Embed Size (px)
Citation preview

SVEUČILIŠTE U ZAGREBUFAKULTET ORGANIZACIJE I INFORMATIKE
V A R A Ž D I N
Mario Peroković
KNUTH – MORRIS – PRATTOV ALGORITAM
SEMINARSKI RAD
Varaždin, 2012.

SVEUČILIŠTE U ZAGREBUFAKULTET ORGANIZACIJE I INFORMATIKE
V A R A Ž D I N
Mario Peroković
Redoviti student
Broj indeksa: 38130/09-R.
Smjer: Informacijski sustavi
Preddiplomski studij
KNUTH – MORRIS – PRATTOV ALGORITAM
SEMINARSKI RAD
Mentor:
Prof. dr. sc. Alen Lovrenčić
Varaždin, siječanj 2012.

Sadržaj
1. UVOD.........................................................................................................................................1
2. BRUTE FORCE ALGORITAM ZA PRETRAŽIVANJE STRINGOVA............................2
3. KNUTH – MORRIS – PRATTOV ALGORITAM................................................................4
3.1. OPIS PROBLEMA....................................................................................................................43.2. SLOŽENOST...........................................................................................................................93.3. IMPLEMENTACIJA..................................................................................................................93.4. POBOLJŠANJE......................................................................................................................11
4. ZAKLJUČAK..........................................................................................................................14
5. LITERATURA.........................................................................................................................15
I

1. Uvod
Knuth – Morris – Prattov algoritam je iz područja pretraživanja/uspoređivanja stringova. To je
vrlo bitno područje za gotovo svakog korisnika računala. Svaki korisnik piše ili uređuje tekst,
organizira tekst u odlomke te vrlo često pretražuje neki tekst ili uzorak teksta s ciljem pronalaska
informacija koje su vezane uz taj uzorak teksta. Ovdje se nameče logički zaključak, a to je da što
je uzorak teksta koji želimo pronaći veći, to algoritam za pronalazak istog mora biti efikasniji.
Takav algoritam se najčešće ne može osloniti samo na abecedni poredak riječi, što bi bio slučaj s
riječnicima. Primjerice1, u molekularnoj biologiji algoritam pretraživanja stringova je vrlo bitan.
Tamo se izvade informacije iz DNK sekvenci te se tada traže neki uzorci u njima i uspoređuju se
sekvence. Takav proces mora biti obavljan često pod pretpostavkom da se ne može očekivati
kompletno podudaranje.
U nastavku rada ću u poglavlju 2 spomenuti nešto o brute force algoritmu za pretraživanje
stringova, dok ću dalje, u poglavlju 3 opisati algoritam iz naslova rada.
Što se tiće oznaka koje ću koristiti, za uzorak teksta ću koristiti P (pattern), za tekst T. |T|
označava duljinu teksta, dok je Tj znak na poziciji j u tekstu T(i..j).
1 Drozdek, A., Data structure and algorithms in C++, Course Technology, Boston, 2004. str 644
1

2. Brute force algoritam za pretraživanje stringova
Laički rečeno, brute force algoritam za pretraživanje stringova bi išao po nizu u kojem se
pretražuje od prvog elementa niza i prvog elementa uzorka. Ukoliko bi se naišlo na promašaj,
pomaknuli bi se za jedno mjesto udesno u nizu u kojem tražimo i nastavili sve dok se ne pronađe
odgovarajući uzorak koji se traži ili došli do kraja niza.
Takav algoritam smo obrađivali i na vježbama pod temom brute force te je algoritam izgledao
ovako2:
ALGORITAM StringMatching(T[0...n - 1], P[0...m - 1])//Implementacija pronalaska stringa//Ulaz: Niz T[0...n-1] tekst i P[0...m-1] string //Izlaz: Indeks gdje se string nalazi ili -1 for i ← 0 to n - m do
j ← 0 while j < m and P[j] = T[i + j] do
j ← j + 1if j = m return i
return -1
Dakle, u prvoj petlji krećemo od početnog znaka niza T, te idemo do n – m iz razloga što,
ukoliko nismo pronašli uzorak u nizu, a ostalo nam je manje znakova niza za pretražiti nego što
ima uzorak znakova, moramo stati.
Isti program sam implementirao u programskom jeziku C++ te prikazujem kod:
#include <iostream>#include <string>using namespace std;
int bruteforce(char niz[], char uzorak[]){ int n = strlen(niz); int m = strlen(uzorak); for(int i = 0; i <= n-m; i++){ int j = 0; while(j<m && uzorak[j]==niz[i+j]) j++; if (j == m) return i; } return -1;}int main(){ char niz[50], uzorak[50]; int rez;
2 MK_-_Algoritmi.ppt, materijali za vježbe
2

cout << "Unesite tekst: "; cin.getline(niz, sizeof(niz)); cout << "Unesite uzorak koji zelite pretraziti: "; cin.getline(uzorak, sizeof(uzorak)); rez = bruteforce(niz, uzorak); if(rez != -1) cout << "Indeks na kojem se nalazi prvo slovo podudarajuceg uzorka: " << rez; else cout << „Podudaranje nije pronadjeno!“; cout << endl << endl; system("pause"); return 0;}
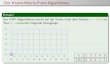
Rezultat za tekst algoritmi, a uzorak gori se nalazi na slici 1.
Slika 1: Rezultat brute force programa za pretraživanje stringova
Ovaj algoritam u najgorem slučaju će morati napraviti svih m (m je duljina uzorka) usporedbi
prije nego pomakne uzorak za 1. Sve to se može dogoditi za svaki od n – m koraka. Upravo radi
toga, u najgorem slučaju Θ(nm).
3

3. Knuth – Morris – Prattov algoritam
Brute force algoritam za pretraživanje stringova je neučinkovit zbog toga što se uzorak pomiće
za jednu poziciju nakon što dođe do promašaja. Za što učinkovitiji algoritam potrebno je da se
uzorak pomakne za što je moguće više pozicija u desno, ali tako da se potencijalni pronalazak
rješenje ne preskoči.
3.1. Opis problema
Srž problema neučinkovitosti brute force algoritma je u tome što taj algoritam provodi
redundantna uspoređivanja. Ta redundancija se može izbjeći promatrajući da uzorak sadrži
identične podnizove na početku uzorka i prije znaka koji se ne podudara. Pojasnit ću na primjeru3
(T označava tekst, a P označava uzorak koji tražimo):
i ↓
ababcdabbabababad <- T1 abababa <- P ↑ j
Nakon promašaja, proces se nastavlja:
i ↓
ababcdabbabababad2 abababa ↑ j
Prvi promašaj se pojavljuje na petom znaku, no do tada prefiksi ab uzorka P i podniza P(2..3),
koji je također ab su uspješno uspoređeni. Uzorak P se sada može pomaknuti desno tako da svoj
podniz ab poravna sa podnizom teksta T(2..3) te proces uspoređivanja sada može krenuti sa
znakom P2 i T4. Zbog toga što se znakovi u podnizu P(2..3) podudaraju s T(2..3) to je kao da se
znakovi P(0..1) podudaraju s T(2..3). Uzevši to u obzir, dvije redundantne usporedbe se mogu
preskočiti, te je rezultat vidljiv u liniji 2.
Da bi mogli izvesti ovakvo pomicanje uzorka potrebno je utvrditi da se prefiks uzorka P
podudara s sufiksom P(0..j), gdje je Pj+1 znak koji se ne podudara. Podudarajući prefiks bi trebao
biti što duži, tako da potencijalno rješenje problema ne bude prijeđeno kada se pomakne uzorak
P.
3 Drozdek, A., Data structure and algorithms in C++, Course Technology, Boston, 2004. str 648
4

Sljedeće što se radi je definiranje polja next. Next može poprimiti sljedeće vrijednosti:
next [ j ]={ −1 za j=0max {k :0<k< j i P [ 0. . k−1 ]=P [ j−k .. j−1 ] ako postoji takav k }
0 inače
Broj next[j] označava duljinu najdužeg sufiksa podniza P(0..j-1) koji je jednak prefiksu istog
podniza.
j-next[j] j-1 ↓ ↓
a..bc...da..be ↑ ↑ 0 next[j]
Uvjet k < j označava da je prefiks također pravilan sufiks. Bez tog uvjeta bi next[2] za P(0..2) =
aab bio 2, zbog toga što je dio aa u isto vrijeme i prefiks i sufiks od aa, no s uvjetom k < j
next[2] = 1, a ne 2.
Primjer, P = abababa
U a b a b a b a
j 0 1 2 3 4 5 6
next[j] -1 0 0 1 2 3 4
Primjetimo da zbog uvjeta da sufiks koji se podudara mora biti najduži mogući, next[5] = 3, za U(1..6) = ababab zato što je aba najduži sufiks od ababa koji se podudara s prefiksom, a nije 1 iako je a također prefiks i sufiks od ababa, ali je aba duži i sastoji se od 3 znaka pa je zato next[5] = 3.
Knuth – Morris – Prattov algoritam je sličan brute force algoritmu za pretraživanje stringova.4
ALGORITAM KnuthMorrisPratt(pattern P, text T)findNext(P, next);i = j = 0;while i ≤ |T| - |P|
while j == -1 or j < |P| and Ti == Pj
i++; //i se povećava samo za pogođene znakovej++;
if j == |P|return a match at i - |P|
j = next[j] //u slučaju promašaja, i se ne mijenjareturn no match;
Funkcija findNext() postoji kako bi se utvrdilo polje next te ću je definirati nešto kasnije.
4 Drozdek, A., Data structure and algorithms in C++, Course Technology, Boston, 2004. str 649
5

Primjerice, za uzorak teksta P = abababa, tekst T = ababcdabbabababad, polje next će
sadržavati vrijednosti: {-1, 0, 0, 1, 2, 3, 4}.5
ababcdabbabababad
1 abababa
2 abababa
3 abababa
4 abababa
5 abababa
6 abababa
7 abababa
Dijagram prikazuje za next[j] = -1 da bi se cijeli uzorak P trebao pomaknuti tako da se prođe
promašeni znak. Glavna razlika između brute force algoritma za pretraživanje stringova i Knuth
– Morris – Prattovog algoritma je ta da se kod Knuth – Morris – Prattovog i nikad ne smanjuje.
U slučaju „pogotka“ znaka i se povećava, a u slučaju promašaja i zadržava vrijednost koju je
imao i prije tako da se promašeni znak u tekstu T može usporediti sa drugim znakom u uzorku P
u sljedećoj iteraciji vanjske while petlje. Jedini slučaj kada se i povećava u slučaju promašenog
znaka je kada se prvi znak uzorka P promaši. Nakon što se utvrdi promašaj na poziciji j ≠ 0 u
uzorku P, tada se P pomiče za j – next[j] pozicija. Ukoliko se promašaj dogodi na prvom znaku
uzorka P tada se uzorak pomiče za jednu poziciju.
Za procjenu složenosti, vidimo da se vanjska while petlja izvršava O(|T|) puta. Unutarnja while
petlja se može izvršiti maksimalno |T| - |P| puta iz razloga što se i povećava u svakoj iteraciji
petlje, a zbog uvjeta vanjske petlje |T| - |P| je maksimalna vrijednost varijable i.
Polje next sadrži duljine najvećih sufiksa koji se podudaraju s prefiksima od P, a to je da dijelovi
P odgovaraju drugim dijelovima uzorka P. Problem uspoređivanja je riješen s Knuth – Morris –
Prattovim algoritmom, jedino u ovom slučaju je uzorak P uspješno uspoređen sam sa sobom. No,
isti algoritam koristi polje next te mora biti promijenjen tako da određuje vrijednosti polja next
koristeći vrijednosti koje je već pronašao. Dakle, kao što je već ranije u definiciji polja next
navedeno, next[0] = -1. Dalje pretpostavimo da su vrijednosti next[0],..., next[i] određene te da
želimo pronaći vrijednost next[i]. Postoje dva slučaja koji se moraju uzeti u obzir.
5 Drozdek, A., Data structure and algorithms in C++, Course Technology, Boston, 2004. str 649
6

U prvom slučaju, najduži sufiks koji se podudara s prefiksom se može pronaći jednostavno,
prilijepiti znak Pi-1 u sufiks koji odgovara poziciji next[i-1], što je točno kada je Pi-1 = Pnext[i-1].
7

a..bc.....................da..bc...
↑ ↑
next[i-1]-1 i-1
↓↓ next[i] = next[i-1]+1
a..bc.....................da..bc...
↑ ↑
next[i-1] i
U ovom slučaju, trenutni sufiks je duži za jedan znak od sufiksa koji je prethodno pronađen, tako
da next[i] = next[i-1]+1.
Što se tiče drugog slučaja, Pi-1 ≠ Pnext[i-1]. Očito je da je ovo promašaj, a promašaji se rješavaju
pomoći polja next. Iz razloga što je Pnext[i-1] promašeni znak treba se provjeriti da li Pi-1 odgovara
Pnext[next[i-1]]. To možemo napraviti tako da pogledamo u next[next[i-1]]. Ukoliko se znakovi
podudaraju u next[i] upisujemo next[next[i-1]]+1.
a..bc..da..be..............fa..bc..da..bc...
↑ ↑
next[i-1]-1 i-1
↓↓ next[i] = next[next[i-1]]+1
a..bc..da..be..............fa..bc..da..bc...
↑ ↑
next[next[i-1]] i
U dijagramu prvi prefiks a..bc..da..b uzorka P(0..i-1) ima prefiks a..b koji je identičan sufiksu.
Razlog zbog kojega je a..b i prefiks i sufiks od a..bc..da..b je u tome što prefiks P(0...j-1) =
a..bc..da..b uzorka P(0...i-1) označenog sa next[i-1] je, prema definiciji, jednak sufiksu P(i-j-
1...i-2) što znači da je sufiks P(j-next[j]...j-1) = a..b također sufiks i od P(i-j-1...i-2).
Dakle, za određivanje vrijednosti next[i] koristimo već određeni vrijednost next[j] koja označava
duljinu kraćeg sufiksa od P(0...j-1) koji se podudara s prefiksom od P.
Algoritam za pronalazak polja next nalazi se na sljedećoj stranici.6
6 Drozdek, A., Data structure and algorithms in C++, Course Technology, Boston, 2004. str 652
8

ALGORITAM findNext(pattern P, table next)next[0] = -1;i = 0;j = -1;while i < |P|
while j == 0 or i < |P| and Pi == Pj
i++;j++;next[i] = j;
j = next[j];
U tablici 1 se nalazi primjer pronalaska next za uzorak P = ababacdd.7
i j next[] P
→ 0 -1 -1 ababacdd
1 0 -1 0 ababacdd
→ 1 -1 -1 0
2 0 -1 0 0 ababacdd
3 1 -1 0 0 1 ababacdd
4 2 -1 0 0 1 2 ababacdd
5 3 -1 0 0 1 2 3 ababacdd
→ 5 1 -1 0 0 1 2 3 ababacdd
→ 5 0 -1 0 0 1 2 3 ababacdd
→ 5 -1 -1 0 0 1 2 3
6 0 -1 0 0 1 2 3 0 ababacdd
→ 6 -1 -1 0 0 1 2 3 0
7 0 -1 0 0 1 2 3 0 0 ababacdd
→ 7 -1 -1 0 0 1 2 3 0 0
8 0 -1 0 0 1 2 3 0 0
Tabela 1: Primjer pronalaska vrijednosti polja next
Vrijednosti varijabli i i j te polje next su označeni strelicom prema desno prije ulaska u unutarnju
while petlju. Ostale linije prikazuju te vrijednosti na kraju unutarnje petlje te usporedbu koja im
7 Drozdek, A., Data structure and algorithms in C++, Course Technology, Boston, 2004. str 652
9

slijedi. Primjerice, u liniji 2, nakon povećavanja i na 1 te j na 0, 0 je dodana u next[1] te tada prvi
i drugi znak uzorka P bivaju uspoređivani što vodi izlasku iz petlje.
3.2. Složenost
Zbog sličnosti ovog algoritma s KnuthMorrisPratt() algoritmom, može se doći do
zaključka da se do polja next može doći u O(|P|) vremenu. Vanjska petlja u
KnuthMorrisPratt() se izvršava u O(|T|) vremenu, tako da se Knuth – Morris – Prattov
algoritam, uključujući i findNext() izvršava u O(|T| + |P|) vremenu.
Nisam spominjao u ovom opisu složenosti abecedni poredak teksta T i uzorka P iz razloga što
Knuth – Morris – Prattov algoritam jednako dobro radi bez obzira na broj različitih znakova u
tekstu i uzorku.
3.3. Implementacija
U programskom jeziku C++ sam implementirao algoritam.
#include <iostream>
#include <string>
using namespace std;
void findNext(char *uzorak, int next[], int m){
int i = 1, j = 0;
next[0] = -1;
next[1] = 0;
while (i < m){
while((j==0) || (i<m) && (uzorak[i]==uzorak[j])){
i++;
j++;
next[i] = j;
}
j = next[j];
}
}
10

int KMP(char niz[], char uzorak[]){
int n = strlen(niz);
int m = strlen(uzorak);
int next[m];
findNext(uzorak, next, m);
int i = 0, j = 0;
while(i <= (n-m)){
while((j==-1) || (j<m) && (niz[i]==uzorak[j])){
i++;
j++;
}
if(j==m) return (i-m);
j = next[j];
}
return -1;
}
int main(){
int rez;
char niz[50], uzorak[50];
cout << "Unesite tekst: ";
cin.getline(niz, sizeof(niz));
cout << "Unesite uzorak koji zelite pretraziti: ";
cin.getline(uzorak, sizeof(uzorak));
rez = KMP(niz,uzorak);
if(rez != -1) cout << "Indeks na kojem se nalazi prvo slovo podudarajuceg uzorka: " << rez;
else cout << "Podudaranje nije pronadjeno!";
cout << endl << endl;
system("pause");
return 0;
}
11

Na slici 2 se nalazi primjer izvršavanja programa, za primjer teksta: sveuciliste u zagrebu, a
uzorak: grebu.
Slika 2: Primjer izvršavanja Knuth – Morris – Prattovog algoritma
3.4. Poboljšanje
Knuth – Morris – Prattov algoritam se može poboljšati eliminiranjem bezizglednih rješenja.
Ukoliko se promašaj dogodi za znakove Ti i Pj, tada se uspoređuje isti znak Ti i znak Pnext[j]+1. No,
ukoliko je Pj = Pnext[j]+1 tada se opet događa isti promašaj što zapravo znači da smo radili
redundantnu usporedbu. Ukoliko imamo P = abababa, T = ababcdabbabababad te next = {-1, 0,
0, 1, 2, 3, 4} te algoritam kreće s:
ababcdabbabababad
1 abababa
2 abababa
Prvi promašaj se pojavljuje za a na petoj poziciji uzorka P te za c u tekstu T. Polje next označava
da u slučaju promašaja na petom znaku uzorka, sam uzorak bi se trebao pomaknuti za dvije
pozicije desno zbog toga što je 4 – next[4] = 2. To znači da se prefiks uzorka P koji sadrži dva
znaka pomiće sa sufiksom uzorka P(0..3) koji također sadrži dva znaka. No, to znači da će se
sada uspoređivati c koji je upravo uzrokovao promašaj te a s treće pozicije uzorka. To je
usporedba koja se već dogodila u prvom koraku gdje se a s pete pozicije uzorka uspoređivao sa
c. Da smo znali da nakon prefiksa ab uzorka P opet slijedi znak a, tada bi se drugo uspoređivanje
12

moglo izbjeći. Za postizanje toga je potrebno polje next promijeniti tako da ono isključuje
redundantne usporedbe. Slijedi definicija „jačeg“ polja next:8
nextS [ j ]={ −1 za j=0max {k :0<k< j i P [ 0.. k−1 ]=P [ j−k .. j−1 ] i Pk+1≠ P jako postoji takav k }
0 inače
8 Drozdek, A., Data structure and algorithms in C++, Course Technology, Boston, 2004. str 653
13

Za određivanje nextS koristi se slijedeći algoritam:
ALGORITAM findNextS(pattern P, table next)next[0] = -1;i = 0;j = -1;while i < |P|
while j == -1 or i < |P| and Pi == Pj
i++;j++;if Pi ≠ Pj
nextS[i] = j;else nextS[i] = nextS[j];
j = next[j];
Ukoliko su znakovi Pi ≠ Pj tada je očito da su next[i] i nextS[i] jednaki. Ukoliko su pak znakovi
Pi i Pj jednaki,
a..bc..da..be..............fa..bc..da..be...
↑ ↑ ↑
j i-j i
tada je poduvjet prekršen, stoga je nextS[i] < next[i] i situacija je sljedeća:
a..bc..da..be..fa.......bc..da..be...
↑ ↑ ↑ ↑
j-nextS[j] j i-nextS[i] i
Podcrtani podnizovi su pravi prefiks i sufiks uzorka P(0...i-1) označen sa nextS[i] koji je kraći od
next[i]. No, prefiks P(0...j-1) = a..bc..da..b uzorka P(...i-1) označenog sa next[i] je prema
definiciji jednak sufiksu P(i – j...i – 1) što znači da je sufiks P(j – nextS[j]...j – 1) = a...b. Dakle,
za određivanje vrijednosti nextS[i] koristimo već određenu vrijednost nextS[j] koja označava
duljinu sufiksa P(0...j – 1).
Primjerice, kada se obrađuje pozicija 11 u uzorku
P = abcabdabcabdfabcabdabcabd
nextS = .....2.....2.............
broj 2 je kopiran sa nextS[5] na nextS[11], a isto tako sa nextS[11] na nextS[24].
P = abcabdabcabdfabcabdabcabd
nextS = .....2.....2............2
14

15

Kada se u kompletni Knuth – Morris – Prattov algoritam uključi findNextS() tada
izvršavanje programa na primjeru P = abababa generira nextS = {-1, 0, -1, 0, -1, 0, -1}.
ababcdabbabababad
1 abababa
2 abababa
3 abababa
4 abababa
Ovu promjenu sam također implementirao u C++, uključivši funkciju findNextS().
void findNextS(char *uzorak, int nextS[], int m){
nextS[0] = -1;
int i = 0, j = -1;
while(i < m){
while((j == -1) || (i < m) && (uzorak[i] == uzorak[j])){
i++;
j++;
if(uzorak[i] == uzorak[j]) nextS[i] = nextS[j];
else nextS[i] = j;
}
j = nextS[j];
}
}
Na slici 3 se nalazi primjer izvršenja programa za primjer teksta: fakultet organizacije i
informatike, a uzorak za traženje: for.
16

Slika 3: Primjer izvršavanja programa koristeći findNextS()
17

4. Zaključak
U radu sam pokušao razjasniti na čemu se temelji Knuth – Morris – Prattov algoritam, a to bi se
nekako laički moglo reći da uzorak koji uspoređuje s tekstom nakon promašaj ne mora pomicati
za samo jedno mjesto udesno, nego za više. Takva operacija se postiže pomoću dodatnog polja
next, kao što sam objasnio u radu.
Kompletni algoritam se odvija u vremenu O(|T| + |P|) što je bolje od brute force pristupa koji u
najgorem slučaju može imati O(|T| * |P|).
Ovo je vrlo zanimljivo i bitno područje proučavanja algoritama zbog toga što se svakodnevno
koristi. Korisnici računala često pretražuju tekstualne dokumente i slično pa je bitno da ovakvi
algoritmi što efikasnije rade.
18

5. Literatura
1. Drozdek, A., Data structure and algorithms in C++, Course Technology, Boston, 2004.
2. MK_-_Algoritmi.ppt, materijali za vježbe asistenta Mladena Koneckog, dostupni na
moodle sustavu 14.01.2012.
19