Embed Size (px)
Citation preview

Kapitel 5
Konfidenzintervalle,Hypothesentests,und einfache Prognosen
“The greatest enemy of knowledge is notignorance, it is the illusion of knowledge.”
(Stephen Hawking)
5.1 Was bisher geschah . . .
Beginnen wir ganz von vorne: Wir haben gehort, dass interessierende Aspektevon Zufallsexperimenten in Zufallsvariablen abgebildet werden konnen. Intuitivkonnen Sie sich unter einer Zufallsvariable eine Zahlenmenge vorstellen, denn je-dem moglichen Ausgang des Zufallsexperiments wird eine reelle Zahl zugeordnet.Mit Dichtefunktionen (bzw. Wahrscheinlichkeitsfunktionen fur diskrete Zufallsvaria-blen) konnen Bereichen dieser Zahlenline Wahrscheinlichkeiten zugeordnet werden.Mit Hilfe der entsprechenden Verteilungsfunktion konnen wir die Wahrscheinlichkeitdafur angeben, dass die Auspragung einer Zufallsvariable einen Wert kleiner als eine(beliebige) Konstante c annehmen wird, vergleiche Abbildung 5.1.
Wir beobachten nur Realisationen einer Zufallsvariable, also welche Zahl nach (hy-pothetischer) Durchfuhrung eines Zufallsexperiments realisiert wurde. In der Regelwird das gedachte Zufallsexperiment haufig wiederholt, und einzelne Realisationenbilden unsere Beobachtungen, also die Daten.
In der induktiven Statistik interpretieren wir diese Daten als Stichprobe, und dasZufallsexperiment kann z.B. die Stichprobenziehung oder ein anderer unbeobachteterMechanismus sein, der die Daten erzeugt (datengenerierender Prozess).
Wir sind an Kennwerten der Grundgesamtheit (z.B. Mittelwerte, Anteile, Regressi-onskoeffizienten, Varianzen, . . . ) interessiert, das heißt, wir versuchen gewissermaßenhinter das Zufallsexperiment zu blicken.
Dazu stellen wir uns hinter jeder einzelnen Beobachtung der Stichprobe (d.h.Realisation xi) eine entsprechende Zufallsvariable xi vor, und mit Hilfe von
1

Angewandte Okonometrie 2
Dichtefunktion:f(x)
xc
Verteilungsfunktion: (kumulierte Dichte)
Pr(x ≤ c) =
=c∫
−∞
f(x) dx
F (x)
xc
1
Abbildung 5.1: Dichtefunktion f(x) und Verteilungsfunktion F (x) einer stetigenZufallsvariable. Die Wahrscheinlichkeit, dass eine stetige Zufalls-variable eine Auspragung kleiner gleich c annimmt, ist gleich derschraffierten Flache unter der Dichtefunktion links von c, odergleich der Lange der Strecke uber c der Verteilungsfunktion.
Schatzfunktionen versuchen wir etwas uber die Kennwerte der Grundgesamtheitzu lernen. Die Schatzfunktion fur den Mittelwert der Grundgesamtheit µ oder den‘wahren’ Steigungskoeffizienten β2 sind z.B.
µ =1
n
n∑
i=1
xi, oder β2 =cov(x, y)
var(x)
Diese Schatzfunktionen sind Funktionen von n Zufallsvariablen, also selbst wiederZufallsvariablen. Die Dichtefunktionen von Schatzfunktionen nennen wir Stichpro-benkennwertverteilung (‘sampling distribution’ ).
Wir konnten zeigen, dass unter gewissen Bedingungen (v.a. der Annahme xi ∼i.i.d.(µ, σ2) fur den Mittelwert, bzw. den Gauss-Markov Annahmen fur das Regres-sionsmodell) diese Schatzfunktionen erwartungstreu, effizient und konsistent sind.1
1Eine Schatzfunktion µ ist erwartungtreu wenn E(µ) = µ, in diesem Fall liegen wir mit un-seren Schatzungen zumindest im Mittel richtig. Effiziente Schatzfunktionen sind varianzminimal,d.h. sie sind genauer als alle anderen linearen erwartungstreuen Schatzfunktionen. KonsistenteSchatzfunktionen werden mit zunehmender Stichprobengroße immer genauer und konvergierenmit zunehmender Stichprobengroße n gegen den wahren Wert µ. Fur die Konsistenz werden meistweniger strenge Annahmen benotigt als fur die Effizienz.

Angewandte Okonometrie 3
Von besonderer Bedeutung ist, dass Schatzfunktionen in der Regel durch irgendeineForm von Mittelung uber insgesamt n Zufallsvariablen xi berechnet werden. Fallsdiese n Zufallsvariablen einige Bedingungen erfullen, z.B. i.i.d. verteilt sind (haufigreichen weniger strenge Bedingungen), sind Gesetze der großen Zahl anwendbar. Insolchen Fallen kann man zeigen, dass diese Schatzfunktionen konsistent sind, alsomit zunehmender Stichprobengroße genauer werden. Mindestens ebenso wichtig ist,dass unter relativ wenig strengen Annahmen haufig auch zentrale Grenzwertsatzegelten. Diese garantieren, dass (entsprechend skalierte) Stichprobenkennwertvertei-lungen von Schatzfunktionen mit zunehmender Stichprobengroße n gegen die Nor-malverteilung konvergieren, unabhangig davon, wie die Grundgesamtheit verteilt ist!Zentrale Grenzwertsatze sind im Prinzip immer anwendbar, wenn uber eine großeAnzahl von i.i.d. verteilten Zufallsvariablen gemittelt wird, wie dies bei praktisch al-len hier diskutierten Schatzfunktionen der Fall ist (haufig reichen dazu auch wenigerstrenge Annahmen als die i.i.d. Annahme).
Diese beiden stochastischen Gesetze bilden den Raketentreibstoff der induktivenStatistik.
5.2 Konfidenzintervalle
Bisher haben wir uns hauptsachlich mit Schatzfunktionen fur Regressionskoeffizien-ten beschaftigt. Diese OLS Schatzer sind Beispiele fur so genannte Punktschatzer,sie ordnen jeder moglichen Stichprobe einen Punkt auf der Zahlengerade zu.
Wenn die Gauss-Markov Annahmen erfullt sind kann man zeigen, dass diese OLSSchatzer effizient sind, d.h. sie bieten in der Klasse der linearen erwartungstreuenSchatzfunktionen die ‘großtmogliche Genauigkeit’ (sie sind ‘BLUE’).
Eine solche ‘großtmogliche Genauigkeit’ ist zwar beruhigend, aber ‘großtmoglich’sagt wenig daruber aus, wie prazise die Schatzung tatsachlich ist. Wenn wir aufGrundlage unserer Schatzungen Entscheidungen treffen mussen wollen wir vermut-lich wissen, inwieweit wir den Schatzungen ‘vertrauen’ konnen, bzw. wie genau siesind.
Die bisher verwendeten Punktschatzer, wie z.B. µ oder β2, konnen uns diese In-formation nicht liefern, sie geben keine Hinweise daruber, wie ‘nahe’ sie beim wah-ren Wert liegen, bzw. wie prazise sie sind, und tauschen damit moglicherweise eineScheingenauigkeit vor.
Wir werden in diesem Kapitel zeigen, dass wir mit Hilfe der Punktschatzer undderen Standardfehler ein Intervall berechnen konnen, das zusatzlich den Stichpro-benfehler2 (‘sampling error’ ) berucksichtigt, und uns damit etwas uber die ‘Vertrau-enswurdigkeit’ einer Schatzung verrat.
Allerdings benotigen wir dazu eine zusatzliche Annahme, namlich dass die entspre-chende Stichprobenkennwertverteilung (zumindest annahernd) normalverteilt ist.3
2In der deutschen Literatur werden ‘Standardfehler’ und ‘Stichprobenfehler’ manchmal syn-onym verwendet. Hier verstehen wir unter dem Stichprobenfehler etwas salopp den Fehler, der beider Schatzung eines Parameters durch wiederholte Stichprobenziehungen aus der gleichen Grund-gesamtheit entsteht.
3Genau genommen mussen wir nur die theoretische Stichprobenkennwertverteilung der

Angewandte Okonometrie 4
Wenn eine Zufallsvariable X mit Erwartungswer µ und Varianz σ2 normalverteiltist schreiben wir dies4
X ∼ N(µ, σ2)
Die Normalverteilungsannahme ist nicht ganz so restriktiv wie sie auf den erstenBlick erscheinen mag. Einerseits sind die Storterme vieler datengenerierender Pro-zesse tatsachlich annahernd normalverteilt, vor allem aber stellen zentrale Grenz-wertsatze unter nicht allzu strengen Annahmen sicher, dass die Stichprobenkenn-wertverteilungen (‘sampling distributions’ ) ziemlich rasch gegen eine Normalvertei-lung konvergieren, und deshalb zumindest asymptotisch gultig bleiben.
Die Rolle der Normalverteilung
Aufgrund zentraler Grenzwertsatze konnen wir also darauf vertrauen, dass Stich-probenkennwerte wie z.B. µ oder β in hinreichend großen Stichproben zumindestannahernd normalverteilt sind, egal wie die Verteilung der Grundgesamtheit aus-sieht. Dies erklart u.a. die herausragende Rolle der Normalverteilung in der induk-tiven Statistik.
Die Normalverteilung hat zudem einige weitere sehr angenehme Eigenschaften, dieunser Leben wesentlich vereinfachen. Eine dieser Eigenschaften ist die Reprodukti-vitat, d.h. jede Linearkombination (lineare Funktion) von n normalverteilten Zufalls-variablen Xi ist selbst wieder normalverteilt.
Wenn z.B. Xi ∼ N(µi, σ2Xi) mit i = 1, . . . , n, dann ist eine Linearkombination Y =
c0 + c1X1 + · · ·+ cnXn (fur konstante ci) auch wieder normalverteilt.
Aufgrund dieser Eigenschaft sind z.B. lineare Schatzfunktionen bei normalverteiltenGrundgesamtheiten auch normalverteilt. Da aber kaum noch jemand an normalver-teilte Grundgesamtheiten glaubt verlassen wir uns in dieser Hinsicht lieber auf denzentralen Grenzwertsatz.
Aber die Reproduktionseigenschaft ist hier aus einem anderen Grund von Bedeu-tung, sie erlaubt uns jede beliebige normalverteilte Zufallsvariable X mit Erwar-tungswert µ und Varianz σ2
X , d.h. X ∼ N(µ, σ2X) in eine standardnormalverteilte
Zufallsvariable Z ∼ N(0, 1) mit Erwartungswert Null und Varianz Eins zu transfor-mieren, das heißt, fur X ∼ N(µ, σ2
X)
Z =X − µ
σX
→ Z ∼ N(0, 1)
Diese sogenannte z-Transformation ist in Abbildung 5.2 dargestellt.
Schatzfunktion kennen, diese muss nicht unbedingt die Normalverteilung sein. Wir werden spaterein Beispiel zeigen, in dem die theoretische Stichprobenkennwertverteilung eine χ2 Verteilung ist.Die folgenden Uberlegungen gelten vollig analog auch fur andere Verteilungen, wir beschrankenuns hier nur aus Grunden der Einfachhheit auf die Normalverteilung.
4Wenn Storterme nicht nur εi ∼ i.i.d.(0, σ2) sind, sondern zusatzlich normalverteilt sind, wirddies haufig geschrieben als
εi ∼ n.i.d.(0, σ2)
wobei n.i.d. fur ‘normally and independent distributed’ steht (das identically folgt automatischaus der Normalverteilungsannahme mit identischen Erwartungswerten und Varianzen). Die obigeSchreibweise εi ∼ N(0, σ2) impliziert nicht notwendigerweise Unabhangigkeit, aber wenn nichtausdrucklich auf darauf hingewiesen wird, wird im Folgenden auch Unabhangigkeit (d.h. E(εiεj) =0 fur i 6= j) angenommen.

Angewandte Okonometrie 5
0.2
0.4
0.6
0.8
0 1 2 3−1−2−3
f(x)
x
µ1 = 1.5
σ1 = 0.5
µ1
µ2 = −2
σ2 = 0.4
µ2 µ3
0.2
0.4
0 1 2 3−1−2−3
f(z)
StandardisierteVerteilung:
Z = Xk−µk
σk, k = 1, 2, 3
µZ = 0σZ = 1
z
Flache:(1− α) = 0.95
α/2 = 0.025 α/2 = 0.025
−1.96 +1.96
Abbildung 5.2: Normalverteile Zufallsvariablen X1, X2, X3 mit unterschiedlichenErwartungswerten und Varianzen konnen standardisiert werdenzu Z ∼ N(0, 1).Der kritische Wert fur α = 0.025 ist z0.025 = 1.96.

Angewandte Okonometrie 6
Von standardnormalverteilten Zufallsvariablen wissen wir, dass 95% aller Realisa-tionen in das Intervall [−1.96, +1.96] fallen werden. Da die Flache unter jederDichtefunktion Eins ist folgt daraus, dass 2.5% der Realisationen links von −1.96und 2.5% der Realisationen rechts von +1.96 erwartet werden, in Summe also 5%.
Jenen Wert, bei dem links und rechts eine Flache von je α/2 abgeschnitten wird, nen-nen wir den kritischen Wert ; fur die Standardnormalverteilung also zcritα/2=0.025 = 1.96;
und α wird Signifikanzniveau genannt (α/2 = 0.025 da links und rechts 2.5% derFlache abgeschnitten werden, vgl. Abbildung 5.2). Fur andere Signifikanzniveausund Verteilungen konnen die kritischen Werte in einer entsprechenden Tabelle nach-geschlagen oder mit Hilfe der Quantilfunktion berechnet werden.
Wir fassen also zusammen: wenn eine Zufallsvariable
X ∼ N(µ, σ2X)
gilt fur diese folgende Wahrscheinlichkeitsaussage
Pr
(−1.96 ≤ X − µ
σX≤ +1.96
)= 0.95 (5.1)
In dieser Form sagt uns diese Wahrscheinlichkeitsaussage, dass wir bei wiederholterDurchfuhrung des Zufallsexperiments erwarten konnen, dass 95% der Realisationenvon Z = (X − µ)/σX in das Intervall [−1.96,+.196] fallen werden.
Wir konnen obige Wahrscheinlichkeitsaussage einfach umschreiben zu
Pr [µ− 1.96 σX ≤ X ≤ µ+ 1.96 σX ] = 0.95
Man beachte, dass hier die Intervallgrenzen µ± 1.96 σX feste Zahlen sind, da µ undσX Parameter der Grundgesamtheit sind.
5.2.1 Das Grundprinzip von Konfidenzintervallen
Am einfachsten versteht man ein Konfidenzintervall, wenn wir Gleichung (5.1) soumschreiben, dass der unbekannte (Lage-) Parameter µ im Zentrum und die Zufalls-variable X in der Unter- und Obergrenze steht, namlich5
Pr [X − 1.96 σX ≤ µ ≤ X + 1.96 σX ] = 0.95
Da nun die die beiden Intervallgrenzen Zufallsvariablen sind andert sich die Wahr-scheinlichkeitsaussage: bei unendlich vielen Wiederholungen des zugrunde liegendenZufallsexperiments konnen wir damit rechnen, dass in 95% der Falle das ‘wahre’ µzwischen den beiden stochastischen Intervallgrenzen liegt.
5Ausgehend von Gleichung (5.1)
Pr (−1.96σX ≤ X − µ ≤ +1.96σX) = 0.95
Pr (−X − 1.96σX ≤ −µ ≤ −X + 1.96σX) = 0.95 /× (−1)
Pr (X + 1.96σX ≥ µ ≥ X − 1.96σX) = 0.95
Pr (X − 1.96σX ≤ µ ≤ X + 1.96σX) = 0.95

Angewandte Okonometrie 7
Oder in anderen Worten, wenn die Annahme X ∼ N(µ, σ2X) erfullt ist wird das
stochastische Intervall in 95% der Wiederholungen das ‘wahre’ µ uberdecken. Diesgilt fur eine einzelne Zufallsvariable X .
Wir interessieren uns aber in den allermeisten Fallen aber nicht fur einzelne Zu-fallsvariablen, sondern fur Schatzfunktionen. Wenn diese, wie OLS Schatzer, diegewichtete Summe von Zufallsvariablen sind, konnen diese Ideen leicht ubertragenwerden werden.
Ein Konfidenzintervall fur den Mittelwert
Am einfachsten kann man dies fur den einfachen Mittelwert zeigen. Wir erinnernuns, dass die Schatzfunktion µ fur den Mittelwert µ bereits eine OLS Schatzfunktionist, d.h., der Mittelwert kann alternativ auch mit Hilfe einer OLS Regression auf dieRegressionskonstante berechnet werden.
Wenn wir nun davon ausgehen, dass fur jede von insgesamt n Zufallsvariablen Xi
(mit i = 1, . . . , n) giltXi ∼ N(µ, σ2
X)
dann wissen wir bereits, dass Schatzfunktion fur den Mittelwert die gewichtetenSumme ist
µ =1
n
n∑
i=1
Xi
Aus der einfuhrenden Statistik ist bekannt, dass der Erwartungswert und die Varianzdieser Schatzfunktion einfach berechnet werden konnen6
E(µ) = µ
σ2µ := var(µ) =
σ2X
n
Selbst wenn die einzelnen Xi nicht normalverteilt sind wissen wir, dass aufgrund deszentralen Grenzwertsatzes die Stichprobenkennwertverteilung von µ mit zunehmen-der Stichprobengroße gegen die Normalverteilung konvergiert (zumindest wenn dieXi ∼ i.i.d.(µ, σ2), aber haufig reichen dazu weniger strenge Annahmen).
Wir fassen also zusammen
µ ∼ N(µ, σ2
µ
)(mit σ2
µ =σ2X
n)
Nun konnen wir das exakt gleiche Spiel von oben fur die Schatzfunktion des Mit-telwertes wiederholen, fur die standardisierte (d.h. z-transformierte) Zufallsvariablegilt die Wahrscheinlichkeitsaussage (fur α = 0.05)
Pr
(−1.96 ≤ µ− µ
σµ≤ +1.96
)= 0.95
6Fur Xi ∼ i.i.d.(µ, σ2X) gilt E( 1
n
∑Xi =
1n [E(X1) + · · ·+ E(Xn)] =
1n [µ+ · · ·+ µ] = 1
n nµ = µundvar[ 1n
∑Xi] =
1n2 [var(X1)+ · · ·+var(Xn)] =
1n2 [σ
2X + · · ·+σ2
X ] = nn2σ
2X =
σ2
X
n wenn var(Xi) = σ2X
fur i = 1, . . . , n und cov(Xi, Xj) = 0 fur i 6= j, d.h. wenn Xi ∼ i.i.d.(µ, σ2X).

Angewandte Okonometrie 8
Im Unterschied zu Gleichung (5.1) untersuchen wir hier nicht eine einzelne Zufalls-variable X ∼ N(µ, σ2
X), sondern die Schatzfunktion µ des arithmetischen Mittels,dessen Standardfehler σµ = σX/
√n ist.
Genau gleich wie fruher schreiben wir dies um, so dass der unbekannte Parameterim Zentrum und die Zufallsvariable µ in den Intervallgrenzen steht (vgl. Fußnote 5)
Pr (µ− 1.96 σµ < µ < µ+ 1.96 σµ) = 0.95
Das bedeutet, dass wir bei wiederholten Stichprobenziehungen damit rechnenkonnen, dass in 95% der Falle die Realisationen der beiden stochastischen Inter-vallgrenzen den wahren und unbeobachtbaren Kennwert µ uberdecken werden.
In anderen Worten, die beiden Intervallgrenzen werden derart bestimmt, dass beigenau 95% aller moglichen Realisationen der wahre Kennwert µ zwischen diesenIntervallgrenzen liegt).
Diese beiden stochastischen Intervallgrenzen bilden ein einfaches theoretisches Kon-fidenzintervall
[µ− 1.96 σµ, µ+ 1.96 σµ] (5.2)
und wie wir gerade gesehen haben handelt es sich dabei nur um eine Umformulierungder ursprunglichen Wahrscheinlichkeitsaussage.
Allerdings hilft uns diese Wahrscheinlichkeitsaussage noch nicht wirklich weiter,denn sie enthalt den in der Regel unbeobachtbaren Parameter σµ = σX/
√n, wobei
σX die Standardabweichung der einzelnen Zufallsvariablen Xi ist.
Eine technische Komplikation – mit einer einfachen Losung
Da unser Konfidenzintervall noch die unbeobachtbare Standardabweichung σµ =σX/
√n enthalt konnen wir es nicht unmittelbar berechnen.
Die naheliegende Idee ist naturlich, dieses Standardabweichung σ aus der Stichprobezu schatzen. Eine Schatzfunktion σX dafur haben wir bereits im letzten Kapitelkennen gelernt (wie ublich kennzeichnen wir die Schatzfunktion als Zufallsvariablemit einem Dach uber dem Symbol des Parameters)
σX =
√1
n− 1
∑
i
(Xi − µ)2
Wenn wir allerdings den Parameter σX mit dessen Schatzfunktion σX ersetzen fuhrtdies zu neuen Problemen, denn die Schatzfunktion σX ist im Gegensatz zu σX eineZufallsvariable mit einer eigenen Stichprobenkennwertverteilung.
Deshalb istµ− µ
σX√n
≁ N(0, 1)
das Verhaltnis zweier Zufallsvariablen, und diese neue Zufallsvariable ist nicht nor-malverteilt!
Fur dieses Problem hat glucklicherweise W.S. Gosset (1908), damals Chef-Braumeister der Guinness Brauerei, schon vor mehr als hundert Jahren eine einfache
Angewandte Okonometrie 9
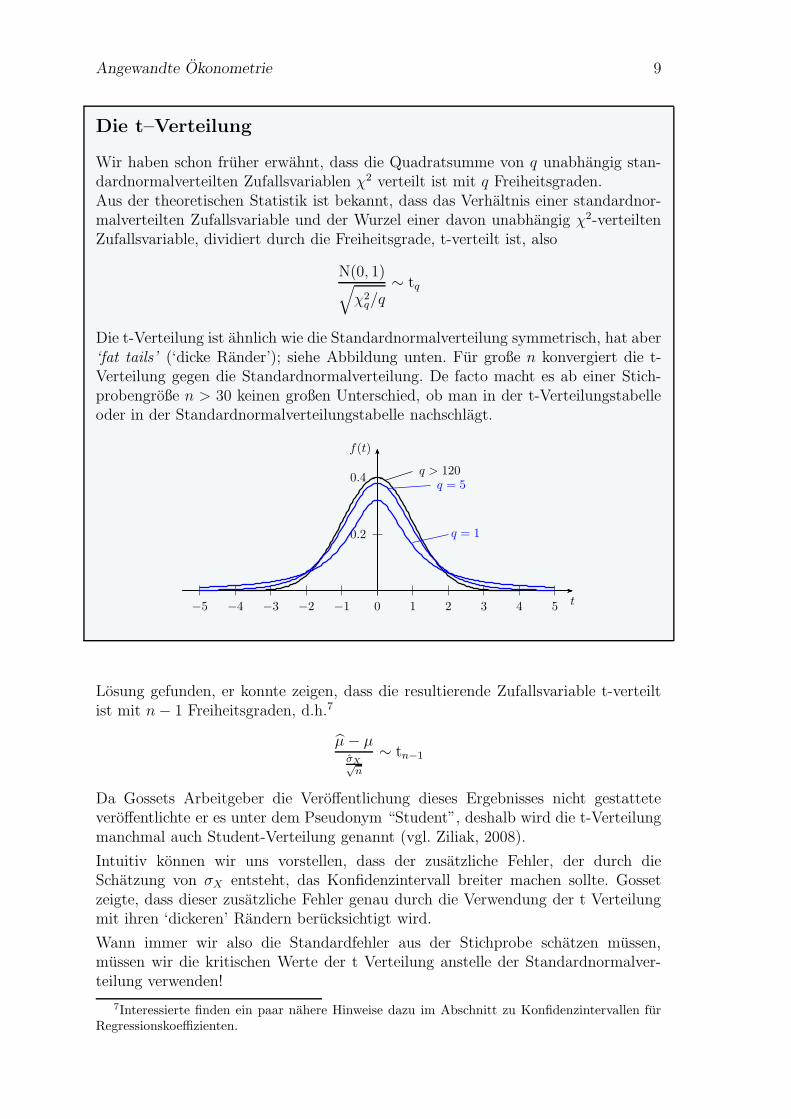
Die t–Verteilung
Wir haben schon fruher erwahnt, dass die Quadratsumme von q unabhangig stan-dardnormalverteilten Zufallsvariablen χ2 verteilt ist mit q Freiheitsgraden.Aus der theoretischen Statistik ist bekannt, dass das Verhaltnis einer standardnor-malverteilten Zufallsvariable und der Wurzel einer davon unabhangig χ2-verteiltenZufallsvariable, dividiert durch die Freiheitsgrade, t-verteilt ist, also
N(0, 1)√χ2q/q
∼ tq
Die t-Verteilung ist ahnlich wie die Standardnormalverteilung symmetrisch, hat aber‘fat tails’ (‘dicke Rander’); siehe Abbildung unten. Fur große n konvergiert die t-Verteilung gegen die Standardnormalverteilung. De facto macht es ab einer Stich-probengroße n > 30 keinen großen Unterschied, ob man in der t-Verteilungstabelleoder in der Standardnormalverteilungstabelle nachschlagt.
0.2
0.4
0 1 2 3 4 5−1−2−3−4−5 t
f(t)
q > 120
q = 1
q = 5
Losung gefunden, er konnte zeigen, dass die resultierende Zufallsvariable t-verteiltist mit n− 1 Freiheitsgraden, d.h.7
µ− µσX√n
∼ tn−1
Da Gossets Arbeitgeber die Veroffentlichung dieses Ergebnisses nicht gestatteteveroffentlichte er es unter dem Pseudonym “Student”, deshalb wird die t-Verteilungmanchmal auch Student-Verteilung genannt (vgl. Ziliak, 2008).
Intuitiv konnen wir uns vorstellen, dass der zusatzliche Fehler, der durch dieSchatzung von σX entsteht, das Konfidenzintervall breiter machen sollte. Gossetzeigte, dass dieser zusatzliche Fehler genau durch die Verwendung der t Verteilungmit ihren ‘dickeren’ Randern berucksichtigt wird.
Wann immer wir also die Standardfehler aus der Stichprobe schatzen mussen,mussen wir die kritischen Werte der t Verteilung anstelle der Standardnormalver-teilung verwenden!
7Interessierte finden ein paar nahere Hinweise dazu im Abschnitt zu Konfidenzintervallen furRegressionskoeffizienten.

Angewandte Okonometrie 10
Mit Hilfe dieses Ergebnisses kann nun einfach das Konfidenzintervall fur den Mit-telwert berechnet werden.
5.2.2 Ein Konfidenzintervall fur den Mittelwert bei unbe-kanntem σX
Die Bestimmung des Konfidenzintervalls ist nun einfach: falls wir den Standardfeh-ler aus der Stichprobe schatzen mussen brauchen wir nur den kritischen Wert derNormalverteilung durch den kritischen Wert der t-Verteilung ersetzen.
Fur
σµ :=σX√n
gilt deshalb die folgende Wahrscheinlichkeitsaussage
Pr
[−tcritα/2,df ≤ µ− µ
σµ≤ +tcritα/2,df
]= 1− α
(vergleichen Sie dies mit der Wahrscheinlichkeitsaussage in Gleichung (5.1, Seite 6).
Wie fruher schreiben wir dies um, sodass der Parameter µ im Zentrum und dieZufallsvariablen µ und σ in den Intervallgrenzen stehen
Pr[µ− tcritα/2,df · σµ ≤ µ ≤ µ+ tcritα/2,df · σµ
]= 1− α
Dies definiert die untere und obere Grenze des (1 − α)× 100 Prozent Konfidenzin-tervalls fur die Schatzfunktion des Mittelwerts µ
[µ− tcritα/2,df · σµ, µ+ tcritα/2,df · σµ
]
Dabei bezeichnet tcritα/2,df den kritischen Wert der t-Verteilung mit df Freiheitsgraden
(fur ‘degrees of freedom’ ). Diesen konnen wir in einer t–Tabelle nachschlagen, siehez.B. Tabelle 5.1.
Wenn wir z.B. 20 Beobachtungen haben und ein 95% Vertrauensintervall berechnenwollen benotigen wir den Bereich der Dichtefunktion, uber dem die Flache den Wert0.95 hat. Diesen Bereich erhalten wir, indem wir links und rechts 2.5% der Flache‘abschneiden’. In unserem Beispiel mussen wir also in Tabelle 5.1 bei α/2 = 0.025,und da wir 20 Beobachtungen haben bei n−1 = 19 Freiheitsgraden nachschlagen; wirerhalten den kritischen Wert +tcrit0.025,19 = 2.093, d.h. wir konnen darauf vertrauen,dass 5% aller moglichen Realisationen in den Bereich links von −tcrit0.025,19 = −2.093und rechts von +tcrit0.025,19 = 2.093 fallen werden, und 95% aller Realisationen in denVertrauensbereich dazwischen.
Bislang haben wir uber Zufallsvariablen gesprochen, also uber alle moglichen Ergeb-nisse des Zufallsexperiments (in unserem Fall Stichprobenziehungen).
Tatsachlich beobachten wir nur eine einzige Stichprobe, und berechnen aus dieserStichprobe eine einzige Realisation der Zufallsvariablen, d.h. ein empirisches Kon-fidenzintervall.

Angewandte Okonometrie 11
Tabelle 5.1: Tabelle: t(q)-Verteilung (rechts-seitig)
q α = 0.1 α = 0.05 α = 0.025 α = 0.01 α = 0.005
1 3.078 6.314 12.706 31.821 63.6572 1.886 2.920 4.303 6.965 9.9253 1.638 2.353 3.182 4.541 5.841...
......
......
...19 1.328 1.729 2.093 2.539 2.86120 1.325 1.725 2.086 2.528 2.84530 1.310 1.697 2.042 2.457 2.75040 1.303 1.684 2.021 2.423 2.70460 1.296 1.671 2.000 2.390 2.660∞ 1.282 1.645 1.960 2.327 2.576
Dazu benotigen wir die Realisation von µ, also den Mittelwert x, sowie die Realisa-tion des Standardfehlers s
x =1
n
n∑
i=1
xi und s =
√√√√ 1
n− 1
n∑
i=1
(xi − x)2
Damit konnen wir das empirische Konfidenzintervall (d.h. die empirische Realisationdes Konfidenzintervalls) fur eine gegebene Stichprobe berechnen
[x− tcritα/2,df
s√n, x+ tcritα/2,df
s√n
]
Hinweis: Beachten Sie, dass Sie sowohl fur die Berechnung des Standardfehlers sals auch fur den kritischen t–Wert die Freiheitsgrade benotigen; in diesem Fall istdf = n− 1.
Ein Beispiel: Wir haben die Korpergroße von 98 TeilnehmerInnen einer Lehrver-anstaltung erhoben. Wir wollen annehmen, dass diese Gruppe unsere interessieren-de Grundgesamtheit bildet. In diesem Sonderfall kennen wir die wahren Werte, diedurchschnittliche Korpergroße aller TeilnehmerInnen ist µ = 173.33, und die Varianzder Korpergroße ist σ2
X = 198
∑98i=1(xi − x)2 = 86.95 (bzw. σX = 9.28). Die durch-
schnittliche Korpergroße aller Studierenden µ und die Varianz σ2X sind fixe — aber
in der Regel unbekannte – Parameter. Das Histogramm fur diese Grundgesamtheitfinden Sie in Abbildung 5.3.
Angenommen eine Forscherin kennt die Werte dieser Grundgesamtheit nicht undbeschließt deshalb auf eigene Faust eine Zufallsstichprobe mit 20 Personen zu ziehen.Sie erhalt folgende 20 Messungen fur die Korpergroßen (in cm): {186, 162, 165, 183,170, 160, 170, 185, 165, 160, 175, 163, 185, 167, 178, 159, 165, 171, 175, 167} undberechnet aus dieser Stichprobe den Mittelwert
x =1
20
20∑
i=1
xi = 170.55
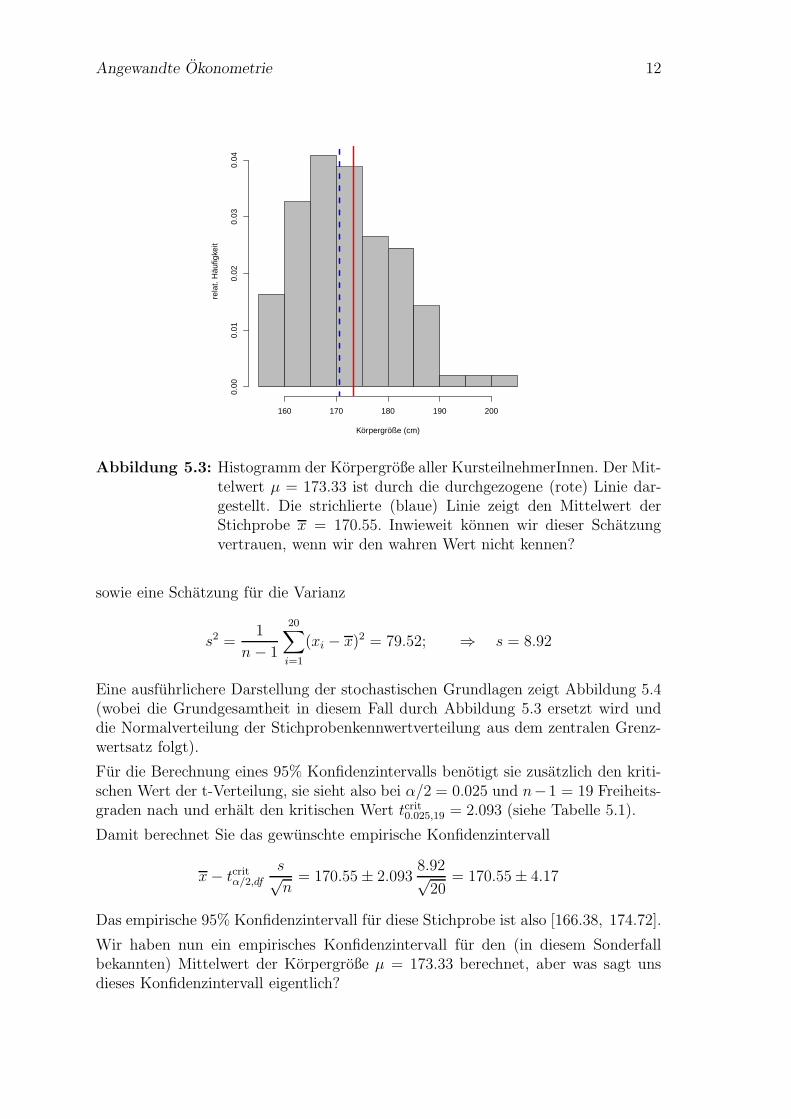
Angewandte Okonometrie 12
Körpergröße (cm)
rela
t. H
äufig
keit
160 170 180 190 200
0.00
0.01
0.02
0.03
0.04
Abbildung 5.3: Histogramm der Korpergroße aller KursteilnehmerInnen. Der Mit-telwert µ = 173.33 ist durch die durchgezogene (rote) Linie dar-gestellt. Die strichlierte (blaue) Linie zeigt den Mittelwert derStichprobe x = 170.55. Inwieweit konnen wir dieser Schatzungvertrauen, wenn wir den wahren Wert nicht kennen?
sowie eine Schatzung fur die Varianz
s2 =1
n− 1
20∑
i=1
(xi − x)2 = 79.52; ⇒ s = 8.92
Eine ausfuhrlichere Darstellung der stochastischen Grundlagen zeigt Abbildung 5.4(wobei die Grundgesamtheit in diesem Fall durch Abbildung 5.3 ersetzt wird unddie Normalverteilung der Stichprobenkennwertverteilung aus dem zentralen Grenz-wertsatz folgt).
Fur die Berechnung eines 95% Konfidenzintervalls benotigt sie zusatzlich den kriti-schen Wert der t-Verteilung, sie sieht also bei α/2 = 0.025 und n−1 = 19 Freiheits-graden nach und erhalt den kritischen Wert tcrit0.025,19 = 2.093 (siehe Tabelle 5.1).
Damit berechnet Sie das gewunschte empirische Konfidenzintervall
x− tcritα/2,df
s√n= 170.55± 2.093
8.92√20
= 170.55± 4.17
Das empirische 95% Konfidenzintervall fur diese Stichprobe ist also [166.38, 174.72].
Wir haben nun ein empirisches Konfidenzintervall fur den (in diesem Sonderfallbekannten) Mittelwert der Korpergroße µ = 173.33 berechnet, aber was sagt unsdieses Konfidenzintervall eigentlich?

Angew
andte
Okonometrie
13
Schatzung von Mittelwerten
Grundgesamtheit
0
0.1
0.2
0.3
0.4
x
f(x)
µ
Zustande vor dem Zufallsexperiment (ex ante) sind nicht beobachtbar!
Z U F A L L S E X P E R I M E N T
Nach dem Zufallsexperiment (ex post) existiert kein Zufall (Realisationen)!
x1 x2 . . . xi . . . xn
Stichprobe (n Realisationen)
X1 ∼ i.i.d.(µ1, σ21)
...
Xi ∼ i.i.d.(µi, σ2i )
...
Xn ∼ i.i.d.(µn, σ2n)
...
n → ∞ . . . Asymptotik
n Zufallsvariablen;identisch & unabhangig verteilt?
(d.h. µ1 = · · · = µn = µ
und σ1 = · · · = σn = σ)
µ = 1n
∑ni=1Xi
Schatz-funktion
E(µ) = µ
var(µ) = σ2
n
Stichprobenkenn-wertverteilung
µb
µ
f(µ)
|
x = 1n
∑ni=1 xi
var(x) =∑
i(xi−x)2
n−1Schatzung (Zahl)
0| bc
x
nicht
beoba
chtbar
indu
ktiv
(Theorie)
deskriptiv
(Empirie)
c©H. Stocker
beobachtbarnicht
beobachtbar
Abbild
ung5.4:Schatzu
ng
eines
Mittelw
ertes,z.B
.der
durch
schnittlich
enKorp
ergroße.

Angewandte Okonometrie 14
5.2.3 Interpretation von empirischen Konfidenzintervallen
Als Jerzy Neyman seine Idee mit den Konfidenzintervallen 1934 erstmals der RoyalStatistical Society vorstellte stieß er nicht auf ungeteilte Begeisterung. Nach demublichen Dank brachte der Chair der Sitzung seine Skepsis zum Ausdruck:
“I am not certain whether to ask for an explanation or to cast a doubt.[. . . ] I am referring to Dr. Neyman’s confidence limits. I am not at allsure that the ‘confidence’ is not a ‘confidence trick’. [. . . ] The statementof the theory is not convincing, and until I am convinced I am doubtfulof its validity.” (Salsburg, 2002, 121)
Die Zweifel des Chairs sind naturlich langst ausgeraumt, aber vielen, die erstmalsmit Konfidenzintervallen konfrontiert werden, geht es ahnlich.
Die anfangliche Verwirrung ruhrt vermutlich daher, dass wir eine Realisation beob-achten, d.h. ein empirisches Konfidenzintervall, fur die Interpretation aber auf diezugrunde liegende Zufallsvariable Bezug nehmen mussen, d.h. auf das theoretischeKonfienzintervall.
Wenn wir auf Grundlage der einen vorliegenden Stichprobe die empirischen Realisa-tionen von x und s verwenden um eine Realisation der unteren und oberen Intervall-grenze des empirischen Konfidenzintervalls zu berechnen, erhalten wir Realisationen,also einfache Zahlen. Da auch der unbekannte Parameter µ eine einfache Zahl istkonnen wir daruber naturlich keine Zufallsaussage treffen.
Die haufig gehorte (und falsche!) Aussage: “ein empirisches Konfidenzintervall gibtden Bereich an, in dem das wahre µ mit 95% Wahrscheinlichkeit liegt” ebenso un-sinnig wie die Behauptung, “die Zahl 170 liegt mit einer Wahrscheinlichkeit von 95%zwischen den Zahlen 150 und 190”.
Wahrscheinlichkeitsaussagen beziehen sich naturlich nie auf Realisationen, sondernauf die zugrunde liegenden Zufallsvariablen, das heißt, um zu einer Wahrscheinlich-keitsaussage zu kommen mussen wir gewissermaßen hinter das Zufallsexperimentzuruck auf die abstrakte Ebene der Zufallsvariablen gehen und unser theoretischesWissen nutzen.
In den meisten Fallen kann man sich dies mit Hilfe der Vorstellung eines (‘repeatedsampling’ ) veranschaulichen: Wenn wir sehr viele Stichproben ziehen wurden undfur jeder dieser Stichproben ein empirisches Konfidenzintervall berechnen wurden,so konnten wir darauf vertrauen, dass z.B. 95% dieser Konfidenzinteravlle das wahreµ uberdecken wurden.
Diese Idee ist in Abbildung 5.5 dargestellt. Diese Abbildung zeigt eine Stichproben-kennwertverteilung sowie sieben Realisationen von empirischen Konfidenzinterval-len, die auf sieben verschiedenen Stichproben beruhen.
Das einzige, was die Forscherin normalerweise beobachten kann, ist ein einzigesdieser sieben empirischen Konfidenzintervalle, z.B. das erste. Der komplette Rest(alles, was in dieser Grafik 5.5 blau eingezeichnet ist) kann nicht direkt beobachtetwerden, dies konnen wir nur aus abstrakten Uberlegungen schließen!
Tatsachlich hat die Forscherin keine Moglichkeit zu erkennen, wo das wahre µ liegt.Offensichtlich uberdeckt in Abbildung 5.5 das erste Konfidenzintervall den wahren

Angewandte Okonometrie 15
f(µ)
µ
Vertrauens-bereich(1− α) α/2α/2
µbc
bc
bc
bc
bc
bc
bc
x1
x2
x3
x4
x5
x6
x7
Wiederholte
Stichproben
ziehungen
(7Realisation
en)
Stichprobenkennwertverteilungvon µ um wahres µ
x1, . . . , x7 sind unterschiedl. Realisationen von µ
Abbildung 5.5: ‘Wahres’ µ und Konfidenzintervalle fur 7 verschiedene Stichpro-ben. In der praktischen Arbeit beobachten wir nur eine einzigeStichprobe und deshalb nur eine einzige Realisation eines Konfi-denzintervalls. Alles, was in dieser Grafik blau eingezeichnet ist,konnen wir nicht direkt beobachten, dies folgt aus der Theo-rie der Stichprobenkennwertverteilungen. Diese sagt uns, dass(1− α)100% aller hypothetischen Konfidenzintervalle bei wieder-holten Stichprobenziehungen das wahre µ uberdecken.Obwohl wir nie sicher sein konnen, ob unser beobachtetes Konfi-denzintervall den wahren Wert µ uberdeckt, gibt uns die Breitedes Konfidenzintervalls wichtige Information uber die Genauig-keit der Schatzung!Quelle: nach Bleymuller (2012).

Angewandte Okonometrie 16
Wert; die Forscherin hat Gluck, aber sie hat keine Moglichkeit aus den Daten zuerkennen, ob dies wirklich gilt.
Nehmen wir an sie hatte zufallig die Stichprobe gezogen, die zu Konfidenzintervall5 fuhrt. Wie Sie in Abbildung 5.5 sehen uberdeckt das 5. Konfidenzintervall daswahre µ nicht. In diesem Fall hatte die Forscherin Pech, aber wiederum hatte siekeine Moglichkeit dies zu erkennen.
Aber wir konnen auf die Wahrscheinlichkeitsaussage mit den stochastischen Inter-vallgrenzen
Pr[µ− tcritα/2,df · σµ ≤ µ ≤ µ+ tcritα/2,df · σµ
]= 1− α
Bezug nehmen und im Sinne des repeated sampling interpretieren (fur α = 0.05):
Wenn wir – hypothetisch – unendlich viele Stichproben ziehen wurden,und fur jede dieser Stichproben ein 95% Konfidenzintervall berechnenwurden, so konnten wir darauf vertrauen, dass 95% dieser Konfidenzin-tervalle den wahren Wert µ uberdecken werden.8
Unsere Forscherin weiß zwar nicht, ob ihr empirisches Konfidenzintervall den wahrenWert µ uberdeckt, aber aufgrund der theoretischen Erkenntnisse kann sie davonausgehen, dass 95% (oder allgemeiner (1−α)× 100%) aller hypothetisch moglichenKonfidenzintervalle den wahren Wert uberdecken werden!
Auf den ersten Moment wirkt diese Aussage wenig hilfreich, wir haben nicht einmalzwei Stichproben, geschweige denn unendlich viele.
Was sollen wir also mit diesem Konfidenzintervall anfangen? Viele Anfanger sind ver-unsichert und frustriert, dass die Realisation des Konfidenzintervalls so wenig uberden wahren Parameter µ verrat, dass sie daruber den wesentlichen Punkt ubersehen,die Breite des Konfidenzintervalls !
Durch die Anwendung dieser Methode wird die Breite des Konfidenzintervalls der-art bestimmt, dass bei wiederholten Stichprobenziehungen genau (1 − α) × 100%aller hypothetisch moglichen Konfidenzintervalle den wahren Wert µ uberdeckenwerden. Damit wird die Breite des Konfidenzintervalls gewissermaßen zu einer en-dogenen Variable, die uns Auskunft uber den Stichprobenfehler gibt, also uber dieVertrauenswurdigkeit der Schatzung. Umso enger ein Konfidenzintervall ist, umsomehr werden wir der Schatzung vertrauen.
Konfidenzintervalle erlauben bei Gultigkeit der zugrunde liegenden Annahmen eineeinfache und unmittelbare Beurteilung der Genauigkeit und damit auch der Ver-trauenswurdigkeit einer Schatzung.
Aber benotigen wir dafur wirklich ein so aufwandiges Verfahren? Ja! Ein großerVorteil von Konfidenzintervallen besteht darin, dass sie nach einer festen und nach-vollziehbaren Regel berechnet werden, und dass alle Forscherinnen, die sich an die-ses Regelwerk halten, zu vergleichbaren Ergebnissen kommen. Sie gehoren deshalb
8Alternativ konnten wir auch sagen, dass das aus der nachsten – noch nicht gezogenen – Stich-probe berechnete 95% Konfidenzintervall mit 95% Wahrscheinlichkeit das wahre µ uberdeckenwird, aber diese Interpretation ist in diesem Zusammenhang weniger hilfreich.

Angewandte Okonometrie 17
langst zum unverzichtbaren Instrumentarium aller empirisch arbeitenden Wissen-schaftler.
Wir werden außerdem spater sehen, dass Konfidenzintervalle in einem sehr engenVerhaltnis zu Hypothesentests stehen, bzw. dass empirische Konfidenzintervalle auchfur Hypothesentests genutzt werden konnen.
Wovon hangt die Breite des Konfidenzintervalls ab?
Konfidenzintervalle erlauben die Beurteilung der Genauigkeit (Prazision) einerSchatzung. Sie werden nach einer transparenten und nachvollziehbaren Regel be-rechnet, und ermoglichen dadurch auch Vergleiche von Schatzungen. Ceteris pari-bus wird man in der Regel eine Schatzung mit einem engeren Konfidenzintervallbevorzugen.
Um zu erkennen, wovon die Breite des Konfidenzintervalls abhangt, mussen wir unsnur an die Determinanten des empirischen Konfidenzintervalls erinnern
x± tcritα/2,df
s√n
mit s =
√√√√ 1
n− 1
n∑
i=1
(xi − x)2
Daraus erkennen wir, dass die Breite des Konfidenzintervalls von der Stichproben-große n, vom frei gewahlten Konfidenzniveau 1−α (uber tcritα/2,df ) und von der Stan-
dardabweichung σ der Grundgesamtheit (die mit s geschatzt wird) abhangt.
Das Konfidenzintervall ist ceteris paribus umso enger, . . .
• je großer die Stichprobe ist, da dies zu einem kleineren Standardfehler desMittelwertes s/
√n fuhrt. Daruber hinaus fuhrt dies uber die Freiheitsgrade
auch zu einem kleineren kritischen Wert tcritα/2,df .
• umso kleiner der Standardfehler der Grundgesamtheit σ2 ist, die durch sgeschatzt wird.
• je kleiner das frei gewahlte Konfidenzniveau 1 − α ist (d.h. ein 90% Konfi-denzintervall ist ceteris paribus enger als ein 99% Konfidenzintervall9). DieserEffekt wirkt sich uber den kritischen Wert tcritα/2,df auf die Breite aus.
Konfidenzintervalle konnen naturlich nicht nur fur Mittelwerte berechnet werden,sondern auch fur Differenzen zwischen Mittelwerten, fur Anteile, und naturlich auchfur Regressionskoeffizienten.
5.2.4 Konfidenzintervalle fur einzelne Regressionskoeffizi-
enten
Die Berechnung von Konfidenzintervallen fur Regressionskoeffizienten funktioniertvollig analog wie fur den Mittelwert µ (der, wie wir bereits fruher gezeigt haben,
9Konfidenzintervalle, die nur in 90% der Falle den wahrenWert enthalten mussen, konnen ceterisparibus schmaler sein als Konfidenzintervalle, die in 99% der Falle den wahren Wert enthaltensollen.

Angewandte Okonometrie 18
ja auch mit Hilfe einer Regression auf die Regressionskonstante berechnet werdenkann).
Sei die PRF (population regression function)
yi = β1 + βhxi2 + · · ·+ βhxih + · · ·+ βkxik + εi
mit i = 1, . . . , n, h ∈ {1, . . . , k}, und βh eine erwartungstreue und normalverteilteSchatzfunktion fur den Parameter βh, dann gilt fur den standardisierten Koeffizien-ten
βh − βh
σβh
∼ N(0, 1)
mit
Pr
[−1.96 ≤ βh − βh
σβh
≤ +1.96
]= 0.95
Wenn wir den Standardfehler σβhbeobachten konnten, konnten wir daraus sofort
ein Konfidenzintervall berechnen. Da wir den Standardfehler aber wieder aus derStichprobe schatzen mussen, ist nach dem Resultat von Gosset (1908) die damitstandardisierte Zufallsvariable t-verteilt mit n − k Freiheitsgraden (k ist die Zahlder geschatzten Koeffizienten)
βh − βh
σβh
∼ tn−k
(beachten Sie das Dach bei σβhim Nenner, σβh
ist eine Zufallsvariable, σβhein
unbekannter Parameter!)
Daraus folgt wieder die Wahrscheinlichkeitsaussage
Pr[βh − tcritα/2,df · σβh
≤ βh ≤ βh + tcritα/2,df · σβh
]= 1− α
und das (1−α)× 100 Prozent Konfidenzintervall fur einen Regressionskoeffizientenh [
βh − tcritα/2,df σβh, βh + tcritα/2,df σβh
]
mit der Realisation, d.h. einem empirischen Konfidenzintervall
bh ± tcritα/2,df sβh
wobei sβhder geschatzte Standardfehler des Koeffizienten h ist.
Fur den Steigungskoeffizienten einer bivariaten Regression ist der empirische Stan-dardfehler z.B.
sβ2=
∑i e
2i
n−2∑i(xi − x)2
Diese Standardfehler werden von allen Regessionsprogrammen standardmaßig aus-gegeben.

Angewandte Okonometrie 19
Beispiel Im Kapitel zur deskriptiven Regressionsanalyse hatten wir ein Beispielmit den Stundenlohnen (StdL) und dem Geschlecht (m = 1 fur Manner und Nullsonst) von 12 Personen. Nun interpretieren wir diese Zahlen als Stichprobe aus einerunbekannten Grundgesamtheit. Das Ergebnis war
StdL = 12.5 + 2.5 m(0.747)*** (1.057)**
R2 = 0.359, s = 1.83, n = 12
(OLS Standardfehler in Klammern)
Wir erinnern uns, dass bei einer Regression auf eine Dummy Variable das Interzeptden Wert von y der Referenzkategorie angibt, und der Koeffizient der Dummy Va-riable den Unterschied zur Referenzkategorie misst. In diesem Beispiel ist also derdurchschnittliche Stundenlohn von Frauen 12.5 Euro, und Manner verdienen um 2.5Euro mehr.
Ein empirisches 95% Konfidenzintervall fur die Lohndifferenz erhalten wir mit demkritischen Wert der t-Verteilung fur α/2 = 0.025 und n− k = 12− 2 = 10 Freiheits-graden tcrit0.025,10 = 2.228 (siehe Tabelle 5.1, Seite 11)
2.5± 2.228 · 1.057 oder [0.145, 4.855]
Stata gibt die Konfidenzintervalle standardmaßig aus. Mit R konnen konnen sie mitder Funktion confint() berechnet werden
d <- read.csv2(url("http://www.uibk.ac.at/econometrics/data/stdl_bsp1.csv"))
eq <- lm(StdL ~ m, data = d)
confint(eq)
# 2.5 % 97.5 %
# (Intercept) 10.8350966 14.164903
# m 0.1454711 4.854529
Hinweis: Da in diesem Fall der Koeffizient von m einfach die Differenz zweier Mit-telwerte ist hatten wir auch mit t.test(d$StdL ~ d$m) einen Mittelwertvergleichdurchfuhren konnen (allerdings unterscheiden sich die Ergebnisse geringfugig, da Rfur den t.test() Welch’s Korrektur anwendet.
Beispiel 2: In einem fruheren Beispiel haben wir den Preis von Gebrauchtautosauf Alter und Kilometerstand regressiert.
Preis = 22649.88 − 1896.26 Alter − 0.031 km(411.87) (235.215) (0.008)
R2 = 0.907, n = 40
(Standardfehler in Klammern)

Angewandte Okonometrie 20
Die Koeffizienten weisen das erwartete Vorzeichen auf und haben die ubliche In-terpretation, z.B. sinkt der erwartete (gefittete) Preis bei konstanter km-Zahl jedesJahr um 1896.26 Euro.
Dies ist eine Punktschatzung, der uns nichts uber die Genauigkeit der Schatzungverrat. Um ein 95% Konfidenzintervall zu berechnen benotigen wir den kritischent-Wert, und um diesen nachschlagen zu konnen die Freiheitsgrade.
Wir haben insgesamt 40 Beobachtungen (n = 40) und drei geschatzte Koeffizienten(b1, b2 und b3), also n−k = 40−3 = 37 Freiheitsgrade. Tabelle 5.1 (Seite 11) gibt unsnur die die kritischen Werte fur 30 und 40 Freiheitsgrade, der kritische Wert fur 40Freiheitsgrade ware z.B. tcrit0.025,40 = 2.021. Wem dies zu ungenau ist kann mit Hilfe derQuantilfunktion eines geeigneten Programmes den genauen Wert tcrit0.025,37 = 2.0262berechnen.10
Die Realisation des 95% Konfidenzintervalls fur das Alter ist also
[−1896.26− 2.0262 ∗ 235.215; −1896.26 + 2.0262 ∗ 235.215]bzw. [−2372.854; −1419.674].
Fur ein 99% Konfidenzintervall ware der kritische Wert tcrit0.005,37 = 2.715409 großer,das Konfidenzintervall also breiter [−2534.968; −1257.56].
Die Realisation des 95% Konfidenzintervalls fur km ist [−0.04695; −0.01507].
Wieder mit R:
df <- read.csv2(url("http://www.hsto.info/econometrics/data/auto40.csv"))
eq1 <- lm(Preis ~ Alter + km, data = df)
confint(eq1, level = 0.99)
# 0.5 % 99.5 %
# (Intercept) 2.153149e+04 2.376828e+04
# Alter -2.534968e+03 -1.257560e+03
# km -5.236829e-02 -9.652361e-03
(man beachte, dass e+04 eine Kurzschreibweise fur 104 ist, d.h. 2.1531e+04=2.153149× 104 = 2.153149× 10000 = 21531.49)
Konfidenzellipsen fur zwei Regressionskoeffizienten
Die Idee von Konfidenzintervallen kann auch auf zwei Regressionsoeffizienten ver-allgemeinert werden, Abbildung 5.6 zeigt eine solche fur die beiden Koeffizientenvon Alter und km des vorhergehenden Beispiels. Die Interpretation ist vollig ana-log zu fruher, bei wiederholten Stichprobenziehungen wurden wir erwarten, dass(1− α) ∗ 100 Prozent der daraus berechneten Konfidenzellipsen das wahre Koeffizi-entenpaar (β2, β3) uberdecken wurden.
Wir werden im Abschnitt uber Hypothesentests auf die Idee der Konfidenzellipsenzuruck kommen. Wir werden dort ebenfalls zeigen, dass ein sehr enger Zusammen-hang zwischen Konfidenzintervallen (bzw. Konfidenzellipsen) und Hypothesentestsbesteht. Etwas vereinfacht besteht ein Konfidenzintervall aus der Menge aller Punk-te, die nicht in Widerspruch zur entsprechenden Nullhypothese stehen; mehr dazuspater.
10Die Funktionen sind fur R: qt(p = 0.975, df = 37) und fur Stata: invttail(37,0.025)(siehe help density functions), und fur EViews: @qtdist(0.975,37).

Angewandte Okonometrie 21
-.06
-.05
-.04
-.03
-.02
-.01
-2,600 -2,400 -2,200 -2,000 -1,800 -1,600 -1,400 -1,200
Alter
km
(b2, b3)
Abbildung 5.6: Empirische Konfidenzellipse fur die zwei Koeffizienten von Alterund km des vorhergehenden Beispiels, Grau strichliert sind dieindividuellen Konfidenzintervalle der Koeffizienten eingezeichnet(erstellt mit EViews).
5.2.5 Das Resultat von Gosset*
Das bekannte Resultat von Gosset lebt heute zwar in den Standardfehlern allerRegressionsoutputs weiter, spielt aber ansonsten keine sehr große Rolle mehr, da dieRechtfertigung heute weitgehend asymptotischen Uberlegungen folgt.
Trotzdem ist es ein wunderschones Resultat, welches nicht nur die Tragweite theo-retischer Uberlegungen zeigt, sondern auch fur weitergehende Analysen wichtig ist.Deshalb wollen wir es fur Interessierte zumindest kurz skizzieren.
Gosset (1908) zeigte, dass fur das Regressionsmodell mit normalverteiltenStortermen yi = β1 + β2xi2 + · · ·+ βhxih + · · ·+ βkxik + εi mit εi ∼ N(0, σ2) gilt
βh − βh
σβh
∼ tn−k
oder in Worten, die mit Hilfe der geschatzten Standardfehler σβhstandardisierten
Koeffizienten sind t-verteilt mit n− k Freiheitsgraden.
Um dies zu zeigen erinnern wir uns aus der einfuhrenden Statistik, dass die Qua-dratsumme von q unabhangig standardnormalverteilten Zufallsvariablen χ2 verteiltist mit q Freiheitsgraden, d.h. fur zi ∼ N(0, 1) gilt
(z21 + z22 + · · ·+ z2q ) ∼ χ2q
Ebenso ist bekannt, dass das Verhaltnis einer standardnormalverteilten Zufallsvaria-ble und der Wurzel einer davon unabhangig χ2-verteilten Zufallsvariable, dividiert

Angewandte Okonometrie 22
durch die Freiheitsgrade, t-verteilt ist, also
N(0, 1)√χ2q/q
∼ tq
Um nun zu zeigen, dass (βh − βh)/σβhtatsachlich t-verteilt ist, erinnern wir uns,
dass die mit Hilfe des ‘wahren’ Standardfehlers σβhstandardisierten Koeffizienten
standardnormalverteilt sindβh − βh
σβh
∼ N(0, 1) (5.3)
wobei βh und σβhfixe, aber unbekannte Parameter der Grundgesamtheit sind (also
keine Zufallsvariablen).
Wenn fur alle Storterme gilt εi ∼ N(0, σ2) (mit i = 1, . . . , n) kann man zeigen, dassdie folgende Zufallsvariable χ2 verteilt ist mit n− k Freiheitsgraden11
∑i ε
2i
σ2∼ χ2
n−k
wobei∑
i ε2i die beobachtbare Quadratsumme der Residuen und σ2 die unbeobacht-
bare Varianz der Storterme ist.
Unter Verwendung des Standardfehlers der Regression σ2 =∑
ε 2i /(n − k) konnen
wir dies umschreiben zu∑
ε 2i
σ2=
(n− k)σ2
σ2=
(n−k)σ2∑
(xi−x)2
σ2∑(xi−x)2
=(n− k)σ2
βh
σ2βh
∼ χ2n−k (5.4)
da σ2βh
= σ2/∑
(xi − x)2 bzw. σ2βh
= σ2/∑
(xi − x)2. Man beachte, dass σ2 die
Varianz der Storterme ist, und σ2βh
die Varianz des Steigungskoeffizienten βh; beide
Varianzen sind unbeobachtbare Parameter, die aus der Stichprobe geschatzt werdenmussen.
Da man obendrein zeigen kann, dass die standardnormalverteilte Zufallsvariable(5.3) und die χ2-verteilte Zufallsvariable (5.4) stochastisch unabhangig sind, ist derQuotient dieser beiden Zufallsvariablen eine t-verteilte Zufallsvariable
N(0, 1)√χ2n−k
n−k
∼ tn−k ⇒βh−βh
σβh√
(n−k)σ2
βh
(n−k)σ2
βh
=
βh−βh
σβh
σβh
σβh
=βh − βh
σβh
∼ tn−k
Die schone Uberraschung dabei ist, dass sich die unbekannte Populationsvarianz σ2βh
herauskurzt.
Damit erhalten wir dieses Resultat von Gosset (1908) fur einen Koeffizienten h desmultiplen Regressionsmodells mit k Regressoren (inkl. Regressionskonstante; mith ∈ {1, . . . , k})
βh − βh
σβh
∼ tn−k
wobei n− k die Freiheitsgrade sind.
11Der Beweis ist etwas aufwandiger, siehe z.B. Johnston and Dinardo (1996, S. 493).
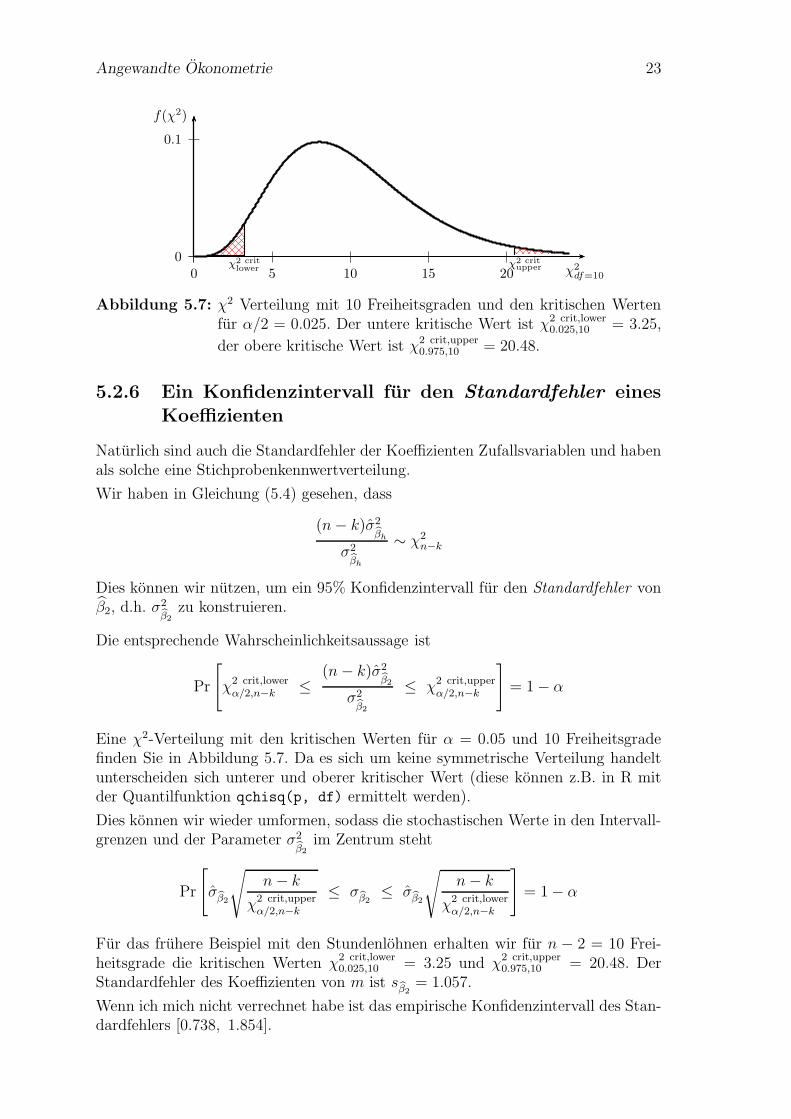
Angewandte Okonometrie 23
0
0.1
0 5 10 15 20
f(χ2)
χ2df=10
χ2 critlower
χ2 critupper
Abbildung 5.7: χ2 Verteilung mit 10 Freiheitsgraden und den kritischen Wertenfur α/2 = 0.025. Der untere kritische Wert ist χ2 crit,lower
0.025,10 = 3.25,
der obere kritische Wert ist χ2 crit,upper0.975,10 = 20.48.
5.2.6 Ein Konfidenzintervall fur den Standardfehler einesKoeffizienten
Naturlich sind auch die Standardfehler der Koeffizienten Zufallsvariablen und habenals solche eine Stichprobenkennwertverteilung.
Wir haben in Gleichung (5.4) gesehen, dass
(n− k)σ2βh
σ2βh
∼ χ2n−k
Dies konnen wir nutzen, um ein 95% Konfidenzintervall fur den Standardfehler vonβ2, d.h. σ
2β2
zu konstruieren.
Die entsprechende Wahrscheinlichkeitsaussage ist
Pr
[χ2 crit,lowerα/2,n−k ≤
(n− k)σ2β2
σ2β2
≤ χ2 crit,upperα/2,n−k
]= 1− α
Eine χ2-Verteilung mit den kritischen Werten fur α = 0.05 und 10 Freiheitsgradefinden Sie in Abbildung 5.7. Da es sich um keine symmetrische Verteilung handeltunterscheiden sich unterer und oberer kritischer Wert (diese konnen z.B. in R mitder Quantilfunktion qchisq(p, df) ermittelt werden).
Dies konnen wir wieder umformen, sodass die stochastischen Werte in den Intervall-grenzen und der Parameter σ2
β2im Zentrum steht
Pr
[σβ2
√n− k
χ2 crit,upperα/2,n−k
≤ σβ2≤ σβ2
√n− k
χ2 crit,lowerα/2,n−k
]= 1− α
Fur das fruhere Beispiel mit den Stundenlohnen erhalten wir fur n − 2 = 10 Frei-heitsgrade die kritischen Werten χ2 crit,lower
0.025,10 = 3.25 und χ2 crit,upper0.975,10 = 20.48. Der
Standardfehler des Koeffizienten von m ist sβ2= 1.057.
Wenn ich mich nicht verrechnet habe ist das empirische Konfidenzintervall des Stan-dardfehlers [0.738, 1.854].

Angewandte Okonometrie 24
5.3 Hypothesentests
Wir haben uns bisher darauf konzentriert, eine moglichst gute Schatzfunktionfur einen statistischen Kennwert der Grundgesamtheit zu finden (z.B. eine
Schatzfunktion µ fur den Mittelwert µ, oder β fur β), sowie eine Schatzfunktionfur deren Standardfehler σ, mit dessen Hilfe wir z.B. Konfidenzintervalle als Indika-toren fur die Vertrauenswurdigkeit unserer Schatzungen berechnen konnten.
Tatsachlich lauft der wissenschaftliche Erkenntnisprozess aber haufig anders. AmAnfang steht meist der Wunsch ein beobachtetes Phanomen zu ‘verstehen’. Aberwas meinen wir mit ‘verstehen’? Offensichtlich erklaren selbst Experten beobach-tete Phanomene hochst unterschiedlich, obwohl sie alle glauben das Phanomen zu‘verstehen’.
Ein bewahrter Ansatz “etwas zu verstehen” besteht darin, den Mechanismus, denden wir hinter dem Phanomen vermuteten, in einem – haufig mathematischen –Modell nachzubilden. Wenn dieses Modell ahnliche Ergebnisse produziert wie diein der Realitat beobachteten Phanomene, dann sind wir einem reproduzierbarenErklarungsansatz zumindest deutlich naher gekommen.
Was wir dafur aber benotigen ist eine Methode, mit der wir uberprufen konnen,inwieweit die Vorhersagen des Modells mit den beobachteten Daten kompatibel sind,oder auch, inwieweit die dem Modell zugrunde liegenden Annahmen ‘realistisch’sind.
Dies ist nicht ganz einfach, da Modelle immer Vereinfachungen sind und nie al-le Aspekte des datengenerierenden Prozesses abbilden konnen, deshalb werdendie Vorhersagen der Modelle kaum jemals exakt mit den beobachteten Datenubereinstimmen. Aber wie groß durfen die Abweichungen sein? Und wie sicher durfenwir sein, dass das Modell tatsachlich eine adequate Beschreibung der hinter dem da-tengenerierenden Prozesses liegenden Gesetzmaßigkeiten liefert? Genau darum gehtes in diesem Kapitel, namlich um das Testen.
Die Anfange der Hypothesentests gehen auf Pioniere wie Francis Ysidro Edgeworth(1885) und Karl Pearson (1900) zuruck, die gegen Ende des 19. Jahrhunderts erst-mals begannen die Grundlagen statistischer Tests zu formulieren und systematischerdarzustellen.
Die moderne Form von Hypothesentests geht vor allem auf drei Personen zuruck, diein den Jahren zwischen 1915 und 1933 die Grundlagen schufen. Auf der einen Seiteder große Pionier der modernen Statistik, R.A. Fisher (1925), und auf der anderenSeite Neyman and Pearson (1928a,b).
Obwohl Fisher und Neyman-Pearson uberzeugt waren, dass ihre Ansatze sichgrundsatzlich unterscheiden, wird in fast allen modernen Lehrbuchern eine Hybrid-form dieser beiden Ansatze prasentiert. Fur eine Diskussion siehe z.B. Gigerenzeret al. (1990), Lehmann (1993), Spanos (1999, 688ff).
Hier werden wir eher aus didaktischen Grunden als um der historischen Gerechtigkeitwillen zuerst kurz den Ansatz von Ronald A. Fisher skizzieren, bevor wir den heuteeher gebrauchlichen Ansatz von Neyman-Pearson prasentieren.
Wir werden allerdings am Schluss sehen, dass alle drei Methoden – Konfidenzinter-valle, p-Werte nach Fisher und Hypothesentests nach Neyman-Pearson – auf den

Angewandte Okonometrie 25
gleichen Grundlagen beruhen und letztendlich zu den gleichen Schlussfolgerungenfuhren.
5.3.1 p – Werte nach R.A. Fisher
Bis herauf zum spaten 19. Jahrhundert waren die Uberlegungen, wie man Informa-tionen aus der Stichprobe mit den theoretischen Vermutungen konfrontieren konnte,eher informeller Natur. Die grundlegende Idee konnte man folgendermaßen skizzie-ren: wenn wir den wahren – aber unbekannten – Wert eines interessierenden Pa-rameters mit θ bezeichnen, und unsere theoretischen Uberlegungen einen Wert θ0erwarten lassen, so hat die Hypothese die Form
θ = θ0
Da θ nicht beobachtbar ist konnen wir dazu keine Aussage machen, aber wenn dieseHypothese wahr ist sollte auch der Unterschied zwischen dem Schatzer θ und derVermutung θ0 ‘moglichst klein’ oder ungefahr Null sein
|θ − θ0| ≈ 0
Obwohl in dieser Fruhzeit noch nicht dargelegt wurde, was konkret unter‘naherungsweise Null’ zu verstehen sei, folgen daraus bereits die zwei zentralen Ele-mente eines Hypothesentests, namlich
1. eine Vermutung uber die Grundgesamtheit θ = θ0; und
2. eine Distanzfunktion |θ − θ0|
Darauf aufbauend entwickelte R. Fisher seinen Ansatz zu Hypothesentests.
Der erste große Beitrag Fishers in diesem Zusammenhang bestand in der Formulie-rung einer expliziten Nullhypothese
H0 : θ = θ0
sowie der Einsicht, welche Implikationen dies fur Hypothesentests hat. Man beach-te, dass sich die Nullhypothese immer auf die unbeobachtbare Grundgesamtheit –also die Parameter der PRF – bezieht, und nicht auf die Schatzung (SRF). DieSchatzungen sind beobachtbar, da gibt es nichts zu vermuten.
Die Nullhypothese wird meist als ‘Negativhypothese’ formuliert, d.h. als Gegenhy-pothese zur theoretischen Vermutung. Die Nullhypothese beschreibt in in diesemSinne haufig einen ‘worst case’ fur die Anfangsvermutung, sodass man wunscht,die Nullhypothese verwerfen zu konnen. Wie wir gleich sehen werden erlaubt dieseVorgangsweise, die Wahrscheinlichkeit fur eine irrtumliche Verwerfung der Nullhy-pothese kontrolliert klein zu halten.
Prinzipiell konnen Forscher frei entscheiden wie sie ihre Nullhypothese formulieren,allerdings gibt es – wie wir spater zeigen werden – eine Einschrankung technischerNatur: die Nullhypothese muss stets so formuliert werden, dass sie das ‘=’ Zeichen(bzw. bei einseitigen Hypothesen das ‘≤’ oder ‘≥’ Zeichen) enthalt (oder in anderenWorten, die H0 darf kein 6=, < oder > enthalten).

Angewandte Okonometrie 26
Im Unterschied zu Neyman-Pearson stellte Fisher seiner Nullhypothese keine ex-plizite Alternativhypothese gegenuber. Die Nullhypothese wird solange als ‘wahr’angenommen, bis sie in ‘zu starken’ Konflikt mit den beobachtbaren Daten – alsoder Stichprobe – gerat.
Auf den Arbeiten von Gosset (1908) aufbauend erkannte Fisher, wie die Distanz|θ − θ0| beurteilt werden kann, namlich durch die Verwendung einer Teststatistik.
Teststatistiken sind neben Nullhypothesen die zweite unverzichtbare Zutat fur Hy-pothesentests. Teststatistiken sind spezielle Zufallsvariablen, deren theoretische Ver-teilung unter Gultigkeit der Nullhypothese bekannt ist. Ahnlich wie Schatzfunktionensind Teststatistiken spezielle Funktionen der Stichprobe, d.h. sie ordnen jeder Stich-probe eine reelle Zahl zu. Im Unterschied zu Schatzern muss die theoretische Stich-probenkennwertverteilung (‘sampling distribution’ ) einer Teststatistik unter H0 abervon vornherein bekannt sein. Teststatistiken durfen naturlich keine unbekannten Pa-rameter enthalten, sonst konnte ihr Wert fur eine konkrete Stichprobe nicht berech-net werden.
Die Herleitung von Teststatistiken ist Aufgabe der theoretischen Statistik und imallgemeinen kein einfaches Unterfangen. Wie wir spater sehen werden sind vieleder gebrauchlichen Teststatistiken asymptotischer Natur, d.h. ihre Verteilung ist furkleine Stichproben unbekannt, konvergiert aber mit zunehmender Stichprobengroßegegen eine bekannte theoretische Verteilung.
Wir wollen die prinzipielle Idee von Teststatistiken hier anhand der einfachen t-Statistik erlautern (ubrigens eine der eher wenigen Teststatistiken, deren theoreti-sche Verteilung auch fur kleine Stichproben bekannt ist). Sie beruht auf dem be-kannten Ergebnis von Gosset (1908), welches wir bereits im Abschnitt uber Konfi-denzintervalle kennen gelernt haben
µ− µ
σµ∼ tn−1 (5.5)
Dies gilt fur den ‘wahren’ Wert µ, der leider unbeobachtbar ist. Aber wenn dieNullhypothese µ = µ0 wahr ist muss gelten
t(S) =µ− µ0
σµ
H0∼ tn−1 (5.6)
wobei S die Menge aller mogliche Stichproben bezeichnet und t(S) ausdrucken soll,dass die Teststatistik t(S) eine Funktion der Stichproben S ist, also ein Zufallsva-
riable. Da dies nur gilt, wenn die Nullhypothese wahr ist, schreiben wirH0∼; dies wird
gelesen als “ist unter H0 verteilt als”. Wenn also H0 : µ = µ0 wahr ist und alle erfor-derlichen Annahmen erfullt sind, dann ist t(S) t-verteilt mit n− 1 Freiheitsgraden.
Die theoretische Stichprobenkennwertverteilung f(t) ist in Abbildung 5.8 eingezeich-net.
Man beachte ubrigens den Unterschied zwischen Gleichung (5.6) und Gleichung(5.5), Gleichung (5.5) enthalt den unbekannten Parameter µ und ist deshalb keineTeststatistik. In Funktion (5.6) wurde der unbekannte Parameter µ durch die be-obachtbare Vermutung unter der H0, d.h. durch das bekannte µ0, ersetzt, deshalb
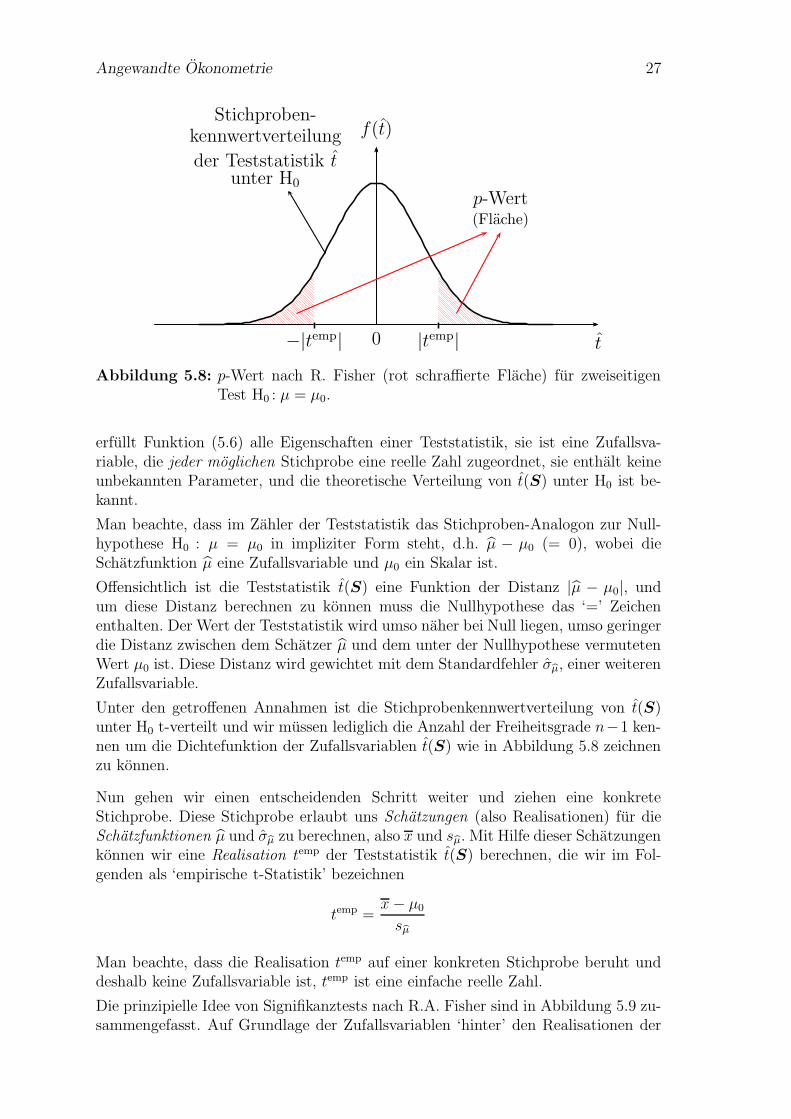
Angewandte Okonometrie 27
p-Wert(Flache)
0 t
f(t)
−|temp| |temp|
Stichproben-kennwertverteilung
der Teststatistik tunter H0
Abbildung 5.8: p-Wert nach R. Fisher (rot schraffierte Flache) fur zweiseitigenTest H0 : µ = µ0.
erfullt Funktion (5.6) alle Eigenschaften einer Teststatistik, sie ist eine Zufallsva-riable, die jeder moglichen Stichprobe eine reelle Zahl zugeordnet, sie enthalt keineunbekannten Parameter, und die theoretische Verteilung von t(S) unter H0 ist be-kannt.
Man beachte, dass im Zahler der Teststatistik das Stichproben-Analogon zur Null-hypothese H0 : µ = µ0 in impliziter Form steht, d.h. µ − µ0 (= 0), wobei dieSchatzfunktion µ eine Zufallsvariable und µ0 ein Skalar ist.
Offensichtlich ist die Teststatistik t(S) eine Funktion der Distanz |µ − µ0|, undum diese Distanz berechnen zu konnen muss die Nullhypothese das ‘=’ Zeichenenthalten. Der Wert der Teststatistik wird umso naher bei Null liegen, umso geringerdie Distanz zwischen dem Schatzer µ und dem unter der Nullhypothese vermutetenWert µ0 ist. Diese Distanz wird gewichtet mit dem Standardfehler σµ, einer weiterenZufallsvariable.
Unter den getroffenen Annahmen ist die Stichprobenkennwertverteilung von t(S)unter H0 t-verteilt und wir mussen lediglich die Anzahl der Freiheitsgrade n−1 ken-nen um die Dichtefunktion der Zufallsvariablen t(S) wie in Abbildung 5.8 zeichnenzu konnen.
Nun gehen wir einen entscheidenden Schritt weiter und ziehen eine konkreteStichprobe. Diese Stichprobe erlaubt uns Schatzungen (also Realisationen) fur dieSchatzfunktionen µ und σµ zu berechnen, also x und sµ. Mit Hilfe dieser Schatzungenkonnen wir eine Realisation temp der Teststatistik t(S) berechnen, die wir im Fol-genden als ‘empirische t-Statistik’ bezeichnen
temp =x− µ0
sµ
Man beachte, dass die Realisation temp auf einer konkreten Stichprobe beruht unddeshalb keine Zufallsvariable ist, temp ist eine einfache reelle Zahl.
Die prinzipielle Idee von Signifikanztests nach R.A. Fisher sind in Abbildung 5.9 zu-sammengefasst. Auf Grundlage der Zufallsvariablen ‘hinter’ den Realisationen der

Angewandte Okonometrie 28
Stichprobe wird eine Teststatistik konstruiert, deren Verteilung unter H0 bekanntist. Da unter der Voraussetzung, dass die H0 wahr ist, auch die Lage der Stichpro-benkennwertverteilung der Teststatistik bekannt ist kann dies genutzt werden, umdie empirischen p-Werte zu bestimmen.
p-Werte fur zweiseitige Hypothesentests
Um die empirischen p–Werte (also Realisationen) zu berechnen benotigen wir nurdie empirische t–Statistik temp und berechnen die Flache unter der Dichtefunktion,die links von −|temp| und rechts von +|temp| liegt.12 Diese Flache entspricht demempirischen p–Wert fur den Test der zweiseitigen Nullhypothese H0 : µ = µ0.
Dies geht auch aus Abbildung 5.8 hervor, die rot eingezeichneten Flache ist gleichdem empirischen p–Wert fur den Test einer zweiseitigen Nullhypothese.
Diese Nullhypothese ist zweiseitig, weil sowohl sehr weit links als auch sehr weitrechts liegende temp-Werte als Indizien gegen die Nullhypothese interpretiert werden.Konkret ist eine Nullhypothese immer zweiseitig, wenn sie das ‘=’ Zeichen enthalt,und sie ist einseitig, wenn sie ein ‘≥’ oder ‘≤’ enthalt.
Vorsicht ist wieder bei der Interpretation geboten, der empirische p–Wert ist eineRealisation, und es macht naturlich uberhaupt keinen Sinn sich zu fragen, wie wahr-scheinlich ein Ereignis ist, welches bereits stattgefunden hat, es hat stattgefunden!
Aber wir konnen uns fragen, wie wahrscheinlich es ist, bei einer hypothetischenneuerlichen Ziehung einer Zufallsstichprobe (oder Wiederholungen des Zufallsexpe-riments) einen mindestens ebenso extremen oder noch extremeren Wert als temp zuerhalten.
Genau diese Wahrscheinlichkeit gibt uns der p-Wert an.
In dieser Interpretation ist der theoretische p-Wert eine Zufallsvariable, und derempirische p-Wert pemp eine Realisation dieser Zufallsvariable, den wir aus einerStichprobe berechnen.
Interpretation von p-Werten: Wenn die Nullhypothese wahr ist undalle erforderlichen Annahmen erfullt sind gibt der p-Wert die Wahr-scheinlichkeit dafur an, dass wir bei einer hypothetischen neuerlichenDurchfuhrung des Zufallsexperiments eine empirische Teststatistik er-halten wurden, die noch extremer ist als die vorliegende empirische Test-statistik.
Da p-Werte Wahrscheinlichkeiten sind konnen sie nur Werte zwischenNull und Eins annehmen. Ein sehr kleiner p-Wert nahe bei Null deutetdarauf hin, dass entweder die Nullhypothese falsch ist, oder dass ein sehrunwahrscheinliches Ereignis eingetreten ist.
12Wir verwenden hier den Absolutbetrag | · | der Teststatistik, da die Teststatistik auch negativsein kann. In diesem Fall konnte ‘links’ und ‘rechts’ von temp irrefuhrend sein.

Angew
andte
Okonometrie
29
Hypothesentest fur einen Regressionskoeffizienten
y = β1 + β2x + εf(x, y)
x
y
Zustande vor dem Zufallsexperiment (ex ante) sind nicht beobachtbar!
Z U F A L L S E X P E R I M E N T
Nach dem Zufallsexperiment (ex post) existiert kein Zufall!
y1
x1
y2
x2
. . .yi
xi
. . .yn
xn
Stichprobe (n Realisationen)
ε1 = y1 − β1 − β2x1, ε1 ∼ N(0, σ21)
......
εi = yi − β1 − β2xi, εi ∼ N(0, σ2i )
......
εn = yn − β1 − β2xn, εn ∼ N(0, σ2n)
...
n → ∞ . . . Asymptotik
n Paare von Zufallsvariablen;εi identisch & unabhangig verteilt?
t = β2−β0
se(β2)
Test-statistik
mit t ∼ tn−k
Stichprobenkenn-
wertverteilung von tunter H0 : β2 = β0
0b
t
f(t)
|
temp = b2−β0
sβ2
empir. p-Wertfur H0 : β2 = β0
| bc
tempb
0
p-Wert
Datengenerierender
Pro
zess(D
GP)
indu
ktiv
(Theorie)
deskriptiv
(Empirie)
c©H. Stocker
beobachtbarnicht
beobachtbar
Abbild
ung5.9:Hypoth
esentest
eines
Regression
skoeffi
zienten

Angewandte Okonometrie 30
Umso kleiner ein p-Wert ist, umso eher werden wir geneigt sein die Nul-lyhpothese zu verwerfen.
Etwas salopp konnen wir den p-Wert auch einfach als Kennzahl dafurinterpretieren, wie gut die Nullhypothese die Daten beschreibt. Ein sehrkleiner p-Wert wird als Evidenz gegen die Nullhypothese interpretiert.
Exkurs:* In historischen Zeiten war die Berechnung der p-Werte aufwandig, aberheute geben so gut wie alle Statistikprogramme die p-Werte automatisch aus. Com-puterprogramme berechnen den p-Wert meist mit Hilfe der Verteilungsfunktion
F (t) =
∫ |temp|
−∞f(v) dv
Den zweiseitigen p-Wert erhalt man aus
pemp = 2[1− F (|temp|, df)]
wobei F (t) in diesem Fall die Verteilungsfunktion der t-Verteilung bezeichnet (nichtdie F-Statistik!), |temp| ist der Absolutwert der empirischen Teststatistik, und unddf steht naturlich wieder fur die Freiheitsgrade (‘degrees of freedom’ ). �
p–Werte fur einseitige Hypothesentests
Viele Hypothesen sind nicht symmetrisch. Wenn z.B. eine neue Trainingsmethodeeingefuhrt wird, so werden wir im Durchschnitt eine Leistungsverbesserung der Teil-nehmer erwarten. Ebenso werden wir bei steigenden Einkommen eine Zunahme derKonsumausgaben erwarten, keine Abnahme.
Solche einseitigen Hypothesen konnen ebenso einfach getestet werden. Auch einseiti-ge Nullypothesen werden ublicherweise als Negativhypothesen formuliert. Vermutenwir z.B., dass ein Kennwert der Grundgesamtheit µ großer ist als µ0, so ist dieNullhypothese (als Negativhypothese)
H0 : µ ≤ µ0
Wenn wir z.B. vermuten, dass die durchschnittliche Leistung nach Einfuhrung ei-ner neuen Trainingsmethode besser ist als die durchschnittliche Leistung vor derEinfuhrung µ0, dann ist die Negativhypothese, dass sich die Leistung nicht verbes-sert hat oder sogar abgenommen hat.
Auf den ersten Blick scheint es unmoglich diese Hypothese zu testen, da µ ≤ µ0
unendlich viele Falle umfasst. Etwas nachdenken zeigt allerdings, dass es genugtden Grenzfall µ = µ0 zu testen, denn wenn man H0 : µ = µ0 verwerfen kann, konnenautomatisch auch alle extremeren Hypothesen µ < µ0 verworfen werden.
Deshalb kann fur einen einseitigen Test die gleiche Teststatistik wie fur zweiseitigeTests verwendet werden, in diesem Fall
temp =µ− µ0
sµ
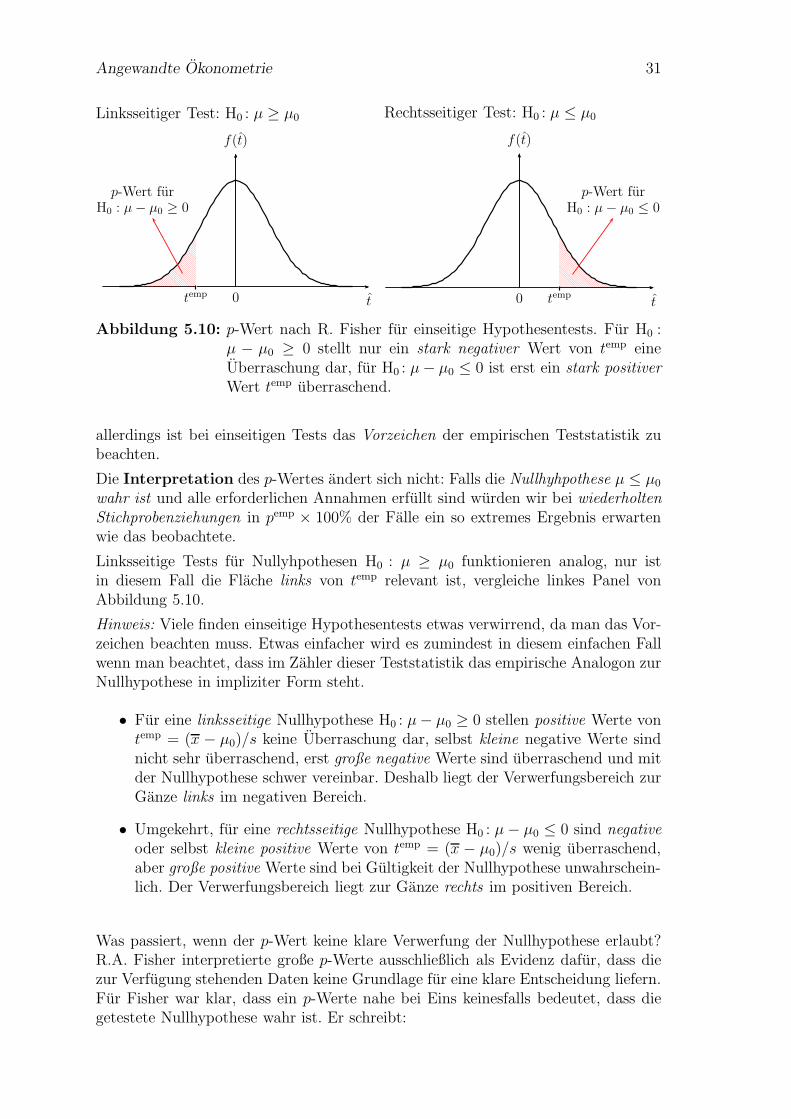
Angewandte Okonometrie 31
Linksseitiger Test: H0 : µ ≥ µ0
p-Wert furH0 : µ− µ0 ≥ 0
0 t
f(t)
temp
Rechtsseitiger Test: H0 : µ ≤ µ0
p-Wert furH0 : µ− µ0 ≤ 0
0 t
f(t)
temp
Abbildung 5.10: p-Wert nach R. Fisher fur einseitige Hypothesentests. Fur H0 :µ − µ0 ≥ 0 stellt nur ein stark negativer Wert von temp eineUberraschung dar, fur H0 : µ− µ0 ≤ 0 ist erst ein stark positiverWert temp uberraschend.
allerdings ist bei einseitigen Tests das Vorzeichen der empirischen Teststatistik zubeachten.
Die Interpretation des p-Wertes andert sich nicht: Falls die Nullhyhpothese µ ≤ µ0
wahr ist und alle erforderlichen Annahmen erfullt sind wurden wir bei wiederholtenStichprobenziehungen in pemp × 100% der Falle ein so extremes Ergebnis erwartenwie das beobachtete.
Linksseitige Tests fur Nullyhpothesen H0 : µ ≥ µ0 funktionieren analog, nur istin diesem Fall die Flache links von temp relevant ist, vergleiche linkes Panel vonAbbildung 5.10.
Hinweis: Viele finden einseitige Hypothesentests etwas verwirrend, da man das Vor-zeichen beachten muss. Etwas einfacher wird es zumindest in diesem einfachen Fallwenn man beachtet, dass im Zahler dieser Teststatistik das empirische Analogon zurNullhypothese in impliziter Form steht.
• Fur eine linksseitige Nullhypothese H0 : µ− µ0 ≥ 0 stellen positive Werte vontemp = (x − µ0)/s keine Uberraschung dar, selbst kleine negative Werte sindnicht sehr uberraschend, erst große negative Werte sind uberraschend und mitder Nullhypothese schwer vereinbar. Deshalb liegt der Verwerfungsbereich zurGanze links im negativen Bereich.
• Umgekehrt, fur eine rechtsseitige Nullhypothese H0 : µ − µ0 ≤ 0 sind negativeoder selbst kleine positive Werte von temp = (x − µ0)/s wenig uberraschend,aber große positive Werte sind bei Gultigkeit der Nullhypothese unwahrschein-lich. Der Verwerfungsbereich liegt zur Ganze rechts im positiven Bereich.
Was passiert, wenn der p-Wert keine klare Verwerfung der Nullhypothese erlaubt?R.A. Fisher interpretierte große p-Werte ausschließlich als Evidenz dafur, dass diezur Verfugung stehenden Daten keine Grundlage fur eine klare Entscheidung liefern.Fur Fisher war klar, dass ein p-Werte nahe bei Eins keinesfalls bedeutet, dass diegetestete Nullhypothese wahr ist. Er schreibt:

Angewandte Okonometrie 32
“For the logical fallacy of believing that a hypothesis has been provedto be true, merely because it is not contradicted by the available facts,has no more right to insinuate itself in statistical than in other kinds ofscientific reasoning. [. . . ] It would, therefore, add greatly to the claritywith which the tests of significance are regarded if it were generallyunderstood that tests of significance, when used accurately, are capableof rejecting or invalidating hypotheses, in so far as the are contradictedby the data: but that they are never capable of establishing them ascertainly true.” (zitiert nach Salsburg, 2002, 107f)
5.3.2 Hypothesentests nach Neyman-Pearson
Auf der Arbeit von R.A. Fisher aufbauend entwickelten Jerzy Neyman (polnischerMathematiker und Statistiker, 1894 – 1981) und Egon Pearson (1895 – 1980, Sohnvon Karl Pearson) die heute verbreitete Form von Hypothesentests.
Alles, was wir bisher uber R. Fishers Signfikanztests gehort haben, bleibt auch furHypothesentests nach Neyman-Pearson gultig, aber bei Neyman-Pearson kommenzwei neue Elemente hinzu
1. Der Nullhypothese wird explizit eine Alternativhypothese HA gegenuber ge-stellt, die immer richtig ist, wenn die Nullhypothese falsch ist, d.h. H0 und HA
schließen sich gegenseitig aus.
Zur Erinnerung, sowohl Null- als auch Alternativhypothese sind stets Aussagenuber unbeobachtbare Parameter der Grundgesamtheit!
2. Es wird a priori ein Signifikanznveau α festgelegt. Im Unterschied zum p–Wert von Fisher, der eine Zufallsvariable ist (bzw. eine Realisation davon), istdas Signifikanznveau α ein fixer Parameter, der von der Forscherin a priorifestgelegt wird.
Diese beiden Erweiterungen erlaubten Neyman-Pearson Hypothesentests als ein-deutigen Entscheidungsregel zu formulieren, die fur jede Stichprobe angibt, ob dieNullhypothese verworfen oder beibehalten werden soll. Diese Entscheidung mussnaturlich nicht richtig sein, aber wie wir gleich sehen werden erlaubt diese Methodikeine klare Beurteilung der moglichen Fehler.
Wir werden im Folgenden die Testmethodik nach Neyman-Pearson nur fur dendenkbar einfachsten Fall vorstellen, fur den Test eines einzelnern Parameters derGrundgesamtheit, aber diese Testmethodik ist deutlich allgemeiner und kann inverschiedenen Zusammenhangen angewandt werden.
Wir beginnen mit einer Ubersicht uber die wesentlichen Schritte eines Hypothesen-tests nach Neyman-Pearson:
Problemanalyse Der erste, wichtigste und meist auch schwierigste Schritt jedesHypothesentests sollte ein Nachdenken uber das zu untersuchende Phanomensein.

Angewandte Okonometrie 33
Festlegung von Null- und Alternativhypothese Auf Grundlage der theoreti-schen Uberlegungen erfolgt die Formulierung der Nullhypothese H0 sowie derdazugehorigen Alternativhypothese HA. In der Alternativhypothese findet sichmeist die Anfangsvermutung, bzw. der erhoffte Fall, die Nullhypothese ist dieNegativhypothese dazu.
Null- und Alternativhypothese schließen sich gegenseitig aus, es kann nur eineder beiden Hypothesen richtig sein. Getestet wird immer die Nullhypothese,und diese muss so formuliert sein, dass sie das ‘=’ (bzw. bei einseitigen Testsdas ‘≤’ oder ‘≥’) enthalt.
Wahl der Teststatistik Wir haben bisher erst eine Teststatistik kennen gelernt,namlich die einfache t-Statistik. Oft stehen aber auch alternative Teststatisti-ken zur Verfugung, die weniger strenge Annahmen benotigen, dafur aber nurasymptotisch gultig sind. Die Wahl der Teststatistik hangt haufig wesentlichdavon ab, welche Annahmen man bereit ist zu akzeptieren.
Festlegung eines Signifikanzniveaus α Im Unterschied zur Testmethodik vonFisher wird hier a priori eine Wahrscheinlichkeit festgelegt, ab der ein Er-eignis als hinreichend unwahrscheinlich beurteilt wird, so dass man beiUberschreitung dieses Schwellenwertes die Nullhypothese auf jeden Fall ver-werfen wird. Diesen Schwellenwert nennen wir Signifikanzniveau (α).
Diese Entscheidung wird bereits vor Durchfuhrung des eigentlichen Tests ge-troffen, ab diesem Zeitpunkt wird das Testverfahren gewissermaßen ‘auf Au-topilot geschaltet’, wir mussen nur noch die restlichen Schritte nach Vorschriftausfuhren und die resultierende Entscheidung akzeptieren.
Annahme- und Verwerfungsbereich Mit Hilfe dieses Signifikanzniveaus undder gewahlten Teststatistik kann man einen kritischen Wert der Teststatistikermitteln. Dies wird in Abbildung 5.11 (Seite 34) fur einen zweiseitigen Testgezeigt. Fur einen zweiseitigen Test definieren wir den Akzeptanzbereich alsjenen Bereich unter der Dichtefunktion der Teststatistik, uber dem die Flache(1 − α) betragt, und als Verwerfungsbereich jenen Bereich an den Randern,der links und rechts die Flachen α/2 ‘abschneidet’.
Wir suchen also in Abbildung 5.11 den kritischen Wert tcritα/2,df , sodass die ge-
samte schraffierte Flache exakt gleich α ist (bei einem zweiseitigen Test alsodie Summe der Flachen links von −|tcritα/2,df | und rechts von +|tcritα/2,df | gleich α
ist).
Diesen kritischen Wert der Verteilung kann man in einer ublichen t–Tabellenachschlagen (oder wenn ein Computer zur Verfugung mit Hilfe der Quantil-funktion berechnen).
Der kritische Wert erlaubt eine Unterteilung des Parameterraums in einenAnnahme- und Verwerfungsbereich, die sich gegenseitig ausschließen Unter ei-nem Parameterraum verstehen wir einfach alle moglichen Werte, die ein inter-essierender Parameter annehmen kann. In vielen Fallen wird dies die Mengeder reellen Zahlen R sein. Der Annahme- und Verwerfungsbereich sind dis-junkte Teilmengen des Parameterraums.
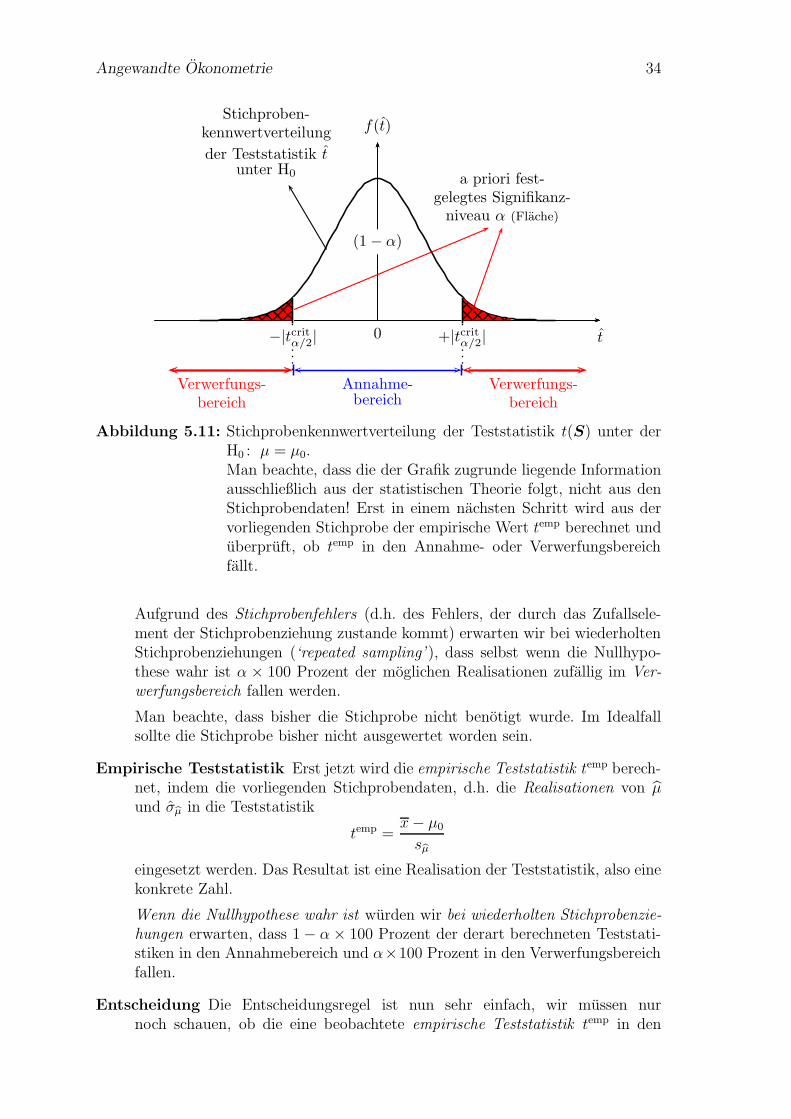
Angewandte Okonometrie 34
a priori fest-gelegtes Signifikanz-niveau α (Flache)
0 t
f(t)
(1− α)
−|tcritα/2| +|tcritα/2|
Stichproben-kennwertverteilung
der Teststatistik tunter H0
Annahme-bereich
Verwerfungs-bereich
Verwerfungs-bereich
Abbildung 5.11: Stichprobenkennwertverteilung der Teststatistik t(S) unter derH0 : µ = µ0.Man beachte, dass die der Grafik zugrunde liegende Informationausschließlich aus der statistischen Theorie folgt, nicht aus denStichprobendaten! Erst in einem nachsten Schritt wird aus dervorliegenden Stichprobe der empirische Wert temp berechnet unduberpruft, ob temp in den Annahme- oder Verwerfungsbereichfallt.
Aufgrund des Stichprobenfehlers (d.h. des Fehlers, der durch das Zufallsele-ment der Stichprobenziehung zustande kommt) erwarten wir bei wiederholtenStichprobenziehungen (‘repeated sampling’ ), dass selbst wenn die Nullhypo-these wahr ist α × 100 Prozent der moglichen Realisationen zufallig im Ver-werfungsbereich fallen werden.
Man beachte, dass bisher die Stichprobe nicht benotigt wurde. Im Idealfallsollte die Stichprobe bisher nicht ausgewertet worden sein.
Empirische Teststatistik Erst jetzt wird die empirische Teststatistik temp berech-net, indem die vorliegenden Stichprobendaten, d.h. die Realisationen von µund σµ in die Teststatistik
temp =x− µ0
sµ
eingesetzt werden. Das Resultat ist eine Realisation der Teststatistik, also einekonkrete Zahl.
Wenn die Nullhypothese wahr ist wurden wir bei wiederholten Stichprobenzie-hungen erwarten, dass 1− α× 100 Prozent der derart berechneten Teststati-stiken in den Annahmebereich und α×100 Prozent in den Verwerfungsbereichfallen.
Entscheidung Die Entscheidungsregel ist nun sehr einfach, wir mussen nurnoch schauen, ob die eine beobachtete empirische Teststatistik temp in den

Angewandte Okonometrie 35
Annahme- oder in den Verwerfungsbereich fallt. Liegt die empirische Teststa-tistik temp im Annahmebereich kann die Nullypothese nicht verworfen werden,liegt temp hingegen im Verwerfungsbereich wird die Nullhypothese verworfen.
Da sich Annahme- und Verwerfungsbereich gegenseitig ausschießen fuhrt diesimmer zu einer eindeutigen Entscheidung.
Mogliche Fehler Die Entscheidung ist zwar eindeutig, aber sie muss deshalb nichtrichtig sein. Konkret konnen zwei Arten von Fehler auftreten, namlich
1. Typ I Fehler: Die Nullhypothese ist tatsachlich wahr, aber wir haben zufallig ei-ne extreme Stichprobe gezogen, weshalb wir die nach dieser Entscheidungsregeldie Nullhypothese trotzdem verwerfen. Bei wiederholten Stichprobenziehungensollte dieser Fehler nicht ofter als in α× 100 Prozent der Falle auftreten.
2. Typ II Fehler: Die Nullhypothese ist tatsachlich falsch, die (erhoffte) Alterna-tivhypothese also richtig, aber die Anwendung der Entscheidungsregel fuhrtdazu, dass die Nullhypothese irrtumlich nicht verworfen wird.
Zusammenfassung Im Wesentlichen enthalt ein Hypothesentest nach Neyman-Pearson folgende Elemente
1. Eine Nullhypothese H0 und Alternativhypothese HA, die sich gegenseitig aus-schließen.
2. Eine Teststatistik t(S), deren Verteilung unter H0 bekannt ist.
3. Ein a priori gewahltes Signifikanzniveau α, und daraus folgend, ein kritischerWert der Teststatistik tcrit.
4. Mit Hilfe der Teststatistik und des Signifikanzniveaus wird der Parameterraumin einen Annahme- und Verwerfungsbereich unterteilt.
5. Eine empirische Teststatistik temp, die man durch Einsetzen der Werte dergegebenen Stichprobe in die Teststatistik erhalt (temp ist eine Realisation derZufallsvariable t(S)).
6. Dies liefert eine einfache Entscheidungsregel: fallt temp in den Annahmebereichwird die Nullhypothese nicht verworfen, fallt temp in den Verwerfungsbereichwird die Nullhypothese verworfen.
7. Bei dieser Entscheidung konnen zwei Arten von Fehler auftreten, Typ I undTyp II Fehler.

Angewandte Okonometrie 36
Beispiel: Um die Vorgangsweise zu erlautern kehren wir zum Beispiel mit derKorpergroße auf Seite 11 zuruck. Dort haben wir fur eine Stichprobe mit 20 Personendie durchschnittliche Korpergroße x und eine Schatzung fur die Varianz s2 berechnet
x =1
20
20∑
i=1
xi = 170.55, s2 =1
n− 1
20∑
i=1
(xi − x)2 = 79.52, s = 8.92
Wir mochten die Nullhypothese testen, dass die durchschnittliche Korpergroße derGrundgesamtheit 175 cm betrage (µ0 = 175), also
H0 : µ = 175
Die Alternativhypothese ist somit µ 6= 175, es handelt sich also um einen zweiseitigenTest.
Diese Nullhypothese konnen wir mit einer einfachen t–Statistik testen
t =µ− µ0
σµ
H0∼ tn−1
Die Stichprobenkennwertverteilung dieser Teststatistik ist in Abbildung 5.11 darge-stellt.
Wir entscheiden uns fur ein Signifikanzniveau von α = 0.05, d.h. wir mussen ineiner t–Tabelle bei α/2 = 0.025 (zweiseitig!) und bei 19 Freiheitsgraden (df = n−1)nachschlagen.
Tabelle 5.1 (Seite 11) entnehmen wir den kritischen Wert tcrit0.025,19 = 2.093. Dasbedeutet:
Akzeptanzbereich: [−2.093, +2.093]Verwerfungsbereich: [−∞, −2.093) und (+2.093,+∞]
Erst jetzt berechnen wir die empirische Teststatistik
temp =x− µ0
sµ=
170.55− 175√79.5220
= −2.231
Entscheidung: Die empirische Teststatistik temp = −2.231 fallt in den Verwerfungs-bereich [−∞, −2.093), deshalb wird die Nullhypothese auf einem Signifikanzniveauα = 0.05 verworfen!
Wenn wir uns ursprunglich fur ein Signifikanzniveau α = 0.01 entschieden hatten,hatten wir den kritische Wert tcrit0.005,19 = 2.861 verwenden mussen und damit einenAkzeptanzbereich [−2.861, +2.861] erhalten. Da die empirische Teststatistik temp =−2.231 in diesen Akzeptanzbereich fallt konnen wir die Nullhypothese auf einemSignifikanzniveau α = 0.01 nicht verwerfen!
Hinweis: Wenn die Nullhypothese nicht verworfen werden kann impliziert dies nicht,dass die Nullhypothese wahr ist; es konnte auch einfach zu viel Rauschen in den Da-ten sein, um den Effekt hinreichend genau messen zu konnen. Außerdem bezieht

Angewandte Okonometrie 37
sich die Nullhypothese in vielen Fallen auf einen Punkt auf der Zahlengerade (z.B.H0 : µ = µ0), und streng genommen ist eine solche Nullhypothese fast sicher falsch.Deshalb sollte man sich mit der schwacheren Aussage begnugen, dass die Nullhypo-these “nicht verworfen” wird.
Hinweis: Falls ein empirischer p-Wert bekannt ist muss der Annahme- und Ver-werfungsbereich nicht explizit bestimmt werden, es reicht den p-Wert mit dem apriori festgelegten Signifikanzniveau zu vergleichen. Ist der p-Wert kleiner als dasSignifikanzniveau kann die Nullhypothese verworfen werden, sonst nicht.
5.3.3 Ein Hypothesentest fur einzelne Regressionskoeffizi-enten
Die Tests einzelner Regressionskoeffizienten verlaufen nach dem ublichen Muster,wir ermitteln eine Teststatistik, in diesem Fall
t =Stochastisches Analogon zur H0 in impliziter Form
Standardfehler vom Zahler
H0∼ tn−k
(n− k bezeichnet die Freiheitsgrade, k ist die Anzahl der geschatzten Regressions-koeffizienten).
Fur die PRFyi = β1 + β1xi1 + · · ·+ βhxih + · · ·+ βkxik + εi
Die am haufigsten getestete Nullhypothese, die auch hinter den von allen Program-men ausgegebenen t-Statistiken und p-Werten liegen, ist, dass der wahre Parameterβh Null ist, d.h.
H0 : βh = 0
Wenn der wahre Parameter βh Null ist bedeutet diess, dass die Variable xh in derGrundgesamtheit keine Wirkung auf y hat.
Da die Standardfehler aus der Stichprobe geschatzt werden mussen ist die theoreti-sche Teststatistik t-verteilt mit n− k Freiheitsgraden
t =βh − 0
σβh
H0∼ tn−k
Fur diese einfache Nullhypothese erhalten wir den empirischen t-Wert einfach, indemwir den Koeffizienten durch dessen Standardfehler dividieren
temp =bhsβh
Naturlich konnen damit auch allgemeinere Hypothesen fur ein beliebiges β0 getestetwerden, in diesem Fall sind die Teststatistiken
theoret.: t =βh − β0
σβh
H0∼ tn−k empirisch: temp =bh − β0
sβh

Angewandte Okonometrie 38
Beispiel 1: Zur Illustration greifen wir auf ein fruheres Beispiel mit den Stun-denlohnen (StdL) zuruck, die wir auf eine Dummyvariable m fur mannlich regres-sieren, d.h. m = 1 fur Manner und m = 0 sonst. Wie wir schon im Kapitel zurdeskriptiven Regressionsanalyse gezeigt haben misst in diesem Fall das Interzeptden durchschnittlichen Stundenlohn der Referenzkategorie, in diesem Fall Frauen,und der Steigungskoeffizient die Differenz zum durchschnittlichen Stundenlohn vonMannern.
Das Regressionsergebnis ist
StdL = 12.5 + 2.5 m(0.747)*** (1.057)**
R2 = 0.359, n = 12
(OLS Standardfehler in Klammern)
Wir nehmen an, dass alle Gauss Markov Annahmen erfullt sind und εi ∼ N(0, σ2)(was fur eine so kleine Stichprobe eine ziemlich verruckte Annahme ist).
Wie schon erwahnt ist die am haufigsten getestete Nullhypothese in Regressionsmo-dellen, dass die Parameter βh der Grundgesamtheit Null sind, also keinen Einflussauf die abhangige Variable haben.
In diesem Beispiel testen wir
H0 : β2 = 0 gegen die Alternativhypothese HA : β2 6= 0
Als Teststatistik wahlen wir (derzeit in Ermangelung besserer Alternativen) dieubliche t Statistik mit n− 2 = 10 Freiheitsgraden
t =β2 − β0
σβh
H0∼ tn−2
mit β0 = 0. Als Signifikanzniveau α wahlen wir alten Traditionen folgend 0.05.
Auf Grundlage des a priori gewahlten Signifikanzniveaus α = 0.05 und der Freiheits-grade konnen wir die kritischen t-Werte bestimmen.
Da es sich um eine zweiseitige Hypothese handelt suchen wir den Wert tcritα/2,df, bei
welchem links und rechts α/2 ∗ 100% der Flache abgeschnitten werden.
Mit Hilfe der kritischen Werte konnen wir den Annahmebereich [−tcritα/2,+tcritα/2] und
die Verwerfungsbereiche [−∞,−tcritα/2) und (+tcritα/2,+∞] festlegen.
In unserem Beispiel mit tcrit0.025,10 = 2.228 ist der Annahmebereich [−2.228; +2.228]und die Verwerfungsbereiche sind [−∞; −2.228) und (+2.228; +∞].
Bisher benotigten wir, abgesehen von den Freiheitsgraden, keine Informationen ausder Stichprobe.
Erst im nachsten Schritt verwenden wir die vorliegende Stichprobe um dieSchatzungen b2 und sβ2
zu berechnen. Durch Einsetzen dieser Schatzungen undder Vermutung β0 in die Teststatistik erhalten wir den empirischen t-Wert
temp =b2 − β0
sβ2
=2.5− 0
1.057= +2.365
Im letzten Schritt brauchen wir nur noch zu uberprufen, in welchen Bereich temp
fallt.

Angewandte Okonometrie 39
• Wenn temp in den Verwerfungsbereich fallt ist entweder ein sehr unwahrschein-liches Ereignis eingetreten, oder die Nullhypothese ist falsch. Was ‘hinreichendunwahrscheinlich’ bedeutet haben wir bereits bei der Wahl des Signifikanzni-veaus entschieden.
• Wenn temp in den Annahmebereich fallt stehen die Stichprobendaten in keinemstarken Widerspruch zur Nullhypothese, wir konnen die Nullhypothese nichtverwerfen.
In diesem Beispiel fallt temp = 2.365 in den Verwerfungsbereich (+2.228; +∞], alsowerden wir die Nullhypothese auf einem Signifikanzniveau von 5% verwerfen.
Hinweis: Hatten wir a priori ein Signifikanzniveau von 1% (α = 0.01) festgelegthatten wir den kritischen Wert tcrit0.005,10 = 3.1693 erhalten. Der Akzeptanzbereich furdieses Signifikanzniveau ist [−3.1693; +3.1693], unsere temp = 2.365 fallt also klarin diesen Akzeptanzbereich und wir hatten die Nullhypothese auf einem Signifikanz-niveau von 1% nicht verwerfen konnen.
Faustregel:
Fur Stichproben mit mehr als 30 Beobachtungen (n > 30) ist der Ko-effizient ‘vermutlich’ auf dem 5% Signifikanzniveau signifikant von Nullverschieden, wenn der Absolutbetrag des empirischen t-Wertes großer als2 ist.
(fur n > 30 ist die Stichprobenkennwertverteilung annahernd normalverteilt, undzcrit0.025 = 1.96 ≈ 2. Da die empirische Teststatistik temp = bh/sβh
folgt obige Faustre-gel.)
5.3.4 t-Test fur eine Linearkombination von mehreren Re-gressionskoeffizienten
Wir haben bisher nur t-Tests fur einzelne Regressionskoeffizienten durchgefuhrt.Die Vorgangsweise lasst sich aber einfach fur Tests einer Linearkombination vonmehreren Regressionskoeffizienten verallgemeinern.
Beginnen wir mit einer einfachen PRF:
yi = β1 + β2xi2 + β3xi3 + εi
Wenn wir zum Beispiel testen mochten, ob die Summe von β2 und β3 den Wert Einshat, lauten Null- und Alternativhypothese
H0 : β2 + β3 = 1 gegen HA : β2 + β3 6= 1
Dies ist ein sehr spezieller Fall von Null- und Alternativhypothese.
Etwas allgemeiner konnen zweiseitige Null- und Alternativhypothesen fur dieseseinfache Modell geschrieben werden als
H0 : c1β2 + c2β3 = β0
HA : c1β2 + c2β3 6= β0

Angewandte Okonometrie 40
wobei c1, c2 und β0 ∈ R unter der Nullhypothese vermutete Parameter (Konstante)sind.
Fur die obige Nullhypothese β2 + β3 = 1 ware naturlich c1 = c2 = 1 und β0 = 1.
Sollte z.B. getestet werden, ob die Parameter β2 und β3 den gleichen Wert haben,wurden wir c1 = +1, c2 = −1 und β0 = 0 wahlen, denn daraus folgt H0 : β2−β3 = 0,bzw. β2 = β3.
Auf diese Weise lassen sich beliebige lineare Nullhypothesen testen, die zwei oderauch mehrere Parameter betreffen. Allerdings konnen auf diese Weise nur einzelneHypothesen getestet werden, einen simultanen Test mehrerer Hypothesen werdenwir erst in einem spateren Abschnitt kennen lernen.
Das Testprinzip fur eine einzelne lineare Hypothese, die mehrere Parameter betrifft,ist einfach: wenn die Nullhypothese wahr ist gilt in der Grundgesamtheit
c1β2 + c2β3 − β0 = 0
Selbst wenn dies in der Grundgesamtheit exakt gilt mussen wir in der Stichprobedamit rechnen, dass aufgrund von Zufallschwankungen dieser Zusammenhang nichtexakt erfullt ist, also
c1β2 + c2β3 − β0 = v
wobei die Zufallsvariable v ‘relativ nahe’ bei Null liegen sollte, wenn die Nullhy-pothese wahr ist. Man beachte, dass v eine Linearkombination der Zufallsvariablenβ2 und β3 ist. Wenn β2 und β3 normalverteilt sind, dann ist auch v normalverteilt.Außerdem ist bei Gultigkeit der Nullhypothese E(v) = 0. Um eine Teststatistik zuerhalten brauchen wir also nur durch den Standardfehler von v zu dividieren. Dav eine Linearkombination der Zufallsvariablen β2 und β3 ist gestaltet sich dies sehreinfach, wir brauchen nur die Rechenregel fur das Rechnen mit Varianzen anzuwen-den13
var(v) = var(c1β2 ± c2β3 − β0) = c21 var(β2) + c22 var(β3)± 2c1c2 cov(β2, β3)
Wir haben bisher zwar nur fur das bivariate Modell einen Schatzer fur die Kovarianzzwischen Interzept und Steigungskoeffizient, d.h. cov(β1, β2), des bivariaten Modellshergeleitet, aber wir werden im Kapitel zur Matrixschreibweise zeigen, dass auchdie Kovarianzen zwischen Steigungskoeffizienten ahnlich einfach berechnet werdenkonnen. Die ublichen Programme geben die Varianz-Kovarianzmatrix der Koeffizi-enten zwar nicht unmittelbar aus, aber man kann einfach mit den entsprechendenBefehlen darauf zugreifen.14
Da die Varianz des Nenners aus der Stichprobe berechnet werden muss ist die Test-statistik15
v
se(v)=
c1β2 ± c2β3 − β0√c21 var(β2) + c22 var(β3)± 2c1c2 cov(β2, β3)
H0∼ tn−k
13var(c0 + c1x ± c2y) = E[(c0 + c1x ± c2y) − E(c0 + c1x ± c2y)]2 = c21 var(x) + c22 var(y) ±
2c1c2 cov(x, y).14In R erhalt man die geschatzte Varianz-Kovarianzmatrix der Koeffizienten mit der Funktion
vcov(...); in Stata mit dem postestimation Befehl e(V), und in EViews mit @coefcov.15Dieser Test ist wie alle t-Tests ein Spezialfall eines Wald Tests, der 1943 von dem Mathematiker
Abraham Wald entwickelt wurde.

Angewandte Okonometrie 41
unter H0 t-verteilt mit n− k Freiheitsgraden.
Diese Teststatistik (t) hat die Form
t =Empirisches Analogon zur H0 in impliziter Form
Standardfehler vom Zahler
H0∼ tn−k
Dies ist offensichtlich nur eine kleine Erweiterung der ublichen Tests fur einen Koef-fizienten fur Falle, in denen eine Hypothese uber eine Linearkombination von zwei(oder mehreren) Koeffizienten getestet werden soll.
Mit Hilfe dieser Teststatistik kann wieder der p-Wert a la Fisher berechnet werden,oder eine Entscheidung nach der Methode Neyman und Pearson gefallt werden.
Beispiel: Angenommen wir erhalten folgende Schatzung einer Cobb-Douglas Pro-duktionsfunktion und mochten testen, ob konstante Skalenertrage vorliegen.16
log(Q) = 2.481 + 0.64 log(K) + 0.257 log(L)(0.129)*** (0.035)*** (0.027)***
R2 = 0.942, n = 25(OLS Standardfehler in Klammern)
Die dazugehorige Varianz-Kovarianzmatrix der Koeffizienten (Coefficient Covarian-ce Matrix ) ist
b1 b2 b3
b1 0.016543 −0.002869 −0.003187b2 −0.002869 0.001206 0.000300b3 −0.003187 0.000300 0.000727
Bei Cobb-Douglas Funktionen liegen konstante Skalenertrage vor, wenn β2+β3 = 1.Die Nullhypothese ist also
H0 : β2 + β3 = 1
(diese Hypothese ist ein Spezialfall von H0 : c1β2+ c2β3 = β0 mit c1 = c2 = β0 = 1)
Die entsprechende t-Statistik ist deshalb
temp =b2 + b3 − 1√
var(b2) + var(b3) + 2 cov(b2, b3)
=0.640 + 0.257− 1√
0.001206 + 0.000727 + 2× 0.000300
=−0.10255√0.002533
= −2.037595955
16Eine Cobb-Douglas Funktion hat die Form Q = AKβ2Lβ3. Durch Logarithmieren erhalt maneine in den Parametern lineare Funktion ln(Q) = β1 + β2 ln(K) + β3 ln(L), mit β1 = ln(A) dieeinfach mit OLS geschatzt werden kann.

Angewandte Okonometrie 42
Der kritische t-Wert fur einen zweiseitigen Test mit n − k = 22 Freiheitsgraden isttcrit0.025,22 = 2.0739, deshalb konnen wir die Nullhypothese konstanter Skalenertrage(sehr knapp) nicht verwerfen.
Um den p-Wert zu berechnen benotigt man den Wert der Verteilungsfunktion.Wenn wir mit Φ(x, q) den Wert der Verteilungsfunktion einer t-Verteilung mitq Freiheitsgraden an der Stelle x bezeichnen errechnet sich der p-Wert als p =2(1− Φ(+2.037595955, 22)) = 0.05379.17
Code zum Beispiel* Solche Tests sind in fast allen Statistik- undOkonometrieprogrammen fix implementiert, aber man kann sie auch einfach pro-grammieren.
R:rm(list=ls(all=TRUE))
CD <- read.table("https://www.uibk.ac.at/econometrics/data/prodfunkt.csv",
dec = ".", sep=";", header=TRUE)
eq1 <- lm(log(Q) ~ log(K) + log(L), data = CD)
tstat <- (coef(eq1)[2] + coef(eq1)[3] - 1) /
sqrt(vcov(eq1)[2,2] + vcov(eq1)[3,3] + 2*vcov(eq1)[2,3])
pval <- 2*(1-(pt(abs(tstat),22)))
# oder einfacher
library(car)
linearHypothesis(eq1, "log(K) + log(L) = 1")
Stata:insheet using "https://www.uibk.ac.at/econometrics/data/prodfunkt.csv", ///
delim(";") names clear
generate logQ = log(q)
generate logK = log(k)
generate logL = log(l)
regress logQ logK logL
matrix V = e(V)
scalar tstat = (_b[logK] + _b[logL] - 1) / ///
sqrt( V[1,1] + V[2,2] + 2*V[1,2])
display "t-statistic: " tstat
display "p-value: " 2*ttail(22,abs(tstat))
* oder viel einfacher
test logK + logL = 1�
Ubung: Wie wurden Sie fur das Modell y = β1+β2x2+β3x3+ ε die Nullhypotheseβ2 = β3 testen? Zeigen Sie dies fur fur das Beispiel mit der Cobb-Douglas Funktion(Losung: temp = 10.48477, p-Wert = 0.0000).
Eine große Einschrankung dieses Tests besteht darin, dass er nicht fur den Testmehrerer Hypothesen verwendet werden kann. Zum Beispiel konnen wir damit nichtdie Nullhypothese H0 : β2 = 0 und β3 = 0 simultan testen. Solche Tests simultanerHypothesen werden wir in einem spateren Abschnitt besprechen.
17In EViews ist der Befehl dazu coef p = 2*(1-@ctdist(@abs(-2.037596),22)); in Excelerhalten Sie den p-Wert mit der Funktion ‘=TVERT(ABS(-2.037595955);22;2)’

Angewandte Okonometrie 43
5.3.5 Einseitige Tests
Einseitige Hypothesentests laufen exakt nach dem gleichen Muster ab, nur in zweiDetails unterscheiden sie sich von zweiseitigen Tests. Erstens liegt der Verwerfungs-bereich je nach Richtung der Nullhypothese zur Ganze am linken oder am rechtenEnde der Dichtefunktion, deshalb ist der kritische Wert α (statt wie beim zweiseiti-gen Test α/2) zu wahlen, und zweitens ist naturlich das Vorzeichen des empirischenund des kritischen Wertes (temp und tcritα ) zu beachten. Im ubrigen gilt, was schonzu einseitigen Tests nach Fisher gesagt wurde.
Die Begriffe linksseitig bzw. rechtsseitig beziehen sich jeweils auf den Verwerfungs-bereich, bei linksseitigen Tests liegt dieser zur Ganze im negativen Bereich der Zah-lengerade, bei rechtsseitigen Tests im positiven Bereich der Zahlengerade. Dement-sprechend liegt die Null immer im Bereich der Nullhypothese.
Abbildung 5.12 soll den Unterschied zwischen ein- und zweiseitigen Hypothesentestsverdeutlichen. Die obere Abbildung zeigt den bisherigen zweiseitigen Test, die untereAbbildung einen rechtsseitigen Test (d.h. einen Test fur H0 : µ ≤ µ0), und dieunterste Abbildung einen linksseitigen Test fur H0 : µ ≥ µ0.
Hinweis: Wenn man unsicher ist wo der Verwerfungsbereich einer einseitigen Null-hypothese liegt ist es manchmal nutzlich die Nullhypothese in impliziter Form zuschreiben, d.h. statt H0 : µ ≤ µ0 schreiben wir H0 : µ − µ0 ≤ 0. In dieser Form isteinfach zu erkennen, dass negative Werte nicht im Widerspruch zur Nullhypothesestehen, und aufgrund des stochastischen Charakters sind auch kleine positive Wertekeine große Uberraschung. Erst Werte die großer sind als der kritische Wert tcritα ste-hen in starkem Widerspruch zur H0, deshalb wird der Verwerfungsbereich zur Ganzeim positiven Bereich liegen, es handelt sich also um eine rechtsseitige Hypothese.
Analoges gilt fur linksseitige Hypothesen.
rechtsseitig: linksseitig:H0 : µ− µ0 ≤ 0 H0 : µ− µ0 ≥ 0
Akzeptanzbereich: [−∞,+tcritα ] [−tcritα ,+∞]
Verwerfungsbereich: (+tcritα ,+∞] [−∞,−tcritα )
Beispiel: Wir haben in einem fruheren Beispiel (Abschnitt 5.3.2, Seite 36) mitder Korpergroße gesehen, dass wir die H0 : µ = 175 fur n = 20 auf einem 1%Signifikanzniveau nicht verwerfen konnen.
Konnen wir die einseitige Nullhypothese µ ≥ 175, bzw. µ − 175 ≥ 0 auf einem 1%Signifikanzniveau verwerfen?
Positive Werte der Teststatistik widersprechen dieser Nullhypothese nicht, selbstleicht negative Werte konnen zufallig passieren, aber stark negative Werte stehenim Widerspruch zur Nullhypothese. Deshalb handelt es sich um eine linksseitigeHypothese, der Verwerfungsbereich liegt zur Ganze im negativen Bereich. kritischenWert fur α = 0.01 (einseitig!) ist tcrit0.001,19 = 2.539.
Der neue Verwerfungsbereich ist also [−∞, −2.539].
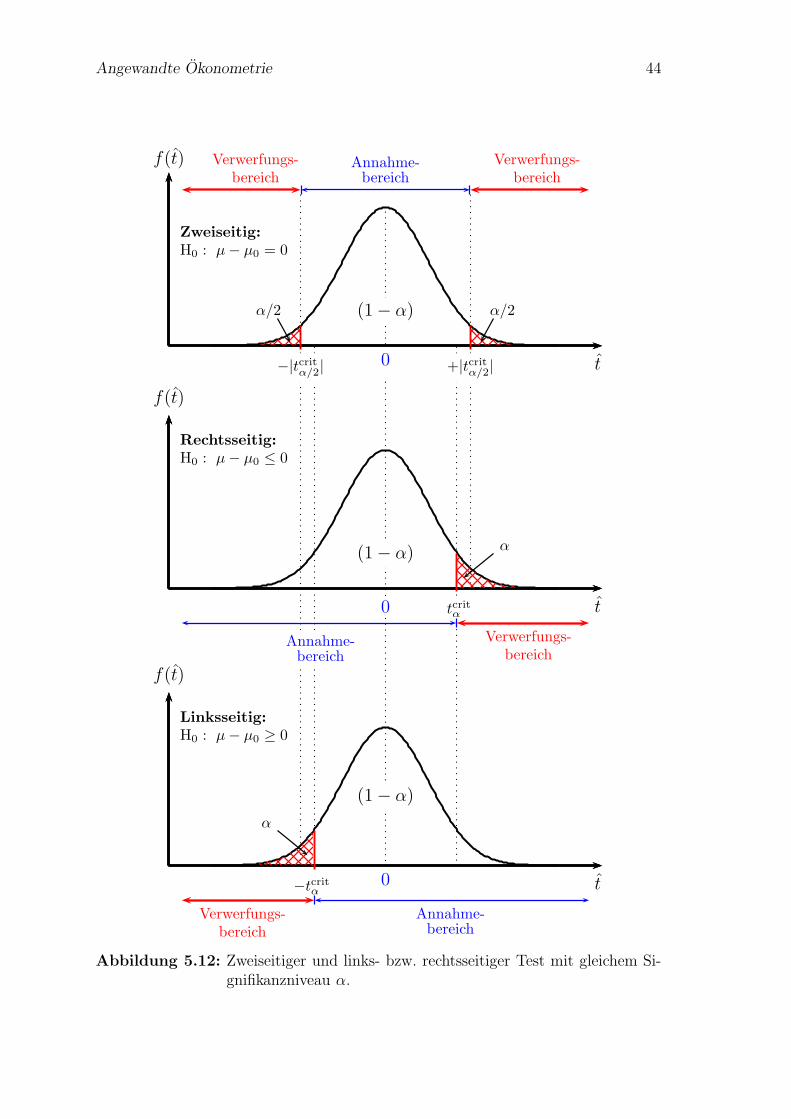
Angewandte Okonometrie 44
f(t)
t
(1− α) α/2α/2
0 +|tcritα/2|−|tcritα/2|
Annahme-bereich
Verwerfungs-bereich
Verwerfungs-bereich
Zweiseitig:H0 : µ− µ0 = 0
f(t)
t0 tcritα
(1− α) α
Annahme-bereich
Verwerfungs-bereich
Rechtsseitig:H0 : µ− µ0 ≤ 0
f(t)
t0−tcritα
(1− α)
α
Annahme-bereich
Verwerfungs-bereich
Linksseitig:H0 : µ− µ0 ≥ 0
Abbildung 5.12: Zweiseitiger und links- bzw. rechtsseitiger Test mit gleichem Si-gnifikanzniveau α.

Angewandte Okonometrie 45
Der empirische t–Wert ist davon nicht betroffen, er bleibt gleich
temp =x− µ0
sµ=
170.55− 175√79.5220
= −2.231
Wie Sie sehen fallt temp auch nicht in den Verwerfungsbereich der linksseitige Null-hypothese, d.h. wir konnen auch die einseitige H0 : µ ≥ 175 nicht auf einem 1%Signifikanzniveau verwerfen. �
Durch die Einfuhrung einer expliziten Alternativhypothese und eines a priori festge-legten Signifikanzniveaus α kann eine eindeutige Entscheidungsregel gefunden wer-den, ob die Nullhypothese verworfen oder nicht verworfen werden soll. Diese Ent-scheidungsregel ist zwar eindeutig, aber das bedeutet nicht, dass die Entscheidungauch richtig sein muss.
5.3.6 Konfidenzintervalle, Fishers p-Wert und Neyman
Pearsons Signifikanzniveau
Konfidenzintervalle, p-Werte und die Entscheidungsregel nach Neyman-Pearson be-ruhen letztendlich alle auf der gleichen Information, deshalb ist es wenig verwun-derlich, dass sie alle zu gleichen Schlussfolgerungen fuhren und in einem gewissenSinne auch austauschbar sind.
Wenn wir z.B. ein 1 − α Konfidenzintervall fur µ zeichnen, und der Wert µ0 derH0 : µ = µ0 innerhalb dieses Konfidenzintervalls liegt, so konnen wir diese H0 nichtablehnen, wenn µ0 aber außerhalb dieses Konfidenzintervalls liegt werden wir die H0
ablehnen.
Ein Konfidenzintervall ist einfach ein Intervall auf der Linie der reellen Zahlen,welches alle reellen Zahlen µ0 enthalt, fur die die Nullhypothese µ = µ0 durch einenentsprechenden Hypothesentest nicht abgelehnt werden kann (vgl. Davidson andMacKinnon, 2003, 177).
Ahnlich verhalt es sich mit den p-Werten. Wenn wir Fishers p-Wert fur einenHypothesentest nach Neyman-Pearson heranziehen wollen brauchen wir nur zuuberprufen, ob der empirische p-Wert großer oder kleiner als das vorher festgelegt Si-gnifikanzniveau α ist. In diesem Fall gibt uns der p-Wert die zusatzliche Information,‘wie stark’ die Nullhypothese abgelehnt (bzw. akzeptiert) wurde.
Allerdings sollte dies nicht daruber hinweg tauschen, dass diese Methoden fur un-terschiedliche Zielsetzungen entwickelt wurden. Konfidenzintervalle sollten uns inerster Linie Information uber die Genauigkeit von Schatzern geben, wahrend Hypo-thesentests uns erlauben zu uberprufen, inwieweit eine a priori vermutete Hypothesemit den beobachteten Stichprobendaten kompatibel ist.
Die Unterscheidung zwischen der Methodologie von Fisher und der von Neyman-Pearson erfolgte hier eher aus padagogischen Grunden, wie schon erwahntprasentieren die meisten Lehrbucher eine Hybridform dieser beiden Testmethoden(fur eine Diskussion siehe z.B. Gigerenzer et al., 1990).
Dem war aber nicht immer so, wie schon erwahnt konnte sich Fisher bis zu sei-nem Lebensende nicht mit der Methode von Neyman-Pearson anfreunden und sahzwischen diesen beiden Methoden unuberbruckbare Gegensatze. Fisher schreibt

Angewandte Okonometrie 46
“Moreover, it is a fallacy, so well known as to be a standard example, toconclude from a test of significance that the null hypothesis is therebyestablished; at most it may be said to be confirmed or strengthened. Inan acceptance procedure, on the other hand, acceptance is irreversible,whether the evidence for it was strong or weak. It is the result of ap-plying mechanically rules laid down in advance; no thought is given tothe particular case, and the tester’s state of mind, or his capacity forlearning, is inoperative. By contrast, the conclusions drawn by a scien-tific worker from a test of significance are provisional, and involve anintelligent attempt to understand the experimental situation.” (Fisher,1955, 73f)
Historisch gesehen hat sich die Vorgangsweise von Neyman-Pearson weitgehend ge-genuber Fisher durchgesetzt, und Fishers p-Wert wird heute vielfach fur Tests imSinne von Neyman-Pearson verwendet, indem er mit dem vorgegebenen Signifikanz-niveau α verglichen wird.
5.3.7 Typ I und Typ II Fehler
Aufgrund des stochastischen Charakters der Teststatistik konnen zwei Arten vonFehlentscheidungen passieren. Zum einen kann eine tatsachlich richtige Nullhypo-these irrtumlich verworfen werden (Typ I Fehler, Verwerfungsfehler), oder einetatsachlich falsche Nullhypothese kann irrtumlich nicht verworfen werden (Typ IIFehler, Nicht-Verwerfungsfehler). Dies wird in Tabelle 5.2 dargestellt.
Tabelle 5.2: Typ I und Typ II Fehler
Entscheidung auf Wahrer WahrerGrundlage eines Sachverhalt: Sachverhalt:statistischen Tests: H0 ist wahr H0 ist falschNullhypothese H0 korrekte Entscheidungwird nicht verworfen (1− α)
Typ II Fehler
Nullhypothese H0 korrekte Entscheidungwird verworfen
Typ I Fehler(1− β: “Power”)
Eine Nullhypothese H0 : µ1 − µ2 = 0 besagt, dass sich die Mittelwerte zweier Grup-pen nicht unterscheiden. In diesem Fall bedeutet ein Typ I Fehler, dass wir dieNullhypothese verwerfen, obwohl in der Grundgesamtheit kein Unterschied besteht.Tatsachlich existiert also kein Unterschied in den Gruppen, aber da die empirischeTeststatistik in den Verwerfungsbereich fallt verwerfen wir sie irrtumlich. In anderenWorten, wir schließen aufgrund des Tests, dass es statistisch signifikante Unterschie-de zwischen den Gruppen gibt, aber dieser Schluss ist falsch!
Bei einem Typ II Fehler verwerfen wir die H0 : µ1 − µ1 = 0 irrtumlich nicht. Dasheißt, es existieren zwar tatsachlich Unterschiede zwischen beiden Gruppen, aberweil die empirische Teststatistik in den Akzeptanzbereich fallt entscheiden wir unsdie Nullhypothese nicht zu verwerfen.

Angewandte Okonometrie 47
In diesem Sinne bedeutet ein Typ II Fehler immer eine “verpasste Entdeckung”, eintatsachlich existierender Unterschied wird nicht erkannt.
Man beachte, dass die Entscheidung immer auf Grundlage der H0 erfolgt, dieublicherweise als Negativhypothese zu unserer Anfangsvermutung formuliert wird.Dies impliziert eine Asymmetrie zwischen Null- und Alternativhypothese. Um dieseAsymmetrie zu rechtfertigen werden Hypothesentests nach Neyman-Pearson haufigmit der Unschuldsvermutung bei einem Gerichtsprozess verglichen. In einer Welt oh-ne Unsicherheit sollten Unschuldige frei gesprochen und Schuldige verurteilt werden.In einer Welt mit Unsicherheit kann es bei Indizienprozessen allerdings passieren,dass analog zu einem Typ I Fehler ein Unschuldiger verurteilt wird, oder – analogzu einem Typ II Fehler – ein Schuldiger freigesprochen wird; vergleiche Tabelle 5.3.
Tabelle 5.3: Vergleich Typ I und Typ II Fehler mit einem Gerichtsurteil
Angeklagter Angeklagterist unschuldig ist schuldig
Gericht falltEntscheidung richtige Entscheidung
Schuldiger wird
“unschuldig”freigesprochen
Gericht falltEntscheidung
Unschuldigerrichtige Entscheidung
“schuldig”wird verurteilt
Wenn alle erforderlichen Annahmen erfullt sind wird die Wahrscheinlichkeit einenTyp I Fehler zu machen unmittelbar durch das Signifikanzniveau α bestimmt.
Pr [Typ I Fehler] = Pr [H0 ablehnenH0|H0 wahr]
= α
Man beachte, dass es sich dabei um eine bedingte Wahrscheinlichkeit handelt: α gibtdie Wahrscheinlichkeit dafur an, dass die Teststatistik in den Verwerfungsbereichfallen wird, gegeben dass die Nullhypothese wahr ist.
Wann immer die potentiellen Kosten eines Typ I Fehlers sehr hoch sind sollte einentsprechend kleines Signifikanzniveau gewahlt werden (z.B. α = 0.01).
Es zeigt sich aber, dass auch dies Kosten hat, denn die Wahl eines kleinen α erhohtautomatisch die Wahrscheinlichkeit eines Typ II Fehlers.
Ein Typ II Fehler (manchmal auch β-Fehler genannt) ist ein ‘Nicht-VerwerfungsFehler’, eine tatsachlich falsche Nullhypothese wird nicht abgelehnt
Pr [Typ II Fehler] = Pr [H0 nicht ablehnen|H0 falsch]
Dies wird anhand des Vergleichs mit einem Indizienprozess unmittelbar klar. Wennman unbedingt vermeiden mochte einen Unschuldigen zu verurteilen (Typ I Fehler)und deshalb sehr strenge Anforderungen an die Beweise stellt (ein kleines α wahlt),

Angewandte Okonometrie 48
Abbildung 5.13: Typ II Fehler; Quelle: die (Un-)Tiefen des Internets.
wird dies automatisch dazu fuhren, dass mancher Schuldige irrtumlich freigesprochenwird (Typ II Fehler).
Wie schon erwahnt kann man sich einen Typ II Fehler intuitiv als eine verpassteChance vorstellen, eine nicht gemachte Entdeckung. Bei einem Typ II Fehler ist dieNullhypothese tatsachlich falsch, der gesuchte Zusammenhang existiert in Wahrheit,aber unsere Teststatistik versagt und wir erkennen den Zusammenhang nicht.
Beispiel Stellen Sie sich vor, es gibt 1000 zu testende Hypothesen, und 100 davonsind tatsachlich war. Aufgrund des Typ I Fehlers wurden Sie bei einem α = 0.05 ca.45 (5% von 900) tatsachlich falsche Hypothesen fur richtig halten.
Aufgrund des Typ II Fehlers wurden Sie einige der tatsachlich richtigen Hypothesennicht erkennen, d.h. fur falsch halten. Wie groß dieser Anteil ist hangt von mehrerenFaktoren ab, u.a. – wie wir spater sehen werden – vom Siginifikanzniveau α. �
Um diese zwei Arten von Fehlern grafisch darstellen zu konnen wahlen wir eine sehreinfache Null- und Alternativhypothese
H0 : µ = µ0 gegen HA : µ = µA
wobei µ0 und µA fixe Zahlen sind, d.h. sowohl Null- als auch Alternativhypotheseumfassen nur einen einzelnen Punkt. Abbildung 5.14 zeigt die Stichprobenkennwert-verteilungen unter H0 und HA.
Die linke durchgezogene Verteilung in Abbildung 5.14 ist die Stichprobenkenn-wertverteilung von µ unter Gultigkeit der Nullhypothese. Wenn die Nullhypothe-se tatsachlich wahr ist fallen bei oftmaliger Wiederholung α × 100 Prozent dergeschatzten µ in den Bereich rechts von tcrit (einseitiger Test), und die schraffierteFlache daruber gibt die Wahrscheinlichkeit fur einen Typ I Fehler an.
Ein Typ II Fehler passiert hingegen, wenn eine tatsachlich falsche Nullypothese nichtverworfen wird. Wenn die Nullypothese falsch ist muss die Alternativhypothese wahrsein, in diesem einfachen Fall also µ = µA.
Die rechte strichlierte Verteilung in Abbildung 5.14 zeigt die Stichprobenkennwert-verteilung von µ wenn die Alternativhypothese richtig ist. Die Wahrscheinlichkeit

Angewandte Okonometrie 49
f(µ)
µ
Stichprobenkennwert-verteilung unterH0 : µ = µ0
µ0
bc
Stichprobenkennwert-verteilung unterHA : µ = µA
µAbc
Typ IFehler
Typ IIFehler
H0 nicht verwerfen H0 verwerfen
tcritαgr
f(µ)
µ
Stichprobenkennwert-verteilung unterH0 : µ = µ0
µ0
bc
Stichprobenkennwert-verteilung unterHA : µ = µA
µAbc
Typ IFehler
Typ IIFehler
H0 nicht verwerfen H0 verwerfen
tcritαkl
Abbildung 5.14: Typ I und Typ II Fehler: Durch die Wahl eines hoheren Signifi-kanzniveaus (d.h. kleineren α) sinkt die Wahrscheinlichkeit einesTyp I Fehlers, aber dadurch steigt die Wahrscheinlichkeit einesTyp II Fehlers.[Folien: local]

Angewandte Okonometrie 50
eines Typ II Fehlers, also dass die Alternativhypothese richtig und die Nullhypothe-se trotzdem nicht abgelehnt wird, entspricht der horizontal schraffierten Flache inAbbildung 5.14 (die Flache unter der strichliert gezeichneten Verteilung links vontcrit).
Wie man aus dem Vergleich der oberen und unteren Abbildung erkennen kann fuhrtdie Wahl eines kleineren α zwar zu einer Abnahme der Wahrscheinlichkeit eines TypI Fehlers, aber gleichzeitig zur Zunahme der Wahrscheinlichkeit eines Typ II Fehlers!
Tatsachlich wissen wir nicht, ob die Null- oder die Alternativhypothese richtig ist,deshalb wissen wir auch nicht welche der beiden Stichprobenkennwertverteilungendie wahre ist. Aber wir wissen, dass nur entweder die Nullhypothese oder die Alter-nativhypothese richtig sein kann.
Wenn die Stichprobenkennwertverteilung unter H0 wahr ist, machen wir bei einemeinseitigen Test in α×100 Prozent der Falle einen Typ I Fehler. Wenn aber die Alter-nativhypothese wahr ist machen wir einen Typ II Fehler, dessen Wahrscheinlichkeitin Abbildung 5.14 durch die Flache des horizontal schraffierten Bereichs (links vontcrit) gegeben ist. Man beachte, dass der Wert des Typ II Fehlers auch vom wahrenµ abhangt.
Daraus lassen sich zwei wichtige Schlussfolgerungen ziehen:
1. Die Wahrscheinlichkeit von Typ I und Typ II Fehler sind invers verknupft, d.h.die Wahl eines hohen Signifikanzniveaus (kleinen α) reduziert zwar die Wahr-scheinlichkeit eines Typ I Fehlers, aber erhoht gleichzeitig die Wahrscheinlich-keit eines Typ II Fehlers (vergleiche obere und untere Grafik in Abbildung5.14).
2. Die Wahrscheinlichkeit eines Typ II Fehlers ist ceteris paribus umso großer, jenaher µA bei µ0 liegt.
Auch wenn es nicht moglich ist beide Arten von Fehlern gleichzeitig zu kontrollieren,so kann man doch zeigen, dass diese Teststrategie zumindest ‘bestmoglich’ in demSinne ist, dass sie unter bestimmten Annahmen fur eine gegebene Wahrscheinlichkeiteines Typ I Fehlers die Wahrscheinlichkeit eines Typ II Fehlers minimiert.
5.3.8 Trennscharfe (Power) eines Tests
Erinnern wir uns, Neyman-Pearson entwickelten ihre Methode u.a. um ein Kriteriumzu finden, das eine Beurteilung der Gute von Testfunktionen ermoglichen sollte. Idealware naturlich ein Test, der falsche Nullhypothesen mit Wahrscheinlichkeit Einsverwirft und korrekte Nullyhpothesen mit Wahrscheinlichkeit Eins nicht verwirft,aber eine solche Teststatistik existiert fur reale Situationen naturlich nicht.
Da die Wahrscheinlichkeiten fur Typ I und Typ II Fehler invers verknupft sind ist eshoffnungslos einen Test zu suchen, der beide Arten von Fehler minimiert. Deshalbentschieden sich Neyman-Pearson die Wahrscheinlichkeit fur einen Typ I Fehler –das Signifikanzniveau α – vorzugeben und Tests zu suchen, die fur ein vorgegebenesα die Wahrscheinlichkeit eines Typ II Fehlers minimieren. Das impliziert indirekt,dass Null- und Alternativhypothese asymmetrisch behandelt werden, ahnlich wie bei
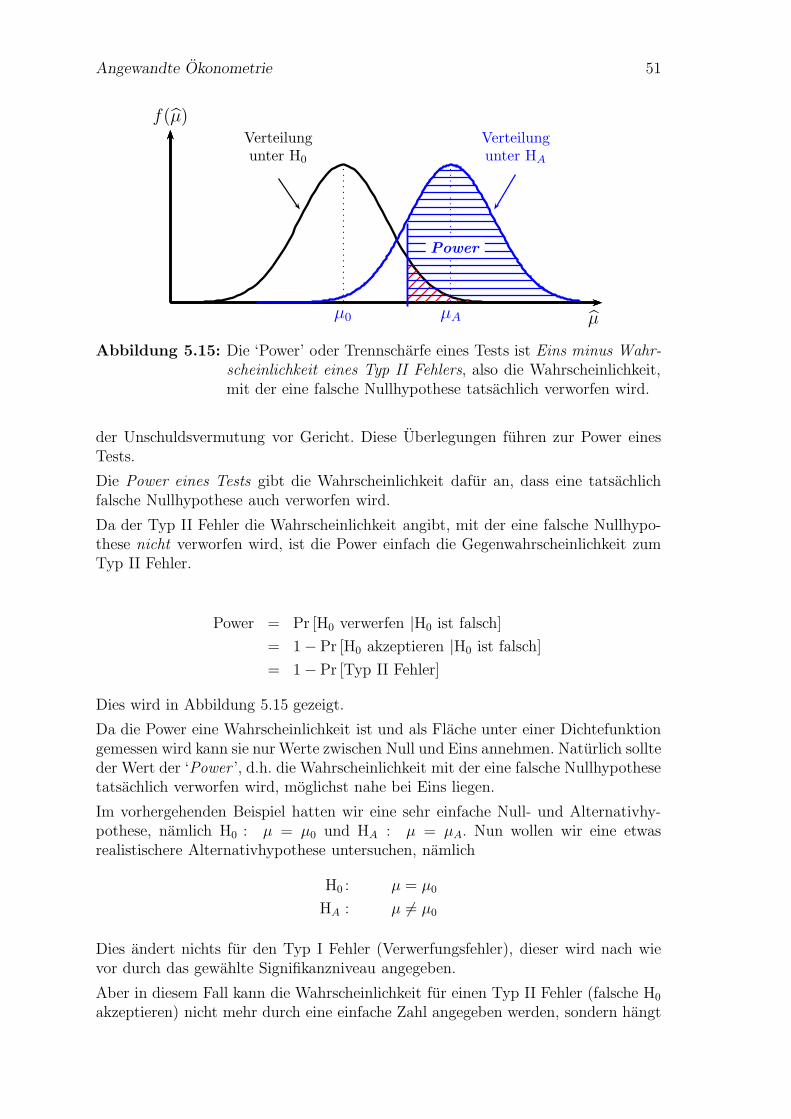
Angewandte Okonometrie 51
f(µ)
µ
Verteilungunter H0
µ0
Verteilungunter HA
µA
Power
Abbildung 5.15: Die ‘Power’ oder Trennscharfe eines Tests ist Eins minus Wahr-scheinlichkeit eines Typ II Fehlers, also die Wahrscheinlichkeit,mit der eine falsche Nullhypothese tatsachlich verworfen wird.
der Unschuldsvermutung vor Gericht. Diese Uberlegungen fuhren zur Power einesTests.
Die Power eines Tests gibt die Wahrscheinlichkeit dafur an, dass eine tatsachlichfalsche Nullhypothese auch verworfen wird.
Da der Typ II Fehler die Wahrscheinlichkeit angibt, mit der eine falsche Nullhypo-these nicht verworfen wird, ist die Power einfach die Gegenwahrscheinlichkeit zumTyp II Fehler.
Power = Pr [H0 verwerfen |H0 ist falsch]
= 1− Pr [H0 akzeptieren |H0 ist falsch]
= 1− Pr [Typ II Fehler]
Dies wird in Abbildung 5.15 gezeigt.
Da die Power eine Wahrscheinlichkeit ist und als Flache unter einer Dichtefunktiongemessen wird kann sie nur Werte zwischen Null und Eins annehmen. Naturlich sollteder Wert der ‘Power ’, d.h. die Wahrscheinlichkeit mit der eine falsche Nullhypothesetatsachlich verworfen wird, moglichst nahe bei Eins liegen.
Im vorhergehenden Beispiel hatten wir eine sehr einfache Null- und Alternativhy-pothese, namlich H0 : µ = µ0 und HA : µ = µA. Nun wollen wir eine etwasrealistischere Alternativhypothese untersuchen, namlich
H0 : µ = µ0
HA : µ 6= µ0
Dies andert nichts fur den Typ I Fehler (Verwerfungsfehler), dieser wird nach wievor durch das gewahlte Signifikanzniveau angegeben.
Aber in diesem Fall kann die Wahrscheinlichkeit fur einen Typ II Fehler (falsche H0
akzeptieren) nicht mehr durch eine einfache Zahl angegeben werden, sondern hangt

Angewandte Okonometrie 52
von µ ab. Wenn µ sehr nahe bei µ0 liegt wird ceteris paribus die Wahrscheinlichkeitfur einen Typ II Fehler hoher sein, und also die Power des Tests niedriger sein.
Dies wird in Abbildung 5.16 gezeigt, die ‘Power’ ist ceteris paribus umso großer, jeweiter der ‘wahre’ Wert µ von µ0 entfernt liegt, sie hangt also von µ ab. Wenn mandie Power als Funktion aller moglichen µ darstellt erhalt man die Teststarkefunktion(‘power function’ ), die im untersten Panel von Abbildung 5.16 dargestellt ist.
Effizientere Schatzfunktionen erlauben trennscharfere Tests
Die ‘Power’ eines Tests nimmt mit der Stichprobengroße zu. Abbildung 5.17 zeigtin der oberen Grafik die Power fur eine kleine Stichprobe (kleines n), und in derunteren Grafik fur eine große Stichprobe. Die zugrunde liegende Null- und Alter-nativhypothese ist in beiden Grafiken gleich. Offensichtlich ist die ‘Power’ bei dergroßen Stichprobe deutlich großer!
Man beachte, dass die Power aus zwei Grunden zunimmt: erstens ist die Varianzder unbeobachtbaren wahren Verteilung bei einer großeren Stichprobe kleiner, undzweitens liegt der kritische Wert der Verteilung tcritαg
naher beim µ0.
Abbildung 5.18 zeigt zwei typische Teststarkefunktionen, eine mit kleinerer ‘Power’(strichlierte Linie) und eine mit großerer ‘Power’.
Frage: Wie sieht die Power-Funktion fur einseitige (links- bzw. rechtsseitige) Testsaus?
5.4 Wie vertrauenswurdig sind publizierte Hypo-
thesentests?
Von Ehen sagt man, dass sie im Himmel geschlossen, aber auf Erden ausgetragenwerden. Ahnlich verhalt es sich mit Hypothesentests, die Theorie wurde ohne Zweifelvon Genies entwickelt, aber ihre Anwendung auf Erden ist nicht immer uber jedenZweifel erhaben.
Es gibt eine ganze Reihe von Grunden, warum man bei Hypothesentests, derengenaues Zustandekommen man nicht kennt (was bei praktisch allen publiziertenStudien der Fall ist) skeptisch bleiben sollte.
5.4.1 Fehlspezifikationen und nicht identifizierte Modelle
Wir haben schon fruher betont, dass der ‘wahre’ datengenerierende Prozess (DGP)nicht beobachtbar ist. Um diesen schatzen zu konnen mussen wir aber Annahmendaruber treffen, wie er aussieht, wir mussen eine Spezifikation wahlen. Wenn wirdabei wichtige Variablen ubersehen, eine falsche Funktionsform unterstellen, oder‘feed-back’ Mechanismen ubersehen, fuhrt dies zu einer Fehlspezifikation und dieresultierenden Schatzer sind weder erwartungstreu noch konsistent.
Außerdem haben wir bisher immer vollig selbstverstandlich echte Zufallsstichprobenunterstellt. Tatsachlich konnen solche fast nur in Lehr- und Marchenbuchern beob-achtet werden. In vielen Fallen ist es fast ein Ding der Unmoglichkeit eine echte

Angewandte Okonometrie 53
0.2
0.4
1 2 3 4 5 6−1−2−3−4−5
Power
f(β)Verteilungunter H0
Verteilungunter HA
1 2 3 4 5 6−1−2−3−4−5
Verteilungunter H0
Verteilungunter HA
1 2 3 4 5 6−1−2−3−4−5
1 2 3 4 5 6−1−2−3−4−5
1 2 3 4 5 6−1−2−3−4−5
1 2 3 4 5 6−1−2−3−4−5
Power
Verteilungunter H0
Verteilungunter HA
1 2 3 4 5 6−1−2−3−4−5
Power
1.0
0.5
α
Abbildung 5.16: Powerfunktion eines zweiseitigen Tests. Die Power ist eine Funk-tion vom wahren Wert µ.
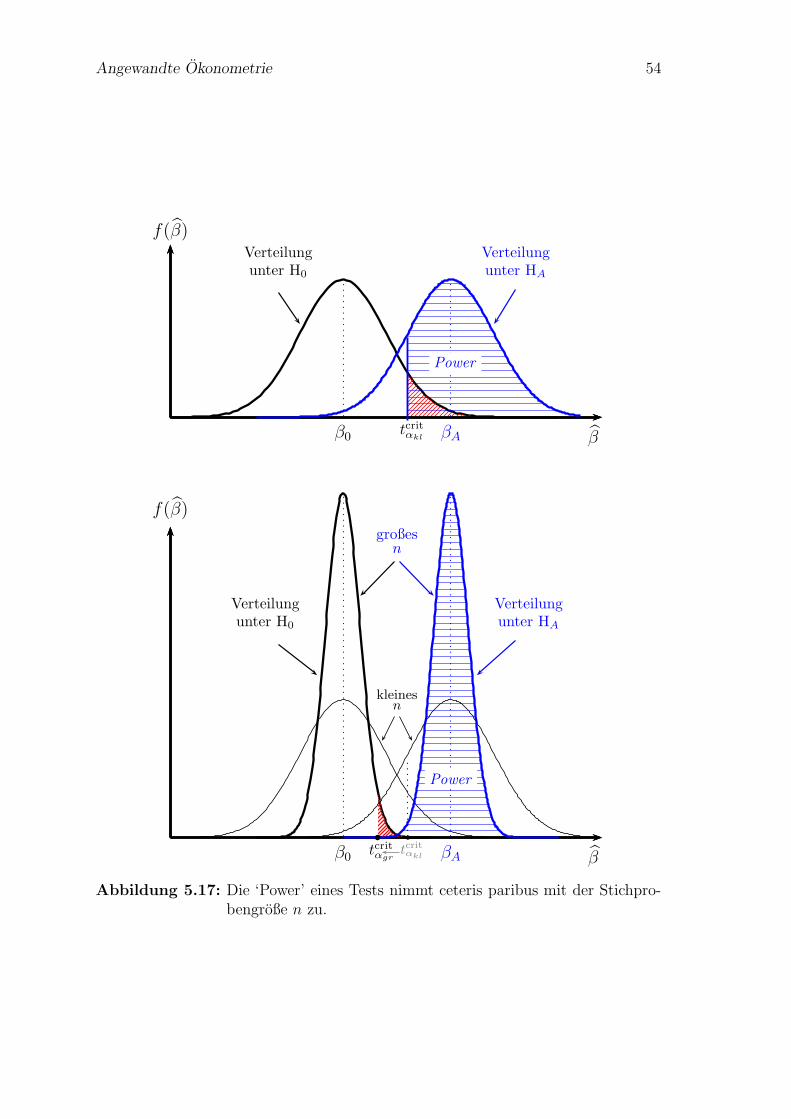
Angewandte Okonometrie 54
f(β)
β
Verteilungunter H0
β0
Verteilungunter HA
βA
Power
tcritαkl
f(β)
β
Verteilungunter H0
β0
Verteilungunter HA
βA
großesn
kleinesn
tcritαkltcritαgr
b b
Power
Abbildung 5.17: Die ‘Power’ eines Tests nimmt ceteris paribus mit der Stichpro-bengroße n zu.

Angewandte Okonometrie 55
µµ0
α0
0.5
1.0
Abbildung 5.18: Teststarkefunktionen (‘Power Functions’) fur zwei Tests (zwei-seitig). Die durchgezogene Teststarkefunktion hat eine großere‘Power’ als die strichlierte.
Zufallsstichprobe zu ziehen und – bei Befragungen – immer ehrliche Antworten zuerhalten. Verzerrte Stichproben fuhren zu verzerrten Ergebnissen, und daran kannkein Hypothesentest etwas andern!
Selbstverstandlich sind auch die Teststatistiken solcher fehlspezifizierter Modellevollig wertlos.
Ein verwandtes Problem sind nicht identifizierte Modelle. Zur Erinnerung, bei nichtidentifizierten Modellen reicht selbst die Kenntnis der ‘wahren’ gemeinsamen Vertei-lung der relevanten Variablen nicht aus um die interessierenden Parameter konsistentschatzen zu konnen. Schatzungen sowie Hypothesentests solcher nicht identifizierterModelle konnen nicht interpretiert werden und sind ebenfalls wertlos.
Statistische Tests setzen korrekt spezifizierte und identifizierbare Modelle voraus.Sind die Modelle falsch spezifiziert sind die Tests nicht interpretierbar. Um Hinweisefur eine moglichst korrekte Spezifikation zu finden ist theoretisches Nachdenkenunumganglich.
Ohne theoretischer Vorarbeit kann auch leicht passieren, was ein beruhmter Stati-stiker einmal einen Typ III Fehler nannte.
“In 1948, Frederick Mosteller (1916-2006) argued that a ‘third kind oferror’ was required to describe circumstances he had observed, namely:
• Type I error: ‘rejecting the null hypothesis when it is true’.
• Type II error: ‘accepting the null hypothesis when it is false’.
• Type III error: ‘correctly rejecting the null hypothesis for the wrongreason’.”1819
18zitiert aus Wikipedia: http://en.wikipedia.org/wiki/Type_I_error; Quelle: Mosteller, F.,A k-Sample Slippage Test for an Extreme Population, The Annals of Mathematical Statistics,Vol.19, No.1, (March 1948), pp.58-65.
19Ein Vorschlag fur einen Typ IV Fehler stammt von dem Harvard Okonom Howard Raiffa,“solving the right problem too late”.

Angewandte Okonometrie 56
Ein nettes Beispiel fur einen solchen ‘Type III error’ liefert die Medizin20
“Selbstversuche haben in der Medizin Tradition. An die Grenze dermenschlichen Belastbarkeit ging dabei der angehende Arzt StubbinsFfirth am Anfang des 19. Jahrhunderts. Er war uberzeugt, dass Mala-ria nicht ansteckend ist, sondern auf ubermaßige Hitze, Essen und Larmzuruckzufuhren sei.
Um seine These zu erharten, setzte er sich selbst der Krankheit aus.Zuerst brachte er nur kleine Mengen von frischem Erbrochenem in sichselbst zugefugte kleine Kratzer ein. Danach tropfte er kleine Mengen inseine Augen. Am Ende der Testreihe aß er die frischen Exkremente einesKranken. Wie durch ein Wunder blieb er tatsachlich gesund. Er sah seineBehauptung somit belegt.”
Der wackere Stubbins Ffirth konnte damals nicht wissen, dass die Malaria durchden Biss der weiblichen Stechmucke Anopheles ubertragen wird, sein heldenmutigerVerzehr frischer Exkremente lieferte offensichtlich keinen Beweis fur die Richtigkeitseiner Hypothese, dass Hitze, Larm und schlechtes Essen die Ursache fur die Malariasei.
Im okonometrischen Sinne ist ihm ein Spezifikationsfehler unterlaufen. Selbst wenner entsprechende Beobachtungsdaten gesammelt und einen Hypothesentest durch-gefuhrt hatte, hatte ihm dies wenig geholfen. Er hatte genauso festgestellt, dass Hitzedie Wahrscheinlichkeit an Malaria zu erkranken statistisch signifikant erhoht, weiler nicht berucksichtigte, dass die Anopheles Mucke vorwiegend in heißen Gegendenvorkommt (‘omitted variable bias’ ).
5.4.2 Data- and Estimator Mining (p-hacking)
Die Theorie der Hypothesentests beruht darauf, dass eine a priori festgelegte Nullhy-pothese einmalig mit den Daten konfrontiert wird. Da die Grundgesamtheit (bzw.der ‘wahre’ datengenerierende Prozess) nicht beobachtbar ist, ist die Versuchunggroß, verschiedene Spezifikationen ‘zu probieren’. Wenn wir bei einem Signifikanzni-veau von 5% hundert Spezifikationen ‘probieren’ mussen wir damit rechnen, in funfFallen die Nullhypothesen irrtumlich zu verwerfen (Typ I Fehler). Es sollte klar sein,dass derart zustande gekommene Ergebnisse wertlos sind.
Ein verwandtes Problem entsteht, wenn man verschiedene Schatz- und Testverfahrenprobiert und anschließend die statistisch signifikanten Ergebnisse selektiert.
Nach Leeb and Potscher (2008) fuhrt die Auswahl von Modellen anhand von vor-ausgehenden Tests (z.B. Modellselektionskriterien wie das R2 oder Aikaike Infor-mationskriterium) dazu, dass die Schatzung von Parametern aus solchen Modellennicht einmal konsistente Ergebnisse liefert, wenn die Schatzung auf der gleichenDatengrundlage erfolgt wie die Modellselektion.21
20zitiert aus http://science.orf.at/science/news/149922, [05.11.2007].21“We consider the problem of estimating the unconditional distribution of a post-model-selection
estimator. The notion of a post-model-selection estimator here refers to the combined procedureresulting from first selecting a model (e.g., by a model-selection criterion such as the Akaike infor-

Angewandte Okonometrie 57
Daten-generierenderProzess (DGP)
“Welt”(nicht direkt beobachtbar)
ModellBeschreibung
& Erklarung
Beobachtungen
Daten
schatzen
&testen
(fur
gegebeneSp
ezifikation!)
Spezifikation
Theorie
Forscherin
Abbildung 5.19: Die ubliche Schatz- und Testtheorie setzt eine korrekte Spezifi-kation voraus. Wenn die Spezifikationssuche datengetrieben istund auf den gleichen Daten wie die Schatzung beruht konnen dieublichen Verfahren fehlerhafte Ergebnisse liefern; siehe Diskussi-on zu ‘pretest estimators’, z.B. Danilov and Magnus (2004)
.
Publizierten Resultaten von Hypothesentests kann man nicht ansehen, wie sie zu-stande gekommen sind, und es ist offensichtlich, dass der ‘publish or perish’ Druckviele Forscher verleitet, gezielt nach signifikanten Ergebnissen zu suchen.
Dies ist naturlich ein altbekanntes Problem, so warnt die American Statistical Societyin ihren ‘Ethical Guidelines for Statistical Practice’
“Running multiple tests on the same data set at the same stage of ananalysis increases the chance of obtaining at least one invalid result. Se-lecting the one ‘significant’ result from a multiplicity of parallel testsposes a grave risk of an incorrect conclusion. Failure to disclose the fullextent of tests and their results in such a case would be highly mislea-ding.”(http://www.amstat.org/about/ethicalguidelines.cfm)
Ein verwandtes Problem ist das so genannte ‘outcome switching’. Im Juli 2012verhangten amerikanische Behorden eine Rekordstrafe von drei Milliarden (!) US-Dollar uber den Pharmakonzern GlaxoSmithKline (GKS). Was war geschehen? In
mation criterion [AIC] or by a hypothesis testing procedure) and then estimating the parameters inthe selected model (e.g., by least squares or maximum likelihood), all based on the same data set.We show that it is impossible to estimate the unconditional distribution with reasonable accuracyeven asymptotically. In particular, we show that no estimator for this distribution can be uniformlyconsistent (not even locally)” (Leeb and Potscher, 2008).

Angewandte Okonometrie 58
einer Versuchsreihe – der mittlerweile beruhmten Studie 329 – wurde ein Psycho-pharmaka (Paxil) auf die Wirksamkeit in Bezug auf auf acht a priori festgelegteErgebnis-Variablen gemessen. Es zeigte sich, dass das Medikament in keiner dieseracht Variablen signifikant bessere Ergebnisse erzielte als Placebos.
Darauf hin entschieden sich die Forscher einen Zusammenhang mit 19 weiteren Va-riablen zu testen, und fanden in vier Fallen tatsachlich signifikante Ergebnisse. Inder Publikation wurden die fruheren Versuchsreihen verschwiegen und vorgegeben,dass diese vier signifikanten Ergebnisse von vornherein festgelegt worden waren.
Spater zeigte sich, dass dieses Medikament nicht nur wirkungslos in Bezug auf diesevier selektierten Ergebnisse war, sondern obendrein schwere Nebenwirkungen hatte.(The Economist, Mar 26th 2016, Clinical trials: For my next trick. . . ).22
Eine spezielle Gefahr des ‘data mining’ besteht darin, dass ex post fast jedes Resultat‘plausibel’ erklart werden kann. Nach F. Nietzsche sind Uberzeugungen die großerenFeinde der Wahrheit als Lugen!
Der Psychologe und Wirtschaftsnobelpreistrager Kahneman (2013, 85) nennt un-ser schnelles, intuitives Denken “a machine for jumping to conclusions”. Dies istbesonders gefahrlich, wenn Ergebnisse kausal interpretiert werden. Hypothesentestsalleine konnen nie Kausalitaten bestatigen, sondern bestenfalls Assoziationen.
Auf diese Gefahr wird manchmal mit dem Schlagwort ‘avoid HARKing’ verwiesen,wobei der Begriff HARKing ein englisches Akronym fur “Hypothesizing After theResults are Known” ist.
Erschwert wird dieses Problem noch dadurch, dass Forscher wie alle anderen Men-schen ‘Fehlwahrnehmungen’ unterliegen, wie z.B. dem beruhmten ‘confirmation bi-as’. Nach George Box neigen Forscher manchmal dazu, sich wie Kunstler in ihreModelle zu verlieben. Uberflussig zu erwahnen, dass dies den klaren Blick trubenkann.
Bereits dem Pionier des empirischen Denkens, Sir Francis Bacon (1561 – 1626), wardies offensichtlich nicht fremd, er schreibt
“The human understanding when it has once adopted an opinion [. . . ]draws all things else to support and agree with it. And though there be agreater number and weight of instances to be found on the other side, yetthese it either neglects and despises, or else by some distinction sets asideand rejects, in order that by this great and pernicious predeterminationthe authority of its former conclusion may remain inviolate.” (FrancisBacon, Novum Organon, XLVI, 1620)
5.4.3 Niedrige Power und Publikationsbias
Ein spezielles Problem besteht darin, dass viele Menschen ein Problem haben be-dingte Wahrscheinlichkeiten richtig zu interpretieren.
In einem korrekt durchgefuhrten Hypothesentest gibt uns der Typ I Fehler die Wahr-scheinlichkeit dafur an, dass die empirische Teststatistik in den Verwerfungsbereichfallt, wenn die Nullhypothese richtig ist.
22http://www.economist.com/news/science-and-technology/21695381-too-many-medical-trials-move-their-goalposts-halfway-through-new-initiative

Angewandte Okonometrie 59
Abbildung 5.20: Unreliable research: Trouble at the lab; Quelle: The Economist,Oct 19th 2013http://www.economist.com/blogs/graphicdetail/2013/10/daily-chart-2
In der Regel interessieren wir uns aber fur eine ganz andere Frage, namlich wie großist die Wahrscheinlichkeit, dass die Nullhypothese falsch ist, wenn die empirischeTeststatistik in den Verwerfungsbereich fallt ! Das ist offensichtlich eine ganz andereFrage, auf die uns ein einfacher Hypothesentest keine Antwort gibt.
Der Economist (Oct 19th 2013) erklart das Problem anhand eines einfachen Zah-lenbeispiels, siehe Abbildung 5.20.
Nehmen wir an es gibt 1000 zu testende Hypothesen, und 100 dieser (Alternativ-)Hypothesen seien tatsachlich wahr, die restlichen 900 falsch.
Die Forscherin weiß dies naturlich nicht, sie testet alle 1000 Hypothesen. Von dentatsachlich falschen 900 Hypothesen wird sie irrtumlich 45 als richtig klassifizieren(5% von 900, Typ I Fehler).
Wenn der gewahlte Test eine (sehr gute) Power von 0.8 hat (also 80% der tatsachlichwahren Hypothesen auch als wahr erkennt) wird sie 20% der 100 tatsachlich richtigenHypothesen irrtumlich verwerfen. Sie glaubt also 80+45 = 125 richtige Hypothesenvorliegen zu haben, davon sind aber 45, das sind 36%, tatsachlich falsch!
Ein besseres Ergebnis wurde sie erzielen, wenn sie die nicht signifikanten Ergebnisseansehen wurde. In 875 (= 1000 − 125) Fallen wird die Hypothese verworfen, beieiner Power von 0.8 in nur 20 Fallen davon zu unrecht, was einer Trefferquote vonfast 98% entspricht. Aber negative Resultate fallen haufig dem ‘Publication Bias’zum Opfer.

Angewandte Okonometrie 60
Hinweis:* Dieses Resultat kann man auch allgemeiner mit Hilfe des Satzes vonBayes zeigen.
Sei
• A das Ereignis die ‘Nullhypothese ist falsch’ (also ist die interessierende Alter-nativhypothese richtig),
• B das Ereignis, die ‘empirische Teststatistik fallt in den Verwerfungsbereich’(d.h. die Forscherin wird die Nullhypothese verwerfen).
Damit konnen wir die Wahrscheinlichkeit fur einen Typ I Fehler und fur die Powerdefinieren.
Der Typ I Fehler gibt die Wahrscheinlichkeit dafur an, dass bei einer neuerlichenZiehung die empirische Teststatistik in den Verwerfungsbereich fallt, wenn die Nul-lypothese richtig ist. Da eine richtige Nullypothese das Komplementarereignis zurfalschen Nullhypothese ist konnen wir schreiben
P (Typ I Fehler) = P (B|A)
Ein Typ II Fehler gibt die Wahrscheinlichkeit dafur an, dass die empirische Test-statistik nicht in den Verwerfungsbereich fallt, wenn die Nullhypothese falsch ist,also P (B|A). Die Power eines Tests ist die Gegenwahrscheinlichkeit fur einen TypII Fehler, also
Power = 1− P (B|A) = P (B|A)Die Power gibt also die Wahrscheinlichkeit dafur an, dass bei einer tatsachlichfalschen Nullhypothese die empirische Teststatistik in den Verwerfungsbereich fallt,ist also ein Maß fur die Treffsicherheit eines Tests.
Wir interessieren uns aber meist nicht fur die Wahrscheinlichkeit eines Typ I Feh-lers, das heißt die Wahrscheinlichkeit, dass die empirische Teststatistik in den Ver-werfungsbereich fallt, wenn die Nullypothese richtig ist P (B|A), sondern fur dieWahrscheinlichkeit dafur, dass die Nullhypothese tatsachlich falsch ist, wenn dieempirische Teststatistik in den Verwerfungsbereich fallt, also fur P (A|B).
In anderen Worten, wir mochten wissen wie groß die Wahrscheinlichkeit dafur ist,dass die Nullhypothese wirklich falsch ist, gegeben wir beobachten eine signifikanteTeststatistik. Dies ist offensichtlich eine komplett andere Frage!
Wenn wir zusatzliche Information haben, namlich die Power des Tests und die apriori Wahrscheinlichkeit P (A) kennen, konnen wir diese Frage mit Hilfe des Satzesvon Bayes beantworten23
P (A|B) =P (B|A)P (A)
P (B|A)P (A) + P (B|A)P (A)
23Die einfache Version des Satzes von Bayes folgt unmittelbar aus der Definition der bedingtenWahrscheinlichkeit
P (A|B) =P (A ∩B)
P (B)=
P (A∩B)P (A) P (A)
P (B)=
P (B|A)P (A)
P (B)
Da A und A eine Partition bilden folgt aus dem Satz der Totalen Wahrscheinlichkeit P (B) =P (B|A)P (A) + P (B|A)P (A).

Angewandte Okonometrie 61
Dazu benotigen wir zusatzlich die Information P (A), d.h. die a priori Wahrschein-lichkeit dafur, dass eine zufallig gezogene Nullhypothese falsch ist (bzw. den Anteilaller falschen Nullhypothesen an der Grundgesamtheit aller ‘testwurdigen’ Nullhy-pothesen). Im folgenden Beispiel werden wir (wie vorhin im Beispiel des Economist)P (A) = 0.1 annehmen.
Wenn wir außerdem ubliche Werte fur die Wahrscheinlichkeit eines Typ I Fehlersund die Power annehmen,
P (Typ I Fehler) = P (B|A) = 0.05
Power = P (B|A) = 0.8
P (A) = 0.1
und einsetzen erhalten wir
P (A|B) =0.8× 0.1
0.8× 0.1 + 0.05× 0.9= 0.64
Das bedeutet, dass gegeben die empirische Teststatistik fallt in den Verwerfungs-bereich die Wahrscheinlichkeit dafur, dass die Nullhypothese tatsachlich falsch ist,lediglich 64 Prozent betragt.
Im Umkehrschluss bedeutet dies, dass unter obigen Annahmen die Wahrscheinlich-keit dafur, dass bei einer gegebenen signifikanten Teststatistik die Nullhypothesetrotzdem richtig ist, 36% (1− 0.64 = 0.36) betragt!
Dabei ist eine Power von 0.8 und eine a priori Wahrscheinlichkeit P (A) = 0.1 nochziemlich optimistisch, wenn die Power nur 0.6 ist und P (A) = 0.05 zeigen bereits 61%aller Hypothesentest ein irrefuhrendes Ergebnis (d.h. die Nullhypothese ist richtigobwohl die empirische Teststatistik in den Verwerfungsbereich fallt). �
Dieses Problem wird durch den ‘Publication Bias’ noch vergroßert. Der ‘PublicationBias’ besteht darin, dass Referees und Zeitschriften haufig nur signifikante Ergebnis-se als publikationswurdig erachten. Dies kann dazu fuhren, dass ein vollig verzerrtesBild der signifikanten Ergebnisse entsteht.
5.4.4 Statistische Signifikanz und Kausalitat
Anfanger machen manchmal den Fehler, statistisch signifikante Zusammenhange mitKausalitat zu verwechseln. Dies ist naturlich volliger Unsinn, ein Hypothesentestalleine kann uns nichts uber mogliche Kausalitatsbeziehungen verraten.
Hypothesentests wurden ausschließlich entwickelt um Stichprobenfehler (‘samplingerrors’ ) zu berucksichtigen, und dies vor allem fur Experimente. Bereits R.A. Fisherwar klar, dass die Rechtfertigung einer moglichen Kausalitatsbeziehung aus dem‘Design of Experiments’ (1935) herruhren muss, reine Hypothesentests sind dazuungeeignet.
Ein Beispiel soll dies verdeutlichen: Angenommen, eine Regression zwischen Wer-beausgaben x und Umsatzen y liefert einen positiven und statistisch signifikantenKoeffizienten fur die Werbeausgaben.

Angewandte Okonometrie 62
Konnen wir daraus schließen, dass hohere Werbeausgaben x hohere Umsatze y ver-ursachen?
Dazu uberlegen wir, welche mogliche Ursachen fur eine beobachtete Korrelationzwischen Werbeausgaben x Umsatze y denkbar sind:
• x ist die Ursache fur y: hohere Werbeausgaben fuhren zu hoheren Umsatzen.
• y ist die Ursache fur x: (reverse causality) hohere Umsatze ermoglichen dieFinanzierung zusatzlicher Werbeausgaben.
Auch bei Simultanitat, z.B. wenn das Angebot und Nachfrage nach Wer-bung durch zwei interdependente Gleichungen beschrieben wird, fuhrt die OLSSchatzung einer Einzelgleichung zu falschen Ergebnissen.
• z ist eine gemeinsame Ursache fur x und y: (confounding variable, Scheinkor-relation), z.B. eine gute Konjunktur fuhrt zu steigenden Umsatzen und zusteigenden Werbeausgaben (‘omitted variable’ ).
• Die Korrelation konnte durch eine verzerrte Stichprobe, Selbstselektion oderahnliches zustande gekommen sein.
• Die Korrelation zwischen x und y tritt in einer perfekten Zufallsstichproberein zufallig auf: dies – und nur dieser Fall – sollte durch einen statistischenTest erkennbar sein.
Obwohl statistische Signifikanz offensichtlich in keiner Weise eine hinreichende Be-dingung fur eine mogliche Kausalitatsbeziehung ist, wird man trotzdem statistischeSignifikanz fordern, um den letzten der obigen Falle kontrolliert klein zu halten,namlich die Moglichkeit eines zufalligen Stichprobenfehlers.
5.4.5 Statistische Signifikanz versus ‘Relevanz’ einer Varia-
blen
Manchmal wird statistische Signifikanz mit der Bedeutung einer Variable verwech-selt (Effektstarke). Statistische Signifikanz sagt nichts daruber aus, ob die Große desgemessenen Koeffizienten auch praktisch relevant ist. Da der geschatzte Koeffizientauch von der Dimension abhangt, in der die Variablen gemessen wurden, kann esmanchmal nutzlich sein, den Koeffizienten einer Variable mit dem Mittelwert dieserVariable zu multiplizieren (bhxh), um einen Eindruck von der quantitativen ‘Bedeu-tung’ einer Variable zu bekommen. Ein Zusammenhang kann zwar statistisch hochsignifikant sein, aber fur praktische Zwecke trotzdem vollig bedeutungslos sein!
Zu beachten ist auch der Zusammenhang zwischen Stichprobengroße und statisti-scher Signifikanz. In sehr großen Stichproben sind selbst winzige Unterschiede oftstatistisch signifikant, und es kann fast jede Nullhypothese verworfen werden, z.B.fur den t-Test
fur n → ∞ : t =βh
σβh
≈ βh
0= ∞
Wie bereits erwahnt sind statistische Signifikanz und okonomische Bedeutung (Re-levanz) zwei verschiedene Paar Schuhe.

Angewandte Okonometrie 63
Die Gultigkeit von Test hangt von einer Reihe von Annahmen ab, die oft schwer zuuberprufen sind, z.B.
• ist die vorliegende Stichprobe tatsachlich eine Zufallsstichprobe, oder ist einsample selection bias zu befurchten?
• ist die der Hypothese zugrunde liegende Kausalitatsvorstellung tatsachlich an-gebracht, oder ist simultane Kausalitat zu befurchten?
• wurden alle relevanten Einflussfaktoren berucksichtigt, oder konnte das Ergeb-nis durch eine unbeobachtete Variable verursacht worden sein (omitted variablebias)?
• usw.
Ein Hypothesentest nach Neyman-Pearson ist in erster Linie eine Entscheidungs-regel, aber diese Entscheidungsregel ist nur anwendbar, wenn sie auf zutreffenderInformation beruht. Ein simpler Hypothesentest alleine kann nicht zwischen Schein-korrelationen und Kausalitat unterscheiden, dazu bedarf es mehr. Erinnern Sie sich,die erste Tugend einer Wissenschaftlerin ist Skepsis. Fragen Sie sich stets ‘was konntedas Ergebnis, dass Sie zu sehen glauben, sonst verursacht haben als das, was Sie zusehen wunschen?’
Tests konnen – vernunftig angewandt – ein sehr machtiges und nutzliches Werkzeugsein, aber man kann damit auch ziemlich viel Unfug treiben.
Zusammenfassend: Blindes Vertrauen ist meistens dumm. Blindes Vertrauen ineinen statistischen Test ist davon keine Ausnahme.
Quelle: https://xkcd.com/892/

Angewandte Okonometrie 64
5.5 Simultane Tests mehrerer linearer Hypothe-
sen
Bisher habe wir nur einzelne Hypothesen mit Hilfe einer t-Statistik getestet. Nunwerden wir zeigen, dass mit Hilfe einer F-Statistik auch mehrere lineare Hypothesensimultan getestet werden konnen.
Die prinzipielle Vorgangsweise bleibt vollig gleich, wir konnen auch hier wieder Kon-fidenzintervalle (bzw. Konfidenzellipsen) und p-Werte berechnen, oder Tests nachNeyman-Pearson durchfuhren. Auch alles was uber Typ I & II Fehler, die Powersowie zur Kritik an Hypothesentests gesagt wurde bleibt uneingeschrankt gultig.
Wir beginnen mit der vermutlich bekanntesten dieser F-Statistiken, mit der F-totalStatistik, die sich in so gut wie jedem Regressionsoutput findet.
5.5.1 ANOVA-Tafel und die F-total Statistik
Wir erinnern uns, dass wir fur die Herleitung des Bestimmtheitsmaßes R2 folgendeStreuungs-Zerlegung vornahmen
∑(yi − y)2
︸ ︷︷ ︸TSS
=∑
(yi − y)2
︸ ︷︷ ︸ESS
+∑
ε2i︸ ︷︷ ︸SSR
wobei TSS fur ‘Total Sum of Squares’, ESS fur ‘Explained Sum of Squares’ und SSRfur ‘Sum of Squared Residuals’24 steht.
Dies fuhrt zu folgender ANOVA-Tafel (‘ANalysis Of VAriance Table’ )
Sum of MeanSquares df Square
Regression ESS k − 1 ESS/(k − 1)Residuen SSR n− k SSR/(n− k)Total TSS n− 1
wobei df fur ‘degrees of freedom’ (Freiheitsgrade) steht.
Mit Hilfe der ANOVA-Tafel, die von den vielen Statistik-Programmen ausgegebenwird, kann man eine F -Statistik fur die Nullhypothese
H0 : β2 = β3 = · · · = βk = 0
konstruieren; das heißt fur die Nullhypothese, dass alle Koeffizienten mit Ausnahmedes Interzepts β1 simultan gleich Null sind, oder in anderen Worten, dass alle k −1 Steigungskoeffizienten simultan gleich Null sind. Eine andere Moglichkeit dieseNullhypothese zu interpretieren ist
H0 : E(y|x2, . . . , xk) = E(y)
24Manchmal wird dafur auch RSS fur ‘Residual Sum Squared’ geschrieben.

Angewandte Okonometrie 65
wenn der bedingte Erwartungswert von y gleich dem unbedingten Erwartungswertist leisten die erklarenden Variablen auch gemeinsam keinen Erklarungsbeitrag. Indiesem Falle erklart eine Regression auf die Regressionskonstante y = β1 + ε dieDaten gleich gut wie die ‘lange’ Regression y = β1 + β2x2 + · · ·+ βkxk + ε.
Die Alternativhypothese ist
HA : mindestens einer der Steigungskoeffizienten ist ungleich Null
Wenn diese Nullhypothese wahr ist, sollten alle x Variablen auch gemeinsam keinenErklarungsbeitrag fur y leisten.
Wenn die Storterme der Grundgesamtheit normalverteilt sind ist bei Zutreffen derNullhypothese die Quadratsumme
∑i(yi − y)2/σ2 bekanntlich χ2-verteilt mit k − 1
Freiheitsgraden, und∑
i ε2i /σ
2 unabhangig davon χ2-verteilt mit n − k Freiheits-graden. Das Verhaltnis zweier unabhangig χ2 verteilten Zufallsvariablen, die beidedurch die entsprechenden Freiheitsgrade dividiert wurden, ist F-verteilt (vgl. Stati-stischen Appendix), deshalb ist die Teststatistik
F -total Statistik =
∑i(yi − y)2∑
i ε2i
n− k
k − 1=
ESS/(k − 1)
SSR/(n− k)
H0∼ F(k−1,n−k)
F-verteilt mit k − 1 Zahler- und n− k Nennerfreiheitsgraden.
Wenn die durch alle erklarenden x Variablen gemeinsam erklarte Streuung ESS sehrklein ist im Verhaltnis zur unerklarten Streuung SSR wurde man einen sehr kleinenWert der empirischen Statistik F emp erwarten. Wenn umgekehrt ESS groß ist imVerhaltnis zu SSR leisten alle x Variablen gemeinsam offensichtlich einen großenErklarungsbeitrag.
Die Nullhypothese β2 = β3 = · · · = βk = 0 wird deshalb verworfen, wenn der empi-rische Wert dieser F -Statistik großer ist als der kritische Wert F crit der F -Statistik,vgl. Abbildung 5.21. Fallt der empirische F emp-Wert in den Verwerfungsbereich wirdH0 verworfen, anderenfalls akzeptiert.
Der zur F -total Statistik gehorende p-Wert ist wieder die Flache unter der Verteilungrechts vom berechneten F emp-Wert, und wird standardmaßig von allen statistischenProgrammpaketen ausgewiesen.
Das Programm STATA liefert z.B. den in Tabelle 5.4 wiedergegebenen Regressions-output fur das Beispiel mit der Produktionsfunktion; im Kopf des Outputs wird diekomplette ANOVA-Tafel wiedergegeben.
Dabei ist Model SS die ESS (‘Explained Sum of Squares’), die Residual SS die SSR(‘Sum of Squared Residuals’) und Total SS die TSS (‘Total Sum of Squares’).
Fur Produktionsfunktions-Beispiel folgt (siehe Tabelle 5.4)
F emp-total Statistik =3.01454182/(3− 1)
0.187112359/(25− 3)= 177.2195
Andere programme geben die ESS und TSS nicht automatisch aus, sondern nur dieF -Statistik mit dem dazugehorigen p-Wert.
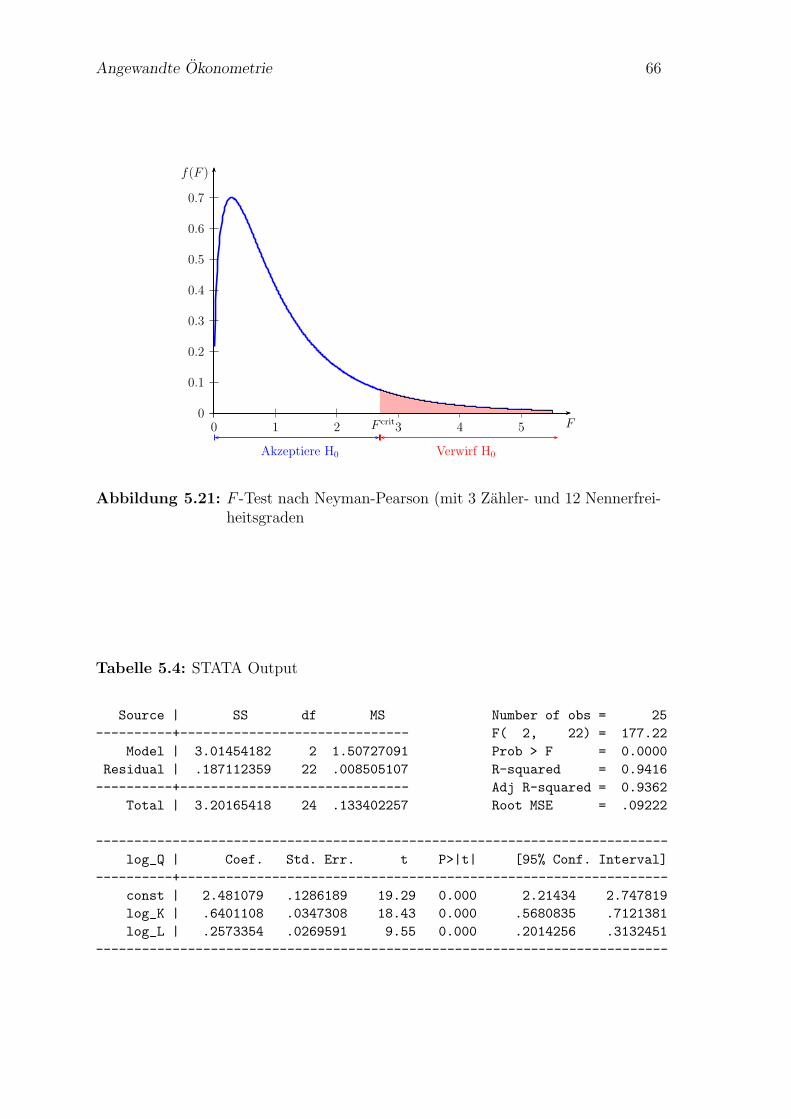
Angewandte Okonometrie 66
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 1 2 3 4 5
f(F )
FF crit
Akzeptiere H0 Verwirf H0
Abbildung 5.21: F -Test nach Neyman-Pearson (mit 3 Zahler- und 12 Nennerfrei-heitsgraden
Tabelle 5.4: STATA Output
Source | SS df MS Number of obs = 25
----------+------------------------------ F( 2, 22) = 177.22
Model | 3.01454182 2 1.50727091 Prob > F = 0.0000
Residual | .187112359 22 .008505107 R-squared = 0.9416
----------+------------------------------ Adj R-squared = 0.9362
Total | 3.20165418 24 .133402257 Root MSE = .09222
---------------------------------------------------------------------------
log_Q | Coef. Std. Err. t P>|t| [95% Conf. Interval]
----------+----------------------------------------------------------------
const | 2.481079 .1286189 19.29 0.000 2.21434 2.747819
log_K | .6401108 .0347308 18.43 0.000 .5680835 .7121381
log_L | .2573354 .0269591 9.55 0.000 .2014256 .3132451
---------------------------------------------------------------------------

Angewandte Okonometrie 67
Exkurs* Diese F -total Statistik kann alternativ auch mit Hilfe des Bestimmtheits-maßes R2 berechnet werden, denn unter Berucksichtigung von TSS = ESS + SSRund R2 = ESS/TSS
F -total Stat =ESS/(k − 1)
SSR/(n− k)
=n− k
k − 1
ESS
SSR
=n− k
k − 1
ESS
TSS− ESS
=n− k
k − 1
[ESS/TSS
1− (ESS/TSS)
]
=n− k
k − 1
[R2
1−R2
]
Also
F -total Statistik =R2/(k − 1)
(1− R2)/(n− k)
�
Die Alternativhypothese, dass zumindest fur einen der Regressoren der wahre Wertdes Regressionskoeffizienten von Null verschieden ist, wird akzeptiert, wenn die Null-hypothese H0 : β2 = β3 = · · · = βk = 0 (d.h. dass alle Koeffizienten mit Ausnahmedes Interzepts β1 gleich Null sind) verworfen wird.
Man beachte, dass es sich dabei um einen simultanen Test von insgesamt k − 1Hypothesen handelt, wobei k − 1 die Anzahl der Steigungskoeffizienten ist.
Dies ist also ein Test, ob alle Regressoren gemeinsam einen Beitrag zur ‘Erklarung’von y leisten. Wenn der p-Wert dieser F -Statistik großer ist als das a priori festgelegteSignifikanzniveau sollte die Schatzung verworfen werden.
Dieser F -total Test wird haufig auch einfach F -Test genannt, zum Beispiel im Re-gressionsoutput fast jeder Statistiksoftware, was aber etwas verwirrend ist, da jedeF -verteilte Teststatistik zu einem F -Test fuhrt, und davon gibt es viele.
Achtung: Man beachte, dass es nicht reicht zu uberprufen, ob alle Koeffizientenindividuell signifikant von Null verschieden sind. Es ist sehr gut moglich und passiertauch haufig, dass kein einziger Koeffizient signifikant von Null verschieden ist, obwohlalle Koeffizienten gemeinsam hoch signifikant von Null verschieden sind! Wie wirspater sehen werden tritt dieser Fall beiMultikollinearitat (d.h. wenn die erklarendenVariablen untereinander hoch korreliert sind) relativ haufig auf.
Konkret, die mit der F -Statistik getestete gemeinsame Nullhypothese H0 : β2 =β3 = · · · = βk = 0 darf nicht durch eine Reihe individueller t-Tests ersetzt werden!
Der Grund dafur liegt darin, dass die F -Statistik die mogliche Korrelation zwischenden OLS-Schatzern β2, β3, . . . , βk berucksichtigt, wahrend diese bei individuellen t-Tests unberucksichtigt bleibt.
Dies wird in Abbildung 5.22 veranschaulicht, die zwei bivariate Normalverteilungenzeigt, links ohne und rechts mit einer Korrelation zwischen den Zufallsvariablen.

Angewandte Okonometrie 68
ρ = 0: ρ = −0.7:
Abbildung 5.22: Bivariate Normalverteilungen ohne und mit Korrelation zwischenden Zufallsvariablen
Wenn die Variablen unkorreliert sind (linke Grafik) wird die gemeinsame Signifi-kanz durch einen Signifikanzkreis dargestellt, bei Korrelation zwischen den Varia-blen (rechte Grafik) durch eine Konfidenzellipse, die umso schmaler wird, je hoherdie Korrelation ist.
Wir werden spater sehen, dass viele der ublichen Teststatistiken fur den simultanenTest mehrerer Hypothesen unter den Standardannahmen F -verteilt sind. Solltenz.B. im Modell
yi = β1 + β2xi2 + β3xi3 + εi
die beiden Koeffizienten β2 und β3 simultan getestet werden, so kann man die fol-gende Teststatistik verwenden:
F =1
2σ2
[S22(β2 − β2)
2 + 2S23(β2 − β2)(β3 − β3) + S33(β3 − β3)2]
H0∼ F2,n−3
mit
S22 =∑
i
(xi2 − x·2)2
S23 =∑
i
(xi2 − x·2)(xi3 − x·3)
S33 =∑
i
(xi3 − x·3)2
Diese Teststatistik ist unter H0 F -verteilt mit 2 Zahler- und n−3 Nennerfreiheitsgra-den. Diese F -Statistik kann fur die Konstruktion einer Konfidenzregion verwendetwerden.
Wenn wir mit F crit den kritischen F -Wert mit 2 Zahler- und n− 3 Nennerfreiheits-graden bezeichnen ist diese Konfidenzregion
[S22(β2 − β2)
2 + 2S23(β2 − β2)(β3 − β3) + S33(β3 − β3)2]≤ F crit(2σ2)
Dies definiert eine Ellipsengleichung, das heißt, bei dem simultanen Test zweierKoeffizienten erhalt man anstelle eines Konfidenzintervalls eine Konfidenzellipse.

Angewandte Okonometrie 69
Sind die Koeffizienten β2 und β3 unkorreliert erhalt man einen Kreis, und umsohoher die Korrelation zwischen β2 und β3 ist, umso schmaler ist die Ellipse.
Werden mehr als zwei Hypothesen gleichzeitig getestet erhalt man einhoherdimensionales Ellipsoid.
Beispiel: Das folgende Beispiel zeigt einen Fall, bei dem die F -Statistik die ge-meinsame Nullhypothese β2 = β3 = 0 ablehnt, die individuellen t-Tests einzeln aberweder die Ablehnung von β2 = 0 noch von β3 = 0 erlauben (auf dem 5% Niveau).
y = 7.888 + 0.2 x2 + 0.634 x3
(5.028) (0.28) (0.344)*
F-Statistik (df: 2, 47): 34.95, p-Wert: 5.023e-10R2 = 0.598, n = 50
Die F -Statistik fur die Nullhypothese H0 : β2 = 0 und β3 = 0 ist in diesem Beispiel34.95 und kann damit mit einer Wahrscheinlichkeit kleiner als 0.0001 verworfenwerden. In diesem Beispiel sind die Regressoren x2 und x3 hoch korreliert, d.h. esliegt Multikollinearitat vor (der Korrelationskoeffizient zwischen x2 und x3 ist 0.95!),was auch zu einer Korrelation zwischen den geschatzten Koeffizienten fuhrt.
Die geschatzte Varianz-Kovarianzmatrix der Koeffizienten ist
b1 b2 b3
b1 25.27815 0.308261 −0.808990b2 0.308261 0.078356 −0.091832b3 −0.808990 −0.091832 0.118481
deshalb ist die Korrelation corr(β2, β3) = −0.0918/√0.0784 ∗ 0.1185 = −0.953.
Aufgrund dieser Korrelation ist die Konfidenzellipse in Abbildung 5.23 ziemlichschmal. Die Konfidenzintervalle fur β2 und β3 einzeln sind in Abbildung 5.23 strich-liert eingezeichnet.
Zur Interpretation von Konfidenzellipsen gilt analoges wie fur Konfidenzinterval-le, wenn sehr viele Stichproben gezogen wurden konnten wir damit rechnen, dass(1 − α) ∗ 100% der resultierenden Konfidenzregionen die wahren Werte β2 und β3
enthalten wurden.
Erinnern wir uns, dass es eine enge Beziehung zwischen Konfidenzintervallen undHypothesentests gibt. Wenn wir den unter der Nullhypothese vermuteten Wert desParameters h mit β ′
h,0 bezeichnen (fur h = 1, . . . , k), kann die Nullhypothese ge-schrieben werden als H0 : βh = β ′
h,0. Wenn der unter H0 vermutete Wert β ′h,0 im
Konfidenzintervall liegt kann die Nullhypothese nicht verworfen werden, wenn derWert β ′
h,0 hingegen außerhalb des Konfidenzintervalls liegt darf die Nullhypotheseverworfen werden. Analoges gilt auch fur die Konfidenzellipse.
In Abbildung 5.23 ist ersichtlich, dass in diesem Beispiel weder die NullhypotheseH0 : β2 = 0 noch die Nullhypothese H0 : β3 = 0 einzeln abgelehnt werden kann,

Angewandte Okonometrie 70
der Nullpunkt liegt innerhalb der beiden individuellen Konfidenzintervalle (als graustrichlierte Linien eingezeichnet).
Hingegen kann die gemeinsame Nullhypothese, dass beide Steigungskoeffizientensimultan gleich Null sind H0 : β2 = 0 und β3 = 0, abgelehnt werden, der Nullpunktliegt außerhalb der Konfidenzellipse!
Man sieht in Abbildung 5.23, dass es sehr viele Punkte wie z.B. (β ′2, β
′3) gibt, die
ahnlich wie der Nullpunkt sowohl im Konfidenzintervall von β2 als auch im Konfi-denzintervall von β3 liegen, aber nicht in der Konfidenzellipse fur β2 und β3.
Andererseits sind auch Falle moglich, wie z.B. Punkt (β ′′2 , β
′′3 ) in Abbildung 5.23, die
außerhalb der beiden individuellen Konfidenzintervalle fur β2 und β3 liegen, aberinnerhalb der Konfidenzellipse. Das bedeutet, dass beide Koeffizienten individuellsignifikant von β ′′
2 und β ′′3 verschieden sind (d.h. es kann sowohl H0 : β2 = β ′′
2
als auch H0 : β3 = β ′′3 individuell verworfen werden), aber dass die gemeinsame
Nullhypothese H0 : β2 = β ′′2 und β3 = β ′′
3 nicht verworfen werden kann.
Im Beispiel von Abbildung 5.23 ist der empirische t-Wert fur die H0 : β2 = 0.85gleich temp = 2.32 (mit p = 0.025), fur H0 : β3 = −0.1 ist temp = 2.132 (p = 0.038),beide Nullhypothesen konnen also auf einem Signifikanzniveau von 5% verworfenwerden. Aber der empirische F-Wert der gemeinsamen Nullhypothese H0 : β2 =0.85 und β3 = −0.1 ist F emp = 2.74 mit p = 0.075, die gemeinsame Nullhypothesekann also auf einem Signifikanzniveau von 5% nicht verworfen werden!
Die t-Statistiken der einzelnen Koeffizienten konnen also signifikant sein, obwohl dieF -Statistik fur die gemeinsame Nullhypothese nicht signifikant ist. Solche Falle sindallerdings selten und treten meist nur bei hoher Multikollinearitat auf.
Als nachstes werden wir eine allgemeinere Moglichkeiten kennen lernen eine F -Statistik zu berechnen, die den Test komplexerer Nullhypothesen erlaubt.
5.5.2 Simultane Tests fur mehrere lineare Restriktionen
Zahlreiche Tests beruhen auf einem Vergleich zweier Modelle. Dabei wird in derRegel ein Modell ohne Restriktion(en) geschatzt und mit einem anderen Modellverglichen, das unter Berucksichtigung einer oder mehrerer Restriktionen geschatztwurde (vgl. Griffiths et al., 1993, Chapter 11). In diesem Fall lasst sich das re-stringierte Modell immer als Speziallfall eines allgemeinen (d.h. nicht restringierten)Modells darstellen. Ein Test zwischen zwei Modellen, bei denen es moglich ist einesder beiden Modelle durch geeignete Parameterrestriktionen in das andere Modelluberzufuhren, wird im Englischen als ‘nested test ’ (geschachtelte Hypothesen) be-zeichnet. In diesem Abschnitt werden wir uns ausschließlich auf solche ‘nested tests ’beschranken.
Ein ganz einfaches Beispiel fur ein Modell ohne Restriktionen sei z.B.
yi = β1 + β2xi2 + β3xi3 + εi
Unter der Restriktion β3 = 0 gilt
yi = β∗1 + β∗
2xi2 + ε∗i

Angewandte Okonometrie 71
-0.4
0.0
0.4
0.8
1.2
1.6
-0.8 -0.4 0.0 0.4 0.8 1.2
β2
β3
(b2, b3)
b
(β ′2,0, β
′3,0)
b
(β ′′2,0, β
′′3,0)
Konfidenzintervallfurb 3
Konfidenzintervall fur b2
b(0, 0)
Abbildung 5.23: 95%-Konfidenzellipse fur beide Koeffizienten und Konfidenzin-tervalle fur die beiden einzelnen Koeffizienten fur die Regressionaus dem Beispiel auf Seite 69. Die t-Statistiken der einzelnenKoeffizienten zeigen, dass die Koeffizienten einzeln nicht signi-fikant von Null verschieden sind (fur α = 0.05), der Nullpunkt(0, 0) liegt innerhalb der individuellen Konfidenzintervalle. Wiedie F -total-Statistik hingegen zeigt sind Koeffizienten gemein-sam hochsignifikant von Null verschieden, der Nullpunkt liegtaußerhalb der Konfidenzellipse! Zum Beispiel konnen weder dieH0 : β2 = 0 noch die H0 : β3 = 0 einzeln verworfen werden, aberdie simultane H0 : β2 = 0 und β3 = 0 wird abgelehnt (der Punkt(0, 0) liegt wie viele weitere Punkte (z.B. (β ′
2,0, β′3,0)) innerhalb
der einzelnen Konfidenzintervalle, aber außerhalb der Konfiden-zellipse.Es ist auch moglich, dass die Nullhypothesen einzeln abgelehntwerden konnen, aber die simultane H0 nicht abgelehnt werdenkann, z.B. werden die H0 : β2 = β ′′
2,0 und die H0 : β3 = β ′′3,0 beide
einzeln verworfen, aber die simultane H0 : β2 = β ′′2,0 und β3 = β ′′
3,0
kann nicht verworfen werden!

Angewandte Okonometrie 72
Wenn das wahre β3 tatsachlich Null ist sollte εi = ε∗i sein, und die beiden Stichpro-
benregressionsfunktionen (SRF) yi = β1+ β2xi2+ β3xi3+ εi und yi = β∗1 + β∗
2xi2+ ε∗isollten ‘sehr ahnliche’ Residuen liefern.
Ein anderes Beispiel: angenommen die Nullhypothese H0 : β3 = 1 sei wahr, dannkann das Modell unter dieser Restriktion geschrieben werden als
yi = β∗∗1 + β∗∗
2 xi2 + 1xi3 + ε∗∗i
und wir konnen die entsprechende SRF in der Form
(yi − xi3) = β∗∗1 + β∗∗
2 xi2 + ε∗∗i
schatzen, wozu wir eine neue abhangige Variable (yi − xi3) bilden mussen.
Im Prinzip werden fur geschachtelte (‘nested’ ) Tests immer zwei Gleichungengeschatzt, eine Gleichung ohne Restriktion(en), das nicht-restringierte (bzw. unre-stringierte) Modell, und eine eine Gleichung mit Restriktion(en) – das restringierteModell – das man im wesentlichen durch Einsetzen der Nullhypothese in das nichtrestringierte Modell erhalt. Dieser Test ist sehr allgemein einsetzbar und kann auchfur den Test mehrerer Restriktionen verwendet werden.
Beispiele fur lineare Restriktionen
Im Folgenden interpretieren wir die H0 als Restriktion(en) und q bezeichnet dieAnzahl der Restriktionen:
• PRF: β1 + β2x2 + β3x3 + ε
Restriktion: H0 : β2 = β3 (q = 1)
SRF ohne Restriktion:y = β1 + β2x2 + β3x3 + ε
SRF mit Restriktion:y = β∗
1 + β∗2 (x2 + x3) + ε∗
Wenn die Nullhypothese β2 = β3 wahr ist wurden wir fur die Schatzungendes restringierten und nicht-restringierten Modells zumindest ‘sehr ahnliche’Ergebnisse erwarten.
• PRF: β1 + β2x2 + β3x3 + β4x4 + ε
Restriktionen: H0 : β2 = 0 & β3 = 0 & β4 = 0 (q = 3)
SRF ohne Restriktion:y = β1 + β2x2 + β3x3 + β4x4 + ε
SRF mit Restriktion:y = β∗
1 + ε∗
Das ist genau die Hypothese, die auch mit der F -total Statistik getestet wird.

Angewandte Okonometrie 73
• PRF: β1 + β2x2 + β3x3 + ε
Restriktion: H0 : β2 + β3 = 1 (q = 1)
SRF ohne Restriktion:y = β1 + β2x2 + β3x3 + ε
SRF mit Restriktion:y = β∗
1 + β∗2x2 + (1− β∗
2)x3 + ε∗
diese Gleichung kann in der folgenden Form geschatzt werden:y − x3 = β∗
1 + β∗2(x2 − x3) + ε∗
Man beachte, dass in diesem Fall zwei neue Variablen y − x3 und x2 − x3
angelegt werden mussen.
• PRF: β1 + β2x2 + β3x3 + β4x4 + ε
Restriktionen: H0 : β2 = 0.5× β3 & β4 = −1 (q = 2)
SRF ohne Restriktion:y = β1 + β2x2 + β3x3 + β4x4 + ε
SRF mit Restriktionen:y + x4 = β∗
1 + β∗3 [0.5x2 + x3] + ε∗
Wenn die entsprechenden Nullhypothesen wahr sind wurden wir fur die Schatzungender Stichprobenregressionsfunktionen des restringierten und nicht-restringierten Mo-dells sehr ahnliche Ergebnisse erwarten, insbesondere sollten sich auch die Quadrat-summen der Residuen des nicht-restringierten und des restringierten Modells nichtstark unterscheiden.
Tatsachlich kann man zeigen, dass aus diesen Quadratsummen der Residuen eineeinfache Teststatistik konstruiert werden kann, die einen Test der Nullhypothese(n)erlaubt.
Wenn wir mit SSRu (Sum od Squared Residuals) die Quadratsumme der Residuenohne Restriktionen (der Subindex u fur unrestricted) und mit SSRr die Quadrat-summe der Residuen des restringierten Modells bezeichnen, so kann man zeigen,dass der Skalar
F =(∑
i ε2r,i −
∑i ε
2u,i)/q
(∑
i ε2u,i)/(n− k)
=(SSRr − SSRu)/q
SSRu/(n− k)
H0∼ Fq,n−k (5.7)
unter H0 F -verteilt ist mit q Zahler– und (n−k) Nennerfreiheitsgraden, wobei∑
i ε2r,i
die Quadratsumme der Residuen des restringierten Modells sind, und q die Anzahlder Restriktionen bezeichnet.25
Die Herleitung dieser Teststatistik ist etwas aufwandiger und ist in Matrixnotationeinfacher zu skizzieren.
Zwischenfrage: Warum muss immer gelten SSRr ≥ SSRu?
Dieser Test ist sehr allgemein und kann fur verschiedenste Tests von Restriktionenauf Koeffizienten verwendet werden.
25Wenn nur eine einzelne Hypothese getestet wird kann man zeigen, dass diese F-Statistik dasQuadrat der entsprechenden t-Statistik ist.

Angewandte Okonometrie 74
Mit Hilfe dieser Teststatistik kann wieder der p-Wert nach Fisher berechnet werden,oder man kann nach Neyman und Pearson vorgehen
1. Formuliere Null- und Alternativhypothese.
2. Lege a priori ein Signifikanzniveau α fest.
3. Verwende die Information uber die Teststatistik und die Freiheitsgrade, um denkritischen Wert F crit
q,n−k in einer F-Tabelle nachzuschlagen. Verwende diesen umAnnahme- und Verwerfungsbereich festzulegen.
4. Schatze das Modell ohne Restriktionen mittels OLS.
Berechne aus diesem nicht restringierten Modell die Quadratsumme der Re-siduen SSRu (in R mit deviance(eqname); in Stata mit dem postestimationBefehl e(rss), in EViews mit eqname.@ssr).
5. Schatze das Modell mit den Restriktionen der Nullhypothese (das restringierteModell).
Berechne daraus die restringierte Quadratsumme der Residuen SSRr.
6. Berechne daraus den empirischen Wert der F -Statistik
F emp =(SSRr − SSRu)/q
SSRu/(n− k)
wobei die Zahlerfreiheitsgrade q die Anzahl der Restriktionen sind, n− k dieNennerfreiheitsgrade.
7. Vergleiche diesen Wert mit dem kritischen Wert der F -Statistik laut TabelleF critq,n−k. Wenn der empirische Wert F emp großer ist als der kritische Wert F crit
q,n−k
wird die Nullhypothese verworfen, anderenfalls darf sie nicht verworfen werden.
Vorsicht: bei fehlenden Werten ist darauf zu achten, dass restringiertes und nicht-restringiertes Modell auf der gleichen Beobachtungszahl beruhen. Wenn einzelne Be-obachtungen einer x Variable fehlen, die im restringierten Modell nicht vorkommt,kann es passieren, dass restringiertes und nicht-restringiertes Modell auf einer an-deren Datengrundlage beruhen und die Statistik deshalb fehlerhaft berechnet wird.Die ubliche okonometrische Software berucksichtigt dies naturlich automatisch, aberwenn man die Statistik ‘handisch’ berechnet muss man darauf achtgeben.
Diese Art Tests konnen mit der ublicher Software naturlich viel einfacher durch-gefuhrt werden.
Beispiel Kehren wir nochmals zum Cobb-Douglas Beispiel (Seite 41) zuruck. DiePRF ist
log(Q) = β1 + β2 log(K) + β3 log(L) + ε
Wir konnten die Hypothese zu den konstanten Skalenertragen H0 : β2+ β3 = 1 auchmit Hilfe dieser F -Statistik testen.

Angewandte Okonometrie 75
Einsetzen dieser H0 in dei PRF fuhrt zum restringierten Modell
log(Q)− log(L) = β∗1 + β∗
2 [log(K)− log(L)] + ε∗
Um zu verdeutlichen, dass mit dieser Methode auch mehrere Hypothesen simultangetestet werden konnen wollen wir die (inhaltlich nicht sehr sinnvolle) simultaneNullhypothese
H0 : β2 + β3 = 1 und β1 = 2
testen.
Die restringierte Regression wird deshalb ohne Interzept geschatzt
log(Q)− log(L)− 2 = β∗∗2 [log(K)− log(L)] + ε∗∗
Wir werden nun die Teststatistik 5.7 anwenden und zeigen, wie dieses Ergebniseinfacher mit den entsprechenden Befehlen der Programme erzielt werden kann.
Stata:
clear
insheet using "https://www.uibk.ac.at/econometrics/data/prodfunkt.csv", ///
delim(";") names clear
generate log_Q = log(q)
generate log_K = log(k)
generate log_L = log(l)
regress log_Q log_K log_L
* Kurz
test log_K + log_L = 1
test _cons = 2, accumulate
* Ergebnis:
* ( 1) log_K + log_L = 1
* ( 2) _cons = 2
*
* F( 2, 22) = 15.55
* Prob > F = 0.0001
*
* Ausfuhrlich
* nicht restringiert
regress log_Q log_K log_L
scalar SSR_u = e(rss)
* restringiert
generate y = log_Q - log_L - 2
generate x = log_K - log_L
regress y x, noconstant
scalar SSR_r = e(rss)
scalar F_Stat = ((SSR_r - SSR_u)/2) / (SSR_u/(25-3))
display "F-Statistik: " F_Stat
display "p-Wert: " Ftail(2,22, F_Stat)

Angewandte Okonometrie 76
R: man kann z.B. den Befehl linearHypothesis() aus dem ‘package’ car verwen-den
rm(list=ls(all=TRUE))
CD <- read.table("https://www.uibk.ac.at/econometrics/data/prodfunkt.csv",
dec = ".", sep=";", header=TRUE)
attach(CD)
eq.u <- lm(log(Q) ~ log(K) + log(L))
# Kurz
library(car)
linearHypothesis(eq.u, c("log(K) + log(L) = 1", "(Intercept) = 2"))
# Ausfurhlich; restringiert
eq.r <- lm( I(log(Q)-log(L)-2) ~ I(log(K)-log(L)) -1 )
F.Stat <- ((deviance(eq.r) - deviance(eq.u))/2) / (deviance(eq.u)/(25-3))
p.val <- 1 - pf(F.Stat, 2, 22)
# F.Stat = 15.55485, p.val = 6.162219e-05
5.5.3 Ein Test auf Strukturbruche (Chow Test)
Der Chow–Test ist ein nutzlicher Test auf Strukturbruche, oder in anderen Worten,ein Test Unterschiede zwischen einzelnen Gruppen oder Zeitperioden.
Zum Beispiel kann der Chow Test verwendet werden um zu testen, ob sich die Koef-fizienten einer Regression, die uber eine Stichprobe von Mannern geschatzt wurde,von den Koeffizienten einer Regression uber eine Stichprobe von Frauen unterschei-den. Kann die entsprechende Nullhypothese verworfen werden wird daraus geschlos-sen, dass in Bezug auf den in der Regressionsgleichung modellierten Zusammenhangsignifikante Unterschiede zwischen Mannern und Frauen bestehen.
Manchmal wird er auch fur Zeitreihen verwendet um zu untersuchen, ob sich dermodellierte Zusammenhang durch ein Ereignis, welches zu einem bestimmten Zeit-punkt eingetreten ist, geandert hat.
Um den Chow Test durchfuhren zu konnen muss der Zeitpunkt des Strukturbruchs(oder die Gruppenzugehorigkeit) a priori bekannt sein. Naturlich mussen auch alleanderen Gauss Markov Annahmen erfullt sein, z.B. durfen sich die Varianzen derStorterme nicht zwischen den Gruppen unterscheiden (keine Heteroskedastizitat).
Angenommen wir vermuten, dass in der Grundgesamtheit zwischen zwei Gruppen(oder Perioden) Unterschiede bestehen, d.h.
yi = β1 + β2xi1 + · · ·+ βkxik + εi
yj = β∗1 + β∗
2xj1 + · · ·+ β∗kxjk + ε∗j
mit i = 1, 2, . . . , n1, j = n1 + 1, n1 + 2, . . . , n.
Die Nullhypothese ist
H0 : β1 = β∗1 , β2 = β∗
2 , . . . , βk = β∗k

Angewandte Okonometrie 77
und die Alternativhypothese, dass mindestens eine dieser Bedingungen nicht erfulltist.
Das nicht-restringierte Modell besteht aus den zwei unabhangig geschatzten Glei-chungen, d.h. man schatzt zwei getrennte Regressionen fur die beiden Gruppen (Sub-samples) mit n1 bzw. n2 Beobachtungen (mit n1 + n2 = n), und berechnet darausdie Quadratsummen der Residuen
yi = β1 + β2xi2 + · · ·+ βkxik + εi → SSR1u
mit i = 1, . . . , n1
yj = β∗1 + β∗
2xj2 + · · ·+ β∗kxjk + ε∗j → SSR2
u
mit j = n1 + 1, . . . , n
Man kann zeigen, dass die nicht-restringierte Quadratsumme der Residuen die Sum-me der Quadratsummen der Residuen der beiden Gleichungen ist, d.h. wenn wir mitSSRu wieder die Quadratsumme der Residuen des nicht-restringierten Modells be-zeichnen
SSRu = SSR1u + SSR2
u
mit (n1 − k) + (n− n1 − k) = n− 2k Freiheitsgraden.
Wenn die Nullhypothese wahr ist stimmen alle Koeffizienten der beiden Modelleuberein, das heißt, das restringierte Modell wird einfach uber alle n Beobachtungen(also uber beide Gruppen) geschatzt.
yi = βr1 + βr
2xi2 + · · ·+ βrkxik + εri → RSSr
mit i = 1, . . . , n.
Chow (1960) hat gezeigt, dass die folgende Teststatistik fur diese NullhypotheseF -verteilt ist
F =(SSRr − SSRu)/k
SSRu/(n− 2k)
H0∼ Fk,n−2k
wobei n wieder die Anzahl der Beobachtungen und k die Anzahl der geschatztenKoeffizienten ist.
Die Gultigkeit dieses Test beruht unter anderem auf der Annahme, dass die Varianzder Storterme σ2 in allen Gruppen (Subsamples) gleich groß ist (keine Heteroskeda-stizitat).
Dieser Test wird haufig auch angewandt um zu testen, ob in einem Zeitpunkt teine Anderung eingetreten ist, indem man eine Regression uber den Zeitraum 1 bistm schatzt, eine zweite Regression uber den Zeitraum tm + 1 bis T , und mittelsder F -Statistik diese beiden Schatzungen mit einer Regression uber den gesamtenZeitraum 1 bis T vergleicht. Zum Beispiel kann damit getestet werden, ob einezu einem Zeitpunkt t gesetzte Maßnahme eine Auswirkung auf den untersuchtenZusammenhang hatte.
Beispiel: Wir mochten testen, ob die Determinanten des Lohneinkommens fur ver-heiratete Menschen gleich sind wie fur Singles. Als Determinanten des Lohneinkom-

Angewandte Okonometrie 78
mens WAGE (= durchschnittlicher Stundenlohn in US-$) verwenden wir die Jahreder Schulbildung (EDUC) und die Jahre an Berufserfahrung (EXPER).26
Tabelle 5.5 zeigt die Schatzergebnisse fur beide Gruppen (Married und Single) ein-zeln, sowie die Schatzung des restringierten Modells uber beide Gruppen.
Tabelle 5.5: Lohngleichungen:
Dependent variable: Wage
restricted unrestrictedAll Married Single
(1) (2) (3)
Constant −3.391∗∗∗ −3.122∗∗ −2.352∗∗∗
(0.767) (1.220) (0.879)
Educ 0.644∗∗∗ 0.668∗∗∗ 0.529∗∗∗
(0.054) (0.080) (0.066)
Exper 0.070∗∗∗ 0.058∗∗∗ 0.058∗∗∗
(0.011) (0.017) (0.014)
Observations 526 320 206R2 0.225 0.182 0.258Residual Std. Error 3.257 3.619 2.503Sum of Squared Res. 5548.16 4151.37 1272.11
Note: ∗p<0.1; ∗∗p<0.05; ∗∗∗p<0.01
Die Quadratsumme der Residuen des nicht-restringierten Modells ist 4151.370 +1272.114 = 5423.484. Die oben angefuhrten Programme berechnen folgende F -Statistik
F emp =(5548.160− 5423.484)/3
5423.484/(526− 6)= 3.9846
Der kritische Wert der F -Statistik fur 3 Zahler- und ∞ Nennerfreiheitsgrade undfur ein Signifikanzniveau von 5% ist 2.60, also kann die Nullhypothese
H0 : βm1 = βs
1, βm2 = βs
2, und βm3 = βs
3
auf einem 5%-Signifikanzniveau verworfen werden (der hochgestellte Index m stehtfur ‘married’ und s fur ‘single’), d.h. es gibt signifikante Lohnunterschiede zwischenVerheirateten und Singles, selbst wenn fur die Schulbildung und Berufserfahrungkontrolliert wird!
Der kritische Wert der F -Statistik fur ein Signifikanzniveau von 1% ist 3.78, die Null-hypothese kann also auch noch auf einem 1%-Signifikanzniveau verworfen werden.
26Die Daten stammen aus dem Begleitmaterial zum Lehrbuch von J. Wooldridge: IntroductoryEconometrics.

Angewandte Okonometrie 79
Das folgende Stata- und R- Programm schatzt das restringierte und nicht-restringierte Modell und berechnet F emp sowie den dazugehorigen p-Wert.
Stata:
clear
use http://www.hsto.info/econometrics/projekte/wage1, clear
// unrestricted
regress wage exper educ
ereturn list
scalar rss_r = e(rss)
scalar N = e(N)
// Married
regress wage exper educ if married == 1
scalar rss_u1 = e(rss)
scalar N1 = e(N)
// Not married
regress wage exper educ if married == 0
scalar rss_u2 = e(rss)
scalar N2 = e(N)
// unrestricted sum of squared residuals
scalar rss_u = rss_u1 + rss_u2
scalar F_Stat = ((rss_r - rss_u)/3)/(rss_u/(N-2*3))
scalar p_value = Ftail(3,N-6,F_Stat)
dis "F-Stat: " F_Stat ", p-value: " p_value
// F-Stat: 3.9845963, p-value: .00798955
R:
rm(list=ls())
library("foreign")
wage1 <- read.dta("http://www.uibk.ac.at/econometrics/data/wage1.dta")
# restringiertes Modell
eq_r <- lm(wage ~ educ + exper,data=wage1)
SSR_r <- deviance(eq_r)
N <- nobs(eq_r)
# nur Verheiratete
eq_u1 <- lm(wage ~ educ + exper, data=subset(wage1,married==1))
SSR_u1 <- deviance(eq_u1)
N1 <- nobs(eq_u1)
# nur Unverheiratete
eq_u2 <- lm(wage ~ educ + exper, data=subset(wage1,married==0))
SSR_u2 <- deviance(eq_u2)
N2 <- nobs(eq_u2)
# SSR fur nicht restringiertes Modell

Angewandte Okonometrie 80
SSR_u <- SSR_u1 + SSR_u2
F_Stat = ((SSR_r - SSR_u)/3)/(SSR_u/(N-2*3))
p_value = 1-pf(F_Stat,3,N-6)
cat("F-Stat: ", F_Stat, ", p-value: ", p_value )
# F-Stat: 3.984596 , p-value: 0.007989545
Naturlich geht das auch viel einfacher, wenn man auf die geeigneten Befehlezuruckgreift.
Fur R liefert das Packet strucchange von Zeileis u.a. die Option fur einen Chow-Test. Hier ein Beispiel:
rm(list=ls())
library(strucchange)
library("foreign")
mydata <- read.dta("http://www.uibk.ac.at/econometrics/data/wage1.dta")
# Sortieren
mydata.sort <- mydata[order(mydata$married), ]
# Strukturbruch finden
brk <- which(mydata.sort$married==1)[1]-1
# Chow Strukturbruchtest
sctest(wage ~ educ + exper, type = "Chow", point = brk,
data = mydata.sort)
# F = 3.9846, p-value = 0.00799
Fur Stata siehe z.B.http://www.stata.com/support/faqs/statistics/computing-chow-statistic/
Ubung: Wie lautet die Formel der Teststatistik fur drei Sub-Samples?
Beim klassischen Chow Strukturbruchtest wird die Nullhypothese getestet, ob diezwei Teilstichproben vom gleichen datengenerierenden Prozess erzeugt wurden. BeiQuerschnittsdaten beruhen die Teilstichproben oft auf klar unterscheidbaren Grup-pen (z.B. Manner & Frauen, Lander, . . . ), aber bei Zeitreihen ist oft weniger klar,wann ein Strukturbruch stattgefunden haben konnte.
Der klassische Chow Strukturbruchtest aber nur anwendbar, wenn der Zeitpunkt desStrukturbruchs a priori bekannt ist.27 Der Quandt-Andrews Test ermoglicht einenStrukturbruchtest auch in Fallen, in denen der Zeitpunkt eines potentiellen Struk-turbruchs nicht bekannt ist, und erlaubt daruber hinaus haufig zugleich Schatzungdes Zeitpunktes eines moglichen Strukturbruchs.
27Auch bei Querschnittsdaten stellt sich dieses Problem manchmal, wenn die Daten nach einerVariable sortiert wurden und ein Schwellenwert vermutet wird, ab dem sich der Zusammenhangandert.

Angewandte Okonometrie 81
5.5.4 Quandt-Andrews Test auf Strukturbruche bei unbe-kannten Bruchzeitpunkten
Die Grundidee des Quandt-Andrews Tests (auch bekannt als ‘Quandt-Likelihood-Ratio-Statistik’ (QLR) oder auch ‘sup-Wald-Statistik’ ) ist einfach. Angenommen wirvermuten, dass ein Strukturbruch zwischen zwei Zeitpunkte t1 und t2 stattgefundenhat; dann wird einfach fur jedes Datum zwischen diesen Zeitpunkten ein ChowStrukturbruchtest durchgefuhrt und die entsprechende F -Statistik berechnet.
Die Quandt-Andrews Statistik (QLR) ist einfach der großte Wert all dieser F Sta-tistiken
QLR = maxt1<t<t2
{F (t0), . . . , F (t1)}
Die Nullhypothese besagt, dass alle Parameter des Regressionsmodells uber die Zeitkonstant sind.
Die Zeitpunkte t1 und t2 sollten nicht zu nahe am Anfang oder Ende der Zeitreiheliegen, da sonst die Eigenschaften dieses asymptotischen Tests sehr schlecht wer-den. Deshalb wird t1 und t2 haufig so gewahlt, dass die ersten und letzten 7.5%der Beobachtungen, die vor t1 bzw. nach t2 liegen, also 15% aller Beobachtungen,ausgeschlossen werden. Diese 15% werden als ‘trimming value’ bezeichnet.
Allerdings ist diese Quandt-Andrews Statistik (QLR) nicht mehr F verteilt, da diegroßte einer Reihe von F Statistiken ausgewahlt wurde. Die Verteilung hangt unteranderem von der Anzahl der getesteten Restriktionen, von den ‘trimming Werten’t1/T und t2/T , usw. ab.
Andrews (1993) konnte die Verteilung dieser Statistik bestimmen und Hansen (1997)ungefahre asymptotische p Werte dazu ermitteln. Deshalb ist diese Statistik sehreinfach anzuwenden. Daruber hinaus hat sie einige nutzliche Eigenschaften
• Ahnlich wie der Chow Strukturbruchtest kann sie fur einen Test aller Regressi-onskoeffizienten oder fur den Test einer Teilmenge der Koeffizienten verwendetwerden.
• Der Test kann auch Hinweise auf mehrere Strukturbruche geben. Diese sindeinfach zu erkennen, indem man die Werte der Teststatistiken fur die einzelnenPerioden betrachtet.
• Falls es einen offensichtlichen Strukturbruch gibt kann man den Zeitpunktmit dem maximalen Wert der F Statistik als Schatzer fur den Zeitpunkt desStrukturbruchs verwenden.
Der Quandt-Andrews Test ist in Stata mit dem Postestimation Befehl estat
sbsingle verfugbar.
In R ist dieser und eine große Zahl weiterer Strukturbruchtests im Packetstrucchange (Zeileis et al., 2002) Zeieis verfugbar.

Angewandte Okonometrie 82
5.5.5 Ein allgemeiner Spezifkationstest: Ramsey’s RESETTest
RESET ist die Abkurzung fur Regression Specification Error Test und wurde vonRamsey (1969) vorgeschlagen. Es ist ein Test fur Spezifikationsfehler sehr allgemeinerArt. Heute wird der RESET Test – wenn uberhaupt – vor allem als Test auf diekorrekte Funktionsform verwendet.
Ist das wahre Modell nicht-linear und wir schatzen irrtumlich eine lineare Regres-sionsgleichung, so wird diese nur in kleinen Bereichen die Daten adaquat abbilden.Eine Einbeziehung von Potenzen der gefitteten Werte von y wurde die Qualitat derSchatzung vermutlich verbessern. Auf dieser Grundidee beruht der RESET Test.
Die Durchfuhrung des Tests ist (in der einfachsten Form) simpel:
1. Schatze das Modell (z.B. y = β1 + β2x2 + ε) mittels OLS und berechne diegefitteten Werte von y, d.h. y.
2. Schatze die ursprungliche Gleichung und inkludiere zusatzlich (nicht-lineare)Transformationen von y. Ublicherweise werden Potenzen von y verwendet, alsoy = β1 + β2x2 + β3y
2 + β4y3 + ε
3. Teste mittels Wald oder LR-Test, ob die Koeffizienten der Transformationenvon y gemeinsam signifikant von Null verschieden sind (z.B. H0 : β3 = β4 =0).
Ein Vorteil des RESET-Tests besteht darin, dass das Alternativmodell nicht explizitspezifiziert werden muss. Andererseits ist der Test nicht konstruktiv und gibt keineHinweise auf die ‘richtige’ Spezifikation (vgl. (Johnston and Dinardo, 1996, 121),(Wooldridge, 2005, 308f)).
In R sind mehrere Versionen dieses Tests mit dem Befehl resettest verfugbar, inStata ist er als ovtest implementiert (etwas irrefuhrend als omitted variable testbenannt).

Angewandte Okonometrie 83
5.6 Prognosen & Prognoseintervalle
“Prediction is very difficult, especiallyabout the future.” (Niels Bohr)
Bisher haben wir uns ausschließlich auf die geschatzten Koeffizienten β1 und β2
sowie auf deren Standardfehler (bzw. Konfidenzintervalle) konzentriert. Nun wollenwir einen Schritt weitergehen und sehen, wie wir diese Schatzer fur die Erstellungvon Prognosen nutzen konnen.
Nehmen wir wieder an, der ‘wahre’ Zusammenhang in der Grundgesamtheit konnedurch yi = β1 + β2xi + εi beschrieben werden, und wir schatzen aus der Stichprobeeine SRF yi = β1+β2xi+εi. Wie wir gleich sehen werden, konnen wir die SRF fur dieErstellung von Prognosen nutzen. Wir werden uns in den folgenden Ausfuhrungenauf das bivariate Regressionsmodell beschranken, die Erweiterung fur das multipleRegressionsmodell ist einfach und folgt den gleichen Uberlegungen.
Bei einer Prognose geht es darum, die Auspragung einer Zufallsvariablen vorherzu-sagen, die nicht beobachtet wurde (z.B. der Wert der abhangigen Variablen y in dernachsten Periode, oder der Konsum einer Person, die nicht befragt wurde).
Gebrauchlichen Konventionen folgend bezeichnen wir den zu prognostizierendenWert der abhangigen Variablen mit y0. Den entsprechenden Wert der erklarendenVariable bezeichnen wir mit x0.
Da Prognosen hauptsachlich fur Zeitreihen relevant sind verwenden wir t als Indexuber die Beobachtungen, und bezeichnen die Große der Stichprobe mit T (d.h. t =1, 2, . . . , T ).
Offensichtlich konnen Prognosen mit Hilfe einer Regression sehr einfach durchgefuhrtwerden, es genugt den Wert von x0 in die SRF einzusetzen. Wenn z.B. eine Gleichung
yt = 15 + 2.5xt
geschatzt wurde, kann fur ein x0 = 4 sofort der Wert y0 = 25 prognostiziert werden.In diesem Abschnitt werden wir nicht nur einfache Prognosen diskutieren, sondernauch Konfidenzintervalle fur die prognostizierten Werte ermitteln.
Bedingte und unbedingte Prognosen Prinzipiell unterscheidet man zwischen“bedingten” und “unbedingten” Prognosen. Bei einer bedingten Prognose wird voneinem a priori bekannten Wert der erklarenden Variable x0 im Prognosezeitraumausgegangen. Eine bedingte Prognose macht also Aussagen uber eine interessierendeVariable y, bedingt auf die Annahme, dass die x Variable den Wert x0 annimmt.Berechnet wird sie einfach, indem man x0 in die geschatzte Regressionsgleichungeinsetzt.
Manchmal mochte man aber einfach eine bestmogliche Prognose fur y, ohne denWert von x0 a priori zu kennen oder spezifische Annahmen uber die x treffen zumussen. Eine solche Prognose nennt man eine unbedingte Prognose. Um eine sol-che unbedingte Prognose machen zu konnen mussen meist in einem ersten SchrittPrognosen fur die x Variable(n) erstellt werden. Da die okonomische Theorie fur diePrognose der erklarenden Variable(n) oft wenig hilfreich ist, werden fur die Prognoseder x Variable(n) haufig Zeitreihenmethoden eingesetzt.

Angewandte Okonometrie 84
Mit Hilfe dieser Prognosen fur die erklarenden Variable(n) wird dann in einem zwei-ten Schritt der Wert der abhangigen Variablen y0 prognostiziert. Wir beschaftigenuns im folgenden ausschließlich mit bedingten Prognosen, einige Hinweise zu unbe-dingten Prognosen finden sich z.B. bei Pindyck and Rubinfeld (1997, 221f).
Wenn das Regressionsmodell zeitverzogerte abhangige Variablen enthalt, z.B.
yt = β1 + β2yt−1 + εi
unterscheidet man außerdem zwischen statischen und dynamischen Prognosen. Beieiner statischen Prognose werden jeweils die realisierten verzogerten Werte yt−1 furdie Prognose herangezogen, fur eine dynamische Prognose werden jeweils die pro-gnostizierten Werte der verzogerten Variable yt−1 eingesetzt. Dynamische Prognosensind v.a. in der Zeitreihenokonometrie von Bedeutung.
Ahnlich wie bei Parameterschatzungen unterscheidet man auch bei Prognosen zwi-schen Punkt- und Intervallprognosen.
5.6.1 Punktprognose
Wir wollen im Folgenden annehmen, dass alle Gauss-Markov Annahmen erfullt seienund dass x0 deterministisch sei. Die PRF sei
y0 = β1 + β2x0 + ε0
mit ε0 ∼ N(0, σ2) bzw. y0 ∼ N(β1 + β2x0, σ2).
Durch Einsetzen von x0 in die Stichprobenregressionsfunktion erhalten wir
y0 = β1 + β2x0
Fur die Realisationen yt = 6 + 0.8xt wurden wir z.B. fur x0 = 5 den Prognosewerty0 = 10 erhalten.
Man beachte, dass sowohl y0 = β1+β2x0 als auch y0 = β1+β2x0+ε0 Zufallsvariablensind, da β1, β2 und ε0 Zufallsvariablen sind.
Erwartungstreue Falls die Gauss-Markov Annahmen erfullt sind kann man ein-fach erkennen, dass y0 ein erwartungstreuer und effizienter Schatzer ist
E(y0) = E(β1 + β2x0 + ε0) = β1 + β2x0 = y0
Ein serioser ‘Wahrsager’ wurde y0 als wahrscheinlichsten Wert fur ein gegebenes x0
vorhersagen.
5.6.2 Intervallschatzer
Um etwas uber die Genauigkeit dieser Vorhersage aussagen zu konnen ist eszweckmaßig einen Intervallschatzer zu berechnen. Im Unterschied zu den Konfiden-zintervallen fur die einzelnen Koeffizienten β1 und β2 mussen wir hier etwas genaueruberlegen, denn es konnen uns zwei verschiedene Dinge interessieren, namlich

Angewandte Okonometrie 85
y
xx x0x0
PRF
rs
y0
b
bb
b
b
unterschiedl.SRFs
b . . . Schatzungen y0
Abbildung 5.24: y0 ist ein unverzerrtrer Schatzer fur y0, d.h. E(y0) = y0
1. fur das Konfidenzintervall fur y0 = β1 + β2x0, oder
2. fur das Prognoseintervall fur y0 = β1 + β2x0 + ε0
Im ersten Fall interessieren wir uns fur die Streuung der ‘mittleren’ y0, denn wirkonnen y0 Erwartungswert einer Stichprobenkennwertverteilung auffassen.
Im zweiten – haufig interessanteren – Fall interessieren wir uns fur die Streuung eineseinzelnen, konkreten y0. In diesem zweiten Fall mussen wir zusatzlich die ‘individu-elle’ Unsicherheit in Form von ε0 berucksichtigen. Man beachte, dass wir die wahrenβ1 und β2 nicht kennen, sondern dass diese selbst erst geschatzt werden mussen.
Wir beginnen mit dem wichtigeren zweiten Fall, dem Prognoseintervall fur y0. ZurBerechnung dieses Prognoseintervalls ist es zweckmaßig mit dem Prognosefehler zubeginnen.
Erwartungswert und Varianz des Prognosefehlers
Der Prognosefehler ist definiert als die Abweichung des tatsachlichen Werts y0 vomprognostizierten Wert y0, d.h.
Prognosefehler = y0 − y0 = (β1 − β1) + (β2 − β2)x0 − ε0
wobei β1, β2 und ε0 Zufallsvariablen sind, und β1, β2 sowie x0 deterministischeGroßen sind.
Nebenbei bemerkt kann man einfach zeigen, dass die Varianz des Prognosefehlersgleich der Varianz von y0 = β1 + β2x0 + ε0 ist, weil
var(y0 − y0) = var[(β1 + β2x0)− (β1 + β2x0 + ε0)
]
= var[β1 + β2x0 + ε0] = var(y0)

Angewandte Okonometrie 86
und weil β1, β2 und x0 deterministische Großen sind.
Der Erwartungswert des Prognosefehlers (y0−y0) ist Null, wenn die Schatzer β1 und
β2 unverzerrt sind und E(ε0) = 0, da
E[y0 − y0] = E[(β1 − β1) + (β2 − β2)x0 − ε0]
= E[(β1 − β1)] + E[(β2 − β2)x0]− E[ε0]
= 0 + 0 + 0 = 0
wenn die OLS Schatzer β1 und β2 erwartungstreu sind.
Die Varianz des Prognosefehlers kann einfach berechnet werden als
var(y0 − y0) = σ2
[1 +
1
T+
(x0 − x)2∑Tt=1(xt − x)2
]
Beweis:
var[y0 − y0] = E[y0 − y0]2
= E[(β1 − β1) + (β2 − β2)x0 − ε0]2
= var(β1) + x20 var(β2) + σ2 + 2x0 cov(β1, β2)
weil ε0 im Erwartungswert mit β1 und β2 unkorreliert ist, da die zu prognostizie-renden Werte y0 und die x0 nicht in die Berechnung der Koeffizienten β1 und β2
eingegangen sind.
Wir erinnern uns, dass
var(β1) =σ2
∑x2t
T∑
(xt − x)2
var(β2) =σ2
∑(xt − x)2
cov(β1, β2) =−xσ2
∑(xt − x)2
wobei t der Laufindex von 1 . . . T und x der Stichprobenmittelwert der ersten TBeobachtungen ist.
Aus∑
(xt − x)2 =∑
(x2t )− T x2 folgt
∑(x2
t ) =∑
(xt − x)2 + T x2. Deshalb ist
var(β1) =σ2
∑x2t
T∑
(xt − x)2= σ2
∑(xt − x)2 + T x2
T∑
(xt − x)2= σ2
[1
T+
x2
∑(xt − x)2
]
Wir setzen nun die Varianzen der Schatzer β1 und β2 in die Varianz des Prognose-fehlers ein
var[y0 − y0] = var(β1) + x20 var(β2) + σ2 + 2x0 cov(β1, β2)
= σ2
[1
T+
x2
∑(xt − x)2
+x20∑
(xt − x)2+ 1 +
−2x0x∑(xt − x)2
]
= σ2
[1 +
1
T+
x20 − 2x0x+ x2
∑(xt − x)2
]
= σ2
[1 +
1
T+
(x0 − x)2∑(xt − x)2
]

Angewandte Okonometrie 87
�
Diese Varianz kann noch nicht geschatzt werden, da sie die unbekannte Varianzder Storterme σ2 enthalt. Wie ublich konnen wir die Varianz des Prognosefehlersaber schatzen, indem wir die unbekannte Fehlervarianz σ2 durch den unverzerrtenSchatzer fur die Fehlervarianz σ2 ersetzen, also
var(y0 − y0) = σ2
[1 +
1
T+
(x0 − x)2∑Tt=1(xt − x)2
]
wobei σ2 =∑
ε 2i /(T −2) das Quadrat des Standardfehlers der Regression (standard
error of the regression) und T die Stichprobengroße ist.
Man kann einfach erkennen, dass
1. die Varianz des Prognosefehlers umso großer ist, je weiter x0 vom Stichproben-Mittelwert x entfernt liegt. Eine Prognose fur einen weit entfernt liegendenx0-Wert ist deshalb ungenauer;
2. die Varianz des Prognosefehlers ist umso kleiner, je großer die Streuung der xist (d.h. je großer
∑(xt − x)2);
3. die Varianz des Prognosefehlers ist umso kleiner, je großer die Anzahl derBeobachtungen T ist; und
4. die Varianz des Prognosefehlers umso großer, je großer der Standardfehler derRegression σ ist
Man kann außerdem zeigen, dass y0 = β1 + β2x0 der beste lineare unverzerrte Pro-gnosewert ist, d.h. y0 ist ein effizienter Schatzer fur y0!
Beispiel:
Gegeben seien die folgenden 5 Beobachtungen fur x und y:
y: 2.6 1.6 4.0 3.0 4.9x: 1.2 3.0 4.5 5.8 7.2
Eine Regression von x auf y gibt die folgende Regressionsgleichung
Dependent Variable: YIncluded observations: 5
Variable Coefficient Std. Error t-Stat. Prob.C 1.498 1.032 1.451 0.243x 0.397 0.214 1.853 0.161R-squared 0.534 SE of regression 1.00427

Angewandte Okonometrie 88
Tabelle 5.6: Beispiel: Prognosen, Varianzen des Prognosefehlers und Konfidenzin-tervalle fur ganzzahlige xt.
x0 y0 var(y0 − y0) y0 ∓ tcrit√var(y0 − y0)
0 1.498 2.074 −3.085 6.0811 1.895 1.722 −2.281 6.0702 2.292 1.461 −1.555 6.1383 2.688 1.293 −0.929 6.3064 3.085 1.216 −0.423 6.5935 3.482 1.230 −0.048 7.0116 3.879 1.337 0.200 7.5587 4.275 1.535 0.333 8.218
Daraus kann man nun die Varianz des Prognosefehlers berechnen
var(y0 − y0) = σ2
[1 +
1
T+
(x0 − x)2∑(xt − x)2
]
= (1.00427)2[1 +
1
5+
(x0 − 4.34)2
21.992
]
da x = 4.34 und∑
(xt − x)2 = 21.992.
In Tabelle 5.6 wurden die Varianzen des Prognosefehlers fur ganzzahlige xt berech-net.
Zum Beispiel erhalten wir fur x0 = 7 ein y0 = 1.498 + 0.397 × 7 = 4.275 und eineVarianz des Prognosefehlers von
var(y0 − y0) = (1.00427)2[1 +
1
5+
(7− 4.34)2
21.992
]= 1.535
Prognoseintervall fur y0
Mit Hilfe der Varianz des Prognosefehlers konnen wir nun ein Prognoseintervall fury0 berechnen. Dazu mussen wir wieder wie ublich eine Standardisierung durchfuhren.Da annahmegemaß (y0 − y0) ∼ N (0, var(y0 − y0)) folgt
y0 − y0√var(y0 − y0)
∼ N(0, 1)
Da σ2 unbekannt ist mussen wir wieder var(y0− y0) durch den Schatzer var(y0− y0)ersetzen und erhalten eine t-verteilte Zufallsvariable
t =y0 − y0√
var(y0 − y0)∼ tT−2
Wenn wir uns fur das 95% Prognoseintervall interessieren benotigen wir den kri-tischen t-Wert tcrit, fur den Pr[t(T−2) > tcrit] = 0.025. Fur T = 5 mit T − 2 = 3Freiheitsgraden ist tcrit = 3.182.

Angewandte Okonometrie 89
Damit konnen wir das Prognoseintervall fur y0 bestimmen:
Pr[−tcrit ≤ tT−2 ≤ tcrit
]= 0.95
Pr
[−tcrit ≤ y0 − y0√
var(y0 − y0)≤ tcrit
]= 0.95
Pr[y0 − tcrit
√var(y0 − y0) ≤ y0 ≤ y0 + tcrit
√var(y0 − y0)
]= 0.95
Das Prognoseintervall fur y0 ist also
y0 ± tcrit√var(y0 − y0)
Die Interpretation ist wie ublich, wenn wir sehr viele Stichproben ziehen wurdenund fur jede Stichprobe ein Prognoseintervall berechnen wurden, so konnten wirdamit rechnen, dass (1− α)100 Prozent dieser Prognoseintervalle den wahren Werty0 enthalten wurden.
Die letzten beiden Spalten von Tabelle 5.6 zeigen die entsprechenden Prognosein-tervalle. Das Konfidenzintervall fur y0 = 4.275 (x0 = 7) erhalt man z.B.
y0 ± tcrit√
var(y0 − y0) = 4.275± 3.182√1.535
bzw.(0.333 ≤ y0|(x0=7) ≤ 8.218)
Abbildung 5.25 zeigt die Beobachtungspunkte (schwarz), die Schatzgerade (Progno-se) und das Prognoseintervall (blau strichliert).
Da wir nur funf Beobachtungspunkte haben ist das Prognoseintervall naturlich ent-sprechend breit.
Konfidenzintervall fur y0
Manchmal sind wir nicht an der Vorhersage eines konkreten y0 interessiert, sondernwir an der Genauigkeit der Prognose eines ‘mittleren’ y0, d.h. an einem Konfidenz-intervall fur y0 = β1 + β2x0.
Die Berechnung der Varianz von y0 erfolgt vollig analog wie im vorhergehenden Fall.
var(y0) = var(β1 + β2x0)
= var(β1) + x20 var(β2) + 2 cov(β1, β2)
= σ2
[1
T+
(x0 − x)2∑(xt − x)2
]
Wenn wir σ2 wieder durch den Schatzer σ2 ersetzen und die Wurzel davon nehmenerhalten wir den Standardfehler von y0 (d.h. σy0). Mit dem kritischen Wert tcrit
konnen wir schließlich das Konfidenzintervall y0 ± tcritσy0 berechnen. Dieses Konfi-denzintervall fur y0 ist naturlich schmaler als das Prognoseintervall fur y0.

Angewandte Okonometrie 90
0
1
2
3
4
5
6
7
8
−1
−2
−3
1 2 3 4 5 6 7 8
y
x
b
b
b
b
b
b b b bb
b
b
b
b
b
b
b
b
bb
b b b
yi = 1.5 + 0.4xbc
tc√
var(y0 − y0)
tc√
var(y0 − y0)
bc
Abbildung 5.25: Prognose und deren Konfidenzintervalle

Angewandte Okonometrie 91
5.7 Beurteilung der Prognosequalitat
Meist wird die Qualitat einer Regression anhand von statistischen Kenngroßen wiez.B. dem Bestimmtheitsmaß R2, den Standardfehlern der Koeffizienten (bzw. den t-oder p-Werten) oder verschiedenen Spezifikationstests (die in einem spateren Kapiteldiskutiert werden) beurteilt.
Die Prognosequalitat einer Regressionsgleichung erlaubt eine davon verschiedeneEinschatzung. Vor allem wenn bei der Spezifikation entsprechendes Data Miningbetrieben wurde ist es nicht ungewohnlich, dass eine geschatzte Gleichung eine sehrgute Anpassung in der Stichprobe hat, aber eine lausige Prognosequalitat aufweist.
Um die Prognosequalitat beurteilen zu konnen kann man ex-post Prognosendurchfuhren, d.h. den Schatzzeitraum einschranken und sich bei der Spezifikati-onssuche nur auf einen Teil der Stichprobe beschranken. In der folgenden Grafikberuht die Schatzung auf der Stichprobe T1 bis T2. Fur die Periode T2 bis T3, fur diedie exogenen Variablen x und die tatsachlich beobachteten yt bekannt sind, kanndann eine ex-post Prognose durchgefuhrt werden. Anhand des ‘Fits’ dieser ex-postPrognose kann anschließend die Qualitat der Regression beurteilt werden. Ist diesezufriedenstellend kann man sich an die eigentliche ex-ante Prognose wagen, d.h. andie Prognose der unbeobachteten Werte y0 in der Zukunft. Diese beruht naturlichauf der gesamten Stichprobe T1 bis T3.
Zeit tT1
Schatzperiode
T2
ex-post
Prognose
Gegenwart
T3
ex-ante
Prognose
Wenn die Gleichung eine verzogerte abhangige Variable enthalt (z.B. yt = β1 +
β2yt−1 + εt) kann man anstelle der tatsachlichen Beobachtungen yt−1 die prognosti-zierten Werte yt−1 einsetzen, also eine dynamische Prognose durchfuhren.
Haufig wird auch eine Prognose uber die gesamte Stichprobe durchgefuhrt und dieprognostizierten (oder ‘gefitteten’) Werte yft mit den tatsachlich beobachteten Wer-ten yt verglichen. Fur den Vergleich zwischen tatsachlichen und prognostiziertenWerten haben sich einige Kennzahlen eingeburgert, die im folgenden kurz vorge-stellt werden.
5.7.1 Root Mean Square Forecast Error (RMS-Fehler)
Der Root Mean Square Error (RMS-Fehler) ist die Wurzel aus dem mittleren qua-dratischen Prognosefehler und ist eine gebrauchliche Kennzahl um die Abweichungder prognostizierten Werte von den tatsachlich beobachteten Werten anzugeben.
RMS-Fehler =
√√√√ 1
T
T∑
t=1
(yft − yt)2

Angewandte Okonometrie 92
mit: yft = prognostizierter Wert von ytyt = tatsachlich realisierter Wert von ytT = Anzahl der Beobachtungen im Prognoseintervall
5.7.2 Mean Absolute Forecast Error (MAE)
Der mittlere absolute Prognosefehler (Mean Absolute Error) ist ein alternatives Maßmit einer anderen Gewichtung zur Beurteilung der Prognosequalitat.
MAE =1
T
T∑
t=1
∣∣∣yft − yt
∣∣∣
Sowohl der Root Mean Square Error als auch derMean Absolute Error sind abhangigvon der Dimension der abhangigen Variablen yt, eignen sich also nur fur einen Ver-gleich verschiedener Modelle zur Prognose der gleichen Datenreihe. Je kleiner derentsprechende Wert ist, umso besser ist die Prognosequalitat.
Im Gegensatz dazu sind die beiden folgenden Kennzahlen unabhangig von der Di-mension der prognostizierten Datenreihe und konnen deshalb fur einen Vergleichvon Prognoseverfahren herangezogen werden.
5.7.3 Mean Absolute Percentage Error (MAPE)
Der mittlere absolute prozentuelle Prognosefehler (MAPE) ist definiert als
MAPE =1
T
T∑
t=1
∣∣∣∣∣yft − yt
yt
∣∣∣∣∣× 100
5.7.4 Theil’s Inequality Coefficient (TIC)
Im Zahler von Theil’s Inequality Coefficient (TIC) steht der Root Mean SquareError, der aber entsprechend gewichtet wird, sodass Theil’s Inequality Coefficientimmer zwischen Null und Eins liegt.
TIC =
√1T
∑Tt=1(y
ft − yt)2√
1T
∑Tt=1(y
ft )
2 +√
1T
∑Tt=1(yt)
2
Umso naher Theil’s Inequality Coefficient bei Null liegt, umso besser ist die Pro-gnosequalitat. Bei einem perfekten Fit ist Theil’s Inequality Coefficient gleich Null,wahrend TIC= 1 das schlechtest mogliche Ergebnis ist.
Mit ein bißchen Algebra kann zeigen, dass∑T
t=1(yft − yt)
2 folgendermaßen zerlegtwerden kann
T∑
t=1
(yft − yt)2 = (yf − y)2 + (σyf − σy)
2 + 2(1− ρ)σyf σy

Angewandte Okonometrie 93
wobei yf und y die Mittelwerte und σyf und σy die Standardabweichungen der
Datenreihen yft und yt sind; und
ρ =
∑Tt=1(y
ft − yf)(yt − y)
T σyf σy
ist der ubliche Korrelationskoeffizient zwischen yft und yt.
Mit Hilfe dieser Zerlegung kann man folgende Anteile berechnen:
1 =(yf − y)2
1T
∑Tt=1(y
ft − yt)2︸ ︷︷ ︸
Bias-Anteil
+(σyf − σy)
2
1T
∑Tt=1(y
ft − yt)2︸ ︷︷ ︸
Varianz-Anteil
+2(1− ρ)σyf σy
1T
∑Tt=1(y
ft − yt)2︸ ︷︷ ︸
Kovarianz-Anteil
• Der Bias Anteil zeigt, wie stark sich der Mittelwert der prognostizierten Rei-he vom Mittelwert der tatsachlichen Beobachtungen unterscheidet. Ein hoherBias Anteil zeigt also, dass sich die prognostizierte Datenreihe stark von dentatsachlichen Daten unterscheidet.
• Der Varianz Anteil zeigt, wie stark sich die Streuung der prognostiziertenReihe der Streuung der tatsachlichen Beobachtungen unterscheidet. Wenn derVarianz-Anteil groß ist bedeutet dies, dass die tatsachlichen Beobachtungenstark schwanken, wahrend die prognostizierten Werte kaum schwanken, bzw.umgekehrt.
• Der Kovarianz Anteil ist schließlich ein Maß fur den unsystematischen Pro-gnosefehler.
Bei einer guten Prognose sollte der Bias- und der Varianz-Anteil moglichst kleinsein. Da sich die Anteile naturlich auf 1 erganzen, sollte der unsystematische Kova-rianzanteil moglichst nahe bei Eins liegen.
Literaturverzeichnis
Andrews, D. W. K. (1993), ‘Tests for parameter instability and structural changewith unknown change point’, Econometrica 61(4), 821–56.
Bleymuller, J. (2012), Statistik fur Wirtschaftswissenschaftler, WiST-Studienkurs,Vahlen.URL: https://books.google.at/books?id=xw7xpwAACAAJ
Chow, G. C. (1960), ‘Tests of Equality Between Sets of Coefficients in Two LinearRegressions’, Econometrica 3, 591–605.
Danilov, D. and Magnus, J. R. (2004), ‘On the harm that ignoring pretesting cancause’, Journal of Econometrics 122(1), 27 – 46.URL: http://www.sciencedirect.com/science/article/pii/S0304407603002689

Angewandte Okonometrie 94
Davidson, R. and MacKinnon, J. G. (2003), Econometric Theory and Methods, Ox-ford University Press, USA.
Edgeworth, F. (1885), Observations and Statistics: an Essay on the Theory of Er-rors of Observation and the First Principles of Statistics, Transactions of theCambridge Philosophical Society.URL: http://books.google.at/books?id=9TesGwAACAAJ
Fisher, R. (1925), Statistical Methods For Research Workers, Cosmo study guides,Cosmo Publications.URL: http://books.google.at/books?id=4bTttAJR5kEC
Fisher, R. (1955), ‘Statistical methods and scientific induction’, Journal of the RoyalStatistical Society. Series B (Methodological) 17(1), pp. 69–78.
Gigerenzer, G., Swijtink, Z., Porter, T., Daston, L., Beatty, J. and Kruger, L. (1990),The Empire of Chance: How Probability Changed Science and Everyday Life (Ideasin Context), reprint edn, Cambridge University Press.
Gosset, W. S. (1908), ‘The probable error of a mean’, Biometrika 6(1), 1–25. Ori-ginally published under the pseudonym “Student”.URL: http://dx.doi.org/10.2307/2331554
Griffiths, W. E., Hill, R. C. and Judge, G. G. (1993), Learning and Practicing Eco-nometrics, 1 edn, Wiley.
Hansen, B. E. (1997), ‘Approximate asymptotic p values for structural-change tests’,Journal of Business & Economic Statistics 15(1), 60–67.
Johnston, J. and Dinardo, J. (1996), Econometric Methods, 4 edn, McGraw-Hill/Irwin.
Kahneman, D. (2013), Thinking, Fast and Slow, reprint edn, Farrar, Straus andGiroux.
Leeb, H. and Potscher, B. M. (2008), ‘Can one estimate the unconditional distribu-tion of post-model-selection estimators?’, Econometric Theory 24(2), 338–376.
Lehmann, E. L. (1993), ‘The Fisher, Neyman-Pearson Theories of Testing Hypo-theses: One Theory or Two?’, Journal of the American Statistical Association88(424), pp. 1242–1249.
Neyman, J. and Pearson, E. S. (1928a), ‘On the use and interpretation of certain testcriteria for purposes of statistical inference: Part i’, Biometrika 20A(1/2), 175–240.URL: http://www.jstor.org/stable/2331945
Neyman, J. and Pearson, E. S. (1928b), ‘On the use and interpretation of certain testcriteria for purposes of statistical inference: Part ii’, Biometrika 20A(3/4), 263–294.URL: http://www.jstor.org/stable/2332112

Angewandte Okonometrie 95
Pearson, K. (1900), ‘On a criterion that a given system of deviations from the proba-ble in the case of a correlated system of variables is such that it can reasonably besupposed to have arisen from random sampling.’, Philosophical Magazine 50, 157–175.
Pindyck, R. S. and Rubinfeld, D. L. (1997), Econometric Models and EconomicForecasts, 4 edn, McGraw-Hill/Irwin.
Ramsey, J. B. (1969), ‘Tests for specification errors in classical linear least squaresregression analysis’, Journal of the Royal Statistical Society, Series B 31, 350–371.
Salsburg, D. (2002), The Lady Tasting Tea: How Statistics Revolutionized Sciencein the Twentieth Century, 1st edition edn, Holt Paperbacks.
Spanos, A. (1999), Probability Theory and Statistical Inference: Econometric Mode-ling with Observational Data, Cambridge University Press.
Wooldridge, J. (2005), Introductory Econometrics: A Modern Approach, 3 edn,South-Western College Pub.
Zeileis, A., Leisch, F., Hornik, K. and Kleiber, C. (2002), ‘strucchange: An R Packa-ge for Testing for Structural Change in Linear Regression Models’, Journal ofStatistical Software 7(2), 1–38.URL: http://www.jstatsoft.org/v07/i02/
Ziliak, S. T. (2008), ‘Retrospectives: Guinnessometrics: The Economic Foundationof “Student’s” t’, Journal of Economic Perspectives 28, 199–216.URL: http://pubs.aeaweb.org/doi/pdfplus/10.1257/jep.22.4.199





























