Embed Size (px)
Citation preview

AI WEBINARDate/Time: Tuesday, June 9 | 9 am PST
Kubernetes & AIwith Run:AI, Red Hat & Excelero

Presenter:Omri Geller
CEO & Co-Founder
Your Host:Tom LeydenVP Marketing
AI WEBINAR
What’s next in technology and innovation?
Kubernetes & AIwith Run:AI, Red Hat & Excelero
Presenter:William Benton
Engineering Manager
Presenter:Gil Vitzinger
Software Developer
Presenter:Omri Geller
CEO & Co-Founder
Your Host:Tom LeydenVP Marketing
AI WEBINAR
What’s next in technology and innovation?
Kubernetes & AIwith Run:AI, Red Hat & Excelero
Presenter:William Benton
Engineering Manager
Presenter:Gil Vitzinger
Software Developer

Kubernetes for AI WorkloadsOmri Geller, CEO and co-founder, Run:AI

A Bit of History
2
Containers scale easily, they’re lightweight and efficient, they can run any workload, are flexible
and can be isolated…But they need orchestration
Bare Metal
Needed flexibility and better utilization
Virtual Machines
Reproducibility and portability
Containers

Track, Schedule and Operationalize
Enter Kubernetes
3
Execute Across Different
Hardware
Create Efficient Cluster
Utilization

Today, 60% of Those Who Deploy Containers Use K8s for Orchestration*
4
*CNCF

Now let’s talk about AI

6
Manual Engineering
Classical Machine Learning
Computing Power Fuels Development of AI
Deep Learning

7
Artificial Intelligence is a Completely Different Ballgame
Experimentation R&D
New accelerators
Distributed computing

Constant hassles
8
Data Science Workflows and Hardware Accelerators are Highly Coupled
Datascientists
Hardwareaccelerators
Workflow Limitations
Under-utilized GPUs

This Leads to Frustration on Both Sides
9
Data Scientists are frustrated – speed and
productivity are low
IT leaders are frustrated – GPU utilization is low

Container ecosystem for Data Science is growing
AI Workloads are Also Built on Containers
10
NGC – Nvidia pre-trained models for AI experimentation on docker containers
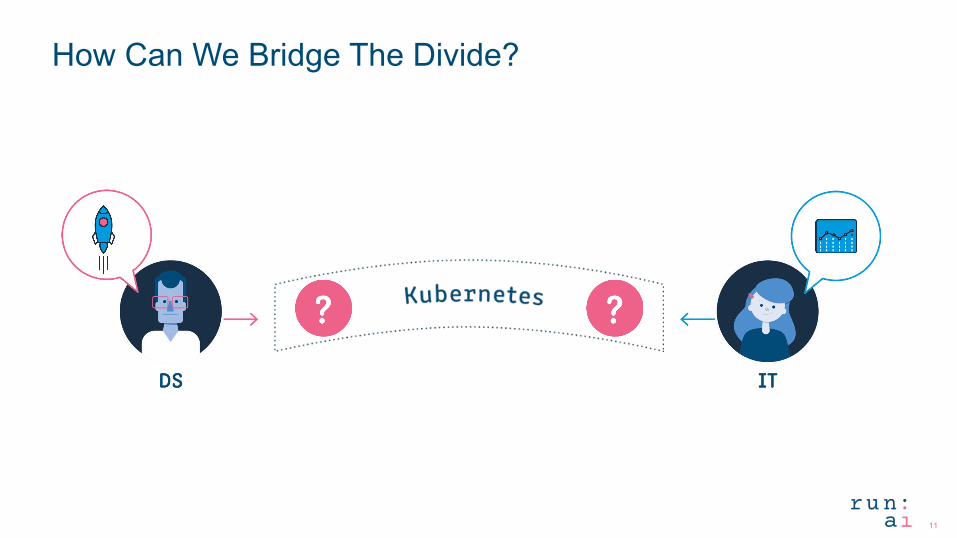
How Can We Bridge The Divide?
11

12
Kubernetes, the “De-facto” Standard for Container Orchestration
Multiple queues
Automatic queueing/de-queueing
Advanced priorities & policies
Advanced scheduling algorithms
Affinity-aware scheduling
Efficient management of distributed workloads
Lacks the following capabilities:

13
Build Training
How is Experimentation Different?

14
Build Training
Distinguishing Between Build and Training Workflows
• Development & debugging• Interactive sessions• Short cycles• Performance is less important• Low GPU utilization

15
Build Training
Distinguishing Between Build and Training Workflows
• Development & debugging• Interactive sessions• Short cycles• Performance is less important• Low GPU utilization
• Training & HPO• Remote execution• Long workloads• Throughput is highly important• High GPU utilization

16
Fixed quotas Guaranteed quotas
How to Solve? Guaranteed Quotas
• Fits build workloads• GPUs are always available
• Fits training workflows• Users can go over quota

17
Fixed quotas Guaranteed quotas
Solution: Guaranteed Quotas
• Fits build workloads• GPUs are always available
• Fits training workflows• Users can go over quota
• More concurrent experiments• More multi-GPU training

18
Queueing Management Mechanism

Run:AI - Stitching it All Together

Run:AI - Applying HPC Concepts to Kubernetes
20
With the advantages of K8s, plus some concepts from the world of HPC & distributed computing, we can bridge the gap
Data Science teams gain productivity
and speed
IT teams gain visibility and maximal GPU
utilization

21
Run:AI - Kubernetes-Based Abstraction Layer
INTEGRABLEEasily integrates with IT and Data Science platforms
MULTI-CLOUDRun on any public, private and hybrid cloud environment
IT GOVERNANCEPolicy based orchestration and queuing management

22
Run:AI
Utilize Kubernetes across IT to improve resource utilization
Speed up experimentation process and time to market
Easily scale infrastructure to meet needs of the business

From 28% to 73% utilization, 2X speed, and $1M savings
23
Challenge
28% AVERAGE GPU UTILIZATION -inefficient and underutilized resources
After implementing Run:AI’s platformSolution
73% AVERAGE GPU UTILIZATION• Enabled 2x more experiments to run• Saved $1M in additional GPU
expenditures for 2020

24
Run:AI at-a-Glance
Venture Funded
• Founded in 2018
• Backed by top VCs
• Offices in Tel Aviv, New York, and Boston
• Fortune 500 customers
• Top cloud and virtualization engineers

Thank you

NVMesh in Kubernetes

What is NVMesh CSI Driver
● What is NVMesh CSI Driver ?
○ CSI - Container Storage Interface
○ NVMesh as a storage backend in Kubernetes
● Main Features
○ Static Provisioning
○ Dynamic Provisioning
○ Block and File System volumes
○ Access Modes (ReadWriteOnce, ReadWriteMany, ReadOnlyMany)
○ Extend volumes
○ Using NVMesh VPGs
29
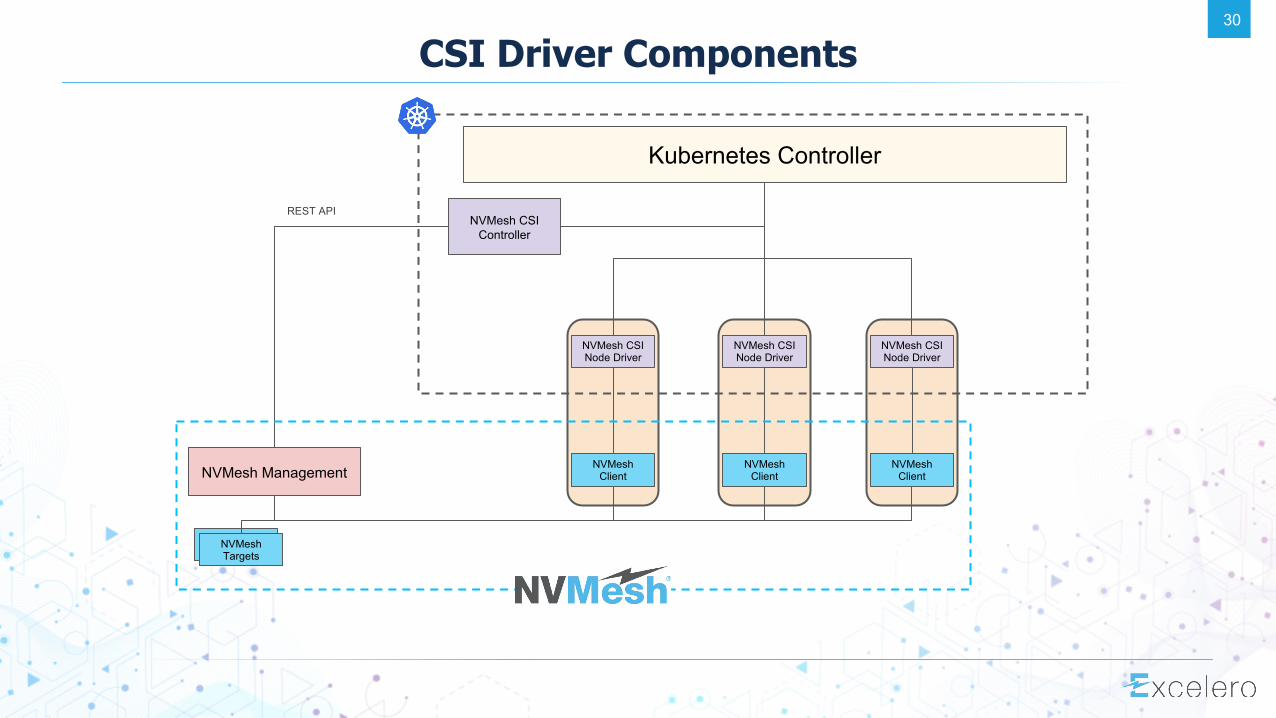
CSI Driver Components
NVMesh Management
NVMesh CSI Controller
Kubernetes Controller
NVMesh CSI Node Driver
NVMesh CSI Node Driver
NVMesh CSI Node Driver
NVMeshClient
NVMeshClient
NVMeshClient
NVMeshTargets
REST API
30

Dynamic Provisioning & Attach Flow
NVMesh CSI Controller
Kubernetes Controller
NVMesh Management
Create Volume
User creates a Persistent Volume Claim (PVC)
NVMeshTargets
31

Dynamic Provisioning & Attach Flow
NVMesh CSI Controller
Kubernetes Controller
NVMesh CSI Node Driver
NVMesh Client NVMesh Management
OS mount
User creates a POD that uses the PVC
Attach / Detach
User App PODs
/dev/nvmesh/v1
K8s internal mount
POD mount
Node
NVMeshTargets
Data
32
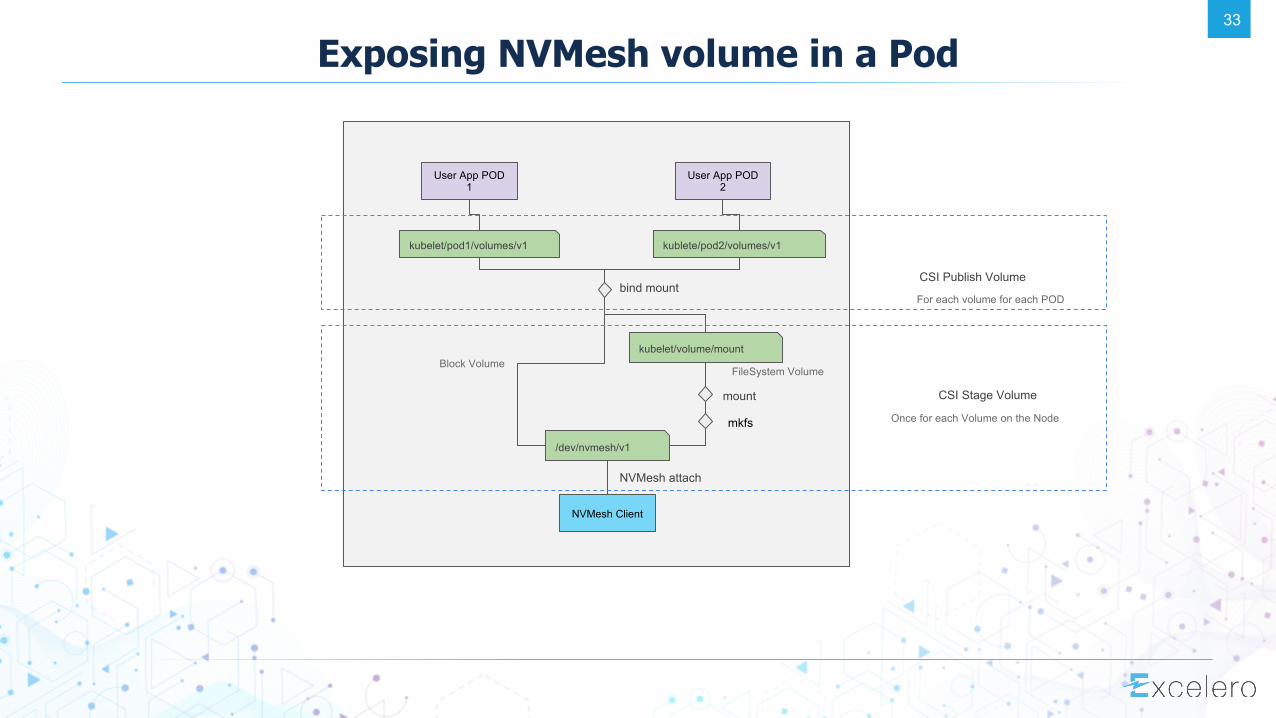
Exposing NVMesh volume in a Pod
kublete/pod2/volumes/v1
/dev/nvmesh/v1
User App POD 1
kubelet/volume/mount
kubelet/pod1/volumes/v1
User App POD 2
FileSystem Volume
mount
NVMesh Client
NVMesh attach
Block Volume
bind mount
mkfs
CSI Publish Volume
For each volume for each POD
CSI Stage Volume
Once for each Volume on the Node
33

Usage Examples
kind: PersistentVolumeClaimapiVersion: v1metadata:
name: block-pvcspec:
accessModes:- ReadWriteMany
volumeMode: Blockresources:requests:
storage: 15GistorageClassName: nvmesh-raid10
kind: StorageClassapiVersion: storage.k8s.io/v1metadata:
name: nvmesh-custom-vpgprovisioner: nvmesh-csi.excelero.comparameters:
vpg: your_custom_vpg
34

Summary
NVMesh Benefits for Kubernetes:
● Persistent storage that scales for stateful applications
● Predictable application performance – ensure that storage is not a bottleneck
● Scale your performance and capacity linearly
● Containers in a pod can access persistent storage presented to that pod, but with the freedom to restart the pod on an alternate physical node
● Choice of Kubernetes PVC access mode to match the storage to the application and file system requirements
35

William Benton Engineering Manager and Senior Principal Engineer Red Hat, Inc.
Machine learning discovery, workflows, and systems on Kubernetes

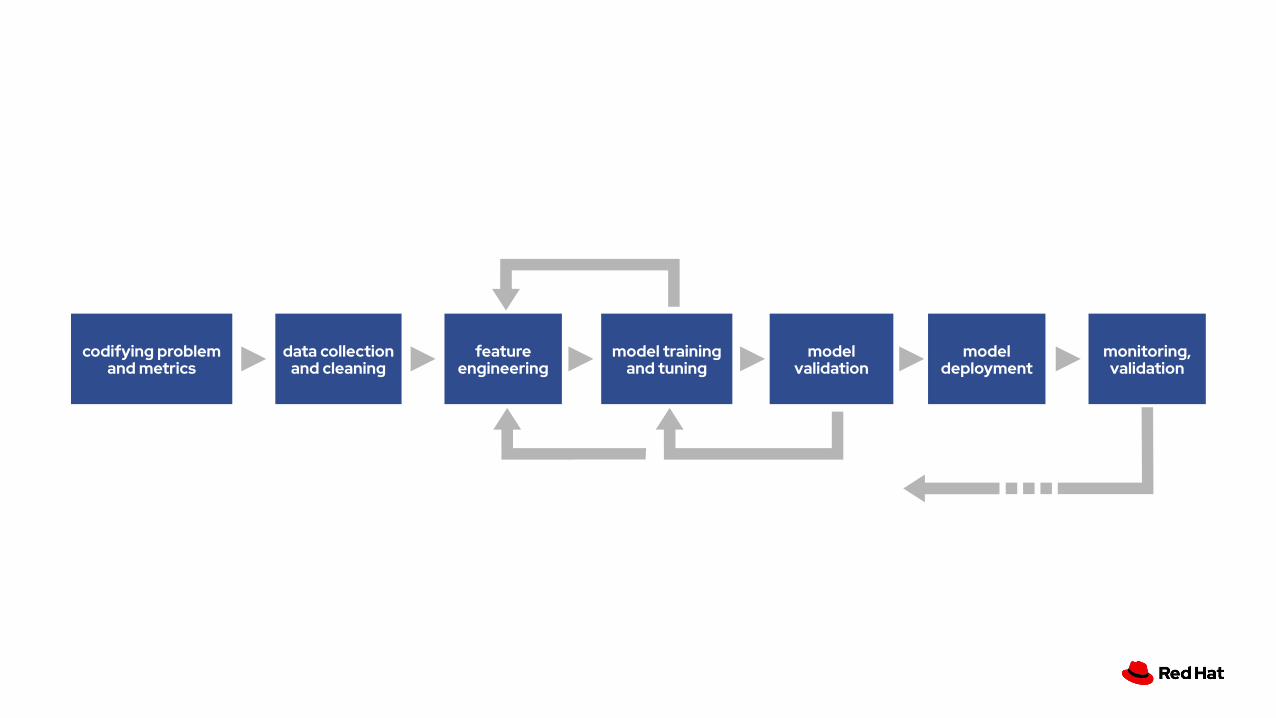
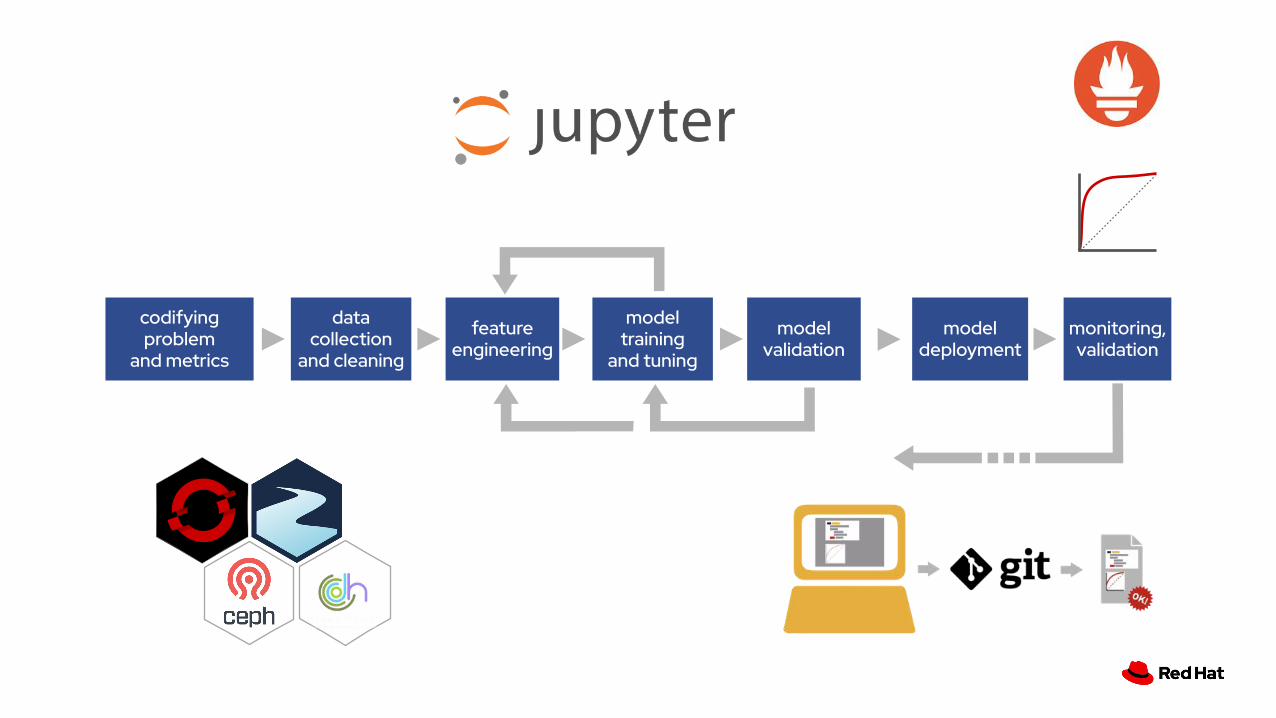
codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

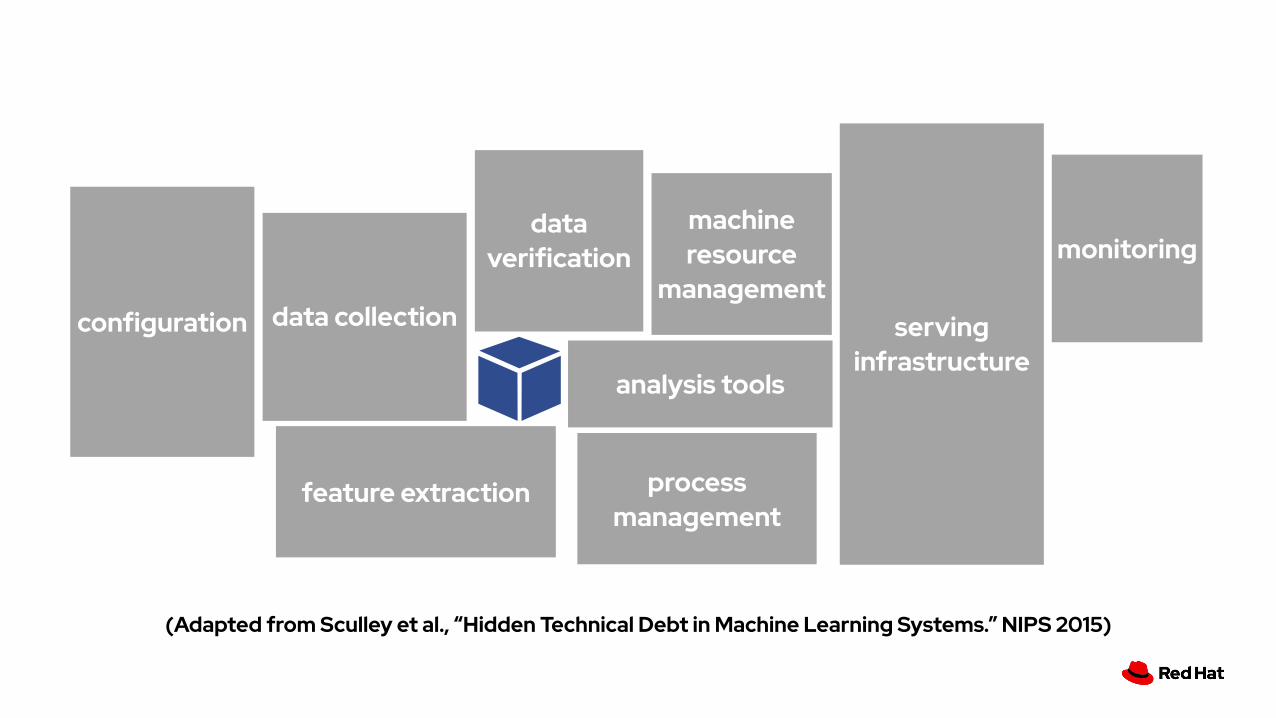
configuration data collection
feature extraction process management
analysis tools
monitoring
serving infrastructure
machine resource
management
data verification
(Adapted from Sculley et al., “Hidden Technical Debt in Machine Learning Systems.” NIPS 2015)
configuration data collection
feature extraction process management
analysis tools
monitoring
serving infrastructure
machine resource
management
data verification
(Adapted from Sculley et al., “Hidden Technical Debt in Machine Learning Systems.” NIPS 2015)
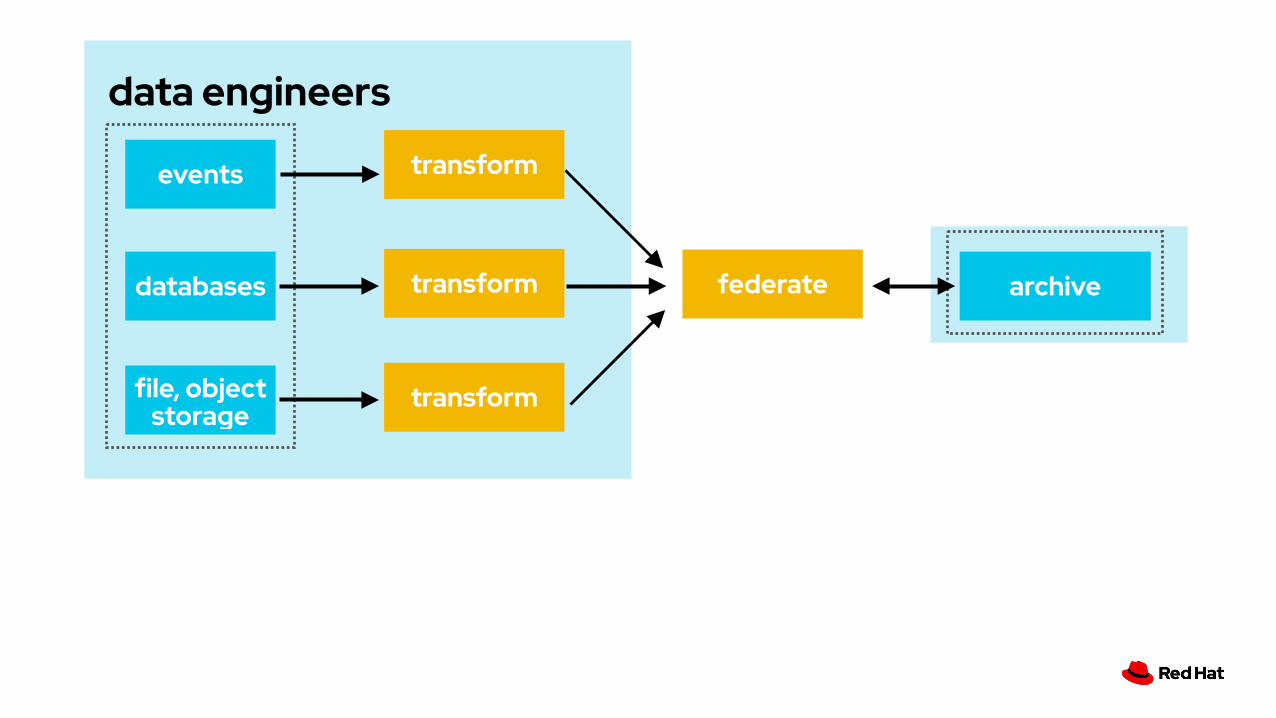
data engineers
federate
events
databases
file, object storage
transform
transform
transform
archive

data scientists
federate
trainmodels
events
databases
file, object storage
developer UItransform
transform
transform

application developers
models
events
databases
file, object storage
management
web and mobile
reporting
transform
transform
transform
archivefederate
train
developer UI
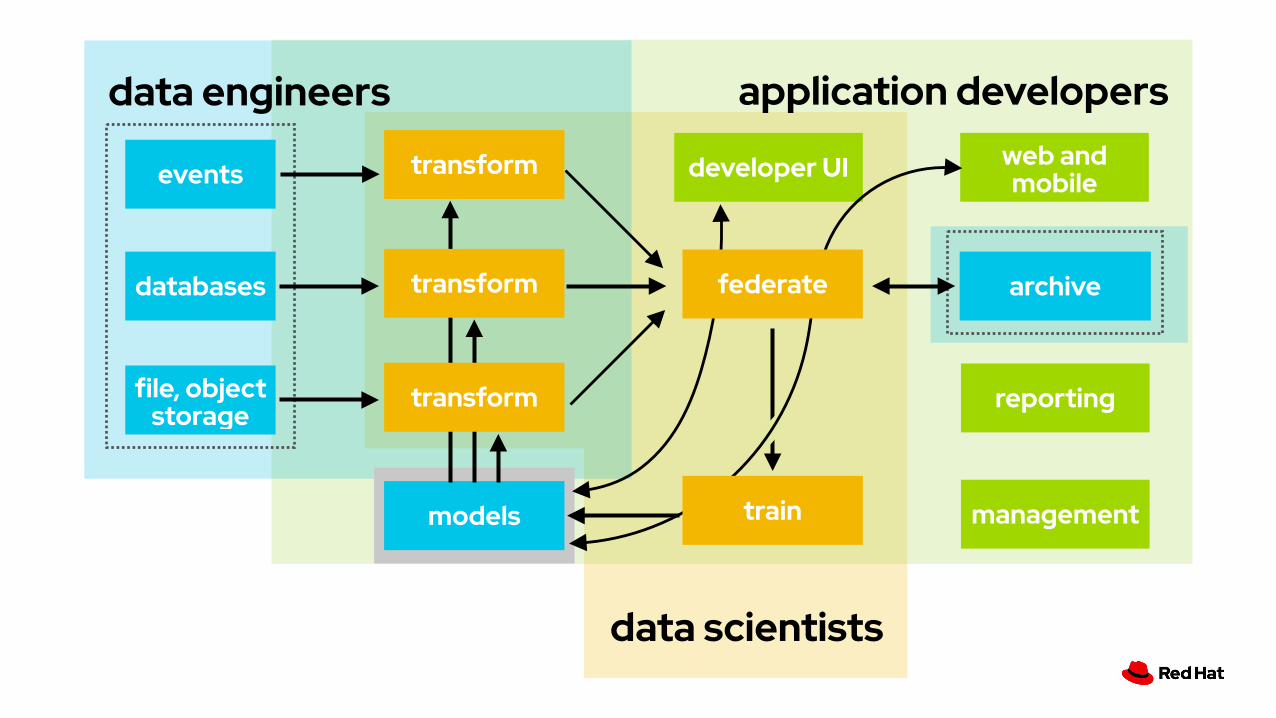
data scientists
application developersdata engineers
models
events
databases
file, object storage
management
web and mobile
reporting
developer UItransform
transform
transform
archive
train
federate
codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and cleaning
model deployment
monitoring, validation

How Kubernetes can help

Immutable images
base image
configuration and installation recipes
user application code
979229b9
33721112 e8cae4f6 2bb6ab16 a8296f7e
a6afd91e 6b8cad3e

Immutable images
base image
configuration and installation recipes
user application code
979229b9
33721112 e8cae4f6 2bb6ab16 a8296f7e
a6afd91e 6b8cad3e

Immutable images
base image
configuration and installation recipes
user application code
979229b9
33721112 e8cae4f6 2bb6ab16 a8296f7e
a6afd91e 6b8cad3e
model in production on 16 July 2019

Stateless microservices

Stateless microservices

Stateless microservices

Stateless microservices

Stateless microservices

Stateless microservices

Stateless microservices

Stateless microservices

Integration and deployment

Integration and deployment
OK!

Integration and deployment
OK!base image
configuration and installation recipes
application codeapplication code
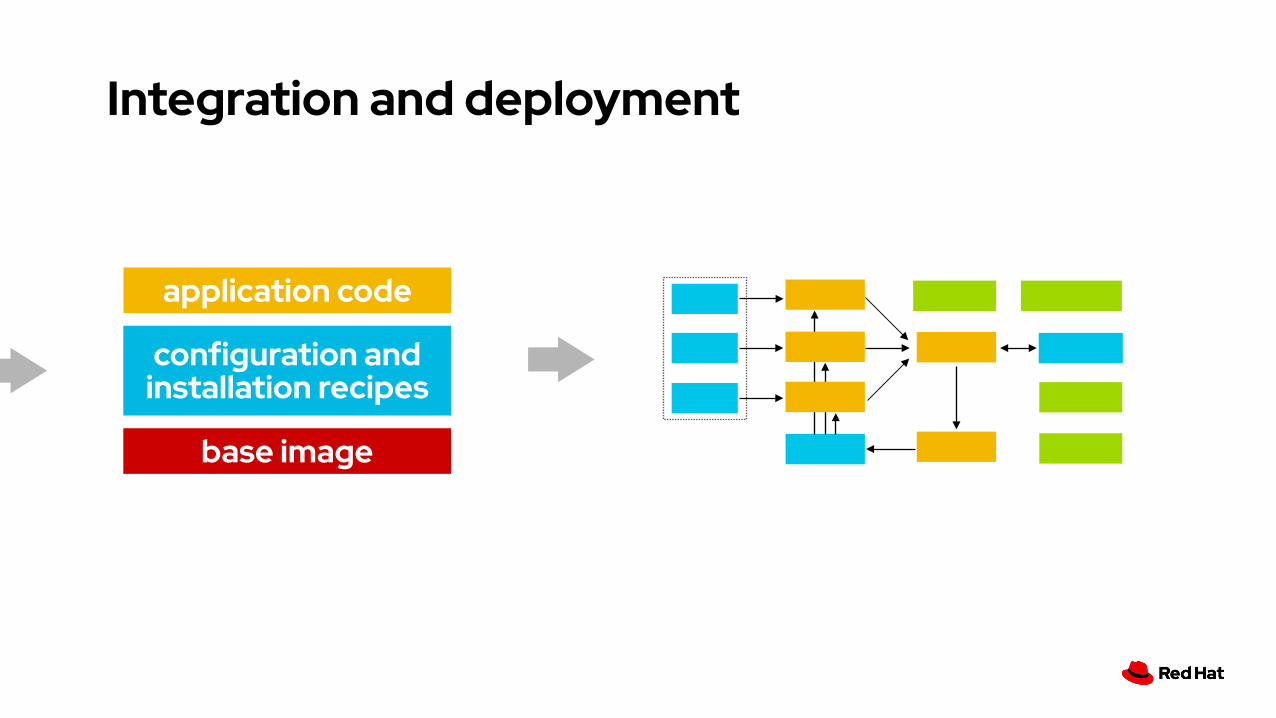
Integration and deployment
base image
configuration and installation recipes
application code

Data drift
Data drift

On-demand discovery with the Open Data Hub



0 0 0 1 1 0 1 0 1 0
0 0 1 0 0 0 1 1 0 0
1 0 1 1 0 1 0 0 0 0
0 0 0 0 0 0 1 1 0 1
0 1 0 0 1 0 0 1 0 0
1 0 0 0 0 1 0 1 1 0
0 0 1 0 1 0 1 0 0 0
0 1 0 0 0 1 0 0 1 1
0 0 0 0 1 0 0 1 0 1
1 1 0 0 0 0 0 0 0 1
0.13 0.13
0.06 0.07
0.07 0.06
0.02 0.08
0.17 0.11
0.11 0.09
0.04 0.18
0.13 0.04
0.13 0.21
0.14 0.03
*
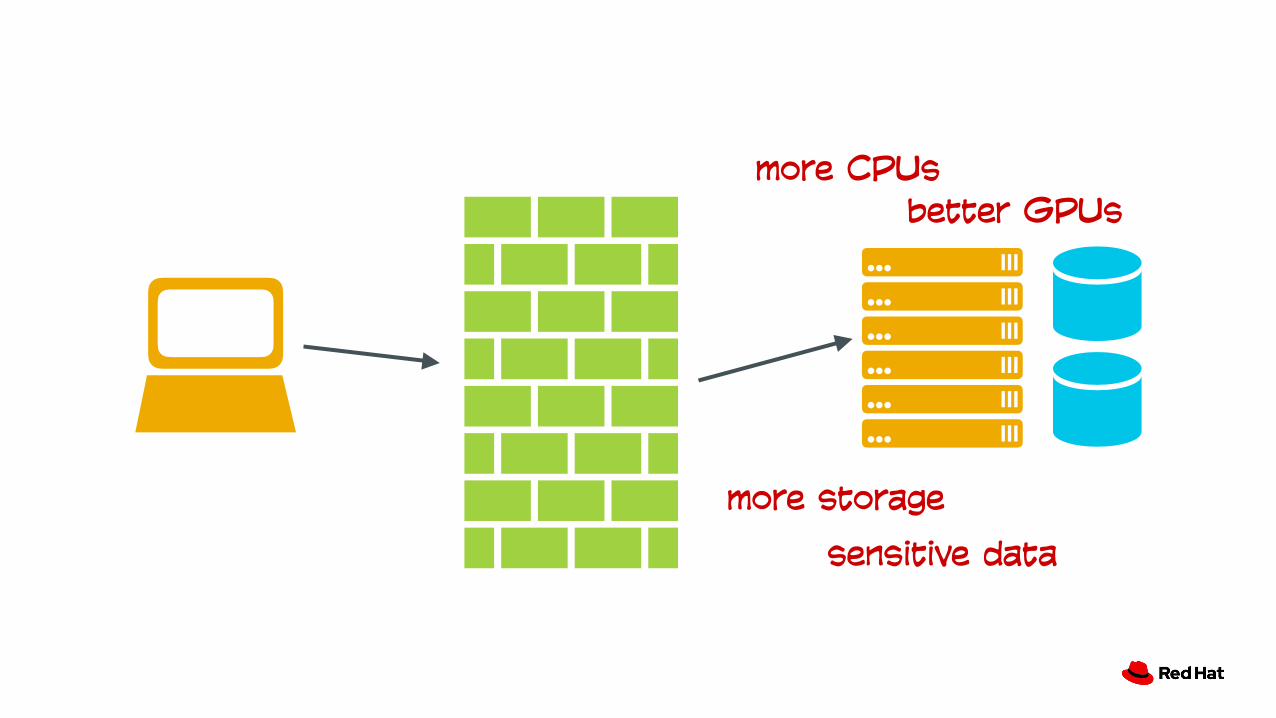
more storage
sensitive data
more CPUsbetter GPUs

PostgreSQL MariaDB Apache Spark SQL
Apache Kafka (via Strimzi)
Red Hat Ceph Storage
TensorFlow Serving PyTorch Serving Seldon
Spark Katib TFJob PyTorch
Argo Kubeflow Pipelines
OpenShift
JupyterHub Apache Superset
Grafana Prometheus
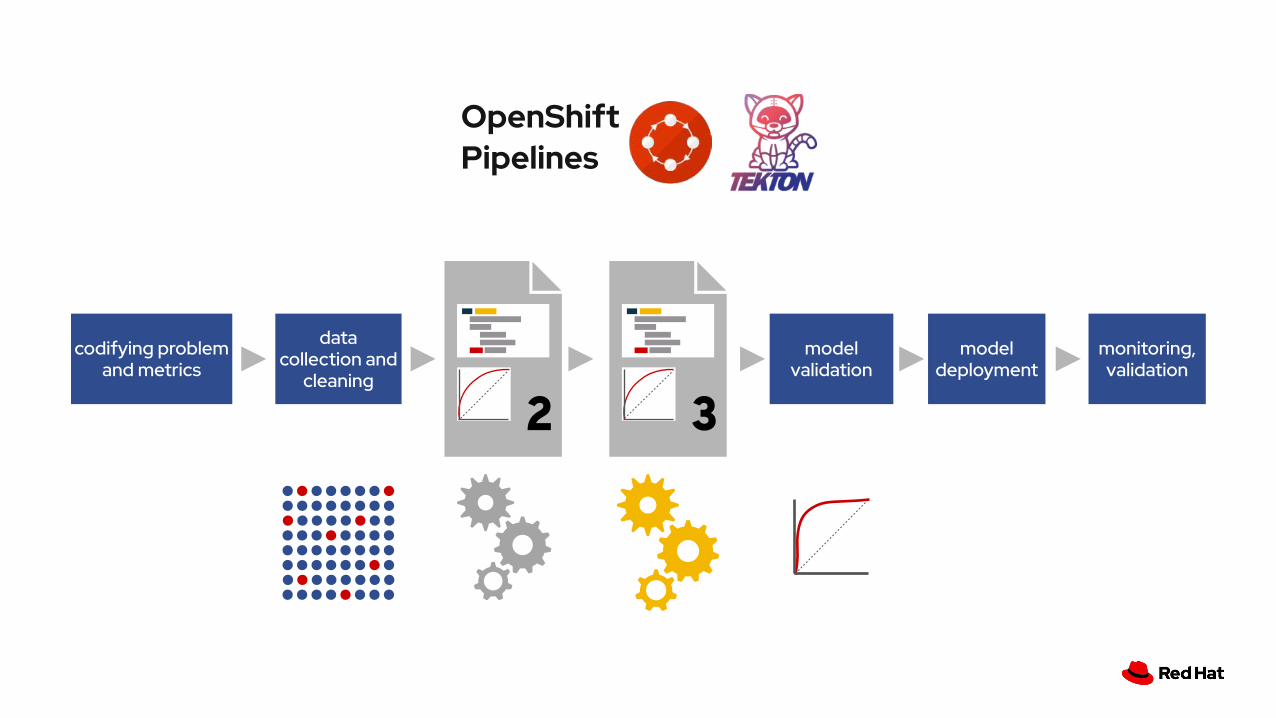
codifying problem
and metrics
feature engineering
model training
and tuning
model validation
data collection
and cleaning
model deployment
monitoring, validation

3
feature engineering
model training
and tuning
model validation
2

codifying problem and metrics
feature engineering
model training and tuning
model validation
data collection and
cleaning
model deployment
monitoring, validation
OpenShift Pipelines
codifying problem and metrics
model validation
data collection and
cleaning
model deployment
monitoring, validation
2 3
OpenShift Pipelines

REST endpoint
OpenShift Serverless

Further resources
Open Data Hub web site: https://opendatahub.io
Contribute: https://github.com/opendatahub-io
Get involved: https://gitlab.com/opendatahub/opendatahub-community
ML workflows on OpenShift and Open Data Hub: https://bit.ly/ml-workflows-ocp


Thank you!































