Embed Size (px)
Citation preview
Kagamimochi: 三段パイプラインプロセッサ
Group No: 01
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
1Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
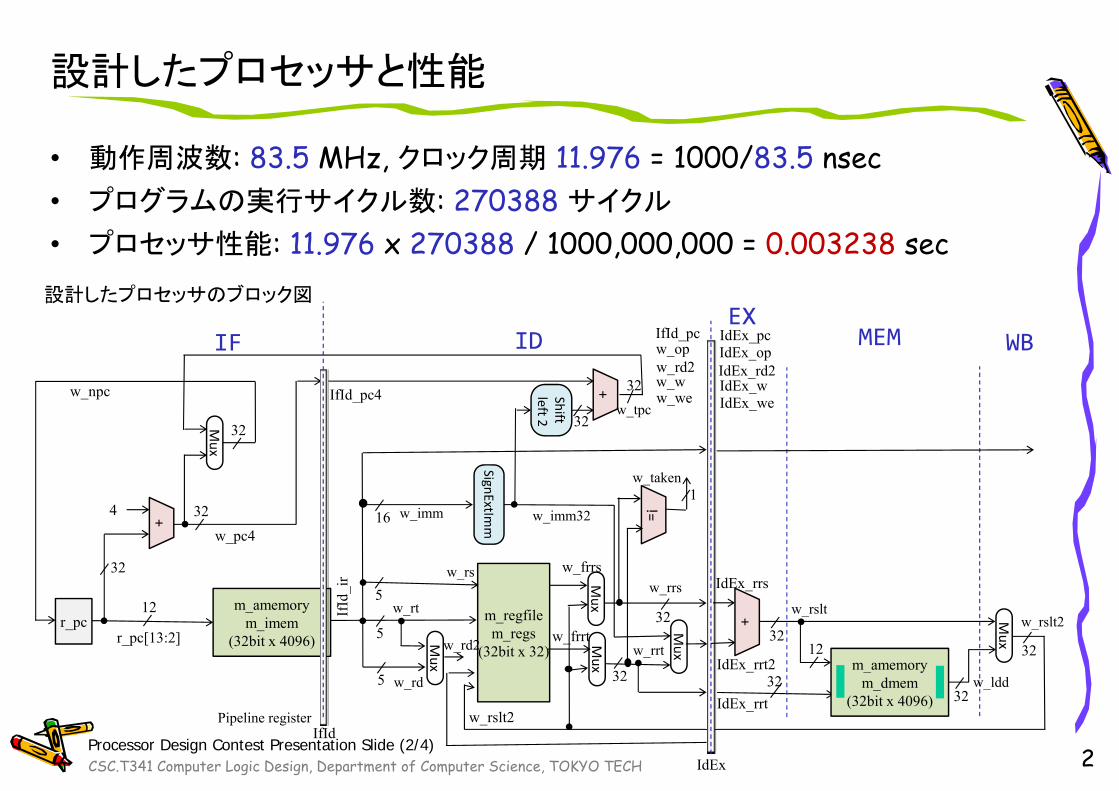
設計したプロセッサと性能
• 動作周波数: 83.5 MHz, クロック周期 11.976 = 1000/83.5 nsec• プログラムの実行サイクル数: 270388 サイクル
• プロセッサ性能: 11.976 x 270388 / 1000,000,000 = 0.003238 sec
2
m_regfilem_regs
(32bit x 32)
+
w_rs
w_rtw_rrs
w_rrt
w_rd
w_rslt
+
r_pc
4
m_amemorym_imem
(32bit x 4096)r_pc[13:2]
32
32
12
32
3232
5
5
5
IF IDEX
MEM
w_imm16
SignExtImm
Mux
w_imm32
Pipeline register
Mux
w_rd2m_amemory
m_dmem(32bit x 4096)
WB
Mux
32
32
12
w_rslt2
w_ldd32
+
Mux
Shiftleft 2
w_npc
32
32
32
!=w_taken
1
w_pc4
w_tpc
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)
IfId_pc4
w_rslt2IfId
w_op
IdEx
IfId_pc
w_rd2
IdEx_pc
IdEx_rrs
IdEx_rrt2
IdEx_rrt
w_we
IfId
_ir
w_w
IdEx_opIdEx_rd2IdEx_wIdEx_we
Mux
w_frrs
Mux
w_frrt
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
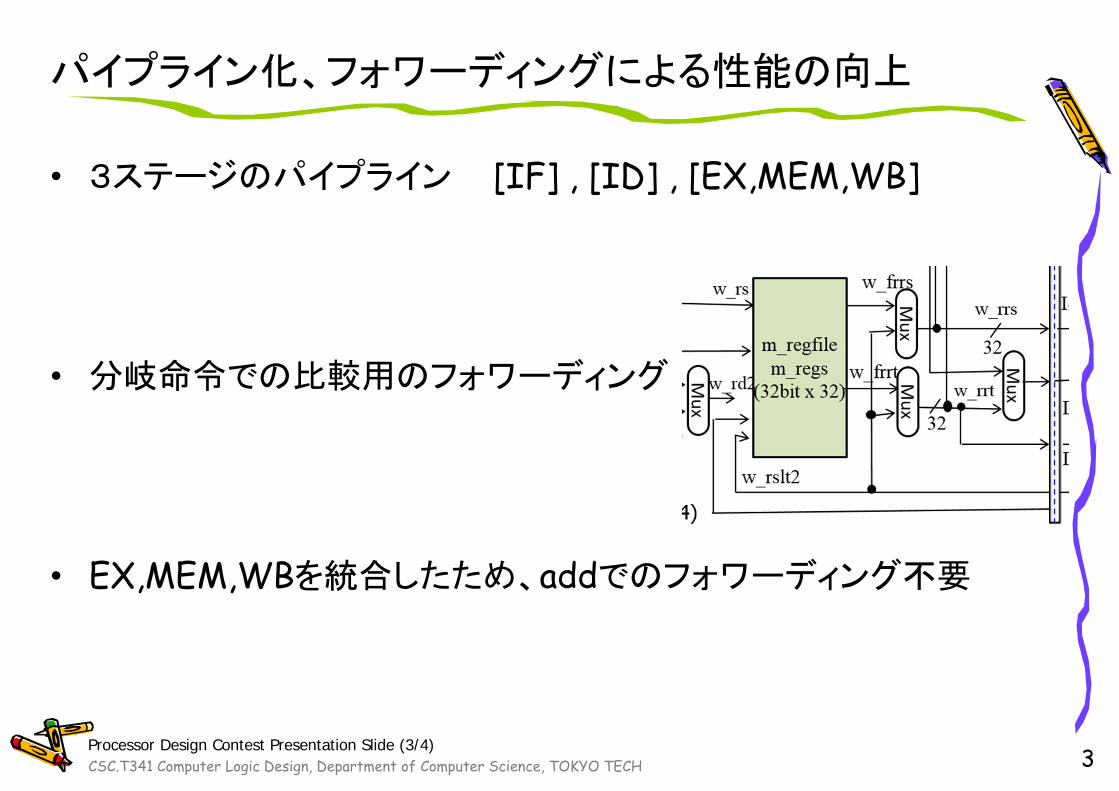
パイプライン化、フォワーディングによる性能の向上
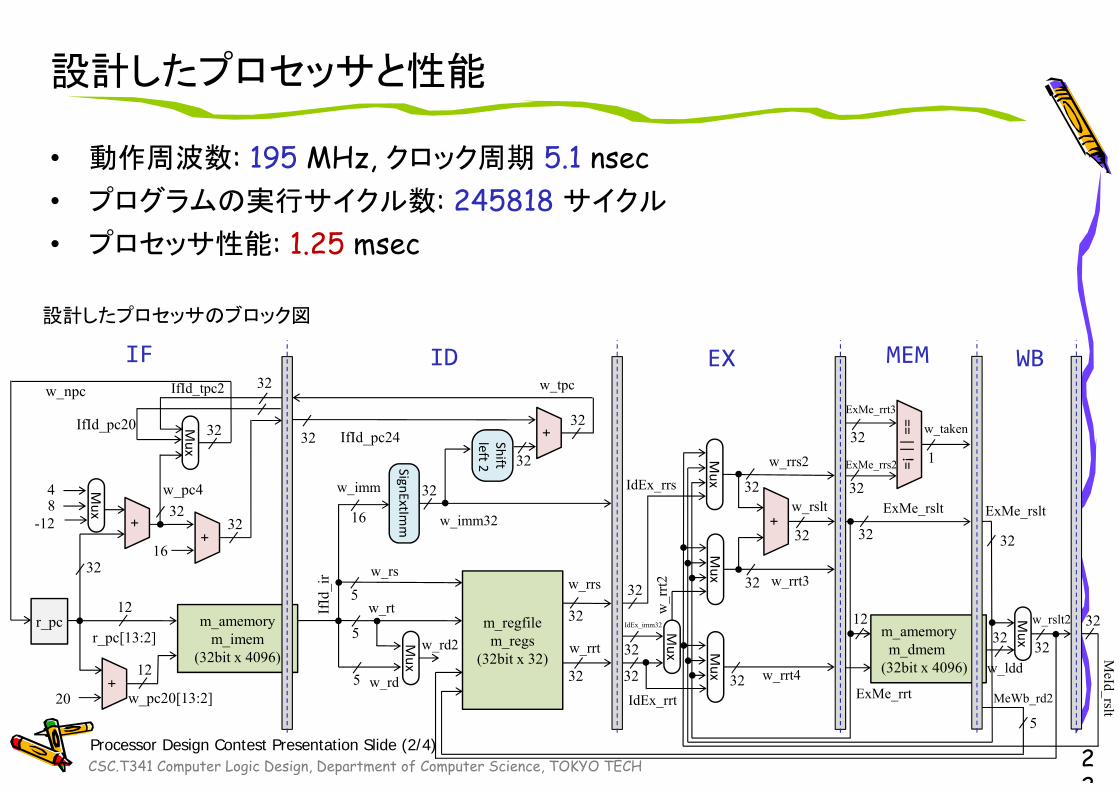
• 3ステージのパイプライン [IF] , [ID] , [EX,MEM,WB]
• 分岐命令での比較用のフォワーディング
• EX,MEM,WBを統合したため、addでのフォワーディング不要
3Processor Design Contest Presentation Slide (3/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
実装できなかった反省点、考察
• 計算結果が0と表示されてしまった。(サイクル数は正しく表示)
原因箇所:パイプライン実装時にLW,SW命令が正しく動作しなかった。
(フォワーディング,add,addi,bneは正しい動作確認済み)
4Processor Design Contest Presentation Slide (4/4)

2044:Vivadoの設定をいじったプロセッサ
Group No: 02
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
5Processor Design Contest Presentation Slide (1/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
Mux m_memory
m_dmem(32bit x 4096)
設計したプロセッサと性能
• 動作周波数: 92.50 (210) MHz, クロック周期 10.81 = 1000/92.50 nsec• プログラムの実行サイクル数: サイクル
• プロセッサ性能: 10.81 x 270390 / 1000,000,000 = 2,922,915.90 sec
6
+w_rt
w_rd
+
r_pc
4
m_amemorym_imem
(32bit x 4096)
w_ir
r_pc[13:2]
32
32
32
12
32
325
5
5
IF ID EX MEM
w_imm16
SignExtImm w_imm32
Mux
WB
3232
32
+Mux Shiftleft 2
w_npc
3232
32!=/ ==w_pc4
w_tpc
設計したプロセッサのブロック図
Mux
Mux
Mux
m_regfilem_regs
(32bit x 32)
Mux
Mux
Mux
Mux

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
工夫した点
• Vivadoの設定を変えた• SynthesisとImplementationの設定を最適化
• Vivado公式ドキュメントより
• ステップ数を変更しようと試みた
• 時間がなかったので実装はできなかった
7Processor Design Contest Presentation Slide (3/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
考察
• 使わないデータパスが存在したため、遅くなってしまった
• 実機では90MHzでしか動かないはずが、実際に200MHz以上で動くのは実際に使わないデータパスが存在するからだと考えられる
• 実行を早くしすぎたり、物理的配置の最適をしすぎると、命令のタイミングが合わないため、結果が出ないと考えられる
8Processor Design Contest Presentation Slide (4/4)

MIPSS: 計算分散とモジュール分解の高速化を用いたパイプラインプロセッサ
Group No: 03
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
9Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
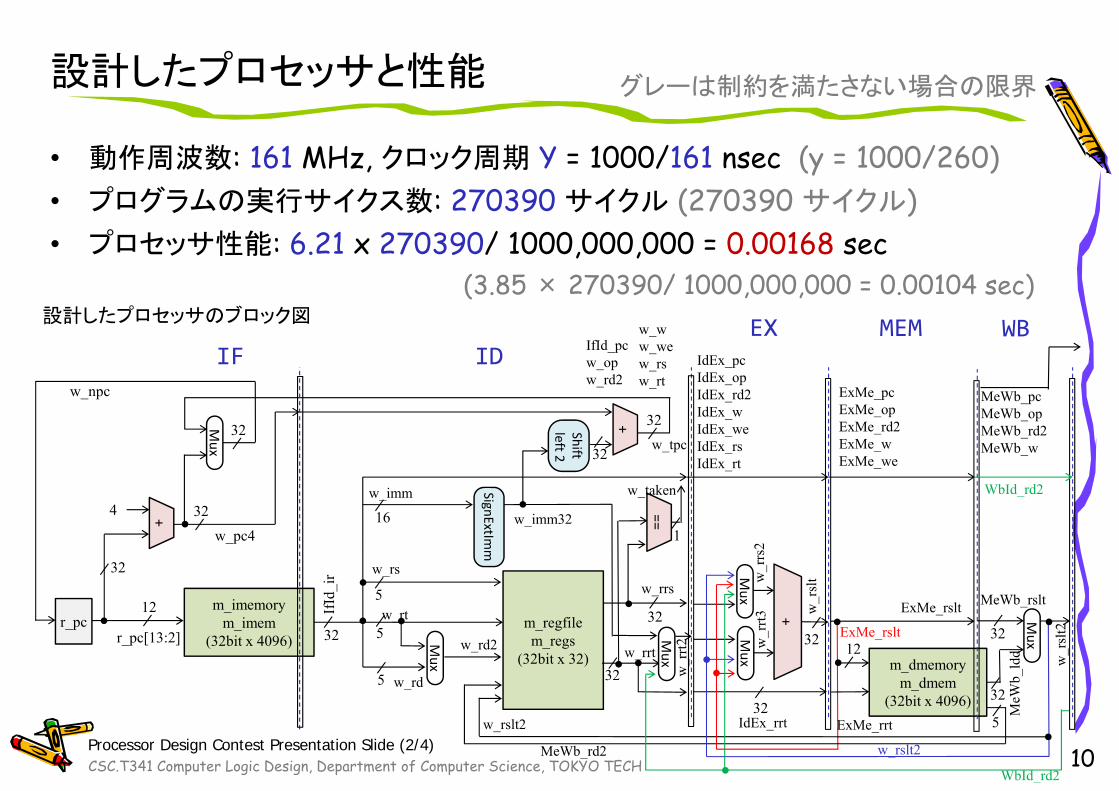
設計したプロセッサと性能
• 動作周波数: 161 MHz, クロック周期 Y = 1000/161 nsec (y = 1000/260)• プログラムの実行サイクス数: 270390 サイクル (270390 サイクル)• プロセッサ性能: 6.21 x 270390/ 1000,000,000 = 0.00168 sec
(3.85 × 270390/ 1000,000,000 = 0.00104 sec)
10
m_regfilem_regs
(32bit x 32)
+
w_rs
w_rt
w_rrs
w_rrt
w_rd
w_r
slt
+
r_pc
4
m_imemorym_imem
(32bit x 4096)
IfId
_ir
r_pc[13:2]
32
32
32
12
32
3232
5
5
5
IF IDEX MEM
w_imm
16
SignExtImm
Mux
w_imm32
w_r
rt2Mux
w_rd2m_dmemory
m_dmem(32bit x 4096)
WB
Mux32
32
12
MeWb_rslt
MeW
b_ld
d
32
+Mux
Shiftleft 2
w_npc
3232
32==
w_taken
1w_pc4
w_tpc
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)
Mux
Mux
w_rslt2
IfId_pcw_opw_rd2
IdEx_pcIdEx_opIdEx_rd2IdEx_wIdEx_weIdEx_rsIdEx_rt
ExMe_pcExMe_opExMe_rd2ExMe_wExMe_we
MeWb_pcMeWb_opMeWb_rd2MeWb_w
WbId_rd2
IdEx_rrt ExMe_rrt
ExMe_rslt
w_r
slt2
WbId_rd2
w_rslt2
ExMe_rslt
w_r
rs2
w_r
rt3MeWb_rd2
5
w_ww_wew_rsw_rt
グレーは制約を満たさない場合の限界
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
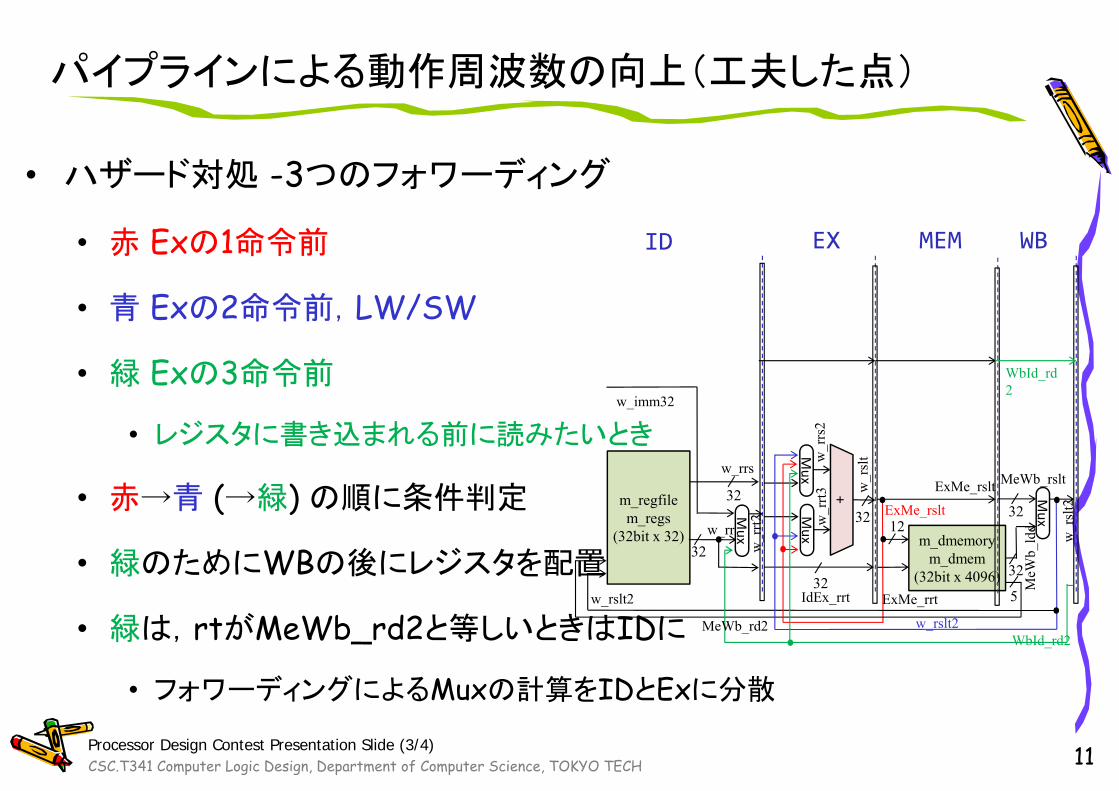
パイプラインによる動作周波数の向上(工夫した点)
Processor Design Contest Presentation Slide (3/4) 11
WbId_rd2
• ハザード対処 -3つのフォワーディング
• 赤 Exの1命令前
• 青 Exの2命令前,LW/SW
• 緑 Exの3命令前
• レジスタに書き込まれる前に読みたいとき
• 赤→青 (→緑) の順に条件判定
• 緑のためにWBの後にレジスタを配置
• 緑は,rtがMeWb_rd2と等しいときはIDに
• フォワーディングによるMuxの計算をIDとExに分散
m_regfilem_regs
(32bit x 32)
+
w_rrs
w_rrt
w_r
slt
32
3232
EX MEM
Mux
w_imm32
w_r
rt2
m_dmemorym_dmem
(32bit x 4096)
WB
Mux32
32
12
MeWb_rslt
MeW
b_ld
d
32
Mux
Mux
w_rslt2
WbId_rd2
IdEx_rrt ExMe_rrt
ExMe_rslt
w_r
slt2
w_rslt2
ExMe_rslt
w_r
rs2
w_r
rt3
ID
5
MeWb_rd2
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
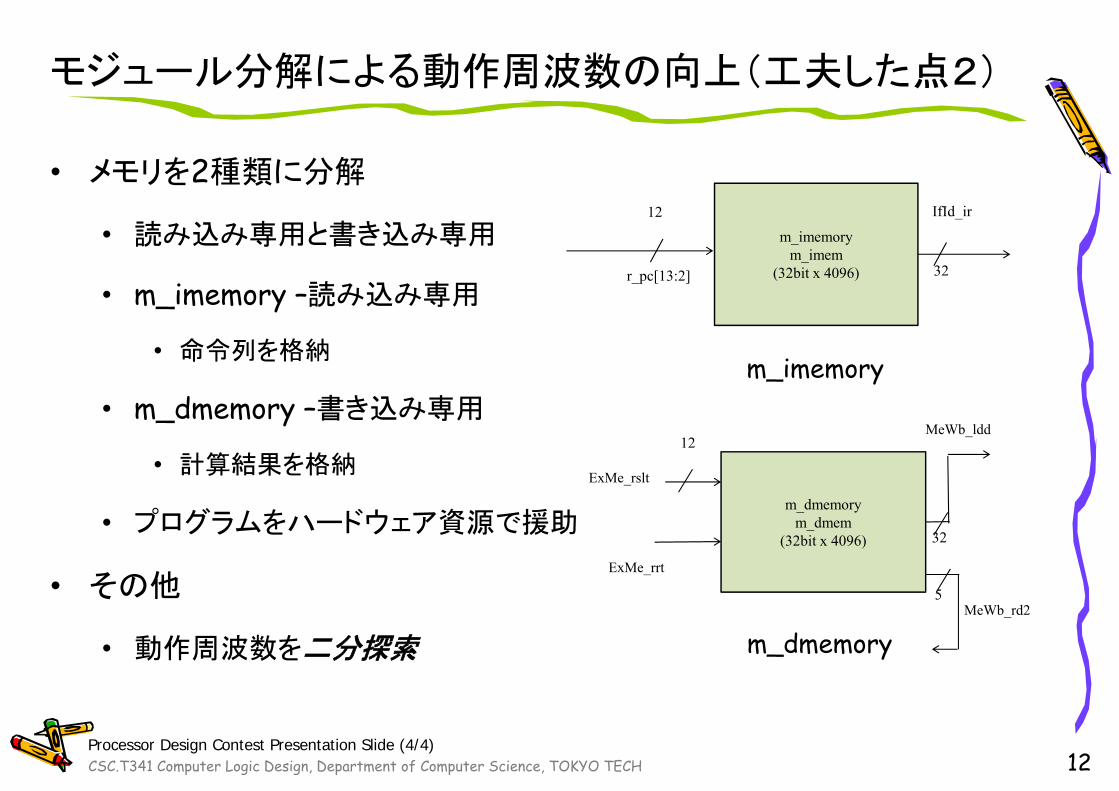
• メモリを2種類に分解
• 読み込み専用と書き込み専用
• m_imemory –読み込み専用
• 命令列を格納
• m_dmemory –書き込み専用
• 計算結果を格納
• プログラムをハードウェア資源で援助
• その他
• 動作周波数を二分探索
モジュール分解による動作周波数の向上(工夫した点2)
Processor Design Contest Presentation Slide (4/4)
m_imemorym_imem
(32bit x 4096)
IfId_ir
r_pc[13:2] 32
12
12
m_dmemorym_dmem
(32bit x 4096) 32
12MeWb_ldd
ExMe_rrt
5
ExMe_rslt
MeWb_rd2
m_imemory
m_dmemory

04: シングルサイクルプロセッサ
Group No: 04
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
13Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
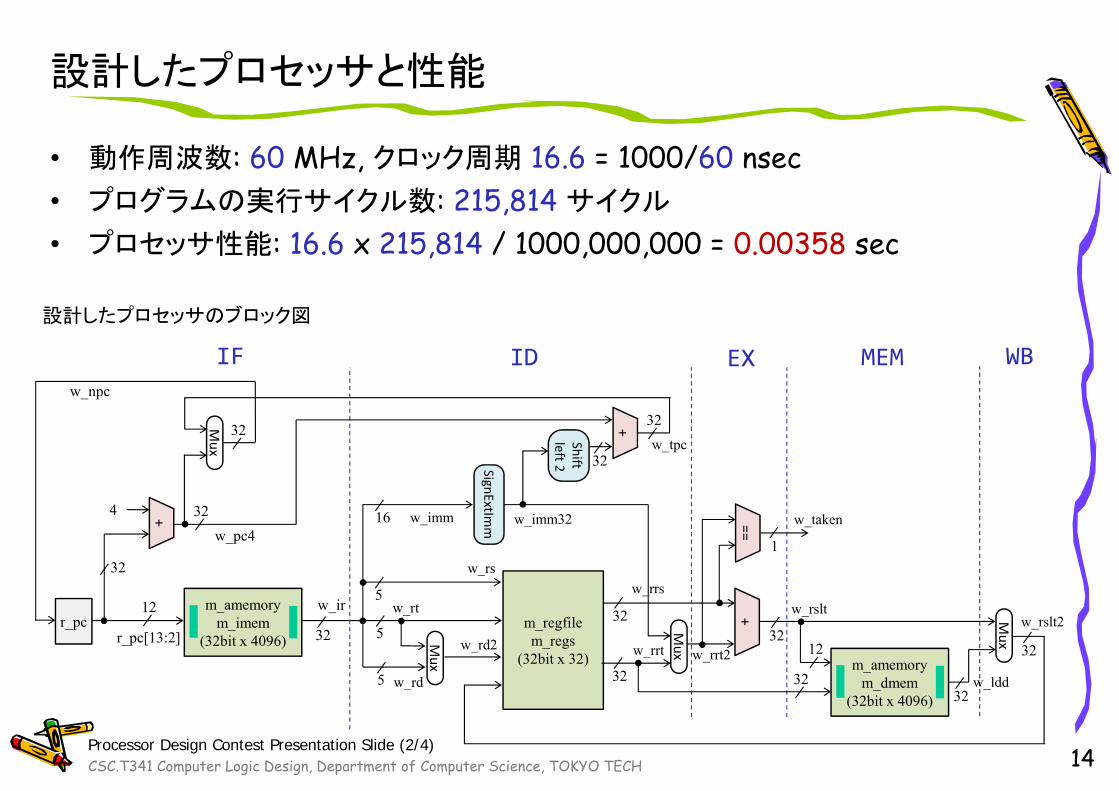
設計したプロセッサと性能
• 動作周波数: 60 MHz, クロック周期 16.6 = 1000/60 nsec• プログラムの実行サイクル数: 215,814 サイクル
• プロセッサ性能: 16.6 x 215,814 / 1000,000,000 = 0.00358 sec
14
m_regfilem_regs
(32bit x 32)
+
w_rs
w_rtw_rrs
w_rrt
w_rd
w_rslt
+
r_pc
4
m_amemorym_imem
(32bit x 4096)
w_ir
r_pc[13:2]
32
32
32
12
32
3232
5
5
5
IF ID EX MEM
w_imm16
SignExtImm
Mux
w_imm32
w_rrt2
Mux
w_rd2m_amemory
m_dmem(32bit x 4096)
WB
Mux
32
32
12
w_rslt2
w_ldd32
+Mux Shiftleft 2
w_npc
3232
32
== w_taken
1w_pc4
w_tpc
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
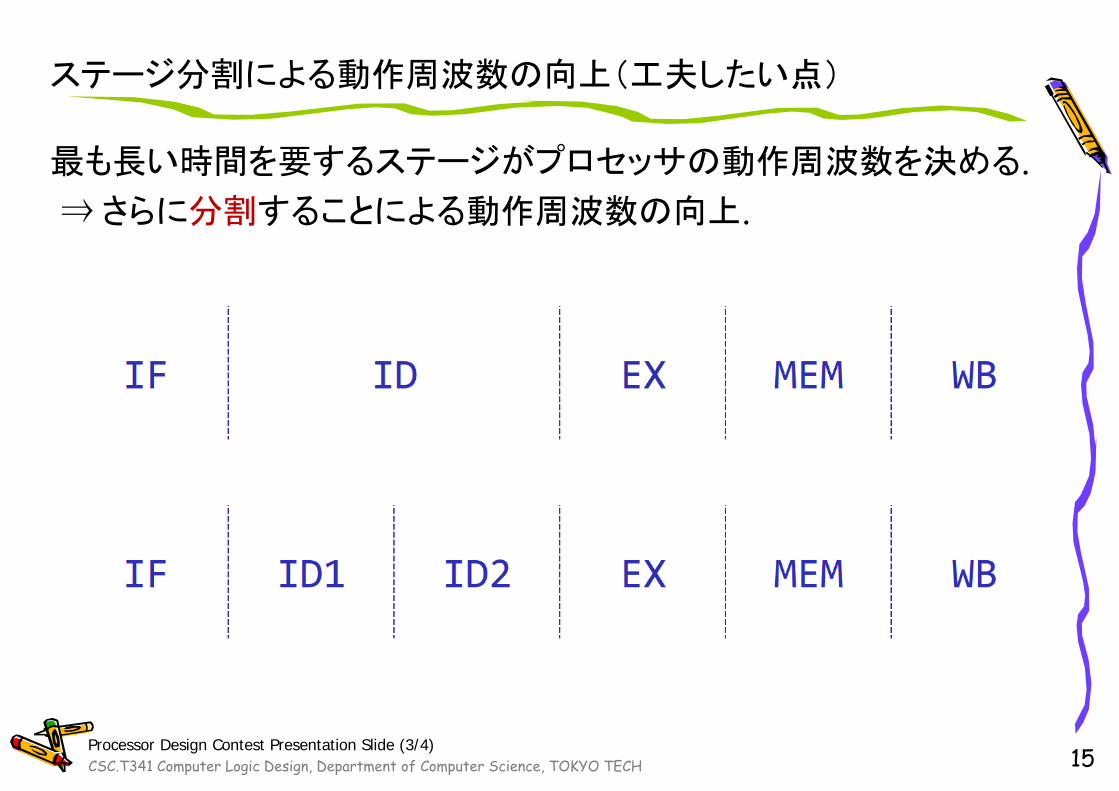
ステージ分割による動作周波数の向上(工夫したい点)
15Processor Design Contest Presentation Slide (3/4)
最も長い時間を要するステージがプロセッサの動作周波数を決める. ⇒さらに分割することによる動作周波数の向上.

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
条件分岐の予想による実行サイクル数の削減(工夫したい点2)
16Processor Design Contest Presentation Slide (4/4)
繰り返し処理の条件分岐では, 分岐するかしないかの比率は偏りが大きい. ⇒同じ条件分岐に出会ったらループの可能性を考え,
前回と同じ結果を予想することによる実行サイクル数の削減.

シングルプロセッサMk-Ⅱ: addiの同時実行による高速化を用いた少し早いシ
ングルプロセッサ
Group No: 05
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
17Processor Design Contest Presentation Slide (1/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
設計したプロセッサと性能
• 動作周波数: 50 MHz, クロック周期 20 = 1000/50 nsec• プログラムの実行サイクル数: 184368 サイクル
• プロセッサ性能: 20 x 184368 / 1000,000,000 = 0.00369 sec
18
m_regfilem_regs
(32bit x 32)
+
w_rs
w_rtw_rrs
w_rrt
w_rd
w_rslt
+
r_pc
4
m_amemorym_imem
(32bit x 4096)
w_ir
r_pc[13:2]
32
32
32
12
32
32
32
5
5
5
IFID
EX MEM
w_imm16
SignExtImm
Mux
w_imm32
w_rrt2
Mux
w_rd2m_amemory
m_dmem(32bit x 4096)
WB
Mux
32
32
12
w_rslt2
w_ldd32
+Mux Shiftleft 2w_npc
3232
32
== w_taken
1w_pc4
w_tpc
Processor Design Contest Presentation Slide (2/4)
+
4Mux
SignExtImm
+
Mux
w_imm32next
16
w_imm32next

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
addi同時実行による実行サイクル数の削減(工夫した点)
• X = X + aX = X + a
• まとめた場合、プログラムカウンタ1つ進めて同じ計算を行わないようにする
• 結果 : サイクル数の大幅削減(245814 → 184368)動作周波数の微減(50MHz時のWNS 0.644ns→0.241ns)実行時間の短縮(0.00492sec → 0.00369sec)
19Processor Design Contest Presentation Slide (3/4)
X = X + a + aまとめて計算

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
さらなる改善の見込み
• パイプライン構造と組み合わせる
プログラミング力が足りなかった
• addiだけでなくあらゆる命令でも同時に実行できるようにする
• addiを4つまとめる
サイクル数はさらに減少した(147501サイクル)しかし、45MHzでも制約を満たさず(40MHzなら満たす)総合的に見るとあまり変わらない(0.00368sec)
20Processor Design Contest Presentation Slide (4/4)

助さん: A pipelined processor with scheduling
Group No: 06
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
21Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
設計したプロセッサと性能
• 動作周波数: 195 MHz, クロック周期 5.1 nsec• プログラムの実行サイクル数: 245818 サイクル
• プロセッサ性能: 1.25 msec
22
m_regfilem_regs
(32bit x 32)
+
w_rs
w_rt
w_rrs
w_rrt
w_rd
w_rslt+
r_pc
4
m_amemorym_imem
(32bit x 4096)r_pc[13:2]
32
32
12
32
32 32
5
5
5
IF ID EX MEM
w_imm
16
SignExtImm
Mux
w_imm32
w_r
rt2
Mux
w_rd2m_amemorym_dmem
(32bit x 4096)
WB
Mux32
w_rslt2
w_ldd
+Mux Shiftleft 2
w_npc
3232
32
== || !=
w_taken
w_pc4
w_tpc
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)
IfId
_ir
IfId_tpc2 32
32
+
20 w_pc20[13:2]
12
IfId_pc20
Mux8
-12 +
16
32
IfId_pc24
32
IdEx_rrt
32
32
IdEx_imm32
Mux
MuxIdEx_rrs
32
Mux
32
w_rrs2
32
32 w_rrt3
32 w_rrt4
32
ExMe_rslt
ExMe_rrt3
32
ExMe_rrs2
32
1
ExMe_rrt
32
ExMe_rslt
32
MeWb_rd2
12
5
MeId_rslt
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
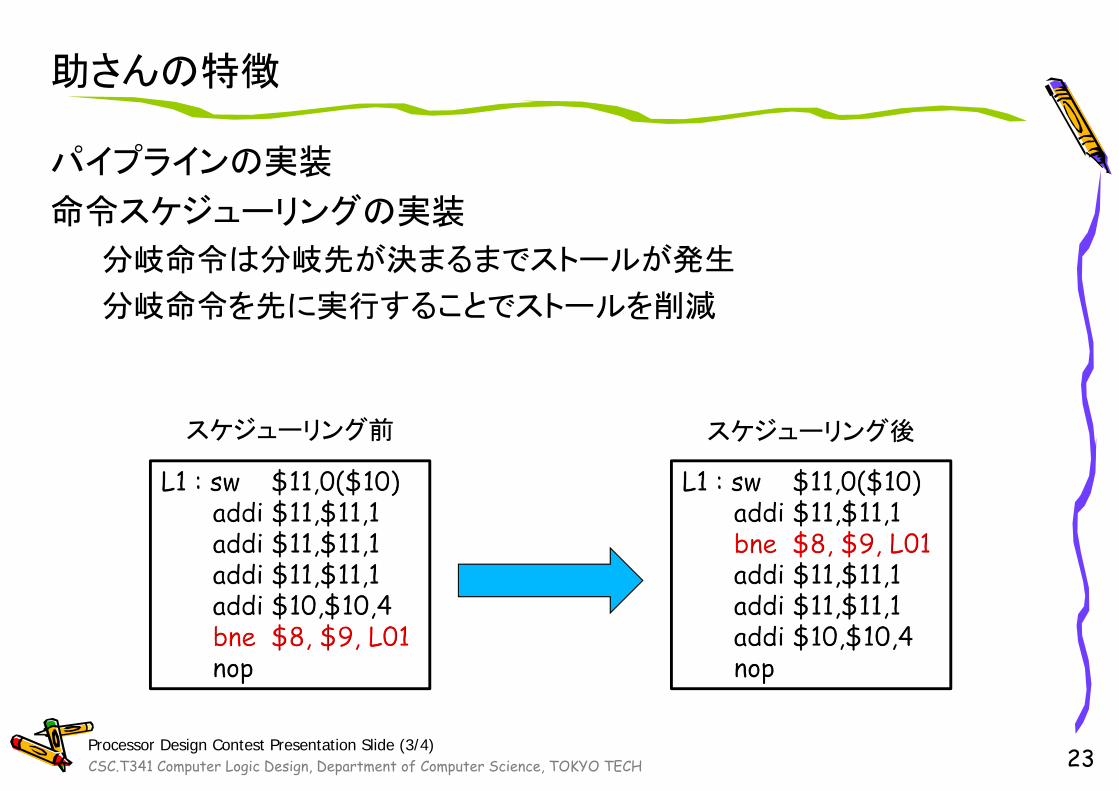
助さんの特徴
パイプラインの実装
命令スケジューリングの実装
分岐命令は分岐先が決まるまでストールが発生
分岐命令を先に実行することでストールを削減
23Processor Design Contest Presentation Slide (3/4)
スケジューリング前 スケジューリング後

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
その他工夫点
フォワーディングの実装
ストールが発生することなくデータハザードを回避
クリティカルパスの分割
レジスタから値を読みだすIDステージがクリティカルパス
IDステージの処理を他のステージに移動
ストラテジーの変更
ストラテジーとは配置配線の方針のこと
速度を優先したり、消費電力を抑えたりできる
今回は速度を優先してPerformance_HighUtilSLRsを採用
Worst Negative Slackが-0.010nsから0.016nsになった
5MHzの高速化に成功
24Processor Design Contest Presentation Slide (4/4)

XX: パイプラインプロセッサ
Group No: 07
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
25Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH 26Processor Design Contest Presentation Slide (2/4)
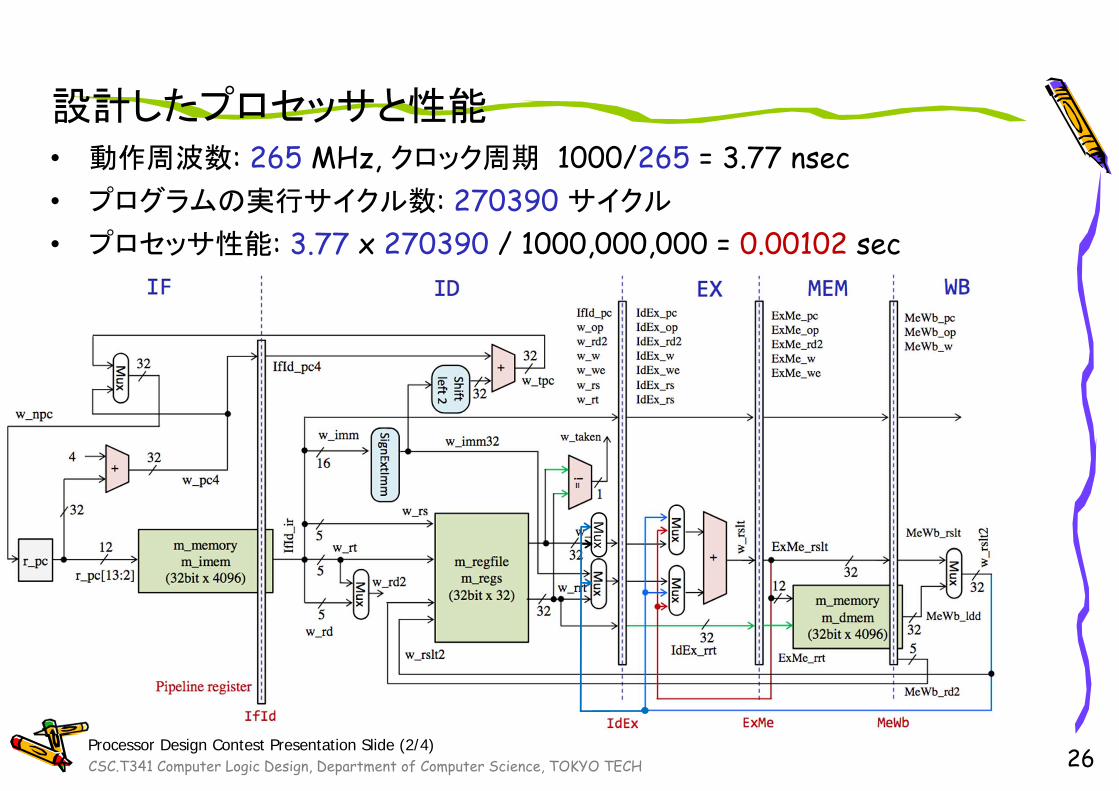
設計したプロセッサと性能• 動作周波数: 265 MHz, クロック周期 1000/265 = 3.77 nsec• プログラムの実行サイクル数: 270390 サイクル
• プロセッサ性能: 3.77 x 270390 / 1000,000,000 = 0.00102 sec
Mux
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
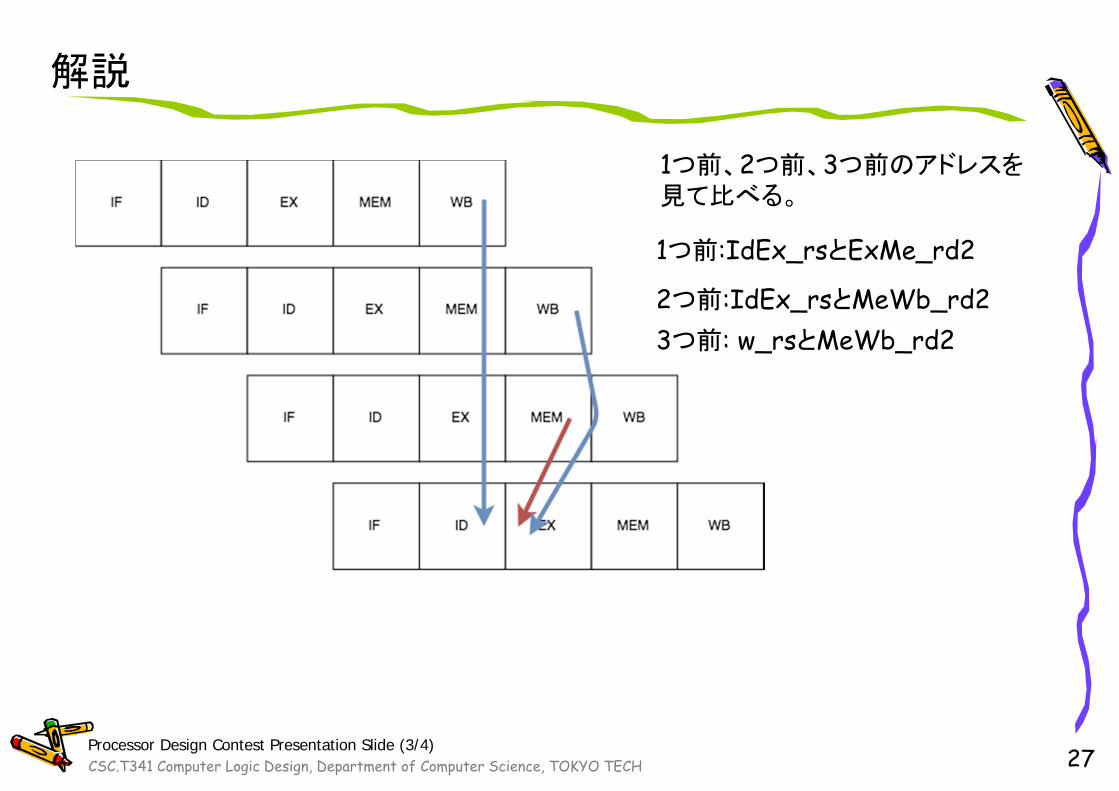
解説
27Processor Design Contest Presentation Slide (3/4)
1つ前、2つ前、3つ前のアドレスを見て比べる。
1つ前:IdEx_rsとExMe_rd2
2つ前:IdEx_rsとMeWb_rd23つ前: w_rsとMeWb_rd2

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
• パイプラインプロセッサを実装することにより動作周波数をできるだけ上げた。
• ストールを挟まず、フォワーディングを実装したので、サイクル数が比較的小さくなった。
28Processor Design Contest Presentation Slide (4/4)

TUBAME プロセッサー
Group No: 08
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
29Processor Design Contest Presentation Slide (1/4)
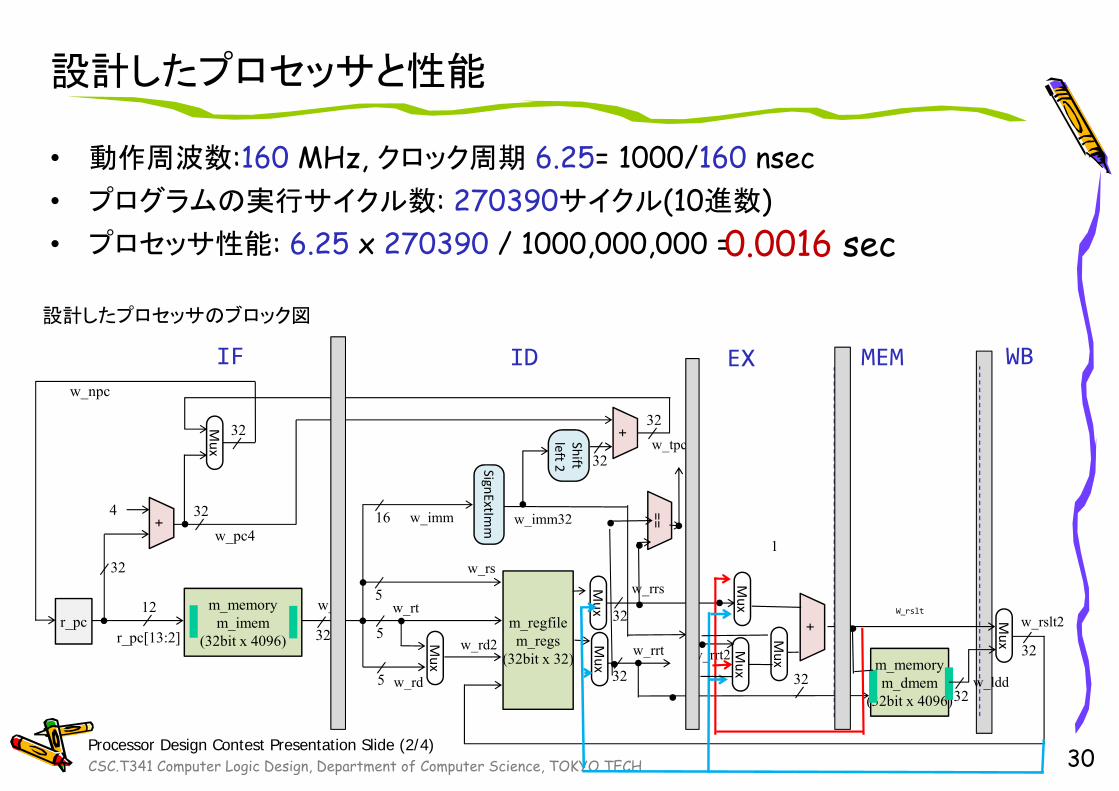
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
設計したプロセッサと性能
• 動作周波数:160 MHz, クロック周期 6.25= 1000/160 nsec• プログラムの実行サイクル数: 270390サイクル(10進数)• プロセッサ性能: 6.25 x 270390 / 1000,000,000 =
30
m_regfilem_regs
(32bit x 32)
+
w_rs
w_rtw_rrs
w_rrt
w_rd
+
r_pc
4
m_memorym_imem
(32bit x 4096)
w_ir
r_pc[13:2]
32
32
32
12
32
325
5
5
IF ID EX MEM
w_imm16
SignExtImm
Mux
w_imm32
w_rrt2
Mux
w_rd2m_memorym_dmem
(32bit x 4096)
WB
Mux
32
32
w_rslt2
w_ldd32
+Mux Shiftleft 2
w_npc
3232
32==
1w_pc4
w_tpc
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)
W_rslt
Mux
Mux
Mux
Mux
0.0016 secsec
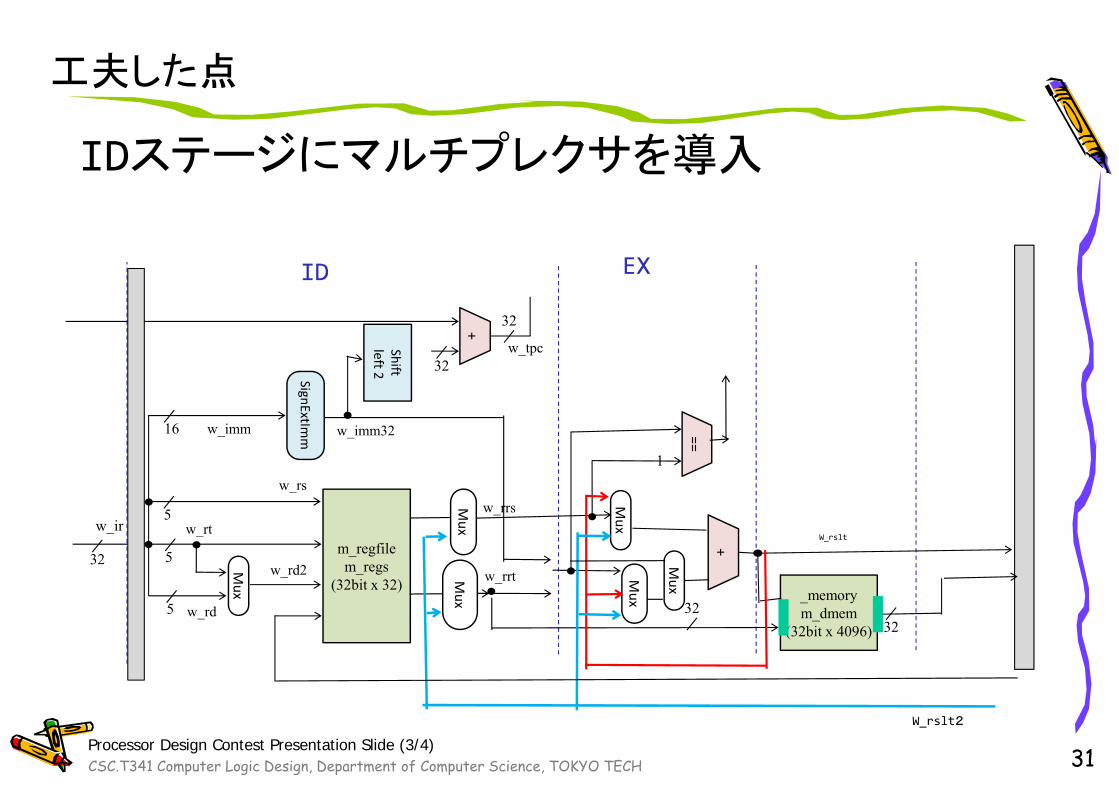
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
工夫した点
31Processor Design Contest Presentation Slide (3/4)
IDステージにマルチプレクサを導入
m_regfilem_regs
(32bit x 32)
+
w_rs
w_rtw_rrs
w_rrt
w_rd
w_ir
32
5
5
5
w_imm16
SignExtImm
Mux
w_imm32
Mux
w_rd2
_memorym_dmem
(32bit x 4096) 3232
+ 32
32
==
1
w_tpc
W_rslt2
Mux
Mux
W_rslt
ID EX
Mux
Mux
Shiftleft 2

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
工夫した(工夫しようとした)点
IDステージを二つに分割
32Processor Design Contest Presentation Slide (4/4)
+
r_pc
4
m_memorym_imem
(32bit x 4096)
32
12
IF
Mux
w_npc
w_pc4
設計した(したかった)プロセッサのブロック図
m_regfilem_regs
(32bit x 32)
w_rt
w_rrs
w_rrt
w_rd
5
5
5
ID EX
w_imm16
SignExtImm w_imm32
Mux
+
Shiftleft 2
32
=!=
w_tpc
Mux
Mux

Proc09: 分岐の高速化を用いたパイプラインプロセッサ
Group No: 09
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
33Processor Design Contest Presentation Slide (1/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
設計したプロセッサと性能
• 動作周波数: 290 MHz, クロック周期 3.45 nsec• プログラムの実行サイクル数: 270404 サイクル
• プロセッサ性能: 0.000932428 sec
34
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
パイプライン、分岐予測による実行サイクル数の削減
• パイプラインの実装• フォワーディング
• MEM(優先), WB → EX• WB → ID (レジスタ内)
• 分岐命令の処理をEXで行う
• ID時点ではレジスタの値は不定
• 分岐予測
• ストールによる分岐実装
• BNE1つにつき3命令消費
• コード内のBNEの条件はほぼ満たされる
• 全て条件を満たすものとして予測
• (2 + 4095 * 6)/(3 + 4096 * 6)• IDでBNEを検知し, PCを書き換え
• コストは1程度(NOP)
35Processor Design Contest Presentation Slide (4/4)
→ ストールほぼなしでの実行が可能

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
ボトルネックの解消による動作周波数の向上
• 各パイプの処理時間
• ID• レジスタ内にフォワーディング機能
• 遅延なしで読み込み可能
• 各ステージの遅延はレジスタへの代入のみ
• 動作周波数の二分探索
• 人力による地道な探索
• 100MHz○ → 500MHz× → 300MHz× → 200MHz○→ 250MHz○ → 275MHz○ → 280, 285, 290MHz
36Processor Design Contest Presentation Slide (3/4)

Group10: パイプライン処理を用いた
フォワーディング型プロセッサ
Group No.10

設計したプロセッサと設計
● 動作周波数: 95MHz● クロック周期: 10.53nsec● 実行サイクル数: 270390サ
イクル
● プロセッサ性能: 0.0028sec
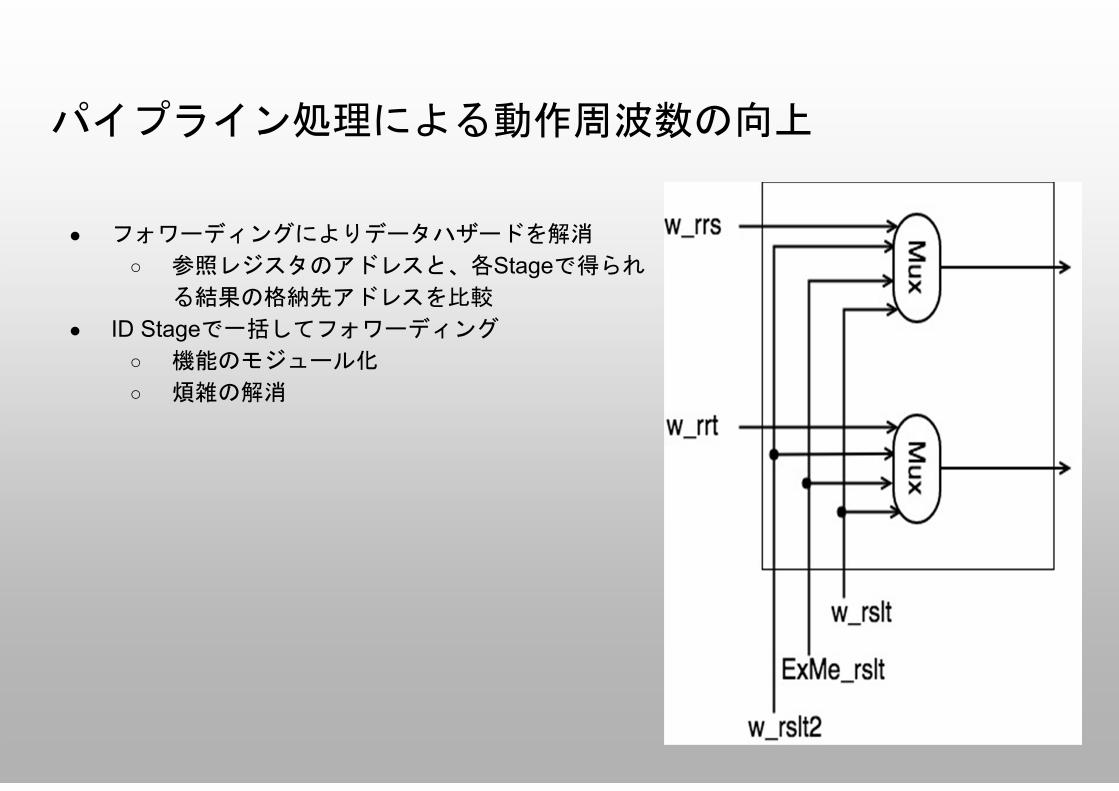
パイプライン処理による動作周波数の向上
● フォワーディングによりデータハザードを解消
○ 参照レジスタのアドレスと、各Stageで得られ
る結果の格納先アドレスを比較
● ID Stageで一括してフォワーディング
○ 機能のモジュール化
○ 煩雑の解消

stallによるデータハザードの回避
● stallを使うアプローチで設計を開始した
● 当初の3サイクルの遅延をstallのみでの解消を試みた結果、必要サイクル数がかな
り増えた
● stall以外にExとMemを統合することによって1サイクルの遅延を解消することが
できた
● さらにフォワーディングによって1サイクルの遅延を解消し、3サイクルの遅延を
解消することができた(結局フォワーディングに頼った)
● 動作周波数: 100MHz● クロック周期: 10nsec● 実行サイクル数: 60045サイクル
● プロセッサ性能: 0.0006sec

パイプラインプロセッサ: パイプラインによる高速化を用いたプロセッサ
Group No: 11
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
41Processor Design Contest Presentation Slide (1/4)
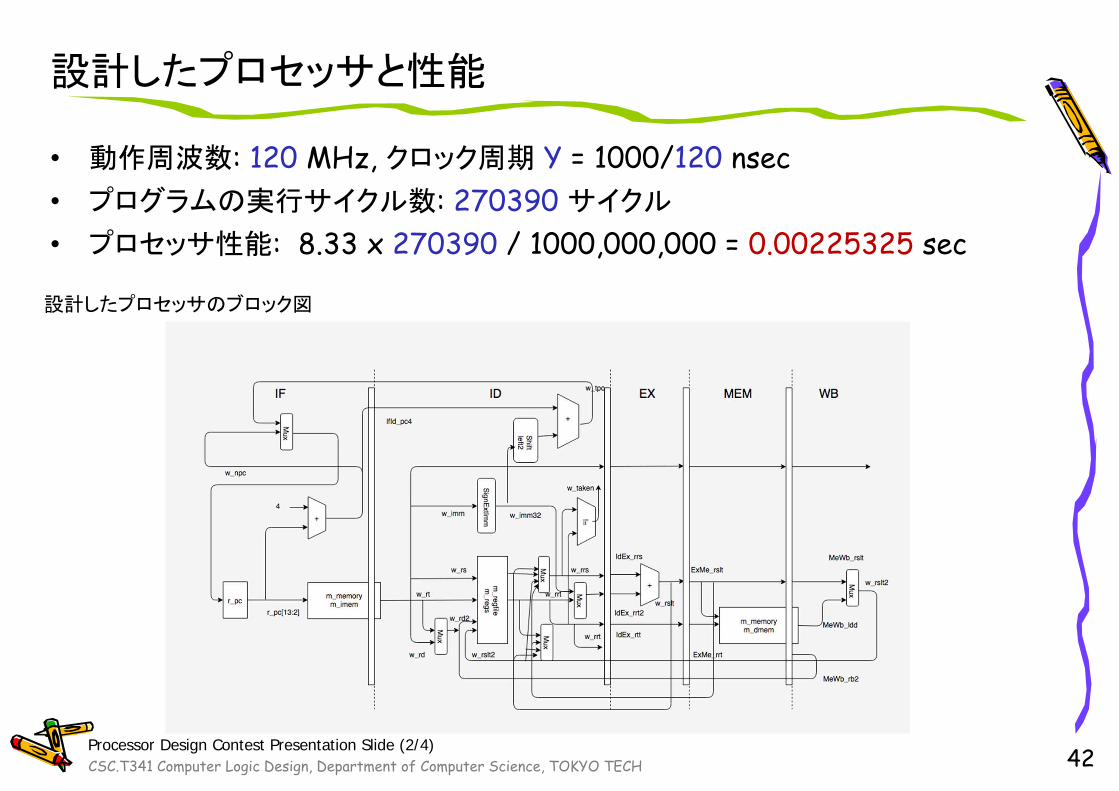
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
設計したプロセッサと性能
• 動作周波数: 120 MHz, クロック周期 Y = 1000/120 nsec• プログラムの実行サイクル数: 270390 サイクル
• プロセッサ性能: 8.33 x 270390 / 1000,000,000 = 0.00225325 sec
42
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
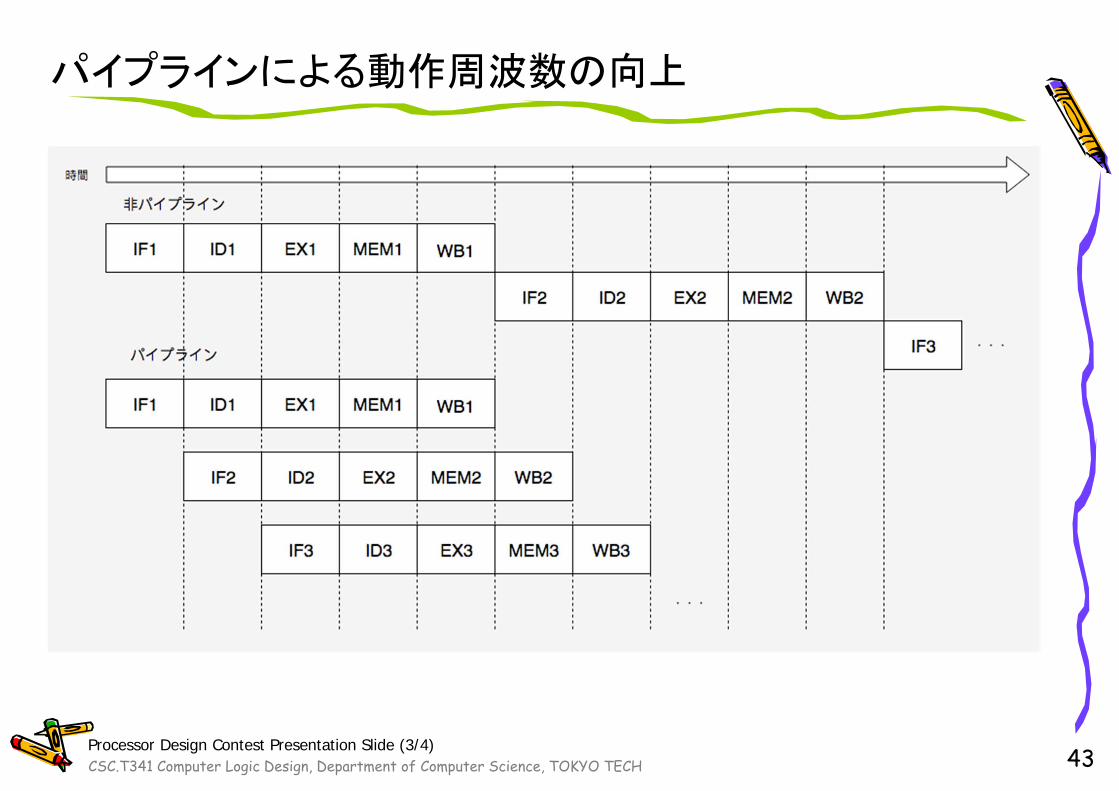
パイプラインによる動作周波数の向上
43Processor Design Contest Presentation Slide (3/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
フォワーディング
フォワーディングが必要となる場合
• add,addiによるレジスタの変化時
• lwによるレジスタの変化時
add,addiによるレジスタ変化に対するフォワーディング
add,addi命令の 1個次の命令にはwbからexにフォワーディング
2個次の命令にはmemからidにフォワーディング
3個次の命令にはwbからidにフォワーディング
lwによるレジスタ変化に対するフォワーディング
lw命令の 2個次の命令にはwbからexにフォワーディング
wbからidにフォワーディング
44Processor Design Contest Presentation Slide (4/4)

processor12: パイプラインを用いたプロセッサ
Group No: 12
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
45Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH 46
m_regfilem_regs
(32bit x 32)
+
w_rs
w_rt
w_rrs
w_rrt
w_rd
+
r_pc
4
m_amemorym_imem
(32bit x 4096)r_pc[13:2]
32
32
12
32
325
5
5
ID
w_imm16
SignExtImm
Mux
w_imm32
Mux
w_rd2m_amemory
m_dmem(32bit x 4096)
Mux
32
32
w_rslt2
MeWb_ldd
+
Mux
Shiftleft 232 3232
w_pc4
w_tpc
Processor Design Contest Presentation Slide (2/4)
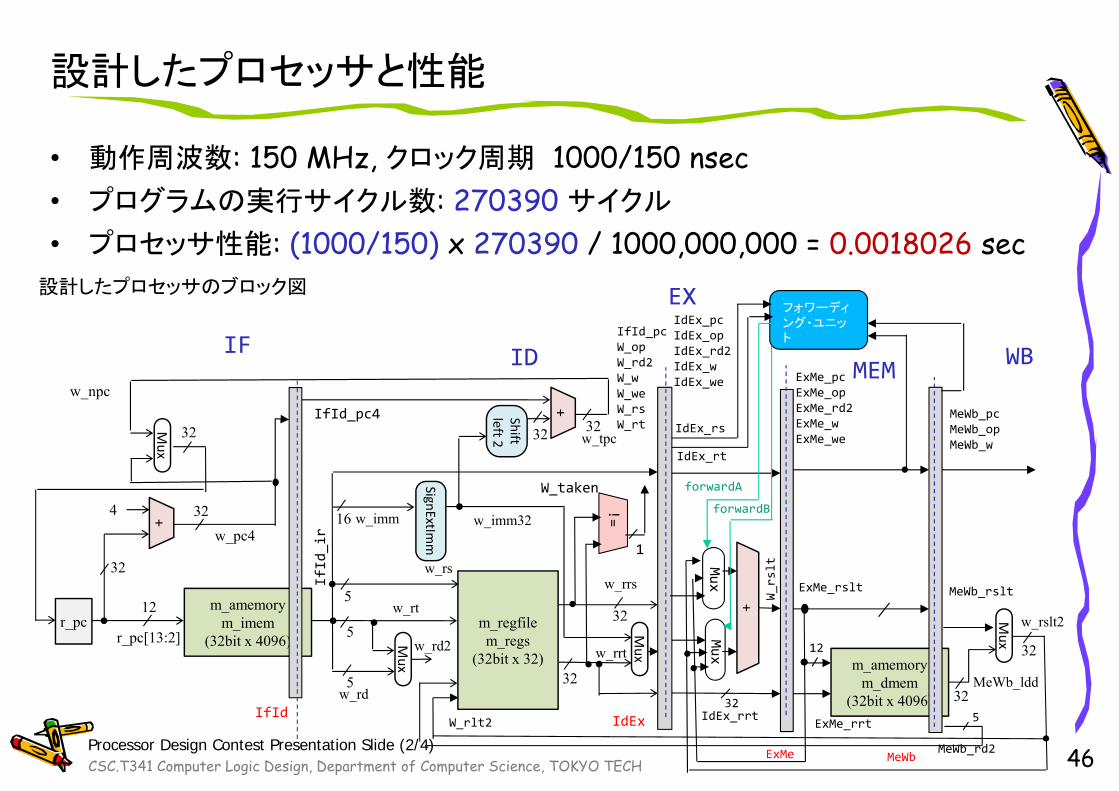
設計したプロセッサと性能
• 動作周波数: 150 MHz, クロック周期 1000/150 nsec• プログラムの実行サイクル数: 270390 サイクル
• プロセッサ性能: (1000/150) x 270390 / 1000,000,000 = 0.0018026 sec
IF
EX
MEM WBw_npc
設計したプロセッサのブロック図
IfId
IfId_pc4
IfId_ir
!=W_taken
1
IfId_pcW_opW_rd2W_wW_weW_rsW_rt
IdEx
IdEx_pcIdEx_opIdEx_rd2IdEx_wIdEx_we
MuxMux
W_rlt2
ExMe_pcExMe_opExMe_rd2ExMe_wExMe_we
MeWb_pcMeWb_opMeWb_w
ExMe_rslt
5
MeWb_rslt
MeWb_rd2
12
IdEx_rrt32
W_rs
lt
ExMe_rrt
ExMe MeWb
フォワーディング・ユニット
IdEx_rs
IdEx_rt
forwardA
forwardB

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
パイプラインの実装
• 処理を平行して行うことで時間短縮を狙う。
• 命令フェッチ、命令デコード、実行、メモリアクセス、書き込みの5ステージに分割して並行して行う。
• 今回は足し上げるのが目的であり、足し算を行う際にひとつ前の結果が必要となるので、データハザードが発生する。
47Processor Design Contest Presentation Slide (3/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
データハザードの対策
• フォワーディングを用いてこれを回避する。
• フォワーディングの条件は、Aに対し、
(ExMe_rd2 != 0) && (ExMe_op == ‘ADDI || ExMe_op == ‘ADD) &&(IdEx_op == ‘ADDI) && (IdEx_rs != 0) && (ExMe_rd2 == IdEx_rs)が真であるとき、ALUの第一オペランドがひとつ前のALUの結果から先送りされてくる。
48Processor Design Contest Presentation Slide (4/4)

遅延処理:命令先読みの高速化を用いたパイプラインプロセッサ
Group No: 13
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
49Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
imem
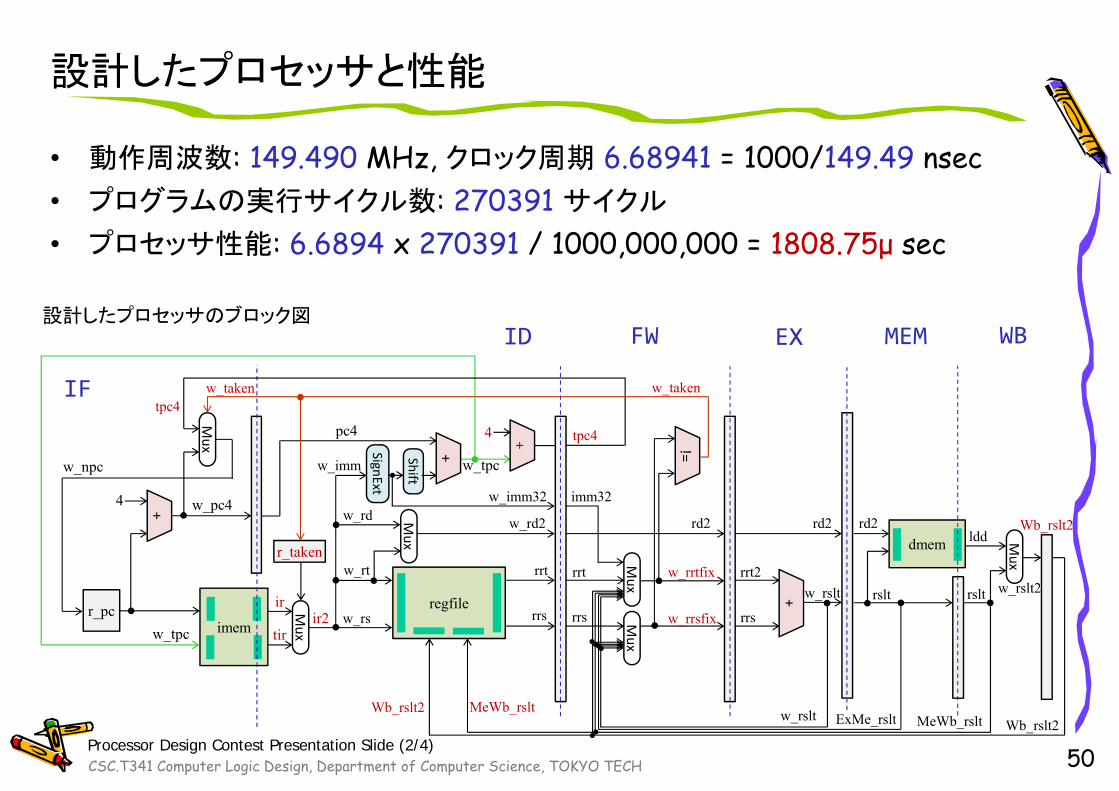
設計したプロセッサと性能
• 動作周波数: 149.490 MHz, クロック周期 6.68941 = 1000/149.49 nsec• プログラムの実行サイクル数: 270391 サイクル
• プロセッサ性能: 6.6894 x 270391 / 1000,000,000 = 1808.75μ sec
50
+
w_rs
w_rt
rrs
rrt
w_rd
w_rslt
+
r_pc
4
ir
IF
ID EX MEM
w_imm
SignExt
w_rd2dmem
WB
Mux
Wb_rslt2ldd
+
Mux
Shift
!=
w_taken
w_pc4
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)
regfile
Mux
Mux
Mux
+
4
Mux
r_taken
FW
tirir2
w_npc
w_tpc
tpc4
w_tpc
tpc4
rrt
rrs
w_rrtfix
w_rrsfix
rd2 rd2 rd2
rslt rslt
pc4
Wb_rslt2MeWb_rsltExMe_rsltMeWb_rsltWb_rslt2
w_taken
w_rslt2w_rslt
w_imm32
rrt2
rrs
imm32
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
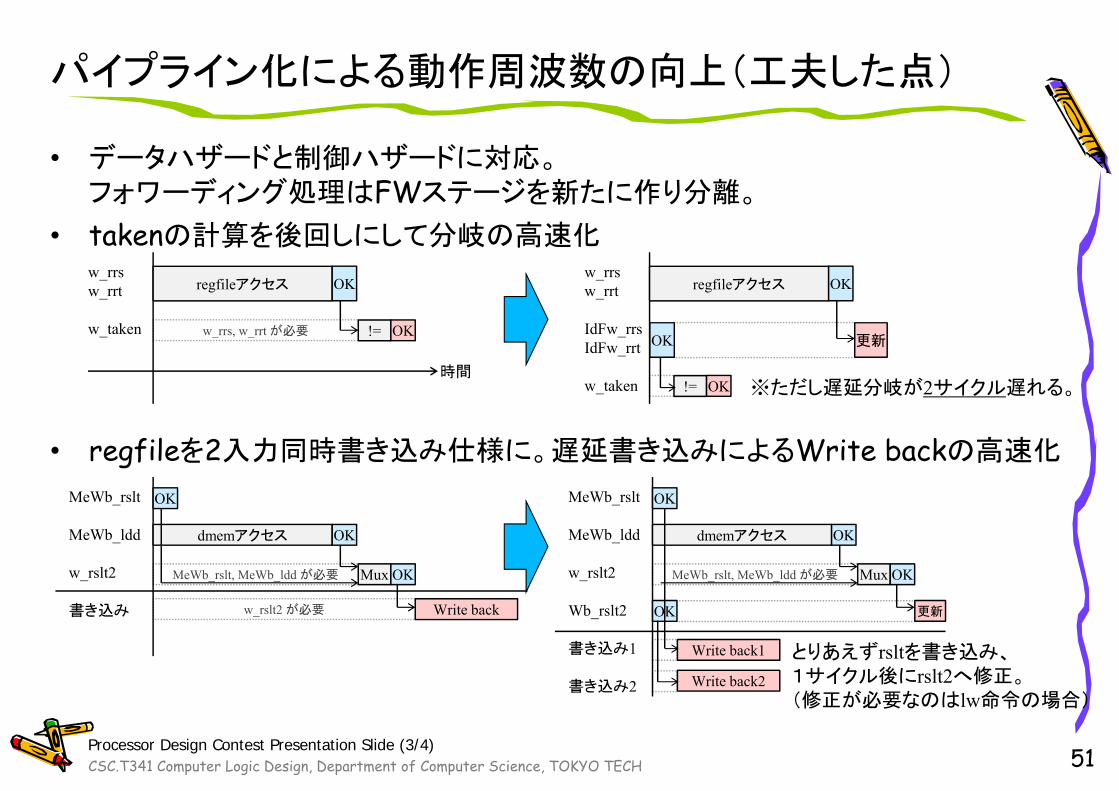
• データハザードと制御ハザードに対応。フォワーディング処理はFWステージを新たに作り分離。
• takenの計算を後回しにして分岐の高速化
• regfileを2入力同時書き込み仕様に。遅延書き込みによるWrite backの高速化
w_rslt2 が必要
MeWb_rslt, MeWb_ldd が必要
パイプライン化による動作周波数の向上(工夫した点)
51Processor Design Contest Presentation Slide (3/4)
MeWb_rslt
MeWb_ldd
w_rslt2
書き込み
dmemアクセス
OK
OK
Mux OK
Write back
MeWb_rslt, MeWb_ldd が必要
MeWb_rslt
MeWb_ldd
w_rslt2
Wb_rslt2
書き込み1
書き込み2
dmemアクセス
OK
OK
Mux OK
Write back1
Write back2
OK 更新
とりあえずrsltを書き込み、1サイクル後にrslt2へ修正。(修正が必要なのはlw命令の場合)
w_rrs, w_rrt が必要
w_rrsw_rrt
w_taken
regfileアクセス OK
!= OK
w_rrsw_rrt
IdFw_rrsIdFw_rrt
w_taken
regfileアクセス OK
!= OK
OK 更新
※ただし遅延分岐が2サイクル遅れる。時間
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
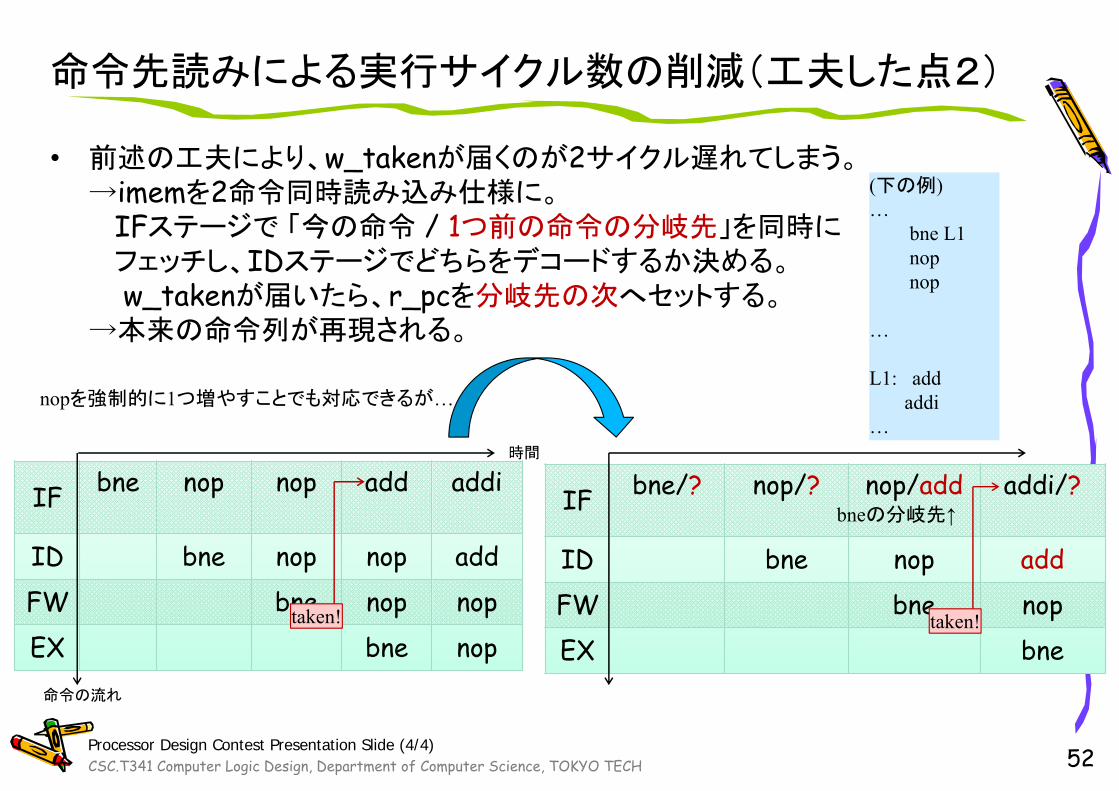
命令先読みによる実行サイクル数の削減(工夫した点2)
• 前述の工夫により、w_takenが届くのが2サイクル遅れてしまう。→imemを2命令同時読み込み仕様に。
IFステージで 「今の命令 / 1つ前の命令の分岐先」を同時にフェッチし、IDステージでどちらをデコードするか決める。w_takenが届いたら、r_pcを分岐先の次へセットする。
→本来の命令列が再現される。
52Processor Design Contest Presentation Slide (4/4)
(下の例)…
bne L1nopnop
…
L1: addaddi
…
IF bne nop nop add addi
ID bne nop nop addFW bne nop nopEX bne nop
IF bne/? nop/? nop/add addi/?
ID bne nop addFW bne nopEX bne
時間
命令の流れ
bneの分岐先↑
taken! taken!
nopを強制的に1つ増やすことでも対応できるが…

14: パイプラインの高速化を用いたプロセッサ
Group No: 14
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
53Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
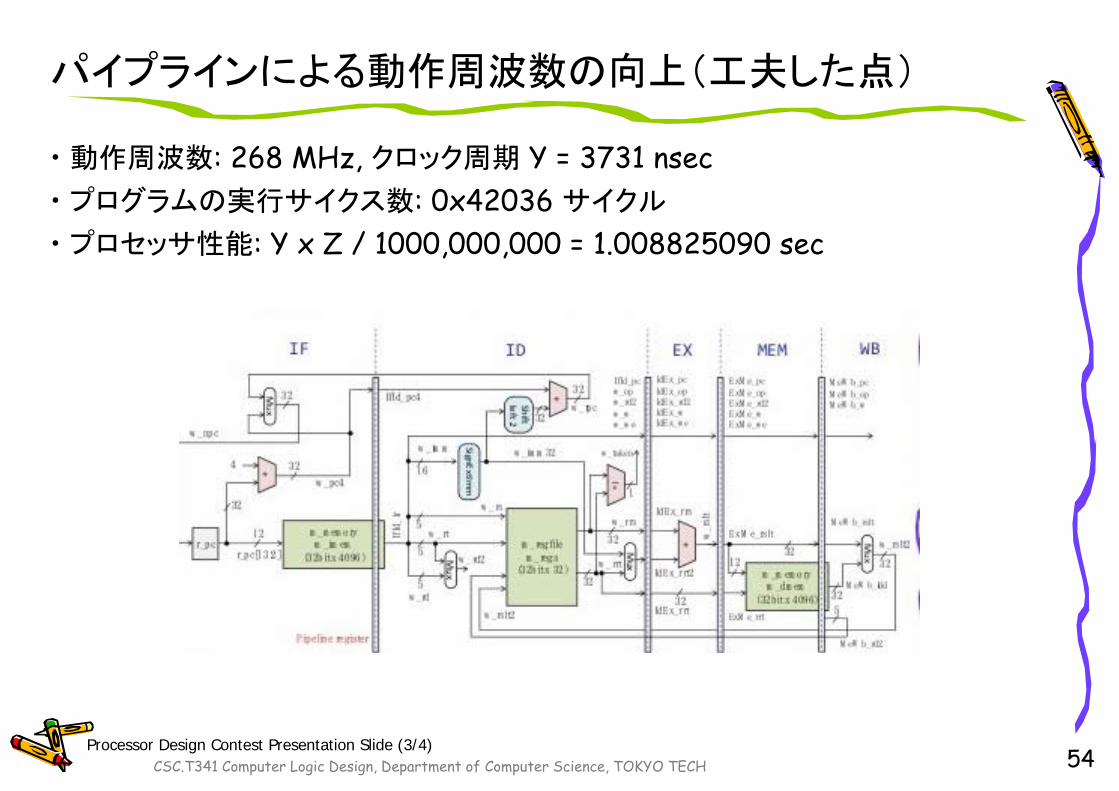
パイプラインによる動作周波数の向上(工夫した点)
• 動作周波数: 268 MHz, クロック周期 Y = 3731 nsec• プログラムの実行サイクス数: 0x42036 サイクル
• プロセッサ性能: Y x Z / 1000,000,000 = 1.008825090 sec
54Processor Design Contest Presentation Slide (3/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
パイプラインの実装
• 資料通りに実装した
• フォワーディングした
• 3つ前までの命令で変更されたレジスタのアドレスを保持し、それが使用される場合についてそれぞれ条件分岐をした
• クロックの立ち上がり時にレジスタが更新されるので、1つ前の命令の結果を保存してフォワーディングに利用した
55Processor Design Contest Presentation Slide (4/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
• 取り組むのが遅かった
• ツラかった
• コミュニケーション不足
• チーム開発はツラい
反省点

いちご: 最適化の先の究極プロセッサ
Group No: 15
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
57Processor Design Contest Presentation Slide (1/4)
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
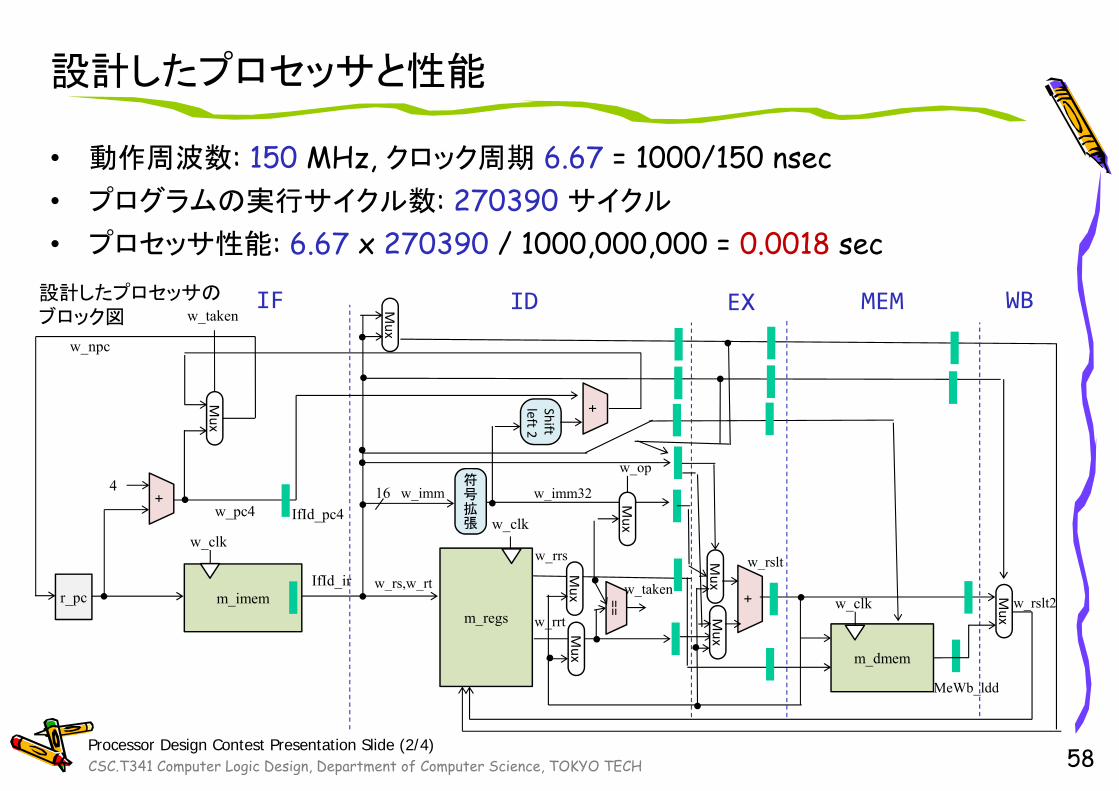
設計したプロセッサと性能
• 動作周波数: 150 MHz, クロック周期 6.67 = 1000/150 nsec• プログラムの実行サイクル数: 270390 サイクル
• プロセッサ性能: 6.67 x 270390 / 1000,000,000 = 0.0018 sec
58
m_regs
+w_rs,w_rt
w_rrs
w_rrt
w_rslt
+
r_pc
4
m_imemIfId_ir
IF ID EX MEM
w_imm16符号拡張
w_imm32
m_dmem
WB
Mux
w_rslt2
MeWb_ldd
+Mux
Shiftleft 2
w_npc
==
w_taken
w_pc4
設計したプロセッサのブロック図
Processor Design Contest Presentation Slide (2/4)
w_taken
IfId_pc4
w_clkw_clk
w_clk
Mux
Mux
w_op
Mux
Mux
Mux
Mux
CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
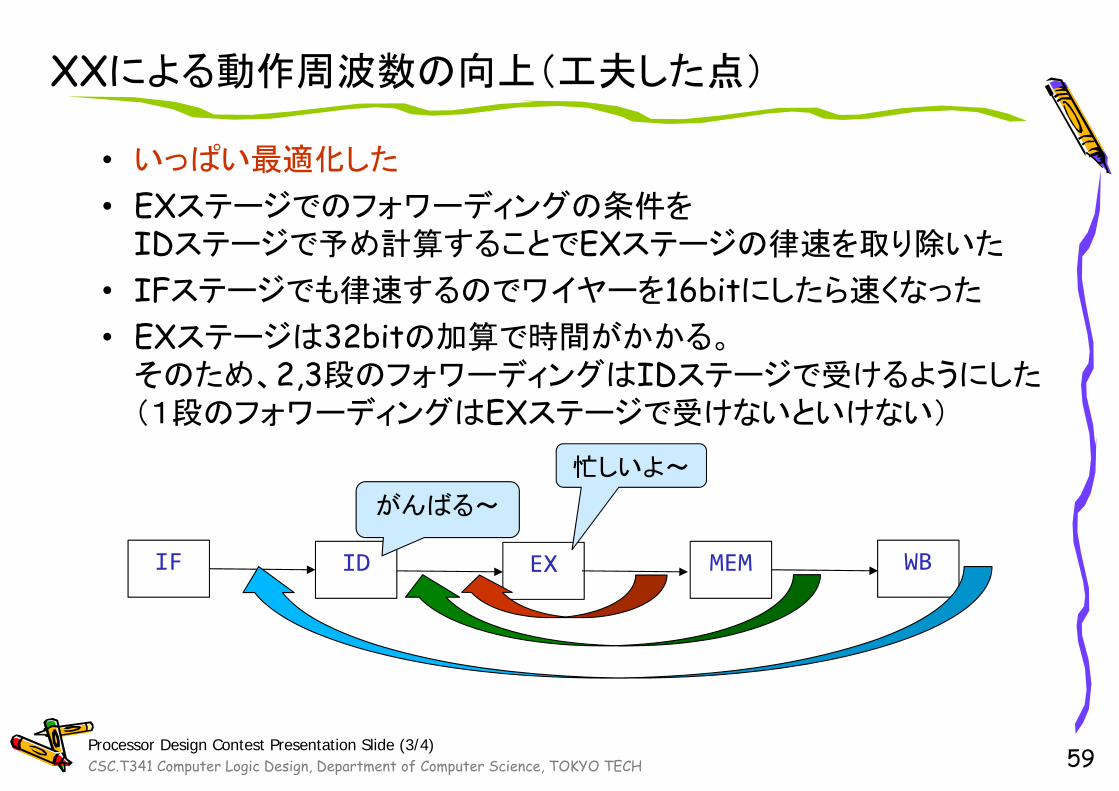
XXによる動作周波数の向上(工夫した点)
• いっぱい最適化した
• EXステージでのフォワーディングの条件をIDステージで予め計算することでEXステージの律速を取り除いた
• IFステージでも律速するのでワイヤーを16bitにしたら速くなった
• EXステージは32bitの加算で時間がかかる。そのため、2,3段のフォワーディングはIDステージで受けるようにした(1段のフォワーディングはEXステージで受けないといけない)
59Processor Design Contest Presentation Slide (3/4)
IF ID EX MEM WB
忙しいよ~
がんばる~

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
XXによる実行サイクル数の削減(工夫した点2)
• 命令アドレスは12bitだから32bitの計算は無駄なので、16bit加算にした(12bit加算はなぜか遅くなった)
• オペコードの条件はAND, OR形式になるよう最適化した。
• その他、要らない配線を消したり、条件を最適化してマルチプレクサの段数を減らしたりした
60Processor Design Contest Presentation Slide (4/4)

proc16: 4サイクルによる簡略化
Group No: 16
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
61Processor Design Contest Presentation Slide (1/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
設計したプロセッサと性能
• 動作周波数: 217.5 MHz, クロック周期 Y = 4.598nsec• プログラムの実行サイクル数: 270389 サイクル
• プロセッサ性能: 4.598 x 270389 / 1000,000,000 = 0.001243 sec
62
m_regfilem_regs
(32bit x 32)
w_rs
w_rt
r_rrs
w_rd
+
r_pc
4
m_amemorym_imem
(32bit x 4096) IfId_irr_pc[13:2]
16
16
125
5
5
IF ID EX/MEM
w_imm16
SignExtImm
Mux
w_imm32
w_rrt2
Mux
w_rd2
WB
+Mux Shiftleft 2
w_npc
1616
32
w_rpc4
w_tpc
Processor Design Contest Presentation Slide (2/4)
IfId-npc
Mux
Mux
!=
w_taken
w_rrs_
w_rrt_
Mux
Mux
+
Mux
Mux
w_rrs3
w_rrt3
IdEx_rrs
IdEx_rrt2
w_rslt MeWb_rslt
MeWb-ldd
w_rslt2
Mewb-ldd
MeWb_rslt
IdEx_rrt
32
m_amemorym_imem
(32bit x 4096
16

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
構造の簡略化による動作周波数の向上(工夫した点)
• 4サイクルプロセッサの導入
• EXとMEMを1サイクルで処理する。
• ALUの処理が加算のみなのでクリティカルパスにならない
->フォワーディング機構を簡略化できた。
ちなみに、4サイクルプロセッサの実行サイクル数は270389サイクルであるが、5サイクルプロセッサの実行サイクル数は270390サイクルである。
63Processor Design Contest Presentation Slide (3/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
動作周波数の向上による性能向上(工夫した点2)
• プログラムカウンタの変更
• クリティカルパスのプログラムカウンタの計算箇所を32ビット加算器から16ビット加算器に変更
• ->動作周波数が200MHzから217.5MHzに改善
64Processor Design Contest Presentation Slide (4/4)

パイプラインプロセッサ
Group No: 17
Course number: CSC.T341Processor Design Contest (2018-05-31) Presentation Slide
65Processor Design Contest Presentation Slide (1/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
設計したプロセッサと性能
• 動作周波数: 50 MHz, クロック周期 20 = 1000/50 nsec• プログラムの実行サイクル数: 270390 サイクル
• プロセッサ性能: 20 x 270390 / 1000,000,000 = 0.0054078 sec
66Processor Design Contest Presentation Slide (2/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
17による動作周波数の向上(工夫した点)
• 必要のないワイヤを極力削った
67Processor Design Contest Presentation Slide (3/4)

CSC.T341 Computer Logic Design, Department of Computer Science, TOKYO TECH
17による実行サイクル数の削減(工夫した点2)
• ワイヤを使わず直接aluにデータを渡してデータハザードを解決した
68Processor Design Contest Presentation Slide (4/4)


























![ベラビスタ御節ベラビスタ御節 【祝いおせち双忘/三段重】 (税別)三五〇〇〇円 [料理内容]四十品 [重箱寸法]八角形 【祝いおせちベラビスタ/三段重】](https://img.pdfslide.net/doc/110x75/5ed4c6dafd1f950b814df6a2/fffc-fffc-coeie.jpg)


