Embed Size (px)
Citation preview

Kelly BocciaAbi Natarajan Konstantin LivitskiSenthil Anand SubbananMeyyappan Meyyappan
1

Agenda
Business Requirements Client Overview Business Problem Business Goal Solution and Scope
Technical Specification System Context Architecture Overview Components & Modules Security Model Document indexing Search Explained
Implementation Plan Resource & Costs Development Environment Production Environment Success Criteria
Prototype Q&A
2

Multi-National Manufacturing & Sales Corporation
Business Growth - Multiple Applications - Multiple Repositories
Business Problem
3

Business Goal
Organize Intellectual Capital and Assets
Accessibility - Connect knowledge workers securely to relevant information
Productivity - Increase productivity and reduce re-work by leveraging knowledge and expertise
Client Overview
4

Solution
Enterprise Knowledge Management Platform
5

System Context
6

Components & Modules
7

Architectural Overview
8

Security Model
• Integrated with existing GLOCO's security infrastructure• Any access requires authentication• To follow a link in search results, user may need additional
authorization for repository access
9

Document indexing
• Document is anything that a search result can point at• Documents are external to the search engine• Documents include text and metadata • Lucene sees each document as a set of named fields
10

How search works
• Lucene sees each document as a set of named fields • A record is created for each document to store some fields
o URL is usually a stored field• The main index is keyed by search term (i.e. inverted)
o Typical text fields are tokenized, filtered, and stemmed into terms o Indexed fields may be discarded after processing o For each term, a list of document IDs is stored to help locate recordso Also stores frequency and proximity
• Search involves retrieval of document IDs by term, and stored fields by the document ID
11
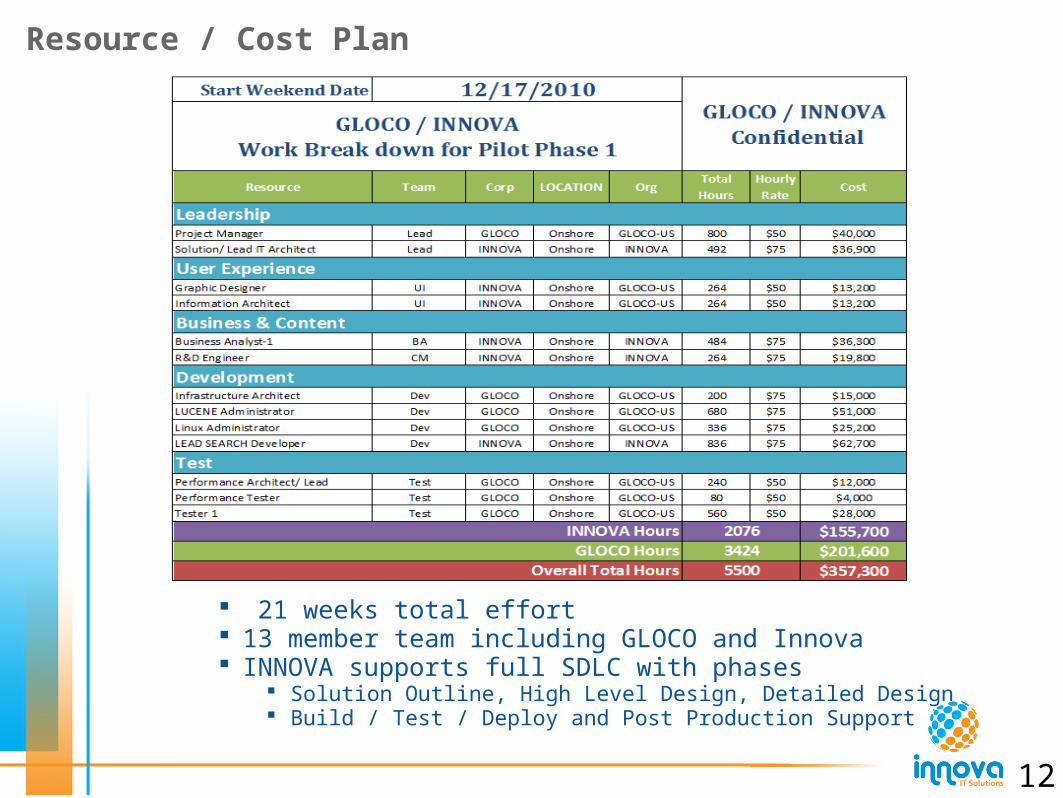
Resource / Cost Plan
21 weeks total effort 13 member team including GLOCO and Innova INNOVA supports full SDLC with phases
Solution Outline, High Level Design, Detailed Design Build / Test / Deploy and Post Production Support
12
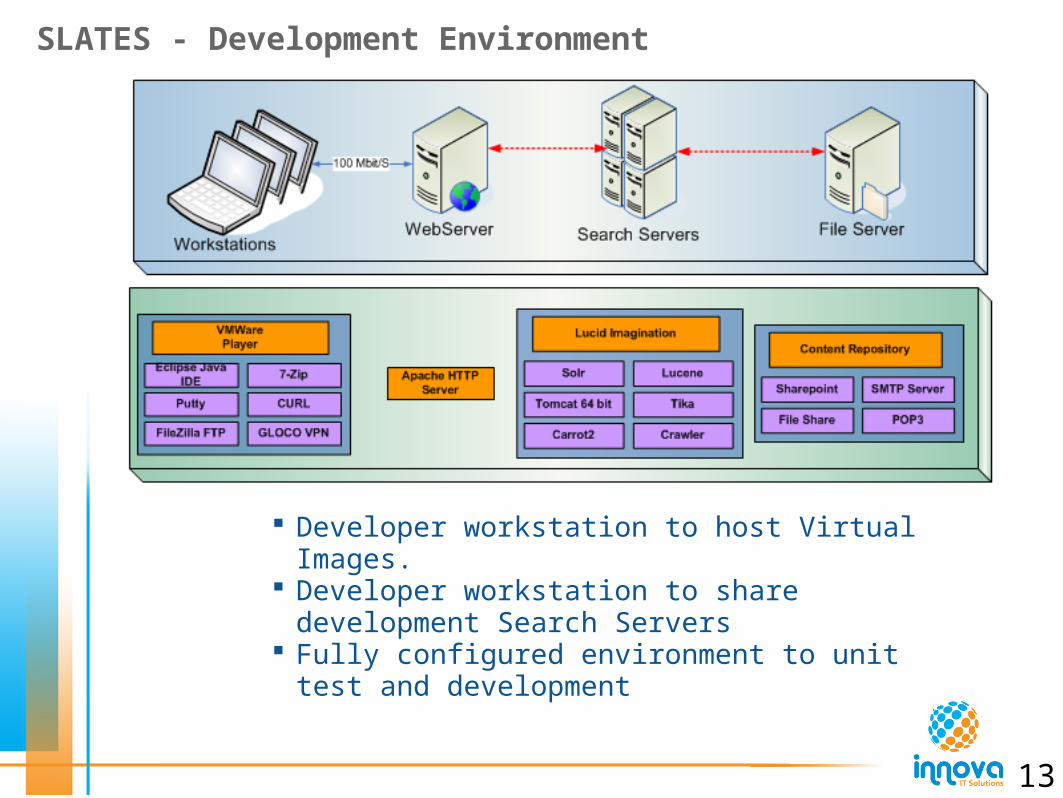
SLATES - Development Environment
Developer workstation to host Virtual Images. Developer workstation to share development
Search Servers Fully configured environment to unit test and
development
13

SLATES - QA / Test and Production
• Sticky load balancer to remember the serving tomcat
• Each Search server
to hold multiple instances.
• Shared / Cached
Network storage to share index
• Similar configuration
for both QA and Production environment
14

Success Criteria and Benchmarks
Most important project success criteria are: 10% time and resource savings on certain R&D activities 75% positive feedback on user surveys 50% of the target user group are actively using the system 5% of available documents have user-defined tags
15

User 1 Searches for the keyword 'Blood Glucose'
16

User 1 gets back the results with the keyword ‘blood glucose’
17

User 1 adds tag ‘diabetes’ to a result
18

Tag ‘diabetes’ is immediately available for searching
19

User 2 searches for keyword ‘diabetes’
20

User 2 gets back a result for keyword ‘diabetes’
21

User 2 clicks on keyword ‘bp testing’ in the tag cloud
22

User 2 gets more results for keyword ‘bp testing’
23

Thank you!
Innova would like to thank:
Zoya KinstlerJeff Parker
Basem NaseimValar Jayaprakash
Classmates Harvard University Extension School
24

Questions?
25

Reference Slides
26

27

Index Growth
• Index size is a percentage of the document corpus size• Maintenance trade-off:
o Expensive segment merges - load all segments, write a new oneo Fragmented index is expensive to query - must read all segments
• Lucene index segments are write-once - helps with concurrency• Updates are done as delete - re-add. Updates should be
batchedo Direct tagging is inefficient
28
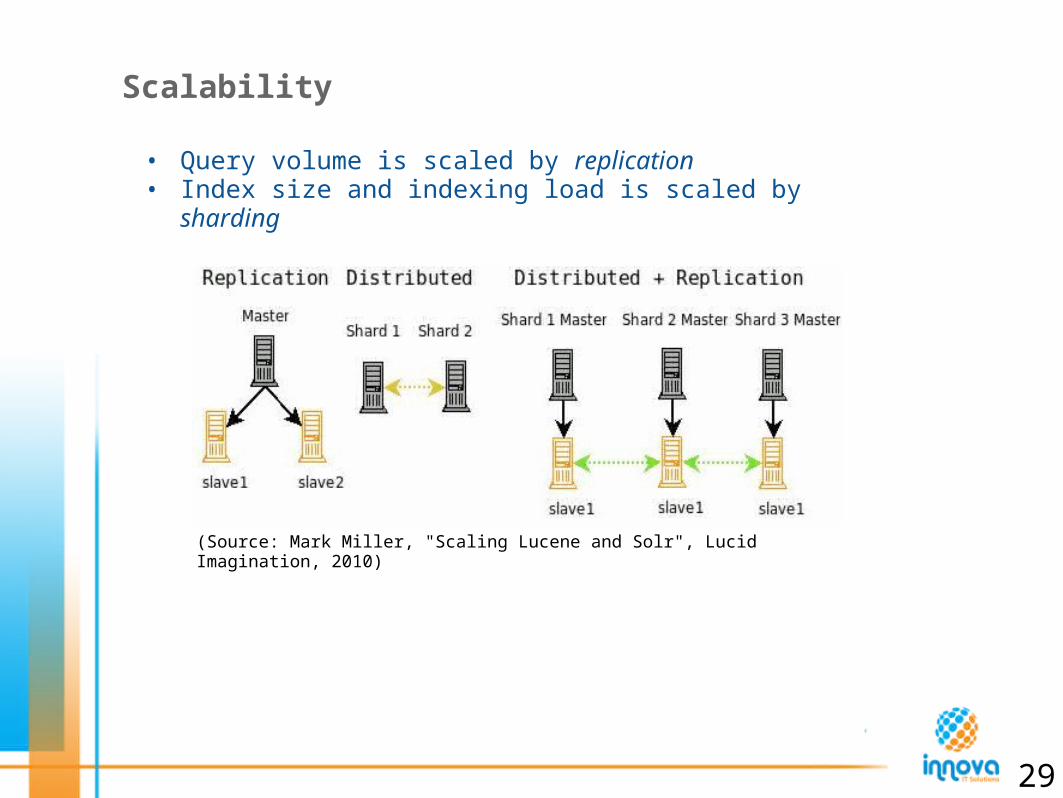
Scalability
(Source: Mark Miller, "Scaling Lucene and Solr", Lucid Imagination, 2010)
• Query volume is scaled by replication• Index size and indexing load is scaled by sharding
29
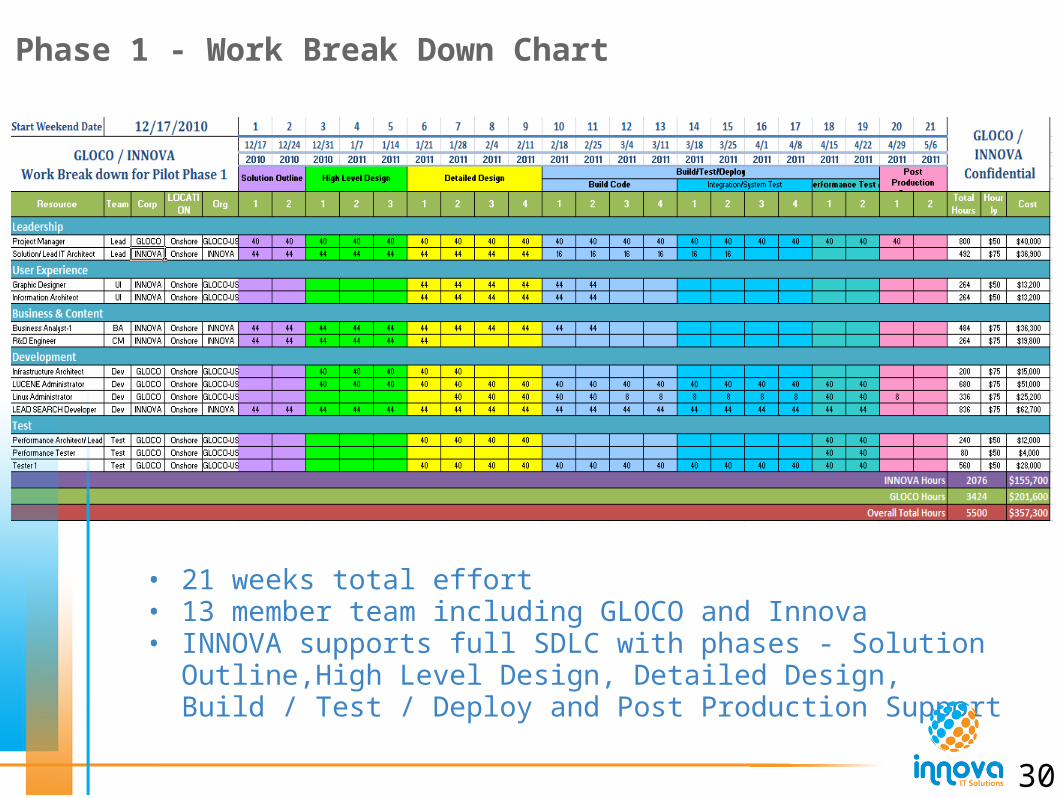
Phase 1 - Work Break Down Chart
• 21 weeks total effort• 13 member team including GLOCO and Innova• INNOVA supports full SDLC with phases - Solution Outline,High
Level Design, Detailed Design, Build / Test / Deploy and Post Production Support
30

Use Case - Search and Tag
31

Hardware / Software - Detailed Configuration
32

Interface Specification
33





























