Embed Size (px)
Citation preview

Language to Logical Form with Neural Attention
Li Dong and Mirella LapataInstitute for Language, Cognition and Computation
School of Informatics, University of Edinburgh10 Crichton Street, Edinburgh EH8 9AB
[email protected], [email protected]
Abstract
Semantic parsing aims at mapping nat-ural language to machine interpretablemeaning representations. Traditional ap-proaches rely on high-quality lexicons,manually-built templates, and linguis-tic features which are either domain-or representation-specific. In this pa-per we present a general method basedon an attention-enhanced encoder-decodermodel. We encode input utterances intovector representations, and generate theirlogical forms by conditioning the outputsequences or trees on the encoding vec-tors. Experimental results on four datasetsshow that our approach performs compet-itively without using hand-engineered fea-tures and is easy to adapt across domainsand meaning representations.
1 Introduction
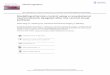
Semantic parsing is the task of translating textto a formal meaning representation such as log-ical forms or structured queries. There has re-cently been a surge of interest in developing ma-chine learning methods for semantic parsing (seethe references in Section 2), due in part to theexistence of corpora containing utterances anno-tated with formal meaning representations. Fig-ure 1 shows an example of a question (left hand-side) and its annotated logical form (right hand-side), taken from JOBS (Tang and Mooney, 2001),a well-known semantic parsing benchmark. In or-der to predict the correct logical form for a givenutterance, most previous systems rely on prede-fined templates and manually designed features,which often render the parsing model domain- orrepresentation-specific. In this work, we aim touse a simple yet effective method to bridge the gapbetween natural language and logical form withminimal domain knowledge.
Sequence
Encoder
Sequence/Tree
Decoder
LSTM
answer(J,(compa
ny(J,'microsoft'),j
ob(J),not((req_de
g(J,'bscs')))))
Attention LayerLSTM
what microsoft jobs
do not require a
bscs?
Input
Utterance
Logical
Form
Figure 1: Input utterances and their logical formsare encoded and decoded with neural networks.An attention layer is used to learn soft alignments.
Encoder-decoder architectures based on recur-rent neural networks have been successfully ap-plied to a variety of NLP tasks ranging from syn-tactic parsing (Vinyals et al., 2015a), to machinetranslation (Kalchbrenner and Blunsom, 2013;Cho et al., 2014; Sutskever et al., 2014), andimage description generation (Karpathy and Fei-Fei, 2015; Vinyals et al., 2015b). As shown inFigure 1, we adapt the general encoder-decoderparadigm to the semantic parsing task. Ourmodel learns from natural language descriptionspaired with meaning representations; it encodessentences and decodes logical forms using recur-rent neural networks with long short-term memory(LSTM) units. We present two model variants,the first one treats semantic parsing as a vanillasequence transduction task, whereas our secondmodel is equipped with a hierarchical tree decoderwhich explicitly captures the compositional struc-ture of logical forms. We also introduce an atten-tion mechanism (Bahdanau et al., 2015; Luong etal., 2015b) allowing the model to learn soft align-ments between natural language and logical formsand present an argument identification step to han-dle rare mentions of entities and numbers.
Evaluation results demonstrate that compared toprevious methods our model achieves similar orbetter performance across datasets and meaningrepresentations, despite using no hand-engineereddomain- or representation-specific features.
arX
iv:1
601.
0128
0v2
[cs
.CL
] 6
Jun
201
6

2 Related Work
Our work synthesizes two strands of research,namely semantic parsing and the encoder-decoderarchitecture with neural networks.
The problem of learning semantic parsers hasreceived significant attention, dating back toWoods (1973). Many approaches learn from sen-tences paired with logical forms following vari-ous modeling strategies. Examples include theuse of parsing models (Miller et al., 1996; Ge andMooney, 2005; Lu et al., 2008; Zhao and Huang,2015), inductive logic programming (Zelle andMooney, 1996; Tang and Mooney, 2000; Thom-spon and Mooney, 2003), probabilistic automata(He and Young, 2006), string/tree-to-tree transfor-mation rules (Kate et al., 2005), classifiers basedon string kernels (Kate and Mooney, 2006), ma-chine translation (Wong and Mooney, 2006; Wongand Mooney, 2007; Andreas et al., 2013), andcombinatory categorial grammar induction tech-niques (Zettlemoyer and Collins, 2005; Zettle-moyer and Collins, 2007; Kwiatkowski et al.,2010; Kwiatkowski et al., 2011). Other worklearns semantic parsers without relying on logical-from annotations, e.g., from sentences paired withconversational logs (Artzi and Zettlemoyer, 2011),system demonstrations (Chen and Mooney, 2011;Goldwasser and Roth, 2011; Artzi and Zettle-moyer, 2013), question-answer pairs (Clarke etal., 2010; Liang et al., 2013), and distant supervi-sion (Krishnamurthy and Mitchell, 2012; Cai andYates, 2013; Reddy et al., 2014).
Our model learns from natural language de-scriptions paired with meaning representations.Most previous systems rely on high-quality lex-icons, manually-built templates, and featureswhich are either domain- or representation-specific. We instead present a general method thatcan be easily adapted to different domains andmeaning representations. We adopt the generalencoder-decoder framework based on neural net-works which has been recently repurposed for var-ious NLP tasks such as syntactic parsing (Vinyalset al., 2015a), machine translation (Kalchbrennerand Blunsom, 2013; Cho et al., 2014; Sutskever etal., 2014), image description generation (Karpathyand Fei-Fei, 2015; Vinyals et al., 2015b), ques-tion answering (Hermann et al., 2015), and sum-marization (Rush et al., 2015).
Mei et al. (2016) use a sequence-to-sequencemodel to map navigational instructions to actions.
Our model works on more well-defined meaningrepresentations (such as Prolog and lambda cal-culus) and is conceptually simpler; it does notemploy bidirectionality or multi-level alignments.Grefenstette et al. (2014) propose a different ar-chitecture for semantic parsing based on the com-bination of two neural network models. The firstmodel learns shared representations from pairs ofquestions and their translations into knowledgebase queries, whereas the second model generatesthe queries conditioned on the learned representa-tions. However, they do not report empirical eval-uation results.
3 Problem Formulation
Our aim is to learn a model which maps naturallanguage input q = x1 · · ·x|q| to a logical formrepresentation of its meaning a = y1 · · · y|a|. Theconditional probability p (a|q) is decomposed as:
p (a|q) =|a|∏t=1
p (yt|y<t, q) (1)
where y<t = y1 · · · yt−1.Our method consists of an encoder which en-
codes natural language input q into a vector repre-sentation and a decoder which learns to generatey1, · · · , y|a| conditioned on the encoding vector.In the following we describe two models varyingin the way in which p (a|q) is computed.
3.1 Sequence-to-Sequence ModelThis model regards both input q and output a assequences. As shown in Figure 2, the encoder anddecoder are two different L-layer recurrent neuralnetworks with long short-term memory (LSTM)units which recursively process tokens one by one.The first |q| time steps belong to the encoder, whilethe following |a| time steps belong to the decoder.Let hl
t ∈ Rn denote the hidden vector at timestep t and layer l. hl
t is then computed by:
hlt = LSTM
(hlt−1,h
l−1t
)(2)
where LSTM refers to the LSTM function beingused. In our experiments we follow the architec-ture described in Zaremba et al. (2015), howeverother types of gated activation functions are pos-sible (e.g., Cho et al. (2014)). For the encoder,h0t = Wqe(xt) is the word vector of the current
input token, with Wq ∈ Rn×|Vq | being a parame-ter matrix, and e(·) the index of the corresponding

LSTMLSTM
LSTMLSTM
LSTMLSTM
LSTMLSTM
LSTMLSTM
LSTMLSTM
Figure 2: Sequence-to-sequence (SEQ2SEQ)model with two-layer recurrent neural networks.
token. For the decoder, h0t = Wae(yt−1) is the
word vector of the previous predicted word, whereWa ∈ Rn×|Va|. Notice that the encoder and de-coder have different LSTM parameters.
Once the tokens of the input sequencex1, · · · , x|q| are encoded into vectors, they areused to initialize the hidden states of the first timestep in the decoder. Next, the hidden vector of thetopmost LSTM hL
t in the decoder is used to pre-dict the t-th output token as:
p (yt|y<t, q) = softmax(Woh
Lt
)ᵀe (yt) (3)
where Wo ∈ R|Va|×n is a parameter matrix, ande (yt) ∈ {0, 1}|Va| a one-hot vector for computingyt’s probability from the predicted distribution.
We augment every sequence with a “start-of-sequence” <s> and “end-of-sequence” </s> to-ken. The generation process terminates once </s>is predicted. The conditional probability of gener-ating the whole sequence p (a|q) is then obtainedusing Equation (1).
3.2 Sequence-to-Tree ModelThe SEQ2SEQ model has a potential drawback inthat it ignores the hierarchical structure of logicalforms. As a result, it needs to memorize variouspieces of auxiliary information (e.g., bracket pairs)to generate well-formed output. In the followingwe present a hierarchical tree decoder which ismore faithful to the compositional nature of mean-ing representations. A schematic description ofthe model is shown in Figure 3.
The present model shares the same encoder withthe sequence-to-sequence model described in Sec-tion 3.1 (essentially it learns to encode input q asvectors). However, its decoder is fundamentallydifferent as it generates logical forms in a top-down manner. In order to represent tree structure,
LSTM
LSTM
LSTM
LSTM
lambda $0 e
and
<n>
LSTM
LSTMLSTM
LSTM
LSTM
LSTM
<n> <n> </s>
LSTM
</s>
from
LSTM
LSTM
LSTM
LSTM
$0 dallas:ci </s>>
LSTM
LSTM
LSTM
LSTM<n> 1600:ti </s>
LSTM
LSTM
departure
_time$0
LSTM
</s>
Parent feedingStart decoding
LSTM Encoder unitLSTM Decoder unit
<n> Nonterminal
Figure 3: Sequence-to-tree (SEQ2TREE) modelwith a hierarchical tree decoder.
we define a “nonterminal” <n> token which in-dicates subtrees. As shown in Figure 3, we pre-process the logical form “lambda $0 e (and (>(de-parture time $0) 1600:ti) (from $0 dallas:ci))” to atree by replacing tokens between pairs of bracketswith nonterminals. Special tokens <s> and <(>denote the beginning of a sequence and nontermi-nal sequence, respectively (omitted from Figure 3due to lack of space). Token </s> represents theend of sequence.
After encoding input q, the hierarchical tree de-coder uses recurrent neural networks to generatetokens at depth 1 of the subtree corresponding toparts of logical form a. If the predicted tokenis <n>, we decode the sequence by conditioningon the nonterminal’s hidden vector. This processterminates when no more nonterminals are emit-ted. In other words, a sequence decoder is used tohierarchically generate the tree structure.
In contrast to the sequence decoder describedin Section 3.1, the current hidden state does notonly depend on its previous time step. In order tobetter utilize the parent nonterminal’s information,we introduce a parent-feeding connection wherethe hidden vector of the parent nonterminal is con-catenated with the inputs and fed into LSTM.
As an example, Figure 4 shows the decodingtree corresponding to the logical form “A B (C)”,where y1 · · · y6 are predicted tokens, and t1 · · · t6denote different time steps. Span “(C)” corre-sponds to a subtree. Decoding in this example hastwo steps: once input q has been encoded, we firstgenerate y1 · · · y4 at depth 1 until token </s> is

t1 t2 t3 t4
t5 t6
y1=A y3=<n>
<s>
q
y6=</s>
<(>
y4=</s>y2=B
y5=C
Figure 4: A SEQ2TREE decoding example for thelogical form “A B (C)”.
predicted; next, we generate y5, y6 by condition-ing on nonterminal t3’s hidden vectors. The prob-ability p (a|q) is the product of these two sequencedecoding steps:
p (a|q) = p (y1y2y3y4|q) p (y5y6|y≤3, q) (4)
where Equation (3) is used for the prediction ofeach output token.
3.3 Attention MechanismAs shown in Equation (3), the hidden vectors ofthe input sequence are not directly used in thedecoding process. However, it makes intuitivelysense to consider relevant information from the in-put to better predict the current token. Followingthis idea, various techniques have been proposedto integrate encoder-side information (in the formof a context vector) at each time step of the de-coder (Bahdanau et al., 2015; Luong et al., 2015b;Xu et al., 2015).
As shown in Figure 5, in order to find rele-vant encoder-side context for the current hiddenstate hL
t of decoder, we compute its attention scorewith the k-th hidden state in the encoder as:
stk =exp{hL
k · hLt }∑|q|
j=1 exp{hLj · hL
t }(5)
where hL1 , · · · ,hL
|q| are the top-layer hidden vec-tors of the encoder. Then, the context vector is theweighted sum of the hidden vectors in the encoder:
ct =
|q|∑k=1
stkhLk (6)
In lieu of Equation (3), we further use this con-text vector which acts as a summary of the encoderto compute the probability of generating yt as:
hattt = tanh
(W1h
Lt +W2c
t)
(7)
LSTM
LSTM
LSTM
LSTM
LSTMAttentionScores
Figure 5: Attention scores are computed by thecurrent hidden vector and all the hidden vectors ofencoder. Then, the encoder-side context vector ct
is obtained in the form of a weighted sum, whichis further used to predict yt.
p (yt|y<t, q) = softmax(Woh
attt
)ᵀe (yt) (8)
where Wo ∈ R|Va|×n and W1,W2 ∈ Rn×n arethree parameter matrices, and e (yt) is a one-hotvector used to obtain yt’s probability.
3.4 Model TrainingOur goal is to maximize the likelihood of the gen-erated logical forms given natural language utter-ances as input. So the objective function is:
minimize−∑
(q,a)∈D
log p (a|q) (9)
where D is the set of all natural language-logicalform training pairs, and p (a|q) is computed asshown in Equation (1).
The RMSProp algorithm (Tieleman and Hin-ton, 2012) is employed to solve this non-convexoptimization problem. Moreover, dropout is usedfor regularizing the model (Zaremba et al., 2015).Specifically, dropout operators are used betweendifferent LSTM layers and for the hidden lay-ers before the softmax classifiers. This techniquecan substantially reduce overfitting, especially ondatasets of small size.
3.5 InferenceAt test time, we predict the logical form for an in-put utterance q by:
a = argmaxa′
p(a′|q)
(10)
where a′ represents a candidate output. How-ever, it is impractical to iterate over all possibleresults to obtain the optimal prediction. Accord-ing to Equation (1), we decompose the probabil-ity p (a|q) so that we can use greedy search (orbeam search) to generate tokens one by one.

Algorithm 1 describes the decoding process forSEQ2TREE. The time complexity of both de-coders is O(|a|), where |a| is the length of out-put. The extra computation of SEQ2TREE com-pared with SEQ2SEQ is to maintain the nonter-minal queue, which can be ignored because mostof time is spent on matrix operations. We imple-ment the hierarchical tree decoder in a batch mode,so that it can fully utilize GPUs. Specifically, asshown in Algorithm 1, every time we pop multi-ple nonterminals from the queue and decode thesenonterminals in one batch.
3.6 Argument Identification
The majority of semantic parsing datasets havebeen developed with question-answering in mind.In the typical application setting, natural languagequestions are mapped into logical forms and ex-ecuted on a knowledge base to obtain an answer.Due to the nature of the question-answering task,many natural language utterances contain entitiesor numbers that are often parsed as arguments inthe logical form. Some of them are unavoidablyrare or do not appear in the training set at all (thisis especially true for small-scale datasets). Con-ventional sequence encoders simply replace rarewords with a special unknown word symbol (Lu-ong et al., 2015a; Jean et al., 2015), which wouldbe detrimental for semantic parsing.
We have developed a simple procedure for ar-gument identification. Specifically, we identifyentities and numbers in input questions and re-place them with their type names and uniqueIDs. For instance, we pre-process the trainingexample “jobs with a salary of 40000” and itslogical form “job(ANS), salary greater than(ANS,40000, year)” as “jobs with a salary of num0”
and “job(ANS), salary greater than(ANS, num0,year)”. We use the pre-processed examples astraining data. At inference time, we also mask en-tities and numbers with their types and IDs. Oncewe obtain the decoding result, a post-processingstep recovers all the markers typei to their corre-sponding logical constants.
4 Experiments
We compare our method against multiple previ-ous systems on four datasets. We describe thesedatasets below, and present our experimental set-tings and results. Finally, we conduct model anal-ysis in order to understand what the model learns.The code is available at https://github.com/donglixp/lang2logic.
4.1 Datasets
Our model was trained on the following datasets,covering different domains and using differentmeaning representations. Examples for each do-main are shown in Table 1.
JOBS This benchmark dataset contains 640queries to a database of job listings. Specifically,questions are paired with Prolog-style queries. Weused the same training-test split as Zettlemoyerand Collins (2005) which contains 500 trainingand 140 test instances. Values for the variablescompany, degree, language, platform, location,job area, and number are identified.
GEO This is a standard semantic parsing bench-mark which contains 880 queries to a database ofU.S. geography. GEO has 880 instances split intoa training set of 680 training examples and 200test examples (Zettlemoyer and Collins, 2005).We used the same meaning representation basedon lambda-calculus as Kwiatkowski et al. (2011).Values for the variables city, state, country, river,and number are identified.
ATIS This dataset has 5, 410 queries to a flightbooking system. The standard split has 4, 480training instances, 480 development instances, and450 test instances. Sentences are paired withlambda-calculus expressions. Values for the vari-ables date, time, city, aircraft code, airport, airline,and number are identified.
IFTTT Quirk et al. (2015) created this datasetby extracting a large number of if-this-then-that

Dataset Length Example
JOBS9.80
22.90what microsoft jobs do not require a bscs?answer(company(J,’microsoft’),job(J),not((req deg(J,’bscs’))))
GEO7.60
19.10what is the population of the state with the largest area?(population:i (argmax $0 (state:t $0) (area:i $0)))
ATIS11.1028.10
dallas to san francisco leaving after 4 in the afternoon please(lambda $0 e (and (>(departure time $0) 1600:ti) (from $0 dallas:ci) (to $0 san francisco:ci)))
IFTTT6.95
21.80
Turn on heater when temperature drops below 58 degreeTRIGGER: Weather - Current temperature drops below - ((Temperature (58)) (Degrees in (f)))ACTION: WeMo Insight Switch - Turn on - ((Which switch? (””)))
Table 1: Examples of natural language descriptions and their meaning representations from four datasets.The average length of input and output sequences is shown in the second column.
recipes from the IFTTT website1. Recipes are sim-ple programs with exactly one trigger and one ac-tion which users specify on the site. Whenever theconditions of the trigger are satisfied, the actionis performed. Actions typically revolve aroundhome security (e.g., “turn on my lights when I ar-rive home”), automation (e.g., “text me if the dooropens”), well-being (e.g., “remind me to drinkwater if I’ve been at a bar for more than twohours”), and so on. Triggers and actions are se-lected from different channels (160 in total) rep-resenting various types of services, devices (e.g.,Android), and knowledge sources (such as ESPNor Gmail). In the dataset, there are 552 triggerfunctions from 128 channels, and 229 action func-tions from 99 channels. We used Quirk et al.’s(2015) original split which contains 77, 495 train-ing, 5, 171 development, and 4, 294 test examples.The IFTTT programs are represented as abstractsyntax trees and are paired with natural languagedescriptions provided by users (see Table 1). Here,numbers and URLs are identified.
4.2 Settings
Natural language sentences were lowercased; mis-spellings were corrected using a dictionary basedon the Wikipedia list of common misspellings.Words were stemmed using NLTK (Bird et al.,2009). For IFTTT, we filtered tokens, channelsand functions which appeared less than five timesin the training set. For the other datasets, we fil-tered input words which did not occur at least twotimes in the training set, but kept all tokens inthe logical forms. Plain string matching was em-ployed to identify augments as described in Sec-tion 3.6. More sophisticated approaches could beused, however we leave this future work.
Model hyper-parameters were cross-validated
1http://www.ifttt.com
Method AccuracyCOCKTAIL (Tang and Mooney, 2001) 79.4PRECISE (Popescu et al., 2003) 88.0ZC05 (Zettlemoyer and Collins, 2005) 79.3DCS+L (Liang et al., 2013) 90.7TISP (Zhao and Huang, 2015) 85.0SEQ2SEQ 87.1− attention 77.9− argument 70.7
SEQ2TREE 90.0− attention 83.6
Table 2: Evaluation results on JOBS.
on the training set for JOBS and GEO. We usedthe standard development sets for ATIS and IFTTT.We used the RMSProp algorithm (with batch sizeset to 20) to update the parameters. The smoothingconstant of RMSProp was 0.95. Gradients wereclipped at 5 to alleviate the exploding gradientproblem (Pascanu et al., 2013). Parameters wererandomly initialized from a uniform distributionU (−0.08, 0.08). A two-layer LSTM was used forIFTTT, while a one-layer LSTM was employedfor the other domains. The dropout rate was se-lected from {0.2, 0.3, 0.4, 0.5}. Dimensions ofhidden vector and word embedding were selectedfrom {150, 200, 250}. Early stopping was usedto determine the number of epochs. Input sen-tences were reversed before feeding into the en-coder (Sutskever et al., 2014). We use greedysearch to generate logical forms during inference.Notice that two decoders with shared word em-beddings were used to predict triggers and actionsfor IFTTT, and two softmax classifiers are used toclassify channels and functions.
4.3 Results
We first discuss the performance of our model onJOBS, GEO, and ATIS, and then examine our re-sults on IFTTT. Tables 2–4 present comparisonsagainst a variety of systems previously described

Method AccuracySCISSOR (Ge and Mooney, 2005) 72.3KRISP (Kate and Mooney, 2006) 71.7WASP (Wong and Mooney, 2006) 74.8λ-WASP (Wong and Mooney, 2007) 86.6LNLZ08 (Lu et al., 2008) 81.8ZC05 (Zettlemoyer and Collins, 2005) 79.3ZC07 (Zettlemoyer and Collins, 2007) 86.1UBL (Kwiatkowski et al., 2010) 87.9FUBL (Kwiatkowski et al., 2011) 88.6KCAZ13 (Kwiatkowski et al., 2013) 89.0DCS+L (Liang et al., 2013) 87.9TISP (Zhao and Huang, 2015) 88.9SEQ2SEQ 84.6− attention 72.9− argument 68.6
SEQ2TREE 87.1− attention 76.8
Table 3: Evaluation results on GEO. 10-fold cross-validation is used for the systems shown in the tophalf of the table. The standard split of ZC05 isused for all other systems.
Method AccuracyZC07 (Zettlemoyer and Collins, 2007) 84.6UBL (Kwiatkowski et al., 2010) 71.4FUBL (Kwiatkowski et al., 2011) 82.8GUSP-FULL (Poon, 2013) 74.8GUSP++ (Poon, 2013) 83.5TISP (Zhao and Huang, 2015) 84.2SEQ2SEQ 84.2− attention 75.7− argument 72.3
SEQ2TREE 84.6− attention 77.5
Table 4: Evaluation results on ATIS.
in the literature. We report results with the fullmodels (SEQ2SEQ, SEQ2TREE) and two abla-tion variants, i.e., without an attention mechanism(−attention) and without argument identification(−argument). We report accuracy which is de-fined as the proportion of the input sentences thatare correctly parsed to their gold standard logicalforms. Notice that DCS+L, KCAZ13 and GUSPoutput answers directly, so accuracy in this settingis defined as the percentage of correct answers.
Overall, SEQ2TREE is superior to SEQ2SEQ.This is to be expected since SEQ2TREE ex-plicitly models compositional structure. On theJOBS and GEO datasets which contain logicalforms with nested structures, SEQ2TREE out-performs SEQ2SEQ by 2.9% and 2.5%, respec-tively. SEQ2TREE achieves better accuracy overSEQ2SEQ on ATIS too, however, the difference issmaller, since ATIS is a simpler domain withoutcomplex nested structures. We find that adding at-
Method Channel +Func F1retrieval 28.9 20.2 41.7phrasal 19.3 11.3 35.3sync 18.1 10.6 35.1classifier 48.8 35.2 48.4posclass 50.0 36.9 49.3SEQ2SEQ 54.3 39.2 50.1− attention 54.0 37.9 49.8− argument 53.9 38.6 49.7
SEQ2TREE 55.2 40.1 50.4− attention 54.3 38.2 50.0
(a) Omit non-English.
Method Channel +Func F1retrieval 36.8 25.4 49.0phrasal 27.8 16.4 39.9sync 26.7 15.5 37.6classifier 64.8 47.2 56.5posclass 67.2 50.4 57.7SEQ2SEQ 68.8 50.5 60.3− attention 68.7 48.9 59.5− argument 68.8 50.4 59.7
SEQ2TREE 69.6 51.4 60.4− attention 68.7 49.5 60.2
(b) Omit non-English & unintelligible.
Method Channel +Func F1retrieval 43.3 32.3 56.2phrasal 37.2 23.5 45.5sync 36.5 24.1 42.8classifier 79.3 66.2 65.0posclass 81.4 71.0 66.5SEQ2SEQ 87.8 75.2 73.7− attention 88.3 73.8 72.9− argument 86.8 74.9 70.8
SEQ2TREE 89.7 78.4 74.2− attention 87.6 74.9 73.5
(c) ≥ 3 turkers agree with gold.
Table 5: Evaluation results on IFTTT.
tention substantially improves performance on allthree datasets. This underlines the importance ofutilizing soft alignments between inputs and out-puts. We further analyze what the attention layerlearns in Figure 6. Moreover, our results showthat argument identification is critical for small-scale datasets. For example, about 92% of citynames appear less than 4 times in the GEO train-ing set, so it is difficult to learn reliable parame-ters for these words. In relation to previous work,the proposed models achieve comparable or betterperformance. Importantly, we use the same frame-work (SEQ2SEQ or SEQ2TREE) across datasetsand meaning representations (Prolog-style logi-cal forms in JOBS and lambda calculus in theother two datasets) without modification. Despitethis relatively simple approach, we observe thatSEQ2TREE ranks second on JOBS, and is tied forfirst place with ZC07 on ATIS.

</s>
degid0 a
requir
not
do
that
num0
pay
job
which
<s>
job(
ANS),
salary_greater_than(
ANS,
num0,
year),
\+((
req_deg(
ANS,
degid0)))
</s>
(a) which jobs pay num0 that donot require a degid0
</s>
ci1 to ci0
from
trip
round
fare
class
first
what
<s>
(lambda
$0e(
exists$1(
and(
round_trip$1)(
class_type$1
first:cl)(
from$1ci0)(
to$1ci1)(=(
fare$1)
$0))))
</s>
(b) what’s first class fareround trip from ci0 to ci1
</s>
tomorrow
ci1 to ci0
from
flight
earliest
the is
what
<s>
argmin$0(
and(
flight$0)(
from$0ci0)(
to$0ci1)(
tomorrow$0))(
departure_time$0)
</s>
(c) what is the earliest flightfrom ci0 to ci1 tomorrow
</s>
co0
the in
elev
highest
the is
what
<s>
argmax
$0
(
and
(
place:t
$0
)
(
loc:t
$0
co0
)
)
(
elevation:i
$0
)
</s>
(d) what is the highest elevationin the co0
Figure 6: Alignments (same color rectangles) produced by the attention mechanism (darker color rep-resents higher attention score). Input sentences are reversed and stemmed. Model output is shown forSEQ2SEQ (a, b) and SEQ2TREE (c, d).
We illustrate examples of alignments producedby SEQ2SEQ in Figures 6a and 6b. Alignmentsproduced by SEQ2TREE are shown in Figures 6cand 6d. Matrices of attention scores are com-puted using Equation (5) and are represented ingrayscale. Aligned input words and logical formpredicates are enclosed in (same color) rectan-gles whose overlapping areas contain the attentionscores. Also notice that attention scores are com-puted by LSTM hidden vectors which encode con-text information rather than just the words in theircurrent positions. The examples demonstrate thatthe attention mechanism can successfully modelthe correspondence between sentences and logi-cal forms, capturing reordering (Figure 6b), many-to-many (Figure 6a), and many-to-one alignments(Figures 6c,d).
For IFTTT, we follow the same evaluation pro-tocol introduced in Quirk et al. (2015). Thedataset is extremely noisy and measuring accu-racy is problematic since predicted abstract syn-tax trees (ASTs) almost never exactly match thegold standard. Quirk et al. view an AST as aset of productions and compute balanced F1 in-stead which we also adopt. The first column inTable 5 shows the percentage of channels selectedcorrectly for both triggers and actions. The sec-ond column measures accuracy for both channelsand functions. The last column shows balancedF1 against the gold tree over all productions in
the proposed derivation. We compare our modelagainst posclass, the method introduced in Quirket al. and several of their baselines. posclass isreminiscent of KRISP (Kate and Mooney, 2006),it learns distributions over productions given in-put sentences represented as a bag of linguisticfeatures. The retrieval baseline finds the closestdescription in the training data based on charac-ter string-edit-distance and returns the recipe forthat training program. The phrasal method usesphrase-based machine translation to generate therecipe, whereas sync extracts synchronous gram-mar rules from the data, essentially recreatingWASP (Wong and Mooney, 2006). Finally, theyuse a binary classifier to predict whether a produc-tion should be present in the derivation tree corre-sponding to the description.
Quirk et al. (2015) report results on the fulltest data and smaller subsets after noise filter-ing, e.g., when non-English and unintelligible de-scriptions are removed (Tables 5a and 5b). Theyalso ran their system on a high-quality subset ofdescription-program pairs which were found in thegold standard and at least three humans managedto independently reproduce (Table 5c). Across allsubsets our models outperforms posclass and re-lated baselines. Again we observe that SEQ2TREE
consistently outperforms SEQ2SEQ, albeit with asmall margin. Compared to the previous datasets,the attention mechanism and our argument iden-

tification method yield less of an improvement.This may be due to the size of Quirk et al. (2015)and the way it was created – user curated descrip-tions are often of low quality, and thus align veryloosely to their corresponding ASTs.
4.4 Error AnalysisFinally, we inspected the output of our model inorder to identify the most common causes of errorswhich we summarize below.
Under-Mapping The attention model used inour experiments does not take the alignment his-tory into consideration. So, some question words,expecially in longer questions, may be ignored inthe decoding process. This is a common prob-lem for encoder-decoder models and can be ad-dressed by explicitly modelling the decoding cov-erage of the source words (Tu et al., 2016; Cohnet al., 2016). Keeping track of the attention his-tory would help adjust future attention and guidethe decoder towards untranslated source words.
Argument Identification Some mentions areincorrectly identified as arguments. For example,the word may is sometimes identified as a monthwhen it is simply a modal verb. Moreover, someargument mentions are ambiguous. For instance,6 o’clock can be used to express either 6 am or 6pm. We could disambiguate arguments based oncontextual information. The execution results oflogical forms could also help prune unreasonablearguments.
Rare Words Because the data size of JOBS,GEO, and ATIS is relatively small, some questionwords are rare in the training set, which makes ithard to estimate reliable parameters for them. Onesolution would be to learn word embeddings onunannotated text data, and then use these as pre-trained vectors for question words.
5 Conclusions
In this paper we presented an encoder-decoderneural network model for mapping natural lan-guage descriptions to their meaning representa-tions. We encode natural language utterancesinto vectors and generate their corresponding log-ical forms as sequences or trees using recur-rent neural networks with long short-term mem-ory units. Experimental results show that en-hancing the model with a hierarchical tree de-coder and an attention mechanism improves per-
formance across the board. Extensive compar-isons with previous methods show that our ap-proach performs competitively, without recourseto domain- or representation-specific features. Di-rections for future work are many and varied. Forexample, it would be interesting to learn a modelfrom question-answer pairs without access to tar-get logical forms. Beyond semantic parsing, wewould also like to apply our SEQ2TREE modelto related structured prediction tasks such as con-stituency parsing.
Acknowledgments We would like to thankLuke Zettlemoyer and Tom Kwiatkowski for shar-ing the ATIS dataset. The support of the EuropeanResearch Council under award number 681760“Translating Multiple Modalities into Text” isgratefully acknowledged.
References[Andreas et al.2013] Jacob Andreas, Andreas Vlachos,
and Stephen Clark. 2013. Semantic parsing as ma-chine translation. In Proceedings of the 51st ACL,pages 47–52, Sofia, Bulgaria.
[Artzi and Zettlemoyer2011] Yoav Artzi and LukeZettlemoyer. 2011. Bootstrapping semanticparsers from conversations. In Proceedings of the2011 EMNLP, pages 421–432, Edinburgh, UnitedKingdom.
[Artzi and Zettlemoyer2013] Yoav Artzi and LukeZettlemoyer. 2013. Weakly supervised learningof semantic parsers for mapping instructions toactions. TACL, 1(1):49–62.
[Bahdanau et al.2015] Dzmitry Bahdanau, KyunghyunCho, and Yoshua Bengio. 2015. Neural machinetranslation by jointly learning to align and translate.In Proceedings of the ICLR, San Diego, California.
[Bird et al.2009] Steven Bird, Ewan Klein, and EdwardLoper. 2009. Natural Language Processing withPython. O’Reilly Media.
[Cai and Yates2013] Qingqing Cai and AlexanderYates. 2013. Semantic parsing freebase: Towardsopen-domain semantic parsing. In 2nd Joint Con-ference on Lexical and Computational Semantics,pages 328–338, Atlanta, Georgia.
[Chen and Mooney2011] David L. Chen and Ray-mond J. Mooney. 2011. Learning to interpret nat-ural language navigation instructions from observa-tions. In Proceedings of the 15th AAAI, pages 859–865, San Francisco, California.
[Cho et al.2014] Kyunghyun Cho, Bart van Merrien-boer, Caglar Gulcehre, Dzmitry Bahdanau, FethiBougares, Holger Schwenk, and Yoshua Bengio.

2014. Learning phrase representations using RNNencoder-decoder for statistical machine translation.In Proceedings of the 2014 EMNLP, pages 1724–1734, Doha, Qatar.
[Clarke et al.2010] James Clarke, Dan Goldwasser,Ming-Wei Chang, and Dan Roth. 2010. Drivingsemantic parsing from the world’s response. In Pro-ceedings of CONLL, pages 18–27, Uppsala, Swe-den.
[Cohn et al.2016] Trevor Cohn, Cong Duy Vu Hoang,Ekaterina Vymolova, Kaisheng Yao, Chris Dyer,and Gholamreza Haffari. 2016. Incorporatingstructural alignment biases into an attentional neu-ral translation model. In Proceedings of the 2016NAACL, San Diego, California.
[Ge and Mooney2005] Ruifang Ge and Raymond J.Mooney. 2005. A statistical semantic parser thatintegrates syntax and semantics. In Proceedings ofCoNLL, pages 9–16, Ann Arbor, Michigan.
[Goldwasser and Roth2011] Dan Goldwasser and DanRoth. 2011. Learning from natural instructions. InProceedings of the 22nd IJCAI, pages 1794–1800,Barcelona, Spain.
[Grefenstette et al.2014] Edward Grefenstette, PhilBlunsom, Nando de Freitas, and Karl MoritzHermann. 2014. A deep architecture for semanticparsing. In Proceedings of the ACL 2014 Workshopon Semantic Parsing, Atlanta, Georgia.
[He and Young2006] Yulan He and Steve Young. 2006.Semantic processing using the hidden vector statemodel. Speech Communication, 48(3-4):262–275.
[Hermann et al.2015] Karl Moritz Hermann, TomasKocisky, Edward Grefenstette, Lasse Espeholt, WillKay, Mustafa Suleyman, and Phil Blunsom. 2015.Teaching machines to read and comprehend. In Ad-vances in Neural Information Processing Systems28, pages 1684–1692. Curran Associates, Inc.
[Jean et al.2015] Sebastien Jean, Kyunghyun Cho,Roland Memisevic, and Yoshua Bengio. 2015. Onusing very large target vocabulary for neural ma-chine translation. In Proceedings of 53rd ACL and7th IJCNLP, pages 1–10, Beijing, China.
[Kalchbrenner and Blunsom2013] Nal Kalchbrennerand Phil Blunsom. 2013. Recurrent continuoustranslation models. In Proceedings of the 2013EMNLP, pages 1700–1709, Seattle, Washington.
[Karpathy and Fei-Fei2015] Andrej Karpathy andLi Fei-Fei. 2015. Deep visual-semantic alignmentsfor generating image descriptions. In Proceedingsof CVPR, pages 3128–3137, Boston, Massachusetts.
[Kate and Mooney2006] Rohit J. Kate and Raymond J.Mooney. 2006. Using string-kernels for learning se-mantic parsers. In Proceedings of the 21st COLINGand 44th ACL, pages 913–920, Sydney, Australia.
[Kate et al.2005] Rohit J. Kate, Yuk Wah Wong, andRaymond J. Mooney. 2005. Learning to transformnatural to formal languages. In Proceedings of the20th AAAI, pages 1062–1068, Pittsburgh, Pennsyl-vania.
[Krishnamurthy and Mitchell2012] Jayant Krish-namurthy and Tom Mitchell. 2012. Weaklysupervised training of semantic parsers. In Pro-ceedings of the 2012 EMNLP, pages 754–765, JejuIsland, Korea.
[Kwiatkowski et al.2010] Tom Kwiatkowski, LukeZettlemoyer, Sharon Goldwater, and Mark Steed-man. 2010. Inducing probabilistic CCG grammarsfrom logical form with higher-order unification. InProceedings of the 2010 EMNLP, pages 1223–1233,Cambridge, Massachusetts.
[Kwiatkowski et al.2011] Tom Kwiatkowski, LukeZettlemoyer, Sharon Goldwater, and Mark Steed-man. 2011. Lexical generalization in CCGgrammar induction for semantic parsing. In Pro-ceedings of the 2011 EMNLP, pages 1512–1523,Edinburgh, United Kingdom.
[Kwiatkowski et al.2013] Tom Kwiatkowski, EunsolChoi, Yoav Artzi, and Luke Zettlemoyer. 2013.Scaling semantic parsers with on-the-fly ontologymatching. In Proceedings of the 2013 EMNLP,pages 1545–1556, Seattle, Washington.
[Liang et al.2013] Percy Liang, Michael I. Jordan, andDan Klein. 2013. Learning dependency-based com-positional semantics. Computational Linguistics,39(2):389–446.
[Lu et al.2008] Wei Lu, Hwee Tou Ng, Wee Sun Lee,and Luke S. Zettlemoyer. 2008. A generative modelfor parsing natural language to meaning representa-tions. In Proceedings of the 2008 EMNLP, pages783–792, Honolulu, Hawaii.
[Luong et al.2015a] Minh-Thang Luong, IlyaSutskever, Quoc V Le, Oriol Vinyals, and Wo-jciech Zaremba. 2015a. Addressing the rare wordproblem in neural machine translation. In Proceed-ings of the 53rd ACL and 7th IJCNLP, pages 11–19,Beijing, China.
[Luong et al.2015b] Thang Luong, Hieu Pham, andChristopher D. Manning. 2015b. Effective ap-proaches to attention-based neural machine trans-lation. In Proceedings of the 2015 EMNLP, pages1412–1421, Lisbon, Portugal.
[Mei et al.2016] Hongyuan Mei, Mohit Bansal, andMatthew R Walter. 2016. Listen, attend, and walk:Neural mapping of navigational instructions to ac-tion sequences. In Proceedings of the 30th AAAI,Phoenix, Arizona. to appear.
[Miller et al.1996] Scott Miller, David Stallard, RobertBobrow, and Richard Schwartz. 1996. A fully sta-tistical approach to natural language interfaces. InACL, pages 55–61.

[Pascanu et al.2013] Razvan Pascanu, Tomas Mikolov,and Yoshua Bengio. 2013. On the difficulty of train-ing recurrent neural networks. In Proceedings of the30th ICML, pages 1310–1318, Atlanta, Georgia.
[Poon2013] Hoifung Poon. 2013. Grounded unsuper-vised semantic parsing. In Proceedings of the 51stACL, pages 933–943, Sofia, Bulgaria.
[Popescu et al.2003] Ana-Maria Popescu, Oren Etzioni,and Henry Kautz. 2003. Towards a theory of naturallanguage interfaces to databases. In Proceedings ofthe 8th IUI, pages 149–157, Miami, Florida.
[Quirk et al.2015] Chris Quirk, Raymond Mooney, andMichel Galley. 2015. Language to code: Learn-ing semantic parsers for if-this-then-that recipes. InProceedings of 53rd ACL and 7th IJCNLP, pages878–888, Beijing, China.
[Reddy et al.2014] Siva Reddy, Mirella Lapata, andMark Steedman. 2014. Large-scale semanticparsing without question-answer pairs. TACL,2(Oct):377–392.
[Rush et al.2015] Alexander M. Rush, Sumit Chopra,and Jason Weston. 2015. A neural attention modelfor abstractive sentence summarization. In Proceed-ings of the 2015 EMNLP, pages 379–389, Lisbon,Portugal.
[Sutskever et al.2014] Ilya Sutskever, Oriol Vinyals,and Quoc V Le. 2014. Sequence to sequence learn-ing with neural networks. In Advances in Neural In-formation Processing Systems 27, pages 3104–3112.Curran Associates, Inc.
[Tang and Mooney2000] Lappoon R. Tang and Ray-mond J. Mooney. 2000. Automated construction ofdatabase interfaces: Intergrating statistical and rela-tional learning for semantic parsing. In Proceedingsof the 2000 EMNLP, pages 133–141, Hong Kong,China.
[Tang and Mooney2001] Lappoon R. Tang and Ray-mond J. Mooney. 2001. Using multiple clause con-structors in inductive logic programming for seman-tic parsing. In Proceedings of the 12th ECML, pages466–477, Freiburg, Germany.
[Thomspon and Mooney2003] Cynthia A. Thomsponand Raymond J. Mooney. 2003. Acquiring word-meaning mappings for natural language interfaces.Journal of Artifical Intelligence Research, 18:1–44.
[Tieleman and Hinton2012] T. Tieleman and G. Hinton.2012. Lecture 6.5—RmsProp: Divide the gradientby a running average of its recent magnitude. Tech-nical report.
[Tu et al.2016] Zhaopeng Tu, Zhengdong Lu, Yang Liu,Xiaohua Liu, and Hang Li. 2016. Modeling cover-age for neural machine translation. In Proceedingsof the 54th ACL, Berlin, Germany.
[Vinyals et al.2015a] Oriol Vinyals, Lukasz Kaiser,Terry Koo, Slav Petrov, Ilya Sutskever, and GeoffreyHinton. 2015a. Grammar as a foreign language. InAdvances in Neural Information Processing Systems28, pages 2755–2763. Curran Associates, Inc.
[Vinyals et al.2015b] Oriol Vinyals, Alexander Toshev,Samy Bengio, and Dumitru Erhan. 2015b. Showand tell: A neural image caption generator. In Pro-ceedings of CVPR, pages 3156–3164, Boston, Mas-sachusetts.
[Wong and Mooney2006] Yuk Wah Wong and Ray-mond J. Mooney. 2006. Learning for semantic pars-ing with statistical machine translation. In Proceed-ings of the 2006 NAACL, pages 439–446, New York,New York.
[Wong and Mooney2007] Yuk Wah Wong and Ray-mond J. Mooney. 2007. Learning synchronousgrammars for semantic parsing with lambda calcu-lus. In Proceedings of the 45th ACL, pages 960–967,Prague, Czech Republic.
[Woods1973] W. A. Woods. 1973. Progress in natu-ral language understanding: An application to lunargeology. In Proceedings of the June 4-8, 1973, Na-tional Computer Conference and Exposition, pages441–450, New York, NY.
[Xu et al.2015] Kelvin Xu, Jimmy Ba, Ryan Kiros,Kyunghyun Cho, Aaron Courville, RuslanSalakhudinov, Rich Zemel, and Yoshua Ben-gio. 2015. Show, attend and tell: Neural imagecaption generation with visual attention. In Pro-ceedings of the 32nd ICML, pages 2048–2057,Lille, France.
[Zaremba et al.2015] Wojciech Zaremba, IlyaSutskever, and Oriol Vinyals. 2015. Recur-rent neural network regularization. In Proceedingsof the ICLR, San Diego, California.
[Zelle and Mooney1996] John M. Zelle and Ray-mond J. Mooney. 1996. Learning to parse databasequeries using inductive logic programming. In Pro-ceedings of the 19th AAAI, pages 1050–1055, Port-land, Oregon.
[Zettlemoyer and Collins2005] Luke S. Zettlemoyerand Michael Collins. 2005. Learning to map sen-tences to logical form: Structured classification withprobabilistic categorial grammars. In Proceedingsof the 21st UAI, pages 658–666, Toronto, ON.
[Zettlemoyer and Collins2007] Luke Zettlemoyer andMichael Collins. 2007. Online learning of relaxedCCG grammars for parsing to logical form. In InProceedings of the EMNLP-CoNLL, pages 678–687,Prague, Czech Republic.
[Zhao and Huang2015] Kai Zhao and Liang Huang.2015. Type-driven incremental semantic parsingwith polymorphism. In Proceedings of the 2015NAACL, pages 1416–1421, Denver, Colorado.