Embed Size (px)
Citation preview

EÖTVÖS LORÁND TUDOMÁNYEGYETEM
INFORMATIKAI KAR
Algoritmusok és Alkalmazásaik Tanszék
Klaszter-analízis és alkalmazásai
Témavezető: Szerző:
Dr. Fekete István Ilonczai Zsolt
egyetemi docens programtervező informatikus MSc
Budapest, 2014

Tartalomjegyzék
1 Bevezetés ....................................................................................................................... 3
2 A klaszterezés elméleti tárgyalása .............................................................................. 5
2.1 Adatpontok .............................................................................................................. 5
2.2 Távolságfüggvények ............................................................................................... 6
2.3 Centroid alapú klaszterező algoritmusok ................................................................ 7
2.3.1 k-közép algoritmus ........................................................................................... 8
2.4 Hierarchikus klaszterező algoritmusok ................................................................. 12
2.4.1 Klaszterek távolságának mérése ..................................................................... 13
2.4.2 Hierarchikus felhalmozó algoritmus .............................................................. 14
2.4.3 Hierarchikus lebontó algoritmus .................................................................... 17
2.5 Sűrűség alapú algoritmusok .................................................................................. 19
2.5.1 DBSCAN algoritmus ...................................................................................... 20
2.5.2 OPTICS algoritmus ........................................................................................ 25
2.6 Rács alapú klaszterező algoritmusok .................................................................... 31
2.6.1 GRIDCLUS algoritmus .................................................................................. 31
2.7 Klaszterezés neurális hálózatok segítségével ........................................................ 38
2.7.1 Neurális hálózatok .......................................................................................... 38
2.7.2 Önszerveződő térképek (SOM) ...................................................................... 40
3 Klaszterezés alkalmazása a képfeldolgozásban ...................................................... 50
3.1 Képek vektoros reprezentációja ............................................................................ 50
3.2 SOM felhasználása a képfeldolgozásban .............................................................. 52
3.3 Képek klaszterezése .............................................................................................. 54
4 Klaszterezést bemutató demóprogram .................................................................... 58
4.1 Felhasználói dokumentáció ................................................................................... 58
4.1.1 A rendszer rövid ismertetése .......................................................................... 58
4.1.2 Rendszerkövetelmények ................................................................................. 58
4.1.3 Üzembe helyezés ............................................................................................ 58
4.1.4 A program használata ..................................................................................... 59
4.2 Megvalósítás ......................................................................................................... 68
5 Irodalomjegyzék ......................................................................................................... 69

3
1 Bevezetés
A klaszter-analízis az informatikának manapság igen széles körben alkalmazott és
kutatott területe. Ez nem véletlen, hiszen az adatok értelmes szétválasztása, különböző
szempontok szerinti csoportosítása a legkülönbözőbb tudományterületeken megjelenő
feladat, mely egyre nagyobb kihívást állít a matematikusok és programozók elé.
Maga a klaszter-analízis vagy klaszterezés nem más, mint egy csoportosítási feladat,
melynek során egy adathalmaz elemeit különböző csoportokba, úgynevezett
klaszterekbe soroljuk. Ezt úgy tesszük, hogy a megoldott feladatnak megfelelően, egy
adott csoport elemei hasonló tulajdonságokkal rendelkezzenek, azaz – tágabb értelembe
véve – közel legyenek egymáshoz. A feladat megoldásához tehát elengedhetetlen egy
alkalmas távolságfogalom definiálása, amely megmutatja, hogy két elem mennyire
közel helyezkedik el, azaz bizonyos tulajdonságaikat figyelembe véve, mennyire
hasonlítanak egymásra.
Alkalmazási területeit tekintve a klaszter-analízis számtalan tudományterületen
nyújt segítséget különböző feladatok megoldására. A biológiában gyakran előforduló
feladat a rendszerezés. Az ökológiában például gyakran használnak klaszter-elemzést
növény- és állatközösségek csoportosítására, rendszertanban különböző egyedek törzs,
rend, illetve faj szerinti rendszerezésére. A bioinformatikán belül a szekvencia-analízis
egy olyan alapvető módszer, melynek alkalmazása során hasonló tulajdonságokért
felelős géneket csoportosítunk. Az orvostudományban, különösképpen a
gyógyszeriparban, különböző óriás gyógyszermolekulák kutatása során találkozhatunk
klaszterezéssel. Ma az egyik legmodernebb orvosi vizsgálat egy speciális képalkotó
eljárás, a PET tomográfia, melynek során pontos, háromdimenziós képet nyerhetünk a
test belsejének adott területéről. A vizsgált terület feltérképezéséhez nagy mennyiségű
adat klaszterezésére van szükség a különböző szövetek elkülönítése érdekében.
Társadalomtudományok esetében kiválóan használható különböző piackutatásoknál,
illetve szociális hálózatok elemzésénél, melynek során a felhasználókat bizonyos
szempontok szerint szeretnénk különböző közösségekbe sorolni. A klaszter-analízis
legkiemelkedőbb, a fentebb leírtakkal szorosan összefonódott alkalmazási területe az
informatika, ahol az ajánló rendszerektől, az adatbányászaton és robotikán át az
evolúciós algoritmusok eredményének kiértékeléséig lépten-nyomon szükségünk van az
ide sorolható módszerekre.

4
A klaszterezés elméleti leírásának nehézsége abban rejlik, hogy maga a probléma
nehezen általánosítható. Minden egyes alkalmazási terület, minden konkrét feladat
legtöbbször nagyon speciális, hiszen meg kell állapítanunk, hogy egy elemet milyen,
hány dimenziós adatponttal reprezentáljunk, mi legyen ezek között a feladatnak
megfelelő távolságmérték, illetve hogy mi számít egy jól elkülönülő klaszternek. A
feladat megoldására számos algoritmus létezik, melyeket megvalósítási stratégiájuk
szerint a szakirodalom különböző osztályokba sorol. Megjegyzem azonban, a
szakirodalommal összhangban, hogy univerzális klaszterező algoritmus nem létezik,
hiszen minden egyes feladatra más-más algoritmussal, esetleg azok ötvözésével kapunk
jó eredményt.
Diplomamunkám célja különböző, reprezentatív klaszterezési algoritmusok
bemutatása és elemzése, valamint egy konkrét alkalmazási terület, a számítógépes
képfeldolgozás vizsgálata. A szakirodalomban fellelhető algoritmusosztályok mellett a
dolgozat saját megközelítési javaslatokat is ad néhány klaszterező algoritmus esetén.
Ezen túlmenően egy olyan demóprogram elkészítése volt a célom, mely grafikus
támogatás mellett lehetőséget nyújt a tanulmányozott és megvizsgált klaszterezési
algoritmusok működésének szemléltetésére, illetve azok felhasználására a számítógépes
képfeldolgozásban.

5
2 A klaszterezés elméleti tárgyalása
Ebben a fejezetben a klaszterezéshez kapcsolódó alapvető fogalmakat részletesen
tárgyaljuk, illetve bemutatjuk a fontosabb klaszter algoritmus-osztályok néhány
reprezentánsát.
Ahogy azt a bevezetésben is említettük, a klaszterezés egy adathalmaz elemeinek
(pontjainak) csoportosítását jelenti bizonyos hasonlósági tulajdonságok alapján.
Klaszter-analízissel legelőször a statisztikában kezdtek el foglalkozni, majd később az
adatbányászat egyik legmeghatározóbb ága lett.
A klaszterezés, holott egy csoportosítási feladat, különbözik az osztályozás
feladatától. Míg osztályozás esetén előre megadott információink vannak a kialakuló
csoportokról, addig klaszterezés során egyedül az adatpontok állnak rendelkezésünkre,
az eredményként kapott csoportok „önszerveződnek”, azaz a pontok maguk alakítják ki
a klasztereket. Azt mondhatjuk, hogy „az osztályozás egy felügyelt (supervised), a
klaszterezés pedig felügyelet nélküli (unsupervised) csoportosítás” [1].
Egy halmaznak, amely n adatpontot tartalmaz összesen Bell-számnyi, azaz
𝑂(𝑒𝑛 𝑙𝑔𝑛) különböző klaszterezése létezik. Legnagyobb nehézség egy klaszterező
algoritmus számára ezen klaszterezések közül kiválasztani azt az egyet, amelyik a
legmegfelelőbb megoldása lesz az adott feladatnak.
2.1 Adatpontok
Klaszterezés során, feladattól függően a legkülönfélébb adatpontokkal kell dolgoznunk.
Általában nagy nehézséget jelent eldönteni, hogy pontjainkat milyen típusú adatként
reprezentáljuk, azaz klaszterezendő elemeinkből hogyan nyerjünk ki
tulajdonságértékeket úgy, hogy azok megfelelően tükrözzék szándékunkat. Például ha a
számítógépen megtalálható fényképeinket szeretnénk klaszterezni átlagos
színárnyalatuk szerint, előbb el kell döntenünk, hogy hogyan ábrázoljuk adatként ezt a
tulajdonságot, ami majd a klaszter algoritmus számára már felhasználható lesz.
[1] Iványi Antal (Szerk.): Informatikai algoritmusok 2. , ELTE Eötvös Kiadó Kft., Budapest 2005, [768], ISBN 9789634637752

6
Egy adatpontot általában n dimenziós vektortérben ábrázolunk, ahol adott dimenzió
az adatpont egy tulajdonságának feleltethető meg. Egy ilyen tulajdonság az adatpont
egy attribútuma. Legyen x egy d dimenziós adatpont, ami tehát a következő d dimenziós
vektor:
𝑥 = (𝑥1, 𝑥2 … 𝑥𝑑 )𝑇
Az adatokat általánosan két nagy csoportba sorolhatjuk:
Numerikus adatok – Ebben az esetben az adatpont, mint n dimenziós vektor
elemei numerikusak, tehát egy adott intervallumból veszik fel értékeiket.
Természetesen ezek az intervallumok az egyes dimenziók mentén eltérőek
lehetnek. Ilyen például egy egyszerű, kétdimenziós adatpont a síkban, mely
két valós számmal reprezentálható, amik a pont síkbeli helyét mutatják.
Másik példa egy szín RGB (Red Green Blue) színkomponensek szerinti
három dimenziós reprezentációja, ahol az adatvektor egy eleme a [0,255]
intervallumból vehet fel értéket.
Bináris adatok – Ebben az esetben az adatpont attribútumai csak két értéket
vehetnek fel. Az attribútum-érték 0, ha az adott adatpont nem rendelkezik az
adott dimenzió szerinti tulajdonsággal, különben pedig 1. Például ha egy
kórházban betegek csoportját szeretnénk klaszterezni kórtörténet szerint,
akkor az adatvektor i. komponense jelentheti azt, hogy a betegnek volt-e már
adott vírusfertőzése, vagy sem.
Megjegyezzük, hogy bináris adatok esetén a numerikus adatoknak megfelelő
klaszterező algoritmusokhoz képest sokszor teljesen más algoritmusokat kell
használnunk, hiszen bináris adatok között a távolságfogalom is máshogyan
értelmezhető. Ebben a dolgozatban a numerikus adatokra vonatkozó klaszterező
algoritmusokat tárgyaljuk.
2.2 Távolságfüggvények
Minden egyes klaszterező algoritmus működéséhez elengedhetetlen egy távolsági
függvény definiálása, ami meghatározza, hogy két klaszterezendő adatpont között
mekkora a távolság, azaz a két adatpont mennyire hasonlít egymásra.

7
Jelöljük az 𝑎 és b adatpont távolságát 𝑑𝑖𝑠𝑡(𝑎, 𝑏)-vel, ahol 𝑎 és b vektorok
dimenziója d. Legyen D az adatpontok halmaza. Ekkor a 𝑑𝑖𝑠𝑡 ∈ 𝐷 × 𝐷 → ℝ
távolságfüggvénytől általában a következő feltételek teljesülését várjuk el:
𝑑𝑖𝑠𝑡(𝑎, 𝑏) ≥ 0
𝑑𝑖𝑠𝑡(𝑎, 𝑎) = 0
𝑑𝑖𝑠𝑡(𝑎, 𝑏) = 𝑑(𝑏, 𝑎) – szimmetria
𝑑𝑖𝑠𝑡(𝑎, 𝑏) ≤ 𝑑𝑖𝑠𝑡(𝑎, 𝑐) + 𝑑𝑖𝑠𝑡(𝑐, 𝑏), ∀𝑐 ∈ 𝐷 𝑒𝑠𝑒𝑡é𝑛
– háromszög egyenlőtlenség
Fontos megjegyeznünk, a fenti tulajdonságokat nem minden esetben követeljük
meg. Bizonyos adatpontok klaszterezése során előfordulhat, hogy a szimmetria, vagy a
háromszög egyenlőtlenség nem teljesül. Ha mind a négy tulajdonság teljesül egy
távolságfüggvényre, akkor a függvényt metrikának nevezzük. A klaszter-analízisben
tehát nem minden távolságfüggvény metrika.
Numerikus attribútumok esetén az egyik legnépszerűbb és egyben legáltalánosabb
távolsági mérték a Minkowski-metrika, melyet a következőképpen definiálunk (p
tetszőleges pozitív szám):
𝑑𝑖𝑠𝑡𝑝(𝑎, 𝑏) = (∑|𝑎𝑖 − 𝑏𝑖|𝑝
𝑑
𝑖=1
)
1𝑝
𝑝 = 1 esetén a Minkowski-metrika egy speciális, másik jól ismert metrikájához
jutunk, ami a Manhattan-távolság. Az klaszterező algoritmusok implementációja során
a Minkowski-metrika egy másik speciális esetét (𝑝 = 2) használtuk fel, ami nem más,
mint az Euklideszi távolság.
𝑑𝑖𝑠𝑡2(𝑎, 𝑏) = √∑ |𝑎𝑖 − 𝑏𝑖|2
𝑑
𝑖=1
2.3 Centroid alapú klaszterező algoritmusok
A centroid alapú vagy particionáló klaszterezési módszerek a legnépszerűbb és egyben
legáltalánosabban felhasználható klaszterező algoritmusokat alapozzák meg. Egy

8
centroid alapú klaszterező algoritmus alapgondolata az, hogy egy adott klasztert annak
képzeletbeli középpontjával, az ún. centroid pontjával reprezentáljunk az algoritmus
működése során. A particionáló elnevezés onnan ered, hogy az algoritmus az
adathalmazt k darab partícióba szervezi, amelyek az eredményül szolgáló klaszterekként
értelmezhetőek. Az algoritmusnak bemeneti paraméterként meg kell adnunk a partíciók
(klaszterek) számát. Ezen előzetes információ szükségességét a klaszterezendő
adatpontokról a szakirodalom a particionáló klaszterező algoritmusok legnagyobb
hátrányának tekinti, hiszen megfelelő információk hiányában általában nagyon nehéz
meghatározni, hogy hány darab klaszterbe szeretnénk sorolni az adatpontjainkat.
2.3.1 k-közép algoritmus
Az egyik legismertebb centroid alapú klaszterező algoritmus a k-közép (k-means)
algoritmus. Mint minden particionáló klaszterező algoritmus esetén, egy adott klasztert
itt is a klaszter adatpontjaihoz tartozó vektorok átlagával reprezentálunk.
Legyen 𝐶𝑖 egy klaszter. Ekkor az őt reprezentáló centroid pont legyen:
𝑟(𝐶𝑖) =1
|𝐶𝑖|∑ 𝑢
𝑢∈𝐶𝑖
Az algoritmus futása során végig k darab centroid pontunk van, a bemenő k,
klaszterszám paraméternek megfelelően. Az algoritmus indulásakor a centroid pontokat
véletlenszerűen választjuk a D klaszterezendő ponthalmazból. Ezek alkotják majd a
kezdeti klasztereket. Megjegyezzük, hogy ez a véletlen választás nem mindig a legjobb
klaszterezést eredményezi majd, ezért ha több előzetes információval rendelkezünk a
pontokat illetően, érdemes lehet konkrétan megadott centroid pontokkal indítanunk az
algoritmust. E kezdeti lépést követően egy ciklusban végigmegyünk az adatpontokon,
és mindegyiket abba a klaszterbe soroljuk, amelyiknek a centroid pontja hozzá
legközelebb helyezkedik el. Ezután újraszámoljuk a centroid pontok értékét, hiszen
ezek az adatpontok átsorolásai miatt megváltoztak. Ezt mindaddig ismételjük, amíg a
centroid pontok változnak. Az algoritmus bemeneti paramétere a klaszterezendő pontok
halmazán (D) kívül az előállítandó klaszterek száma (k).

9
A k-közép algoritmus pszeudokódja a következő[2]:
k-közép(D, k)
1. Válasszunk tetszőleges k darab elemet az adathalmazból. Ezek lesznek a kezdeti
klaszterközéppontok;
2. AMÍG változnak a klaszterközéppontok:
3. Minden elemet ahhoz a klaszterhez rendelünk, melynek centroid pontjához
leginkább hasonló (legközelebb helyezkedik el);
4. Frissítjük a klaszterek átlagát, azaz újraszámoljuk a centroid pontok helyzetét;
5. AMÍG_VÉGE.
A k-közép algoritmus egy konvergencia feladat megoldásaként is felfogható, hiszen
az algoritmus nem tesz mást, mint egy olyan klaszterezést keres, amelyben az
adatpontok és a klaszterük centroid pontjainak négyzetes távolságösszege minimális.
Ezt az adott klaszterezéshez tartozó minimalizálandó értéket a klaszterezés hibájának
vagy négyzetes hiba kritériumfüggvénynek nevezzük. Ha C egy adathalmaz
klaszterezése, akkor a hozzá tartozó hiba kritériumfüggvény:
𝐸(𝐶) = ∑ ∑ 𝑑(𝑢, 𝑟(𝐶𝑖))2
𝑢∈𝐶𝑖
𝑘
𝑖=1
Bár a k-közép algoritmus minimalizálja az 𝐸(𝐶) négyzetes hibafüggvényt,
előfordulhat, hogy elakad egy lokális minimumpontban. Ennek kiküszöbölésére
érdemes az algoritmust többször futtatni, különböző kezdeti centroid pontokkal, így
megkeresve a globális minimumot. Azt a klaszterezési eredményt fogadjuk el a
többszöri futtatás után, amelyik a legjobb eredményt adja.
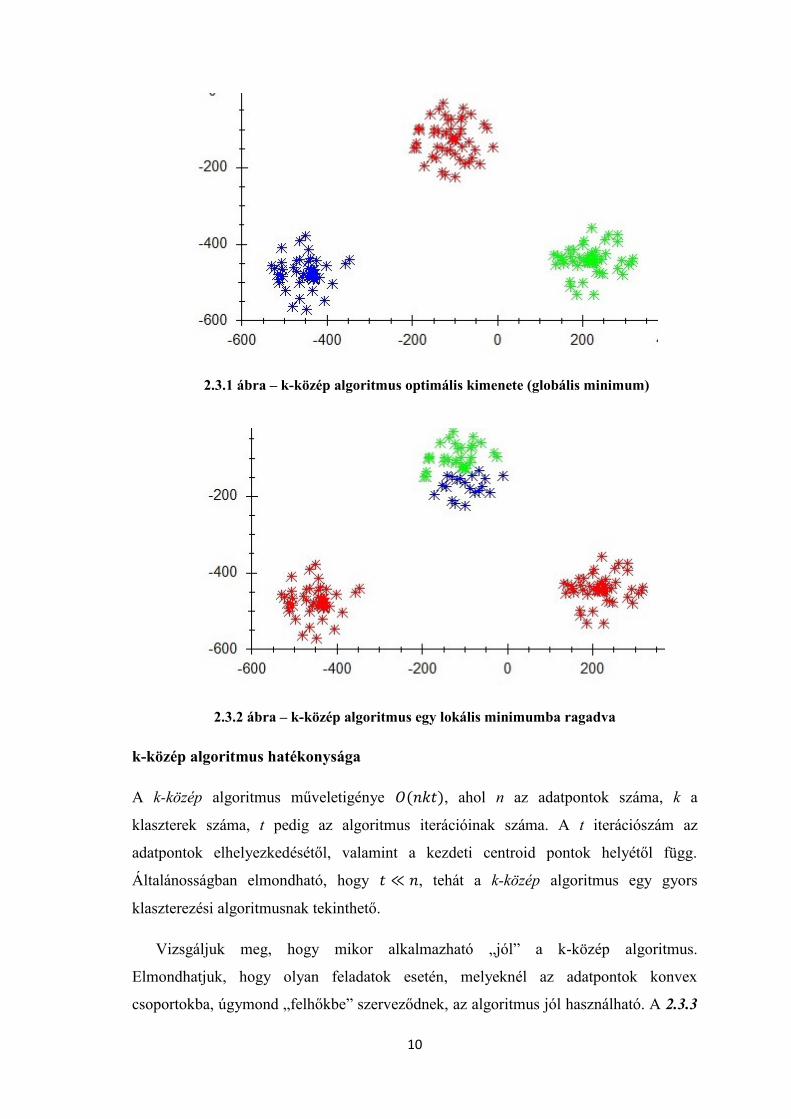
A 2.3.1 ábra a k-közép algoritmus helyes eredményét szemlélteti síkbeli pontok
esetén. Az ábrán az azonos színű adatpontok azonos klaszterben vannak. A 2.3.2 ábra a
k-közép algoritmus kimenetét szemlélteti egy lokális minimumba ragadva. Ez az
eredmény a kezdeti centroid pontok „rossz” választásának köszönhető (valószínűleg két
kezdeti centroid pont is a felső ponthalmazban volt).
[2] Jiawei Han – Micheline Kamber: Adatbányászat koncepciók és technikák, Panem Könyvkiadó Kft., 2004, [532], ISBN 9789635453948
10
2.3.1 ábra – k-közép algoritmus optimális kimenete (globális minimum)
2.3.2 ábra – k-közép algoritmus egy lokális minimumba ragadva
k-közép algoritmus hatékonysága
A k-közép algoritmus műveletigénye 𝑂(𝑛𝑘𝑡), ahol n az adatpontok száma, k a
klaszterek száma, t pedig az algoritmus iterációinak száma. A t iterációszám az
adatpontok elhelyezkedésétől, valamint a kezdeti centroid pontok helyétől függ.
Általánosságban elmondható, hogy 𝑡 ≪ 𝑛, tehát a k-közép algoritmus egy gyors
klaszterezési algoritmusnak tekinthető.
Vizsgáljuk meg, hogy mikor alkalmazható „jól” a k-közép algoritmus.
Elmondhatjuk, hogy olyan feladatok esetén, melyeknél az adatpontok konvex
csoportokba, úgymond „felhőkbe” szerveződnek, az algoritmus jól használható. A 2.3.3

11
ábrán ez a tulajdonság nem teljesül. Az algoritmus sűrűség-alapú klasztereknél sem
alkalmazható jól, hiszen ebben az esetben a klaszterek sűrűsége, nem pedig az
adatpontok elhelyezkedése, illetve azok átlaga számít.
2.3.3 ábra – k-közép algoritmus egy rossz eredménye nem konvex szerveződésű
adatpontok esetén
A fentebb leírt típusú klaszterek esetén, mint ahogy azt majd később látni fogjuk, a
sűrűség alapú klaszterezési algoritmusok adnak majd jó eredményt.
Említettük, hogy a k-közép algoritmus nagy hátránya, hogy bemeneti paraméterként
meg kell adnunk a klaszterek számát. Ennek következtében, valamint mivel az
algoritmus klaszter átlagokkal számol, az eredmény nagyon érzékeny lesz a kívülálló
pontokra, hiszen ezek rossz irányba tolhatják el a klaszterek centroid pontjait. A másik
probléma az, hogy az algoritmus minden kívülálló pontot besorol egy klaszterbe, holott
ezek csak rontanak az eredményen.
Definíció: Kívülálló pontnak vagy zajpontnak nevezzük azt az adatpontot, amelyik
jelentősen eltér az összes többi adatponttól, azaz nem része egyik klaszternek sem.
2.3.3 ábra – k-közép algoritmus működése kívülálló pontok esetén

12
A k-közép algoritmusnak számtalan módosítása létezik, melyek főként a kezdeti
centroid pontok választásában, illetve a klaszterek átlagszámolásában különböznek.
2.4 Hierarchikus klaszterező algoritmusok
A hierarchikus klaszterező algoritmusok osztálya olyan algoritmusokat tartalmaz,
melyek a klasztereket kizárólag az adatpontok egymáshoz viszonyított távolságát
felhasználva állapítják meg. Az alapgondolat az, hogy egy adott pont sokkal inkább
kötődik egy hozzá közelebb eső adatponthoz, mint egy távolihoz a klaszterek
kialakulása során. A hierarchikus elnevezés azt hivatott tükrözni, hogy az algoritmus az
adathalmaz klasztereit egy hierarchikus adatszerkezet szerint dolgozza fel. Ez az
adatszerkezet általában egy fa, melynek a csúcsai klaszterek. Egy hierarchikus
algoritmus működése során minden egyes iteráció a fának egy új szintjét határozza meg.
Tágabb értelembe véve a fa levelei az adatpontok, a fa gyökere pedig az a klaszter,
amelyik az összes adatpontot tartalmazza. A közbülső, lehetséges klaszterezések a fa
köztes szintjein helyezkednek el. A 2.4.1 ábra az algoritmus futása során felépülő fát
szemlélteti. A gyökérszinten (0. szint) egy darab klaszter van, ami az összes adatpontot
tartalmazza, míg a levélszinten (2. szint) minden adatpont egy különálló klaszter.
2.4.1 ábra – Klaszterhierarchia
A hierarchikus klaszterező algoritmusok csoportján belül két algoritmustípusról
beszélhetünk, annak függvényében, hogy a hierarchia építését a fa leveleitől, illetve
annak gyökerétől kezdjük. Ezeket a következő alfejezetekben részletesen tárgyaljuk:
Hierarchikus felhalmozó (agglomerative) algoritmus
Hierarchikus lebontó (divisive) algoritmus

13
Egy hierarchikus algoritmus estében szükségünk van egy megállási feltételre, hiszen
általában nem szeretnénk az egész hierarchikus fát felépíteni. Elegendő addig a szintig
elmennünk, amelyikben a csúcsok már a feladatnak megoldásának megfelelő
klasztereket reprezentálják. Ez a megállási feltétel lehet például a klaszterek száma (ha
azt előre ismerjük), vagy a klaszterek között értelmezett maximális távolság elérése,
azaz ha már túl távol esnek a klaszterek egymástól, álljon meg az algoritmus. Ez a
megállási feltétel tekinthető az algoritmus bemenő paraméterének is.
2.4.1 Klaszterek távolságának mérése
A hierarchikus algoritmusok működéséhez szükségünk van két klaszter közötti
távolságfogalom bevezetésére, mely kézenfekvő módon az adatpontok között
értelmezett távolságfüggvényre épül.
Legyenek 𝐶𝑖 és 𝐶𝑗 klaszterek, melyek között a távolságot a következő
klasztertávolság értékekkel szoktuk definiálni, ha a d egy távolságfüggvény két adatpont
között:
Klaszterek minimális távolsága:
𝑑𝑚𝑖𝑛(𝐶𝑖 , 𝐶𝑗) = 𝑚𝑖𝑛𝑢∈𝐶𝑖,𝑣∈𝐶𝑗𝑑(𝑢, 𝑣)
Klaszterek maximális távolsága:
𝑑𝑚𝑎𝑥(𝐶𝑖 , 𝐶𝑗) = 𝑚𝑎𝑥𝑢∈𝐶𝑖,𝑣∈𝐶𝑗𝑑(𝑢, 𝑣)
Klaszterek átlagos távolsága (ez vektortérben a centroidok távolságaként is
értelmezhető):
𝑑𝑚𝑒𝑎𝑛(𝐶𝑖 , 𝐶𝑗) = 𝑑 (1
|𝐶𝑖|∑ 𝑢
𝑢∈𝐶𝑖
,1
|𝐶𝑗|∑ 𝑣
𝑣∈𝐶𝑗
)
Az algoritmusok bemutatására szolgáló demóprogramban ez a három
klasztertávolság érték került implementálásra.

14
2.4.2 Hierarchikus felhalmozó algoritmus
Hierarchikus felhalmozó klaszterező algoritmus indulásakor minden egyes adatpont
külön klaszterben van. Ha a klaszterhierarchiák fáját tekintjük, akkor azt mondhatjuk,
hogy az algoritmus a fa leveleitől indul, minden egyes iterációban a gyökér felé
haladva. Minden egyes szinten csak két klaszter egyesül, mégpedig az a kettő,
melyeknek klasztertávolsága minimális.
A hierarchikus felhalmozó algoritmusok közül azt az algoritmust, amely a
klaszterek távolságához a klaszterek minimális távolságát használja (𝑑𝑚𝑖𝑛), egyszerű
láncmódszer algoritmusnak (Single linkage clustering), azt, amelyik a maximális
távolságot (𝑑𝑚𝑎𝑥) teljes láncmódszer algoritmusnak (Complete linkage clustering),
amelyik pedig az átlagos távolságot (𝑑𝑚𝑒𝑎𝑛) használja, átlagos láncmódszer
algoritmusnak (Average linkage clustering) nevezzük.
Jelöljük 𝐶𝑖 és 𝐶𝑗 klaszterek távolságát 𝑑∗(𝐶𝑖, 𝐶𝑗)-vel (𝑑∗ az előbbi alfejezetben
bemutatott klasztertávolságok valamelyike). Az algoritmus bemenő paraméterei a
klaszterezendő ponthalmaz (D), valamint az algoritmus megállási feltétele (például egy
k klaszterszám). Az algoritmus pszeudokódja a következő:
Hierarchikus felhalmozó(D, megállási feltétel)
1. Minden adatpontot külön klaszterbe sorolunk;
2. AMÍG a megállási feltétel (pl. k darab klaszterünk van) hamis, ismételd:
3. Egyesítjük azt a 𝐶𝑖 és 𝐶𝑗 klasztert, melyekre 𝑑∗(𝐶𝑖, 𝐶𝑗) minimális. Ha
több ilyen klaszterpár is létezik, akkor az egyiket egyesítjük ezek közül.
4. AMÍG_VÉGE.
Hierarchikus felhalmozó algoritmus hatékonysága
Ha n az adatpontok száma, az algoritmus műveletigénye általános esetben 𝑂(𝑛3), az
adatpontjaink távolságát egy távolságmátrixban eltárolva 𝑂(𝑛2) hatékonyságú lesz.
Elmondhatjuk tehát, hogy az algoritmus nagy adathalmazok esetén egy lassú
algoritmusnak tűnik, azonban ez bizonyos esetekben javítható.
A hierarchikus felhalmozó algoritmusok közül az egyszerű láncmódszer algoritmus
esetén a műveletigény akár 𝑂(𝑛 𝑙𝑜𝑔𝑛) is lehet, ha adott az adatpontoknak egy gráf
reprezentációja. A következőkben megmutatjuk, hogy ez hogyan lehetséges.

15
Mivel ebben az esetben az algoritmus a minimális klasztertávolságok szerint halad,
azt a két klasztert összevonva egy iterációban, melyeknek minimális klasztertávolsága
minimális, az algoritmus tekinthető egyfajta minimális költségű feszítőfa építő
algoritmusnak is.
Tekintsük a klaszterezendő adatpontok halmazát egy irányítatlan teljes egyszerű
gráfnak a következőképpen. A gráf csúcsai legyenek maguk az adatpontok, a köztük
lévő élek súlyai pedig a pontok egymástól mért távolságai. Futtassunk ezen a gráfon egy
minimális költségű feszítőfát kiszámító algoritmust. Tudjuk, hogy a piros-kék
algoritmusnak van 𝑂(𝑛 𝑙𝑜𝑔𝑛) műveletigényű implementációja, ahol n a gráf csúcsainak
száma (a mi esetünkben az adatpontok száma), ezért ezen algoritmus használata
kézenfekvőnek tűnik. Miután megkaptuk a minimális költségű feszítőfát, nincs más
dolgunk, mint a fa legnagyobb súlyú p darab élét kitörölni. Ezáltal a fát több kisebb fára
vágtuk szét, melyek valójában az adatpontok klaszterei. p értékét a klaszterező
algoritmus megállási feltételének megfelelően kell megállapítani. Ha például az a
megállási feltételünk, hogy k darab klaszterünk legyen, akkor addig vágjuk el
folyamatosan a fát mindig a legnagyobb él szerint, ameddig meg nem kaptuk a kívánt
klaszterezést. Így tehát az algoritmus műveletigénye 𝑂(𝑛 𝑙𝑜𝑔𝑛 + 𝑝) = 𝑂(𝑛 𝑙𝑜𝑔𝑛).
Megjegyezzük, hogy az algoritmus feltételezi, hogy az adatpontoknak egy gráf-
reprezentációja adott, azaz az adatpontjainkat például távolságmátrixban kell
ábrázolnunk, aminek létrehozása további költségekkel járhat. Ez azonban az
algoritmusnak egy előfeltétele, nem pedig része.
A fenti módszer az egyszerű láncmódszer algoritmussal megegyező klaszterezést
adja eredményül.
Az algoritmus pszeudokódja a következő:
1. Építsük fel az adatpontjaink gráfjának megfelelő minimális költségű feszítőfát
(jelenleg 1 darab fánk van egy erdőben);
2. AMÍG a megállási feltétel hamis (a fák száma kisebb a kívánt klaszterszámnál):
3. Töröljük ki az erdő legnagyobb élét;
4. AMÍG_VÉGE.
Vizsgáljuk meg, mikor működik jól a hierarchikus felhalmozó klaszterezési
algoritmus. Elmondhatjuk, hogy mint minden hierarchikus algoritmus, szinte minden

16
adatpont halmazra meglehetősen rugalmas módon alkalmazható, azonban sokszor
elavultnak tekintik őket az új, más megközelítéseket használó klaszterezési
algoritmusokkal szemben.
Holott a hierarchikus felhalmozó klaszterező algoritmus kijavítja a k-közép
algoritmus klaszter-átlagpont (centroid) miatti esetleges lokális minimumok hibáit, az
algoritmus legnagyobb hátrányának az tekinthető, hogy döntései nem visszavonhatóak.
Ha az algoritmus adott iterációjában két klasztert egyesítünk, azok később már nem
bonthatóak szét, az algoritmus ezzel az egyesített klaszterrel dolgozik tovább. Azt
mondhatjuk tehát, hogy az algoritmus klaszteregyesítő lépései kritikusak, hiszen a rossz
egyesítések nem megfelelő végső klaszterezéshez vezethetnek. Érdemes tehát általában
a hierarchikus klaszterező algoritmusokat valamelyik másik klaszterező algoritmussal
ötvözni. Erre látunk majd példát a következő alfejezetben.
A hierarchikus felhalmozó algoritmus a k-közép algoritmussal ellentétben jól
működik nem konvex csoportokba szerveződő klaszterek esetén is (2.4.2 ábra),
azonban hasonlóan érzékeny a kívülálló pontokra, hiszen ezeket hibásan besorolhatja a
hozzájuk legközelebb eső klaszterbe (2.4.3 ábra).
2.4.2 ábra – Hierarchikus felhalmozó algoritmus nem konvex alakú klaszterekre
2.4.3 ábra Hierarchikus felhalmozó algoritmus rossz működése kívülálló pontokra (1)

17
Kívülálló pontok esetén kiütközhet az algoritmus legnagyobb hibája is, mégpedig
az, hogy két közelinek vélt klaszter egyesítése már nem vonható vissza. Így fordulhat
elő az, hogy két, „jól láthatóan” különálló klasztert az algoritmus hamarabb egyesít,
mint valamelyiküket egy kívülálló ponttal, hiszen klasztertávolságuk kisebb, mint
bármelyik klaszter távolsága a kívülálló pont klaszterének távolságától (2.4.4 ábra).
2.4.4 ábra Hierarchikus felhalmozó algoritmus rossz működése kívülálló pontokra (2)
2.4.3 Hierarchikus lebontó algoritmus
A hierarchikus lebontó algoritmus kitűnő példa a különböző klaszterezési algoritmusok
ötvözésére. Maga az algoritmus a hierarchikus felhalmozó algoritmussal ellentétesen
működik, a hierarchikus fa gyökerétől a levelek felé haladva. Induláskor minden
adatpont egy közös klaszterben helyezkedik el. Az algoritmus, futása során ezt a nagy
klasztert osztja folyamatosan egyre kisebb részekre, amíg el nem éri a megállási
feltételt. Ez a megállási feltétel általában egy adott klaszterszám elérését jelenti. Minden
egyes iterációban az algoritmus kiválaszt egy klasztert, amit valamilyen módon
kettéoszt.
Az algoritmus működéséhez két kritikus tényező eldöntése szükséges. Az egyik a
kettéosztandó klaszter kiválasztása adott iterációban, a másik pedig a kettéosztás módja.
A kettéosztandó klaszter kiválasztásának legegyszerűbb módja, ha a legnagyobb
elemszámú klasztert választjuk. A kiválasztott klaszter kettéosztása többféleképpen
történhet, de a legkézenfekvőbb megoldás az, ha egy másik klaszterezési algoritmus
segítségével végezzük el. Az algoritmus implementációja során mi a k-közép
algoritmust választottuk. Döntésünk azzal indokolható, hogy a k-közép algoritmus egy
viszonylag általánosan jól használható algoritmus, illetve az algoritmus bemeneti

18
klaszterszám paramétere itt pont kapóra jön, hiszen mi fel szeretnénk osztani a
klaszterünket, jelen esetben két részre, azaz a paraméter értéke 𝑘 = 2 lesz. Az
algoritmus bemenő paraméterei a klaszterezendő adatpontok halmaza (D), valamint a
megállási feltétel.
Az algoritmus pszeudokódja a következő:
Hierarchikus lebontó(D, megállási feltétel)
1. Minden adatpontot egy közös klaszterbe sorolunk;
2. AMÍG a megállási feltétel (pl. k darab klaszterünk van) hamis, ismételd:
3. Bontsuk ketté a legnagyobb elemszámú klasztert a k-közép algoritmus
szerint;
4. AMÍG_VÉGE.
Hierarchikus lebontó algoritmus hatékonysága
Az algoritmus műveletigényéről elmondható, hogy nagyjából megegyezik az algoritmus
által használt kettéosztó klaszterezési algoritmus műveletigényével. A mi esetünkben ez
a k-közép algoritmus, melynek műveletigénye 𝑂(𝑛𝑘′𝑡), ahol n az adatpontok száma,
k’=2, t pedig a klaszterezéshez szükséges iterációszám (𝑡 ≪ 𝑛). Ez a „belső kettéosztó”
klaszterezési algoritmus pontosan (𝑘 − 1)-szer hívódik meg, ahol k az algoritmus
bemeneti klaszterszám-paramétere (megállási feltétele). Általában 𝑘 ≪ 𝑛, így
összefoglalva az algoritmus műveletigénye 𝑂(𝑛).
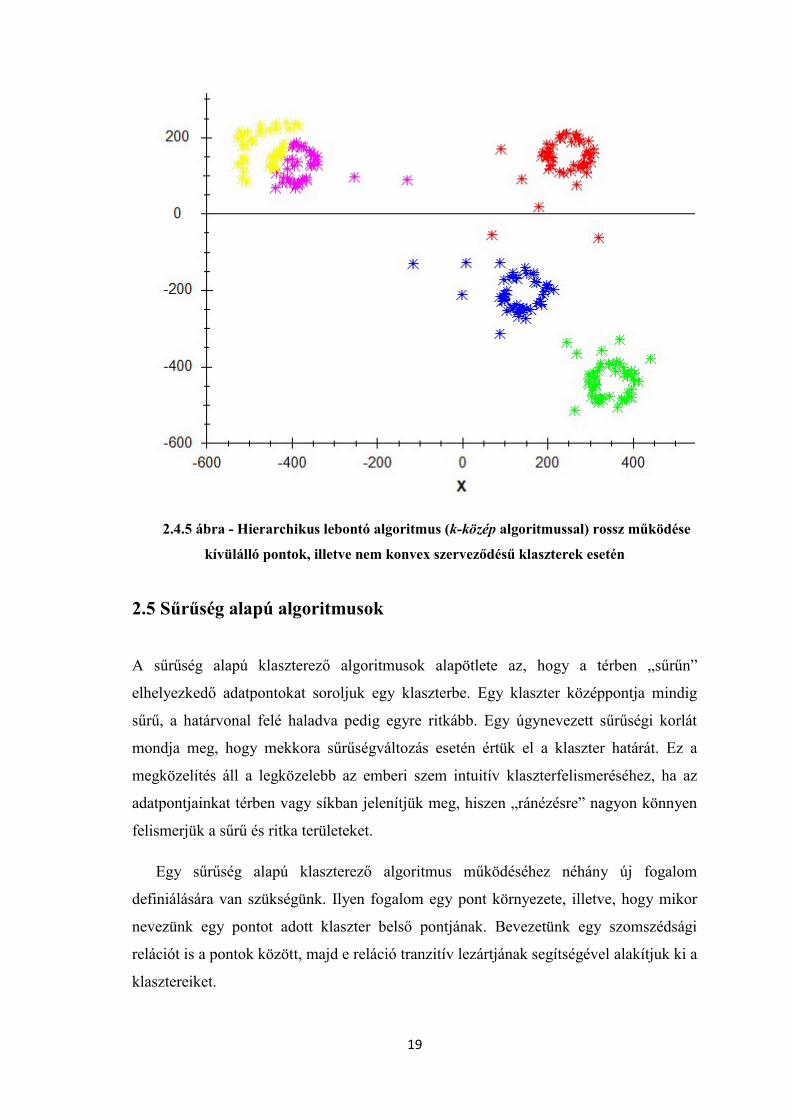
Az algoritmusnak a k-közép algoritmussal megegyező hátrányai lesznek. Általában
csak azokat a klasztereket ismeri fel jól, amelyek konvex szerveződésű pontokból
állnak, illetve ugyanúgy érzékeny a kívülálló pontokra.
19
2.4.5 ábra - Hierarchikus lebontó algoritmus (k-közép algoritmussal) rossz működése
kívülálló pontok, illetve nem konvex szerveződésű klaszterek esetén
2.5 Sűrűség alapú algoritmusok
A sűrűség alapú klaszterező algoritmusok alapötlete az, hogy a térben „sűrűn”
elhelyezkedő adatpontokat soroljuk egy klaszterbe. Egy klaszter középpontja mindig
sűrű, a határvonal felé haladva pedig egyre ritkább. Egy úgynevezett sűrűségi korlát
mondja meg, hogy mekkora sűrűségváltozás esetén értük el a klaszter határát. Ez a
megközelítés áll a legközelebb az emberi szem intuitív klaszterfelismeréséhez, ha az
adatpontjainkat térben vagy síkban jelenítjük meg, hiszen „ránézésre” nagyon könnyen
felismerjük a sűrű és ritka területeket.
Egy sűrűség alapú klaszterező algoritmus működéséhez néhány új fogalom
definiálására van szükségünk. Ilyen fogalom egy pont környezete, illetve, hogy mikor
nevezünk egy pontot adott klaszter belső pontjának. Bevezetünk egy szomszédsági
relációt is a pontok között, majd e reláció tranzitív lezártjának segítségével alakítjuk ki a
klasztereiket.

20
Sűrűség alapú algoritmusok segítségével tetszőleges alakú klasztereket
felismerhetünk, feltéve, hogy azok pontjainak sűrűsége eléri az algoritmus által használt
sűrűségkorlátot. Az ilyen típusú algoritmusok másik nagy előnye, hogy zajos, sok
kívülálló pontot tartalmazó adathalmazok esetén is jól működnek.
2.5.1 DBSCAN algoritmus
A legrégebbi és egyben legnépszerűbb sűrűség alapú klaszterező algoritmus a
DBSCAN algoritmus, mely két bemenő paraméterrel dolgozik[3]. Az egyik paraméter
egy szomszédsági sugár, a másik pedig egy sűrűségi korlát. Az algoritmus szerint egy
klaszter nem más, mint azon pontok maximális halmaza, melyek sűrűség alapján
elérhetőek egymásból. Így tehát bevezetésre kerül egy elérhetőség-fogalom a pontok
között, a sűrűség-elérhetőség.
Vizsgáljuk meg a DBSCAN-hez, mint a legalapvetőbb sűrűség alapú algoritmushoz
szükséges fogalmakat. Jelöljük a klaszterezendő adatpontok halmazát D-vel, valamint
legyen d az adatpontok között értelmezett távolságfüggvény (metrika).
Definíció: Egy 𝑝 ∈ 𝐷 pont 𝜺-sugarú környezete a következő halmaz:
𝑁𝜀(𝑝) = {𝑞 ∈ 𝐷|𝑑(𝑝, 𝑞) ≤ 𝜀}
Egy metrikus térben adott pont környezetét egy 𝜀-sugarú gömbbel
reprezentálhatunk.
Definíció: Az 𝑁𝜀(𝑝) halmaz elemeit a p pont szomszédainak nevezzük.
Definíció: Egy p adatpont 𝜀 sugárra vonatkozó sűrűségén szomszédainak |𝑁𝜀(𝑝)|
számát értjük.
Definíció: A 𝜇 pozitív egész számot sűrűségi korlátnak nevezzük, ha megadja adott
pont szomszédainak minimális számát. Egy adatpont akkor vehet részt egy klaszter
létrehozásában, ha legalább ennyi szomszéddal rendelkezik.
[3] Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu: "A density-based algorithm for discovering clusters in large spatial databases with noise", Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96). AAAI Press. pp. 226–231. ISBN 1-57735-004-9, 1996.

21
Definíció: A p pontot nagy sűrűségű pontnak vagy magpontnak nevezzük, ha
sűrűsége legalább annyi, mint a 𝜇 sűrűségi korlát (|𝑁𝜀(𝑝)| ≥ 𝜇), különben pedig kis
sűrűségű pontnak nevezzük.
A DBSCAN algoritmus működése során az adatpontok három típusát különbözteti
meg:
Magpont – Olyan pont, melynek sűrűsége legalább annyi, mint a sűrűségi
korlát
Határpont – Olyan pont, mely egy magpont szomszédságában található,
azonban sűrűsége kisebb a 𝜇-sűrűségi korlátnál.
Kívülálló pont (zajpont) – Olyan pont, amelyik az első két kategóriába nem
sorolható be.
2.5.1 ábra – Adatpontok típusai adott ε és 𝝁 = 𝟒 esetén
Definíció: A q adatpont közvetlenül sűrűség-elérhető a p adatpontból, ha p
magpont és q a p pont szomszédja (adott 𝜀-sugár szerint).
Megjegyezzük, hogy a közvetlen sűrűség-elérhetőség egy aszimmetrikus reláció,
hiszen a q pont nem feltétlenül magpont.
Definíció: A q adatpont sűrűség-elérhető a p adatpontból, ha létezik egy olyan
𝑝 = 𝑎1, 𝑎2, … , 𝑎𝑛, 𝑎𝑛+1 = 𝑞 pontok sorozata, hogy 𝑎𝑖+1 közvetlenül sűrűség-
elérhető 𝑎𝑖-ből ∀𝑖 ∈ (1. . 𝑛) esetén.

22
Jól látható, hogy a sűrűség-elérhetőség nem más, mint a közvetlen sűrűség-
elérhetőség fogalmának általánosítása (tranzitív lezártja), tehát ez sem lehet egy
szimmetrikus reláció a pontok között. A klaszterek megfelelő leírásához viszont egy
szimmetrikus relációra van szükségünk, ezért bevezetjük a következő relációt, ami már
szimmetrikus.
Definíció: A p és q pontok sűrűség-összekapcsoltak, ha mindketten sűrűség-
elérhetőek egy o pontból.
2.5.2 ábra – p és q pontok sűrűség-összekapcsoltak 𝝁 = 𝟒 esetén. A közvetlenül
sűrűség-elérhető pontokat piros nyilakkal kapcsoltuk össze.
A fent definiált fogalmak segítségével már elő tudjuk állítani az algoritmus bemenő
paramétereinek megfelelő klaszterezést. Az algoritmus futása után egy C klaszter a
következő két kritériumnak fog megfelelni:
Összekapcsoltság: ∀𝑝, 𝑞 ∈ 𝐶 esetén p és q sűrűség-összekapcsoltak;
Maximalitás: ∀𝑝, 𝑞 ∈ 𝐶 esetén, ha 𝑝 ∈ 𝐶 és q sűrűség-elérhető p-ből, akkor
𝑞 ∈ 𝐶.
A DBSCAN algoritmus pszeudokódja a következő (D-adatpont halmaz, 𝜀-sugár, 𝜇-
sűrűségi korlát):
DBSCAN(𝐷, 𝜀, 𝜇)
1. MINDEN 𝑝 ∈ 𝐷 pontra:
2. HA p magpont és még nem dolgoztuk fel:
3. Legyen C az összes p-ből sűrűség-elérhető, fel nem dolgozott pontok
halmaza;
4. Nyilvánítsunk minden C-beli elemet feldolgozottnak;

23
5. C legyen egy új, az algoritmus által megtalált klaszter;
6. KÜLÖNBEN nyilvánítsuk p-t kívülálló pontnak (még nem feldolgozott);
7. MINDEN_VÉGE.
Az algoritmus futása után az adatpontok lehetnek kívülálló pontok, illetve
feldolgozott pontok, melyek valamelyik iteráció szerinti klaszterhez tartoznak.
A DBSCAN algoritmus hatékonysága
Az algoritmus magja adott pontból sűrűség-elérhető pontokat keres. Ehhez meg kell
vizsgálnunk az érintett pontok környezetét, ami az összes n darab adatpont lekérdezését
jelenti. Adott pont környezetét azonban, megfelelő implementációval (például pontok
színezésével), elegendő csak egyszer megvizsgálni, tehát az algoritmus műveletigénye
𝑂(𝑛2), ahol n az adatpontok száma. Bizonyos esetekben, ha az adatpontokról több
előzetes információval rendelkezünk, esetleg térbeli indexeket használunk, akkor egy
pont ε-sugarú környezetét kevesebb, mint n lekérdezéssel is megkaphatjuk (𝑂(𝑙𝑜𝑔𝑛)),
így az algoritmus műveletigénye 𝑂(𝑛 ∗ 𝑙𝑜𝑔𝑛)-re csökken.
A DBSCAN algoritmus nagy előnye az eddig bemutatott klaszterező
algoritmusokkal szemben, hogy nincs szüksége a klaszterszám előzetes
meghatározására. Ez az algoritmus során, a klaszterek feltérképezése közben
automatikusan kiderül.
Az algoritmus képes tetszőleges alakú és méretű klaszterek feltárására, amennyiben
azok a bemeneti paramétereknek megfelelő sűrűségűek (2.5.3 ábra), ugyanakkor nem
érzékeny a kívülálló pontokra, ezáltal zajszűrőként is kiválóan használható (2.5.4 ábra).
Ez utóbbi annak köszönhető, hogy az algoritmus külön kezeli a kívülálló pontokat a
klaszterek mellett.
2.5.3 ábra – DBSCAN algoritmus tetszőleges alakú klaszterek esetén (azonos sűrűséggel)

24
2.5.4 ábra – DBSCAN algoritmus működése kívülálló pontokra (piros színű, egyik
klaszterhez sem tartozó pontok)
A DBSCAN algoritmus egyik hátránya, hogy nagyon érzékeny a bemeneti
paraméterekre, hiszen ezek nagyon kevés változtatásával is teljesen eltérő klaszterezést
adhat eredményül. A legnagyobb kihívást az algoritmus használata során e két
paraméter megfelelő megválasztása jelenti. A 2.5.5 ábrán látható klaszterezés esetében
például túl kicsinek választottuk a szomszédsági sugarat.
Az algoritmus másik hátránya, hogy nem képes megfelelően kezelni a változó
sűrűségű klasztereket, függetlenül a bemeneti paraméterek megválasztásától (2.5.6
ábra). Ez érthető is, hiszen az algoritmus kizárólag sűrűségük alapján térképezi fel a
klasztereket.
2.5.5 ábra – DBSCAN algoritmus működése rosszul megválasztott bemeneti
paraméterek esetén (túl kicsi ε)

25
2.5.6 ábra – DBSCAN algoritmus rossz működése változó sűrűségű klaszterek esetén
2.5.2 OPTICS algoritmus
Mint ahogy azt már az előbbi alfejezetben említettük, a DBSCAN algoritmus rendkívül
érzékeny a bemenő paraméterek értékeire. Ezt az érzékenységet próbálja kiküszöbölni
az OPTICS[4] algoritmus, pontosabban az ε-szomszédsági sugár paraméter pontos
megválasztásának kérdését egyszerűsíti. Az OPTICS önmagában nem egy klaszterező
algoritmus[5]. Konkrét klasztereket az algoritmus kimenetének utólagos feldolgozásával
kaphatunk.
Az algoritmus a DBSCAN klaszterező algoritmus alapötletéhez hasonlóan működik,
azonban kimenete az adatpontok egy sorrendje, valamint minden adatpontra bizonyos
numerikus értékek, melyek a pont környezetét jellemzik sűrűség tekintetében. Az
adatpontok eme sorrendje valójában egy sűrűség alapú klaszterezési struktúrát
reprezentál, melynek segítségével többféle klaszterezést is megkaphatunk. Ezek a
klaszterezések a DBSCAN algoritmusnak megfelelő klaszterezések, azonban egy széles
bemeneti paraméterskálát lefedve. Maga az ötlet azon alapszik, hogy sűrűség alapú
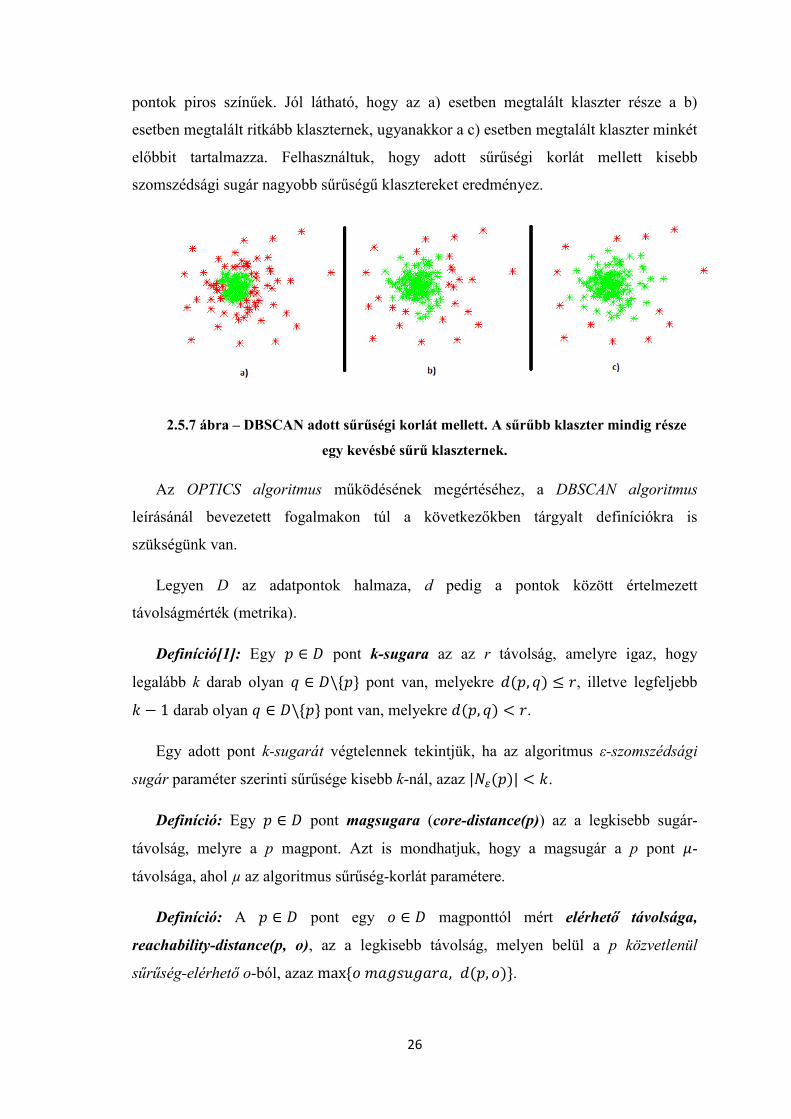
klaszterezések esetén egy sűrűbb klaszter minden esetben része egy kevésbé sűrű
klaszternek. Erre láthatunk példát a 2.5.6 ábrán, ahol ugyanazon adatpontokra
különböző sűrűségű klasztereket kerestünk. A megtalált klaszterek zöld, míg a kívülálló
[4] Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, Jörg Sander: "OPTICS: Ordering Points To Identify the Clustering Structure". ACM SIGMOD international conference on Management of data. ACM Press. pp. 49–60, 1999.
[5] Hinneburg A., Keim D.: “An Efficient Approach to Clustering in Large Multimedia Databases with
Noise”, Proc. 4th Int. Conf. on Knowledge Discovery & Data Mining, New, York City, NY, 1998.
26
pontok piros színűek. Jól látható, hogy az a) esetben megtalált klaszter része a b)
esetben megtalált ritkább klaszternek, ugyanakkor a c) esetben megtalált klaszter minkét
előbbit tartalmazza. Felhasználtuk, hogy adott sűrűségi korlát mellett kisebb
szomszédsági sugár nagyobb sűrűségű klasztereket eredményez.
2.5.7 ábra – DBSCAN adott sűrűségi korlát mellett. A sűrűbb klaszter mindig része
egy kevésbé sűrű klaszternek.
Az OPTICS algoritmus működésének megértéséhez, a DBSCAN algoritmus
leírásánál bevezetett fogalmakon túl a következőkben tárgyalt definíciókra is
szükségünk van.
Legyen D az adatpontok halmaza, d pedig a pontok között értelmezett
távolságmérték (metrika).
Definíció[1]: Egy 𝑝 ∈ 𝐷 pont k-sugara az az r távolság, amelyre igaz, hogy
legalább k darab olyan 𝑞 ∈ 𝐷\{𝑝} pont van, melyekre 𝑑(𝑝, 𝑞) ≤ 𝑟, illetve legfeljebb
𝑘 − 1 darab olyan 𝑞 ∈ 𝐷\{𝑝} pont van, melyekre 𝑑(𝑝, 𝑞) < 𝑟.
Egy adott pont k-sugarát végtelennek tekintjük, ha az algoritmus ε-szomszédsági
sugár paraméter szerinti sűrűsége kisebb k-nál, azaz |𝑁𝜀(𝑝)| < 𝑘.
Definíció: Egy 𝑝 ∈ 𝐷 pont magsugara (core-distance(p)) az a legkisebb sugár-
távolság, melyre a p magpont. Azt is mondhatjuk, hogy a magsugár a p pont 𝜇-
távolsága, ahol µ az algoritmus sűrűség-korlát paramétere.
Definíció: A 𝑝 ∈ 𝐷 pont egy 𝑜 ∈ 𝐷 magponttól mért elérhető távolsága,
reachability-distance(p, o), az a legkisebb távolság, melyen belül a p közvetlenül
sűrűség-elérhető o-ból, azaz max {𝑜 𝑚𝑎𝑔𝑠𝑢𝑔𝑎𝑟𝑎, 𝑑(𝑝, 𝑜)}.

27
2.5.8 ábra – Magsugár; elérhető távolság 𝝁 = 𝟒 esetén.
A fentebb leírt definíciók segítségével már vizsgálhatjuk az algoritmus működését.
Mint ahogyan azt említettük, az algoritmus az adatpontok egy sorrendjét adja
eredményül. Ez a sorrend a pontok lehető legkisebb (legközelebbi magpont szerinti)
elérhető távolságaik szerint növekvően rendezett. Ez biztosítja azt, hogy az algoritmus
futása során előbb mindig a legsűrűbb klaszterek pontjait dolgozza fel, hiszen egy
sűrűbb klaszter megtalálásához adott sűrűségkorlát esetén kisebb szomszédsági sugár
szükséges. Ezen rendezés felhasználásával tudjuk majd előállítani a konkrét
klasztereket.
Az algoritmus az adatpontok egy lineáris rendezésén kívül a következő értékeket
határozza meg minden egyes 𝑝 ∈ 𝐷 adatpontra:
p magsugara (core-distance(p));
p-nek egy megfelelően választott 𝑜 ∈ 𝐷 magponttól mért elérhető távolsága
(reachability-distance(p,o)).
Az OPTICS a DBSCAN algoritmushoz hasonlóan ugyancsak két bemeneti
paraméterrel dolgozik. Az egyik paraméter a szomszédsági sugár (ε), a másik pedig egy
sűrűségi korlát (µ). Ha az algoritmust adott ε és µ paraméterekkel futtatjuk, akkor a
kimenetből egy utólagos feldolgozás után az összes, DBSCAN algoritmusnak megfelelő
klaszterezés megkapható, ahol a DBSCAN paraméterei 𝜀′ ≤ 𝜀 és 𝜇′ = 𝜇.
Az OPTICS és DBSCAN algoritmusok közötti fő különbség az, hogy míg a
DBSCAN működése során tetszőlegesen választ a közvetlenül elérhető pontokból, addig

28
az OPTICS mindig a pillanatnyilag elérhető legnagyobb sűrűségű környezetből választ
egy új klaszter bejárása során.
Az algoritmus megvalósításakor szükségünk van egy speciális adatszerkezetre,
amely a vizsgálandó pontokat elérhető távolságuk szerint rendezetten tárolja. Ez lehet
például egy rendezett lista vagy egy fordított prioritásos sor, ahol a prioritások az
elérhető távolságok. Nevezzük a továbbiakban ezt a rendezett adatszerkezetet rList-nek.
Az rList egy eleme (p, r) alakú, ahol p a pont, r pedig az elérhető távolság.
A fentiek ismeretében már megfogalmazhatjuk az OPTICS algoritmus
pszeudokódját (D-adatpont halmaz, 𝜀-szomszédsági sugár, 𝜇-sűrűségi korlát).
OPTICS(D, ε, µ)
1. MINDEN 𝑜 ∈ 𝐷 adatpontra:
2. HA o pont feldolgozatlan, AKKOR:
3. Adjuk hozzá az (o, ε) elemet az rList-hez;
4. AMÍG az rList nem üres:
5. Válasszuk ki az rList első elemét. Ez legyen (o, r_dist);
6. Kérjük le az o pont 𝑁𝜀(𝑜) szomszédait és határozzuk meg o magsugarát;
legyen ez c_dist = core-distance(o);
7. Legyen az o pont címkéje „feldolgozott”;
8. Írjuk ki fájlba az (o, r_dist, c_dist) hármast;
9. HA o magpont, azaz 𝑐_𝑑𝑖𝑠𝑡 ≤ 𝜀, AKKOR:
10. MINDEN 𝑝 ∈ 𝑁𝜀(𝑜) feldolgozatlan pontra:
11. Határozzuk meg a p pont o magponttól mért elérhető távolságát,
azaz 𝑟_𝑑𝑖𝑠𝑡𝑝 = 𝑟𝑒𝑎𝑐ℎ𝑎𝑏𝑖𝑙𝑖𝑡𝑦_𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒(𝑝, 𝑜)-t;
12. HA p ponthoz tartozó bejegyzés nincs az rList-ben, AKKOR:
13. Adjuk hozzá a (𝑝, 𝑟_𝑑𝑖𝑠𝑡𝑝) elemet az rList-hez;
14. KÜLÖNBEN HA (𝑝, 𝑜𝑙𝑑_𝑟_𝑑𝑖𝑠𝑡) ∈ 𝑟𝐿𝑖𝑠𝑡 és
𝑟_𝑑𝑖𝑠𝑡𝑝 ≤ 𝑜𝑙𝑑_𝑟_𝑑𝑖𝑠𝑡, AKKOR:
15. Frissítsük a p ponthoz tartozó bejegyzést rList-ben
(𝑝, 𝑟_𝑑𝑖𝑠𝑡𝑝)-re;
16. MINDEN_VÉGE;
17. AMÍG_VÉGE;
18. MINDEN_VÉGE.

29
Az algoritmus indulásakor minden adatpont „feldolgozatlan” címkével rendelkezik.
Amikor egy ponthoz tartozó numerikus értékeket meghatároztuk, kiírjuk egy listába
(fájlba). Az algoritmus futása után a pontok a fájlban már megfelelő sorrendben fognak
szerepelni a további feldolgozáshoz (klaszterezés).
Az algoritmus által fájlba kiírt adatokból már tetszőleges DBSCAN klaszterezést
megkaphatunk, melynek sűrűségi korlátja megegyezik az OPTICS sűrűségi korlátjával,
illetve szomszédsági sugara legfeljebb akkora, mint az OPTICS szomszédsági sugara.
Nevezzük az OPTICS kimeneteként szolgáló fájlt rend_fájl-nak. Az alább látható,
pszeudokóddal leírt algoritmussal megkaphatunk egy ilyen klaszterezést az OPTICS
algoritmus kimenetéből. Az algoritmus neve ExtractDBSCAN-Clustering, bemenő
paraméterei pedig ε’ szomszédsági sugár, valamint µ sűrűségi korlát. Fontos előfeltétel
az algoritmushoz, hogy 𝜀′ ≤ 𝜀, valamint 𝜇′ = 𝜇, ahol ε és µ az OPTICS algoritmus
paraméterei, amiből az adatfájlt kaptuk.
ExtractDBSCAN-Clustering(rend_fájl, ε’, µ)
1. 𝑘𝑙𝑎𝑠𝑧𝑡𝑒𝑟𝐼𝐷 ≔ 0 (kívülálló pontok klaszterindexe);
2. MINDEN 𝑖 ≔ 1 𝑡𝑜 |𝐷| esetén:
3. Kérjük le a rend_fájl i. elemét. Legyen ez (o, r_dist, c_dist);
4. HA 𝑟_𝑑𝑖𝑠𝑡 > 𝜀′ AKKOR:
5. HA 𝑐_𝑑𝑖𝑠𝑡 ≤ 𝜀′ AKKOR:
6. klaszterID++; (új klaszter jön létre);
7. Az o pontot besoroljuk a klaszterID indexű klaszterbe;
8. KÜLÖNBEN az o pontot besoroljuk a 0 indexű klaszterbe (kívülálló pont
lesz);
9. KÜLÖNBEN (𝑟_𝑑𝑖𝑠𝑡 ≤ 𝜀′): az o pontot besoroljuk a klaszterID indexű
klaszterbe;
10. MINDEN_VÉGE.
Az OPTICS algoritmus hatékonysága
Az OPTICS algoritmus futása során minden egyes adatpont környezetét egyszer
vizsgálja meg. Az algoritmus műveletigénye tehát 𝑂(𝑛 ∗ 𝑠𝑧𝑜𝑚𝑠𝑧é𝑑𝑜𝑘_𝑣𝑖𝑧𝑠𝑔á𝑙𝑎𝑡𝑎),

30
ahol n az adatpontok száma. Egy adott pont szomszédainak vizsgálata a DBSCAN
algoritmushoz hasonlóan, általánosságban n darab lekérdezést igényel, tehát a
műveletigény 𝑂(𝑛2). Térbeli indexek használata esetén ez a műveletigény itt is 𝑂(𝑛 ∗
𝑙𝑜𝑔𝑛)-re csökkenthető.
Az OPTICS algoritmus kimenetéből klaszterezést előállító ExtractDBSCAN-
Clustering algoritmus csak egyszer olvassa végig az eredményfájlt, ami pontosan
adatpontszámnyi bejegyzést tartalmaz. Tehát a műveletigény az ExtractDBSCAN-
Clustering algoritmus esetén 𝑂(𝑛), ahol n az adatpontok száma.
Vizsgáljuk meg a DBSCAN és OPTICS algoritmusok működése közötti alapvető
különbségeket. Jól láthatóan az OPTICS algoritmus egy bonyolultabb, precízebb
feltérképezést végez a pontokra azok környezetét illetően. Míg a DBSCAN
algoritmusban adott pont sűrűségét egy logikai értékkel leírhatjuk (magpont vagy sem),
addig az OPTICS a pontok sűrűségére egy numerikus értéket ad (magsugár). A
DBSCAN algoritmus szerint két pont sűrűség összekapcsoltságát ugyancsak leírhatjuk
egy logikai értékkel (sűrűség összekapcsolt vagy sem), az OPTICS algoritmusban
viszont ezt is egy numerikus érték reprezentálja, az elérhető távolság. További
különbség, hogy míg a DBSCAN algoritmus pontbejárási stratégiája véletlenszerű
(random), úgy az OPTICS algoritmusé mohó (greedy), hiszen mindig a lehető
legnagyobb sűrűségű környezettel rendelkező pontot választja a feltérképezés során. A
2.5.9 ábra ezeket a különbségeket foglalja össze Aidong Zhang előadásai alapján[6].
DBSCAN OPTICS
Pont sűrűsége Logikai érték
(magpont vagy sem)
Numerikus érték
(magsugár)
Sűrűség összekapcsoltság
Logikai érték
(sűrűség összekapcsolt vagy
sem)
Numerikus érték
(elérhető távolság)
Pontkiválasztási stratégia
a futás során véletlenszerű (random) mohó (greedy)
2.5.9 ábra – DBSCAN és OPTICS algoritmusok összehasonlítása
[6] Aidong Zhang, University at Buffalo, The State University of New York, http://www.cse.buffalo.edu/faculty/azhang/cse601/, 2014.05.10

31
2.6 Rács alapú klaszterező algoritmusok
Az eddig bemutatott klaszterező algoritmusok nagyon lassú működést
eredményezhetnek nagy adathalmazok esetén. Láthattuk, hogy bizonyos algoritmusok
futási ideje legrosszabb esetben 𝑂(𝑛2), ami a gyakorlatban többször előforduló
hatalmas, akár több millió adatpontot tartalmazó halmazok esetén már nem tűnik
hatékony algoritmusnak. Ilyen nagy adathalmazok klaszterezése esetén nyújtanak
segítséget a rács alapú klaszterező algoritmusok.
Egy rács alapú klaszterező algoritmus egy speciális algoritmus, mely egyaránt
rendelkezik a hierarchikus, illetve sűrűség alapú klaszterező algoritmusok bizonyos
jellemzőivel. Az algoritmus alapötlete az, hogy ne magukat az adatpontokat
klaszterezzük, hanem ehelyett bontsuk fel az adatpontok vektorterét részekre,
úgynevezett hipertéglalapokra, melyekben elhelyezzük az adatpontokat, mindegyiket a
megfelelő helyre, majd ezen hipertéglalapokra futtassunk le egy algoritmust, ami már az
adatpontok klaszterezését eredményezi. Az algoritmusról azt mondhatjuk, hogy
bizonyos értelemben hierarchikus algoritmus, hiszen a vektortér celláit
(hipertéglalapok) egy hierarchiába szervezve dolgozza fel. Ez a feldolgozás a cellák
sűrűsége alapján történik, ezért az algoritmus egy sűrűség alapú algoritmusnak is
tekinthető.
2.6.1 GRIDCLUS algoritmus
A rács alapú klaszterező algoritmusok közül részletesen a legalapvetőbb, 1993-ban
Erich Schikuta által megalkotott GRIDCLUS[7] algoritmust mutatjuk be, pontosabban
annak egy módosított változatát. Az egyszerűbb megértés érdekében az algoritmust két
dimenziós adatpontokra részletezzük, ez azonban könnyen kiterjeszthető nagyobb
dimenziók esetére is, hiszen egyedül a cellák indexelése változik.
A GRIDCLUS, mint minden rács alapú klaszterező algoritmus, egy teljesen új
megközelítéssel dolgozik. Eszerint nincs szükségünk az adatpontok közötti
[7] Erich Schikuta: „Grid-Clustering: A Fast Hierarchical Clustering Method for Very Large Data Sets”, Center for Research on Parallel Computation, Proceedings of the 13th International Conference on Pattern Recognition Volume IV, Track D: Parallel and Connectionist Systems: 101-105 vol 2. DOI: 10.1109/ICPR.1996.546732, 1993.

32
távolságfogalomra, ugyanis ezeket a hipertéglalapokra felosztott vektortérben helyezzük
el, majd ezen téglalapok feldolgozásával alakítjuk ki a klaszterezést.
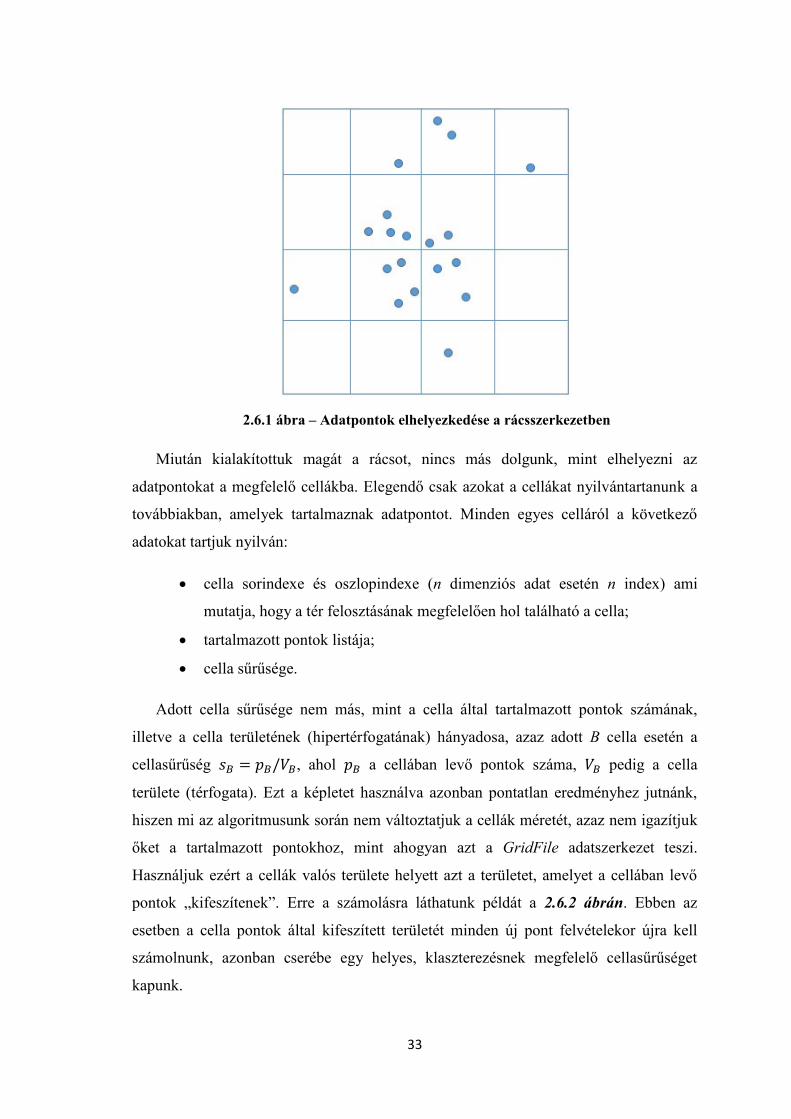
Az algoritmus első lépésben felépíti az adatpontoknak megfelelő térbeli
rácsszerkezetet, majd minden egyes adatpontot hozzárendel a rács pontosan egy
cellájához. Fontos, hogy a hozzárendelés után az adatpontokat tartalmazó cellák, mint
halmazok, egymással páronként diszjunktak legyenek.
Vizsgáljuk meg, hogyan építhetjük fel a klaszterezéshez szükséges rácsszerkezetet.
Mint ahogyan azt Erich Schikuta tudományos cikkében olvashatjuk, a felépítéshez több,
célzottan erre a feladatra optimalizált adatszerkezet létezik. Ilyen többek között a
GridFile[8] adatszerkezet, melyről több elemzést is olvashatunk[9].
A GRIDCLUS algoritmus implementációja során a GridFile adatszerkezet
használatát nélkülözve, a következőképpen hozzuk létre a klaszterezéshez szükséges
rácsszerkezetet.
Első lépésben kiválasztjuk a vektortérből azt a hipertéglalapot, amelyik minden
adatpontunkat tartalmazza. Ez meghatározható akár egy előzetes durva becsléssel,
azonban ha nem tudjuk megbecsülni a téglalap méreteit, válasszuk a lehető legnagyobb
téglalapot, amit az implementációnk megenged. Ez a téglalap legyen a mi esetünkben
egy egyszerű négyzet, hiszen kétdimenziós pontok esetén demonstráljuk az algoritmust.
Második lépésben osszuk fel az előbb megkapott hipertéglalapot (négyzetet)
dimenziói mentén egyenlő méretű cellákra. Kétdimenziós esetben ez kisebb, egyenlő
méretű négyzeteket jelent. Megjegyezzük, hogy a felosztás finomsága nagyban
befolyásolhatja a klaszterezés pontosságát. Minél sűrűbb a felosztás, annál pontosabb
klaszterezési eredményt kapunk. Úgy is fogalmazhatunk, hogy nagyobb felosztás esetén
nagyobb sűrűségű klasztereket kapunk, a sűrűség alapú klaszterező algoritmusok
terminológiája szerint.
[8] K.H. Hinrichs: The grid file system: implementation and case studies of applications, Diss. ETH Nr. 7734, Zurich, 1985.
[9] H. Hromada: The GRIDCLUS data analysis system, diploma thesis Univ. Vienna, Vienna, 1989.
33
2.6.1 ábra – Adatpontok elhelyezkedése a rácsszerkezetben
Miután kialakítottuk magát a rácsot, nincs más dolgunk, mint elhelyezni az
adatpontokat a megfelelő cellákba. Elegendő csak azokat a cellákat nyilvántartanunk a
továbbiakban, amelyek tartalmaznak adatpontot. Minden egyes celláról a következő
adatokat tartjuk nyilván:
cella sorindexe és oszlopindexe (n dimenziós adat esetén n index) ami
mutatja, hogy a tér felosztásának megfelelően hol található a cella;
tartalmazott pontok listája;
cella sűrűsége.
Adott cella sűrűsége nem más, mint a cella által tartalmazott pontok számának,
illetve a cella területének (hipertérfogatának) hányadosa, azaz adott B cella esetén a
cellasűrűség 𝑠𝐵 = 𝑝𝐵/𝑉𝐵, ahol 𝑝𝐵 a cellában levő pontok száma, 𝑉𝐵 pedig a cella
területe (térfogata). Ezt a képletet használva azonban pontatlan eredményhez jutnánk,
hiszen mi az algoritmusunk során nem változtatjuk a cellák méretét, azaz nem igazítjuk
őket a tartalmazott pontokhoz, mint ahogyan azt a GridFile adatszerkezet teszi.
Használjuk ezért a cellák valós területe helyett azt a területet, amelyet a cellában levő
pontok „kifeszítenek”. Erre a számolásra láthatunk példát a 2.6.2 ábrán. Ebben az
esetben a cella pontok által kifeszített területét minden új pont felvételekor újra kell
számolnunk, azonban cserébe egy helyes, klaszterezésnek megfelelő cellasűrűséget
kapunk.

34
2.6.2 ábra – Cellák sűrűsége: a) esetben 𝒔𝑩 = 𝟎, b) esetben 𝒔𝑩 = 𝟑/(𝒃𝒙 ∗ 𝒃𝒚);
c) esetben 𝒔𝑩 = 𝟔/(𝒄𝒙 ∗ 𝒄𝒚)
Miután létrehoztuk az adatpontoknak megfelelő rácsszerkezetet, ami nem más, mint
a nyilvántartott cellák összessége, kialakítjuk a cellák egy hierarchiáját, azaz rendezzük
őket sűrűség szerint csökkenő sorrendben.
Rendezés után lefuttatjuk a GRIDCLUS algoritmus részét, ami nem az adatpontokat,
hanem a rácsszerkezet celláit gyűjti klaszterekbe. Így nyilvánvalóan megkapjuk a cellák
által tartalmazott pontok klaszterezését is.
A GRIDCLUS algoritmus pszeudokódja a következő (D az adatpontok halmaza, f a
rács felosztása):
GRIDCLUS(D, f)
1. Hozzuk létre az adatpontoknak megfelelő rácsszerkezetet f felosztás szerint.
Legyenek a rácsszerkezet nyilvántartott cellái 𝐵1, 𝐵2, … , 𝐵𝑘.
2. Rendezzük a cellákat sűrűségük szerint csökkenő sorrendbe. Legyen az
eredmény sorozat 𝑆 =< 𝐵1′ , 𝐵2′ , … , 𝐵𝑘′ >. A cellák i’. indexe az eredeti i.
index permutációjára utal.
3. Jelöljünk meg minden cellát „nem aktív” és „nem klaszterezett” címkével.
4. AMÍG az S sorozat tartalmaz „nem aktív” cellát:
5. Legyen az első megtalált „nem aktív” cella indexe ind.
6. Keressük meg az éppen aktuális aktív cellákat, azaz S-nek azt az ind indextől
kezdődő részsorozatát, melyre a cellák sűrűsége megegyezik, vagy csak
nagyon kis mértékben tér el. Ezen 𝐵𝑖𝑛𝑑, 𝐵𝑖𝑛𝑑+1, … , 𝐵𝑖𝑛𝑑+𝑗 (0 ≤ 𝑗 ≤ 𝑘 − 𝑖𝑛𝑑)
cellákat jelöljük meg „aktív” cellaként.

35
7. MINDEN B cellára a 𝐵𝑖𝑛𝑑, 𝐵𝑖𝑛𝑑+1, … , 𝐵𝑖𝑛𝑑+𝑗 cellák közül:
8. HA B „nem klaszterezett”, AKKOR:
9. Létrehozunk egy új C klasztert;
10. A B cellát hozzáadjuk a C klaszterhez;
11. A B cellát „klaszterezettnek” nyilvánítjuk;
12. NEIGHBOR-SEARCH(B, C);
13. MINDEN_VÉGE;
14. Minden S-beli cellát „nem klaszterezettnek” nyilvánítunk;
15. AMÍG_VÉGE.
Az algoritmus működése során meghívja a NEGHBOR-SEARCH nevű rekurzív
eljárást, ami a paraméterül kapott cella szomszédait rekurzívan megvizsgálva állítja elő
a főalgoritmus egy klaszterét. A klaszter kialakításában a cella összes olyan szomszédja
részt vesz, amelyik „aktív”, de még „nem klaszterezett”. Az eljárás pszeudokódja alább
olvasható.
NEIGHBOR-SEARCH(B, C)
1. MINDEN 𝐵𝑠𝑧 cellára a B szomszéd cellái közül:
2. HA 𝐵𝑠𝑧 „aktív” és „nem klaszterezett”, AKKOR:
3. Hozzáadjuk a 𝐵𝑠𝑧 cellát a C klaszterhez;
4. A 𝐵𝑠𝑧 cellát „klaszterezettnek” nyilvánítjuk;
5. NEIGHBOR-SEARCH(𝐵𝑠𝑧, C);
6. MINDEN_VÉGE.
Felmerülhet a kérdés, hogy a NEIGHBOR-SEARCH eljárásban mely cellák
számítanak a B cella szomszédainak. Említettük, hogy minden egyes cella esetén
nyilvántartjuk annak helyét a rácsszerkezetben, egy sor-, illetve oszlopindex
segítségével (n dimenzió esetén n darab index). Egy cellának d dimenzióban összesen
3𝑑 − 1 darab szomszédja lehet. Ezen szomszédok különböznek egymástól a cellát tőlük
elválasztó hipersík dimenziójának függvényében, ami összesen 𝑑 − 1 féle lehet. Erich
Schikuta szerint elegendő csak a 𝑑 − 1 dimenziós hipersíkok által határolt szomszédok
bejárása, hiszen az eredményt csak ezek befolyásolják számottevően.

36
A 2.6.3 ábrán a B rácscella szomszédai láthatóak. 1 dimenziós síkkal (egy éllel)
elválasztott szomszédok a B1, B2, B3, B4, 0 dimenziós síkkal (síkbeli ponttal) elválasztott
szomszédok pedig a C1, C2, C3, C4.
2.6.3 ábra – A B cella szomszédai két dimenzióban
GRIDCLUS algoritmus hatékonysága
Az algoritmus teljes műveletigénye függ a rácsszerkezet létrehozásának költségétől, a
rácscellák sűrűség szerinti rendezésének költségétől, valamint a cellák klaszterezésének
költségétől. A klaszterezés során minden cellát csak egyszer kérdezünk le, ami 𝑂(𝑐)
futásidőt eredményez, ahol c a cellák száma. Megjegyezzük, hogy a rácsszerkezetben
adott szomszéd lekérése konstans idejű a cellák megfelelő indexelésének köszönhetően,
valamint általában 𝑐 ≪ 𝑛, ahol n az adatpontok száma. A rácscellák sűrűség szerinti
sorba rendezésének műveletigénye a kiválasztott rendezési algoritmustól függ. A
hatékonyság szempontjából leglényegesebb elem a rácsszerkezet létrehozásának
költsége. Ez nagyban függ a rácsszerkezet implementációjától, azonban általánosan a
költség 𝑂(𝑛), ahol n az adatpontok száma, hiszen minden egyes pontot egyszer
lekérdezünk, majd elhelyezzük a megfelelő rácscellába. A rácscellák sűrűségének
számítása konstans idejű, az adatpontok dimenziószámától függ. Mivel a cellák száma
nagy adathalmazok esetén elhanyagolható az adatpontok számához képest, azaz 𝑐 ≪ 𝑛,
ezért az algoritmus teljes műveletigénye 𝑂(𝑛).
Mint ahogy azt már említettük, az algoritmus paramétere, a rácsrendszer felosztása
nagyban befolyásolja az algoritmus pontosságát. Kis felosztás esetén nagyméretű cellák
keletkeznek, melyek elfedik az általuk tartalmazott adatpontok struktúráját. Ebben az
esetben pontatlan eredményt kaphatunk, azonban az algoritmus nagyon kevés számítást

37
igényel. Nagy felosztás esetén kisméretű cellák keletkeznek, melyek segítségével
pontosabbá válik a klaszterezés, azonban az algoritmus több számítást igényel.
A GRIDCLUS algoritmus tulajdonképpen egy sűrűség alapú algoritmushoz
hasonlóan működik, ahol a sűrűség alapú algoritmusok paramétereit (szomszédsági
sugár és sűrűségkorlát) egy darab paraméterrel helyettesítünk, ami nem más, mint a
rácsszerkezet felosztása. Minél nagyobb a felosztás, annál sűrűbb klasztereket talál az
algoritmus. Ez az analógia azzal magyarázható, hogy itt is egy sűrűségfogalom, a
cellasűrűség segítségével klaszterezünk (2.4.6 ábra).
2.6.4 ábra – GRIDCLUS algoritmus működése egyre nagyobb rácsfelosztás esetén
(balról jobbra haladva)
A GRIDCLUS algoritmus a sűrűség alapú klaszterező algoritmusokhoz hasonló
tulajdonságokkal rendelkezik. Képes tetszőleges alakú klaszterek felfedezésére
megfelelő rácsfelosztás esetén, ugyanakkor rosszul kezeli a váltakozó sűrűségű
klasztereket. Nagy hátránya a sűrűség alapú klaszterező algoritmusokkal szemben, hogy
nem képes kezelni a kívülálló pontokat. Míg egy sűrűség alapú algoritmus külön
klasztert tart nyilván a kívülálló pontok számára, addig a GRIDCLUS ezeket általában
külön egyelemű klaszterekbe sorolja. Könnyen adódhat az ötlet a javításra, miszerint
reprezentálja a kívülálló pontokat az egyelemű klaszterek uniója.
2.6.5 ábra – GRIDCLUS működése kívülálló pontok esetén

38
A GRIDCLUS algoritmus sokszor pontatlan eredményt adhat, főleg váltakozó
sűrűségű klaszterek esetén, azonban megfelelő rácsfelosztással az algoritmus gyors,
ugyanakkor jól elkülönülő klasztereket hoz létre. A gyakorlatban emiatt a rács alapú
algoritmusokat a legtöbb esetben egy elő-klaszterezési algoritmusként alkalmazzák
nagyméretű adathalmazok esetén, azaz a módszer által kapott klasztereket utólag egy
másik klaszterező algoritmusnak vetik alá, ezzel pontosítva az eredményt.
2.7 Klaszterezés neurális hálózatok segítségével
A klaszter-analízis feladatát vizsgálhatjuk egy teljesen új megvilágításban is, neurális
hálózatok segítségével. Mint a mesterséges intelligencia tudományának eszközei, a
neurális hálózatok az emberi agyhoz hasonlóan tanulásra képes rendszerek, melyek
tanító minták alapján képesek összefüggések, szabályszerűségek felismerésére. Ha ezek
a szabályszerűségek egy adathalmaz pontjainak kapcsolatait tükrözik, akkor egy
neurális hálózat a klaszterezési feladat megoldására is alkalmazható.
2.7.1 Neurális hálózatok
A mesterséges intelligencia tudományának egyik legmeghatározóbb ága a neurális
hálózatok, melyek manapság igen nagy népszerűségnek örvendenek a legkülönfélébb
alkalmazási területeken. Ez a tudományág viszonylag újnak tekinthető, ugyanakkor
sikeresen alkalmazható olyan speciális feladatok megoldására, melyek nagy
problématérrel rendelkeznek és hagyományos, algoritmikus megközelítésük bonyolult,
nehéz számítások útján vezet eredményhez.
Neurális hálózatok kiválóan alkalmazhatóak különböző csoportosítási problémák
megoldására, így a klaszterezés feladata is egyszerűen elvégezhető speciális, pont erre a
feladatra optimalizált neuronhálók segítségével.
A neurális hálózatok alapötletét a természet ihlette. Megalkotásánál célunk egy
olyan rendszer létrehozása, mely az emberi agyhoz hasonlóan képes „gondolkodni”,
azaz bizonyos minták és tapasztalatok alapján tanulásra képes, így kialakítva, esetleg
folyamatosan tökéletesítve feladatmegoldó képességét. Egy biológiai neurális
rendszerhez hasonlóan, amely idegsejtekből, valamint az azok közötti szinapszisokból
áll, egy mesterséges neuronháló architektúrája is elemei feldolgozó egységekből,

39
úgynevezett neuronokból, valamint az eszek közötti kapcsolatokból épül fel. Ezen
kapcsolatokat a neuronok közötti súlyozott élek reprezentálják. Minél nagyobb egy
adott él súlya, annál szorosabb kapcsolatban van az általa összekötött két neuron.
A mesterséges neurális hálózat definíciója a következő:
Definíció: „Neurális hálózatnak nevezzük azt a hardver vagy szoftver
megvalósítású, párhuzamos, elosztott működésre képes információ-feldolgozó eszközt,
amely:
azonos, vagy hasonló típusú – általában nagy számú – lokális feldolgozást végző
műveleti elem, neuron (processing element, neuron) többnyire rendezett
topológiájú, nagymértékben összekapcsolt rendszeréből áll,
rendelkezik tanulási algoritmussal (learning algorithm), mely általában minta
alapján való tanulást jelent, és amely az információ-feldolgozás módját
határozza meg,
rendelkezik a megtanult információ felhasználását lehetővé tevő információ
előhívási, vagy röviden előhívási algoritmussal (recall algorithm).”[10]
Minden neurális hálózat alap építőöve a neuron, mely a hálózat processzáló eleme
(2.7.1 ábra). Egy neuron bemenő élekből, egy feldolgozó vagy processzáló egységből,
valamint a neuron kimenetéből áll. A neuron – működését leegyszerűsítve – egy
kimenetet állít elő bemenő impulzusok (adatok) élsúlyozott összegéből egy belső
függvény segítségével.
Egy neuron bemenetének élsúlyozott összege ∑ 𝑤𝑖𝑢𝑖 ahol 𝑤𝑖 az i. bemeneti él súlya,
𝑢𝑖 pedig az i. input. A neuron y kimenete az előbb kiszámolt súlyozott összegre
alkalmazott aktivációs függvény (belső függvény) eredménye: 𝑦 = 𝑓(∑ 𝑤𝑖𝑢𝑖). Az f
aktivációs függvény gyakorlatilag bármilyen függvény lehet, azonban a legtöbb esetben
az identikus függvény, vagy valamilyen speciális szigmoid függvény.
[10] Horváth Gábor: Neurális hálózatok, Hungarian Edition Panem Könyvkiadó Kft., Budapest 2006, [447], ISBN 963545464-3

40
2.7.1 ábra – Elemi neuron
Egy neurális hálózaton belül a neuronok rétegekbe szerveződnek.
Megkülönböztetünk bemeneti réteget, közbülső, úgynevezett rejtett rétegeket, valamint
kimeneti réteget. A rétegekben elhelyezett neuronok közötti kapcsolatokat általában
mátrixok segítségével reprezentáljuk, ahol a mátrix adott eleme két neuron közötti él
súlya.
A különböző neurális hálózatok közül a klaszterezés feladatának megoldására a
legalkalmasabb az úgynevezett Kohonen-hálózat, mely egy speciális tulajdonságtérkép
segítségével képes a tanító adatpontok közötti kapcsolatok topologikus eltárolására.
2.7.2 Önszerveződő térképek (SOM)
Az önszerveződő térkép (Self-Organizing Map) vagy Kohonen-hálózat[11] az egyik
legszélesebb körben alkalmazott, Teuvo Kohonen által feltalált neurális hálózat, melyet
a Finn Akadémia professzora mutatott be a nyolcvanas években[12]. Az egyszerű
hálózati topológiájából adódóan a Kohonen-hálózat különösen jól működik nagy
dimenziójú pontokat tartalmazó tanító adathalmazok esetén. A hálózat képes a tanító
adatpontok közötti szemantikus kapcsolatok topologikus eltárolása mellett az
adatpontok alacsonyabb dimenziós reprezentálására is[13].
A Kohonen-hálózat szerkezetét tekintve két rétegből áll:
bemeneti réteg (input layer)
[11] Kohonen, T.: The self-organizing map, Helsinki University of Technology, Espoo Sep, ISSN: 0018-9219, Digital Object Identifier: 10.1109/5.58325, 1990. [12] Kohonen, T.: Self-organized formation of topologically correct feature maps. Biological Cybernetics, 43:59-69, 1982. [13] Kohonen, T.: Self-Organizing Maps, Third, extended edition, Springer, 2001.

41
kimeneti réteg (output layer)
A bemeneti réteg egy neuronból áll, mely teljesen összekapcsolt a kimeneti réteggel.
Két hálózati réteg teljesen összekapcsolt, ha minden, adott rétegben levő neuron
kapcsolatban van az összes, másik rétegben levő neuronnal. A kimeneti réteg neuronjai
egy rácson helyezkednek el, melyet térképnek nevezünk. Ez a rács kvadratikus
topológiájú (𝑛 ∗ 𝑛 - es), azaz minden egyes neuron négy közvetlen szomszéddal
rendelkezik (2.7.2 ábra). A gyakorlatban egyéb rétegtopológiák is ismertek (pl.
hexagonális topológia), ezek azonban általánosságban nem minősülnek jobbnak a
kvadratikus topológiánál, implementációjuk viszont jóval bonyolultabb.
2.7.2 ábra – SOM hálózati topológiája. A kék neuronok a kimeneti réteget (térkép)
alkotják, a zöld neuron pedig a bemeneti réteget.
A hálózat neuronjai reprezentálhatóak egy-egy súlyvektorral (feature vector),
melyek dimenziója megegyezik a tanító adatpontok dimenziójával. Ha a bemenő
adatpont n dimenziós, akkor a térkép (kimeneti réteg) minden egyes neuronja egy n
dimenziós vektort tartalmaz. A bemeneti réteg neuronja minden egyes lépésben az
éppen aktuális bemenő adatvektort tartalmazza. A térkép neuronjai közötti kapcsolat a
2.7.2 ábrán csak a szomszédságot hivatott reprezentálni, hiszen ezek között nincs a
hagyományos értelembe vett információáramlás.

42
A hálózat tanítása
A Kohonen-hálózat működésének első és egyben legfontosabb fázisa, az összes
neurális hálózathoz hasonlóan a tanítás, melynek során a hálózat képes a minta
bemenetek közötti hasonlóságok alapján megváltoztatni szerkezeti topológiáját. Tanítás
előtt a hálózatot inicializálnunk kell. Ez általában a kimeneti réteg neuronjait
reprezentáló vektorok véletlen értékekkel való feltöltését jelenti, azonban léteznek
egyéb módszerek is. Ilyen például a súlyvektorok random tanító adatokkal való
feltöltése, vagy a gradiens módszer, melynek során a térképet egy adott vektortól
indulva fokozatosan nagyobb vektorokkal töltjük fel átlósan haladva. Tanító adatokkal
való feltöltés esetén kevesebb iterációszám is elegendő a tanító algoritmusnak, hiszen a
rácspontok geometriailag közelebb lesznek a tanító adatokhoz.
A tanítás célja, hogy a térkép neuronjainak súlyvektorait úgy változtassuk meg a
tanító adatok segítségével, hogy azok később tükrözzék a mintaadatok közötti
hasonlóságokat.
A hálózat tanítása egy felügyelet nélküli tanítás, azaz nincs szükségünk a bemenő
minta adatpontokhoz tartozó elvárt kimenetekre, hiszen a hálózat kimeneti rétege egy
önszerveződő térkép, amely magától adaptálódik a bemenethez.
A tanuló algoritmus minden egyes iterációjában a következő három dolog változik:
BMU (Best Matching Unit)
Szomszédsági függvény értéke
Tanulási ráta értéke
A BMU nem más, mint a térkép azon neuronja, melynek súlyvektora a legközelebb
áll az éppen aktuális tanító bemenethez. Azt a neuront keressük, melynek súlyvektora és
a bemenő adat közötti távolság minimális. Ez a távolság legyen a két vektor euklideszi
távolsága (a és b d-dimenziós vektorok):
𝑑(𝑎, 𝑏) = √∑(𝑎𝑖 − 𝑏𝑖)2
𝑑
𝑖=1
Minden iterációban a térkép a BMU körüli bizonyos sugárban változik úgy, hogy a
térkép neuronjainak súlyvektorait próbáljuk közelíteni a bemenő adatvektorhoz. Ez a

43
sugár a tanulás minden egyes iterációjában csökken. A szomszédsági függvény, illetve a
tanulási ráta azt mondja meg, hogy milyen mértékben változtassuk mega BMU körüli
neuronok súlyait, azaz mennyire legyen nagy a hatása az adott bemenetnek a térkép
topológiájára[14]. Maga a szomszédsági függvény határozza meg az információ terjedését
a BMU körül, a tanulási ráta pedig a súlyok változtatásának nagyságát szabályozza,
azaz minél távolabb kerülünk a BMU-tól, annál kevésbé változzanak a súlyok.
Mind a szomszédsági függvény, mind pedig a tanulási ráta az aktuális iterációszám
monoton csökkenő függvénye. Ez azt jelenti, hogy a tanulás kezdetén egy mintaadat
szinte a térkép egészére kihat, majd az iterációszám növekedésével csak lokális
módosulásokat idéz elő, a BMU körüli neuronok súlyvektorait illetően[15].
A tanulási algoritmus pszeudokódja a következő:
(1) Inicializáljuk a térkép neuronjainak súlyvektorait véletlen értékekkel.
Hatékonyabb a tanítás, ha ezen értékek abból az intervallumból vannak, melyből
a tanító adatok vehetik fel értékeiket. Ha a tanító adatoktól nagyon eltérő
értékekkel inicializáljuk a hálózatot, a tanítás több iterációt igényel.
(2) Válasszunk véletlenszerűen a tanító adatok közül. Legyen ez a választás a t.
iterációban 𝑣𝑡.
(3) Keressük meg a 𝑣𝑡-hez legközelebbi neuront a térképen. Ez lesz a BMU.
(4) A térkép (W) minden egyes neuronja esetén módosítsuk a súlyvektorokat a
következő képletek szerint:
𝑊𝑖,𝑗(𝑡 + 1) = 𝑊𝑖,𝑗(𝑡) + (𝑣𝑡 − 𝑊𝑖,𝑗(𝑡)) ∗ 𝜃(𝑡) ∗ 𝛼(𝑡)
𝜃(𝑡) = 𝑒−𝑑
2𝑟
𝑟 = 𝑅𝑒−𝑡𝑇
𝛼(𝑡) = 𝐴𝑒−𝑡𝑇
Ahol: t – aktuális iterációszám
T – iterációk száma
𝑊𝑖,𝑗(𝑡) – a térkép i. sorában és j. oszlopában található neuron súlyvektora
𝑣𝑡 – input vektor a t. iterációban
[14] Kohonen, T., Kaski, S. and Lappalainen, H.: Self-organized formation of various invariant-feature filters in the adaptive-subspace SOM, Neural Computation, 9: 1321-1344, 1997. [15] Kaski, S., Kangas, J., and Kohonen, T.: Bibliography of self-organizing map (SOM) papers: 1981-1997. Neural Computing Surveys, 1: 102-350, 1998.

44
𝜃 – szomszédsági függvény
𝛼 – tanulási ráta
d – a BMU és 𝑊𝑖,𝑗(𝑡) közötti euklideszi távolság a térkép szerint
(síkbeli)
r – aktuális szomszédsági sugár
R – a térkép sugara (a rácsba illeszthető kör sugara)
A – a tanulási ráta kezdeti értéke (tetszőleges lehet)
(5) Ismételjük meg az algoritmust a 2. lépéstől T-szer.
SOM működése színek esetén
Tanítás után a térkép hűen tükrözi az őt alkotó neuronokon keresztül a tanító adatpontok
tulajdonságait, illetve az azok közti kapcsolatokat topologikus módon eltárolja.
Vizsgáljuk meg ezt egy példán keresztül.
Egy olyan Kohonen-hálózatot szeretnénk létrehozni, amely színek betanulására
képes. Legyenek a tanító adatpontjaink olyan háromdimenziós vektorok, melyek
színeket reprezentálnak. Tudjuk, hogy egy adott szín reprezentálható a
színkomponenseinek RGB (Red Green Blue) hármasával. Legyen tehát egy színt
reprezentáló vektor 𝑣 = (𝑅, 𝐺, 𝐵)𝑇, ahol az R, G és B súlyok 0 és 255 közötti egész
értékek. Ennek megfelelően a térkép neuronjai is háromdimenziós vektorokat
tartalmaznak, melyek súlyai egy szín R, G és B értékei.
A térképet megjeleníthetjük oly módon, hogy minden csomópontját egy négyzettel
reprezentáljuk, melynek színe az általa tartalmazott RGB értéknek megfelelő.
Legyen a térképünk egy 40 ∗ 40-es méretű rács, melynek háromdimenziós
súlyvektorait a tanítás kezdetén véletlen módon inicializáljuk, azaz a vektorok súlyai
véletlenszerűen kapnak egy 0 és 255 közötti értéket.
Legyenek a tanító adataink nyolc darab színt (2.7.3 ábra) reprezentáló
háromdimenziós vektorok. A térkép állapota inicializáció után 2.7.4 ábrán látható.

45
2.7.3 ábra – A hálózat tanító adatainak megfelelő színek
2.7.4 ábra – Színeket reprezentáló SOM térkép inicializációja random értékekkel
Tanítás után a térkép topológiája a tanító színeknek megfelelően változik (2.7.5
ábra). Jól látható, hogy a térkép a tanító színeket tükröző területekre bomlik. Egy ilyen
terület „középpontjában” található az illető tanító adathoz tartozó, tanítás során
legtöbbször kiválasztott BMU (Best Matching Unit). A színterületek között átmenetek
figyelhetőek meg, melyek a tanító adatpontok közötti kapcsolatokat tükrözik. Ez azt
jelenti, hogy a térkép nem csak a tanító adatokat reprezentálja, hanem olyan
színértékeket is, melyek a tanító adatokhoz hasonlóak, esetleg két tanító adatpont között
helyezkednek el. Megfigyelhetjük, hogy a színterületek pozíciója sem teljesen
véletlenszerű, hiszen a térkép az adatpontok kapcsolatait is figyelembe véve
szerveződik. Ennek megfelelően például a narancssárga szín minden esetben a sárga és
piros színterületek között fog elhelyezkedni, mint a két szín „keveréke”. Megjegyezzük,
hogy minél nagyobb az iterációszám a tanítás során, annál kevésbé jelennek meg az
átmenetek, azaz a színterületek annál élesebben elhatárolódnak. Vigyáznunk kell tehát,

46
nehogy „túltanítsuk” a hálózatot (overlearning), hiszen ekkor elvész az adatpontok
közötti átmenetek információja és ezzel együtt a neuronhálózat általánosító képessége.
2.7.5 ábra – Színeket reprezentáló SOM térkép tanítás után
Osztályozás SOM segítségével
Vizsgáljuk meg, hogyan használható a SOM önszerveződő térkép az osztályozás
feladatának megoldására. Mint ahogy azt a második fejezet elején említettük, az
osztályozást az különbözteti meg a klaszterezéstől, hogy a klaszterezéssel ellentétben
egy felügyelt csoportosítási feladat, azaz rendelkezünk előzetes információkkal az
adatpontokat illetően. Ilyen információ például, hogy előre tudjuk, milyen csoportokba
akarjuk szervezni az adatpontjainkat.
Tekintsük az előbb bemutatott, nyolc darab színnel betanított SOM térképet. A
neurális hálózat segítségével osztályozni szeretnénk tetszőleges színt a hálózatot
betanító színek nyolc csoportjának valamelyikébe. Egy tanító adat tehát egy osztályt
reprezentál. Ahhoz, hogy ezt megtehessük a tanító adatainknak reprezentáns adatoknak
kell lenniük az osztályozás szempontjából. Tehát az osztályozás során egy zöldes
színárnyalat a „zöld” osztályba kerül, míg egy kékes szín a „kék” osztályába. Ezt a
következőképpen tehetjük meg:

47
1. A hálózatot betanító színekhez megkeressük az azokhoz tartozó legközelebbi
neuront a térképen, azaz a tanító adatok BMU-jait. Ezen pozíciókat eltároljuk.
2. Megkeressük az osztályozandó színhez tartozó legközelebbi neuront a hálón.
Legyen ez 𝐵𝑀𝑈𝑜.
3. Az osztályozandó színt abba az osztályba soroljuk, melyet reprezentáló tanító adat
BMU-ja a térképen legközelebb helyezkedik el 𝐵𝑀𝑈𝑜-hoz.
Egy gyakorlati példa lehet, hogy fényképeket szeretnénk színek szerint osztályozni
az általunk betanított SOM térkép segítségével. Ebben az esetben első dolgunk a
képeket egyetlen színnel reprezentálni, hiszen a SOM térképünk háromdimenziós
vektorként reprezentált színeket vár bemenetként. Legyen a képeket reprezentáló szín a
kép domináns színe. Ezt úgy kaphatjuk meg, hogy statisztikát készítünk a képet
pixelekre lebontva, minden egyes előforduló szín esetén nyilvántartva, hogy az
hányszor szerepelt a képen. Legyen a kép domináns színe a három leggyakrabban
szerepelt szín átlaga. Ezt követően a kép domináns színét osztályozzuk az előbb
bemutatott lépések szerint, ezzel megkapva a képek osztályozását is.
2.7.6 ábra – Képek osztályozás előtt és után

48
A 2.7.6 ábrán jól látható a képek osztályokba szerveződése. Az ábra bal oldalán a
képeket osztályonként egymás után jelenítettük meg, előbb a piros színnek megfelelő
osztályba került képeket, majd a világoszöld, sötétzöld, stb. színűeket.
Klaszterezés SOM segítségével
A klaszter-analízis egy felügyelet nélküli csoportosítási feladat, tehát semmilyen
előzetes információról nem rendelkezünk a klaszterezendő adatpontjainkról. Egy SOM
önszerveződő térkép tekintetében ez azt jelenti, hogy klasztereket reprezentáló
referenciapontokkal sem rendelkezünk, amivel a hálózatot betaníthatnánk. Nincs más
választásunk, mint az klaszterezendő adathalmaz összes pontját tanító adatnak
nyilvánítani és velük betanítani a hálózatot. Ez nem baj, hiszen a SOM térkép képes az
adatpontok tulajdonságait és azok közötti kapcsolatokat egy kétdimenziós rácsban
eltárolni. Ez a rács maga az önszerveződő térkép, mely tekinthető egy
dimenziócsökkentő hálónak is, hiszen az n dimenziós adatpontokat egy kétdimenziós
síkba vetíti le, megőrizve azok tulajdonságait.
Felmerül a kérdés, hogy hogyan lehet a teljes adathalmaz által betanított SOM
neuronhálót a klaszterezési feladat megoldására felhasználni. A válasz viszonylag
egyszerű. Használjuk ki SOM térkép dimenziócsökkentő tulajdonságát, azaz az
adatpontjainkat ne n dimenzióban klaszterezzük, hanem az önszerveződő térkép
kétdimenziós síkjában.
Az első probléma, amivel szembetaláljuk magunkat az, hogy a térkép síkjában
nincsenek olyan neuronok, melyek a tanító adatpontok vektorait tartalmaznák. Ezt
könnyen kiküszöbölhetjük úgy, hogy azt a térképen elhelyezkedő neuront választjuk a
tanító adatpont reprezentánsának, ami a legközelebb áll hozzá, azaz az ő BMU-ját. Ily
módon minden tanító adatpontot hozzákapcsoltunk a térkép egy neuronjához. Tudjuk,
hogy a hálózat tanítása után, elegendő tanítási iterációszám esetén a tanuló adatpontok
szinte teljesen megegyeznek BMU-jaikkal, hiszen a tanítás során a BMU minden
iterációban közeledik a tanító adatponthoz.
Miután minden klaszterezendő adatponthoz hozzárendeltük annak BMU-ját, nincs
más dolgunk, mint a térkép síkjában klaszterezni a BMU-kat, ezzel megkapva a nagy
dimenziós adatpontok klaszterezését is. Ez a síkbeli klaszterezés bármilyen eddig
bemutatott klaszterezési algoritmussal történhet.

49
Megjegyezzük, hogy a térkép méretének megfelelő megválasztása, illetve a tanítás
iterációszáma kulcsfontosságú lehet a klaszterezés eredményét illetően. Ha túl
nagyméretű térképet választunk, azaz sokkal több neuronból áll a térkép, mint ahány
adatpontunk van, akkor a helyes eredményhez nagyobb tanítási iterációszám szükséges.
Ha jóval kevesebb a neuronok száma az adatpontok számánál, akkor egy neuronhoz sok
adatpont kapcsolódhat a BMU neuronok által. Ez problémát okozhat akkor, ha ezek az
adatpontok nem ugyanazon klaszter elemei, hiszen a síkbeli klaszterezés már nem képes
őket szétbontani.
A SOM klaszterező algoritmus pszeudokódja a következő:
1. Tanítsuk be a hálózatot a klaszterezendő adatpontokat használva tanító
adathalmazként;
2. Keressük meg az adatpontokhoz tartozó BMU-kat. Legyenek ezek n darab
adatpont esetén rendre 𝐵𝑀𝑈1, 𝐵𝑀𝑈2, … , 𝐵𝑀𝑈𝑛;
3. Reprezentáljuk minden BMU-t egy síkbeli ponttal, ahol a pont koordinátái a
BMU pozíciójának sor-, illetve oszlopindexe a térképen. Legyenek ezek a
pontok rendre 𝑝1, 𝑝2, . . , 𝑝𝑛.
4. Klaszterezzük az eddig bemutatott klaszterező algoritmusok valamelyikével a
𝑝1, 𝑝2, . . , 𝑝𝑛 pontokat az egyszerű síkbeli euklideszi távolságfogalmat
felhasználva.
5. A kapott klaszterezésnek megfelelően megkaptuk az az adatpontok
klaszterezését is, hiszen a 𝑝𝑖 síkbeli pont klasztere az i. adatpont klasztere is
egyben.

50
3 Klaszterezés alkalmazása a képfeldolgozásban
A számítógépes képfeldolgozás az informatikának manapság igen nagy hangsúllyal
rendelkező területe. Ez ma már nem csak a tudományos célokra használt
képprocesszálásban merül ki, hiszen egyre nagyobb teret kap a mindennapi felhasználás
is. A fényképezőgéppel felszerelt mobil eszközök megjelenésének köszönhetően
hatalmas képmennyiség keletkezik, melynek jelentős része az interneten is közzétett.
Ezen fényképek feldolgozása és megfelelő rendszerezése egyre nagyobb kihívást jelent.
A digitális képek feldolgozása tágabb értelemben tekinthető a jelfeldolgozás egy
ágának is, ahol egy fényképet, mint kétdimenziós jelet dolgozunk fel. Egy digitális
fényképet a legtöbb esetben pixelek mátrixának tekintünk.
Egy gyakorlati feladat lehet képfeldolgozás során, hogy adott képhez hasonló
képeket szeretnénk keresni, illetve képek egy halmazát szeretnénk csoportosítani
(klaszterezni) bizonyos szempontok szerint. Ebben a fejezetben azt vizsgáljuk, hogy
hogyan alkalmazhatóak az eddig bemutatott klaszterező algoritmusok ezen feladatok
megoldására.
3.1 Képek vektoros reprezentációja
Mielőtt képekre alkalmazhatnánk algoritmusainkat, előbb azokat reprezentálnunk kell
egy tulajdonságvektorral (feature vector). Ezen vektorok lesznek az adatpontok az
algoritmusok számára. A tulajdonságvektornak tükröznie kell, hogy milyen szempontok
szerint szeretnénk vizsgálni a képeket. Ilyen szempont lehet például a kép domináns
színe vagy textúra-hisztogramja. Minél részletesebben és minél több szempont alapján
vizsgájuk a képet, annál nagyobb dimenziójú lesz a tulajdonságvektor.
Egy képről különböző adatokat gyűjthetünk. Ezek lehetnek a kép egészére kiterjedő
adatok (hisztogram), illetve csak a kép adott területére kiterjedő adatok (terület átlagok).
Mindkét esetben vizsgálhatjuk a képet szín, illetve textúra szerint is. Színek esetén a
képek pixeleinek színkomponenseit, azok RGB (Red Green Blue) értékét vesszük
figyelembe. Mindhárom színkomponenst egy 0 és 255 közötti egész szám reprezentál.

51
Mielőtt elkezdenénk a képekről adatokat gyűjteni, az egységes feldolgozás
érdekében 50 ∗ 50 pixelméretűre skálázzuk őket. Ennek megvalósítására a legtöbb
programkönyvtár beépített támogatást nyújt.
Szín-hisztogram esetén a tulajdonságvektor kinyerése a következőképpen történik.
A kép pixeleit színkomponensekre (RGB) lebontva különböző csoportokba soroljuk.
Minden egyes színkomponensre 16 csoportot hozunk létre (16 ∗ 16 = 256). Egy
színkomponens összesen 256 értéket vehet fel 0 és 255 között. Minden egyes pixel
színkomponensét a 16 csoport egyikébe soroljuk. Ha a színkomponens értéke 𝑒, akkor
őt az 𝑒/16 sorszámú csoportba tesszük, növelve annak elemszámát. A „/” egész osztást
jelent. Az első csoportba kerülnek tehát a nullához közeli értékek, a 16.-ba pedig a 255-
höz közeliek. Legyen az térkép adott színkomponensre vonatkozó tulajdonságvektora a
csoportok számosságait tartalmazó 16 dimenziós vektor. Mivel egy pixel színe három
színkomponensből áll, így a képet reprezentáló szín-hisztogram tulajdonságvektor egy
16 ∗ 3 = 48 dimenziós vektor.
Vizsgáljuk meg, hogyan számolhatjuk ki egy kép textúráját. A textúra azt méri,
hogy a kép pixelei mennyire különböznek az őket körülvevő pixelektől, azaz mennyire
változatos (zajos) a kép. Első lépésben a képet szürkeárnyalatossá tesszük, hiszen
textúra szempontjából a színeknek jelentősége elhanyagolható. Egy pixel
szürkeárnyalata (gray scale) a következőképpen számolható az RGB értékből:
𝑔𝑟𝑎𝑦 𝑠𝑐𝑎𝑙𝑒 = ⌊𝑅 ∗ 0.3 + 𝐺 ∗ 0.59 + 𝐵 ∗ 0.11⌋
Megjegyezzük, hogy a szürkeárnyalat is egy 0 és 255 közötti érték.
Egy szürkeárnyalatos kép adott pixelének textúrája legyen az őt körülvevő pixelek
közötti legnagyobb eltérés, tehát a szomszédai közötti legnagyobb szürkeárnyalat és
legkisebb szürkeárnyalat különbsége. Ez is egy 0 és 255 közötti egész érték.
A kép textúra-hisztogramot tükröző tulajdonságvektorát a színkomponensek
tulajdonságvektoraihoz hasonlóan kaphatjuk meg. A pixeleket 16 csoportba tesszük,
textúráiknak megfelelően. Ha a pixel textúrája 𝑡, akkor a 𝑡/16-odik csoportba kerül. Az
első csoportba a legalacsonyabb textúrájú pixelek kerülnek, míg az utolsóba a
legmagasabb textúrával rendelkezők. A tulajdonságvektor egy 16 dimenziós vektor lesz,
mely a csoportok számosságait tartalmazza.

52
Területi átlagok számolása esetén a képet 𝑛 ∗ 𝑛 egyenlő részre osztjuk (lásd 3.1.1
ábra). A tulajdonságvektor ezen területekre vonatkozó átlagokból áll. Textúra esetén ez
egy 𝑛 ∗ 𝑛 dimenziós tulajdonságvektort eredményez, melynek elemei a területek pixel-
textúráinak átlaga, szín esetén pedig egy 𝑛 ∗ 𝑛 ∗ 3 dimenziós vektor, mely a területek
átlagszíneit reprezentálja (egyszerű számtani közép színkomponensenként).
3.1.1 ábra – Kép felosztása 3*3 egyenlő részre területi átlag számolása esetén
Egy kép egészét reprezentáló tulajdonságvektor az előbb bemutatott
tulajdonságvektorok valamelyike, esetleg azok konkatenációja, attól függően, hogy
milyen tulajdonságokkal szeretnénk reprezentálni az adott képet.
3.2 SOM felhasználása a képfeldolgozásban
A 2.7.2 fejezetben tárgyaltaknak megfelelően az önszerveződő térkép kiválóan kezeli a
nagy dimenziós adatokat, így a képeket reprezentáló tulajdonságvektorokat is, melyek
akár százas nagyságrendű dimenziószámot is elérhetnek.
Tegyük fel, hogy az a feladatunk, hogy adott mintaképhez hasonló képeket
keressünk egy képadatbázisban. Ennek a feladatnak a megoldására a SOM neurális
hálózat használata kézenfekvőnek tűnik, hiszen az képes a képeket egy kétdimenziós
rácsszerkezetben eltárolni, melyben a keresés már egyszerű feladattá válik. A feladat
megoldásához a következőket kell tennünk:
Tanítsuk be a hálózatot az adatbázis képeiből kinyert tulajdonságvektorokkal;

53
Keressük meg minden egyes tanító adat BMU-ját a térképen. Legyenek ezek n darab
tanító adat esetén 𝐵𝑀𝑈1, 𝐵𝑀𝑈2, … , 𝐵𝑀𝑈𝑛;
A mintakép (amihez hasonló képeket keresünk) tulajdonságvektorához tartozó
BMU-t keressük meg a térképen. Legyen ez 𝐵𝑀𝑈𝑚;
Keressük meg a térképen a 𝐵𝑀𝑈𝑚-hez legközelebbi k darab BMU-t a
𝐵𝑀𝑈1, 𝐵𝑀𝑈2, … , 𝐵𝑀𝑈𝑛 közül. Ezek reprezentálják majd a mintaképhez hasonló
képeket, azaz a 𝐵𝑀𝑈𝑗 a j. képet reprezentálja a képhalmazból.
A pontos eredmény elérésének érdekében fontos, hogy az képadatbázis méretének
megfelelően válasszuk meg a térkép méretét. Mivel nagydimenziós adatokkal
dolgozunk, előnyösebb a térképet minél nagyobb méretűre állítani, hiszen az adatpontok
közötti átmenetek fontos szerepet játszanak. Minél nagyobb az adatok dimenziója, annál
nagyobb térkép használata javasolt. Például egy 40 darab képet tartalmazó adatbázis
esetén legalább 10 ∗ 10-es térkép ajánlott a pontos eredmény eléréséhez kizárólag szín-
hisztogram tulajdonságvektorokat használva.
3.2.1 ábra – Mintaképhez hasonló képek keresése (1)
A 3.2.1 ábrán a baloldali mintaképhez sorban a három legközelebbi kép látható. A
képek tulajdonságvektorait szín-hisztogram és szín terület-átlaggal nyertük 3 ∗ 3-as
képfelosztással. Megjegyezzük, hogy a mintakép nem szükséges az adatbázis része
legyen.
3.2.2 ábra – Mintaképhez hasonló képek keresése (2)

54
A 3.2.2 ábrán a baloldali képhez sorban a hat legközelebbi kép látható. A
mintaképp egy igen magas textúrájú kép a zebra csíkjainak, valamint a háttér
zajosságának köszönhetően, ezért ajánlott a textúra-hisztogram, illetve a textúra terület-
átlag használata is a képek tulajdonságvektorainak kinyerésénél. A példában egy 20 ∗
20-as SOM térképet alkalmaztunk 1000 iterációszámmal 40 képet tartalmazó adatbázis
esetén.
Megjegyezzük, hogy a tulajdonságvektorok kinyeréséhez, valamint a SOM
neuronhálózat méretéhez ideális beállítások nincsenek, hiszen ezek az aktuális
képadatbázistól függenek. Minden adatbázishoz, a képek változatosságától függően más
és más, egyedi beállítások szükségesek, melyeket empirikus úton találhatunk meg.
A SOM önszerveződő térképek képek klaszterezésére is jól használhatóak. Ezt a
következő alfejezetben tárgyaljuk.
3.3 Képek klaszterezése
Ebben a fejezetben egy gyakorlati példára való alkalmazhatóságát vizsgáljuk néhány
eddig bemutatott klaszterezési algoritmusnak. A megoldandó feladat nem más, mint egy
képadatbázis elemeinek klaszterezése bizonyos képjellemzők szerint. Ezen jellemzőket
a képeket reprezentáló tulajdonságvektorok tartalmazzák, melyeket a 3.1 fejezetben
mutattunk be részletesen. A klaszterezendő adatpontjaink tehát ezek a
tulajdonságvektorok, melyek képekből való kinyerési módja jelentős módon
befolyásolja a klaszterezés eredményét.
A képek klaszterezésének legalkalmasabb módszere a SOM neurális hálózat általi
megközelítés. Ez nem véletlen, hiszen az önszerveződő térkép ereje pont abban rejlik,
hogy nagy dimenziós adatok – jelen esetben képek tulajdonságvektorai – közötti
hasonlóságokat síkbeli pontokba szervezve képes eltárolni. Ezen síkbeli pontok a
képekhez tartozó legközelebbi neuronok, a térkép BMU neuronjai.
Alkalmazzuk a képek tulajdonságvektoraival betanított SOM neurális hálózatot
klaszterezésre a 2.7.2 fejezetben bemutatott algoritmus szerint. Az térkép síkjában a
BMU neuronok klaszterezéséhez bármelyik eddig bemutatott klaszterezési algoritmus
alkalmazható. A 3.3.1 ábrán a képadatbázis néhány klasztere látható egyszerű
hierarchikus felhalmozó klaszterezési algoritmust használva, mint a SOM klaszterező
módszer belső algoritmusa. A klaszterek külön sorban helyezkednek el. A térkép mérete

55
7 ∗ 7-es, 1000 iterációval betanítva. A képek tulajdonságvektorainak kinyerésénél szín-
hisztogramot, 4 ∗ 4-es felosztású szín terület-átlagot, valamint 3 ∗ 3-as felosztású
textúra terület-átlagot használtunk. Jól látható, hogy a terület átlagoknak köszönhetően a
program felismeri, ha a képek például azonos háttérrel rendelkeznek. Ennek
köszönhető, hogy a fehér háttérrel rendelkező képek egymáshoz közeli klaszterekbe
kerülnek (első két sor). Ha a felhalmozó algoritmus bemeneti paramétere (klaszterszám)
kisebb, ezek a képek azonos klaszterbe kerülnek, hiszen az algoritmus egyesíti őket,
mint két közeli klasztert.
3.3.1 ábra – SOM klaszterezés hierarchikus felhalmozó algoritmussal
A 3.3.2 ábrán az előbbihez teljesen hasonló beállítások mellett látható a SOM
klaszterezés egy részlete k-közép algoritmus használatával. Mivel a k-közép algoritmus
könnyen egy lokális minimumba ragadhat, ezért a helyes klaszterezés érdekében
érdemes többször lefuttatni azt, kiválasztva az eredmények közül a legjobbnak tűnőt.
3.3.2 ábra – SOM klaszterezés k-közép algoritmust használva

56
A következőkben vizsgáljuk meg, hogyan alkalmazhatóak a klaszterező
algoritmusok „natív” módon a képadatbázis klaszterezésére. „Natív” mód alatt azt
értjük, hogy az algoritmusok számára klaszterezendő pontok maguk a képeket
reprezentáló tulajdonságvektorok, azaz nem használunk egy dimenziócsökkentő SOM
neuronhálózatot.
A legjobb eredményt a k-közép algoritmus használatával érhetjük el, ami nem
véletlen, hiszen az jól használható magas dimenziójú adatpontok esetén is. Hátránya
viszont a lokális minimumba ragadáson kívül, hogy a kívülálló pontokat is a
klaszterekhez sorolja. A 3.3.3 ábrán egy ilyen klaszterezés részletét láthatjuk. Az alsó
képsornak megfelelő klaszterbe, a kék domináns színű képek közé egy ilyen kívülálló,
„sárga” kép került.
3.3.3 ábra – Képek klaszterezése k-közép algoritmussal
A hierarchikus lebontó algoritmus a k-közép algoritmushoz hasonlóan működik,
hiszen annak implementációjában a k-közép algoritmus segítségével vágjuk ketté a
klasztereket.
Hierarchikus felhalmozó algoritmus esetén a klaszterezés felettébb érzékeny a
kívülálló pontokra, hiszen ezek miatt akár két teljesen különböző klaszter is egyesülhet.
Erre láthatunk példát a 3.3.4 ábrán, ahol az alsó két sorban levő klaszterek erősen eltérő
képeket is tartalmaznak.

57
3.3.4 ábra – Képek klaszterezése hierarchikus felhalmozó algoritmussal
A sűrűség alapú klaszterezés rosszul működik váltakozó sűrűségű klaszterek esetén,
mely egy képadatbázis esetén gyakran előfordulhat. Ebben az esetben az algoritmus a
bemeneti paramétereinek értékeitől függetlenül rosszul működik. A másik problémát az
adatpontok magas dimenziószáma okozza, hiszen emiatt a paraméterek (szomszédsági
sugár és sűrűségi korlát) megfelelő értékei nehézkesen, empirikus úton határozhatóak
meg.

58
4 Klaszterezést bemutató demóprogram
4.1 Felhasználói dokumentáció
4.1.1 A rendszer rövid ismertetése
Az általunk készített demóprogram egy grafikus felületen keresztül lehetőséget nyújt az
eddig bemutatott klaszterező algoritmusok működésének szemléltetésére síkbeli
adatpontok esetén. Minden algoritmus tetszőlegesen paraméterezhető különböző
vezérlők segítségével. Lehetőségünk van a klaszterezendő adatpontok generálására,
valamint azok tetszőleges szerkesztésére.
A rendszer az algoritmusok működésének bemutatásán túlmenően lehetőséget
biztosít a klaszterezés egy speciális felhasználásának szemléltetésére a számítógépes
képfeldolgozásban. Ez nem más, mint digitális képek csoportosítása (klaszterezése)
bizonyos szempontok szerint.
4.1.2 Rendszerkövetelmények
A rendszer használatához alapvető szoftverkövetelményként meg kell említenünk a
Microsoft Windows operációs rendszert, valamint a .NET keretrendszer 4.5-ös
verzióját. Hardverkövetelmények tekintetben legalább 1.6 Ghz-es órajelű processzor és
1 GB RAM memória ajánlott, mindemellett szükségünk van a programot tartalmazó
DVD olvasásához szükséges optikai meghajtóra.
4.1.3 Üzembe helyezés
A program telepítése az adathordozón található Setup.exe telepítő-fájl segítségével
történik. A futtatható fájl megnyitásával elindul egy telepítési varázsló, mely végigvezet
minket a telepítési lépéseken. Kiválaszthatjuk a telepítés célmappáját, illetve
beállíthatjuk, hogy szeretnénk-e a program számára gyorsindító ikont az asztalra, illetve
az operációs rendszer Start menüjébe. Telepítés során a program forráskódja mellett, a
rendszer által használt képek, valamint egy minta képadatbázis (LearningData) is a
telepítési mappába kerül. Telepítés után nincs más dolgunk, mint az asztal vagy a Start
menü ikonjára kattintva használatba venni a programot.
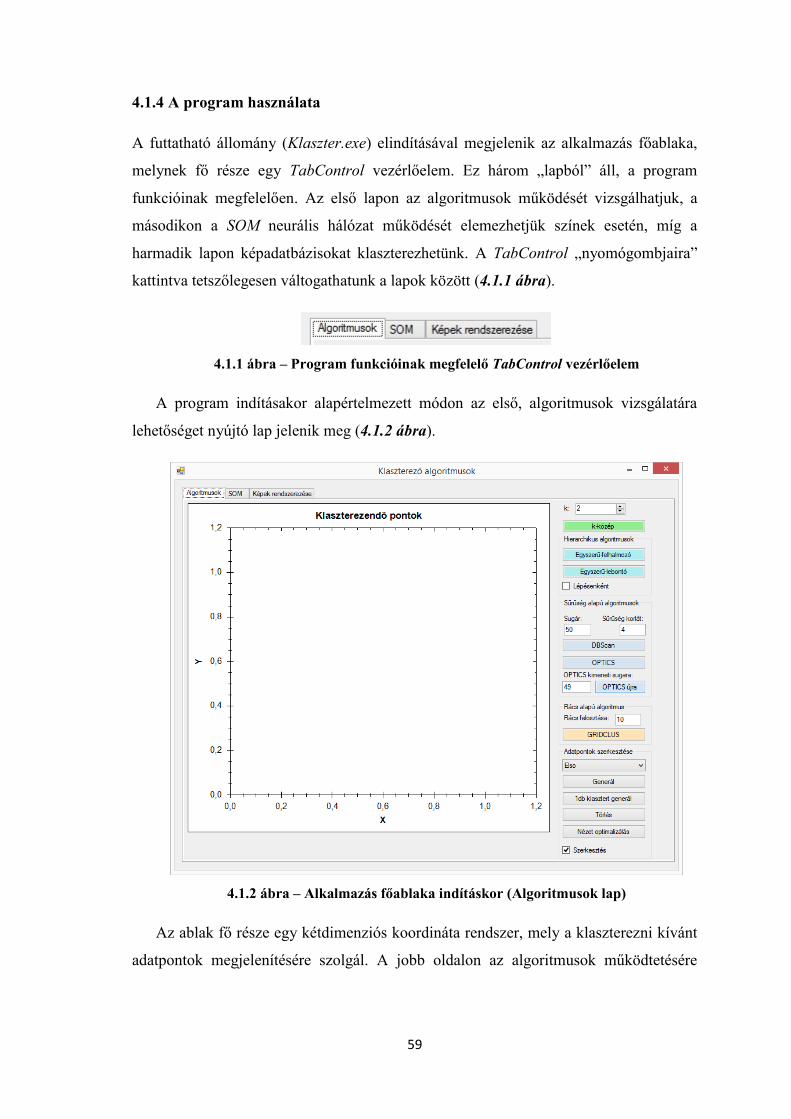
59
4.1.4 A program használata
A futtatható állomány (Klaszter.exe) elindításával megjelenik az alkalmazás főablaka,
melynek fő része egy TabControl vezérlőelem. Ez három „lapból” áll, a program
funkcióinak megfelelően. Az első lapon az algoritmusok működését vizsgálhatjuk, a
másodikon a SOM neurális hálózat működését elemezhetjük színek esetén, míg a
harmadik lapon képadatbázisokat klaszterezhetünk. A TabControl „nyomógombjaira”
kattintva tetszőlegesen váltogathatunk a lapok között (4.1.1 ábra).
4.1.1 ábra – Program funkcióinak megfelelő TabControl vezérlőelem
A program indításakor alapértelmezett módon az első, algoritmusok vizsgálatára
lehetőséget nyújtó lap jelenik meg (4.1.2 ábra).
4.1.2 ábra – Alkalmazás főablaka indításkor (Algoritmusok lap)
Az ablak fő része egy kétdimenziós koordináta rendszer, mely a klaszterezni kívánt
adatpontok megjelenítésére szolgál. A jobb oldalon az algoritmusok működtetésére

60
szolgáló vezérlőelemek találhatóak, algoritmus-típusok szerint csoportosítva. A legalsó
csoportban találhatóak az adatpontok szerkesztésére vonatkozó vezérlők (4.1.3 ábra).
4.1.3 ábra – Adatpontok szerkesztésére vonatkozó vezérlőelemek
Lehetőségünk van a koordinátarendszerre tetszőleges adatpontot elhelyezni
egérkattintással, ha a „Szerkesztés” CkeckBox ki van jelölve. Ezen túlmenően
lehetőségünk van ponthalmazok generálására is. Egy ponthalmaz generálása mindig
adott pont köré történik. Összesen négyféle ponthalmazt generálhatunk az első,
legördülő menü vezérlőelem beállításától függően. Ezen ponthalmazok az őket
tartalmazó pontok elhelyezkedésében különböznek. A pontok elhelyezkedésével a
normális eloszlást próbáltuk közelíteni. Az első egy sugárirányba tetszőleges távolságra
szétszórt pontok halmaza, a második a középpont körül adott távolágra elhelyezkedő
köríveken véletlenszerűen szétszórt pontokat tartalmaz. A harmadik ponthalmaz az
elsőhöz hasonló, azzal a különbséggel, hogy kevésbé távol szóródtak a pontok a
középponttól, a negyedik pedig a középpont körüli adott körív mentén szórt pontokból
áll. Ezen pontgenerálási módszerek eredménye rendre balról jobbra haladva a 4.1.4
ábrán látható.
A „Generál” feliratú nyomógombra kattintva k darab, a koordinátarendszerben
véletlenszerűen elhelyezett ponthalmazt generálhatunk. Ezt a k darabszámot a főablak
legelső vezérlőelemének segítségével adhatjuk meg. Ez egy csak pozitív egész
számokat megengedő NumericUpDown vezérlő (4.1.5 ábra), mely egyúttal bizonyos
algoritmusok klaszter-darabszám bemenő paraméterét is beállítja.
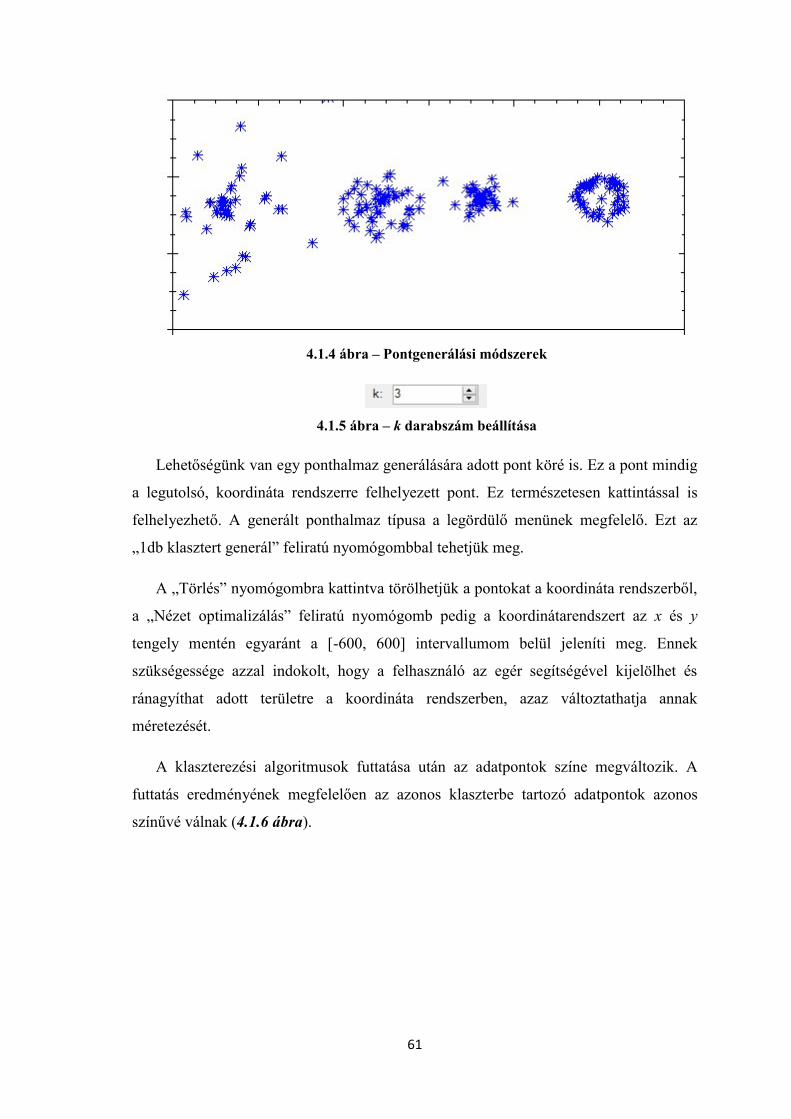
61
4.1.4 ábra – Pontgenerálási módszerek
4.1.5 ábra – k darabszám beállítása
Lehetőségünk van egy ponthalmaz generálására adott pont köré is. Ez a pont mindig
a legutolsó, koordináta rendszerre felhelyezett pont. Ez természetesen kattintással is
felhelyezhető. A generált ponthalmaz típusa a legördülő menünek megfelelő. Ezt az
„1db klasztert generál” feliratú nyomógombbal tehetjük meg.
A „Törlés” nyomógombra kattintva törölhetjük a pontokat a koordináta rendszerből,
a „Nézet optimalizálás” feliratú nyomógomb pedig a koordinátarendszert az x és y
tengely mentén egyaránt a [-600, 600] intervallumom belül jeleníti meg. Ennek
szükségessége azzal indokolt, hogy a felhasználó az egér segítségével kijelölhet és
ránagyíthat adott területre a koordináta rendszerben, azaz változtathatja annak
méretezését.
A klaszterezési algoritmusok futtatása után az adatpontok színe megváltozik. A
futtatás eredményének megfelelően az azonos klaszterbe tartozó adatpontok azonos
színűvé válnak (4.1.6 ábra).

62
4.1.6 ábra – Klaszterezés eredménye
A „k-közép” feliratú gombra kattintva a k-közép klaszterező algoritmust futtathatjuk
le az adatpontokra. Az algoritmus klaszterszám paramétere a 4.1.5 ábrán látható
vezérlő segítségével állítható. Ez a hierarchikus algoritmusok bemenő paramétere
(megállási feltétele) is egyben.
A hierarchikus klaszterező algoritmusok esetében lehetőségünk van lépésenkénti
futtatásra is, ha be van jelölve a „Lépésenként” feliratú CheckBox vezérlő (4.1.7 ábra).
4.1.7 ábra – Hierarchikus klaszterező algoritmusok vezérlői
A sűrűség alapú klaszterező algoritmusok vezérlőinek csoportja a 4.1.8 ábrán
látható. A „Sugár”, illetve „Sűrűség korlát” feliratú TextBox vezérlők segítségével
adhatjuk meg a DBSCAN és OPTICS algoritmusok bemenő paramétereit. A „DBScan”
feliratú nyomógombra kattintva lefut a DBSCAN algoritmus és megjelenik annak
eredménye a koordinátarendszerben. Az „OPTICS” nyomógombra kattintva felépül a
háttérben az adatpontok sűrűség szerinti rendezett sorozata (kimeneti adatszerkezet) az

63
előbb említett paramétereknek megfelelően, illetve megjelenik az azoknak megfelelő
DBSCAN klaszterezés is. Az „OPTICS újra” feliratú gombra kattintva ezen
adatszerkezet segítségével megkapható az összes olyan sűrűség alapú DBSCAN
klaszterezés, mely az eredeti bemenő paraméterhez képest kisebb szomszédsági sugárral
operál. Ezt a sugarat a nyomógombtól balra található TextBox vezérlő segítségével
állíthatjuk.
4.1.8 ábra – Sűrűség alapú algoritmusok vezérlői
Az tervezésnél ügyeltünk az adatbeviteli hibák kezelésére is. Helytelen adatbevitel
esetén a program hibát jelez (4.1.9 ábra).
4.1.9 ábra – Hibás adatbevitel
Rács alapú klaszterező algoritmus esetén egyedüli bemenő paraméter a rács
felosztásának mérete. Ez a „Rács felosztása” címkéjű TextBox vezérlővel állítható
(4.1.10 ábra). A „GRIDCLUS” feliratú nyomógombra kattintva lefut az algoritmus és
megjelenik az eredmény a koordinátarendszerben.
4.1.10 ábra – Rács alapú klaszterező algoritmus vezérlői
A TabControl második, „SOM” feliratú lapján az önszerveződő térkép tanítását
vizsgálhatjuk színeket reprezentáló bemenő adatokra. Az lap bal oldalán található a

64
színek vektorait tartalmazó neuronokból álló 40 ∗ 40-es méretű önszerveződő térkép,
mely kezdetben véletlenszerű értékekkel van feltöltve (4.1.11 ábra).
4.1.11 ábra – Alkalmazás „SOM” lapja indításkor
A „SOM tanítás” feliratú gombra kattintva a térképet 8 darab színnel betanítjuk
1000 iterációszámmal. Ezen tanító adatok tanítás utáni BMU neuronjaink színei (maguk
a tanító színek is egyben) a térkép alatt láthatóak.
Az „Osztályoz” feliratú nyomógomb lenyomásával az ablak jobb oldalán található
képeket osztályozhatjuk domináns színük szerint, az önszerveződő térkép segítségével,
az azt betanító színeknek megfelelően. Egy osztályozás utáni állapot a 4.1.12 ábrán
látható.

65
4.1.12 ábra – Alkalmazás „SOM” lapja osztályozás után
A TabControl harmadik lapján képadatbázisok klaszterezését valósíthatjuk meg
különböző klaszterezési algoritmusok segítségével, valamint adott képhez hasonló
képeket kereshetünk. Az első, „Vektorok betöltése” feliratú vezérlőcsoport (GroupBox)
a képek betöltéséért felel (4.1.13 ábra). A „Képek betöltése” nyomógombra kattintva
kiválaszthatunk egy képeket tartalmazó mappát, ami a felhasznált képadatbázisként
szolgál (4.1.14 ábra). Az alkalmazás könyvtárában található egy erre célra szolgáló
minta képadatbázis a „LearningData” nevű mappában. A „Feature-vektorok” feliratú
gomb segítségével az előbb betöltött képadatbázis képeiből tulajdonságvektorokat
nyerhetünk ki az erre vonatkozó vezérlők beállításainak megfelelően. Színhisztogramot
a program automatikusan gyűjt a képekből. A szín terület-átlag felosztását a
„Képfelosztás” címkéjű NumericUpDown vezérlővel állíthatjuk. Textúra hisztogram,
illetve egy 3 ∗ 3-as felosztású textúra terület-átlag kinyerése az ezeknek megfelelő
CheckBox vezérlők megjelölésével történik.
66
4.1.13 ábra – Képek betöltéséért felelő vezérlők
4.1.14 ábra – Képadatbázis kiválasztása
A képek tulajdonságvektoraival betanítható SOM önszerveződő térkép beállítása a
4.1.15 ábrán látható vezérlők segítségével történik. A „SOM tanítás” feliratú gombra
kattintva betaníthatjuk a hálózatot.
4.1.15 ábra – SOM tanítása
A SOM neurális hálózat betanítása után adott mintaképhez hasonló képet is
kereshetünk a képadatbázisból. A mintakép nem szükséges a tanító adathalmaz része
legyen. A „Kép választása” feliratú nyomógomb segítségével kiválaszthatunk egy
tetszőleges képet a számítógépről. Ez a kép a nyomógomb jobb oldalán meg is jelenik.
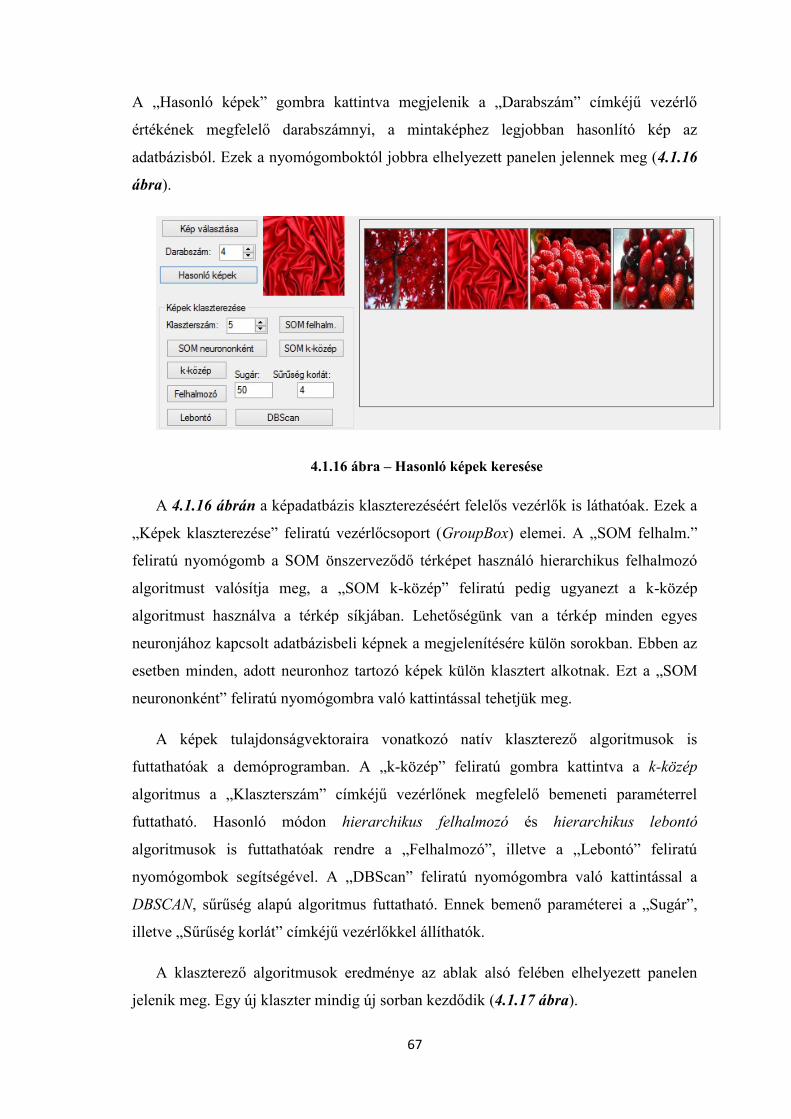
67
A „Hasonló képek” gombra kattintva megjelenik a „Darabszám” címkéjű vezérlő
értékének megfelelő darabszámnyi, a mintaképhez legjobban hasonlító kép az
adatbázisból. Ezek a nyomógomboktól jobbra elhelyezett panelen jelennek meg (4.1.16
ábra).
4.1.16 ábra – Hasonló képek keresése
A 4.1.16 ábrán a képadatbázis klaszterezéséért felelős vezérlők is láthatóak. Ezek a
„Képek klaszterezése” feliratú vezérlőcsoport (GroupBox) elemei. A „SOM felhalm.”
feliratú nyomógomb a SOM önszerveződő térképet használó hierarchikus felhalmozó
algoritmust valósítja meg, a „SOM k-közép” feliratú pedig ugyanezt a k-közép
algoritmust használva a térkép síkjában. Lehetőségünk van a térkép minden egyes
neuronjához kapcsolt adatbázisbeli képnek a megjelenítésére külön sorokban. Ebben az
esetben minden, adott neuronhoz tartozó képek külön klasztert alkotnak. Ezt a „SOM
neurononként” feliratú nyomógombra való kattintással tehetjük meg.
A képek tulajdonságvektoraira vonatkozó natív klaszterező algoritmusok is
futtathatóak a demóprogramban. A „k-közép” feliratú gombra kattintva a k-közép
algoritmus a „Klaszterszám” címkéjű vezérlőnek megfelelő bemeneti paraméterrel
futtatható. Hasonló módon hierarchikus felhalmozó és hierarchikus lebontó
algoritmusok is futtathatóak rendre a „Felhalmozó”, illetve a „Lebontó” feliratú
nyomógombok segítségével. A „DBScan” feliratú nyomógombra való kattintással a
DBSCAN, sűrűség alapú algoritmus futtatható. Ennek bemenő paraméterei a „Sugár”,
illetve „Sűrűség korlát” címkéjű vezérlőkkel állíthatók.
A klaszterező algoritmusok eredménye az ablak alsó felében elhelyezett panelen
jelenik meg. Egy új klaszter mindig új sorban kezdődik (4.1.17 ábra).

68
4.1.17 ábra – Klaszterezés eredménye
4.2 Megvalósítás
A demóprogramot C# nyelven, a .NET keretrendszer támogatásával valósítottuk
meg, Windows Forms könyvtárszerkezeten alapuló klienstechnológia segítségével. Az
implementáció során igyekeztünk minél jobban kihasználni a C# programozási nyelv
fejlett nyelvi elemeit, valamint törekedtünk a kód minél könnyebb átláthatóságának
fenntartására. Ennek érdekében magyarázatokkal, megfelelő tördelésekkel segítettük a
kód egyszerűbb megértését és olvashatóságát.
A megvalósítás során szükségünk volt a ZedGraph[16] nevű, nyílt forráskódú
könyvtárra, mely egy, különböző grafikonok megjelenítését támogató könyvtár. Ennek
segítségével rajzoltuk ki síkbeli koordinátarendszerbe az adatpontjainkat. A ZedGraph
könyvtár az LGPL (Lesser General Public Licence) jogvédelem alatt áll.
[16] http://sourceforge.net/projects/zedgraph/ - 2014.05.10

69
5 Irodalomjegyzék
[1] Iványi Antal (Szerk.): Informatikai algoritmusok 2. , ELTE Eötvös Kiadó Kft.,
Budapest 2005, [768], ISBN 9789634637752.
[2] Jiawei Han – Micheline Kamber: Adatbányászat koncepciók és technikák, Panem
Könyvkiadó Kft., 2004, [532], ISBN 9789635453948.
[3] Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu: "A density-based
algorithm for discovering clusters in large spatial databases with noise",
Proceedings of the Second International Conference on Knowledge Discovery and
Data Mining (KDD-96). AAAI Press. pp. 226–231. ISBN 1-57735-004-9, 1996.
[4] Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, Jörg Sander: "OPTICS:
Ordering Points To Identify the Clustering Structure". ACM SIGMOD international
conference on Management of data. ACM Press. pp. 49–60, 1999.
[5] Hinneburg A., Keim D.: “An Efficient Approach to Clustering in Large Multimedia
Databases with Noise”, Proc. 4th Int. Conf. on Knowledge Discovery & Data
Mining, New, York City, NY, 1998.
[6] Aidong Zhang, University at Buffalo, The State University of New York,
http://www.cse.buffalo.edu/faculty/azhang/cse601/, 2014.05.10
[7] Erich Schikuta: „Grid-Clustering: A Fast Hierarchical Clustering Method for Very
Large Data Sets”, Center for Research on Parallel Computation, Proceedings of the
13th International Conference on Pattern Recognition Volume IV, Track D: Parallel
and Connectionist Systems: 101-105 vol 2. DOI: 10.1109/ICPR.1996.546732,
1993.
[8] K.H. Hinrichs: The grid file system: implementation and case studies of
applications, Diss, ETH Nr. 7734, Zurich, 1985.
[9] H. Hromada: The GRIDCLUS data analysis system, diploma thesis Univ. Vienna,
Vienna, 1989.
[10] Horváth Gábor: Neurális hálózatok, Hungarian Edition Panem Könyvkiadó Kft.,
Budapest 2006, [447], ISBN 963545464-3.

70
[11] Kohonen, T.: The self-organizing map, Helsinki University of Technology, Espoo
Sep, ISSN: 0018-9219, Digital Object Identifier: 10.1109/5.58325, 1990.
[12] Kohonen, T.: Self-organized formation of topologically correct feature maps,
Biological Cybernetics, 43:59-69, 1982.
[13] Kohonen, T.: Self-Organizing Maps, Third, extended edition, Springer, 2001.
[14] Kohonen, T., Kaski, S. and Lappalainen, H.: Self-organized formation of various
invariant-feature filters in the adaptive-subspace SOM, Neural Computation, 9:
1321-1344, 1997.
[15] Kaski, S., Kangas, J., and Kohonen, T.: Bibliography of self-organizing map (SOM)
papers: 1981-1997. Neural Computing Surveys, 1: 102-350, 1998.







![numerikus analízis[2]](https://img.pdfslide.net/doc/110x75/577dace61a28ab223f8e7ed3/numerikus-analizis2.jpg)





















