061 0.640 ± 0.057 0.639 ± 0.059 0.638 ± 0.0610.20 0.634 ± 0.060 0.636 ± 0.060 0.641 ± 0.063 0.643 ± 0.061 0.643 ± 0.063 0.641 ± 0.0580.25 0.631 ± 0.061 0.635 ± 0.059 0.636 ± 0.060 0.637 ± 0.060 0.636 ± 0.061 0.634 ± 0.0590.30 0.630 ± 0.059 0.631 ± 0.061 0.632 ± 0.060 0.630 ± 0.059 0.630 ± 0.058 0.629 ± 0.050
1
2
(a) Piazza
12
3
4
(b) Stop
1
2
3
4
5
6
(c) Piano
Fig. 4: Reward maps learned by the our model for threedifferent search targets which are piazza, stop signal andpiano respectively in the context of Scanpath Prediction. Thenumber means user’s vision trajectory for searching targetitem which is the largest number refers to. For example, in(a) 2 represents piazza, in (b) 4 represents to stop sign andin (c), 6 represents to the piano. In addition, the hotmaprepresent the highest reward area which will be awarded toagent.
5 RELATED WORK
User behavior tendency modeling has been an active topicin research, and most previous efforts have been focusingon feature engineering rather than an end-to-end learningstructure. Kim et al. [7] considers long-term interest as areasonable representation of general interest and acknowl-edges its importance for personalization services. On thisbasis, Liu et al. [57] propose a framework that considers
both long-term and short-term interest for user behaviormodeling. Rather than establishing static models, Chung etal. [58] models long-term and short-term user profile scoresto model user behaviors incrementally. Recently, Song etal. [59] propose to jointly model long-term and short-termuser interest for recommendation based on deep learningmethods. Pi et al. [60] further propose a MIMN model for se-quential user behavior modeling. Despite good performanceon their respective tasks, all the above methods are task-specific and lack generalization ability.
Reinforcement learning is widely used for user behav-ior modeling in recommendation systems. Zheng et al. [2]adopt deep Q-learning to build up user profile during theinteraction process in a music recommendation system. Zouet al. [61] improve the Q-learning structure to stabilizedthe reward function and make the recommendation robust.[34], [62], [63] apply reinforcement learning for extractinguser’s interest from a knowledge graph. Liu et al. [35]embed user’s information into a latent space and conductrecommendation via deep reinforcement learning. Differentfrom those mentioned works, Pan et al. [52] applies the pol-icy gradient directly to optimize the recommendation policy.Chen et al. [53] integrates the GAN into the reinforcementlearning framework so that user’s side information to enrichthe latent space to improve the recommendation accuracy.Shang et al. [64] considers the environment co-founder fac-tors and propose a multi-agent based reinforcement learningmethod for recommendation. All the above studies requiredefining accurate reward functions, which are hard to obtainin the real world.
Inverse reinforcement learning emerges where rewardfunctions cannot be defined [20]. Lee et al. [65] firstly usethe inverse reinforcement learning to learn user’s behaviorstyles. However, general inverse reinforcement learning iscomputationally expensive. Ho et al. [21] propose a genera-tive reinforcement learning approach to improve efficiency.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 10
Fu et al. [30] further extend the idea to a general form toobtain a more stable reward function. Kostrikov et al. [31]find a generative method may suffer instability in training,which can be relieved by using EM-distance instead ofJS-divergence. Yang et al. [15] first introduces the inversereinforcement learning into the scanpath prediction anddemonstrate the superior performance. IRL demonstratesthe huge potential and widely used in robot learning asit can empower agent to learn from the demonstration indifferent environments and tasks without dramatical explo-ration about the environment or familiar with the tasks.Chen et al. [22] expands this idea into recommender systemand shows the feasibility of IRL in recommendation task.
6 CONCLUSION AND FUTURE WORK
In this paper, we propose a new method based on advantageactor-critic network with inverse reinforcement learning foruser behavior modeling, to overcome the adverse impactcaused by an inaccurate reward function. In particular,we use the wasserstein GAN instead of GAN to increasetraining stability and a reply buffer for off-policy learningto increase sample efficiency.
Comparison of our method with several state-of-the-artmethods in three different scenarios (namely traffic signalcontrol, recommendation system, and scanpath prediction)demonstrate our method’s feasibility in those scenarios andsuperior performance to baseline methods.
Experience replay can boost the sample efficiency byswitching the sampling process from the environment toreplay buffer. However, it is not ideal as some tasks mayintroduce a giant state and action spaces such as recommen-dation. Sampling from such giant state and action spacesare not efficient. Moreover, not every experience are usefuleven it comes from the demonstration. The major reason isthat expert demonstrations are sampled from replay bufferrandomly and may orthogonal with the current state andlead to opposed actions. The possible solutions including,the state-aware experience replay method or prioritizedexperience replay based methods [66]. Another potentialimprovement leads by the Wasserstein GAN as the Lips-chitz constraint is hard to enforce and may lead to modelconverge issue.
REFERENCES
[1] J. Hong, E.-H. Suh, J. Kim, and S. Kim, “Context-aware system forproactive personalized service based on context history,” ExpertSystems with Applications, vol. 36, no. 4, pp. 7448–7457, 2009.
[2] G. Zheng, F. Zhang, Z. Zheng, Y. Xiang, N. J. Yuan, X. Xie,and Z. Li, “Drn: A deep reinforcement learning framework fornews recommendation,” in Proceedings of the 2018 World Wide WebConference, 2018, pp. 167–176.
[3] S. Zhang, L. Yao, A. Sun, and Y. Tay, “Deep learning basedrecommender system: A survey and new perspectives,” ACMComputing Surveys (CSUR), vol. 52, no. 1, pp. 1–38, 2019.
[4] L. Hu, L. Cao, S. Wang, G. Xu, J. Cao, and Z. Gu, “Diversify-ing personalized recommendation with user-session context.” inIJCAI, 2017, pp. 1858–1864.
[5] X. Xu, F. Dong, Y. Li, S. He, and X. Li, “Contextual-bandit basedpersonalized recommendation with time-varying user interests.”in AAAI, 2020, pp. 6518–6525.
[6] X. Wang, Y. Wang, D. Hsu, and Y. Wang, “Exploration in in-teractive personalized music recommendation: a reinforcementlearning approach,” ACM Transactions on Multimedia Computing,Communications, and Applications (TOMM), vol. 11, no. 1, pp. 1–22,2014.
[7] H. R. Kim and P. K. Chan, “Learning implicit user interest hi-erarchy for context in personalization,” in Proceedings of the 8thinternational conference on Intelligent user interfaces, 2003, pp. 101–108.
[8] T. B. Sheridan, “Human–robot interaction: status and challenges,”Human factors, vol. 58, no. 4, pp. 525–532, 2016.
[9] E. Schmerling, K. Leung, W. Vollprecht, and M. Pavone, “Mul-timodal probabilistic model-based planning for human-robot in-teraction,” in 2018 IEEE International Conference on Robotics andAutomation (ICRA). IEEE, 2018, pp. 1–9.
[10] M. Siam, C. Jiang, S. Lu, L. Petrich, M. Gamal, M. Elhoseiny, andM. Jagersand, “Video object segmentation using teacher-studentadaptation in a human robot interaction (hri) setting,” in 2019International Conference on Robotics and Automation (ICRA). IEEE,2019, pp. 50–56.
[11] C. Badii, P. Bellini, D. Cenni, A. Difino, M. Paolucci, and P. Nesi,“User engagement engine for smart city strategies,” in 2017IEEE International Conference on Smart Computing (SMARTCOMP).IEEE, 2017, pp. 1–7.
[12] P. Bellini, D. Cenni, P. Nesi, and I. Paoli, “Wi-fi based city users’behaviour analysis for smart city,” Journal of Visual Languages &Computing, vol. 42, pp. 31–45, 2017.
[13] S. Seko, T. Yagi, M. Motegi, and S. Muto, “Group recommendationusing feature space representing behavioral tendency and powerbalance among members,” in Proceedings of the fifth ACM conferenceon Recommender systems, 2011, pp. 101–108.
[14] Y. Shi, M. Larson, and A. Hanjalic, “Collaborative filtering beyondthe user-item matrix: A survey of the state of the art and futurechallenges,” ACM Computing Surveys (CSUR), vol. 47, no. 1, pp.1–45, 2014.
[15] Z. Yang, L. Huang, Y. Chen, Z. Wei, S. Ahn, G. Zelinsky, D. Sama-ras, and M. Hoai, “Predicting goal-directed human attention usinginverse reinforcement learning,” in Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition, 2020, pp.193–202.
[16] A. L. Bazzan, “Opportunities for multiagent systems and multia-gent reinforcement learning in traffic control,” Autonomous Agentsand Multi-Agent Systems, vol. 18, no. 3, p. 342, 2009.
[17] H. Liu, Y. Zhang, W. Si, X. Xie, Y. Zhu, and S.-C. Zhu, “Interactiverobot knowledge patching using augmented reality,” in 2018 IEEEInternational Conference on Robotics and Automation (ICRA). IEEE,2018, pp. 1947–1954.
[18] S.-Y. Chen, Y. Yu, Q. Da, J. Tan, H.-K. Huang, and H.-H. Tang,“Stabilizing reinforcement learning in dynamic environment withapplication to online recommendation,” in Proceedings of the 24thACM SIGKDD International Conference on Knowledge Discovery &Data Mining, 2018, pp. 1187–1196.
[19] H. Chen, X. Dai, H. Cai, W. Zhang, X. Wang, R. Tang, Y. Zhang,and Y. Yu, “Large-scale interactive recommendation with tree-structured policy gradient,” in Proceedings of the AAAI Conferenceon Artificial Intelligence, vol. 33, 2019, pp. 3312–3320.
[20] A. Y. Ng, S. J. Russell et al., “Algorithms for inverse reinforcementlearning.” in Icml, vol. 1, 2000, p. 2.
[21] J. Ho and S. Ermon, “Generative adversarial imitation learning,”in Advances in neural information processing systems, 2016, pp. 4565–4573.
[22] X. Chen, L. Yao, A. Sun, X. Wang, X. Xu, and L. Zhu, “Generativeinverse deep reinforcement learning for online recommendation,”arXiv preprint arXiv:2011.02248, 2020.
[23] P. Abbeel and A. Y. Ng, “Apprenticeship learning via inverse re-inforcement learning,” in Proceedings of the twenty-first internationalconference on Machine learning. ACM, 2004, p. 1.
[24] U. Syed, M. Bowling, and R. E. Schapire, “Apprenticeship learningusing linear programming,” in Proceedings of the 25th internationalconference on Machine learning, 2008, pp. 1032–1039.
[25] U. Syed and R. E. Schapire, “A game-theoretic approach to ap-prenticeship learning,” in Advances in neural information processingsystems, 2008, pp. 1449–1456.
[26] M. Bloem and N. Bambos, “Infinite time horizon maximum causalentropy inverse reinforcement learning,” in 53rd IEEE Conferenceon Decision and Control. IEEE, 2014, pp. 4911–4916.
[27] B. D. Ziebart, J. A. Bagnell, and A. K. Dey, “Modeling interactionvia the principle of maximum causal entropy,” 2010.
[28] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley,S. Ozair, A. Courville, and Y. Bengio, “Generative adversarialnets,” in Advances in neural information processing systems, 2014, pp.2672–2680.

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 11
[29] X. Nguyen, M. J. Wainwright, M. I. Jordan et al., “On surrogateloss functions and f-divergences,” The Annals of Statistics, vol. 37,no. 2, pp. 876–904, 2009.
[30] J. Fu, K. Luo, and S. Levine, “Learning robust rewardswith adverserial inverse reinforcement learning,” in InternationalConference on Learning Representations, 2018. [Online]. Available:https://openreview.net/forum?id=rkHywl-A-
[31] I. Kostrikov, K. K. Agrawal, D. Dwibedi, S. Levine, and J. Tompson,“Discriminator-actor-critic: Addressing sample inefficiency andreward bias in adversarial imitation learning,” in InternationalConference on Learning Representations, 2019. [Online]. Available:https://openreview.net/forum?id=Hk4fpoA5Km
[32] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley,D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deepreinforcement learning,” in International conference on machine learn-ing, 2016, pp. 1928–1937.
[33] V. R. Konda and J. N. Tsitsiklis, “Actor-critic algorithms,” inAdvances in neural information processing systems, 2000, pp. 1008–1014.
[34] X. Chen, C. Huang, L. Yao, X. Wang, W. Liu, and W. Zhang,“Knowledge-guided deep reinforcement learning for interactiverecommendation,” arXiv preprint arXiv:2004.08068, 2020.
[35] F. Liu, H. Guo, X. Li, R. Tang, Y. Ye, and X. He, “End-to-end deepreinforcement learning based recommendation with supervisedembedding,” in Proceedings of the 13th International Conference onWeb Search and Data Mining, 2020, pp. 384–392.
[36] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza-tion,” arXiv preprint arXiv:1412.6980, 2014.
[37] Z. Wang, V. Bapst, N. Heess, V. Mnih, R. Munos, K. Kavukcuoglu,and N. de Freitas, “Sample efficient actor-critic with experiencereplay,” arXiv preprint arXiv:1611.01224, 2016.
[38] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein gan,” arXivpreprint arXiv:1701.07875, 2017.
[39] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. C.Courville, “Improved training of wasserstein gans,” in Advancesin neural information processing systems, 2017, pp. 5767–5777.
[40] C. Villani, Optimal transport: old and new. Springer Science &Business Media, 2008, vol. 338.
[41] M. Lucic, K. Kurach, M. Michalski, S. Gelly, and O. Bousquet,“Are gans created equal? a large-scale study,” in Advances in neuralinformation processing systems, 2018, pp. 700–709.
[42] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, “Trustregion policy optimization,” in International conference on machinelearning, 2015, pp. 1889–1897.
[43] J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High-dimensional continuous control using generalized advantage esti-mation,” arXiv preprint arXiv:1506.02438, 2015.
[44] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov,“Proximal policy optimization algorithms,” arXiv preprintarXiv:1707.06347, 2017.
[45] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan,T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch:An imperative style, high-performance deep learning library,” inAdvances in neural information processing systems, 2019, pp. 8026–8037.
[46] P. A. Lopez, M. Behrisch, L. Bieker-Walz, J. Erdmann, Y.-P.Flotterod, R. Hilbrich, L. Lucken, J. Rummel, P. Wagner, andE. Wießner, “Microscopic traffic simulation using sumo,” inThe 21st IEEE International Conference on Intelligent TransportationSystems. IEEE, 2018. [Online]. Available: https://elib.dlr.de/124092/
[47] Y. Gao, H. Xu, J. Lin, F. Yu, S. Levine, and T. Darrell,“Reinforcement learning from imperfect demonstrations,” 2018.[Online]. Available: https://openreview.net/forum?id=BJJ9bz-0-
[48] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa,D. Silver, and D. Wierstra, “Continuous control with deep rein-forcement learning,” arXiv preprint arXiv:1509.02971, 2015.
[49] G. A. Rummery and M. Niranjan, On-line Q-learning using con-nectionist systems. University of Cambridge, Department ofEngineering Cambridge, UK, 1994, vol. 37.
[50] J.-C. Shi, Y. Yu, Q. Da, S.-Y. Chen, and A.-X. Zeng, “Virtual-taobao:Virtualizing real-world online retail environment for reinforce-ment learning,” in Proceedings of the AAAI Conference on ArtificialIntelligence, vol. 33, 2019, pp. 4902–4909.
[51] X. Bai, J. Guan, and H. Wang, “A model-based reinforcementlearning with adversarial training for online recommendation,” in
Advances in Neural Information Processing Systems, 2019, pp. 10 735–10 746.
[52] F. Pan, Q. Cai, P. Tang, F. Zhuang, and Q. He, “Policy gradients forcontextual recommendations,” in The World Wide Web Conference,2019, pp. 1421–1431.
[53] X. Chen, S. Li, H. Li, S. Jiang, Y. Qi, and L. Song, “Generativeadversarial user model for reinforcement learning based recom-mendation system,” in International Conference on Machine Learning,2019, pp. 1052–1061.
[54] C. Chen, A. Seff, A. Kornhauser, and J. Xiao, “Deepdriving: Learn-ing affordance for direct perception in autonomous driving,” inProceedings of the IEEE International Conference on Computer Vision,2015, pp. 2722–2730.
[55] N. Ballas, L. Yao, C. Pal, and A. Courville, “Delving deeper intoconvolutional networks for learning video representations,” arXivpreprint arXiv:1511.06432, 2015.
[56] S. Fujimoto, H. Van Hoof, and D. Meger, “Addressing func-tion approximation error in actor-critic methods,” arXiv preprintarXiv:1802.09477, 2018.
[57] H. Liu and M. Zamanian, “Framework for selecting and deliveringadvertisements over a network based on combined short-term andlong-term user behavioral interests,” Mar. 15 2007, uS Patent App.11/225,238.
[58] C. Y. Chung, A. Gupta, J. M. Koran, L.-J. Lin, and H. Yin, “Incre-mental update of long-term and short-term user profile scores ina behavioral targeting system,” Mar. 8 2011, uS Patent 7,904,448.
[59] Y. Song, A. M. Elkahky, and X. He, “Multi-rate deep learning fortemporal recommendation,” in Proceedings of the 39th InternationalACM SIGIR conference on Research and Development in InformationRetrieval, 2016, pp. 909–912.
[60] Q. Pi, W. Bian, G. Zhou, X. Zhu, and K. Gai, “Practice onlong sequential user behavior modeling for click-through rateprediction,” in Proceedings of the 25th ACM SIGKDD InternationalConference on Knowledge Discovery & Data Mining, 2019, pp. 2671–2679.
[61] L. Zou, L. Xia, P. Du, Z. Zhang, T. Bai, W. Liu, J.-Y. Nie, and D. Yin,“Pseudo dyna-q: A reinforcement learning framework for inter-active recommendation,” in Proceedings of the 13th InternationalConference on Web Search and Data Mining, 2020, pp. 816–824.
[62] K. Zhao, X. Wang, Y. Zhang, L. Zhao, Z. Liu, C. Xing, and X. Xie,“Leveraging demonstrations for reinforcement recommendationreasoning over knowledge graphs,” in Proceedings of the 43rdInternational ACM SIGIR Conference on Research and Developmentin Information Retrieval, 2020, pp. 239–248.
[63] P. Wang, Y. Fan, L. Xia, W. X. Zhao, S. Niu, and J. Huang, “Kerl:A knowledge-guided reinforcement learning model for sequentialrecommendation,” in Proceedings of the 43rd International ACM SI-GIR Conference on Research and Development in Information Retrieval,2020, pp. 209–218.
[64] W. Shang, Y. Yu, Q. Li, Z. Qin, Y. Meng, and J. Ye, “Environ-ment reconstruction with hidden confounders for reinforcementlearning based recommendation,” in Proceedings of the 25th ACMSIGKDD International Conference on Knowledge Discovery & DataMining, 2019, pp. 566–576.
[65] S. J. Lee and Z. Popovic, “Learning behavior styles with inverse re-inforcement learning,” ACM transactions on graphics (TOG), vol. 29,no. 4, pp. 1–7, 2010.
[66] T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritizedexperience replay,” arXiv preprint arXiv:1511.05952, 2015.









![EmotiGAN: Emoji Art using Generative Adversarial Networkscs229.stanford.edu/proj2017/final-reports/5244346.pdfA. Generative Adversarial Networks A Generative Adversarial Network[4]](https://img.pdfslide.net/doc/110x75/5ecde2ffc9dc5a794236dce0/emotigan-emoji-art-using-generative-adversarial-a-generative-adversarial-networks.jpg)